
An Artificial Intelligence Approach for Estimating the Turbidity of Artisanal Wine and Dosage of Clarifying Agents


 ,
,  ,
,  , and
, and 
Abstract
1. Introduction
2. Materials and Methods
2.1. Winemaking
2.2. Wine Storage and Clarification
2.3. Theoretical Turbidity Threshold Determination
2.4. Data Analysis
2.5. Neural Net Fitting Model
2.6. Regression Learner Model
2.7. Model Validation
3. Results and Discussion
3.1. Turbidity Data Analysis
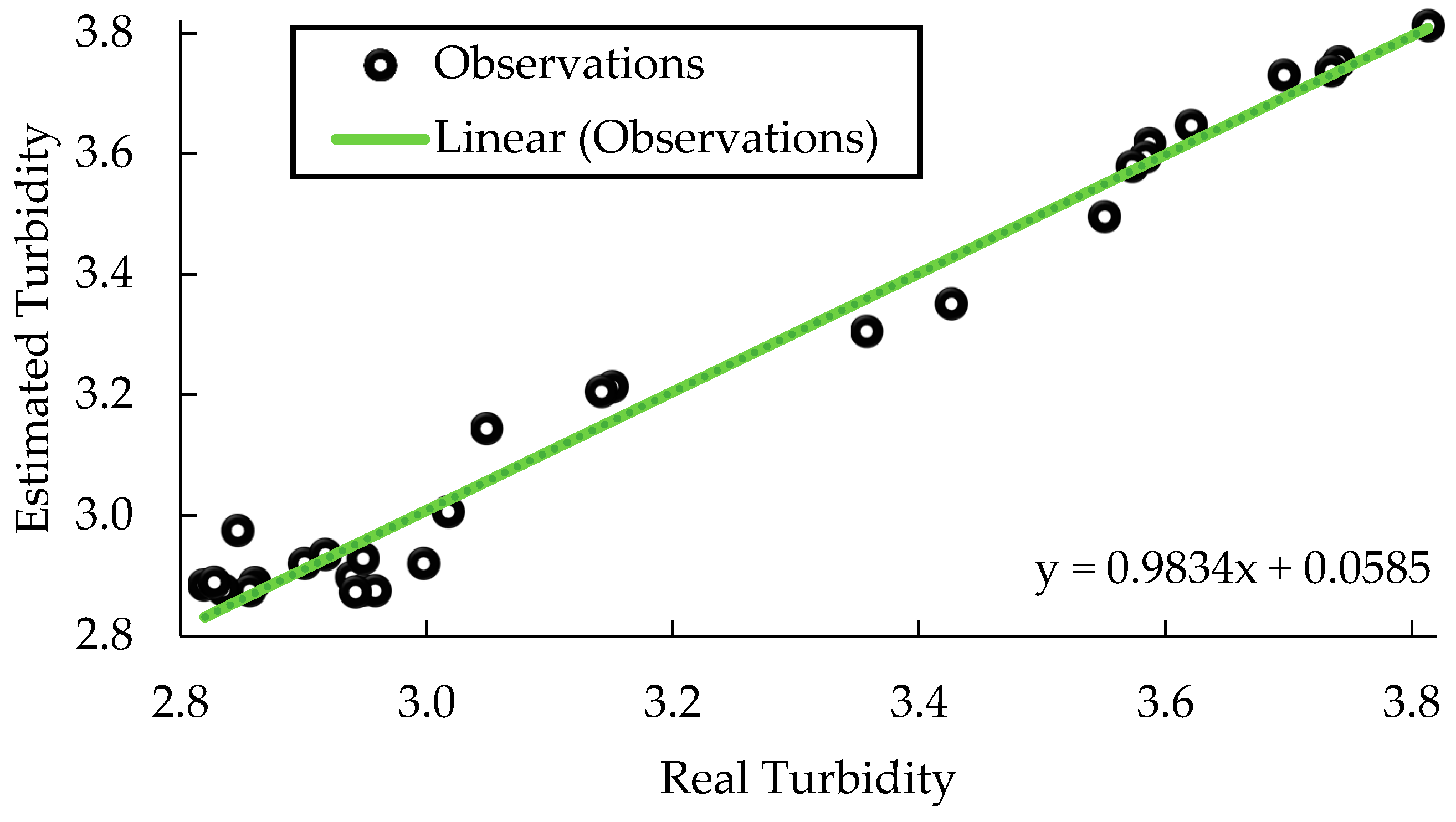
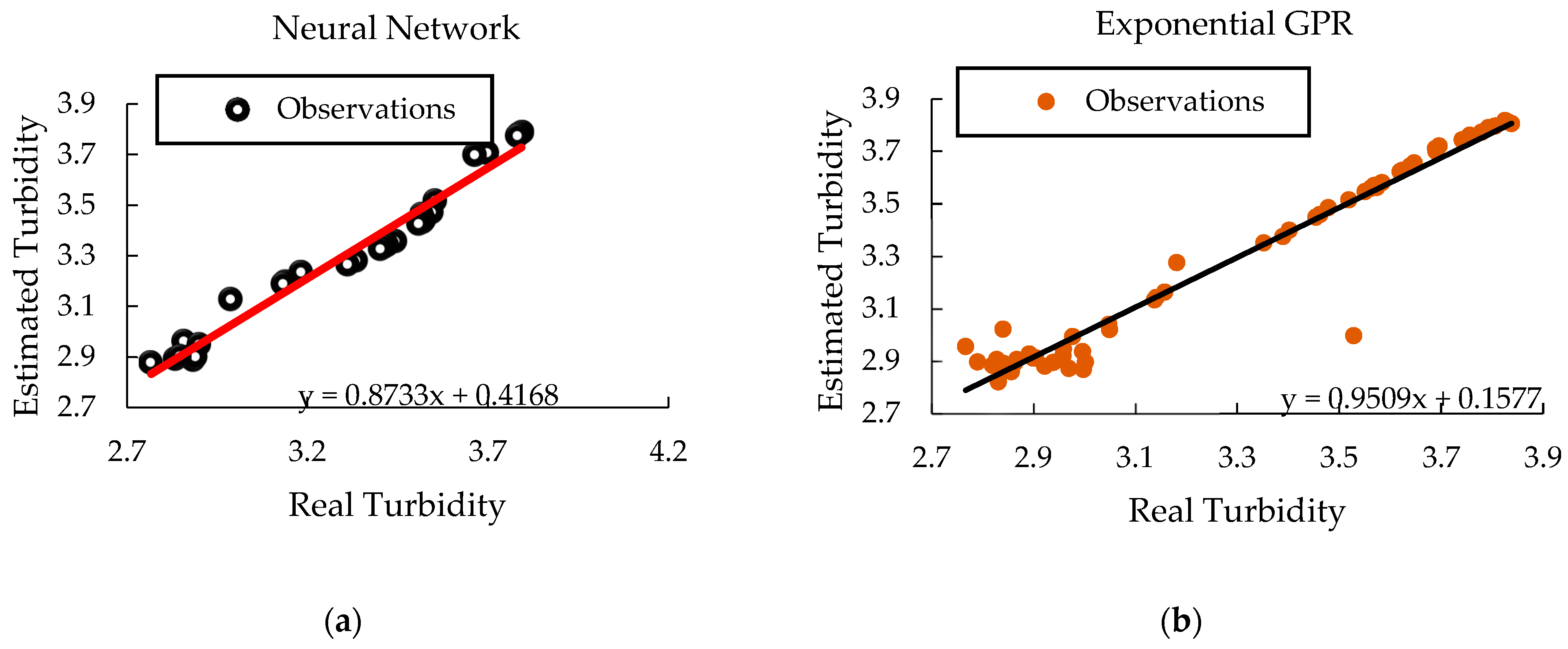
3.2. Neural Net Fitting Turbidity Prediction Model
3.3. Turbidity Prediction Model with Regression Learner
3.4. Mathematical Model Validation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vernhet, A. Red Wine Clarification and Stabilization; Elsevier Inc.: Amsterdam, The Netherlands, 2018; ISBN 9780128144008. [Google Scholar]
- Carrión Gutiérrez, C.V.; Barrazueta Rojas, S.G.; Mendoza Zurita, G.X.; Lara Freire, M.L. Mejoramiento De Las Propiedades Físicoquímicas Del Vino Usando Distintos Niveles De Bentonita. Cienc. Digit. 2018, 2, 67–87. [Google Scholar] [CrossRef]
- Dıblan, S.; Özkan, M. Effects of Various Clarification Treatments on Anthocyanins, Color, Phenolics and Antioxidant Activity of Red Grape Juice. Food Chem. 2021, 352, 129321. [Google Scholar] [CrossRef] [PubMed]
- Mierczynska-Vasilev, A.; Smith, P.A. Current State of Knowledge and Challenges in Wine Clarification. Aust. J. Grape Wine Res. 2015, 21, 615–626. [Google Scholar] [CrossRef]
- Jones-Moore, H.R.; Jelley, R.E.; Marangon, M.; Fedrizzi, B. The Interactions of Wine Polysaccharides with Aroma Compounds, Tannins, and Proteins, and Their Importance to Winemaking. Food Hydrocoll. 2022, 123, 107150. [Google Scholar] [CrossRef]
- Li, S.Y.; Duan, C.Q.; Han, Z.H. Grape Polysaccharides: Compositional Changes in Grapes and Wines, Possible Effects on Wine Organoleptic Properties, and Practical Control during Winemaking. Crit. Rev. Food Sci. Nutr. 2023, 63, 1119–1142. [Google Scholar] [CrossRef] [PubMed]
- Mercurio, M.D.; Dambergs, R.G.; Cozzolino, D.; Herderich, M.J.; Smith, P.A. Relationship between Red Wine Grades and Phenolics. 1. Tannin and Total Phenolics Concentrations. J. Agric. Food Chem. 2010, 58, 12313–12319. [Google Scholar] [CrossRef] [PubMed]
