
A Novel Malware Detection Model in the Software Supply Chain Based on LSTM and SVMs


Abstract
1. Introduction
- (1)
- The BO-SVM model is innovatively applied to address the malware classification problem in the SSC. Through optimization of the hyperparameters of the SVM model, this model can significantly improve the efficiency and accuracy of the SVM model.
- (2)
- A novel LSTM-BO-SVM model is also proposed for malware detection in the SSC. This model further improves the BO-SVM accuracy and reliability. By adopting the temporal analysis capability of the LSTM network a priori, the multidimensional features of malware can be captured. Based on these, the BO-SVM performance can be enhanced.
- (3)
- Expensive experiments are conducted in order to comprehensively evaluate the performance of the BO-SVM model and the LSTM-BO-SVM model. The experimental results verify the high efficiency and robustness.
2. Related Work
3. Technical Overview
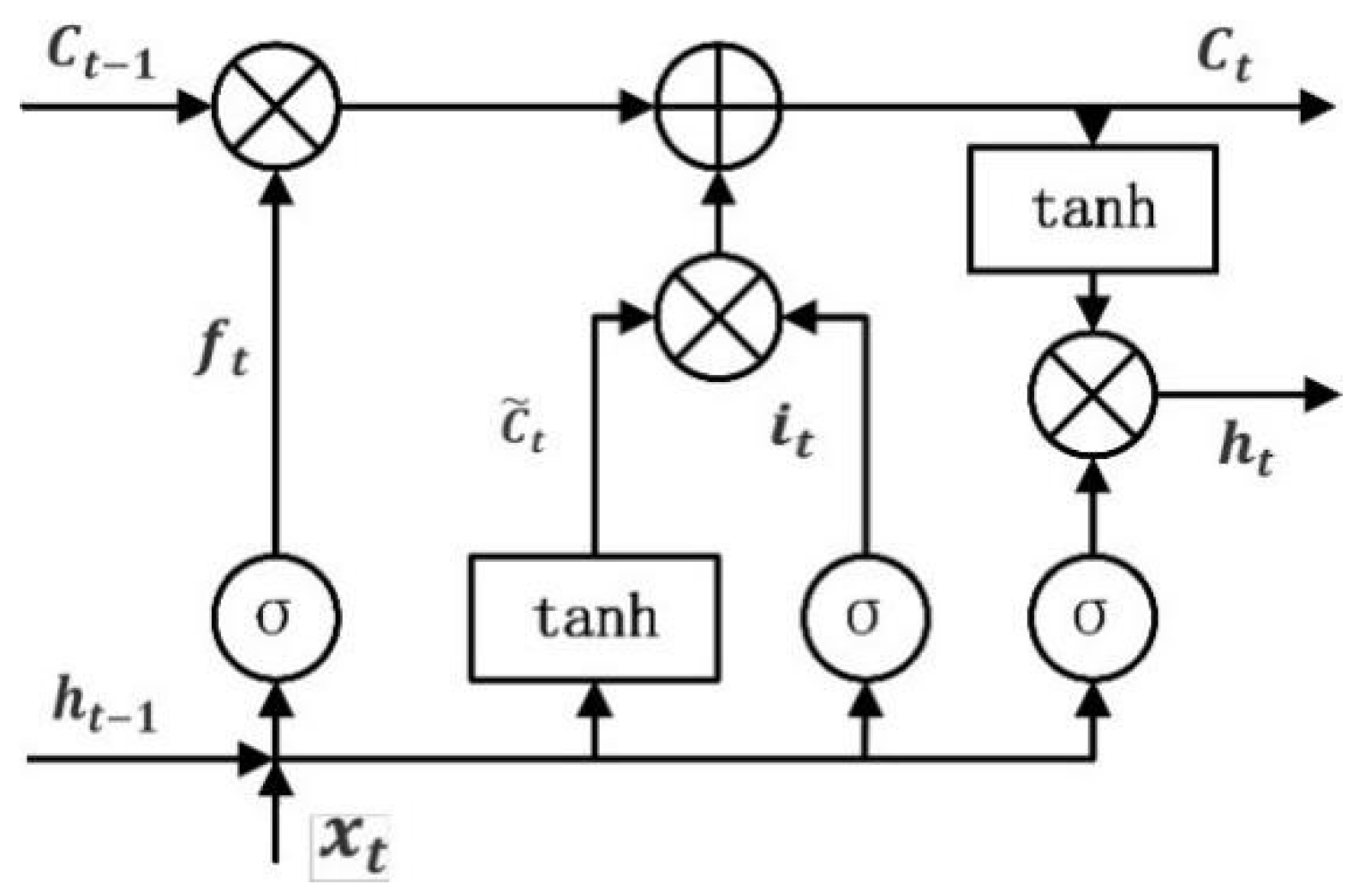
3.1. Long Short-Term Memory Network
- Forget Gate: Decides which data to discard from the cell state.
- Input Gate: Determines what fresh data to store in the cell state.
- Output Gate: Decides what data to output from the cell state.
3.2. Support Vector Machines
3.3. Bayesian Optimization
- Probabilistic Surrogate Model Selection: At each iteration, a surrogate model is chosen to approximate the objective function. Common surrogate models include Gaussian process (GP) regression and RF, among others. In this paper, GP regression is selected as the surrogate model, the expression of which is detailed in Equation (6).In Equation (6), the mean function represents the mathematical expectation of the data sample. is the covariance function.
- Sampling Strategy Selection: The subsequent sample point is selected by evaluating the uncertainty or the confidence level within the surrogate model. This iterative process is referred to as the sampling strategy. Well-established sampling strategies encompass the Gaussian process upper confidence bound and the Expected Improvement (EI), among others. In this paper, EI is utilized as the sampling strategy, with its functional form delineated in Equation (7).In Equation (7), represents the function value of the sampling point, represents the maximum value in the searched points, , is the distribution function of the standard normal distribution, and is the probability density function of the standard normal distribution.
- Surrogate Model Update: The surrogate model is refined by new candidate solutions, which include both actual observations of the objective function and a collection of previous candidate solutions.
- Iteration: The process iterates by repeating steps 2 and 3 until a pre-specified number of iterations is reached or the desired objective is achieved. The optimal candidate solution and its corresponding optimal value of the objective function are then identified as the outputs.
4. Proposed SSC Malware Detection Model
4.1. The Construction of the BO-SVM Model
- Input the malware dataset D: Select the malware dataset as the input. The dataset D is defined as a matrix, where each line is denoted as , wherein represents each line, each feature, and c the label.
- Data preprocessing D: The primary tasks of the preprocessing of the data in this research are to handle missing values and software feature outliers. After that, the data are standardized.
- Split the malware dataset: The processed data are divided into a training set T1 and a test set S1.
- Dimensionality reduction: Apply PCA to the training set T1 and the test set S1. The T1 is defined as a matrix and the S1 is defined as a matrix, wherein The same parameters are used for the PCA algorithm to maintain the consistency of the data. Generate the training set T2 and test set S2 after dimension reduction. The T2 is defined as a matrix, where each line is denoted as , wherein, . The test set S2 is defined as a matrix.
- Initialize the SVM model: Initialize the SVM model with the default hyperparameters and .
- Generate the candidate solution space P: Generate the candidate solution space P for the hyperparameters and by defining the parameter search range.
- Update the P: Add new candidate solutions to the P after each iteration, and input all candidate solutions in the set into the GP regression model.
- Perform GP regression calculation: The GP regression model shown in Equation (6) is used to calculate the function values and probability distributions for all candidate solutions. That is, the confidence of each candidate solution is obtained.
