
Comparative Study for Sentiment Analysis of Financial Tweets with Deep Learning Methods


 and
and 
Abstract
1. Introduction
2. Related Studies
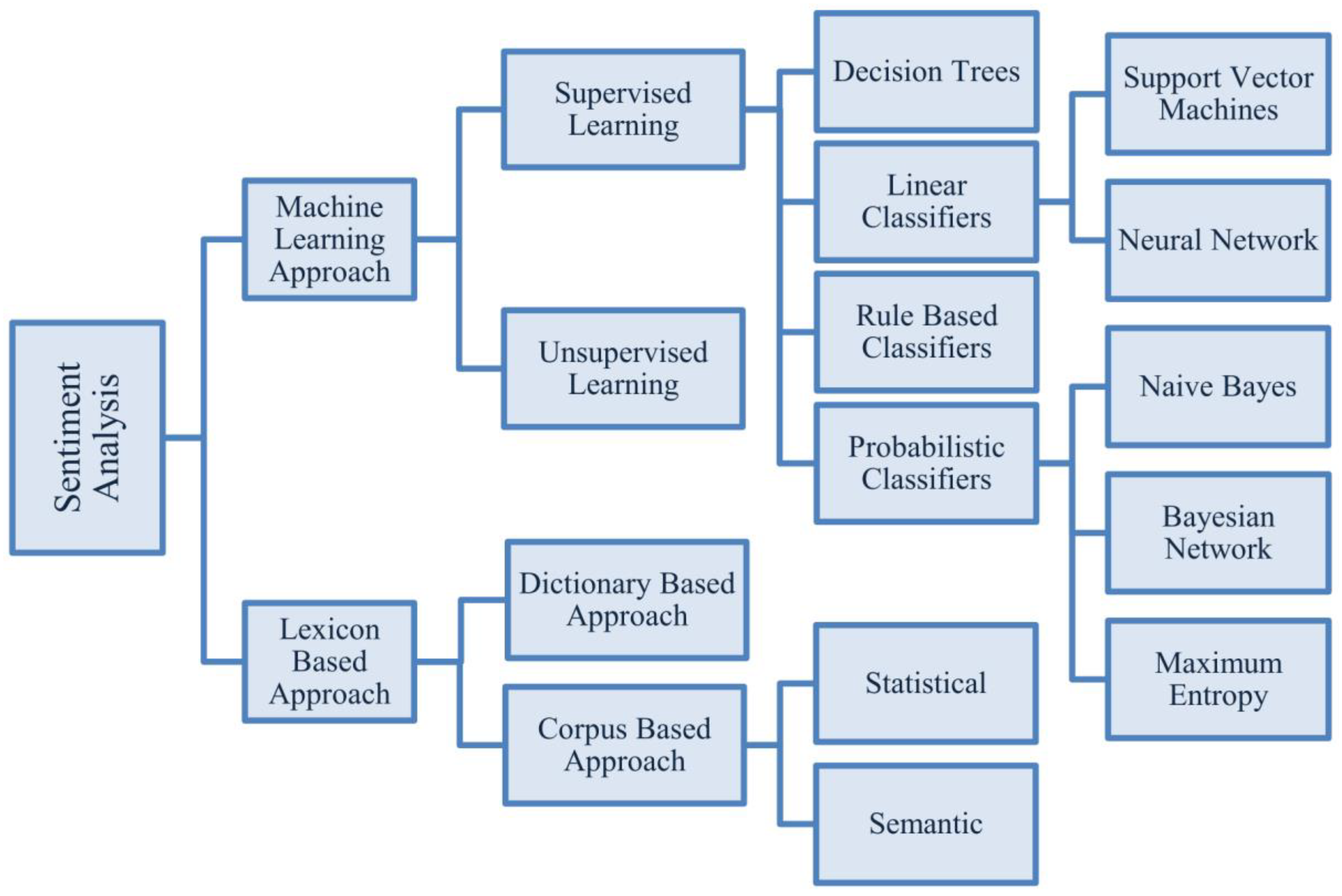
3. Materials and Methods
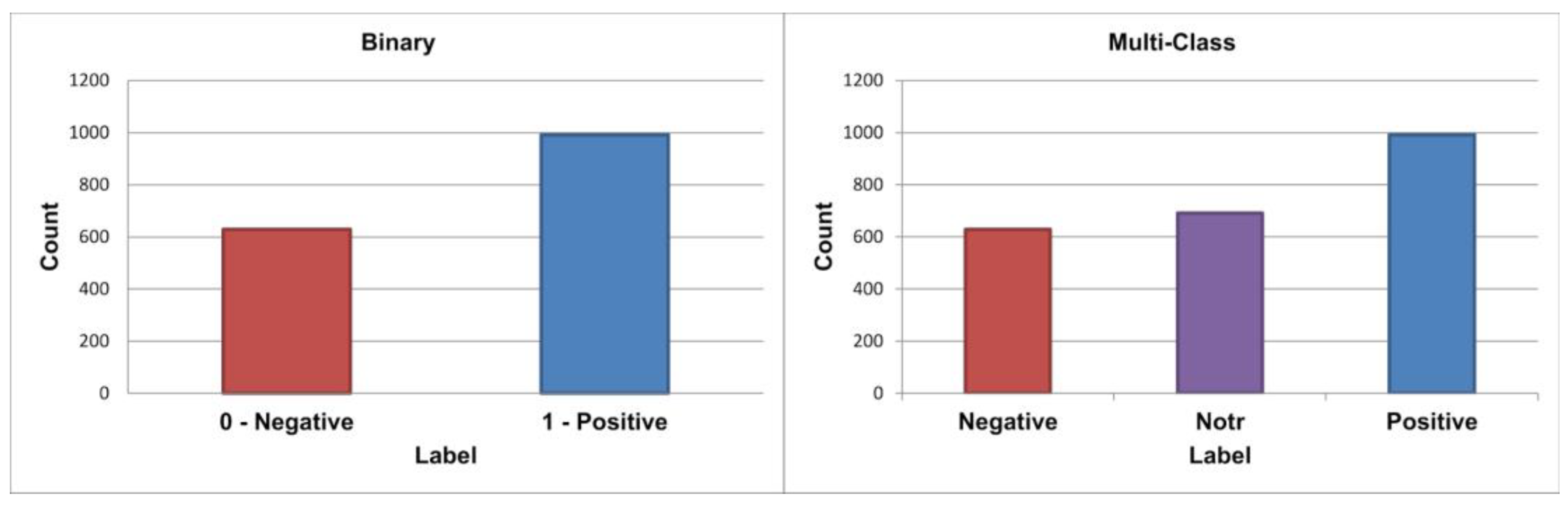
3.1. Datasets
3.2. Tweet Pre-Processing Phase
- Removing unnecessary sections of tweets (external links and usernames (signified with @sign), URL (http://...), stop words, #tags, retweets (starts with “RT”), punctuations, unnecessary whitespaces, etc.);
- Transforming characters to lowercase;
- Removing numbers;
- Correcting spelling/writing errors (normalization) and restoring popular abbreviations to their full forms (e.g., mrb to merhaba). ITU Turkish NLP Web Service API [7] was used for the normalization process.
