
Study on Classification of Fishing Vessel Operation Types Based on Dilated CNN-IndRNN

Abstract
1. Introduction
2. Methods
2.1. Data Preparation
2.2. Data Preprocessing
3. Model Building
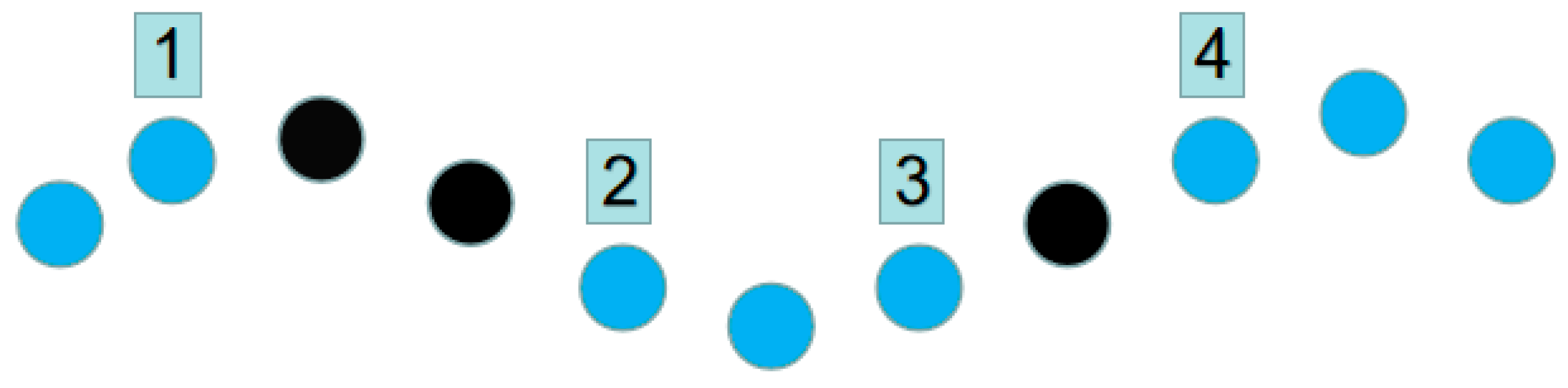
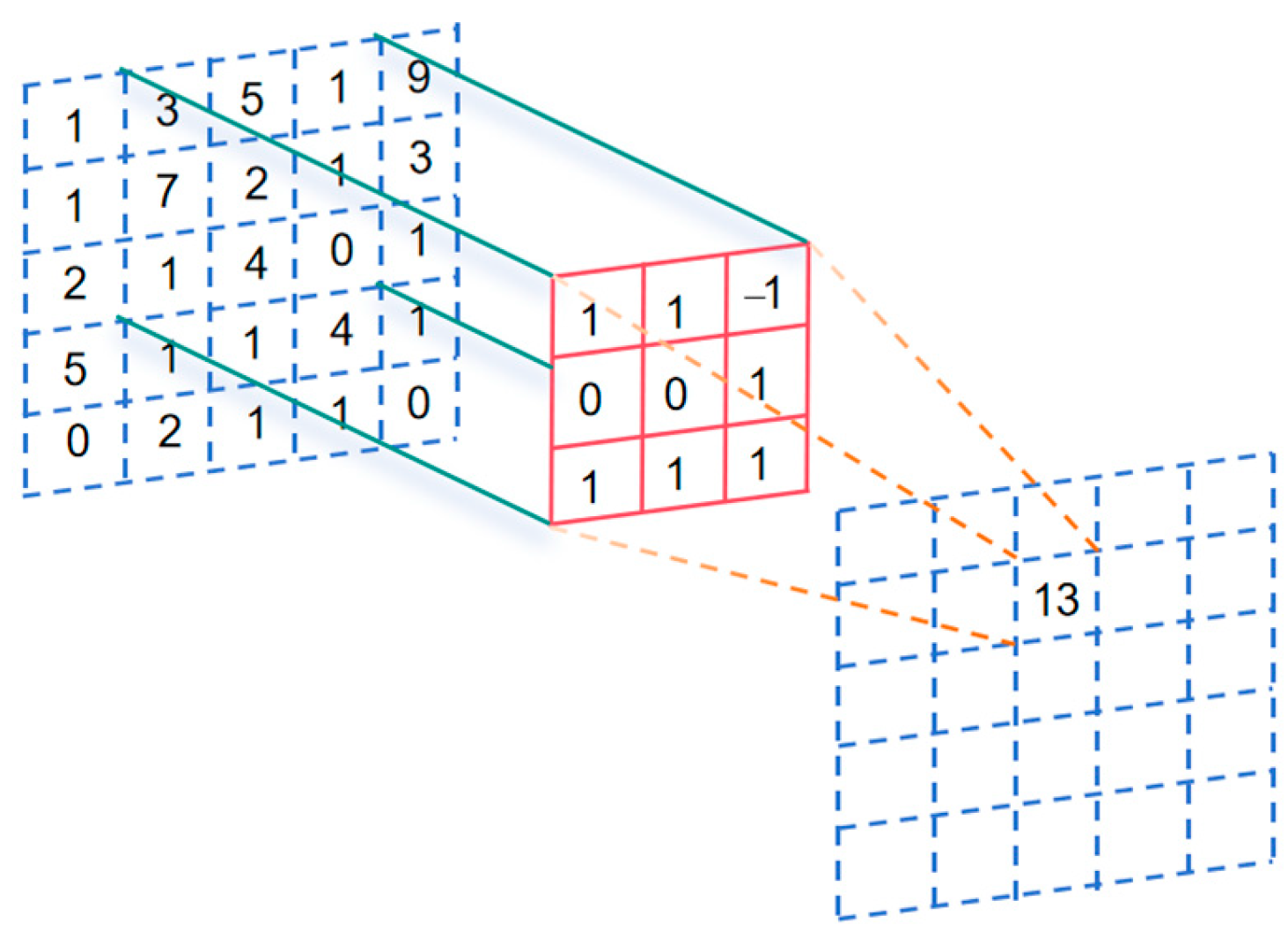
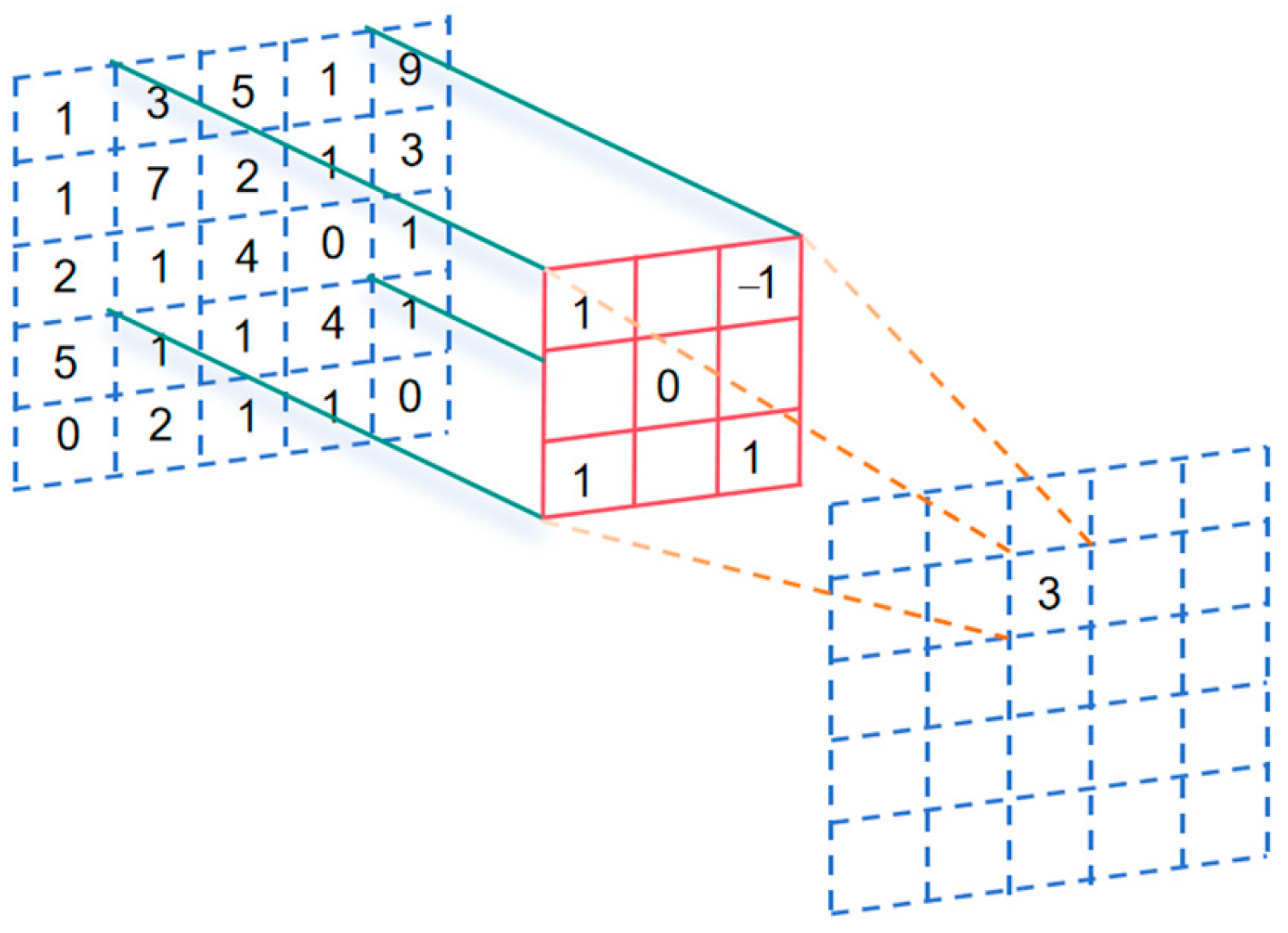
3.1. Dilated CNN
- (1)
- Convolution kernel size. Receptive field controlled by convolutional kernel size. Larger convolution kernels can capture more contextual information, but they also increase the amount of computation and the number of parameters.
- (2)
- The number of convolutional layers. The perceptual field of each output feature map increases as the depth of the network increases because the output feature map of each convolutional layer is a summary of a certain region on the input feature map of the previous layer.
- (3)
- Step size and pooling operation. The step size is the distance the convolution kernel slides over the input feature map, and the pooling operation downsamples the input feature map. Larger step sizes and pooling operations reduce the size of the sensory field because each output feature map element is associated with only a portion of the input feature map [24,25].
