
Enhancing Imbalanced Sentiment Analysis: A GPT-3-Based Sentence-by-Sentence Generation Approach


Abstract
1. Introduction
- This study provides an explanation of the text generation procedure using prompt-based generation, specifically utilizing sentence-by-sentence generation techniques.
- It proposes methods for detecting duplication, both among generated sentences and between generated sentences and the original input data included in the prompt.
- It compares five deep-learning models for sentiment classification using various kinds of datasets obtained from the results of sentence generation.
2. Related Work
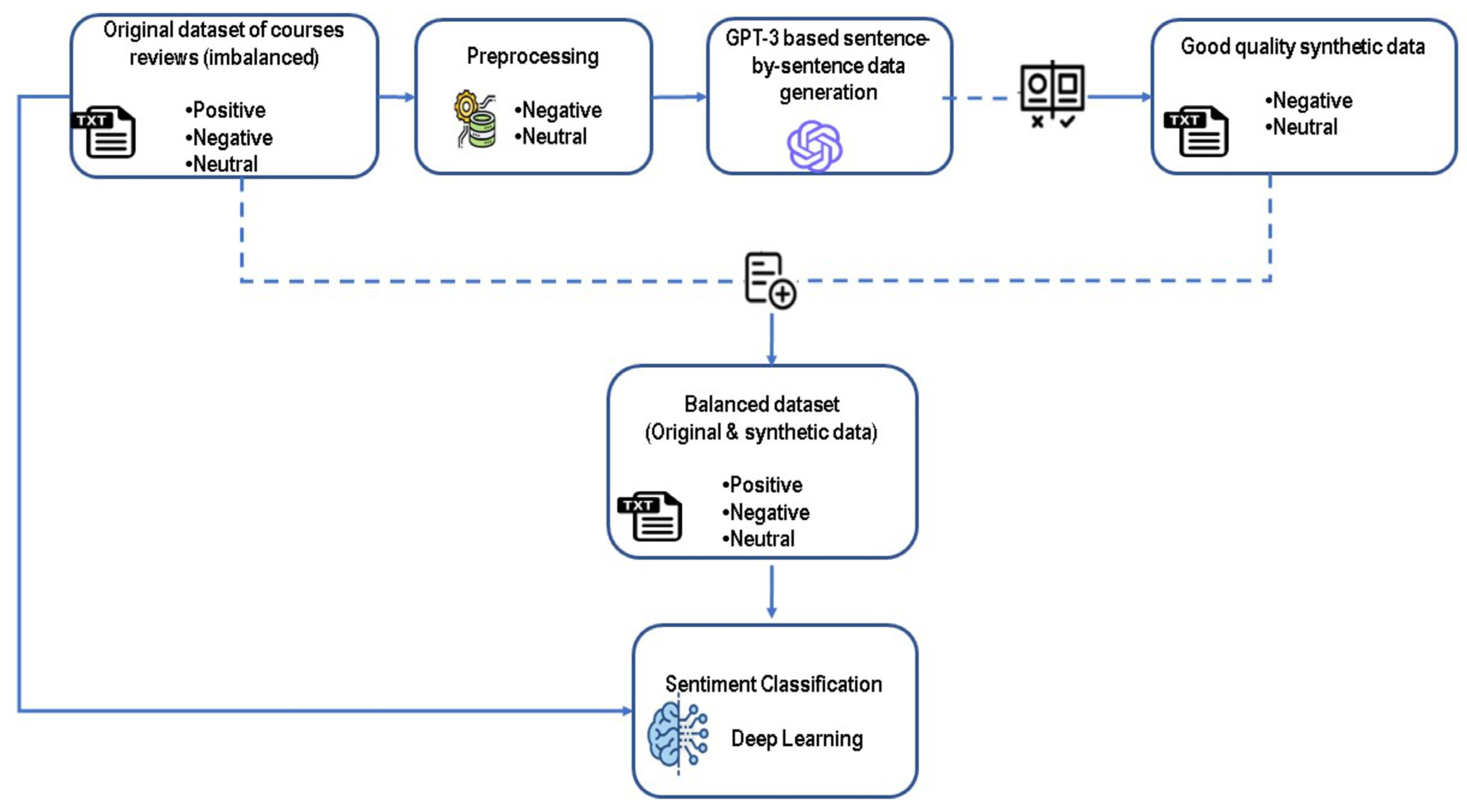
3. Proposed Approach
4. Experimental Details
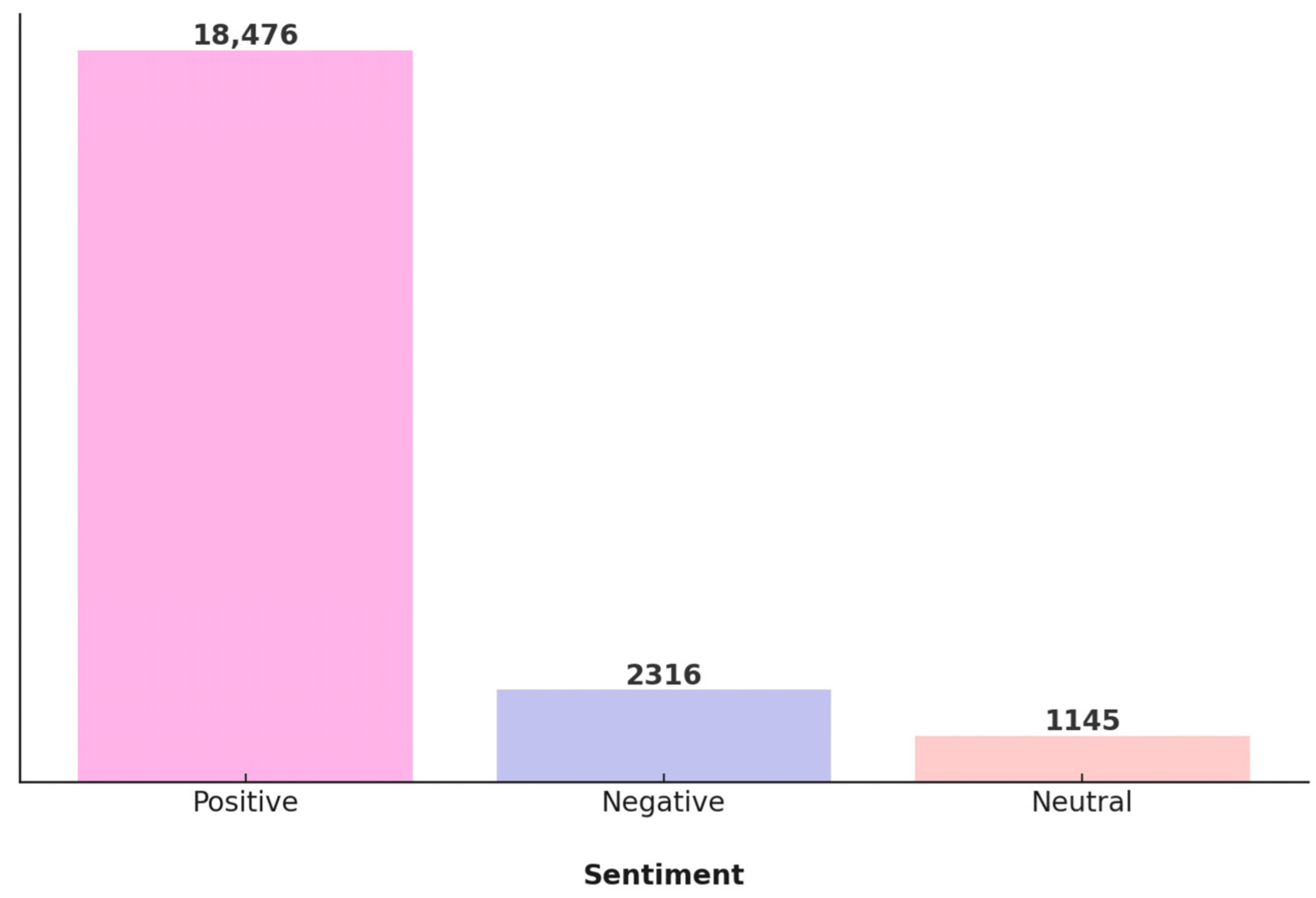
4.1. Dataset
4.2. Sentence-by-Sentence Data Generation
4.2.1. Preprocessing of the Input Data
4.2.2. The Synthetic Data Generation Process
- Essentially, this method is based on prompt-based text generation, also known as the prompting method.
- The process includes using the original text input data within the prompt itself.
- A single prompt can be used to produce one or more outputs, depending on our requirements.
- This technique utilizes all of the data within the original dataset.
- Model: “text-davinci-003”. At the time our research was conducted, this model stood out as the best among the GPT-3 variants available.
- Temperature: 0.9. We set the temperature parameter to 0.9, which we found to strike a balance between coherence and diversity. A temperature setting at this level encourages the model to produce text outputs that are varied and interesting yet still maintain logical consistency with the input text.
- Maximum Tokens: input tokens + 10. This parameter setting ensures that the length of the generated text is relatively similar to that of the input data. By allowing the model to generate a maximum of 10 additional tokens beyond the input, we ensure that the synthetic data expand on the original text without deviating too much in length, preserving the natural flow of the data.
4.2.3. The Evaluation of Generated Data
- The “input” refers to the original course review data included in the prompt, which serves as a reference for the GPT-3 model during the synthetic data generation process.
- The “output” is the synthetic data generated by the GPT-3 model in response to the given prompt.
- Exploration of generated data using novelty and diversity scores
- 2.
- Data duplication analysis
- Overall Duplication: This refers to instances of complete duplication across the dataset, determined through direct calculation.
