1. Introduction
This report describes a new quantum hybrid algorithm for solving systems of linear equations modulo 2. In such problems, we want to find an n-vector x such that , where A is an matrix and b is an m-vector, all values are 0 or 1, and arithmetic is performed modulo 2, so that .
Linear equations with binary coefficients are less ubiquitous than those with real coefficients, but they still have key mathematical applications and commercial uses. For example, solving binary linear equations is an important step in state-of-the-art sieving approaches to integer factorization, in which we want to find large square numbers that are products of combinations of numbers whose prime factors are known, which means we want their exponents to be even [
1,
2].
This paper presents a new quantum hybrid algorithm for solving systems of binary linear equations, which as far as we know is the first to apply quantum computing to this problem. The solution’s approach has two steps. First, we define a quantum circuit implementing matrix–vector products over the relevant finite vector spaces. Our circuit has one gate for each non-zero entry in the coefficient matrix. Then, we derive a variational cost function that can be optimized in order to produce solutions to the given system. This frames the problem as one of optimizing a variational quantum circuit, which has become a standard approach in quantum machine learning on NISQ (noisy intermediate-scale quantum) hardware ([
3], Chapter 5).
Solving systems of simultaneous linear equations is a standard problem, and is most familiar in situations where the coefficients in the equations are real or complex numbers. When the coefficient matrix is not square, direct methods leveraging the LU or QR decompositions emerge as the natural choice [
4]. Obtaining these factorizations incurs a computational cost of
, which sets a useful baseline expectation for such algorithms. As shown in
Section 6, the Mod2VQLS approach uses a number of matrix–vector product calculations, which scales linearly in the system dimension. It is also comparable to the state-of-the art block Wiedemann method, which also leverages sparsity in the coefficient matrix. We note that the block Wiedemann method has been used in recent record-breaking RSA factorization calculations [
5].
The rest of the paper is organized as follows.
Section 2 introduces quantum gates and circuits used throughout the paper.
Section 3 explains the construction of a quantum circuit that implements the crucial matrix–vector multiplication operation for binary-valued matrices and vectors.
Section 4 pairs this circuit with a variational component that can be optimized in a hybrid quantum–classical computing framework in order to solve linear systems. In particular, this section introduces a simple rotations ansatz that is especially well-suited to the problem.
