

Real-Time Analysis of Facial Expressions for Mood Estimation



Abstract
1. Introduction
2. Affective States: Emotions and Moods
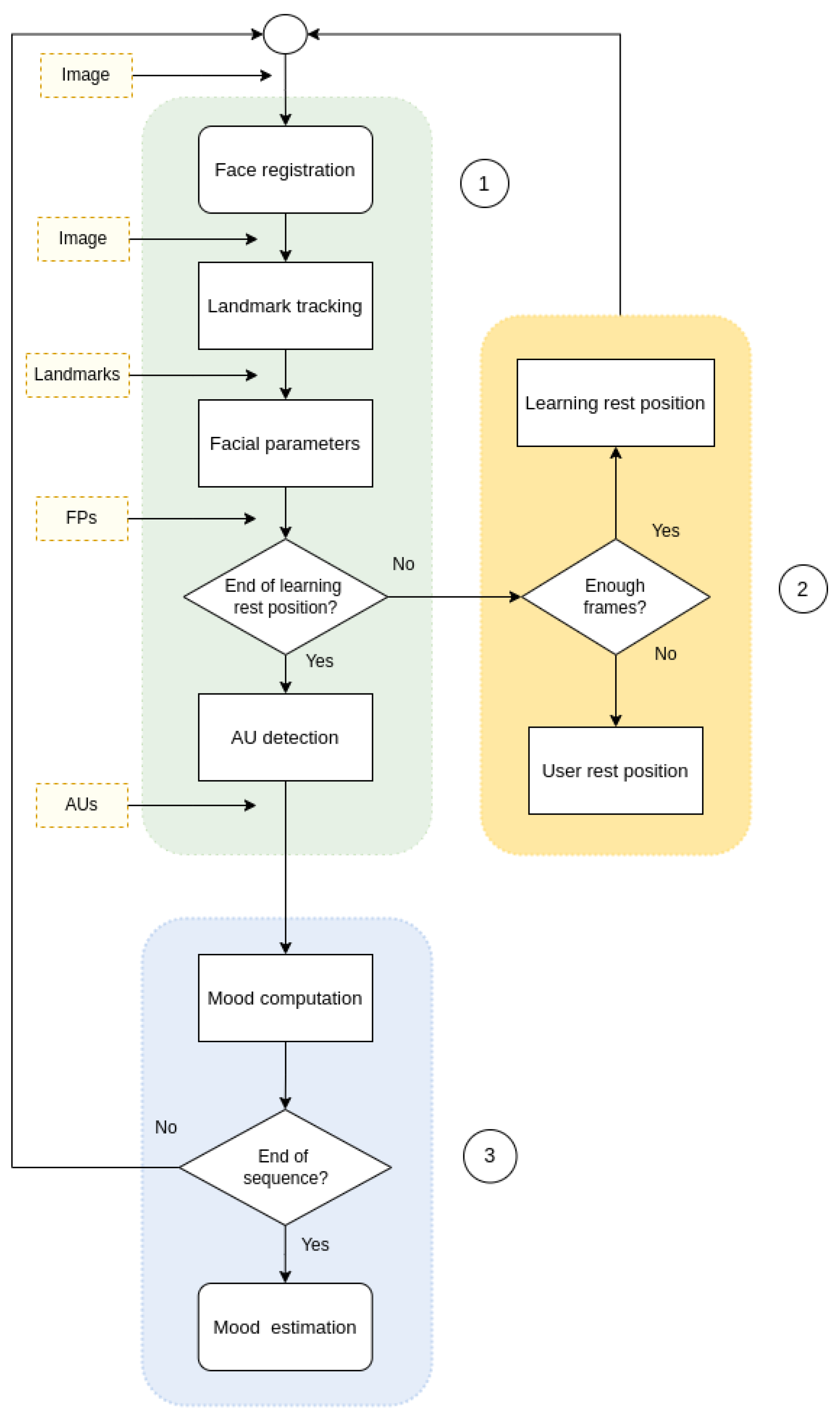
3. Vision-Based Mood Estimation
- Detect the characteristic facial points of the subject in each image frame to identify the AUs corresponding to the movement of the facial points with respect to the resting patterns.
- Define a resting pattern corresponding to the distances between the characteristic facial points of the subject.
- Obtain, for each image of the sequence, the activation probability distribution of the AUs and determine the similarity between the probability distributions for each possible mood to estimate mood as the maximum of the computed similarities.