- (1)
- Expanding the sensory field. One-dimensional inflated convolution expands the sensory field by adjusting the dilated rate. A larger dilated rate increases the range of observation of the input sequence by the convolution kernel, thus providing broader contextual information. This is useful for capturing long-term dependencies and understanding associations at long distances in the sequence.
- (2)
- Reduced number of parameters. Compared to traditional one-dimensional convolution, one-dimensional inflated convolution can use a smaller convolution kernel size to achieve the same range of sensory fields. By introducing the dilated rate, the number of parameters in the model can be effectively reduced, reducing the computational burden of the model and improving its efficiency.
- (3)
- Maintaining sequence length. In the traditional one-dimensional convolution, the convolution operation causes the length of the output sequence to shrink. And one-dimensional dilated convolution can keep the length of the input sequence and the output sequence the same by adjusting the dilated rate, which avoids the loss of information. Multi-scale feature extraction is possible; by applying one-dimensional dilated convolution at different levels and different dilated rates, features at multiple scales can be extracted at the same time. This helps to capture patterns and correlations on different time scales in sequence data and enhances the expressive power of the model.
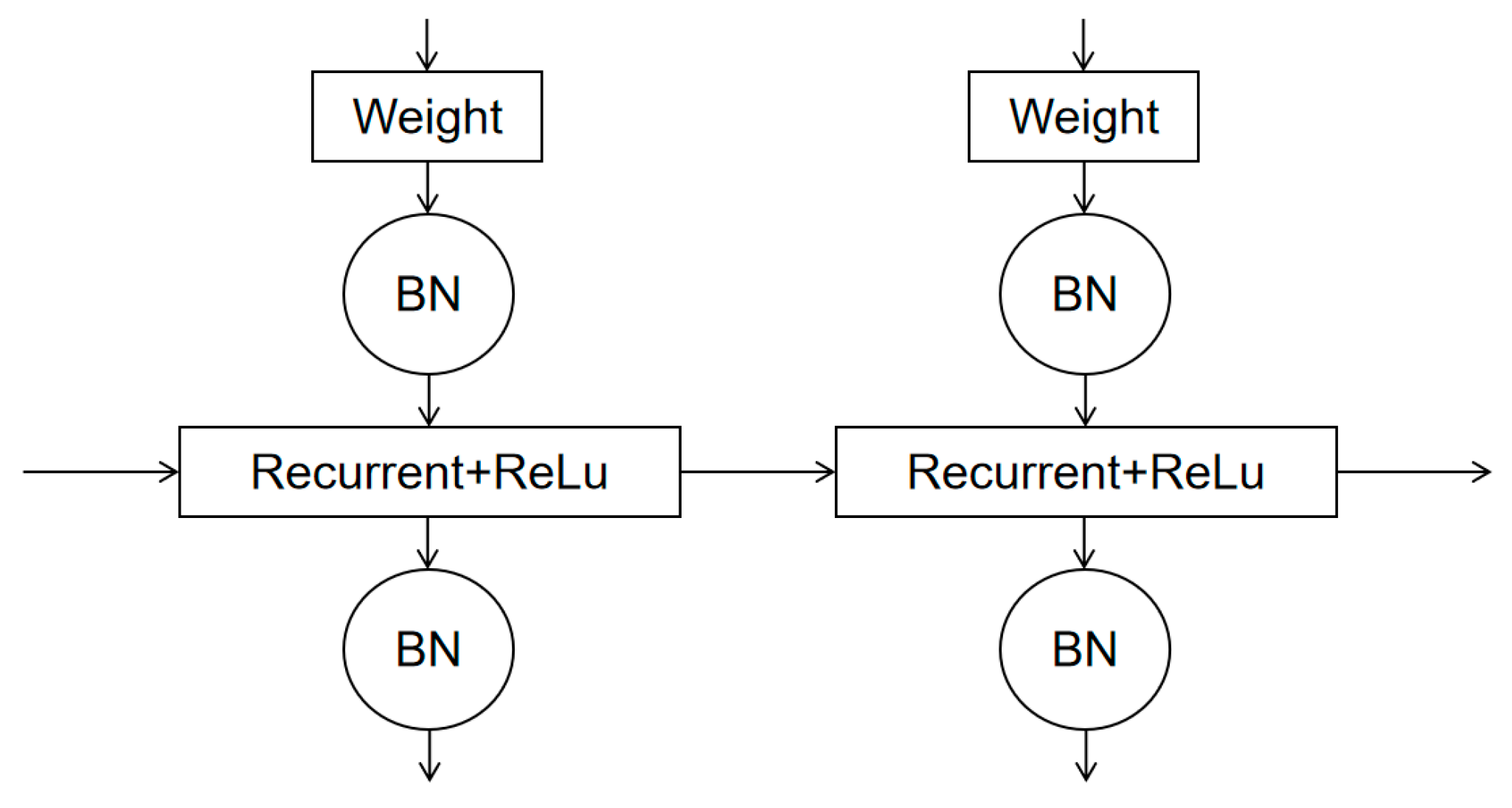
3.2. IndRNN
3.3. Dilated CNN-IndRNN
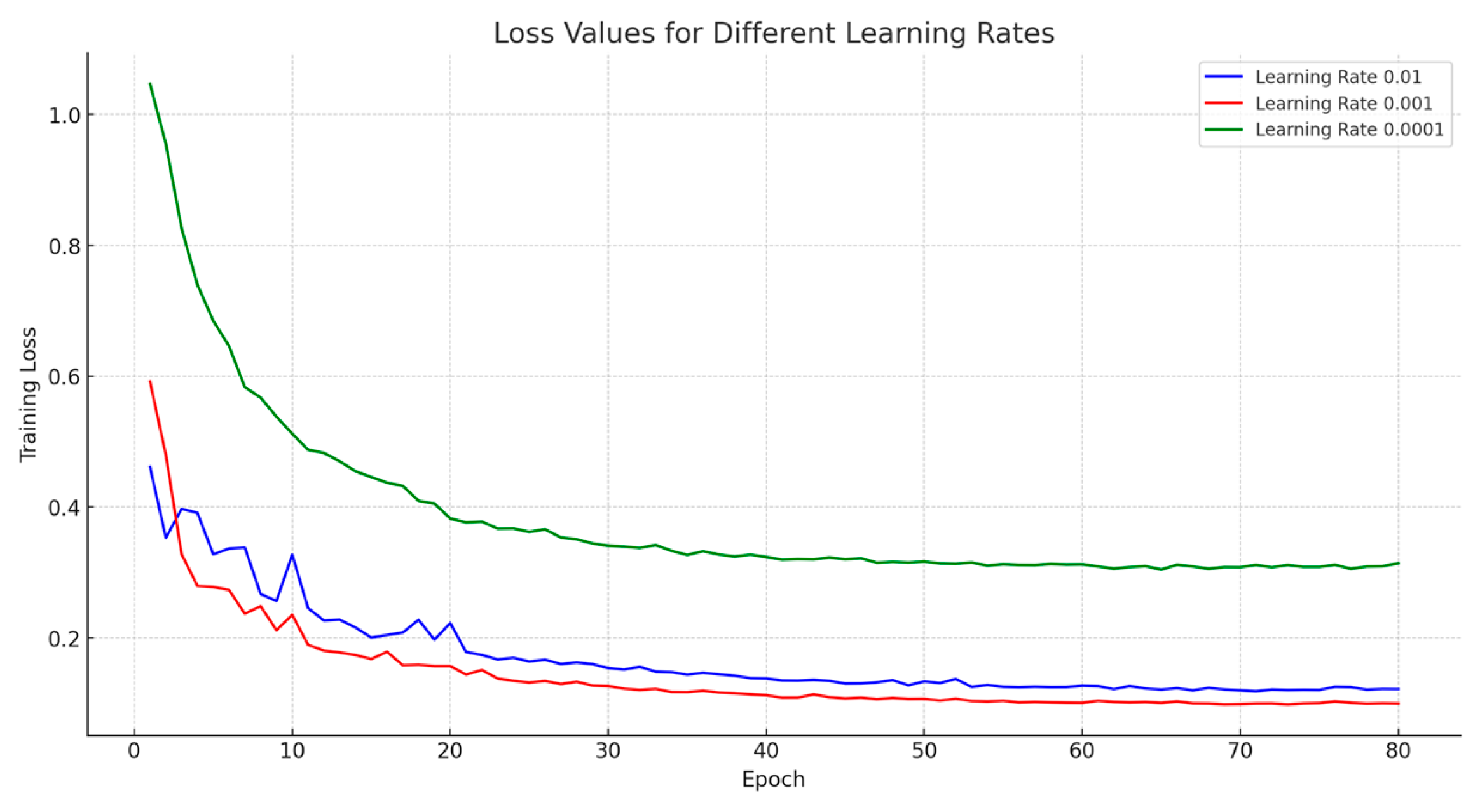
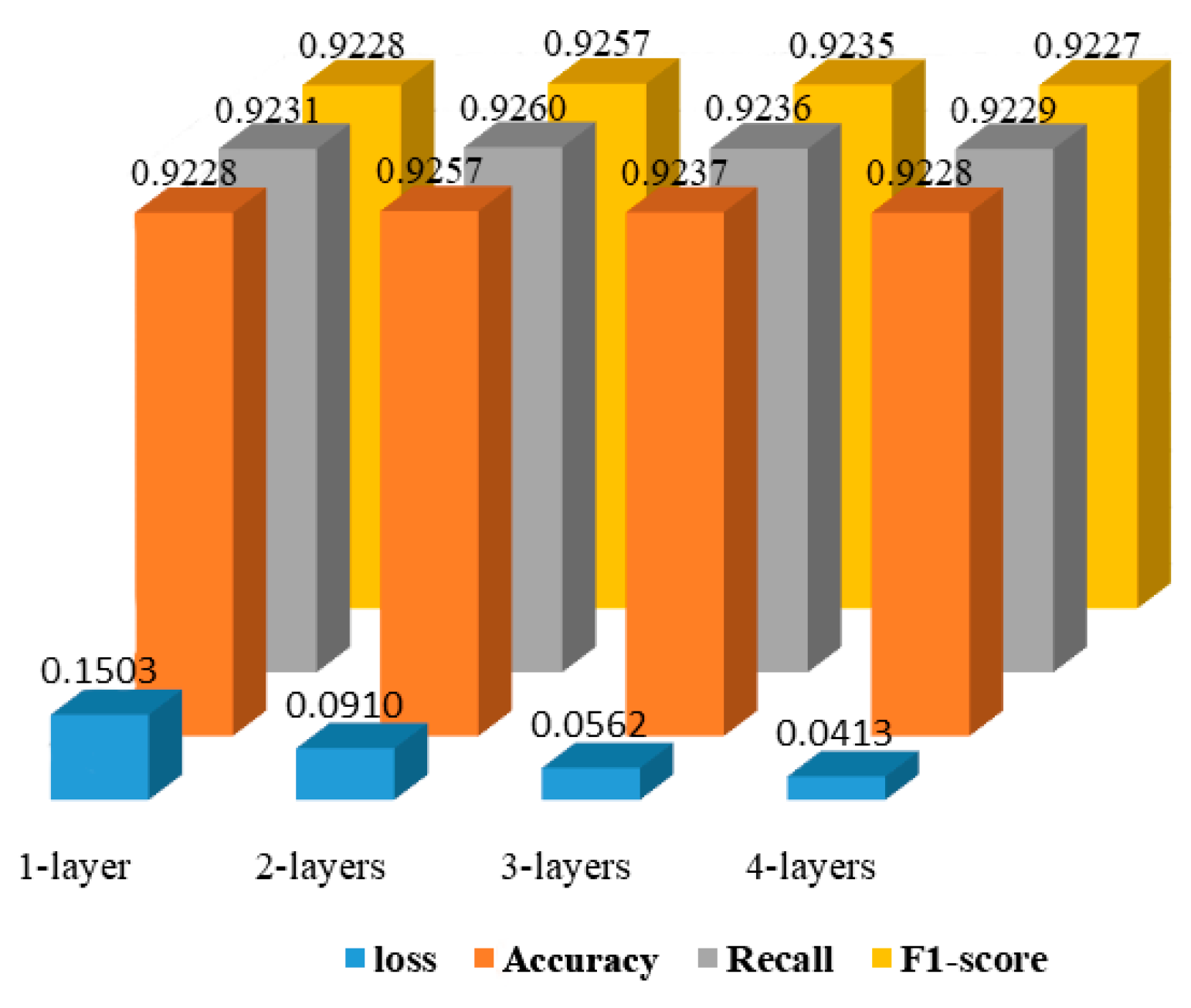
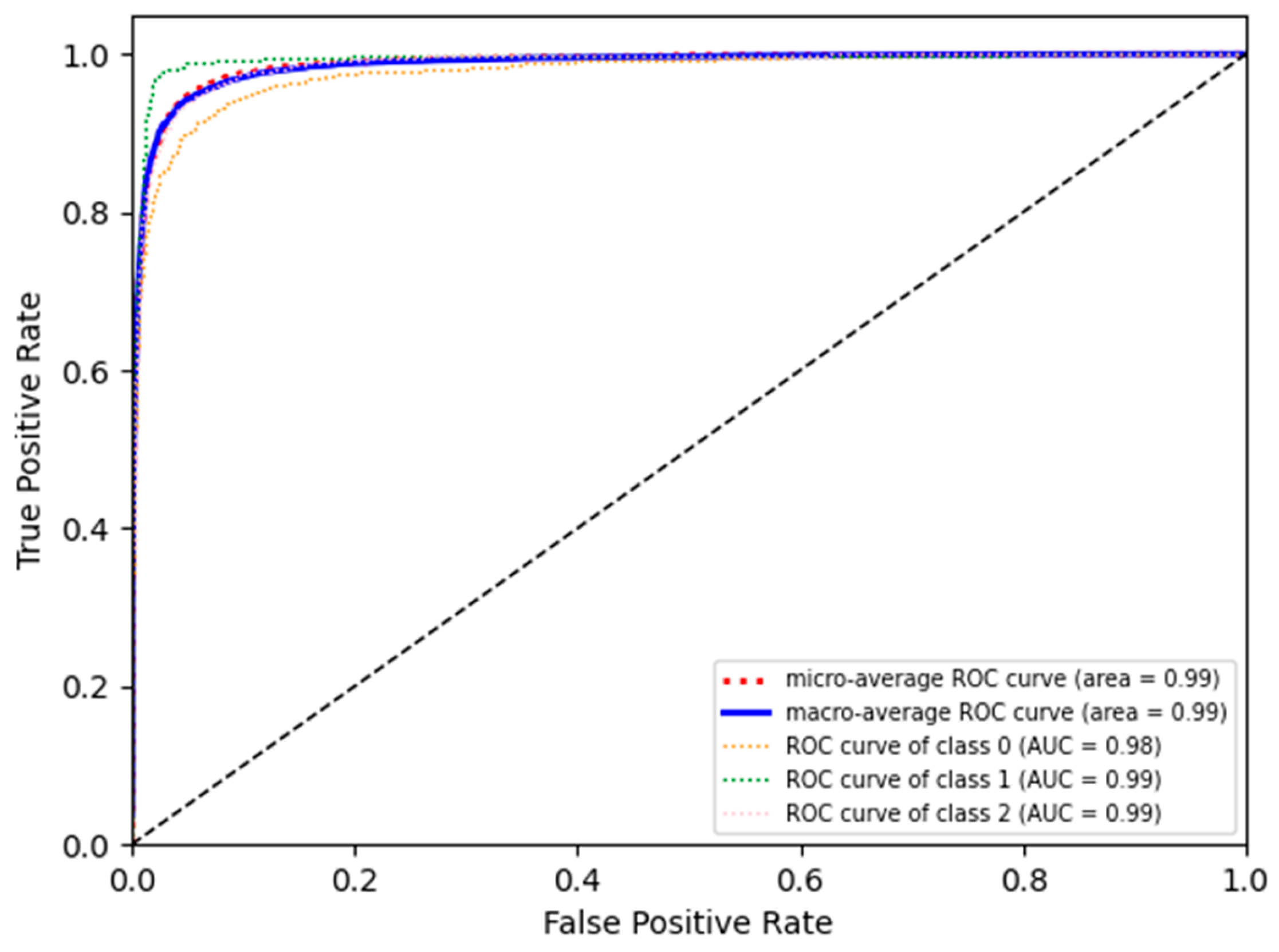
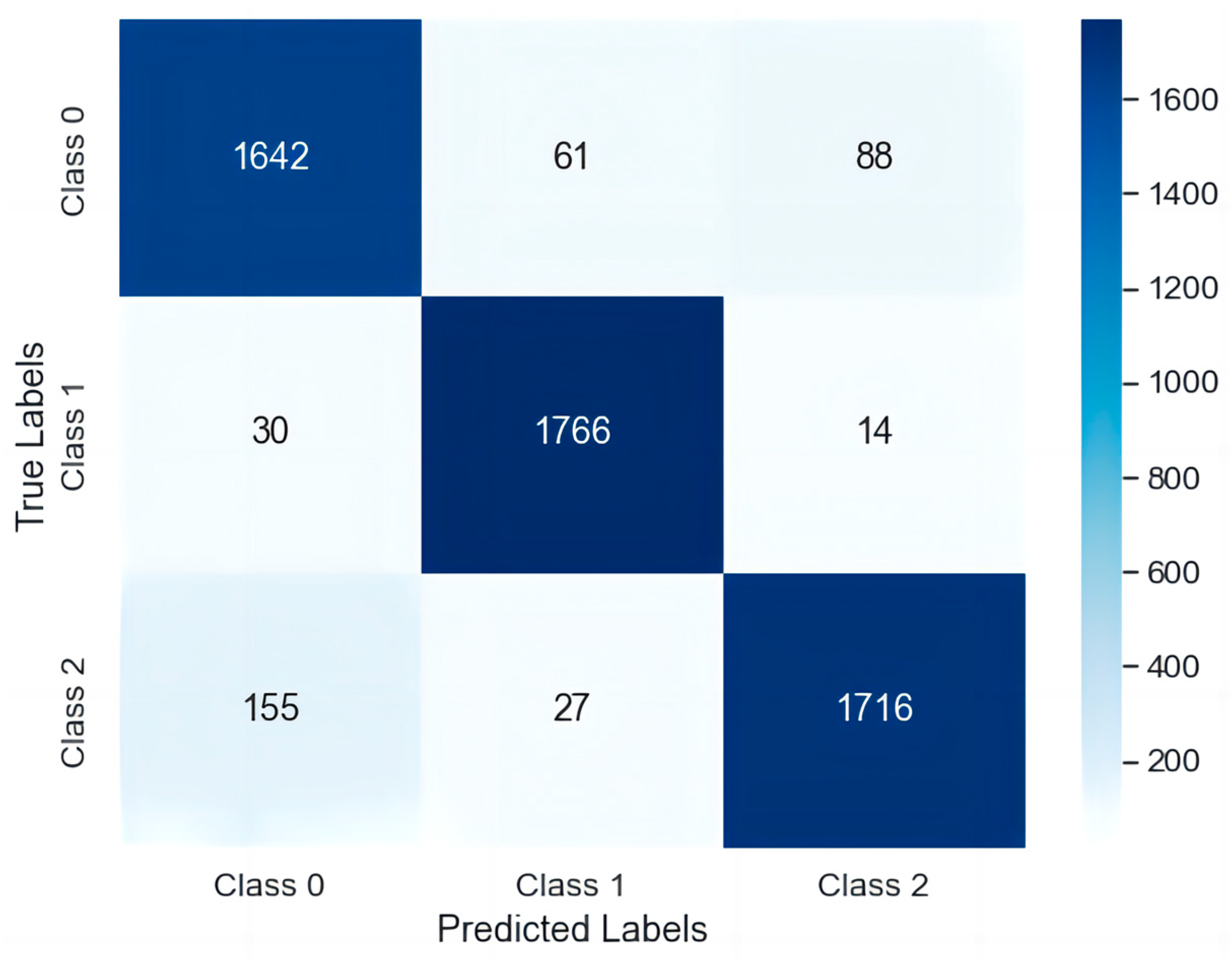
