

Optimal Concordant Tests


College of Health Solutions, Arizona State University, 425 N. 5th Street, #137, Phoenix, AZ 85004, USA
Appl. Sci. 2024, 14(11), 4536; https://doi.org/10.3390/app14114536
Submission received: 25 April 2024
/
Revised: 16 May 2024
/
Accepted: 23 May 2024
/
Published: 25 May 2024
(This article belongs to the Special Issue Applied Biostatistics: Challenges and Opportunities)
Abstract
In meta-analyses, unlike model-based methods, such as fixed- or random-effect models, the p-value combining methods are distribution-free and robust. How to appropriately and powerfully combine p-values obtained from various sources remains an important but challenging topic in statistical inference. For cases where all or a majority of the individual alternative hypotheses have the same but unknown direction, concordant tests based on one-sided p-values can substantially improve the detecting power. However, there exists no test that is uniformly most powerful; therefore, figuring out how to choose a robust and powerful test to combine one-sided p-values for a given data set is desirable. In this paper, we propose and study a class of gamma distribution-based concordant tests. Those concordant tests are optimal under specific conditions. An asymptotically optimal concordant test is also studied. The excellent performances of the proposed tests were demonstrated through a numeric simulation study and real data example.
1. Introduction
Due to recent technical developments, larger volume data, including genome-wide genomic data, can be generated rapidly and at a low cost. As a consequence, powerful statistical approaches, including p-value combination tests, are highly desirable for analyzing these data sets. For instance, meta-analyses, when applied to genome-wide association studies (GWASs), have discovered many associated genetic variants that could not be identified from a single GWAS. With the development and application of advanced powerful p-value combination tests, we expect that many more casual genetic variants will be identified through existing data.
In meta-analyses, p-value combination methods are important alternatives to model-based techniques [1,2], especially when the fixed- or random-effect models have a lack of fit [3]. In the literature, many p-value combination methods, although first proposed a long time ago, are still widely used nowadays. These methods include popular ones: Fisher test [4], Pearson test [5], minimal p-test [6], z-test [7], and chi-square test [8,9]. Recently, we studied a class of p-value combination tests based on gamma distribution, which include those popular tests as special cases [10]. However, as noticed by Birnbaum, there exists no uniformly most powerful (UMP) p-value combination test for all conditions [11]. Therefore, robust methods that have good power under many conditions are desirable [12].
Under some conditions, we may know or reasonably assume that all or most of the true effects under the individual alternative hypotheses have the same but unknown direction. In this case, the concordant tests which use one-sided p-values have been shown to be more powerful than those methods based on two-sided p-values, such as the chi-square test [1]. For instance, in GWASs, studies with the same phenotype are usually conducted among several different subpopulations, from which the effect of a causal genetic variant may have the same direction but various sizes. Then, if the commonly used fixed- and random-effect meta-analyses are applied to combine the results from individual studies, they may lose the power to detect the associated genetic variants. To improve the detecting power, in this paper, we study a class of concordant tests based on gamma distribution, and then an optimal concordant test based on constrained likelihood ratio test (CLRT) is developed.
The rest of the manuscript is organized as follows. In Section 2, we first introduce the Pearson’s concordant test, which was studied by Owen [1] (Section 2.1). In Section 2.2, we describe our proposed generalized concordant tests based on gamma distribution and study their properties as UMP tests under some conditions. The asymptotically UMP concordant test based on CLRT is proposed and studied in Section 2.3. In Section 3, we compare the performances of the proposed concordant tests with some existing methods through a simulation study. In addition, an example of a real data application is illustrated to demonstrate the desired performance of the proposed tests. This paper concludes in Section 4 with a discussion and conclusions.
2. Methods
Suppose we have independent studies. For each study, , we can perform a two-sample test for testing the null hypothesis, , against the alternative hypothesis, , where is the mean difference between two populations. The corresponding p-value is denoted as . Throughout this paper, we assume under , where stands for the uniform distribution between 0 and 1. In a meta-analysis, we consider testing the global null hypothesis, = , vs. the global alternative hypothesis, , using the observed p-values.
For a concordant test, we assume, under the global alternative, that the majority of the non-zero mean differences have the same but unknown direction (positive or negative): and at least one strictly greater than holds, or and at least one strictly less than holds (). Although, under this setting, a two-sided p-value can still be calculated from each data set and then used in p-value combination, in this paper, we focus on the concordant tests which use one-sided p-values, , obtained from the directional alternatives or for all values . In general, either the right- or left-sided p-values can be used, as they will produce the same result. Without loss of generality, we use the right-sided individual p-values hereafter, unless otherwise specified.
