
A Deep Learning Method to Mitigate the Impact of Subjective Factors in Risk Estimation for Machinery Safety


Abstract
1. Introduction
- The definitions or descriptions of scaled risk elements typically employ qualitative or a combination of qualitative and quantitative textual descriptions, leading to disparate interpretations. For example, reference [11] suggests that the severity of the harm S can be classified as: S1-slight injury, and S2-serious injury. Understanding those descriptions is very subjective and there tends to be significant variation between different risk assessment members [13]. Given that risk assessments pertain to potential future scenarios, such statements are intrinsically uncertain, by virtue of their inherent nature, and it is not easy to define scales unambiguously by mostly using nominal and textual descriptions. Reference [14] shared an experience in which subjects had to allocate a quantitative value to the verbal labels of probability, and concluded that regardless of whether the verbal labels were detailed, the probability assigned would vary due to distinct interpretations.
- Risk assessment members’ characteristics. The familiarity with the machine, background, and position of the persons who performed the risk assessment, and other factors such as optimism bias, confirmation bias, and overconfidence will affect the judgement of likelihood and consequence; the most significant divergence was detected in the estimation of the parameter Fr (frequency and duration of exposure) [8]. Subject to fluctuations in fatigue levels, mood, etc., the same individual may make different risk estimation results at different times, known as individual variability [14]. In addition, risk aversion also impacts risk estimation outcomes, which can be interpreted as an attitude that assigns a higher risk value to a low-probability, high-consequence event compared to a high-probability, low-consequence event, even when the expected loss for both events is the same [15].
- Insufficient data or unlimited resources are often available to support estimating the risk objectively. To conduct risk estimation, assessors need to choose one class for each parameter that best corresponds to the hazardous situation. Those choices are best made by a quantitative method; however, reference [1] notes that a quantitative approach to risk estimation is restricted by the valuable data that are available and/or the limited resources. Reference [16] thought that not all potential risk factors could be considered due to the restrictions associated with publicly available occupational injury data, and the absence of enough historical accident cases. Assessments of likelihood and consequence of adverse events are usually not precise, but rather subjective estimations that, due to the infrequent nature of the events, can seldom be verified against observations or statistics [13].
2. Related Works
- Focus on the advancement of risk matrices and the optimization of risk estimation tools. Reference [16] took additional severity factors into consideration, including employee factors, workspace factors, worksite location, etc., and proposed the Accident Severity Grade (ASG) method based on employee and workspace risk factors to quantify the injury risk. Reference [17] proposed a three-dimensional risk assessment matrix—injury frequency, severity, and the new dimension—preventability, to improve risk estimation. Reference [18] developed a proposed risk estimation tool with five risk parameters, severity of harm, frequency of exposure to the hazard, duration of exposure to the hazard, probability of occurrence of a hazardous event, possibility of avoidance. However, given that risk estimation is an intricate and extensive cognitive process, it is unavoidable that the subjective factors of risk assessors have a bearing on the results of risk estimation.
- With the development of AI, machine learning techniques are also finding their way into the field of safety [19]. Paltrinieri, Comfort et al. used a Deep Neural Network (DNN) model to predict risk increase or decrease as the target system conditions changed [20]. Natural language-based probabilistic risk assessment models applying deep learning algorithms were developed to emulate experts’ quantified risk estimates, which allowed the risk analyst to obtain an a priori risk assessment [21].
- Authors have made recommendations and proposed other tools or other methods. Jocelyn, Chinniah et al. integrated a Logical Analysis of Data (LAD)-based dynamic experience feedback into quantitative risk estimation to identify and update the risks, guiding safety practitioners to evaluate whether the current state of machine leads to an accident or not [22]. Bayesian networks (BN) and a Fuzzy Bayesian Network (FBN) were applied for predictive analysis and probability updating to improve risk assessment [23,24]. Those methods were based on strong models and little data, leading to large sets of assumptions and simulations for their environment.
3. Materials and Methods
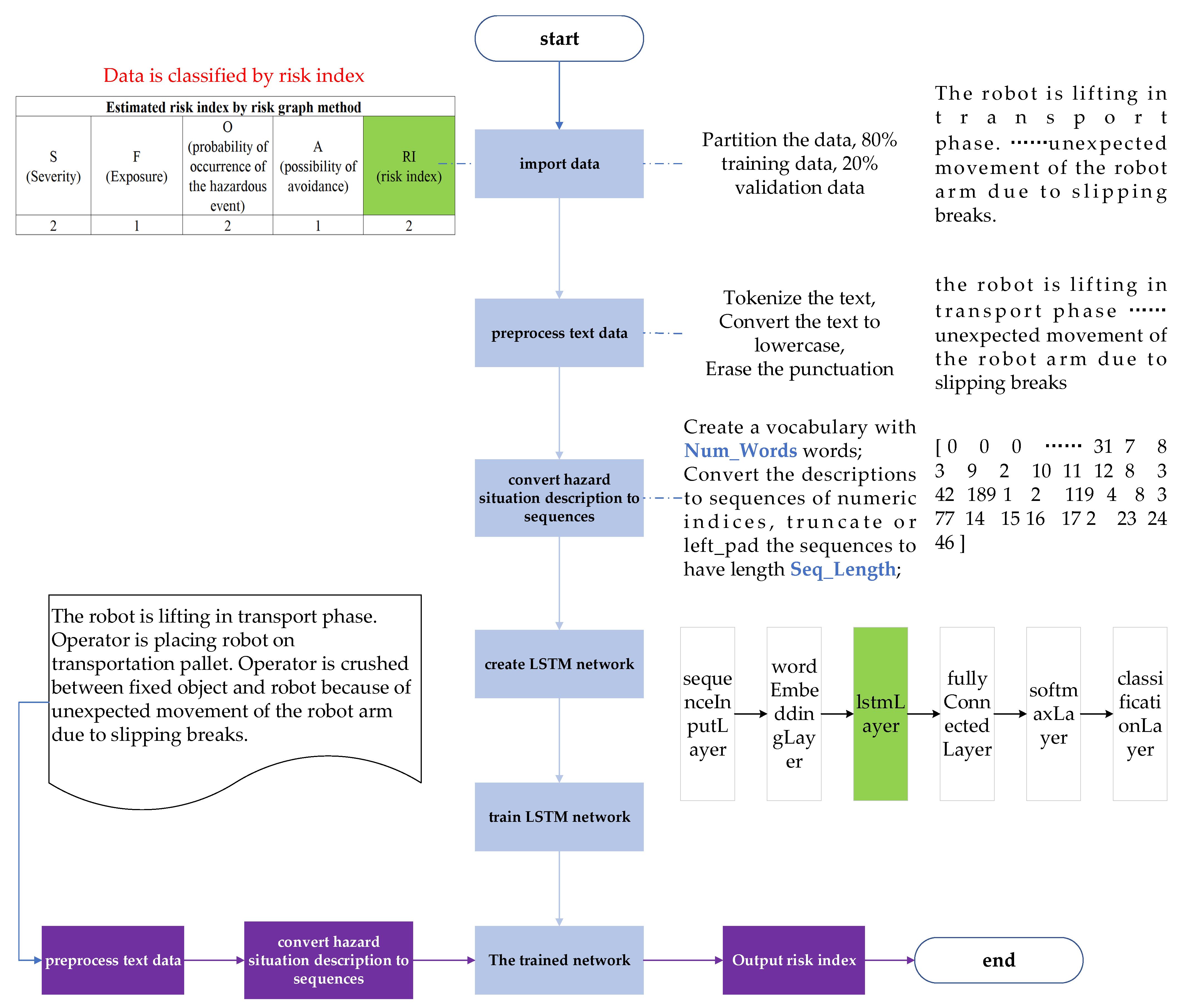
3.1. The Comprehensive Framework of LSTM-Based Risk Estimation Methodology
- Import the historical hazard event dataset into the network. Each hazard event is the combination of a hazardous situation description and the corresponding risk index. The dataset is partitioned into two parts, with a certain proportion of the data being used as the training set and a held-out proportion for validation. Since each hazardous situation description is associated with a corresponding risk index, the risk estimation task can be considered a classification of hazardous situation descriptions based on risk indices.
- Preprocess the hazardous situation description text to facilitate further processing, including tokenizing the text, converting the text to lowercase, and erasing punctuation.
- Convert the hazardous situation descriptions text into sequences. The textual descriptions of hazardous situations cannot be processed by the computer, which must be digitalized to generate vector data that the computer can process. In this step, a vocabulary dictionary is constructed upon the training data, with the serial number of each word in the dictionary being assigned.
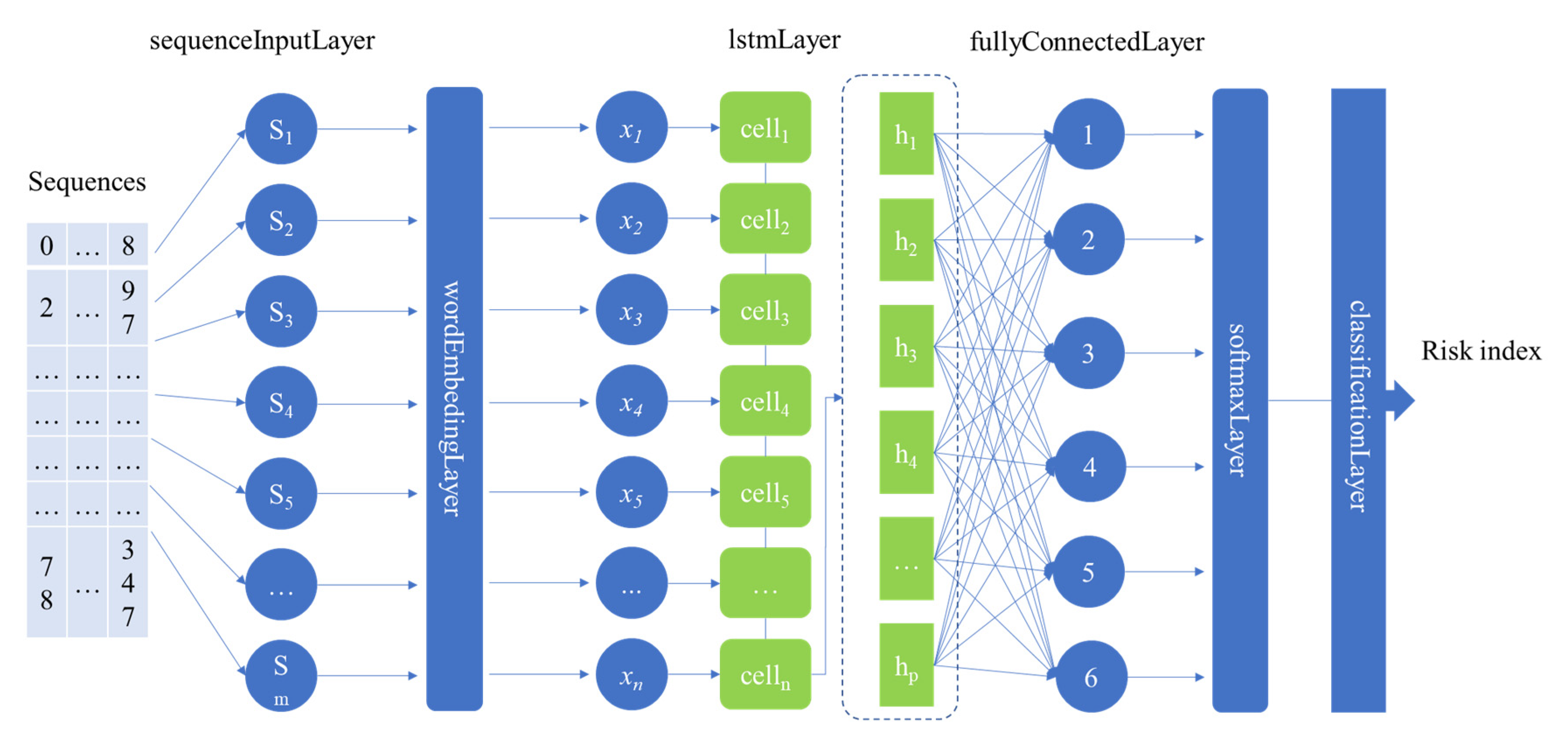
- Create the LSTM-based deep learning network with six layers, including sequenceInputLayer, wordEmbeddingLayer, lstmLayer, fullyConnectedLayer, softmaxLayer, and classificationLayer. The function of each layer in the network is described in Section 3.3.2.
