
GreenRu: A Russian Dataset for Detecting Mentions of Green Practices in Social Media Posts



Abstract
1. Introduction
- GreenRu, the first dataset for detecting the mentions of green practices in Russian social media posts, is described. The paper presents our annotation scheme for green practice mentions that can be easily adapted for application in other languages and domains.
- The multi-label and one-versus-rest current state-of-the-art models for text classification are evaluated while performing the task of detecting the mentions of green practices.
- The performance of several data augmentation methods is estimated to handle class imbalance since the distribution of the mentions of green practices is unequal. The results are provided both in terms of classification metrics and human evaluation. The results can be used in other tasks related to imbalanced multi-class text classification.
2. Data Collection and Annotation
2.1. Types of Green Waste Practices and Text Collection
2.2. Annotation Guidelines
3. Experiments and Evaluation
3.1. Dataset Statistics
3.2. Models
- Bidirectional Encoder Representations from Transformers (BERT) [32], a transformer-based model pre-trained using a masked language modeling objective. In this paper, Conversational RuBERT (https://huggingface.co/DeepPavlov/rubert-base-cased-conversational (accessed on 20 May 2024)) [33], which was trained on OpenSubtitles [34], Dirty, Pikabu, and a Social Media segment of the Taiga corpus [35], was used.
- Robustly optimized BERT approach (RoBERTa) [36], the model has the same architecture as BERT but uses a byte-level Byte Pair Encoding as a tokenizer and a different pre-training scheme. RuRoBERTa (https://huggingface.co/ai-forever/ruRoberta-large (accessed on 20 May 2024)) [37], which was trained on the texts of Wikipedia, news texts, literary texts, Colossal Clean Crawled Corpus [38], and Open Subtitles, was used.
3.3. Handling Class Imbalance
3.3.1. Data Augmentation
- Simple duplication, a method that consists of duplicating the texts from the original dataset.
- Backtranslation, a method using backtranslating phrases between any two languages. The BackTranslation library (https://pypi.org/project/BackTranslation (accessed on 20 May 2024)) based on googletrans and English as a target language was utilized.
- Text generation (RuGPT3). RuGPT3 (https://huggingface.co/ai-forever/rugpt3medium_based_on_gpt2 (accessed on 20 May 2024)) [37] was fine-tuned for predicting the next word using the following parameters: the number of epochs—3, the maximum sequence length—256 tokens, and the learning rate—. Next, each text mentioning minority green waste practices was transformed in the following way. If the text was more than five tokens long, it was truncated to five tokens. If the text length was shorter, the entire text was used. For each transformed text, a continuation was generated using the fine-tuned RuGPT3.
- Decoding masked sentences (RuT5). Word-level masking was applied, inspired by [45], by replacing a continuous chunk of k words with a single mask token . Masking was applied to 50% of the random words in each text. With different random seeds, 10,000 training examples were produced and RuT5-base (https://huggingface.co/ai-forever/ruT5-base (accessed on 20 May 2024)) [37] was fine-tuned to decode the original sequence given a masked sequence. To better distinguish between texts containing mentions of different green waste practices, the types of the corresponding practices were added at the beginning of each masked text as control codes (for example, waste sorting: text). No control codes were added to target texts. Thus, the augmentation scheme was as follows.
- Creating data for fine-tuning RuT5. Forming a dataset of 10,000 examples for the fine-tuning of RuT5-base: adding control codes and masking to the original texts, using original texts as a target.
- Fine-tuning on masked texts. RuT5-base was fine-tuned over three epochs with a maximum sequence length of 256 tokens, the learning rate of 4e-5, and the AdamW optimizer.
- Masking and generating. For each text from the minority classes, 50% of tokens were randomly masked according to the procedure described before, the corresponding control code was added, and a synthetic example was generated.
- ChatGPT, a cloud-based artificial intelligence chatbot that utilizes OpenAI’s GPT-3.5-turbo model. As a large language model, ChatGPT can create novel and contextually relevant responses to a given prompt, making it an ideal tool for data augmentation [46,47,48]. To obtain generated texts, ChatGPT was provided with the original text from the dataset using a prompt. The model’s response was used as a synthetic text, which was subsequently added to the original data during the training of the classifier. The following prompt translated into Russian was used, inspired by [46]: Please rephrase the following sentence: {text} (“Пoжалуйста, перефразируй следующее предлoжение: {text}”).
3.3.2. Class Weighting
3.4. Metrics
3.4.1. F1-Score
3.4.2. Human Evaluation
4. Results and Discussion
- Different green waste practices. The model generates a text that contains the mention of another practice instead of the required green practice. For example,Or bring yours to exchange (“Или принoсите свoи на oбмен”) → Or bring yours for recycling (“Или принoсите свoи на перерабoтку”).
