
DietNerd: A Nutrition Question-Answering System That Summarizes and Evaluates Peer-Reviewed Scientific Articles


Abstract
1. Introduction
- A combined parsing/prompt pipeline that takes a question, fetches relevant articles, and summarizes them.
- An analysis of each relevant article that extracts the purpose, the design of the experiment, the main conclusion, risks and benefits of the dietary change tested, study statistics, and any possible conflicts of interest.
- Accuracy tests based on systematic surveys that show a high semantic similarity of the responses of DietNerd with those surveys for 64% of the articles and moderate semantic similarity for the rest.
- User tests with registered dietitians to assess the clarity, accuracy, and completeness of our summary responses compared to state-of-the-art systems show that DietNerd ranked among the best in the state of the art.
- DietNerd is unique among state-of-the-art systems in offering a safety analysis, showing the pros and cons of a diet intervention, based on peer-reviewed research.
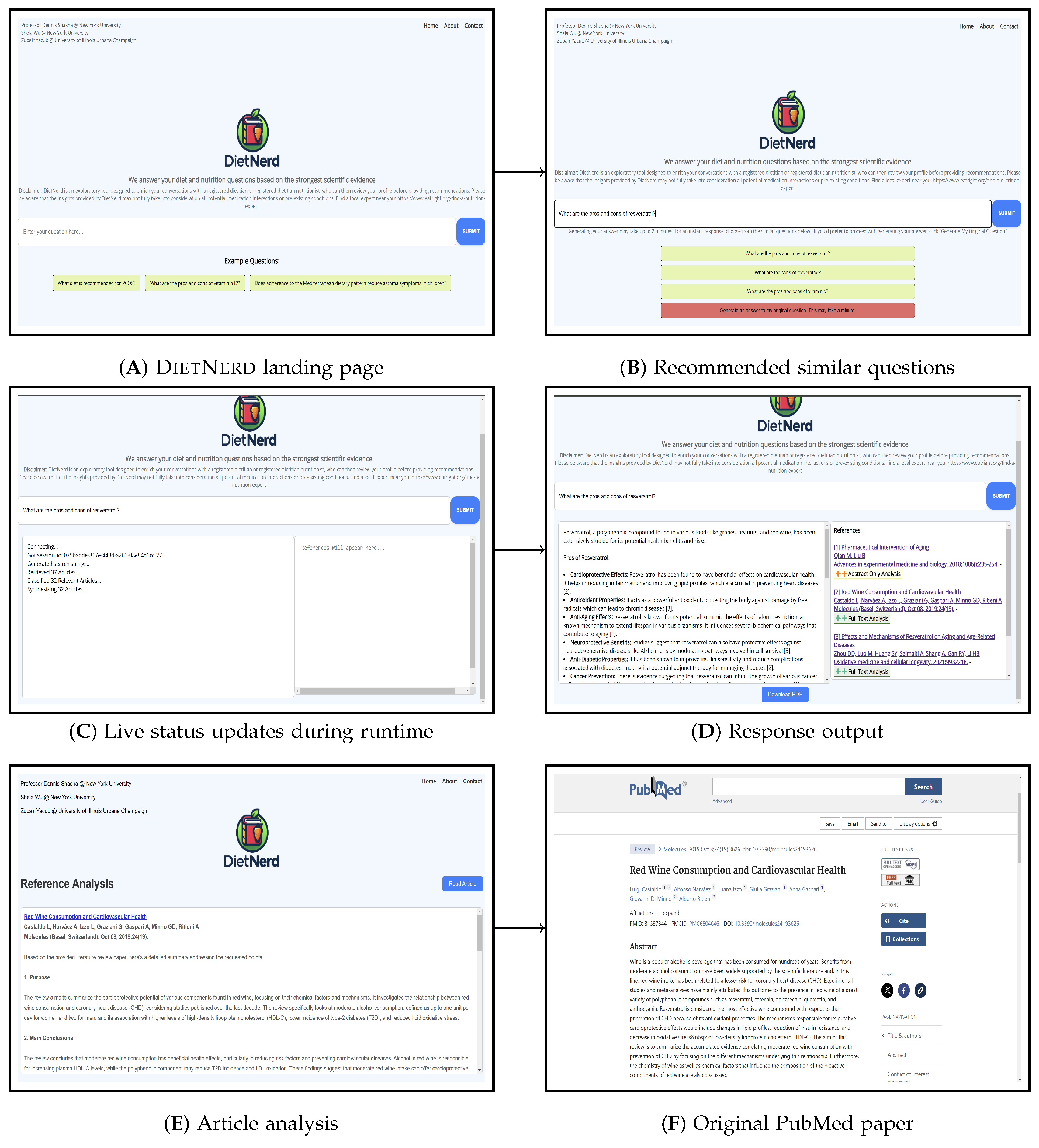
DietNerd in Action
2. Related Work
3. Materials and Methods
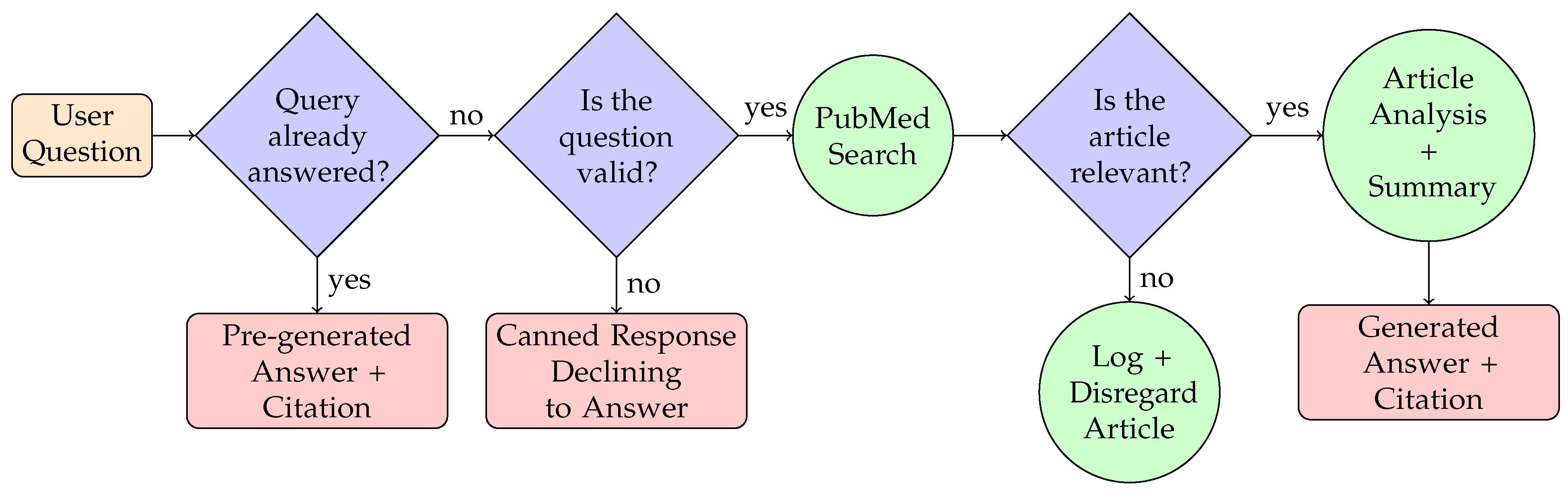
3.1. Algorithm Overview
| Algorithm 1: DietNerdAlgorithm Text: Start from a user question Q, as also illustrated in Figure 2. The condition on previous question-answer pairs requires database access. The de novo generation of an answer entails several prompts as detailed in Section 3.2.2, Section 3.2.3, Section 3.2.5, Section 3.2.7, Section 3.2.8 and Section 3.2.9 and their corresponding appendices |
 |
3.2. System Design and Architecture
3.2.1. Question Match against Question-Answer Database
3.2.2. Question Validity
3.2.3. Query Generation for Safe Responses
- General Query Generation LLM: Generates one PubMed query that represents the user’s question and is designed to retrieve articles that provide general context.
- Points of Contention Query Generation LLM: Generates the remaining four PubMed queries by identifying the top four controversial debates surrounding the topic(s) in question and creating a custom query per point of contention. These queries are intended to surface safety considerations, because controversy in the health domain mostly pertains to safety.
3.2.4. Article Retrieval
- Stage 1:
- Using the API’s ESearch utility [28], the system runs each query through PubMed, identifies the ten most relevant articles per query, and stores a list of PubMed IDs (PMIDs). Therefore, for each question, the system can retrieve up to fifty articles.
- Stage 2:
- Each of the five PMID lists is fed to the EFetch utility [28], which then retrieves article data in the form of Extensible Markup Language (XML) files.
3.2.5. Relevance Classifier and Safety Considerations
- It contains information that is helpful in answering the user’s question.
- It contains a safety aspect that would be important to include in the answer.
- It is NOT an animal-based study.
3.2.6. Article Match against Article Analysis Database
3.2.7. Full Text Parser
- (a)
- Extract a unique article identifier from the hyperlink and concatenate it into URL strings that link to the full-text version of the article.
- (b)
- Navigate directly to the provided hyperlink.
3.2.8. Strength of Claim Analysis
3.2.9. Safety-Conscious Output Synthesis
4. Website Interface Architecture
4.1. Back-End Structure
- 1.
- API Endpoints: The FastAPI application defines several key endpoints, including:
- check_valid: Validates user queries using the function defined in Section 3.2.2.
- process_query: Initiates the full query processing workflow, using the functions defined in Section 3.2.3 through Section 3.2.9.
- sse: Implements Server-Sent Events (sse) to give the user real-time updates while the generation workflow is running.
- db_sim_search: Performs a similarity search on existing questions, using the algorithm defined in Section 3.2.1.
- db_get: Retrieves stored answers from the database.
- 2.
- Asynchronous Processing: The back-end utilizes asynchronous programming techniques, specifically Python’s asyncio library and FastAPI’s asynchronous capabilities to handle concurrent requests efficiently.
- 3.
- Background Tasks: Long-running processes, such as query processing, are handled as background tasks to prevent blocking the main thread.
