

A Rotating Object Detector with Convolutional Dynamic Adaptive Matching


Abstract
1. Introduction
- (1)
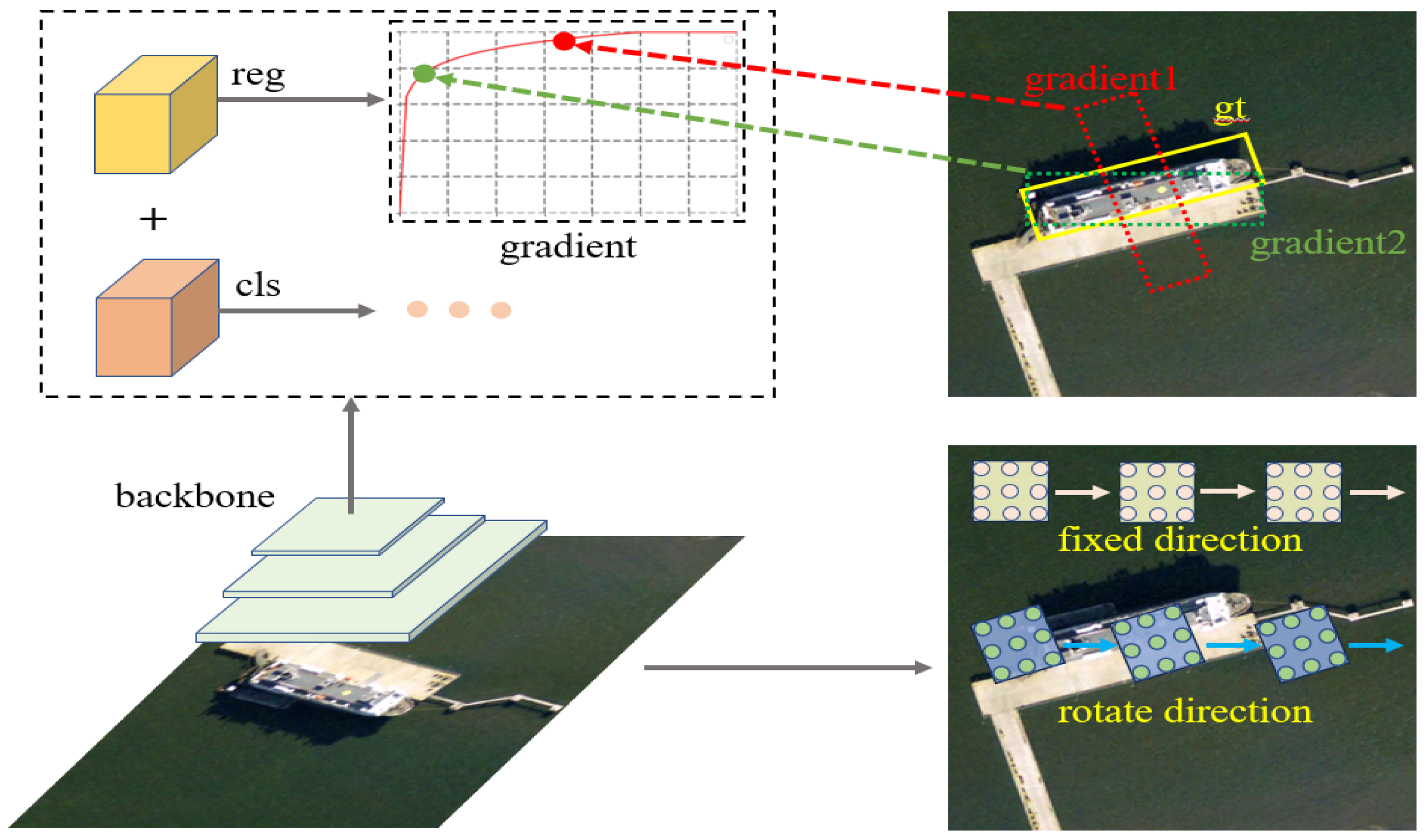
- We systematically analyze the problem of feature misalignment and imbalanced gradients caused by different quality samples during the training process of the current RS detector.
