
Machine Learning for Predicting Neurodevelopmental Disorders in Children





Abstract
Featured Application
Abstract
1. Introduction
- Autism spectrum disorders (ASD), which are characterized by behavior and communication difficulties;
- Attention deficit hyperactivity disorder (ADHD), which is characterized by inattention, impulsivity, and hyperactivity;
- Intellectual disability (ID), indicated by cognitive impairments;
- Specific learning disorder (SLD), characterized by a deficiency in communication;
- Communication disorders (CDs), illustrated by persistent difficulties in language acquisition and usage.
2. Materials and Methods
2.1. Data Measurements
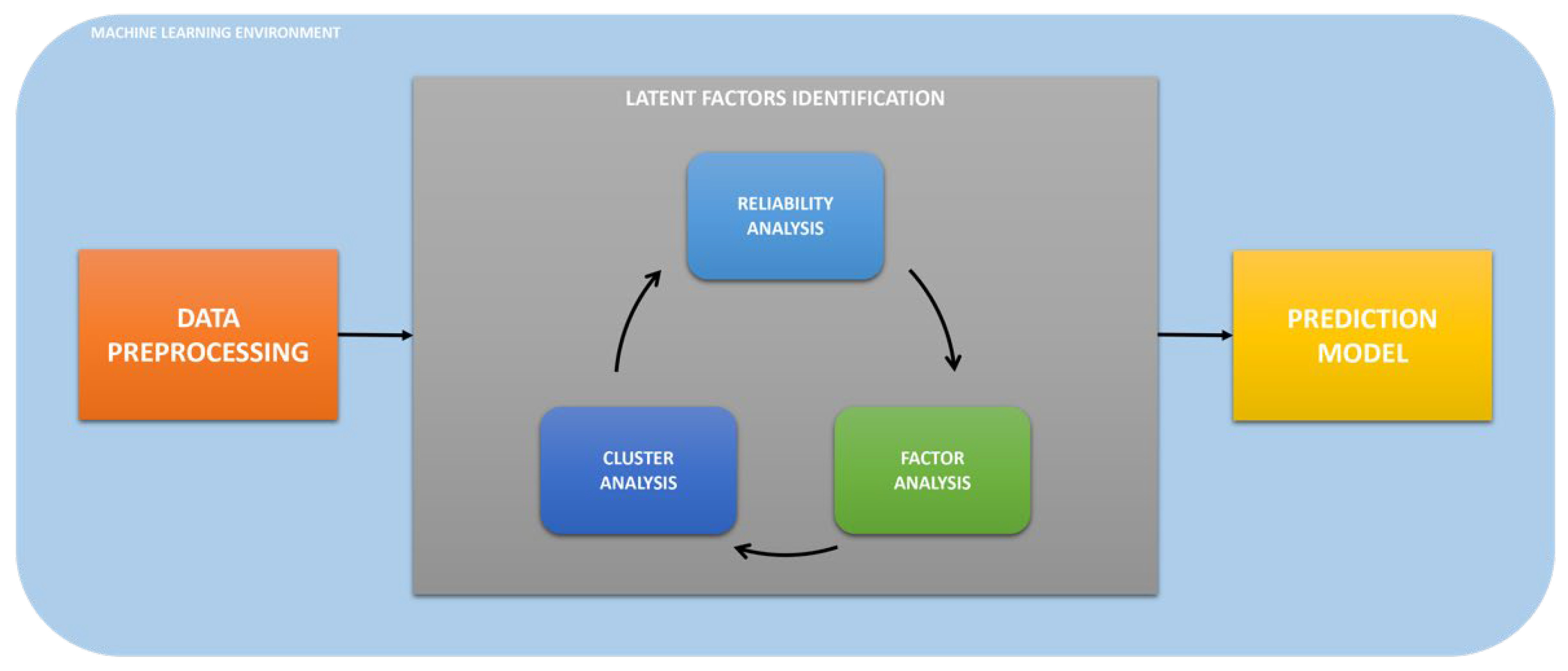
2.2. Analysis Workflow
2.3. Application Context
2.4. Data Preprocessing
- We addressed the issue of missing data, which constituted 2.1% of the initial dataset comprising 520 instances, by employing the “impute” widget of the Orange data mining software. Specifically, we utilized a model-based imputer (simple tree) approach. This method constructs a decision tree for each attribute with missing values, using the remaining attributes to predict and impute the missing data. This technique is particularly noted for its ability to maintain the intrinsic structure of the data and provide a statistically sound solution for handling incomplete observations in datasets.
- We selected the 13 features under study using the “select column” widget.
- We standardized the selected variables using the “continue” widget, with mean = 0 and SD = 1.
- We considered only inliers using the “outliers” widget.