- 4.
- Database Interactions: The system interacts with two MySQL databases to store and retrieve processed question-answer pairs and article analyses.
- 5.
- Hosting: The FastAPI back-end is deployed on an Amazon Web Services (AWS) Elastic Compute Cloud (EC2) t2.small instance.
4.2. JavaScript Front-End Logic
- 1.
- API Communication: Handles all API calls to the FastAPI back-end, including query submission, answer retrieval, and similarity search.
- 2.
- Real-time Updates: Implements an EventSource to receive real-time updates from the server during query processing, using the SSE endpoint defined in Section 4.1.
- 3.
- Response Formatting: Processes and formats the API responses for display, including handling references and citations.
- 4.
- PDF Generation: Incorporates functionality to generate PDF reports of the query results using the jsPDF library.
- 5.
- User Interface Management: Manages dynamic User Interface elements such as displaying similar questions and handling user interactions.
- Algorithm Implementation
- 1.
- Question Submission: When a user submits a question, the question is first checked for validity using the check_valid endpoint, defined in Section 4.1.
- 2.
- Database Check: If valid, the system checks if an answer already exists in the database using the db_get endpoint, defined in Section 4.1.
- 3.
- Similar Questions: If no exact match is found, the system performs a similarity search to suggest questions already answered by our system to the user’s question using the sim_search endpoint in Section 4.1, and offers these questions as options.
- 4.
- Real-time Processing: If the user requests a new answer for their question:
- A session ID is generated and returned to the client.
- The process_query endpoint (Section 4.1) is called and the answer generation workflow starts.
- The client establishes an SSE connection to receive updates, using the SSE endpoint in Section 4.1.
- The FastAPI back-end processes the question asynchronously, sending progress updates to the client.
- 5.
- Result Delivery: The final answer, along with references and citations, is sent to the client and displayed to the user.
5. Quality Evaluation of DietNerd
6. Automated Accuracy Evaluation
6.1. Benchmark Dataset Development
- The article title contains a question.
- The question addresses a specific dietary intervention.
- The topic inquires about a clear health outcome.
6.2. Generated Responses Dataset
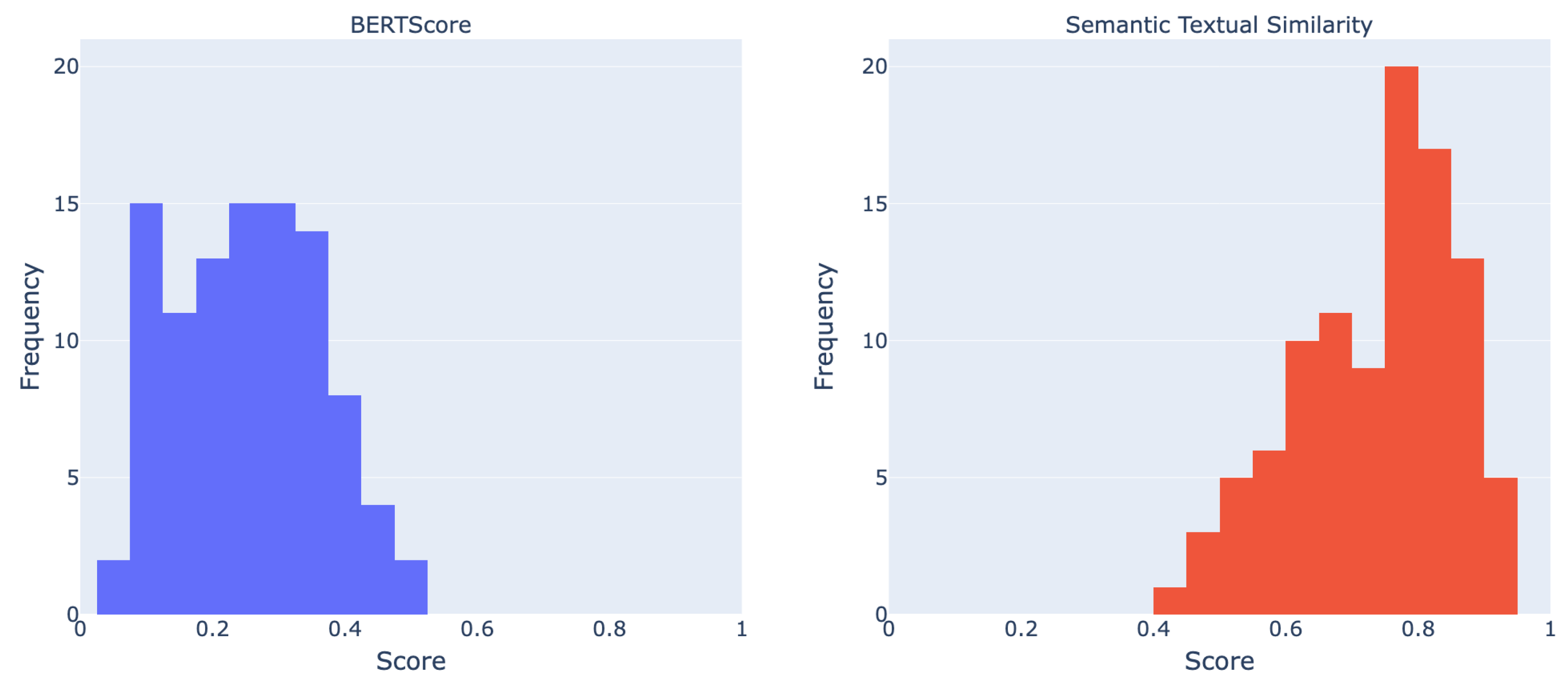
6.3. Metric Selection
6.4. Quantitative Results
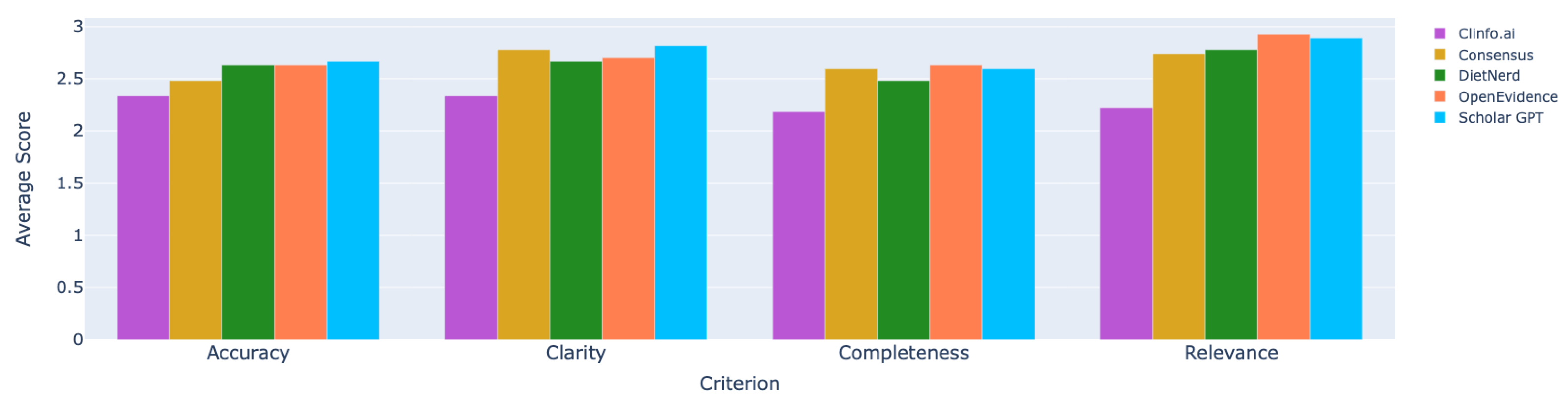
7. Domain Expert Cross-Tool Comparison Experiment
7.1. Questions and Feedback Criteria
- Relevance: How relevant was the response to the question(s) asked?
- Accuracy: Was any of the information misleading or factually incorrect?
- Completeness: Did the response miss significant information or context?
- Clarity: Was the response clearly presented?
- Overall Quality: How would you rate the overall quality of this response?
- Excellent You would use the tool that generated this response again and would recommend it to others.
- Pretty Good: The response was reasonable, but not quite good enough to recommend.
- Okay: This response was more or less accurate, but incomplete or unclear.
- Pretty Bad: This response had significant problems in either accuracy or clarity.
- Horrible: This response was just unacceptable.
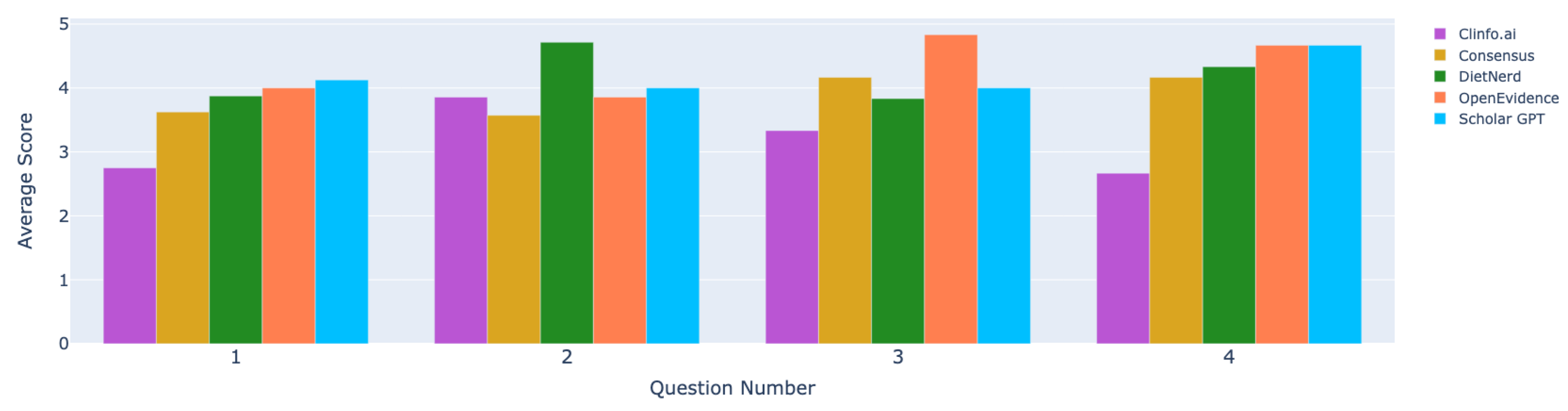
7.2. Quantitative Results of Expert Analysis
8. Feedback from Non-Professional Users
- “Wow! Thank you for sending it to me! I have already had advice for my arthritis!!!”