2.1. Pearson’s Concordant Test
Owen [1] revisited and studied the following Pearson’s concordant test, whose test statistic is defined as follows:
where represents the one-sided p-values obtained from the same directional alternatives. The two components, and , in are obtained through the popular Fisher test for combining independent p-values [4]. Therefore, under the global null hypothesis, each component is the random variable, , which has a chi-square distribution with degrees of freedom equal to . Furthermore, although and are not independent, the p-value of the Pearson’s concordant test defined in (1) can be easily approximated using the upper bound, , where is the observed test statistic. In addition, the approximation is very accurate when the true p-value is small [1].
2.2. Concordant Tests Based on Gamma Distribution
The above Pearson’s concordant test can be extended to concordant tests based on gamma distribution. For this purpose, we first study a class of combination tests based on gamma distribution [10].
For given shape parameter and scale parameter , a p-value combination test statistic based on the gamma distribution can be constructed as follows:
where is the inverse function of the cumulative distribution function (CDF), , of the random variable , whose probability density function (PDF) is for , where the gamma function . The right-sided p-value of the test defined in (2) can be defined as follows:
where is the random variable having gamma distribution with the shape parameter, , and the scale parameter, ; and and are the CDF and the survival function of .
It can be shown that, due to the property of gamma distribution, parameter has no effect on the test defined in (2) and (3) [10]. Therefore, for simplicity, we use in the above test and denote as hereafter. Furthermore, we can prove the following properties for the above class of gamma distribution-based tests [10]: (i) is equivalent to the Tippett’s minimal-p test; (ii) is the same as the chi-square test with degrees of freedom equal to ; (iii) is equavalent to Fisher test; and (iv) is the same as the z-test. Therefore, the class of gamma distribution-based tests, , includes many popular tests as special cases. This observation motivates us to generalize the Pearson’s concordant test.
We propose the gamma distribution-based concordant test with the following test statistic:
where and are the gamma distribution-based tests using the left- and right-sided p-values, respectively.
It is easy to see that when , is equivalent to the Pearson’s concordant test . Therefore, is a generalization of the Pearson’s concordant test. We show that the p-value for the proposed concordant test, , can also be estimated in a similar way as : . Now, we study the properties of . First we need the following definitions and lemmas [13].
Definition 1.
A function on is nondecreasing if it is nondecreasing in each of its arguments when the other values are held fixed.
Definition 2.
Let be random variables with a joint distribution. These random variables are associated if the covariance holds for all nondecreasing functions, and , for which the covariance is defined.
Lemma 1.
(Theorem 2.1 of Esary, Proschan, and Walkup 1967 [13]) Independent random variables are associated.
Lemma 2.
(Theorem 5.1 of Esary, Proschan, and Walkup 1967 [13]) Let be associated random variables, , then and for all .
Lemma 3.
For integer , let have independent components. Set , and . Then, for any , and , .
Proof.
Denote and . It is easy to see that both and are nondecreasing functions of . And the components of are independent and hence associated. Therefore, we have
□
The concordant test, , defined in (4) has the following property.
Theorem 1.
Let be a random vector with independent components, and denote , , and . For any , let , , and . Then
Proof.
From Lemmas 2 and 3, we have . On the other hand, from Bonferroni inequality, we have . □
Under the condition specified in Theorem 1 (i.e., the global null hypothesis), it is easy to see that and have the same distribution; hence, .
From Theorem 1, we have the following result.
Corollary 1.
Suppose , for , let , then .
From Corollary 1, the p-value of the concordant test, , defined in (4), can be easily approximated by twice of the p-value from , i.e., . The approximation is very accurate if the true p-value (e.g., the p-value from the sampling distribution under the alternative) is small, as is even much smaller under this situation.
In the following subsection, we study an optimal concordant test when the optimal value for is unknown and needs to be estimated from the data.
2.3. Optimal Concordant Test
For a given set of one-sided p-values, the class of concordant tests, , proposed in the previous section, Section 2.2, with different values can be applied. However, in order to control type I error, the value must be chosen before we see the data. But usually, the optimal value is unknown, and therefore how to choose an optimal value for is critical in practice. We may choose a set of values to apply the tests to the data and then use the smallest p-value among them. There are two limitations associated with this procedure. First, we need to adjust for multiple comparisons, which may result in power loss. Second, the final result will depend on the chosen values; it might be difficult to determine those values. To circumvent these difficulties, we propose to estimate the optimal value from the data, and therefore an asymptotically optimal concordant test can be constructed accordingly.
