1. Introduction
For a long time, the maritime field has been facing many challenges, including collision risks caused by human factors, illegal smuggling and infiltration, maritime traffic control, maritime emergency rescue, and port management. In order to solve these problems, ship target recognition technology has gradually become the focus of scholars’ research. This technology provides new solutions to potential problems in the maritime field with its fast and accurate recognition performance, data integration, and monitoring capabilities.
In recent years, CNN (convolutional neural networks) technology has occupied an important position in the field of ship target recognition due to its excellent feature extraction ability, hierarchical feature learning ability, and generalization ability. Depending on the different ways and processes of target detection tasks, the target detection algorithms are usually divided into two categories: single-stage target detection and two-stage target detection. The two-stage target detection algorithm first generates candidate areas through the region proposal network and then performs target detection and classification on these candidate areas. It can usually achieve high detection accuracy and is suitable for complex scenes and small target detection. Common two-stage target detection algorithms include Faster R-CNN [
1], Mask R-CNN [
2], and Cascade R-CNN [
3]. Different from the two-stage target detection algorithm, the one-stage target detection algorithm detects the target directly from the image without generating candidate frames. This is suitable for scenarios that require high detection speed, for example, YOLO [
4], SSD [
5], RetinaNet [
6], YOLOv3 [
7], and other algorithms. However, the detection accuracy is relatively low.
Yolov5 is currently an algorithm with good comprehensive detection performance and fast detection speed, and it is widely used in target recognition tasks in different fields. In marine transportation, there are many types of marine structures, large scale differences, and harsh marine environments (such as fog, occlusion, and backlight), which makes marine target detection face great challenges. In addition, in order to reduce operating costs, the hardware resources carried by ships are limited. Therefore, in order to meet the needs of multi-scene and different-scale ship target detection on edge devices with limited computing resources, this study designed and tested a lightweight multi-scale ship target recognition algorithm YOLOv5s_ESGW (ESGW is composed of the abbreviations of Ef-ficientNetV2, Shuffle Attention, Ghostnet, and Wise-IoU, representing the model improvement process). The main contributions include the following: (1) A multi-scenario and multi-scale ship visible light dataset is produced. The dataset covers mainstream ship types of different scales and also includes scenes such as fog, occlusion, and backlight. (2) Based on a lightweight network, the feature extraction capability, network depth, and width of the Yolov5 model are optimized, and the number of model parameters and calculations are compressed while ensuring the model detection accuracy, thereby improving the model’s inference speed. (3) A lightweight attention module is integrated into the model to express important feature information in the image, suppress unimportant feature information, and improve the model’s detection capability. (4) Wise-IoU is used as the bounding box loss function to improve the model’s detection accuracy for objects of different sizes and shapes, better measure the similarity between the predicted box and the true box, and improve the model’s detection performance and robustness.
The rest of this paper is organized as follows:
Section 2 introduces the related work on maritime ship target recognition.
Section 3 gives a detailed introduction to the model and improved method proposed in this study.
Section 4 introduces and discusses the experimental arrangement and results. Finally,
Section 5 summarizes this study and its prospects.
2. Related Works
Based on different types of image target recognition methods, many scholars have conducted in-depth research on the recognition and detection of ships and marine structures. In order to improve the detection accuracy and robustness of ship targets, Huang et al. [
8] proposed a new method for ship target recognition, namely Ship-YOLOv3, by improving the network structure of the YOLOv3 model. Hong et al. [
9] improved it based on YOLOv3 and achieved accurate identification of multi-scale ship targets. The detection performance of the improved algorithm on multi-sensor images, such as synthetic aperture radar (SAR) and optical images, was verified. In order to improve the recognition speed and accuracy of ship targets, Zou et al. [
10] proposed an improved SSD algorithm based on the MobilenetV2 neural network for ship target recognition and detection. Hu et al. [
11] improved the SSD model based on the resnet50 network to enhance the feature expression ability of the network model and improve the accuracy of small-scale marine life detection. Zhang et al. [
12] used the Mask R-CNN algorithm and the Faster R-CNN algorithm to establish a ship feature extraction and recognition model to improve the accuracy of ship target recognition and the performance of target detection and classification. To improve the detection accuracy and speed of ship targets in different scenarios, Qi et al. [
13] improved the Faster R-CNN model using scene narrowing technique and image downscaling method to improve the computational speed and detection accuracy of the model. Zhou et al. [
14] optimized the loss function of the YOLOv5s model by comparing the loss function of the model to improve the detection accuracy of the model for multi-type and small-scale ship targets. These methods demonstrate the value of deep learning image algorithms for multi-scale target detection on ships. Although researchers have adopted different improvement methods to improve the accuracy and robustness of ship target detection models, most studies use single form of training data and do not consider the detection performance of multi-scale ship targets under complex sea conditions. There is still a need to further improve the dataset and optimize the detection performance of the model.
