
Research on Road Pattern Recognition of a Vision-Guided Robot Based on Improved-YOLOv8


Abstract
1. Introduction
2. Experiment and Data Acquisition Processing
2.1. Experimental Design
2.1.1. Experimental Platform Construction
2.1.2. Control of Experimental Variable Condition
2.1.3. Specific Selection and Sampling of the Pavement Environment
2.2. Pavement Image Data and Its Classification
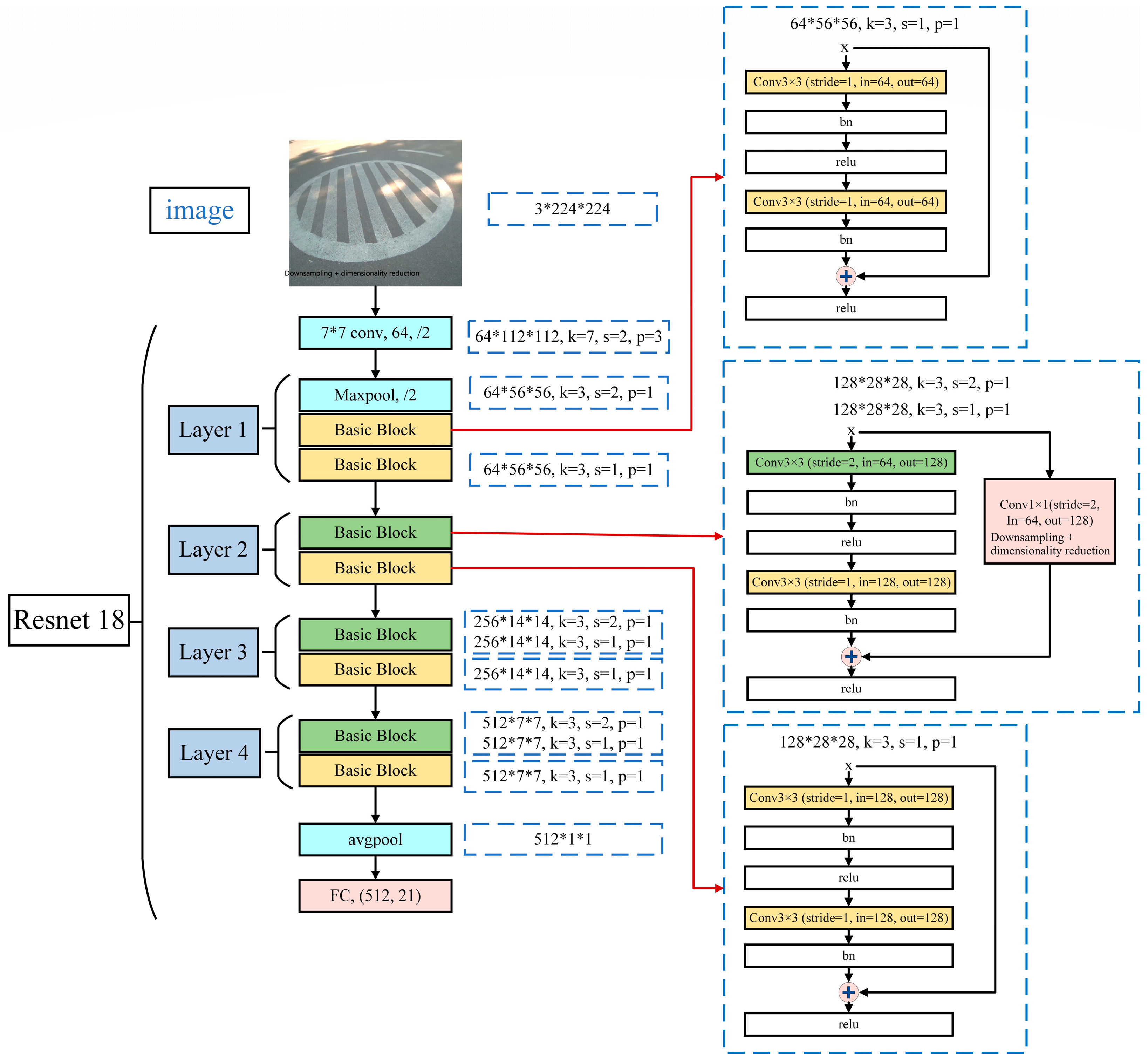
3. Research on Pavement Pattern Recognition Based on Resnet 18
3.1. Construction of a Pavement Pattern Recognition Model Based on Resnet 18
3.2. Analysis of Pavement Pattern Recognition Results Based on Resnet 18
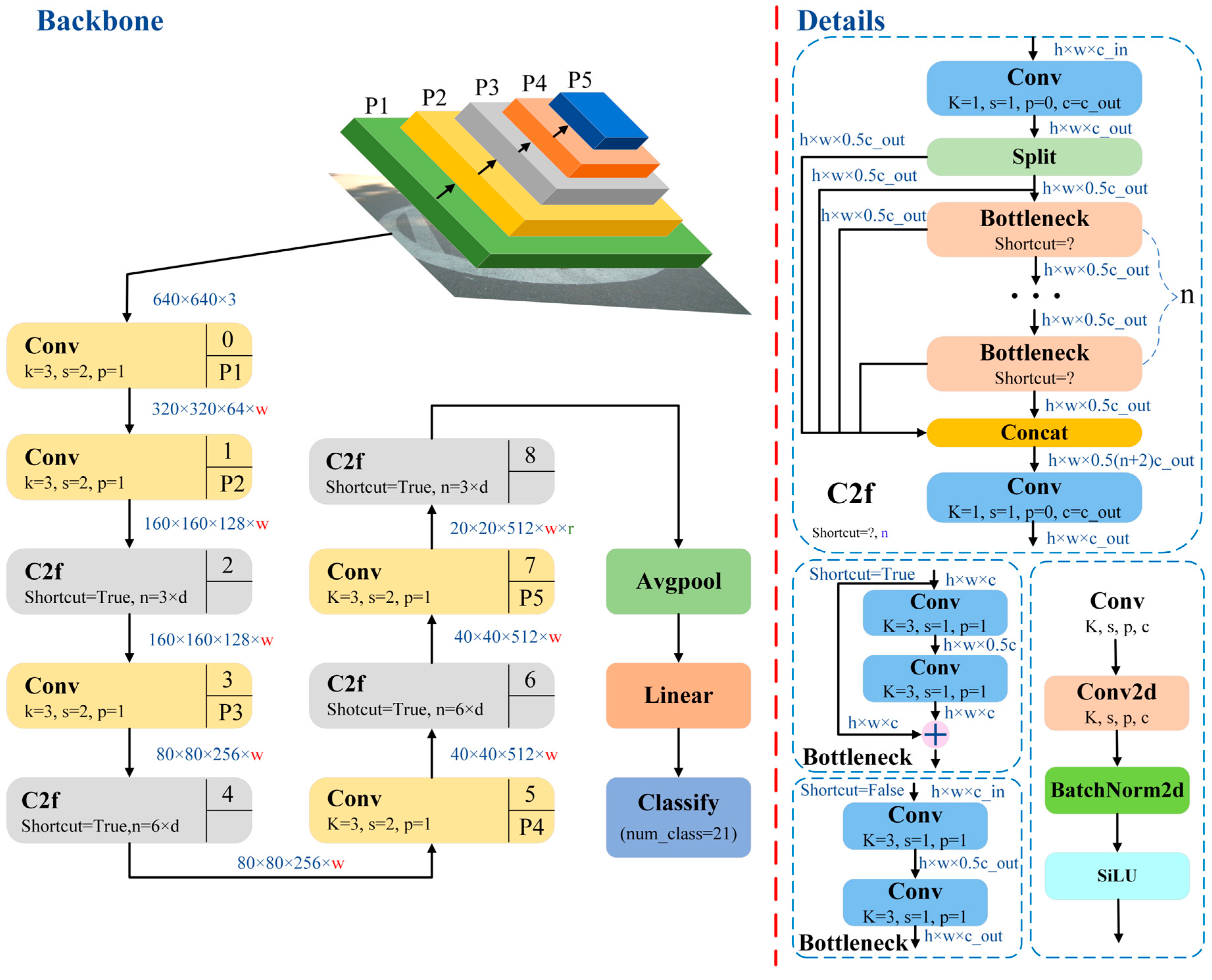
4. Research on Road Pattern Recognition Based on YOLOv8
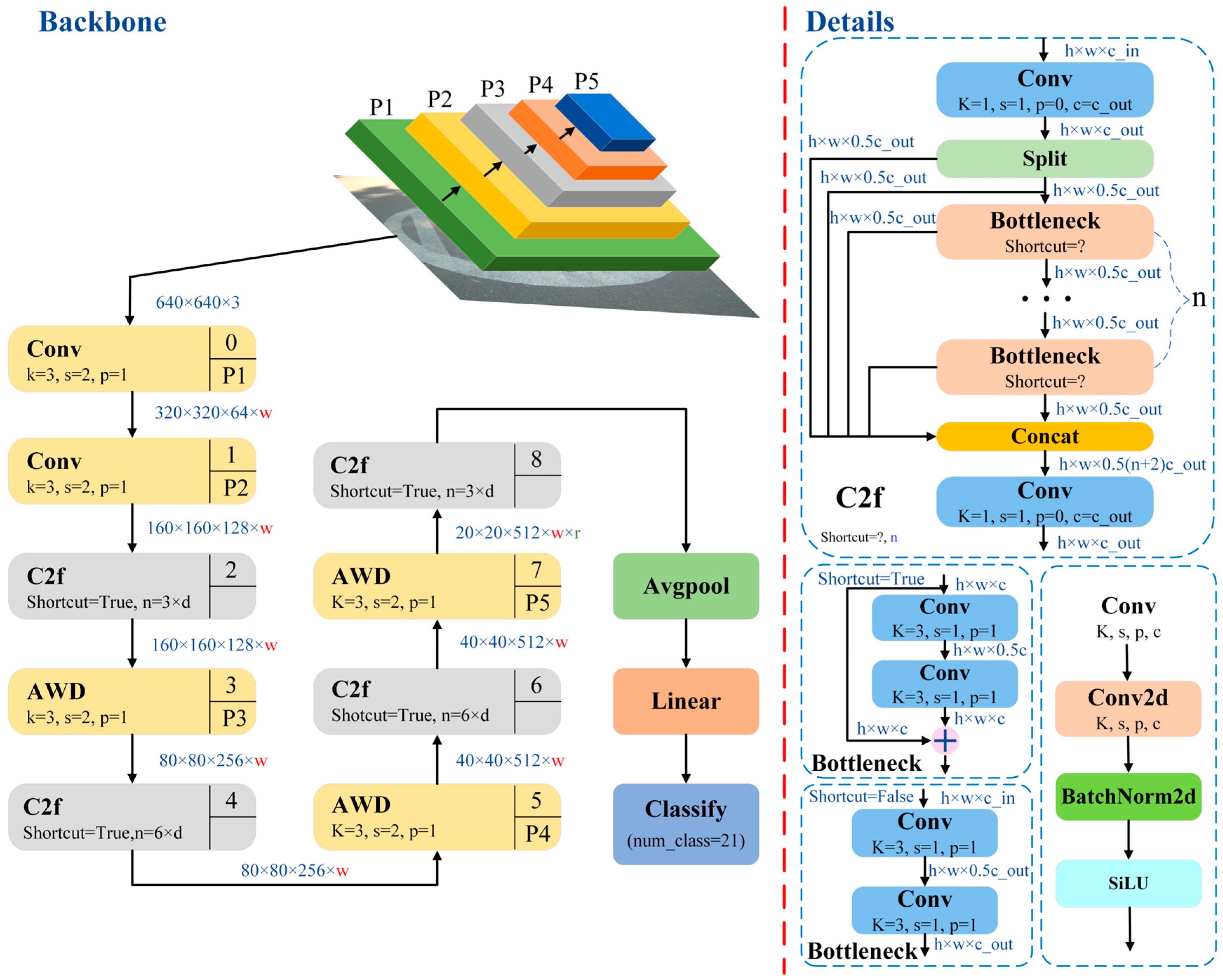
4.1. Construction of Pavement Pattern Recognition Model Based on YOLOv8n
