1. Introduction
Floating-point number representation and calculations form the backbone of science and engineering computations. They allow one to represent and approximate the continuous ranges of quantities/values on discrete systems such as digital computers. However, any floating-point representation, including the IEEE floating-point standard, by its very nature has finite precision and suffers from truncation errors, which makes operations on them non-associative [
1]. This is particularly obvious when representing numbers that fall in large dynamical ranges. For example, the expression
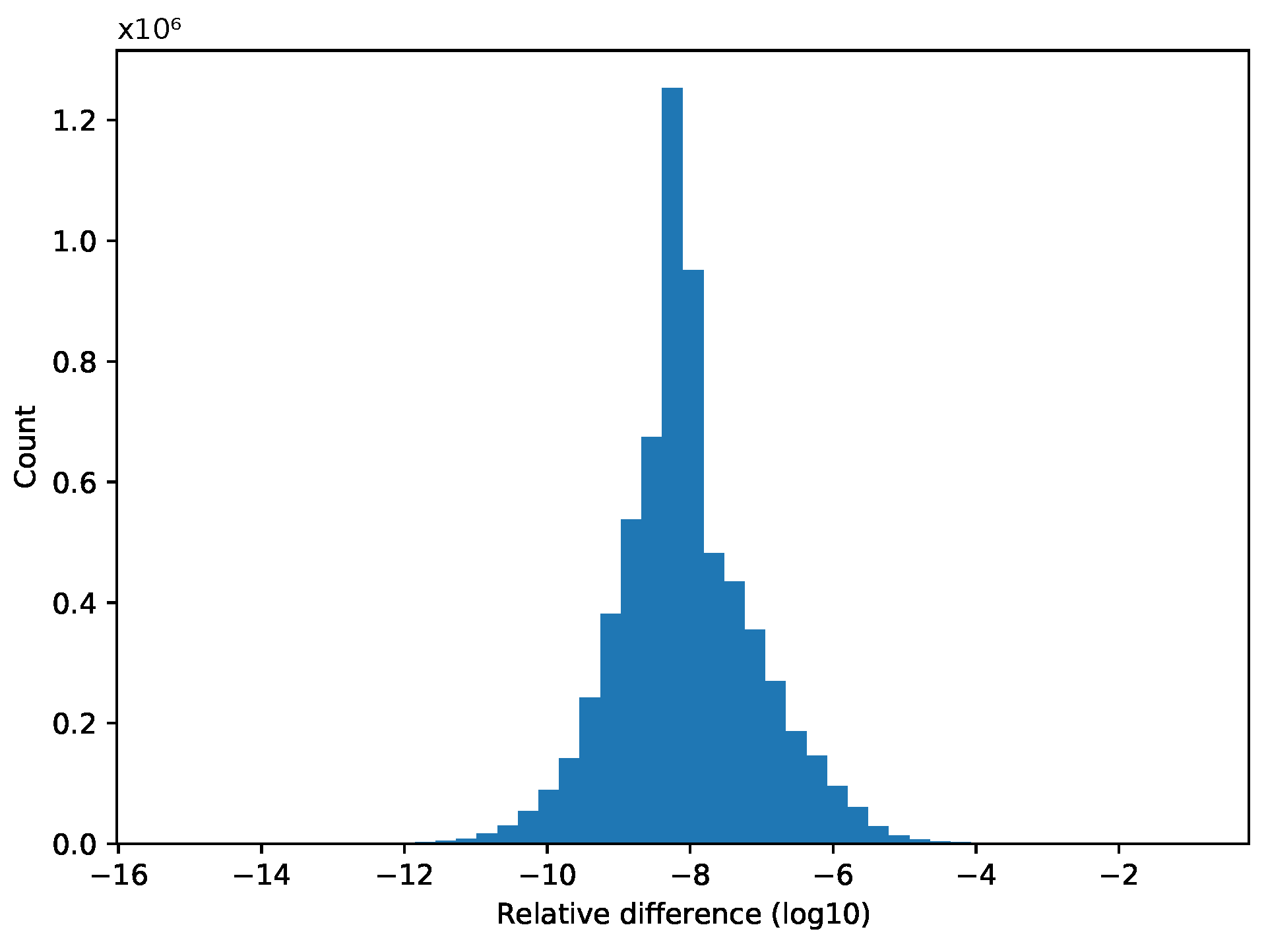
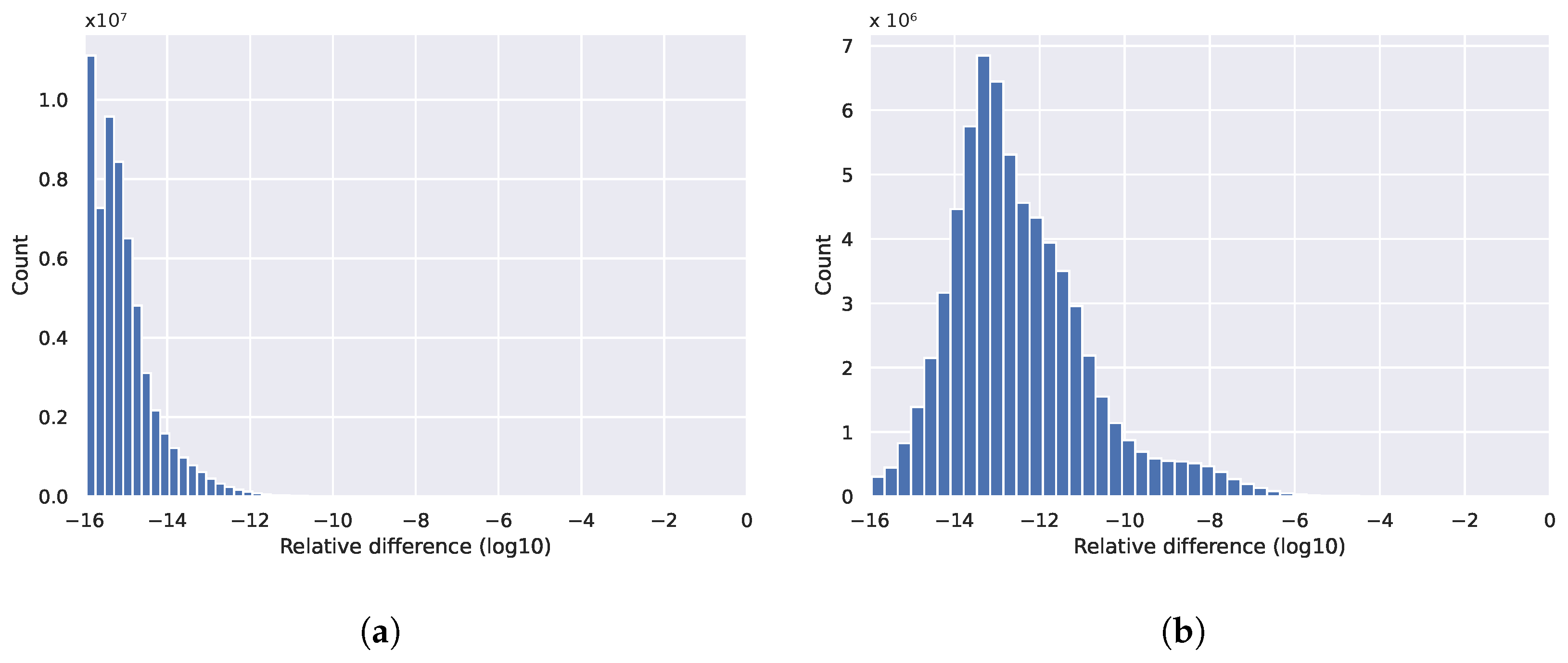
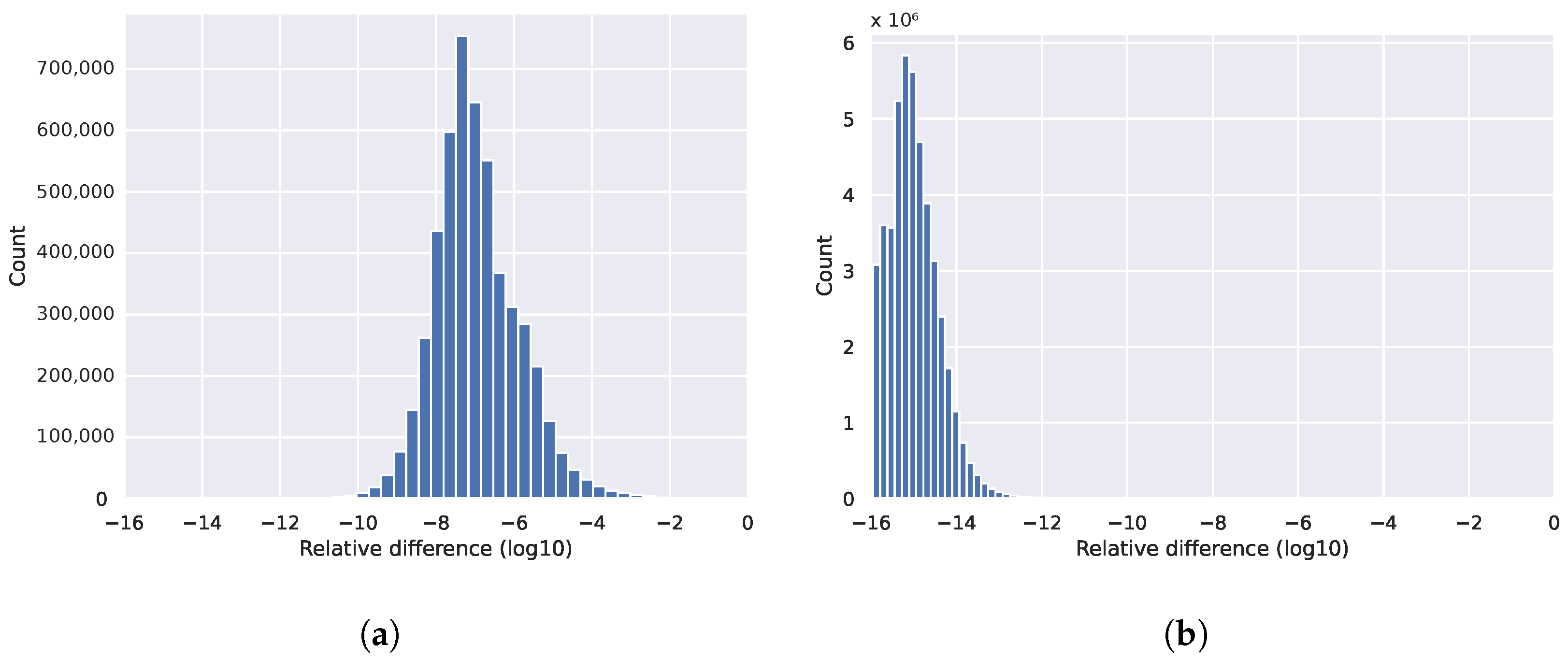
has a different answer than
when, for example,
,
and
with a 64 bit representation;
in the former case and
in the latter. The issue is compounded in parallel systems, where the associativity is applied in a non-deterministic manner. Thus, the exact truncation events and the order in which they are performed lead to slightly different results. Over long executions, the errors accumulate, potentially leading to larger inconsistencies between results from multiple runs.