In order to meet the demand of target detection tasks at the edge and mobile ends, more and more scholars are paying close attention to the technology of model lightweighting. The main goal of this study is to reduce the complexity of the model as much as possible while ensuring the accuracy of model detection. To meet this demand, Wang et al. [
15] optimize the filter structure and parameters of the target detection network by the multi-objective firefly optimization algorithm (MFA) to trade off the recognition accuracy and size of the target detection model. Zheng et al. [
16] improved the YOLOv5s model by lightweighting based on MobileNetV3-Small and ConvNeXt lightweight networks to enhance the feature expression ability and detection accuracy of the model and reduce the complexity of the model to a larger extent. Yu et al. [
17] improved the feature extraction ability and generalization ability of the model based on the proposed SCUPA module and GCHE module to achieve the purpose of reducing the complexity of the model and improving the accuracy of model detection. Zhang et al. [
18] used structured pruning and knowledge distillation methods to compress the VGGNet network model, which greatly reduced the computational cost of the model. Zhang et al. [
19] improved the YOLOv5 model based on depthwise convolution (DWConv) and CA attention mechanism, compressing the parameters of the model as much as possible to improve the detection accuracy and speed of the model. Wu et al. [
20] applied multi-scale detection technology and an SE attention mechanism to improve the YOLOv4-tiny model to integrate multi-level semantic information to achieve real-time detection and early warning of ship fires in complex environments. Yang et al. [
21] adopt the lightweight feature extraction networks IMNet and Slim-bifpn to improve the YOLOv5 model, which enhances the feature extraction capability of the model and reduces the number of parameters to achieve fast and accurate recognition of small-scale ship targets on platforms with limited computational resources.
Table 1 lists the main improvement methods and shortcomings of the related work above.
Most of the above research used lightweight feature extraction networks to improve the target recognition model or use pruning strategies to improve the model itself in a lightweight way [
13,
16]. Although the detection speed of the model has been improved to a certain extent after these methods, the model complexity is still at a high level [
14,
15,
16,
17]. Some studies have also added attention mechanisms to the improved model to improve the detection accuracy of the model [
19,
20,
21], but it is more suitable for detecting small targets, and the detection accuracy is still at a low level. In order to fully compress the complexity of the model and meet the requirements of ship target detection on hardware platforms with limited computing resources, a lightweight detection model YOLOv5s_ESGW suitable for different scenarios and multi-scale targets was developed.
3. Data and Methods
3.1. Dataset Production
The types of ships on the surface vary in scale and shape, making ship target detection more difficult than that of other objects. At the same time, the marine environment is complex, and ship images may be acquired under different conditions, such as different lighting and different visibility. Firstly, this research produced MSDs (Marine Structure Datasets), datasets for ship target detection and classification. The collected ship images are mainly acquired from the shipboard CCTV system or drawn from the network. The target types obtained include lighthouses, sailboats, buoys, rail bars, cargo ships, naval vessels, passenger ships, and fishing boats. A total of 7354 images were collected and stored in JPG format. The dataset contains 826 lighthouse targets, 1143 sailboat targets, 776 buoy targets, 2632 rail bar targets, 717 cargo ship targets, 1884 naval vessel targets, 1742 passenger ship targets, and 901 fishing boat targets. The collected and produced datasets were manually labeled with target information using LabelImg, and the datasets were data-enhanced and calibrated. The final file in xml format is stored, and the specific dataset production process is shown in
Figure 1. The produced dataset is randomly divided into training, testing, and validation sets in a ratio of 8:1:1. The format of the produced dataset is the standard Pascal VOC (Visual Object Classes) format dataset, which is used for subsequent training and validation of the recognition model.
3.2. Baseline Model Adopted
The objective of this research is to construct a lightweight ship target detection model that achieves a balance between model detection accuracy and complexity to meet the requirements for applications on shipboard processing platforms with limited computational and memory resources. Yolov5 is currently a target detection algorithm that is widely used and has advanced detection performance. This model has fast and accurate inference capabilities and detection accuracy. Currently, there are four main network structures of the Yolov5 model, including Yolov5m, Yolov5l, Yolov5x, and Yolov5s. The performance of these models is verified by training and testing on publicly available datasets, as shown in
Table 2. From the comprehensive model performance comparison, it is concluded that Yolov5s model has the lowest complexity and relatively faster detection speed, which is more suitable for deployment on hardware devices with limited computational resources. Yolov5x has the highest detection accuracy, but the model is more complex. Therefore, in this research, the Yolov5s model was used as a baseline and improved using a lightweighting method to reduce the number of parameters of the model while ensuring the model’s detection accuracy.