Section 5 presents initial proof-of-concept experiments, showing that in low dimensions, with the rotations ansatz, the number of iterations needed to find a solution scales linearly in the number of dimensions (with a scaling factor around 4).
Section 6 compares the method introduced here with established classical and quantum alternatives, and
Section 7 discusses more of the potential applications.
We shall use the following notation throughout. We let denote the field with the two elements . (In other works, is sometimes written as , or , where stands for Galois Field.) Addition in is written using the symbol ⊕, so that , , and . We fix an matrix A and an m-vector b with . In addition, we let x denote an arbitrary element of . The problem of solving the linear system is to find x such that , in this case over (so all arithmetic is modulo 2).
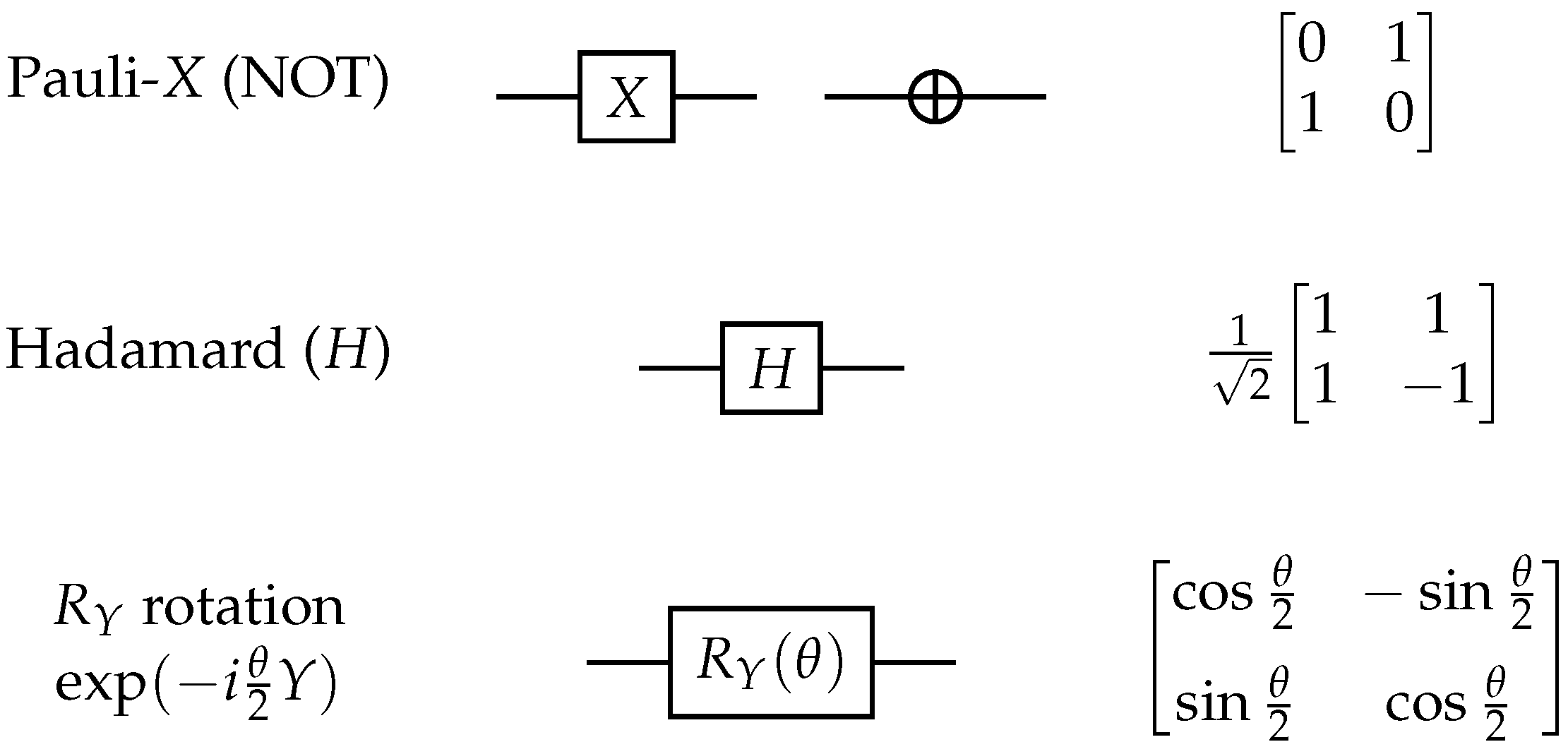
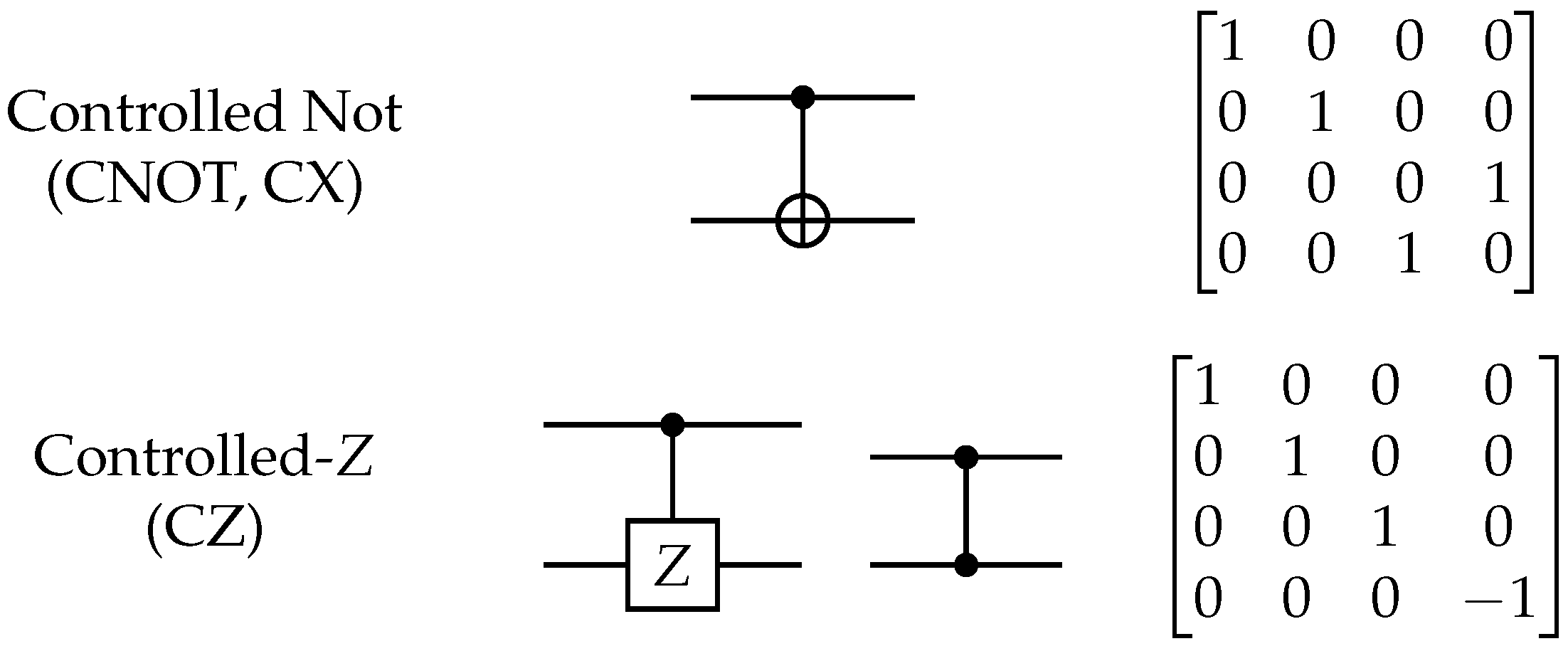
2. Quantum Circuits and Gates Used in this Paper
This background section briefly reviews the quantum gates used in the circuits below. These include the single-qubit Pauli-
X gate and fractional
Y-rotation gate
(
Figure 1), and the 2-qubit CNOT and controlled-
Z gates (
Figure 2).
The Pauli-X gate is commonly used to flip a qubit between the and gates, which is why it is also sometimes called the quantum NOT gate. X-gates directed at different qubits can be used to prepare an input state representing a binary-valued vector: the state is prepared by applying an X-gate to each of the qubits to be switched to the state.
The Hadamard (H) gate is commonly used to put a qubit into a superposition state; for example, it maps a qubit prepared in the state to the superposition . Applying an H-gate to each qubit in an array is used to initialize a binary vector all of whose coordinates have a 50:50 chance of being observed in the or state.
The CNOT gate is a 2-qubit entangling gate, which acts upon the state . In the standard basis, its behavior can be described as “performing a NOT operation on the target qubit if the control qubit is in state ”.
The Pauli-
X, Hadamard, CNOT, and CX gates are self-inverse: performing these operations twice gives the identity map. These periodic properties are crucial for performing the binary arithmetic operations in the matrix–vector product of
Section 3.
The
rotates a single qubit through an angle
around the
Y-axis on the Bloch sphere (Nielsen and Chuang [
6], Chapter 1). The angle
can be varied, and optimizing these angles for many gates is the task of the variational algorithm in
Section 4. The controlled-
Z gate is similar to the CNOT gate and entangles two qubits; in the standard basis, its action is symmetric (in the sense that it does not matter which qubit is considered to be the control and which the target qubit).
3. Implementing the Matrix–Vector Product as a Quantum Circuit
This section introduces a quantum circuit that implements the binary-valued matrix–vector product , where A is a matrix and x is a vector, and both have values in as defined above.