- (2)
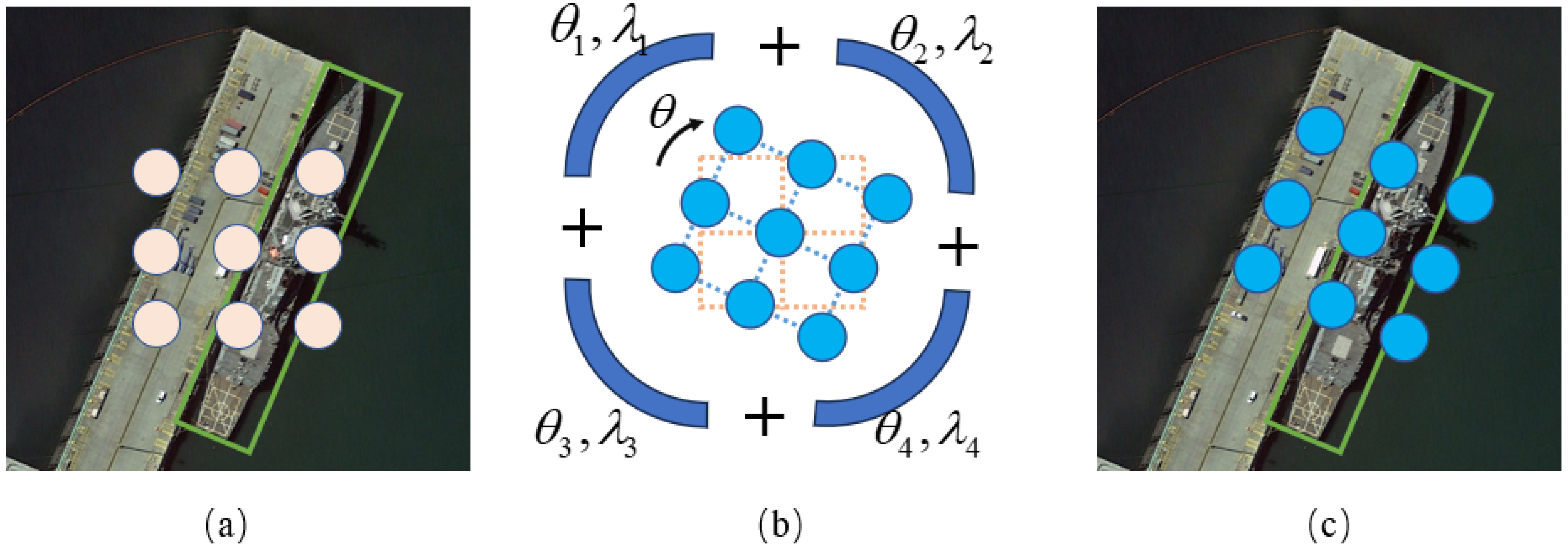
- In the feature extraction stage, we design a plug-and-play rotating dynamic convolution that can adaptively align the convolution with the target direction based on the spatial distribution of the target.
- (3)
- In training, we design a gradient adaptive equalization loss function to optimize the contribution of gradients from different samples to regression loss and improve the training stability.
2. Related Work
- A.
- Rotating object detection
- B.