The Yolov5 model consists of an input, a backbone network, a neck, and a head. On the input side, a series of processes are performed on the image, including mosaic data augmentation, image sizing, and adaptive anchor frame computation. Mosaic data augmentation utilizes random cropping, flipping, rotating, and color transformations to add variety and complexity to the training dataset. To ensure that fixed-size images can be used during inference, unified scaling technology is used to process input images of different sizes. The backbone network can extract rich and effective features from the input image through the combination and hierarchical stacking of Conv, C3, SPPF, and other modules. The Conv module is the core module in the backbone network. It is mainly used to extract target feature information, prevent over-fitting, and accelerate convergence. The C3 module is a multi-path convolution structure that can increase the depth and width of the network and improve the richness of features. SPPF is a spatial pyramid pooling module that can perform pooling operations on feature maps of different scales to extract feature information of different scales.
In the Yolov5 neck, the feature pyramid structure of FPNs (Feature Pyramid Networks) and PANs (Path Aggregation Networks) is used to fuse shallow graphic features and deep semantic features. At the same time, it can also extract effective information from multi-scale feature maps, thereby improving the performance of target detection. The detection head module is mainly responsible for multi-scale target detection on the extracted feature information, including the location, category, and confidence of the target frame. The detected target information is processed using techniques such as non-maximum suppression to obtain the final target detection result.
3.3. The Improved Yolov5s_ESGW Model
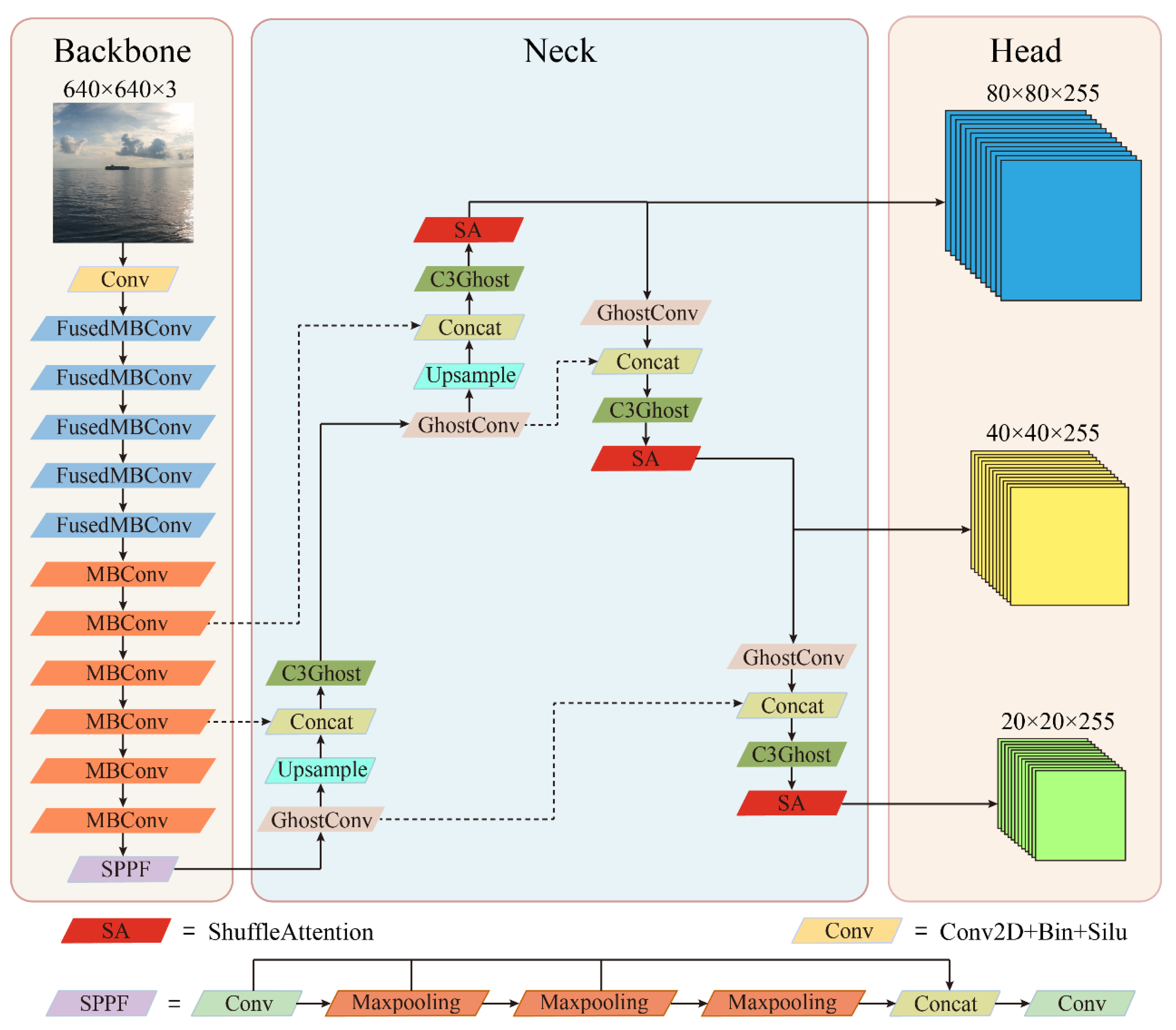
In order to ensure the accuracy of model detection and reduce the number of parameters and calculations of the model as much as possible, this paper proposes a lightweight ship target detection model. The improved Yolov5s_ESGW model structure diagram is shown in
Figure 2. Compared with the baseline model, the improved model mainly integrates the ideas of EfficientNetV2 and Ghostnet networks and makes lightweight improvements to the feature extraction network. The Shuffle Attention mechanism is also integrated into the model, which enables the network to more effectively capture the correlation between space and channels, thereby improving the network’s expressiveness. In addition, the model’s loss function is also optimized to better improve the model’s target box prediction ability. The following is a detailed description of the method for improving this model.
3.3.1. Lightweight
In order to meet the application of image recognition models on platforms with limited computing resources, existing image recognition models need to be lightweight and deployed. Therefore, in this research, the lightweight EfficientNetV2 [
22] network is utilized to improve the backbone network of yolov5s based on the Yolov5s model. As shown in