- “The output was pretty consistent with what I’ve learned over my years living with psoriatic arthritis and the various diets I have tried and information I have read. That was a nice summary!”
- “I was really impressed with the results! The information provided was precise, thorough, and covered the issue from various perspectives.”
- “It was a smooth user experience. The similar questions feature was very helpful and provided an immediate informative response. The PDF download is also very convenient.”
- “The answers matched the findings I had come across when researching this topic on my own time—there were even quite a few new things I learned. I especially appreciated the inclusion of dosages and exact numbers. These were things I tried to source but was having trouble easily finding within the studies and research articles I read. Also, having the articles analyses and the full-text vs abstract-only indicator makes the vetting process much easier when I’m trying to filter out which research and journals I can trust.”
- “The responses were indeed helpful. I found my intentions were identified accurately and the responses were quite relevant to my questions. I particularly like the references presented besides the response—at least I get to know the information source and have access to verify the information that DietNerd provides to me. It could be helpful to include more details of what this tool can provide on the website, like a user manual, and to have a type of “history” section that helps users easily retrieve previous questions and answers when needed. Lastly, it would be very helpful if the system could support follow-up questions so that users may narrow down their questions as they get more responses.”
9. Conclusions
10. Limitations and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Automated Accuracy Evaluation Results
- Question 1:
- Question Text: Are anti-inflammatory foods associated with a protective effect for cutaneous melanoma?
- Reference Text: Food components considered as anti-inflammatory, such as vitamin D, vitamin A, folic acid, niacin, vitamin C, omega-3 fatty acids, and carotenoids (-carotene, lutein, zeaxanthin, and lycopene), were not associated with a protective effect for melanoma. Other anti-inflammatory food items, such as tea, fruits, and vegetables, except for citrus fruits that were borderline associated with an increased risk, were not associated with cutaneous melanoma. In conclusion, the only anti-inflammatory food item that was consistently associated with a protective effect for cutaneous was coffee in particular caffeinated coffee.
- System Generated Text: While these findings are promising, they are primarily based on observational studies, reviews of existing literature, and a limited number of clinical trials. The mechanisms by which these foods and compounds exert their effects are complex and not fully understood. Additionally, the studies vary in their methodologies, populations studied, and the types of anti-inflammatory compounds examined.
- Question 2:
- Question Text: Does omega-3 PUFAs supplementation improve metabolic syndrome and related cardiovascular diseases?
- Reference Text: Supplementation of omega-3 polyunsaturated fatty acids had a favorable effect on improving triglyceride, total cholesterol, high-density lipoprotein, systolic blood pressure, diastolic blood pressure, interleukin-6, tumor necrosis factor-, C-reactive protein, and interleukin-1 levels, yet did not affect low-density lipoprotein, monocyte chemoattractant protein-1, intracellular adhesion molecule-1, and soluble endothelial selectin among patients with metabolic syndrome and related cardiovascular diseases.
- System Generated Text: In conclusion, omega-3 polyunsaturated fatty acids supplementation can be beneficial for reducing triglycerides and improving some cardiovascular risk factors in individuals with metabolic syndrome. However, the effects on cholesterol levels and other metabolic markers can vary. It is advisable for individuals considering omega-3 supplements to consult with healthcare providers to tailor the approach based on personal health needs and risks.
- Question 3:
- Question Text: Is dairy consumption associated with depressive symptoms or disorders in adults?
- Reference Text: Findings were mixed, with one study reporting a positive association; five studies reporting no association; and seven studies reporting mixed associations depending on dairy type, gender or population group. We found conflicting and inconsistent associations in studies that were generally of fair quality. Future longitudinal and intervention studies that employ more rigorous dietary assessment methods are warranted.
- System Generated Text: There is some evidence suggesting that dairy consumption might be associated with lower depressive symptoms, particularly in specific populations such as those with multiple sclerosis or post-myocardial infarandomized controlled trialion. More comprehensive studies are required to establish a clear causal relationship between dairy consumption and depressive symptoms in the general adult population. Given the mixed evidence, individuals should consider maintaining a balanced diet and consult healthcare professionals for personalized dietary advice, especially if experiencing depressive symptoms.
- Question 4:
- Question Text: Does taking vitamin, mineral and fatty acid supplements prevent cognitive decline?
- Reference Text: There was little evidence of a beneficial effect from taking B vitamins or antioxidant supplements on global cognitive function in later life. Larger-scale randomized controlled trials of longer duration in selected age groups are needed.
- System Generated Text: The benefits of Vitamin B are potentially lowering homocysteine levels, which might reduce the risk of cognitive decline and dementia. The benefits of polyunsaturated fatty acids are that they can enhance cognitive functions and may counteract the negative effects of poor dietary habits. The benefits of combination therapies are potential synergistic benefits in cognitive function from combinations like estrogen, statins, and polyunsaturated fatty acids. While the benefits are promising, the studies often call for more research to fully understand the effectiveness and safety of long-term supplementation. Dosage and the specific combinations of supplements need to be carefully considered to avoid potential adverse effects. Individuals, particularly those at risk of cognitive decline or with existing mild cognitive impairment, might consider discussing with healthcare providers the possibility of incorporating certain supplements into their regimen. However, it is crucial to do so under professional guidance to tailor the supplement type and dosage to individual health needs and conditions.
- Question 5:
- Question Text: Does ginger supplementation lower blood pressure?
- Reference Text: Pooled analysis suggested that ginger supplementation can reduced systolic blood pressure and diastolic blood pressure. When studies were categorized based on participants’ mean age, ginger dosage and duration of intervention, systolic blood pressure and diastolic blood pressure were significantly decreased only in the subset of studies with mean age less than or equal to 50 years, follow-up duration of less than or equal to 8 weeks and ginger doses greater than or equal to 3 g per day. Our findings revealed that ginger supplementation has favorable effects on blood pressure. Nonetheless, further studies are warranted before definitive conclusions may be reached.
- System Generated Text: In conclusion, while there is some evidence supporting the potential of ginger to aid in blood pressure management, particularly through its vasodilatory properties and possible synergistic effects with anti-hypertensive medications, the evidence is not uniformly strong or conclusive. Further research, particularly large-scale human clinical trials, is needed to better understand the role of ginger in blood pressure regulation and its long-term health impacts.
- Question 6:
- Question Text: Can improved legume varieties optimize iron status in low- and middle-income countries?
- Reference Text: Evidence shows that, in addition to repletion of biomarkers of iron status, consumption of improved legumes is associated with both clinical and functional outcomes. The prevalence of iron deficiency decreases with consumption of improved legumes, with increases of less than or equal to 3.0 g/L in Hb concentrations. Improvement in cognition and brain function in women has been reported as well. However, further research is necessary in more at-risk groups and also to show if the reported improvements in status markers translate to improved health outcomes. Evidence from the included studies shows potential from consumption of improved legumes suggesting them to be a sustainable solution to improve iron status.
- System Generated Text: Improved varieties of legumes that incorporate higher levels of bioavailable iron and lower inhibitors like phytic acid and polyphenols can significantly contribute to better iron status, particularly in regions where legumes are a dietary staple. Biofortification appears to be a sustainable and effective strategy to combat iron deficiency in low- and middle-income countries, potentially reducing the global disease burden associated with micronutrient deficiencies. While the current evidence is promising, ongoing research and careful implementation are necessary to optimize the benefits of biofortified legumes and ensure they reach the populations most in need.
- Question 7:
- Question Text: Are Atkins and other low-carbohydrate diets a hoax or an effective tool for weight loss?
- Reference Text: The apparent paradox that ad-libitum intake of high-fat foods produces weight loss might be due to severe restriction of carbohydrate depleting glycogen stores, leading to excretion of bound water, the ketogenic nature of the diet being appetite suppressing, the high protein-content being highly satiating and reducing spontaneous food intake, or limited food choices leading to decreased energy intake. Long-term studies are needed to measure changes in nutritional status and body composition during the low-carbohydrate diet, and to assess fasting and postprandial cardiovascular risk factors and adverse effects. Without that information, low-carbohydrate diets cannot be recommended.
- System Generated Text: In conclusion, low-carbohydrate diets like the Atkins diet are not a hoax and can be effective for weight loss and improving certain metabolic health markers. However, individuals considering these diets should be aware of the potential challenges related to long-term adherence and the need for further research into their long-term safety and efficacy. As with any diet, it is advisable to consult healthcare professionals before making significant changes to dietary habits.
- Question 8:
- Question Text: Is vitamin d supplementation useful for weight loss programs?
- Reference Text: The meta-analyzed mean differences for random effects showed that cholecalciferol supplementation deceases the body mass index by −0.32 kg/m2 and the waist circumference by −1.42 cm, but does not statistically affect weight loss. This analysis lays the foundation for defining the potential clinical efficacy of vitamin D supplementation as a potential therapeutic option for weight loss programs, but further studies are needed to confirm the validity of these findings and delineate potential underlying mechanisms.
- System Generated Text: Vitamin D supplementation can be beneficial for improving metabolic markers in obese individuals, which might support weight loss efforts indirectly. Direct effects of vitamin D on weight loss are not strongly supported by current evidence. Obese individuals might require higher doses of vitamin D to achieve adequate serum levels. Combining vitamin D supplementation with other weight loss strategies and consulting healthcare providers for personalized advice is recommended.
- Question 9:
- Question Text: Can vitamin E supplementation affect obesity indices?
- Reference Text: There was no significant effect of vitamin E supplementation on weight, body mass index and waist circumference. However, vitamin E supplementation might be associated with increasing body mass index in people with normal body mass index (18.5–24.9).