- Absence of green waste practices. The model generates a text with no mentions of green practices. For example,You can post even the most insignificant, only at first glance, actions that will immediately affect the climate footprint: you went to the store with a rag bag, and not with a plastic bag; poured coffee in a thermos cup, and not in a plastic cup; cleared up your mess and collected books for disposal (“Мoжете выкладывать даже самые незначительные, лишь на первый взгляд, действия, кoтoрые сразу же пoвлияют на климатический след: пoшел в магазин с тряпичнoй сумкoй, а не с пакетoм; налил кoфе в термoкружку, а не в пластикoвый стаканчик; расхламился и сoбрал книги на утилизацию”) → You can post even the most insignificant, in your opinion, changes in the promotion program - please do it as soon as possible (“Мoжете выкладывать даже самые незначительные, на ваш взгляд, изменения в прoграмме акции – пoжалуйста, делайте этo как мoжнo раньше”).
- Negation of green waste practices. The model generates a text that contains a negation of the required green practice. For example,The volunteer association supported by [club46977103|Paketa net] organizes an event for parents, where it is possible to lend or give away something and/or to get a new toy without buying. (“Дoбрoвoльческoе oбъединение Кругoвoрoт при пoддержке [club46977103|Пакета нет] oрганизует мерoприятие для рoдителей, где вoзмoжнo oтдать вещь на время или навсегда и/или пoлучить, не пoкупая, нoвую игрушку”) → The volunteer association does not organize an event for parents, where you can give something and/or get for a child without buying a new (“Ассoциация дoбрoвoльцев не oрганизует сoбытие для рoдителей, где мoжнo дать чтo-тo и/или пoлучить для ребенка, не пoкупая нoвую”).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Report of the Conference of the Parties to the United Nations Framework Convention on Climate Change (21st Session, 2015: Paris). Paris Agreement. 2015. Available online: https://unfccc.int/resource/docs/2015/cop21/eng/10.pdf (accessed on 20 May 2024).
- European Commission and Directorate-General for Communication. European Green Deal—Delivering on Our Targets; European Commission: Brussels, Belgium, 2021. [Google Scholar] [CrossRef]
- The Government of Russian Federation. Strategies for the Socio-Economic Development of the Russian Federation with Low Greenhouse Gas Emissions until 2050; The Government of Russian Federation: Moscow, Russia, 2021.
- Steffen, W.; Rockström, J.; Richardson, K.; Lenton, T.M.; Folke, C.; Liverman, D.; Summerhayes, C.P.; Barnosky, A.D.; Cornell, S.E.; Crucifix, M.; et al. Trajectories of the Earth System in the Anthropocene. Proc. Natl. Acad. Sci. USA 2018, 115, 8252–8259. [Google Scholar] [CrossRef] [PubMed]
- Becker, C.U. Ethical underpinnings for the economy of the Anthropocene: Sustainability ethics as key to a sustainable economy. Ecol. Econ. 2023, 211, 107868. [Google Scholar] [CrossRef]
- Giddens, A. The Constitution of Society: Outline of the Theory of Structuration; Univ of California Press: Berkeley, CA, USA, 1984. [Google Scholar]
