
Automatic Speech Recognition Advancements for Indigenous Languages of the Americas



Abstract
1. Introduction
2. Related Work
3. Experimental Setup and Dataset Description
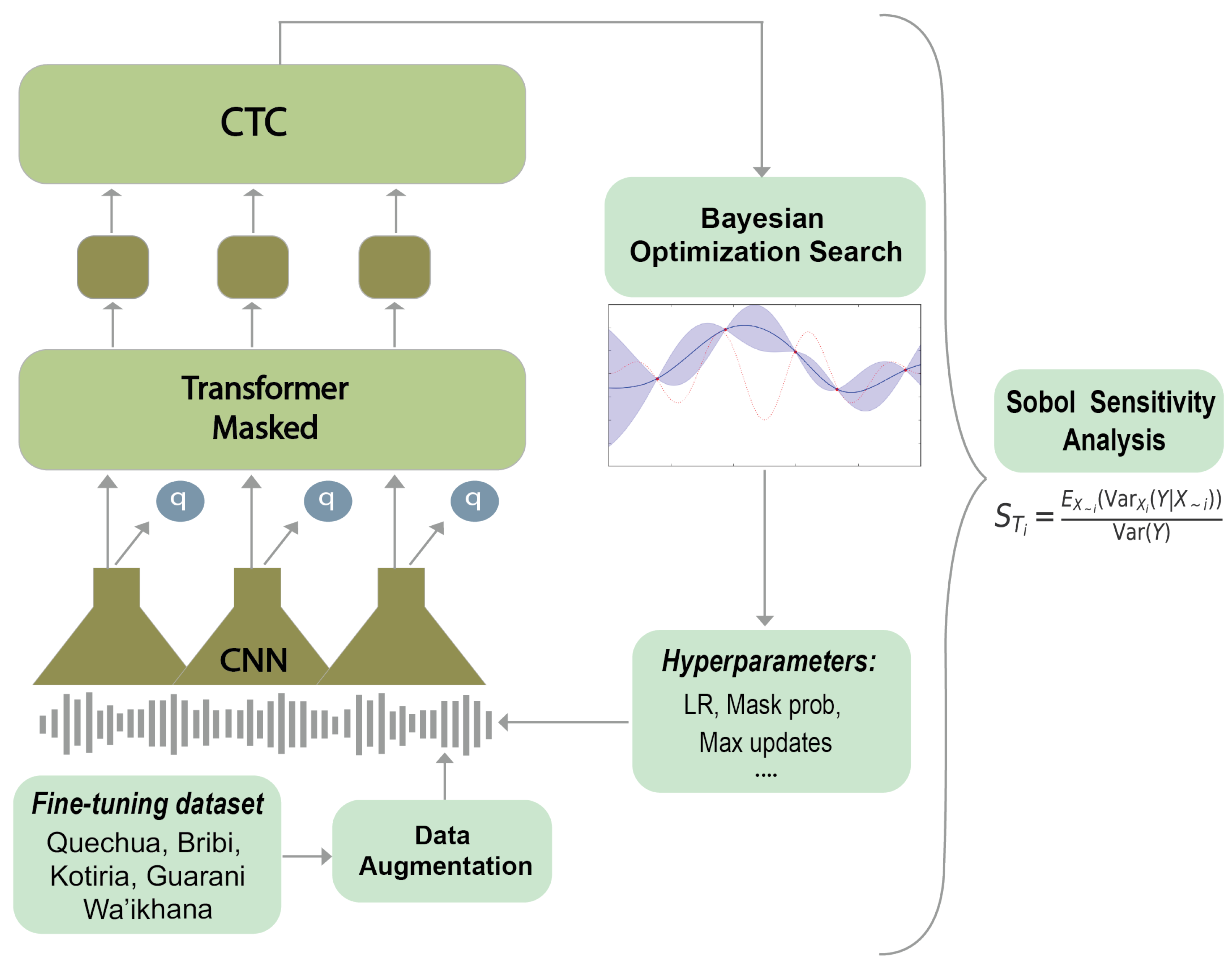
3.1. Main Architecture and Pre-Trained Models
3.2. Data
3.3. Decoding Strategy and Language Models
3.4. Hyperparameter Fine-Tuning
3.5. Sobol’ Sensitivity Analysis for Hyperparameter Explanation
4. Results
5. Conclusions and Future Work
6. Data and Models Accessibility
- Quechua (https://huggingface.co/ivangtorre/wav2vec2-xlsr-300m-quechua) (accessed on 12 September 2023)
- Kotiria (https://huggingface.co/ivangtorre/wav2vec2-xlsr-300m-kotiria) (accessed on 12 September 2023)
- Wa’ikhana (https://huggingface.co/ivangtorre/wav2vec2-xlsr-300m-waikhana) (accessed on 12 September 2023)
- Guarani (https://huggingface.co/ivangtorre/wav2vec2-xlsr-300m-guarani) (accessed on 12 September 2023)
- Bribri (https://huggingface.co/ivangtorre/wav2vec2-xlsr-300m-bribri) (accessed on 12 September 2023).