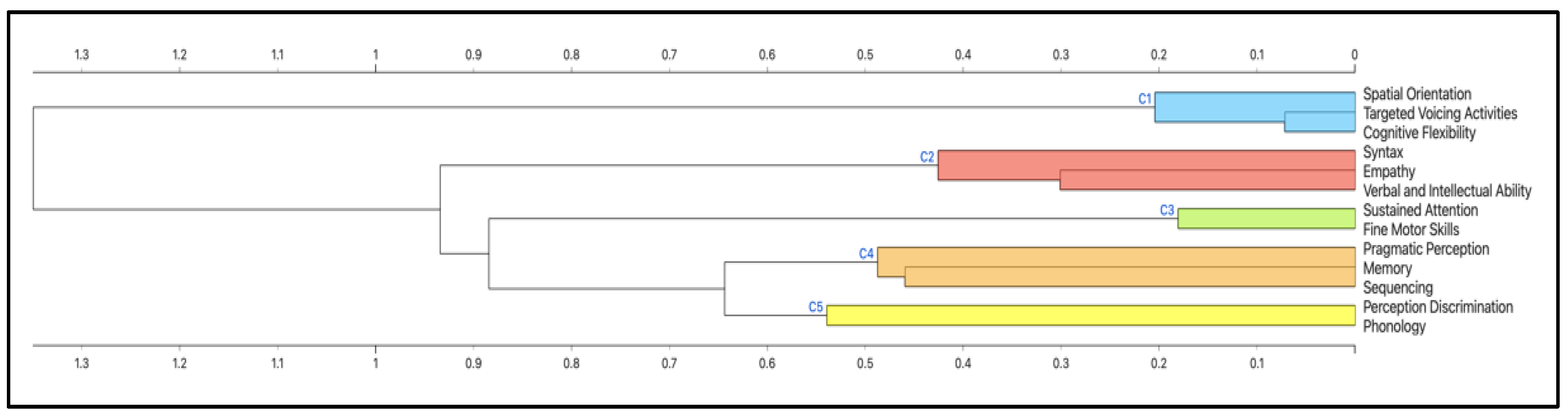
2.5. Cluster Analysis
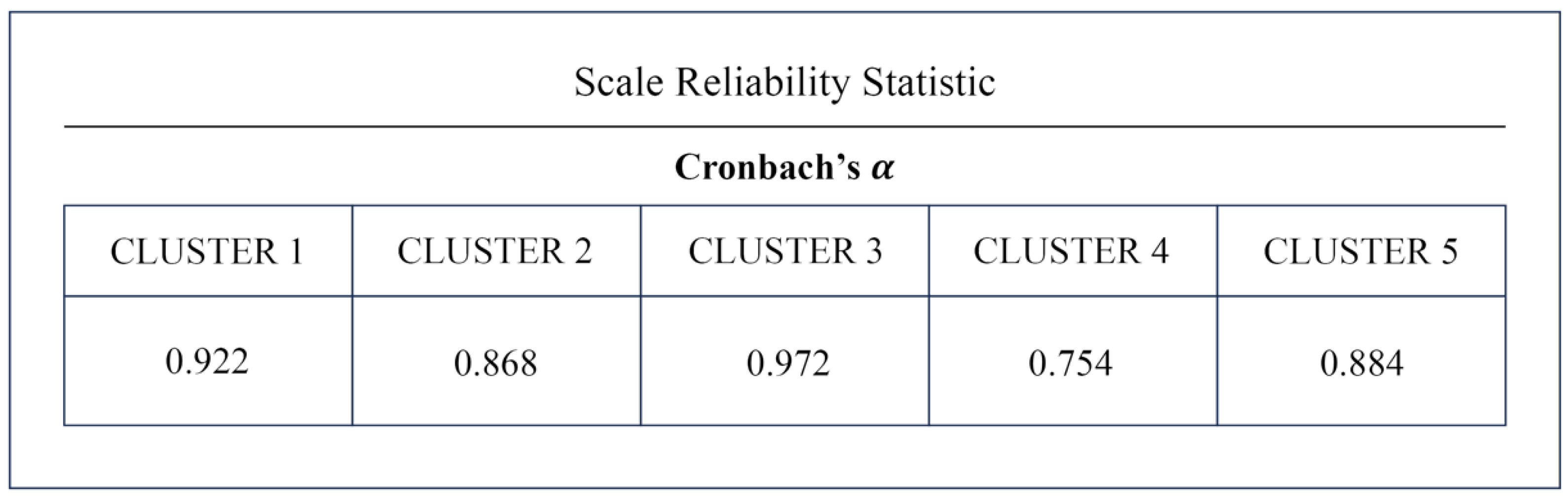
2.6. Reliability Analysis
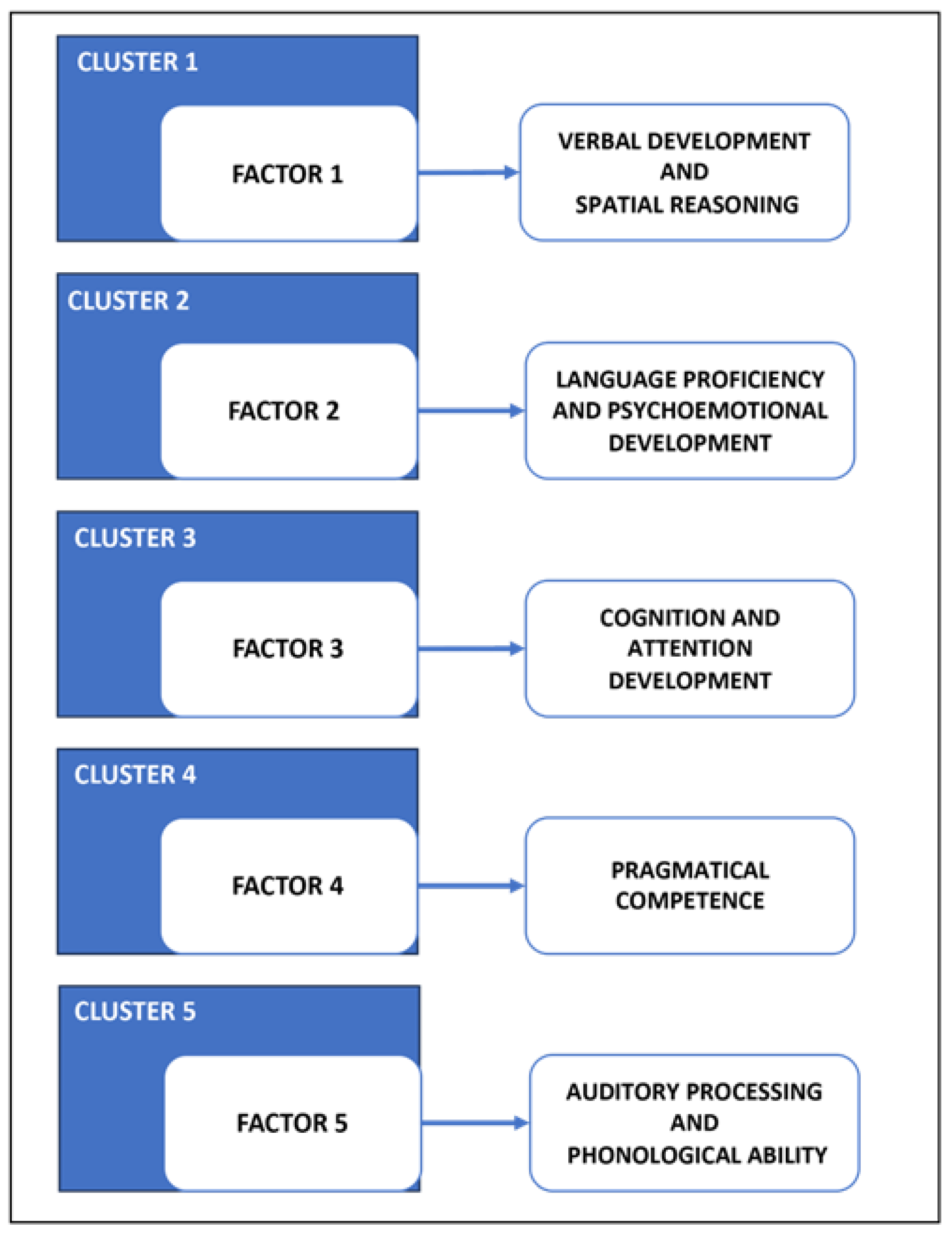
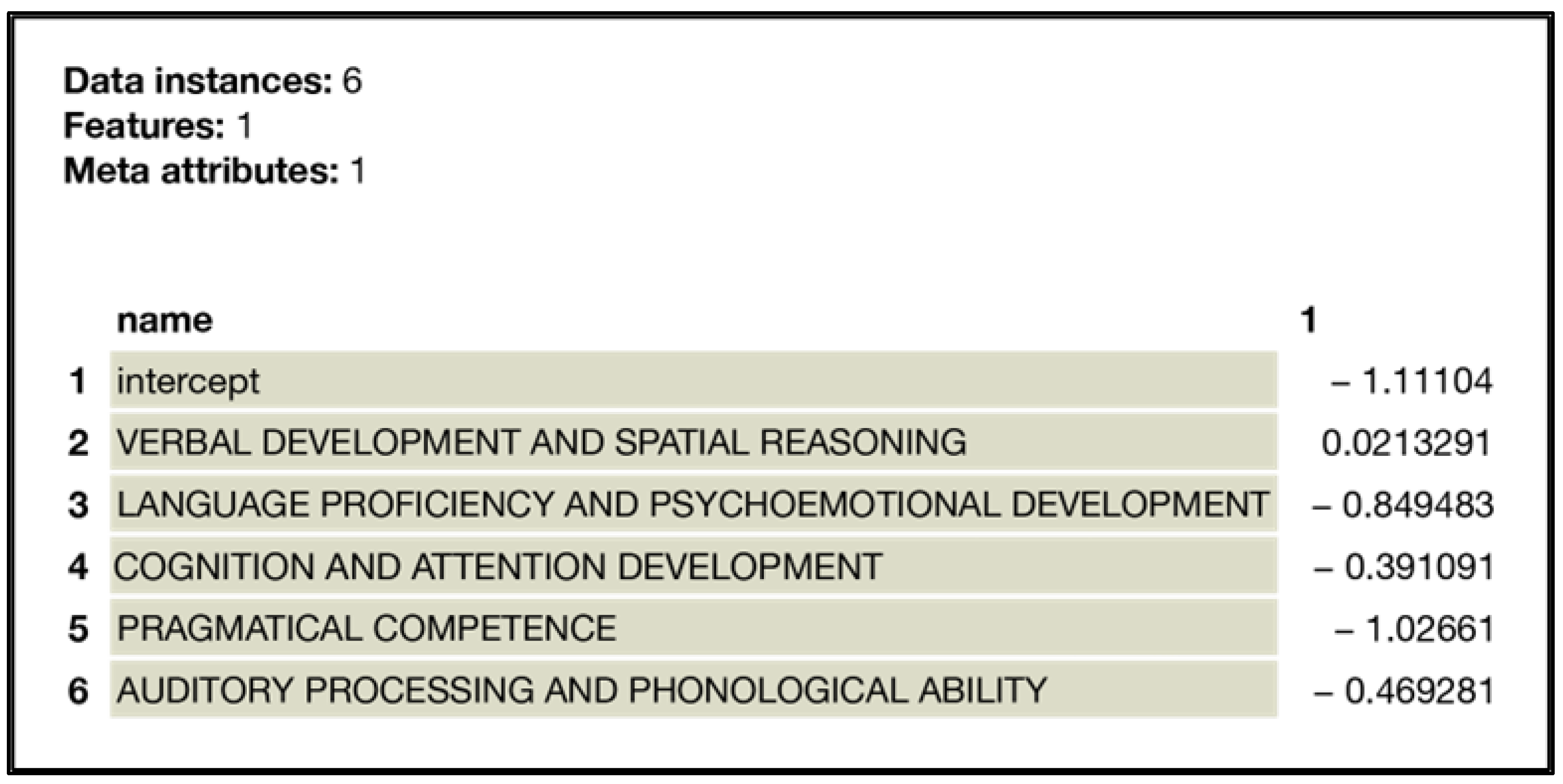
2.7. Factor Analysis
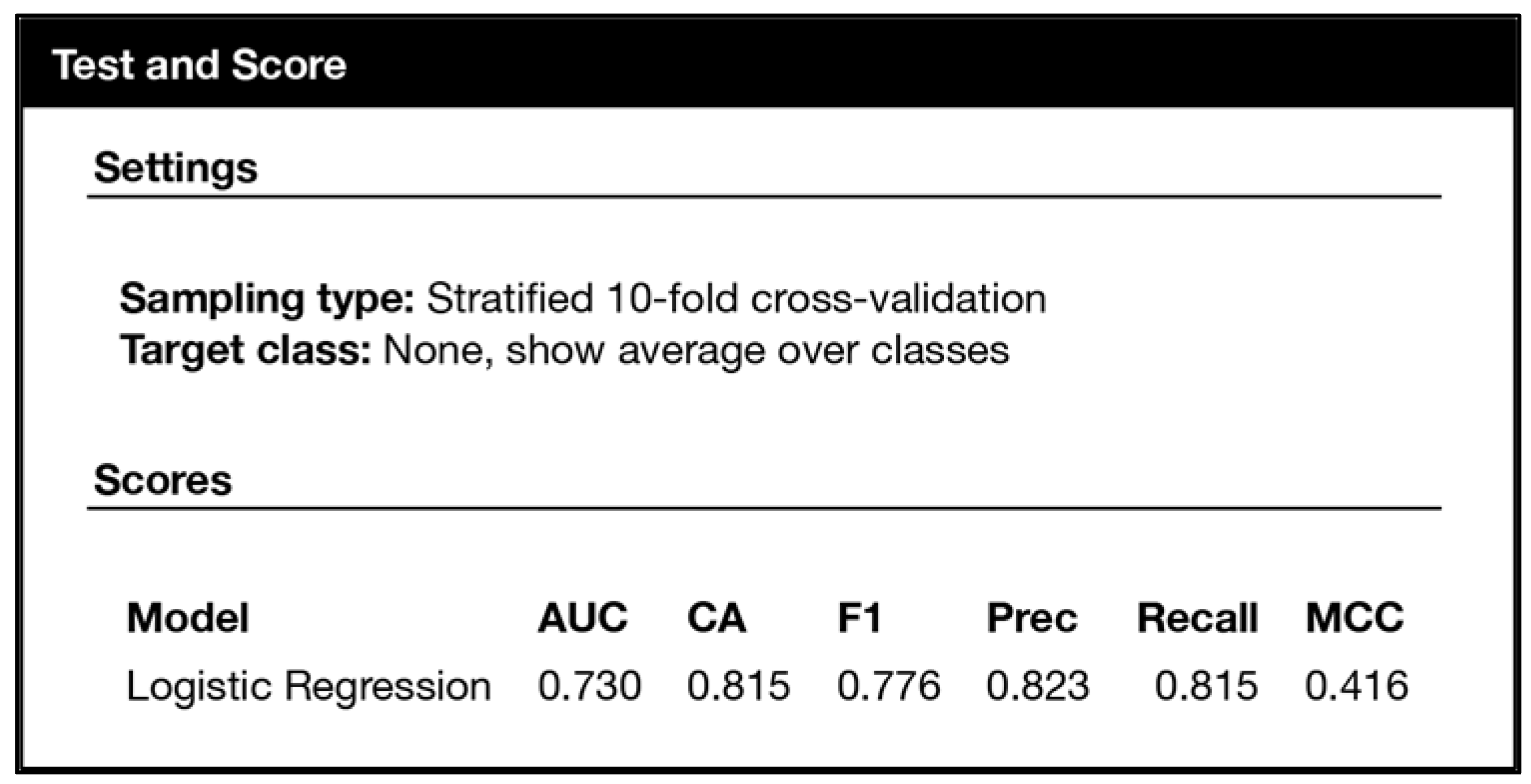
2.8. Prediction Model
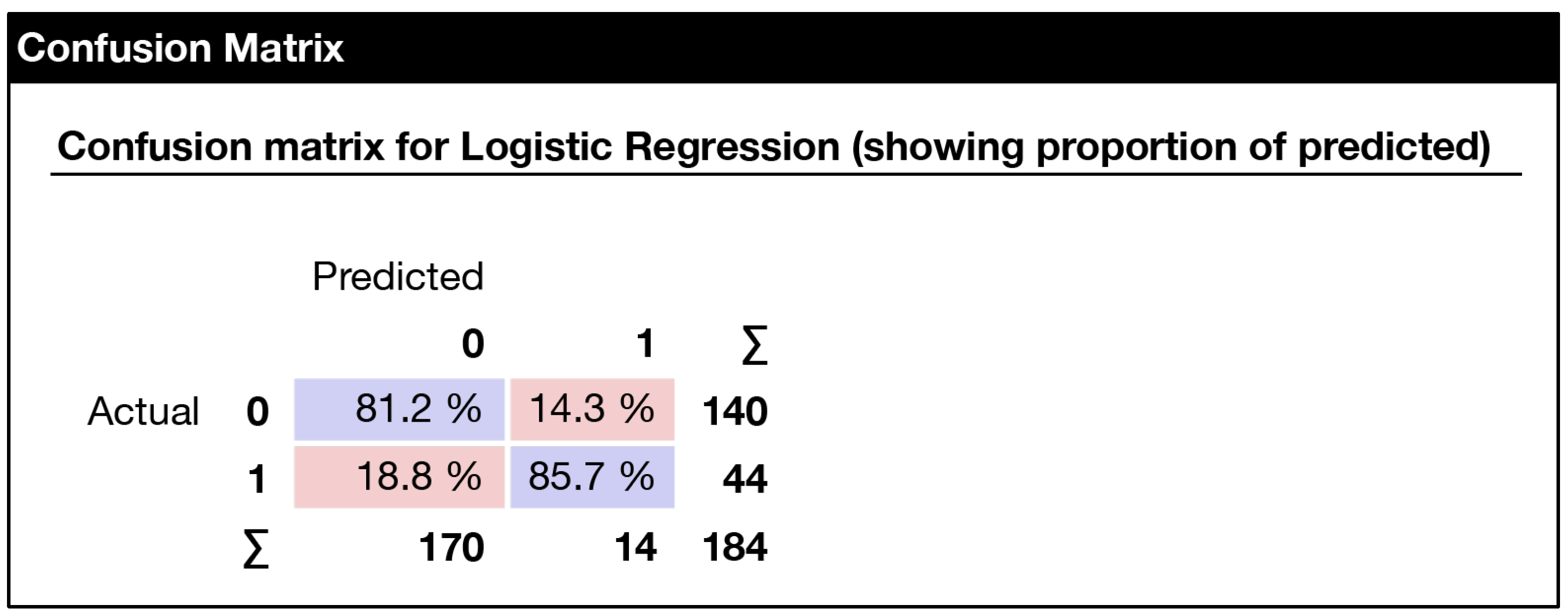
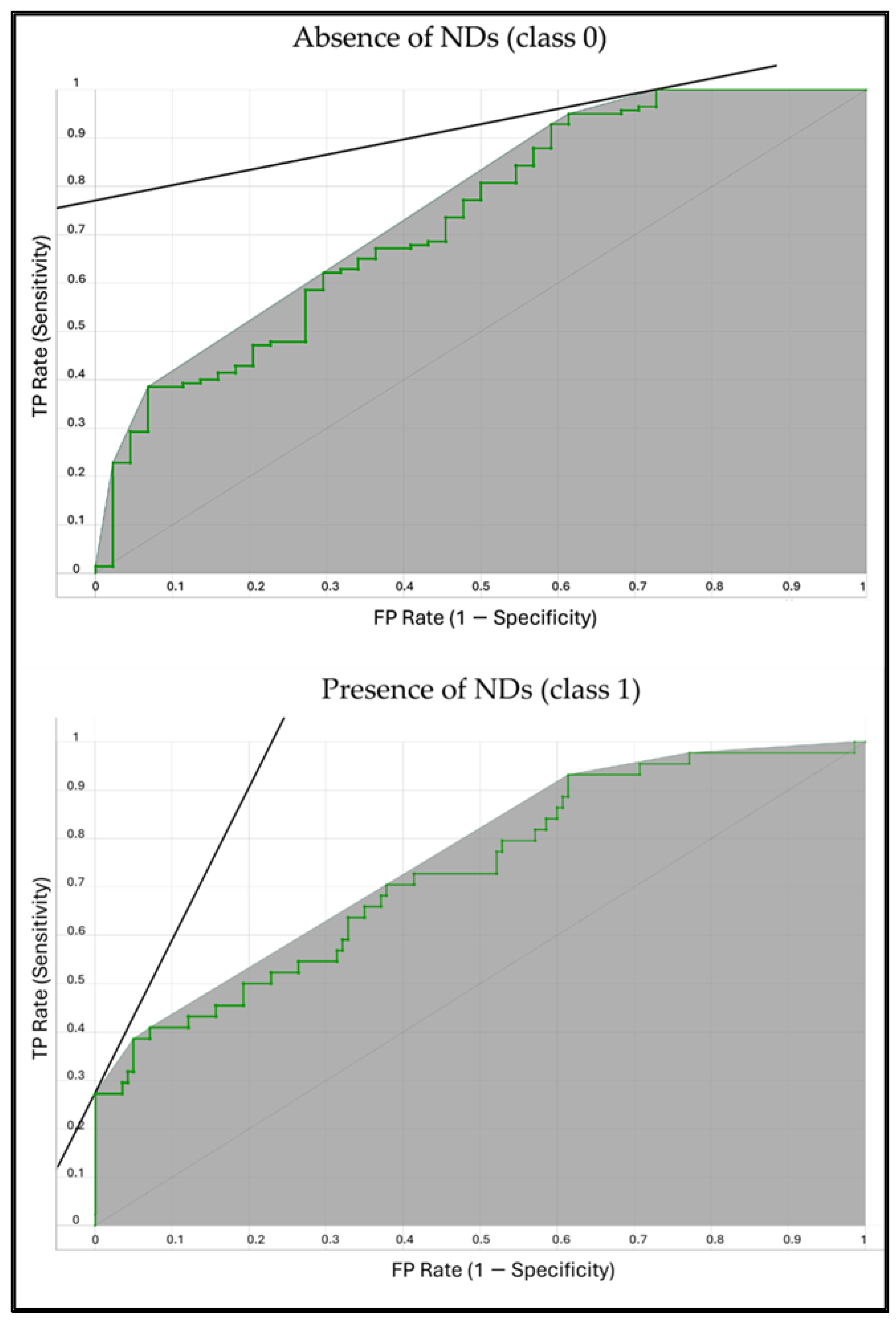
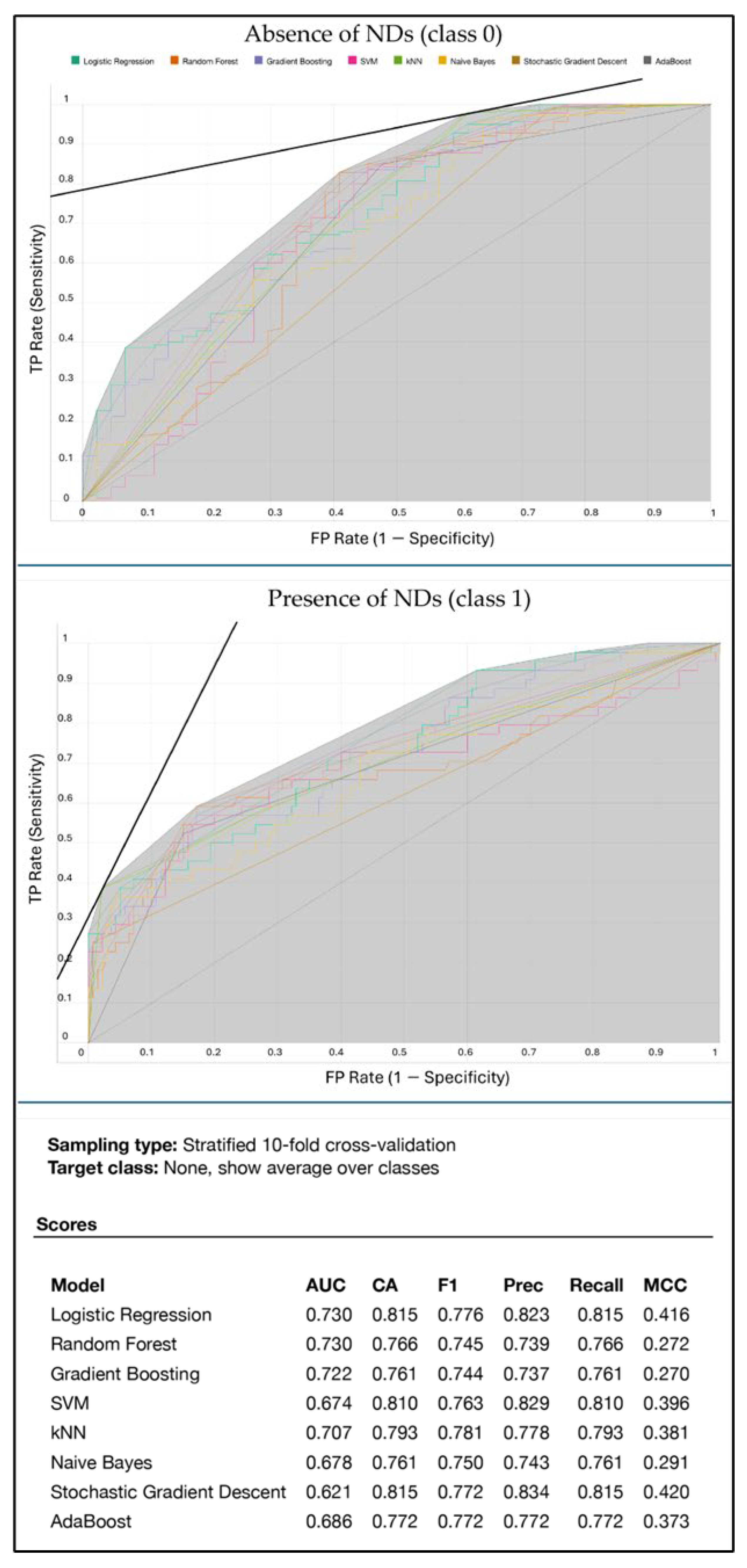
3. Experimental Results and Discussion
3.1. Experiments
3.2. Advantages and Limitations of Applying Machine Learning in the Study of Neurodevelopmental Disorders
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADHD | attention deficit hyperactivity disorder |
| ASDs | autism spectrum disorders |
| AUC | area under the curve |
| CA | accuracy |
| CDs | communication disorders |
| CNN | convolutional neural networks |
| DL | deep learning approaches |
| DLD | developmental language disorder |
| F1 | F1 score |
| FN | false negative |
| FP | false positive |
| GDD | global developmental delay |
| GDPR | general data protection regulation |
| ID | intellectual disability |
| k-NN | k-nearest neighbor |
| LDA | linear discriminant analysis |
| LPC | linear predictive coding |
| MCC | Matthews correlation coefficient |
| MFCC | mel-frequency cepstral coefficients |
| ML | machine learning |
| NDs | neurodevelopmental disorders |
| Prec | precision |
| RBF | radial basis function |
| RBFNN | radial basis function neural network |
| ROC | receiver operating characteristic |
| SG | serious game |
| SGD | stochastic gradient descent |
| SLD | specific learning disorder |
| SVM | support vector machine |
| TD | typically developed individuals |
| TN | true negative |
| TP | true positive |
References
- American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders, 5th ed.; American Psychiatric Association: Arlington, VA, USA, 2013; ISBN 978-0-89042-555-8. [Google Scholar]
- Thapar, A.; Cooper, M.; Rutter, M. Neurodevelopmental Disorders. Lancet Psychiatry 2017, 4, 339–346. [Google Scholar] [CrossRef] [PubMed]