- Intra-Duplication: This measures the duplication of outputs associated with each specific input. For example, if input1 has 3 (three) duplicate outputs and input2 has 4 (four), the intra-duplication count is the sum of these, equating to 7.
- Inter-Duplication: This type of duplication occurs across different inputs, meaning an output for one input exactly matches an output for another input. This calculation is non-mutually exclusive with intra-duplication. For instance, if input1 generates 3 (three) outputs that are duplicated within its set, and input2 has 1 output that duplicates 1 from input1, the inter-duplication count is 3.
- 3.
- Obtaining good-quality synthetic data
- Step 1.
- Removal of exact duplicates among outputs
- Step 2.
- Removal of similar outputs
- (1)
- Sorting the data based on the output column using lexical sorting, where the data are arranged alphabetically from A to Z. This method groups similar outputs together based on the beginning words or tokens, aiding in the process of identifying duplicates or closely related sequences within the generated text.
- (2)
- Calculating the similarity score between and .In our analysis, we define a similarity score measure to assess the degree of similarity between consecutive outputs generated by the GPT-3 model. This formula, while adapted from Jaccard similarity, as presented by Qurashi et al. [25], incorporates a distinctive approach that aligns more closely with our specific requirements for processing text generated by GPT-3. Let us assume that we have outputs generated by the GPT-3 model. In this context, represents a set of words in , and represents a set of words in , where . The similarity score between and is computed by dividing the count of identical words found in both and by the total number of words in , as expressed in Formula (3):Here, denotes the number of identical words between and , and refers to the total count of words in .It is crucial to note that, unlike the Jaccard similarity index, which is symmetrical and hence, the similarity score of equals , our adapted formula is asymmetrical: is not equal to . This asymmetry arises because our calculation focuses solely on the proportion of common elements in relative to its total size, without considering the size of . This methodological choice is intentional and aligns with our goal of identifying and removing duplications within sorted outputs, where the placement of outputs in the sorted order is significant for identifying duplications.