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Thiede, B.C.; Gray, C. Characterizing the indigenous forest peoples of Latin America: Results from census data. World Dev. 2020, 125, 104685. [Google Scholar] [CrossRef] [PubMed]
- UNESCO. How Can Latin American and Caribbean Indigenous Languages Be Preserved? 2021. Available online: https://unesdoc.unesco.org/ark:/48223/pf0000387186 (accessed on 2 July 2023).
- McQuown, N.A. The indigenous languages of Latin America. Am. Anthropol. 1955, 57, 501–570. [Google Scholar] [CrossRef]
- Chiblow, S.; Meighan, P.J. Language is land, land is language: The importance of Indigenous languages. Hum. Geogr. 2022, 15, 206–210. [Google Scholar] [CrossRef]
- UNESCO. Indigenous Languages: Gateways to the World. 2022. Available online: https://www.unesco.org/en/articles/cutting-edge-indigenous-languages-gateways-worlds-cultural-diversity (accessed on 2 July 2023).
- Global predictors of language endangerment and the future of linguistic diversity. Nat. Ecol. Evol. 2020, 6, 163–173. [CrossRef]
- Ferguson, J.; Weaselboy, M. Indigenous sustainable relations: Considering land in language and language in land. Curr. Opin. Environ. Sustain. 2020, 43, 1–7. [Google Scholar] [CrossRef]
- Mager, M.; Kann, K.; Ebrahimi, A.; Oncevay, F.; Zevallos, R.; Wiemerslage, A.; Denisov, P.; Ortega, J.; Stenzel, K.; Alvarez, A.; et al. La Modelización de la Morfología Verbal Bribri. 2023. Available online: https://neurips.cc/virtual/2022/competition/50096 (accessed on 12 August 2023).
- Umaña, A.C. Chibchan languages. In The Indigenous Languages of South America; Campbell, L., Grondona, V., Eds.; De Gruyter Mouton: Berlin, Germany, 2012; pp. 391–440. [Google Scholar] [CrossRef]
- Feldman, I.; Coto-Solano, R. Neural Machine Translation Models with Back-Translation for the Extremely Low-Resource Indigenous Language Bribri. In Proceedings of the 28th International Conference on Computational Linguistics, International Committee on Computational Linguistics, Barcelona, Spain, 8–13 December 2020. [Google Scholar] [CrossRef]
- Kann, K.; Ebrahimi, A.; Mager, M.; Oncevay, A.; Ortega, J.E.; Rios, A.; Fan, A.; Gutierrez-Vasques, X.; Chiruzzo, L.; Giménez-Lugo, G.A.; et al. AmericasNLI: Machine translation and natural language inference systems for Indigenous languages of the Americas. Front. Artif. Intell. 2022, 5, 266. [Google Scholar] [CrossRef] [PubMed]
- Adelaar, W. Guaraní. In Encyclopedia of Language & Linguistics, 2nd ed.; Brown, K., Ed.; Elsevier: Oxford, UK, 2006; pp. 165–166. [Google Scholar] [CrossRef]
- Costa, W. ‘Culture Is Language’: Why an Indigenous Tongue Is Thriving in Paraguay. 2020. Available online: https://www.theguardian.com/world/2020/sep/03/paraguay-guarani-indigenous-language (accessed on 10 July 2023).
