
Integration of Deep Learning and Collaborative Robot for Assembly Tasks

 ,
,  ,
,  , , , , , , and
, , , , , , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
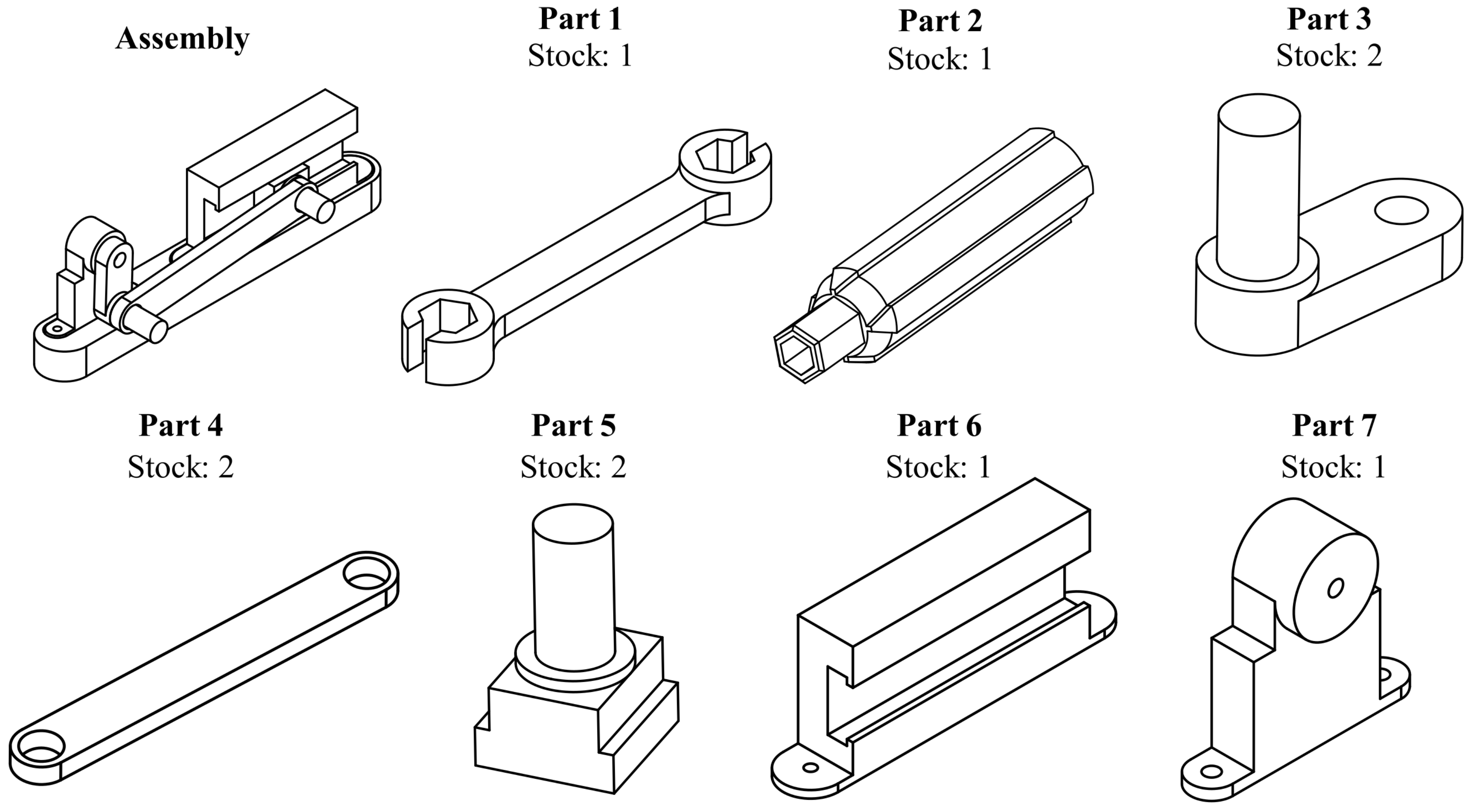
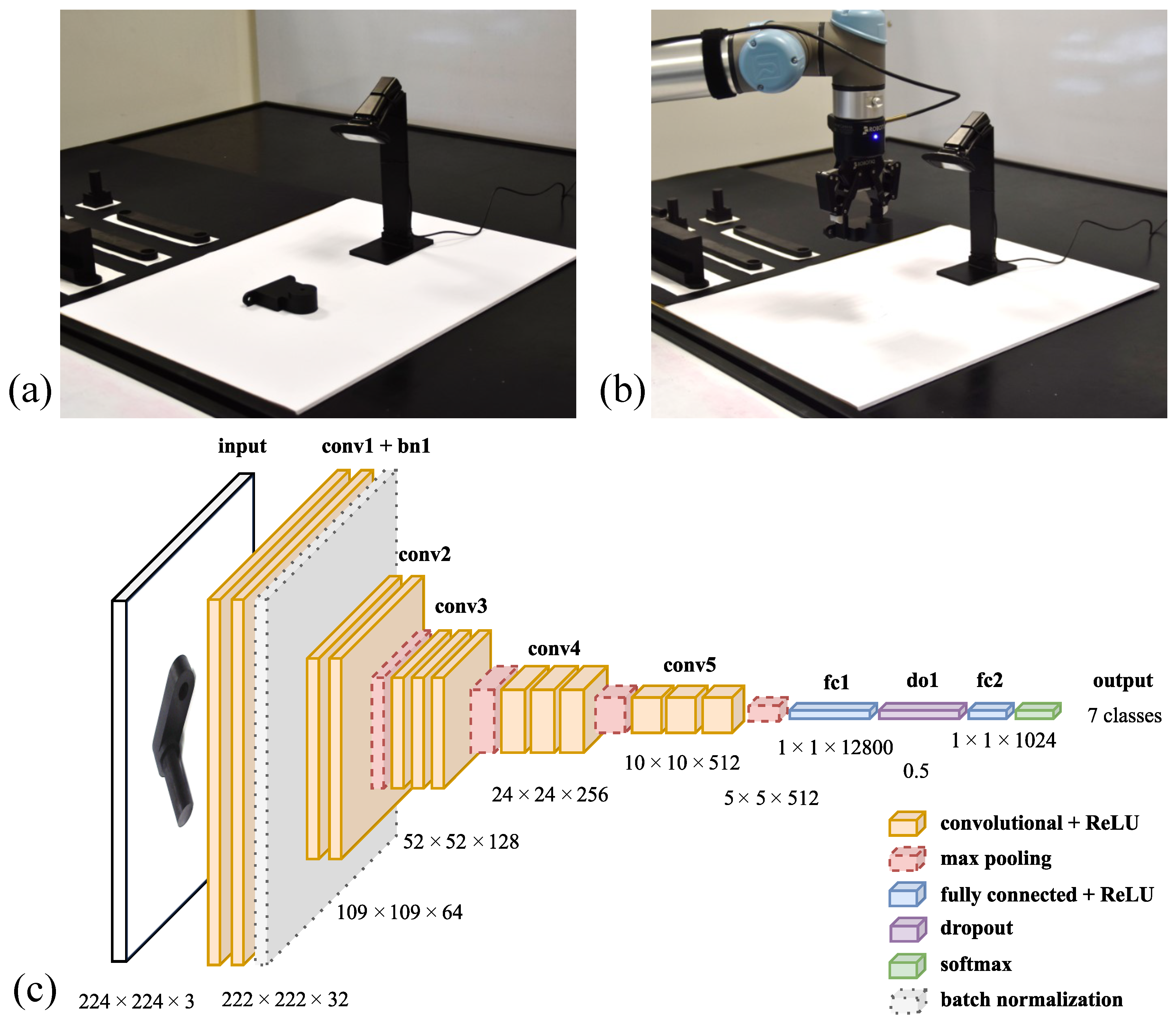
2.1. Object Classification
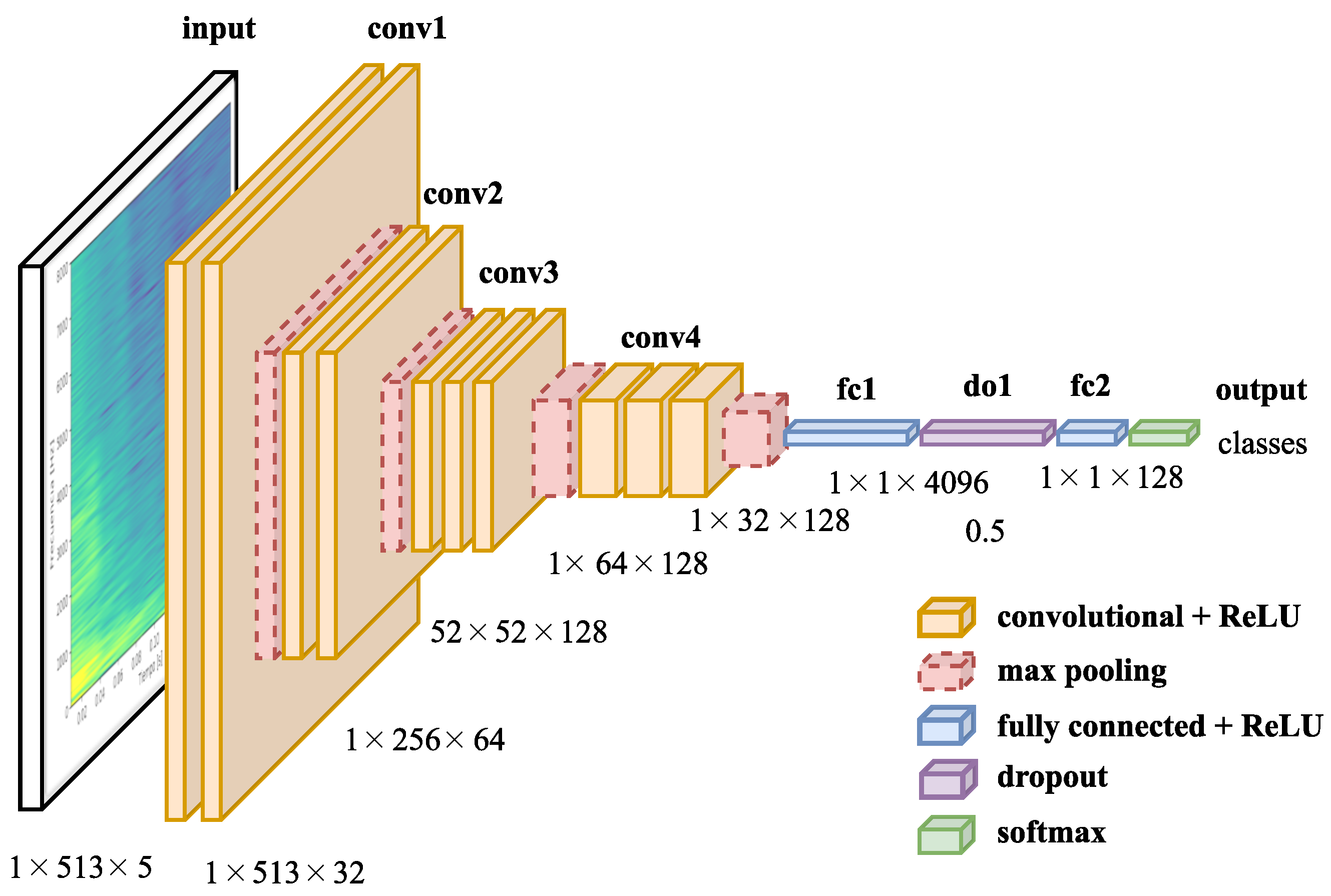
2.2. Voice Recognition
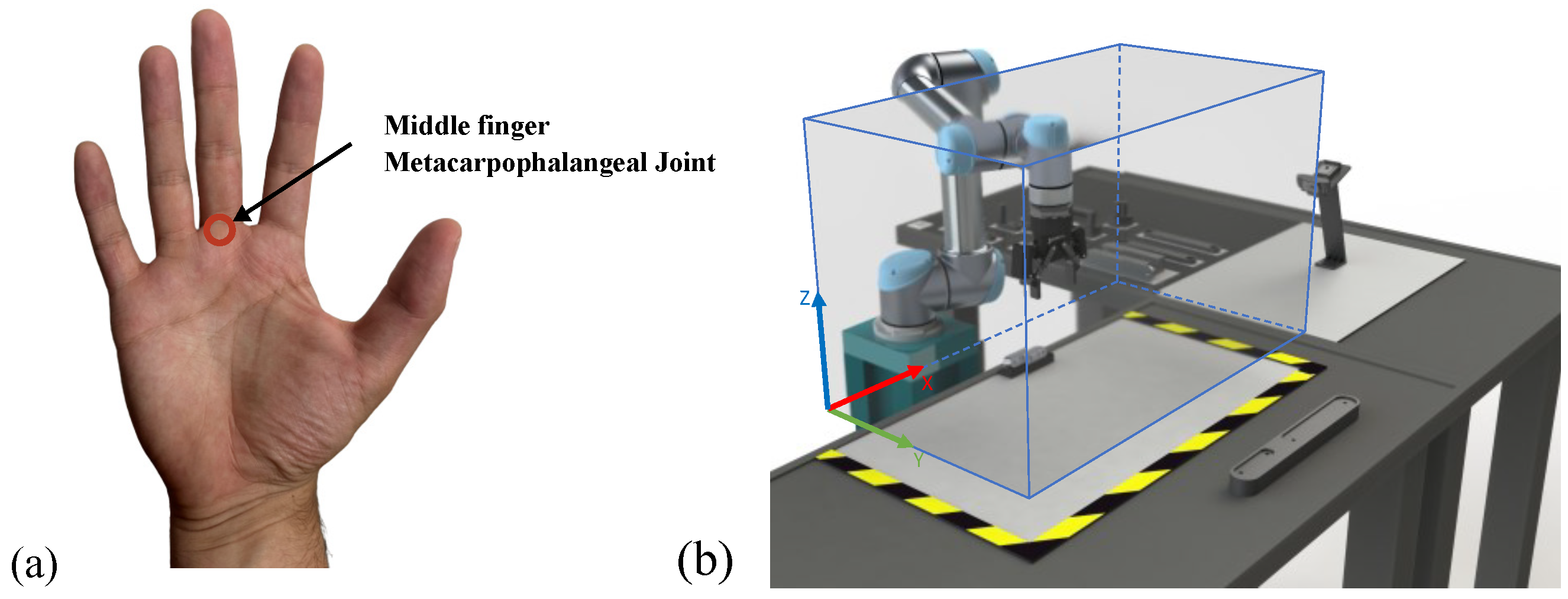
2.3. Human Body Tracking
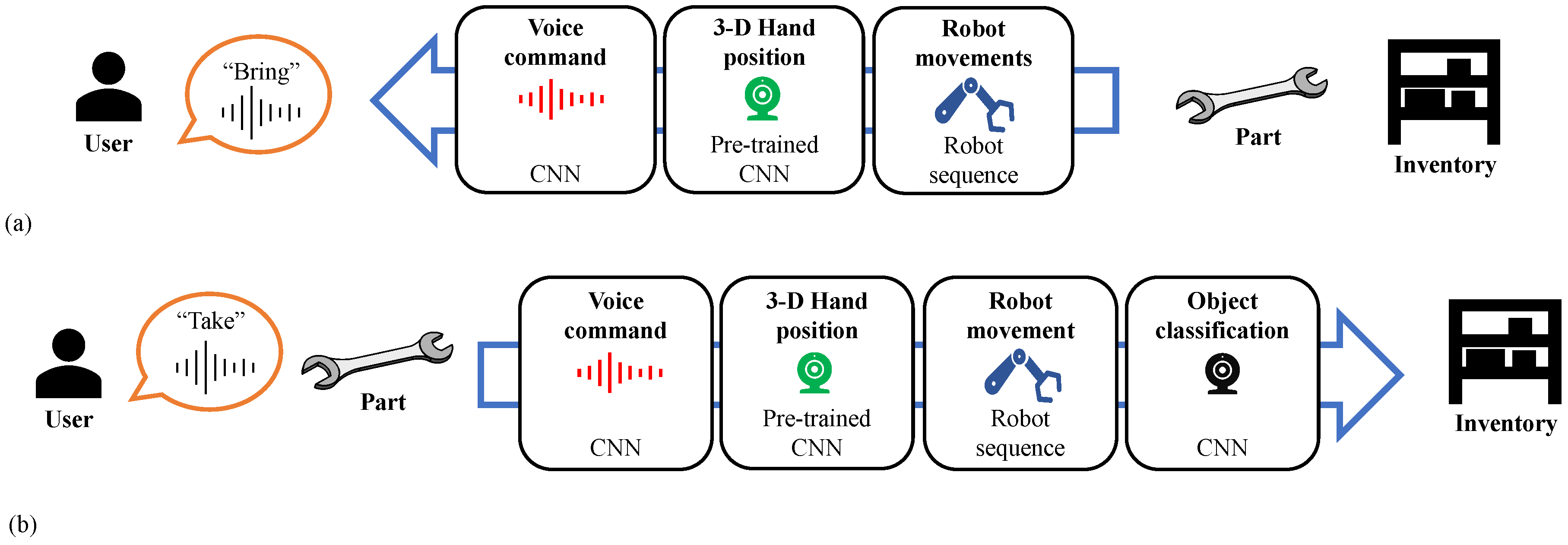
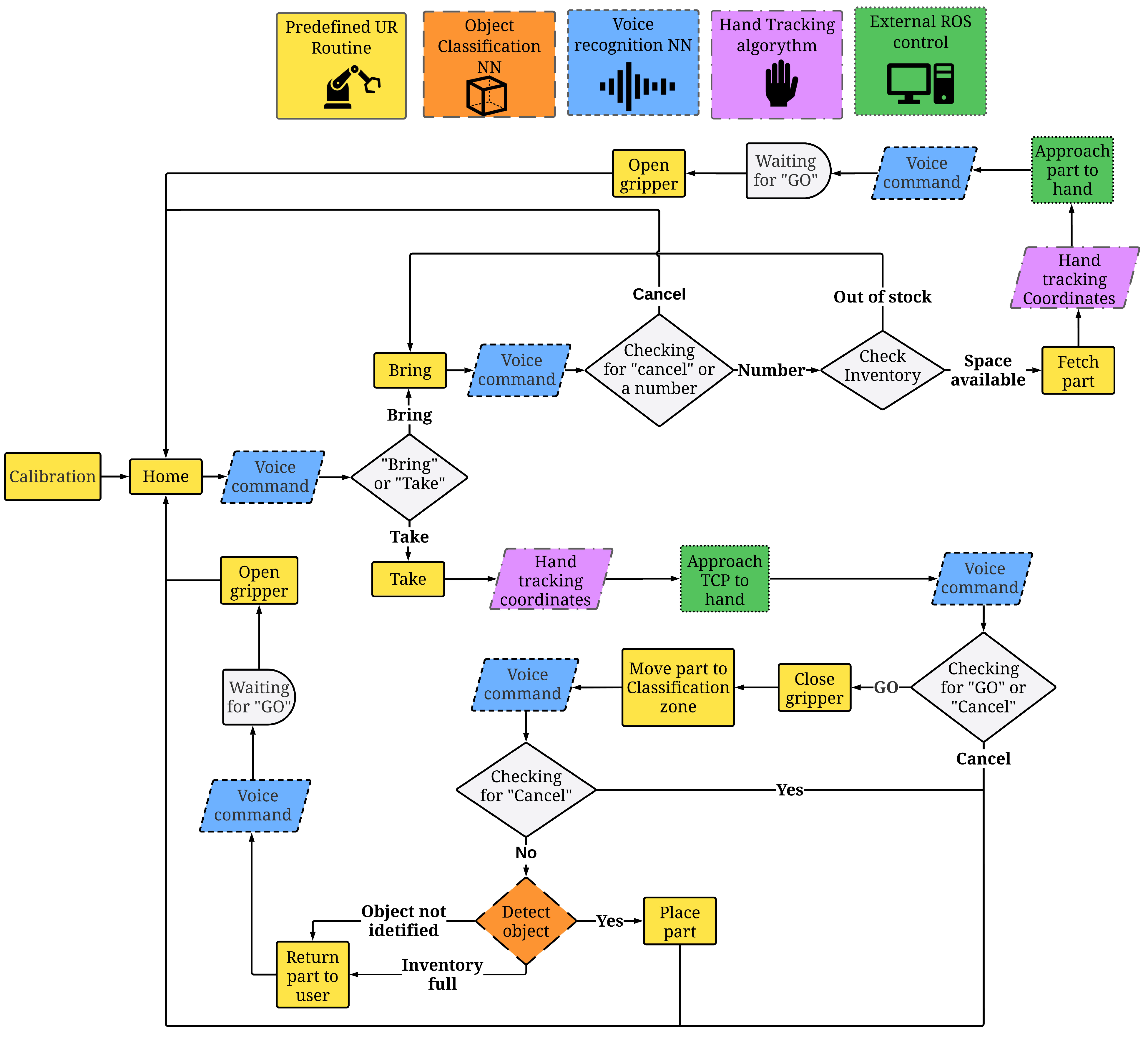
3. Implementation
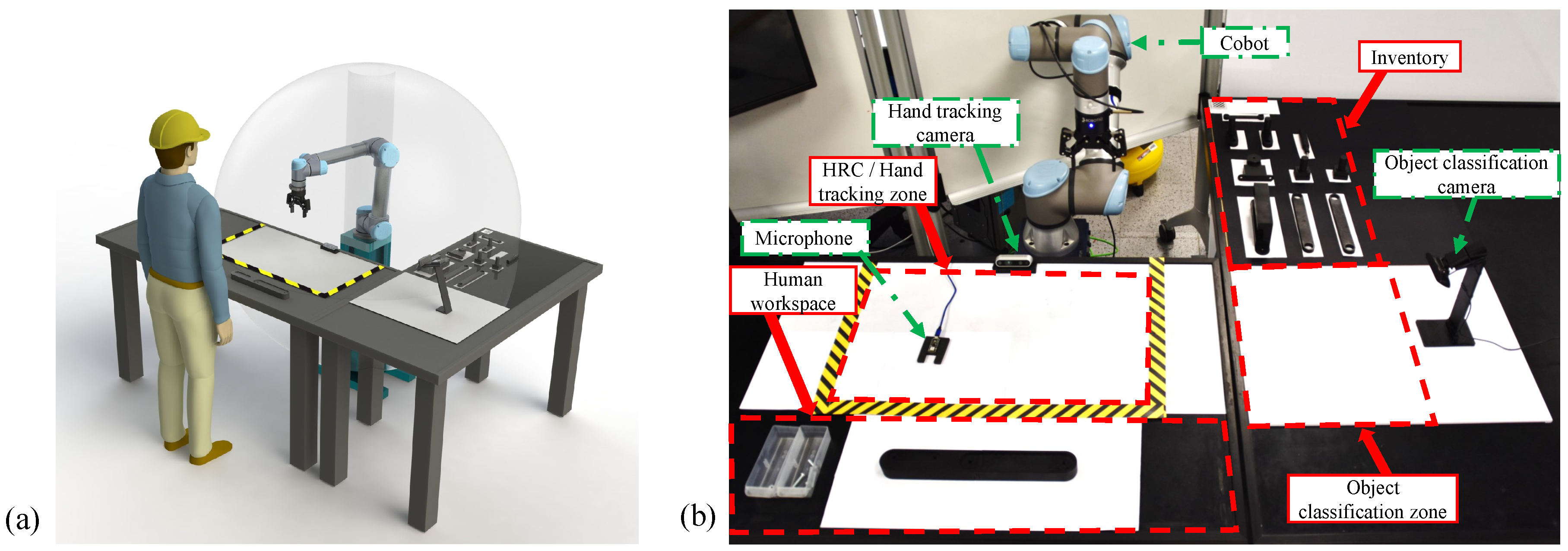
3.1. Assembly and Layout Design
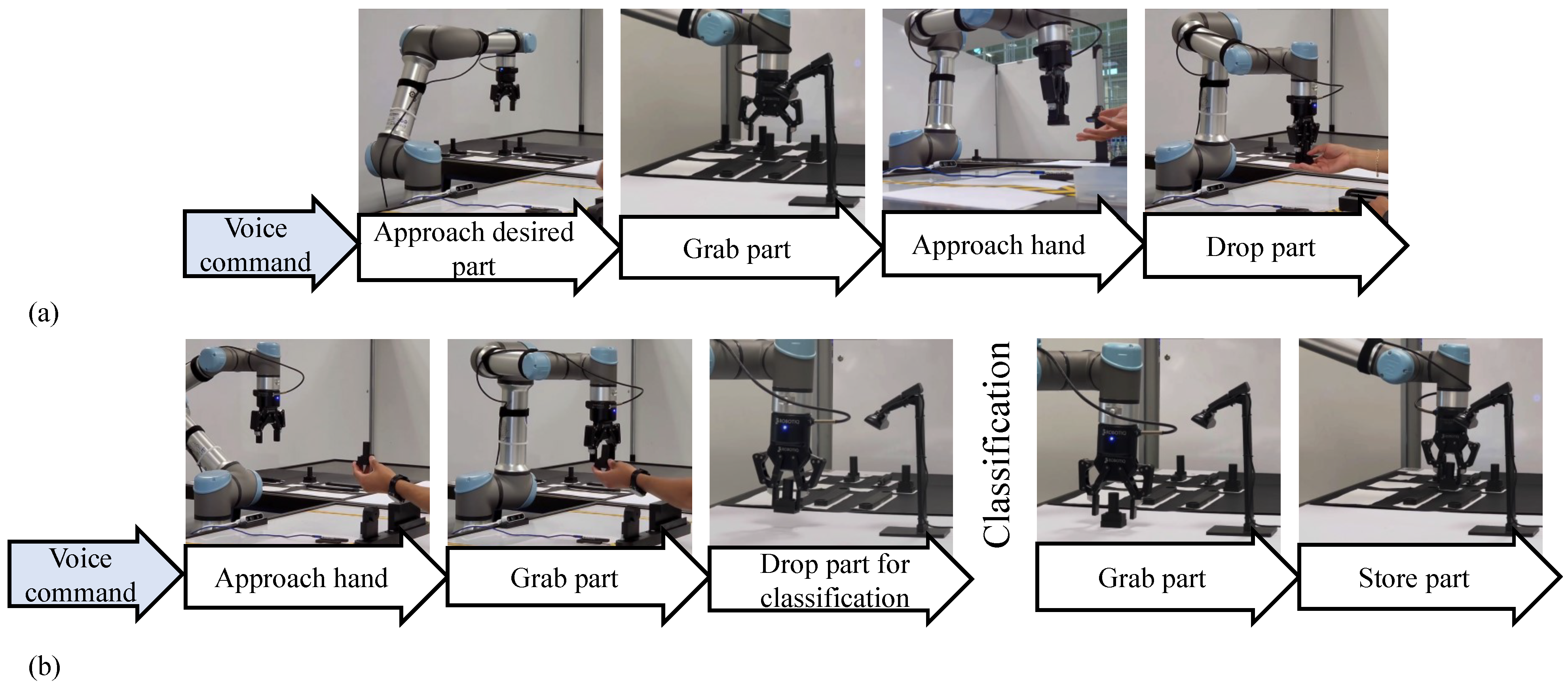
3.2. Robot Operation and Routines
3.3. Object Classification System
3.4. Voice Recognition System
3.5. Hand-Tracking System
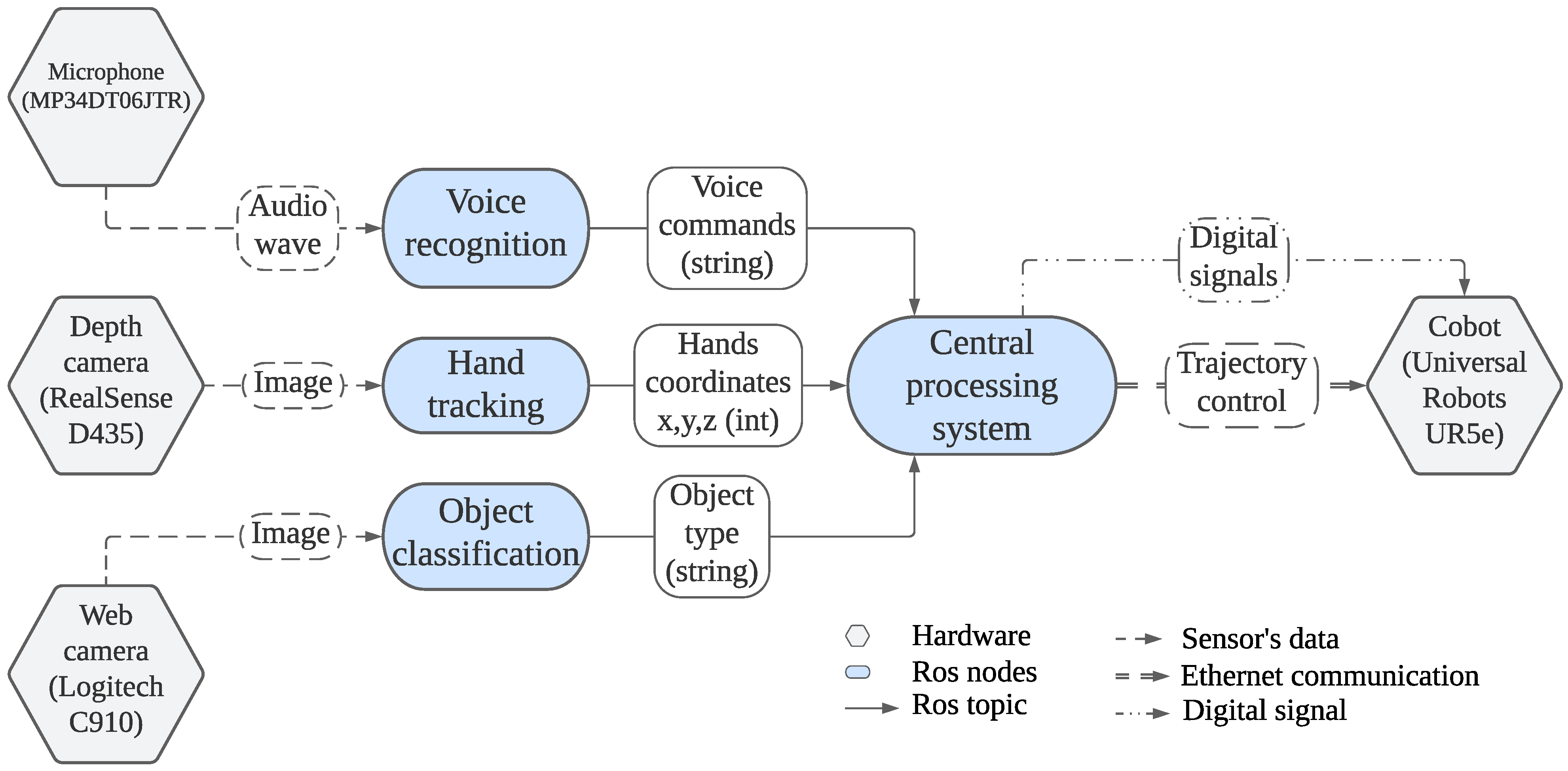
3.6. Systems Integration
4. Experimental Setup: Isolated Systems and Integration
5. Results
5.1. Object Classification
5.2. Voice Recognition
5.3. Hand Tracking
5.4. Integrated System
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Galin, R.; Meshcheryakov, R. Review on human–robot interaction during collaboration in a shared workspace. Lect. Notes Comput. Sci. 2019, 11659, 63–74. [Google Scholar] [CrossRef]
- Tsarouchi, P.; Michalos, G.; Makris, S.; Athanasatos, T.; Dimoulas, K.; Chryssolouris, G. On a human–robot workplace design and task allocation system. Int. J. Comput. Integr. Manuf. 2017, 30, 1272–1279. [Google Scholar] [CrossRef]