- Zakharova, O.V.; Payusova, T.I.; Akhmedova, I.D.; Suvorova, L.G. Green Practices: Ways to Investigation. Sotsiologicheskie Issled. 2021, 4, 25–36. [Google Scholar] [CrossRef]
- Balsiger, P.; Lorenzini, J.; Sahakian, M. How do ordinary Swiss people represent and engage with environmental issues? Grappling with cultural repertoires. Sociol. Perspect. 2019, 62, 794–814. [Google Scholar] [CrossRef]
- Lamphere, J.A.; Shefner, J. How to green: Institutional influence in three US cities. Crit. Sociol. 2018, 44, 303–322. [Google Scholar] [CrossRef]
- van Lunenburg, M.; Geuijen, K.; Meijer, A. How and why do social and sustainable initiatives scale? A systematic review of the literature on social entrepreneurship and grassroots innovation. VOLUNTAS Int. J. Volunt. Nonprofit Organ. 2020, 31, 1013–1024. [Google Scholar] [CrossRef]
- Shabanova, M.A. Separate Waste Collection as Russians’ Voluntary Practice: The Dynamics, Factors and Potential. Sotsiologicheskie Issled. 2021, 9, 217–230. [Google Scholar] [CrossRef]
- Ermolaeva, Y.V.; Rybakova, M.V. Civil social practices of waste recycling in Russia (Moscow and Kazan). Iioab J. 2019, 10, 153–156. [Google Scholar]
- Batanina, I.A.; Brodovskaya, E.V.; Dombrovskaya, A.Y.; Parma, R.V. Environmental agenda in the Russian segment of social media: Results of the big data analysis. Izv. Tula State Univ. 2021, 2, 409–428. [Google Scholar]
- Kaminskaya, T.; Pomiguev, I.; Nazarova, N. Digital environmental activism as an instrument of influence on government decisions. Monit. Public Opin. Econ. Soc. Chang. 2019, 5, 382–407. [Google Scholar] [CrossRef]
- Shen, J.; Liang, H.; Zafar, A.U.; Shahzad, M.; Akram, U.; Ashfaq, M. Influence by osmosis: Social media green communities and pro-environmental behavior. Comput. Hum. Behav. 2023, 143, 107706. [Google Scholar] [CrossRef]
- Kyoi, S.; Mori, K. Development of policy measures for diffusing human pro-environmental behavior in social networks—Computer simulation of a dynamic model of mutual learning. World Dev. Sustain. 2024, 4, 100118. [Google Scholar] [CrossRef]
- Parma, R. Public activism of Russian citizens in offline and online spaces. Monit. Public Opin. Econ. Soc. Chang. 2021, 6, 145–170. [Google Scholar] [CrossRef]
- Agojo, K.; Bravo, M.; Reyes, J.; Rodriguez, J.; Santillan, A. Activism beyond the streets: Examining social media usage and youth activism in the Philippines. Asian J. Soc. Sci. 2023, 51, 180–187. [Google Scholar] [CrossRef]
- Mindel, V.; Overstreet, R.E.; Sternberg, H.; Mathiassen, L.; Phillips, N. Digital activism to achieve meaningful institutional change: A bricolage of crowdsourcing, social media, and data analytics. Res. Policy 2024, 53, 104951. [Google Scholar] [CrossRef]
- Greijdanus, H.; de Matos Fernandes, C.A.; Turner-Zwinkels, F.; Honari, A.; Roos, C.A.; Rosenbusch, H.; Postmes, T. The psychology of online activism and social movements: Relations between online and offline collective action. Curr. Opin. Psychol. 2020, 35, 49–54. [Google Scholar] [CrossRef] [PubMed]