- (3)
- Defining the cut-off thresholds. In this step, we set the threshold to 0.8, 0.75, and 0.5.
- (4)
- Removing if its similarity score to the subsequent output is greater than or equal to the cut-off threshold.
- (5)
- Performing steps (2) to (4) until .
- Step 3.
- Removal of outputs similar to inputs
- (1)
- Computing the similarity score between and using Formula (3).Let us assume that produces for .In this case, represents a set of words in , and represents a set of words in .
- (2)
- Using the threshold and criteria for removing outputs as described in Step 3 for points (3) and (4).
- (3)
- Performing steps (1) to (2) until .
- “The discussion forums for this course could have been more helpful.”
- “The discussion forums for this course were unhelpful.”
- Step 4.
- Anomaly Data Removal
- Step 5.
- Coherency checking
- Step 6.
- Reevaluating novelty, diversity, and similarity for good-quality synthetic data
4.3. Sentiment Classification
- Stage 1: Preprocessing
- Stage 2: Sentiment Classification
- RNN uses two layers of SimpleRNN with 256 units each, implementing a dropout rate of 0.5.
- CNN consists of three Conv1D layers with 128, 128, and 256 filters, each followed by a dropout of 0.5.
- LSTM features two LSTM layers, each with 256 units, and a dropout rate of 0.5.
- BiLSTM employs two layers of Bidirectional LSTM, with 256 units per layer and a dropout rate of 0.5.
- GRU incorporates two GRU layers with 256 units each, accompanied by a dropout of 0.5.
- Stage 3: Evaluation
5. Results
5.1. Sentence-by-Sentence Generation
5.1.1. The Generated Data
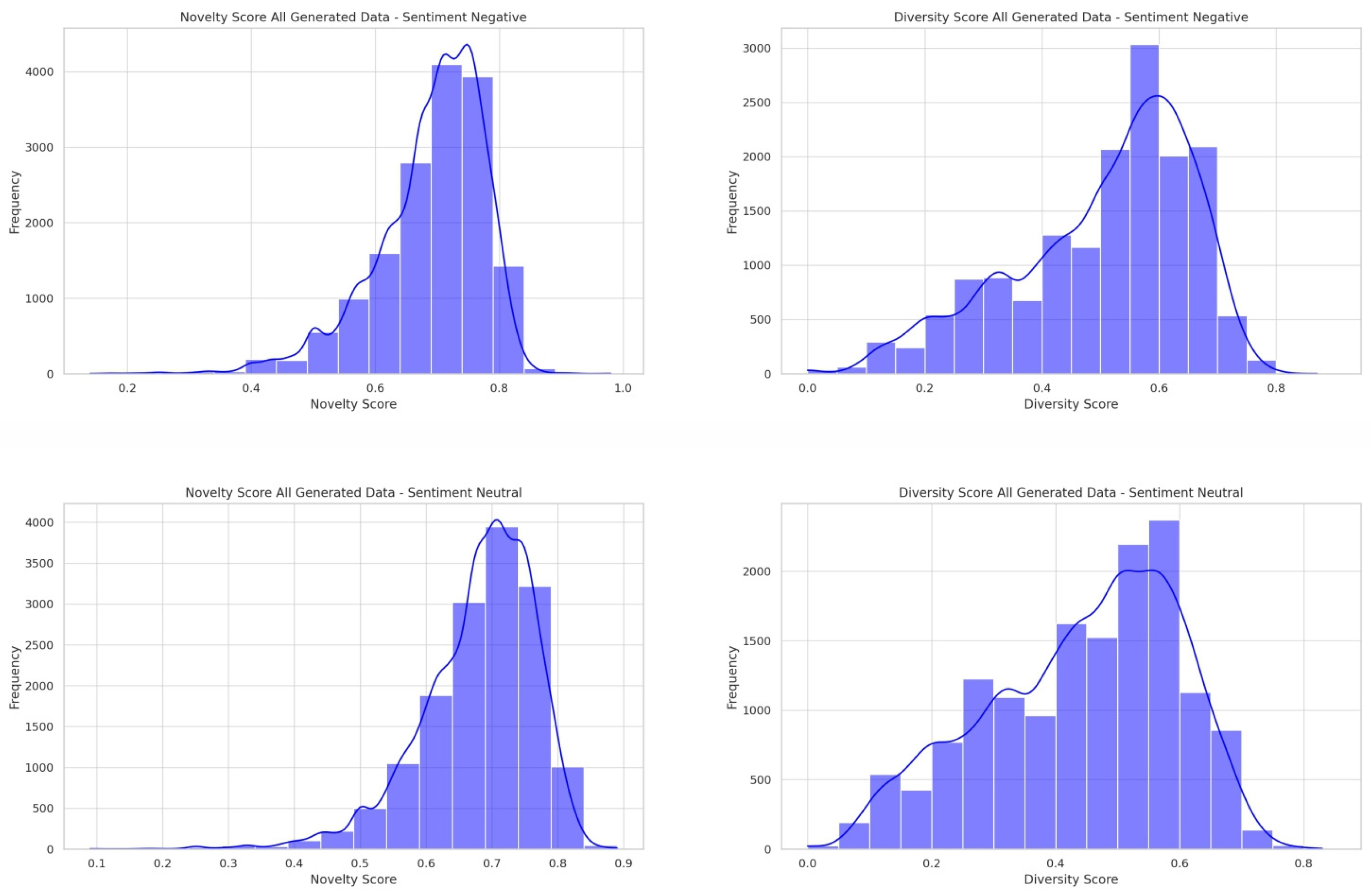
5.1.2. Evaluation of Generated Synthetic Data
- (1)
- Exploration of all generated data using novelty and diversity scores
- (2)
- Data duplication analysis
- (3)
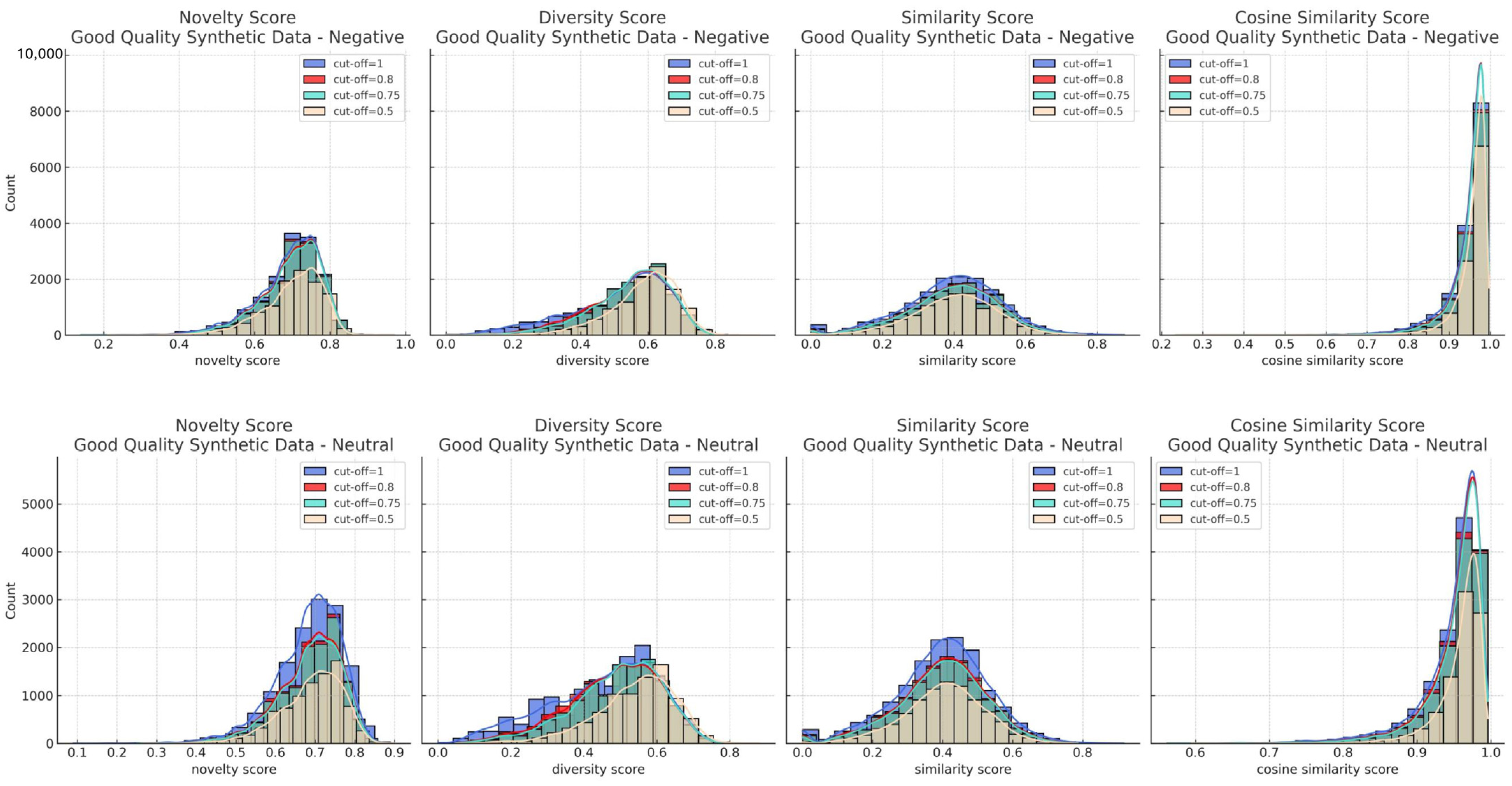
- Good-quality synthetic data
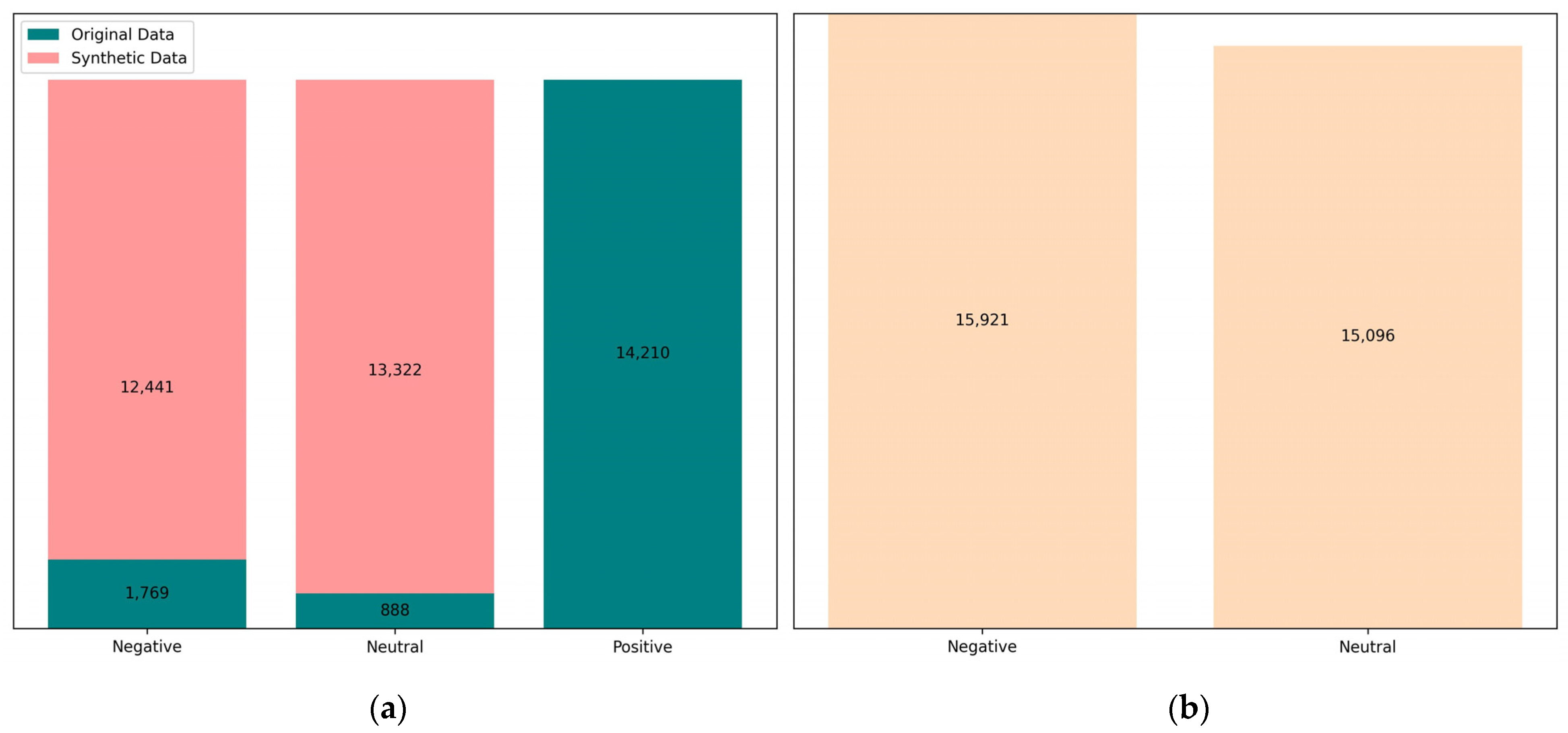
- Cut-off =1A cut-off of 1 is referred to as an exact duplication, which is identified using the “duplicated” function in the pandas library. From the overall duplication, one entry is selected to be retained in the dataset of unique outputs. A total of 571 data points were removed due to being duplicates of other outputs. After removing duplicates, no exact duplications between outputs and inputs were detected. There was only one data anomaly for negative sentiment, characterized by a novelty value of 0.98. Conversely, no data anomalies were found in the neutral sentiment data. From this process, a total of 15,349 outputs of good-quality synthetic data for negative sentiment were obtained.