- Kwame, A.; Petrucka, P.M. A Literature-Based Study of Patient-Centered Care and Communication in Nurse-Patient Interactions: Barriers, Facilitators, and the Way Forward. BMC Nurs. 2021, 20, 158. [Google Scholar]
- Homberg, J.R.; Kyzar, E.J.; Nguyen, M.; Norton, W.H.; Pittman, J.; Poudel, M.K.; Gaikwad, S.; Nakamura, S.; Koshiba, M.; Yamanouchi, H.; et al. Understanding Autism and Other Neurodevelopmental Disorders through Experimental Translational Neurobehavioral Models. Neurosci. Biobehav. Rev. 2016, 65, 292–312. [Google Scholar] [CrossRef] [PubMed]
- Vakadkar, K.; Purkayastha, D.; Krishnan, D. Detection of Autism Spectrum Disorder in Children Using Machine Learning Techniques. SN Comput. Sci. 2021, 2, 386. [Google Scholar] [CrossRef] [PubMed]
- De Barros, F.R.D.; da Silva, C.N.F.; de Castro Michelassi, G.; Brentani, H.; Nunes, F.L.; Machado-Lima, A. Computer Aided Diagnosis of Neurodevelopmental Disorders and Genetic Syndromes Based on Facial Images-a Systematic Literature Review. Heliyon 2023, 9, e20517. [Google Scholar]
- Lombardo, M.V.; Pierce, K.; Eyler, L.T.; Carter Barnes, C.; Ahrens-Barbeau, C.; Solso, S.; Campbell, K.; Courchesne, E. Different Functional Neural Substrates for Good and Poor Language Outcome in Autism. Neuron 2015, 86, 567–577. [Google Scholar] [CrossRef]
- Young, S.; Adamo, N.; Ásgeirsdóttir, B.B.; Branney, P.; Beckett, M.; Colley, W.; Cubbin, S.; Deeley, Q.; Farrag, E.; Gudjonsson, G. Females with ADHD: An Expert Consensus Statement Taking a Lifespan Approach Providing Guidance for the Identification and Treatment of Attention-Deficit/Hyperactivity Disorder in Girls and Women. BMC Psychiatry 2020, 20, 404. [Google Scholar] [CrossRef]
- Abi-Jaoude, E.; Naylor, K.T.; Pignatiello, A. Smartphones, Social Media Use and Youth Mental Health. Can. Med. Assoc. J. 2020, 192, E136–E141. [Google Scholar] [CrossRef] [PubMed]
- Filippello, P.; Buzzai, C.; Messina, G.; Mafodda, A.V.; Sorrenti, L. School Refusal in Students with Low Academic Performances and Specific Learning Disorder. The Role of Self-Esteem and Perceived Parental Psychological Control. Int. J. Disabil. Dev. Educ. 2020, 67, 592–607. [Google Scholar] [CrossRef]