The trick is to notice that binary arithmetic may be implemented with controlled-NOT operations. The NOT gate switches the state of an individual qubit between
and
, and the
gate performs such an operation only if the so-called
control qubit is in state
. In particular, the
gate acts on the two-qubit state
as
Now let
denote the
n-qubit quantum state corresponding to
x and notice that
Thus the
m-qubit state
can be prepared by applying the quantum circuit
to the tensor product
. Here,
denotes a
gate controlled by the
qubit and targeting the
one. The product operator
in these definitions denotes composition, so it is implemented by applying the gates in sequence. Both products in Relation (
2) may be taken in any order. We note that
requires
qubits and
N quantum gates, with
N denoting the number of non-zero entries in
A.
In particular, we obtain the following theorem.
Theorem 1. Usingas in Relation (
2)
, with denoting the m-qubit all-zero state, and with denoting the concatenation/tensor product of and , we have Proof. The proof follows from an easy argument by induction on
n that is left to the reader: the base case
can be easily established for all
m by verifying that the
ith qubit in the output register is zero precisely when
, and the inductive step follows from a quick calculation considering the inductive hypothesis and the action of the
gate, as in Relation (
1). □
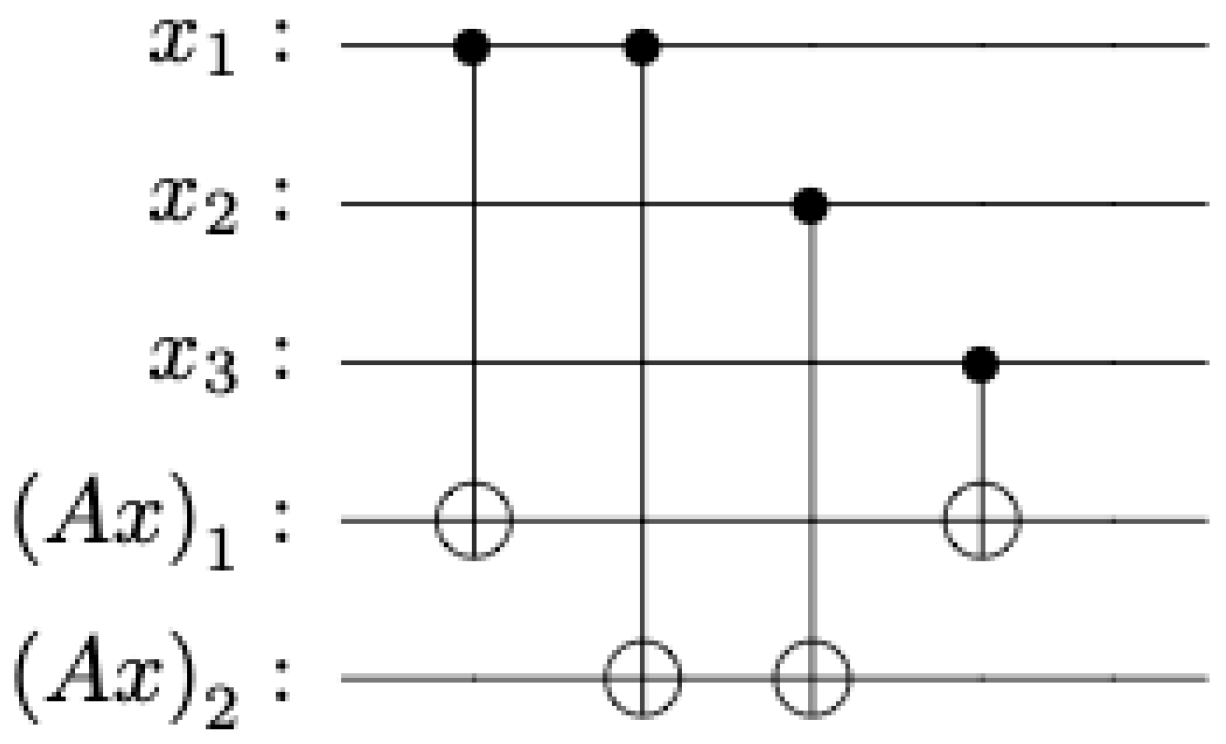
Example 1. The following example elucidates Theorem 1. For concreteness, consider the matrix The diagram in Figure 3 shows how the operatoris implemented explicitly as a quantum circuit. These circuits work because the self-inverse behavior of the
X and CNOT gates is ideal for binary arithmetic over
. It is possible that the periodic nature of other gates could be used similarly to perform arithmetic operations over other finite fields, but such an adaptation is not straightforward unless we consider qu
dits instead of qu
bits, because the way several CNOT gates combine angles into a single target qubit does not perform like group addition for fields other than
. More precisely, the
X and
gates rotate their target qubits through angles 0 and
, which is all we need for the 0 and 1 elements of
, but if this is extended to a larger set of angles
for
, the use of CNOT gates to combine different contributions into a single target qubit as in
Figure 4 is nonlinear [
7]. It follows that the coordinates of the output vector
b are not the same as the sums of the various inputs
, except for the two-element field
.
4. Solving the Linear System Using a Variational Quantum Algorithm
Now we propose a Variational Quantum Algorithm (VQA) designed to solve the linear system . As with any VQA, there are two main ingredients: a variational ansatz and a cost function that serves as the optimization objective. The ansatz gives a circuit pattern or template with gate parameters (typically angles) that can be varied and optimized. In this report we consider one objective function and compare two different ansatze: a rotations ansatz specially designed for the task, and a more generic brickwork ansatz.
The system as a whole is called
, which stands for Modulo 2 Variational Quantum Linear Solver.
