
Denoising Multiscale Back-Projection Feature Fusion for Underwater Image Enhancement

Abstract
1. Introduction
- Novel denoising back-projection feature fusion mechanism: We present a novel denoising back-projection feature fusion mechanism to effectively integrate multiscale features in underwater image enhancement. This mechanism significantly improves the quality of enhanced images by filtering noise and preserving fine details.
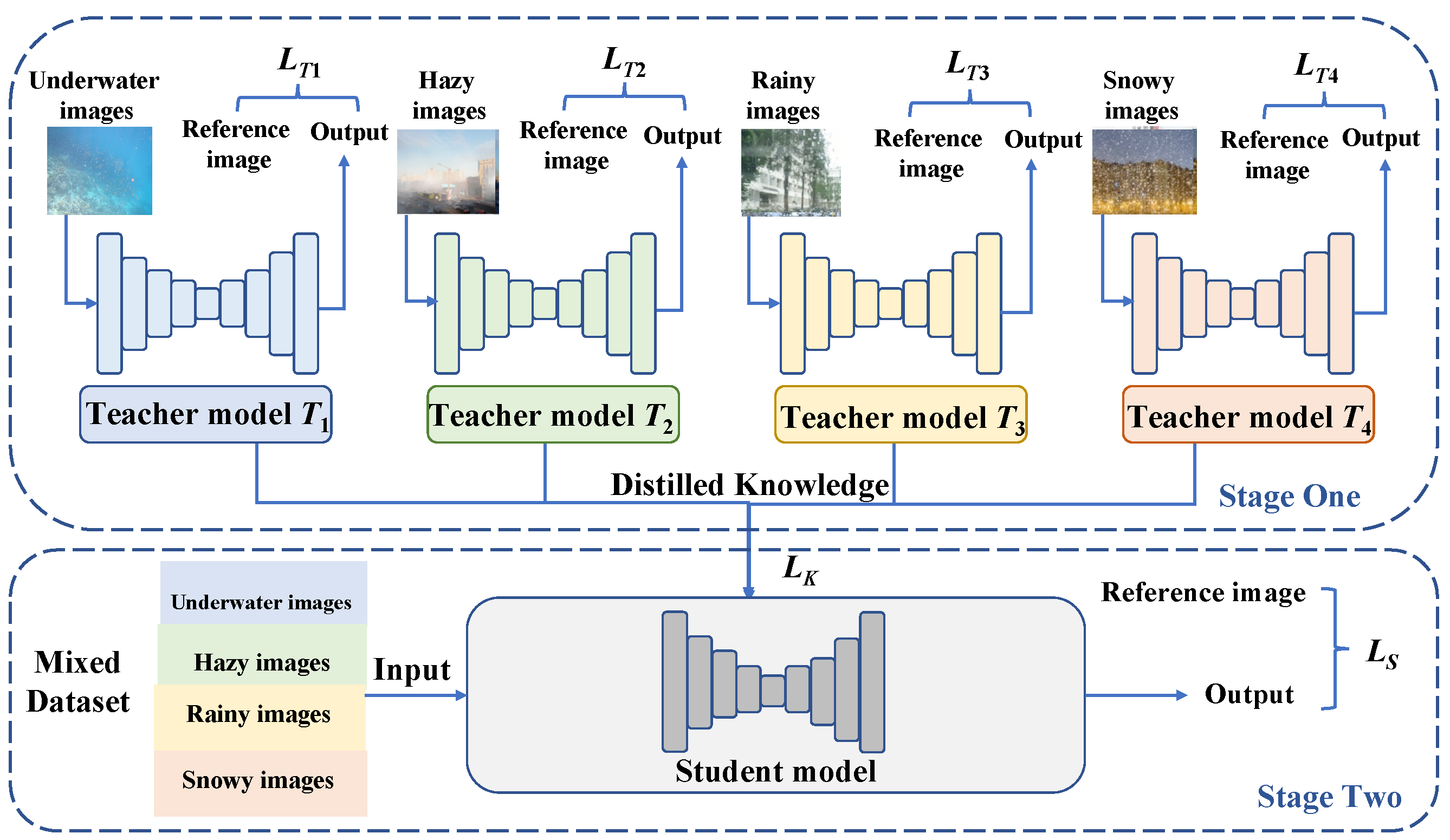
- Multiple degradation knowledge distillation strategy: We introduce a multiple degradation knowledge distillation strategy, enabling our method to generalize across various types of degradation images.