- Bourgeron, T. What Do We Know about Early Onset Neurodevelopmental Disorders? In Translational Neuroscience: Toward New Therapies; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- American Psychiatric Association. DSM-5 Intellectual Disability Fact Sheet. 2013. Available online: https://www.psychiatry.org/File%20Library/Psychiatrists/Practice/DSM/APA_DSM-5-Intellectual-Disability.pdf (accessed on 25 December 2023).
- Harris, J.C. New Classification for Neurodevelopmental Disorders in DSM-5. Curr. Opin. Psychiatry 2014, 27, 95–97. [Google Scholar] [CrossRef]
- Merrells, J.; Buchanan, A.; Waters, R. “We Feel Left out”: Experiences of Social Inclusion from the Perspective of Young Adults with Intellectual Disability. J. Intellect. Dev. Disabil. 2019, 44, 13–22. [Google Scholar]
- Alam, S.; Raja, P.; Gulzar, Y. Investigation of Machine Learning Methods for Early Prediction of Neurodevelopmental Disorders in Children. Wirel. Commun. Mob. Comput. 2022, 2022, 5766386. [Google Scholar] [CrossRef]
- van Rooij, D.; Zhang-James, Y.; Buitelaar, J.; Faraone, S.V.; Reif, A.; Grimm, O. Structural Brain Morphometry as Classifier and Predictor of ADHD and Reward-Related Comorbidities. Front. Psychiatry 2022, 13, 869627. [Google Scholar] [PubMed]
- Wong, J.; Cohn, E.S.; Coster, W.J.; Orsmond, G.I. “Success Doesn’t Happen in a Traditional Way”: Experiences of School Personnel Who Provide Employment Preparation for Youth with Autism Spectrum Disorder. Res. Autism Spectr. Disord. 2020, 77, 101631. [Google Scholar] [CrossRef]
- Moreau, C.; Deruelle, C.; Auzias, G. Machine Learning for Neurodevelopmental Disorders. In Machine Learning for Brain Disorders; Colliot, O., Ed.; Humana: New York, NY, USA, 2023; ISBN 978-1-07-163194-2. [Google Scholar]
- Toki, E.I.; Tatsis, G.; Tatsis, V.A.; Plachouras, K.; Pange, J.; Tsoulos, I.G. Applying Neural Networks on Biometric Datasets for Screening Speech and Language Deficiencies in Child Communication. Mathematics 2023, 11, 1643. [Google Scholar] [CrossRef]