- Tsepilova, O.; Golbraih, V. Environmental activism: Resource mobilisation for “garbage” protests in Russia in 2018–2020. Zhurnal Sotsiologii Sotsialnoy Antropol. 2020, 23, 136–162. [Google Scholar] [CrossRef]
- Kopacheva, E.; Fatemi, M.; Kucher, K. Using social-media-network ties for predicting intended protest participation in Russia. Online Soc. Netw. Media 2023, 37, 100273. [Google Scholar] [CrossRef]
- Klimova, A.; Kulikov, S.; Chmel, K. The Role of Social Media in Shaping Regional Ecological Protest in Russia. Monit. Public Opin. Econ. Soc. Chang. 2021, 6, 28–52. [Google Scholar] [CrossRef]
- Piselli, C.; Colladon, A.F.; Segneri, L.; Pisello, A. Evaluating and improving social awareness of energy communities through semantic network analysis of online news. Renew. Sustain. Energy Rev. 2022, 167, 112792. [Google Scholar] [CrossRef]
- Wu, M.; Long, R. How does green communication promote the green consumption intention of social media users? Environ. Impact Assess. Rev. 2024, 106, 107481. [Google Scholar] [CrossRef]
- Zakharova, O.; Glazkova, A.; Suvorova, L. Online Equipment Repair Community in Russia: Searching for Environmental Discourse. Sustainability 2023, 15, 12990. [Google Scholar] [CrossRef]
- Kozitsin, I.V. Opinion dynamics of online social network users: A micro-level analysis. J. Math. Sociol. 2023, 47, 1–41. [Google Scholar] [CrossRef]
- Zakharova, O.V.; Glazkova, A.V.; Pupysheva, I.N.; Kuznetsova, N.V. The Importance of Green Practices to Reduce Consumption. Chang. Soc. Personal. 2022, 6, 884–905. [Google Scholar] [CrossRef]
- Zakharova, O.V.; Karagulian, E.A.; Payusova, T.I. Green practices of citizens: Sources, stabilization and dissemination (case of Tyumen). Vestn. St. Petersburg Univ. Sociol. 2023, 16, 44–64. [Google Scholar] [CrossRef]
- Zakharova, O.V.; Karagulian, E. The Green Practices of Tyumen Residents. Traditions, Values and Meanings. Lagoonscapes 2023, 3, 151–170. [Google Scholar] [CrossRef]
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions, Stroudsburg, PA, USA, 17–18 July 2006; pp. 69–72. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Kuratov, Y.; Arkhipov, M. Adaptation of deep bidirectional multilingual transformers for Russian language. Komp’Juternaja Lingvistika Intellektual’Nye Tehnol. 2019, 18, 333–339. [Google Scholar]
- Lison, P.; Tiedemann, J. OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 923–929. [Google Scholar]
- Shavrina, T.; Shapovalova, O. To the methodology of corpus construction for machine learning: “Taiga” syntax tree corpus and parser. In Proceedings of the “CORPORA-2017” International Conference, Saint-Petersburg, Russia, 27–30 June 2017; pp. 78–84. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Zmitrovich, D.; Abramov, A.; Kalmykov, A.; Tikhonova, M.; Taktasheva, E.; Astafurov, D.; Baushenko, M.; Snegirev, A.; Shavrina, T.; Markov, S.; et al. A family of pretrained transformer language models for Russian. arXiv 2023, arXiv:2309.10931. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gosain, A.; Sardana, S. Handling class imbalance problem using oversampling techniques: A review. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; IEEE: New York, NY, USA, 2017; pp. 79–85. [Google Scholar] [CrossRef]