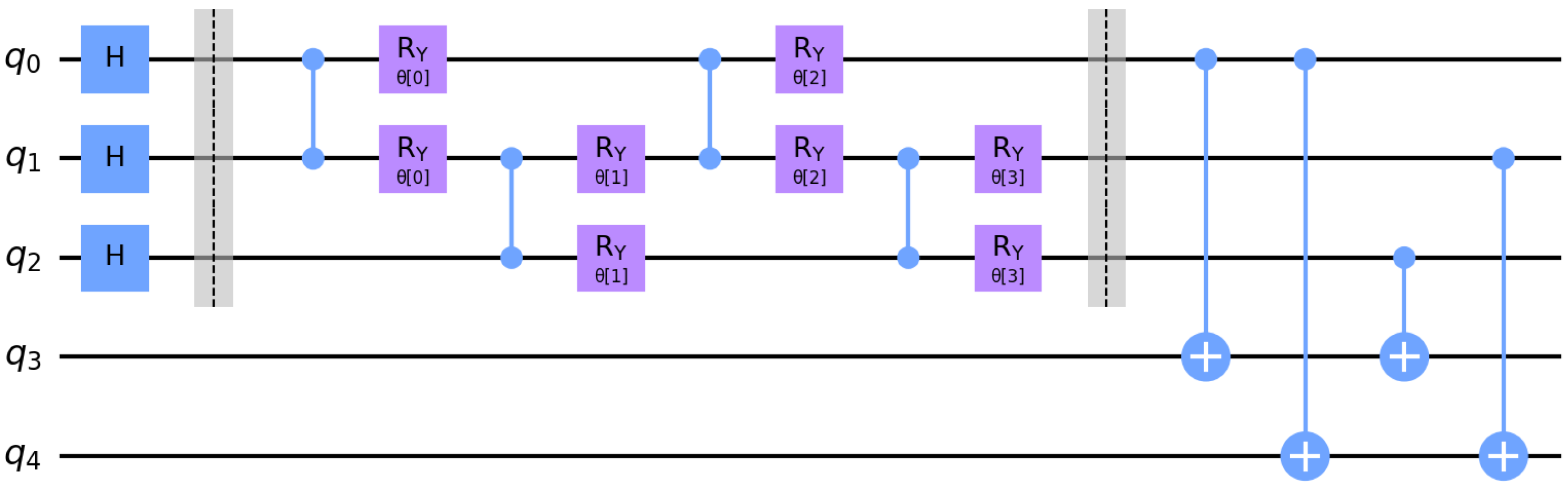
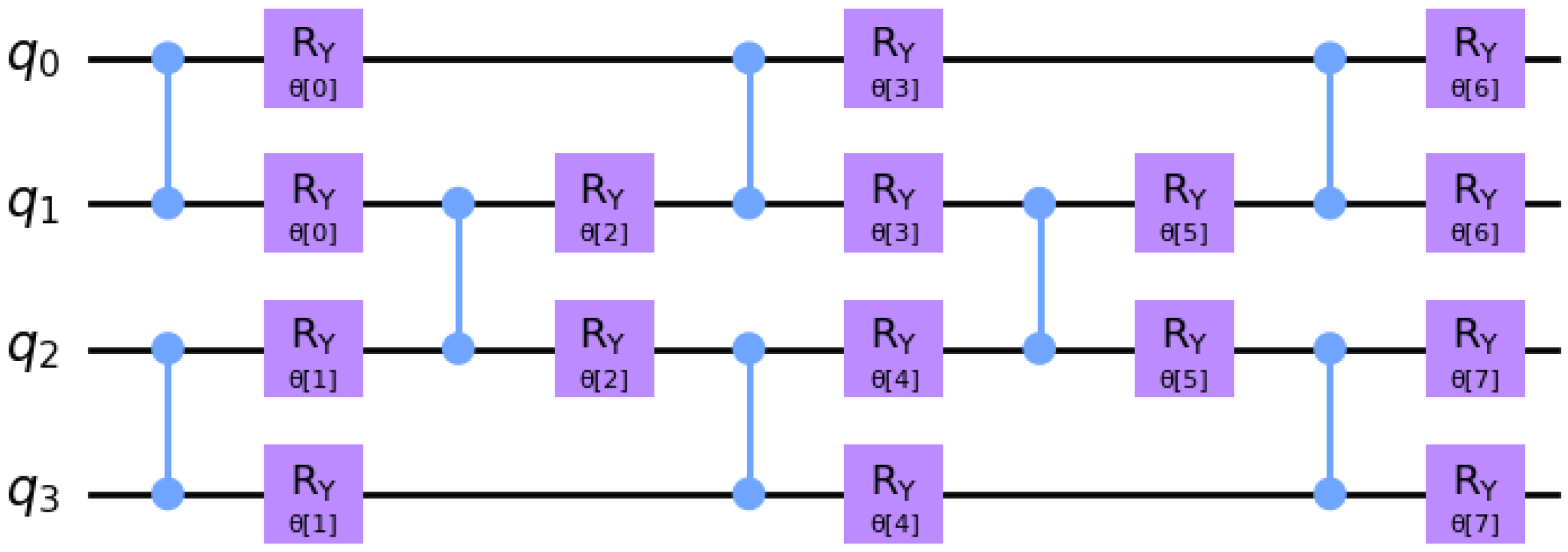
Figure 5 illustrates the full variational circuit evaluated by
when solving the linear system described in Example 1. In this case, the brickwork layout variational ansatz described in
Section 4.2 is used, with 4 layers.
Our cost function here measures the overlap between the projector
and the subspace orthogonal to
, which is given by
We note that this cost function has appeared before in [
9] as Equation (
3) in the setting of solving square linear systems with
real entries.
Some algebra shows that
can be evaluated by computing the expected energy of an Ising Hamiltonian:
where we have omitted the dependence on
for simplicity of notation. Notice that the second term is the expected value of the rank-1 Ising Hamiltonian
with eigenvalue 1 corresponding to the eigenstate
, computed with respect to the variational state
. Although it may be difficult to express this Hamiltonian as a linear combination of tensor products of Pauli matrices, we do not need to construct or even to know it explicitly; all we need is an oracle that can lazily evaluate the Hamiltonian’s eigenvalues.
4.1. Rotations Ansatz
Now we turn to our variational ansatze. The first is a simple rotations pattern that is particularly well-suited for the Mod2VQLS cost function
. This ansatz is just a product of single-qubit rotations about the
Y-axis; in particular, we take
with
denoting an
rotation applied on the
r qubit and each parameter
. This circuit is interesting because it does not add to the overall computational cost of each iteration, and it is amenable to direct mathematical analysis.
In particular, we can derive an explicit formula for the variational cost as a function of the circuit parameters.