- Stenzel, K. Kotiria ’differential object marking’ in cross-linguistic perspective. Amerindia 2008, 32, 153–181. Available online: https://amerindia.cnrs.fr/wp-content/uploads/2021/02/Stenzel-Kristine-Kotiria-differential-object-marking-in-cross-linguistic-perspective.pdf (accessed on 12 September 2023).
- Endangered Language Project. Endangered Language Project Catalogue. 2023. Available online: https://www.endangeredlanguages.com/ (accessed on 12 July 2023).
- Crevels, M. Language endangerment in South America: The clock is ticking. In The Indigenous Languages of South America; Campbell, L., Grondona, V., Eds.; De Gruyter Mouton: Berlin, Germany, 2012; pp. 167–234. [Google Scholar] [CrossRef]
- Ethnologue. Languages of the World. 2023. Available online: https://www.ethnologue.com/ (accessed on 12 July 2023).
- UNESCO. World Atlas of Languages. 2023. Available online: https://en.wal.unesco.org/world-atlas-languages (accessed on 12 July 2023).
- Pearce, A.J.; Heggarty, P. “Mining the Data” on the Huancayo-Huancavelica Quechua Frontier. In History and Language in the Andes; Heggarty, P., Pearce, A.J., Eds.; Palgrave Macmillan US: New York, NY, USA, 2011; pp. 87–109. [Google Scholar] [CrossRef]
- Lagos, C.; Espinoza, M.; Rojas, D. Mapudungun according to its speakers: Mapuche intellectuals and the influence of standard language ideology. Curr. Issues Lang. Plan. 2013, 14, 105–118. [Google Scholar] [CrossRef]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Seltzer, M.L.; Khudanpur, S. A study on data augmentation of reverberant speech for robust speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5220–5224. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Synnaeve, G.; Xu, Q.; Kahn, J.; Likhomanenko, T.; Grave, E.; Pratap, V.; Sriram, A.; Liptchinsky, V.; Collobert, R. End-to-end asr: From supervised to semi-supervised learning with modern architectures. arXiv 2019, arXiv:1911.08460. [Google Scholar]
- Xu, Q.; Likhomanenko, T.; Kahn, J.; Hannun, A.; Synnaeve, G.; Collobert, R. Iterative pseudo-labeling for speech recognition. arXiv 2020, arXiv:2005.09267. [Google Scholar]
- Baevski, A.; Zhou, H.; Mohamed, A.; Auli, M. wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations. arXiv 2020, arXiv:2006.11477. [Google Scholar]
- Yi, C.; Wang, J.; Cheng, N.; Zhou, S.; Xu, B. Applying wav2vec2.0 to Speech Recognition in various low-resource languages. arXiv 2020, arXiv:2012.12121. [Google Scholar]
- Parikh, A.; ten Bosch, L.; van den Heuvel, H.; Tejedor-Garcia, C. Comparing Modular and End-To-End Approaches in ASR for Well-Resourced and Low-Resourced Languages. In Proceedings of the 6th International Conference on Natural Language and Speech Processing (ICNLSP 2023), Virtual, 16–17 December 2023; pp. 266–273. [Google Scholar]
- Baevski, A.; Hsu, W.N.; Conneau, A.; Auli, M. Unsupervised speech recognition. Adv. Neural Inf. Process. Syst. 2021, 34, 27826–27839. [Google Scholar]
- Wang, D.; Zheng, T.F. Transfer learning for speech and language processing. In Proceedings of the 2015 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Hong Kong, China, 6–19 December 2015; pp. 1225–1237. [Google Scholar]