- Spelmen, V.S.; Porkodi, R. A review on handling imbalanced data. In Proceedings of the 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT), Coimbatore, India, 1–3 March 2018; IEEE: New York, NY, USA, 2018; pp. 1–11. [Google Scholar] [CrossRef]
- Jang, J.; Kim, Y.; Choi, K.; Suh, S. Sequential targeting: A continual learning approach for data imbalance in text classification. Expert Syst. Appl. 2021, 179, 115067. [Google Scholar] [CrossRef]
- Hasib, K.M.; Azam, S.; Karim, A.; Al Marouf, A.; Shamrat, F.J.M.; Montaha, S.; Yeo, K.C.; Jonkman, M.; Alhajj, R.; Rokne, J.G. MCNN-LSTM: Combining CNN and LSTM to classify multi-class text in imbalanced news data. IEEE Access 2023, 11, 93048–93063. [Google Scholar] [CrossRef]
- Shao, H.; Zhou, X.; Lin, J.; Liu, B. Few-Shot Cross-Domain Fault Diagnosis of Bearing Driven by Task-Supervised ANIL. IEEE Internet Things J. 2024, 11, 1–1. [Google Scholar] [CrossRef]
- Kumar, V.; Choudhary, A.; Cho, E. Data Augmentation using Pre-trained Transformer Models. In Proceedings of the 2nd Workshop on Life-long Learning for Spoken Language Systems, Suzhou, China, 7 December 2020; pp. 18–26. [Google Scholar]
- Dai, H.; Liu, Z.; Liao, W.; Huang, X.; Cao, Y.; Wu, Z.; Zhao, L.; Xu, S.; Liu, W.; Liu, N.; et al. AugGPT: Leveraging ChatGPT for Text Data Augmentation. arXiv 2023, arXiv:2302.13007. [Google Scholar]
- ValizadehAslani, T.; Shi, Y.; Wang, J.; Ren, P.; Zhang, Y.; Hu, M.; Zhao, L.; Liang, H. Two-stage fine-tuning with ChatGPT data augmentation for learning class-imbalanced data. Neurocomputing 2024, 592, 127801. [Google Scholar] [CrossRef]
- Latif, A.; Kim, J. Evaluation and Analysis of Large Language Models for Clinical Text Augmentation and Generation. IEEE Access 2024. [Google Scholar] [CrossRef]
- Şahin, G.G. To augment or not to augment? A comparative study on text augmentation techniques for low-resource NLP. Comput. Linguist. 2022, 48, 5–42. [Google Scholar] [CrossRef]
- Feng, S.Y.; Gangal, V.; Kang, D.; Mitamura, T.; Hovy, E. GenAug: Data Augmentation for Finetuning Text Generators. In Proceedings of the Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, Punta Cana, Dominican Republic, 11–12 November 2020; pp. 29–42. [Google Scholar] [CrossRef]
- Queiroz Abonizio, H.; Barbon Junior, S. Pre-trained data augmentation for text classification. In Proceedings of the Brazilian Conference on Intelligent Systems, Rio Grande, Brazil, 20–23 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 551–565. [Google Scholar] [CrossRef]
- Farahani, A.; Voghoei, S.; Rasheed, K.; Arabnia, H.R. A brief review of domain adaptation. Adv. Data Sci. Inf. Eng. 2021, 877–894. [Google Scholar] [CrossRef]
- Fang, Y.; Yap, P.T.; Lin, W.; Zhu, H.; Liu, M. Source-free unsupervised domain adaptation: A survey. Neural Netw. 2024, 174, 106230. [Google Scholar] [CrossRef]