- Cut-off = 0.8Contrasting with a cut-off of 1, good-quality output with a cut-off of 0.8 was achieved by discarding outputs that have a similarity of 80% or higher to other outputs or to the input, as well as removing anomalous data. A total of 1558 data points were discarded due to similarities to other outputs, and 99 data points were removed due to similarities to the input. By applying a cut-off of 0.8, a total of 14,263 good-quality synthetic data outputs for negative sentiment were obtained.
- Cut-off = 0.75Following the same process as with a cut-off of 0.8, using a cut-off of 0.75 resulted in 13,935 outputs of good-quality synthetic data for negative sentiment, while 1986 outputs were of bad quality.
- Cut-off = 0.5With a cut-off of 50, a total of 10,699 good-quality synthetic data outputs were produced, along with 5222 bad-quality outputs.
- (4)
- Evaluation of good-quality synthetic data
5.2. Sentiment Classification
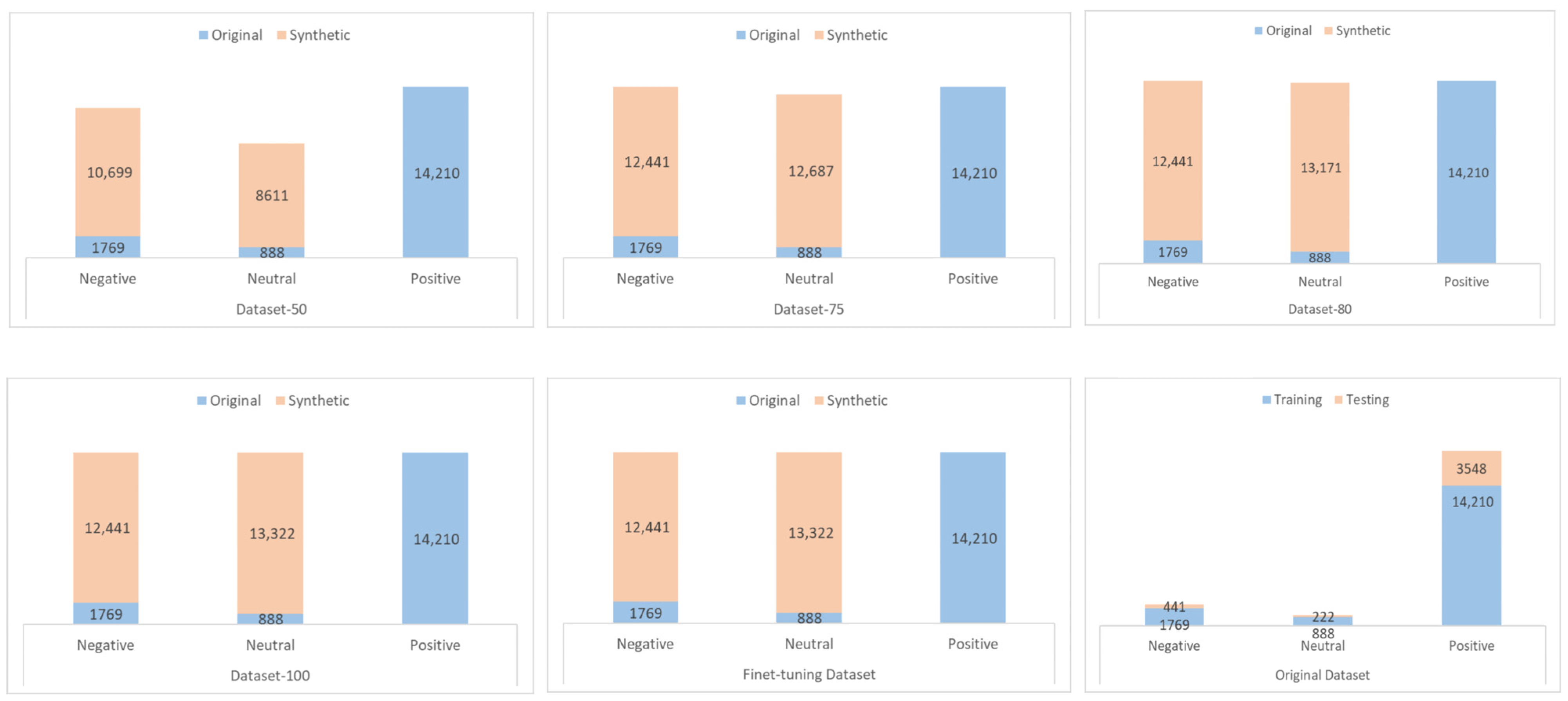
5.2.1. Distribution of Dataset for Sentiment Classification
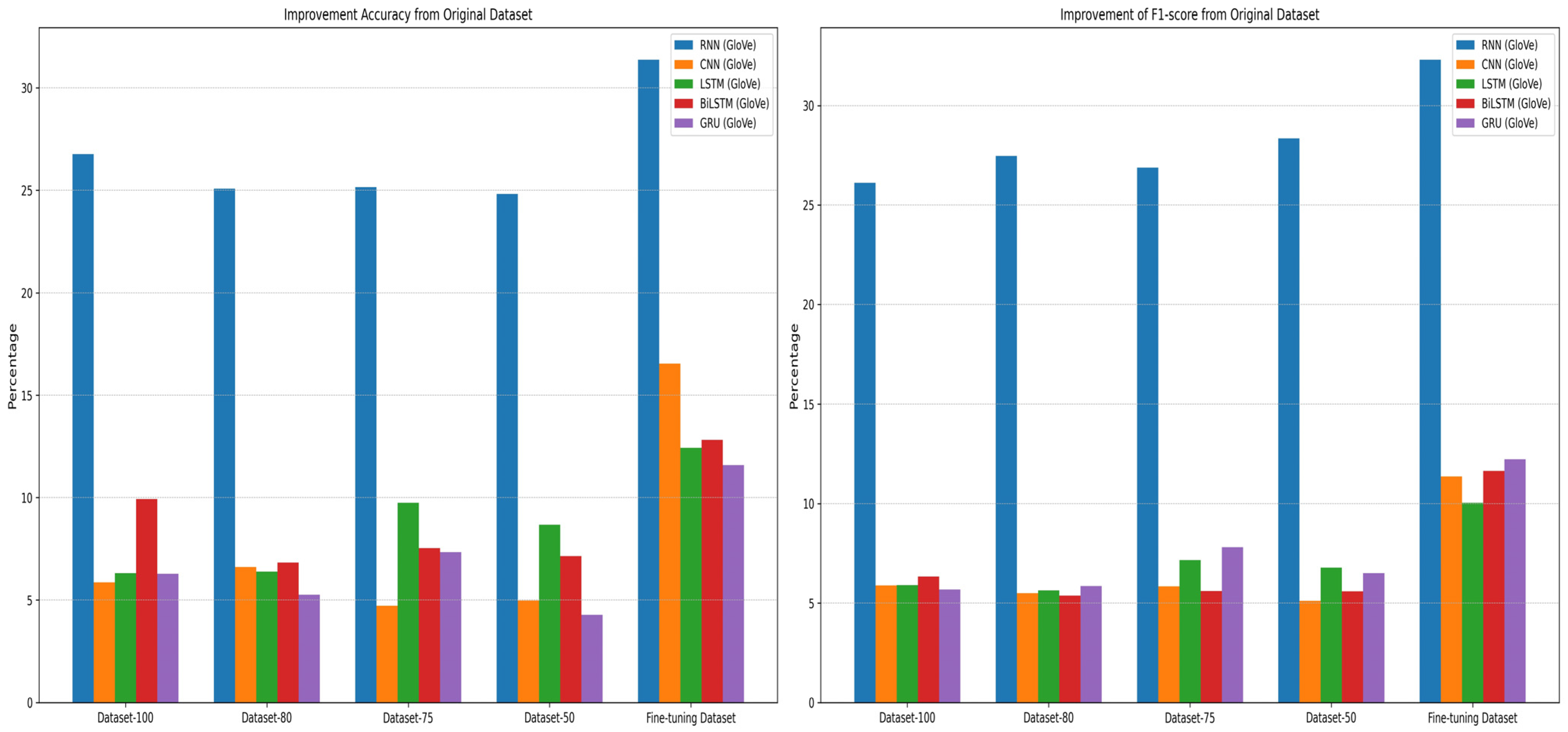
5.2.2. Sentiment Classification Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bordoloi, M.; Biswas, S.K. Sentiment Analysis: A Survey on Design Framework, Applications and Future Scopes. Artif. Intell. Rev. 2023, 56, 12505–12560. [Google Scholar] [CrossRef] [PubMed]
- Sangeetha, J.; Kumaran, U. Sentiment Analysis of Amazon User Reviews Using a Hybrid Approach. Meas. Sens. 2023, 27, 100790. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, Z.; Yao, X.; Yang, Q. A Machine Learning-Based Sentiment Analysis of Online Product Reviews with a Novel Term Weighting and Feature Selection Approach. Inf. Process. Manag. 2021, 58, 102656. [Google Scholar] [CrossRef]
- Li, Y.; Sun, G.; Zhu, Y. Data Imbalance Problem in Text Classification. In Proceedings of the IEEE 2010 Third International Symposium on Information Processing, Qingdao, China, 15–17 October 2010; pp. 301–305. [Google Scholar]