Execution of parallel applications and the results produced by their floating-point number computations lead us to the notion of numerical reproducibility. In the strictest sense, this means obtaining bitwise identical results from multiple runs of the same code that consume the same inputs. A less stringent requirement would be to accept results with errors less than machine precision, leading to the need for a tolerance range for results. However, strict bitwise reproducibility could be essential for some applications, with many codes [
2,
3,
4,
5,
6,
7] implementing algorithms and techniques to enforce the required accuracy. Bitwise reproducibility is also useful for validating ported codes between different architectures. For example, by turning off fused multiply-add (FMA) operations and other optimizations, we can compare the output of a new GPU implementation to a previously trusted (validated) CPU implementation. If both produce the same result, then there is a high probability that we have managed to create the new version without introducing new errors. For relative debugging we already have examples of automatic test environments [
8], with bitwise reproducibility, we can avoid the problem of choosing the margin of error.
Numerical reproducibility stands as a vital concern in the landscape of parallel computing, where the attainment of bitwise identical results across multiple executions is a sought-after goal. This emphasis on reproducibility becomes especially significant in computational domains like computational fluid dynamics (CFD), where the reliability and accuracy of conclusions drawn from simulation results are of paramount importance. In practice, the application of various algorithms and techniques in codes addressing challenges such as the wind vulnerability of structures [
9] and modeling nonlinear aeroelastic forces [
10] underscores the broader need for ensuring that the conclusions derived from these simulations are not only insightful but also reproducible.
Bitwise reproducibility, however, often comes at a performance cost. Time spent on carrying out order-preserving techniques to obtain identical results adds additional overhead, compounding total time-to-solution. As such, careful trade-offs should be considered depending on the application domain and the validation and performance requirements. Much of the current literature focuses on providing one-off solutions to this problem for specific applications. Many of them rely on Kahan’s compensated solution method [
11], where after adding up the high-order parts of two elements, the low-order error is stored and is accumulated with the low-order part of the next summation. Many apply this method specifically in their own applications [
3,
4,
7]. Another widely used method is introduced by Demmel et al. [
12] where a variable number of bins are created for different magnitudes and then are used to accumulate the given magnitude part of the operands. We can see some examples of the usage of Demmel’s method in [
3,
13]. Other application-specific methods also exist, for example, sorted particle potentials in [
6] and the use of integer conversions as in [
14]. Most of these solutions require altering the code manually, often using a different number representation, making code maintenance difficult and expensive. This is especially problematic for large codebases. Additionally, most of these solutions address a single target architecture, making it even more laborious and costly when aiming to develop and maintain a performance-portable application.
The underlying goal of this paper is to explore the challenges in achieving reproducibility, specifically bitwise reproducibility for the domain of unstructured mesh computations, one of the seven dwarfs [
15] in HPC. The distinctive feature of unstructured mesh computations is the existence of data-driven indirections (such as mapping from edges to vertices) and computations that indirectly increment/read-write data, which causes data to race in a parallel environment. Although we are not aware of a systematic approach for unstructured meshes, we can see a number of similar works for other domains. The reproBLAS project [
16] covers many use cases in the field of dense linear algebra with reproducible execution. Apostal et al. [
17] created a code scanner, which can automatically recognize certain reductions where reproducibility might cause problems. In this paper, on top of providing a general solution applicable to a wide range of unstructured-mesh applications, we showcase how reproducibility can be implemented within the OP2 domain specific language (DSL). This paper is an extension of early work demonstrating the temporary array method on two simple benchmarks [
18]. Our results enable us to deliver reproducibility automatically to a number of existing applications, written using OP2, including a full-scale industrial computational fluid dynamics (CFD) code, executing on both CPU and GPU cluster systems. Specifically, we make the following contributions:
We identify key sources of non-determinism in unstructured mesh computations and propose three techniques for addressing them for this domain: (1) use of temporary arrays for indirect increments, (2) coloring for indirect increments and read-writes, and (3) reproducible reductions.
To use a coloring approach for reproducible execution, we develop a deterministic coloring algorithm, which depends only on the mesh and is independent of the partitioning of the mesh (including the number of partitions).
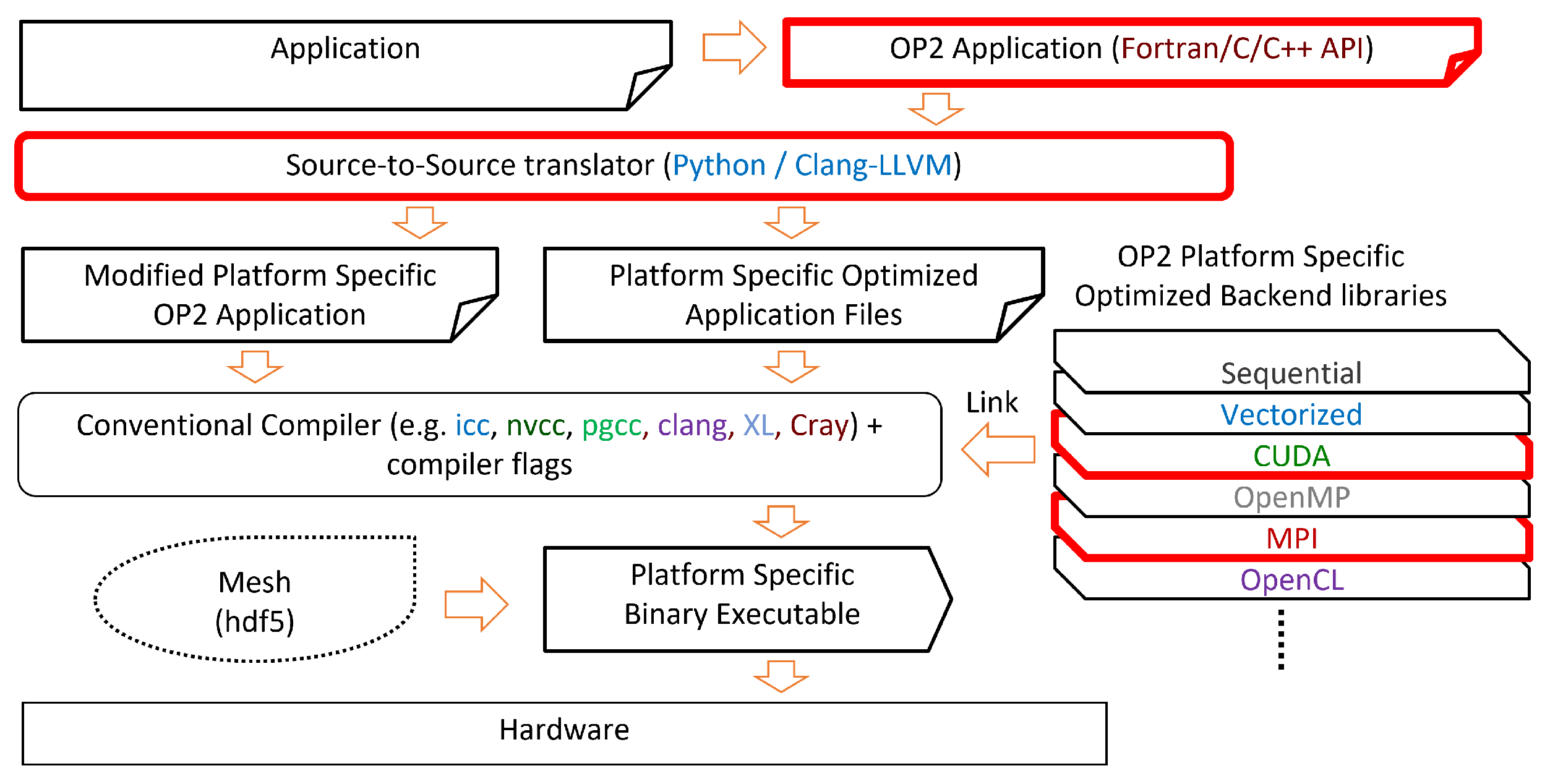
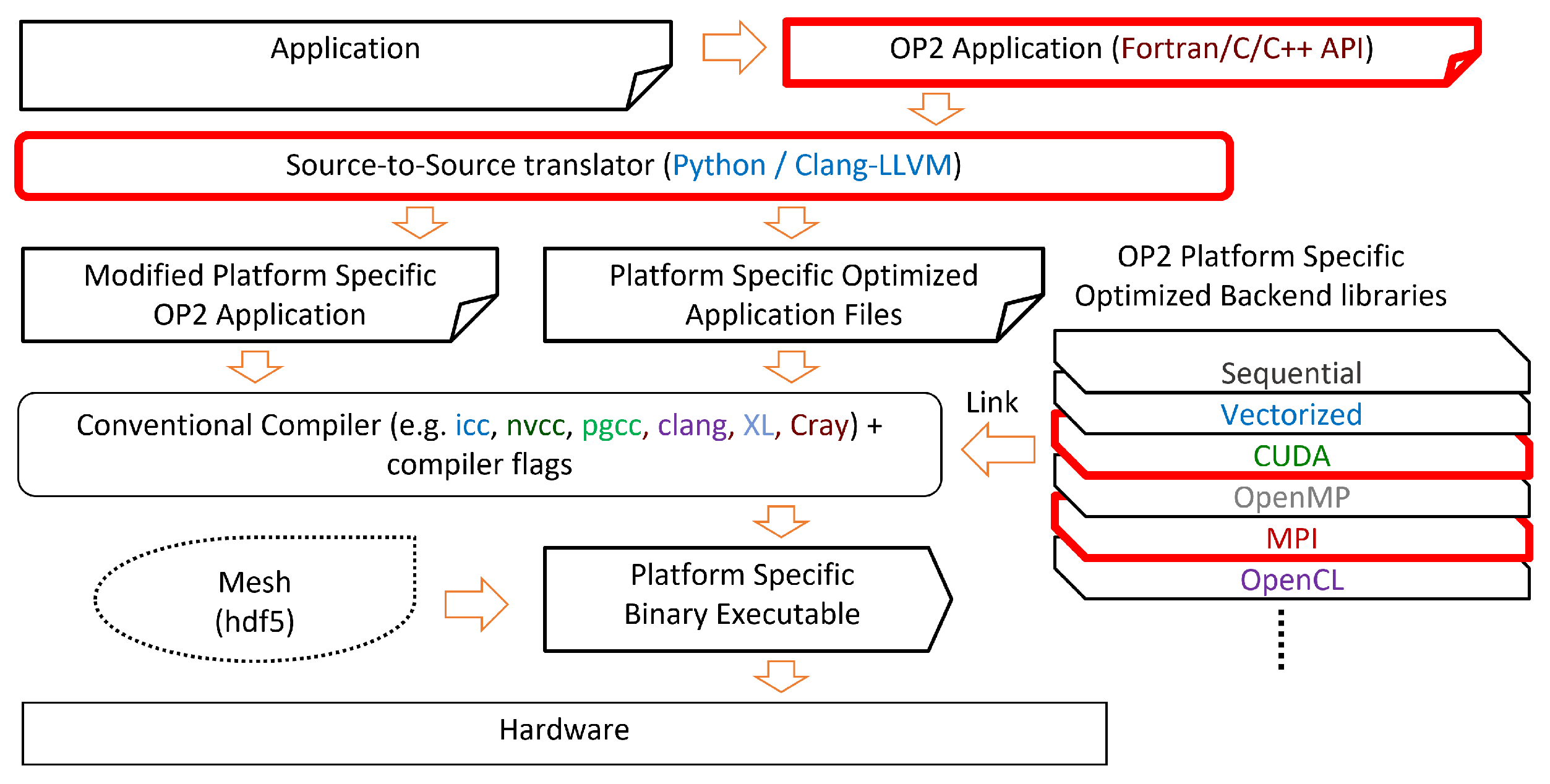
The above-developed techniques and algorithms are implemented within the OP2 DSL, in order to automatically generate target-specific parallel code that produces reproducible results when executed on modern large-scale systems with multi-core and many-core processor architectures. Leveraging OP2’s source-to-source translation, we can deliver bitwise reproducibility without changes to the user code.