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Full Name | Abbreviation |
| Convolutional Neural Network | CNN |
| Long Short-Term Memory | LSTM |
| Support Vector Machine | SVM |
| Vessel Monitoring System | VMS |
| Global Positioning System | GPS |
| Automatic Identification System | AIS |
| Independently Recurrent Neural Network | IndRNN |
| Dots Per Inch | DPI |
References
- Worm, B.; Hilborn, R.; Baum, J.K.; Branch, T.A.; Collie, J.S.; Costello, C.; Fogarty, M.J.; Fulton, E.A.; Hutchings, J.A.; Jennings, S.; et al. Rebuilding global fisheries. Science 2009, 325, 578–585. [Google Scholar] [CrossRef]
- Duarte, C.M.; Agusti, S.; Barbier, E.; Britten, G.L.; Castilla, J.C.; Gattuso, J.P.; Fulweiler, R.W.; Hughes, T.P.; Knowlton, N.; Lovelock, C.E.; et al. Rebuilding marine life. Nature 2020, 580, 39–51. [Google Scholar] [CrossRef] [PubMed]
- Kasperski, S.; Holland, D.S. Income diversification and risk for fishermen. Proc. Natl. Acad. Sci. USA 2013, 110, 2076–2081. [Google Scholar] [CrossRef] [PubMed]
- Macfadyen, G.; Huntington, T.; Cappell, R. Abandoned, Lost or Otherwise Discarded Fishing Gear; FAO Fisheries and Aquaculture Technical Paper No. 523; FAO: Rome, Italy, 2009. [Google Scholar]
- Sumaila, U.R.; Lam, V.W.; Miller, D.D.; Teh, L.; Watson, R.A.; Zeller, D.; Cheung, W.W.; Côté, I.M.; Rogers, A.D.; Roberts, C.; et al. Winners and losers in a world where the high seas is closed to fishing. Sci. Rep. 2019, 9, 8481. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Guo, H.; Shi, Q. Anomaly Detection of Fishing Vessels Based on AIS Data. IEEE Access 2020, 8, 131682–131694. [Google Scholar]
- Rashidi, T.H.; Qiu, Z.; Lin, T. Detecting suspicious fishing vessel behaviors from AIS data using deep learning. IEEE Access 2021, 9, 30188–30200. [Google Scholar]