- Padurariu, C.; Breaban, M.E. Dealing with Data Imbalance in Text Classification. Procedia Comput. Sci. 2019, 159, 736–745. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Elkins, K.; Chun, J. Can GPT-3 Pass a Writer’s Turing Test? J. Cult. Anal. 2020, 5, 1–16. [Google Scholar] [CrossRef]
- Floridi, L.; Chiriatti, M. GPT-3: Its Nature, Scope, Limits, and Consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Skondras, P.; Zervas, P.; Tzimas, G. Generating Synthetic Resume Data with Large Language Models for Enhanced Job Description Classification. Future Internet 2023, 15, 363. [Google Scholar] [CrossRef]
- Abramski, K.; Citraro, S.; Lombardi, L.; Rossetti, G.; Stella, M. Cognitive Network Science Reveals Bias in GPT-3, GPT-3.5 Turbo, and GPT-4 Mirroring Math Anxiety in High-School Students. Big Data Cogn. Comput. 2023, 7, 124. [Google Scholar] [CrossRef]
- Suhaeni, C.; Yong, H.-S. Mitigating Class Imbalance in Sentiment Analysis through GPT-3-Generated Synthetic Sentences. Appl. Sci. 2023, 13, 9766. [Google Scholar] [CrossRef]
- Obiedat, R.; Qaddoura, R.; Al-Zoubi, A.M.; Al-Qaisi, L.; Harfoushi, O.; Alrefai, M.; Faris, H. Sentiment Analysis of Customers’ Reviews Using a Hybrid Evolutionary SVM-Based Approach in an Imbalanced Data Distribution. IEEE Access 2022, 10, 22260–22273. [Google Scholar] [CrossRef]
- Wen, H.; Zhao, J. Sentiment Analysis of Imbalanced Comment Texts Under the Framework of BiLSTM. In Proceedings of the IEEE 2023 6th International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 26–29 May 2023; pp. 312–319. [Google Scholar]
- Tan, K.L.; Lee, C.P.; Lim, K.M. RoBERTa-GRU: A Hybrid Deep Learning Model for Enhanced Sentiment Analysis. Appl. Sci. 2023, 13, 3915. [Google Scholar] [CrossRef]
- Wu, J.-L.; Huang, S. Application of Generative Adversarial Networks and Shapley Algorithm Based on Easy Data Augmentation for Imbalanced Text Data. Appl. Sci. 2022, 12, 10964. [Google Scholar] [CrossRef]
- Department of Computer Science, Avinashilingam Institute for Home Science and Higher Education for Women, Coimbatore, India; George, S.; Srividhya, V. Performance Evaluation of Sentiment Analysis on Balanced and Imbalanced Dataset Using Ensemble Approach. Indian J. Sci. Technol. 2022, 15, 790–797. [Google Scholar] [CrossRef]
- Cai, T.; Zhang, X. Imbalanced Text Sentiment Classification Based on Multi-Channel BLTCN-BLSTM Self-Attention. Sensors 2023, 23, 2257. [Google Scholar] [CrossRef]