Figure 3, the unique feature of EfficientNetV2 is that it further optimizes the inference speed and training speed by integrating perceptual neural architecture search and scaling strategies. The Fused-MBConv module is introduced into its model, bringing a richer search space to EfficientNetV2. Compared with EfficientNetV1, EfficientNetV2 achieves significant improvements in training speed, achieving up to 6.8 times shorter training time. This means that EfficientNetV2 can utilize computing resources in a more efficient manner, accelerate training, and be more suitable for various application scenarios with limited computing resources.
The MBConv block in EfficientNetV2 achieves a model with better detection performance and fewer parameters by using an inverted residual structure and depth-separable convolution. As shown in
Figure 3a, MBConv uses 1 × 1-dimensional expansion convolution to expand the number of input channels, which helps extract higher-level feature information and gives the network rich expressive capabilities. In order to reduce the amount of calculation, the MBConv module uses depthwise separable convolution and integrates SENet [
23], which improves the computational efficiency of the model while ensuring the model detection performance. To improve the computational efficiency and performance of the model, EfficientNetV2 introduces a new module, Fused-MBConv. As shown in
Figure 3b, it mainly merges Conv 1 × 1 and DWconv in the MBConv module into a 3 × 3 convolution. This study draws on the ideas of MBConv and Fused-MBConv modules to reconstruct the feature extraction network of the baseline model, optimize the depth and width of the backbone network, and fully compress the complexity and computational cost of the model. Experiments show that after using the Fused-MBConv module, the number of parameters of the model will increase to a certain extent. However, it avoids memory reading and writing at each stage, thereby reducing the computational burden and making the model’s computational efficiency significantly improved compared to before.
In order to further compress the detection model, the lightweight Ghostnet network is used to improve the neck network of the Yolov5s model. As shown in
Figure 4, first, the GhostConv module is used to replace the Conv module in the neck network of the original model. Compared with the Conv module, the GhostConv module mainly uses ordinary convolution operations and grouped convolution to obtain relevant feature maps, which can significantly reduce the number of parameters and calculation costs of the model. Then, the GhostBottleneck module integrated into the GhostConv module is used to replace the bottleneck in the C3 module and obtain a new C3Ghost module. Through such improvements, feature maps similar to the original model can be obtained at a lower cost, achieving a trade-off between model detection accuracy and complexity.
3.3.2. Shuffle Attention
The attention mechanism is a method that simulates human vision and cognitive systems and has wide applications in the field of deep learning. It can selectively focus on important feature information related to the target and is often used to improve the detection performance and generalization ability of the model. This study mainly integrates the Shuffle Attention [
24] mechanism into the appropriate position of the recognition model. It mainly disrupts the order of input data, so the model needs to reconsider the order of data when processing data, thereby improving the model’s feature expression ability. As shown in
Figure 5, Shuffle Attention mainly includes the following parts.