- Zhai, H.Y.; Li, S.Y.; Zhao, X.; Lan, Y.B.; Zhang, X.K.; Shi, Y.; Duan, C.Q. The Compositional Characteristics, Influencing Factors, Effects on Wine Quality and Relevant Analytical Methods of Wine Polysaccharides: A Review. Food Chem. 2023, 403, 134467. [Google Scholar] [CrossRef] [PubMed]
- Guilcatoma, B.; Pablo, J.; Sangucho, Y.; Maricela, J.; Castellano, I.T.; Maricela, A.; Latacunga -Ecuador, M. Aplicación de Tres Agentes Clarificantes Yausa (Abutilon insigne p.) Gelatina Y Bentonita Para Clarificar el Vino de Uvilla (Physalis peruviana l.) En el Emprendimiento de la Parroquia de Canchagua. Bachelor’s Thesis, Universidad Técnica de Cotopaxi, Latacunga, Ecuador, 2018. [Google Scholar]
- Chuma Barrigas, W. Evaluación Del Proceso De Clarificación De Vino De Uva, Artesanal E Industrial, Utilizando Látex De Papaya Papaína Y Gel De ‘Yausabara’ Pavonia Sepium. Bachelor’s Thesis, Universidad Técnica del Norte, Imbabura, Ecuador, 2018. [Google Scholar]
- Quezada Moreno, W.; Quezada Torres, W.; Gallardo Aguilar, I. Plantas Mucilaginosas En La Clarificación Del Jugo de La Caña de Azúcar. Rev. Cent. Azúcar 2016, 43, 2. [Google Scholar]
- Al-Risheq, D.I.M.; Shaikh, S.M.R.; Nasser, M.S.; Almomani, F.; Hussein, I.A.; Hassan, M.K. Enhancing the Flocculation of Stable Bentonite Suspension Using Hybrid System of Polyelectrolytes and NADES. Colloids Surf. A Physicochem. Eng. Asp. 2022, 638, 128305. [Google Scholar] [CrossRef]
- Lukić, I.; Horvat, I.; Radeka, S.; Delač Salopek, D.; Markeš, M.; Ivić, M.; Butorac, A. Wine Proteome after Partial Clarification during Fermentation Reveals Differential Efficiency of Various Bentonite Types. J. Food Compos. Anal. 2024, 126, 305–315. [Google Scholar] [CrossRef]
- Basha, M.S.A.; Desai, K.; Christina, S.; Sucharitha, M.M.; Maheshwari, A. Enhancing Red Wine Quality Prediction through Machine Learning Approaches with Hyperparameters Optimization Technique. In Proceedings of the 2023 Second International Conference on Electrical, Electronics, Information and Communication Technologies, Trichirappalli, India, 5–7 April 2023; pp. 1–8. [Google Scholar]
- Fuentes, S.; Torrico, D.D.; Tongson, E.; Viejo, C.G. Machine Learning Modeling of Wine Sensory Profiles and Color of Vertical Vintages of Pinot Noir Based on Chemical Fingerprinting, Weather and Management Data. Sensors 2020, 20, 3618. [Google Scholar] [CrossRef]