3.3. Feature Extraction
3.3.1. Bag of Words (BoW)
3.3.2. Word Embedding
3.4. Classifier Models
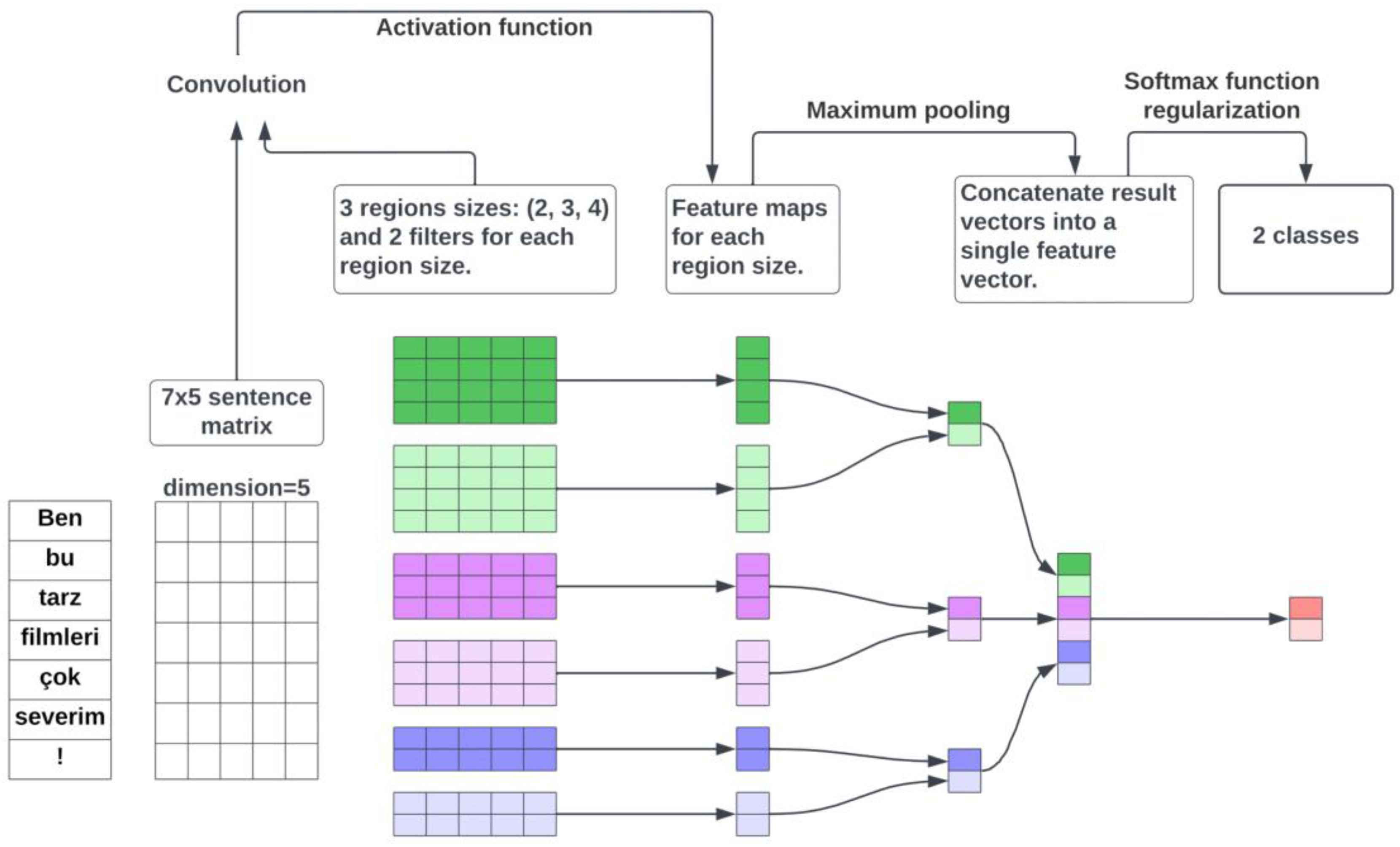
3.4.1. Convolutional Neural Networks (CNN)
3.4.2. Recurrent Neural Networks (RNNs)
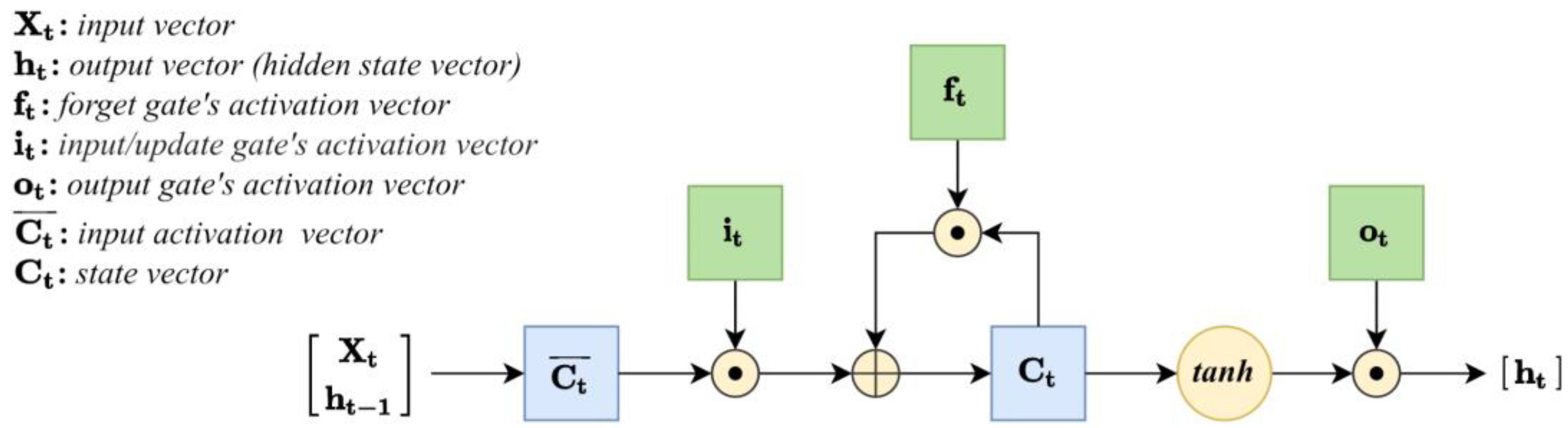
3.4.3. Long Short-Term Memory (LSTM)
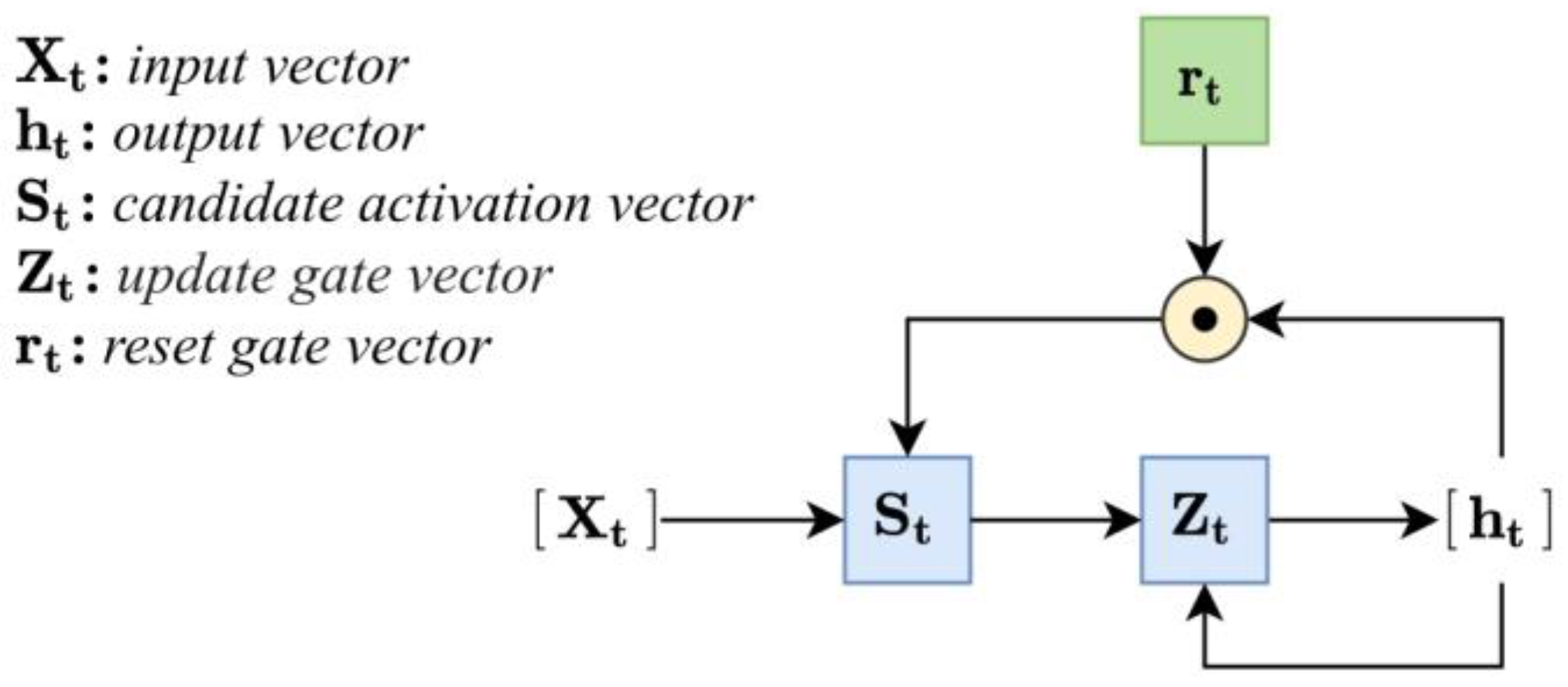
3.4.4. Gated Recurrent Unit
4. Experimental Setup and Results
4.1. Simple Neural Network Model
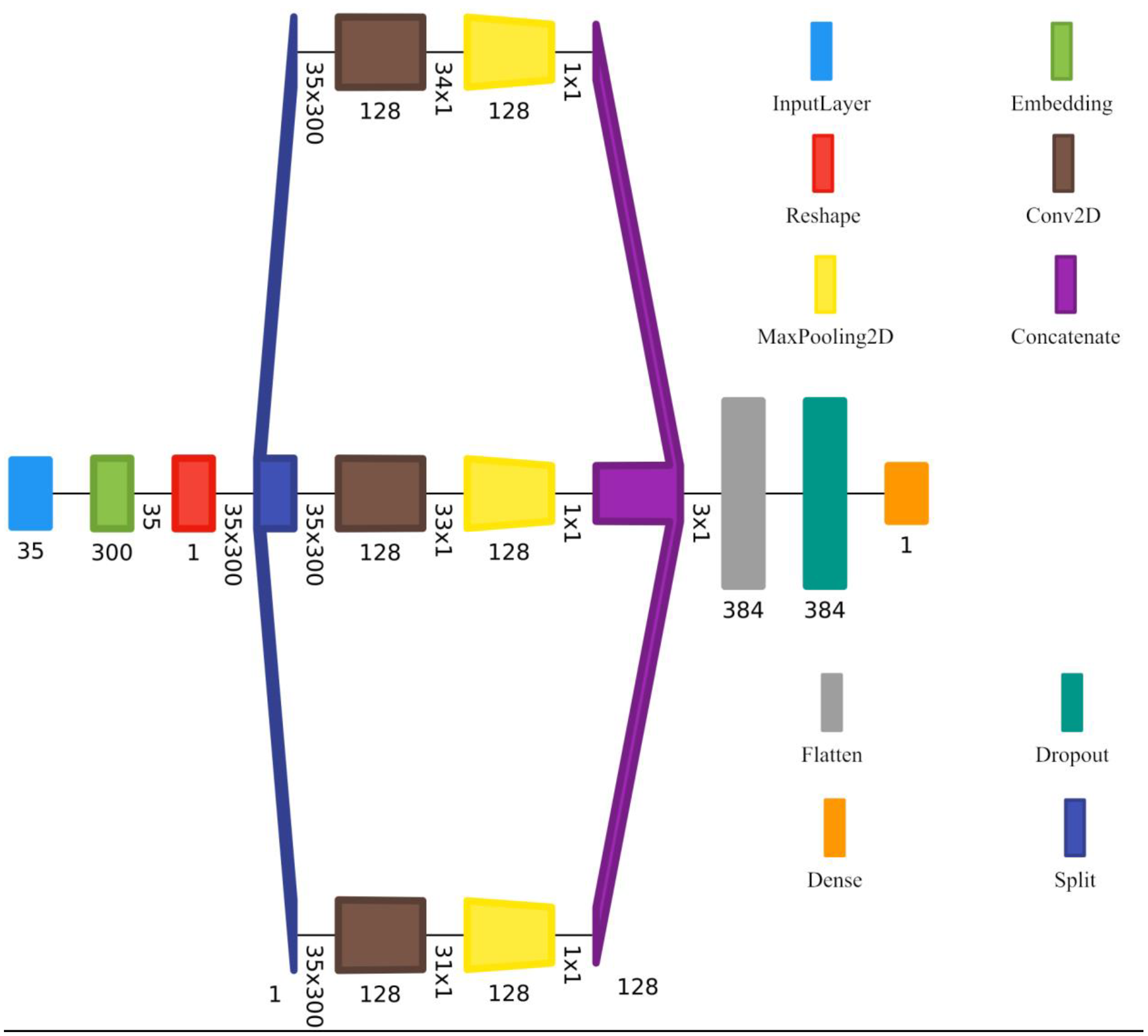
4.2. Convolutional Neural Network (CNN) Model
4.3. Long Short-Term Memory (LSTM) Model
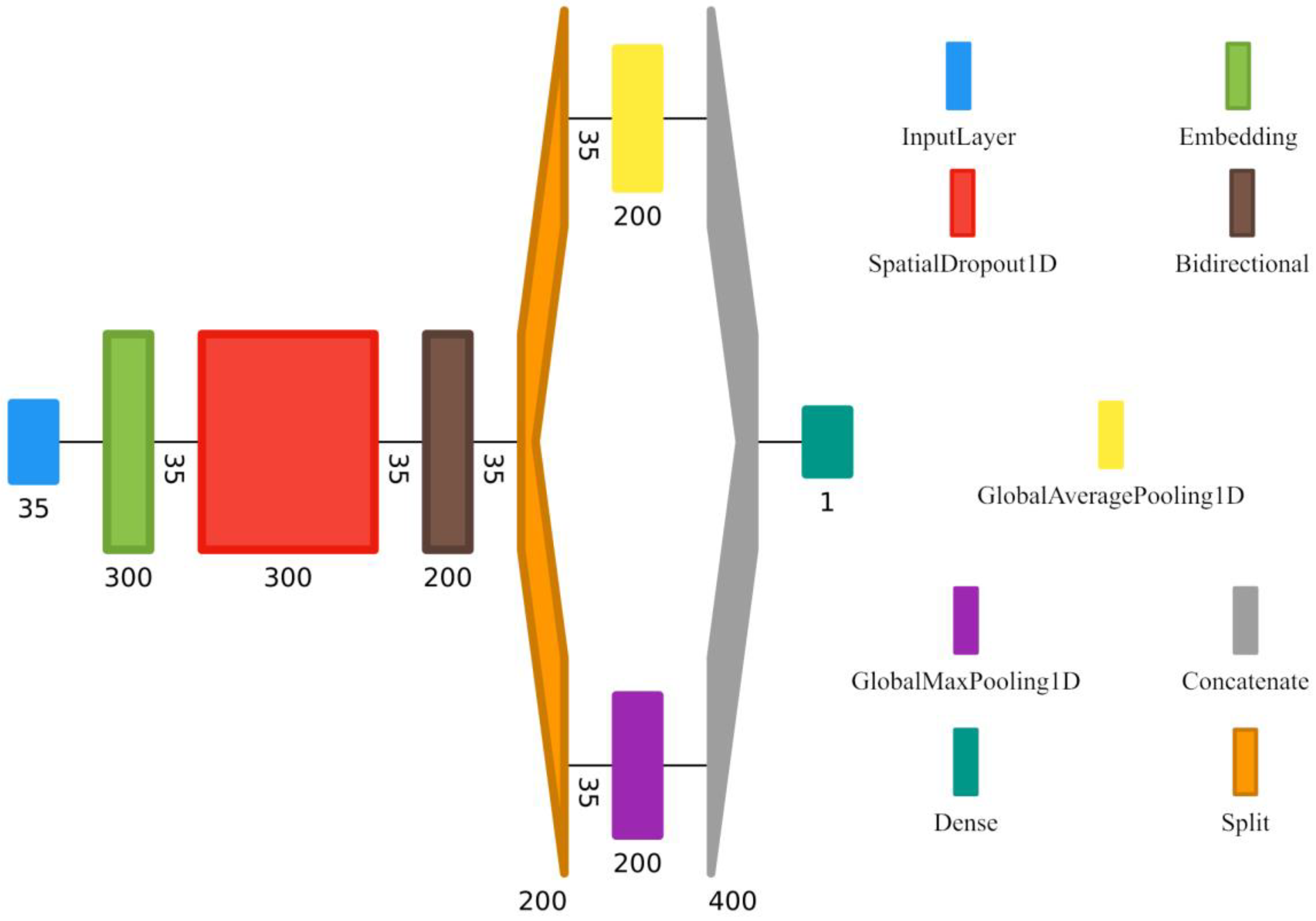
4.4. Gated Recurrent Units (GRU) Model
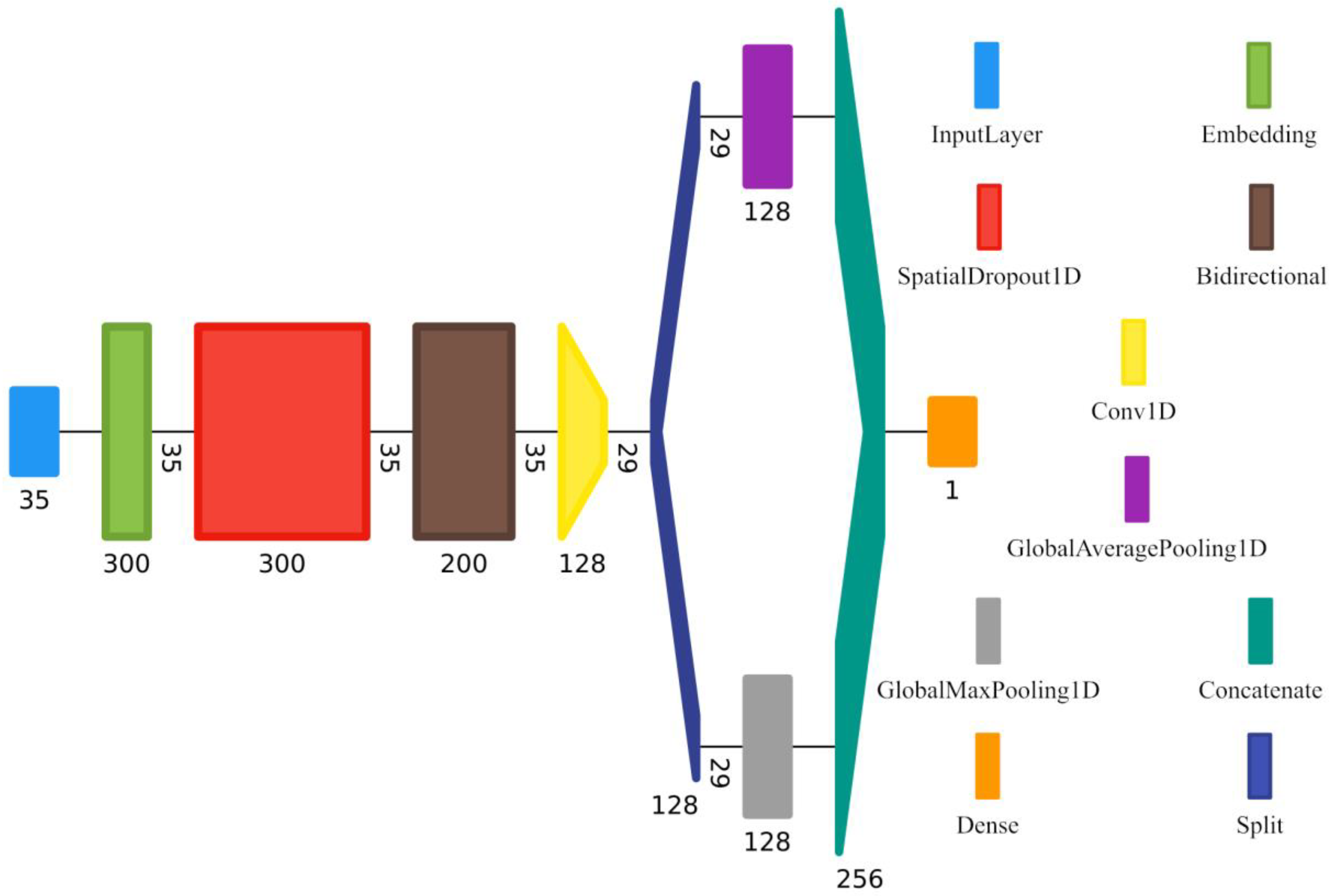
4.5. GRU-CNN Model
4.6. Supporting Findings and Conclusions
4.6.1. Creation and Processing of Datasets
4.6.2. Feature Extraction Techniques and Algorithm Deployment
4.6.3. Experiment Design and Outcome