- Generate new candidate solutions: A new candidate solution is generated using the EI sampling strategy shown in Equation (7). The EI sampling strategy uses the resulting confidence to determine the next candidate solution to evaluate.
- Fit the SVM model: Use the new candidate solution as hyperparameters and to fit the SVM model. Then, calculate the accuracy of the current SVM model.
- Make a judgment: Determine whether the stopping criterion is reached (the optimized model accuracy or the number of iterations approach the threshold). If it is met, carry out step 12; otherwise, go back to step 7.
- Evaluate the BO-SVM model: First, select a candidate solution with the highest accuracy as the hyperparameters and . Then, test the trained BO-SVM model using the test set S2 to check if it meets the criteria (whether the accuracy is up to the required level). If it does, proceed to the next step; otherwise, go back to step 5 to retrain the model.
- Obtain the optimal SVM model: After the above steps, the optimized model BO-SVM is achieved.
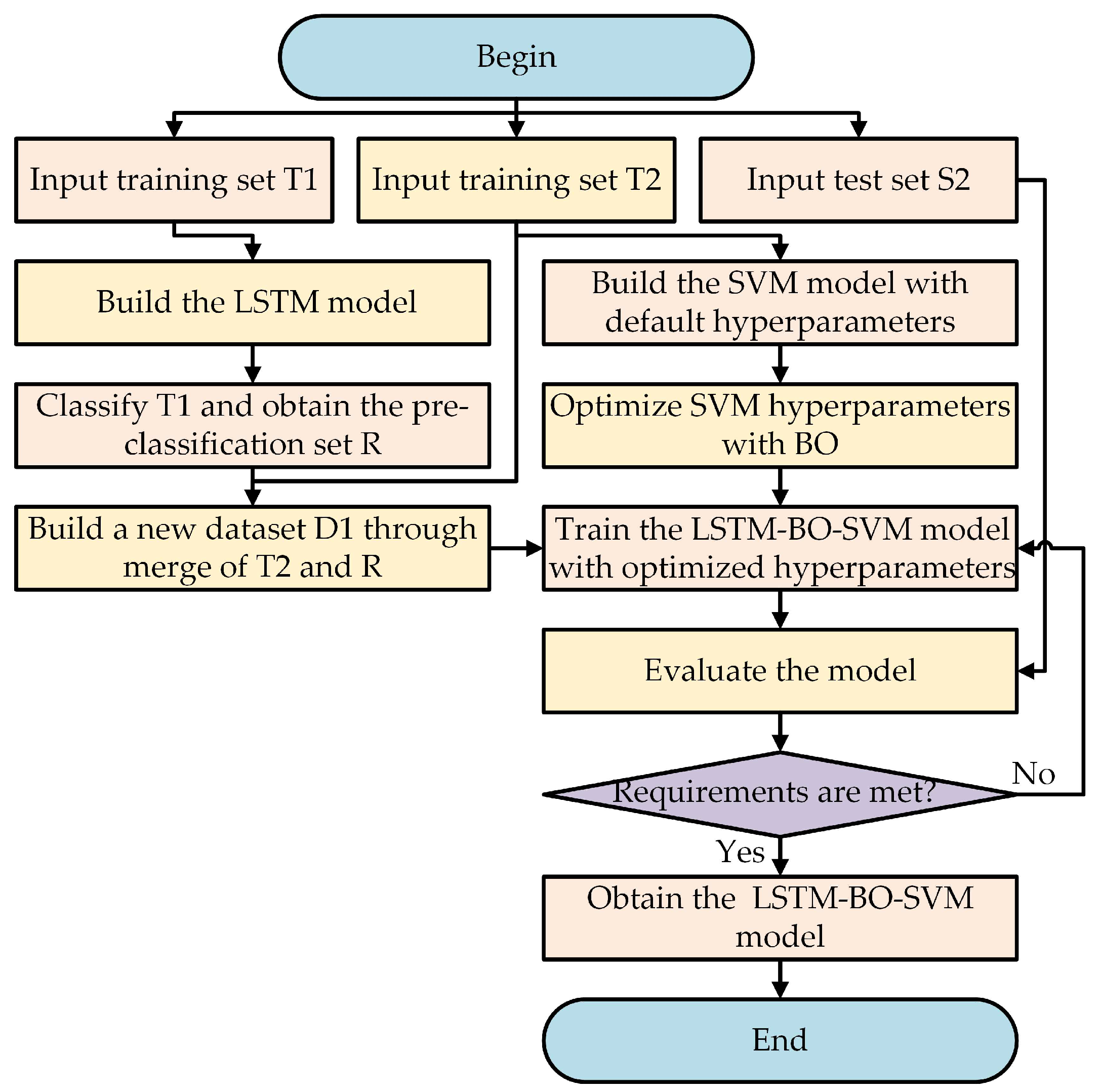
4.2. The Construction of the LSTM-BO-SVM Model
- Input: The T1, T2, and S2 datasets are input into the model.
- Build the LSTM model: An initialized LSTM model is first built, and then the LSTM model is trained using the training set T1. The specific establishment process of the LSTM model is shown in Section 4.3.
- Classify T1 and obtain the pre-classification set R: Use the trained LSTM model to pre-classify the training set T1 and obtain the pre-classification set R. The R is defined as a matrix, where each line is denoted as and wherein represents the pre-classification label.
- Build a new dataset D1: Merge the training set T2 with the pre-classification set R to form a new training set D1. The training set D1 is defined as a matrix, where each line is denoted as Specifically, the column in R is added to the training set T2 as a new feature column.
- Build the SVM model: Build an SVM model with default hyperparameters and initialize the BO algorithm.
- Optimize the SVM hyperparameters with BO: The BO algorithm is used to optimize the Gaussian kernel parameter and penalty factor in the SVM model to obtain the optimal parameters, and the optimal parameters are transferred to the SVM model to obtain the BO-SVM model.
- Train the LSTM-BO-SVM model with optimized hyperparameters: The LSTM-BO-SVM model is trained using the training set D1, and the training is saved.
- Evaluate the model: The test set S2 is used to evaluate the classification performance of the LSTM-BO-SVM model. If the requirements (the accuracy is up to the requirement) are met, proceed to the next step; otherwise, go back to step 7 to retrain the model.
- Obtain the optimal LSTM-BO-SVM model: After the above steps, the optimized model LSTM-BO-BO-SVM is achieved.
4.3. The Construction of the LSTM Model
- Input: The T1 and S1 datasets are input into the model.
- Split the T1: Divide the T1 into a validation set V1 and a training set .
- Train the LSTM model: Train the LSTM model using the and V1 datasets. During the training process, the model parameters are constantly adjusted to obtain the optimal parameters.
- Evaluate the model with V1: Use the test set V1 to assess the model’s performance. Determine whether the stopping criterion is reached (training rounds or model accuracy reaches a threshold), and if so, proceed to step 5; otherwise, go back to step 3.
- Obtain the trained LSTM model: After the above steps, obtain a trained LSTM model.
- Obtain the software pre-classification set R: Input the training set T1 into the trained LSTM model to obtain the pre-classification results of T1 and form the set R.
5. Experimental Results and Analysis
5.1. Experimental Dataset
5.2. Data Preprocessing
5.2.1. Data Preprocessing for ClaMP Dataset
- Firstly, all features need to be of a numerical type in order to be recognized by ML algorithms. As a unique characteristic feature in ClaMP, “Packing type” was converted into a numerical feature using the factorize() function from the Pandas library.