3.1. Identification of the Activation of Action Units
3.2. Mood Estimation
4. Performance Evaluation
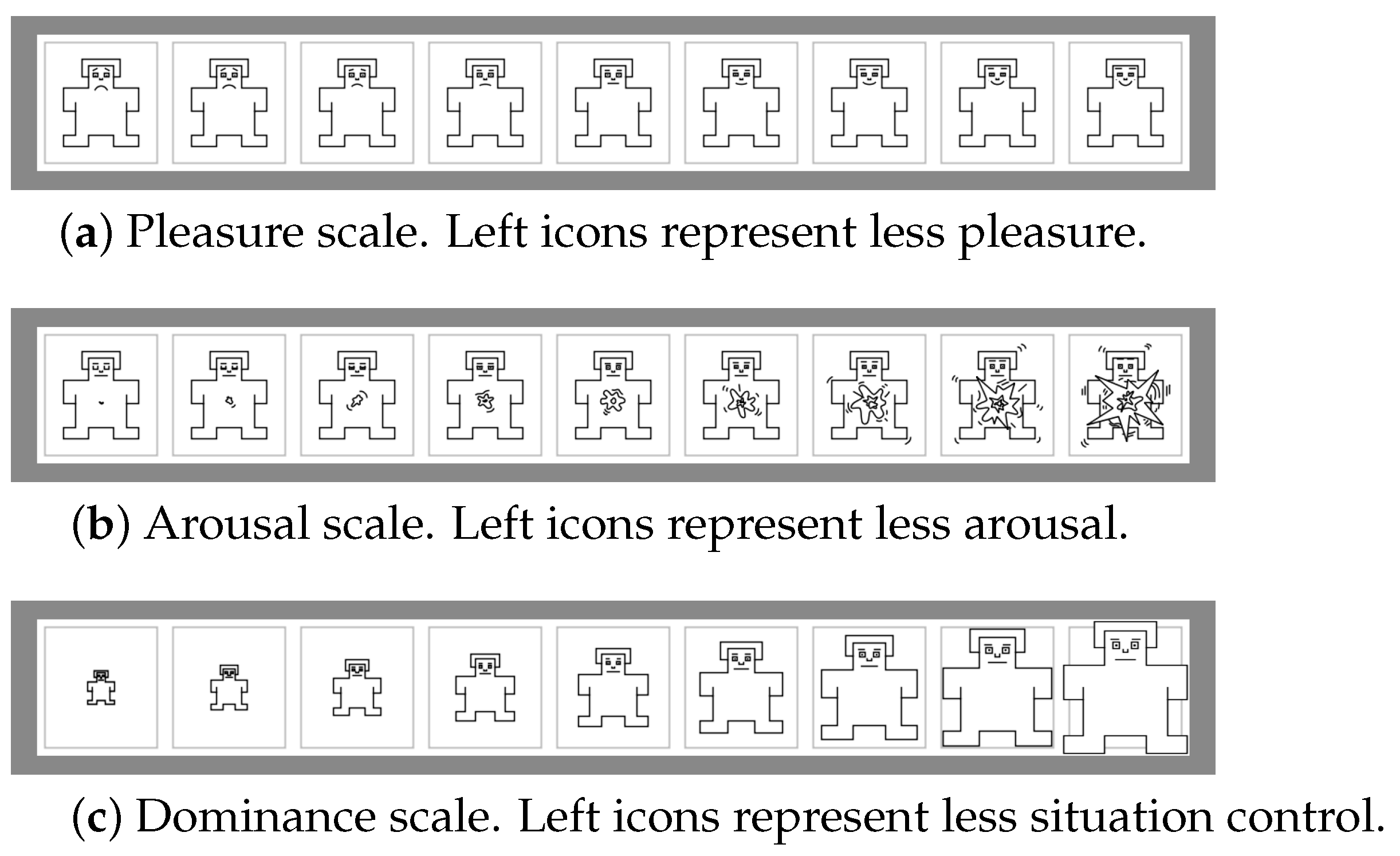
4.1. Material: Data Set for Evaluation
- The experiment was explained to the participant, mainly the questionnaire to be completed in the last step. The participant signed the informed consent and demographic data were gathered.
- A randomly selected video from the set prepared to elicit one of the eight mood categories was presented to the participant. A maximum of two videos was shown to the participants.
- While the stimulus video was playing, the participant’s face was recorded. The only recommendation given to the participant was to remain moderately centered in front of the camera.
