
Semantic Segmentation of Urban Remote Sensing Images Based on Deep Learning


Abstract
1. Introduction
2. Land Division and Classification Method Proposed
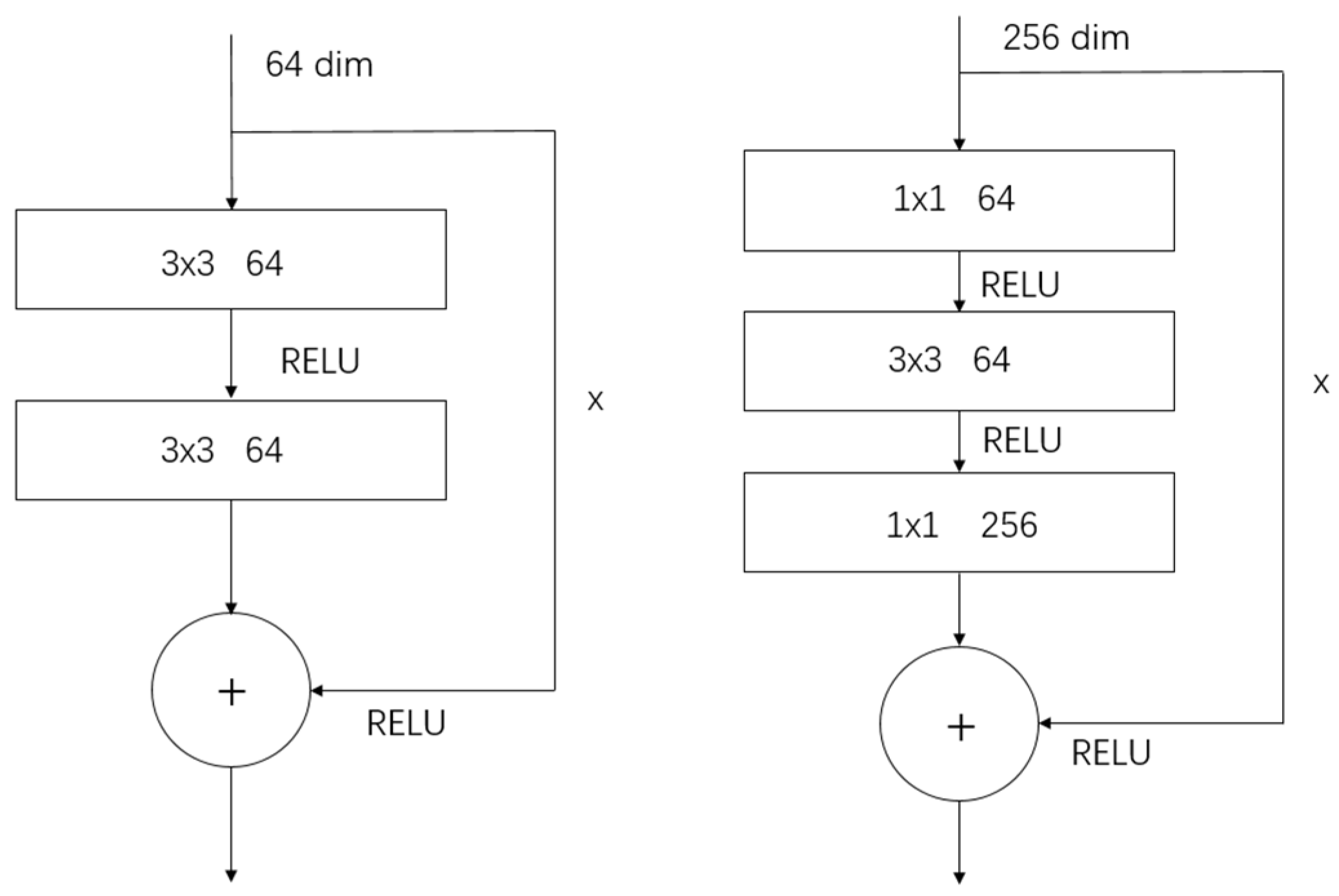
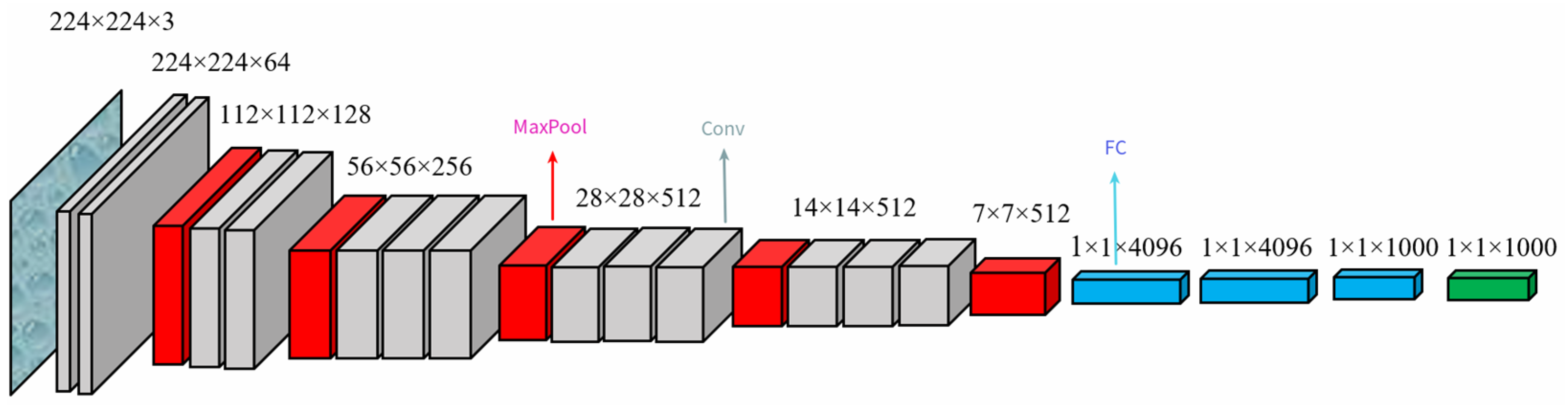
2.1. Backbone Network
2.2. U-Net Network
2.3. Network Improvements Based on Attention Mechanisms
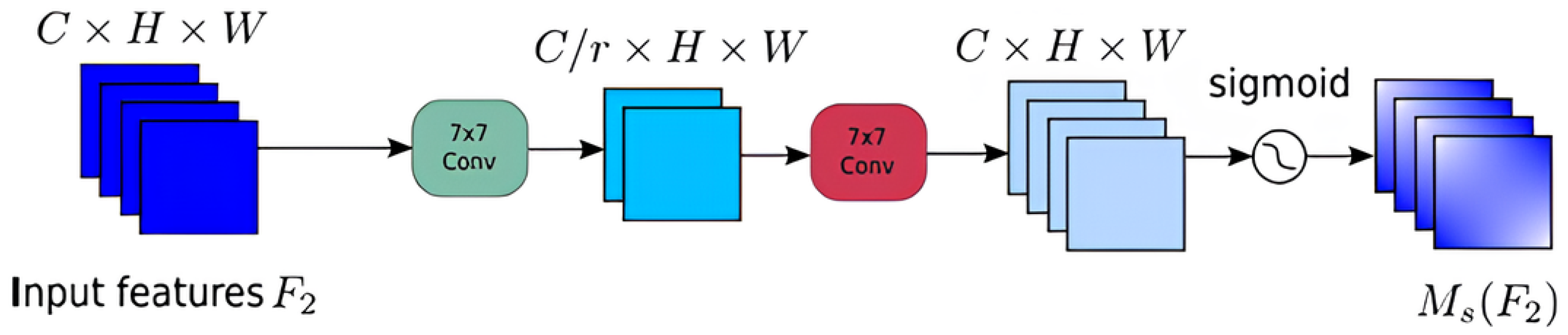
2.3.1. Spatial Attention Module
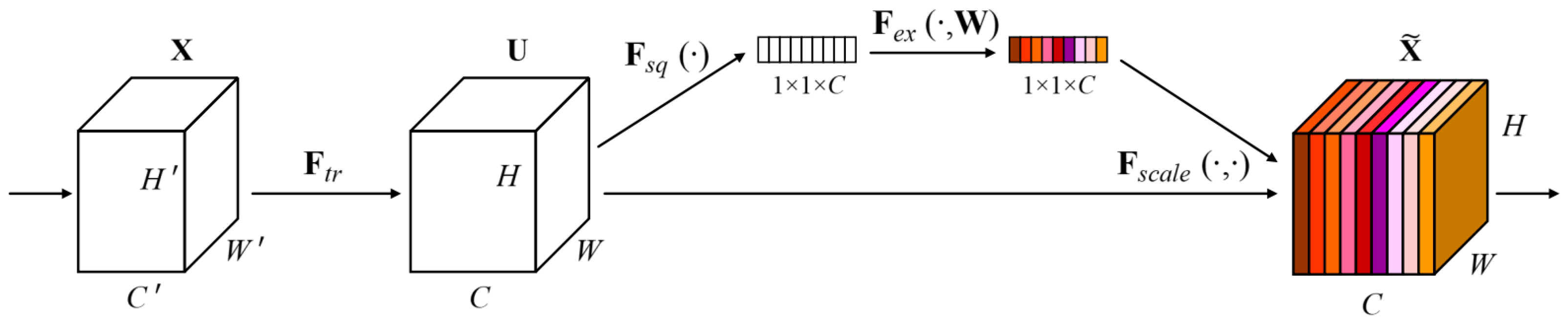
2.3.2. SE Attention Module
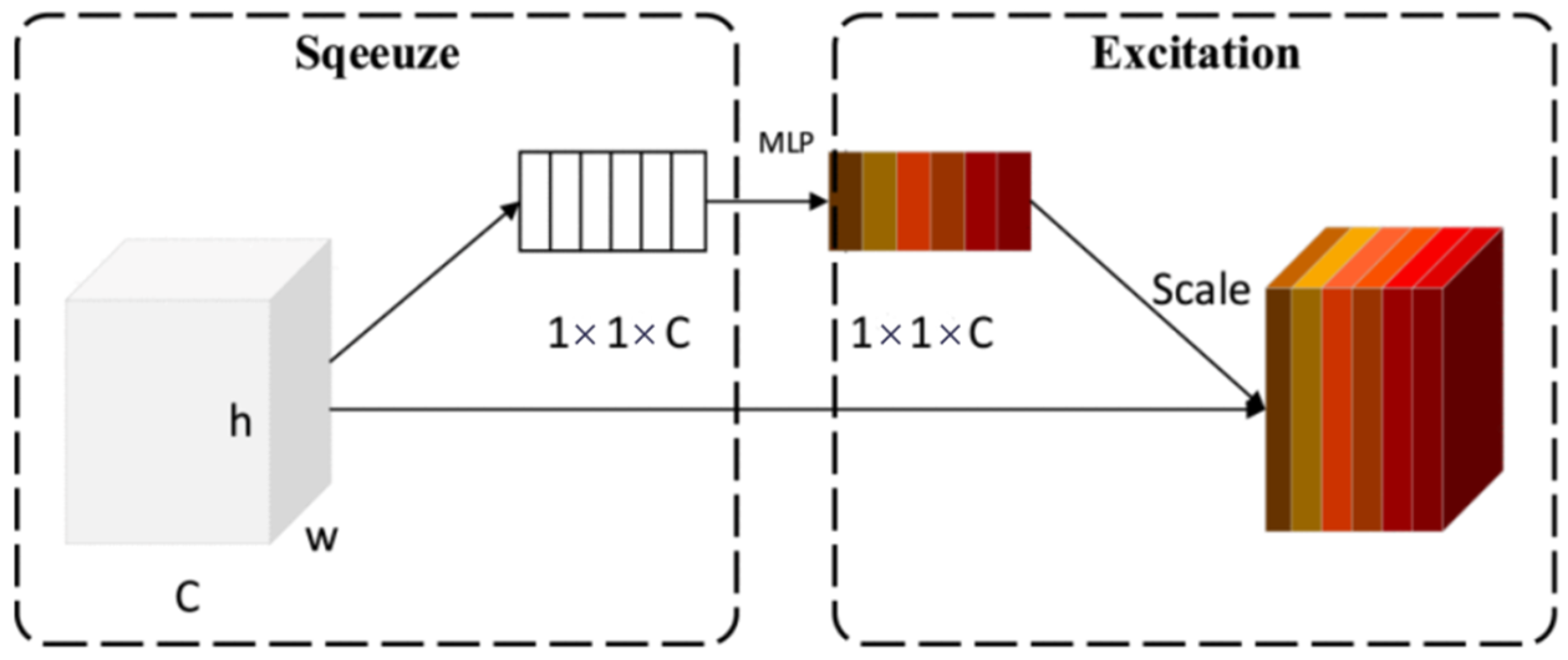
2.3.3. Channel Attention Module
3. Dataset and Results
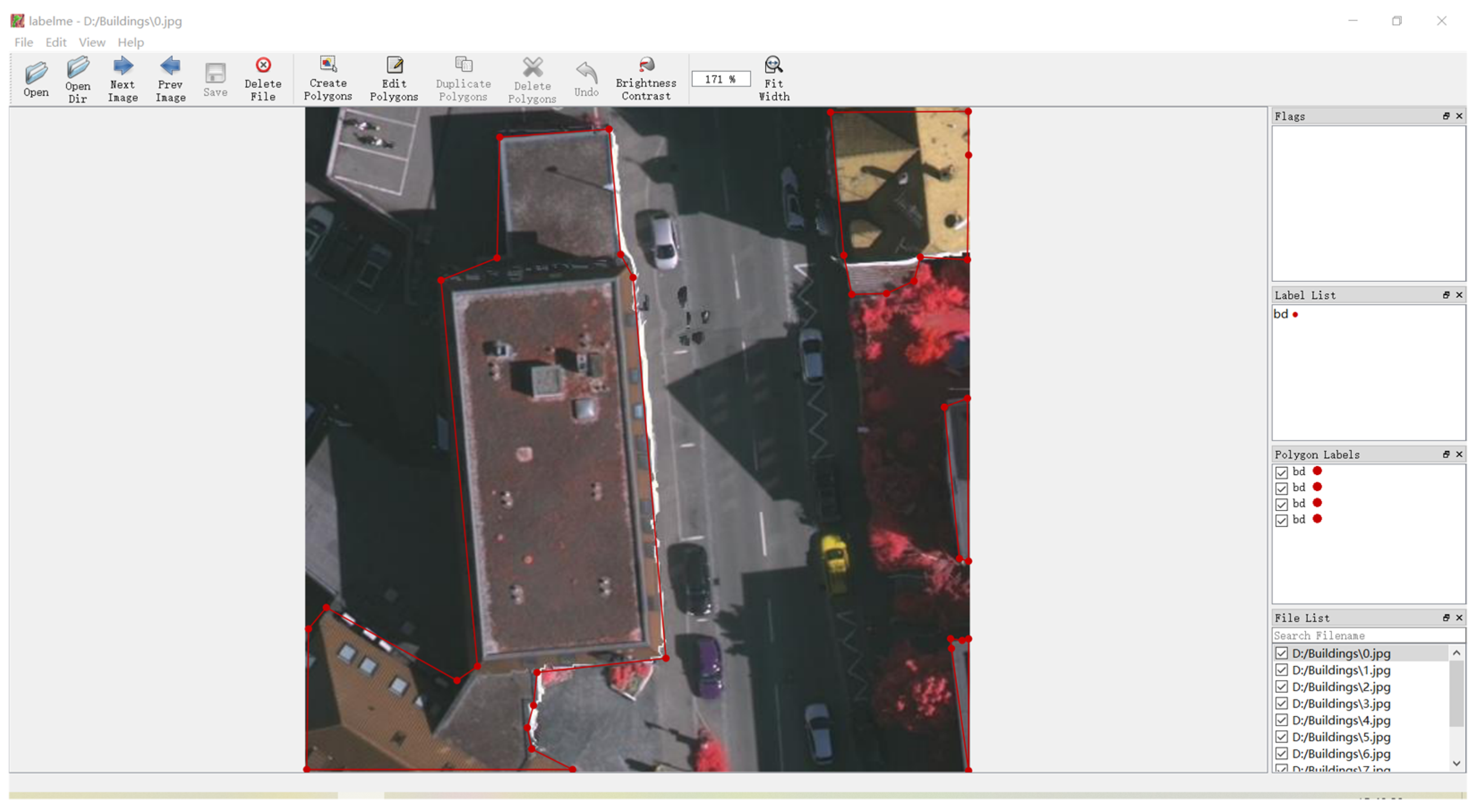
3.1. Datasets and Preprocessing
3.2. Experimental Environment and Evaluation Index
3.2.1. Experimental Environment
3.2.2. Model Evaluation Index
3.3. Experimental Results
3.3.1. Trunk Network Selection Comparative Experiment
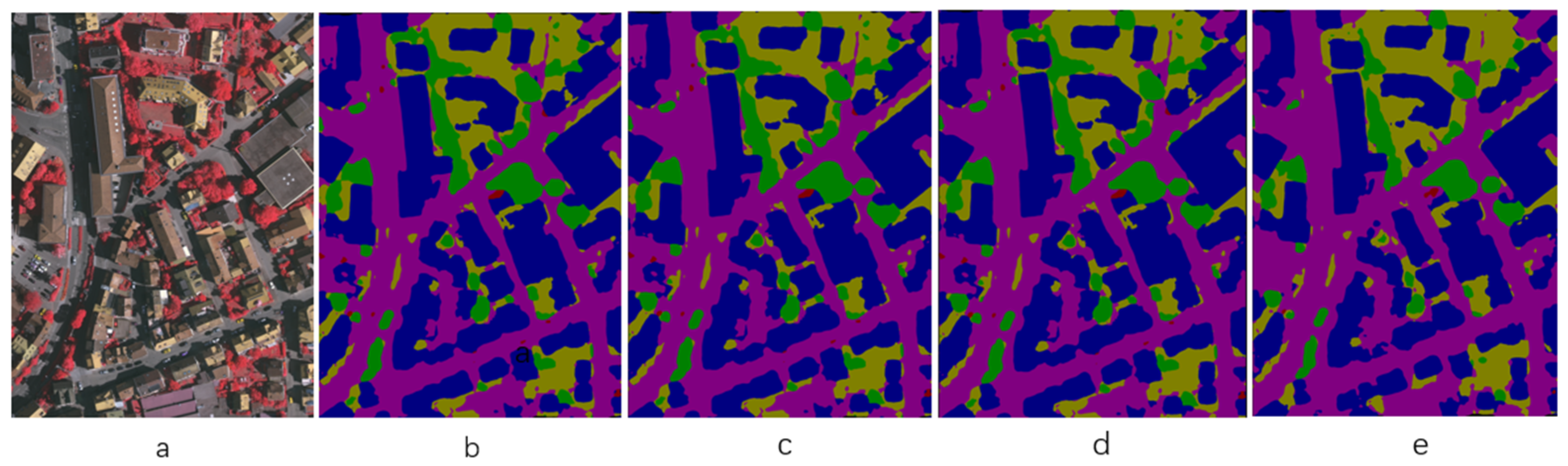
3.3.2. An Improved Experiment Based on Vgg+Unet Network
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bhargavi, K.; Jyothi, S. A survey on threshold based segmentation technique in image processing. Int. J. Innov. Res. Dev. 2014, 3, 234–239. [Google Scholar]
- Cai, H.; Yang, Z.; Cao, X.; Xia, W.; Xu, X. A new iterative triclass thresholding technique in image segmentation. IEEE Trans. Image Process. 2014, 23, 1038–1046. [Google Scholar] [CrossRef] [PubMed]