- Malik, A.A.; Pandey, V. Drive the Cobots Aright: Guidelines for Industrial Application of Cobots. In Proceedings of the ASME 2022 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, St. Louis, MO, USA, 14–17 August 2022; Volume 5. [Google Scholar] [CrossRef]
- Müller, R.; Vette, M.; Mailahn, O. Process-oriented Task Assignment for Assembly Processes with Human-robot Interaction. Procedia CIRP 2016, 44, 210–215. [Google Scholar] [CrossRef]
- El Zaatari, S.; Marei, M.; Li, W.; Usman, Z. Cobot programming for collaborative industrial tasks: An overview. Robot. Auton. Syst. 2019, 116, 162–180. [Google Scholar] [CrossRef]
- Cherubini, A.; Passama, R.; Crosnier, A.; Lasnier, A.; Fraisse, P. Collaborative manufacturing with physical human–robot interaction. Robot. Comput.-Integr. Manuf. 2016, 40, 1–13. [Google Scholar] [CrossRef]
- Galin, R.; Meshcheryakov, R.; Kamesheva, S.; Samoshina, A. Cobots and the benefits of their implementation in intelligent manufacturing. IOP Conf. Ser. Mater. Sci. Eng. 2020, 862, 032075. [Google Scholar] [CrossRef]
- Javaid, M.; Haleem, A.; Singh, R.P.; Rab, S.; Suman, R. Significant applications of Cobots in the field of manufacturing. Cogn. Robot. 2022, 2, 222–233. [Google Scholar] [CrossRef]
- Shaikh, T.A.; Rasool, T.; Verma, P. Machine intelligence and medical cyber-physical system architectures for smart healthcare: Taxonomy, challenges, opportunities, and possible solutions. Artif. Intell. Med. 2023, 146, 102692. [Google Scholar] [CrossRef]
- Shinde, P.P.; Shah, S. A Review of Machine Learning and Deep Learning Applications. In Proceedings of the 2018 4th International Conference on Computing, Communication Control and Automation (ICCUBEA 2018), Pune, India, 16–18 August 2018. [Google Scholar] [CrossRef]
