
Loop Closure Detection Based on Compressed ConvNet Features in Dynamic Environments


Abstract
:1. Introduction
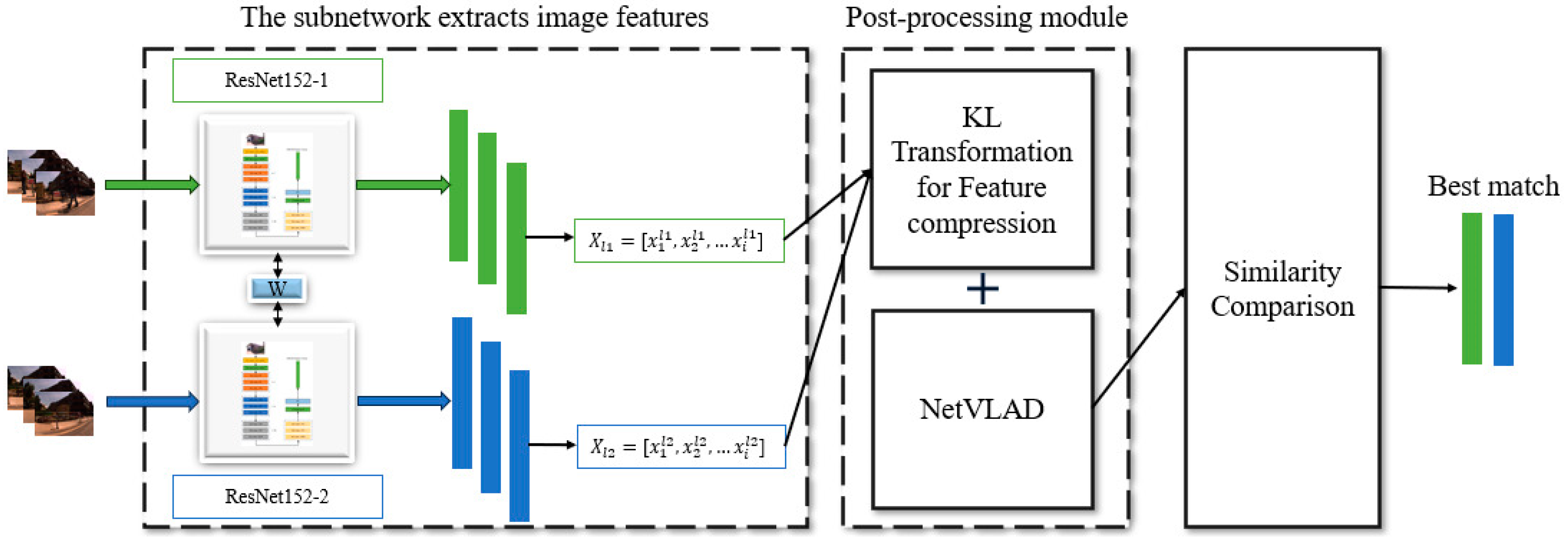
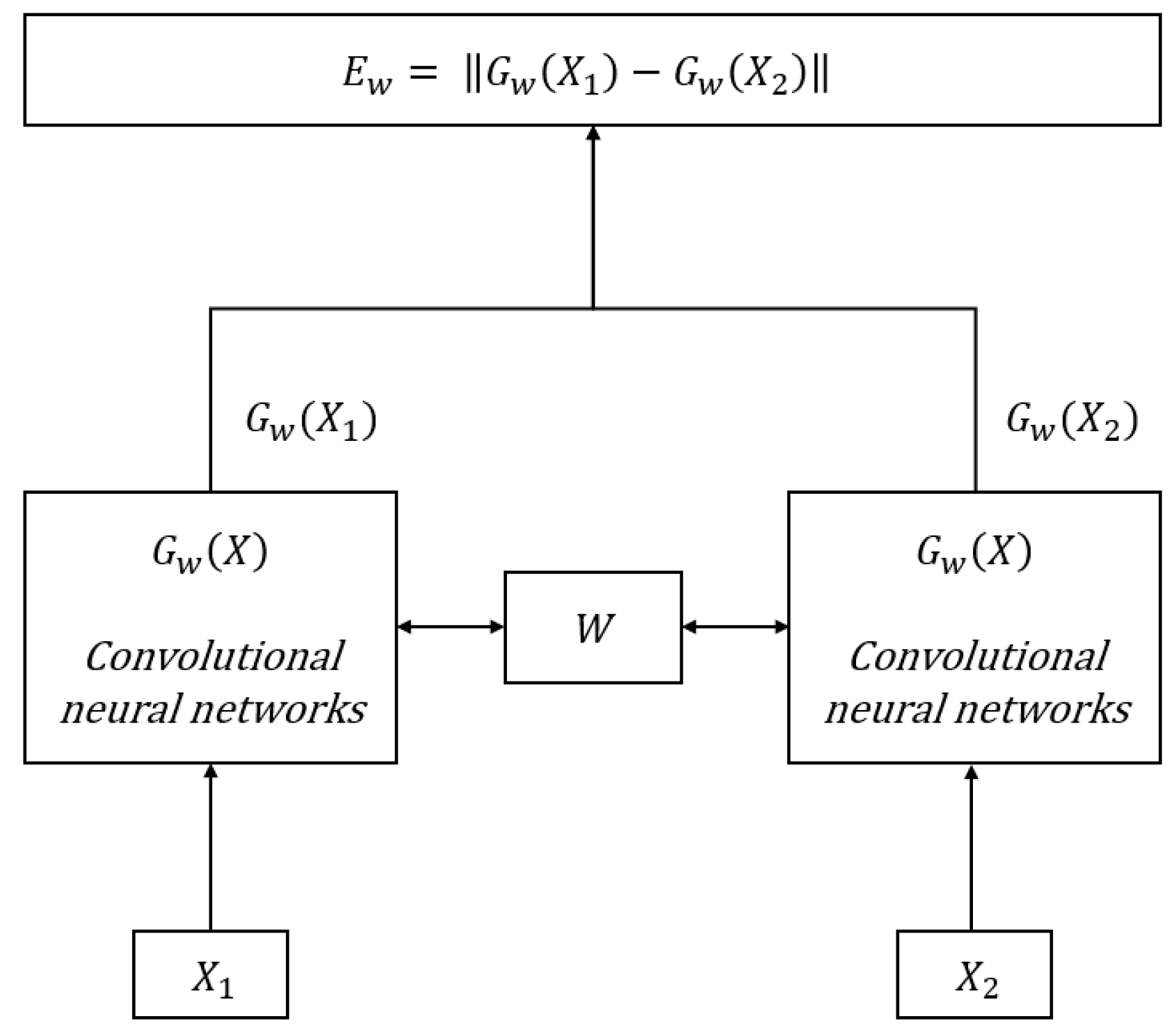
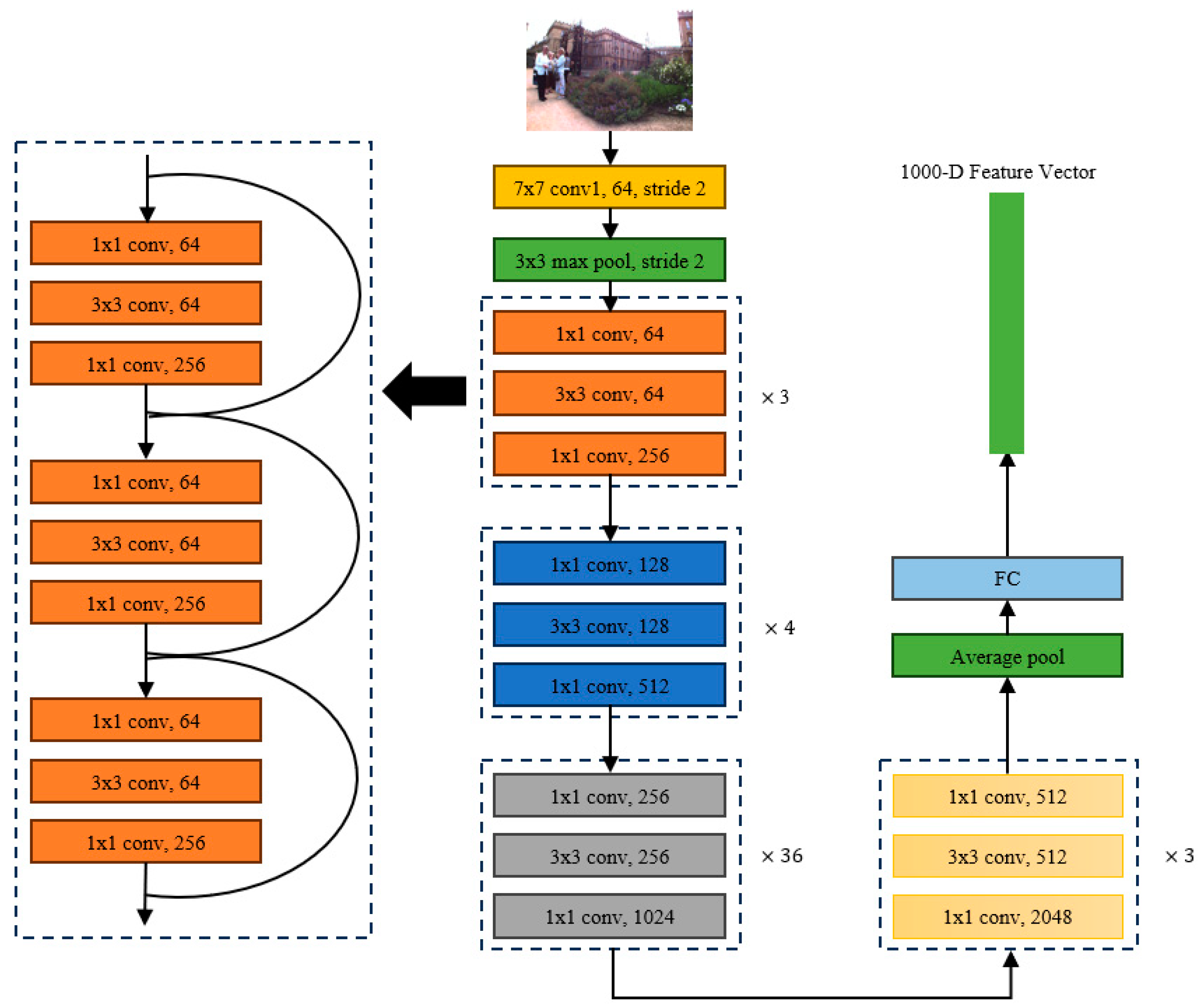
- Utilization of Pre-trained ResNet152 as Backbone Feature Extractor: This work employed a pre-trained ResNet152 as the backbone feature-extraction sub-network and designs a Siamese neural network with shared weights. After training, this network can perform holistic feature extraction on input image sequences, generating advanced image feature vectors for image-similarity detection. Considering that the primary objective of loop closure detection is to identify the location of the images, the Places-365 dataset was selected for feature-extraction training during the process of network training.
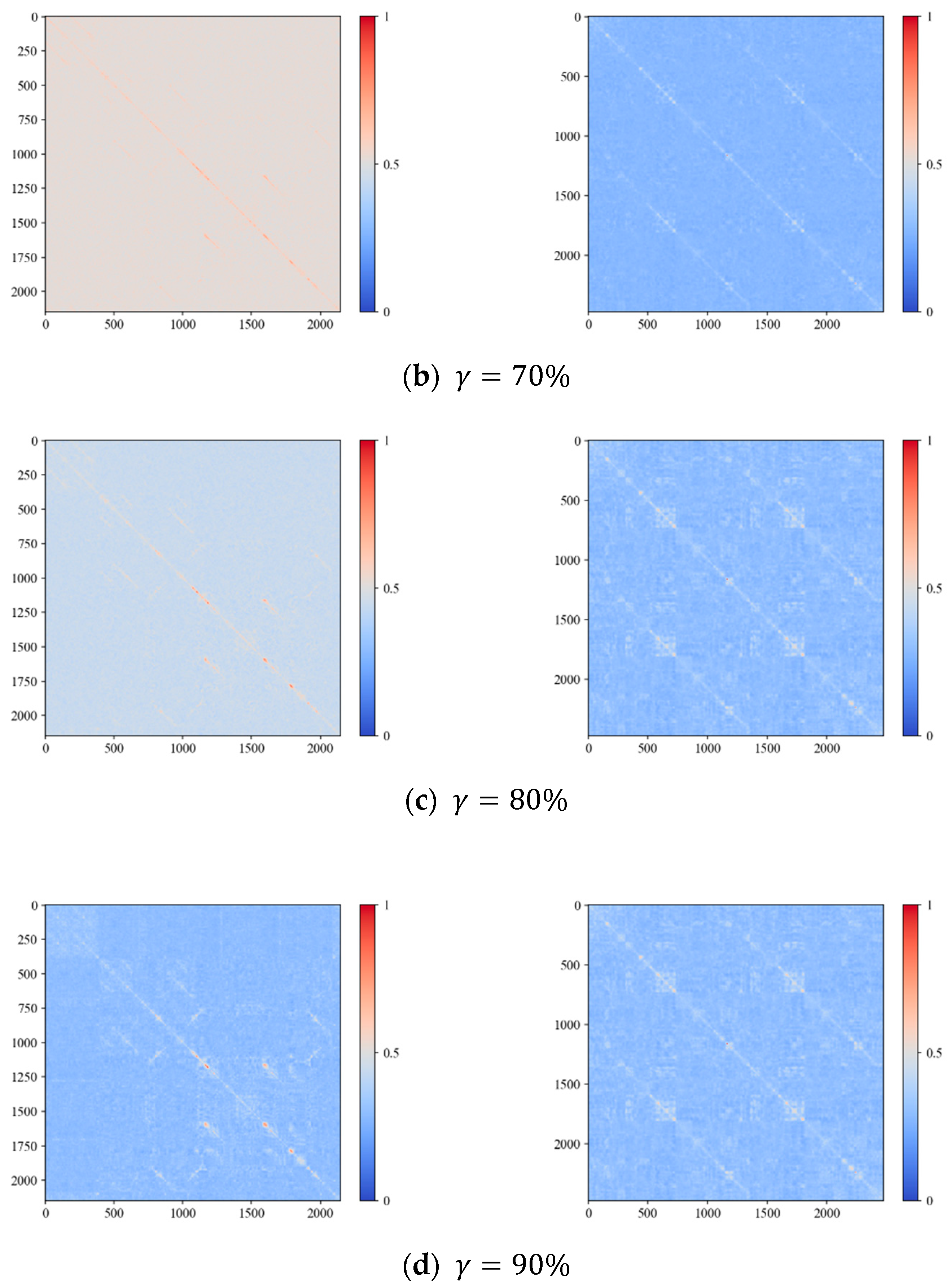