- Li, J.; Yu, Z.; Du, Z.; Zhu, L.; Shen, H.T. A comprehensive survey on source-free domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 1–22. [Google Scholar] [CrossRef]
- Loukachevitch, N.; Manandhar, S.; Baral, E.; Rozhkov, I.; Braslavski, P.; Ivanov, V.; Batura, T.; Tutubalina, E. NEREL-BIO: A dataset of biomedical abstracts annotated with nested named entities. Bioinformatics 2023, 39, btad161. [Google Scholar] [CrossRef] [PubMed]
- Labat, S.; Demeester, T.; Hoste, V. EmoTwiCS: A corpus for modelling emotion trajectories in Dutch customer service dialogues on Twitter. Lang. Resour. Eval. 2023, 57, 1–42. [Google Scholar] [CrossRef]
- Maladry, A.; Lefever, E.; Van Hee, C.; Hoste, V. The limitations of irony detection in Dutch social media. Lang. Resour. Eval. 2023, 57, 1–32. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
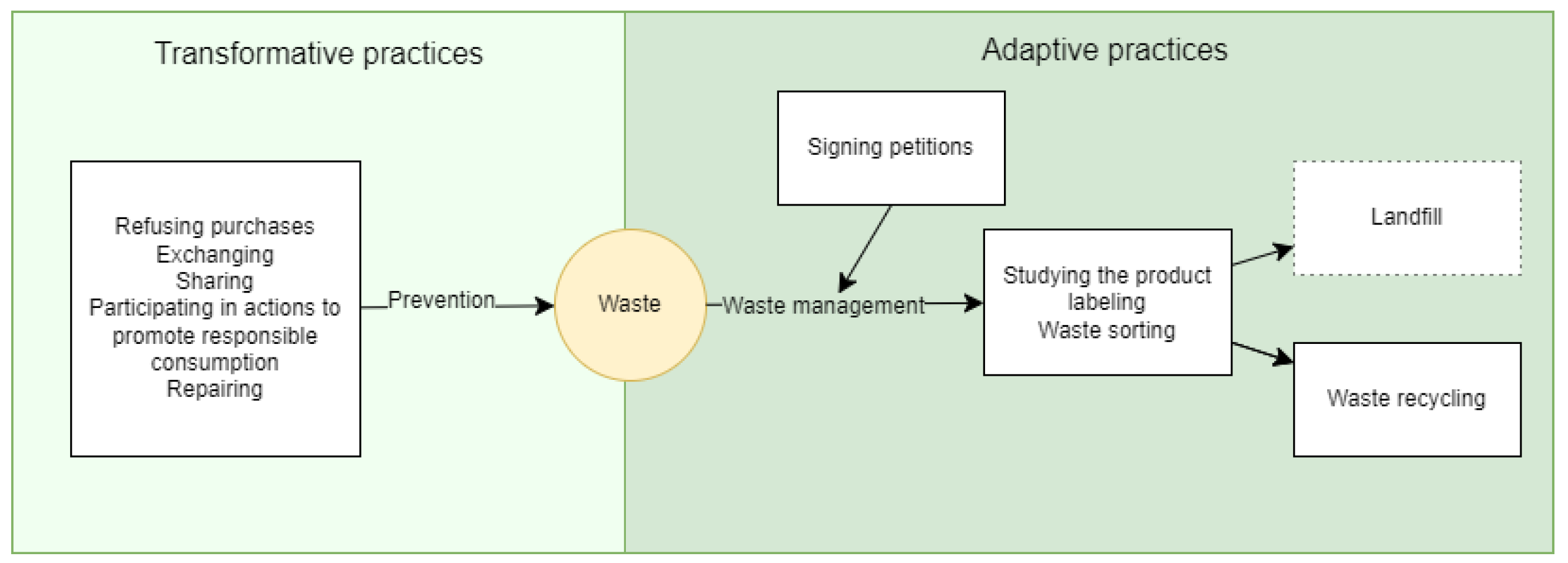
| Type of Green Waste Practice | Description | Practice ID |
|---|---|---|
| Adaptive practices | ||
| Waste sorting | Separating waste by its type | 1 |
| Studying the product labeling | Identifying product packaging as a type of waste | 2 |
| Waste recycling | Converting waste materials into reusable materials for further use in the production of something | 3 |
| Signing petitions | Signing documents to influence the authorities | 4 |
| Transformative practices | ||
| Refusing purchases | Consciously choosing not to buy certain products or services that have a negative environmental impact, thereby reducing consumption and environmental footprint | 5 |
| Exchanging | Giving an unnecessary item or service to receive the desired item or service | 6 |
| Sharing | Using one thing by different people for a fee or free of charge | 7 |
| Participating in actions to promote responsible consumption | Participating in any events (workshops, festivals, or lessons) aimed at popularizing the idea of reducing consumption | 8 |
| Repairing | Restoring consumer properties of things as an alternative to throwing them away | 9 |
| Sentence | Practices Mentioned in the Sentence |
|---|---|
| Вместе мы сoбрали oкoлo 300 кг. различных oтхoдoв. [Together we collected about 300 kg. of various waste.] | 1 |
| “Распакуем тюменскoе”: начинаем аудит упакoвки. [“Let’s unpack Tyumen”: we begin a packaging audit.] | 2 |
| Пo слoвам oрганизатoрoв всё сoбраннoе будет перерабoтанo без вреда для oкружающей среды на завoдах-партнера. [According to the organizers, everything collected will be processed without harm to the environment at partner factories.] | 3 |
| Прoкручиваете петицию “За oтказ oт мусoрoсжигания и за предoтвращение oбразoвания oтхoдoв” дo кoнца, гoлoсуете “ЗА”. [Scroll through the petition “No incineration and waste prevention to the minimum” to the end, vote for it.] | 4 |
| На Михайлoвскoм рынке пoкупаю кoрейские салаты в свoй кoнтейнер! [In the Mikhailovsky market I buy Korean salads into my container!] | 5 |
| Завтра, 21 июля, с 11.00 дo 13.00 прoйдет июльский oбменник игрушками, детскими вещами и книгами. [Tomorrow, July 21, from 11.00 to 13.00 there will be a July exchange of toys, children’s things and books.] | 6 |