- Rai, R.; Tiwari, M.K.; Ivanov, D.; Dolgui, A. Machine learning in manufacturing and industry 4.0 applications. Int. J. Prod. Res. 2021, 59, 4773–4778. [Google Scholar] [CrossRef]
- Borboni, A.; Reddy, K.V.V.; Elamvazuthi, I.; AL-Quraishi, M.S.; Natarajan, E.; Ali, S.S.A. The Expanding Role of Artificial Intelligence in Collaborative Robots for Industrial Applications: A Systematic Review of Recent Works. Machines 2023, 11, 111. [Google Scholar] [CrossRef]
- Semeraro, F.; Griffiths, A.; Cangelosi, A. Human–robot collaboration and machine learning: A systematic review of recent research. Robot. Comput.-Integr. Manuf. 2023, 79, 102432. [Google Scholar] [CrossRef]
- Makrini, I.E.; Merckaert, K.; Lefeber, D.; Vanderborght, B. Design of a collaborative architecture for human-robot assembly tasks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1624–1629. [Google Scholar] [CrossRef]
- Murali, P.K.; Darvish, K.; Mastrogiovanni, F. Deployment and evaluation of a flexible human–robot collaboration model based on AND/OR graphs in a manufacturing environment. Intell. Serv. Robot. 2020, 13, 439–457. [Google Scholar] [CrossRef]
- Chen, M.; Soh, H.; Hsu, D.; Nikolaidis, S.; Srinivasa, S.; Chen, M.; Nikolaidis, S.; Soh, H.; Hsu, D. Trust-Aware Decision Making for Human-Robot Collaboration. ACM Trans. Hum.-Robot Interact. (THRI) 2020, 9, 1–23. [Google Scholar] [CrossRef]
- Shukla, D.; Erkent, O.; Piater, J. Learning semantics of gestural instructions for human-robot collaboration. Front. Neurorobotics 2018, 12, 7. [Google Scholar] [CrossRef] [PubMed]
