

A Stock Prediction Method Based on Deep Reinforcement Learning and Sentiment Analysis


Abstract
Featured Application
Abstract
1. Introduction
- Data Innovation: Most of the datasets for stock prediction models come from the U.S. stock market, and there are fewer stock prediction models about China. However, there are huge differences between the Chinese stock market and the U.S. stock market, so the models applicable to other countries are not necessarily applicable to China. In order to get stable gains in the Chinese stock market, it is necessary to construct stock prediction models based on Chinese dataset. In this paper, 118 stocks are selected as the dataset. These 118 stocks are ranked among the top 150 stocks in China for two consecutive years in 2022 and 2023. The final experimental results show that our model can benefit from the Chinese stock market.
- Method Innovation: Few studies have combined DRL and sentiment analysis to form stock prediction models. This paper uses the Q-learning algorithm based on convolutional neural networks to train stock prediction models, and adds sentiment indices as rewards (R) and states (S) into DQN, respectively, to obtain two models, SADQN-R (Sentiment Analysis Deep Q-Network-R) and SADQN-S (Sentiment Analysis Deep Q-Network-S). We tested the trained SADQN-R and SADQN-S on the test set and compared them with several other methods, and the results show that SADQN-S has the best performance among all methods.
- Application Innovation: Most of the previous stock prediction methods use the historical data of a stock to predict the future direction of that stock. Newly listed stocks do not have historical data and cannot be predicted accurately. In this paper, the train set and test set are from different stocks. The test results show that our model applied to newly-listed stocks can achieve high returns.
2. Related Work
3. Preliminaries
3.1. Neural Networks
3.2. CNN
3.3. Deep Reinforcement Learning
3.3.1. Basic Knowledge
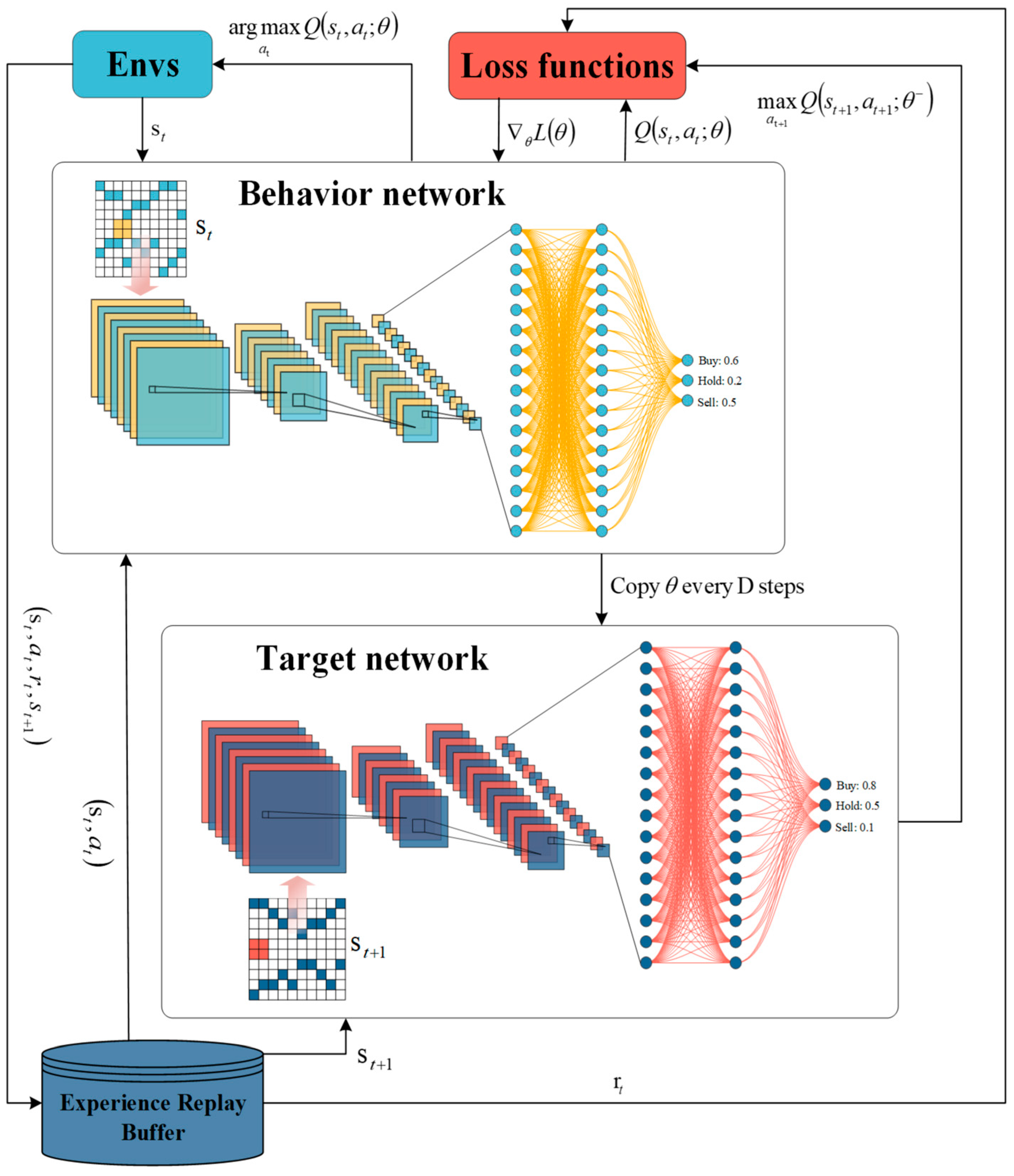
3.3.2. DQN and DDQN
- Set up two networks, the behavior network and the target network . The behavior network is responsible for controlling agent and collecting experience; target network is responsible for computing :where i is the number of iterations and is the discount rate. The in Equation (9) is the reward given to the agent by the environment after the agent performs the action.