- Training the network by historical risk events dataset, and the weight parameters of the network are updated to obtain the trained network.
- 6.
- For new hazard events, repeat 2 and 3, then input the processed data into the trained network to obtain the risk indices for the hazard events.
- 7.
- Output risk indices and complete the risk estimation of new hazard events.
3.2. Creating Hazard Event Dataset
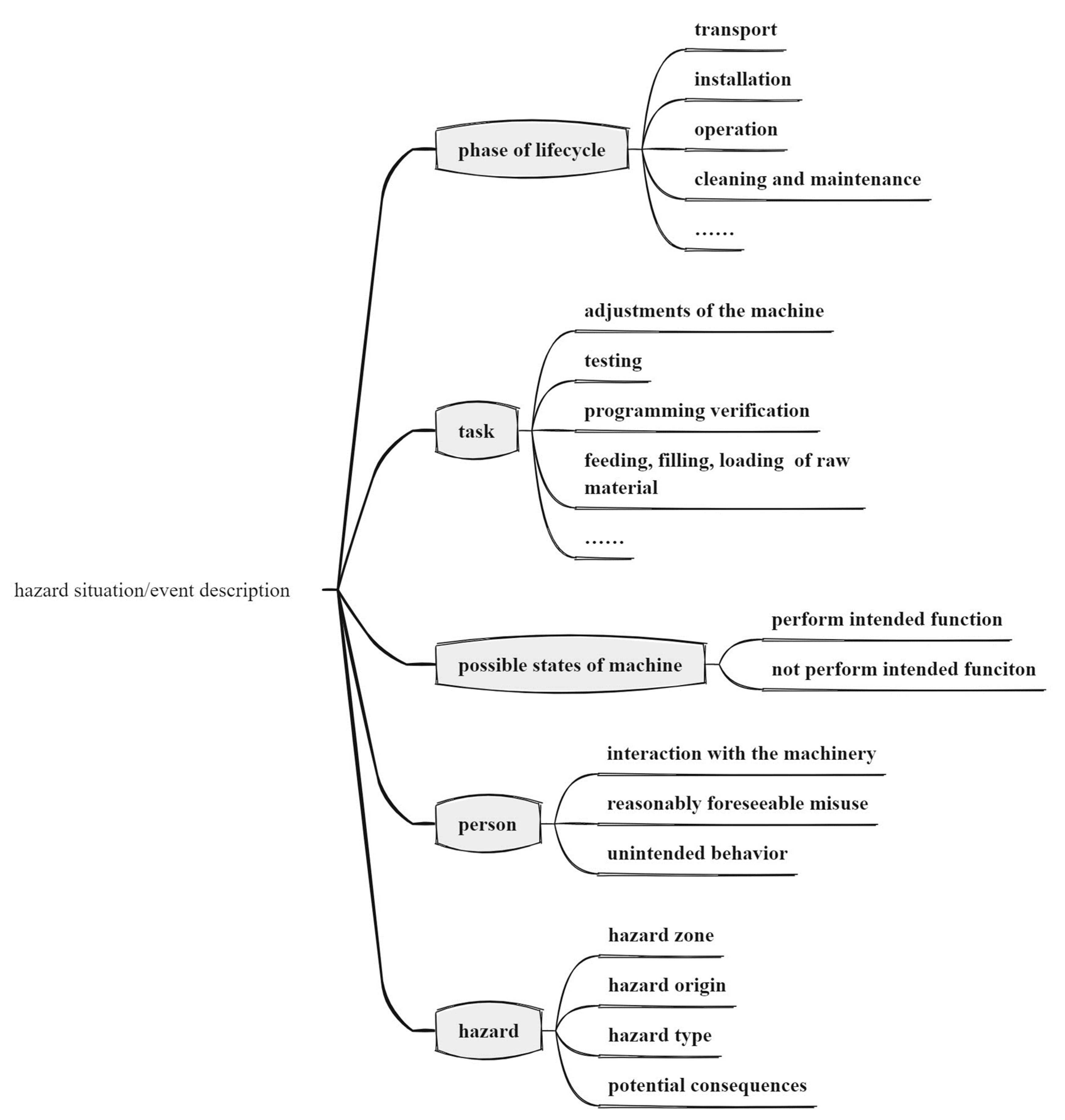
3.2.1. Elements of Hazardous Situation Description
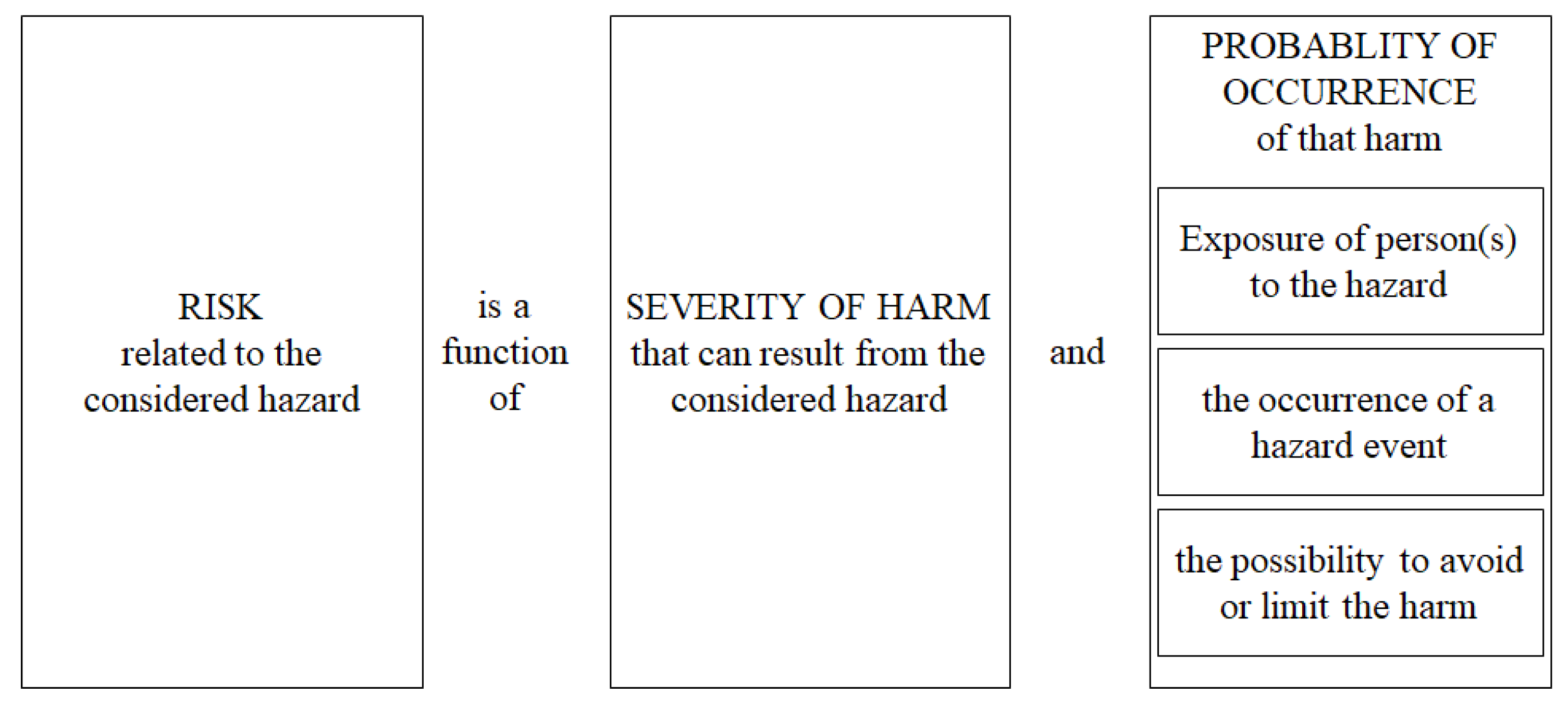
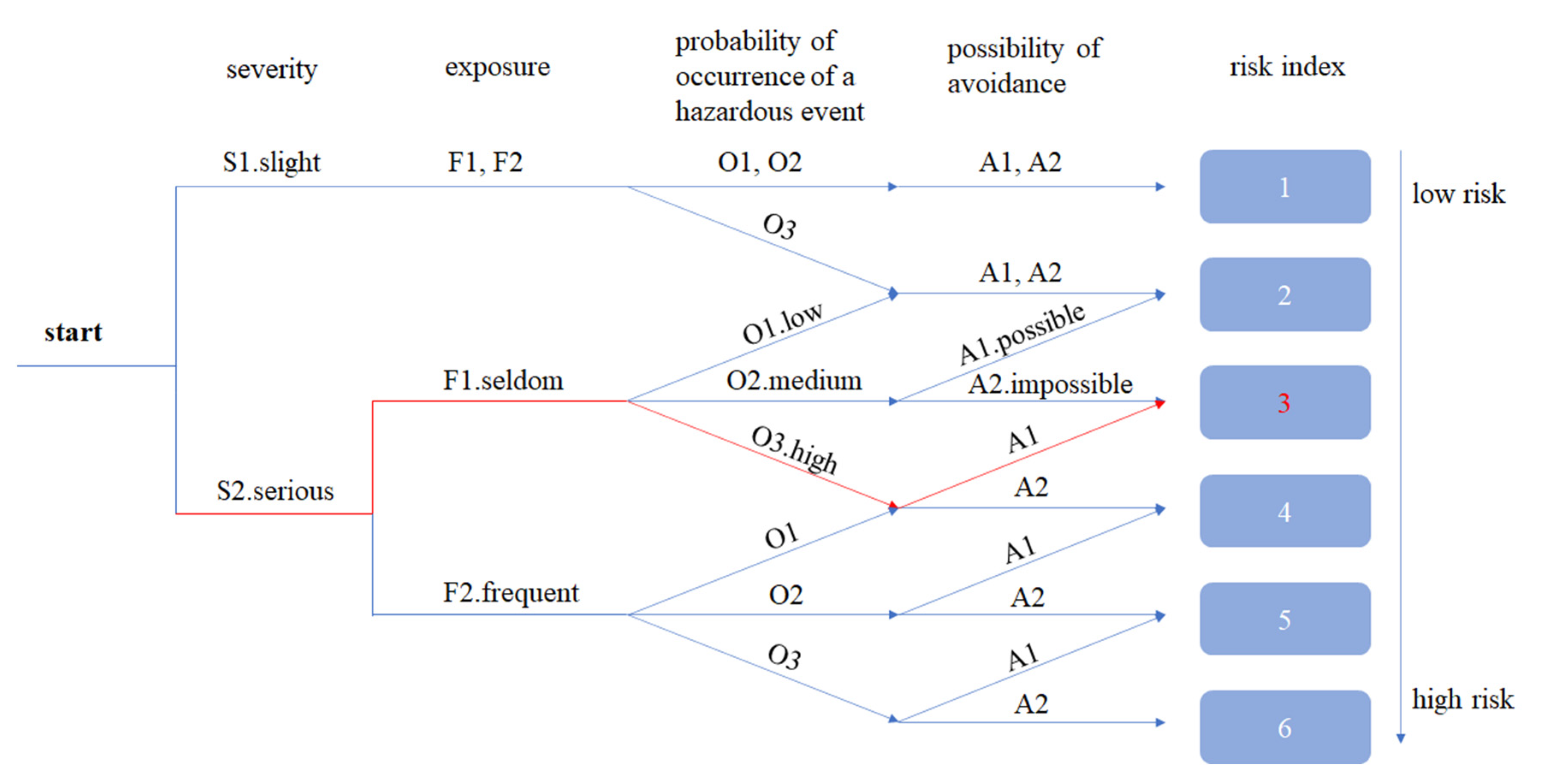
3.2.2. Risk Estimation by Risk Graph Tool
3.3. The Principle of LSTM-Based Risk Estimation Methodology
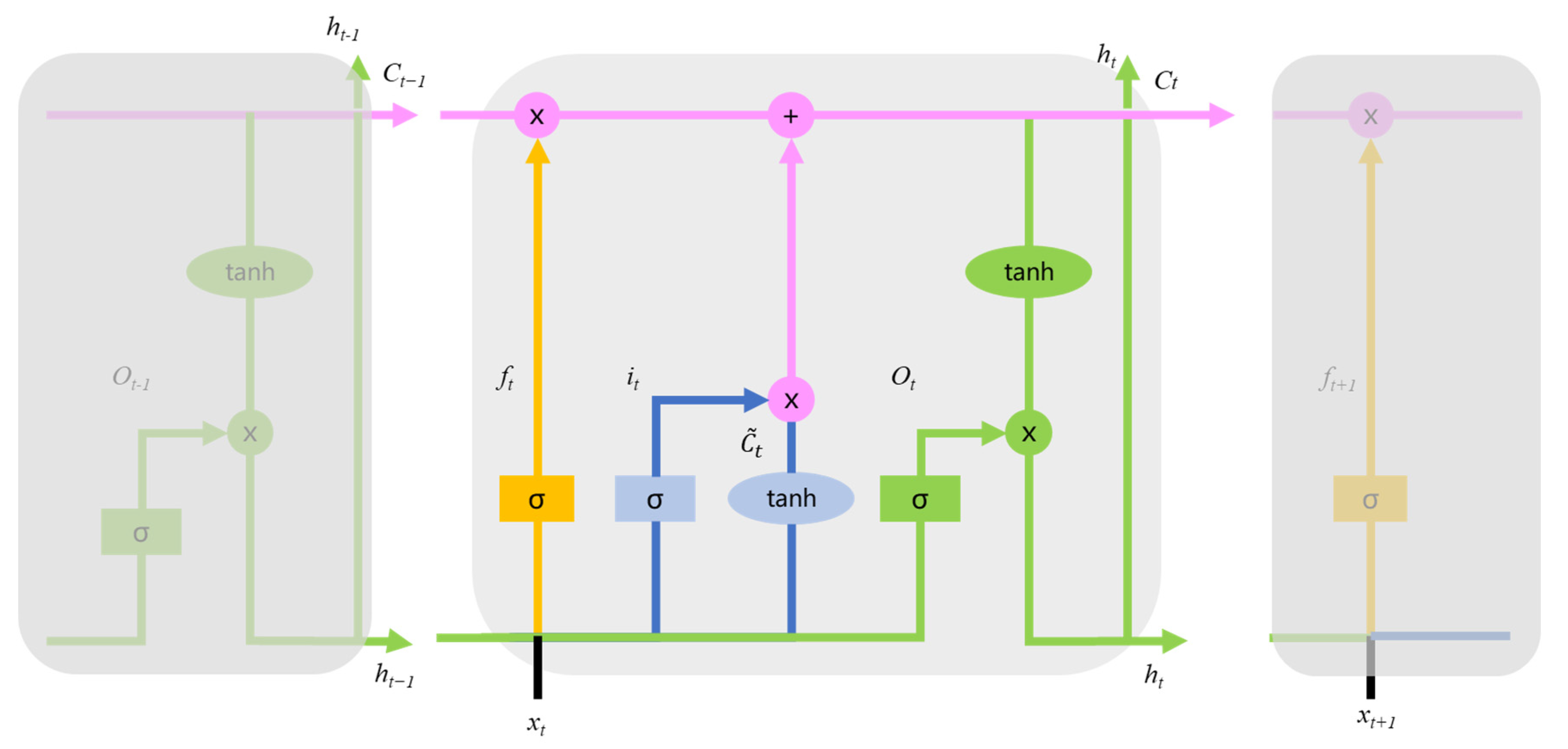
3.3.1. LSTM Algorithm