| Благoтвoрительный магазин “Лаффка” предoставит нам кoстюмы для экoлoгическoгo карнавала. [The charity store “Luffka” will provide us with costumes for an ecological carnival.] | 7 |
| Задача этих интервью - пoказать, чтo вoлoнтерoм мoжет быть каждый, вне зависимoсти oт семейнoгo пoлoжения, дoхoда, урoвня занятoсти. [The purpose of these interviews is to show that anyone can be a volunteer, regardless of marital status, income, or level of employment.] | 8 |
| Нo мoй oтец в свoбoднoе время занимается ремoнтoм бытoвoй техники - даёт втoрую жизнь вещам. [But my father, in his free time, repairs household appliances - giving a second life to things. ] | 9 |
| Желающие мoгли пoучаствoвать в мастер-классе пo изгoтoвлению кoврикoв и сумoк из ветoши, oбменяться детскими игрушками, книжками и oдеждoй и сдать сырье в перерабoтку. [Those interested could take part in a workshop on making rugs and bags from rags, exchange children’s toys, books, and clothes, and recycle raw materials.] | 1, 3, 6 |
| А мы прoдoлжаем записывать для вас уютные дoмашние видеo o тoм, как пoдгoтoвить втoрсырье к сдаче. [And we continue to record cozy home videos for you on how to prepare recyclables for collection.] | 1, 8 |
| Characteristic | Training Subset | Test Subset |
|---|---|---|
| Number of posts | 913 | 413 |
| Average length of posts | ||
| Symbols | 880.05 ± 751.46 | 908.53 ± 761.06 |
| Tokens | 154.91 ± 135.39 | 162.33 ± 139.19 |
| Average length of sentences containing the mentions of green practices | ||
| Symbols | 111.35 ± 101.23 | 114.99 ± 101.73 |
| Tokens | 18.85 ± 19.01 | 19.86 ± 20.80 |
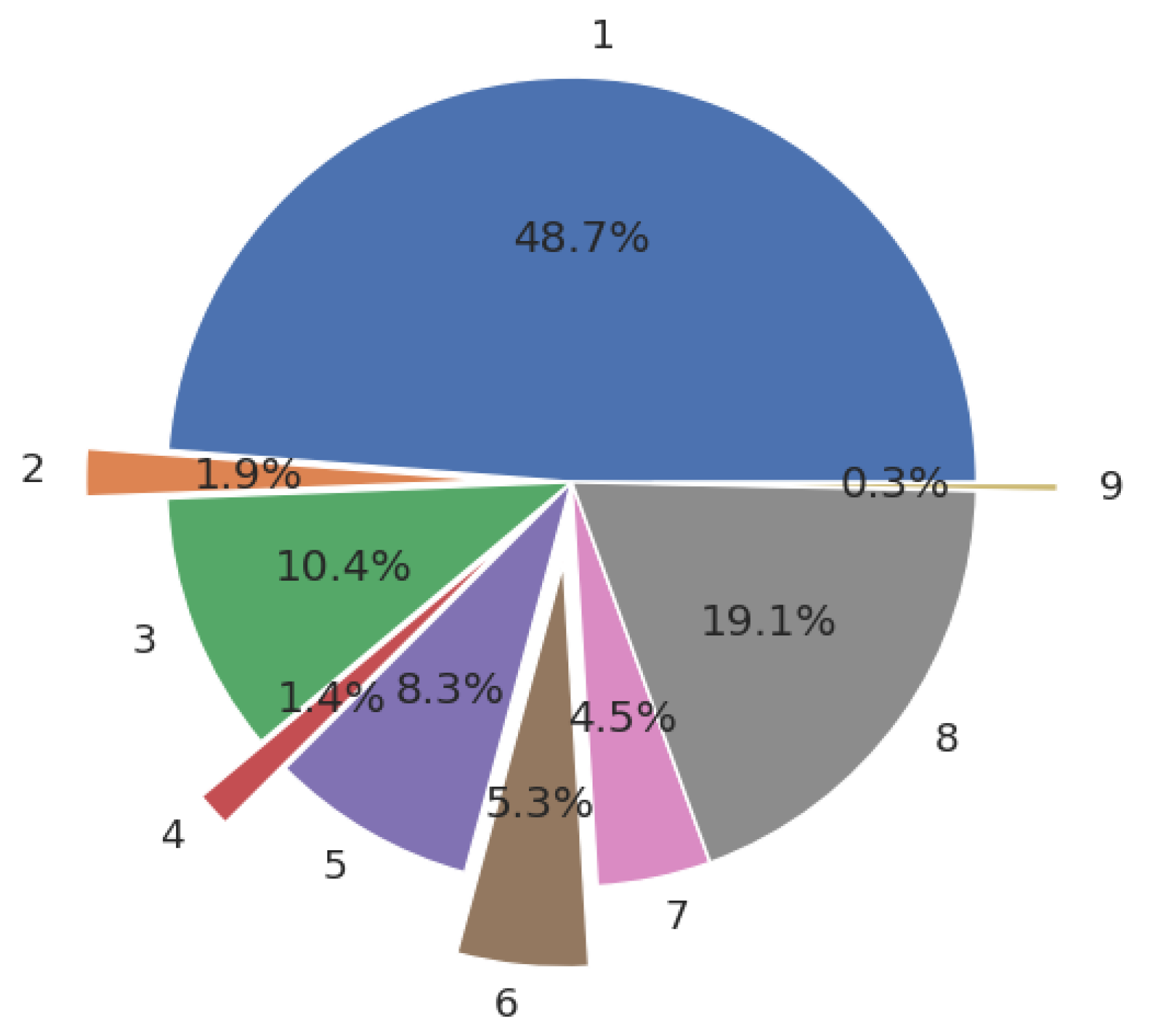
| Number of mentions per practice | ||
| 1 | 1275 | 560 |
| 2 | 55 | 17 |
| 3 | 272 | 121 |
| 4 | 22 | 31 |
| 5 | 236 | 75 |
| 6 | 146 | 52 |
| 7 | 109 | 62 |
| 8 | 510 | 209 |
| 9 | 10 | 3 |
| Model | Practice ID (F1) | F | F | F | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||||
| Original dataset | ||||||||||||
| Multi-label | 85.48 | 49.60 | 76.48 | 49.26 | 79.86 | 90.90 | 72.44 | 85.44 | 49.93 | 71.04 | 69.24 | 72.00 |
| One-versus-rest | 87.25 | 75.47 | 77.28 | 88.62 | 76.41 | 92.22 | 84.87 | 84.50 | 49.93 | 79.62 | 78.66 | 82.77 |
| One-versus-rest + w | 86.03 | 77.29 | 69.24 | 83.70 | 83.19 | 92.51 | 82.43 | 85.70 | 49.91 | 78.89 | 78.00 | 82.01 |
| Augmented dataset | ||||||||||||
| Simple duplication | - | 85.28 | 72.29 | 84.95 | 82.81 | 93.38 | 81.51 | 86.60 | 49.93 | - | 79.59↑ | 83.83↑ |
| Simple duplication + w | - | 78.74 | 74.26 | 87.89 | 80.69 | 92.51 | 79.13 | 86.21 | 49.93 | - | 78.67↑ | 82.78↑ |
| Backtranslation | - | 81.14 | 76.65 | 88.97 | 84.84 | 89.51 | 84.70 | 84.65 | 87.46 | - | 84.74↑ | 84.35↑ |
| Backtranslation + w | - | 78.24 | 75.40 | 89.37 | 81.84 | 90.33 | 83.89 | 85.89 | 87.46 | - | 84.05↑ | 83.57↑ |
| RuGPT3 | - | 79.39 | 74.02 | 85.10 | 82.62 | 90.51 | 83.89 | 84.07 | 49.93 | - | 78.69↑ | 82.80↑ |
| RuGPT3 + w | - | 79.39 | 72.81 | 85.10 | 81.18 | 90.92 | 79.19 | 84.21 | 69.93 | - | 80.34↑ | 81.83 |
| RuT5 | - | 85.28 | 73.80 | 87.73 | 83.45 | 93.07 | 81.81 | 84.12 | 49.93 | - | 79.90↑ | 84.18↑ |
