
Swin-FER: Swin Transformer for Facial Expression Recognition


Abstract
1. Introduction
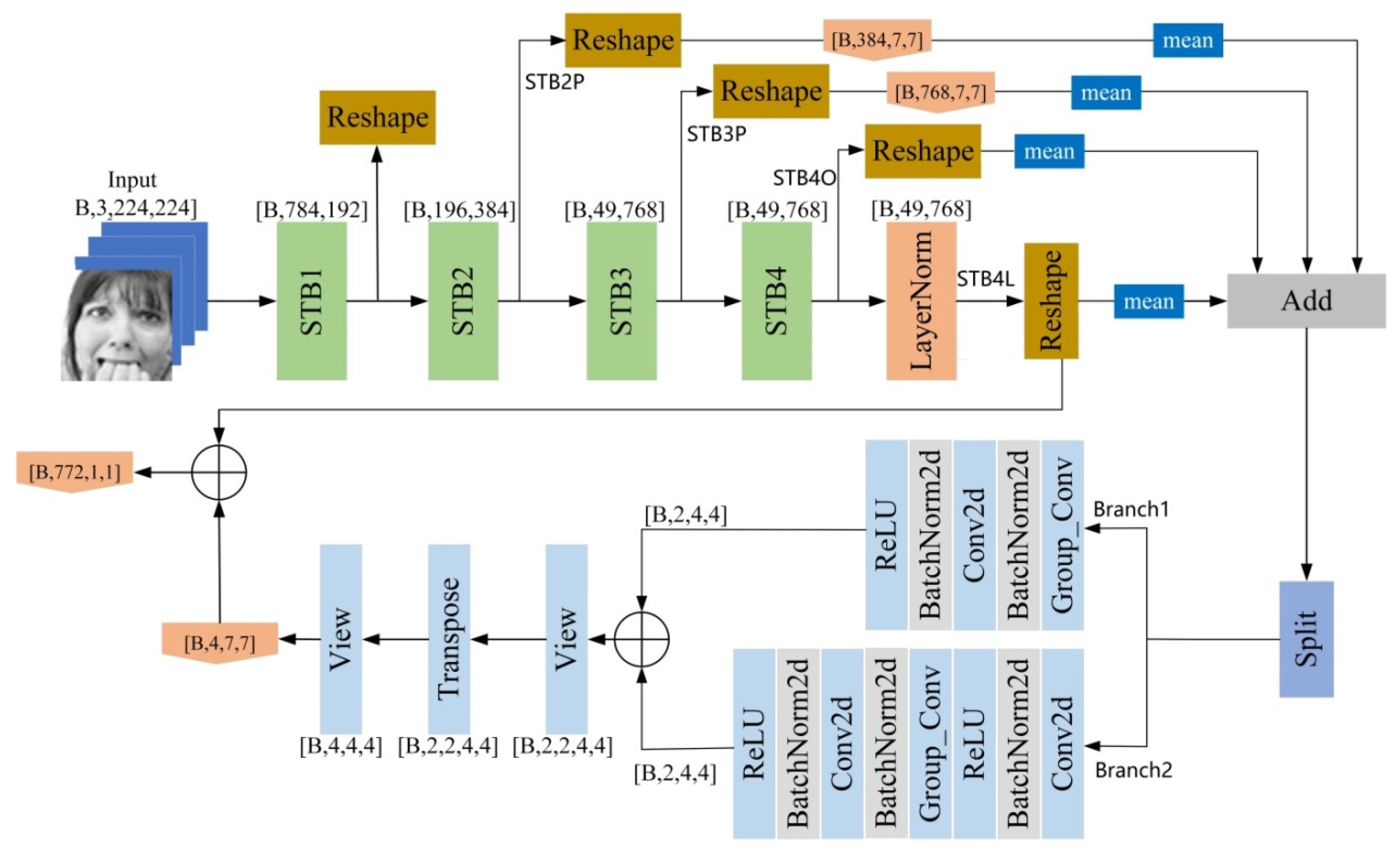
- Swin-Fer adopts a fusion strategy from middle to deep layers to capture facial expression features more accurately. This guides the network to learn the relationships between local and global features effectively, thus enhancing the ability of expression recognition.