- System Generated Text: In conclusion, while vitamin E may offer benefits for conditions associated with obesity, such as liver health, direct evidence supporting its role in reducing obesity indices is lacking. More research is needed to clarify its effects on obesity itself and to establish appropriate dosages and safety profiles.
- Question 10:
- Question Text: Does milk and dairy consumption during pregnancy influence fetal growth and infant birthweight?
- Reference Text: A beneficial fetal growth-increase was most pronounced for increasing maternal milk intake in the lower end of the consumption range. Evidence from prospective cohort studies is limited but suggestive that moderate milk consumption relative to none or very low intake, is positively associated with fetal growth and infant birthweight in healthy, Western populations.
- System Generated Text: The reviewed studies collectively suggest that milk and dairy consumption during pregnancy can have a beneficial impact on fetal growth and infant birthweight. While the evidence supports the positive effects of milk intake on increasing birth size and weight, further research is warranted to fully understand the scope and mechanisms of these benefits. Pregnant women should consider incorporating an appropriate amount of milk and dairy products into their diet as part of a balanced nutritional intake, but as always, it is advisable to consult with a healthcare provider or a registered dietitian to tailor dietary choices to individual health needs and conditions.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Question ID | BERTScore | Semantic Textual Similarity Score |
|---|---|---|
| 1 | −0.05000561476 | 0.4619983435 |
| 2 | 0.04257367551 | 0.7880448103 |
| 3 | 0.05669873953 | 0.6459783316 |
| 4 | 0.09011174738 | 0.4866028428 |
| 5 | 0.112316452 | 0.8278418779 |
| 6 | 0.1420929581 | 0.782550931 |
| 7 | 0.1335987002 | 0.5825534463 |
| 8 | 0.09624969959 | 0.7047141194 |
| 9 | 0.1313056201 | 0.6806269884 |
| 10 | 0.1734389067 | 0.8265659809 |
| 11 | 0.1661651731 | 0.7380071878 |
| 12 | 0.1925661564 | 0.5359122753 |
| 13 | 0.1281296313 | 0.7117017508 |
| 14 | 0.1761084497 | 0.8007249832 |
| 15 | 0.2037310153 | 0.6995931864 |
| 16 | 0.1045408845 | 0.7638986111 |
| 17 | 0.1353729814 | 0.5902849436 |
| 18 | 0.1489517093 | 0.6677079201 |
| 19 | 0.1576663405 | 0.6904413104 |
| 20 | 0.09014988691 | 0.7761998773 |
| 21 | 0.220869258 | 0.7093069553 |
| 22 | 0.197660163 | 0.6442862749 |
| 23 | 0.1274724007 | 0.6228430271 |
| 24 | 0.1643767655 | 0.6819694638 |
| 25 | 0.1949167997 | 0.8983559608 |
| 26 | 0.09089576453 | 0.8193558455 |
| 27 | 0.2125929147 | 0.7806860805 |
| 28 | 0.2025323808 | 0.7680702806 |
| 29 | 0.07705853134 | 0.6463490129 |
| 30 | 0.1016499028 | 0.6045994163 |
| 31 | 0.207694903 | 0.5410217047 |
| 32 | 0.2101981193 | 0.8683655262 |
| 33 | 0.2119964212 | 0.759580493 |
| 34 | 0.2190889716 | 0.501537323 |
| 35 | 0.2211948782 | 0.8102539182 |
| 36 | 0.2251022607 | 0.7882441282 |
| 37 | 0.2355180681 | 0.7829395533 |
| 38 | 0.2355689257 | 0.8067421913 |
| 39 | 0.292994827 | 0.5838332176 |
| 40 | 0.2401511967 | 0.6783252954 |
| 41 | 0.2437100112 | 0.7428564429 |
| 42 | 0.2452854663 | 0.6010507941 |
| 43 | 0.2286607176 | 0.8102938533 |
| 44 | 0.09178114682 | 0.5382189751 |
| 45 | 0.2444279939 | 0.7610019445 |
| 46 | 0.2511603236 | 0.7856425643 |
| 47 | 0.2512062192 | 0.742957592 |
| 48 | 0.2558661997 | 0.807508707 |
| 49 | 0.2530550361 | 0.7625072002 |
| 50 | 0.2962216735 | 0.7891664505 |
| 51 | 0.2587529421 | 0.5696384311 |
| 52 | 0.2611985803 | 0.654742837 |
| 53 | 0.264541626 | 0.4389564097 |
| 54 | 0.2786568105 | 0.8205165863 |
| 55 | 0.2795863152 | 0.7718273997 |
| 56 | 0.2803887129 | 0.9213430285 |
| 57 | 0.2814955115 | 0.6929318309 |
| 58 | 0.2833760977 | 0.7235119343 |
| 59 | 0.09830898792 | 0.572914362 |
| 60 | 0.1070303246 | 0.5689245462 |
| 61 | 0.2842413485 | 0.8167885542 |
| 62 | 0.2847544849 | 0.6485208273 |
| 63 | 0.2884128988 | 0.7158298492 |
| 64 | 0.2979023457 | 0.8750890493 |
| 65 | 0.298217386 | 0.8679254055 |
| 66 | 0.3084926307 | 0.8777817488 |
| 67 | 0.3093059659 | 0.4605668187 |
| 68 | 0.3115234673 | 0.8180803061 |
| 69 | 0.4968356788 | 0.9338030219 |
| 70 | 0.330129087 | 0.7585834861 |
| 71 | 0.328743279 | 0.6795406938 |
| 72 | 0.3350864351 | 0.7533646822 |
| 73 | 0.4113920033 | 0.914045155 |
| 74 | 0.337575525 | 0.6367307901 |
| 75 | 0.3420274854 | 0.8524702787 |
| 76 | 0.3301834762 | 0.8520085812 |
| 77 | 0.342875421 | 0.8358888626 |
| 78 | 0.3463438153 | 0.8626087308 |
| 79 | 0.347088635 | 0.756069839 |
| 80 | 0.381343931 | 0.8439093828 |
| 81 | 0.3507251441 | 0.847517252 |
| 82 | 0.350726217 | 0.784525454 |
| 83 | 0.3604282737 | 0.8269191384 |
| 84 | 0.3648406863 | 0.7977852821 |
| 85 | 0.09125140309 | 0.6629832387 |
| 86 | 0.09588064998 | 0.6290306449 |
| 87 | 0.09667455405 | 0.5115911365 |
| 88 | 0.0865451619 | 0.6453903913 |
| 89 | 0.3744304478 | 0.8571535945 |
| 90 | 0.3821184337 | 0.8458015919 |
| 91 | 0.3994865716 | 0.9185526371 |
| 92 | 0.4133167565 | 0.8013061285 |
| 93 | 0.3931872249 | 0.7404608727 |
| 94 | 0.3941654861 | 0.6610897183 |
| 95 | 0.4802063406 | 0.8897250295 |
| 96 | 0.415214628 | 0.9021199942 |
| 97 | 0.4389337003 | 0.8694944382 |
| 98 | 0.4423240721 | 0.8887104988 |
| 99 | 0.4559440911 | 0.7602285743 |
| 100 | 0.4427044094 | 0.854303658 |
Appendix B. Domain Expert Feedback
Appendix B.1. Question 1: Any Advice on the Best Food/Diet to Lose Weight and Feel High Energy?