- Rozo, L.; Silvério, J.; Calinon, S.; Caldwell, D.G. Learning controllers for reactive and proactive behaviors in human-robot collaboration. Front. Robot. AI 2016, 3, 30. [Google Scholar] [CrossRef]
- Munzer, T.; Toussaint, M.; Lopes, M. Efficient behavior learning in human–robot collaboration. Auton. Robot. 2018, 42, 1103–1115. [Google Scholar] [CrossRef]
- Grigore, E.C.; Roncone, A.; Mangin, O.; Scassellati, B. Preference-Based Assistance Prediction for Human-Robot Collaboration Tasks. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4441–4448. [Google Scholar] [CrossRef]
- Nikolaidis, S.; Ramakrishnan, R.; Gu, K.; Shah, J. Efficient Model Learning from Joint-Action Demonstrations for Human-Robot Collaborative Tasks. In Proceedings of the 2015 10th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Portland, OR, USA, 2–5 March 2015; pp. 189–196. [Google Scholar] [CrossRef]
- Chen, X.; Jiang, Y.; Yang, C. Stiffness Estimation and Intention Detection for Human-Robot Collaboration. In Proceedings of the 15th IEEE Conference on Industrial Electronics and Applications (ICIEA 2020), Kristiansand, Norway, 9–13 November 2020; pp. 1802–1807. [Google Scholar] [CrossRef]
- Yip, M.; Salcudean, S.; Goldberg, K.; Althoefer, K.; Menciassi, A.; Opfermann, J.D.; Krieger, A.; Swaminathan, K.; Walsh, C.J.; Huang, H.H.; et al. Artificial intelligence meets medical robotics. Science 2023, 381, 141–146. [Google Scholar] [CrossRef]
