


Multi-Modal Emotion Recognition for Online Education Using Emoji Prompts


Abstract
1. Introduction
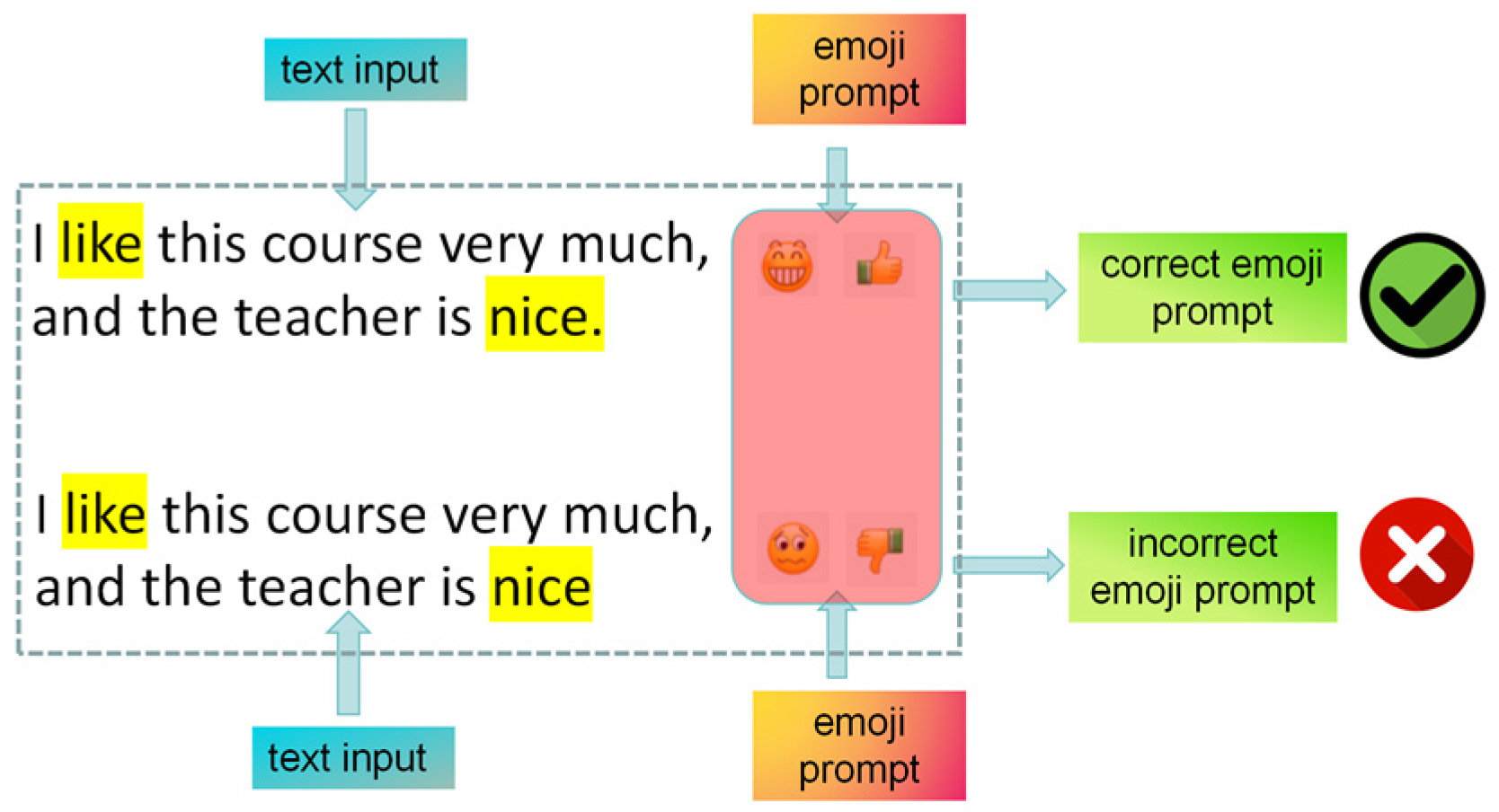
- In multi-modal sentiment recognition, we used emoji emoticons as prompts, rather than relying solely on text data.