- Bieniek, A.; Moga, A. An efficient watershed algorithm based on connected components. Pattern Recognit. 2000, 33, 907–916. [Google Scholar] [CrossRef]
- Chien, S.Y.; Huang, Y.W.; Chen, L.G. Predictive watershed: A fast watershed algorithm for video segmentation. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 453–461. [Google Scholar] [CrossRef]
- Zhou, S.; Wang, J.; Zhang, S.; Liang, Y.; Gong, Y. Active contour model based on local and global intensity information for medical image segmentation. Neurocomputing 2016, 186, 107–118. [Google Scholar] [CrossRef]
- Wang, L.; Chang, Y.; Wang, H.; Wu, Z.; Pu, J.; Yang, X. An active contour model based on local fitted images for image segmentation. Inf. Sci. 2017, 418, 61–73. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. DeepUNet: A deep fully convolutional network for pixel-level sea-land segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic segmentation of urban buildings from VHR remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local attention embedding to improve the semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 426–435. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, W.; Deng, X.; Zhang, M.; Cheng, Q. Multilabel remote sensing image retrieval based on fully convolutional network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 318–328. [Google Scholar] [CrossRef]
- Li, H.; Qiu, K.; Chen, L.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic segmentation network with spatial and channel attention mechanism for high-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 905–909. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-resolution context extraction network for semantic segmentation of remote sensing images. Remote Sens. 2020, 13, 71. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention network for semantic segmentation of fine-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing swin transformer and convolutional neural network for remote sensing image semantic segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- Li, H.; Li, Y.; Zhang, G.; Liu, R.; Huang, H.; Zhu, Q.; Tao, C. Global and local contrastive self-supervised learning for semantic segmentation of HR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Xu, R.; Wang, C.; Zhang, J.; Xu, S.; Meng, W.; Zhang, X. Rssformer: Foreground saliency enhancement for remote sensing land-cover segmentation. IEEE Trans. Image Process. 2023, 32, 1052–1064. [Google Scholar] [CrossRef]
- Li, Y.; Chen, W.; Huang, X.; Gao, Z.; Li, S.; He, T.; Zhang, Y. MFVNet: A deep adaptive fusion network with multiple field-of-views for remote sensing image semantic segmentation. Sci. China Inf. Sci. 2023, 66, 140305. [Google Scholar] [CrossRef]
- Ma, Z.; Xia, M.; Lin, H.; Qian, M.; Zhang, Y. FENet: Feature enhancement network for land cover classification. Int. J. Remote Sens. 2023, 44, 1702–1725. [Google Scholar] [CrossRef]