4.2. Analysis of Pavement Pattern Recognition Results Based on YOLO v8n
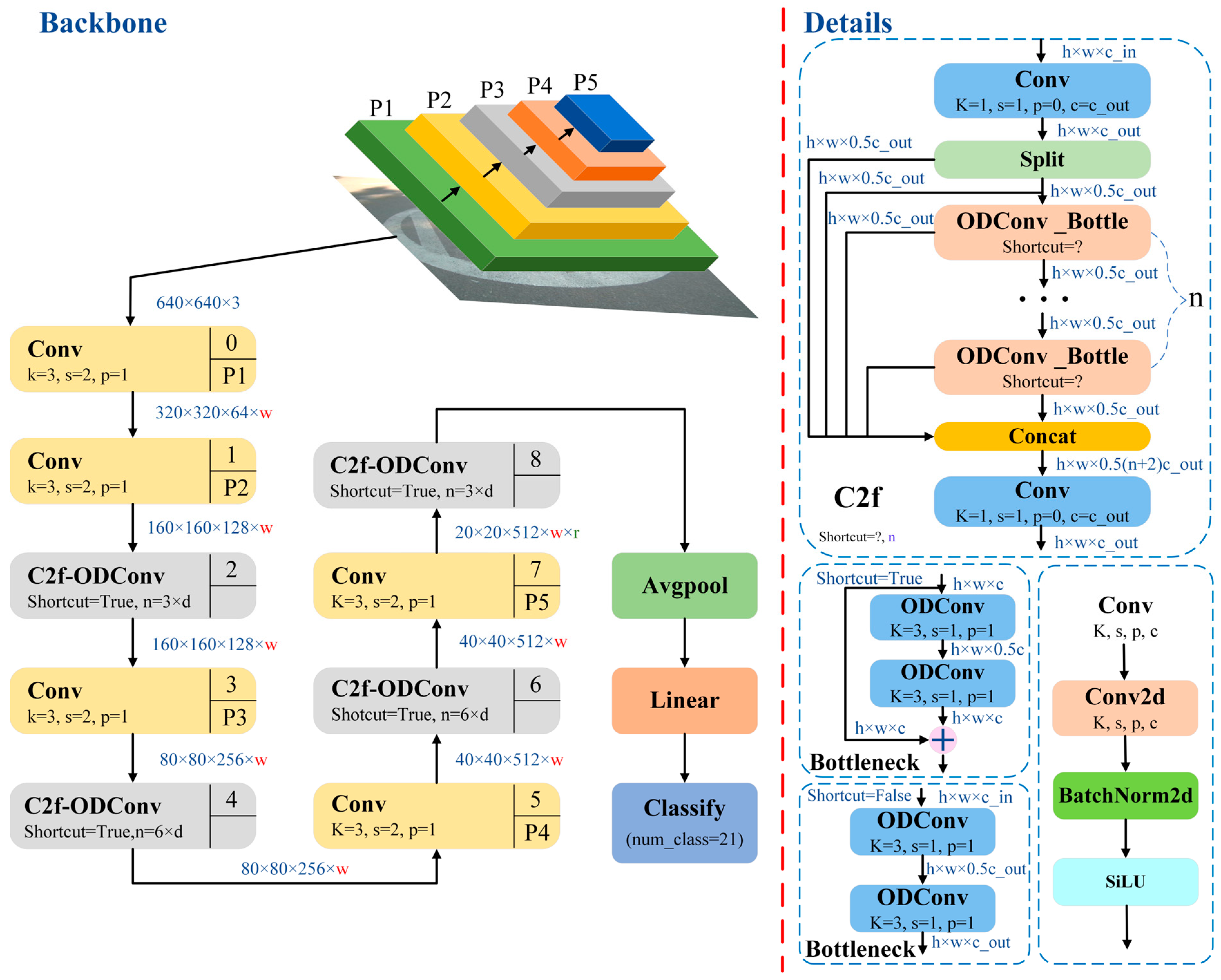
5. Research on Pavement Recognition Based on Improved YOLO v8
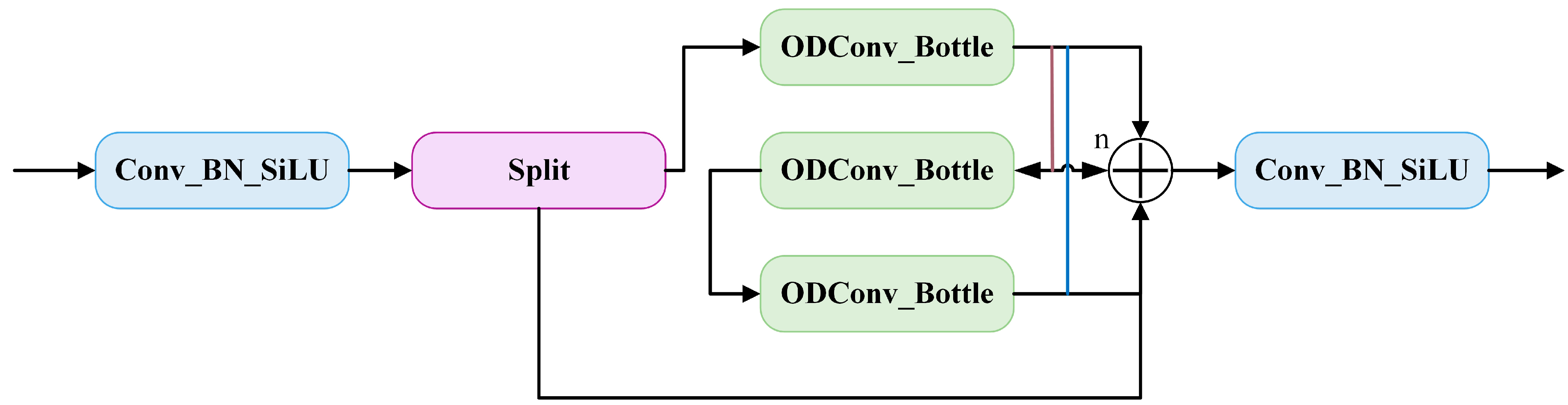
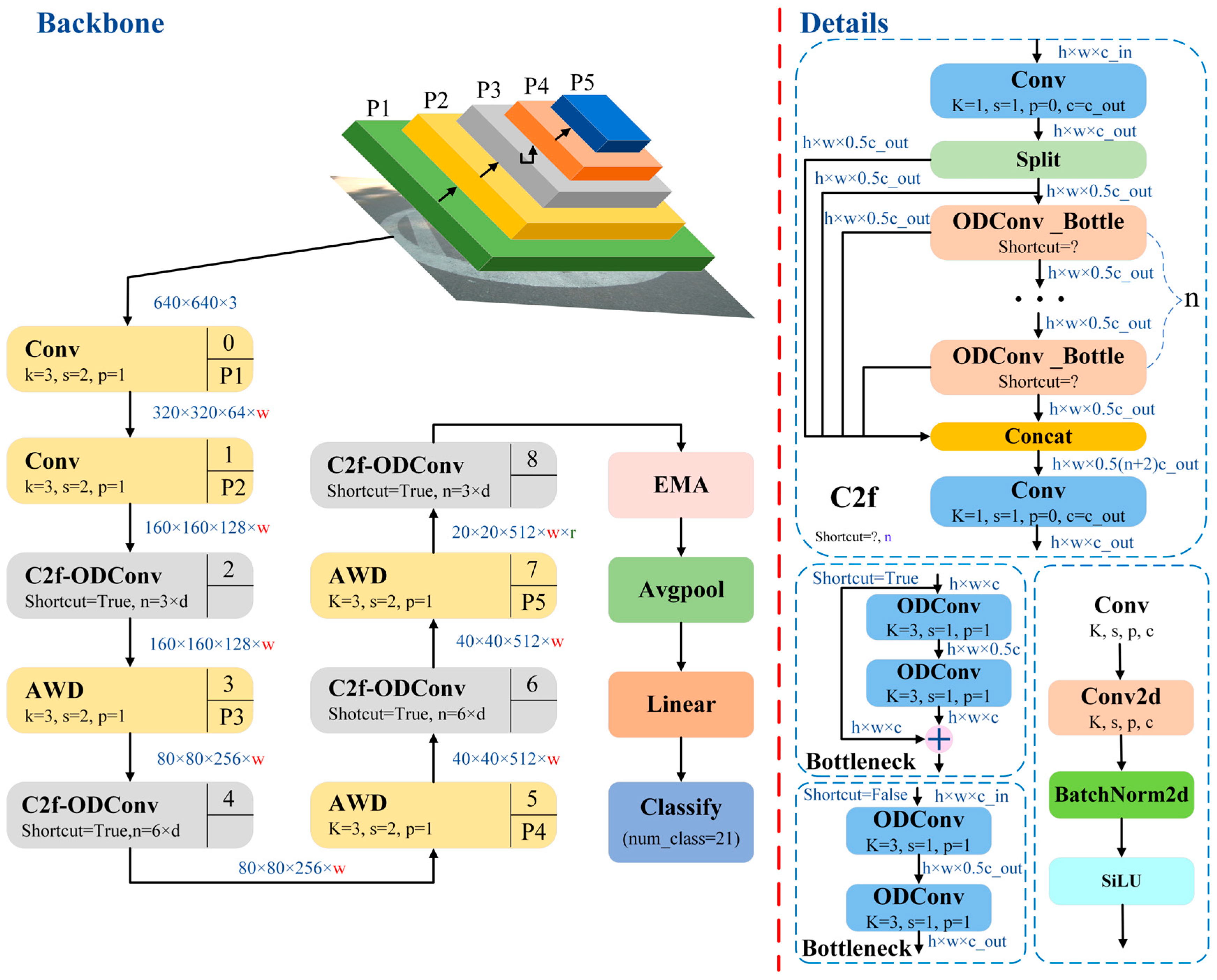
5.1. Research on Improvement of YOLO v8 Pavement Recognition Model Based on the C2f-ODConv Module
5.2. Research on Improvement of YOLO v8 Pavement Recognition Model Based on the AWD Adaptive Weight Downsampling Module
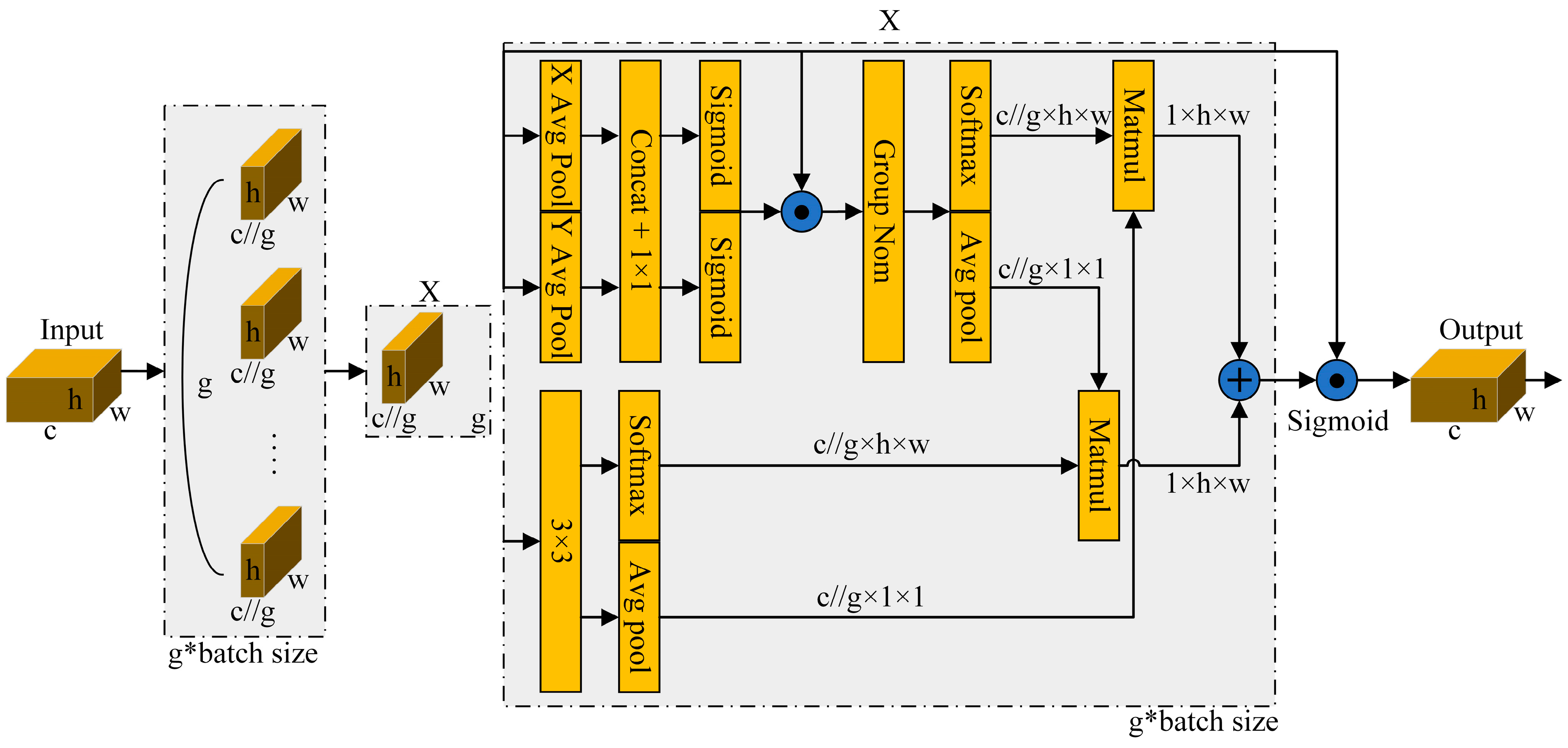
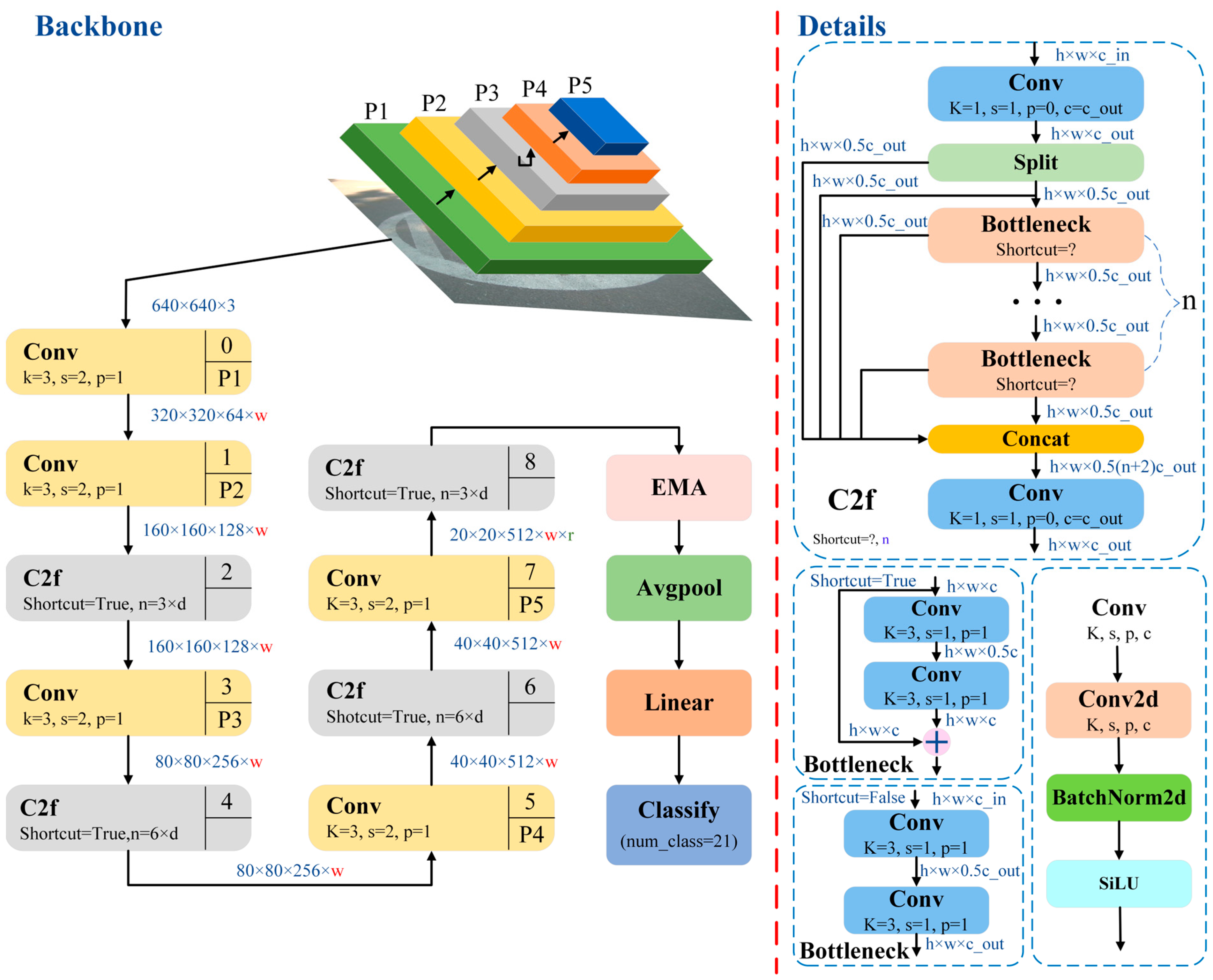
5.3. Research on Improvement of YOLO v8 Pavement Recognition Model Based on the EMA Attention Mechanism
5.4. Research on Comprehensive Improvement of the YOLO v8 Pavement Recognition Model Based on Multimodule Collaboration
5.5. Analysis of Pavement Pattern Recognition Results Based on Improved YOLO v8