- We studied the effectiveness of emoji emoticons as features in multi-modal pre-training.
2. Related Works
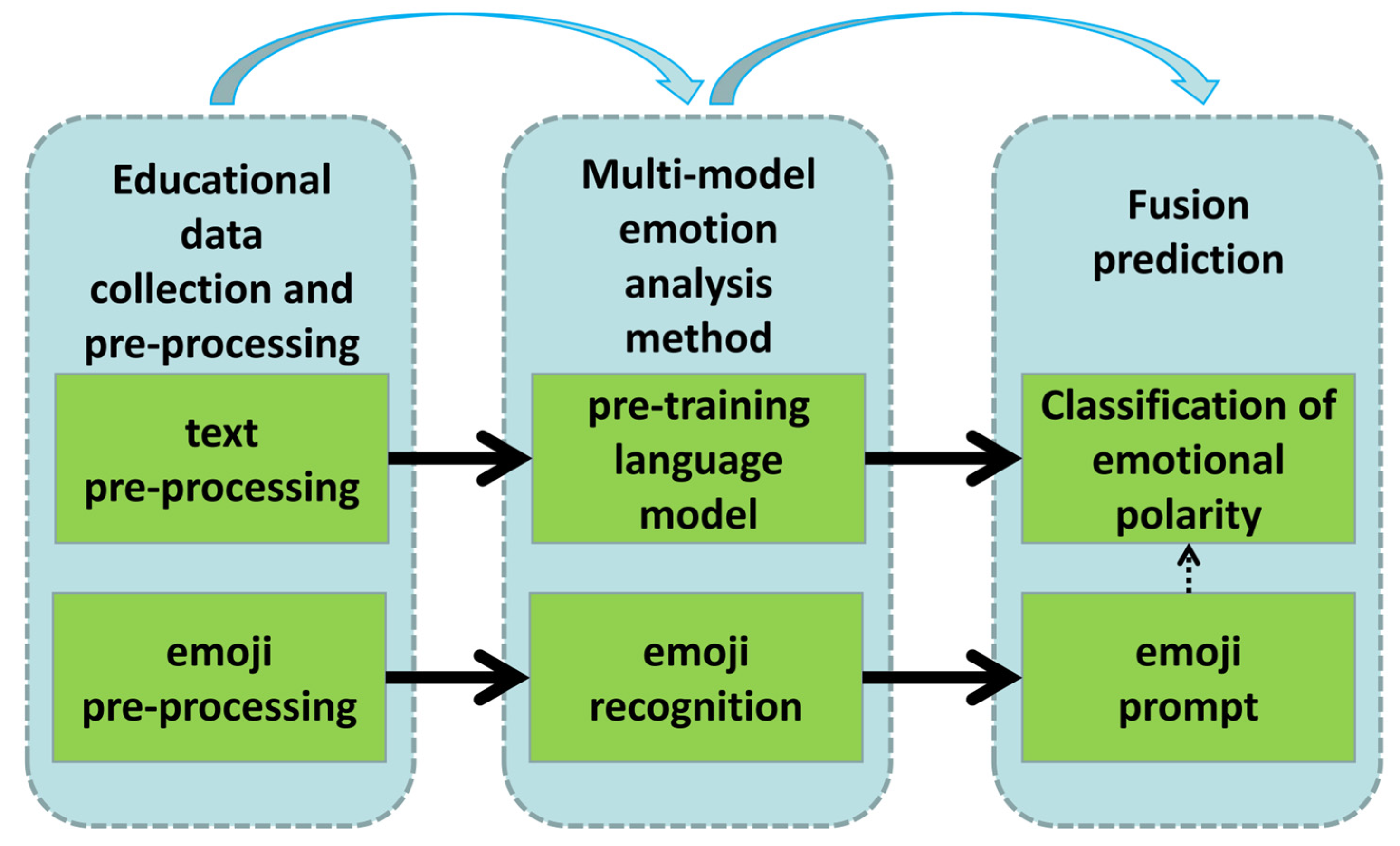
3. The Proposed Method
3.1. Educational Data Collection and Pre-Processing
3.2. Multi-Modal Emotion Analysis Method
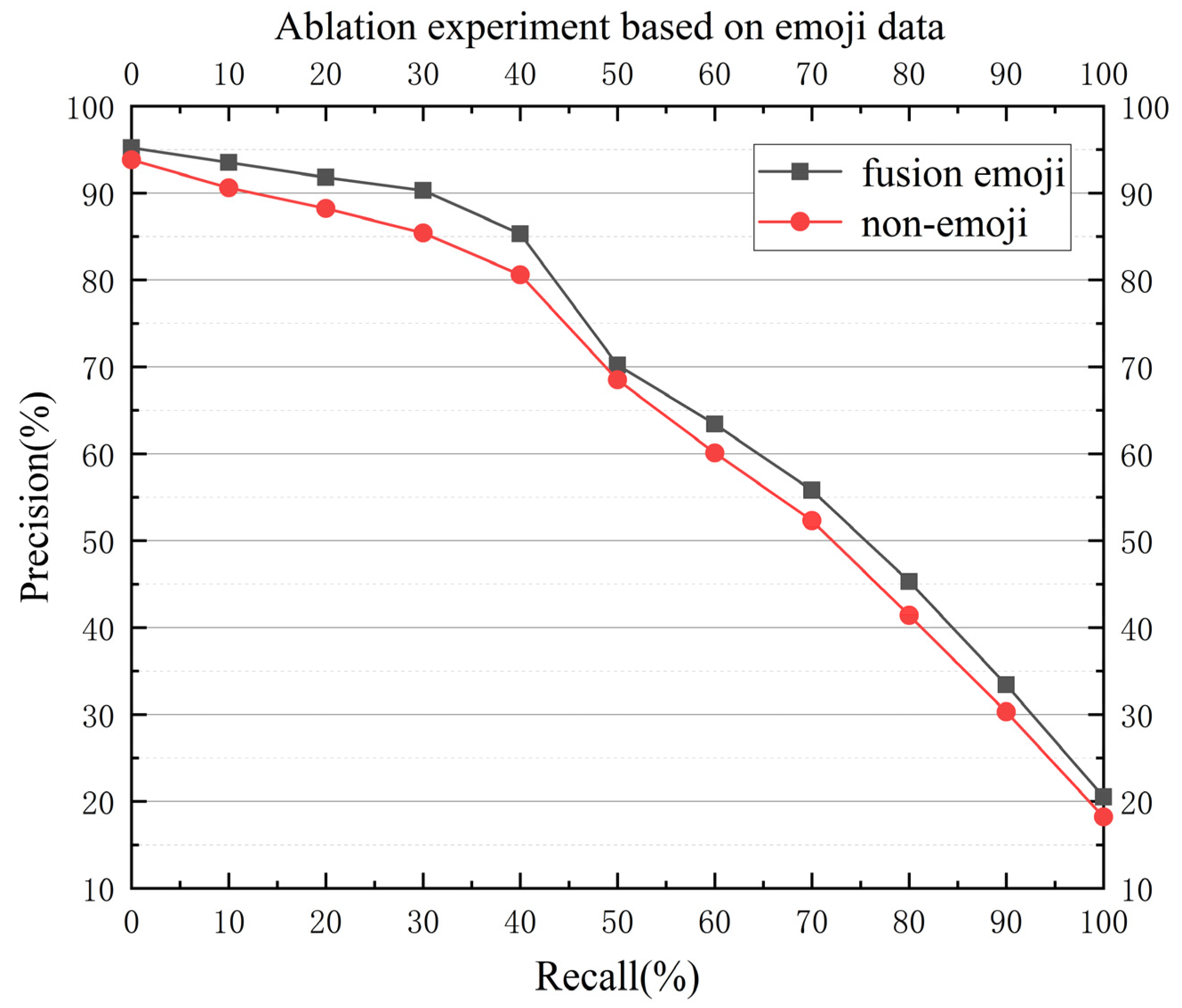
4. Experimental Results and Analyses
4.1. Datasets and Baseline Methods
4.2. Experiments and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl. Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Peng, S.; Cao, L.; Zhou, Y.; Ouyang, Z.; Yang, A.; Li, X.; Jia, W.; Yu, S. A survey on deep learning for textual emotion analysis in social networks. Digit. Commun. Netw. 2022, 8, 745–762. [Google Scholar] [CrossRef]
- Shelke, N.; Chaudhury, S.; Chakrabarti, S.; Bangare, S.L.; Yogapriya, G.; Pandey, P. An efficient way of text-based emotion analysis from social media using LRA-DNN. Neurosci. Inform. 2022, 2, 100048. [Google Scholar] [CrossRef]
- Chand, H.V.; Karthikeyan, J. CNN based driver drowsiness detection system using emotion analysis. Intell. Autom. Soft Comput. 2022, 31. [Google Scholar] [CrossRef]
- Nandwani, P.; Verma, R. A review on sentiment analysis and emotion detection from text. Soc. Netw. Anal. Min. 2021, 11, 81. [Google Scholar] [CrossRef] [PubMed]
- Guo, H.; Gao, W. Metaverse-powered experiential situational English-teaching design: An emotion-based analysis method. Front. Psychol. 2022, 13, 859159. [Google Scholar] [CrossRef]
- Yeung, M.K. A systematic review and meta-analysis of facial emotion recognition in autism spectrum disorder: The specificity of deficits and the role of task characteristics. Neurosci. Biobehav. Rev. 2022, 133, 104518. [Google Scholar] [CrossRef] [PubMed]
- Sharma, P.; Joshi, S.; Gautam, S.; Maharjan, S.; Khanal, S.R.; Reis, M.C.; Barroso, J.; de Jesus Filipe, V.M. Student engagement detection using emotion analysis, eye tracking and head movement with machine learning. In Proceedings of the International Conference on Technology and Innovation in Learning, Teaching and Education, Lisbon, Portugal, 31 August–2 September 2022; pp. 52–68. [Google Scholar]