- Dynamic network
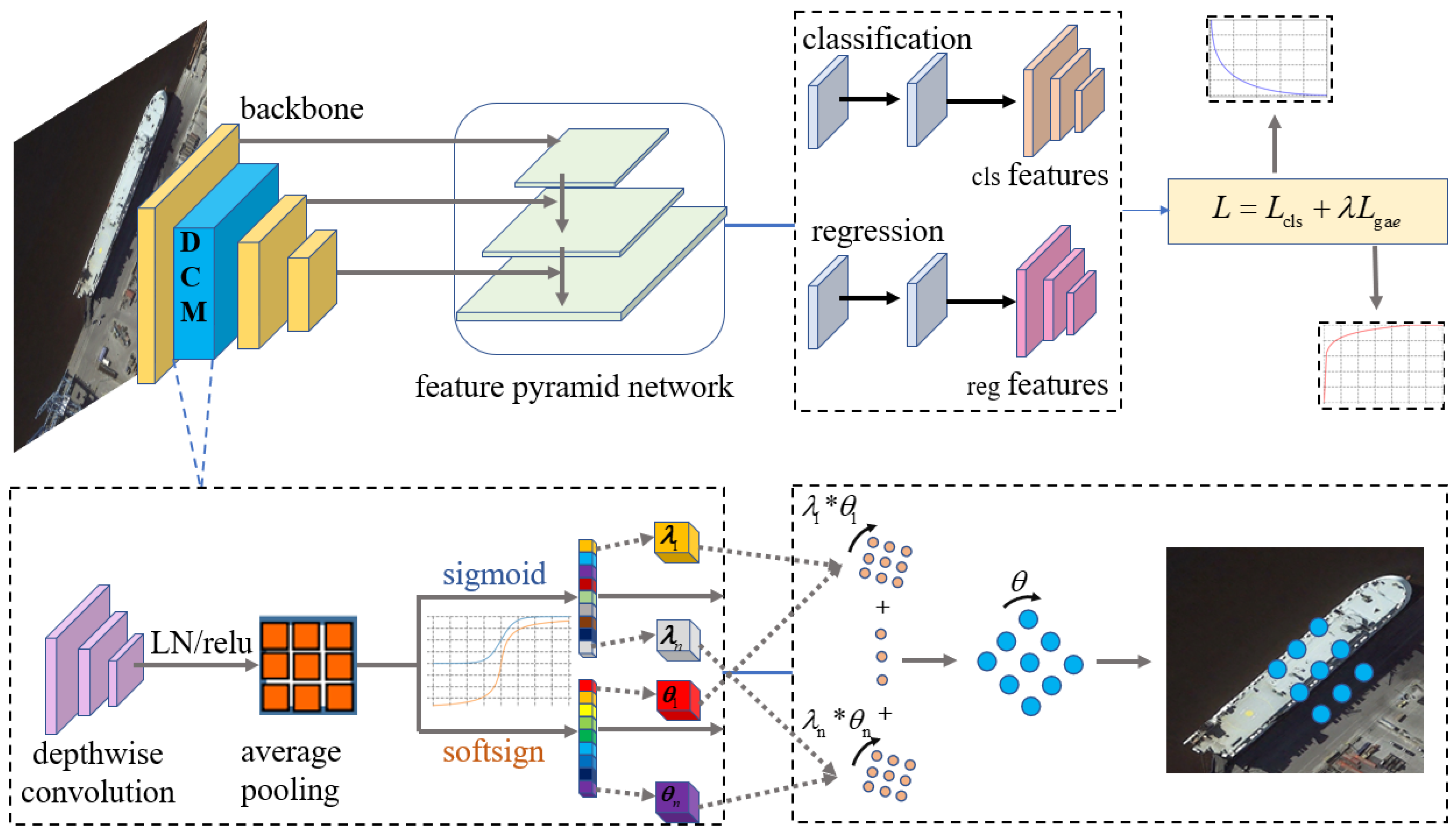
3. Method
3.1. Dynamic Convolution
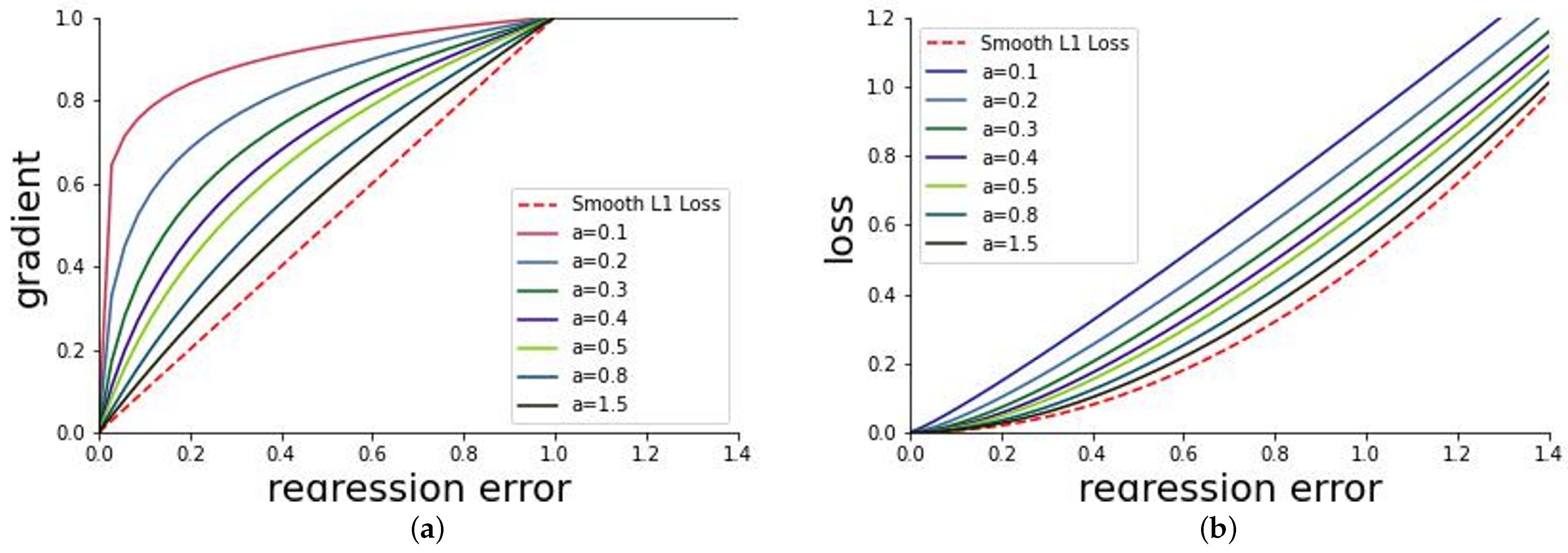
3.2. Gradient Adaptive Equalization Loss
4. Experiment
4.1. Datasets
4.2. Evaluation
4.3. Parameter Settings
4.4. Ablation Studies
4.4.1. Evaluate Different Modules
4.4.2. Evaluate DCM
4.4.3. Evaluate GAE
4.5. Comparative Experiment
4.5.1. Experiment on DOTA
4.5.2. Experiment on HRSC-2016
4.5.3. Experiment on UCAS-AOD
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 29 October–2 November 2019; pp. 8231–8240. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar] [CrossRef]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-Oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]
- Pan, X.; Ren, Y.; Sheng, K.; Dong, W.; Yuan, H.; Guo, X.; Ma, C.; Xu, C. Dynamic Refinement Network for Oriented and Densely Packed Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11204–11213. [Google Scholar] [CrossRef]
- Huang, Z.; Li, W.; Xia, X.; Wang, H.; Jie, F.; Tao, R. LO-Det: Lightweight Oriented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Ming, Q.; Zhou, Z.; Miao, L.; Zhang, H.; Li, L. Dynamic Anchor Learning for Arbitrary-Oriented Object Detection. Proc. AAAI Conf. Artif. Intell. 2021, 35, 2355–2363. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector; Springer: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef]
- Graves, A. Adaptive Computation Time for Recurrent Neural Networks. arXiv 2016, arXiv:1603.08983. [Google Scholar]
- Shazeer, N.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q.V.; Hinton, G.E.; Dean, J. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv 2017, arXiv:1701.06538. [Google Scholar]
- Deng, C.; Jing, D.; Han, Y.; Wang, S.; Wang, H. FAR-Net: Fast Anchor Refining for Arbitrary-Oriented Object Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery; Springer: Cham, Switzerland, 2018; Volume 11363, pp. 150–165. [Google Scholar] [CrossRef]
- Ran, Q.; Wang, Q.; Zhao, B.; Wu, Y.; Pu, S.; Li, Z. Lightweight Oriented Object Detection Using Multiscale Context and Enhanced Channel Attention in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5786–5795. [Google Scholar] [CrossRef]
- Dai, Y.; Yu, J.; Zhang, D.; Hu, T.; Zheng, X. RODFormer: High-Precision Design for Rotating Object Detection with Transformers. Sensors 2022, 22, 2633. [Google Scholar] [CrossRef]