| Evaluator | System | Criterion | Feedback | Rating |
|---|---|---|---|---|
| 0001 | DietNerd | Relevance | The response was fairly relevant, however, it appeared to have a strong weight loss focus and less of a focus on high energy | 2 |
| 0001 | DietNerd | Accuracy | The conclusion discusses the importance of a balanced diet, but the response separates out a “Balanced Diet” into bulletpoint #6, which may lead readers to distinguish a balanced diet from the other diets mentioned when a balanced diet can/should be incorporated into all of these dietary patterns. | 2 |
| 0001 | DietNerd | Completeness | Discussion on how each of the dietary patterns support energy levels and not just weight loss. Additionally, the conclusion discusses consulting a “registered dietitian” OR “nutritionist” when there is no regulation regarding the term “nutritionist”. I would recommend suggesting a consultation with a “registered dietitian” or “registered dietitian nutritionist” as those are the two credentials for licensed practitioners. | 2 |
| 0001 | DietNerd | Clarity | The pros and cons discusses the specific diets listed, but the way that this answer is formatted, it reads like the Pros/Cons list should be discussing all of the diets mentioned. It may be more effective to list the points in the pro/con list under each respective diet instead of under the entire list of dietary patterns. | 2 |
| 0001 | DietNerd | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
| 0001 | Scholar GPT | Relevance | I felt that this response was definitely more relevant than Response 1A, as it provided a few strategies as well as dietary patterns for both weight management and energy maintenance | 3 |
| 0001 | Scholar GPT | Accuracy | The point regarding avoiding processed foods may be better described as reducing “added sugars and unhealthy fats” or as “ultra high processed foods” in the diet as many foods can be minimally processed and part of a healthy diet. (for example, washing an apple is technically “processing” the apple). It also misses a discussion that ultra processed foods often include these added sugars and trans fats—so the point isn’t avoiding processed foods, but the additives in them. | 2 |
| 0001 | Scholar GPT | Completeness | As not all dietary patterns are appropriate for all individuals, it is crucial to prompt the reader to discuss their individual situation with a healthcare professional, notably a Registered Dietitian/Registered Dietitian Nutritionist. | 2 |
| 0001 | Scholar GPT | Clarity | Yes | 3 |
| 0001 | Scholar GPT | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0001 | Consensus | Relevance | This response focuses very heavily on weight loss with little discussion on energy levels. | 2 |
| 0001 | Consensus | Accuracy | The low energy density diet is misleading—it does not provide an adequate discussion on maintaining a balanced diet which would assist with energy levels, and solely discusses how the low energy density diet would help with weight loss. The point about decreasing overall energy intake “while still allowing for larger volumes of food” is also unclear. Does this mean that after eating foods lower in kcal that the individual can eat ad libitum? I fear that this point could be potentially dangerous. Additionally, the “Balanced Macronutrient Diet” isn’t exactly a diet but a dietary behavior that should be the goal in any diet that is pitched to a patient/individual. Modified Fat Diet—this may also be misleading as it may lead the reader to increase consumption of fats in general in their diet. Fat contains the most kcal/gram so an increase in fat consumption in the diet likely won’t aid in weight loss? Additionally, the push for calorie counting may also increase disordered eating habits when not guided by a medical professional. | 1 |
| 0001 | Consensus | Completeness | As not all dietary patterns are appropriate for all individuals, it is important to include a prompt to seek individual recommendations from a healthcare professional, most notably, a Registered Dietitian/Registered Dietitian Nutritionist | 2 |
| 0001 | Consensus | Clarity | The response was short and formatted in a bulleted fashion which can increase readability. | 3 |
| 0001 | Consensus | Overall | Pretty Bad—This response had significant problems in either accuracy or clarity. | 2 |
| 0001 | Clinfo.ai | Relevance | This response doesn’t really discuss the high energy component of the question. Additionally, it mentions anti-obesity and weight loss medication which is not food/diet at all. | 1 |
| 0001 | Clinfo.ai | Accuracy | The TLDR section discusses the “best” diet for wt loss, however, this is largely not true from person to person. I feel that phrasing this summary in this way may be dangerous to readers where a reduced energy high protein diet combined with wt loss meds is inappropriate. Additionally the recommendation of a reduced energy diet to promote energy levels can be confusing and misleading to individuals. | 1 |
| 0001 | Clinfo.ai | Completeness | It mentions the need for individualized counseling but does not direct the reader to who they should discuss this with. Additionally, this response doesn’t really answer the question (i.e., foods/diets that help with both energy maintenance and wt loss). | 1 |
| 0001 | Clinfo.ai | Clarity | It may be difficult for the general reader to understand the significance of a systematic review vs. other types of research. The large chunk of text may also reduce readership. This may be more of a personal thing but I don’t really like that the second paragraph summarizing the information is titled “TLDR” just seems kind of unprofessional. | 1 |
| 0001 | Clinfo.ai | Overall | Horrible—This response was just unacceptable. | 1 |
| 0001 | OpenEvidence | Relevance | Relevant! I enjoyed the discussion of adherence along with the nutritional component of sustained energy levels and weight management. | 3 |
| 0001 | OpenEvidence | Accuracy | I’m hesitant about greenlighting the Low-Fat Vegan Diet, as the description describes more of a plant-forward diet rather than a Vegan Diet which restricts all animal products. While this may play a role in weight loss, the potential for micronutrient deficiencies may be high if conducted without guidance, thus leading to potential lower energy levels. I feel that the descriptions of each of these dietary patterns could use a little more explanation of what they entail and whether they promote both energy levels and weight management or if its only one or the other. | 2 |
| 0001 | OpenEvidence | Completeness | As not all dietary patterns are appropriate for all individuals, it is important to include a prompt to seek individual recommendations from a healthcare professional, most notably, a Registered Dietitian/Registered Dietitian Nutritionist | 2 |
| 0001 | OpenEvidence | Clarity | I thought so- | 3 |
| 0001 | OpenEvidence | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0002 | DietNerd | Relevance | Extremely relevant and accurate | 3 |
| 0002 | DietNerd | Accuracy | No | 3 |
| 0002 | DietNerd | Completeness | No | 3 |
| 0002 | DietNerd | Clarity | Yes it was | 3 |
| 0002 | DietNerd | Overall | Excellent—You would use the tool that generated this response again and would recommend it to others. | 5 |
| 0002 | Scholar GPT | Relevance | The reponse was very relevant. The advices contributed a lot for the lose weight need. | 3 |
| 0002 | Scholar GPT | Accuracy | No, it is clear. | 3 |
| 0002 | Scholar GPT | Completeness | No, it didn’t. | 3 |
| 0002 | Scholar GPT | Clarity | Yes, it was. | 3 |
| 0002 | Scholar GPT | Overall | Excellent—You would use the tool that generated this response again and would recommend it to others. | 5 |
| 0002 | Consensus | Relevance | It was relevant and complete. | 3 |
| 0002 | Consensus | Accuracy | No. | 3 |
| 0002 | Consensus | Completeness | No. | 3 |
| 0002 | Consensus | Clarity | Yes, totally. | 3 |
| 0002 | Consensus | Overall | Excellent—You would use the tool that generated this response again and would recommend it to others. | 5 |
| 0002 | Clinfo.ai | Relevance | Less relevant then the prior ones. | 2 |
| 0002 | Clinfo.ai | Accuracy | The vegan diet could have be better discussed on order to increase results on losing weight. | 2 |
| 0002 | Clinfo.ai | Completeness | Yes. Vegan diet could have be deeper explored. | 2 |
| 0002 | Clinfo.ai | Clarity | Yes, it was. | 3 |
| 0002 | Clinfo.ai | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
| 0002 | OpenEvidence | Relevance | It was very relevant. | 3 |
| 0002 | OpenEvidence | Accuracy | No. | 3 |
| 0002 | OpenEvidence | Completeness | No. | 3 |
| 0002 | OpenEvidence | Clarity | Yes, it was. | 3 |
| 0002 | OpenEvidence | Overall | Excellent—You would use the tool that generated this response again and would recommend it to others. | 5 |
| 0003 | DietNerd | Relevance | The responses are all relevant. | 3 |
| 0003 | DietNerd | Accuracy | For the low-carb diets response, I would specify “healthy fats” since some fats are not as beneficial (such as, trans fats and saturated fats). | 2 |
| 0003 | DietNerd | Completeness | Intermittent fasting has many caveats such as, including a moderate caloric deficit. It may also not necessarily be energy promoting if fasting windows are too long. Would likely not recommend this to patients/clients. | 2 |
| 0003 | DietNerd | Clarity | Yes | 3 |
| 0003 | DietNerd | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0003 | Scholar GPT | Relevance | The responses are all relevant. | 3 |
| 0003 | Scholar GPT | Accuracy | No | 3 |
| 0003 | Scholar GPT | Completeness | No. Would also probably include the disclaimer of consulting with a medical professional or registered dietitian to get tailored recommendations for people with medical conditions. | 2 |
| 0003 | Scholar GPT | Clarity | Yes | 3 |
| 0003 | Scholar GPT | Overall | Excellent—You would use the tool that generated this response again and would recommend it to others. | 5 |
| 0003 | Consensus | Relevance | Pretty relevant | 3 |
| 0003 | Consensus | Accuracy | No, none of the information in that response was factually incorrect or misleading. | 3 |
| 0003 | Consensus | Completeness | Would probably re-phrase the low-energy-density diets to something like “moderate caloric deficit”. Having a diet entirely of lower calorie foods could result in lower energy levels and is not sustainable. | 2 |
| 0003 | Consensus | Clarity | Yes | 3 |
| 0003 | Consensus | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
| 0003 | Clinfo.ai | Relevance | Pretty relevant | 3 |
| 0003 | Clinfo.ai | Accuracy | No | 3 |
| 0003 | Clinfo.ai | Completeness | No | 3 |
| 0003 | Clinfo.ai | Clarity | It is fairly presented. The formats of the previous responses are a little more clear but I like the TLDR section. This response would probably be more suitable for people with higher literacy levels and health literacy. | 2 |
| 0003 | Clinfo.ai | Overall | Excellent—You would use the tool that generated this response again and would recommend it to others. | 5 |
| 0003 | OpenEvidence | Relevance | Very | 3 |
| 0003 | OpenEvidence | Accuracy | Would probably swap out the low-fat vegan diets response to a “plant forward diet”. A low-fat vegan diet can be a little too restrictive and less sustainable for long term healthy eating habits. Sometimes vegan “diet foods/products” can be more pricey and not available to some people who can’t afford them. | 2 |
| 0003 | OpenEvidence | Completeness | No, not necessarily. | 3 |
| 0003 | OpenEvidence | Clarity | Yes. I particularly liked the mention of behavioral and supportive interventions. | 3 |
| 0003 | OpenEvidence | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0004 | DietNerd | Relevance | Not totally relevant. | 2 |
| 0004 | DietNerd | Accuracy | No. | 3 |
| 0004 | DietNerd | Completeness | Did not specifically mention or address high energy levels. Detail seemed to be lacking. | 2 |
| 0004 | DietNerd | Clarity | No—the pros and cons section was not relevant to the question and was a bit confusing since various dietary patterns were listed. | 1 |
| 0004 | DietNerd | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
| 0004 | Scholar GPT | Relevance | Very—I like that the response covered the specific foods/food components and then the recommended dietary patterns. The response also addressed both weight loss and energy levels. | 3 |
| 0004 | Scholar GPT | Accuracy | No | 3 |
| 0004 | Scholar GPT | Completeness | No | 3 |
| 0004 | Scholar GPT | Clarity | Yes | 3 |
| 0004 | Scholar GPT | Overall | Excellent—You would use the tool that generated this response again and would recommend it to others. | 5 |