- Rice, C.E.; Carpenter, L.A.; Morrier, M.J.; Lord, C.; DiRienzo, M.; Boan, A.; Skowyra, C.; Fusco, A.; Baio, J.; Esler, A.; et al. Defining in Detail and Evaluating Reliability of DSM-5 Criteria for Autism Spectrum Disorder (ASD) among Children. J. Autism Dev. Disord. 2022, 52, 5308–5320. [Google Scholar] [CrossRef] [PubMed]
- Fletcher, J.M.; Miciak, J. The Identification of Specific Learning Disabilities: A Summary of Research on Best Practices; Meadows Center for Preventing Educational Risk: Austin, TX, USA, 2019. [Google Scholar]
- Heller, M.D.; Roots, K.; Srivastava, S.; Schumann, J.; Srivastava, J.; Hale, T.S. A Machine Learning-Based Analysis of Game Data for Attention Deficit Hyperactivity Disorder Assessment. Games Health J. 2013, 2, 291–298. [Google Scholar] [CrossRef] [PubMed]
- Kou, J.; Le, J.; Fu, M.; Lan, C.; Chen, Z.; Li, Q.; Zhao, W.; Xu, L.; Becker, B.; Kendrick, K.M. Comparison of Three Different Eye-tracking Tasks for Distinguishing Autistic from Typically Developing Children and Autistic Symptom Severity. Autism Res. 2019, 12, 1529–1540. [Google Scholar] [CrossRef]
- Wei, Q.; Xu, X.; Xu, X.; Cheng, Q. Early Identification of Autism Spectrum Disorder by Multi-Instrument Fusion: A Clinically Applicable Machine Learning Approach. Psychiatry Res. 2023, 320, 115050. [Google Scholar] [CrossRef] [PubMed]
- Iwauchi, K.; Tanaka, H.; Okazaki, K.; Matsuda, Y.; Uratani, M.; Morimoto, T.; Nakamura, S. Eye-Movement Analysis on Facial Expression for Identifying Children and Adults with Neurodevelopmental Disorders. Front. Digit. Health 2023, 5, 952433. [Google Scholar] [CrossRef]
- Andrés-Roqueta, C.; Katsos, N. A Distinction Between Linguistic and Social Pragmatics Helps the Precise Characterization of Pragmatic Challenges in Children with Autism Spectrum Disorders and Developmental Language Disorder. J. Speech Lang. Hear. Res. 2020, 63, 1494–1508. [Google Scholar] [CrossRef]
- Song, C.; Jiang, Z.-Q.; Liu, D.; Wu, L.-L. Application and Research Progress of Machine Learning in the Diagnosis and Treatment of Neurodevelopmental Disorders in Children. Front. Psychiatry 2022, 13, 960672. [Google Scholar] [CrossRef]
- Emanuele, M.; Nazzaro, G.; Marini, M.; Veronesi, C.; Boni, S.; Polletta, G.; D’Ausilio, A.; Fadiga, L. Motor Synergies: Evidence for a Novel Motor Signature in Autism Spectrum Disorder. Cognition 2021, 213, 104652. [Google Scholar] [CrossRef]