- Droste, R.; Drukker, L.; Papageorghiou, A.T.; Noble, J.A. Automatic Probe Movement Guidance for Freehand Obstetric Ultrasound. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020; Proceedings, Part III. Springer: Berlin/Heidelberg, Germany, 2020; pp. 583–592. [Google Scholar] [CrossRef]
- Ahmad, M.A.; Ourak, M.; Gruijthuijsen, C.; Deprest, J.; Vercauteren, T.; Poorten, E.V. Deep learning-based monocular placental pose estimation: Towards collaborative robotics in fetoscopy. Int. J. Comput. Assist. Radiol. Surg. 2020, 15, 1561–1571. [Google Scholar] [CrossRef]
- Kwon, J.; Park, D. Hardware/Software Co-Design for TinyML Voice-Recognition Application on Resource Frugal Edge Devices. Appl. Sci. 2021, 11, 11073. [Google Scholar] [CrossRef]
- Ionescu, T.B.; Schlund, S. Programming cobots by voice: A human-centered, web-based approach. Procedia CIRP 2021, 97, 123–129. [Google Scholar] [CrossRef]
- Matsusaka, Y.; Fujii, H.; Okano, T.; Hara, I. Health exercise demonstration robot TAIZO and effects of using voice command in robot-human collaborative demonstration. In Proceedings of the RO-MAN 2009—The 18th IEEE International Symposium on Robot and Human Interactive Communication, Toyama, Japan, 27 September–2 October 2009; pp. 472–477. [Google Scholar] [CrossRef]
- Sekkat, H.; Tigani, S.; Saadane, R.; Chehri, A.; García, O.R. Vision-Based Robotic Arm Control Algorithm Using Deep Reinforcement Learning for Autonomous Objects Grasping. Appl. Sci. 2021, 11, 7917. [Google Scholar] [CrossRef]