- Cortez, P.; Cerdeira, A.; Almeida, F.; Matos, T.; Reis, J. Modeling Wine Preferences by Data Mining from Physicochemical Properties. Decis. Support Syst. 2009, 47, 547–553. [Google Scholar] [CrossRef]
- Sun, X.; Wu, B.; Wu, H.; Zhu, H.; Liu, Y. Design of Vineyard Production Monitoring System Based on Wireless Sensor Networks. In Proceedings of the 2011 International Conference on Electronic & Mechanical Engineering and Information Technology, Harbin, China, 12–14 August 2011; Volume 5, pp. 2517–2520. [Google Scholar]
- Anastasi, G.; Farruggia, O.; Re, G.L.; Ortolani, M. Monitoring High-Quality Wine Production Using Wireless Sensor Networks. In Proceedings of the 2009 42nd Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 5–9 January 2009; pp. 1–7. [Google Scholar] [CrossRef]
- Pirnau, A.; Feher, I.; Sârbu, C.; Hategan, A.R.; Guyon, F.; Magdas, D.A. Application of Fuzzy Algorithms in Conjunction with 1H-NMR Spectroscopy to Differentiate Alcoholic Beverages. J. Sci. Food Agric. 2023, 103, 1727–1735. [Google Scholar] [CrossRef]
- Tao, Y.; Wu, D.; Zhang, Q.-A.; Sun, D.-W. Ultrasound-Assisted Extraction of Phenolics from Wine Lees: Modeling, Optimization and Stability of Extracts during Storage. Ultrason. Sonochem. 2014, 21, 706–715. [Google Scholar] [CrossRef]
- Duarte, D.P.; Oliveira, N.; Georgieva, P.; Nogueira, R.N.; Bilro, L. Wine classification and turbidity measurement by clustering and regression models. In Proceedings of the Conftele 2015: 10th Conference on Telecommunications, Aveiro, Portugal, 17–18 September 2015; pp. 317–320. [Google Scholar]
- Galeano-Arias, L.F.; Aguirre, S.G.; Castrillón-Gómez, O.D. Wine Quality Analysis through Artificial Intelligence Techniques. Inf. Technol. 2021, 32, 17–26. [Google Scholar] [CrossRef]
- Jain, K.; Kaushik, K.; Gupta, S.K.; Mahajan, S.; Kadry, S. Machine Learning-Based Predictive Modelling for the Enhancement of Wine Quality. Sci. Rep. 2023, 13, 17042. [Google Scholar] [CrossRef] [PubMed]
- Mingione, E.; Leone, C.; Almonti, D.; Menna, E.; Baiocco, G.; Ucciardello, N. Artificial Neural Networks Application for Analysis and Control of Grapes Fermentation Process. Procedia CIRP 2022, 112, 22–27. [Google Scholar] [CrossRef]