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, J.; Liu, H.; Chen, H.; Mao, F. Road Types Identification Method of Unmanned Tracked Vehicles Based on Fusion Features. Acta Armamentarii 2023, 44, 1267–1276. [Google Scholar]
- Yamaguchi, T.; Mizutani, T. Road crack detection interpreting background images by convolutional neural networks and a self-organizing map. Comput. Aided Civ. Infrastruct. Eng. 2023, 1–25. [Google Scholar] [CrossRef]
- Oum, Y.O.; Hahn, M. Wavelet-morphology based detection of incipient linear cracks in asphalt pavements from RGB camera imagery and classification using circular Radon transform. Adv. Eng. Inform. 2016, 30, 481–499. [Google Scholar] [CrossRef]
- Tedeschi, A.; Benedetto, F. A real-time automatic pavement crack and pothole recognition system for mobile Android-based devices. Adv. Eng. Inform. 2017, 32, 11–25. [Google Scholar] [CrossRef]
- Wu, W.; Tian, S.; Zhang, Z.; Jin, B.; Qiu, Z. Research on Surface Geometry Parameter Recognition and Model Reconstruction of Uneven Road. Automot. Eng. 2023, 45, 273–284. [Google Scholar]
- Wu, W.; Tian, S.; Zhang, Z.; Zhang, B. Research on Semantic Segmentation of Uneven Features of Unpaved Road. Automot. Eng. 2023, 45, 1468–1478. [Google Scholar]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Zhao, J.; Liu, Y.; Zhu, B.; Li, Y.; Li, Y.; Kong, D.; Jiang, H. Research on Road Recognition Algorithm of Off-Road Vehicle Based on Shap-Rf Framework. Chin. J. Theor. Appl. Mech. 2022, 54, 2922–2935. [Google Scholar]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef]
- Chao, F.; Ping, S. Multi-scale Feature Fusion Network for Few-Shot Bridge Pavement Crack Segmentation. Radio Eng. 2023. Available online: https://link.cnki.net/urlid/13.1097.TN.20230904.0843.002 (accessed on 27 June 2023).