First, the input feature is divided into groups along the channel dimension, denoted as . In order to extract important feature information of the target, the feature information of each group is divided into two branches . Among them, is used to extract the channel attention features of the target, and is used to extract the spatial attention features of the target.
Secondly, the input feature
is used to extract the target feature information using channel attention and spatial attention mechanisms, respectively. The channel attention mechanism in Sa-net is similar to the SE attention module. In order to reduce the amount of calculation, Sa-net uses a combination of global averaging pooling (GAP), scale, and Sigmoid to extract important feature information.
where
is channel-wise statistics, and
and
are parameters utilized for scaling and shifting
.
The spatial attention mechanism uses Group Norm (
GN) and
to obtain spatial feature information. The specific expression is as follows:
where
.
Finally, the and obtained from the two branches are combined and concatenated to achieve aggregation of all feature information. In addition, the channel shuffle operation is used to reorganize the information within the group and realize the circulation of information between different groups.
3.3.3. Wise-IoU Loss Algorithm
In the target detection task, bounding box loss, as one of the important loss functions, plays an important role in improving the accuracy and stability of model prediction. The bounding box loss is mainly used to optimize the difference between the bounding boxes predicted by the model and the true bounding boxes. Specifically, this loss function optimizes the model by calculating the distance or difference between the predicted and true bounding boxes. For the ship visible light dataset, the scenes included are complex, and the target scales vary greatly. This study uses Wise-IoU (Intersection over Union) [
25] as the bounding box loss function for ship target detection to achieve more accurate detection of ship multi-scale targets. Wise-IoU is based on IoU loss, giving different weights to samples of each category to reduce the difference between better and worse quality categories. This improves the generalization performance of the model.
As shown in
Figure 6,
represents the center point coordinates and width and height of the anchor box;
represent the center point coordinates, width, and height of the target frame, respectively;
and
represent the width and height of the smallest enclosing rectangle of the anchor box and target box, respectively; and
and
, respectively, represent the width and height of the overlap between the anchor box and the target box. The calculation method of
is as shown in Formulas (1)–(3). Among them,
can significantly increase the
of ordinary quality anchor frames, and
can significantly reduce the
of high-quality anchor frames.
In addition, an outlier degree (
) is introduced to characterize the quality of the anchor box, and its calculation method is shown in Formula (9). When
is smaller, it represents higher anchor box quality. At the same time, a small gradient gain is assigned to it so that the bounding box regression focuses on the normal quality anchor box. For a larger
, assigning a smaller gradient gain can effectively suppress the risk of low-quality examples generating large harmful gradients. Finally, the non-monotone focusing factor
is used to optimize
, and the specific calculation method is shown in Formulas (7) and (8).
3.4. Evaluation Indicators
This research uses indicators such as average detection time, number of parameters, FLOPs (floating-point operations), and model size to evaluate the complexity of the target detection model. At the same time, in order to quantify the effectiveness of the improved ship target detection model, precision, recall rate, and mAP (mean average precision) are used as evaluation indicators. The calculation formula for each evaluation index is as follows:
where
TP (True Positive) indicates the number of samples that are actually positive and correctly predicted as positive by the classifier.
TN (True Negative) indicates the number of samples that are actually negative and correctly predicted as negative by the classifier.
FN (False Negative) indicates the number of samples that are actually positive but predicted as negative by the model.
FP (False Positive) denotes the number of samples that are actually negative cases but are predicted as positive cases by the model. mAP indicates how well the model detects on all categories. mAP0.5 represents the mean average precision when the IOU threshold is 0.5.
4. Experimental Results and Discussion
4.1. Experimental Environment
The software and hardware environments used in this study are the same before and after the improvement of the ship target recognition model. The details are shown in
Table 3. Meanwhile, the training parameters set during the training process are all the same. The size of the input image of the training model is 640 × 640 pixels, the epoch is 300, the batch size is 32, the initial learning rate is 0.01, the weight decay coefficient is 0.0005, the learning rate momentum is 0.937, the model optimizer is Adam, and the cosine annealing method is used for the adjustment strategy of the learning rate.