- Akter, T.; Ali, M.H.; Khan, M.I.; Satu, M.S.; Uddin, M.J.; Alyami, S.A.; Ali, S.; Azad, A.; Moni, M.A. Improved Transfer-Learning-Based Facial Recognition Framework to Detect Autistic Children at an Early Stage. Brain Sci. 2021, 11, 734. [Google Scholar] [CrossRef] [PubMed]
- Vargason, T.; Frye, R.E.; McGuinness, D.L.; Hahn, J. Clustering of Co-Occurring Conditions in Autism Spectrum Disorder During Early Childhood: A Retrospective Analysis of Medical Claims Data. Autism Res. 2019, 12, 1272–1285. [Google Scholar] [CrossRef] [PubMed]
- Mohammed, V.A.; Mohammed, M.A.; Mohammed, M.A.; Logeshwaran, J.; Jiwani, N. Machine Learning-Based Evaluation of Heart Rate Variability Response in Children with Autism Spectrum Disorder. In Proceedings of the 2023 Third International Conference on Artificial Intelligence and Smart Energy (ICAIS), Coimbatore, India, 2–4 February 2023; pp. 1022–1028. [Google Scholar]
- Kanhirakadavath, M.R.; Chandran, M.S.M. Investigation of Eye-Tracking Scan Path as a Biomarker for Autism Screening Using Machine Learning Algorithms. Diagnostics 2022, 12, 518. [Google Scholar] [CrossRef]
- Chen, H.; Song, Y.; Li, X. Use of Deep Learning to Detect Personalized Spatial-Frequency Abnormalities in EEGs of Children with ADHD. J. Neural Eng. 2019, 16, 066046. [Google Scholar] [CrossRef] [PubMed]
- Dubreuil-Vall, L.; Ruffini, G.; Camprodon, J.A. Deep Learning Convolutional Neural Networks Discriminate Adult ADHD From Healthy Individuals on the Basis of Event-Related Spectral EEG. Front. Neurosci. 2020, 14, 251. [Google Scholar] [CrossRef]
- Ahire, N.; Awale, R.; Wagh, A. Electroencephalogram (EEG) Based Prediction of Attention Deficit Hyperactivity Disorder (ADHD) Using Machine Learning. Appl. Neuropsychol. Adult 2023, 1–12. [Google Scholar] [CrossRef]
- Aggarwal, G.; Singh, L. Comparisons of Speech Parameterisation Techniques for Classification of Intellectual Disability Using Machine Learning. In Research Anthology on Physical and Intellectual Disabilities in an Inclusive Society; IGI Global: Hershey, PA, USA, 2022; pp. 828–847. [Google Scholar]