- We evaluate the model on different datasets against other underwater enhancement models. The results indicate that the proposed method achieves the best performance for underwater images with complex degradation. The results of knowledge distillation validate the effectiveness and applicability of our method to address multiple degradation scenarios.
2. Related Work
2.1. Underwater Image Enhancement
2.2. Back-Projection
2.3. Knowledge Distillation
3. Methodology
3.1. Overview
3.2. Revisiting the Back-Projection Algorithm
- Initialization: The algorithm initializes the low-resolution image for the first iteration as
- Reconstruction of high-resolution image: At each iteration, a high-resolution image, , is reconstructed from the previous iteration’s low-resolution image, :where is a constant back-projection kernel, differing from deep learning filters that are typically trained. Here, ∗ denotes a spatial convolution operator, and is the upsampling operator with a scaling factor, s.
- Reconstruction error computation: We compute the reconstruction error, , which is defined as the difference between the low-resolution image and the synthesized high-resolution image of by using the following equation:where represents downsampling with scaling factor s. is a blur filter, which is an unlearned predefined parameter.
- Back-projection of error to high-resolution image: The high-resolution image is updated by back-projecting the reconstruction error as follows:where is the same filter as in Equation (2). The high-resolution image on the right side of this expression is from the reconstruction step in Equation (2). The reconstruction error, , is from Equation (3).
3.3. Multiscale Back-Projection Feature Fusion
| Algorithm 1: Feature fusion process of MBFF for . | |
| Input: Feature F, Fusion feature | |
| Output: The fused feature | |
| 1 | Calculate deconvolution and convolution times: |
| 2 | |
| 3 | |
| 4 | |
| 5 | Upsampling F with multiple deconvolutions: |
| 6 | |
| 7 | Calculate the differences between and : |
| 2 | |
| 9 | Down-sampling the differences with multiple convolutions: |
| 10 | |
| 11 | Add the back-projection feature with F: |
| 12 | |
3.4. Denoising Block
3.5. Encoder with DeMBFF
| Algorithm 2: Feature fusion process for encoder with DeMBFF. |
 |
3.6. Decoder with DeMBFF
| Algorithm 3: Feature fusion process for decoder with DeMBFF. |
 |
3.7. Loss Functions
4. Multiple Degradation Knowledge Distillation
5. Experiment and Analysis
5.1. Datasets
- The UIEB dataset is an underwater real image dataset with clear images, where the clear images and the enhanced images serve as ground truth. It consists of 950 real-world underwater images, 890 of which have the corresponding clear images.
- The EUVP underwater dataset contains a large collection (20,000) of paired and unpaired underwater images of poor and good perceptual quality. A total of 12,000 of the images have paired clear images, and 8000 of the images have unpaired clear images. The dataset was captured using seven different cameras and contains photos of different visibilities and sea areas.
- The RUIE real underwater dataset comprises 4200 unpaired underwater images captured by moving cameras at different moments in an underwater scene. The images in the dataset exhibit different color shifts and visibility.
- The Rain 1400 dataset consists of 1000 pairs of rainy and clear images. The dataset generates 14 rainy images for each clear image, which have different orients.
- The RESIDE hazy dataset is a hazy image dataset with several conditions, which include the training set and the test set. The training data consists of a collection of paired hazy images and clear images. The test set consists of 510 pairs of hazy and clear images.
- The CSD snowy dataset contains 10,000 pairs of snowy images and clear images. The synthetic snowy images simulate snowflakes and snow stripes with different transparencies, sizes, and positions, effectively reflecting real-world snowy scenes.
5.2. Evaluation Metrics
- PSNR [50] reflects the proximity to the reference, where a higher PSNR value represents similar image content.
- SSIM [51] represents the degree of similarity of structure and texture for an image pair.
- UIQM [52] consists of three image attribute measurements: underwater image color measurement (UICM), underwater image sharpness measurement (UISM), and underwater image contrast measurement (UIConM). UIQM is a linear combination of these methods, and each property is inspired by the human visual system to assess an aspect of underwater image degradation. A higher value indicates better human visual perception of the color, sharpness, and contrast of the image. The UIQM is calculated as follows:where , , and are weighting coefficients. In this paper, we follow the literature [52] and set these as , , and , respectively.