4.2. Ablation Experiment and Functional Verification
To verify the detection performance of the proposed model, five sets of ablation experiments were used in this study, as shown in
Table 4. The first set of experiments uses the original yolov5s model for training as the baseline model for ablation experiments. The second set of experiments used MBConv and Fused-MBConv modules to improve the backbone part of the yolov5s model. Compared with the baseline model, the improved model adopts a compound scaling strategy and stage-wise architecture in the feature extraction network and optimizes the width, depth, and resolution of the model. At the same time, depthwise separable convolution is integrated into the MBConv module, which greatly reduces the amount of calculation and parameters of the model while ensuring the detection performance. The GFLOPs and parameter count of the model decreased by 64.56% and 22.90%, respectively. The detection performance of the model is comparable to that of the baseline model, with mAP0.5 increasing by 0.1% and detection accuracy decreasing by 0.9%. In order to further improve the detection performance of the model, the third set of experiments added a lightweight attention mechanism based on the second set of experiments. Among them, the addition of the Shuffle Attention mechanism has made the overall performance of the model the most obvious improvement. The detection accuracy and mAP0.5 have increased by 0.4% and 0.2%, respectively, and the number of GFLOPs and parameters has hardly increased. This is mainly because the Shuffle Attention mechanism can better capture the correlation between channels, improve the model’s ability to express important features, and suppress unimportant feature information, thereby enhancing the detection performance of the model. To further compress the GFLOPs and parameters of the model, the fourth group of experiments, based on the third group of experiments, improved the model head layer by using the idea of generating redundant feature information through a cheap linear transformation in the Ghost network, thereby reducing the computational cost of the model. Compared with previous improvements, the GFLOPs and parameters of the model dropped by 10.71% and 25.83%, respectively, but the detection accuracy and mAP0.5 dropped by 0.3% and 1.4%, respectively. Based on the fourth set of experiments, the fifth set of experiments uses the Wise-IOU loss function to improve the model and more accurately evaluate the degree of overlap between the predicted bounding box and the true bounding box. Compared with the fourth group, the detection accuracy of the model increased by 1.6%, and the mAP0.5 value increased by 0.1%. The results of five ablation experiments show that the improvement measures proposed in this study can significantly reduce the complexity of the model while ensuring that the detection accuracy of the model remains basically unchanged.
To further verify the detection efficiency of the improved model, this study compared the detection speed of different models on CPU (model: Intel(R) Core(TM) i7-12700H). As shown in
Table 5, the baseline model requires 85.2 ms for each image detection. With the improvement of model lightweighting, the method proposed in the fifth set of ablation experiments has the fastest detection speed on the CPU, at 60.0ms. Compared with the baseline model, the inference time is reduced by 29.58%, and the mAP0.5 value is increased by 0.001. Overall, this study has a significant effect on improving multi-scale ship target detection methods.
4.3. Experimental Results and Analysis
To further verify the detection performance of the proposed model, this study trained and tested Yolov5s and the improved lightweight Yolov5s_ESGW model on MSD.
Figure 7 shows the changes in mAP0.5 values of the two models during the training process.
Figure 8 compares the detection speed and complexity of the two models.
Figure 9 shows the detection results of ship visible light targets by the two models in scenarios such as heavy fog, semi-obstruction, and targets of different scales.
Figure 10 shows the ability of the two models to extract regions of interest during the training process.
Figure 7 shows the change process of mAP0.5 during the training process. In the first 50 epochs, the mAP0.5 values of the two models increased rapidly. From the 50th epoch to the 125th epoch training, the mAP0.5 value gradually increased slowly, reaching about 0.8. At this stage, the original Yolov5s model mAP0.5 value is higher than the method proposed in this study. However, the mAP0.5 value of the original Yolov5s model fluctuates greatly. From the 125th epoch to the end of training, the mAP0.5 values of both models tend to be stable. At this time, the mAP0.5 value of the method proposed in this study generally shows an upward trend and is significantly higher than the original Yolov5s model. This shows that the detection model proposed in this study has excellent detection performance.
Figure 8 shows a comparative analysis of the parameters, detection time for each picture, mAP0.5 value, GFLOPs, and file size of the original Yolov5s model and the improved Yolov5s_ESGW model. The parameter volume of the improved Yolov5s_ESGW model is 4.02M, GFLOPs is 5, each picture detection takes 60ms, mAP0.5 is 82.5%, and the file size is 8.02MB. Compared with the Yolov5s baseline model, the number of parameters decreased by 42.82%, the detection time of each picture decreased by 29.58%, the mAP0.5 value increased by 0.1%, GFLOPs decreased by 68.35%, and the file size was reduced by 41.46%. Taken together, the algorithm proposed in this study requires fewer calculations and parameters and has excellent detection performance. At the same time, the demand for hardware computing resources during the ship target detection process is low, and they are more suitable for deployment in edge terminals or embedded devices.