| 0004 | Consensus | Relevance | Pretty relevant. | 3 |
| 0004 | Consensus | Accuracy | No. | 3 |
| 0004 | Consensus | Completeness | Did not mention/address energy levels; only addressed/focused on weight loss. | 2 |
| 0004 | Consensus | Clarity | Yes. | 3 |
| 0004 | Consensus | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0004 | Clinfo.ai | Relevance | Low relevancy—this response mentioned both diet and medications however the question asked for ‘best food/diet’. | 1 |
| 0004 | Clinfo.ai | Accuracy | No. | 3 |
| 0004 | Clinfo.ai | Completeness | Yes—minimal information/detail provided on the foods/dietary patterns to promote weight loss and high energy levels. | 1 |
| 0004 | Clinfo.ai | Clarity | It was clear enough. | 3 |
| 0004 | Clinfo.ai | Overall | Pretty Bad—This response had significant problems in either accuracy or clarity. | 2 |
| 0004 | OpenEvidence | Relevance | Mostly relevant. | 2 |
| 0004 | OpenEvidence | Accuracy | No. | 3 |
| 0004 | OpenEvidence | Completeness | Did not mention anything about energy levels. | 2 |
| 0004 | OpenEvidence | Clarity | Yes. | 3 |
| 0004 | OpenEvidence | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
| 0005 | DietNerd | Relevance | Very relevant | 3 |
| 0005 | DietNerd | Accuracy | No | 3 |
| 0005 | DietNerd | Completeness | I don’t think so | 3 |
| 0005 | DietNerd | Clarity | yes | 3 |
| 0005 | DietNerd | Overall | Excellent—You would use the tool that generated this response again and would recommend it to others. | 5 |
| 0005 | Scholar GPT | Relevance | Relevent | 3 |
| 0005 | Scholar GPT | Accuracy | Low glycemic index foods are no longer relevant (it’s outdated) for weight loss. | 2 |
| 0005 | Scholar GPT | Completeness | No | 3 |
| 0005 | Scholar GPT | Clarity | Yes | 3 |
| 0005 | Scholar GPT | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0005 | Consensus | Relevance | Relevant | 3 |
| 0005 | Consensus | Accuracy | Low glycemic index foods may mislead audiences to believe weight loss is achieved by choosing such foods, but in reality, is choosing low calorie foods (which are likely a low GI food) | 2 |
| 0005 | Consensus | Completeness | No | 3 |
| 0005 | Consensus | Clarity | Yes | 3 |
| 0005 | Consensus | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0005 | Clinfo.ai | Relevance | Somewhat | 2 |
| 0005 | Clinfo.ai | Accuracy | The references are too old | 1 |
| 0005 | Clinfo.ai | Completeness | N/A— references are too old | 1 |
| 0005 | Clinfo.ai | Clarity | Yes, but not to the general public, This format is easy for clinicians who are used to reading literature summaries, but may be too difficult for others. | 2 |
| 0005 | Clinfo.ai | Overall | Pretty Bad—This response had significant problems in either accuracy or clarity. | 2 |
| 0005 | OpenEvidence | Relevance | Relevant | 3 |
| 0005 | OpenEvidence | Accuracy | No but try to keep references within 5 years | 2 |
| 0005 | OpenEvidence | Completeness | No | 3 |
| 0005 | OpenEvidence | Clarity | Yes | 3 |
| 0005 | OpenEvidence | Overall | Excellent—You would use the tool that generated this response again and would recommend it to others. | 5 |
| 0006 | DietNerd | Relevance | Very relevant | 3 |
| 0006 | DietNerd | Accuracy | I feel that intermittent fasting offers the least flexibility of any of the diets. I would also include information on needing to be in a calorie deficit in order to lose weight. | 2 |
| 0006 | DietNerd | Completeness | For the minimal information listed, it was well represented. The balanced diet is very similar to the Mediterranean Diet. That could be included as a bullet point rather than a diet itself. | 2 |
| 0006 | DietNerd | Clarity | Yes | 3 |
| 0006 | DietNerd | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0006 | Scholar GPT | Relevance | I feel like when asking the question of “best food” I would be looking for specifics ie. banana, chicken, asparagus, etc. I think framing it with “tips” or “guidance” is better suited. The word diet is listed in ways that are more so “meal patterns” | 2 |
| 0006 | Scholar GPT | Accuracy | Eating an abundance of low glycemic foods can still raise blood sugar, I’d change the work can prevent to may prevent. I would also give examples in the food groups listed. | 2 |
| 0006 | Scholar GPT | Completeness | no | 3 |
| 0006 | Scholar GPT | Clarity | Yes | 3 |
| 0006 | Scholar GPT | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
| 0006 | Consensus | Relevance | relevant, I like how it says dietary strategies verses diets. | 3 |
| 0006 | Consensus | Accuracy | 1. low energy density is misleading becuase we are looking for nutrient rich/dense meals, I see that this is worded to focus on lower calories but is confusing. | 2 |
| 0006 | Consensus | Completeness | the second study in high protein diets says “Triglyceride change was negatively correlated with animal-protein intake” I would change how this reads that these diets improve lipid profiles, especially when consuming higher saturated fat from animal sources. | 2 |
| 0006 | Consensus | Clarity | 5. is not presented clearly, I would want to see more explanation on “careful food selection” | 2 |
| 0006 | Consensus | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0006 | Clinfo.ai | Relevance | I dont think including medications fits the question | 2 |
| 0006 | Clinfo.ai | Accuracy | I think adding in weight loss medications muddies the point of the question. the answer seems to be pointing towards the use of medications as a necessary accompaniment | 2 |
| 0006 | Clinfo.ai | Completeness | a lot of information is missing in terms of comparing high protein and vegan diets, I think more explanation could be added on animal vs plant proteins | 2 |
| 0006 | Clinfo.ai | Clarity | yes | 3 |
| 0006 | Clinfo.ai | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
| 0006 | OpenEvidence | Relevance | relevant | 3 |
| 0006 | OpenEvidence | Accuracy | 2. I would say can improve TG and HDL | 2 |
| 0006 | OpenEvidence | Completeness | 4. I would say why it’s beneficial, labs? wt loss? … the other diets promote moderate animal products and dairy, and mention the benefits | 2 |
| 0006 | OpenEvidence | Clarity | 5. this isn’t a diet, I would include this in the summary as well as to consult or work with a dietitian. these responses all lead the user to continue to do more research | 2 |
| 0006 | OpenEvidence | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0007 | DietNerd | Relevance | Relevant, but much too brief, not detailed enough. | 2 |
| 0007 | DietNerd | Accuracy | I would not recommend intermittent fasting if there is a goal of “high energy”. There is no research to support that. Need to define what “balanced diet” means. | 2 |
| 0007 | DietNerd | Completeness | I just felt the explanation of each diet was much too summarized. | 2 |
| 0007 | DietNerd | Clarity | see above. | 2 |
| 0007 | DietNerd | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0007 | Scholar GPT | Relevance | Relevant but again, too brief. What does “low glycemic” mean? The average American may not know this. What does “appropriate portions” mean? This is vague. | 2 |
| 0007 | Scholar GPT | Accuracy | See above. | 2 |
| 0007 | Scholar GPT | Completeness | No mention of pros/cons (which I liked from Q1) or that they should seek personalized guidance from a registered dietitian or health professional. This is very important, since some of these answers contradict one another so may be confusing—i.e., recommending Plant Based, but then recommending Low Carb, High Protein. | 2 |
| 0007 | Scholar GPT | Clarity | I think these answers are too brief and not nuanced enough. (Why one diet may be better for someone versus someone else) | 2 |
| 0007 | Scholar GPT | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
| 0007 | Consensus | Relevance | Relevant but again, way too summarized. need to explain terms and concepts more. | 2 |
| 0007 | Consensus | Accuracy | see above. and see my comment to previous question. | 2 |
| 0007 | Consensus | Completeness | No mention of seeking guidance from RD or health professional. | 2 |
| 0007 | Consensus | Clarity | No, especially the conclusion. This line is extremely vague: For effective weight loss and sustained high energy levels, consider a diet low in energy density, high in protein, and balanced in macronutrients with an emphasis on low-GI foods and healthy fats | 2 |
| 0007 | Consensus | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
| 0007 | Clinfo.ai | Relevance | Relevant, but I think the way the information is presented would be overwhelming for the average American. Probably would be easier to read with bulletpoints/subheadings. This is also just looking at ONE systematic review. (i’m not clear how comprehensive it was) | 2 |
| 0007 | Clinfo.ai | Accuracy | The information is accurate, though I do not think it’s accurate to say “The best diet for weight loss and high energy appears to be a reduced-energy, high-protein diet” after what was previously stated. | 2 |
| 0007 | Clinfo.ai | Completeness | pros and cons of each diet and meds. | 2 |
| 0007 | Clinfo.ai | Clarity | Again, I feel that this is all very summarized. I understand the need for that, but then there should be links to more information. (i.e., what intermittent fasting is) | 2 |
| 0007 | Clinfo.ai | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
| 0007 | OpenEvidence | Relevance | Relevant and I appreciate that behavioral support and the importance of meal plans reflecting “personal and cultural preferences” was included | 3 |
| 0007 | OpenEvidence | Accuracy | Mention a registered dietitian… “professional guidance” by who? It’s important to point people in the right direction. | 2 |
| 0007 | OpenEvidence | Completeness | see above. Also again, terminology should be defined or at least linked to articles that provide more information. | 2 |
| 0007 | OpenEvidence | Clarity | It’s still very summarized, but better than some of the others. | 2 |
| 0007 | OpenEvidence | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0008 | DietNerd | Relevance | Pretty Good | 3 |
| 0008 | DietNerd | Accuracy | Low-carb diets would likely not help w/energy levels | 2 |
| 0008 | DietNerd | Completeness | With energy levels and wt loss, the composition of the diet is important (what was noted in the response), but where said calories are coming from is also important, which is more focused on what foods are being consumed rather than their macronutrient breakdown | 2 |
| 0008 | DietNerd | Clarity | Somewhat | 2 |
| 0008 | DietNerd | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
| 0008 | Scholar GPT | Relevance | Mostly relevant | 3 |
| 0008 | Scholar GPT | Accuracy | Do no recommend keto diet for high energy | 2 |
| 0008 | Scholar GPT | Completeness | Much more balanced than 1A, I would add something about movement/exercise too | 2 |
| 0008 | Scholar GPT | Clarity | Yes | 3 |
| 0008 | Scholar GPT | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0008 | Consensus | Relevance | Good | 3 |
| 0008 | Consensus | Accuracy | No | 3 |
| 0008 | Consensus | Completeness | No | 3 |
| 0008 | Consensus | Clarity | Yes | 3 |
| 0008 | Consensus | Overall | Pretty Good—The response was reasonable, but not quite good enough to recommend. | 4 |
| 0008 | Clinfo.ai | Relevance | Meh | 2 |
| 0008 | Clinfo.ai | Accuracy | No | 3 |
| 0008 | Clinfo.ai | Completeness | It noted IF being still under investigation, and assuming this is a broad scale recommendation (to males and females), I’d note that it works differently in males and females based on hormonal fluctuations. I also don’t love the idea of noting wt loss medications as a route to take when seeking out weight loss, as those should be recommended by a doctor given very specific circumstances | 2 |
| 0008 | Clinfo.ai | Clarity | Mostly | 2 |
| 0008 | Clinfo.ai | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
| 0008 | OpenEvidence | Relevance | Good | 3 |
| 0008 | OpenEvidence | Accuracy | No | 3 |
| 0008 | OpenEvidence | Completeness | Low carb diets will likely not yield high energy levels | 2 |
| 0008 | OpenEvidence | Clarity | Mostly | 2 |
| 0008 | OpenEvidence | Overall | Okay—This response was more or less accurate, but incomplete or unclear. | 3 |
Appendix C. LLM Implementation Details
Appendix C.1. Question Validity
- Functionality Overview:
- –
- Determines if the user’s question is one that we can answer. While DietNerd can recommend general diets that may be suitable for certain health conditions, DietNerd does not answer questions around recipe creation and questions that are asked on behalf of an animal.