- Iyer, A.; Das, S.S.; Teotia, R.; Maheshwari, S.; Sharma, R.R. CNN and LSTM based ensemble learning for human emotion recognition using EEG recordings. Multimed. Tools Appl. 2023, 82, 4883–4896. [Google Scholar] [CrossRef]
- Yang, L.; Shen, Z.; Zeng, J.; Luo, X.; Lin, H. COSMIC: Music emotion recognition combining structure analysis and modal interaction. Multimed. Tools Appl. 2024, 83, 12519–12534. [Google Scholar] [CrossRef]
- Chen, Q.; Tan, M.; Qi, Y.; Zhou, J.; Li, Y.; Wu, Q. V2C: Visual voice cloning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21242–21251. [Google Scholar]
- Cong, G.; Qi, Y.; Li, L.; Beheshti, A.; Zhang, Z.; Hengel, A.V.D.; Huang, Q. StyleDubber: Towards multi-scale style learning for movie dubbing. arxiv 2024, arXiv:2402.12636. [Google Scholar]
- Houssein, E.H.; Hammad, A.; Ali, A.A. Human emotion recognition from EEG-based brain–computer interface using machine learning: A comprehensive review. Neural Comput. Appl. 2022, 34, 12527–12557. [Google Scholar] [CrossRef]
- Tu, G.; Wen, J.; Liu, C.; Jiang, D.; Cambria, E. Context-and sentiment-aware networks for emotion recognition in conversation. IEEE Trans. Artif. Intell. 2022, 3, 699–708. [Google Scholar] [CrossRef]
- Wang, Y.; Song, W.; Tao, W.; Liotta, A.; Yang, D.; Li, X.; Gao, S.; Sun, Y.; Ge, W.; Zhang, W.; et al. A systematic review on affective computing: Emotion models, databases, and recent advances. Inf. Fusion 2022, 83, 19–52. [Google Scholar] [CrossRef]
- Li, W.; Li, Y.; Liu, W.; Wang, C. An influence maximization method based on crowd emotion under an emotion-based attribute social network. Inf. Process. Manag. 2022, 59, 102818. [Google Scholar] [CrossRef]
- Yang, X.; Feng, S.; Zhang, Y.; Wang, D. Multimodal sentiment detection based on multi-channel graph neural networks. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Bangkok, Thailand, 1–6 August 2021; pp. 328–339. [Google Scholar]
- Neogi, A.S.; Garg, K.A.; Mishra, R.K.; Dwivedi, Y.K. Sentiment analysis and classification of Indian farmers’ protest using twitter data. Int. J. Inf. Manag. Data Insights 2021, 1, 100019. [Google Scholar] [CrossRef]