- At the end, participants completed the SAM questionnaire to obtain the mood values in the PAD space. Because PAD levels were difficult to understand for some participants, a post-processing stage was carried out, and sequences with strong discrepancy regarding the stimuli were discarded.
4.2. Procedure
- First level.
- Positive and Negative.
- Second level.
- Exalted, Calm, Anxious, and Bored.
- Third level.
- Elated, Dependent, Relaxed, Docile, Hostile, Anxious, Bored, and Disdainful.
4.3. Results
5. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Grabowski, K.; Rynkiewicz, A.; Lassalle, A.; Baron-Cohen, S.; Schuller, B.; Cummins, N.; Baird, A.; Podgórska-Bednarz, J.; Pienia̧żek, A.; ucka, I. Emotional expression in psychiatric conditions: New technology for clinicians. Psychiatry Clin. Neurosci. 2019, 73, 50–62. [Google Scholar] [CrossRef] [PubMed]
- Barreto, A.M. Application of facial expression studies on the field of marketing. In Emotional Expression: The Brain and the Face; FEELab Science Books: Porto, Portugal, 2017; Volume 9, pp. 163–189. [Google Scholar]
- Sariyanidi, E.; Gunes, H.; Cavallaro, A. Automatic Analysis of Facial Affect: A Survey of Registration, Representation, and Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1113–1133. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P.; Friesen, W. Facial Action Coding System: Manual; Consulting Psychologists Press: Palo Alto, CA, USA, 1978. [Google Scholar]
- Friesen, W.V.; Ekman, P. EMFACS-7: Emotional Facial Action Coding System. Psychol. Comput. Sci. 1983. [Google Scholar]
- Ekman, P.; Davidson, R. The Nature of Emotion; Oxford University Press: Oxford, UK, 1994. [Google Scholar]
- Pantic, M.; Patras, I. Detecting facial actions and their temporal segments in nearly frontal-view face image sequences. In Proceedings of the 2005 IEEE International Conference on Systems, Man and Cybernetics, Waikoloa, HI, USA, 12 October 2005; Volume 4, pp. 3358–3363. [Google Scholar]
- Kotsia, I.; Pitas, I. Facial expression recognition in image sequences using geometric deformation features and support vector machines. Image Process. IEEE Trans. 2007, 16, 172–187. [Google Scholar] [CrossRef] [PubMed]
- Valstar, M.; Pantic, M. Fully Automatic Recognition of the Temporal Phases of Facial Actions. IEEE Trans. Syst. Man Cybern. Part B 2011, 42, 28–43. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Z.; Pantic, M.; Roisman, G.; Huang, T. A survey of affect recognition methods: Audio, visual, and spontaneous expressions. Pattern Anal. Mach. Intell. IEEE Trans. 2009, 31, 39–58. [Google Scholar] [CrossRef] [PubMed]
- McDuff, D.; Kaliouby, R.E.; Kassam, K.; Picard, R. Affect valence inference from facial action unit spectrograms. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010; pp. 17–24. [Google Scholar]
- Nicolaou, M.A.; Gunes, H.; Pantic, M. Output-associative RVM regression for dimensional and continuous emotion prediction. Image Vis. Comput. 2012, 30, 186–196. [Google Scholar] [CrossRef]
- Wang, Y.; Song, W.; Tao, W.; Liotta, A.; Yang, D.; Li, X.; Gao, S.; Sun, Y.; Ge, W.; Zhang, W.; et al. A systematic review on affective computing: Emotion models, databases, and recent advances. Inf. Fusion 2022, 83–84, 19–52. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep Facial Expression Recognition: A Survey. IEEE Trans. Affect. Comput. 2022, 13, 1195–1215. [Google Scholar] [CrossRef]