- Leza, J.M.I. La Medida de Turbidez Como Elemento Auxiliar de La Filtración. Enoviticultura 2011, 10, 36–41. [Google Scholar]
- Dahal, K.R.; Dahal, J.N.; Banjade, H.; Gaire, S. Prediction of Wine Quality Using Machine Learning Algorithms. Open J. Stat. 2021, 11, 278–289. [Google Scholar] [CrossRef]
- Jana, D.K.; Bhunia, P.; Adhikary, S.D.; Mishra, A. Analyzing of Salient Features and Classification of Wine Type Based on Quality through Various Neural Network and Support Vector Machine Classifiers. Results Control Optim. 2023, 11, 100219. [Google Scholar] [CrossRef]
- Lin, S.; Kim, J.; Hua, C.; Kang, S.; Park, M.H. Comparing Artificial and Deep Neural Network Models for Prediction of Coagulant Amount and Settled Water Turbidity: Lessons Learned from Big Data in Water Treatment Operations. J. Water Process Eng. 2023, 54, 103949. [Google Scholar] [CrossRef]
- Bazalar, M.; Tejerina, M.; Paganini, J.; Gonzalez, S. Selección de Una Arquitectura de Red Neuronal Artificial Eficiente Para Predecir El Coeficiente de Difusividad Másica Del Aguaymanto (Physalis peruviana L.) Deshidratado Osmoconvectivamente; Universidad Nacional de Trujillo (Perú): Trujillo, Perú, 2013. [Google Scholar]
- Noor, A.Z.M.; Fauadi, M.H.F.M.; Jafar, F.A.; Bakar, M.H.A. Optimal Number of Hidden Neuron Identification for Sustainable Manufacturing Application. Int. J. Recent Technol. Eng. 2019, 8, 2447–2453. [Google Scholar] [CrossRef]
- Alcivar-Cevallos, R.; Zambrano-romero, W.D. Predicción Del Rendimiento de Cultivos Agrícolas Usando Aprendizaje Automático. Rev. Arbitr. Interdiscip. Koin. 2020, 5, 144–160. [Google Scholar] [CrossRef]
- De Porcento, J.; Mendaros, Y.; Moral, R.M.; Cortes, E.P. Enhanced Power Demand Forecasting Accuracy in Heavy Industries Using Regression Learner-Based Approched Machine Learning Model. J. Environ. Energy Sci. 2023, 1, 4–12. [Google Scholar] [CrossRef]
- Sureiman, O.; Mangera, C. F-Test of Overall Significance in Regression Analysis Simplified. J. Pract. Cardiovasc. Sci. 2020, 6, 116. [Google Scholar] [CrossRef]
- Quezada, W.; Gallardo, I. Obtención de Extractos de Plantas Mucilaginosas Para La Clarificación de Jugos de Caña Obtainment of Mucilaginous Plant Extrax for Clarification of Cane Juice. Technol. Química 2014, 34, 91–98. [Google Scholar]