5.3. Experimental Setup
5.4. Training Process
5.5. Comparative Methods
5.6. Qualitative Analysis
5.7. Quantitative Evaluation
5.8. Ablation Experiments
- w/o DeMBFF: A base U-Net model without an MBFF or denoising block, which includes a simple encoder, decoder, and jump connections;
- With a DB: A base U-Net model with a denoising block (DB) in the encoder and decoder;
- With MBFF: A base U-Net model with MBFF and without a DB in the encoder and decoder;
- With DeMBFF: The full model that includes encoders and decoders with the DeMBFF mechanism.
5.9. Results for Multi-Type Degradation Image Enhancement
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kashif, I.; Michael, O.; Anne, J.; Rosalina, S.A.; Hj, T.A.Z. Enhancing the low quality images using Unsupervised Colour Correction Method. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010. [Google Scholar]
- Chiang, J.Y.; Chen, Y.C. Underwater Image Enhancement by Wavelength Compensation and Dehazing. IEEE Trans. Image Process. 2012, 21, 1756–1769. [Google Scholar] [CrossRef] [PubMed]
- Akkaynak, D.; Trebitz, T. Sea-Thru: A Method For Removing Water From Underwater Images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, C.; Anwar, S.; Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Pritish, U.; Wu, Z.; Wang, Z. All-in-One Underwater Image Enhancement Using Domain-Adversarial Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhou, J.; Gai, Q.; Zhang, D.; Lam, K.; Zhang, W.; Fu, X. IACC: Cross-Illumination Awareness and Color Correction for Underwater Images Under Mixed Natural and Artificial Lighting. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Zhang, D.; Zhou, J.; Zhang, W.; Lin, Z.; Yao, J.; Polat, K.; Alenezi, F.; Alhudhaif, A. ReX-Net: A reflectance-guided underwater image enhancement network for extreme scenarios. Expert Syst. Appl. 2023, 231, 120842. [Google Scholar] [CrossRef]
- Liu, X.; Gao, Z.; Chen, B.M. MLFcGAN: Multilevel Feature Fusion-Based Conditional GAN for Underwater Image Color Correction. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1488–1492. [Google Scholar] [CrossRef]
- Wu, S.; Luo, T.; Jiang, G.; Yu, M.; Xu, H.; Zhu, Z.; Song, Y. A Two-Stage Underwater Enhancement Network Based on Structure Decomposition and Characteristics of Underwater Imaging. IEEE J. Ocean. Eng. 2021, 46, 1213–1227. [Google Scholar] [CrossRef]
- Islam, M.J.; Luo, P.; Sattar, J. Simultaneous Enhancement and Super-Resolution of Underwater Imagery for Improved Visual Perception. In Proceedings of the Robotics: Science and Systems XVI, Virtual Event, Corvalis, OR, USA, 12–16 July 2020. [Google Scholar]
- Zhou, J.; Zhang, D.; Zhang, W. Cross-view enhancement network for underwater images. Eng. Appl. Artif. Intell. 2023, 121, 105952. [Google Scholar] [CrossRef]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing underwater images and videos by fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Zhou, J.; Wang, S.; Lin, Z.; Jiang, Q.; Sohel, F. A Pixel Distribution Remapping and Multi-prior Retinex Variational Model for Underwater Image Enhancement. IEEE Trans. Multimed. 2024, 99, 1–12. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, Y.; Li, C.; Zhang, W. Multicolor Light Attenuation Modeling for Underwater Image Restoration. IEEE J. Ocean. Eng. 2023, 48, 1322–1337. [Google Scholar] [CrossRef]
- Zhou, J.; Pang, L.; Zhang, D.; Zhang, W. Underwater Image Enhancement Method via Multi-Interval Subhistogram Perspective Equalization. IEEE J. Ocean. Eng. 2023, 48, 474–488. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar]
- Song, W.; Wang, Y.; Huang, D.; Liotta, A.; Perra, C. Enhancement of Underwater Images With Statistical Model of Background Light and Optimization of Transmission Map. IEEE Trans. Broadcast. 2020, 66, 153–169. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, Q.; Jiang, Q.; Ren, W.; Lam, K.M.; Zhang, W. Underwater camera: Improving visual perception via adaptive dark pixel prior and color correction. Int. J. Comput. Vis. 2023. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, J.; Cao, Y.; Wang, Z. A deep CNN method for underwater image enhancement. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 1382–1386. [Google Scholar]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An Underwater Image Enhancement Benchmark Dataset and Beyond. IEEE Trans. Image Process. 2020, 29, 4376–4389. [Google Scholar] [CrossRef]