Various unstructured mesh applications, ranging from smaller benchmarks (Airfoil [
19], Aero [
20]), a CFD mini-app (MG-CFD [
21]) to a large-scale industrial CFD application (Rolls-Royce Hydra [
22]), previously developed with the OP2 DSL are used to evaluate our proposed algorithms. Numerical results as well as the impact on performance when executed on CPUs, GPUs, and their scalability on clusters are explored.
To the best of our knowledge, our work is the first to provide a general solution for bitwise reproducibility on unstructured mesh applications. We show that this solution achieves good results in terms of accuracy and performance in industrial applications, such as Rolls-Royce Hydra, demonstrating the practicability of this work for production codes.
The rest of this paper is organized as follows: in
Section 2 we discuss related works, in
Section 3 we present background on floating-point number presentations and computations and introduce the sources of non-reproducibility, with examples from a number of applications. In this section, we also describe the unstructured mesh application class and OP2’s abstraction and framework. In
Section 4 we describe multiple methods with which we achieved bitwise reproducibility. In
Section 5 we examine the performance of these techniques, and in
Section 6 we draw conclusions. The codes developed for this paper are available in the
Supplementary Materials, which were accessed on 3 January 2024.
2. Related Works
Bitwise reproducibility is a widely researched problem, usually investigated in a specific application.
Mascagni et al. [
2] list the main sources of non-reproducibility in a neuroscience application: (i) the introduction of floating-point errors in an inner product; (ii) the introduction of floating-point errors at each an increasing number of time steps during temporal refinement (ii) and (iii) differences in the output of library mathematical functions at the level of round-off error. They highlight the importance of numerical reproducibility without providing a general solution.
Liyang et al. created a special method [
6] for molecular dynamics applications in the LAMPPS Molecular Dynamics Simulator [
23]. From each particle, the potentials are calculated first and then stored temporarily. Then they loop over every particle again, sort the components for one element, and accumulate them in ascending order. This way, they were able to eliminate the effect of non-associative accumulation.
Langlois et al. [
3] tested multiple techniques for reproducible execution on an industrial free-surface flow application: the 2D simulation of the Malpasset dam break. All methods passed, but their main purpose is to determine how easy it is to use them. Kahan’s compensated solution method [
11] appeared to be the easiest to apply and provided accurate results for low computing overhead. The integer conversion provided in Tomawac [
14] was also easy to derive and introduced a low overhead. The solution that uses reproducible sums [
12] was efficient, but was applied less easily in their case and introduced a significant communication overhead.
He et al. [
4] experimented on a dynamical weather science application. They tested several methods, such as Kahan’s [
11], or the double-double number technique [
24] which is an unevaluated sum of two IEEE double precision numbers. They also provide an MPI operator for reductions.
Taufer et al. [
5] were looking into a molecular dynamics application, whereby reproducibility meant that results of the same simulation running on GPU and CPU lead to the same scientific conclusions; in their case, bitwise reproducibility was not necessary. They tried double precision arithmetic, which partially corrected the drifting, but was significantly slower than single precision, comparable to CPU performance. They created a library of float-float composite type, which is comparable in accuracy to double, but the performance loss is only 7%, versus a loss of 182% of normal double precision.
Robey et al. also experimented with a dynamical fluid application [
7]. They tried to sort their data first and then sum, but that was too slow. They applied Ozawa’s pair-wise summation [
25], which produced less truncation, but not bitwise reproducibility, although this method is quick and can run in parallel. The double-double technique used too much memory, so finally they used Kahan’s [
11] and Knuts’s [
26] approach due to their simplicity, low additional cost and their added precision.
Apostal et al. [
17] developed a source code scanner to recognize reductions over MPI in C or C++ codes and automatically modify them to use Kahan’s summation [
11] or an algorithm developed by Demmel and Nguyen [
12].
Olsson et al. [
27] defined some transformation techniques to describe concurrent applications written in the SR programming language to achieve reproducibility. They can transform an arbitrary SR program into two parts: one for recording a sequence of events and one for replaying those events.
Reproducible Basic Linear Algebra Subprograms [
16] (ReproBLAS), intends to provide users with a set of parallel and sequential linear algebra routines that guarantee bitwise reproducibility independent of the number of processors, data partitioning, reduction scheduling, or the sequence in which the sums are computed in general. The BLAS are commonly used in scientific programs, and the reproducible versions provided in the ReproBLAS will provide high performance while reducing user effort for debugging, correctness checking, and understanding the reliability of programs.
Graph coloring is a widely used method in HPC to maximize parallel efficiency, without facing any race conditions. We can see a detailed example of using coloring techniques in the work of Zhang et al. [
28]. Their paper addresses challenges in parallelizing unstructured CFD on GPUs, employing graph coloring for data locality optimization and parallelization, resulting in substantial speed-up with GPU codes outperforming serial CPU versions by 127 times and parallel CPU versions by more than thirty times in the same MPI ranks.
4. Theory and Calculation
In this section we describe our techniques to solve the two main problems which cause non-reproducibility, local element-wise reductions and global reductions. Most of our methods focus on the local reductions. For global reductions we utilize ReproBLAS. Most of our examples in this section use an edges→cells mapping, but all of these algorithms are implemented generally using the dimension of the specific mapping.
To solve the issue of ordering in local (element-wise) reductions, we provide two separate approaches: (1) a method storing increments temporarily and applying them later in a fixed order and (2) different reproducible coloring techniques, which later can be used as colored execution, maintaining deterministic ordering. For all of these techniques, we must provide a common deterministic seed that will always be the same, even with different numbers of MPI processes. That common seed is the global ID of all elements in the whole mesh. If there are multiple MPI processes, then the global IDs of each element must be communicated between the processes. If an element is owned by the given process, then its global ID can be looked up from an internal data array of OP2. If an element is not owned, then its global ID must be imported from the MPI process that owns it. All of our techniques use two main parts: (1) the OP2 backend must calculate the execution order and (2) the generated code must execute the computations in this order. We apply the reproducible execution methods only on kernels where the order of summation does matter. These are loops with global reductions, indirect incrementing operations (OP_INC), or operations with an indirect read and write access pattern (OP_RW).
4.1. Temporary Array Method
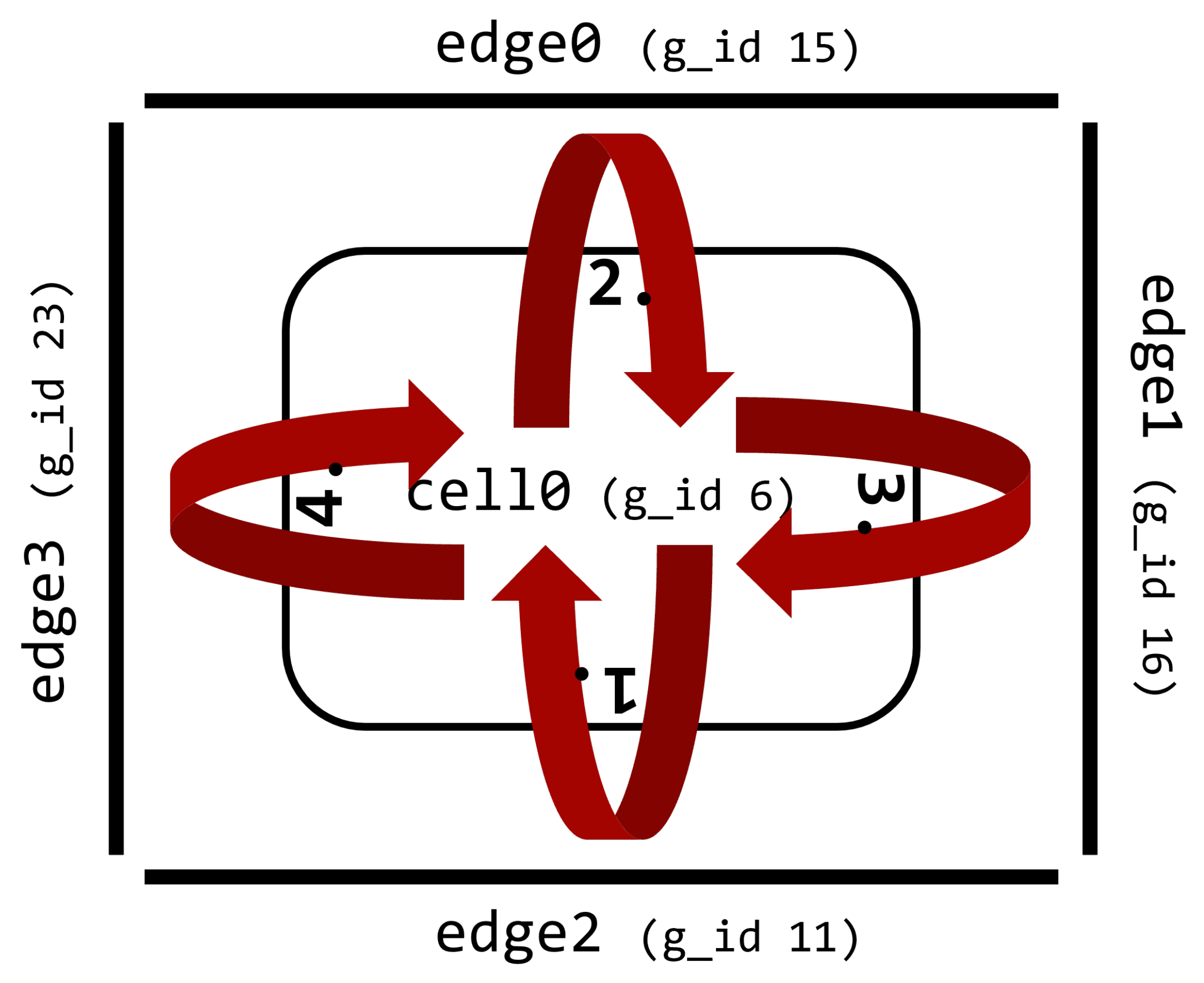
A temporary array-based technique can be used to ensure reproducibility for incrementing operations. Consider using an edge→cells mapping and an incrementing operation. Here, we would iterate through all the edges, calculate values, and add them to a variable defined on a neighboring cell. To achieve reproducibility, we modify this structure by storing the calculated increments in a temporary array defined on the edges, and after all the increments are calculated, we iterate through all the cells and apply these increments in a fixed order defined by the global_IDs of the edges. In
Figure 5 we can see an example of this method, where
edge2’s global_ID is the smallest, so the value from
edge2 is applied first on the cell, then
edge0, etc.