- Kunze, J.; Kirsch, L.; Kurenkov, I.; Krug, A.; Johannsmeier, J.; Stober, S. Transfer learning for speech recognition on a budget. arXiv 2017, arXiv:1706.00290. [Google Scholar]
- Yi, J.; Tao, J.; Wen, Z.; Bai, Y. Language-adversarial transfer learning for low-resource speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 27, 621–630. [Google Scholar] [CrossRef]
- Yu, Z.; Zhang, Y.; Qian, K.; Wan, C.; Fu, Y.; Zhang, Y.; Lin, Y.C. Master-ASR: Achieving Multilingual Scalability and Low-Resource Adaptation in ASR with Modular Learning. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 40475–40487. [Google Scholar]
- Ebrahimi, A.; Mager, M.; Wiemerslage, A.; Denisov, P.; Oncevay, A.; Liu, D.; Koneru, S.; Ugan, E.Y.; Li, Z.; Niehues, J.; et al. Findings of the Second AmericasNLP Competition on Speech-to-Text Translation. In Proceedings of the NeurIPS 2022 Competition Track, PMLR, New Orleans, LA, USA, 28 November–9 December 2022; pp. 217–232. [Google Scholar]
- Mager, M.; Gutierrez-Vasques, X.; Sierra, G.; Meza, I. Challenges of language technologies for the indigenous languages of the Americas. arXiv 2018, arXiv:1806.04291. [Google Scholar]
- Mager, M.; Oncevay, A.; Ebrahimi, A.; Ortega, J.; Gonzales, A.R.; Fan, A.; Gutierrez-Vasques, X.; Chiruzzo, L.; Giménez-Lugo, G.; Ramos, R.; et al. Findings of the AmericasNLP 2021 shared task on open machine translation for indigenous languages of the Americas. In Proceedings of the First Workshop on Natural Language Processing for Indigenous Languages of the Americas; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 202–217. [Google Scholar]
- Agüero Torales, M.M. Machine Learning approaches for Topic and Sentiment Analysis in multilingual opinions and low-resource languages: From English to Guarani. Proces. Leng. Nat. 2023, 70, 235–238. [Google Scholar]
- Gasser, M. Machine translation and the future of indigenous languages. In Proceedings of the I Congreso Internacional de Lenguas y Literaturas Indoamericanas, Temuco, Chile, 12–13 October 2006. [Google Scholar]
- Jimerson, R.; Liu, Z.; Prud’hommeaux, E. An (unhelpful) guide to selecting the best ASR architecture for your under-resourced language. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 1008–1016. [Google Scholar]
- Sasmal, S.; Saring, Y. Robust automatic continuous speech recognition for’Adi’, a zero-resource indigenous language of Arunachal Pradesh. Sādhanā 2022, 47, 271. [Google Scholar] [CrossRef]
- Coto-Solano, R.; Nicholas, S.A.; Datta, S.; Quint, V.; Wills, P.; Powell, E.N.; Koka‘ua, L.; Tanveer, S.; Feldman, I. Development of automatic speech recognition for the documentation of Cook Islands Māori. Proc. Lang. Resour. Eval. Conf. 2022, 13, 3872–3882. [Google Scholar]
- Chuctaya, H.F.C.; Mercado, R.N.M.; Gaona, J.J.G. Isolated automatic speech recognition of Quechua numbers using MFCC, DTW and KNN. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 24–29. [Google Scholar] [CrossRef]
- Adams, O.; Wiesner, M.; Watanabe, S.; Yarowsky, D. Massively multilingual adversarial speech recognition. arXiv 2019, arXiv:1904.02210. [Google Scholar]