- Naik, A.; Swarnakar, A.; Mittal, K. Shallow-UWnet: Compressed Model for Underwater Image Enhancement (Student Abstract). In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Virtual Event, 2–9 February 2021; pp. 15853–15854. [Google Scholar]
- Fu, Z.; Lin, X.; Wang, W.; Huang, Y.; Ding, X. Underwater Image Enhancement Via Learning Water Type Desensitized Representations. In Proceedings of the ICASSP 2022, Virtual and Singapore, 23–27 May 2022; pp. 2764–2768. [Google Scholar]
- Mu, P.; Qian, H.; Bai, C. Structure-Inferred Bi-level Model for Underwater Image Enhancement. In Proceedings of the MM ’22: The 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 2286–2295. [Google Scholar]
- Zhou, J.; Li, B.; Zhang, D.; Yuan, J.; Zhang, W.; Cai, Z.; Shi, J. UGIF-Net: An Efficient Fully Guided Information Flow Network for Underwater Image Enhancement. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Zhou, J.; Sun, J.; Zhang, W.; Lin, Z. Multi-view underwater image enhancement method via embedded fusion mechanism. Eng. Appl. Artif. Intell. 2023, 121, 105946. [Google Scholar] [CrossRef]
- Fabbri, C.; lslam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Li, J.; Katherine, S.; M.Eustice, R.; Johnson-Roberson, M. WaterGAN: Unsupervised generative network to enable real-time color correction of monocular underwater images. IEEE Robot. Autom. Lett. 2018, 3, 387–394. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast Underwater Image Enhancement for Improved Visual Perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Zhou, J.; Sun, J.; Li, C.; Jiang, Q.; Zhou, M.; Lam, K.M.; Zhang, W.; Fu, X. HCLR-Net: Hybrid Contrastive Learning Regularization with Locally Randomized Perturbation for Underwater Image Enhancement. Int. J. Comput. Vis. 2024. [Google Scholar] [CrossRef]
- Irani, M.; Peleg, S. Motion Analysis for Image Enhancement: Resolution, Occlusion, and Transparency. J. Vis. Commun. Image Represent. 1993, 4, 324–335. [Google Scholar] [CrossRef]
- Dai, S.; Han, M.; Wu, Y.; Gong, Y. Bilateral Back-Projection for Single Image Super Resolution. In Proceedings of the 2007 IEEE International Conference on Multimedia and Expo, ICME 2007, IEEE Computer Society, Beijing, China, 2–5 July 2007; pp. 1039–1042. [Google Scholar]
- Zhao, Y.; Wang, R.; Jia, W.; Wang, W.; Gao, W. Iterative projection reconstruction for fast and efficient image upsampling. Neurocomputing 2017, 226, 200–211. [Google Scholar] [CrossRef]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep Back-Projection Networks for Single Image Super-Resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4323–4337. [Google Scholar] [CrossRef] [PubMed]
- Luo, C.; Li, B.; Liu, F. Iterative Back Projection Network Based on Deformable 3D Convolution. IEEE Access 2023, 11, 122586–122597. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Wang, L.; Yoon, K. Knowledge Distillation and Student-Teacher Learning for Visual Intelligence: A Review and New Outlooks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3048–3068. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Xu, P.; Chang, X.; Yang, L.; Zhang, Y.; Yao, L.; Chen, X. When Object Detection Meets Knowledge Distillation: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10555–10579. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Gou, J.; Sun, L.; Yu, B.; Wan, S.; Tao, D. Hierarchical Multi-Attention Transfer for Knowledge Distillation. ACM Trans. Multim. Comput. Commun. Appl. 2024, 20, 51:1–51:20. [Google Scholar] [CrossRef]
- Chen, X.; Su, J.; Zhang, J. A Two-Teacher Framework for Knowledge Distillation. In Proceedings of the Advances in Neural Networks—ISNN 2019—16th International Symposium on Neural Networks, ISNN 2019, Moscow, Russia, 10–12 July 2019; Proceedings, Part I. Lu, H., Tang, H., Wang, Z., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2019; Volume 11554, pp. 58–66. [Google Scholar]