Theorem 2. For each , define . In addition, let denote the inverse image of b under A. Then,with and denoting the ansatz defined by Relation (
4).
Proof. The theorem follows from direct calculation. First, note that
So, a quick induction, left to the reader as an exercise, shows that
Combined with Theorem 1, the last equation yields an expression for our variational quantum state:
We use this expression to compute the variational cost with respect to
. In particular, let
and use Relation (
3) to write
Now, since
is real, we see that
so
as desired. □
Moreover, we can obtain a similar formula for the gradient of the cost function with respect to the circuit parameters.
Theorem 3. For each , the cost function varies likewith respect to . Here, ⊕
denotes binary addition over and denotes the jth standard basis vector in . Proof. The theorem follows from a direct computation using the chain rule. The key is to notice that differentiating
swaps a sine for a cosine and vice versa; for instance, if
, and we fix
and
for simplicity of notation, we see that
Theorem 3 helps us understand the critical points on the variational cost landscape. In particular, it shows that the gradient
is smooth, and moreover, each of its entries is a trigonometric polynomial on the
variables
and
, for
. Thus, every critical point of the cost surface satisfies
. When combined with the Pythagorean identities
, the equation
characterizes an algebraic variety defined by
polynomials in
variables. Hence Bezout’s Theorem [
10], Chapter 2 implies that
has at most
real extrema.
It is interesting to note that when
is an
-th root of unity, our variational cost can be written in terms of
quantum integers or
q-integers, which are ubiquitous in
q-calculus, the representation theory of quantized enveloping algebras and quantum groups, and in the theory of crystal bases, amongst others [
11,
12,
13,
14,
15]. We conjecture that these points characterize the extrema of our cost function. The conjecture is motivated by the size of the variety characterized by
together with the Pythagorean identities as computed by Bezout’s Theorem and by the explicit computations summarized by Theorem 5.
Definition 1. For any complex and any integer n, the quantum integer or q-integer is defined by In this setting, quantum integers appear in the coefficients
. In particular, let
for any
, let
denote a primitive
-th root of unity, and notice
We use the last identity to prove the existence of globally optimal parameters for our variational circuit. It is important to observe these guarantees are not typically offered by VQAs; for instance, QAOA can only guarantee such parameters in the limit of infinite circuit depth.
We will need the following identities.
Lemma 4. If denotes a primitive -th root of unity, then the following identities relating ξ-integers hold: Proof. The lemma follows from direct calculation. For example,
The second equality follows because and , so that . The last equality holds because is an -th root of unity; in particular, . □
Theorem 5. Let for some . First, suppose for some . Then, is a global minimum of if satisfies ; otherwise, is a global maximum of the cost function.
Now assume for some odd integer k and let denote the rank of A over . In this case, .
Proof. First, notice our cost function is non-negative; for any
, we have
This follows from Relation (
5), which writes
as a superposition over a tensor product of computational basis states with amplitudes given by
. In addition,
is bounded above by 1 because each
is non-negative. This means
for every
.
Thus, to prove the first claim, it remains to be shown that when
, the cost function vanishes if
belongs to the inverse image
and it is unity otherwise. This follows from direct calculation:
Note that the product in the second equality vanishes whenever because .
For the second claim, write
for some integer
m and with
. Now recall the well-known ‘summation rule’
for quantum integers ([
12], Relation V1.1.2). When combined with Lemma 4, the summation rule implies
In addition, note that if
, Relation (
6) implies
. Thus, if
denotes the (integer) sum of the elements of
x, we see that
In the fourth equality we used Lemma 4 to simplify . In the fifth equality we applied Lemma 4 again, this time substituting .
To conclude, we recall the solution set
is an affine space in
with one point for each element of the kernel of
A. Hence, if we let
denote the dimension of
over
and we recall the Rank–Nullity Theorem we obtain the desired result:
4.2. Brickwork Ansatz
The other variational ansatz we consider comprises a brickwork layout of parametrized two-qubit gates. For instance,
Figure 6 illustrates a brickwork layout ansatz with a depth of 5 layers on 4 qubits. The two-qubit ‘brick’ design was used by authors including [
9] for general linear solving and [
16] for electron simulation. Various other general-purpose ansatz designs could be tried.
With enough layers, it should be possible for the brickwork ansatz to provide solutions to the equation , and intuitively, we expected that convergence would be slower but that the method might find more solutions overall. In practice, the convergence was considerably slower, and in most cases, the number of extra solutions found was modest.
4.3. Variational Parameter Optimization
Along with the quantum circuits, hybrid systems like Mod2VQLS rely on classical algorithms to optimize the variational parameters (for example, the parameters in the examples so far). Parameter optimization in variational quantum circuits has become an important topic in quantum machine learning, partly because it is a signification barrier to overcome if variational quantum circuits are to deliver valuable applications on NISQ hardware.
A considerable challenge here is that automatic differentiation (“autodiff”) is not straightforward on quantum computers: finite-difference methods require too many nearby calculations, and even when an analytic expression for gradients is available using a ‘parameter shift rule’, these expressions have to be evaluated separately for each parameter ([
3], §5.3). As fresh problems are encountered, it is possible that quantum computers are not well-suited to computing gradients, and that there is no quantum approach to training variational networks that is as generally effective as classical backpropagation [
17].
Simplex-based methods are a well-established alternative to gradient-based methods. In the simple one-dimensional case, binary search is an elementary example. In more dimensions, an
n-dimensional
simplex is the convex hull of
n linearly independent vertices, and the search algorithm converges by iteratively partitioning the simplex and reducing to a smaller simplex that contains the desired solution. (For example, a triangle subdivided by a suitable line, or a tetrahedron subdivided by a suitable plane.) This is the backbone of many procedures, including the famous 1965 simplex algorithm of Nelder and Mead [
18]. Nelder–Mead can sometimes be improved using interpolation based on the values of the objective function at the vertices, leading to the COBYLA algorithm published in 1994 [
19]. SciPy’s COBYLA implementation was used in the Mod2VQLS experiments presented below.