- Using the data dimension transformation strategy, the whole network model can perceive more spatial dimension information. In addition, in order to improve the generalization ability of the model, the mean module and the split module, as well as group convolution, are introduced. While achieving satisfactory experimental results, the parameter count is kept largely unchanged.
- The proposed method achieves an accuracy of 71.11% on the Fer2013 dataset under natural conditions and 100% on the CK+ dataset in laboratory environments. The sensitivity and specificity of the model, as indicated by the area under the curve, are also good.
2. Related Works
2.1. Transformer for Facial Expression Recognition
2.2. Overview of the Swin Transformer
3. Proposed Method
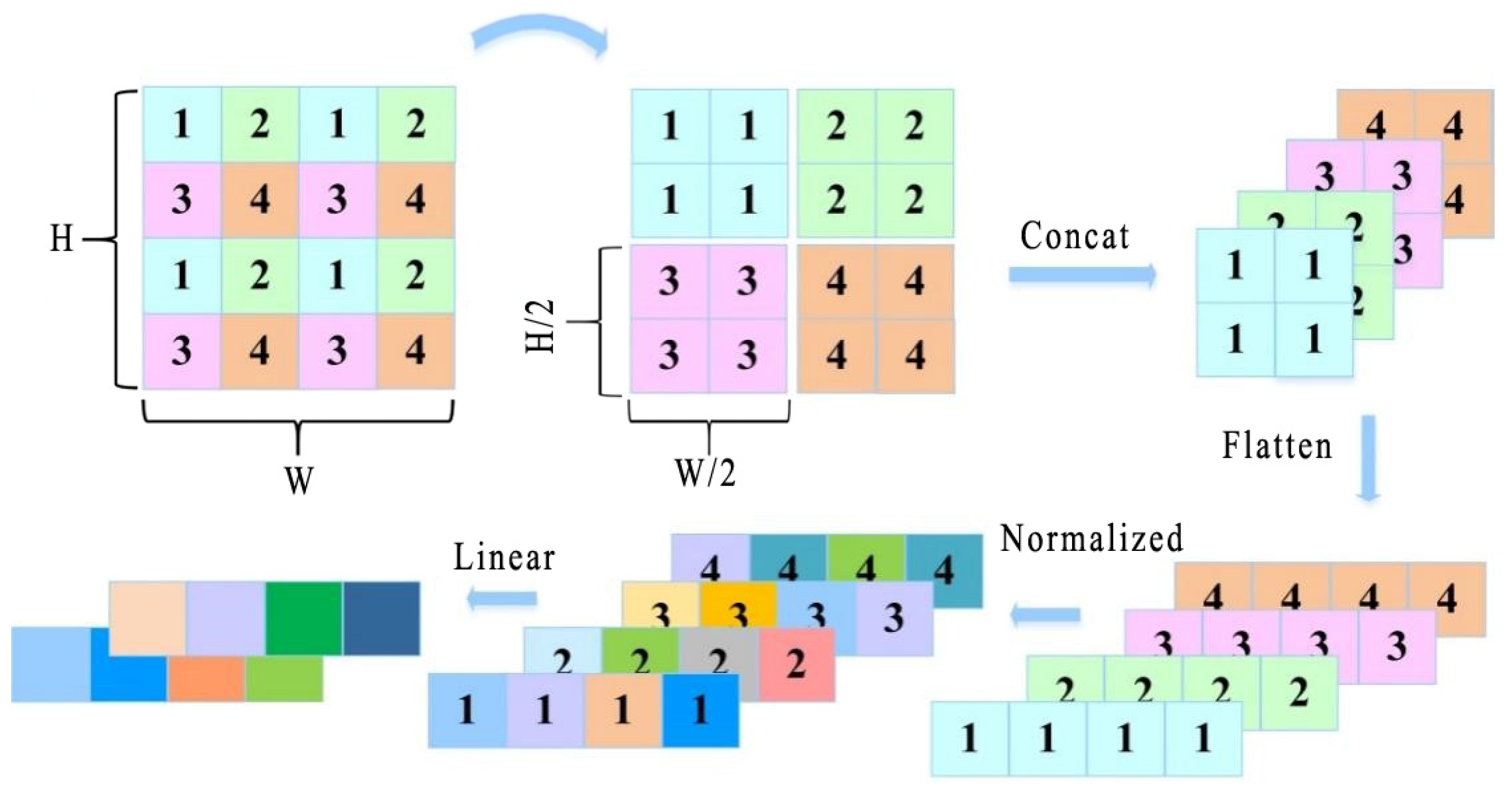
3.1. Patch Merging
3.2. Dimensional Transformation of Data
3.3. Mean Module
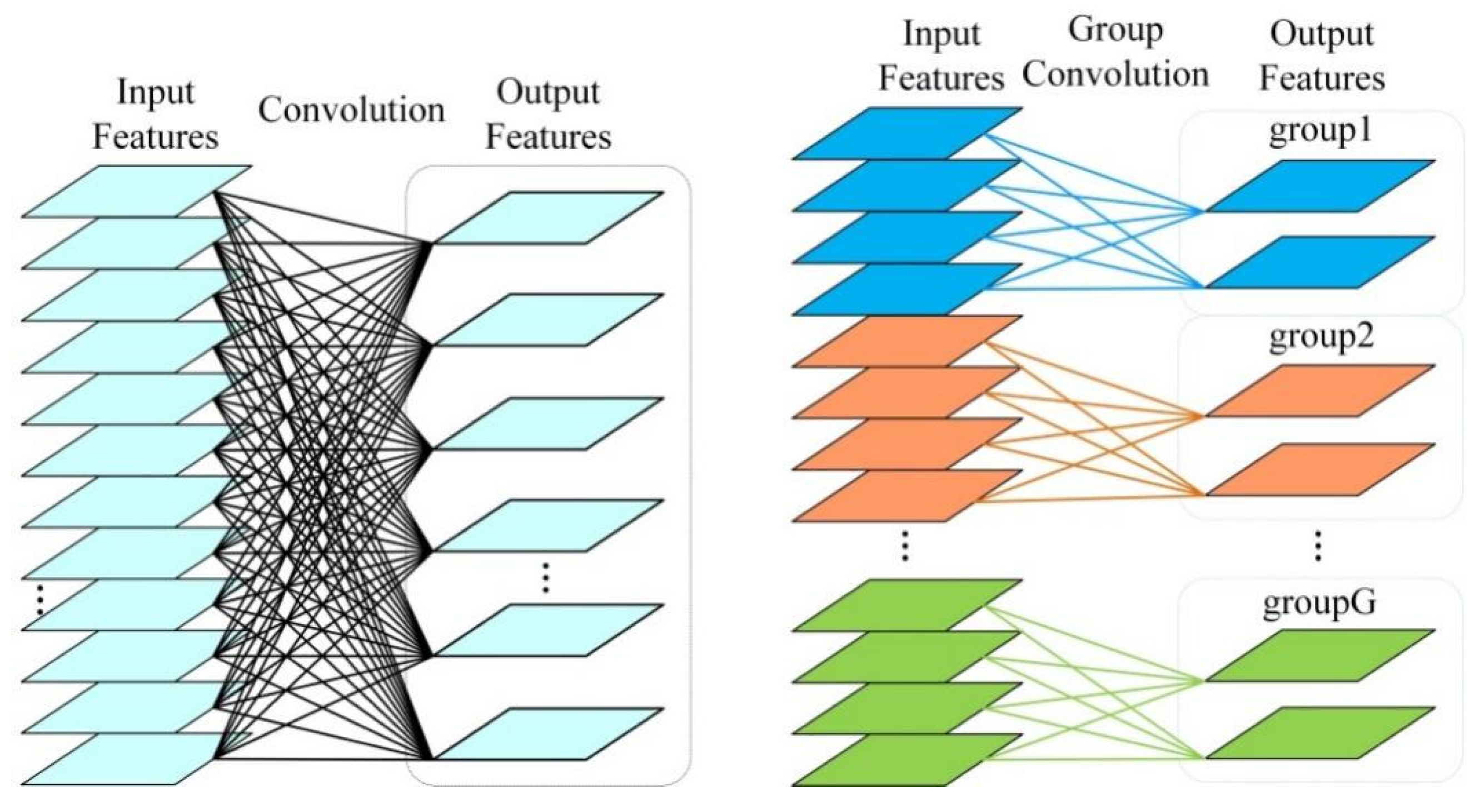
3.4. Split Module
4. Experiment Results and Analysis
4.1. Experimental Datasets
4.2. Experimental Environment
4.3. Experimental Results
4.4. Comparison of Experimental Accuracy
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rahali, A.; Akhloufi, M.A. End-to-end transformer-based models in textual-based NLP. AI 2023, 4, 54–110. [Google Scholar] [CrossRef]
- Ma, F.; Sun, B.; Li, S. Facial expression recognition with visual transformers and attentional selective fusion. IEEE Trans. Affect. Comput. 2021, 14, 1236–1248. [Google Scholar] [CrossRef]
- Shi, C.; Zhao, S.; Zhang, K.; Wang, Y.; Liang, L. Face-based age estimation using improved Swin Transformer with attention-based convolution. Front. Neurosci. 2023, 17, 1136934. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Z.; Zhang, S.; Chi, N.; Dai, Q. A versatile Wavelet-Enhanced CNN-Transformer for improved fluorescence microscopy image restoration. Neural Netw. 2024, 170, 227–241. [Google Scholar] [CrossRef] [PubMed]
- Shen, X.; Han, D.; Guo, Z.; Chen, C.; Hua, J.; Luo, G. Local self-attention in transformer for visual question answering. Appl. Intell. 2023, 53, 16706–16723. [Google Scholar] [CrossRef]