- Sun, L.; Li, C.; Shen, S. Detecting Illegal Fishing Vessels Using Automatic Identification System Data Based on Machine Learning Algorithms. Ocean Eng. 2020, 211, 107580. [Google Scholar]
- O’Neill, F.G.; Handegard, N.O.; Gargan, P.G. Use of a Vessel Monitoring System (VMS) to improve spatial management measures for a data-poor deep-water fishery. ICES J. Mar. Sci. 2019, 76, 1766–1777. [Google Scholar]
- Solomon, J.A.; Cox, S.P.; Carr-Harris, C. Validation of GPS loggers and vessel monitoring systems for use on fishing vessels. Fish. Res. 2020, 230, 105648. [Google Scholar]
- Teixeira, J.B.; Santana, J.A.; Pennino, M.G. A systematic approach to identify fishing areas based on VMS data: Application to the Brazilian pair trawl fishery targeting Argentine hake. Fish. Res. 2019, 215, 1–9. [Google Scholar]
- Ibrahim, H.; Haroun, R.; Moustafa, M. Evaluation of trawling, gillnetting and longlining fishing gear efficiency and sustainability in the Red Sea. Fish. Res. 2019, 209, 30–41. [Google Scholar]
- Campbell, R.A.; Walmsley, S.F.; Robinson, G. Fishing gear classification based on fish behaviour to assist fisheries management. Fish. Res. 2013, 147, 428–441. [Google Scholar]
- Ulman, A.; Bekişoğlu, Ş.; Moutopoulos, D.K. The impact of trawl fishery on the ecosystem in the south-eastern Black Sea. J. Mar. Biol. Assoc. UK 2015, 95, 1051–1061. [Google Scholar]
- Kroodsma, D.A.; Mayorga, J.; Hochberg, T.; Miller, N.A.; Boerder, K.; Ferretti, F.; Wilson, A.; Bergman, B.; White, T.D.; Block, B.A. Tracking the global footprint of fisheries. Science 2018, 359, 904–908. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.L.; Lee, K.M. Convolutional neural network based geartype ide-ntification from automatic identification system trajectory data. Appl. Sci. 2020, 10, 4010. [Google Scholar] [CrossRef]