4.4. Alternatives
There are several alternatives and ways this design could be varied. With the quantum parts of the system, one could use a different two-qubit block in the brickwork layout ansatz. More generally, we could use a different ansatz altogether. In particular, it might be beneficial to incorporate linear-algebraic information into the ansatz, such as something that encourages the superposition to be orthogonal to the range of
A, in case
. Also, a swap test could be used for computing
as part of the quantum circuit itself [
20]. This may serve as a way to mitigate the measurement error, at the cost of requiring additional qubits.
For the classical parts of the system, we have discussed the reason for choosing a simplex-based rather than a gradient-based optimizer. This broad-strokes distinction leaves many opportunities for more specific combinations to be evaluated. Other optimization algorithms including SPSA (gradient-free) and AMSGrad (gradient-based) have also been evaluated by Pellow-Jarman et al. [
21]. Finding ideal combinations of classical optimizers and quantum circuit ansatze is likely to remain an important research topic.
5. Experimental Results
This section describes the results of experiments evaluating the performance of Mod2VQLS solvers using both the rotation and brickwork ansatze.
In each dimension from 1 to 9, we generated ten consistent binary linear systems by constructing
matrices
A and
n-vectors
x with independent and uniformly selected entries in
and then computing
. Then, we solved the systems using Mod2VQLS, using both the brickwork and rotation ansatze. Solving a linear system entails optimizing the model’s variational parameters and then measuring the optimized state
. We tested all the computational states observed in the optimized superposition in order to determine whether they were valid solutions to the linear system in question. We counted the number of distinct valid and invalid solutions proposed, as well as the average number of iterations required for convergence of the variational method. We used SciPy 1.11’s COBYLA implemetation to update the variational parameters in our circuits; we note this optimization routine only requires a single quantum circuit execution per iteration. Circuits were coded and simulated using the Qiskit Python package [
22].
In the brickwork case, the number of layers in the variational ansatz is an extra configuration parameter. From experimenting, we found that at least two layers were needed and that matching the number of layers/parameters to the number of dimensions produced a reasonable tradeoff between solution iterations and correctness.
Our results are presented in
Table 1. The rotations ansatz performed quite simply and effectively, always finding a correct solution, and occasionally finding more than one, with a reasonably small number of iterations. The rotations ansatz proposed no invalid solutions. The brickwork ansatz was more costly and error-prone, using more iterations and producing some invalid solutions. The brickwork ansatz was also able to find a greater variety of valid solutions, though not dramatically so.
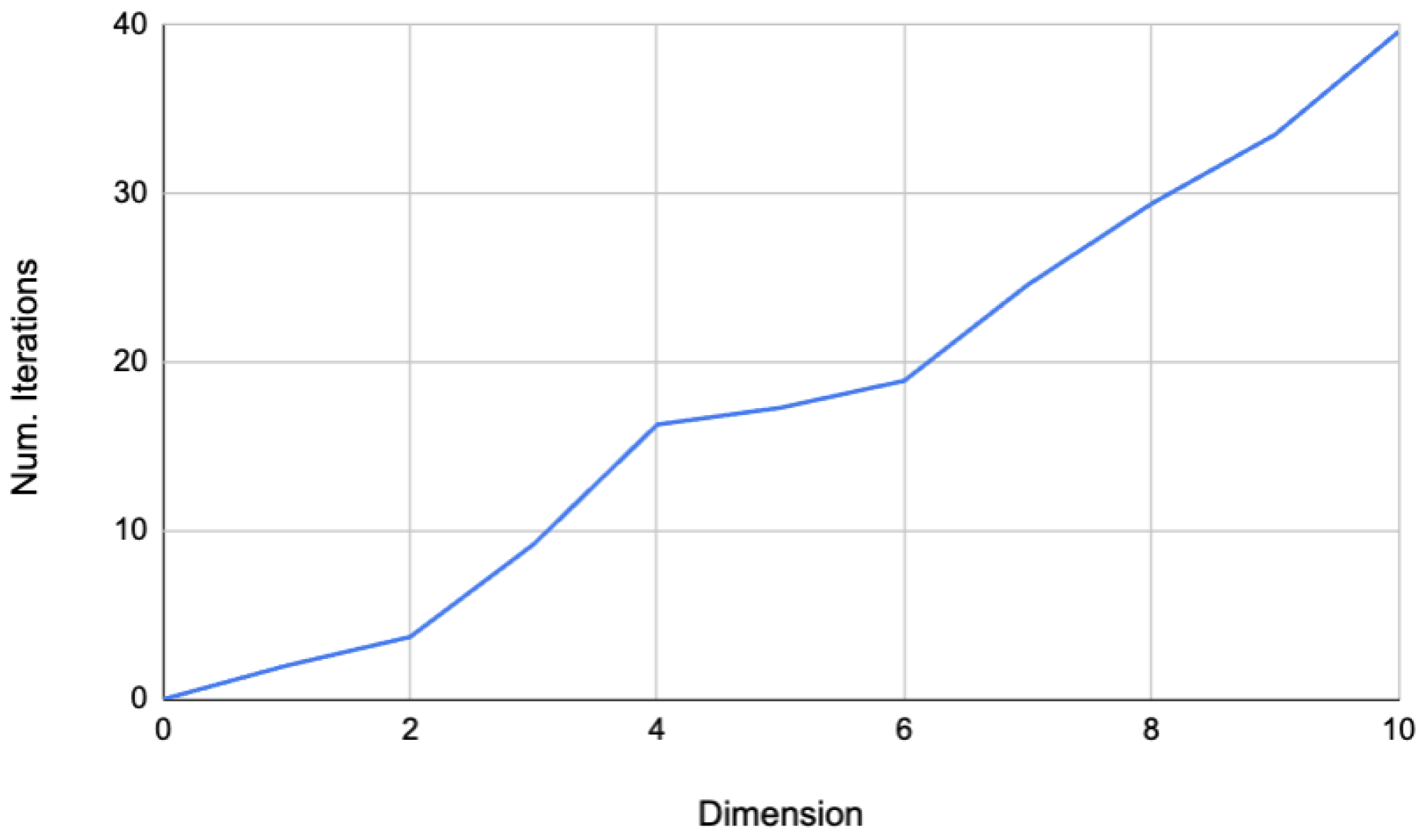
Figure 7 shows the growth in the number of iterations used by Mod2VQLS with the rotations ansatz. The growth is roughly linear in small dimensions, with a slope of (just under) 4. This allows for comparison with block Wiedemann, as explained in
Section 6 below.