- Incorporation of KL Transformation for Feature Compression: To mitigate the impact of dynamic environments on image-similarity detection, reduce the probability of false detections, and preserve important information within features to the maximum extent, this paper introduced KL transformation as a standalone feature-compression module. Inserted at the output end of the Siamese neural network, it compresses and reduces the dimensionality of the high-level feature information outputted by the network. The KL transformation aims to eliminate redundancy in information and adjusts the compression ratio based on different scenes and object configurations in the images.
- Generation of Spatially Informed Image Descriptors using NetVLAD: The compressed features were inputted into NetVLAD to generate image descriptors with spatial information for similarity detection. The proposed method was tested using publicly available datasets. To evaluate model performance, different backbone networks for feature extraction and various compression methods were tested in loop closure detection. Results indicate that the compressed features exhibit enhanced representational capabilities for dynamic scenes.
2. Materials and Methods
- Input images into the Siamese neural network pre-trained on the Places-365 dataset for global feature extraction;
- Utilize the KL compression module to compress the extracted features;
- Input the compressed features into NetVLAD to generate image descriptors for similarity detection.
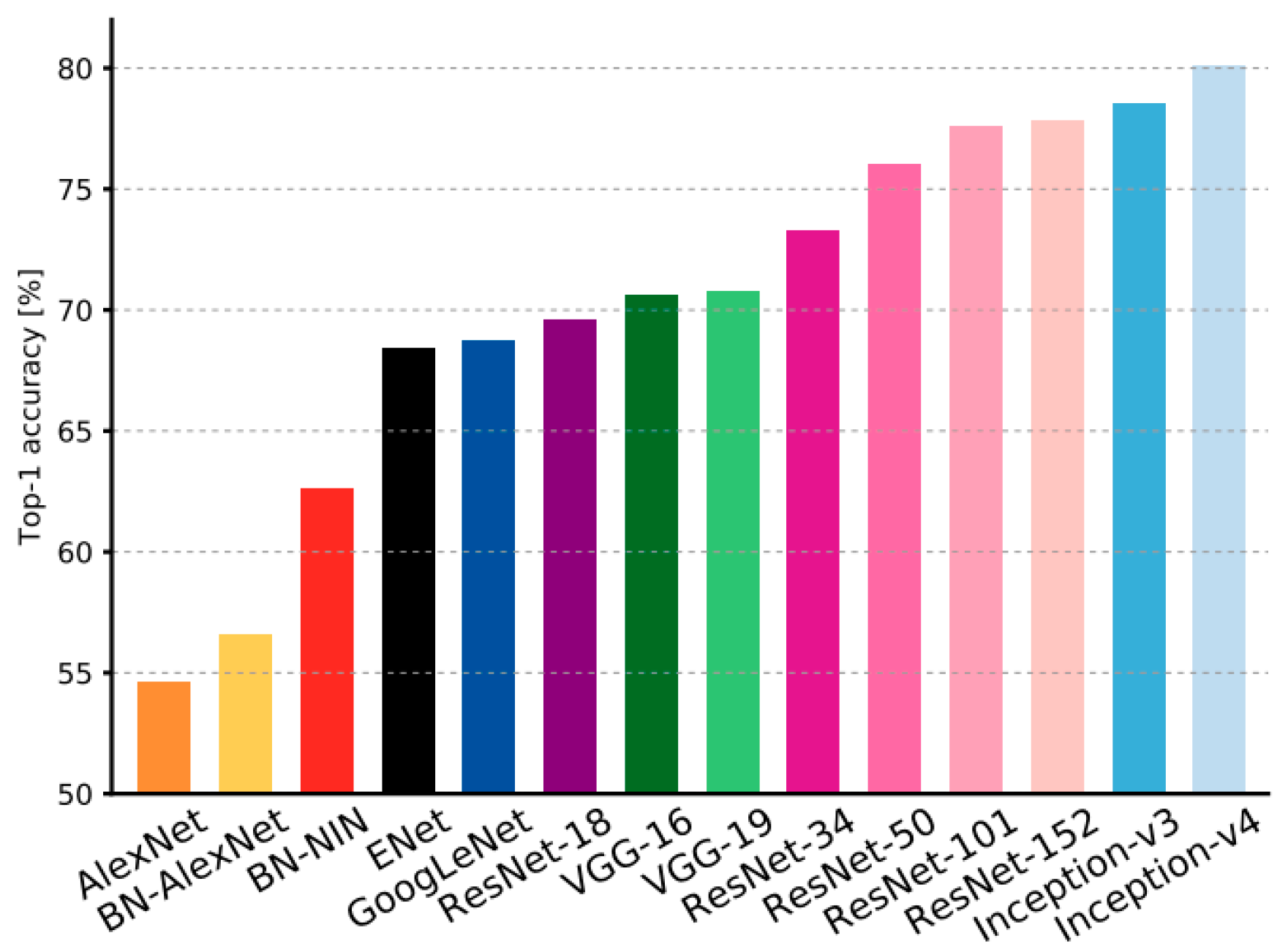
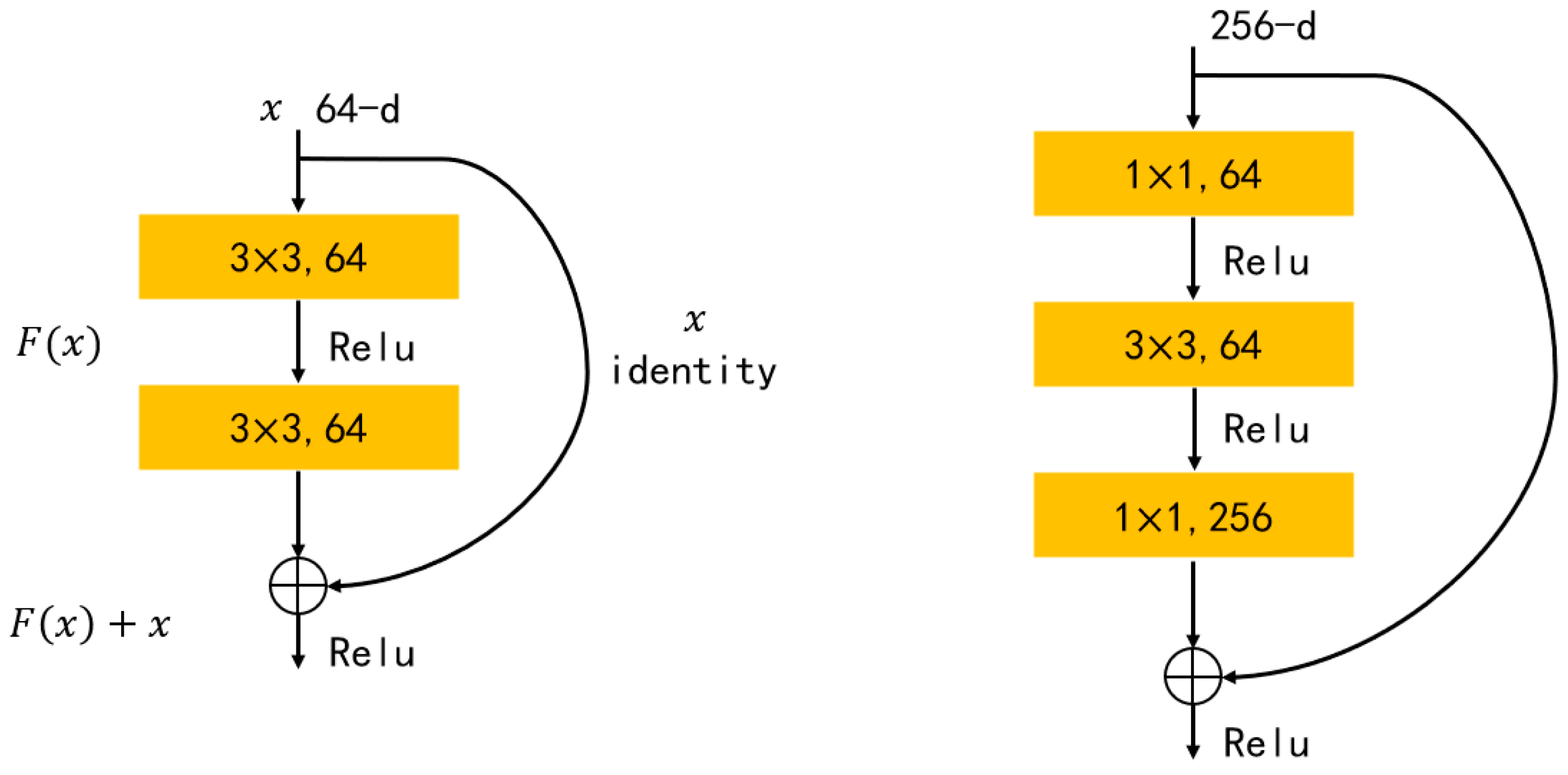
2.1. Feature Extraction by the Backbone Network
2.2. Feature Compression
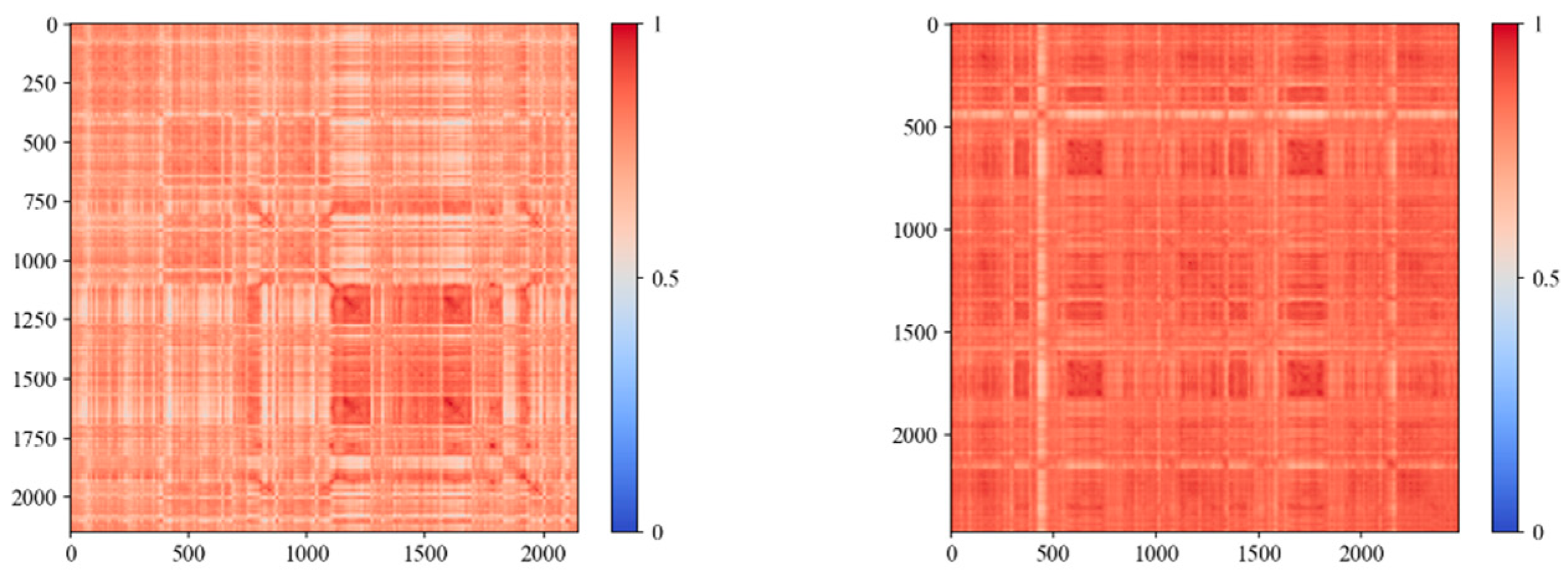
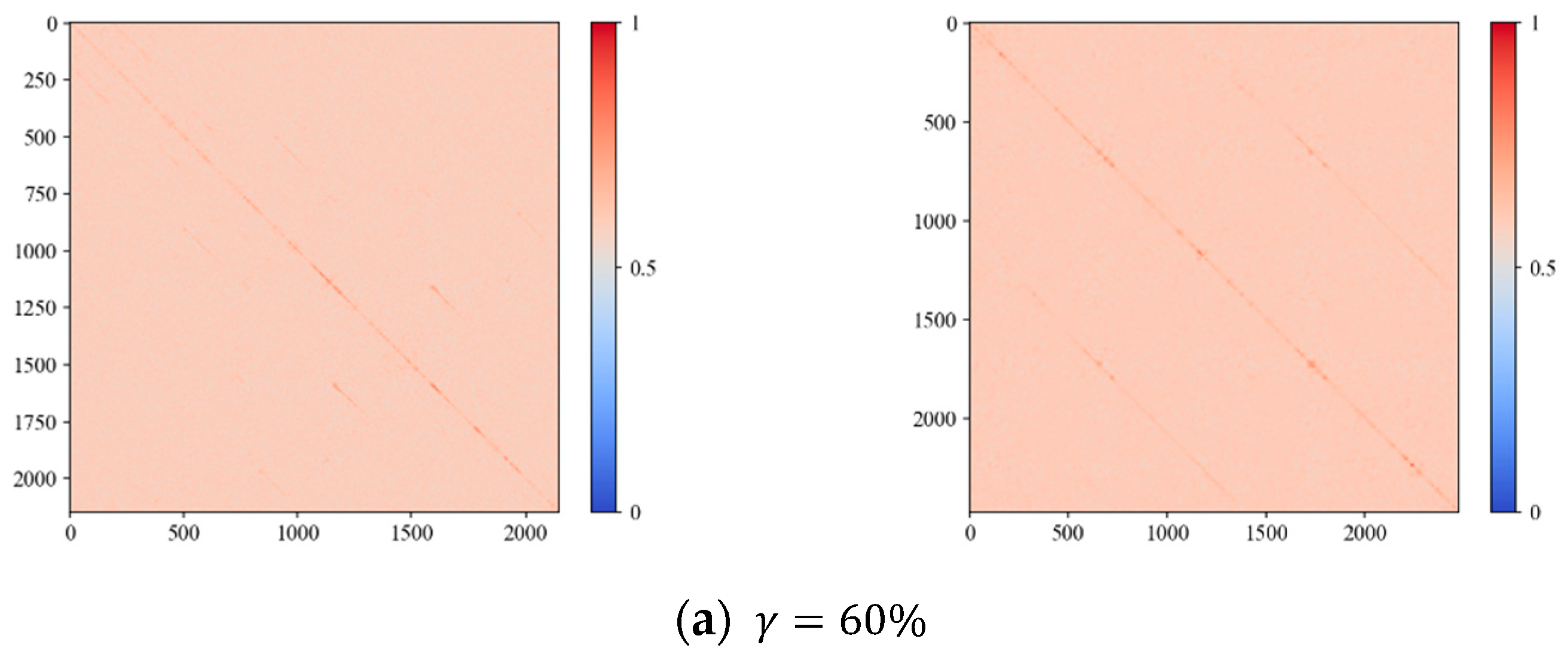
2.3. Image Similarity Calculation
3. Results
3.1. Introduction to the Dataset
3.2. Evaluation Criteria
3.3. Experimental Comparison
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Chatial, R.; Laumond, J.P. Position referencing and consistent world modeling for mobile robots. In Proceedings of the IEEE International Conference on Robotics and Automation, St. Louis, MO, USA, 25–28 March 1985; Volume 2, pp. 138–145. [Google Scholar]