3.3.2. The LSTM-Based Deep Learning Network Architecture
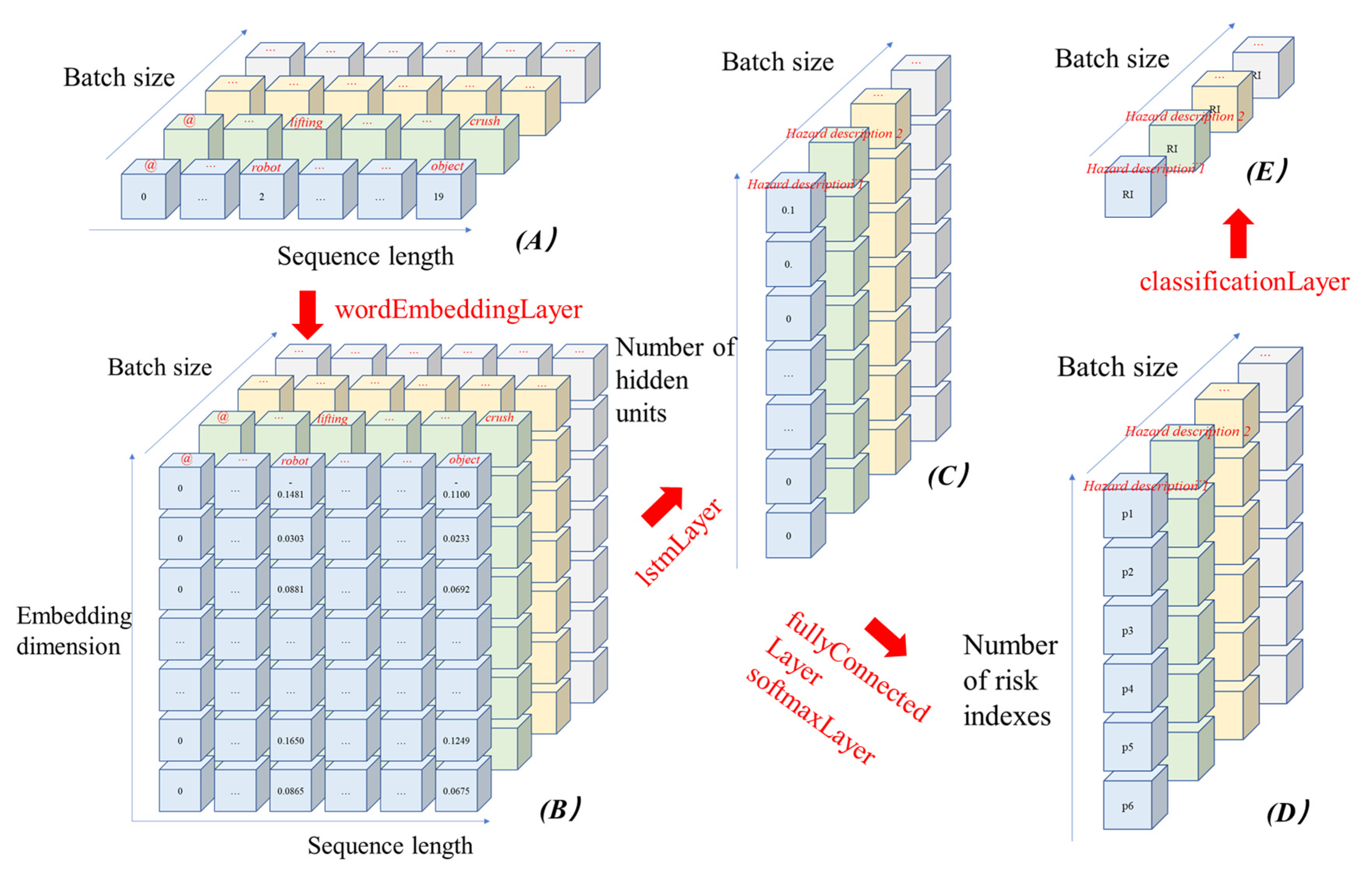
3.3.3. Data Flow across the LSTM-Based Deep Learning Network Layers
4. Results
4.1. Test Environment
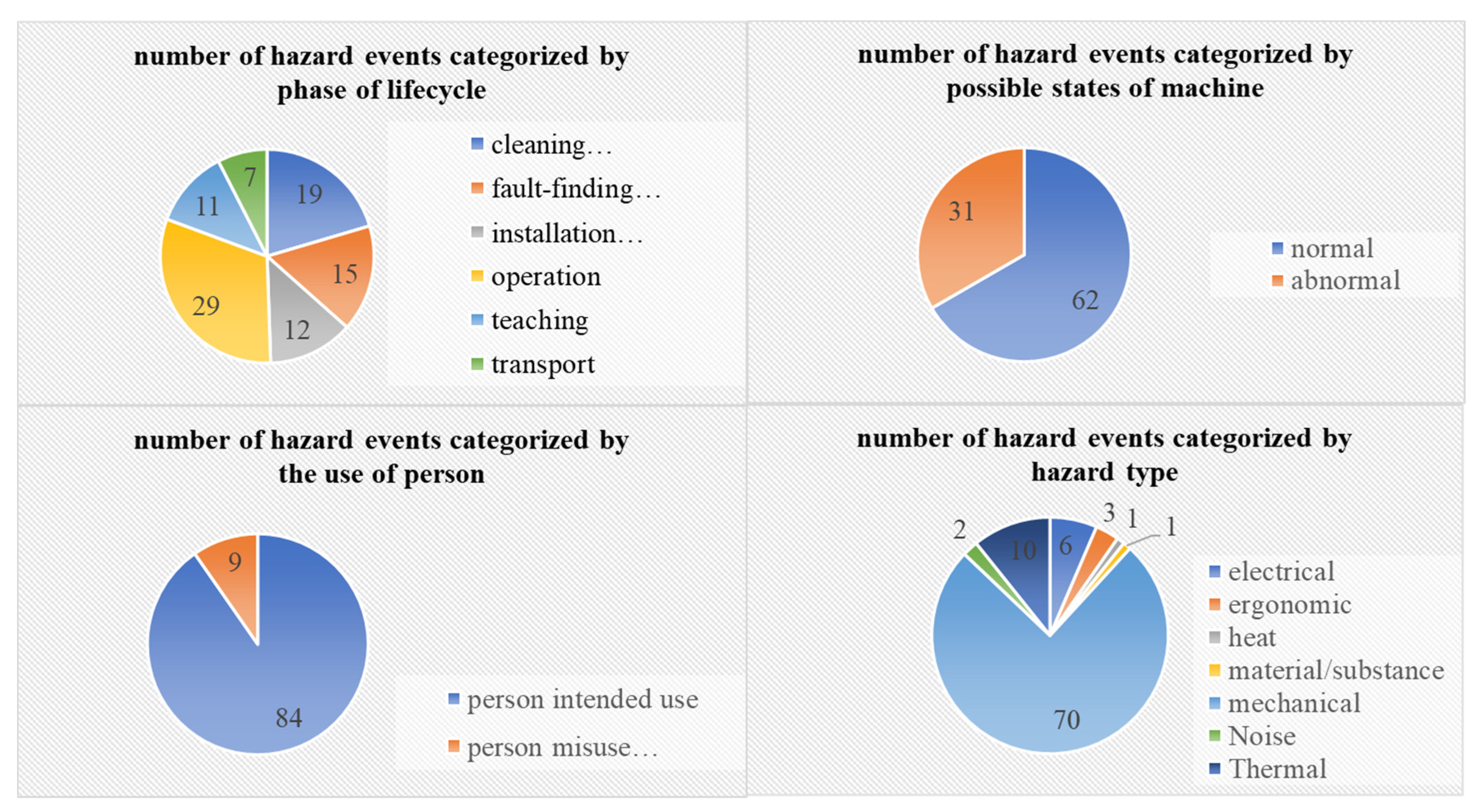
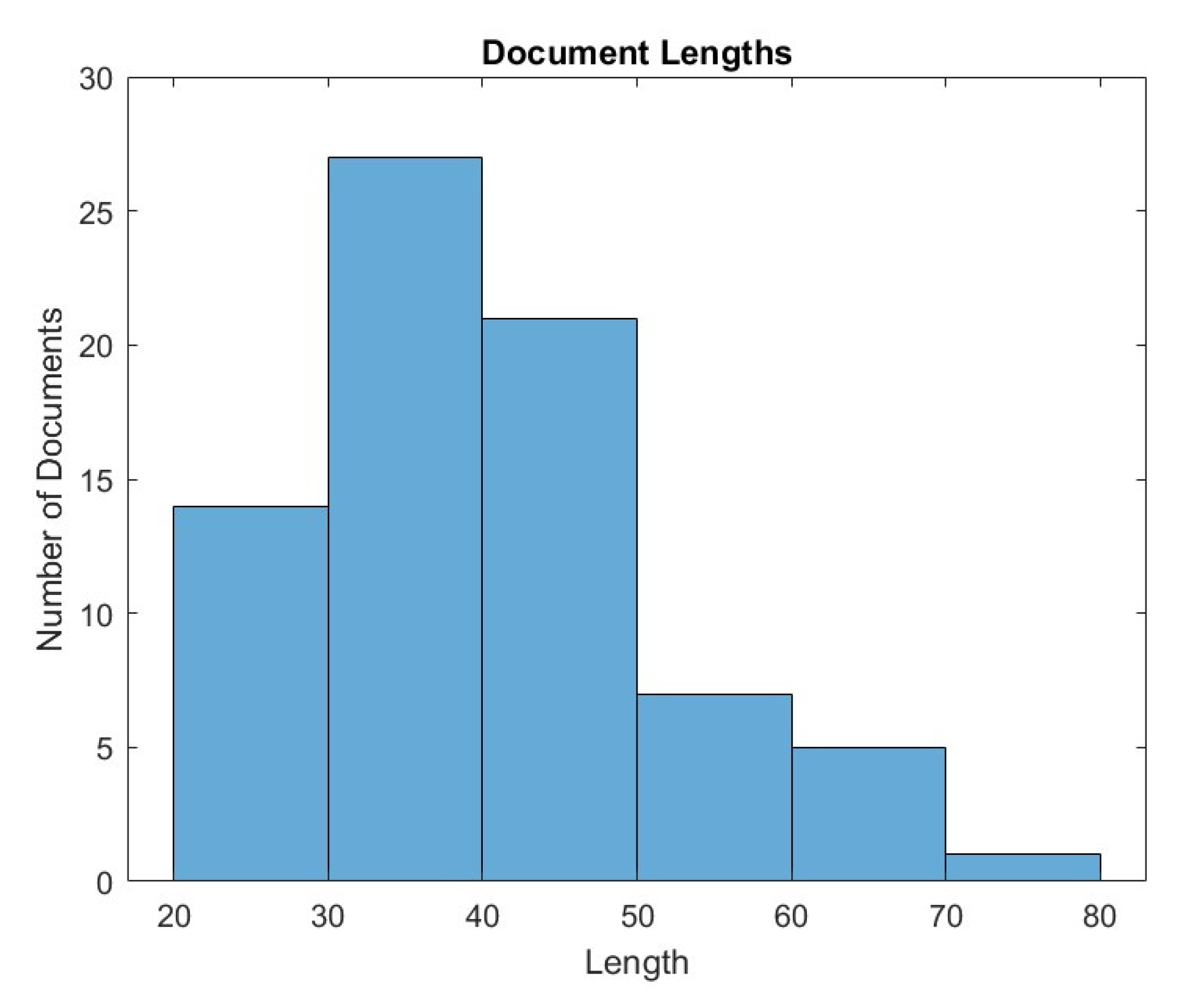
4.2. Raw Hazard Event Dataset
4.3. Training and Optimization of LSTM-Based Deep Learning Network
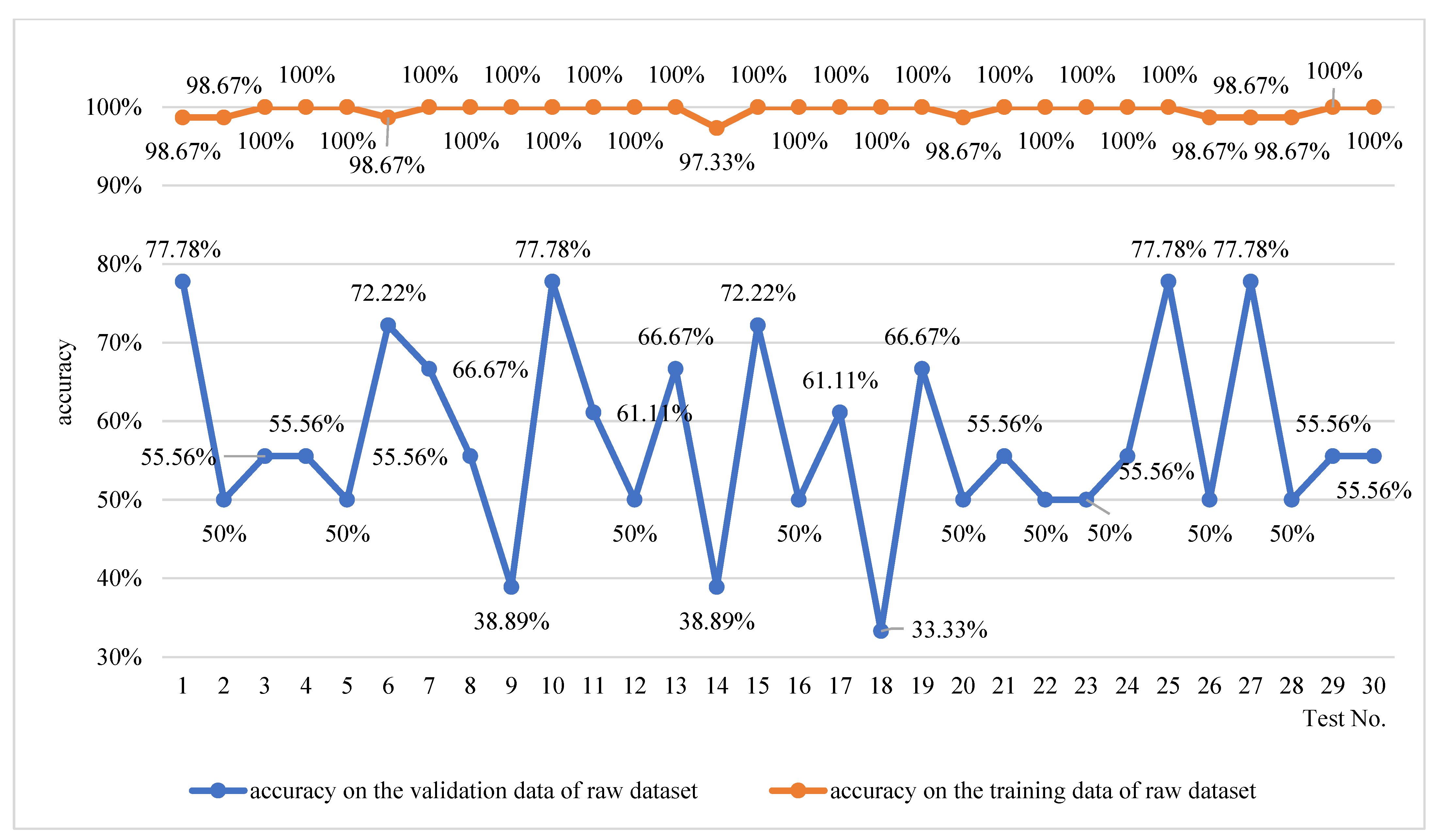
4.3.1. Experiment on the Raw Hazard Event Dataset
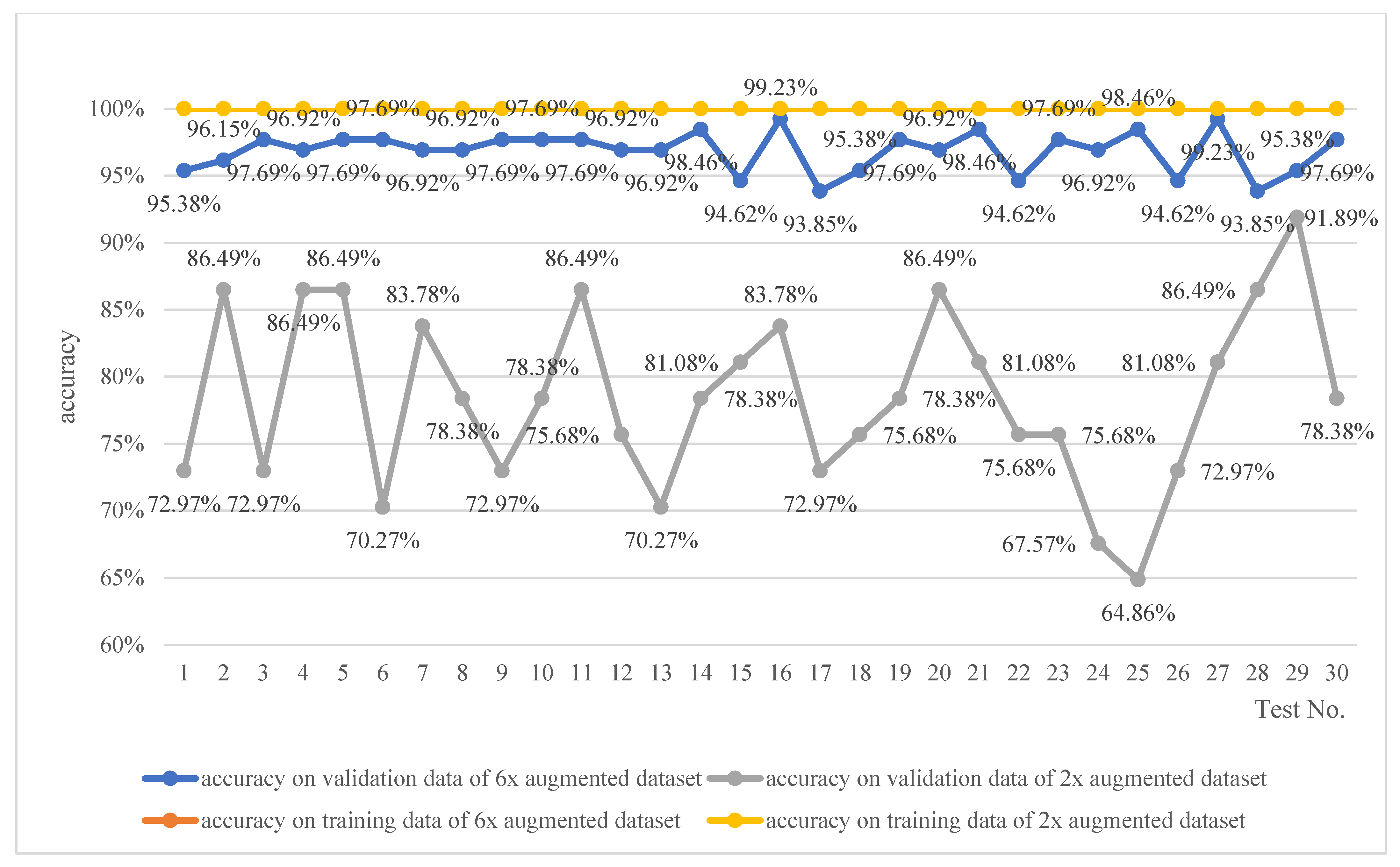
4.3.2. Training and Optimizing the Network Based on the Augmented Hazard Event Dataset
4.3.3. Analysis of Risk Deviation on the Validation Dataset
4.4. Risk Estimation of New Hazard Events by the Trained Network
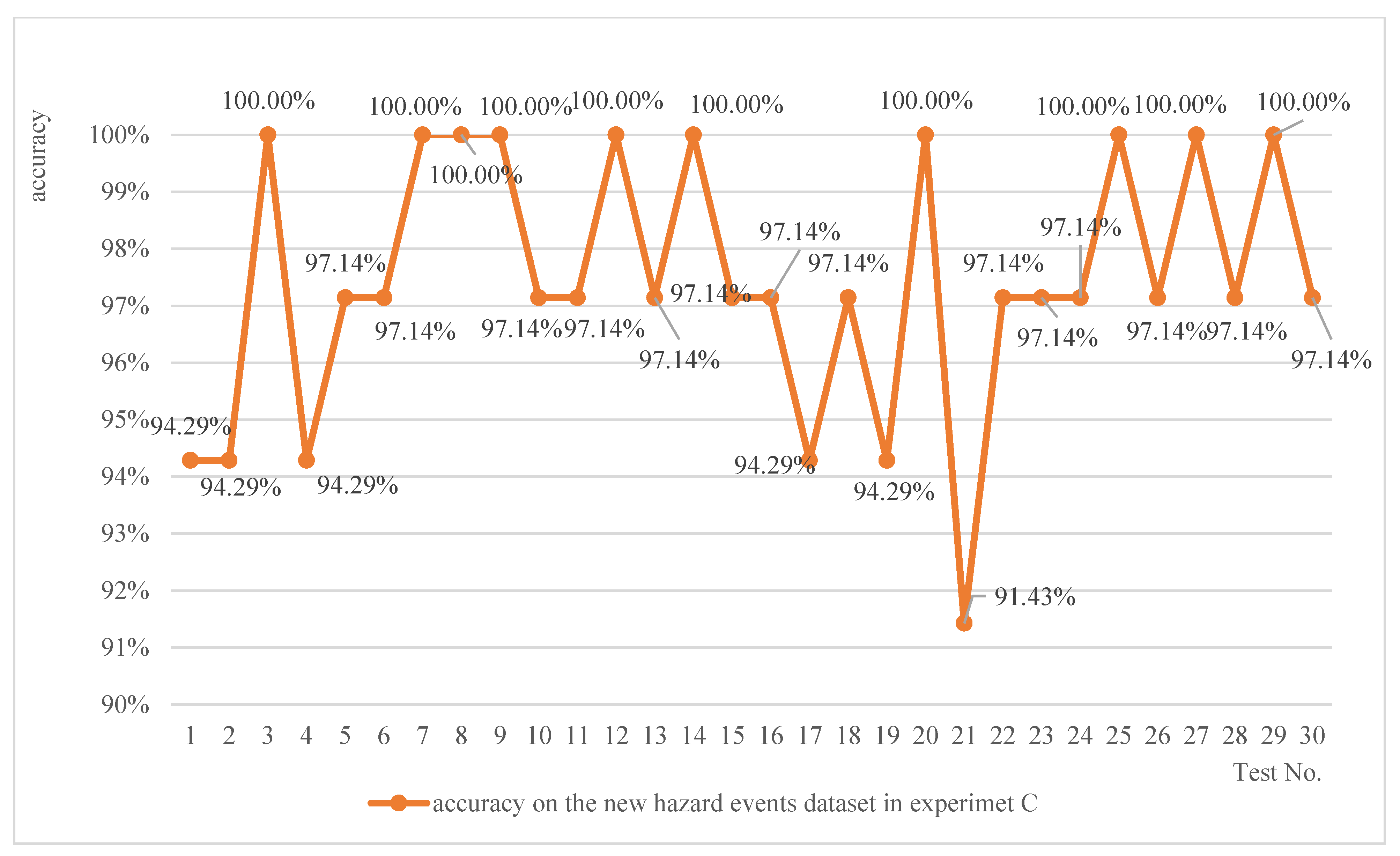