- Ridge, M.; Sommer, S.; Dycus, D.A. Addressing Enzymatic Clarification Challenges of Muscat Grape Juice. Fermentation 2021, 7, 198. [Google Scholar] [CrossRef]
- Xian, W. Clarifying Effect of Yacon, Pear and Roxburgh Rose Mixture Fermented Fruit Wine. China Brew. 2013, 14, 155. [Google Scholar]
- Sommer, S.; Tondini, F. Sustainable Replacement Strategies for Bentonite in Wine Using Alternative Protein Fining Agents. Sustainability 2021, 13, 860. [Google Scholar] [CrossRef]
- Sahin, G.; Işık, G.; van Sark, W. Predictive Modeling of PV Solar Power Plant Efficiency Considering Weather Conditions: A Comparative Analysis of Artificial Neural Networks and Multiple Linear Regression. Energy Rep. 2023, 10, 2837–2849. [Google Scholar] [CrossRef]
- Incio-Flores, F.A.; Capuñay-Sanchez, D.L.; Estela-Urbina, R.O. Artificial Neural Network Model to Predict Academic Results in Mathematics II. Rev. Electron. Educ. 2023, 27, 1. [Google Scholar] [CrossRef]
- Gavin, H.P. The Levenberg-Marquardt Algorithm for Nonlinear Least Squares Curve-Fitting Problems; Department of Civil and Environmental Engineering, Duke University: Durham, NC, USA, 2022. [Google Scholar]
- Rubio, J.D.J. Stability Analysis of the Modified Levenberg-Marquardt Algorithm for the Artificial Neural Network Training. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3510–3524. [Google Scholar] [CrossRef] [PubMed]
- Li, J. The Application and Modeling of the Levenberg-Marquardt Algorithm. In Proceedings of the 2010 2nd International Conference on E-business and Information System Security, Wuhan, China, 22–23 May 2010. [Google Scholar] [CrossRef]
- Mammadli, S. Financial Time Series Prediction Using Artificial Neural Network Based on Levenberg-Marquardt Algorithm. Procedia Comput. Sci. 2017, 120, 602–607. [Google Scholar] [CrossRef]
- Astray, G.; Mejuto, J.C.; Martínez-Martínez, V.; Nevares, I.; Alamo-Sanza, M.; Simal-Gandara, J. Prediction Models to Control Aging Time in Red Wine. Molecules 2019, 24, 826. [Google Scholar] [CrossRef] [PubMed]
- Hosu, A.; Cristea, V.-M.; Cimpoiu, C. Analysis of Total Phenolic, Flavonoids, Anthocyanins and Tannins Content in Romanian Red Wines: Prediction of Antioxidant Activities and Classification of Wines Using Artificial Neural Networks. Food Chem. 2014, 150, 113–118. [Google Scholar] [CrossRef] [PubMed]