- Lili, M.; Pantao, Y.; Yuchen, Z.; Kai, C.; Fangfang, W.; Nana, Q. Research on SLAM Algorithm of Mobile Robot Based on the Fusion of 2D LiDAR and Depth Camera. IEEE Access 2020, 8, 157628–157642. [Google Scholar]
- Masone, C.; Caputo, B. A Survey on Deep Visual Place Recognition. IEEE Access 2021, 9, 19516–19547. [Google Scholar] [CrossRef]
- Garcia, F.E.; Ortiz, A. iBoW-LCD: An Appearance-based Loop Closure Detection Approach Using Incremental Bags of Binary Words. IEEE Robot. Autom. Lett. 2018, 3, 3051–3057. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Fan, Y.; Gongshen, L.; Kui, M.; Zhaoying, S. Neural feedback text clustering with BiLSTM-CNN-Kmeans. IEEE Access 2018, 6, 57460–57469. [Google Scholar] [CrossRef]
- Cummins, M.; Newman, P. Appearance-only SLAM at Large Scale with FAB-MAP 2.0. Int. J. Robot. Res. 2011, 30, 1100–1123. [Google Scholar] [CrossRef]
- Angeli, A.; Filliat, D.; Doncieux, S.; Meyer, J.-A. Fast and Incremental Method for Loop-Closure Detection Using Bags of Visual Words. IEEE Trans. Robot. 2008, 24, 1027–1037. [Google Scholar] [CrossRef]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. Modest-vocabulary loop-closure detection with incremental bag of tracked words. Robot. Auton. Syst. 2021, 141, 103782. [Google Scholar] [CrossRef]
- Li, Y.; Wei, W.; Zhu, H. Incremental Bag of Words with Gradient Orientation Histogram for Appearance-Based Loop Closure Detection. Appl. Sci. 2023, 13, 6481. [Google Scholar] [CrossRef]
- Gao, X.; Zhang, T. Loop closure detection for visual SLAM systems using deep neural networks. In Proceedings of the 2015 34th Chinese Control Conference (CCC), Hangzhou, China, 28–30 July 2015; pp. 5851–5856. [Google Scholar]
- Xia, Y.; Li, J.; Qi, L.; Yu, H.; Dong, J. An evaluation of deep learning in loop closure detection for visual SLAM. In Proceedings of the 2017 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Exeter, UK, 21–23 June 2017; pp. 85–91. [Google Scholar]