- Arena, P.; Fortuna, L.; Occhipinti, L.G.; Xibilia, M.G. Neural Networks for Quaternion-valued Function Approximation. In Proceedings of the IEEE International Symposium on Circuits and Systems—ISCAS ’94, London, UK, 30 May–2 June 1994; pp. 307–310. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking Rotated Object Detection with Gaussian Wasserstein Distance Loss. Proc. Mach. Learn. Res. 2021, 139, 11830–11841. [Google Scholar]
- Yang, X.; Zhou, Y.; Zhang, G.; Yang, J.; Wang, W.; Yan, J.; Zhang, X.; Tian, Q. The KFIoU Loss for Rotated Object Detection. arXiv 2023, arXiv:2201.12558. [Google Scholar]
- Xu, C.; McAuley, J.J. A Survey on Dynamic Neural Networks for Natural Language Processing. In Proceedings of the Findings of the Association for Computational Linguistics: EACL 2023, Dubrovnik, Croatia, 2–6 May 2023; pp. 2325–2336. [Google Scholar] [CrossRef]
- Wang, Y.; Han, Y.; Wang, C.; Song, S.; Tian, Q.; Huang, G. Computation-efficient Deep Learning for Computer Vision: A Survey. arXiv 2023, arXiv:2308.13998. [Google Scholar] [CrossRef]
- Yang, L.; Han, Y.; Chen, X.; Song, S.; Dai, J.; Huang, G. Resolution Adaptive Networks for Efficient Inference. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2366–2375. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Song, J.; Yang, X. Sparse Label Assignment for Oriented Object Detection in Aerial Images. Remote Sens. 2021, 13, 2664. [Google Scholar] [CrossRef]
- Teerapittayanon, S.; McDanel, B.; Kung, H.T. BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks. arXiv 2017, arXiv:1709.01686. [Google Scholar]
- Wang, X.; Yu, F.; Dou, Z.; Darrell, T.; Gonzalez, J.E. SkipNet: Learning Dynamic Routing in Convolutional Networks; Springer: Cham, Switzerland, 2018; Volume 11217, pp. 420–436. [Google Scholar] [CrossRef]
- Su, H.; Jampani, V.; Sun, D.; Gallo, O.; Learned-Miller, E.G.; Kautz, J. Pixel-Adaptive Convolutional Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11166–11175. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A High Resolution Optical Satellite Image Dataset for Ship Recognition and Some New Baselines. In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods ICPRAM, Porto, Portugal, 24–26 February 2017; pp. 324–331. [Google Scholar] [CrossRef]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar] [CrossRef]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.J.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar] [CrossRef]