- Wang, S.; Kodagoda, S.; Shi, L.; Wang, H. Road-Terrain Classification For Land Vehicles. IEEE Veh. Technol. Mag. 2017, 12, 34–41. [Google Scholar] [CrossRef]
- Liu, H.; Liu, C.; Han, L.; He, P.; Nie, S. Road Information Recognition Based on Multi-Sensor Fusion in Off-Road Environment. Trans. Beijing Inst. Technol. 2023, 43, 783–791. [Google Scholar]
- Shi, W.; Li, Z.; Lv, W.; Wu, Y.; Chang, J.; Li, X. Laplacian Support Vector Machine for Vibration-Based Robotic Terrain Classification. Electronics 2020, 9, 513. [Google Scholar] [CrossRef]
- Jiang, C.; Ye, Y.; Hong, L.; Tian, W.; Shuo, D.; Jian, L. Multi-distress detection method for asphalt pavements based on multi-branch deep learning. J. Southeast Univ. Nat. Sci. Ed. 2023, 53, 123–129. [Google Scholar]
- Dimastrogiovanni, M.; Cordes, F.; Reina, G. Terrain Estimation for Planetary Exploration Robots. Appl. Sci. 2020, 10, 6044. [Google Scholar] [CrossRef]
- Wang, Q.; Xu, J.; Su, J.; Zong, G.; Xue, M. Study on Pavement Condition Recognition Method Based on Improved ALexNet Model. J. Highw. Transp. Res. Dev. 2023, 40, 209–218. [Google Scholar]
- Qin, Y.; Xiang, C.; Wang, Z.; Dong, M. Road excitation classification for semi-active suspension system based on system response. J. Vib. Control. 2017, 24, 2732–2748. [Google Scholar] [CrossRef]
- Wang, X.; Li, S.; Liang, X.; Li, S.; Zheng, J. Fast Identification Model for Complex Pavement based on Structural Reparameterization and Adaptive Attention. China J. Highw. Transp. 2023. Available online: https://link.cnki.net/urlid/61.1313.U.20231127.0947.002 (accessed on 27 June 2023).