- Zevallos, R.; Cordova, J.; Camacho, L. Automatic speech recognition of quechua language using hmm toolkit. In Proceedings of the Annual International Symposium on Information Management and Big Data, Lima, Peru, 21–23 August 2019; pp. 61–68. [Google Scholar]
- Zevallos, R.; Bel, N.; Cámbara, G.; Farrús, M.; Luque, J. Data Augmentation for Low-Resource Quechua ASR Improvement. arXiv 2022, arXiv:2207.06872. [Google Scholar]
- Maldonado, D.M.; Villalba Barrientos, R.; Pinto-Roa, D.P. Eñe’ e: Sistema de reconocimiento automático del habla en Guaraní. In Proceedings of the Simposio Argentino de Inteligencia Artificial (ASAI 2016)-JAIIO 45 (Tres de Febrero, 2016), Buenos Aires, Argentina, 5–9 September 2016. [Google Scholar]
- Peterson, K.; Tong, A.; Yu, Y. OpenASR20: An Open Challenge for Automatic Speech Recognition of Conversational Telephone Speech in Low-Resource Languages. In Proceedings of the Interspeech, Brno, Czech Republic, 30 August–3 September 2021; pp. 4324–4328. [Google Scholar]
- Peterson, K.; Tong, A.; Yu, Y. OpenASR21: The Second Open Challenge for Automatic Speech Recognition of Low-Resource Languages. Proc. Interspeech 2022, 4895–4899. [Google Scholar]
- Koumparoulis, A.; Potamianos, G.; Thomas, S.; da Silva Morais, E. Resource-efficient TDNN Architectures for Audio-visual Speech Recognition. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; pp. 506–510. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, W.Q. Improving automatic speech recognition performance for low-resource languages with self-supervised models. IEEE J. Sel. Top. Signal Process. 2022, 16, 1227–1241. [Google Scholar] [CrossRef]
- Coto-Solano, R.; Sofía, F.S. Alineación forzada sin entrenamiento para la anotación automática de corpus orales de las lenguas indígenas de Costa Rica. Káñina 2017, 40, 175–199. [Google Scholar] [CrossRef]
- Coto-Solano, R. Explicit Tone Transcription Improves ASR Performance in Extremely Low-Resource Languages: A Case Study in Bribri. In Proceedings of the First Workshop on Natural Language Processing for Indigenous Languages of the Americas; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 173–184. [Google Scholar] [CrossRef]
- Chen, C.C.; Chen, W.; Zevallos, R.; Ortega, J. Evaluating Self-Supervised Speech Representations for Indigenous American Languages. arXiv 2023, arXiv:2310.03639. [Google Scholar]
- Coto-Solano, R. Evaluating Word Embeddings in Extremely Under-Resourced Languages: A Case Study in Bribri. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 4455–4467. [Google Scholar]
- Prud’hommeaux, E.; Jimerson, R.; Hatcher, R.; Michelson, K. Automatic speech recognition for supporting endangered language documentation. Lang. Doc. Conserv. 2021, 15, 491–513. [Google Scholar]
- Krasnoukhova, O. Attributive modification in South American indigenous languages. Linguistics 2022, 60, 745–807. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Yi, C.; Wang, J.; Cheng, N.; Zhou, S.; Xu, B. Transfer Ability of MonolingualWav2vec2.0 for Low-resource Speech Recognition. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Virtual, 18–22 July 2021; pp. 1–6. [Google Scholar] [CrossRef]