- Breitenbach, J.; Raab, D.; Fezer, E.; Sauter, D.; Baumgartl, H.; Buettner, R. Automatic Diagnosis of Intellectual and Developmental Disorder Using Machine Learning Based on Resting-State EEG Recordings. In Proceedings of the 2021 17th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Bologna, Italy, 11–13 October 2021; pp. 7–12. [Google Scholar]
- Song, C.; Jiang, Z.-Q.; Hu, L.-F.; Li, W.-H.; Liu, X.-L.; Wang, Y.-Y.; Jin, W.-Y.; Zhu, Z.-W. A Machine Learning-Based Diagnostic Model for Children with Autism Spectrum Disorders Complicated with Intellectual Disability. Front. Psychiatry 2022, 13, 993077. [Google Scholar] [CrossRef]
- Haft, S.L.; Greiner de Magalhães, C.; Hoeft, F. A Systematic Review of the Consequences of Stigma and Stereotype Threat for Individuals with Specific Learning Disabilities. J. Learn. Disabil. 2023, 56, 193–209. [Google Scholar] [CrossRef]
- Nilsson Benfatto, M.; Öqvist Seimyr, G.; Ygge, J.; Pansell, T.; Rydberg, A.; Jacobson, C. Screening for Dyslexia Using Eye Tracking during Reading. PLoS ONE 2016, 11, e0165508. [Google Scholar] [CrossRef] [PubMed]
- Chawla, M.; Panda, S.N.; Khullar, V. Assistive Technologies for Individuals with Communication Disorders. In Proceedings of the 2022 10th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 13 October 2022; pp. 1–5. [Google Scholar]
- Jacobs, G.R.; Voineskos, A.N.; Hawco, C.; Stefanik, L.; Forde, N.J.; Dickie, E.W.; Lai, M.-C.; Szatmari, P.; Schachar, R.; Crosbie, J.; et al. Integration of Brain and Behavior Measures for Identification of Data-Driven Groups Cutting across Children with ASD, ADHD, or OCD. Neuropsychopharmacology 2021, 46, 643–653. [Google Scholar] [PubMed]
- Toki, E.I.; Tatsis, G.; Tatsis, V.A.; Plachouras, K.; Pange, J.; Tsoulos, I.G. Employing Classification Techniques on SmartSpeech Biometric Data towards Identification of Neurodevelopmental Disorders. Signals 2023, 4, 401–420. [Google Scholar] [CrossRef]
- CMUSphinx 2022. Available online: https://cmusphinx.github.io/2022/10/release/ (accessed on 25 December 2023).