To achieve this modified execution, a few extra preparations must be conducted in the backend, which are shown in Algorithm 1. After the global_IDs are shared, the next step is to create a reversed mapping for every map. The reversed mapping is needed so we can iterate through the cells and in each iteration we can access the edges connected to the given cell. This reversed map uses local indices which might be in different order in different MPI ranks. That is why we need to reorder them by using their previously shared global indices. Another modification conducted on the reversed map is that it actually stores indices of a temporary array where the increments from the edges are stored for a cell. In other words, if the kth element in line n (kth edge connection of cell n) of the reversed map is x, then it means that in the temporary increments array at location x the increment for cell n from edge k can be found.
The main disadvantage of this method is the need for significant additional memory to store the reversed mapping, and to store the increments. The reversed map uses a Compressed sparse row (CSR) format, which consists of a main array of increment indexes (integers), with the size of set_from_size∗original_map_dimension, and another array indexing the previous array with a size of set_to_size+1. The temporary arrays themselves can use much more memory: set_from_size∗map_dimension∗data_element_size.
| Algorithm 1 Algorithm of generating incrementing order |
exchange global IDs = number of maps for to do create reversed mapping for map m = target set’s size of map m for to do sort the reversed connections of i by global IDs end for end for
|
After creating the reversed map with the correct order, we generate a new
op_par_loop implementation code to use this modified method. The main changes can be seen in Algorithm 2. After the initialization phase, it is imperative to set all elements in a temporary array to zero to accommodate individual increments. This step is crucial as the user kernel performs the increments, and proper initialization is required beforehand. Moreover, this approach ensures that the data remain in the cache, enhancing overall performance. Then we can call the kernel function for all edges to access the elements defined on the cells. If a parameter is accessed through an
OP_READ or
OP_WRITE method, then the execution order does not matter, so we can use the original method of directly storing the new state in the data. If the parameter is incremented (
OP_INC), then we need to store each increment value in the
tmp_incs array instead of adding it to the actual data. After the iteration on edges is completed and all increments are calculated, we need to apply those to the actual data on cells. For that, we start a new cell-based loop on the cells and by using the reversed mapping with the fixed ordering, for each cell, we can gather and apply the increments. This method is generally applicable to other types of mappings as well.
| Algorithm 2 Algorithm for applying the order of increments |
= source set’s size of the original map = the dimension of the original map = target set’s size of the original map for to do end for for to do prepare regular access indices for and parameters call kernel function, using the array for parameters end for for to do for all connection i of n do apply the temporary increment from connection i on the final location of the data end for end for
|
4.2. Reproducible Coloring
The temporary arrays method only works for increment-type operations, where increments can be stored separately. If a kernel not only increments a variable but also reads and rewrites it (OP_RW), then the kernel call from one edge must be executed, storing its result in the cell before another edge accessing that cell can be executed. Although OP2 still requires that the computation be associative, we cannot store the increments separately. This problem needs a solution to be able to really execute the kernel calls in a predefined fixed order and achieve reproducibility. To solve this issue, we can apply a regular coloring scheme with the following restriction, we are looking for an equivalence class of colorings where if the color of one element is smaller than that of another connected element in the case of one coloring, then it should also be the same in the case of any other coloring.
We have three main approaches to solve this problem. An initial trivial solution is to choose the global index of the edge as the color. With this, we have as many colors as edges in any given subgraph, but we do not have multiple edges with the same color. This is useful for MPI-only parallelization, but not for a shared memory method. The advantage is that this trivial method can be solved without actually coloring the elements. We can just use the numbering from the global_ids for ordering sequential execution. This trivial execution schedule can be considered as a special case of colored execution and in fact they use the same generated code. Therefore, we refer to it as a coloring method. The second method is a non-distributed method, we apply a greedy coloring algorithm on the whole mesh in a single process as a pre-processing step and save the assigned colors in a file. When we rerun the application on multiple processes, we load and distribute the saved colors the same way as we distribute the mesh elements between the processes. With greedy coloring, we can generate a near-optimal number of colors, thus we have a high degree of parallelism. The drawback of this option is that we have to execute the pre-processing part in a single process. This carries the restriction that the whole mesh must be able to fit into the memory on a single node. The third method is a novel distributed coloring scheme, which does not suffer from this restriction.
Distributed Reproducible Coloring Method
We base our method on an algorithm developed by Osama et al. [
57]. This original non-reproducible parallel method can be seen in Algorithm 3 between lines 7 and 40. We iterate through each element, calculate a local hash value and then compare it to its (as yet uncolored) neighbors’ hash values. If the examined hash value is a local minimum or maximum in its neighborhood in a given iteration, then we can assign it a color. In our implementation we use Robert Jenkins’ 32 bit integer hash function [
58]. This hash function is a custom, non-cryptographic function that operates on unsigned integers. It uses a combination of bitwise operations and arithmetic with specific constants to compute the hash of an input.
| Algorithm 3 Algorithm for reproducible coloring in a distributed graph |
- 1:
create neighbor lists - 2:
global_done = 0 - 3:
local_done = false - 4:
if set_size == 0 then - 5:
local_done = true - 6:
end if - 7:
iteration = 0 - 8:
low_color = 0 - 9:
high_color = 1 - 10:
while global_done < number of subgraphs do - 11:
if not local_done then - 12:
for all element e in from_set do - 13:
if e has no color then - 14:
calculate hash value of e in iteration i - 15:
is_min = true - 16:
is_max = true - 17:
for all neighbors n of e do - 18:
if n has no color then - 19:
calculate hash value of n in iteration i - 20:
if n’s hash < = e’s hash then - 21:
is_min = false - 22:
else if n’s hash > = e’s hash then - 23:
is_max = false - 24:
end if - 25:
end if - 26:
end for - 27:
if is_min then - 28:
give low_color as color of e - 29:
number of noncolored elements - 30:
end if - 31:
if is_max then - 32:
give high_color as color of e - 33:
number of noncolored elements - 34:
end if - 35:
end if - 36:
end for - 37:
if number of noncolored elements == 0 then - 38:
local_done = true - 39:
end if - 40:
end if - 41:
exchange halo color values - 42:
reduce local_done values into global_done - 43:
low_color += 2 - 44:
high_color += 2 - 45:
iteration += 1 - 46:
end while
|
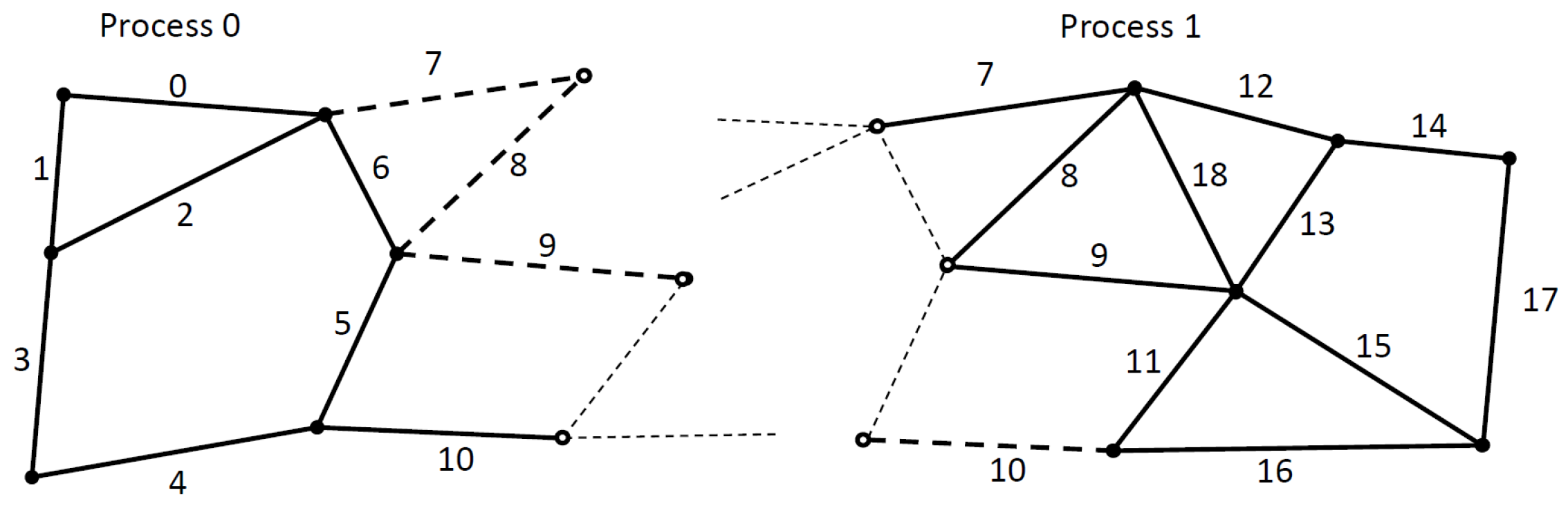
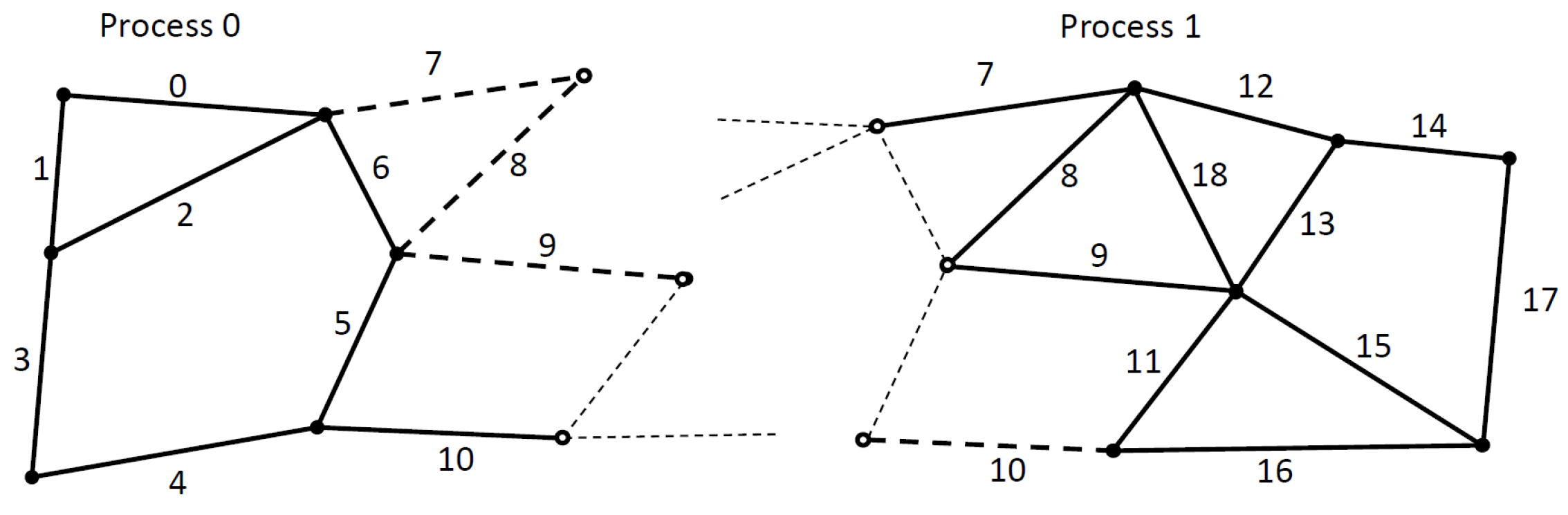
The difficulty of applying this algorithm in a distributed graph comes from two sources. First, in each iteration of the previously described algorithm, we must know if the neighbor element already received a color, or not. Thus, we need to synchronize the assigned colored values on the borders of each subgraph (MPI partition). Secondly, it is difficult to figure out all the neighbors of an element on the border of a subgraph in a standard owner-computed model. We can see an example of this problem in
Figure 6. Solid dots and continuous lines are the owned elements. In this example, we use an edge → nodes mapping, thus we import one layer of halo elements (e.g., edge 7, 8, 9 on Process 0) so we can update the owned nodes from all attached edges (so far it is a standard owner compute model). However, to calculate the smallest hash value in a neighborhood, we also need to communicate edges even around the non-owned nodes (e.g., edge 0, 2, 5, 6 on Process 1). Our extension to distributed execution can also be applied to other iterative coloring techniques that use only local information (the algorithm is not sequential) and are deterministic even with different graph partitioning. The number of colors is not explicitly minimized.