- Baykal, H.; Yildirim, H.K. Application of Artificial Neural Networks (ANNs) in Wine Technology. Crit. Rev. Food Sci. Nutr. 2013, 53, 415–421. [Google Scholar] [CrossRef] [PubMed]
- Ye, W.; Melkumian, A.V. Forecasting Australian Red Wine Sales with SARIMA and ANNs. In Proceedings of the 2020 International Symposium on Frontiers of Economics and Management Science (FEMS 2020), Dalian, China, 20–21 March 2020; pp. 140–144. [Google Scholar]
- Hernández, D.; Espinosa, J.; Peñaloza, M.; Rodriguez, J.; Chacón, J.; Toloza, C.; Arenas, M.; Carrillo, S.; Bermúdez, V. Sobre El Uso Adecuado Del Coeficiente de Correlación de Pearson: Definición, Propiedades y Suposiciones. Rev. Arch. Venez. Farmacol. Ter. 2018, 37, 587–595. [Google Scholar]
- Cerna Cueva, A.F.; Rosas Echevarría, C.W.; Perales Flores, R.S.; Ataucusi Flores, P.L. Predicción de La Generación de Residuos Sólidos Domiciliarios Con Machine Learning En Una Zona Rural de Puno. Tecnia 2022, 32, 44–52. [Google Scholar] [CrossRef]
- Sirivanth, P.; Krishna Rao, N.V.; Manduva, J.; Sekhar, G.C.; Tajeswi, M.; Veeresh, C.; Kaushik, J.V. A SVM Based Wine Superiority Estimatation Using Advanced ML Techniques. In Proceedings of the 2021 3rd International Conference on Advances in Computing, Communication Control and Networking (ICAC3N) 2021, Greater Noida, India, 17–18 December 2011; pp. 207–211. [Google Scholar] [CrossRef]
- Liu, Y. Optimization of Gradient Boosting Model for Wine Quality Evaluation. In Proceedings of the 2021 3rd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 3–5 December 2021; pp. 128–132. [Google Scholar] [CrossRef]
- Er, Y.; Atasoy, A. The Classification of White Wine and Red Wine According to Their Physicochemical Qualities. Int. J. Intell. Syst. Appl. Eng. 2016, 4, 23. [Google Scholar] [CrossRef]
- Patkar, G.S.; Balaganesh, D. Smart Agri Wine: An Artificial Intelligence Approach to Predict Wine Quality. J. Comput. Sci. 2021, 17, 1099–1100. [Google Scholar] [CrossRef]
- Xu, Y.; Goodacre, R. On Splitting Training and Validation Set: A Comparative Study of Cross-Validation, Bootstrap and Systematic Sampling for Estimating the Generalization Performance of Supervised Learning. J. Anal. Test. 2018, 2, 249–262. [Google Scholar] [CrossRef] [PubMed]