4.6.4. Acknowledgment of Limitations and Biases
4.7. Pros and Cons of Employed Methods
4.7.1. Advantages
- (1)
- This study embraces a diverse array of machine learning algorithms, providing a comprehensive evaluation of their efficacy in sentiment classification.
- (2)
- Emphasis is placed on the advantageous use of pre-trained word embeddings, particularly fastText, for enhancing model performance.
- (3)
- Valuable insights are offered into the practical applications of sentiment analysis within the Turkish stock market, holding potential significance for decision-makers.
4.7.2. Disadvantages
- (1)
- This article candidly acknowledges drawbacks related to dataset size, biases in data collection and the subjective nature of manual sentiment labeling.
- (2)
- This study falls short in providing an in-depth exploration of model interpretability and the underlying reasons for sentiments observed in financial tweets.
5. Constraints
Potential Biases
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Twitter. It’s What’s Happening. Available online: https://twitter.com/ (accessed on 10 June 2019).
- Twitter Statistics—Statistic Brain. Available online: https://twitter.com/StatisticBrain (accessed on 20 July 2020).
- Cambria, E.; Schuller, B.B.; Xia, Y.; Havasi, C. New Avenues in Opinion Mining and Sentiment Analysis. IEEE Intell. Syst. 2013, 28, 15–21. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis and Opinion Mining. In Synthesis Lectures on Human Language Technologies; Springer: Cham, Switzerland, 2012; Volume 5, pp. 1–167. [Google Scholar] [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment Analysis Algorithms and Applications: A Survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar] [CrossRef]
- Memis, E.; Kaya, H. Association Rule Mining on the BIST100 Stock Exchange. In Proceedings of the 3rd International Symposium on Multidisciplinary Studies and Innovative Technologies, ISMSIT 2019—Proceedings, Ankara, Turkey, 11–13 October 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019. [Google Scholar]
- Eryiğit, G. ITU Turkish NLP Web Service. In Proceedings of the Demonstrations at the 14th Conference of the European Chapter of the Association for Computational Linguistics (EACL), Gothenburg, Sweden, 26–30 April 2014; Association for Computational Linguistics: Gothenburg, Sweden, 2014. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Advances in Neural Information Processing Systems; 2013. Available online: https://proceedings.neurips.cc/paper_files/paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf (accessed on 10 June 2019).