In this subsection, we make the following assumption: are independently and identically distributed with the following density function for parameters and :
For the above densify function, , it is not difficult to show that when , . Therefore, corresponds to the global null hypothesis. In addition, we have the following property [10].
Proposition 1.
Suppose that are with the common density function defined in (5) with parameters and . If both and are known, then the gamma distribution-based test, , is uniformly most powerful (UMP).
When both parameters and in (5) are unknown, they can be estimated via the constrained maximum likelihood estimation (CMLE), from which the following constrained likelihood ratio test (CLRT) can be defined:
where and are the CMLEs for parameters and , respectively, through maximizing the log-likelihood function with the constrains and .
Proposition 2.
The asymptotic distribution of the test is a mixture of chi-square distributions, , where is the chi-square distribution with ; is the random variable with probability 1 of being 0; and the weights , , and are determined by the null and the alternative hypothesis.
The above asymptotic result may not be directly applicable to estimate the p-value for this test. First, the number of p-values, , is usually small, and the asymptotic result may not provide approximate solutions. Second and more seriously, the above weights, , are difficult to obtain. Hence, here we use a simple resampling method to approximate the null distribution and to estimate the p-value of . More specifically, for a given sample size , we randomly sample independent null p-values from the uniform distribution U(0,1) and then calculate the test statistic using (6). Repeat this process for B times (e.g., ) to get the empirical null distribution of the test statistic, which will be used to approximate the p-value of :, where is the test statistic from the resampling, and is the observed test statistic from the data.
For , we have the following result [10]:
Proposition 3.
Under the conditions specified in (5), the CLRT-based test, , is asymptotically UMP.
We now propose an optimal concordant test. Denote , and , and then define the following concordant test statistic:
Note that the null distributions of are identical. For the concordant test, , we have the following property.
Theorem 2.
Let be a random vector with independent components, and let , , and . For any , let , , and . Then, .
Proof.
First notice that and are both nondecreasing functions of associated random variables, . The rest of the proof is similar to that for Theorem 1. □
In addition, we have the following result for .
Corollary 2.
Suppose ; for , let , and then .
From Corollary 2, the p-value of the concordant test, , defined in (7) can be estimated by the upper bound, , where is the p-value from the CLRT-based test, , and can be estimated using the resampling method described previously. Again, when the true p-value is small, this approximation is very accurate.
3. Results
3.1. Numeric Results from Simulation Study
In this section, we assess the performance of the proposed tests through a simulation study. In the simulation, we compare the proposed optimal concordant test, , with gamma distribution-based concordant tests, , (i.e., the Owen’s Pearson concordant test), and , using one-sided p-values.
In the simulation study, we want to combine fifty () randomly simulated independent p-values using different methods. We assume that a number, , out of these n p-values are from the true individual alternative hypotheses, and the rest () are from the true individual null hypotheses. The n-m p-values from the true null hypotheses are randomly sampled from the uniform distribution with range 0 and 1. For a true individual alternative hypothesis, , the p-value is obtained via a normal variable, . To consider the situations where the true effects from different studies may have opposite directions (positive and negative), we randomly set of the to have the same direction (positive or negative), and the rest of has the other direction. A one-sided (right-sided) p-value for each true individual alternative hypothesis is obtained via the standard z-test, i.e., , where Z is the standard normal distribution, , and is the simulated number as described above.
For the hypotheses under true alternative, we consider three different scenarios for the effects of . Scenario 1: We use , where , , and when there are 10, 20, 40, and 50 true individual alternatives, respectively. Scenario 2: We set , where and when the number of true individual alternatives is , respectively. Scenario 3: We consider , when respectively. Note that, in the simulation, we consider the following: (i) The constants (e.g., , the parameters in the normal distribution for and the uniform distribution for ) are chosen in a way that the empirical powers are appreciable for comparison. (ii) The sum of the absolute effect sizes is equal to for all the three scenarios. (iii) The degree of heterogeneity of the effect sizes among the true individual alternatives decreases from Scenario 1 to Scenario 3 for each given .
The empirical power values of the tests are estimated as the rejection proportions based on replicates, with 0.05 as the significance level. For the CLRT-based concordant test, , we use samples to estimate the p-values from the resampling method described in Section 2.3.