- Tu, J.; Wei, X.; Huang, B.; Fan, H.; Jian, M.; Li, W. Improvement of Sap Flow Estimation by Including Phenological Index and Time-Lag Effect in Back-Propagation Neural Network Models. Agric. For. Meteorol. 2019, 276–277, 107608. [Google Scholar] [CrossRef]
- Xu, B.; Kuplicki, R.; Sen, S.; Paulus, M.P. The Pitfalls of Using Gaussian Process Regression for Normative Modeling. PLoS ONE 2021, 16, e0252108. [Google Scholar] [CrossRef] [PubMed]
- Tchakala, M.; Tafticht, T.; Rahman, M.J. An Efficient Approach for Short-Term Load Forecasting Using the Regression Learner Application. In Proceedings of the 2023 4th International Conference on Clean and Green Energy Engineering (CGEE), Ankara, Turkiye, 26–28 August 2023; pp. 31–34. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | Square Sum | Degrees of Freedom | Mean Square | F | p-Value |
|---|---|---|---|---|---|
| Model | 16.99 | 1 | 16.99 | 548.84 | <0.0001 |
| Clarifying | 16.99 | 1 | 16.99 | 548.84 | <0.0001 |
| Error | 5.91 | 191 | 0.03 | ||
| Total | 22.9 | 192 |
| Node Number | LM | BR | SCG | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | MSE | NRSME | AIC | R2 | MSE | NRSME | AIC | R2 | MSE | NRSME | AIC | |
| 10 | 0.978 | 0.005 | 7.19 | −712.6 | 0.853 | 0.032 | 17.93 | −465.9 | 0.876 | 0.027 | 16.61 | −486.6 |
| 15 | 0.974 | 0.006 | 7.74 | −692.9 | 0.866 | 0.029 | 17.36 | −474.7 | 0.856 | 0.031 | 17.79 | −468.1 |
| 20 | 0.984 | 0.003 | 5.52 | −784.2 | 0.862 | 0.031 | 17.70 | −469.4 | 0.893 | 0.026 | 16.08 | −495.3 |
| 25 | 0.988 1 | 0.003 1 | 5.42 1 | −788.8 1 | 0.979 | 0.005 | 7.12 | −715.3 | 0.834 | 0.034 | 18.49 | −457.7 |
| 30 | 0.982 | 0.004 | 6.76 | −729.5 | 0.980 | 0.004 | 5.96 | −763.4 | 0.867 | 0.035 | 18.92 | −451.4 |
| 35 | 0.949 | 0.014 | 12.00 | −574.4 | 0.978 | 0.005 | 7.19 | −712.6 | 0.773 | 0.047 | 21.74 | −413.9 |
| 40 | 0.979 | 0.006 | 7.67 | −695.2 | 0.981 | 0.003 | 5.33 | −793.5 | 0.856 | 0.031 | 17.79 | −468.1 |
| 45 | 0.973 | 0.006 | 7.93 | −686.2 | 0.971 | 0.006 | 7.54 | −700.0 | 0.867 | 0.031 | 17.67 | −469.8 |
| 50 | 0.982 | 0.005 | 7.05 | −718.0 | 0.975 | 0.006 | 7.60 | −697.6 | 0.850 | 0.031 | 17.62 | −470.7 |
| 55 | 0.968 | 0.007 | 8.60 | −664.2 | 0.978 | 0.006 | 7.47 | −702.4 | 0.886 | 0.033 | 18.30 | −460.5 |
| 60 | 0.976 | 0.005 | 7.19 | −712.6 | 0.978 | 0.004 | 6.76 | −729.5 | 0.852 | 0.036 | 19.14 | −448.4 |
| 65 | 0.897 | 0.019 | 13.77 | −537.2 | 0.979 | 0.003 | 5.87 | −767.3 | 0.841 | 0.032 | 18.10 | −463.4 |