- Chen, H.; Xia, R.; Yu, J. Reinforced counterfactual data augmentation for dual sentiment classification. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 269–278. [Google Scholar]
- Liang, B.; Su, H.; Yin, R.; Gui, L.; Yang, M.; Zhao, Q.; Yu, X.; Xu, R. Beta distribution guided aspect-aware graph for aspect category sentiment analysis with affective knowledge. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and in the Barcelo Bavaro Convention Centre, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 208–218. [Google Scholar]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. Dual graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual Event, 1–6 August 2021; pp. 6319–6329. [Google Scholar]
- Liang, B.; Su, H.; Gui, L.; Cambria, E.; Xu, R. Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks. Knowl. Based Syst. 2022, 235, 107643. [Google Scholar] [CrossRef]
- Singh, M.; Jakhar, A.K.; Pandey, S. Sentiment analysis on the impact of coronavirus in social life using the BERT model. Soc. Netw. Anal. Min. 2021, 11, 33. [Google Scholar] [CrossRef] [PubMed]
- Jing, N.; Wu, Z.; Wang, H. A hybrid model integrating deep learning with investor sentiment analysis for stock price prediction. Expert Syst. Appl. 2021, 178, 115019. [Google Scholar] [CrossRef]
- Li, H.; Chen, Q.; Zhong, Z.; Gong, R.; Han, G. E-word of mouth sentiment analysis for user behavior studies. Inf. Process. Manag. 2022, 59, 102784. [Google Scholar] [CrossRef]
- Dashtipour, K.; Gogate, M.; Adeel, A.; Larijani, H.; Hussain, A. Sentiment analysis of persian movie reviews using deep learning. Entropy 2021, 23, 596. [Google Scholar] [CrossRef]
- Dashtipour, K.; Gogate, M.; Cambria, E.; Hussain, A. A novel context-aware multimodal framework for persian sentiment analysis. Neurocomputing 2021, 457, 377–388. [Google Scholar] [CrossRef]
- Daudert, T. Exploiting textual and relationship information for fine-grained financial sentiment analysis. Knowl. Based Syst. 2021, 230, 107389. [Google Scholar] [CrossRef]
- Zhao, A.; Yu, Y. Knowledge-enabled BERT for aspect-based sentiment analysis. Knowl. Based Syst. 2021, 227, 107220. [Google Scholar] [CrossRef]