- Mikolov, T.; Karafiat, M.; Burget, L.; Cernocky, J.; Khudanpur, S. Recurrent Neural Network Based Language Model. In Proceedings of the Interspeech 2010, Chiba, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.Y.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive Deep Models for Semantic Compositionality over a Sentiment Treebank. In Proceedings of the EMNLP 2013—2013 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing [Review Article]. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Grave, E.; Bojanowski, P.; Gupta, P.; Joulin, A.; Mikolov, T. Learning Word Vectors for 157 Languages. In Proceedings of the LREC 2018, 11th International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2018; pp. 3483–3487. [Google Scholar]
- Nasukawa, T. Sentiment Analysis: Capturing Favorability Using Natural Language Processing Definition of Sentiment Expressions. In Proceedings of the 2nd International Conference on Knowledge Capture, Sanibel Island, FL, USA, 23–25 October 2003; pp. 70–77. [Google Scholar] [CrossRef]
- Martínez-Cámara, E.; Martín-Valdivia, M.T.; Urena-López, L.A.; Montejo-Ráez, A.R. Sentiment analysis in Twitter. Nat. Lang. Eng. 2014, 20, 1–28. [Google Scholar] [CrossRef]
- Almohaimeed, A.S. Using Tweets Sentiment Analysis to Predict Stock Market Movement. Master’s Thesis, Auburn University, Auburn, Alabama, 2017. [Google Scholar]
- Şimşek, M.U.; Özdemir, S. Analysis of the Relation between Turkish Twitter Messages and Stock Market Index. In Proceedings of the 2012 6th International Conference on Application of Information and Communication Technologies (AICT), Tbilisi, Georgia, 17–19 October 2012. [Google Scholar] [CrossRef]
- Yıldırım, M.; Yüksel, C.A. Sosyal Medya Ile Hisse Senedi Fiyatinin Günlük Hareket Yönü Arasindaki Ilişkinin Incelenmesi: Duygu Analizi Uygulamasi. Uluslararası İktisadi ve İdari İncelemeler Derg. 2017, 33–44. [Google Scholar] [CrossRef]
- Ozturk, S.S.; Ciftci, K. A Sentiment Analysis of Twitter Content as a Predictor of Exchange Rate Movements. Rev. Econ. Anal. 2014, 6, 132–140. [Google Scholar] [CrossRef]
- Eliaçik, A.B.; Erdogan, N. Mikro Bloglardaki Finans Toplulukları Için Kullanıcı Ağırlıklandırılmış Duygu Analizi Yöntemi. Ulus. Yazılım Mühendisliği Sempozyumu 2015, 782–793. [Google Scholar]
- Akgül, E.S.; Ertano, C.; Diri, B. Twitter Verileri Ile Duygu Analizi Sentiment Analysis with Twitter. Pamukkale Univ. Muh. Bilim. Derg. 2016, 22, 106–110. [Google Scholar] [CrossRef]
- Bollen, J.; Mao, H.; Zeng, X. Twitter Mood Predicts the Stock Market. J. Comput. Sci. 2011, 2, 1–8. [Google Scholar] [CrossRef]
- Velioglu, R.; Yildiz, T.; Yildirim, S. Sentiment Analysis Using Learning Approaches over Emojis for Turkish Tweets. In Proceedings of the UBMK 2018—3rd International Conference on Computer Science and Engineering, Sarajevo, Bosnia and Herzegovina, 20–23 September 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 303–307. [Google Scholar]
- Smailović, J.; Grčar, M.; Lavrač, N.; Žnidaršič, M. Stream-Based Active Learning for Sentiment Analysis in the Financial Domain. Inf. Sci. 2014, 285, 181–203. [Google Scholar] [CrossRef]
- Bilgin, M.; Sentürk, I.F. Danışmanlı ve Yarı Danışmanlı Öğrenme Kullanarak Doküman Vektörleri Tabanlı Tweetlerin Duygu Analizi. J. BAUN Inst. Sci. Technol. 2019, 21, 822–839. [Google Scholar] [CrossRef]
- Ayata, D.; Saraclar, M.; Ozgur, A. Makine Öǧrenmesi ve Kelime Vektör Temsili Ile Türke Tweet Sentiment Analizi. In Proceedings of the 2017 25th Signal Processing and Communications Applications Conference, SIU 2017, Antalya, Turkey, 15–18 May 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017. [Google Scholar]
- Park, H.W.; Lee, Y. How Are Twitter Activities Related to Top Cryptocurrencies’ Performance? Evidence from Social Media Network and Sentiment Analysis. Drus. Istraz. 2019, 28, 435–460. [Google Scholar] [CrossRef]
- Nyakurukwa, K.; Seetharam, Y. Does Online Investor Sentiment Explain Analyst Recommendation Changes? Evidence from an Emerging Market. Manag. Financ. 2023, 49, 187–204. [Google Scholar] [CrossRef]
- Choi, J.J. Popular Personal Financial Advice versus the Professors. J. Econ. Perspect. 2022, 36, 167–192. [Google Scholar] [CrossRef]
- Kraaijeveld, O.; De Smedt, J. The Predictive Power of Public Twitter Sentiment for Forecasting Cryptocurrency Prices. J. Int. Financ. Mark. Institutions Money 2020, 65, 101188. [Google Scholar] [CrossRef]
- Duffy, D.; Durkan, J.; Timoney, K.; Casey, E. Quarterly Economic Commentary, Winter 2012; The Economic and Social Research Institute: Dublin, Ireland, 2012. [Google Scholar]
- Yang, S.Y.; Mo, S.Y.K.; Liu, A. Twitter Financial Community Sentiment and Its Predictive Relationship to Stock Market Movement. Quant. Financ. 2015, 15, 1637–1656. [Google Scholar] [CrossRef]
- Varanasi, R.A.; Hanrahan, B.V.; Wahid, S.; Carroll, J.M. TweetSight: Enhancing Financial Analysts’ Social Media Use. In Proceedings of the 8th International Conference on Social Media & Society, Toronto, ON, Canada, 28–30 July 2017; pp. 1–10. [Google Scholar]
- Özgür, A.; Özgür, L.; Güngör, T. Text Categorization with Class-Based and Corpus-Based Keyword Selection. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2005; Volume 3733, pp. 606–615. [Google Scholar]
- Nabi, J. Machine Learning—Text Processing; Towards Data Science: Toronto, ON, Canada, 2018. [Google Scholar]
- Harris, Z.S. Distributional Structure. Distrib. Struct. WORD 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013—Workshop Track Proceedings, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the EMNLP 2014—2014 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL HLT 2019—Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the MM 2014—Proceedings of the 2014 ACM Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; Association for Computing Machinery, Inc.: New York, NY, USA, 2014; pp. 675–678. [Google Scholar]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 512–519. [Google Scholar]
- Collobert, R.; Weston, J. A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning. In Proceedings of the Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Elvis Deep Learning for NLP: An Overview of Recent Trends. Available online: https://medium.com/dair-ai/deep-learning-for-nlp-an-overview-of-recent-trends-d0d8f40a776d (accessed on 24 August 2018).