- Gomes, N.M.; Martins, F.N.; Lima, J.; Wörtche, H. Reinforcement Learning for Collaborative Robots Pick-and-Place Applications: A Case Study. Automation 2022, 3, 223–241. [Google Scholar] [CrossRef]
- Aswad, F.E.; Djogdom, G.V.T.; Otis, M.J.; Ayena, J.C.; Meziane, R. Image generation for 2D-CNN using time-series signal features from foot gesture applied to select cobot operating mode. Sensors 2021, 21, 5743. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, I.R.; Barbosa, G.; Filho, A.O.; Cani, C.; Sadok, D.H.; Kelner, J.; Souza, R.; Marquezini, M.V.; Lins, S. A New Mechanism for Collision Detection in Human–Robot Collaboration using Deep Learning Techniques. J. Control. Autom. Electr. Syst. 2022, 33, 406–418. [Google Scholar] [CrossRef]
- Liu, H.; Fang, T.; Zhou, T.; Wang, Y.; Wang, L. Deep Learning-based Multimodal Control Interface for Human-Robot Collaboration. Procedia CIRP 2018, 72, 3–8. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef]
- Chen, Q.; Song, Z.; Dong, J.; Huang, Z.; Hua, Y.; Yan, S. Contextualizing object detection and classification. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 13–27. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. In Proceedings of the Computer Vision Conference (CVC 2019), Las Vegas, NV, USA, 2–3 May 2019; pp. 128–144. [Google Scholar] [CrossRef]
- Singh, A.P.; Nath, R.; Kumar, S. A Survey: Speech Recognition Approaches and Techniques. In Proceedings of the 2018 5th IEEE Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (UPCON), Gorakhpur, India, 2–4 November 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Lyashenko, V.; Laariedh, F.; Sotnik, S.; Ayaz Ahmad, M. Recognition of Voice Commands Based on Neural Network. TEM J. 2021, 10, 583–591. [Google Scholar] [CrossRef]