- The StandardScaler() function was called in the Scikit-learn library to normalize the data in ClaMP.
- The PCA technique was utilized to select the first 20 principal features of the ClaMP dataset, with the aim of lowering the original dataset’s dimensionality while retaining more data variability.
- After randomly disrupting the dataset, random sampling was executed to divide it into an 80% training set and a 20% testing set.
5.2.2. Data Preprocessing for CICMalDroid-2020 Dataset
- Considering that some features in the dataset are called with high frequency, with a maximum value of 3,697,410, the value may shrink to close to zero after normalization, which may affect the classification accuracy. To alleviate this issue, we set values above 10,000 in this article to 10,000 before applying StandardScaler() for normalization.
- Considering that binary classification is the main topic of this paper, i.e., distinguishing benign software and malware, this paper selectively used SMS malware samples and benign software samples in the dataset. Finally, the resulting dataset of 5699 samples contained 1795 benign software samples and 3904 malware samples.
- The first 40 principal components from the CICMalDroid-2020 dataset were selected using the PCA technique to enhance the model’s performance.
- The dataset was randomly disrupted and then random sampling was used to divide it into an 80% training set and a 20% test set.
5.3. Evaluation Metrics
- Training time [23]: The training time was measured by timing the time from when the model initiated training until the training process was completely finished, and was determined by calculating the difference between these two time points.
- Detection time [23]: The detection time was measured by timing from the moment the model initiated detection until the detection process was completely finished, and was determined by calculating the difference between these two time points.
- Computation time [23]: The computational time is the sum of the model training time and the detection time.
- Accuracy [14]: Accuracy represents the proportion of accurately predicted samples to all samples. It is a simple and intuitive metric to evaluate the ability of a model to correctly classify examples. As shown in Equation (8):In the formula, (Negatives) represents the malware label, while (Positives) stands for benign software. represents the software with true and predicted ; represents the software with true and predicted ; represents the software with true and predicted ; and represents the software with true and predicted .
- Precision [14]: Precision is the percentage of samples that, when all samples are predicted by the model to be positive categories, are actually positive categories. This is shown in Equation (9).
- Recall rate [14]: Recall rate is used to measure how many of the true positive class samples the model correctly predicted as positive. This is shown in Equation (10).
- F1-Score [14]: F1-Score is used to assess how well a classification model is performing and overall consideration for both precision and recall rate. Equation (11) illustrates how it is calculated.
5.4. Experimental Results and Analysis
5.4.1. Evaluation of BO-SVM Efficiency
- Basic SVM model: SVM model with default parameter settings.
- ACO-SVM model: SVM model optimized based on the Ant Colony Optimization (ACO) algorithm.
- PSO-SVM model: SVM model optimized based on the PSO algorithm.
- BO-DT model: A Decision Tree (DT) model optimized based on the BO algorithm.
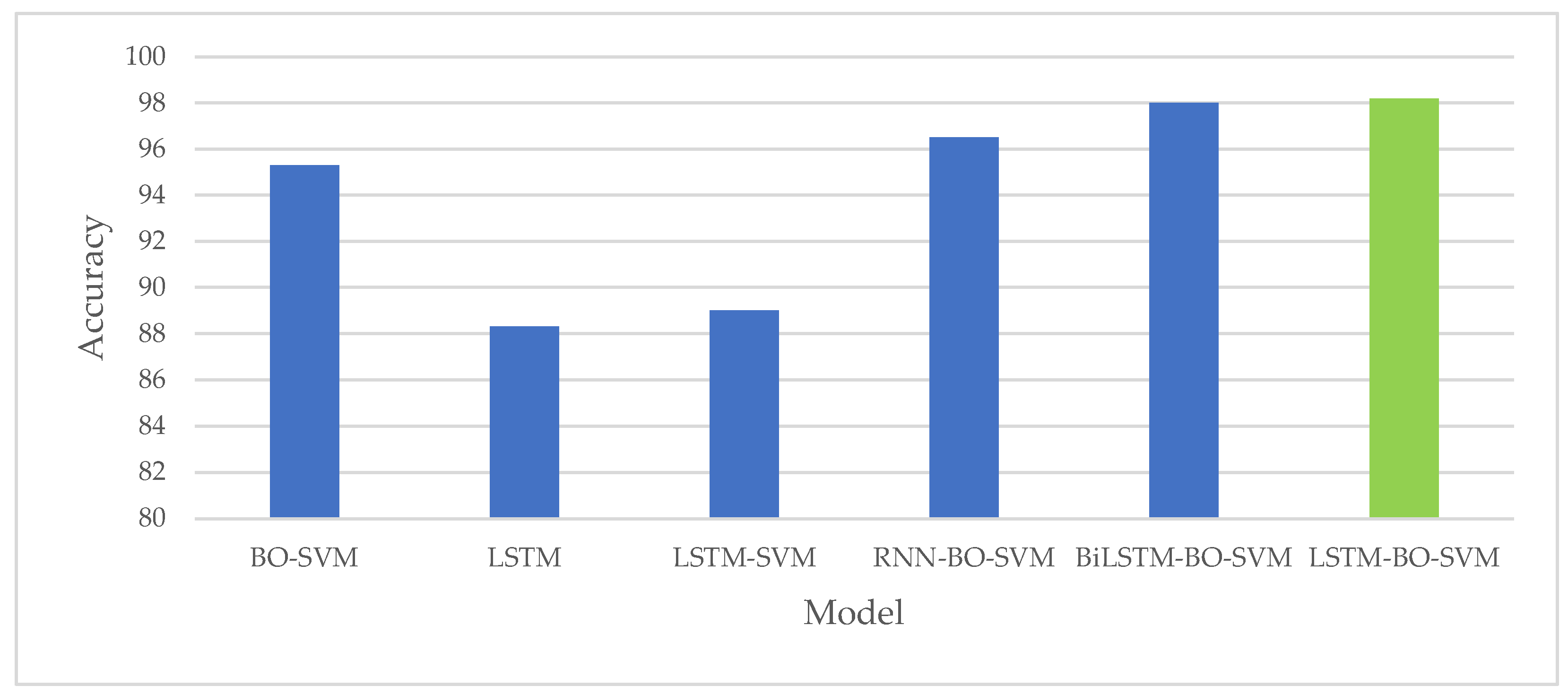
5.4.2. Evaluation of LSTM-BO-SVM Model Efficiency
- RNN-BO-SVM model: First, use an RNN for pre-classification, and then use the BO algorithm to optimize the SVM model; finally, use the optimized SVM model to complete the classification.
- BiLSTM-BO-SVM model: First, use Bidirectional Long Short-Term Memory (BiLSTM) for pre-classification, and then use the BO algorithm to optimize the SVM model; finally, use the optimized SVM model to complete the final classification.
- BO-SVM model: First, use the BO to optimize the SVM model, and then use the optimized SVM model to complete the final classification.
- LSTM-SVM model: First, use the LSTM model for pre-classification, and then use the SVM model to complete the classification.
- Basic LSTM model: Use the LSTM model alone to complete the final classification.