- Li, X.; Xu, F.; Liu, F.; Lyu, X.; Tong, Y.; Xu, Z.; Zhou, J. A synergistical attention model for semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Chen, J.; Xia, M.; Wang, D.; Lin, H. Double branch parallel network for segmentation of buildings and waters in remote sensing images. Remote Sens. 2023, 15, 1536. [Google Scholar] [CrossRef]
- Song, P.; Li, J.; An, Z.; Fan, H.; Fan, L. CTMFNet: CNN and transformer multiscale fusion network of remote sensing urban scene imagery. IEEE Trans. Geosci. Remote Sens. 2022, 61, 1–14. [Google Scholar] [CrossRef]
- Fu, Y.; Zhang, X.; Wang, M. DSHNet: A Semantic Segmentation Model of Remote Sensing Images based on Dual Stream Hybrid Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4164–4175. [Google Scholar] [CrossRef]
- Pang, S.; Shi, Y.; Hu, H.; Ye, L.; Chen, J. PTRSegNet: A Patch-to-Region Bottom-Up Pyramid Framework for the Semantic Segmentation of Large-Format Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3664–3673. [Google Scholar] [CrossRef]
- Wang, M.; She, A.; Chang, H.; Cheng, F.; Yang, H. A deep inverse convolutional neural network-based semantic classification method for land cover remote sensing images. Sci. Rep. 2024, 14, 7313. [Google Scholar] [CrossRef]