- Ansari, M.I.; Hasan, T.; Member, S. SpectNet: End-to-End Audio Signal Classification Using Learnable Spectrograms. arXiv 2022, arXiv:2211.09352. [Google Scholar]
- Bobick, A.; Davis, J. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [PubMed]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Zhang, F.; Bazarevsky, V.; Vakunov, A.; Tkachenka, A.; Sung, G.; Chang, C.L.; Grundmann, M. MediaPipe Hands: On-device Real-time Hand Tracking. arXiv 2020, arXiv:2006.10214. [Google Scholar]
- Hung, P.D.; Minh, T.; Hoang, L.; Minh, P. Vietnamese speech command recognition using recurrent neural networks. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 194–201. [Google Scholar] [CrossRef]
- Paxton, C.; Hundt, A.; Jonathan, F.; Guerin, K.; Hager, G.D. CoSTAR: Instructing collaborative robots with behavior trees and vision. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar] [CrossRef]
- Morrison, D.; Corke, P.; Leitner, J. Learning robust, real-time, reactive robotic grasping. Int. J. Rob. Res. 2020, 39, 183–201. [Google Scholar] [CrossRef]
- Darvish, K.; Bruno, B.; Simetti, E.; Mastrogiovanni, F.; Casalino, G. Interleaved Online Task Planning, Simulation, Task Allocation and Motion Control for Flexible Human-Robot Cooperation. In Proceedings of the RO-MAN 2018—27th IEEE International Symposium on Robot and Human Interactive Communication, Nanjing, China, 27–31 August 2018; pp. 58–65. [Google Scholar] [CrossRef]