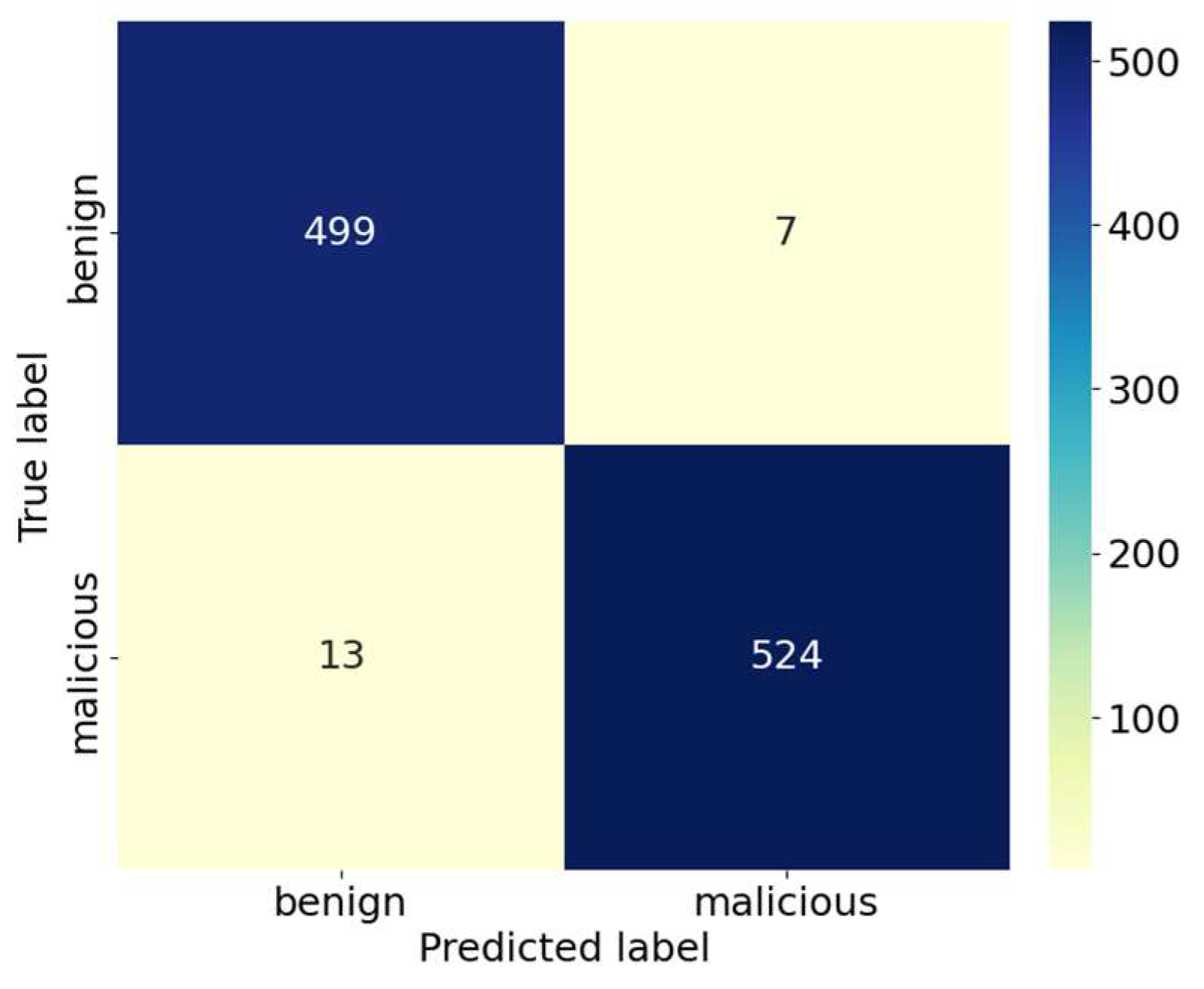
- Confusion matrix
- 2.
- Accuracy Comparison
- 3.
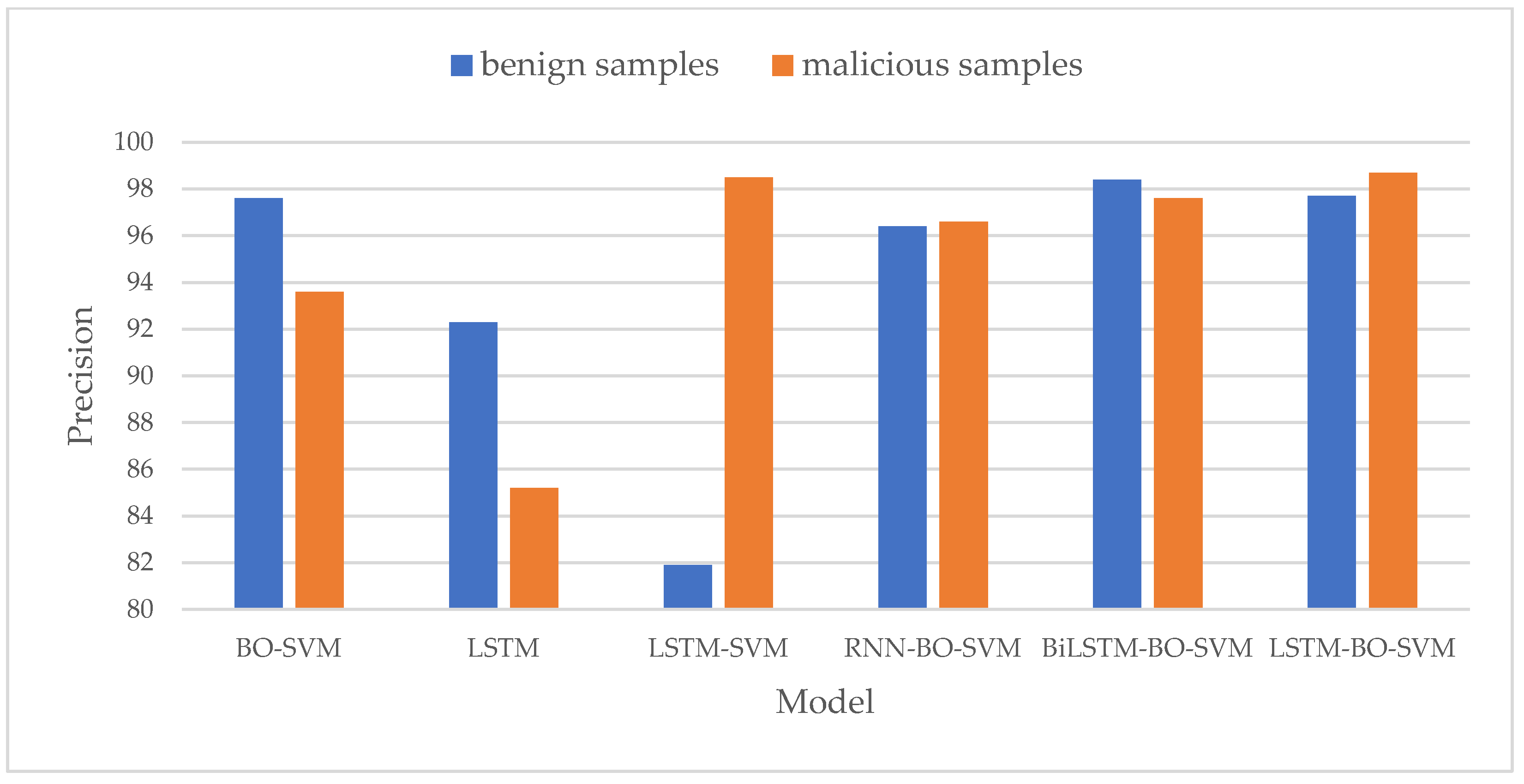