- Li, H.; Li, L.; Zhao, L.; Liu, F. ResU-Former: Advancing Remote Sensing Image Segmentation with Swin Residual Transformer for Precise Global–Local Feature Recognition and Visual–Semantic Space Learning. Electronics 2024, 13, 436. [Google Scholar] [CrossRef]
- Xin, Y.; Fan, Z.; Qi, X.; Geng, Y.; Li, X. Enhancing Semi-Supervised Semantic Segmentation of Remote Sensing Images via Feature Perturbation-Based Consistency Regularization Methods. Sensors 2024, 24, 730. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, Y.; Dong, J.; Yu, B. A Knowledge Distillation-based Ground Feature Classification Network with Multiscale Feature Fusion in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 2347–2359. [Google Scholar] [CrossRef]
- Xie, J.; Pan, B.; Xu, X.; Shi, Z. MiSSNet: Memory-inspired Semantic Segmentation Augmentation Network for Class-Incremental Learning in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5607913. [Google Scholar] [CrossRef]
- Zhang, L.; Tan, Z.; Zhang, G.; Zhang, W.; Li, Z. Learn more and learn useful: Truncation Compensation Network for Semantic Segmentation of High-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4403814. [Google Scholar]
- Zhao, W.; Cao, J.; Dong, X. Multilateral Semantic with Dual Relation Network for Remote Sensing Images Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 506–518. [Google Scholar] [CrossRef]
- Liu, J.; Hua, W.; Zhang, W.; Liu, F.; Xiao, L. Stair Fusion Network with Context Refined Attention for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4701517. [Google Scholar] [CrossRef]