4.3. Parallel Global Reduction
Global reductions are another source of non-reproducibility in MPI applications. This operation is commonly conducted by performing a local sum on each process, then calling MPI_Reduce, however, this assumes associativity. If we use different numbers of MPI processes, then we would sum different elements and even a different number of elements locally, which again can produce different results. To solve this issue, we introduced another temporary storage. If a kernel performs an increment reduction, then we give a temporary storage point to store the increment for the result of each element. Then, in each MPI process, we reduce these increments reproducibly by using the ReproBLAS library. First, we create a local ReproBLAS’s double_binned variable for every MPI process, then we use binnedBLAS_dbdsum to collect those into the local_sum. After that, we use reproBLAS’s method to call an MPI_Allreduce with the binnedMPI_DBDBADD operator. Finally, we convert the result back to a regular double precision variable and return it.
4.4. Reproducible Codegeneration with OP2
Using OP2’s source-to-source translator, a user can easily generate reproducible code from an app that already has an implementation using OP2. A few flags are responsible for controlling the mechanisms that allow reproducible code to be generated. In the translator scripts these are: reproducible—needed for all methods, repr_temp_array—for using temporary arrays, repr_coloring—for using reproducible coloring method and trivial_coloring which will produce the trivial coloring version. To enable the greedy coloring technique, the -op_repro_greedy_coloring command line flag must be used with the application.
5. Performance Results
We measured our techniques with four test applications, introduced in
Section 3.8. All results are the average of 10 measurements.