- Akkaradamrongrat, S.; Kachamas, P.; Sinthupinyo, S. Text Generation for Imbalanced Text Classification. In Proceedings of the IEEE 2019 16th International Joint Conference on Computer Science and Software Engineering (JCSSE), Chonburi, Thailand, 10–12 July 2019; pp. 181–186. [Google Scholar]
- Habbat, N.; Nouri, H.; Anoun, H.; Hassouni, L. Using AraGPT and Ensemble Deep Learning Model for Sentiment Analysis on Arabic Imbalanced Dataset. ITM Web Conf. 2023, 52, 02008. [Google Scholar] [CrossRef]
- Habbat, N.; Nouri, H.; Anoun, H.; Hassouni, L. Sentiment Analysis of Imbalanced Datasets Using BERT and Ensemble Stacking for Deep Learning. Eng. Appl. Artif. Intell. 2023, 126, 106999. [Google Scholar] [CrossRef]
- Shaikh, S.; Daudpota, S.M.; Imran, A.S.; Kastrati, Z. Towards Improved Classification Accuracy on Highly Imbalanced Text Dataset Using Deep Neural Language Models. Appl. Sci. 2021, 11, 869. [Google Scholar] [CrossRef]
- Imran, A.S.; Yang, R.; Kastrati, Z.; Daudpota, S.M.; Shaikh, S. The Impact of Synthetic Text Generation for Sentiment Analysis Using GAN Based Models. Egypt. Inform. J. 2022, 23, 547–557. [Google Scholar] [CrossRef]
- Kastrati, Z.; Arifaj, B.; Lubishtani, A.; Gashi, F.; Nishliu, E. Aspect-Based Opinion Mining of Students’ Reviews on Online Courses. In Proceedings of the ACM 2020 6th International Conference on Computing and Artificial Intelligence, Tianjin, China, 23–26 April 2020; pp. 510–514. [Google Scholar]
- Liu, Z.; Wang, J.; Liang, Z. CatGAN: Category-Aware Generative Adversarial Networks with Hierarchical Evolutionary Learning for Category Text Generation. arXiv 2019, arXiv:1911.06641. [Google Scholar] [CrossRef]
- Qurashi, A.W.; Holmes, V.; Johnson, A.P. Document Processing: Methods for Semantic Text Similarity Analysis. In Proceedings of the IEEE 2020 International Conference on INnovations in Intelligent SysTems and Applications (INISTA), Novi Sad, Serbia, 24–26 August 2020; pp. 1–6. [Google Scholar]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Schofield, A.; Thompson, L.; Mimno, D. Quantifying the Effects of Text Duplication on Semantic Models. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 2737–2747. [Google Scholar]
- Lee, K.; Ippolito, D.; Nystrom, A.; Zhang, C.; Eck, D.; Callison-Burch, C.; Carlini, N. Deduplicating Training Data Makes Language Models Better. arXiv 2022, arXiv:2107.06499. [Google Scholar]