- Sun, Y.; Bi, F.; Gao, Y.; Chen, L.; Feng, S. A Multi-Attention UNet for Semantic Segmentation in Remote Sensing Images. Symmetry 2022, 14, 906. [Google Scholar] [CrossRef]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. arXiv 2021, arXiv:1908.05612. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Xu, G.; Zhang, K.; Sun, X. Rotation-aware and multi-scale convolutional neural network for object detection in remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 161, 294–308. [Google Scholar] [CrossRef]
- Huang, Z.; Li, W.; Xia, X.; Tao, R. A General Gaussian Heatmap Label Assignment for Arbitrary-Oriented Object Detection. IEEE Trans. Image Process. 2022, 31, 1895–1910. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Yang, X.; Dong, Y. Optimization for Arbitrary-Oriented Object Detection via Representation Invariance Loss. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multim. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Qiu, H.; Li, H.; Wu, Q.; Meng, F.; Ngan, K.N.; Shi, H. A2RMNet: Adaptively aspect ratio multi-scale network for object detection in remote sensing images. Remote Sens. 2019, 11, 1594. [Google Scholar] [CrossRef]
- Li, C.; Xu, C.; Cui, Z.; Wang, D.; Zhang, T.; Yang, J. Feature-Attentioned Object Detection in Remote Sensing Imagery. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3886–3890. [Google Scholar] [CrossRef]
- Fu, K.; Chang, Z.; Zhang, Y.; Sun, X. Point-Based Estimator for Arbitrary-Oriented Object Detection in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4370–4387. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Li, H.; Zhang, H.; Xia, G. Learning Center Probability Map for Detecting Objects in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4307–4323. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward Arbitrary-Oriented Ship Detection With Rotated Region Proposal and Discrimination Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, J.; Li, K.; Xie, X.; Lang, C.; Yao, Y.; Han, J. Anchor-Free Oriented Proposal Generator for Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Yang, Y.; Tang, X.; Cheung, Y.; Zhang, X.; Liu, F.; Ma, J.; Jiao, L. AR2Det: An Accurate and Real-Time Rotational One-Stage Ship Detector in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Ren, Z.; Tang, Y.; He, Z.; Tian, L.; Yang, Y.; Zhang, W. Ship Detection in High-Resolution Optical Remote Sensing Images Aided by Saliency Information. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Li, J.; Xia, G. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Ming, Q.; Miao, L.; Zhou, Z.; Dong, Y. CFC-Net: A Critical Feature Capturing Network for Arbitrary-Oriented Object Detection in Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Liao, M.; Zhu, Z.; Shi, B.; Xia, G.; Bai, X. Rotation-Sensitive Regression for Oriented Scene Text Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5909–5918. [Google Scholar] [CrossRef]