Table 1 summarizes the details of the different machine setups we used for our measurements.
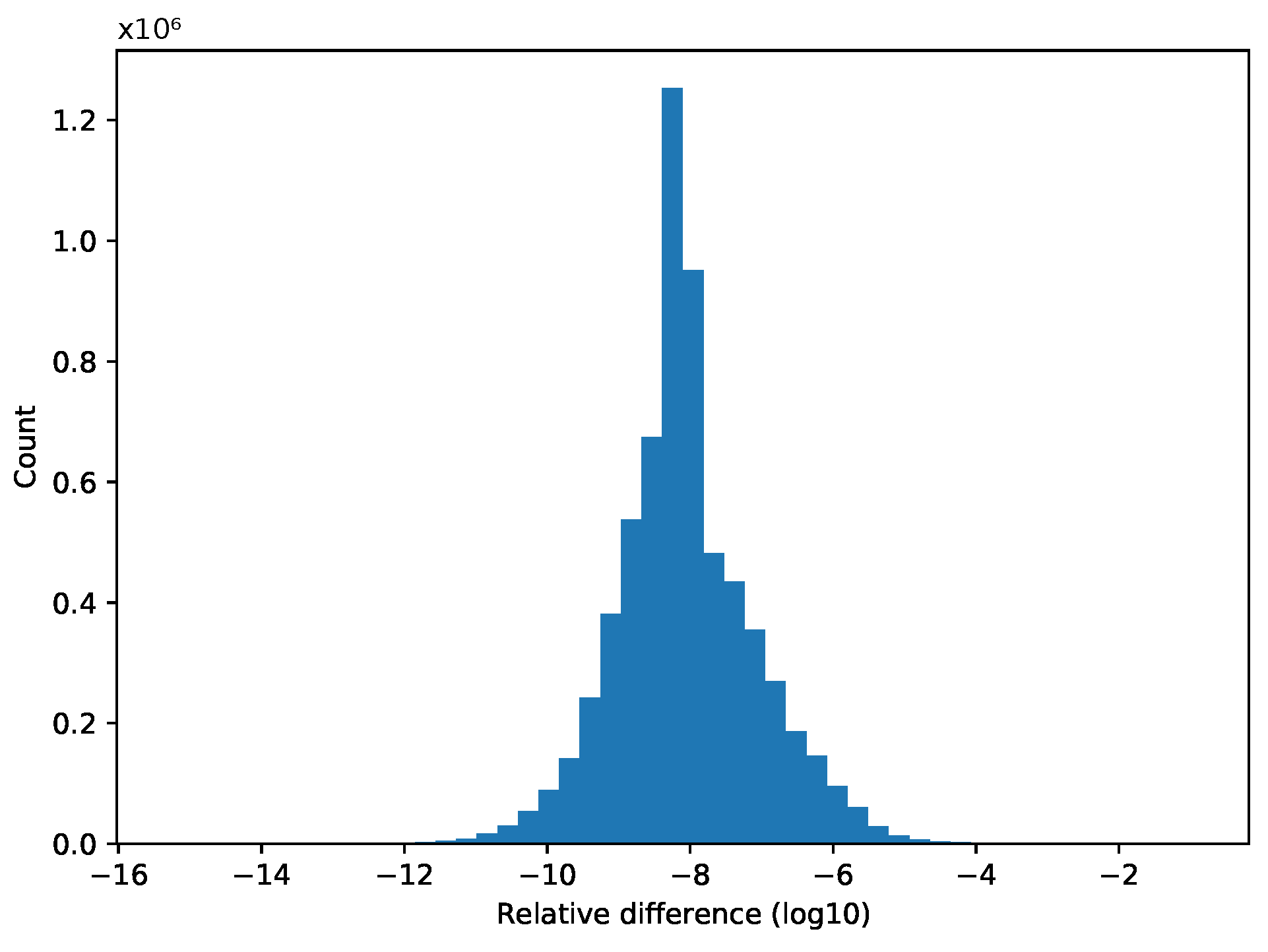
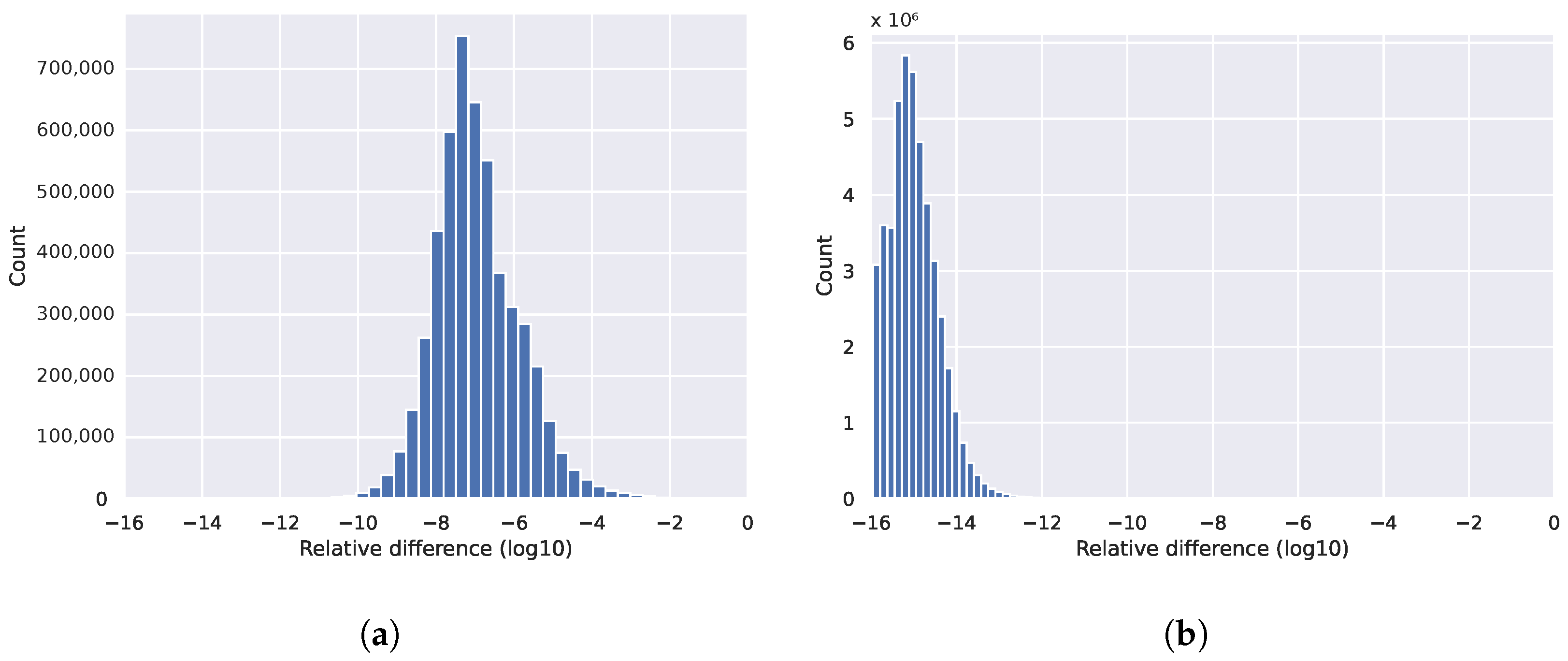
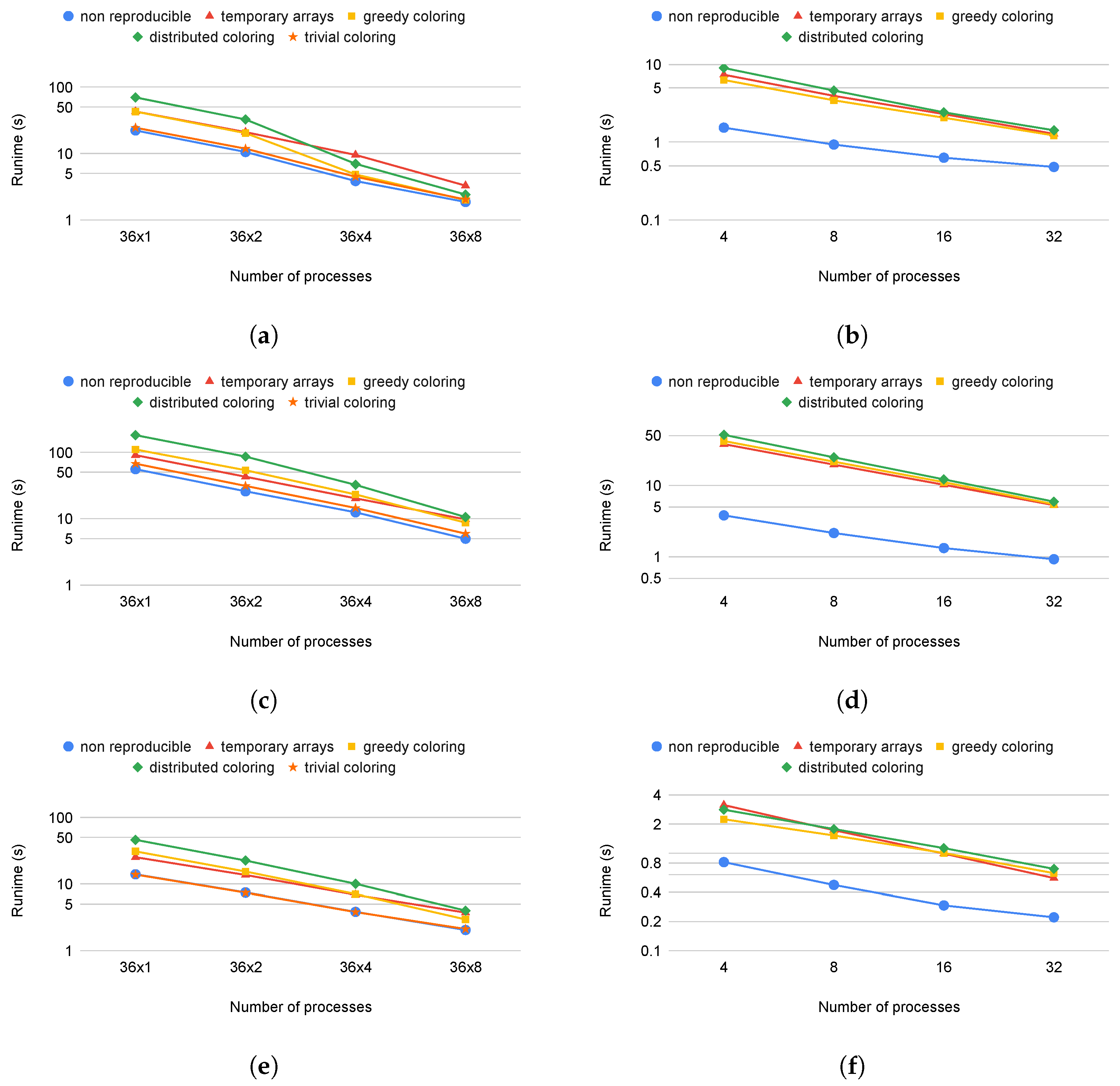
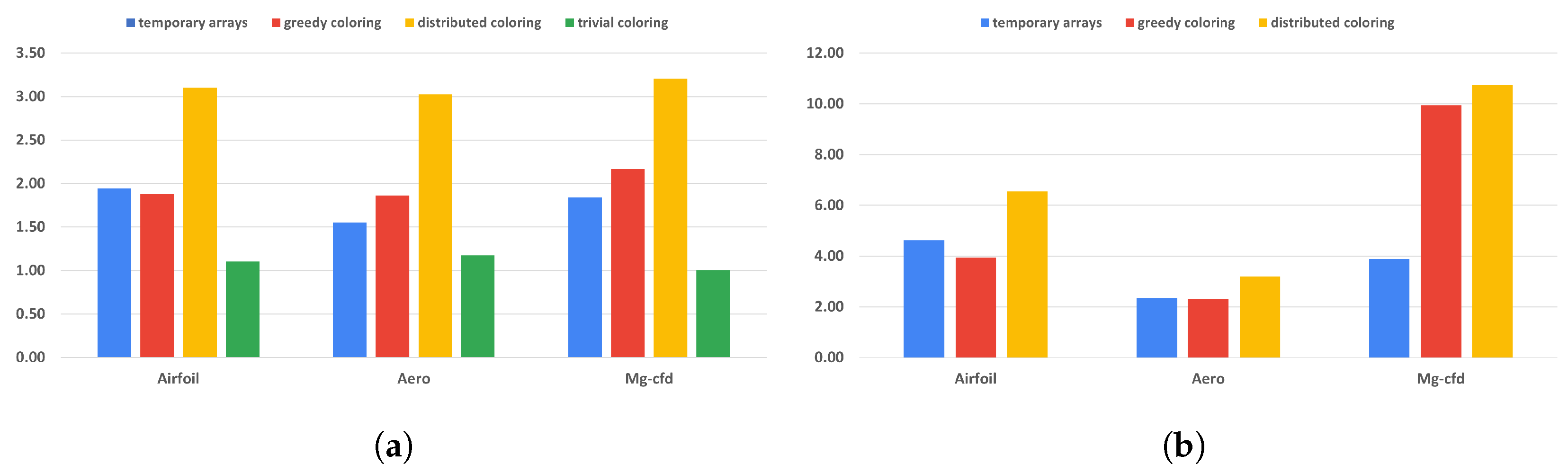
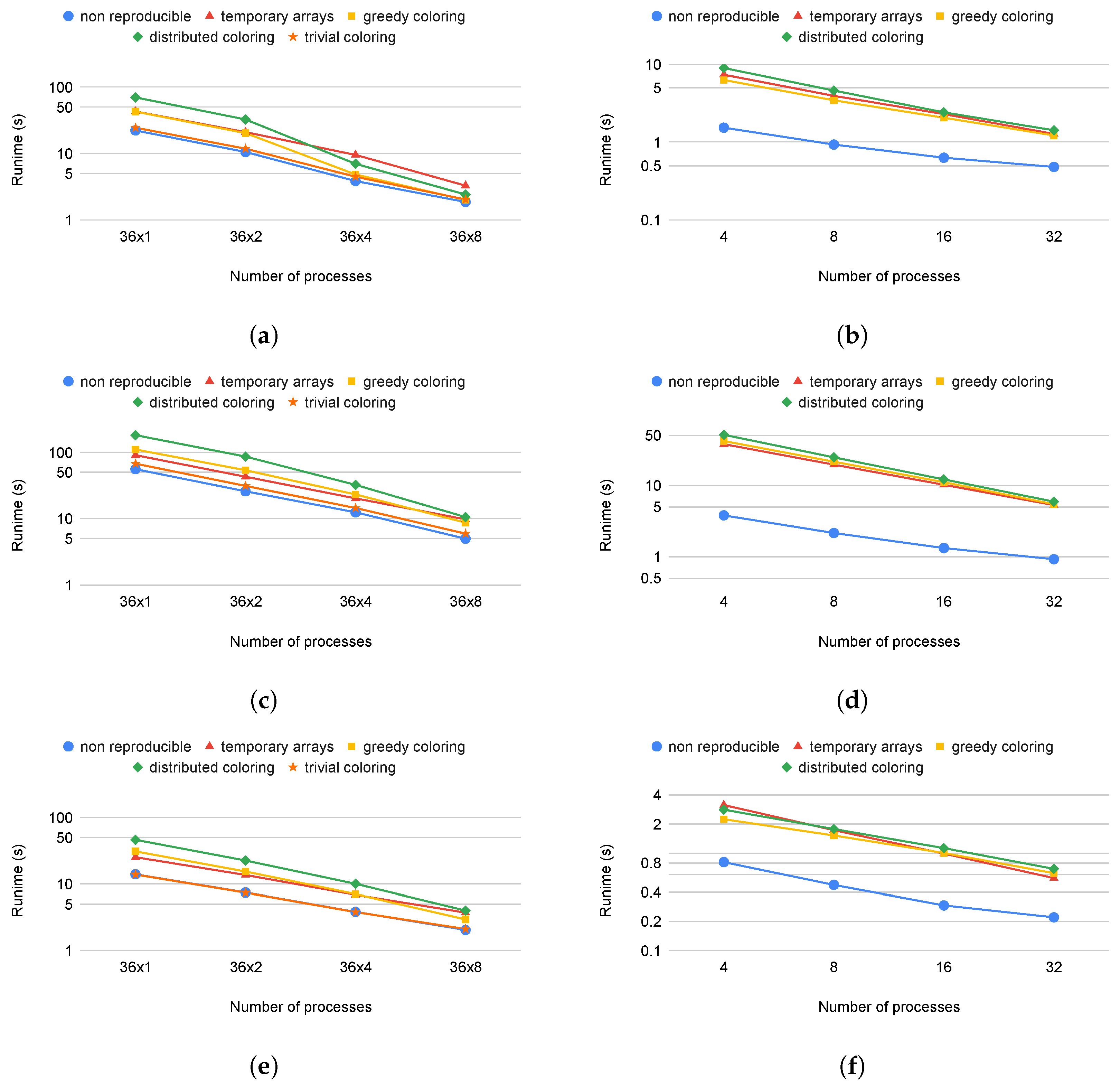
All of our methods provide full reproducibility at the expense of additional computations, suboptimal scheduling, or redundant memory usage. The overall cost of these techniques is visualized in
Figure 7 and
Figure 8 and in
Table 2. We compare each run with its original, non-reproducible version. On CPU systems, slowdowns are between 1 and 3.21 times. The difference between the greedy and distributed coloring methods comes down to data reuse and cache line utilization, because of the different number of colors used. The main reason for that is that the data for neighboring elements are located close in memory, but when using coloring, adjacent elements will have different colors, leading to poor utilization. A few examples of the number of colors used are shown in
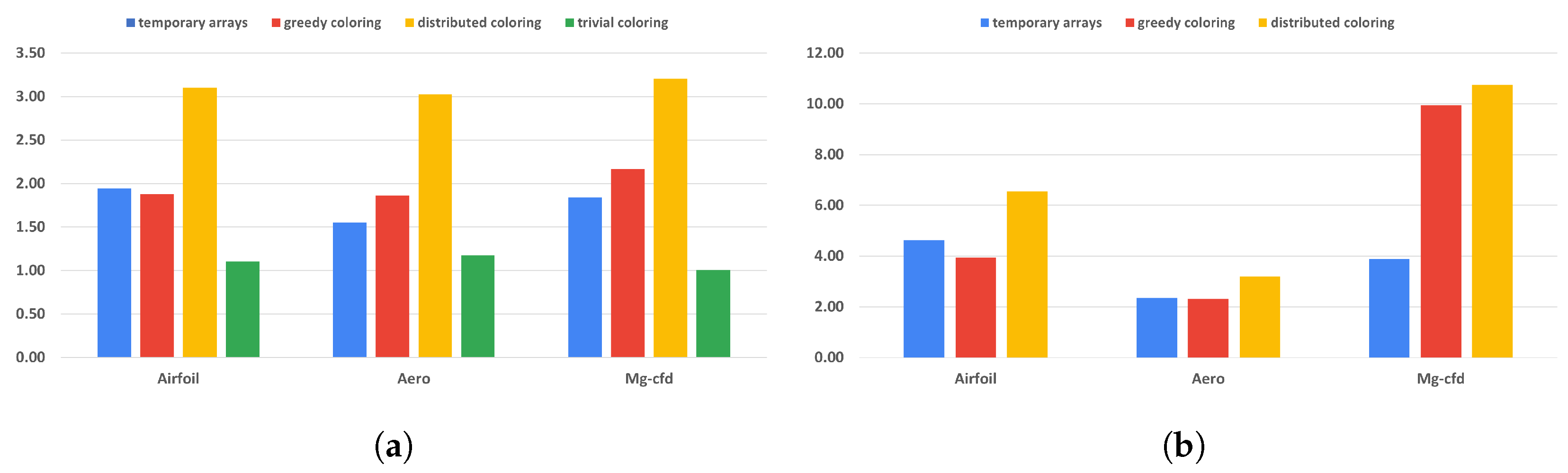
Table 3. While the greedy scheme leads to near-optimal color counts, the parallel scheme yields much higher color counts particularly in 3D. The performance of the trivial coloring scheme is close to the reference, since it uses a similar order of execution to the nonreproducible version, with the only differences around the borders of MPI partitions. Since with the trivial scheme we still require sequential execution within a process, we cannot use additional parallelization techniques, such as CUDA or OpenMP. In contrast, the slowdown on GPUs is more significant, because they are even more sensitive to data access patterns and cache locality than CPUs. In particular, with the usage of the temporary arrays, we have to iterate