- Input Variables:
- –
- query (str): The user’s question.
- Output Variables:
- –
- question_validity (str): A string indicating whether the question is valid or not. Possible responses can only either be “True”, “False—Recipe”, or “False—Animal”.
- LLM Settings:
- –
- gpt-4-turbo
- –
- Prompt Strategy: few-shot learning
- –
- temperature = 0.2
- –
- top_p = 0.5
- Prompt:

Appendix C.2. Query Generation
- Functionality Overview:
- –
- One prompt generates a keyword query to PubMed about the general topic of the user query and another prompt generates four keyword searches to PubMed to elicit points of contention. These points of contention are fundamental to our safety analysis.
- *
- The General Query Generation LLM builds one query directly from the user’s question. This query retrieves articles that provide general context.
- *
- The Point of Contention Query Generation LLM generates four distinct queries that attempt to represent the top points of contention around the user’s question. We have found that points of contention often reveal safety issues.
- Input Variables:
- –
- query (str): The user’s question
- Output Variables:
- –
- general_query (str): The broad query that will retrieve articles related to a specific topic.
- –
- query_contention (str): A list of 4 queries to represent the top points of contention around the topic.
- –
- query_list (list): A list of all 5 queries generated.
- LLM Settings—General Query Generation:
- –
- gpt-4-turbo
- –
- Prompt Strategy: few-shot learning
- –
- temperature = 0.7
- –
- top_p = 0.1
- Prompt—General Query Generation:

- LLM Settings—Points of Contention Query Generation:
- –
- gpt-4-turbo
- –
- Prompt Strategy: few-shot learning
- –
- temperature = 0.6
- –
- top_p = 1
- Prompt—Points of Contention Query Generation:


Appendix C.3. Relevance Classifier
- Functionality Overview:
- –
- Classifies an article as relevant or irrelevant based on its abstract. An article is considered relevant if it contains information that is helpful in answering the question, it contains a safety aspect that would be important to include in the answer, or it is NOT an animal-based study.
- Input Variables:
- –
- article (dict): A dictionary containing the fetched PubMed article data.
- –
- user_query (str): The original query from the user.
- Output Variables:
- –
- pmid (str): PubMed ID of the article.
- –
- article_is_relevant (bool): Whether the article is relevant or not.
- –
- article (dict): The input article dictionary.
- LLM Settings:
- –
- gpt-3.5-turbo
- –
- Prompt Strategy: zero-shot learning
- –
- temperature = 0.8
- –
- top_p = 0.5
- Prompt:

Appendix C.4. Full-Text Section Mapping
- Functionality Overview:
- –
- This function is only used if the article’s full text is available directly in PubMed.
- –
- Captures only the most relevant sections from an article’s full text to be cognizant of token size and context windows.
- –
- Does a case-sensitive check to see which of the section titles provided within a given article best matches the required section titles.
- Input Variables:
- –
- list_of_strings (list): A list of all of an article’s section titles to search through.
- –
- required_titles (list): A list of titles that are deemed to be the most relevant and helpful to include.
- Output Variables:
- –
- sections_to_pull (list): A list of matched section titles.
- LLM Settings:
- –
- gpt-3.5-turbo
- –
- Prompt Strategy: zero-shot learning
- –
- temperature = 0.1
- –
- top_p = 1
- Prompt:


Appendix C.5. Strength of Claim Assessment
- Functionality Overview:
- –
- Handles multiple article types and sources
- –
- Performs in-depth content analysis and summarization
- –
- Extracts critical metadata and bibliographic information
- –
- Adapts analysis based on article type (review vs. study)
- –
- Focuses on technical details and statistical metrics
- Input Variables:
- –
- article (dict): A dictionary containing the raw article data.
- Output Variables:
- –
- article_json (dict): A dictionary containing processed article information, including title, publication type, URL, abstract, “is relevant” flag, citation, PMID, PMCID, “full text” flag, and strength of claim analysis.
- LLM Settings:
- –
- gpt-4-turbo
- –
- Prompt Strategy: zero-shot learning
- –
- temperature = 0.6
- –
- top_p = 1
- Prompt for Review Type Articles:


- Prompt for Study Type Articles:

Appendix C.6. Final Output Synthesis
- Functionality Overview:
- –
- Generate the final response to the user’s question based on the strongest level of evidence in the provided article summaries
- Input Variables:
- –
- all_relevant_articles (list): List of all relevant article summaries.
- –
- query (str): User question.
- Output Variables:
- –
- final_output (str): Final response to the user’s question.
- LLM Settings:
- –
- gpt-4-turbo
- –
- Prompt Strategy: few-shot learning
- –
- temperature = 0.5
- –
- top_p = 1
- Prompt:

Appendix D. System Diagram

References
- Yu, E.; Rimm, E.; Qi, L.; Rexrode, K.; Albert, C.M.; Sun, Q.; Willett, W.C.; Hu, F.B.; Manson, J.E. Diet, Lifestyle, Biomarkers, Genetic Factors, and Risk of Cardiovascular Disease in the Nurses’ Health Studies. Am. J. Public Health 2016, 106, 1616–1623. [Google Scholar] [CrossRef] [PubMed]
- Firth, J.; Marx, W.; Dash, S.; Carney, R.; Teasdale, S.B.; Solmi, M.; Stubbs, B.; Schuch, F.B.; Carvalho, A.F.; Jacka, F.; et al. The Effects of Dietary Improvement on Symptoms of Depression and Anxiety: A Meta-Analysis of Randomized Controlled Trials. Psychosom. Med. 2019, 81, 265–280. [Google Scholar] [CrossRef] [PubMed]
- Fassier, P.; Chhim, A.S.; Andreeva, V.A.; Hercberg, S.; Latino-Martel, P.; Pouchieu, C.; Touvier, M. Seeking health- and nutrition-related information on the Internet in a large population of French adults: Results of the NutriNet-Santé study. Br. J. Nutr. 2016, 115, 2039–2046. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A. Here’s How To Use AI—Like ChatGPT And Bard—For Everyday Tasks Like Creating A Budget, Finding Airfare Or Planning Meals. Forbes. 2023. Available online: https://www.forbes.com/sites/ariannajohnson/2023/04/10/heres-how-to-use-ai-like-chatgpt-and-bard-for-everyday-tasks-like-creating-a-budget-finding-airfare-or-planning-meals (accessed on 1 August 2024).
- Lozano, A.; Fleming, S.L.; Chiang, C.C.; Shah, N. Clinfo.ai: An open-source retrieval-augmented large language model system for answering medical questions using scientific literature. In Proceedings of the Pacific Symposium on Biocomputing 2024, Kohala Coast, HI, USA, 3–7 January 2024; pp. 8–23. [Google Scholar]
- Lozano, A.; Fleming, S.L.; Chiang, C.C.; Shah, N. PubMedRS-200 Dataset. 2023. Available online: https://github.com/som-shahlab/Clinfo.AI/blob/main/PubMedRS-200/PubMedRS-200.csv (accessed on 1 August 2024).
- Olson, E.; Salem, C. Consensus. Available at OpenAI’s GPT Marketplace. 2022. Available online: https://chatgpt.com/g/g-bo0FiWLY7-consensus (accessed on 1 August 2024).
- Consensus. How It Works & Consensus FAQ’s. Available online: https://consensus.app/home/blog/welcome-to-consensus/ (accessed on 1 August 2024).
- Awesomegpts.ai. Scholar GPT. Available at OpenAI’s GPT Marketplace, March 2023. Available online: https://chatgpt.com/g/g-kZ0eYXlJe-scholar-gpt (accessed on 1 August 2024).
- Nadler, D.; Ziegler, Z.; Wulff, J.; Smith, M.; Hernandez, E.; Lehman, E.; Xu, J.; Ferreira, F.; Esdaile, J.; Hu, H.; et al. OpenEvidence. 2021. Available online: https://www.openevidence.com/ (accessed on 1 August 2024).
- CB Insights. AI 100: The Most Promising Artificial Intelligence Startups of 2024. 2024. Available online: https://www.cbinsights.com/research/report/artificial-intelligence-top-startups-2024/ (accessed on 1 August 2024).
- Business Insider. OpenEvidence AI Becomes the First AI in History to Score above 90% on the United States Medical Licensing Examination (USMLE). 2023. Available online: https://markets.businessinsider.com/news/stocks/openevidence-ai-becomes-the-first-ai-in-history-to-score-above-90-on-the-united-states-medical-licensing-examination-usmle-1032446924 (accessed on 1 August 2024).
- Hippocratic AI. StatPearls Semantic Search. Available at Hippocratic Medical Questions Website. 2024. Available online: https://hippocratic-medical-questions.herokuapp.com/ (accessed on 1 August 2024).
- Elicit. Elicit. Available at Elicit Website. 2023. Available online: https://elicit.com (accessed on 24 January 2023).