When all of the 50 p-values are from null hypotheses, the empirical power is the type 1 error rate. All methods considered here were able to control the type I error rate: their empirical powers under this situation were close to 0.05 when the significance level 0.05 was used.
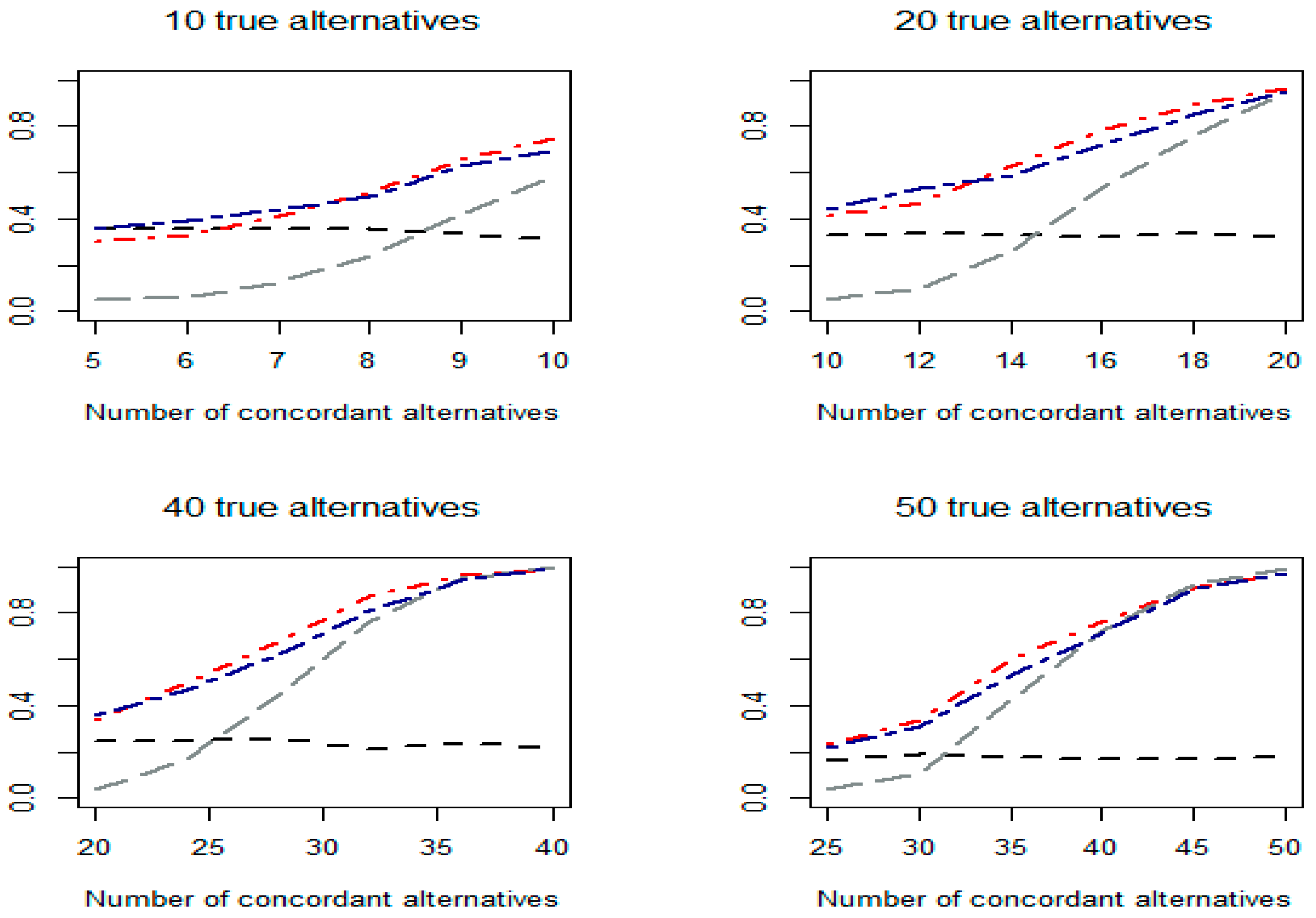
Figure 1, Figure 2 and Figure 3 plot the empirical power values for the concordant tests based on minimal p, (denoted as Min_CC), Fisher (denoted as Fisher_CC, i.e., Pearson’s concordant test), z-test (denoted as Z_CC), and the proposed concordant test, (denoted as LRT_CC), when one-sided p-values under Scenarios 1 to 3, respectively, are used.