- Storm-Furru, S.; Bruckner, S. VA-TRAC: Geospatial Trajectory Analysis for Monitoring, Identification, and Verification in Fishing Vessel Operations. Comput. Graph. Forum 2020, 39, 101–114. [Google Scholar] [CrossRef]
- Park, J.W.; Lee, K.M.; Kim, K.I. Automatic identifica-tion system based fishing trajectory data preprocessing method using map reduce. Int. J. Recent Technol. Eng. 2019, 8, 352–356. [Google Scholar]
- De Souza, E.N.; Boerder, K.; Matwin, S.; Worm, B. Improving Fishing Pattern Detection from Satellite AIS Using Data Mining and Machine Learning. PLoS ONE 2017, 11, e0158248. [Google Scholar]
- Candela, L.; Arvanitidis, C. Challenges and opportunities in using vessel monitoring systems and automatic identification systems (VMS/AIS) to support the ecosystem approach to fisheries. Aquat. Conserv. Mar. Freshw. Ecosyst. 2017, 27, 156–167. [Google Scholar]
- Powell, M.J.D. A hybrid method for nonlinear equations. Numer. Methods Nonlinear Algebr. Equ. 1981, 12, 663–683. [Google Scholar]
- Yao, Y.; Jiang, Z.; Zhang, H. Ship detection in optical remote sensing images based on deep convolutional neural networks. J. Appl. Remote Sens. 2017, 11, 042611. [Google Scholar] [CrossRef]
- Bono, F.M.; Cinquemani, S.; Chatterton, S.; Pennacchi, P. A deep learning approach for fault detection and RUL estimation in bearings. In NDE 4.0, Predictive Maintenance, and Communication and Energy Systems in a Globally Networked World, Proceedings of the SPIE Smart Structures + Nondestructive Evaluation, Long Beach, CA, USA, 18 April 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12049, pp. 71–83. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Arai, T.; Watanabe, S.; Hotta, K. Convolutional neural networks for super-resolution of raw time-of-flight depth images. IEEE Trans. Image Process. 2017, 26, 4226–4237. [Google Scholar]