- Define a loss function:
- The parameters are updated using the gradient descent method. A partial derivation of the parameter yields the following gradient:
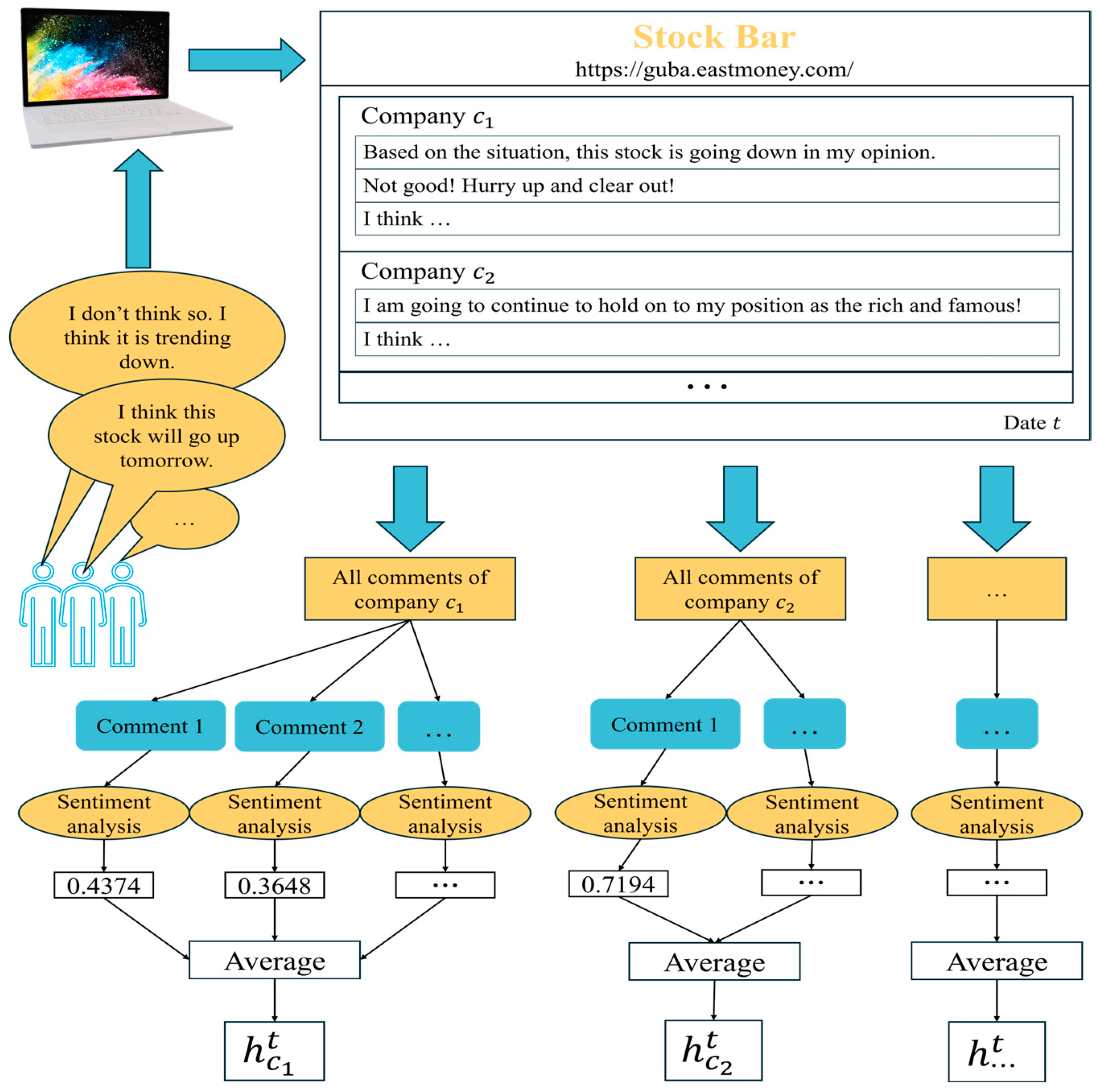
3.4. Sentiment Analysis
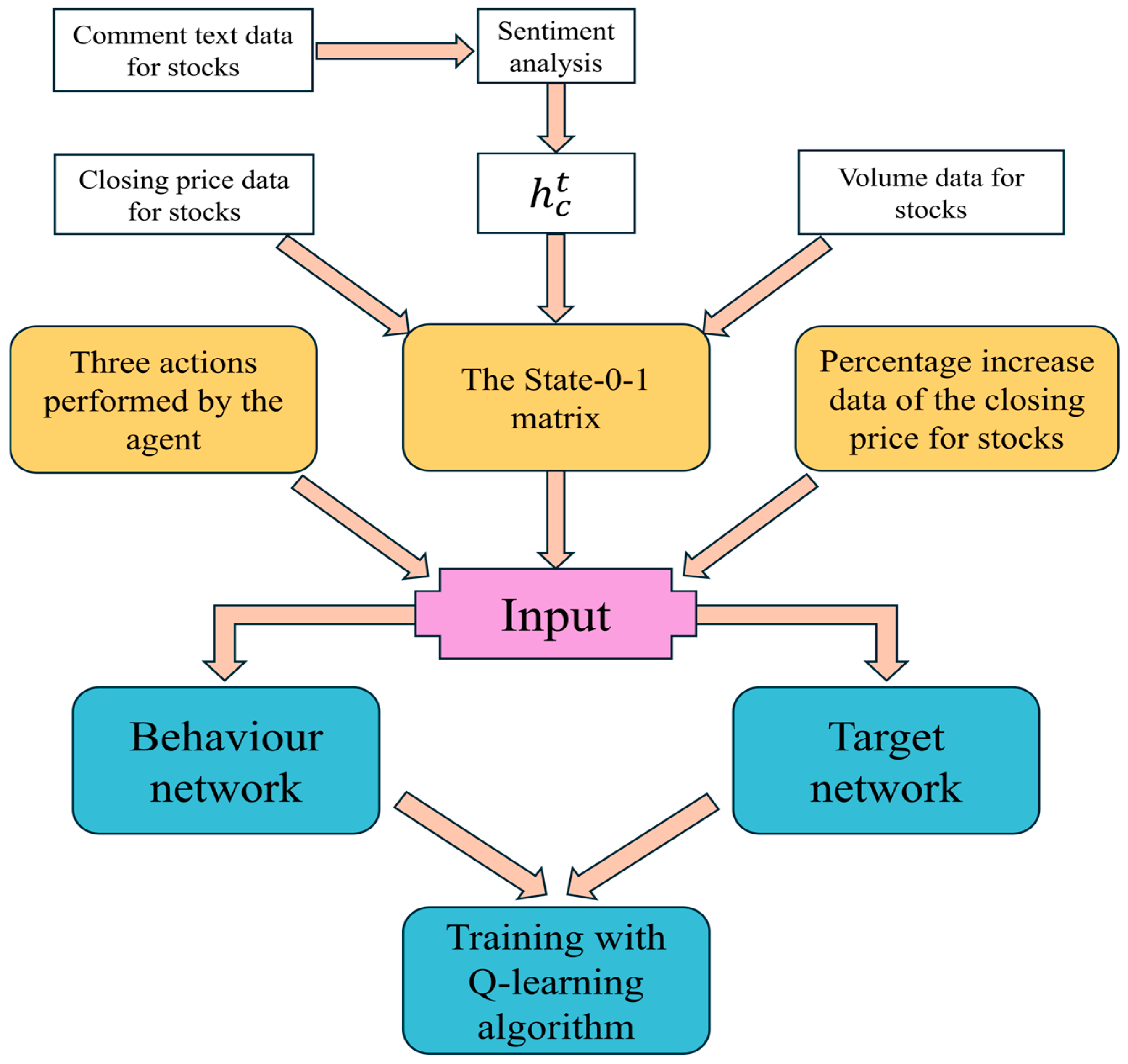
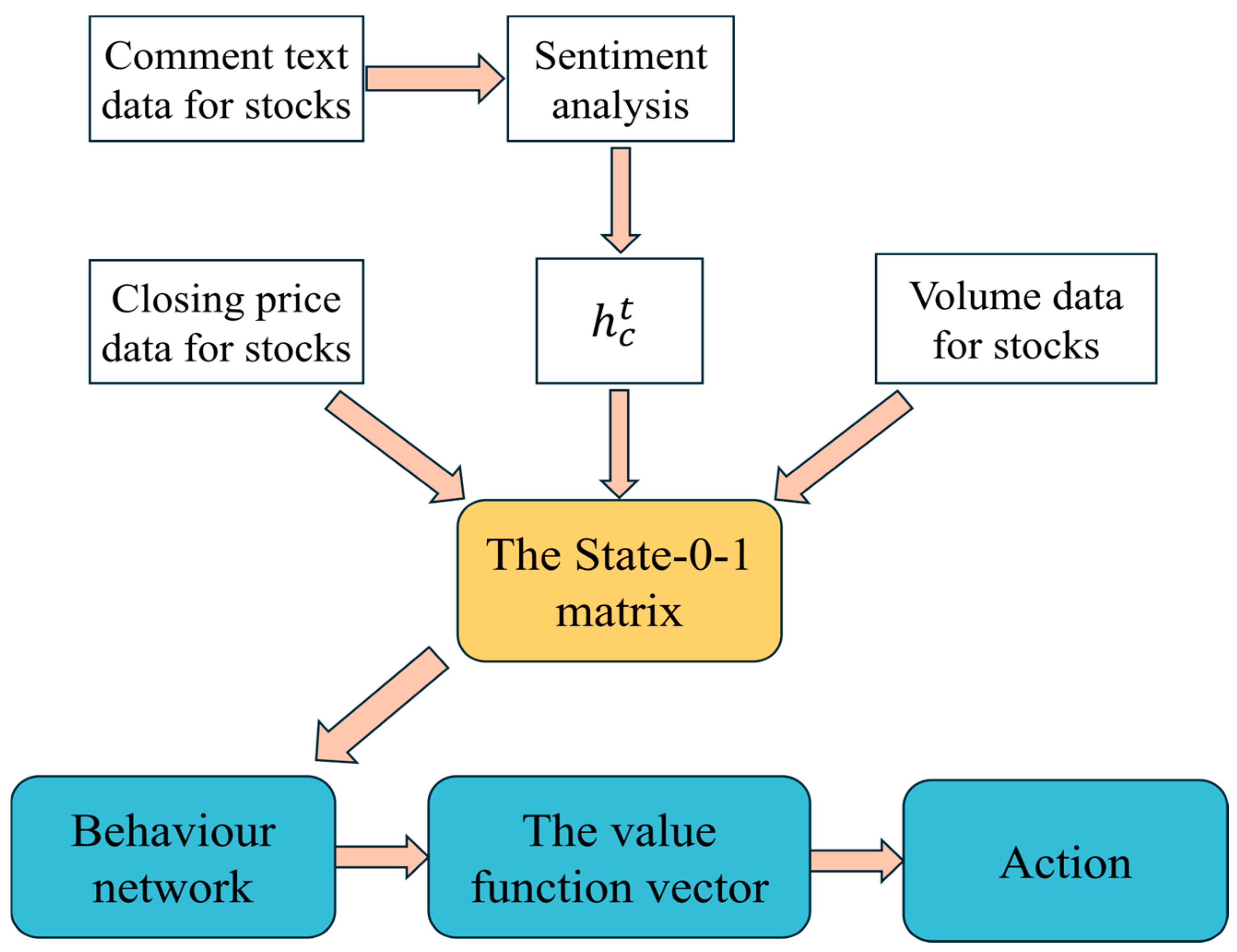
4. Methodology
4.1. Modeling the Environment for RL Task