- He, Q.; Liu, J.; Huang, Z. WSRC: Weakly Supervised Faster RCNN Toward Accurate Traffic Object Detection. IEEE Access 2023, 11, 1445–1455. [Google Scholar] [CrossRef]
- Aladhadh, S.; Mahum, R. Knee Osteoarthritis Detection Using an Improved CenterNet With Pixel-Wise Voting Scheme. IEEE Access 2023, 11, 22283–22296. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| With DCM | With GAE | mAP (%) |
|---|---|---|
| ✗ | ✗ | 84.35 |
| ✓ | ✗ | 88.69 |
| ✗ | ✓ | 87.23 |
| ✓ | ✓ | 90.14 |
| With DCM | With GAE | mAP (%) |
|---|---|---|
| ✗ | ✗ | 86.79 |
| ✓ | ✗ | 88.14 |
| ✗ | ✓ | 87.43 |
| ✓ | ✓ | 90.52 |
| n Number | mAP (%) | Params (M) |
|---|---|---|
| 0 | 84.32 | 73.24 |
| 1 | 87.24 | 74.38 |
| 2 | 88.46 | 78.42 |
| 4 | 90.41 | 79.57 |
| 8 | 88.66 | 96.52 |
| Settings | mAP (%) |
|---|---|
| smooth-L1 | 84.35 |
| 87.85 | |
| 90.41 | |
| 88.64 | |
| 88.59 | |
| 85.37 | |
| 84.02 | |
| 79.82 |
| Methods | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Single-stage: | ||||||||||||||||
| DRN [4] | 88.91 | 80.22 | 43.52 | 63.35 | 73.48 | 70.69 | 84.94 | 90.14 | 83.85 | 84.11 | 50.12 | 58.41 | 67.62 | 68.60 | 52.50 | 70.70 |
| R3Det [29] | 88.76 | 83.09 | 50.91 | 67.27 | 76.23 | 80.39 | 86.72 | 90.78 | 84.68 | 83.24 | 61.98 | 61.35 | 66.91 | 70.63 | 53.94 | 73.79 |
| FFA3 [30] | 88.80 | 74.40 | 48.90 | 57.90 | 63.60 | 75.90 | 79.60 | 90.80 | 80.30 | 82.90 | 54.30 | 60.00 | 66.90 | 66.80 | 42.50 | 68.90 |
| GGHL [31] | 89.74 | 85.63 | 44.50 | 77.48 | 76.72 | 80.45 | 86.16 | 90.83 | 88.18 | 86.25 | 67.07 | 69.40 | 73.38 | 68.45 | 70.15 | 76.95 |
| DAL [6] | 88.68 | 76.55 | 45.08 | 66.80 | 67.00 | 76.76 | 79.74 | 90.84 | 79.54 | 78.45 | 57.71 | 62.27 | 69.05 | 73.14 | 60.11 | 71.44 |
| RIDet-O [32] | 88.94 | 78.45 | 46.87 | 72.63 | 77.63 | 80.68 | 88.18 | 90.55 | 81.33 | 83.61 | 64.85 | 63.72 | 73.09 | 73.13 | 56.87 | 74.70 |
| CADNet [33] | 87.80 | 82.40 | 49.40 | 73.50 | 71.10 | 63.50 | 76.60 | 90.9 | 79.20 | 73.30 | 48.40 | 60.90 | 62.00 | 67.00 | 62.20 | 69.90 |
| Two-stage: | ||||||||||||||||
| ICN [12] | 81.36 | 74.30 | 47.70 | 70.32 | 64.89 | 67.82 | 69.98 | 90.76 | 79.06 | 78.20 | 53.64 | 62.90 | 67.02 | 64.17 | 50.23 | 68.16 |
| RRPN [34] | 88.52 | 71.20 | 31.66 | 59.30 | 51.85 | 56.19 | 57.25 | 90.81 | 72.84 | 67.38 | 56.69 | 52.84 | 53.08 | 51.94 | 53.58 | 61.01 |