- Dong, L.; Wei, F.; Tan, C.; Tang, D.; Zhou, M.; Xu, K. Adaptive recursive neural network for target-dependent twitter sentiment classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (volume 2: Short papers), Baltimore, Maryland, 22–27 June 2014; pp. 49–54. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based LSTM for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, Texas, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- Xue, W.; Li, T. Aspect based sentiment analysis with gated convolutional networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 2514–2523. [Google Scholar]
- Li, J.; Huang, G.; Zhou, Y. A Sentiment Classification Approach of Sentences Clustering in Webcast Barrages. J. Inf. Process. Syst. 2020, 16, 718–732. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; AL-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O. Semeval-2016 task 5: Aspect based sentiment analysis. In Proceedings of the Pro-Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 19–30. [Google Scholar]
- Xing, B.; Liao, L.; Song, D.; Wang, J.; Zhang, F.; Wang, Z.; Huang, H. Earlier attention? aspect-aware LSTM for aspect-based sentiment analysis. arXiv 2019, arXiv:1905.07719. [Google Scholar]
- Jiang, Q.; Chen, L.; Xu, R.; Ao, X.; Yang, M. A challenge dataset and effective models for aspect-based sentiment analysis. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6280–6285. [Google Scholar]
- Wang, Y.; Sun, A.; Huang, M.; Zhu, X. Aspect-level sentiment analysis using as-capsules. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2033–2044. [Google Scholar]
- Yin, R.; Su, H.; Liang, B.; Du, J.; Xu, R. Extracting the collaboration of entity and attribute: Gated interactive networks for aspect sentiment analysis. In Proceedings of the Natural Language Processing and Chinese Computing: 9th CCF International Conference, NLPCC 2020, Zhengzhou, China, 14–18 October 2020; pp. 802–814. [Google Scholar]