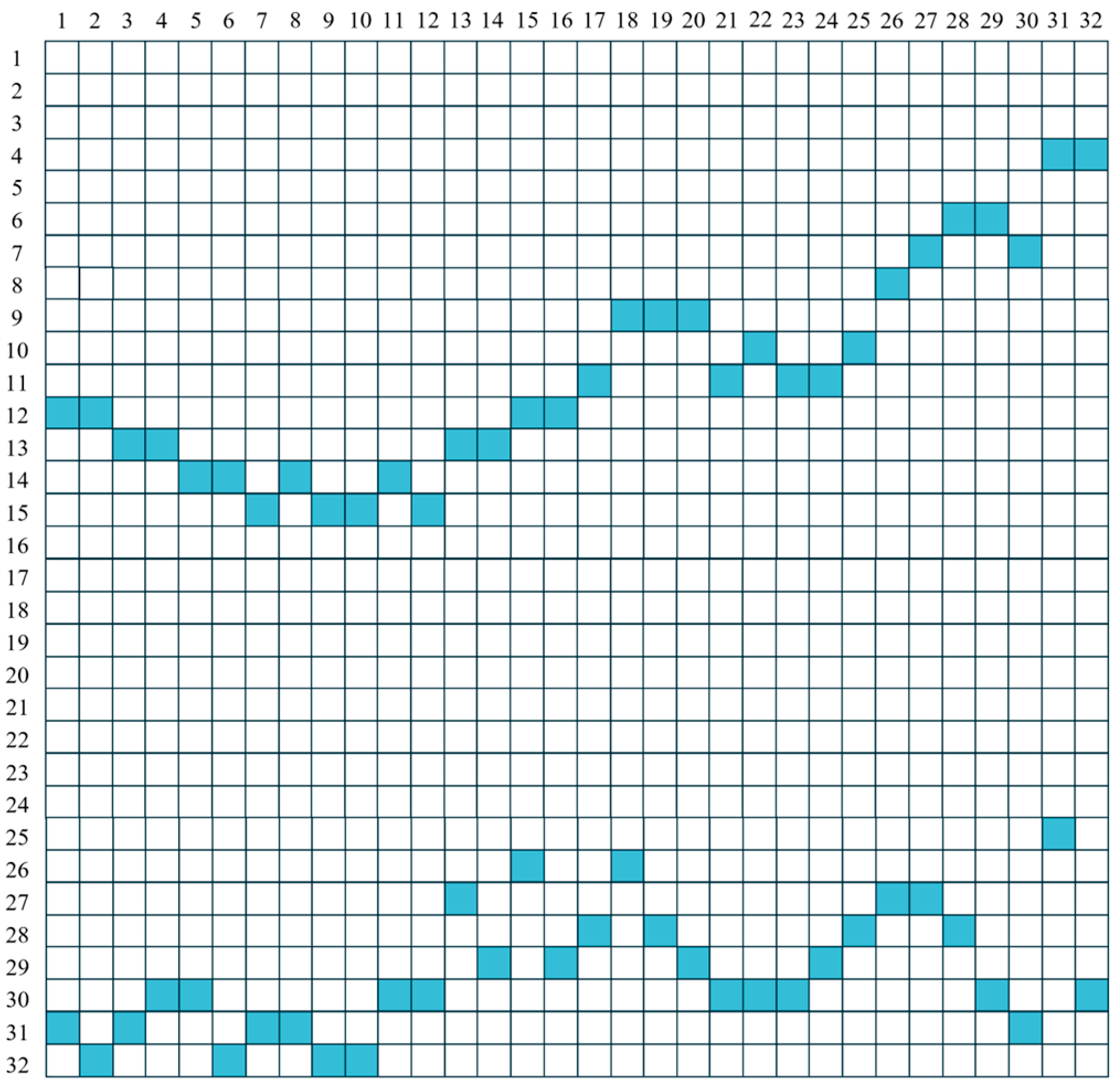
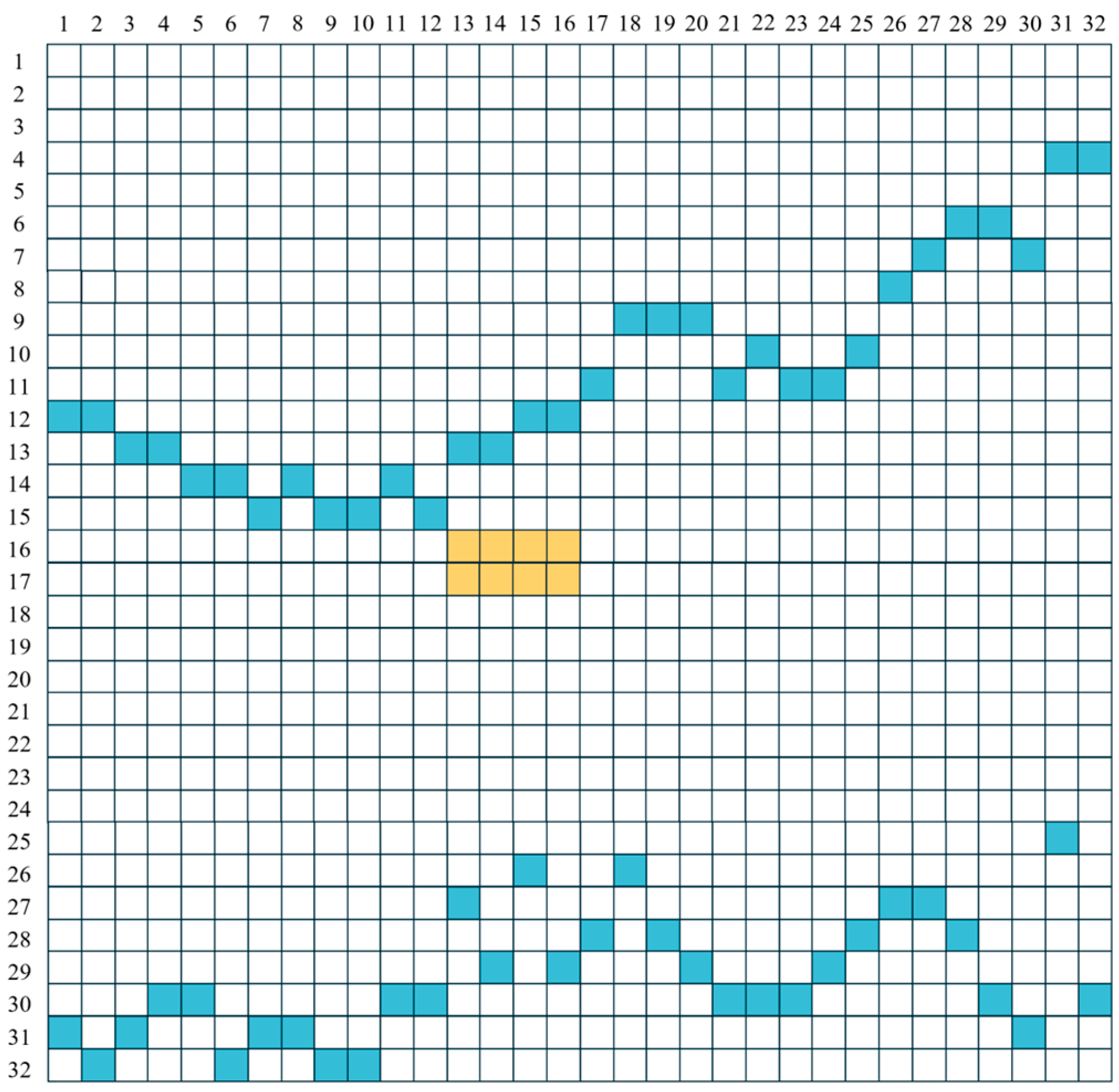
- State
- Action
- Reward
- Course of dealing
4.2. Network Settings for Deep Learning
4.3. Methods
- 1.
- DQN and DDQN
- 2.
- SADQN-R
- 3.
- SADQN-S
- 4.
- Baseline methods
- Uniform Buy and Hold: Funds are evenly distributed at the initial moment and subsequently held at all times.
- Uniform Constant Rebalanced Portfolio: Adjust the allocation of funds at every moment to always maintain an even distribution.
- Universal Portfolio: The returns of many kinds of investment portfolios are calculated based on statistical simulations, and the weighting of these portfolios is calculated based on the returns.