- Chitty-Venkata, K.T.; Mittal, S.; Emani, M.; Vishwanath, V.; Somani, A.K. A survey of techniques for optimizing transformer inference. J. Syst. Archit. 2023, 144, 102990. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Electr Network, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhou, M.; Liu, X.; Yi, T.; Bai, Z.; Zhang, P. A superior image inpainting scheme using Transformer-based self-supervised attention GAN model. Expert Syst. Appl. 2023, 233, 120906. [Google Scholar] [CrossRef]
- Xue, F.; Wang, Q.; Guo, G. Transfer: Learning relation-aware facial expression representations with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Electr Network, Montreal, QC, Canada, 11–17 October 2021; pp. 3601–3610. [Google Scholar]
- Kim, S.; Nam, J.; Ko, B.C. Facial Expression Recognition Based on Squeeze Vision Transformer. Sensors 2022, 22, 3729. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Q. Former-dfer: Dynamic facial expression recognition transformer. In Proceedings of the 29th ACM International Conference on Multimedia, Electr Network, Chengdu, China, 20–24 October 2021; pp. 1553–1561. [Google Scholar]
- Liang, X.; Xu, L.; Zhang, W.; Zhang, Y.; Liu, J.; Liu, Z. A convolution-transformer dual branch network for head-pose and occlusion facial expression recognition. Vis. Comput. 2023, 39, 2277–2290. [Google Scholar] [CrossRef]
- Qin, L.; Wang, M.; Deng, C.; Wang, K.; Chen, X.; Hu, J.; Deng, W. SwinFace: A Multi-Task Transformer for Face Recognition, Expression Recognition, Age Estimation and Attribute Estimation. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 2223–2234. [Google Scholar] [CrossRef]
- Bie, M.; Xu, H.; Liu, Q.; Gao, Y.; Che, X. Multi-dimension and Multi-level Information Fusion for Facial Expression Recognition. J. Imaging Sci. Technol. 2023, 67, 1–11. [Google Scholar] [CrossRef]
- Kim, J.H.; Kim, N.; Won, C.S. Global–local feature learning for fine-grained food classification based on Swin Transformer. Eng. Appl. Artif. Intell. 2024, 133, 108248. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghan, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 20–22 June 2023; pp. 14420–14430. [Google Scholar]