- Toussaint, M.; Munzer, T.; Mollard, Y.; Wu, L.Y.; Vien, N.A.; Lopes, M. Relational activity processes for modeling concurrent cooperation. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5505–5511. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mendez, E.; Ochoa, O.; Olivera-Guzman, D.; Soto-Herrera, V.H.; Luna-Sánchez, J.A.; Lucas-Dophe, C.; Lugo-del-Real, E.; Ayala-Garcia, I.N.; Alvarado Perez, M.; González, A. Integration of Deep Learning and Collaborative Robot for Assembly Tasks. Appl. Sci. 2024, 14, 839. https://doi.org/10.3390/app14020839
Mendez E, Ochoa O, Olivera-Guzman D, Soto-Herrera VH, Luna-Sánchez JA, Lucas-Dophe C, Lugo-del-Real E, Ayala-Garcia IN, Alvarado Perez M, González A. Integration of Deep Learning and Collaborative Robot for Assembly Tasks. Applied Sciences. 2024; 14(2):839. https://doi.org/10.3390/app14020839
Chicago/Turabian StyleMendez, Enrico, Oscar Ochoa, David Olivera-Guzman, Victor Hugo Soto-Herrera, José Alfredo Luna-Sánchez, Carolina Lucas-Dophe, Eloina Lugo-del-Real, Ivo Neftali Ayala-Garcia, Miriam Alvarado Perez, and Alejandro González. 2024. "Integration of Deep Learning and Collaborative Robot for Assembly Tasks" Applied Sciences 14, no. 2: 839. https://doi.org/10.3390/app14020839
APA StyleMendez, E., Ochoa, O., Olivera-Guzman, D., Soto-Herrera, V. H., Luna-Sánchez, J. A., Lucas-Dophe, C., Lugo-del-Real, E., Ayala-Garcia, I. N., Alvarado Perez, M., & González, A. (2024). Integration of Deep Learning and Collaborative Robot for Assembly Tasks. Applied Sciences, 14(2), 839. https://doi.org/10.3390/app14020839