- Park, S.; Kwak, N. Feature-Level Ensemble Knowledge Distillation for Aggregating Knowledge from Multiple Networks. In Proceedings of the ECAI 2020—24th European Conference on Artificial Intelligence, Santiago de Compostela, Spain, 29 August–8 September 2020; pp. 1411–1418. [Google Scholar]
- Yuan, F.; Shou, L.; Pei, J.; Lin, W.; Gong, M.; Fu, Y.; Jiang, D. Reinforced Multi-Teacher Selection for Knowledge Distillation. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; pp. 14284–14291. [Google Scholar]
- Ye, X.; Jiang, R.; Tian, X.; Zhang, R.; Chen, Y. Knowledge Distillation via Multi-Teacher Feature Ensemble. IEEE Signal Process. Lett. 2024, 31, 566–570. [Google Scholar] [CrossRef]
- Romano, Y.; Elad, M. Boosting of Image Denoising Algorithms. SIAM J. Imaging Sci. 2015, 8, 1187–1219. [Google Scholar] [CrossRef]
- Wang, Z.; Sheikh, A.C.B.H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-world Underwater Enhancement: Challenges, Benchmarks, and Solutions under Natural Light. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 4861–4875. [Google Scholar] [CrossRef]
- Fu, X.; Huang, J.; Zeng, D.; Huang, Y.; Ding, X.; Paisley, J.W. Removing Rain from Single Images via a Deep Detail Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, IEEE Computer Society, Honolulu, HI, USA, 21–26 July 2017; pp. 1715–1723. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking Single-Image Dehazing and Beyond. IEEE Trans. Image Process. 2019, 28, 492–505. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Fang, H.; Hsieh, C.; Tsai, C.; Chen, I.; Ding, J.; Kuo, S. ALL Snow Removed: Single Image Desnowing Algorithm Using Hierarchical Dual-tree Complex Wavelet Representation and Contradict Channel Loss. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 4176–4185. [Google Scholar]
- Wang, Z.; Bovik, A.C. Mean squared error: Love it or leave it? A new look at Signal Fidelity Measures. IEEE Signal Process. Mag. 2009, 26, 98–117. [Google Scholar] [CrossRef]
- Wang, S.; Ma, K.; Yeganeh, H.; Wang, Z.; Lin, W. A Patch-Structure Representation Method for Quality Assessment of Contrast Changed Images. IEEE Signal Process. Lett. 2015, 22, 2387–2390. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2016, 41, 541–551. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Drews, P., Jr.; do Nascimento, E.; F. Moraes, S.B.; Campos, M. Transmission Estimation in Underwater Single Images. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 825–830. [Google Scholar]
- Fu, Z.; Lin, H.; Yang, Y.; Chai, S.; Sun, L.; Huang, Y.; Ding, X. Unsupervised Underwater Image Restoration: From a Homology Perspective. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Virtual Event, 22 February–1 March 2022; pp. 643–651. [Google Scholar]
- Dong, J.; Pan, J. Physics-Based Feature Dehazing Networks. In Proceedings of the Computer Vision - ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXX; Lecture Notes in Computer Science. Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12375, pp. 188–204. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature Fusion Attention Network for Single Image Dehazing. In Proceedings of the The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; pp. 11908–11915. [Google Scholar]
- Wu, H.; Qu, Y.; Lin, S.; Zhou, J.; Qiao, R.; Zhang, Z.; Xie, Y.; Ma, L. Contrastive Learning for Compact Single Image Dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Computer Vision Foundation/IEEE, Virtual, 19–25 June 2021; pp. 10551–10560. [Google Scholar]
- Yang, Y.; Wang, C.; Liu, R.; Zhang, L.; Guo, X.; Tao, D. Self-augmented Unpaired Image Dehazing via Density and Depth Decomposition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 2027–2036. [Google Scholar]
- Li, R.; Tan, R.T.; Cheong, L. All in One Bad Weather Removal Using Architectural Search. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Computer Vision Foundation/IEEE, Seattle, WA, USA, 13–19 June 2020; pp. 3172–3182. [Google Scholar]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive Image Deraining Networks: A Better and Simpler Baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Computer Vision Foundation/IEEE, Long Beach, CA, USA, 16–20 June 2019; pp. 3937–3946. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Huang, B.; Luo, Y.; Ma, J.; Jiang, J. Multi-Scale Progressive Fusion Network for Single Image Deraining. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Computer Vision Foundation/IEEE, Seattle, WA, USA, 13–19 June 2020; pp. 8343–8352. [Google Scholar]