- Cheng, S.; Zhou, G. Facial expression recognition method based on improved VGG convolutional neural network. International J. Pattern Recognit. Artif. Intell. 2020, 34, 2056003. [Google Scholar] [CrossRef]
- Yang, J.; Li, C.; Zhang, P.; Dai, X.; Xiao, B.; Yuan, L.; Gao, J. Focal attention for long-range interactions in vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 30008–30022. [Google Scholar]
- Alamsyah, D.; Pratama, D. Implementasi Convolutional Neural Networks (CNN) untuk Klasifikasi Ekspresi Citra Wajah pada FER-2013 Dataset. (JurTI) J. Teknol. Inf. 2020, 4, 350–355. [Google Scholar] [CrossRef]
- Nie, H. Face Expression Classification Using Squeeze-Excitation Based VGG16 Network. In Proceedings of the 2nd International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 14–16 January 2022; pp. 482–485. [Google Scholar]
- Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-emotion: Facial expression recognition using attentional convolutional network. Sensors 2021, 21, 3046. [Google Scholar] [CrossRef] [PubMed]
- Zu, F.; Zhou, C.J.; Wang, X. An improved convolutional neural network based on centre loss for facial expression recognition. Int. J. Adapt. Innov. Syst. 2021, 3, 58–73. [Google Scholar] [CrossRef]
- Pan, L.; Shao, W.; Xiong, S.; Lei, Q.; Huang, S.; Beckman, E.; Hu, Q. SSER: Semi-Supervised Emotion Recognition Based on Triplet Loss and Pseudo Label. Knowl.-Based Syst. 2024, 292, 111595. [Google Scholar] [CrossRef]
- Shen, T.; Xu, H. Facial Expression Recognition Based on Multi-Channel Attention Residual Network. CMES-Comput. Model. Eng. Sci. 2023, 135, 539–560. [Google Scholar]
- Zhu, X.; He, Z.; Zhao, L.; Dai, Z.; Yang, Q. A Cascade Attention Based Facial Expression Recognition Network by Fusing Multi-Scale Spatio-Temporal Features. Sensors 2022, 22, 1350. [Google Scholar] [CrossRef] [PubMed]
- Aouayeb, M.; Hamidouche, W.; Soladie, C.; Kpalma, K.; Seguier, R. Learning vision transformer with squeeze and excitation for facial expression recognition. arXiv 2021, arXiv:2107.03107. [Google Scholar]