- Li, S.; Li, W.; Cook, C. Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5457–5466. [Google Scholar]
- Li, Y.; Hu, S.; Zhang, J. IndRNN for Time Series Forecasting: A Case Study of Debris Flow Forecasting. Remote Sens. 2020, 12, 2882. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Output Shape | Param | |
|---|---|---|---|
| 1 | Linear_1 | [128, 64, 128] | 2688 |
| 2 | LeakyReLU_1 | [128, 64, 128] | 0 |
| 3 | Dropout_1 | [128, 64, 128] | 0 |
| 4 | IndRNNv2_1 | [128, 64, 128] | 128 |
| Conv1d_1_1 | [128, 128, 64] | 16,512 | |
| 6 | Dropout_2 | [128, 64, 128] | 0 |
| 7 | Attention_1 | [128, 128] | 128 |
| 8 | Linear_1_1 | [128, 64, 128] | 16,512 |
| 9 | BatchNorm1d_1 | [128, 128] | 256 |
| 10 | Dropout_3 | [128, 64, 128] | 0 |
| 11 | Conv1d_1 | [128, 64, 64] | 24,640 |
| 12 | AdaptiveAvgPool1d_1 | [128, 64, 1] | 0 |
| 13 | LeakyReLU_2 | [128, 64] | 0 |
| 14 | BatchNorm1d_2 | [128, 64] | 128 |
| 15 | Linear_2 | [128, 128] | 24,704 |
| 16 | Linear_3 | [128, 64] | 12,352 |
| 17 | LeakyReLU_3 | [128, 192] | 0 |
| 18 | Dropout_3 | [128, 192] | 0 |
| 19 | Linear_4 | [128, 3] | 579 |
| Sequence Length | Batch Size | Acc |
|---|---|---|
| 32 | 64 | 91.74 |
| 32 | 128 | 91.38 |
| 32 | 256 | 91.16 |
| 64 | 64 | 92.54 |
| 64 | 128 | 92.39 |
| 64 | 256 | 92.32 |
| 128 | 64 | 93.12 |
| 128 | 128 | 92.98 |
| 128 | 256 | 92.43 |
| 256 | 64 | 93.01 |
| 256 | 128 | 92.76 |
| 256 | 256 | 92.68 |
| Dilation Rate | Acc |
|---|---|
| 2 | 92.45 |
| 3 | 93.04 |
| 4 | 92.88 |
| 5 | 92.37 |
| Parameters | Numerical Value | |
|---|---|---|