- Bai, Q.; Luo, X.; Wang, Y.; Wei, T. DHRNet: A Dual-branch Hybrid Reinforcement Network for Semantic Segmentation of Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 4176–4193. [Google Scholar] [CrossRef]
- Kumar, S.; Kumar, A.; Lee, D.G. RSSGLT: Remote Sensing Image Segmentation Network based on Global-Local Transformer. IEEE Geosci. Remote Sens. Lett. 2023, 21, 8000305. [Google Scholar] [CrossRef]
- Wang, W.; Ran, L.; Yin, H.; Sun, M.; Zhang, X.; Zhang, Y. Hierarchical Shared Architecture Search for Real-time Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–13. [Google Scholar] [CrossRef]
- Ullah, A.; Elahi, H.; Sun, Z.Y.; Khatoon, A.; Ahmad, I. Comparative Analysis of AlexNet, ResNet18 and SqueezeNet with Diverse Modification and Arduous Implementation. Arab. J. Sci. Eng. 2022, 47, 2397–2417. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention, Proceedings of the MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. SCA-CNN: Spatial and Channel-Wise Attention in Convolutional Networks for Image Captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6298–6306. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Semantic Information | ID | RGB Channel Value |
|---|---|---|
| Background | 0 | (RGB: 255, 0, 0) |
| Car | 1 | (RGB: 255, 255, 0) |
| Tree | 2 | (RGB: 0, 255, 0) |
| Low vegetation | 3 | (RGB: 0, 255, 255) |