- N, K.D.; Wang, P.; Bozza, B. Using Large Self-Supervised Models for Low-Resource Speech Recognition. In Proceedings of the Proc. Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 2436–2440. [Google Scholar] [CrossRef]
- Torre, I.G.; Romero, M.; Álvarez, A. Improving aphasic speech recognition by using novel semi-supervised learning methods on aphasiabank for english and spanish. Appl. Sci. 2021, 11, 8872. [Google Scholar] [CrossRef]
- Tang, J.; Chen, W.; Chang, X.; Watanabe, S.; MacWhinney, B. A New Benchmark of Aphasia Speech Recognition and Detection Based on E-Branchformer and Multi-task Learning. arXiv 2023, arXiv:2305.13331. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv 2022, arXiv:2212.04356. [Google Scholar]
- Babu, A.; Wang, C.; Tjandra, A.; Lakhotia, K.; Xu, Q.; Goyal, N.; Singh, K.; von Platen, P.; Saraf, Y.; Pino, J.; et al. XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale. arXiv 2021, arXiv:2111.09296. [Google Scholar]
- Ardila, R.; Branson, M.; Davis, K.; Henretty, M.; Kohler, M.; Meyer, J.; Morais, R.; Saunders, L.; Tyers, F.M.; Weber, G. Common voice: A massively-multilingual speech corpus. arXiv 2019, arXiv:1912.06670. [Google Scholar]
- Gales, M.J.; Knill, K.M.; Ragni, A.; Rath, S.P. Speech recognition and keyword spotting for low-resource languages: BABEL project research at CUED. In Proceedings of the Fourth International Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU-2014), St. Petersburg, Russia, 14–16 May 2014; pp. 16–23. [Google Scholar]
- Pratap, V.; Xu, Q.; Sriram, A.; Synnaeve, G.; Collobert, R. MLS: A Large-Scale Multilingual Dataset for Speech Research. arXiv 2020, arXiv:2012.03411. [Google Scholar]
- Wang, C.; Riviere, M.; Lee, A.; Wu, A.; Talnikar, C.; Haziza, D.; Williamson, M.; Pino, J.; Dupoux, E. VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 993–1003. [Google Scholar] [CrossRef]
- Valk, J.; Alumäe, T. VoxLingua107: A Dataset for Spoken Language Recognition. arXiv 2020, arXiv:2011.12998. [Google Scholar]
- Corpus Oral Pandialectal de la Lengua Bribri. 2017. Available online: http://bribri.net (accessed on 12 September 2023).
- Grammar and Multilingual Practices through the Lens of Everyday Interaction in Two Endangered Languages in the East Tukano Family. 2017. Available online: http://hdl.handle.net/2196/00-0000-0000-0010-7D1A-A (accessed on 12 September 2023).
- Kotiria Linguistic and Cultural Archive. Endangered Languages Archive. 2017. Available online: http://hdl.handle.net/2196/00-0000-0000-0002-05B0-5 (accessed on 12 September 2023).
- Siminchikkunarayku. Available online: https://www.siminchikkunarayku.pe/ (accessed on 12 September 2023).
- Universidad de Costa Rica. Portal de la Lengua Bribri SE’IE. 2021. Available online: https://vinv.ucr.ac.cr/es/tags/lengua-bribri (accessed on 12 September 2023).
- live.bible.is. Available online: https://live.bible.is (accessed on 12 September 2023).
- Brown, M.; Tucker, K. Data from Quipu Project (12-2018). 2020. Available online: https://research-information.bris.ac.uk/en/datasets/data-from-quipu-project-12-2018 (accessed on 12 September 2023).