- Kandpal, N.; Wallace, E.; Raffel, C. Deduplicating Training Data Mitigates Privacy Risks in Language Models. arXiv 2022, arXiv:2202.06539. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Input | Output |
|---|---|---|
| 1 | the discussion forums for this course was not quite helpful. | the discussion forums for this course could have been more helpful. |
| 2 | the discussion forums for this course was not quite helpful. | the discussion forums for this course were unhelpful. |
| Model | Main Layer: Unit/Filter, Dropout | Fully Connected Layer: Unit, Activation, Dropout | Output Layer | Hyperparameters: Optimizer, Learning Rate, Batch Size |
|---|---|---|---|---|
| RNN | SimpleRNN: 256 (2 layers), 0.5 | 256, ReLU, 0.5 | Dense(3, softmax) | Adam, 0.0005, 32 |
| CNN | Conv1D: 128, 128, 256, 0.5 | 256, ReLU, 0.5 | Dense(3, softmax) | Adam, 0.0005, 32 |
| LSTM | LSTM: 256 (2 layers), 0.5 | 256, ReLU, 0.5 | Dense(3, softmax) | Adam, 0.0005, 32 |
| BiLSTM | BiLSTM: 256 (2 layers), 0.5 | 256, ReLU, 0.5 | Dense(3, softmax) | Adam, 0.0005, 32 |
| GRU | GRU: 256 (2 layers), 0.5 | 256, ReLU, 0.5 | Dense(3, softmax) | Adam, 0.0005, 32 |
| Original Input Data | Prompt | Generated Output Data |
|---|---|---|
| instructor doesn’t seem to be passionate about giving the lecture | Please generate a review sentence about a course that has a similar meaning to this review: “instructor doesn’t seem to be passionate about giving the lecture”. Keep the generated review under the given maximum token. | The instructor appears to lack enthusiasm while delivering the class. |
| instructor is not clear and too fast! | Please generate a review sentence about a course that has a similar meaning to this review: “instructor is not clear and too fast!”. Keep the generated review under the given maximum token. | The instructor is confusing and moves too quickly! |
| it is very easy and unusefull course. | Please generate a review sentence about a course that has a similar meaning to this review: “it is very easy and unusefull course.” Keep the generated review under the given maximum token. | It is a straightforward yet unhelpful course. |
| Sentiment | The Number of Replications | Frequency | |||
|---|---|---|---|---|---|
| Unique Outputs | Overall Duplication | Intra- Duplication | Inter- Duplication | ||