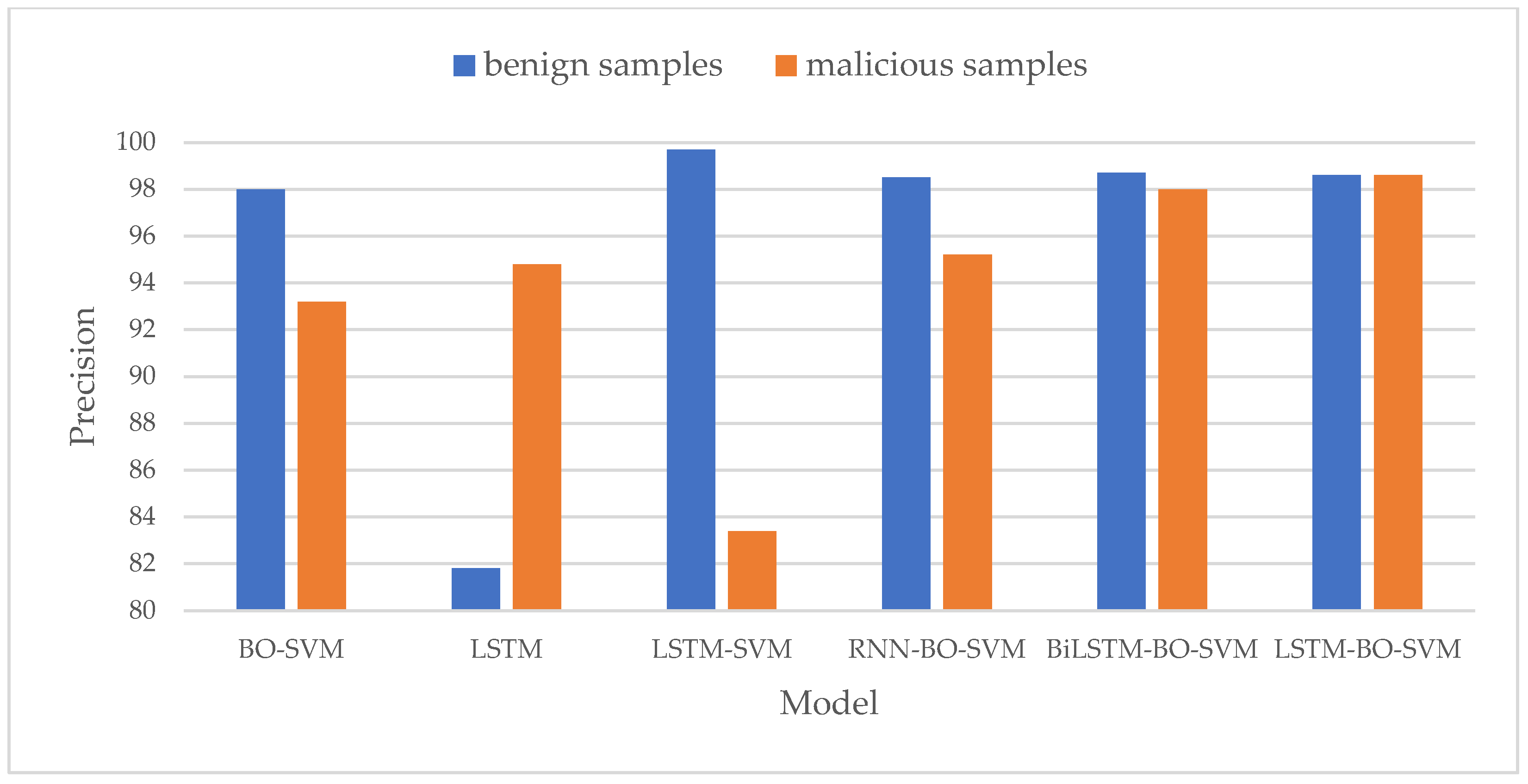
- Precision Comparison
- 4.
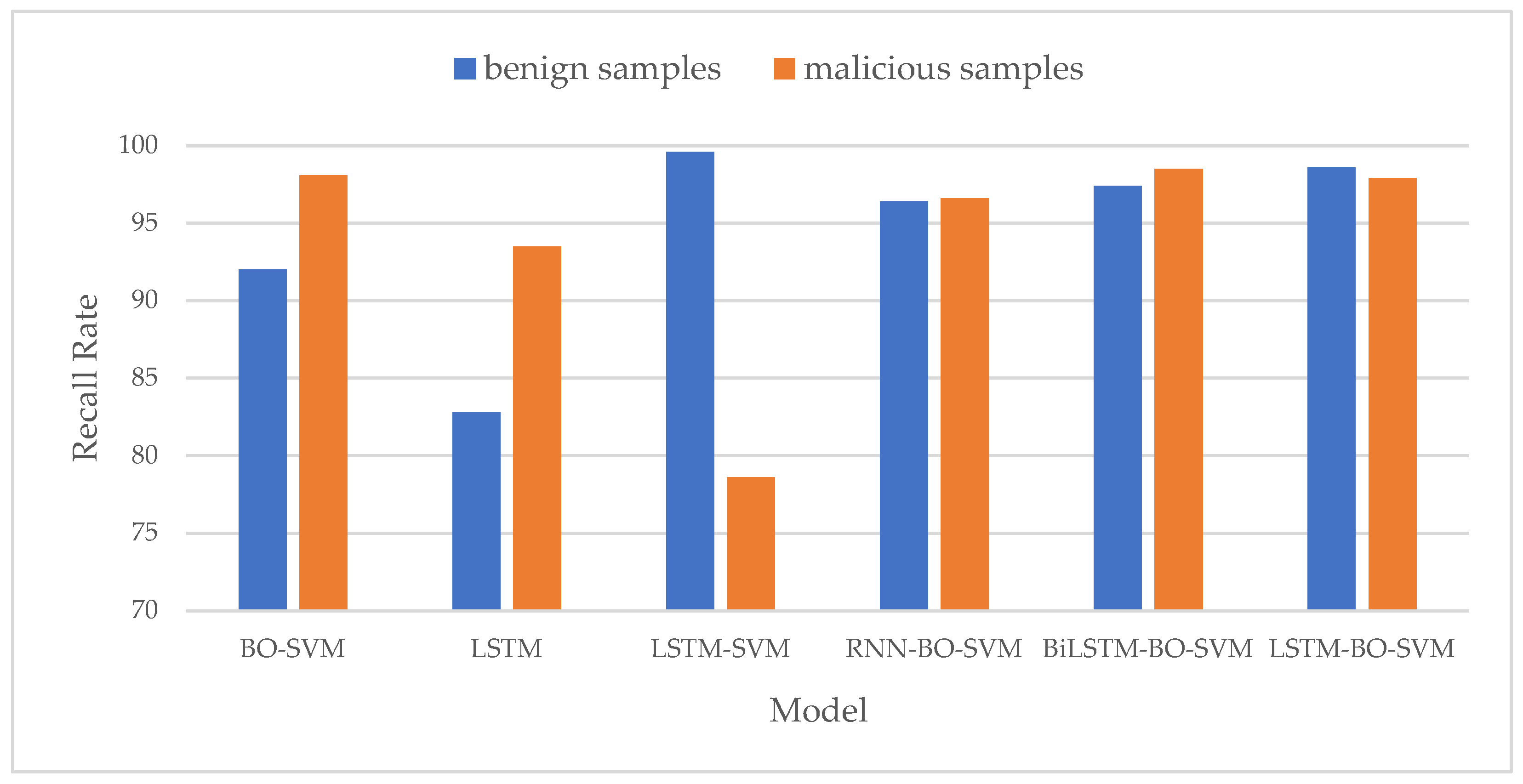