- Zhao, Z.; Liu, Q.; Zhou, F. Robust lightweight facial expression recognition network with label distribution training. In Proceedings of the AAAI conference on artificial intelligence (AAAI), Online, 2–9 February 2021; Volume 35, pp. 3510–3519. [Google Scholar]
- Pourmirzaei, M.; Montazer, G.A.; Esmaili, F. Using self-supervised auxiliary tasks to improve fine-grained facial representation. arXiv 2021, arXiv:2105.06421. [Google Scholar]
- Savchenko, A.V. Facial expression and attributes recognition based on multi-task learning of lightweight neural networks. In Proceedings of the IEEE 19th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 16–18 September 2021; pp. 119–124. [Google Scholar]
- Wen, Z.; Lin, W.; Wang, T.; Xu, G. Distract your attention: Multi-head cross attention network for facial expression recognition. Biomimetics 2023, 8, 199. [Google Scholar] [CrossRef] [PubMed]
- Wagner, N.; Mätzler, F.; Vossberg, S.R.; Schneider, H.; Pavlitska, S.; Zöllner, J.M. CAGE: Circumplex Affect Guided Expression Inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 4683–4692. [Google Scholar]
- Li, J.; Nie, J.; Guo, D.; Hong, R.; Wang, M. Emotion separation and recognition from a facial expression by generating the poker face with vision transformers. arXiv 2022, arXiv:2207.11081. [Google Scholar]
- Zhang, L.; Verma, B.; Tjondronegoro, D.; Chandran, V. Facial expression analysis under partial occlusion: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–49. [Google Scholar] [CrossRef]
- Shao, J.; Qian, Y. Three convolutional neural network models for facial expression recognition in the wild. Neurocomputing 2019, 355, 82–92. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Expression | Surprise | Happy | Disgust | Anger | Fear | Sad | Contempt | Total |
|---|---|---|---|---|---|---|---|---|
| Train | 225 | 186 | 159 | 123 | 66 | 75 | 48 | 882 |
| Test | 24 | 21 | 18 | 12 | 9 | 9 | 6 | 99 |
| Total | 249 | 207 | 177 | 135 | 75 | 84 | 54 | 981 |
| Expression | Happy | Neutral | Sad | Fear | Angry | Surprise | Disgust | Total |