5. Experiments
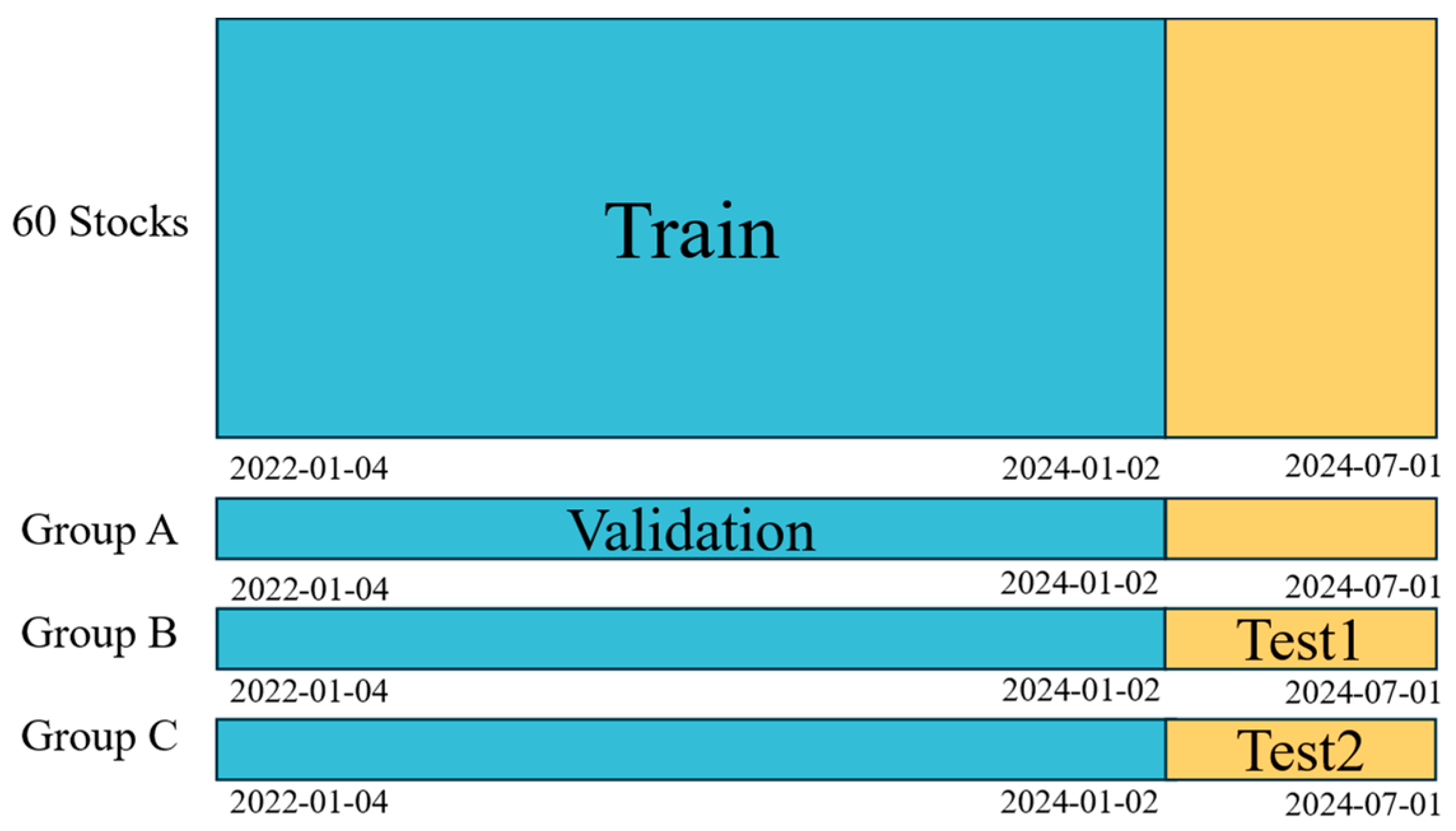
5.1. Dataset
5.1.1. Data Source
- In 2020, Chinese accelerating economic recovery pushed Chinese stock market values past the peaks set during the stock market bubble of 2015, and the total market value of Chinese stock market surpassed USD 10 trillion. The Chinese stock market is large enough and representative enough to be the subject of study;
- While the US stock market is mainly dominated by institutional investors, the Chinese stock market is mainly dominated by retail investors [46]. From the establishment of the Chinese stock market in 1990 to 2023, the number of retail investors has exceeded 220 million. This makes the Chinese stock market highly predictable.
5.1.2. Data Preprocessing
5.2. Comparison Experiments
- GPU: RTX 3080 × 2(20 GB) × 1;
- CPU: 10 vCPU Intel(R) Xeon(R) Gold 6148 CPU @ 2.40 GHz;
- Random access memory (RAM): 60 GB.
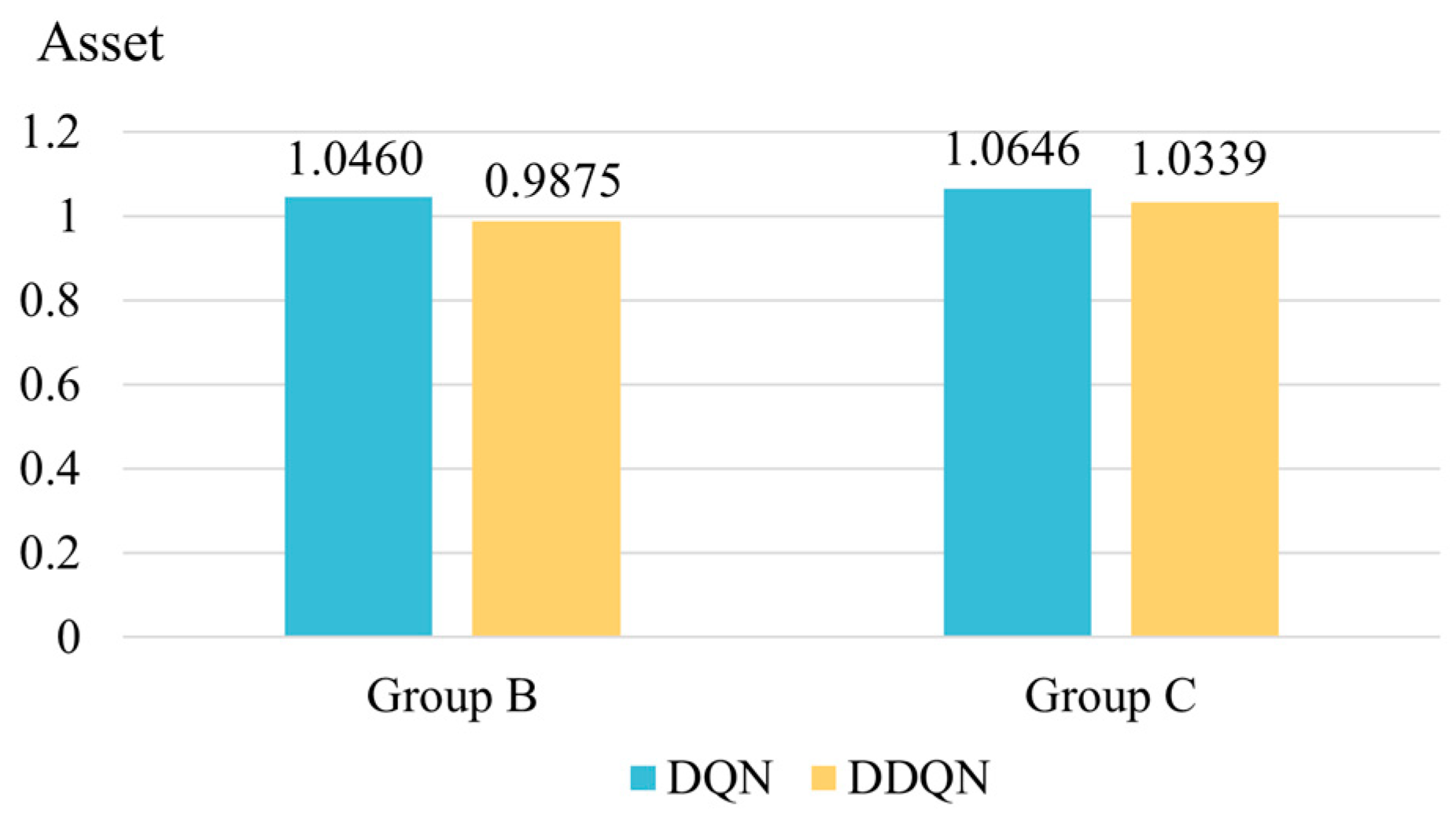
5.2.1. Comparison Experiment between DQN and DDQN
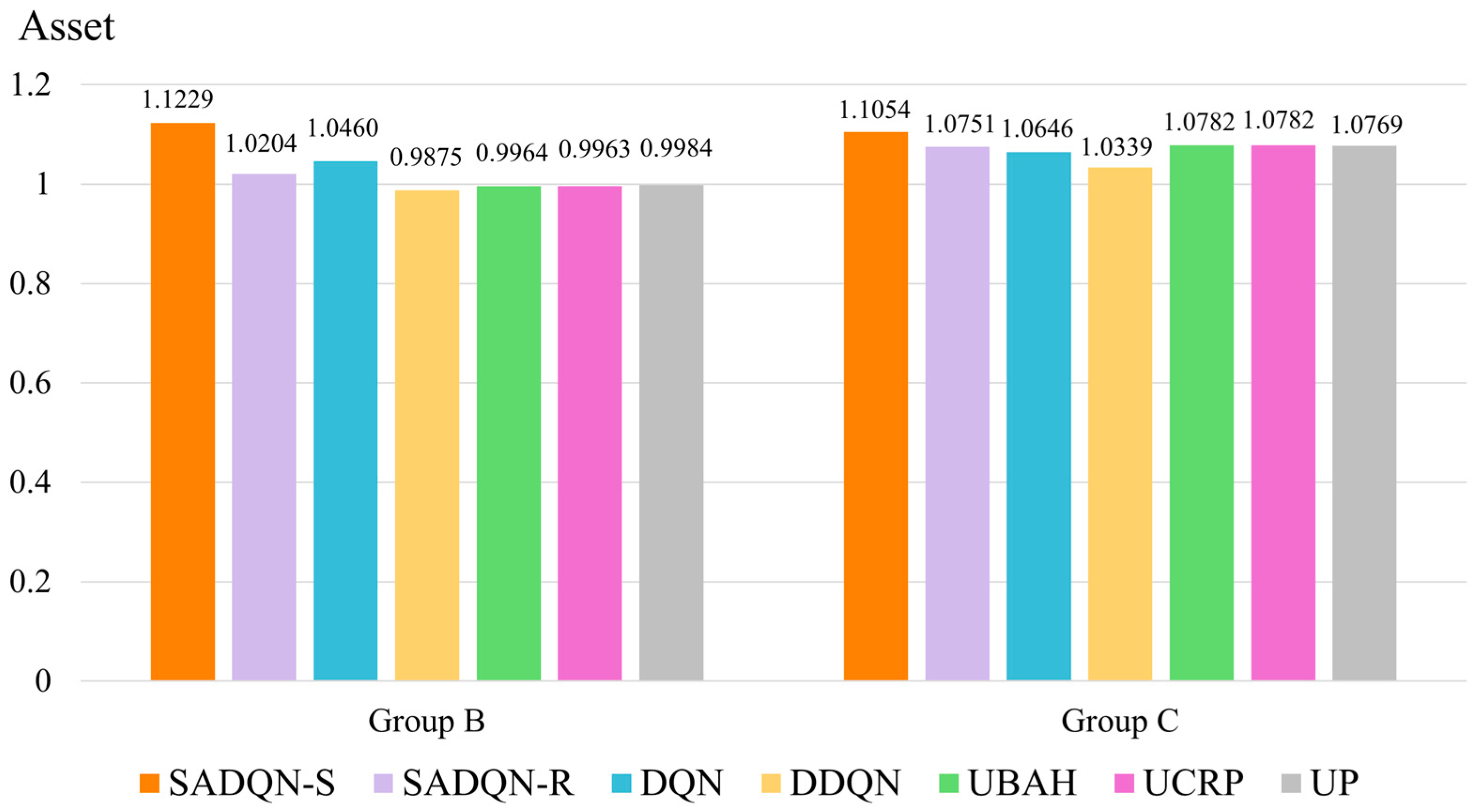
5.2.2. Comparison Experiment for All Methods
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of Parameters | Meaning of Parameters |
|---|---|
| state at moment | |
| action at moment | |
| reward at moment | |
| return at moment | |
| policy | |
| state-value function | |
| action-value function | |
| value function vector of company at moment | |
| asset allocation weight | |
| percentage increase in closing price of company at moment | |
| average sentiment analysis index for company at moment |
| Algorithm A1. DQN |
| 1. Initialize replay memory to capacity |
| 2. Initialize action-value function with random weights |
| 3. Initialize target action-value function with weights |
| 4. For episode do |
| 5. Initialize sequence and preprocessed sequence |
| 6. For do |
| 7. With probability select a random action |
| 8. otherwise select |
| 9. Execute action , in emulator and observe reward , and image |
| 10. Set and preprocess |
| 11. Store transition in |
| 12. Sample random minibatch of transitions from |
| 13. Set |
| 14. Perform a gradient descent step on with respect to the network parameters |
| 15. Every steps reset |
| 16. End For |
| 17. End For |
| Algorithm A2. State-0-1 |
| Require: INPUT_FILE_PATH: Path to Input File |
| Ensure: Processed data is written to the output file in the specified directory |
| 1. OUTPUT_DIRECTORY Path to Output Directory |
| 2. ORDER 32 |
| 3. NUM_INTERVALS (ORDER − 2)/2 |
| 4. INTERVAL_LENGTH 1/NUM_INTERVALS |
| 5. TRADE_START_INDEX ORDER-NUM_INTERVALS |
| 6. excel_data ReadExcel(file_path, usecols = |
| 7. [‘closing_price’, ‘volume’]) |
| 8. closing_price,volume excel_data[‘closing_price’], excel_data[‘volume’] |
| 9. max_price, min_price max(closing_price), min(closing_price) |
| 10. max_volume, min_volume max(volume), min(volume) |
| 11. for i = 0, len(closing_price) − 1 do |
| 12. closing_price[i] (closing_price[i] − min_price)/(max_price-min_price) |
| 13. volume[i] (volume[i] − min_volume)/(max_volume − min_volume) |
| 14. end for |
| 15. matrix_list [ ] |
| 16. length len(closing_price) |
| 17. for day = 0, length − ORDER do |
| 18. matrix zeros((ORDER, ORDER)) |
| 19. for i = 0, ORDER − 1 do |
| 20. closing_interval determine_interval(closing_price[day+i], NUM_INTERVALS) |
| 21. volume_intervaldetermine_interval(volume[day+i], NUM_INTERVALS) |
| 22. matrix[NUM_INTERVALS - closing_interval, i] 1 |
| 23. matrix[TRADE_START_INDEX + NUM_INTERVALS − volume_interval, i] 1 |
| 24. end for |
| 25. matrix_list.append(matrix) |
| 26. end for |
| 27. with open(OUTPUT_DIRECTORY + ‘/output.txt’, ‘a’): |
| 28. tmp ‘ ’ if is_first_company else ‘F’ |