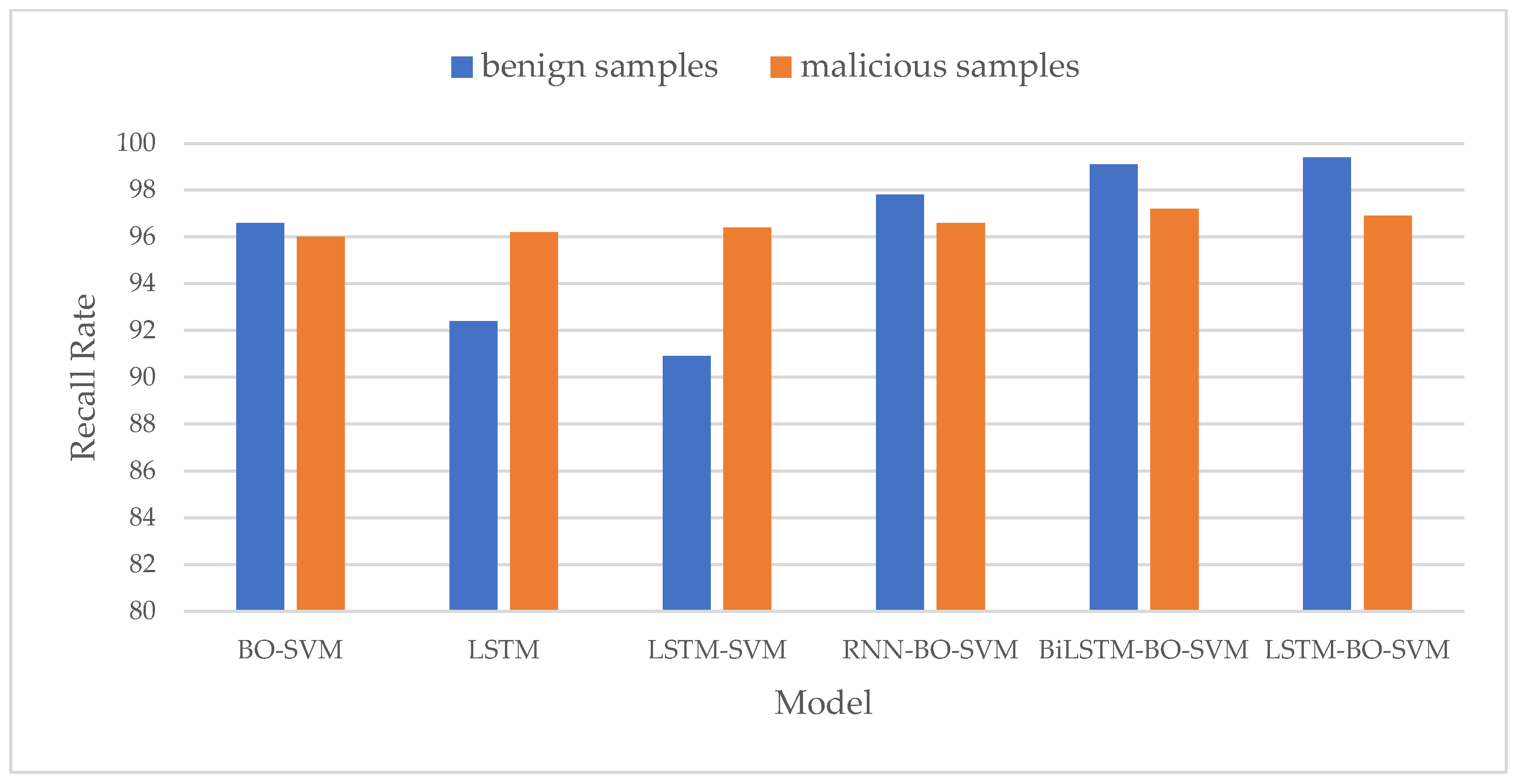
- Recall Rate Comparison
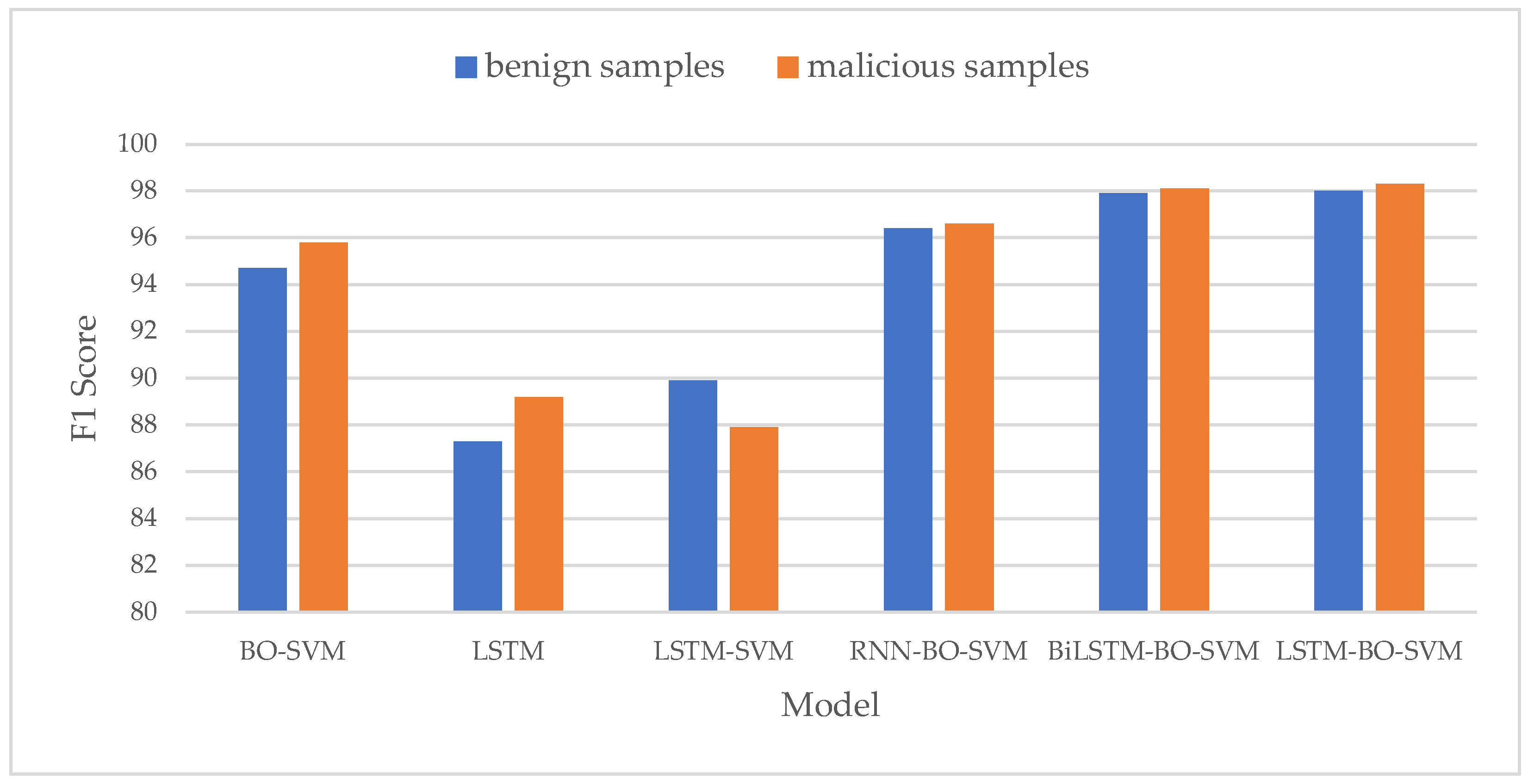
- 5.