- Wang, W.; Zhang, B.; Wu, K.; Chepinskiy, S.A.; Zhilenkov, A.A.; Chernyi, S.; Krasnov, A.Y. A visual terrain classification method for mobile robots’ navigation based on convolutional neural network and support vector machine. Trans. Inst. Meas. Control. 2021, 44, 744–753. [Google Scholar] [CrossRef]
- Xu, T.; Jiang, Z.; Liang, Y.; Chen, Z.; Sun, L. Pavement Distress Detection Based on Historical Information. J. Tongji Univ. Nat. Sci. 2022, 50, 562–570. [Google Scholar]
- Chen, C.; Chandra, S.; Han, Y.; Seo, H. Deep Learning-Based Thermal Image Analysis for Pavement Defect Detection and Classification Considering Complex Pavement Conditions. Remote Sens. 2022, 14, 106. [Google Scholar] [CrossRef]
- Kou, F.; He, J.; Li, M.; Xu, J.; Wu, D. Adaptive Fuzzy Control of an Electromagnetic Hybrid Suspension Based on Road Recognition. J. Vib. Shock. 2023, 42, 303–311. [Google Scholar]
- Dewangan, D.K.; Sahu, S.P. RCNet: Road classification convolutional neural networks for intelligent vehicle system. Intell. Serv. Robot. 2021, 14, 199–214. [Google Scholar] [CrossRef]
- Zhang, L.; Guan, K.; Ding, X.; Guo, P.; Wang, Z.; Sun, F. Tire-Road Friction Estimation Method Based on Image Recognition and Dynamics Fusion. Automot. Eng. 2023, 45, 1222–1234. [Google Scholar]
- Yousefzadeh, M.; Azadi, S.; Soltani, A. Road profile estimation using neural network algorithm. J. Mech. Sci. Technol. 2010, 24, 743–754. [Google Scholar] [CrossRef]
- Du, Z.; Zhang, W.; Zhu, X. Road Roughness Assessment based on Fusion of Connected-Vehicles Data. China J. Highw. Transp. 2024, 1–26. Available online: http://kns.cnki.net/kcms/detail/61.1313.U.20230627.0943.004.html (accessed on 27 June 2023).
- Bai, C.; Guo, J.; Guo, L.; Song, J. Deep Multi-Layer Perception Based Terrain Classification for Planetary Exploration Rovers. Sensors 2019, 19, 3102. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, M.; Liu, C.; Xu, H.; Zhang, X. Intelligent identification of asphalt pavement cracks based on semantic segmentation. J. Zhejiang Univ. Eng. Sci. 2023, 57, 2094–2105. [Google Scholar]
- Šabanovič, E.; Žuraulis, V.; Prentkovskis, O.; Skrickij, V. Identification of Road-Surface Type Using Deep Neural Networks for Friction Coefficient Estimation. Sensors 2020, 20, 612. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Bao, Y.; Yang, W.; Chu, Q.; Wang, G. Standardized constructing method of a roadside multi-source sensing dataset. J. Jilin Univ. Eng. Technol. Ed. 2024, 1–7. [Google Scholar] [CrossRef]
- Cheng, C.; Chang, J.; Lv, W.; Wu, Y.; Li, K.; Li, Z.; Yuan, C.; Ma, S. Frequency-Temporal Disagreement Adaptation for Robotic Terrain Classification via Vibration in a Dynamic Environment. Sensors 2020, 20, 6550. [Google Scholar] [CrossRef]
- Chen, J.; Ji, X.; Que, Y.; Dai, Y.; Jiang, Z. Classification Recognition of Pavement Disaster with Small Sample Size Based on Improved VGG Algorithm. J. Hunan Univ. Nat. Sci. 2023, 50, 206–216. [Google Scholar]
- Andrades, I.S.; Aguilar, J.J.C.; García, J.M.V.; Carrillo, J.A.C.; Lozano, M.S. Low-Cost Road-Surface Classification System Based on Self-Organizing Maps. Sensors 2020, 20, 6009. [Google Scholar] [CrossRef] [PubMed]
- Xiao, L.; Li, W.; Yuan, B.; Cui, Y.; Gao, R.; Wang, W. A Pavement Crack Identification Method Based on Improved Instance Segmentation Model. Geomat. Inf. Sci. Wuhan Univ. 2023, 48, 765–776. [Google Scholar] [CrossRef]
- Yousaf, M.H.; Azhar, K.; Murtaza, F.; Hussain, F. Visual analysis of asphalt pavement for detection and localization of potholes. Adv. Eng. Inform. 2018, 38, 527–537. [Google Scholar] [CrossRef]
- Zhao, J.; Wu, H.; Chen, L. Road Surface State Recognition Based on SVM Optimization and Image Segmentation Processing. J. Adv. Transp. 2017, 2017, 6458495. [Google Scholar] [CrossRef]
- Bonfitto, A.; Feraco, S.; Tonoli, A.; Amati, N. Combined regression and classification artificial neural networks for sideslip angle estimation and road condition identification. Veh. Syst. Dyn. 2019, 58, 1766–1787. [Google Scholar] [CrossRef]
- Oumaa, Y.O.; Hahn, M. Pothole detection on asphalt pavements from 2D-colour pothole images using fuzzy c-means clustering and morphological reconstruction. Autom. Constr. 2017, 83, 196–211. [Google Scholar] [CrossRef]