- Elman, J.L. Finding Structure in Time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Girosi, F.; Jones, M.; Poggio, T. Regularization Theory and Neural Networks Architectures. Neural Comput. 1995, 7, 219–269. [Google Scholar] [CrossRef]
- Park, S.; Kwak, N. Analysis on the Dropout Effect in Convolutional Neural Networks. In Proceedings of the Computer Vision–ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers, Part II 13;. Springer: Cham, Switzerland, 2017; pp. 189–204. [Google Scholar]
- Wang, L.; Han, M.; Li, X.; Zhang, N.; Cheng, H. Review of Classification Methods on Unbalanced Data Sets. IEEE Access 2021, 9, 64606–64628. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Yap, B.W.; Rani, K.A.; Rahman, H.A.A.; Fong, S.; Khairudin, Z.; Abdullah, N.N. An Application of Oversampling, Undersampling, Bagging and Boosting in Handling Imbalanced Datasets. In Proceedings of the First International Conference on Advanced Data and Information Engineering (DaEng-2013), Kuala Lumpur, Malaysia, 16–18 December 2013; Springer: Singapore, 2014; pp. 13–22. [Google Scholar]
- Bäuerle, A.; Van Onzenoodt, C.; Ropinski, T. Net2Vis: Transforming Deep Convolutional Networks into Publication-Ready Visualizations. arXiv 2019, arXiv:1902.04394. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Description |
|---|---|
| Language Emphasis | Enhances sentiment analysis capabilities in Turkish, a language with limited linguistic resources, thereby broadening applicability across diverse cultural contexts. |
| Financial Domain | Specializes in Turkish financial tweets, offering valuable perspectives into market sentiment and investor behaviors within this specific domain. |
| Multiple Deep Learning Models | Evaluates and contrasts five distinct deep learning architectures tailored for Turkish financial tweets, delivering comprehensive insights into their respective performances. |
| Utilization of Pre-trained Embeddings | Investigates and illustrates the efficacy of utilizing pre-trained word embedding from fastText for sentiment analysis in Turkish, contributing to the optimization of the analytical process. |
| Aspect | Description |
|---|---|
| Financial Market Sentiment Analysis | Assists traders, analysts and portfolio managers in making informed decisions by evaluating investor sentiment. |
| Risk Identification and Management | Pinpoints potential risks and opportunities in specific stocks or sectors, aiding in the formulation and execution of effective risk management strategies. |
| Enhanced Investor Communication | Facilitates personalized communication with investors based on social media feedback, thereby enhancing engagement and overall satisfaction. |
| Informed Market Research | Offers valuable insights into public perceptions of financial products, services and regulations, serving as a foundation for market research and informed product development initiatives. |
| Aspect | Comparison | Proposal |
|---|---|---|
| Sentiment Analysis vs. Traditional Analysis | Provides additional layer of information. | Integrate sentiment analysis results into existing analytical frameworks. |
| Machine Learning Models vs. Conventional Models | Leverages word embedding techniques and pre-trained embedding. | Explore the integration of machine learning models into algorithmic trading strategies. |
| Social Media Influence vs. Market Fundamentals | Suggests correlation between social media sentiments and stock market movements. | Consider incorporating social media analytics into risk management strategies. |
| Pre-trained Word Embedding vs. Customized Approaches | Better performance compared to customized word embedding approaches. | Explore pre-trained embedding for sentiment analysis. |
| Real-Time Sentiment Integration | Real-time sentiment analysis tools that integrate financial tweets’ sentiments into trading platforms. | Implement real-time sentiment analysis tools. |
| Algorithmic Trading Strategies | Algorithmic trading strategies that incorporate sentiment analysis signals. | Develop and test algorithmic trading strategies that incorporate sentiment analysis signals. |
| Risk Management Enhancement | Consider social media sentiment as an additional risk factor. | Enhance risk management models by considering social media sentiment as an additional risk factor. |
| Education and Awareness | Awareness campaigns and educational programs for market participants. | Conduct awareness campaigns and educational programs for market participants. |
| Collaboration with NLP Experts | Collaboration with natural language processing (NLP) experts. | Financial institutions should collaborate with NLP experts. |
| Cross-Disciplinary Research | Cross-disciplinary research collaborations between finance professionals, data scientists and social media analysts. | Encourage cross-disciplinary research collaborations. |
| Continuous Model Optimization | Continuous optimization strategies for sentiment analysis models. | Implement continuous optimization strategies for sentiment analysis models. |
| Neural Network Type | Number of Hidden Layers | Layer Sizes | Activation Functions |
|---|---|---|---|