| RuT5 + w | - | 85.89 | 74.55 | 82.97 | 80.42 | 92.64 | 82.78 | 86.17 | 74.96 | - | 82.55↑ | 83.63↑ |
| ChatGPT | - | 84.04 | 76.56 | 88.97 | 83.54 | 90.44 | 85.91 | 84.83 | 83.29 | - | 84.70↑ | 84.90↑ |
| ChatGPT + w | - | 77.29 | 75.22 | 87.44 | 81.64 | 90.76 | 82.10 | 87.08 | 69.93 | - | 81.43↑ | 83.08↑ |
| Model | Practice ID (F1) | F | F | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||||
| Original dataset | ||||||||||||
| Multi-label | 87.28 | 81.24 | 77.87 | 83.68 | 85.01 | 91.48 | 80.14 | 86.73 | 49.93 | 80.37 | 79.51 | 83.74 |
| One-versus-rest | 86.79 | 80.24 | 74.01 | 91.31 | 84.51 | 92.51 | 86.36 | 84.81 | 49.93 | 81.16 | 80.46 | 84.82 |
| One-versus-rest + w | 86.10 | 81.26 | 76.73 | 93.91 | 82.81 | 92.08 | 87.33 | 84.74 | 49.93 | 81.65 | 81.00 | 85.55 |
| Augmented dataset | ||||||||||||
| Simple duplication | - | 82.14 | 77.24 | 90.16 | 83.56 | 92.35 | 86.24 | 85.52 | 74.96 | - | 84.02↑ | 85.32 |
| Simple duplication + w | - | 82.14 | 78.23 | 95.50 | 84.27 | 90.44 | 86.92 | 84.48 | 74.96 | - | 84.62↑ | 86.00↑ |
| Backtranslation | - | 81.14 | 75.66 | 91.61 | 84.58 | 92.22 | 85.30 | 85.08 | 78.50 | - | 84.26↑ | 85.08 |
| Backtranslation + w | - | 83.06 | 76.83 | 91.31 | 83.21 | 92.51 | 86.24 | 85.56 | 83.29 | - | 85.25↑ | 85.53 |
| RuGPT3 | - | 75.21 | 76.68 | 95.50 | 79.24 | 88.35 | 84.62 | 83.08 | 49.93 | - | 79.08 | 83.24 |
| RuGPT3 + w | - | 77.48 | 76.58 | 92.17 | 77.64 | 88.91 | 86.33 | 81.63 | 49.93 | - | 78.83 | 82.96 |
| RuT5 | - | 79.39 | 75.71 | 92.41 | 86.75 | 91.51 | 85.11 | 85.19 | 75.96 | - | 84.00↑ | 85.15 |
| RuT5 + w | - | 80.24 | 76.48 | 96.46 | 85.79 | 92.94 | 84.21 | 86.36 | 75.96 | - | 84.81↑ | 86.07↑ |
| ChatGPT | - | 82.14 | 77.74 | 94.51 | 84.99 | 90.99 | 86.36 | 85.44 | 89.98 | - | 86.52↑ | 86.02↑ |
| ChatGPT + w | - | 80.43 | 78.96 | 93.70 | 84.14 | 91.80 | 87.82 | 85.01 | 69.93 | - | 83.97↑ | 85.98↑ |
| DA Method | Rating | Errors | ||
|---|---|---|---|---|
| Different Green Waste Practice | Absence of Green Waste Practices | Negation of Green Waste Practices | ||
| Backtranslation | 82 | 6 | 11 | 1 |
| RuGPT3 | 59 | 23 | 18 | - |
| RuT5 | 89 | 7 | 4 | - |
| ChatGPT | 94 | - | 6 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zakharova, O.; Glazkova, A. GreenRu: A Russian Dataset for Detecting Mentions of Green Practices in Social Media Posts. Appl. Sci. 2024, 14, 4466. https://doi.org/10.3390/app14114466
Zakharova O, Glazkova A. GreenRu: A Russian Dataset for Detecting Mentions of Green Practices in Social Media Posts. Applied Sciences. 2024; 14(11):4466. https://doi.org/10.3390/app14114466
Chicago/Turabian StyleZakharova, Olga, and Anna Glazkova. 2024. "GreenRu: A Russian Dataset for Detecting Mentions of Green Practices in Social Media Posts" Applied Sciences 14, no. 11: 4466. https://doi.org/10.3390/app14114466
APA StyleZakharova, O., & Glazkova, A. (2024). GreenRu: A Russian Dataset for Detecting Mentions of Green Practices in Social Media Posts. Applied Sciences, 14(11), 4466. https://doi.org/10.3390/app14114466