From the simulation study, we have the following observations. First, under Scenario 1 (Figure 1), where the effect sizes under alternative hypotheses are extremely heterogeneous, usually the minimal p-based concordant test (i.e., ) performs better than the Pearson’s concordant test (), which in turn outperforms the z-test-based concordant test (). Second, under Scenarios 2 and 3, when the degrees of heterogeneity of the effect sizes among individual alternative hypotheses are less extreme than in Scenario 1, and the usually perform better or much better than (Figure 2 and Figure 3). Third, for the three concordant tests with fixed values, namely , , and , one may perform well under some conditions but do poorly under others. Fourth, under all conditions considered, the CLRT-based concordant test, , always has the best or the second-best power. This demonstrates that, as expected, is a robust test, meaning that, under many conditions, it has reasonable detection power compared with other tests.
3.2. Real Data Application
In this section, we demonstrate the usefulness of the proposed tests by applying them to a real-world problem. A data set from a meta-analysis is used. In that meta-analysis, results from 12 randomized trials—each examined the effect of patient rehabilitation designed for geriatric patients versus usual care on improving functional outcome at 3–12-month follow-ups—were collected [15,16]. The 12 estimated odds ratios (ORs) from the individual studies are listed in Table 1.
The commonly used fixed-effect model for meta-analyses was inadequate for this data set, as the p-value from the Cochran’s test for homogeneity was 0.021. Hence, the random-effect model of the meta-analysis was applied, which estimated the overall OR as 1.36 with a 95% CI (1.08, 1.71) [16]. However, when we applied the goodness-of-fit test for the random-effect model, we obtained a p-value of 0.025 [3], which indicates a lack of fit of the random-effect model for this data set. We then applied the p-value combination methods to test whether there is an overall effect among these 12 independent trials.
To use the p-value combination methods, we need the individual p-values. For each trial, the corresponding p-value is calculated based on the reported 95% CI of the OR. If we use U and L to denote the upper and lower limits of the 95% CI, then the test statistic can be approximated as which is asymptotically distributed as under the null hypothesis that there is no difference between the new treatment and the control. Since the sample sizes of these 12 trials were relatively large, ranging from 108 to 1388, their p-values can be reasonably estimated using the asymptotic null distribution by comparing the test statistic with . For example, the right-sided p-value can be calculated as , where Z has a standard normal distribution, , and is the test statistic calculated as described above.
We first calculate the one-sided p-value for each trial and then use the values for the concordant tests. The p-values from the concordant tests , , , and are 0.013, 0.00017, 0.00031, and 0.00030, respectively. For comparison, we also applied the gamma distribution-based tests to this data set, using two-sided p-values calculated from each individual trial. The resulting p-values are 0.013, 0.0068, 0.075, and 0.0047 from , , , and , respectively. As expected, under the situation that a majority of the trials have the same direction (10 out of the 12 estimated ORs were greater than 1), concordant tests are usually more powerful than the corresponding gamma distribution-based tests using two-sided p-values. Noticeably, the z-test-based concordant test, , obtained a much smaller p-value (0.00031) compared with the z-test using two-sided p-values (0.075). Among the concordant tests, the proposed test has the second smallest p-value (0.00030).
4. Discussion and Conclusions
In this paper, we studied a class of gamma distribution-based concordant tests, which include the Pearson’s concordant test as a special case. We also proposed and studied a CLRT-based concordant test, which is asymptotically optimal, robust, and powerful under many conditions. The advantages of the proposed tests were demonstrated based on numeric simulation study and real data application.
In addition to their use for meta-analyses, the proposed concordant tests have many other applications. In a two-way contingency table, if at least one of the two variables is ordinal, a trend test may be more powerful than the popular unidirectional Pearson’s chi-square test [17]. One challenge in trend tests is how to appropriately assign scores for each level of the ordinal variable; results can be quite different with different score assignments. Our proposed concordant test, , can circumvent this difficulty and provide another solution. Specifically, by using the asymptotically independent statistics with the same direction obtained by the Lancaster’s chi-square partition [18,19], we can obtain asymptotically independent one-sided p-values, to which can be applied.
The proposed tests will also be very useful for detecting casual genetic variants associated with diseases when applied to GWASs. It offers an alternative but powerful tool to combine information from different (subpopulations) but related studies (similar phenotype). We would expect that many genetic variants will be identified in the near future due to the new approach. In the future, we will also study how to combine dependent or correlated p-values.