| Building | 4 | (RGB: 0, 0, 255) |
| Impervious surface | 5 | (RGB: 255, 255, 255) |
| Disposition | Model |
|---|---|
| CPU model | Intel® Core™ i5-10400 CPU:Santa Clara, CA, USA |
| GPU version | NVIDIA GeForce RTX 2060: Santa Clara, CA, USA |
| Hard disk | Kingston SA2000M8500G (A2000 NVMe PCIe SSD):Fountain Valley, CA, USA |
| Main board | N9x0SD2 |
| python | 3.9 |
| torch | 2.3.0 |
| CUDA | 12.4 |
| Argument | Value |
|---|---|
| batch size | 4 |
| epoch | 20 |
| Input size | 512 × 512 |
| Init_lr | 0.0001 |
| optimizer_type | adam |
| momentum | 0.9 |
| num_classes | 6 |
| Model | MPA | MIoU |
|---|---|---|
| Resnet50+Unet | 53.59 | 42.95 |
| Unet | 71.85 | 59.44 |
| Vgg+Unet | 87.12 | 75.83 |
| Attention Mechanism | MPA | MIoU | Accuracy |
|---|---|---|---|
| Vgg+Unet | 87.12 | 75.83 | 90.12 |
| Spatial | 87.77 | 79.35 | 90.28 |
| SE | 88.66 | 79.23 | 90.58 |
| Channel | 87.87 | 80.65 | 91.26 |
| Attention Mechanism | MPA | MIoU | Accuracy |
|---|---|---|---|
| Vgg+Unet | 87.12 | 75.83 | 90.12 |
| Spatial | 86.72 | 78.44 | 89.49 |
| SE | 87.36 | 78.19 | 89.95 |
| Channel | 87.57 | 79.40 | 90.46 |
| Network | Vgg | Channel | CE_Loss | MPA | MIoU | Accuracy |
|---|---|---|---|---|---|---|
| 71.85 | 59.44 | 79.84 | ||||
| √ | 87.12 | 75.83 | 90.12 | |||
| U-Net | √ | √ | 87.57 | 79.40 | 90.46 | |
| √ | √ | 72.38 | 72.38 | 89.41 | ||
| √ | √ | √ | 87.87 | 80.65 | 91.26 |