- Wang, M.; Ye, L.; Sun, X. Adaptive online terrain classification method for mobile robot based on vibration signals. Int. J. Adv. Robot. Syst. 2021, 18, 1–14. [Google Scholar] [CrossRef]
- Liang, G.; Zhao, T.; Shangguan, Z.; Li, N.; Wu, M.; Lyu, J.; Du, Y.; Wei, Y. Experimental study of road identification by LSTM with application to adaptive suspension damping control. Mech. Syst. Signal Process. 2022, 177, 1–20. [Google Scholar] [CrossRef]
- Yiğit, H.; Köylü, H.; Eken, S. Estimation of road surface type from brake pressure pulses of ABS. Expert Syst. Appl. 2023, 212, 1–11. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhu, W.; He, Y.; Li, Y. YOLOv8-based Spatial Target Part Recognition. In Proceedings of the 2023 IEEE 3rd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 26–28 May 2023; Volume 3, pp. 1684–1687. [Google Scholar]
- Su, Z.; Huang, Z.; Qiu, F.; Guo, C.; Yin, X.; Wu, G. Weld defect detection of Aviation Aluminum alloy based on improved YOLOv8. J. Aerosp. Power 2024, 39, 20230414. [Google Scholar]
- Li, C.; Zhou, A.; Yao, A. Omni-dimensional dynamic convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar]
- Zhang, X.; Liu, C.; Yang, D.; Song, T.; Ye, Y.; Li, K.; Song, Y. RFAConv: Innovating Spatital Attention and Standard Convolutional Operation. arXiv 2023, arXiv:2304.03198. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf (accessed on 27 June 2023). [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resolution Ratio | Frame Rate | Whether There Is Distortion | Driving Mode | Focusing Mode |
| 640 × 480 | 30 frames per second | Distortionless | USB interface | Manual focus possible |
| Power supply mode | Type | Lens size | Wide angle | |
| USB power supply | DF200-1080p | 2.8 mm | 100° |
| asphalt | Classification | good + dry | good + wet | slight + dry | slight + wet | - | - |
| Quantity | 318 | 216 | 182 | 92 | - | - | |
| brick | Classification | good + dry | good + wet | severe + dry | severe + wet | - | - |
| Quantity | 481 | 301 | 32 | 57 | - | - | |
| cement | Classification | good + dry | good + wet | severe + dry | severe + wet | slight + dry | slight + wet |
| Quantity | 231 | 205 | 62 | 84 | 117 | 147 | |
| dirt | Classification | good + dry | good + wet | severe + water | slight + wet | - | - |
| Quantity | 108 | 118 | 26 | 52 | - | - | |
| gravel | Classification | good + dry | good + water | good + wet | - | - | - |
| Quantity | 95 | 170 | 84 | - | - | - |
| Model | Imagesize | Parameters | GFLOPS | Top1acc-val | Infer-Time | FPS |
|---|---|---|---|---|---|---|
| Resnet 18 | 224 | 11,187,285 | 1.82 | 0.884 | 2.7 | 370 |
| Model | Imagesize | Parameters | GFLOPS | Top1acc-val | Infer-Time | FPS |
|---|---|---|---|---|---|---|
| YOLO v8 | 224 | 1,111,317 | 0.19 | 0.915 | 0.8 | 1250 |
| Model | Parameters | GFLOPS | Top1acc-val | Infer-Time | FPS |
|---|---|---|---|---|---|
| YOLO v8 | 36,226,645 | 99.1 | 0.825 | 2 | 500 |
| Model | Improved Point | Imagesize | Parameters | GFLOPS | Top1acc-val |
|---|---|---|---|---|---|
| Yolo v8n-C | Yolo v8n + C2f-ODConv | 224 | 1,146,273 | 0.10 | 0.927 |
| Yolo v8n-A | Yolo v8n + AWD | 224 | 832,437 | 0.17 | 0.921 |
| Yolo v8n-E | Yolov8n + EMA | 224 | 1,121,685 | 0.19 | 0.921 |
| Yolo v8n-CAE | Yolo v8n + C2f-ODConv + AWD + EMA | 224 | 877,761 | 0.09 | 0.932 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Yang, Y. Research on Road Pattern Recognition of a Vision-Guided Robot Based on Improved-YOLOv8. Appl. Sci. 2024, 14, 4424. https://doi.org/10.3390/app14114424
Zhang X, Yang Y. Research on Road Pattern Recognition of a Vision-Guided Robot Based on Improved-YOLOv8. Applied Sciences. 2024; 14(11):4424. https://doi.org/10.3390/app14114424
Chicago/Turabian StyleZhang, Xiangyu, and Yang Yang. 2024. "Research on Road Pattern Recognition of a Vision-Guided Robot Based on Improved-YOLOv8" Applied Sciences 14, no. 11: 4424. https://doi.org/10.3390/app14114424
APA StyleZhang, X., & Yang, Y. (2024). Research on Road Pattern Recognition of a Vision-Guided Robot Based on Improved-YOLOv8. Applied Sciences, 14(11), 4424. https://doi.org/10.3390/app14114424