- Pantazoglou, F.K.; Papadakis, N.K.; Kladis, G.P. Implementation of the Generic Greek Model for CMU Sphinx Speech Recognition Toolkit. In Proceedings of the eRA-12 International Scientific Conference, Athens, Greece, 24–26 October 2017. [Google Scholar]
- Santamato, V.; Esposito, D.; Tricase, C.; Faccilongo, N.; Marengo, A.; Pange, J. Assessment of Public Health Performance in Relation to Hospital Energy Demand, Socio-Economic Efficiency and Quality of Services: An Italian Case Study. In Proceedings of the Computational Science and Its Applications—ICCSA 2023 Workshops, Athens, Greece, 3–6 July 2023; Proceedings, Part III; Springer: Berlin/Heidelberg, Germany, 2023; pp. 505–522. [Google Scholar]
- Shipe, M.E.; Deppen, S.A.; Farjah, F.; Grogan, E.L. Developing Prediction Models for Clinical Use Using Logistic Regression: An Overview. J. Thorac. Dis. 2019, 11, S574–S584. [Google Scholar] [CrossRef] [PubMed]
- Barua, P.D.; Vicnesh, J.; Gururajan, R.; Oh, S.L.; Palmer, E.; Azizan, M.M.; Kadri, N.A.; Acharya, U.R. Artificial Intelligence Enabled Personalised Assistive Tools to Enhance Education of Children with Neurodevelopmental Disorders—A Review. Int. J. Environ. Res. Public Health 2022, 19, 1192. [Google Scholar] [CrossRef]
- Bastiaansen, J.A.J.; Veldhuizen, E.E.; De Schepper, K.; Scheepers, F.E. Experiences of Siblings of Children with Neurodevelopmental Disorders: Comparing Qualitative Analysis and Machine Learning to Study Narratives. Front. Psychiatry 2022, 13, 719598. [Google Scholar] [CrossRef]
- Donnelly, N.; Cunningham, A.; Salas, S.M.; Bracher-Smith, M.; Chawner, S.; Stochl, J.; Ford, T.; Raymond, F.L.; Escott-Price, V.; van den Bree, M.B.M. Identifying the Neurodevelopmental and Psychiatric Signatures of Genomic Disorders Associated with Intellectual Disability: A Machine Learning Approach. Mol. Autism 2023, 14, 19. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | Missing | Mean | Median | SD | Minimum | Maximum | Shapiro–Wilk | ||
|---|---|---|---|---|---|---|---|---|---|
| W 1 | p | ||||||||
| Verbal and Intellectual Ability | 473 | 0 | 0.01044 | 0.2126 | 0.988 | −3.14 | 1.967 | 0.867 | <0.001 |
| Targeted Voicing Activities | 473 | 0 | −0.01477 | −0.1942 | 0.987 | −1.39 | 2.237 | 0.945 | <0.001 |
| Syntax | 473 | 0 | −0.00858 | −0.1187 | 0.966 | −2.07 | 3.754 | 0.973 | <0.001 |
| Phonology | 473 | 0 | 0.00696 | 0.1522 | 0.996 | −2.66 | 0.728 | 0.709 | <0.001 |
| Pragmatic Perception | 473 | 0 | −0.00269 | −0.1956 | 0.996 | −1.05 | 1.539 | 0.835 | <0.001 |
| Fine Motor Skills | 473 | 0 | 0.04876 | 0.6805 | 0.976 | −2.08 | 0.680 | 0.668 | <0.001 |
| Spatial Orientation | 473 | 0 | −0.00736 | 0.0439 | 0.983 | −2.47 | 2.583 | 0.967 | <0.001 |
| Sequencing | 473 | 0 | 0.02351 | 0.2785 | 0.971 | −3.23 | 2.152 | 0.909 | <0.001 |
| Memory | 473 | 0 | −0.01280 | −0.2555 | 0.995 | −1.27 | 2.552 | 0.915 | <0.001 |
| Perception/Discrimination | 473 | 0 | 0.03179 | 0.6658 | 1.001 | −3.25 | 0.666 | 0.673 | <0 .001 |
| Sustained Attention | 473 | 0 | 0.00765 | 0.4987 | 0.966 | −2.22 | 1.934 | 0.742 | <0.001 |
| Cognitive Flexibility | 473 | 0 | −0.00714 | 0.1278 | 1.000 | −2.67 | 1.538 | 0.856 | <0.001 |
| Empathy | 473 | 0 | 0.02312 | 0.3207 | 0.964 | −2.92 | 2.394 | 0.887 | <0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Toki, E.I.; Tsoulos, I.G.; Santamato, V.; Pange, J. Machine Learning for Predicting Neurodevelopmental Disorders in Children. Appl. Sci. 2024, 14, 837. https://doi.org/10.3390/app14020837
Toki EI, Tsoulos IG, Santamato V, Pange J. Machine Learning for Predicting Neurodevelopmental Disorders in Children. Applied Sciences. 2024; 14(2):837. https://doi.org/10.3390/app14020837
Chicago/Turabian StyleToki, Eugenia I., Ioannis G. Tsoulos, Vito Santamato, and Jenny Pange. 2024. "Machine Learning for Predicting Neurodevelopmental Disorders in Children" Applied Sciences 14, no. 2: 837. https://doi.org/10.3390/app14020837
APA StyleToki, E. I., Tsoulos, I. G., Santamato, V., & Pange, J. (2024). Machine Learning for Predicting Neurodevelopmental Disorders in Children. Applied Sciences, 14(2), 837. https://doi.org/10.3390/app14020837