- Boughanem, H.; Ghazouani, H.; Barhoumi, W. Facial Emotion Recognition in-the-Wild Using Deep Neural Networks: A Comprehensive Review. SN Comput. Sci. 2024, 5, 96. [Google Scholar] [CrossRef]
- AlBdairi, A.J.A.; Xiao, Z.; Alkhayyat, A.; Humaidi, A.J.; Fadhel, M.A.; Taher, B.H.; Alzubaidi, L.; Santamaría, J.; Al-Shamma, O. Face recognition based on deep learning and FPGA for ethnicity identification. Appl. Sci. 2022, 12, 2605. [Google Scholar] [CrossRef]
- Rouast, P.V.; Adam, M.T.P.; Chiong, R. Deep Learning for Human Affect Recognition: Insights and New Developments. IEEE Trans. Affect. Comput. 2021, 12, 524–543. [Google Scholar] [CrossRef]
- Picard, R.W. Affective Computing; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Darwin, C. The Expression of Emotions in Man and Animals; Murray: London, UK, 1873. [Google Scholar]
- Ekman, P. Emotion in the Human Face; Cambridge University Press: Cambridge, UK, 1982. [Google Scholar]
- Plutchik, R. Emotions: A Psychoevolutionary Synthesis; Harper & Row: New York, NY, USA, 1980. [Google Scholar]
- Whissell, C. The dictionary of affect in language. In Emotion: Theory, Research, and Experience, Volume 4: The Measurement of Emotions; Plutchik, R., Kellerman, H., Eds.; Academic Press: New York, NY, USA, 1989; Chapter 5; pp. 113–131. [Google Scholar]
- Russell, J.A. Measures of emotion. In Emotion: Theory, Research, and Experience. The Measurement of Emotions; Plutchik, R., Kellerman, H., Eds.; Academic Press: New York, NY, USA, 1989; Volume 4, Chapter 4; pp. 83–111. [Google Scholar]
- Cochrane, T. 8 dimensions for the emotions. Soc. Sci. Inf. Spec. Issue The Lang. Emot. Concept. Cult. Issues 2009, 48, 379–420. [Google Scholar]
- Sedikides, C. Changes in the Valence of the Self as a Function of Mood. Rev. Personal. Soc. Psychol. 1992, 14, 271–311. [Google Scholar]
- Neumann, R.; Seibt, B.; Strack, F. The influence of mood on the intensity of emotional responses: Disentangling feeling and knowing. Cogn. Emot. 2001, 15, 725–747. [Google Scholar] [CrossRef]
- Mehrabian, A. Pleasure-arousal-dominance: A general framework for describing and measuring individual differences in temperament. Curr. Psychol. 1996, 14, 261–292. [Google Scholar] [CrossRef]
- Arifin, S.; Cheung, P.Y.K. A computation method for video segmentation utilizing the pleasure-arousal-dominance emotional information. In Proceedings of the MM ’07: Proceedings of the 15th ACM International Conference on Multimedia, Augsburg, Bavaria, Germany, 23–28 September 2007; pp. 68–77. [CrossRef]
- Arellano, D.; Perales, F.J.; Varona, J. Mood and Its Mapping onto Facial Expressions. In Proceedings of the Articulated Motion and Deformable Objects; Perales, F.J., Santos-Victor, J., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 31–40. [Google Scholar]
- Biehn, C. Facial Expression Repertoire (FER). 2005. Available online: http://research.animationsinstitut.de/ (accessed on 18 January 2014).
- Saragih, J.M.; Lucey, S.; Cohn, J.F. Deformable model fitting by regularized landmark mean-shift. Int. J. Comput. Vis. 2011, 91, 200–215. [Google Scholar] [CrossRef]
- Valstar, M.; Pantic, M. Induced Disgust, Happiness and Surprise: An Addition to the Mmi Facial Expression Database. In Proc. 3rd Intern. Workshop on EMOTION (Satellite of LREC): Corpora for Research on Emotion and Affect; 2010; p. 65. Available online: https://ibug.doc.ic.ac.uk/research/mmi-database/ (accessed on 4 July 2024).