- F1-Score Comparison
- 6.
- Training and Detection Time Comparison
- 7.
- Comparison with Related Work
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ji, S.; Wang, Q.; Chen, A.; Zhao, B.; Ye, T.; Zhang, X.; Wu, J.; Li, J.; Yi, J.; Wu, Y. Open-source software supply chain security research review. J. Softw. 2023, 3, 1330–1364. [Google Scholar]
- Masum, M.; Nazim, M.; Faruk, M.J.H.; Shahriar, H.; Valero, M.; Khan, M.A.H.; Uddin, G.; Barzanjeh, S.; Saglamyurek, E.; Rahman, A. Quantum machine learning for software supply chain attacks: How far can we go? In Proceedings of the 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC), Los Alamitos, CA, USA, 27 June–1 July 2022; pp. 530–538. [Google Scholar]
- Sonatype. 2020 State of the Software Supply Chain. Available online: https://www.globenewswire.com/ (accessed on 8 July 2024).
- Sonicwall. Sonicwall Cyber Threat Report. Available online: https://www.sonicwall.com/medialibrary/en/white-paper/2023-cyber-threat-report.pdf (accessed on 6 July 2023).
- Aslan, Ö.A.; Samet, R. A comprehensive review on malware detection approaches. IEEE Access 2020, 8, 6249–6271. [Google Scholar] [CrossRef]
- Liu, Z.W.C. Malware code classification based on multi-feature fusion BiLSTM. Electronics 2022, 18, 67–72. [Google Scholar]
- Taheri, R.; Javidan, R.; Shojafar, M.; Pooranian, Z.; Miri, A.; Conti, M. On defending against label flipping attacks on malware detection systems. Neural Comput. Appl. 2020, 32, 14781–14800. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Lin, Y.; Li, H.; Zhang, J. A novel method for malware detection on ML-based visualization technique. Comput. Secur. 2020, 89, 101682. [Google Scholar] [CrossRef]
- Jahangir, M.T.; Wakeel, M.; Asif, H.; Ateeq, A. Systematic Approach to Analyze the Avast IOT-23 Challenge Dataset for Malware Detection Using Machine Learning. In Proceedings of the 2023 18th International Conference on Emerging Technologies (ICET), Peshawar, Pakistan, 6–7 November 2023; pp. 234–239. [Google Scholar]
- Xiong, S.; Zhang, H. A Multi-model Fusion Strategy for Android Malware Detection Based on Machine Learning Algorithms. J. Comput. Sci. Res. 2024, 6, 1–11. [Google Scholar] [CrossRef]
- Akhtar, M.S.; Feng, T. Detection of malware by deep learning as CNN-LSTM machine learning techniques in real time. Symmetry 2022, 14, 2308. [Google Scholar] [CrossRef]
- Hosseini, S.; Nezhad, A.E.; Seilani, H. Android malware classification using convolutional neural network and LSTM. J. Comput. Virol. Hacki. 2021, 17, 307–318. [Google Scholar] [CrossRef]
- Kim, J.; Ban, Y.; Ko, E.; Cho, H.; Yi, J.H. MAPAS: A practical deep learning-based android malware detection system. Int. J. Inf. Secur. 2022, 21, 725–738. [Google Scholar] [CrossRef]
- Hemalatha, J.; Roseline, S.A.; Geetha, S.; Kadry, S.; Damaševičius, R. An efficient densenet-based deep learning model for malware detection. Entropy 2021, 23, 344. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Ma, L.; Yang, W.; Zhong, Y. A method for windows malware detection based on deep learning. J. Signal. Process Sys. 2021, 93, 265–273. [Google Scholar] [CrossRef]
- Di Mauro, M.; Galatro, G.; Liotta, A. Experimental review of neural-based approaches for network intrusion management. IEEE Trans. Netw. Serv. 2020, 17, 2480–2495. [Google Scholar] [CrossRef]
- Dong, S.; Xia, Y.; Peng, T. Network abnormal traffic detection model based on semi-supervised deep reinforcement learning. IEEE Trans. Netw. Serv. 2021, 18, 4197–4212. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V. A novel machine learning approach for detecting first-time-appeared malware. Eng. Appl. Artif. Intel. 2024, 131, 107801. [Google Scholar] [CrossRef]
- Zhao, M.; Zhang, X.; Zhu, W.; Zhu, S. Malware detection method based on LSTM-SVM model. J. East China Univ. Sci. Technol. 2022, 48, 677–864. [Google Scholar]
- Damaševičius, R.; Venčkauskas, A.; Toldinas, J.; Grigaliūnas, Š. Ensemble-based classification using neural networks and machine learning models for windows pe malware detection. Electronics 2021, 10, 485. [Google Scholar] [CrossRef]
- Pardhi, P.R.; Rout, J.K.; Ray, N.K.; Sahu, S.K. Classification of malware from the network traffic using hybrid and deep learning based approach. SN Comput. Sci. 2024, 5, 162. [Google Scholar] [CrossRef]
- Laghrissi, F.; Douzi, S.; Douzi, K.; Hssina, B. Intrusion detection systems using long short-term memory (LSTM). J. Big Data 2021, 8, 65. [Google Scholar]
- Feng, R.; Chen, Z.; Yi, S. Research on maize variety identification based on Bayesian optimization SVM. Spectrosc. Spectr. Anal. 2022, 42, 1698–1703. [Google Scholar]
- Kurani, A.; Doshi, P.; Vakharia, A.; Shah, M. A comprehensive comparative study of artificial neural network (ANN) and support vector machines (SVM) on stock forecasting. Ann. Data Sci. 2023, 10, 183–208. [Google Scholar] [CrossRef]
- Yang, F.; Zhao, W. Bearing fault diagnosis based on Bayesian optimized SVM. Coal Mine Mach. 2022, 43, 178–180. [Google Scholar]
- Berkenkamp, F.; Krause, A.; Schoellig, A.P. Bayesian optimization with safety constraints: Safe and automatic parameter tuning in robotics. Mach. Learn. 2023, 112, 3713–3747. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Kuppusamy, K.; Aghila, G. A learning model to detect maliciousness of portable executable using integrated feature set. J. King Saud Univ.-Comput. Inf. Sci. 2019, 31, 252–265. [Google Scholar] [CrossRef]
- Mahdavifar, S.; Abdul Kadir, A.F.; Fatemi, R.; Alhadidi, D.; Ghorbani, A.A. Dynamic Android Malware Category Classification using Semi-Supervised Deep Learning. In Proceedings of the 2020 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 17–22 August 2020; pp. 515–522. [Google Scholar]
- Samaneh, M.; Dima, A.; Ghorbani, A.A. Effective and Efficient Hybrid Android Malware Classification Using Pseudo-Label Stacked Auto-Encoder. Int. J. Pure Appl. Sci. 2022, 30, 22. [Google Scholar]
- Beştaş, M.Ş.; Dinler, Ö.B. Detection of Android Based Applications with Traditional Metaheuristic Algorithms. Int. J. Interact. Des. Manuf. 2023, 9, 381–392. [Google Scholar] [CrossRef]