Funding
This work was partially supported by the National Institutes of Health grants 1R03DE030259 and UL1TR002529. The content is solely the responsibility of the author and does not necessarily represent the official views of the NIH.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The author declares no conflict of interest.
References
- Owen, A.B. Karl Pearson’s meta-analysis revisited. Ann. Stat. 2009, 37, 3867–3892. [Google Scholar] [CrossRef] [PubMed]
- Hedges, L.; Olkin, I. Statistical Methods for Meta-Analysis; Academic: San Diego, CA, USA, 1985. [Google Scholar]
- Chen, Z.; Zhang, G.; Li, J. Goodness-of-fit test for meta-analysis. Sci. Rep. 2015, 5, 16983. [Google Scholar] [CrossRef] [PubMed]
- Fisher, R.A. Statistical Methods for Research Workers, 4th ed.; Oliver and Boyd: Edinburgh, UK, 1932. [Google Scholar]
- Pearson, K. On a New Method of Determining “Goodness of Fit”. Biometrika 1934, 26, 425–442. [Google Scholar]
- Tippett, L.H.C. Methods of Statistics; Williams Norgate: London, UK, 1931. [Google Scholar]
- Stouffer, S.A.; Suchman, E.A.; Devinney, L.C.; Star, S.A.; Williams, R.M., Jr. The American Soldier: Adjustment During Army Life. (Studies in Social Psychology in World War II); Princeton Univ. Press: Princeton, NJ, USA, 1949; Volume 1. [Google Scholar]
- Lancaster, H. The combination of probabilities: An application of orthonormal functions. Aust. J. Stat. 1961, 3, 20–33. [Google Scholar] [CrossRef]
- Chen, Z.; Nadarajah, S. On the optimally weighted z-test for combining probabilities from independent studies. Comput. Stat. Data Anal. 2014, 70, 387–394. [Google Scholar] [CrossRef]
- Chen, Z. Optimal Tests for Combining p-Values. Appl. Sci. 2022, 12, 322. [Google Scholar] [CrossRef]
- Birnbaum, A. Combining Independent Tests of Significance. J. Am. Stat. Assoc. 1954, 49, 559–574. [Google Scholar]
- Chen, Z. Robust tests for combining p-values under arbitrary dependency structures. Sci. Rep. 2022, 12, 3158. [Google Scholar] [CrossRef] [PubMed]
- Esary, J.D.; Proschan, F.; Walkup, D.W. Association of random variables, with applications. Ann. Math. Stat. 1967, 38, 1466–1474. [Google Scholar] [CrossRef]
- Self, S.G.; Liang, K.-Y. Asymptotic properties of maximum likelihood estimators and likelihood ratio tests under nonstandard conditions. J. Am. Stat. Assoc. 1987, 82, 605–610. [Google Scholar] [CrossRef]
- Bachmann, S.; Finger, C.; Huss, A.; Egger, M.; Stuck, A.E.; Clough-Gorr, K.M. Inpatient rehabilitation specifically designed for geriatric patients: Systematic review and meta-analysis of randomised controlled trials. Bmj 2010, 340, c1718. [Google Scholar] [CrossRef] [PubMed]
- Riley, R.D.; Higgins, J.P.; Deeks, J.J. Interpretation of random effects meta-analyses. Bmj 2011, 342, d549. [Google Scholar] [CrossRef] [PubMed]
- Cochran, W. Some methods for strengthening the common chi-square tests. Biometrics 1954, 10, 417–451. [Google Scholar] [CrossRef]
- Lancaster, H. The derivation and partition of χ2 in certain discrete distributions. Biometrika 1949, 36, 117–129. [Google Scholar] [CrossRef]
- Chen, Z. A new association test based on Chi-square partition for case-control GWA studies. Genet. Epidemiol. 2011, 35, 658–663. [Google Scholar] [CrossRef]
Figure 1.
Empirical power values of the tests based on one-sided p-values under Scenario 1.