Figure 9 shows the detection results of ship visible light targets of different scales by the two models in different scenarios. It can be seen that compared with the original Yolov5s model, the Yolov5s_ESGW model proposed in this article has higher reliability in detecting different targets. In the scenes in
Figure 9c,d, there is backlighting, heavy fog, etc., and the baseline model misses the detection of small targets. But the Yolov5s_ESGW model can detect it accurately. In the scenes of
Figure 9e,f where there is heavy fog and wave obstruction, both models are able to identify the target information. But the Yolov5s_ESGW model has higher detection confidence. Overall, the Yolov5s_ESGW model proposed in this article has better detection performance.
As shown in
Figure 10, this study selected targets of different types and scales for comparative analysis. The dark red area indicates the area that the model is more interested in and contributes more to the final output of the model. In
Figure 10a–e, compared with the original Yolov5s model, the Yolov5s_ESGW model proposed in this study improved the sailboat, buoy, cargo ship, and naval vessel target detection results by 0.03, 0.02, 0.05, and 0.07, respectively. It can be seen from the heat map that the Yolov5s_ESGW model almost covers the target area of different scales, is more concentrated, and has brighter colors. At the same time, the Yolov5s_ESGW model is less affected by interference in areas without targets and can express richer feature information of detected targets. Therefore, the Yolov5s_ESGW model has better feature extraction capabilities, a wider detection range, and strong anti-interference ability for areas other than the detection target.
4.4. Comparison of Algorithm Performance and Complexity
In order to further verify the detection advantages of the proposed method, this paper conducts comparison and verification with mainstream lightweight models, including the Yolov5s model, Yolov7-tiny [
30], and the latest YOLOv8n that incorporate different lightweight networks and attention mechanisms. The details are shown in
Table 6. Compared with the other five models, the mAP0.5 values of the method proposed in this article increased by 0.008, 0.014, 0.020, 0.024, and 0.003, respectively, and the P values increased by 0.001, 0.005, 0.035, 0.042, and 0.019, respectively. This shows that the model proposed in this study is highly accurate in identifying ship multi-scale targets. The Yolov5s model integrated with the ShuffleNetv2 network and LSKblock [
31] attention mechanism has a smaller GFLOPs value. However, the mAP0.5 value, detection time, and parameter amount of this model are relatively high. The Yolov8n model has a smaller parameter amount and detection time, which is slightly different from the parameter amount and detection time of the model proposed in this article. However, the model proposed in this article has more advantages in target detection accuracy, computational complexity, and mAP0.5 value. In general, the multi-scale ship target recognition model proposed in this article is lightweight and reaches a level comparable to the latest algorithm (Yolov8n) in terms of detection time. It is superior to the latest algorithms in terms of detection capabilities and is more suitable for multi-scale ship target detection tasks in different scenarios.
5. Conclusions
This study proposes a lightweight multi-scale ship target detection model, Yolov5s_ESGW, based on the Yolov5 model, which can be used for ship target recognition in various scenarios such as fog, occlusion, and those involving small targets. The main improvements of Yolov5s_ESGW can be divided into three categories. First, the width and depth of the model are improved based on the lightweight Efficient-NetV2 network and Ghost module, respectively. The main purpose is to compress the calculation amount and parameter amount of the model as much as possible and improve the detection speed of the model; secondly, a lightweight attention module is embedded after the C3Ghost module to improve the feature expression ability of the model; finally, Wise-IoU calculation is used as the bounding box loss to improve the detection performance and generalization ability of the model. The performance of the Yolov5s_ESGW model is trained and tested on the collected and produced MSD dataset. The test results show that the Yolov5s_ESGW model proposed in this study is better than the original Yolov5s model, with the number of parameters, GFLOPs value, and model file size decreasing by 42.82%, 68.35%, and 41.46%, respectively. The mAP0.5 value of the improved model has increased by 0.001, the inference speed has increased by 29.58%, and the detection accuracy (P) is basically the same as the original Yolov5s model. Compared with other mainstream lightweight detection models, this model has the advantages of high detection accuracy, a small amount of calculation and parameters, and fast inference speed.
However, it is undeniable that the dataset used in this study contains relatively few targets, types, and scenarios and cannot fully cover all ship navigation scenarios. In addition, this technology has not been combined with other technologies to comprehensively improve ship driving performance, such as the integration of radar, AIS, and image detection data. In the future, the dataset needs to be further improved to increase the diversity of data. Based on this research result, combined with advanced sensors, further in-depth research will be conducted on ship BEV technology and visual navigation technology to achieve reconstruction of complex navigation situations. In practical applications, this technology can improve the navigation performance of ships, enhance the anti-collision warning capability of ships, enrich the means of maritime traffic control, and promote the safe operation of ships. In addition, this research result shows a low demand for hardware computing power, which can reduce the cost of deploying this technology on the ship side in the future, and it has certain economic value and application prospects.