- Heafield, K. KenLM: Faster and smaller language model queries. In Proceedings of the Sixth Workshop on Statistical Machine Translation, Edinburg, UK, 30–31 July 2011; pp. 187–197. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; De Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Sobol, I.M. Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates. Math. Comput. Simul. 2001, 55, 271–280. [Google Scholar] [CrossRef]
- Langie, K.M.G.; Tak, K.; Kim, C.; Lee, H.W.; Park, K.; Kim, D.; Jung, W.; Lee, C.W.; Oh, H.S.; Lee, D.K.; et al. Toward economical application of carbon capture and utilization technology with near-zero carbon emission. Nat. Commun. 2022, 13, 7482. [Google Scholar] [CrossRef]
- Schneider, K.; Van der Werf, W.; Cendoya, M.; Mourits, M.; Navas-Cortés, J.A.; Vicent, A.; Oude Lansink, A. Impact of Xylella fastidiosa subspecies pauca in European olives. Proc. Natl. Acad. Sci. USA 2020, 117, 9250–9259. [Google Scholar] [CrossRef] [PubMed]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A review of machine learning interpretability methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef] [PubMed]
- Antoniadis, A.; Lambert-Lacroix, S.; Poggi, J.M. Random forests for global sensitivity analysis: A selective review. Reliab. Eng. Syst. Saf. 2021, 206, 107312. [Google Scholar] [CrossRef]
- Wang, Z.; Li, M.; Ren, F.; Ma, B.; Yang, H.; Zhu, Y. Sobol sensitivity analysis and multi-objective optimization of manifold microchannel heat sink considering entropy generation minimization. Int. J. Heat Mass Transf. 2023, 208, 124046. [Google Scholar] [CrossRef]
- Cai, D.; Li, M. Leveraging ASR Pretrained Conformers for Speaker Verification Through Transfer Learning and Knowledge Distillation. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 1–14. [Google Scholar] [CrossRef]
- Kakuba, S.; Poulose, A.; Han, D.S. Deep Learning Approaches for Bimodal Speech Emotion Recognition: Advancements, Challenges, and a Multi-Learning Model. IEEE Access 2023, 11, 113769–113789. [Google Scholar] [CrossRef]
- Shahamiri, S.R. Speech Vision: An End-to-End Deep Learning-Based Dysarthric Automatic Speech Recognition System. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 852–861. [Google Scholar] [CrossRef] [PubMed]
- Romero, M.; Gomez, S.; Torre, I.G. ASR advancements for indigenous languages: Quechua, Guarani, Bribri, Kotiria, and Wa’ikhana. arXiv 2024, arXiv:2404.08368. [Google Scholar]


{kind=link}
{kind=link}
| Train | Dev | Test | ||||
|---|---|---|---|---|---|---|
| Primary | Speed Augm. | External | Total | Primary | Primary | |
| Bribri | h | h | h | h | h | h |
| Guarani | h | h | - | h | h | h |
| Kotiria | h | h | h | h | h | h |
| Wai’khana | h | h | - | h | h | h |
| Quechua | h | h | h | h | h | h |
| Minimum Value | Maximum Value | |
|---|---|---|
| Learning rate | ||
| Max number of updates | 10k | 100k |
| Freeze fine-tune updates | 0 | 50k |
| Activation dropout | ||
| Mask probability | ||
| Mask channel probability |
| Language | Learning Rate | Max Updates | Freeze Fine-Tune | Mask Channel | Activation Dropout | WER | CER |
|---|---|---|---|---|---|---|---|
| Quechua | 90k | 5k | |||||
| Kotiria | 40k | 5k | |||||
| Bribri | 90k | 8k | |||||
| Guarani | 90k | 9k | |||||
| Wa’ikhana | 130k | 1k |
| Parameter | S1 | ST |
|---|---|---|
| Freeze fine-tune updates | ||
| Activation dropout | ||
| Mask prob | ||
| Mask channel prob | ||
| Learning rate (lr) | ||
| Max update |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Romero, M.; Gómez-Canaval, S.; Torre, I.G. Automatic Speech Recognition Advancements for Indigenous Languages of the Americas. Appl. Sci. 2024, 14, 6497. https://doi.org/10.3390/app14156497
Romero M, Gómez-Canaval S, Torre IG. Automatic Speech Recognition Advancements for Indigenous Languages of the Americas. Applied Sciences. 2024; 14(15):6497. https://doi.org/10.3390/app14156497
Chicago/Turabian StyleRomero, Monica, Sandra Gómez-Canaval, and Ivan G. Torre. 2024. "Automatic Speech Recognition Advancements for Indigenous Languages of the Americas" Applied Sciences 14, no. 15: 6497. https://doi.org/10.3390/app14156497
APA StyleRomero, M., Gómez-Canaval, S., & Torre, I. G. (2024). Automatic Speech Recognition Advancements for Indigenous Languages of the Americas. Applied Sciences, 14(15), 6497. https://doi.org/10.3390/app14156497