| SCRDet [1] | 89.98 | 80.65 | 52.09 | 68.36 | 68.36 | 60.32 | 72.41 | 90.52 | 87.94 | 86.86 | 65.02 | 66.68 | 66.25 | 68.24 | 65.21 | 72.61 |
| RMNet [35] | 89.84 | 83.39 | 60.06 | 73.46 | 79.25 | 73.07 | 87.88 | 90.90 | 87.02 | 87.35 | 60.74 | 69.05 | 79.88 | 79.74 | 65.17 | 78.45 |
| FAOD [36] | 90.21 | 79.58 | 45.49 | 76.41 | 73.18 | 68.27 | 79.56 | 90.83 | 83.40 | 84.68 | 53.40 | 65.42 | 74.17 | 69.69 | 64.86 | 73.28 |
| FR-Est [37] | 89.63 | 81.17 | 50.44 | 70.19 | 73.52 | 77.98 | 86.44 | 90.82 | 84.13 | 83.56 | 60.64 | 66.59 | 70.59 | 66.72 | 60.55 | 74.20 |
| CenterMap [38] | 88.88 | 81.24 | 53.15 | 60.65 | 78.62 | 66.55 | 78.10 | 88.83 | 77.80 | 83.61 | 49.36 | 66.19 | 72.10 | 72.36 | 58.70 | 71.74 |
| Ours | 90.23 | 86.71 | 61.24 | 84.65 | 70.09 | 80.54 | 88.01 | 90.45 | 87.46 | 76.89 | 69.89 | 81.37 | 78.91 | 68.89 | 71.48 | 79.38 |
| Each abbreviation is represented as: | ||||||||||||||||
| Full Name | plane | baseball diamond | bridge | ground track field | small vehicle | large vehicle | ship | tennis court | basketball court | storage tank | soccerball field | roundabout | harbor | swimming pool | helicopter | – |
| Methods | Backbone | Size | mAP (%) |
|---|---|---|---|
| Two-stage: | |||
| CNN [39] | Res101 | 800 × 800 | 73.1 |
| PN [40] | VGG16 | - | 79.6 |
| AOPG [41] | Res50 | 800 × 800 | 80.6 |
| RoI-Trans [2] | Res101 | 512 × 800 | 86.2 |
| Single-stage: | |||
| Det [1] | Res101 | 800 × 800 | 89.3 |
| RRD [42] | VGG16 | 384 × 384 | 84.3 |
| OPLD [43] | Res101 | 800 × 800 | 88.4 |
| AR2Det [44] | Res101 | 512 × 512 | 89.6 |
| SDet [45] | Res101 | 800 × 800 | 89.2 |
| ours | Res101 | 800 × 800 | 90.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, L.; Zhou, Y.; Li, X.; Hu, S.; Jing, D. A Rotating Object Detector with Convolutional Dynamic Adaptive Matching. Appl. Sci. 2024, 14, 633. https://doi.org/10.3390/app14020633
Yu L, Zhou Y, Li X, Hu S, Jing D. A Rotating Object Detector with Convolutional Dynamic Adaptive Matching. Applied Sciences. 2024; 14(2):633. https://doi.org/10.3390/app14020633
Chicago/Turabian StyleYu, Leibo, Yu Zhou, Xianglong Li, Shiquan Hu, and Dongling Jing. 2024. "A Rotating Object Detector with Convolutional Dynamic Adaptive Matching" Applied Sciences 14, no. 2: 633. https://doi.org/10.3390/app14020633
APA StyleYu, L., Zhou, Y., Li, X., Hu, S., & Jing, D. (2024). A Rotating Object Detector with Convolutional Dynamic Adaptive Matching. Applied Sciences, 14(2), 633. https://doi.org/10.3390/app14020633