| 1 | Learning Rate | 0.001 |
| 2 | Batch size | 64 |
| 3 | Sequence length | 128 |
| 4 | Epochs | 80 |
| 5 | Optimizer | Adam |
| 6 | Dilation rate | 3 |
| 7 | Number of convolution layers | 4 |
| Model | Acc | Pre | macro-F1 | Recall |
|---|---|---|---|---|
| Dilated CNN | 0.8874 | 0.8880 | 0.8869 | 0.8882 |
| IndRNN | 0.9090 | 0.9099 | 0.9094 | 0.9101 |
| CNN-LSTM | 0.9156 | 0.9132 | 0.9122 | 0.9124 |
| Dilated CNN-IndRNN | 0.9312 | 0.9310 | 0.9310 | 0.9314 |
| CNN | 0.8687 | 0.8692 | 0.8677 | 0.8694 |
| LSTM | 0.9076 | 0.9103 | 0.9068 | 0.9066 |
| Transformer | 0.8956 | 0.8949 | 0.8960 | 0.8950 |
| TCN | 0.8645 | 0.8631 | 0.8630 | 0.8645 |
| GRU | 0.8663 | 0.8649 | 0.8642 | 0.8657 |
| Bi-LSTM | 0.8905 | 0.8897 | 0.8898 | 0.8903 |
| Bi-GRU | 0.8725 | 0.8728 | 0.8715 | 0.8713 |
| RNN | 0.8587 | 0.8571 | 0.8582 | 0.8569 |
| LightGBM | 0.9301 | 0.9208 | 0.9168 | 0.9064 |
| ConvLSTM | 0.9105 | 0.9102 | 0.9111 | 0.9106 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Fu, S.; Bao, X. Study on Classification of Fishing Vessel Operation Types Based on Dilated CNN-IndRNN. Appl. Sci. 2024, 14, 4402. https://doi.org/10.3390/app14114402
Yu J, Fu S, Bao X. Study on Classification of Fishing Vessel Operation Types Based on Dilated CNN-IndRNN. Applied Sciences. 2024; 14(11):4402. https://doi.org/10.3390/app14114402
Chicago/Turabian StyleYu, Jiachen, Shunlong Fu, and Xiongguan Bao. 2024. "Study on Classification of Fishing Vessel Operation Types Based on Dilated CNN-IndRNN" Applied Sciences 14, no. 11: 4402. https://doi.org/10.3390/app14114402
APA StyleYu, J., Fu, S., & Bao, X. (2024). Study on Classification of Fishing Vessel Operation Types Based on Dilated CNN-IndRNN. Applied Sciences, 14(11), 4402. https://doi.org/10.3390/app14114402