| 70 | 0.979 | 0.007 | 8.12 | −679.9 | 0.979 2 | 0.002 2 | 4.93 2 | −814.4 2 | 0.867 | 0.031 | 17.76 | −468.5 |
| 75 | 0.975 | 0.006 | 7.93 | −686.2 | 0.983 | 0.004 | 6.37 | −745.4 | 0.830 | 0.038 | 19.55 | −442.5 |
| 80 | 0.957 | 0.008 | 8.95 | −653.5 | 0.984 | 0.003 | 5.79 | −771.4 | 0.886 3 | 0.018 3 | 13.51 3 | −542.3 3 |
| 85 | 0.982 | 0.004 | 6.60 | −735.6 | 0.982 | 0.004 | 6.60 | −735.6 | 0.789 | 0.057 | 24.00 | −387.2 |
| 90 | 0.969 | 0.008 | 8.89 | −655.2 | 0.982 | 0.005 | 6.83 | −726.5 | 0.818 | 0.048 | 22.00 | −410.8 |
| 95 | 0.941 | 0.015 | 12.29 | −567.9 | 0.984 | 0.003 | 5.79 | −771.4 | 0.839 | 0.031 | 17.73 | −469.0 |
| 100 | 0.978 | 0.006 | 7.87 | −688.4 | 0.982 | 0.004 | 6.37 | −745.4 | 0.835 | 0.036 | 19.08 | −449.1 |
| Model | R2 | MSE | NRSME | AIC |
|---|---|---|---|---|
| ANN | 0.985 | 0.004 | 6.01 | −160.12 |
| Exponential GPR | 0.943 | 0.008 | 8.14 | −283.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De La Cruz Rojas, E.M.; Nuñez-Pérez, J.; Lara-Fiallos, M.; Pais-Chanfrau, J.-M.; Espín-Valladares, R.; DelaVega-Quintero, J.C. An Artificial Intelligence Approach for Estimating the Turbidity of Artisanal Wine and Dosage of Clarifying Agents. Appl. Sci. 2024, 14, 4416. https://doi.org/10.3390/app14114416
De La Cruz Rojas EM, Nuñez-Pérez J, Lara-Fiallos M, Pais-Chanfrau J-M, Espín-Valladares R, DelaVega-Quintero JC. An Artificial Intelligence Approach for Estimating the Turbidity of Artisanal Wine and Dosage of Clarifying Agents. Applied Sciences. 2024; 14(11):4416. https://doi.org/10.3390/app14114416
Chicago/Turabian StyleDe La Cruz Rojas, Erika Mishell, Jimmy Nuñez-Pérez, Marco Lara-Fiallos, José-Manuel Pais-Chanfrau, Rosario Espín-Valladares, and Juan Carlos DelaVega-Quintero. 2024. "An Artificial Intelligence Approach for Estimating the Turbidity of Artisanal Wine and Dosage of Clarifying Agents" Applied Sciences 14, no. 11: 4416. https://doi.org/10.3390/app14114416
APA StyleDe La Cruz Rojas, E. M., Nuñez-Pérez, J., Lara-Fiallos, M., Pais-Chanfrau, J.-M., Espín-Valladares, R., & DelaVega-Quintero, J. C. (2024). An Artificial Intelligence Approach for Estimating the Turbidity of Artisanal Wine and Dosage of Clarifying Agents. Applied Sciences, 14(11), 4416. https://doi.org/10.3390/app14114416