through the increment data twice, once when populating it and once when gathering the results, each time with a different access pattern. If we optimize for one stage, then the other will suffer from the non-coalesced data accesses. This is even true for the coloring methods. If we reorganize the data in a set according to one map, then later, using another map to the same set, we again obtain inefficient access patterns.
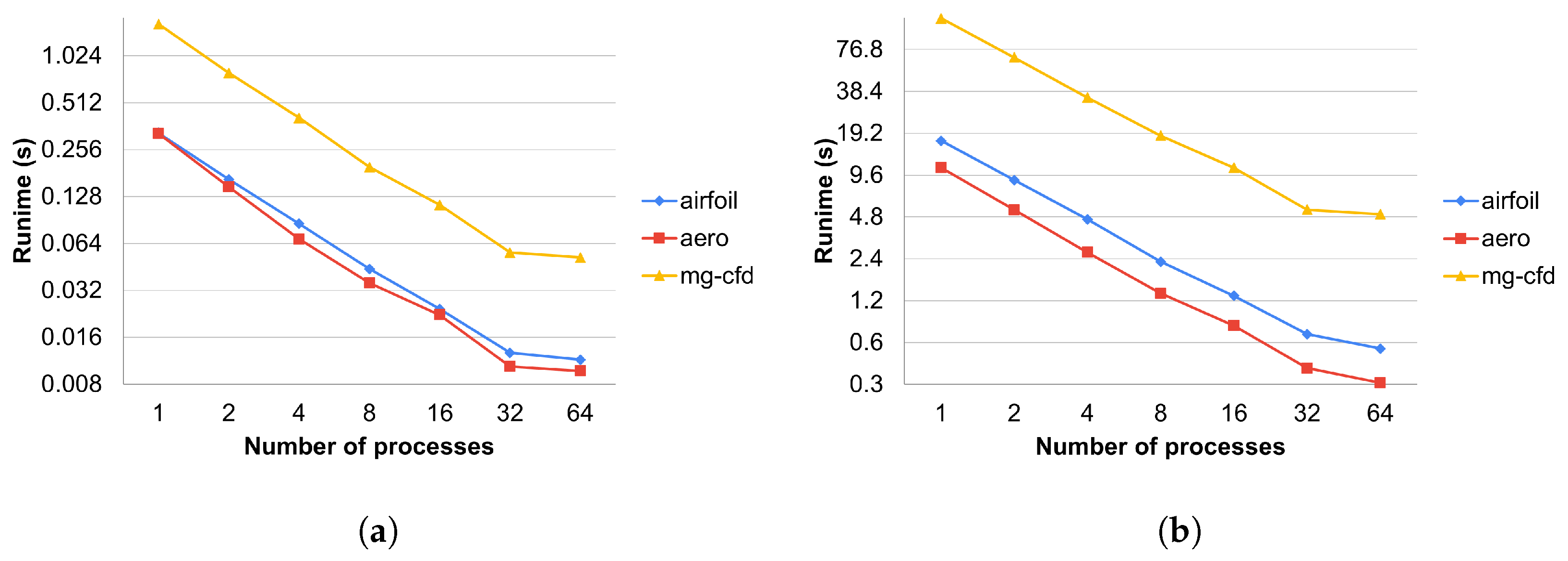
The runtime overhead of the preprocessing preparations of the temporary array and coloring methods against the number of MPI processes are detailed in
Figure 9 and using only one process in
Table 4.
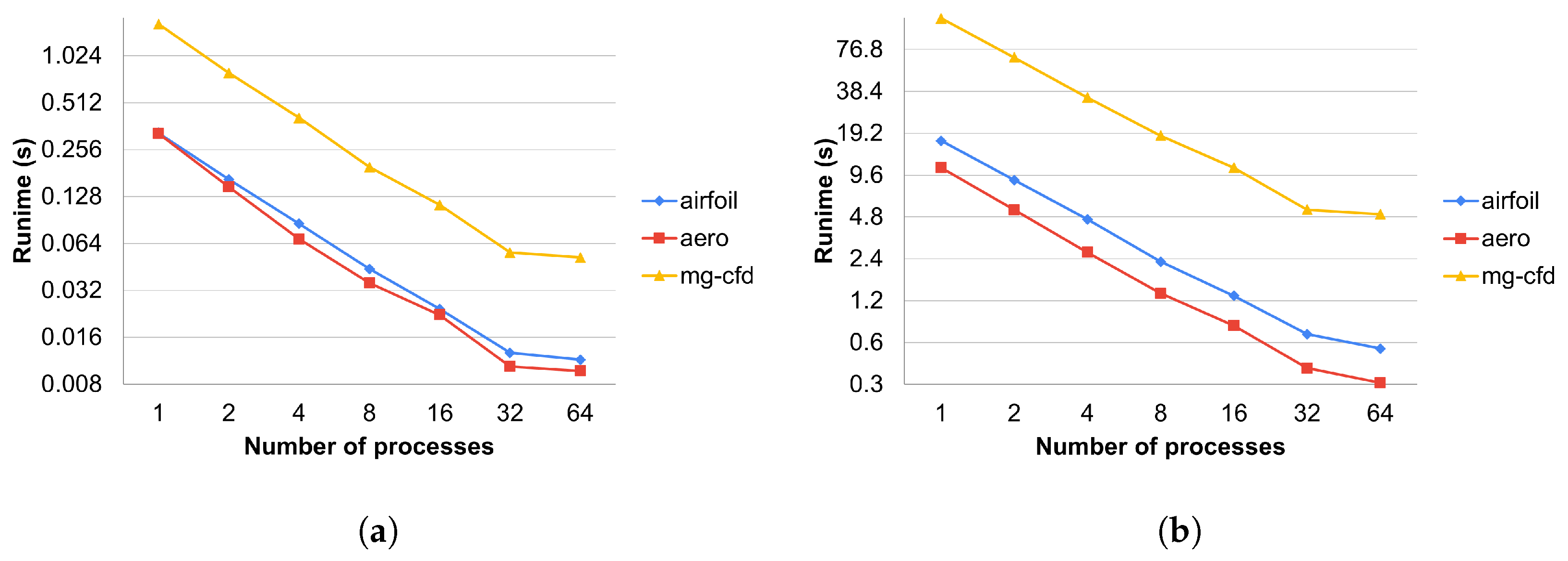
Figure 10 shows how well the test applications scale with the different methods using one, two, four, and eight nodes on the Cirrus cluster. On the CPU side, all methods have the same parallel efficiency on each application, except the distributed and greedy coloring methods on Airfoil, where we can observe superlinear scaling (
Figure 10a) since much of the data used can fit into the cache if they are divided between at least four nodes. We cannot observe this on the temporary array method, because it uses extra memory to store increments separately. Apart from the reductions (discussed in detail below), MPI communications and communication times do not differ between reproducible and non-reproducible. For non-reproducible execution, the communication overhead (as a fraction of total runtime) will become higher using multiple nodes. In the case of reproducible execution, because we spend more time in the colored execution, we spend a smaller fraction of the total time in communications. Therefore, the relative difference is decreasing and the slowdown effect with any method compared to the non-reproducible is less when more nodes are used.