| Simple Neural Network (Binary Classification) | Typically 1–2 | Varies, depends on problem complexity | Hidden: ReLU, Output: Sigmoid |
| Convolutional Neural Network (CNN) | Multiple convolutional and pooling layers, followed by fully connected layers | Convolutional layers: filter size determines neuron count, fully connected layers: variable | Convolutional: ReLU, Output: Sigmoid or Softmax (depending on task) |
| Recurrent Neural Networks (RNN) | One or more recurrent layers | Number of recurrent units (neurons) per layer | tanh or ReLU |
| Long Short-Term Memory (LSTM) | Multiple layers of memory cells | Number of memory cells (neurons) per layer | Specialized within memory cells (sigmoid, tanh) |
| Gated Recurrent Unit (GRU) | Multiple layers possible | Number of gated units (neurons) per layer | Specialized gating mechanisms (sigmoid, tanh) |
| Classification | Embedding | Train/Test | Max Accuracy (%) |
|---|---|---|---|
| Binary | Word Embedding | Train | 100.00 |
| Test | 80.25 | ||
| Pre-trained word embedding | Train | 100.00 | |
| Test | 79.32 | ||
| Multi-class | Word Embedding | Train | 99.57 |
| Test | 63.85 | ||
| Pre-trained word embedding | Train | 99.51 | |
| Test | 65.23 |
| Classification | Embedding | Train/Test | Max Accuracy (%) |
|---|---|---|---|
| Binary | Word Embedding | Train | 100.00 |
| Test | 77.23 | ||
| Pre-trained word embedding | Train | 100.00 | |
| Test | 83.02 | ||
| Multi-class | Word Embedding | Train | 99.73 |
| Test | 63.71 | ||
| Pre-trained word embedding | Train | 99.73 | |
| Test | 72.72 |
| Classification | Embedding | Train/Test | Max Accuracy (%) |
|---|---|---|---|
| Binary | Word Embedding | Train | 98.30 |
| Test | 74.69 | ||
| Pre-trained word embedding | Train | 100.00 | |
| Test | 79.32 | ||
| Multi-class | Word Embedding | Train | 99.24 |
| Test | 59.52 | ||
| Pre-trained word embedding | Train | 99.24 | |
| Test | 61.69 |
| Classification | Embedding | Train/Test | Max Accuracy (%) |
|---|---|---|---|
| Binary | Word Embedding | Train | 100.00 |
| Test | 80.25 | ||
| Pre-trained word embedding | Train | 100.00 | |
| Test | 80.31 | ||
| Multi-class | Word Embedding | Train | 99.62 |
| Test | 62.99 | ||
| Pre-trained word embedding | Train | 99.68 | |
| Test | 64.07 |
| Classification | Embedding | Train/Test | Max Accuracy (%) |
|---|---|---|---|
| Binary | Word Embedding | Train | 100.00 |
| Test | 80.56 | ||
| Pre-trained word embedding | Train | 100.00 | |
| Test | 80.25 | ||
| Multi-class | Word Embedding | Train | 99.68 |
| Test | 61.47 | ||
| Pre-trained word embedding | Train | 99.68 | |
| Test | 64.29 |
| Model | Max. Training Accuracy (%) | Max. Testing Accuracy (%) | Average of Max Testing Accuracies of All Folds (%) |
|---|---|---|---|
| Binary NN model with word embedding | 100.00 | 80.25 | 76.68 |
| Binary NN model with pre-trained word embedding | 100.00 | 79.32 | 76.19 |
| Multiclass NN model with word embedding | 99.57 | 63.85 | 61.59 |
| Multiclass NN model with pre-trained word embedding | 99.51 | 65.23 | 61.59 |
| Binary CNN model with word embedding | 100.00 | 77.23 | 75.82 |
| Binary CNN model with pre-trained word embedding | 100.00 | 83.02 | 78.35 |
| Multiclass CNN model with word embedding | 99.73 | 63.71 | 61.98 |
| Multiclass CNN model with pre-trained word embedding | 99.73 | 72.73 | 65.05 |
| Binary LSTM model with word embedding | 98.30 | 74.69 | 72.36 |
| Binary LSTM model with pre-trained word embedding | 100.00 | 79.32 | 75.14 |
| Multiclass LSTM model with word embedding | 99.24 | 59.52 | 58.34 |
| Multiclass LSTM model with pre-trained word embedding | 99.24 | 61.69 | 58.69 |
| Binary GRU model with word embedding | 100.00 | 80.25 | 76.93 |
| Binary GRU model with pre-trained word embedding | 100.00 | 80.31 | 77.60 |
| Multiclass GRU model with word embedding | 99.73 | 62.99 | 60.94 |
| Multiclass GRU model with pre-trained word embedding | 99.68 | 64.07 | 62.67 |
| Binary GRU-CNN model with word embedding | 100.00 | 80.56 | 76.44 |
| Binary GRU-CNN model with pre-trained word embedding | 100.00 | 80.24 | 78.47 |
| Multiclass GRU-CNN model with word embedding | 99.68 | 61.47 | 60.08 |
| Multiclass GRU-CNN model with pre-trained word embedding | 99.68 | 64.29 | 62.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Memiş, E.; Akarkamçı, H.; Yeniad, M.; Rahebi, J.; Lopez-Guede, J.M. Comparative Study for Sentiment Analysis of Financial Tweets with Deep Learning Methods. Appl. Sci. 2024, 14, 588. https://doi.org/10.3390/app14020588
Memiş E, Akarkamçı H, Yeniad M, Rahebi J, Lopez-Guede JM. Comparative Study for Sentiment Analysis of Financial Tweets with Deep Learning Methods. Applied Sciences. 2024; 14(2):588. https://doi.org/10.3390/app14020588
Chicago/Turabian StyleMemiş, Erkut, Hilal Akarkamçı (Kaya), Mustafa Yeniad, Javad Rahebi, and Jose Manuel Lopez-Guede. 2024. "Comparative Study for Sentiment Analysis of Financial Tweets with Deep Learning Methods" Applied Sciences 14, no. 2: 588. https://doi.org/10.3390/app14020588
APA StyleMemiş, E., Akarkamçı, H., Yeniad, M., Rahebi, J., & Lopez-Guede, J. M. (2024). Comparative Study for Sentiment Analysis of Financial Tweets with Deep Learning Methods. Applied Sciences, 14(2), 588. https://doi.org/10.3390/app14020588