These experiments demonstrate proof-of-concept, in that the Mod2VQLS system does find correct solutions. They also demonstrate that there are performance tradeoffs, and that different choices of ansatz may be appropriate, depending on whether the task requires searching for any solution, or a more exhaustive search for all solutions.
These results are preliminary. The Mod2VQLS algorithm should be tested on larger systems of linear equations and compared with the results of classical solvers. The robustness of the circuits at larger scales with different kinds of noise has not yet been analyzed.
6. Related Classical and Quantum Methods for Solving Linear Systems
This section compares Mod2VQLS with quantum alternatives for solving systems of linear equations and classical alternatives for solving systems of binary linear equations.
6.1. Quantum Linear Solvers
Important families of quantum linear solvers are based on the renowned HHL algorithm of Harrow, Hasidim, and Lloyd [
23], and the VQLS (Variational Quantum Linear Solver) algorithm of [
9]. The HHL algorithm is an exact method for solving linear equations, with several papers proposing applications and improvements including [
24], though also with significant caveats [
25]. The VQLS approach is more recent, from the current era where variational methods are expected to perform well on real NISQ hardware, which has already encouraged subsequent research into VQLS, including the use of dynamic ansatze [
26], comparing different optimizers [
21], and applications to differential equations [
27].
Mod2VQLS is different from these methods, particularly with its support for binary vectors, and non-square matrices. To date, works on matrix multiplication and solving linear equations using quantum computing have addressed the cases of real- and complex-valued matrices. (This is sometimes stated explicitly, and sometimes implied by the assumption that the vector coordinates are represented by complex amplitudes.) The recent work of [
27] adapts the VQLS of [
9] to finite-element methods for solving differential equations, but here the ‘elements’ are subdomains supporting a function, not elements of a finite field, and the functions in question are still continuous. As far as we know, our proposal here is the first attempt to address this problem with matrices over
, or any finite field.
In addition,
can tackle matrices of any size and rank, whereas both HHL and VQLS are restricted to square matrices with full rank. This again is sometimes stated explicitly, and sometimes implied by the assumption that the matrix operator
A is a quantum unitary operator. Indeed, the runtime of both HHL and VQLS depends on the condition number of the coefficient matrix, so effectively they assume the coefficient matrix is not only invertible, but
robustly so (well-conditioned). When
A is square, and moreover enjoys additional structural properties like invertibility, symmetry, or positive-definiteness, faster iterative methods including various Krylov subspace iterations and conjugate gradient are available [
28].
The ability to work with matrices of different sizes and ranks is especially beneficial for solving problems where the matrix sizes are not fixed in advance. A case-in-point is the integer factoring problems investigated by [
2], which motivated the development of
. In this application, each equation (each row of the matrix
A) is discovered independently in a massively parallel data collection phase. We are not looking for a unique solution to a fixed system of equations, but
any solution to any subset of this system of equations. The
works especially well for this, because the optimized variational circuit produces a superposition over multiple solutions to
.
On the flip side, while HHL and VQLS
promise an exponential speed-up over classical solvers, because they leverage a dense amplitude encoding that requires
qubits to represent the linear system
with an
coefficient matrix
,
can only promise a polynomial speed-up over the fastest-known classical solvers (which are already polynomial), because
requires circuits with
qubits for solving the system
with an
coefficient matrix
A. Thus, it is important to note that Mod2VQLS promises at most a polynomial, not an exponential speed-up. Also, the ability to work with non-square matrices comes at a computational cost: as seen in
Figure 3, we produce a mapping from
to
using
qubits, but seen as a whole, the circuit is really a reversible unitary transformation on the space
. So, the ability to map between spaces of different dimensions in Mod2VQLS comes at the cost using disjoint sets of qubits for the input and output spaces.
6.1.1. Specific Differences from HHL
The
encoding furnishes several advantages that address the HHL caveats delineated by [
25]. For starters, in HHL the load vector
must be loaded onto the quantum processor and this task in itself may require an exponential number of steps (with respect to the number of qubits in the circuit) ([
25], Caveat 1). By contrast, in our setting the load vector
b is merely an
m-bit string so it corresponds to an
m-qubit computational basis state. As such, it can be efficiently loaded on the quantum computer using at most
m NOT or Pauli-
X gates, although it turns out it is not even necessary to load
b onto the quantum processor in our current implementation.
Moreover, HHL assumes that the quantum computer can apply the unitary operator
efficiently for various values of
t ([
25], Caveat 2). In our setting, the closest analog is applying the matrix–vector product operator defined below, and doing so requires precisely
N two-qubit gates, where
N is the number of non-zero entries in
A. The complexity here indicates that
directly benefits from the sparsity of
A, which is useful in applied settings where one typically deals with large, (very) sparse matrices. For instance, the matrices encountered in recent large factoring calculations have millions of rows and columns, but only a few hundred non-zero entries per row.
Finally, extracting the solution vector
upon executing the HHL algorithm requires an exponential number of circuit measurements ([
25], Caveat 4). Again, the exponential here is with respect to the number of qubits in the HHL circuit. By contrast, in our modulo 2 setting the solution vector
x is an
n-bit string, which corresponds to an
n-qubit computational basis state, so it can be read off from the optimized quantum ansatz using a fixed number of shots. An added benefit of our method is that the optimized quantum ansatz obtained upon running
is a superposition over computational basis states corresponding to every possible solution to
, so we can effectively sample the solution set by measuring the optimized quantum state. This is quite useful in the factoring application, where we typically need to find more than one element in the kernel of the coefficient matrix in order to build a factor.