- Li, Y.; Yin, C.; Zhong, S.h.; Pan, X. Multi-instance multi-label learning networks for aspect-category sentiment analysis. arXiv 2020, arXiv:2010.02656. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Cai, H.; Tu, Y.; Zhou, X.; Yu, J.; Xia, R. Aspect-category based sentiment analysis with hierarchical graph convolutional network. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 833–843. [Google Scholar] [CrossRef]
- Muffo, M.; Cocco, A.; Negri, E.; Bertino, E.; Sreekumar, D.V.; Pennesi, G.; Lorenzon, R. SBERTiment: A new pipeline to solve aspect-based sentiment analysis in the zero-shot setting. In Proceedings of the International FLAIRS Conference Proceedings, Clearwater, FL, USA, 14–17 May 2023. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Division | Positive | Negative | Neutral |
|---|---|---|---|---|
| Restaurant | Training | 2164 | 807 | 637 |
| Testing | 727 | 196 | 196 | |
| Laptop | Training | 976 | 851 | 455 |
| Testing | 337 | 128 | 167 | |
| Training | 1507 | 1528 | 3016 | |
| Testing | 172 | 169 | 336 |
| Positive | ||||
| 老铁/old friend | 暴富/parvenu | 么么哒/like | 666/amazing | 233/laugh |
| 漂亮/beautiful | 忠诚/devotion | 干净/clean | 加油/come on | 实惠/substantial |
| 友善/friendly | 优秀/excellent | 欢喜/joyful | 权威/authoritative | 舒服/comfortable |
| 健康/healthy | 天使/angel | 安静/calm | 专心/concentrate | 准确/accurate |
| 完美/perfect | 容易/easy | 完整/intact | 昌盛/prosperity | 雄心/ambition |
| 和平/peace | 活力/vigor | 坚定/firm | 亮点/highlight | 赚/earn |
| 幸福/happiness | 新/new | 勤奋/industrious | 开通/accomplish | 稳了/confirmed |
| 诚信/faithful | 文明/civilized | 出名/famous | 真实/real | 成熟/mature |
| 聪明/clever | 积极/active | 精英/elite | 捷报/good news | 保险/assure |
| Negative | ||||
| 凉了/washed-up | 傻逼/sucker | 垃圾/rubbish | 智障/mentally retarded | 滚/scat |
| 毒/poison | 暴力/violence | 非法/illegality | 心机/craftiness | 虚假/sham |
| 嘈杂/noisy | 漏洞/leak | 事故/accident | 亏/deficit | 变态/abnormal |
| 浪费/waste | 花样/trick | 失败/failure | 冲突/conflict | 陈旧/obsolete |
| 妒忌/jealous | 谣言/rumor | 病人/patient | 恶势力/vicious power | 残/incomplete |
| 色情/erotic | 淫秽/bawdry | 错误/error | 失误/mistake | 流氓/immoral |
| 疯狂/insane | 缺少/lack | 敌对/hostility | 脆弱/weak | 蠢/foolish |
| 黑客/hacker | 陷阱/trap | 脏/dirty | 不合格/unqualified | 不安/uneasy |
| 诈骗/cheat | 自负/conceited | 丑陋/ugly | 恶意/malevolence | 烦恼/upset |
| Model | Restaurant | Laptop | ||||