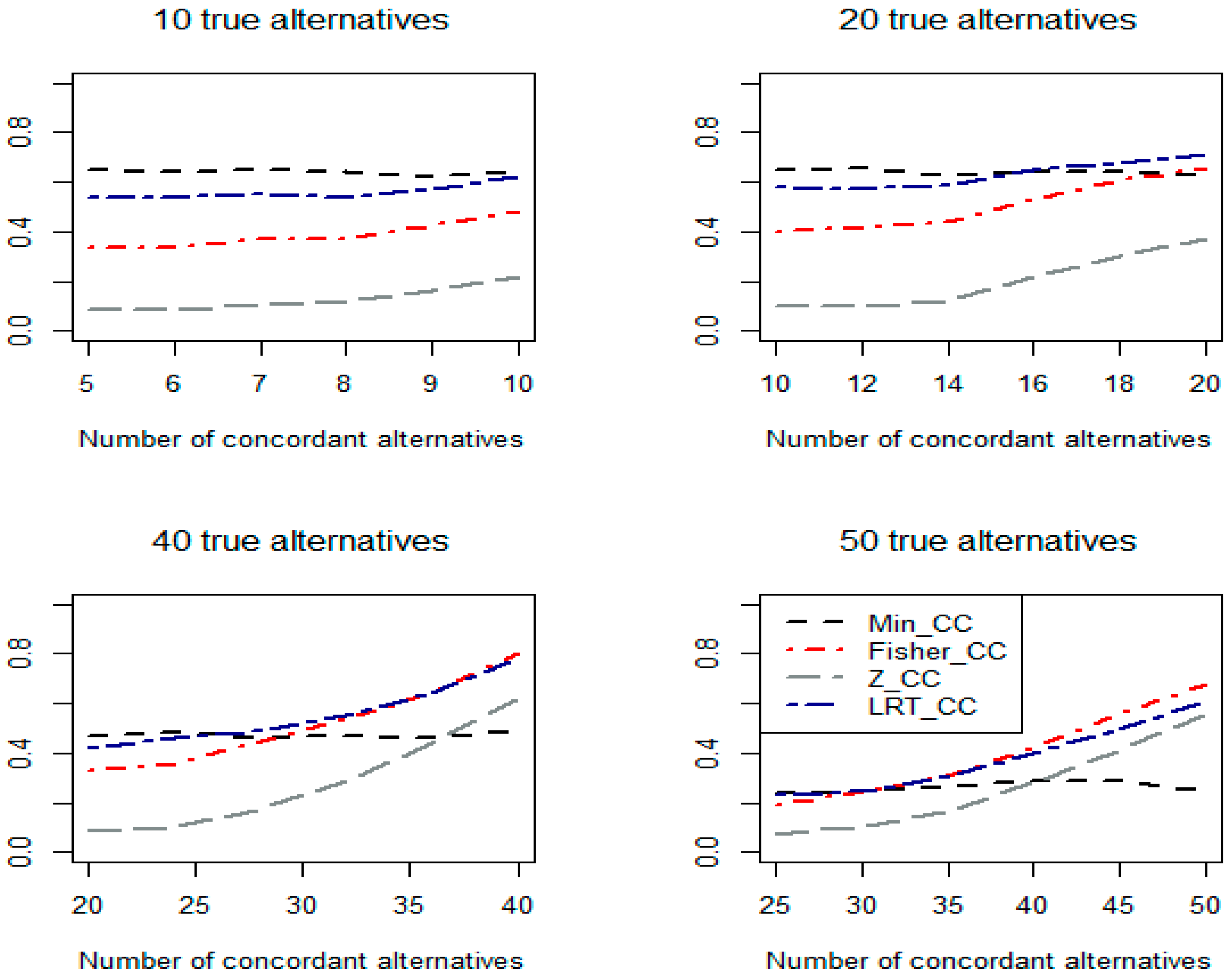
Figure 2.
Empirical power values of the tests based on one-sided p-values under Scenario 2.