| Negative | 9 | 15,058 | 863 | 767 | 311 |
| Neutral | 17 | 14,029 | 1067 | 1042 | 124 |
| Sentiment | Cut-Off | Similar Outputs | Similar to Inputs | Anomaly | Bad | Good | Total Output | % Bad |
|---|---|---|---|---|---|---|---|---|
| Negative | 1 | 571 | 0 | 1 | 572 | 15,349 | 15,921 | 3.59% |
| 0.80 | 1558 | 99 | 1 | 1658 | 14,263 | 15,921 | 10.41% | |
| 0.75 | 1889 | 96 | 1 | 1986 | 13,935 | 15,921 | 12.47% | |
| 0.50 | 5147 | 74 | 1 | 5222 | 10,699 | 15,921 | 32.80% | |
| Neutral | 1 | 715 | 0 | 0 | 715 | 14,381 | 15,096 | 4.74% |
| 0.80 | 1855 | 70 | 0 | 1925 | 13,171 | 15,096 | 12.75% | |
| 0.75 | 2343 | 66 | 0 | 2409 | 12,687 | 15,096 | 15.96% | |
| 0.50 | 6441 | 44 | 0 | 6485 | 8611 | 15,096 | 42.96% |
| Dataset | RNN (GloVe) | CNN (GloVe) | LSTM (GloVe) | BiLSTM (GloVe) | GRU (GloVe) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | |
| Dataset-100 | 60.10% | 56.61% | 60.77% | 60.18% | 60.64% | 60.38% | 63.54% | 60.73% | 62.18% | 60.13% |
| Dataset-80 | 58.40% | 57.97% | 61.53% | 59.80% | 60.72% | 60.14% | 60.45% | 59.77% | 61.16% | 60.28% |
| Dataset-75 | 58.48% | 57.37% | 59.64% | 60.13% | 64.08% | 61.65% | 61.16% | 60.00% | 63.24% | 62.24% |
| Dataset-50 | 58.16% | 58.84% | 59.90% | 59.42% | 63.00% | 61.27% | 60.76% | 59.99% | 60.18% | 60.94% |
| Fine-tuning Dataset | 64.71% | 62.80% | 71.46% | 65.66% | 66.76% | 64.54% | 66.44% | 66.03% | 67.49% | 66.67% |
| Original Dataset | 33.33% | 30.49% | 54.92% | 54.31% | 54.33% | 54.50% | 53.62% | 54.40% | 55.90% | 54.44% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suhaeni, C.; Yong, H.-S. Enhancing Imbalanced Sentiment Analysis: A GPT-3-Based Sentence-by-Sentence Generation Approach. Appl. Sci. 2024, 14, 622. https://doi.org/10.3390/app14020622
Suhaeni C, Yong H-S. Enhancing Imbalanced Sentiment Analysis: A GPT-3-Based Sentence-by-Sentence Generation Approach. Applied Sciences. 2024; 14(2):622. https://doi.org/10.3390/app14020622
Chicago/Turabian StyleSuhaeni, Cici, and Hwan-Seung Yong. 2024. "Enhancing Imbalanced Sentiment Analysis: A GPT-3-Based Sentence-by-Sentence Generation Approach" Applied Sciences 14, no. 2: 622. https://doi.org/10.3390/app14020622
APA StyleSuhaeni, C., & Yong, H.-S. (2024). Enhancing Imbalanced Sentiment Analysis: A GPT-3-Based Sentence-by-Sentence Generation Approach. Applied Sciences, 14(2), 622. https://doi.org/10.3390/app14020622