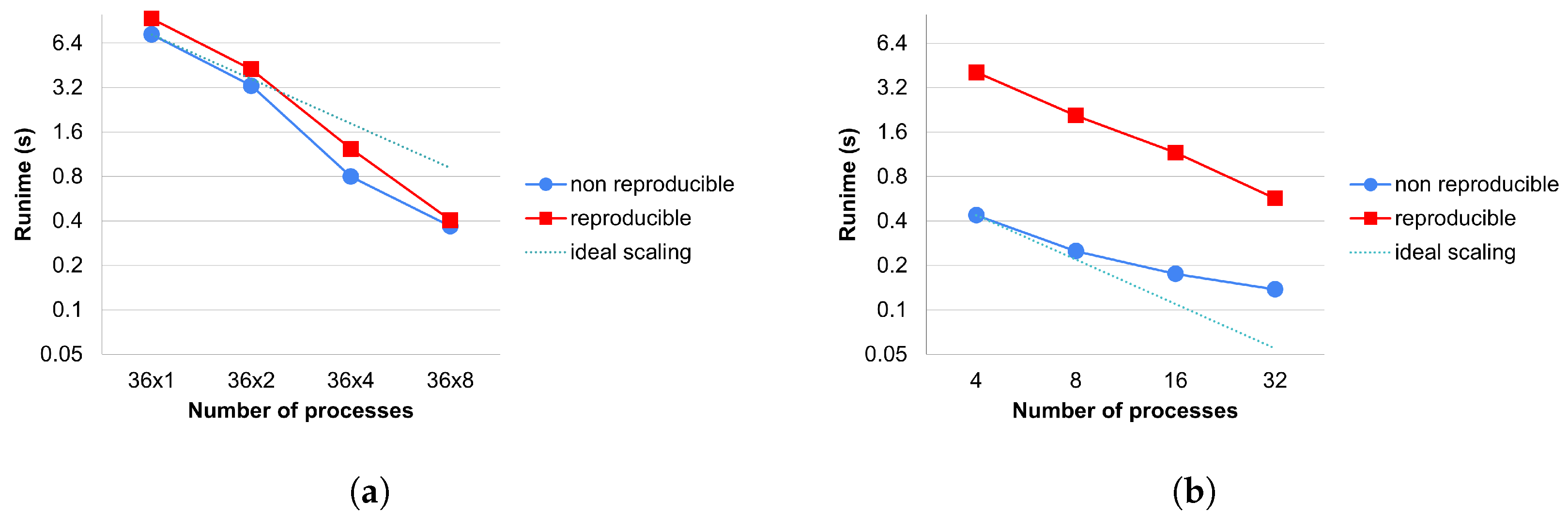
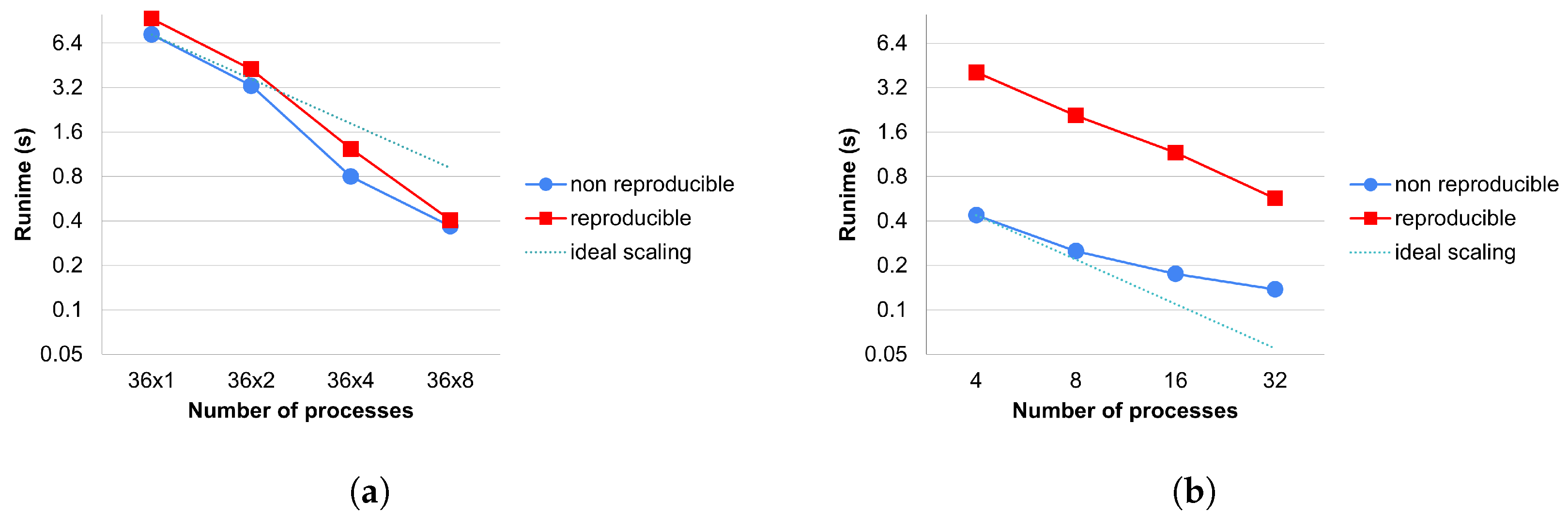
We can observe the strong scaling of a reduction kernel in
Figure 11. Since all reproducible methods use the same reduction technique, there is no separate measurement for them. Again on CPUs, we can see the superlinear effect as the application fits more and more into the cache. We can also observe that there is an additional cost of the reduction caused by the reproBlas functions. The most significant factor in the cost of reproducible reduction is that we must write all the values to be reduced into a separate array and perform a reduction on it within a process. This leads to extra memory movement compared to the reference version. This is particularly expensive on GPUs because this array must be copied to the host to perform the local summation.
MPI_reduce is not significantly more expensive.
Using only MPI parallelization, the overhead is quite small (between 1 and 1.12 times). Using shared memory parallelism, it is a bit greater due to the bad cache locality. In some extreme cases, we can even lose the speedup gain from GPUs, our reproducible methods work better on CPU-only systems.
6. Conclusions
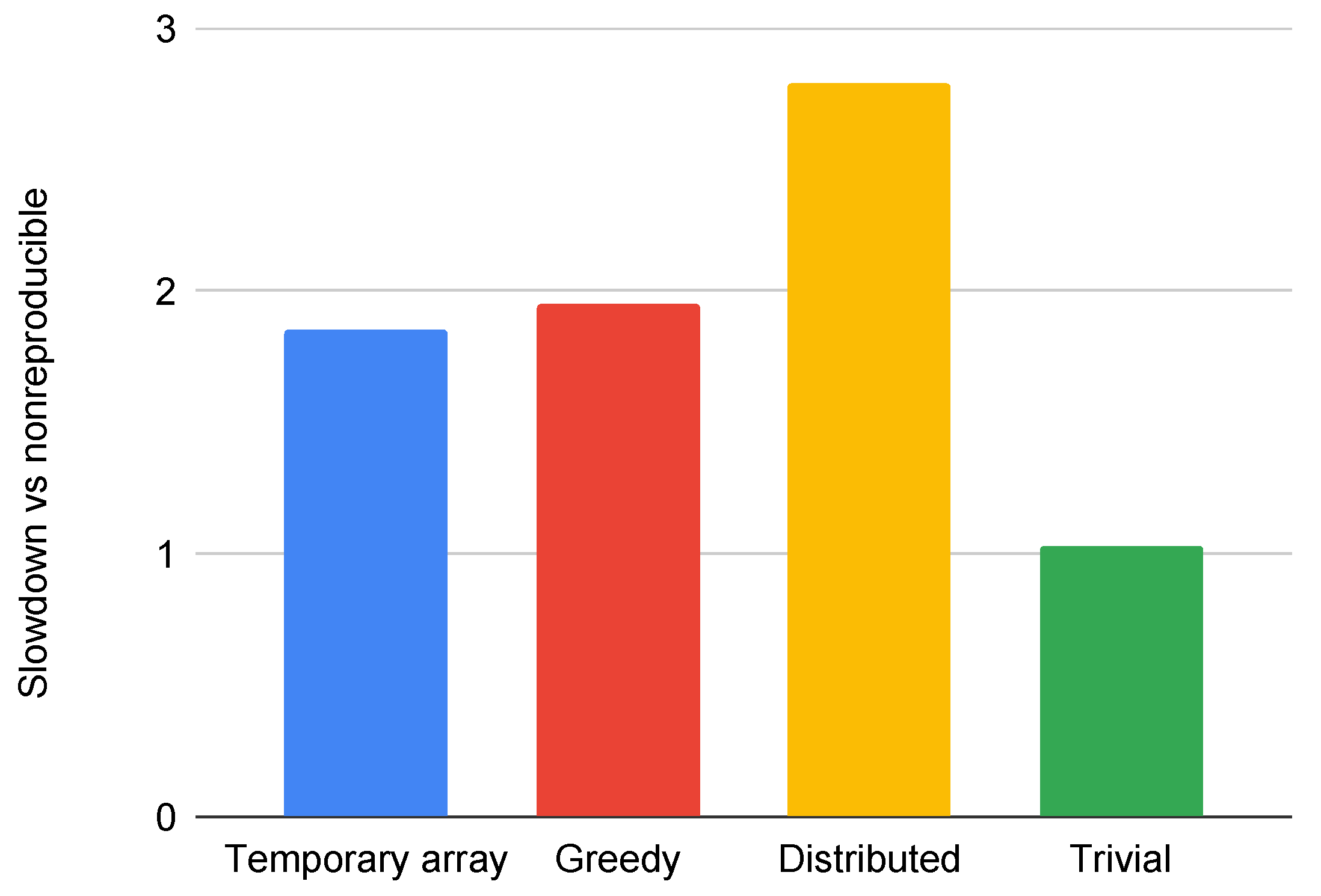
In this paper, we examined the non-reproducibility phenomenon that occurs due to the non-associative property of the floating-point number representation on applications defined on unstructured meshes. We compared the differences in results without reproducibility across a range of applications, including Rolls-Royce’s production application, Hydra. Non-reproducibility is a widely studied problem; however, we have not yet found an effective solution for distributed systems that could also be applied to arbitrarily partitioned meshes. In this work, we developed a collection of parallel and distributed algorithms to create a plan and then execute it, guaranteeing the reproducibility of the results. Of these, we highlight a graph coloring scheme that gives the same colors regardless of how many parts the graph was partitioned into. We implemented all of our methods in the OP2 DSL and then we showed how they can be automatically applied without user intervention to any application that is already using OP2. We demonstrated that on CPU systems, our methods can achieve bitwise reproducible results with a slowdown between 1 and 3.21 times in various applications, and on GPU systems with a slowdown between 2.31 and 10.7 times due to the modified data access patterns.
While there are alternative methods addressing the issue of reproducible reduction, their complexity is akin to ours and from the perspective of OP2, the choice of method is non-critical. This is why we do not draw comparisons on this aspect, as the time spent on reductions is relatively short. Our work stands out in the development of a generalized method ensuring reproducible execution, applicable to various applications. This is in contrast to other solutions that are application-specific. There are several general methods available. Kahan’s method, although popular, does not guarantee reproducibility, just higher accuracy. The most straightforward method involves sorting the elements before adding them. The most general method, perhaps, is the binned method, like in the ReproBLAS library. However, all these methods are more complex and mainly more expensive in computing and/or in memory usage. By leveraging the properties of the unstructured mesh, we can keep the costs low, thus presenting a more efficient solution.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}