|---|---|---|---|---|---|---|---|---|
| Train | 7215 | 4965 | 4830 | 4097 | 3995 | 3171 | 436 | 28,709 |
| Test | 1774 | 1233 | 1247 | 1024 | 958 | 831 | 111 | 7178 |
| Total | 8989 | 6198 | 6077 | 5121 | 4953 | 4002 | 547 | 35,877 |
| Parameter Name | Parameters |
|---|---|
| Batch size | 80 |
| Learning rate | 0.0001 |
| Optimizer | Adam |
| Seed | 1024 |
| Image size | 224 |
| Method | Fer2013 | CK+ |
|---|---|---|
| EdgeViT | 0.5935 | 0.725 |
| EfficientFormer | 0.6053 | 0.7125 |
| Vision transformer | 0.6848 | 0.85 |
| Swin transformer | 0.7070 | 0.9625 |
| Swin-Fer | 0.7111 | 1 |
| Network | Number of Parameters |
|---|---|
| EdgeViT | 11.30 M |
| EfficientFormer | 19.8 M |
| Vision transformer | 21.42 M |
| Swin transformer | 27.53 M (27530120 B) |
| Swin-Fer | 27.53 M (27530190 B) |
| Network | Fer2013 | CK+ |
|---|---|---|
| CNN using the Adamax optimizer [20] | 66% | - |
| VGG16+SE Block [21] | 66.8% | 99.18% |
| DeepEmotion [22] | 70.02% | 98% |
| Swin transformer | 70.70% | 96.25% |
| Improved CNN based on center loss [23] | 71.39% | 96.64% |
| SSER [24] | 71.62% | 97.59% |
| Multi-Channel Attention Residual Network [25] | 72.7% | 98.8% |
| ResNet-50 + pyramid + cascaded attention block + GRU [26] | - | 99.23% |
| ViT+SE [27] | - | 99.8% |
| Swin-Fer | 71.11% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bie, M.; Xu, H.; Gao, Y.; Song, K.; Che, X. Swin-FER: Swin Transformer for Facial Expression Recognition. Appl. Sci. 2024, 14, 6125. https://doi.org/10.3390/app14146125
Bie M, Xu H, Gao Y, Song K, Che X. Swin-FER: Swin Transformer for Facial Expression Recognition. Applied Sciences. 2024; 14(14):6125. https://doi.org/10.3390/app14146125
Chicago/Turabian StyleBie, Mei, Huan Xu, Yan Gao, Kai Song, and Xiangjiu Che. 2024. "Swin-FER: Swin Transformer for Facial Expression Recognition" Applied Sciences 14, no. 14: 6125. https://doi.org/10.3390/app14146125
APA StyleBie, M., Xu, H., Gao, Y., Song, K., & Che, X. (2024). Swin-FER: Swin Transformer for Facial Expression Recognition. Applied Sciences, 14(14), 6125. https://doi.org/10.3390/app14146125