6.1.2. Specific Differences from VQLS
There are a few additional differences that distinguish Mod2VQLS from the VQLS of Bravo-Prieto et al. [
9] and subsequent developments. They use a dense encoding, which means that their cost function can be evaluated by executing quantum circuits with a logarithmic number of qubits. This is in contrast to our encoding, which requires a linear number of qubits. With the particular implementation details of the VQLS routine explained in [
9] in mind, we see that our encoding has several benefits. For instance, in this context
is a unitary operation that can be performed using
N gates, where
N is the number of non-zero entries in the coefficient matrix. By contrast, the
A operator in [
9] is a
linear combination of
L unitaries, and
L may be exponential in the number of qubits in their circuit. Moreover, the authors do not explain how to achieve such a decomposition in general; however, in Appendix A, they provide some hints for how to proceed when the coefficient matrix is sparse. In this section, they assume access to some oracle
that can effectively query the entries of
A. Regardless, it is not clear how to implement this oracle and indeed the authors comment that, “The gate complexity of both of these strongly depends on the form and precision with which the matrix elements of
A are specified” ([
9], Appendix A).
Also in [
9], the cost function
vanishes when the norm of
vanishes, making it deficient in the sense that non-solutions to
correspond to local extrema. By contrast, the variational state
used here is normalized because
is a unitary operation. Thus, there is no need to normalize the cost function, as in Equation (
5) of [
9] and consider the more complicated so-called
local cost functions.
6.2. Classical Approach to Mod2 Linear Solving
Lacking prior literature on quantum binary linear solvers, we instead compare Mod2VQLS with the computational complexity of the block Wiedemann method, which is the fastest known classical algorithm for dealing with sparse unstructured systems over finite fields [
29]. This method requires a linear number of matrix–vector multiplications plus a quadratic number of arithmetic operations in
. In fact, large-scale implementations, like the one leveraged in the record-breaking RSA-240 calculation described in [
5], have used
matrix–vector multiplications and it is not known if less than
can be used [
30].
In our quantum setting, we consider the cost of executing our matrix–vector product circuit
from
Section 3. The results from our numerical experiments using the rotations ansatz described in
Section 4.1, as recorded in
Table 1, indicate that the gate complexity of our simple quantum algorithm is on par with the state-of-the-art block Wiedemann approach: the number of matrix–vector multiplications needed to achieve a solution is linear in the system dimension and we do not require the additional quadratic number of field operations or linear storage. (However, our method requires at least one qubit per variable, so large-scale systems encountered in practice will require larger quantum computers).
7. Applications of Mod2VQLS and Related Techniques
Mod2VQLS was motivated by the use of modulo 2 linear algebra in integer factorization [
2]. In this use-case, the goal is to find relations of the form
, by multiplying various equations with known factors to obtain suitable
and
. This requires that exponents of all the factors in the prime factorizations of both
and
are even; thus, assembling such a combination by multiplying several equations becomes translated into finding a suitable binary vector
x so that
. The surprising importance of this ‘playing with numbers’ game is explained by Pomerance [
1].
In the integer factorization application, the dimension n is determined by the number of (small) prime factors used in the ‘factor basis’ used to search for nearby composite numbers. The number of such relations determines the number of rows of A and the dimension m of the target space. This number is unknown at the beginning of the process; ideally, using the smallest number of relations possible reduces the burden on the ‘search phase’ of the algorithm, but this number is often large in practice. Hence it was a requirement for Mod2VQLS to work with a range of dimensions, and in particular, without the square matrix constraint that the number of equations must be equal to the number of unknowns.
The are other applications for binary linear solvers as well as integer factoring. The solution of some Boolean satisfiability problems can be optimized using Gaussian elimination with binary arithmetic, especially for cases with XOR constraints [
31]. (Quantum approaches to more general Boolean satisfiability problems are surveyed by Alonso et al. [
32].) Applications in cryptography and cryptanalysis, such as finding inverses of elements in the finite field
, have encouraged research on optimizing solutions of binary linear systems [
33,
34]. A component that solves linear systems modulo 2 is therefore required in various applications. Choosing an optimal approach typically depends on features including the dimension, number of equations, and sparsity; research on this problem is ongoing [
35]. While it is unlikely that Mod2VQLS would have a significant enough advantage over block Wiedermann to motivate the expense of developing quantum computers for this purpose, it is much more likely that large-scale quantum computers will become commercially available for a range of applications, and that Mod2VQLS will have particular niches in this environment.
More generally, computations over the field
are fundamental in information and coding theory, and the data structures used sometimes overlap with work in quantum computing. For example, low-density parity-check (LDPC) codes work by comparing values between “value nodes” and “check nodes” in a bipartite graph [
36,
37]. Quantum graph learning is also a current field of research [
38,
39], and there are various proposed methods for developing quantum LDPC codes [
40,
41]. These methods involve various operations over
, most of which do not involve solving complete sets of equations. An extra consideration is that some quantum processes can be parallelized in ways that enhance the security of distributed information [
42], so there may be incentives for using quantum computers for specific system processes, beyond the traditional goals of reducing computational complexity and speeding-up classically intractable computations. As described in
Section 3 above, the simple circuit design for computing the product of a matrix and a vector over
is the heart of the Mod2VQLS system, and components like this may end up being put to many different uses as the quantum computing ecosystem develops.
8. Conclusions
Variational quantum circuits provide design patterns that can be applied to a range of mathematical problems, especially ones that can be expressed as optimization problems with respect to some cost function. This paper demonstrated the Mod2VQLS system, which applies this design pattern to the problem of solving linear systems modulo 2. The key ingredients are a circuit for computing the matrix multiplication, a variational ansatz including parameters to optimize, and a classical optimization process. The rotation ansatz provided the most direct path to results, largely because its simple design made it amenable to analytical methods.
At the scales available to quantum computers today, the results here are potentially promising, but do not compete with classical solvers. The goal of this research is to investigate potential advantages at larger scale: we expect that medium-scale quantum computers will find their first regular commercial uses as part of larger hybrid pipelines. Understanding the quantum opportunities, and in particular, their scaling properties on real data sizes and distributions, will be crucial for guiding the choice between quantum opportunities. The Mod2VQLS system presented here is a worked example of how such proposals can be implemented and investigated today.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}