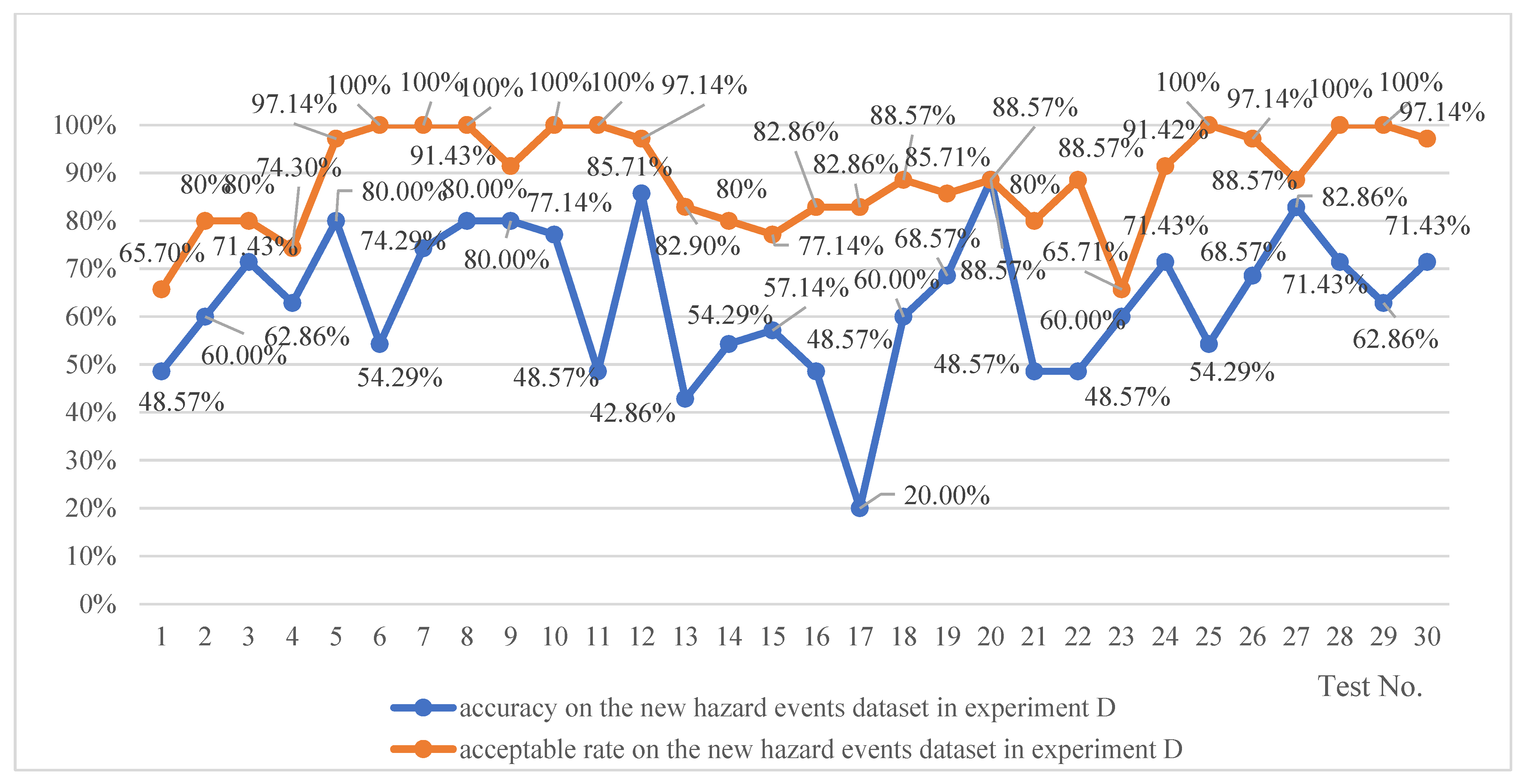
4.4.1. Estimating the Risk of New Hazard Events Similar to the Existing Ones
4.4.2. Estimating the Risk of New Hazard Events Completely Different from the Existing Ones
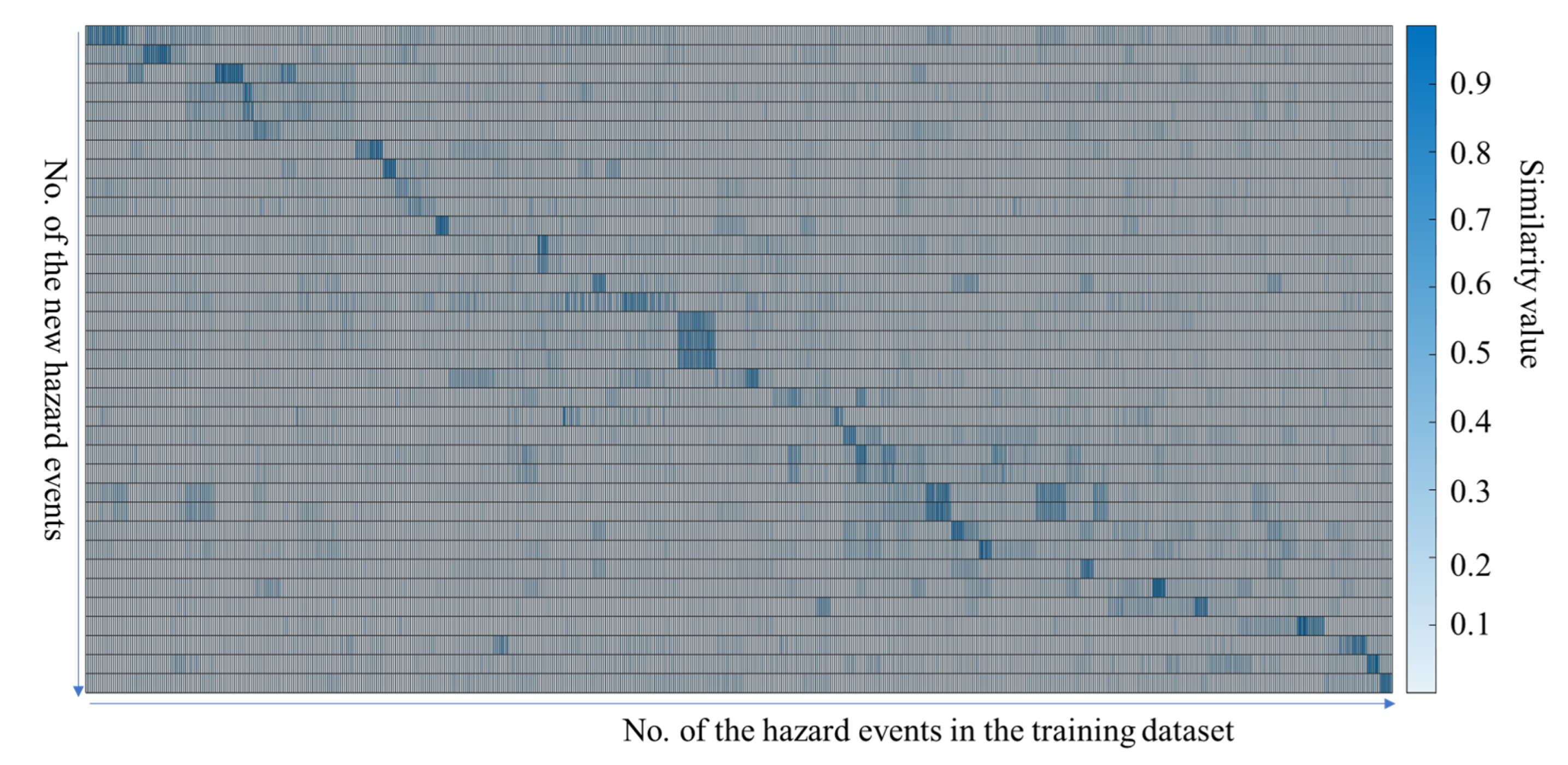
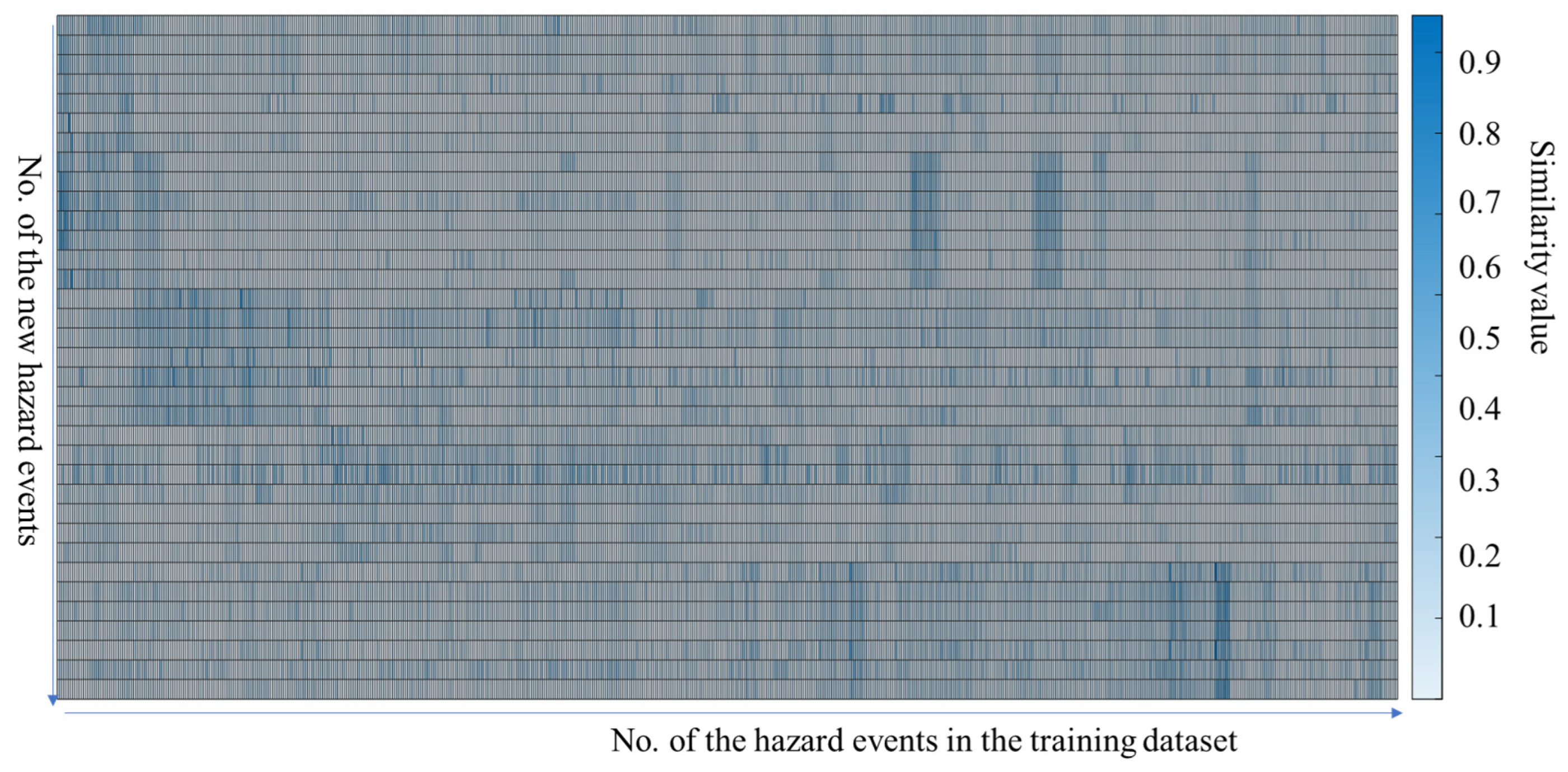
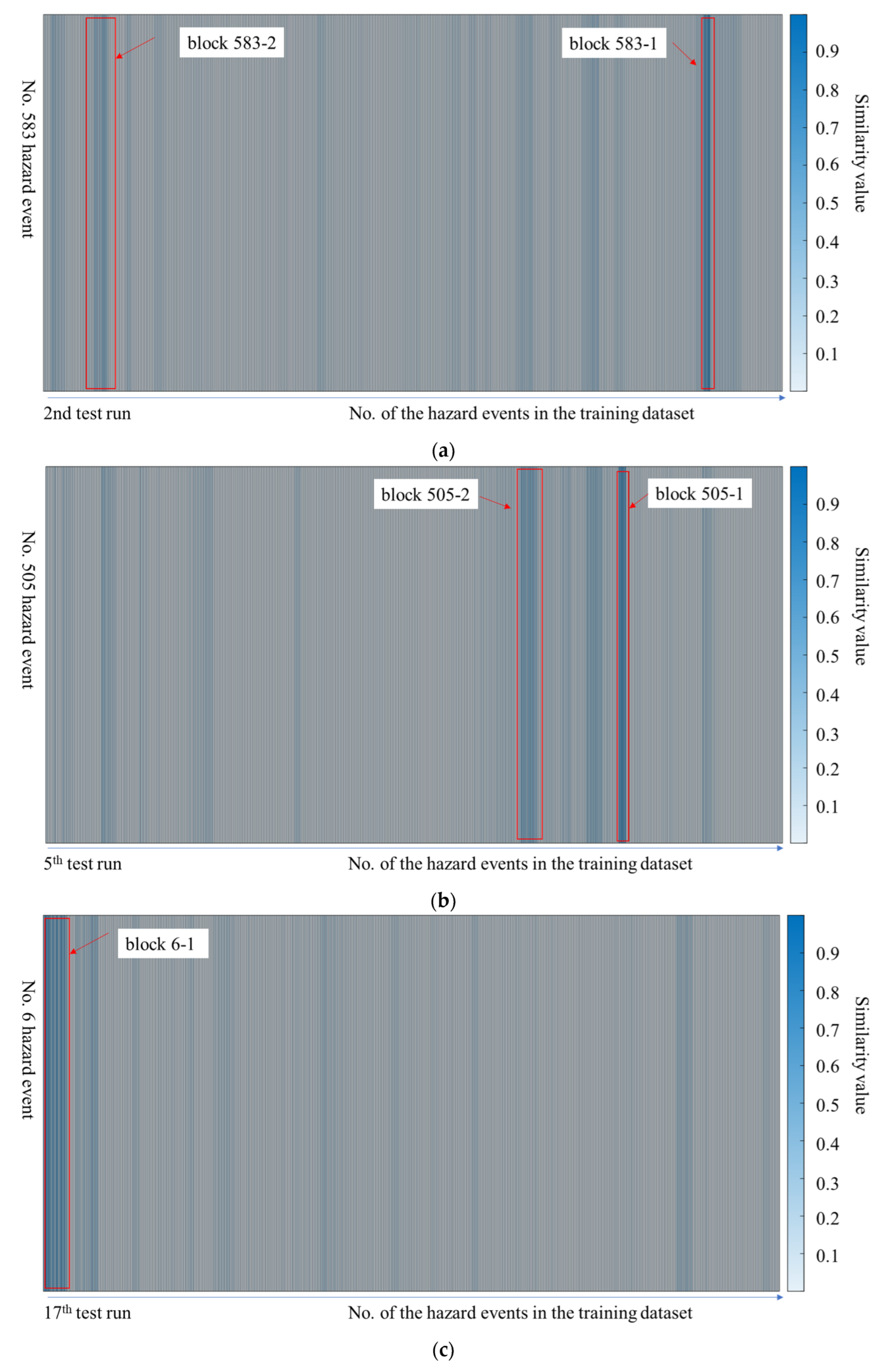
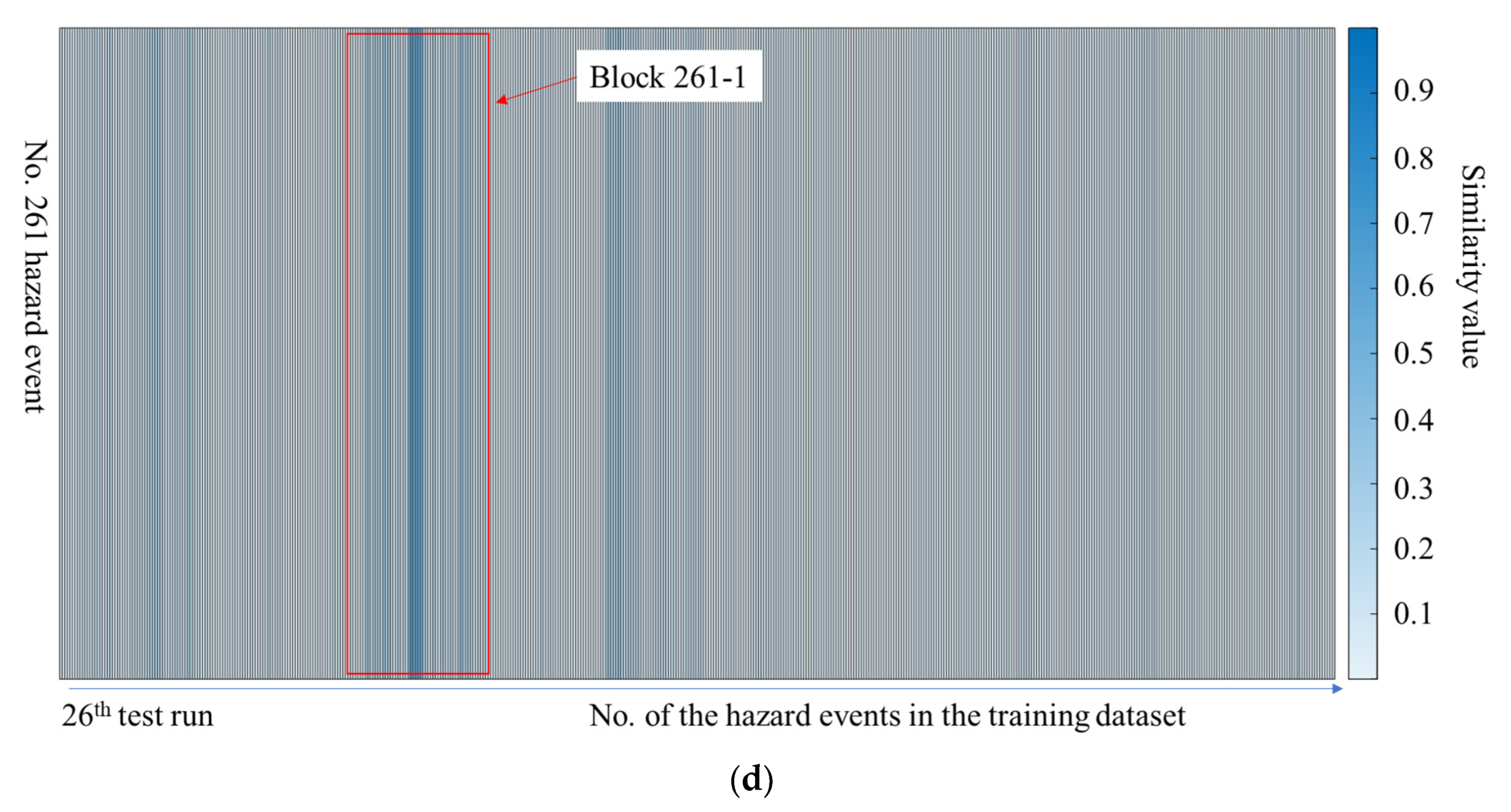
4.4.3. The Similarity between the New Hazard Events and the Existing Ones
4.5. Comparison with Other Methods
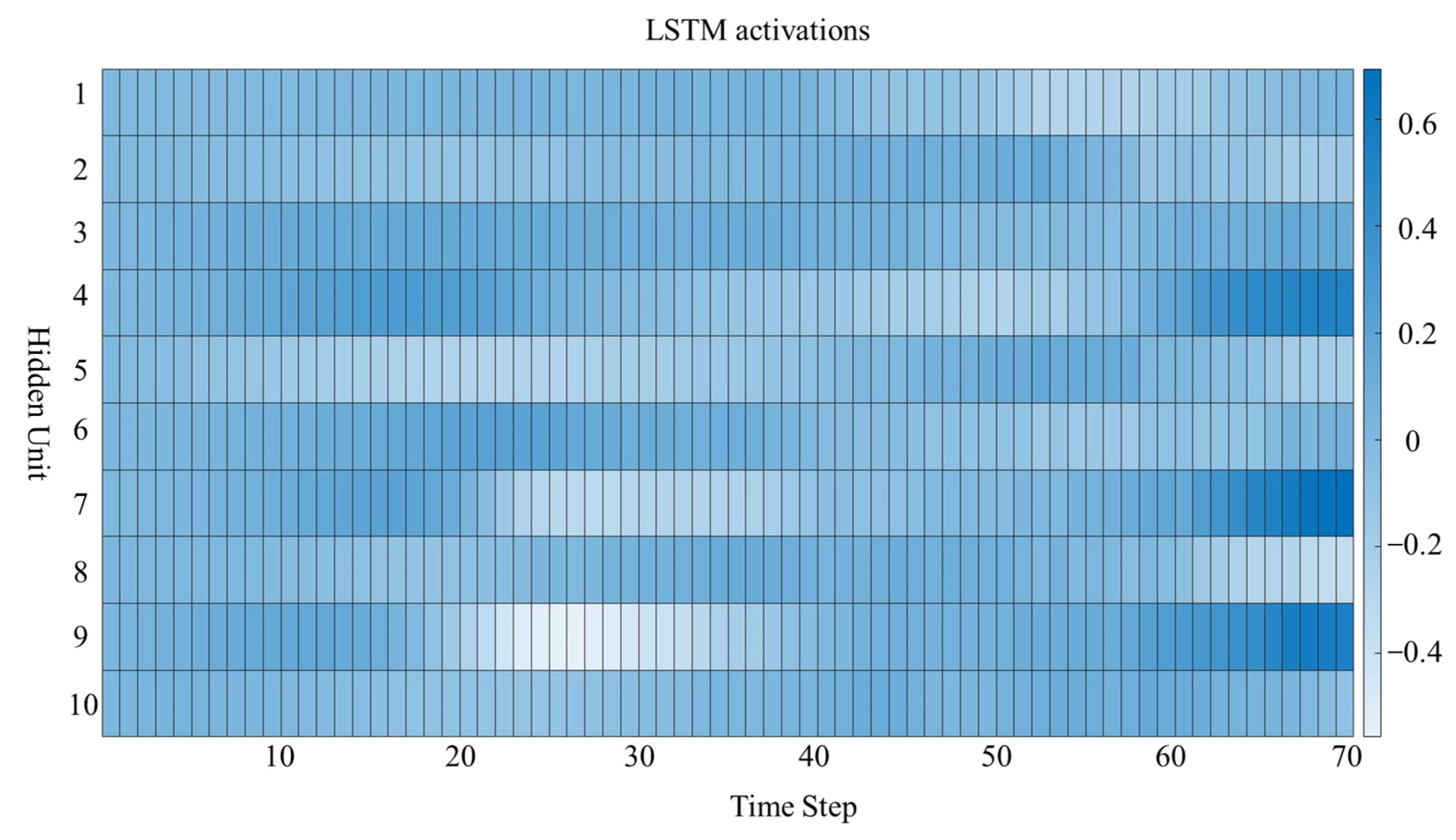
4.6. Model Explanation
5. Discussion
- In the raw hazard event dataset experiment, the overfitting problem aroused due to the limited dataset. Comparing the performance of the trained network based on the raw dataset, 2× augmented