Author Contributions
Conceptualization, P.Z. (Peng Zhang); data curation, J.D. (Junwei Dong) and W.G.; formal analysis, P.Z. (Peng Zhang), P.Z. (Peiqiao Zhu) and J.Z.; funding acquisition, Z.S.; investigation, Z.S. and W.G.; methodology, P.Z. (Peng Zhang); project administration, Z.S. and J.D. (Jun Ding); software, P.Z. (Peng Zhang); supervision, J.D. (Jun Ding); validation, P.Z. (Peiqiao Zhu), J.D. (Jun Ding) and J.D (Junwei Dong); visualization, P.Z. (Peiqiao Zhu), J.Z. and W.G.; writing—original draft, P.Z. (Peng Zhang); writing—review and editing, J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
The work was supported by The Development and Application Project of Ship CAE Software (2024–2026).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available in the article. For further inquiries, please contact the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Huang, H.; Sun, D.; Wang, R.; Zhu, C.; Liu, B. Ship target detection based on improved YOLO network. Math. Probl. Eng. 2020, 2020, 1–10. [Google Scholar] [CrossRef]
- Hong, Z.; Yang, T.; Tong, X.; Zhang, Y.; Jiang, S.; Zhou, R.; Han, Y.; Wang, J.; Yang, S.; Liu, S. Multi-scale ship detection from SAR and optical imagery via a more accurate YOLOv3. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6083–6101. [Google Scholar] [CrossRef]
- Zou, Y.; Zhao, L.; Qin, S.; Pan, M.; Li, Z. Ship target detection and identification based on SSD_MobilenetV2. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 1676–1680. [Google Scholar]
- Hu, K.; Lu, F.; Lu, M.; Deng, Z.; Liu, Y. A marine object detection algorithm based on SSD and feature enhancement. Complexity 2020, 2020, 1–14. [Google Scholar] [CrossRef]
- Zhang, D.; Zhan, J.; Tan, L.; Gao, Y.; Župan, R. Comparison of two deep learning methods for ship target recognition with optical remotely sensed data. Neural Comput. Appl. 2021, 33, 4639–4649. [Google Scholar] [CrossRef]
- Qi, L.; Li, B.; Chen, L.; Wang, W.; Dong, L.; Jia, X.; Huang, J.; Ge, C.; Xue, G.; Wang, D. Ship target detection algorithm based on improved faster R-CNN. Electronics 2019, 8, 959. [Google Scholar] [CrossRef]
- Zhou, J.; Jiang, P.; Zou, A.; Chen, X.; Hu, W. Ship target detection algorithm based on improved YOLOv5. J. Mar. Sci. Eng. 2021, 9, 908. [Google Scholar] [CrossRef]
- Wang, J.; Cui, Z.; Jiang, T.; Cao, C.; Cao, Z. Lightweight deep neural networks for ship target detection in SAR imagery. IEEE Trans. Image Process. 2022, 32, 565–579. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Zhang, Y.; Qian, L.; Zhang, X.; Diao, S.; Liu, X.; Cao, J.; Huang, H. A lightweight ship target detection model based on improved YOLOv5s algorithm. PLoS ONE 2023, 18, e0283932. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Wu, T.; Zhang, X.; Zhang, W. An efficient lightweight SAR ship target detection network with improved regression loss function and enhanced feature information expression. Sensors 2022, 22, 3447. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Liu, Y.; Zhou, Y.; Yin, Q.; Li, H.-C. A lossless lightweight CNN design for SAR target recognition. Remote Sens. Lett. 2020, 11, 485–494. [Google Scholar] [CrossRef]
- Zhang, M.; Rong, X.; Yu, X. Light-SDNet: A lightweight CNN architecture for ship detection. IEEE Access 2022, 10, 86647–86662. [Google Scholar] [CrossRef]
- Wu, H.; Hu, Y.; Wang, W.; Mei, X.; Xian, J. Ship fire detection based on an improved YOLO algorithm with a lightweight convolutional neural network model. Sensors 2022, 22, 7420. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Ju, Y.; Zhou, Z. A super lightweight and efficient sar image ship detector. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, Q.-L.; Yang, Y.-B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2235–2239. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based attention module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7464–7475. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.-M.; Yang, J.; Li, X. Large selective kernel network for remote sensing object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 17–24 June 2023; pp. 16794–16805. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}