- Fu, X.; Qi, Q.; Zha, Z.; Zhu, Y.; Ding, X. Rain Streak Removal via Dual Graph Convolutional Network. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, 2–9 February 2021; pp. 1352–1360. [Google Scholar]
- Ye, Y.; Chang, Y.; Zhou, H.; Yan, L. Closing the Loop: Joint Rain Generation and Removal via Disentangled Image Translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Computer Vision Foundation/IEEE, Virtual, 19–25 June 2021; pp. 2053–2062. [Google Scholar]
- Liu, Y.; Jaw, D.; Huang, S.; Hwang, J. DesnowNet: Context-Aware Deep Network for Snow Removal. IEEE Trans. Image Process. 2018, 27, 3064–3073. [Google Scholar] [CrossRef]
- Chen, W.; Fang, H.; Ding, J.; Tsai, C.; Kuo, S. JSTASR: Joint Size and Transparency-Aware Snow Removal Algorithm Based on Modified Partial Convolution and Veiling Effect Removal. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI. Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2020; Volume 12366, pp. 754–770. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Input Size | Filter Size | Stride | Activation Function | Output Size | |
|---|---|---|---|---|---|---|
| 1 | Convolution layer | 1 | ReLU | |||
| Convolution layer | 2 | ReLU | ||||
| 2 | Convolution layer | 2 | ReLU | |||
| Encoder | 2 | ReLU | ||||
| 3 | Convolution layer | 2 | ReLU | |||
| Encoder | 2 | ReLU | ||||
| 4 | Convolution layer | 2 | ReLU | |||
| Encoder | 2 | ReLU | ||||
| 5 | Convolution layer | 2 | ReLU | |||
| Encoder | 2 | ReLU | ||||
| 6 | Decoder | 2 | ReLU | |||
| Deconvolution layer | 2 | ReLU | ||||
| 7 | Decoder | 2 | ReLU | |||
| Deconvolution layer | 2 | ReLU | ||||
| 8 | Decoder | 2 | ReLU | |||
| Deconvolution layer | 2 | ReLU | ||||
| 9 | Decoder | 2 | ReLU | |||
| Deconvolution layer | 2 | ReLU | ||||
| 10 | Convolution layer | 2 | ReLU | |||
| Convolution layer | 1 | ReLU |
| Metric | DCP | UDCP | DeepSesr | Funie-GAN | MLFCGAN | UWCNN-SD | USUIR | SCNET | Ours |
|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | |||||||||
| SSIM↑ | |||||||||
| UIQM↑ | |||||||||
| UICM↑ | |||||||||
| UISM↑ | |||||||||
| UIConM ↑ |
| Metric | DCP | UDCP | DeepSesr | Funie-GAN | MLFCGAN | UWCNN-SD | USUIR | SCNET | Ours |
|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | |||||||||
| SSIM↑ | |||||||||
| UIQM↑ | |||||||||
| UICM↑ | |||||||||
| UISM↑ | |||||||||
| UIConM↑ |
| Metric | DCP | UDCP | DeepSesr | Funie-GAN | MLFCGAN | UWCNN-SD | USUIR | SCNET | Ours |
|---|---|---|---|---|---|---|---|---|---|
| UIQM↑ | |||||||||
| UICM↑ | |||||||||
| UISM↑ | |||||||||
| UIConM↑ |
| Dataset | Ablation | Denosing Block | MBFF | PSNR | SSIM | UIQM |
|---|---|---|---|---|---|---|
| UIEB | w/o DeMBFF | × | × | |||
| with DB | ✓ | × | ||||
| with MBFF | × | ✓ | ||||
| with DeMBFF | ✓ | ✓ |
| Encoder/Decoder Number | Params (M) | PSNR | SSIM | UIQM | UICM | UISM | UIConM |
|---|---|---|---|---|---|---|---|
| 2 | 1.99 | ||||||
| 3 | 8.35 | ||||||
| 4 | 31.35 | ||||||
| 5 | 131.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, W.; Song, Y.; Chen, J. Denoising Multiscale Back-Projection Feature Fusion for Underwater Image Enhancement. Appl. Sci. 2024, 14, 4395. https://doi.org/10.3390/app14114395
Qu W, Song Y, Chen J. Denoising Multiscale Back-Projection Feature Fusion for Underwater Image Enhancement. Applied Sciences. 2024; 14(11):4395. https://doi.org/10.3390/app14114395
Chicago/Turabian StyleQu, Wen, Yuming Song, and Jiahui Chen. 2024. "Denoising Multiscale Back-Projection Feature Fusion for Underwater Image Enhancement" Applied Sciences 14, no. 11: 4395. https://doi.org/10.3390/app14114395
APA StyleQu, W., Song, Y., & Chen, J. (2024). Denoising Multiscale Back-Projection Feature Fusion for Underwater Image Enhancement. Applied Sciences, 14(11), 4395. https://doi.org/10.3390/app14114395