| 29. for matrix_index, matrix in enumerate(matrix_list) do |
| 30. for i, row in enumerate(matrix) do line row.tolist() |
| 31. tmp tmp + ‘ ’ .join([str(int(c)) For c in line]) + ‘ ’ |
| 32. end for |
| 33. tmp tmp + ‘E’ if matrix_index len(matrix_list) − 1 else ‘ ’ |
| 34. end for |
| 35. f.write(tmp) |
| Algorithm A3. Portfolio |
| 1. Initialize 0 |
| 2. for all do |
| 3. if and then |
| 4. |
| 5. else if and then |
| 6. |
| 7. end if |
| 8. end for |
| 9. |
| 10. for all |
| 11. |
| 12. for all |
References
- Adebiyi, A.A.; Adewumi, A.O.; Ayo, C.K. Comparison of arima and artificial neural networks models for stock price prediction. J. Appl. Math. 2014, 2014, 614342. [Google Scholar] [CrossRef]
- Yan, X.; Zhang, G. Application of kalman filter in the prediction of stock price. In 5th International Symposium on Knowledge Acquisition and Modeling (KAM 2015); Atlantis Press: Amsterdam, The Netherlands, 2015; pp. 197–198. [Google Scholar] [CrossRef]
- Zhang, Z.; Hong, W.-C. Electric load forecasting by complete ensemble empirical mode decomposition adaptive noise and support vector regression with quantum-based dragonfly algorithm. Nonlinear Dyn. 2019, 98, 1107–1136. [Google Scholar] [CrossRef]
- Zhang, Z.; Hong, W.-C. Application of variational mode decomposition and chaotic grey wolf optimizer with support vector regression for forecasting electric loads. Knowl.-Based Syst. 2021, 228, 107297. [Google Scholar] [CrossRef]
- Adnan, R.M.; Dai, H.-L.; Mostafa, R.R.; Parmar, K.S.; Heddam, S.; Kisi, O. Modeling multistep ahead dissolved oxygen concentration using improved support vector machines by a hybrid metaheuristic algorithm. Sustainability 2022, 14, 3470. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2018, 37, 421–436. [Google Scholar] [CrossRef]
- Zhang, M.; McCarthy, Z.; Finn, C.; Levine, S.; Abbeel, P. Learning deep neural network policies with continuous memory states. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 520–527. [Google Scholar] [CrossRef]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1–40. [Google Scholar]
- Lenz, I.; Knepper, R.A.; Saxena, A. DeepMPC: Learning deep latent features for model predictive control. In Proceedings of the Robotics: Science and Systems, Rome, Italy, 13–17 July 2015; pp. 10–25. [Google Scholar]
- Guo, H. Generating text with deep reinforcement learning. arXiv 2015, arXiv:1510.09202. [Google Scholar]
- Li, J.; Monroe, W.; Ritter, A.; Galley, M.; Gao, J.; Jurafsky, D. Deep reinforcement learning for dialogue generation. arXiv 2016, arXiv:1606.01541. [Google Scholar]
- Narasimhan, K.; Kulkarni, T.; Barzilay, R. Language understanding for text- based games using deep reinforcement learning. arXiv 2015, arXiv:1506.08941. [Google Scholar]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep reinforcement learning framework for autonomous driving. arXiv 2017, arXiv:1704.02532. [Google Scholar] [CrossRef]
- Caicedo, J.C.; Lazebnik, S. Active object localization with deep reinforcement learning. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2488–2496. [Google Scholar] [CrossRef]
- Lee, J.; Kim, R.; Koh, Y.; Kang, J. Global stock market prediction based on stock chart images using deep Q-network. IEEE Access 2019, 7, 167260–167277. [Google Scholar] [CrossRef]
- Chen, L.; Gao, Q. Application of deep reinforcement learning on automated stock trading. In Proceedings of the 2019 IEEE 10th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 18–20 October 2019; pp. 29–33. [Google Scholar] [CrossRef]
- Li, Y.; Ni, P.; Chang, V. Application of deep reinforcement learning in stock trading strategies and stock forecasting. Computing 2020, 102, 1305–1322. [Google Scholar] [CrossRef]