|---|---|---|---|---|---|---|
| Accuracy | F1 | Accuracy | F1 | Accuracy | F1 | |
| ATAE-LSTM (Wang et al., 2016) [31] | 0.785 | 0.598 | 0.753 | 0.629 | 0.842 | 0.629 |
| GTRU (Xue et al., 2018) [32] | 0.776 | 0.574 | 0.753 | 0.627 | 0.847 | 0.609 |
| AA-LSTM (Xing et al., 2019) [35] | 0.777 | 0.586 | 0.762 | 0.631 | 0.856 | 0.611 |
| CapsNet (Jiang et al., 2019) [36] | 0.781 | 0.616 | 0.747 | 0.618 | 0.838 | 0.614 |
| AS-Capsules (Wang et al., 2019) [37] | 0.793 | 0.619 | 0.752 | 0.621 | 0.845 | 0.625 |
| GIN (Yin et al., 2020) [38] | 0.812 | 0.624 | 0.759 | 0.632 | 0.871 | 0.650 |
| MIMLLN (Li et al., 2020) [39] | 0.783 | 0.606 | 0.753 | 0.614 | 0.858 | 0.635 |
| BERT (Devlin et al., 2018) [40] | 0.824 | 0.644 | 0.816 | 0.662 | 0.886 | 0.736 |
| GIN-BERT (Yin et al., 2020) [38] | 0.840 | 0.660 | 0.830 | 0.653 | 0.895 | 0.749 |
| MIMLLN-BERT (Li et al., 2020) [39] | 0.828 | 0.651 | 0.830 | 0.624 | 0.881 | 0.731 |
| Hier-GCN-BERT (Cai et al., 2020) [41] | 0.843 | 0.663 | 0.833 | 0.658 | 0.897 | 0.746 |
| Ours | 0.856 | 0.682 | 0.848 | 0.684 | 0.912 | 0.785 |
| Model | Restaurant | Laptop | ||||
|---|---|---|---|---|---|---|
| Accuracy | F1 | Accuracy | F1 | Accuracy | F1 | |
| Seed word prompt (Ours) | 0.856 | 0.682 | 0.848 | 0.684 | 0.912 | 0.785 |
| No feed words (Ours) | 0.031↓ | 0.026↓ | 0.033↓ | 0.031↓ | 0.035↓ | 0.032↓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, X.; Zhou, Y.; Li, J. Multi-Modal Emotion Recognition for Online Education Using Emoji Prompts. Appl. Sci. 2024, 14, 5146. https://doi.org/10.3390/app14125146
Qin X, Zhou Y, Li J. Multi-Modal Emotion Recognition for Online Education Using Emoji Prompts. Applied Sciences. 2024; 14(12):5146. https://doi.org/10.3390/app14125146
Chicago/Turabian StyleQin, Xingguo, Ya Zhou, and Jun Li. 2024. "Multi-Modal Emotion Recognition for Online Education Using Emoji Prompts" Applied Sciences 14, no. 12: 5146. https://doi.org/10.3390/app14125146
APA StyleQin, X., Zhou, Y., & Li, J. (2024). Multi-Modal Emotion Recognition for Online Education Using Emoji Prompts. Applied Sciences, 14(12), 5146. https://doi.org/10.3390/app14125146