- He, K.; Mao, R.; Lin, Q.; Ruan, Y.; Lan, X.; Feng, M.; Cambria, E. A Survey of Large Language Models for Healthcare: From Data, Technology, and Applications to Accountability and Ethics. arXiv 2024, arXiv:2310.05694. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv 2021, arXiv:2005.11401. [Google Scholar] [CrossRef]
- Li, J.; Yuan, Y.; Zhang, Z. Enhancing LLM Factual Accuracy with RAG to Counter Hallucinations: A Case Study on Domain-Specific Queries in Private Knowledge-Bases. arXiv 2024, arXiv:2403.10446. [Google Scholar] [CrossRef]
- Funer, F. Accuracy and Interpretability: Struggling with the Epistemic Foundations of Machine Learning-Generated Medical Information and Their Practical Implications for the Doctor-Patient Relationship. Philos. Technol. 2022, 35, 5. [Google Scholar] [CrossRef]
- Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.-T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. LaMDA: Language Models for Dialog Applications. arXiv 2022, arXiv:2201.08239. [Google Scholar] [CrossRef]
- Glaese, A.; McAleese, N.; Trȩbacz, M.; Aslanides, J.; Firoiu, V.; Ewalds, T.; Rauh, M.; Weidinger, L.; Chadwick, M.; Thacker, P.; et al. Improving Alignment of Dialogue Agents via Targeted Human Judgements. arXiv 2022, arXiv:2209.14375. [Google Scholar] [CrossRef]
- Bar-Haim, R.; Kantor, Y.; Venezian, E.; Katz, Y.; Slonim, N. Project Debater APIs: Decomposing the AI Grand Challenge. arXiv 2021, arXiv:2110.01029. [Google Scholar] [CrossRef]
- Shuster, K.; Xu, J.; Komeili, M.; Ju, D.; Smith, E.M.; Roller, S.; Ung, M.; Chen, M.; Arora, K.; Lane, J.; et al. BlenderBot 3: A Deployed Conversational Agent That Continually Learns to Responsibly Engage. arXiv 2022, arXiv:2208.03188. [Google Scholar] [CrossRef]
- Christiano, P.; Leike, J.; Brown, T.B.; Martic, M.; Legg, S.; Amodei, D. Deep Reinforcement Learning from Human Preferences. arXiv 2023, arXiv:1706.03741. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training Language Models to Follow Instructions with Human Feedback. arXiv 2022, arXiv:2203.02155. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, S.; Galley, M.; Chen, Y.-C.; Brockett, C.; Gao, X.; Gao, J.; Liu, J.; Dolan, B. DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation. arXiv 2020, arXiv:1911.00536. [Google Scholar] [CrossRef]
- Sayers, E. A General Introduction to the E-Utilities. 2009. Available online: https://www.ncbi.nlm.nih.gov/books/NBK25497/ (accessed on 17 November 2022).
- National Library of Medicine. The 9 E-Utilities and Associated Parameters Available at National Library of Medicine. Available online: https://www.nlm.nih.gov/dataguide/eutilities/utilities.html (accessed on 11 September 2024).
- Luxford, K. ‘First, do no harm’: Shifting the paradigm towards a culture of health. Patient Exp. J. 2016, 3, 5–8. [Google Scholar] [CrossRef]
- PubMed Central. PubMed Central: An Archive of Biomedical and Life Sciences Journal Literature. Available at National Center for Biotechnology Information. Available online: https://www.ncbi.nlm.nih.gov/pmc/ (accessed on 1 August 2024).
- National Library of Medicine. Publication Types. Available at National Library of Medicine. Available online: https://www.nlm.nih.gov/mesh/pubtypes.html (accessed on 1 August 2024).
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. arXiv 2020, arXiv:1904.09675. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Anschütz, M.; Lozano, D.M.; Groh, G. This is not correct! Negation-aware Evaluation of Language Generation Systems. arXiv 2023, arXiv:2307.13989. [Google Scholar] [CrossRef]
- Cer, D.; Yang, Y.; Kong, S.-Y.; Hua, N.; Limtiaco, N.; St. John, R.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder. arXiv, 2018; arXiv:1803.11175. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Lin, C.-Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Ng, J.-P.; Abrecht, V. Better Summarization Evaluation with Word Embeddings for ROUGE. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing 2015, Lisbon, Portugal, 17–21 September 2015; pp. 1925–1930. [Google Scholar] [CrossRef]
- Xia, P.; Zhang, L.; Li, F. Learning similarity with cosine similarity ensemble. Inf. Sci. 2015, 307, 39–52. [Google Scholar] [CrossRef]
- Katari, M.S.; Shasha, D.; Tyagi, S. Statistics Is Easy: Case Studies on Real Scientific Datasets, 1st ed.; Synthesis Lectures on Mathematics & Statistics; Springer: Cham, Switzerland, 2021; Volume 1, p. XI, 62. [Google Scholar] [CrossRef]
- Allied Health Workforce Projections, 2016–2030: Registered Dieticians Allied Health Workforce Project. Available online: https://bhw.hrsa.gov/sites/default/files/bureau-health-workforce/data-research/registered-dieticians-2016-2030.pdf (accessed on 10 September 2024).
- Lipscomb, R. Health Coaching: A New Opportunity for Dietetics Professionals. J. Am. Diet. Assoc. 2006, 106, 801–803. [Google Scholar] [CrossRef]
- Gharibi, M.; Zachariah, A.; Rao, P. FoodKG: A Tool to Enrich Knowledge Graphs Using Machine Learning Techniques. Front. Big Data 2020, 3, 12. [Google Scholar] [CrossRef]

| System | Full-Text Extraction (When Available) | Research Quality Analysis | Safety Analysis | Conversational | Multiple Databases Accessed |
|---|---|---|---|---|---|
| Clinfo.ai | ✓ | ✓ | |||
| Consensus | ✓ | ✓ | ✓ | ||
| DietNerd | ✓ | ✓ | ✓ | ||
| OpenEvidence | ✓ | ||||
| Scholar GPT | ✓ | ✓ | ✓ |
| Query ID | Query Type | Summary | Query |
|---|---|---|---|
| 1 | General Query | - | (“St. John’s Wort” OR Hypericum) AND (“depression medication” OR antidepressants) AND safety |
| 2 | Point of Contention | Interaction of St. John’s Wort with Antidepressants The most debated argument is around the potential interaction of St. John’s Wort with antidepressants, particularly SSRIs. Some studies suggest a risk of serotonin syndrome, whereas others argue that the interaction might not be clinically significant. | (“St. John’s Wort” OR Hypericum) AND antidepressants AND interaction |
| 3 | Point of Contention | Efficacy of St. John’s Wort as a Complementary Treatment The debate revolves around whether St. John’s Wort can enhance the effects of standard antidepressants and improve treatment outcomes. While some studies suggest a potential benefit, others find no significant effect. | (“St. John’s Wort” OR Hypericum) AND antidepressants AND efficacy |
| 4 | Point of Contention | Safety of St. John’s Wort in Polypharmacy There is a contention about the safety of St. John’s Wort in patients who are on multiple medications. Concerns about potential drug interactions and side effects are discussed. | (“St. John’s Wort” OR Hypericum) AND polypharmacy AND safety |
| 5 | Point of Contention | Impact of St. John’s Wort on Antidepressant Withdrawal The debate is whether St. John’s Wort can help manage withdrawal symptoms from antidepressants. Some argue it may ease the process, while others caution against potential risks. | (“St. John’s Wort” OR Hypericum) AND antidepressants AND withdrawal |
| “Study”-Type Papers | “Review”-Type Papers |
|---|---|
| Purpose & Design | Purpose |
| Main Conclusions | Main Conclusions |
| Risks | Risks |
| Benefits | Benefits |
| Type of Study | Search Methodology & Scope |
| Testing Subject | Selection Criteria |
| Size of Study | Quality Assessment of Included Studies |
| Length of Study | Synthesis & Analysis |
| Statistical Analysis of Results | Sources of Funding or Conflicts of Interest |
| Significance Level | |
| Confidence Interval | |
| Effect Size | |
| Sources of Funding or Conflicts of Interest |
| Question | Reference Text | Generated Text |
|---|---|---|
| Does omega-3 PUFAs supplementation improve metabolic syndrome and related cardiovascular diseases? | Supplementation of omega-3 polyunsaturated fatty acids had a favorable effect on improving triglyceride, total cholesterol, high-density lipoprotein, systolic blood pressure, diastolic blood pressure, interleukin-6, tumor necrosis factor-, C-reactive protein, and interleukin-1 levels, yet did not affect low-density lipoprotein, monocyte chemoattractant protein-1, intracellular adhesion molecule-1, and soluble endothelial selectin among patients with metabolic syndrome and related cardiovascular diseases. | In conclusion, omega-3 polyunsaturated fatty acids supplementation can be beneficial for reducing triglycerides and improving some cardiovascular risk factors in individuals with metabolic syndrome. However, the effects on cholesterol levels and other metabolic markers can vary. It is advisable for individuals considering omega-3 supplements to consult with healthcare providers to tailor the approach based on personal health needs and risks. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.; Yacub, Z.; Shasha, D. DietNerd: A Nutrition Question-Answering System That Summarizes and Evaluates Peer-Reviewed Scientific Articles. Appl. Sci. 2024, 14, 9021. https://doi.org/10.3390/app14199021
Wu S, Yacub Z, Shasha D. DietNerd: A Nutrition Question-Answering System That Summarizes and Evaluates Peer-Reviewed Scientific Articles. Applied Sciences. 2024; 14(19):9021. https://doi.org/10.3390/app14199021
Chicago/Turabian StyleWu, Shela, Zubair Yacub, and Dennis Shasha. 2024. "DietNerd: A Nutrition Question-Answering System That Summarizes and Evaluates Peer-Reviewed Scientific Articles" Applied Sciences 14, no. 19: 9021. https://doi.org/10.3390/app14199021
APA StyleWu, S., Yacub, Z., & Shasha, D. (2024). DietNerd: A Nutrition Question-Answering System That Summarizes and Evaluates Peer-Reviewed Scientific Articles. Applied Sciences, 14(19), 9021. https://doi.org/10.3390/app14199021