- Carta, S.; Corriga, A.; Ferreira, A.; Podda, A.S.; Recupero, D.R. A multi-layer and multi-ensemble stock trader using deep learning and deep reinforcement learning. Appl. Intell. 2021, 51, 889–905. [Google Scholar] [CrossRef]
- Yu, X.; Wu, W.; Liao, X.; Han, Y. Dynamic stock-decision ensemble strategy based on deep reinforcement learning. Appl. Intell. 2023, 53, 2452–2470. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Chen, Z.; He, W.; Wu, T.; Ren, J. An integrated framework of deep learning and knowledge graph for prediction of stock price trend: An application in Chinese stock exchange market. Appl. Soft Comput. 2020, 91, 106205. [Google Scholar] [CrossRef]
- Liu, Q.; Tao, Z.; Tse, Y.; Wang, C. Stock market prediction with deep learning: The case of China. Financ. Res. Lett. 2022, 46, 102209. [Google Scholar] [CrossRef]
- Tetlock, P.E. Cognitive style and political ideology. J. Personal. Soc. Psychol. 1983, 45, 118–126. [Google Scholar] [CrossRef]
- Kim, S.-M.; Hovy, E. Determining the sentiment of opinions. In COLING 2004: Proceedings of the 20th International Conference on Computational Linguistics; COLING: Geneva, Switzerland, 2004; pp. 1367–1373. [Google Scholar]
- Baker, M.; Wurgler, J. Investor sentiment and the cross-section of stock returns. J. Financ. 2006, 61, 1645–1680. [Google Scholar] [CrossRef]
- Rupande, L.; Muguto, H.T.; Muzindutsi, P.-F. Investor sentiment and stock return volatility: Evidence from the johannesburg stock exchange. Cogent Econ. Financ. 2019, 7. [Google Scholar] [CrossRef]
- Gite, S.; Khatavkar, H.; Kotecha, K.; Srivastava, S.; Maheshwari, P.; Pandey, N. Explainable stock prices prediction from financial news articles using sentiment analysis. Peer J Comput. Sci. 2021, 7, 340. [Google Scholar] [CrossRef]
- Zhu, E. BERTopic-Driven Stock Market Predictions: Unraveling Sentiment Insights. arXiv 2024, arXiv:2404.02053. [Google Scholar]
- Deng, Y.; Bao, F.; Kong, Y.; Ren, Z.; Dai, Q. Deep Direct Reinforcement Learning for Financial Signal Representation and Trading. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 653–664. [Google Scholar] [CrossRef]
- Jiang, Z.; Xu, D.; Liang, J. A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem. arXiv 2017, arXiv:1706.10059. [Google Scholar]
- Shin, H.G.; Ra, I.; Choi, Y.H. A Deep Multimodal Reinforcement Learning System Combined with CNN and LSTM for Stock Trading. In Proceedings of the 2019 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 16–18 October 2019; pp. 7–11. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, B.; Tu, S.; Zhang, K.; Xu, L. DeepTrader: A Deep Reinforcement Learning Approach for Risk-Return Balanced Portfolio Management with Market Conditions Embedding. Proc. AAAI Conf. Artif. Intell. 2021, 35, 643–650. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, Y.; Tang, K.; Wu, J.; Xiong, Z. AlphaStock: A Buying-Winners-and-Selling-Losers Investment Strategy using Interpretable Deep Reinforcement Attention Networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 1900–1908. [Google Scholar] [CrossRef]
- Millea, A. Deep Reinforcement Learning for Trading-A Critical Survey. Data 2021, 6, 119. [Google Scholar] [CrossRef]
- Pricope, T.V. Deep Reinforcement Learning in Quantitative Algorithmic Trading: A Review. arXiv 2021, arXiv:2106.00123. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, UK, 2018; pp. 10–11. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In International Conference on Machine Learning; PMLR: Birmingham, UK, 2016; pp. 1995–2003. Available online: https://proceedings.mlr.press/v48/wangf16.html (accessed on 10 July 2024).