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Kanade, T.; Cohn, J.F.; Tian, Y. Comprehensive database for facial expression analysis. In Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition (Cat. No. PR00580), Grenoble, France, 28–30 March 2000; pp. 46–53. [Google Scholar]
- Kailath, T. The divergence and Bhattacharyya distance measures in signal selection. IEEE Trans. Commun. Technol. 1967, 15, 52–60. [Google Scholar] [CrossRef]
- Bradley, M.M.; Lang, P.J. International Affective Picture System. In Encyclopedia of Personality and Individual Differences; Zeigler-Hill, V., Shackelford, T., Eds.; Springer: Cham, Switzerland, 2017. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Exuberant (+P +A +D) | Bored (−P −A −D) |
| Docile (+P −A −D) | Hostile (−P +A +D) |
| Dependent (+P +A −D) | Disdainful (−P −A +D) |
| Relaxed (+P −A +D) | Anxious (−P +A −D) |
| Facial Parameter | Description |
|---|---|
| FP1 | Inner eyes distance (SCALE) |
| FP2 | Mean eyebrow–eyeline distance (right) |
| FP3 | Inner eyebrow–eyeline distance (right) |
| FP4 | Mean eyebrow–eyeline distance (left) |
| FP5 | Inner eyebrow–eyeline distance (left) |
| FP6 | Open eye distance (right) |
| FP7 | Open eye distance (left) |
| FP8 | Horitzontal mouth width |
| FP9 | Horitzontal mouth height |
| FP10 | Vertical distance between mouth and nouse |
| FP11 | Vertical distance between chin and nouse |
| FP12 | Lips distance |
| Action Unit | Probabilistic Rule |
|---|---|
| AU1 | & & |
| AU2 | & & |
| AU4 | & & |
| AU5 | & & |
| AU6 | & & & |
| AU10 | & |
| AU12 | & |
| AU15 | & |
| AU25 | & |
| AU26 | & |
| AU43 | & & & |
| AU | TP | FP | TN | FN | Spec | Acc |
|---|---|---|---|---|---|---|
| AU1 | 31 | 669 | 5338 | 4 | 88.42 | 88.42 |
| AU2 | 27 | 871 | 5171 | 3 | 85.58 | 85.61 |
| AU4 | 168 | 306 | 5525 | 73 | 94.75 | 93.76 |
| AU5 | 58 | 238 | 5761 | 15 | 96.03 | 95.83 |
| AU6 | 252 | 732 | 4981 | 107 | 87.19 | 86.18 |
| AU10 | 243 | 1306 | 4518 | 5 | 77.58 | 78.41 |
| AU12 | 434 | 1128 | 4435 | 75 | 79.72 | 80.19 |
| AU15 | 7 | 676 | 5367 | 22 | 88.81 | 88.50 |
| AU25 | 775 | 1139 | 3792 | 366 | 76.90 | 75.21 |
| AU26 | 216 | 1251 | 4433 | 172 | 77.99 | 76.56 |
| AU43 | 272 | 344 | 5361 | 95 | 93.97 | 92.77 |
| Total | 2483 | 8690 | 54,682 | 937 | 86.29 | 85.59 |
| Mood | Action Units (AUs) |
|---|---|
| Exuberant | AU6, AU5, AU12, AU25, AU26 |
| Bored | AU1, AU2, AU4, AU15, AU43 |
| Docile | AU1, AU2, AU12, AU43 |
| Hostile | AU4, AU10, AU5, AU15, AU25, AU26 |
| Anxious | AU1, AU2, AU4, AU5, AU15, AU25, AU26 |
| Relaxed | AU6, AU12, AU43 |
| Dependent | AU1, AU2, AU5, AU12, AU25, AU26 |
| Disdainful | AU4, AU15, AU43 |
| Mood (SAM) | Dimensions | Coincidences | Sequences |
|---|---|---|---|
| Positive | P+ | 32 | 33 |
| Negative | P− | 33 | 36 |
| Level 1 | 65 | 69 | |
| Exalted | P+, A+ | 14 | 21 |
| Calm | P+, A− | 11 | 12 |
| Anxious | P−, A+ | 12 | 16 |
| Bored | P−, A− | 14 | 20 |
| Level 2 | 51 | 69 | |
| Elated | P+, A+, D+ | 11 | 15 |
| Dependent | P+, A+, D− | 3 | 6 |
| Relaxed | P+, A−, D+ | 9 | 9 |
| Docile | P+, A−, D- | 1 | 3 |
| Hostile | P−, A+, D+ | 3 | 5 |
| Anxious | P−, A+, D− | 8 | 11 |
| Disdainful | P−, A−, D+ | 2 | 7 |
| Bored | P−, A−, D− | 7 | 13 |
| Level 3 | 44 | 69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Filippini, J.S.; Varona, J.; Manresa-Yee, C. Real-Time Analysis of Facial Expressions for Mood Estimation. Appl. Sci. 2024, 14, 6173. https://doi.org/10.3390/app14146173
Filippini JS, Varona J, Manresa-Yee C. Real-Time Analysis of Facial Expressions for Mood Estimation. Applied Sciences. 2024; 14(14):6173. https://doi.org/10.3390/app14146173
Chicago/Turabian StyleFilippini, Juan Sebastián, Javier Varona, and Cristina Manresa-Yee. 2024. "Real-Time Analysis of Facial Expressions for Mood Estimation" Applied Sciences 14, no. 14: 6173. https://doi.org/10.3390/app14146173
APA StyleFilippini, J. S., Varona, J., & Manresa-Yee, C. (2024). Real-Time Analysis of Facial Expressions for Mood Estimation. Applied Sciences, 14(14), 6173. https://doi.org/10.3390/app14146173