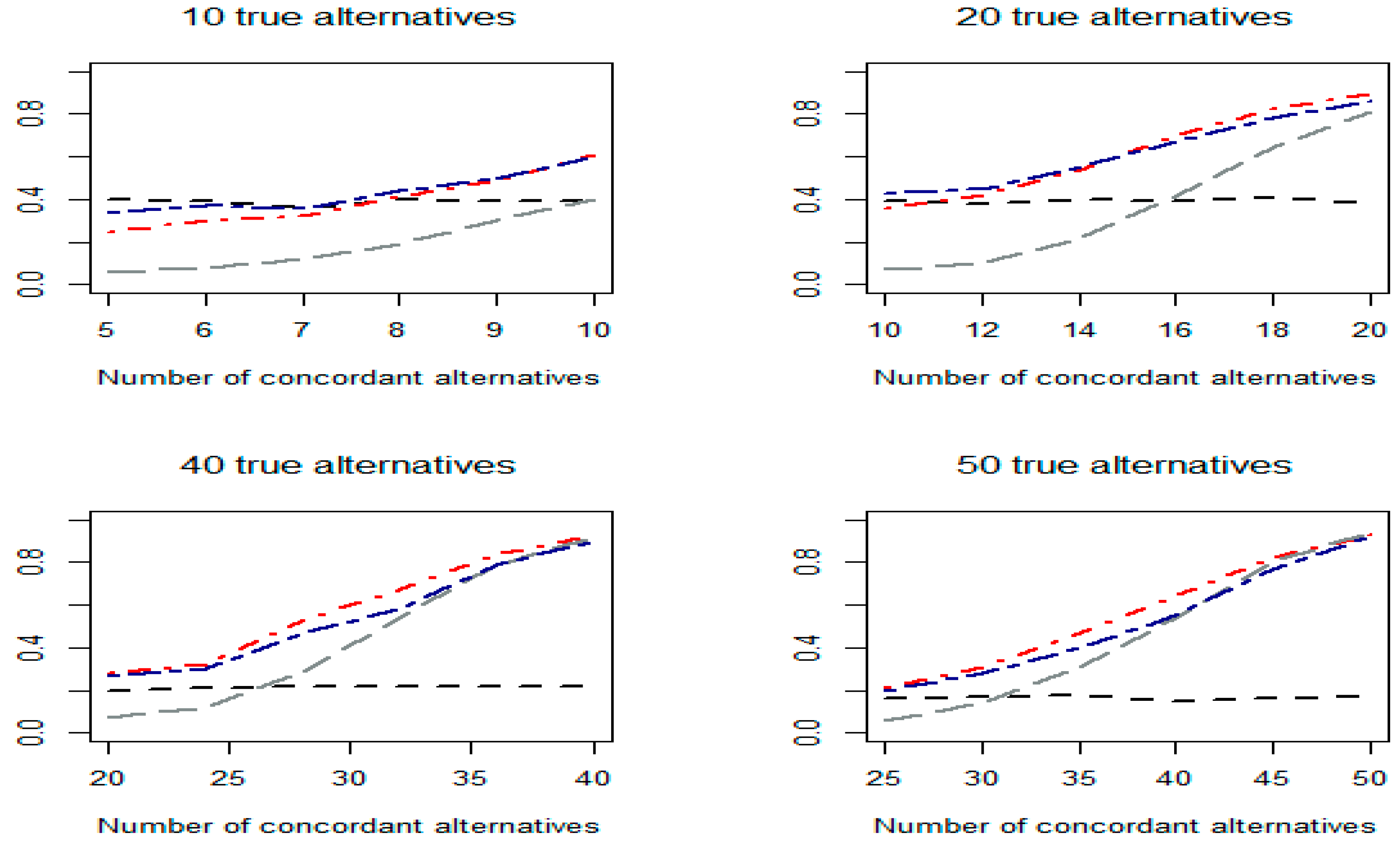
Figure 3.
Empirical power values of the tests based on one-sided p-values under Scenario 3.

{kind=link}
{kind=link}
{kind=link}
Table 1.
Estimated odds ratio and its 95% CI from each study in a meta-analysis with 12 trials. Data were taken from Bachmann et al. [15] and Riley et al. [16].
| Study | OR | 95% CI | Study | OR | 95% CI | Study | OR | 95% CI |
|---|---|---|---|---|---|---|---|---|
| 1 | 1.11 | 0.51, 2.39 | 5 | 0.88 | 0.39, 1.95 | 9 | 1.06 | 0.63, 1.79 |
| 2 | 0.97 | 0.78, 1.21 | 6 | 1.28 | 0.71, 2.30 | 10 | 2.95 | 1.54, 5.63 |
| 3 | 1.13 | 0.73, 1.72 | 7 | 1.19 | 0.69, 2.08 | 11 | 2.36 | 1.18, 4.72 |
| 4 | 1.08 | 0.42, 2.75 | 8 | 3.82 | 1.37, 10.60 | 12 | 1.68 | 1.05, 2.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chen, Z. Optimal Concordant Tests. Appl. Sci. 2024, 14, 4536. https://doi.org/10.3390/app14114536
AMA Style
Chen Z. Optimal Concordant Tests. Applied Sciences. 2024; 14(11):4536. https://doi.org/10.3390/app14114536
Chicago/Turabian StyleChen, Zhongxue. 2024. "Optimal Concordant Tests" Applied Sciences 14, no. 11: 4536. https://doi.org/10.3390/app14114536
APA StyleChen, Z. (2024). Optimal Concordant Tests. Applied Sciences, 14(11), 4536. https://doi.org/10.3390/app14114536
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.