| Semantic Information | Number of Pixels | Percentage of Surface |
|---|---|---|
| Impervious surface | 13,704 | 0.20% |
| Car | 21,243 | 0.32% |
| Tree | 1,380,016 | 20.54% |
| Low vegetation | 1,786,765 | 26.60% |
| Building | 1,601,524 | 23.84% |
| Background | 1,915,024 | 28.50% |
| Semantic Information | Number of Pixels | Percentage of Surface |
|---|---|---|
| Impervious surface | 6927 | 0.14% |
| Car | 37,879 | 0.79% |
| Tree | 174,257 | 3.61% |
| Low vegetation | 176,063 | 3.65% |
| Building | 3,433,466 | 71.16% |
| Background | 996,467 | 20.65% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Wu, J.; Xie, H.; Xiao, D.; Ran, M. Semantic Segmentation of Urban Remote Sensing Images Based on Deep Learning. Appl. Sci. 2024, 14, 7499. https://doi.org/10.3390/app14177499
Liu J, Wu J, Xie H, Xiao D, Ran M. Semantic Segmentation of Urban Remote Sensing Images Based on Deep Learning. Applied Sciences. 2024; 14(17):7499. https://doi.org/10.3390/app14177499
Chicago/Turabian StyleLiu, Jingyi, Jiawei Wu, Hongfei Xie, Dong Xiao, and Mengying Ran. 2024. "Semantic Segmentation of Urban Remote Sensing Images Based on Deep Learning" Applied Sciences 14, no. 17: 7499. https://doi.org/10.3390/app14177499
APA StyleLiu, J., Wu, J., Xie, H., Xiao, D., & Ran, M. (2024). Semantic Segmentation of Urban Remote Sensing Images Based on Deep Learning. Applied Sciences, 14(17), 7499. https://doi.org/10.3390/app14177499