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In International Conference on Machine Learning; PMLR: Birmingham, UK, 2016; pp. 1928–1937. Available online: https://proceedings.mlr.press/v48/mniha16.html (accessed on 10 July 2024).
- Hessel, M.; Modayil, J.; Van Hasselt, H.; Schaul, T.; Ostrovski, G.; Dabney, W.; Horgan, D.; Piot, B.; Azar, M.; Silver, D. Rainbow: Combining improvements in deep reinforcement learning. Proc. AAAI Conf. Artif. Intell. 2018, 32. [Google Scholar] [CrossRef]
- Horgan, D.; Quan, J.; Budden, D.; Barth-Maron, G.; Hessel, M.; Van Hasselt, H.; Silver, D. Distributed prioritized experience replay. arXiv 2018, arXiv:1803.00933. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. Proc. AAAI Conf. Artif. Intell. 2016, 30. [Google Scholar] [CrossRef]
- Cavalcante, R.C.; Brasileiro, R.C.; Souza, V.L.; Nobrega, J.P.; Oliveira, A.L. Computational intelligence and financial markets: A survey and future directions. Expert Syst. Appl. 2016, 55, 194–211. [Google Scholar] [CrossRef]
- Lim, B.; Zohren, S.; Roberts, S. Enhancing time series momentum strategies using deep neural networks. arXiv 2019, arXiv:1904.04912. [Google Scholar]
- Leippold, M.; Wang, Q.; Zhou, W. Machine learning in the Chinese stock market. J. Financ. Econ. 2022, 145, 64–82. [Google Scholar] [CrossRef]
- Khan, S.; Alghulaiakh, H. ARIMA model for accurate time series stocks forecasting. Int. J. Adv. Comput. Sci. Appl. 2020, 11. [Google Scholar] [CrossRef]
- Afeef, M.; Ihsan, A.; Zada, H. Forecasting stock prices through univariate ARIMA modeling. NUML Int. J. Bus. Manag. 2018, 13, 130–143. [Google Scholar]
- Raudys, A.; Pabarškaitė, Ž. Optimising the smoothness and accuracy of moving average for stock price data. Technol. Econ. Dev. Econ. 2018, 24, 984–1003. [Google Scholar] [CrossRef]
- Rahman, M.A. Forecasting Stock Prices through Exponential Smoothing Techniques in The Creative Industry of The UK Stock Market. Int. J. Asian Bus. Manag. 2024, 3, 323–338. [Google Scholar] [CrossRef]
- Martin, R.; Johan, J. Integrated system in forecasting stocks of goods using the exponential smoothing method. J. Appl. Bus. Technol. 2021, 2, 13–27. [Google Scholar] [CrossRef]
- Abraham, R.; Samad, M.E.; Bakhach, A.M.; El-Chaarani, H.; Sardouk, A.; Nemar, S.E.; Jaber, D. Forecasting a stock trend using genetic algorithm and random forest. J. Risk Financ. Manag. 2022, 15, 188. [Google Scholar] [CrossRef]
- Yin, L.; Li, B.; Li, P.; Zhang, R. Research on stock trend prediction method based on optimized random forest. CAAI Trans. Intell. Technol. 2023, 8, 274–284. [Google Scholar] [CrossRef]
- Li, X.; Sun, Y. Stock intelligent investment strategy based on support vector machine parameter optimization algorithm. Neural Comput. Appl. 2020, 32, 1765–1775. [Google Scholar] [CrossRef]
- Nabi, R.M.; Soran Ab, M.S.; Harron, H. A novel approach for stock price prediction using gradient boosting machine with feature engineering (gbm-wfe). Kurd. J. Appl. Res. 2020, 5, 28–48. [Google Scholar] [CrossRef]
| Q-Table | ||||||
|---|---|---|---|---|---|---|
| Securities Code | Amount of Comments | Securities Code | Amount of Comments | ⋯ | Securities Code | Amount of Comments |
|---|---|---|---|---|---|---|
| 000001 | 79,722 | 000858 | 118,561 | ⋯ | 601916 | 22,295 |
| 000002 | 82,502 | 000983 | 42,376 | ⋯ | 601916 | 22,295 |
| 000039 | 13,332 | 001872 | 3735 | ⋯ | 601939 | 16,470 |
| 000063 | 121,742 | 001979 | 22,767 | ⋯ | 601985 | 38,764 |
| 000333 | 55,628 | 002142 | 23,694 | ⋯ | 601988 | 24,239 |
| 000568 | 41,006 | 002304 | 34,658 | ⋯ | 601995 | 36,199 |
| 000617 | 68,873 | 002352 | 33,436 | ⋯ | 603288 | 53,185 |
| 000651 | 144,022 | 002415 | 70,002 | ⋯ | 603993 | 41,070 |
| 000708 | 6328 | 002475 | 61,227 | ⋯ | 688981 | 65,854 |
| 000776 | 44,098 | 002714 | 68,077 | ⋯ | 900948 | 6934 |
| Hyperparameter | Meaning of Hyperparameter | Value |
|---|---|---|
| maxiter | The maximum number of iterations | 550,000 |
| batch_size | The batch size | 32 |
| buffer_size | The capacity of the memory buffer | 1000 |
| learning_rate | The learning rate | 0.001 |
| gamma | The discount factor | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, S.; Shen, H. A Stock Prediction Method Based on Deep Reinforcement Learning and Sentiment Analysis. Appl. Sci. 2024, 14, 8747. https://doi.org/10.3390/app14198747
Du S, Shen H. A Stock Prediction Method Based on Deep Reinforcement Learning and Sentiment Analysis. Applied Sciences. 2024; 14(19):8747. https://doi.org/10.3390/app14198747
Chicago/Turabian StyleDu, Sha, and Hailong Shen. 2024. "A Stock Prediction Method Based on Deep Reinforcement Learning and Sentiment Analysis" Applied Sciences 14, no. 19: 8747. https://doi.org/10.3390/app14198747
APA StyleDu, S., & Shen, H. (2024). A Stock Prediction Method Based on Deep Reinforcement Learning and Sentiment Analysis. Applied Sciences, 14(19), 8747. https://doi.org/10.3390/app14198747