- Rani, S.; Tripathi, K.; Kumar, A. Machine learning aided malware detection for secure and smart manufacturing: A comprehensive analysis of the state of the art. Int. J. Interact. Des. Manuf. 2023, 1–28. [Google Scholar] [CrossRef]
- Anggraini, N.; Pamungkas, M.S.T.; Rozy, N.F. Performance Optimization of Naïve Bayes Algorithm for Malware Detection on Android Operating Systems with Particle Swarm Optimization. In Proceedings of the 2023 11th International Conference on Cyber and IT Service Management (CITSM), Makassar, Indonesia, 10–11 November 2023; pp. 1–5. [Google Scholar]
- Singh, P.; Borgohain, S.K.; Kumar, J. Investigation and pre-processing of CLaMP mlaware dataset for machine learning models. In Proceedings of the 2022 6th International Conference on Electronics, Communication and Aerospace Technology, Coimbatore, India, 1–3 December 2022; pp. 891–895. [Google Scholar]
- Mohamed, S.E.; Ashaf, M.; Ehab, A.; Shereef, O.; Metwaie, H.; Amer, E. Detecting malicious android applications based on API calls and permissions using machine learning algorithms. In Proceedings of the 2021 International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 26–27 May 2021; pp. 1–6. [Google Scholar]
- Sawadogo, Z.; Mendy, G.; Dembele, J.M.; Ouya, S. Android malware detection: Investigating the impact of imbalanced data-sets on the performance of machine learning models. In Proceedings of the 2022 24th International Conference on Advanced Communication Technology (ICACT), PyeongChang, Republic of Korea, 13–16 February 2022; pp. 435–441. [Google Scholar]
- Musikawan, P.; Kongsorot, Y.; You, I.; So-In, C. An Enhanced Deep Learning Neural Network for the Detection and Identification of Android Malware. IEEE Internet Things J. 2023, 10, 8560–8577. [Google Scholar] [CrossRef]
- Bhagwat, S.; Gupta, G.P. Android malware detection using hybrid meta-heuristic feature selection and ensemble learning techniques. In Proceedings of the International Conference on Advances in Computing and Data Sciences, Kurnool, India, 22–23 April 2022; pp. 145–156. [Google Scholar]
- Kattamuri, S.J.; Penmatsa, R.K.V.; Chakravarty, S.; Madabathula, V.S.P. Swarm optimization and machine learning applied to PE malware detection towards cyber threat intelligence. Electronics 2023, 12, 342. [Google Scholar] [CrossRef]
- Raju, P.; Raju, K.S.; Kalidindi, A. Feature selection and performance improvement of malware detection system using cuckoo search optimization and rough sets. Int. J. Adv. Comput. Sci. App. 2020, 11, 2020. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Quantity (Unit: PCS) |
|---|---|
| Benign software | 2488 |
| Malware | 2624 |
| Total | 5112 |
| Name | Quantity (Unit: PCS) |
|---|---|
| Adware | 1253 |
| Banking malware | 2100 |
| SMS malware | 3904 |
| Mobile risk software | 2546 |
| Benign software | 1795 |
| Total | 11,598 |
| Model | Parameter | Value |
|---|---|---|
| BO-SVM | Kernel | RBF |
| ACO-SVM | Kernel | RBF |
| Ant Count | 30 | |
| MaxIter | 100 | |
| Pheromone factor | 3 | |
| Pheromone constant | 500 | |
| Heuristic function factor | 4 | |
| Pheromone volatilization factor | 0.3 | |
| PSO-SVM | Kernel | RBF |
| Particle Size | 30 | |
| MaxIter | 100 | |
| Inertia Weight | 0.9 | |
| Acceleration Coefficients 1 | 2 | |
| Acceleration Coefficients 2 | 2 | |
| Velocity Limits_min | −5 | |
| Velocity Limits_max | 5 | |
| SVM | Kernel | RBF |
| 5 | ||
| 1.0 |
| Model | Accuracy (%) | Training Time (in Seconds) | ||
|---|---|---|---|---|
| ClaMP | CICMalDroid-2020 | ClaMP | CICMalDroid-2020 | |
| BO-SVM | 95.3 | 96.4 | 34.6 | 40.5 |
| ACO-SVM | 95.0 | 96.0 | 5185.4 | 5434.5 |
| PSO-SVM | 94.8 | 95.8 | 4223.4 | 4734.2 |
| BO-DT | 95.1 | 95.7 | 32.4 | 35.4 |
| SVM | 87.5 | 94.3 | 1.7 | 3.1 |
| Anggraini et al. [34] KNN | 93.5 | \ | \ | \ |
| Datasets | Model | Training Time (in Seconds) | Detection Time (in Seconds) |
|---|---|---|---|
| ClaMP | LSTM-BO-SVM | 136.94 | 1.23 |
| BO-SVM | 34.68 | 0.22 | |
| LSTM | 110.49 | 0.96 | |
| LSTM-SVM | 113.09 | 1.27 | |
| RNN-BO-SVM | 124.63 | 1.11 | |
| BiLSTM-BO-SVM | 160.58 | 2.89 | |
| CICMalDroid-2020 | LSTM-BO-SVM | 496.63 | 1.58 |
| BO-SVM | 45.56 | 0.32 | |
| LSTM | 450.4 | 1.12 | |
| LSTM-SVM | 456.58 | 1.35 | |
| RNN-BO-SVM | 412.12 | 1.04 | |
| BiLSTM-BO-SVM | 560.47 | 3.21 |
| Dataset | Reference | Year | Method | Accuracy (%) | Computation Time (in Seconds) |
|---|---|---|---|---|---|
| ClaMP | Masum et al. [2] | 2022 | QNN | 52.1 | 2698 |
| QSVM | 73.5 | 10000 | |||
| Raju et al. [40] | 2020 | RF | 92 | \ | |
| Proposed | 2024 | BO-SVM | 95.3 | 34.9 | |
| Kattamuri et al. [39] | 2023 | ACO, DT | 97.69 | 4365 | |
| Proposed | 2024 | LSTM-BO-SVM | 98.2 | 138.17 | |
| CICMalDroid-2020 | Mohamed et al. [35] | 2021 | KNN | 85 | \ |
| SVM | 86 | \ | |||
| DT | 88 | \ | |||
| Musikawan et al. [37] | 2022 | DNN | 93.5 | 305.15 | |
| Sawadogo et al. [36] | 2022 | Hist GB, SMOTE | 94.09 | \ | |
| Hist GB | 95.25 | \ | |||
| Bhagwat et al. [38] | 2022 | XGBoost | 95.3 | \ | |
| Proposed | 2024 | BO-SVM | 96.4 | 45.88 | |
| LSTM-BO-SVM | 98.6 | 498.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, S.; Li, H.; Fu, X.; Jiao, Y. A Novel Malware Detection Model in the Software Supply Chain Based on LSTM and SVMs. Appl. Sci. 2024, 14, 6678. https://doi.org/10.3390/app14156678
Zhou S, Li H, Fu X, Jiao Y. A Novel Malware Detection Model in the Software Supply Chain Based on LSTM and SVMs. Applied Sciences. 2024; 14(15):6678. https://doi.org/10.3390/app14156678
Chicago/Turabian StyleZhou, Shuncheng, Honghui Li, Xueliang Fu, and Yuanyuan Jiao. 2024. "A Novel Malware Detection Model in the Software Supply Chain Based on LSTM and SVMs" Applied Sciences 14, no. 15: 6678. https://doi.org/10.3390/app14156678
APA StyleZhou, S., Li, H., Fu, X., & Jiao, Y. (2024). A Novel Malware Detection Model in the Software Supply Chain Based on LSTM and SVMs. Applied Sciences, 14(15), 6678. https://doi.org/10.3390/app14156678