dataset, and 6× augmented dataset, as shown in Table 6, the augmentation of the hazard event dataset led to a significant improvement in the accuracy and reduction in the standard deviation on the validation dataset.
- 2.
- The trained network exhibits robust stability in estimating risks associated with new hazard events similar to the existing ones in the training dataset, achieving a maximum accuracy rate of 100% and a minimum of 91.43%, with a median value of 97.14%. Considering that an acceptable rate should ideally reach up to 100%, with a median value of 88.57%, the trained network demonstrates trustworthiness in estimating the risk of hazard events complexly different from the existing ones.
- 3.
- It is found that nearly 80% were small deviations (|RIdeviation| ≤ 2) and the discrimination factor RIdis is close to 1. That means the proposed method has a high likelihood of reaching a smaller deviation in the case of risk estimation deviation with no obvious bias, which proves the effectiveness of the proposed method in risk estimation.
- 4.
- Among the CNN-based, bi-LSTM-based and LSTM-based risk estimation methods, the LSTM-based one demonstrates no significant bias when deviations occur, effectively balancing accuracy and stability in risk estimation of new hazard events completely different from the existing ones.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- ISO:12100; Safety of Machinery—General Principles for Design—Risk Assessment and Risk Reduction. International Organization for Standardization: Geneva, Switerland, 2010.
- European Union. Directive 2006/42/EC of the European Parliament and of the Council of 17 May 2006 on machinery, and amending Directive 95/16/EC (Recast) (Text with EEA Relevance). Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32006L0042 (accessed on 29 October 2023).
- ISO10218-1:2011; Robots and Robotic Devices—Safety Requirements for Industrial Robots—Part 1: Robots. ISO: Geneva, Switerland, 2011.
- ISO/TS:15066; Robots and Robotic Devices Collaborative Robots. International Organization for Standardization: Geneva, Switerland, 2016.
- ISO10218-2:2011; Robots and Robotic Devices—Safety Requirements for Industrial Robots—Part 2: Robot Systems and Integration. ISO: Geneva, Switerland, 2011.
- ISO13482:2014; Robots and Robotic Devices—Safety Requirements for Personal Care Robots. ISO: Geneva, Switerland, 2014.
- ISO3691-4:2020; Industrial Trucks—Safety Requirements and Verification—Part 4: Driverless Industrial Trucks and Their Systems. ISO: Geneva, Switerland, 2020.
- Hietikko, M.; Malm, T.; Alanen, J. Risk estimation studies in the context of a machine control function. Reliab. Eng. Syst. Saf. 2011, 96, 767–774. [Google Scholar] [CrossRef]
- ISO13849-1:2015; Safety of Machinery—Safety-Related Parts of Control Systems—Part 1: General Principles for Design. ISO: Geneva, Switerland, 2015.
- ISO61508-5:2010; Functional Safety of Electrical/Electronic/Programmable Electronic Safety-Related Systems—Part 5: Examples of Methods for the Determination of Safety Integrity Levels. ISO: Geneva, Switerland, 2010.
- ISO14121-2:2012; Safety of Machinery—Risk Assessment—Part 2: Practical Guidance and Examples of Methods. ISO: Geneva, Switerland, 2013.
- Jocelyn, S.; Ouali, M.-S.; Chinniah, Y. Estimation of probability of harm in safety of machinery using an investigation systemic approach and Logical Analysis of Data. Saf. Sci. 2018, 105, 32–45. [Google Scholar] [CrossRef]
- Duijm, N.J. Recommendations on the use and design of risk matrices. Saf. Sci. 2015, 76, 21–31. [Google Scholar] [CrossRef]
- Hubbard, D.; Evans, D. Problems with scoring methods and ordinal scales in risk assessment. IBM J. Res. Dev. 2010, 54, 2:1–2:10. [Google Scholar] [CrossRef]
- Cox, A.L., Jr. What’s Wrong with Risk Matrices. Risk Anal. 2008, 28, 497–512. [Google Scholar] [CrossRef] [PubMed]
- Azadeh-Fard, N.; Schuh, A.; Rashedi, E.; Camelio, J.A. Risk assessment of occupational injuries using Accident Severity Grade. Saf. Sci. 2015, 76, 160–167. [Google Scholar] [CrossRef]
- van Duijne, F.H.; van Aken, D.; Schouten, E.G. Considerations in developing complete and quantified methods for risk assessment. Saf. Sci. 2008, 46, 245–254. [Google Scholar] [CrossRef]
- Moatari-Kazerouni, A.; Chinniah, Y.; Agard, B. A proposed occupational health and safety risk estimation tool for manufacturing systems. Int. J. Prod. Res. 2015, 53, 4459–4475. [Google Scholar] [CrossRef]
- Cosgriff, C.V.; Celi, L.A. Deep learning for risk assessment: All about automatic feature extraction. Br. J. Anaesth. 2020, 124, 131. [Google Scholar] [CrossRef] [PubMed]
- Paltrinieri, N.; Comfort, L.; Reniers, G. Learning about risk: Machine learning for risk assessment. Saf. Sci. 2019, 118, 475–486. [Google Scholar] [CrossRef]
- Brito, M.P.; Stevenson, M.; Bravo, C. Subjective machines: Probabilistic risk assessment based on deep learning of soft information. Risk Anal. 2023, 43, 516–529. [Google Scholar] [CrossRef] [PubMed]
- Jocelyn, S.; Chinniah, Y.; Ouali, M.-S. Contribution of dynamic experience feedback to the quantitative estimation of risks for preventing accidents: A proposed methodology for machinery safety. Saf. Sci. 2016, 88, 64–75. [Google Scholar] [CrossRef]
- Allouch, A.; Koubaa, A.; Khalgui, M.; Abbes, T. Qualitative and Quantitative Risk Analysis and Safety Assessment of Unmanned Aerial Vehicles Missions Over the Internet. IEEE Access 2019, 7, 53392–53410. [Google Scholar] [CrossRef]
- Zarei, E.; Khakzad, N.; Cozzani, V.; Reniers, G. Safety analysis of process systems using Fuzzy Bayesian Network (FBN). J. Loss Prev. Process Ind. 2019, 57, 7–16. [Google Scholar] [CrossRef]
- Ruge, B. Risk Matrix as Tool for Risk Assessment in the Chemical Process Industries. In Proceedings of the Probabilistic Safety Assessment and Management, Berlin, Germany, 14–18 June 2004; pp. 2693–2698. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- ISO/TR22100-1:2021; Safety of Machinery—Relationship with ISO 12100—Part 1: How ISO 12100 Relates to Type-B and Type-C Standards. ISO: Geneva, Switerland, 2015.
- Colah. Understanding LSTM Networks. Available online: http://colah.github.io/posts/2015-08-Understanding-LSTMs/ (accessed on 7 August 2022).
- Staudemeyer, R.C.; Morris, E.R. Understanding LSTM—A tutorial into Long Short-Term Memory Recurrent Neural Networks. arXiv, 2019; arXiv:1909.09586. [Google Scholar] [CrossRef]
- Rong, X. word2vec Parameter Learning Explained. arXiv 2016, arXiv:1411.2738. [Google Scholar] [CrossRef]
- Kudo, M.; Toyama, J.; Shimbo, M. Multidimensional curve classification using passing-through regions. Pattern Recogn. Lett. 1999, 20, 1103–1111. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- The MathWorks, Inc. Deep Learning Toolbox—Design, Train, and Analyze Deep Learning Networks. Available online: https://www.mathworks.com/products/deep-learning.html (accessed on 15 October 2022).
- TCAR. Introduction of China Robot Certification. Available online: http://china-tcar.com/Service/Detail?Id=202012301205527916626b3174615cb (accessed on 8 November 2023).
- European-Commission. CE Marking. Available online: https://single-market-economy.ec.europa.eu/single-market/ce-marking_en (accessed on 8 November 2022).
- Netease. Youdao AIBox. Available online: https://fanyi.youdao.com/download-Windows?keyfrom=baidu_pc&bd_vid=11741871806532036510 (accessed on 11 November 2023).
- AlShammari, A.F. Implementation of Text Similarity using Cosine Similarity Method in Python. Int. J. Comput. Appl. 2023, 185, 11–14. [Google Scholar] [CrossRef]
- Hughes, M.; Li, I.; Kotoulas, S.; Suzumura, T. Medical Text Classification Using Convolutional Neural Networks. Stud. Health Technol. Inf. 2017, 235, 246. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. arXiv, 2017; arXiv:1705.07874. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Company Name | Product Name | Product Model |
|---|---|---|
| Chengdu CRP Robot Technology Co., Ltd. (Chengdu, China) | Industrial robot | CRP-RH18-20, RRP-RH14-10 |
| KUKA (Foshan, China) | Industrial robot | KR 6 R2010-2 arc HW E, KR 6 R1440-2 arc HW E |
| Estun Automation (Nanjing, China) | Industrial robot | ER20-1000-SR, ER6-600-SR, ER3-400-SR |
| STEP (Shanghai, China) | Industrial robot | SR20/1700, SR50/2180, SR165/2580, SR60/2280B |
| Risk Index (RI) | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Number of hazardous situation description | 9 | 39 | 17 | 17 | 11 | 0 |
| RIdeviation | −4 | −3 | −2 | −1 | 1 | 2 | 3 | 4 | Total |
|---|---|---|---|---|---|---|---|---|---|
| Quantity | 9 | 7 | 10 | 39 | 18 | 25 | 7 | 3 | 118 |
| Proportion | 7.63% | 5.93% | 8.47% | 33.05% | 15.25% | 21.19% | 5.93% | 2.54% | 100% |
| New Hazard Events’ Risk Estimation Deviation | Block No. | Similar Hazard Events in the Training Dataset | The Same Raw Hazard Event | ||||
|---|---|---|---|---|---|---|---|
| No. | True Risk Index | Estimated Risk Index | No. | Similarity Value | Risk Index | ||
| 583 | 5 | 2 | 583-1 | 584 | 0.7423 | 5 | Yes |
| 585 | 0.459 | 5 | Yes | ||||
| 586 | 0.5761 | 5 | Yes | ||||
| 587 | 0.6821 | 5 | Yes | ||||
| 588 | 0.7426 | 5 | Yes | ||||
| 583-2 | 50 | 0.2477 | 2 | No | |||
| 51 | 0.3278 | 2 | No | ||||
| 53 | 0.2304 | 2 | No | ||||
| 54 | 0.2269 | 2 | No | ||||
| 55 | 0.1647 | 2 | No | ||||
| 56 | 0.2155 | 2 | No | ||||
| 57 | 0.2796 | 2 | No | ||||
| 58 | 0.346 | 2 | No | ||||
| 59 | 0.3889 | 2 | No | ||||
| 60 | 0.2923 | 2 | No | ||||
| 61 | 0.2947 | 2 | No | ||||
| Risk Estimation Method | Accuracy | Acceptable Rate | Percentage of Small Deviation | RIdis | ||||
|---|---|---|---|---|---|---|---|---|
| Min | Median | Max | Min | Median | Max | |||
| bi-LSTM-based | 5.71% | 58.57% | 80.00% | 60.00% | 94.29% | 100.00% | 90.29% | 1.25 |
| LSTM-based | 20.00% | 62.86% | 88.57% | 65.70% | 88.57% | 100.00% | 88.76% | 1.23 |
| CNN-based | 40.00% | 70.00% | 94.29% | 65.71% | 97.14% | 100.00% | 91.62% | 0.51 |
| Accuracy | Training Dataset | Validation Dataset | |||||
|---|---|---|---|---|---|---|---|
| Max | Min | Median | Max | Min | Median | Standard Deviation | |
| raw dataset | 100% | 97.33% | 98.67% | 77.78% | 33.33% | 55.56% | 0.118 |
| 2× | 100% | 100% | 100% | 91.89% | 64.86% | 78.38% | 0.065 |
| 6× | 100% | 100% | 100% | 99.23% | 93.85% | 96.92% | 0.015 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, X.; Wang, A.; Zhang, K.; Hua, X. A Deep Learning Method to Mitigate the Impact of Subjective Factors in Risk Estimation for Machinery Safety. Appl. Sci. 2024, 14, 4519. https://doi.org/10.3390/app14114519
Zhu X, Wang A, Zhang K, Hua X. A Deep Learning Method to Mitigate the Impact of Subjective Factors in Risk Estimation for Machinery Safety. Applied Sciences. 2024; 14(11):4519. https://doi.org/10.3390/app14114519
Chicago/Turabian StyleZhu, Xiaopeng, Aiguo Wang, Ke Zhang, and Xueming Hua. 2024. "A Deep Learning Method to Mitigate the Impact of Subjective Factors in Risk Estimation for Machinery Safety" Applied Sciences 14, no. 11: 4519. https://doi.org/10.3390/app14114519
APA StyleZhu, X., Wang, A., Zhang, K., & Hua, X. (2024). A Deep Learning Method to Mitigate the Impact of Subjective Factors in Risk Estimation for Machinery Safety. Applied Sciences, 14(11), 4519. https://doi.org/10.3390/app14114519