- Ma, J.; Wang, S.; Zhang, K.; He, Z.; Huang, J.; Mei, X. Fast and robust loop-closure detection via convolutional auto-encoder and motion consensus. IEEE Trans. Lndustrial Inform. 2021, 18, 3681–3691. [Google Scholar] [CrossRef]
- Zhang, X.; Zheng, L.; Tan, Z.; Li, S. Loop Closure Detection Based on Residual Network and Capsule Network for Mobile Robot. Sensors 2022, 22, 7137. [Google Scholar] [CrossRef] [PubMed]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. LEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 Million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context; Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Hou, Y.; Zhang, H.; Zhou, S. Convolutional neural network-based image representation for visual loop closure detection. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 2238–2245. [Google Scholar]
- Sünderhauf, N.; Shirazi, S.; Dayoub, F.; Upcroft, B.; Milford, M. On the performance of convnet features for place recognition. In Proceedings of the 2015 IEEE/RSJ international conference on intelligent robots and systems (IROS), Hamburg, Germany, 28 September 2015–2 October 2015; pp. 4297–4304. [Google Scholar]
- Liu, Y.; Xiang, R.; Zhang, Q.; Ren, Z.; Cheng, J. Loop closure detection based on improved hybrid deep learning architecture. In Proceedings of the 2019 IEEE International Conferences on Ubiquitous Computing & Communications (IUCC) and Data Science and Computational Intelligence (DSCI) and Smart Computing, Networking and Services (SmartCNS), Shenyang, China, 21–23 October 2019; pp. 312–317. [Google Scholar]
- Kim, J.J.; Urschler, M.; Riddle, P.J.; Wicker, J.S. SymbioLCD: Ensemble-Based Loop Closure Detection using CNN-Extracted Objects and Visual Bag-of-Words. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September 2021–1 October 2021; pp. 5425–5431. [Google Scholar]
- Kuang, X.; Guo, J.; Bai, J.; Geng, H.; Wang, H. Crop-Planting Area Prediction from Multi-Source Gaofen Satellite Images Using a Novel Deep Learning Model: A Case Study of Yangling District. Remote Sens. 2023, 15, 3792. [Google Scholar] [CrossRef]
- Chen, Y.; Zhong, Y.; Wang, W.; Peng, H. Fast and robust loop-closure detection using deep neural networks and matrix transformation for a visual SLAM system. J. Electron. Imaging 2022, 31, 061816. [Google Scholar] [CrossRef]
- Hossain, M.M.; Hossain, M.A.; Musa Miah, A.S.; Okuyama, Y.; Tomioka, Y.; Shin, J. Stochastic Neighbor Embedding Feature-Based Hyperspectral Image Classification Using 3D Convolutional Neural Network. Electronics 2023, 12, 2082. [Google Scholar] [CrossRef]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I. Signature Verification using a “Siamese” Time Delay Neural Network. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 25. [Google Scholar] [CrossRef]
- Canziani, A.; Paszke, A.; Culurciello, E. An Analysis of Deep Neural Network Models for Practical Applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
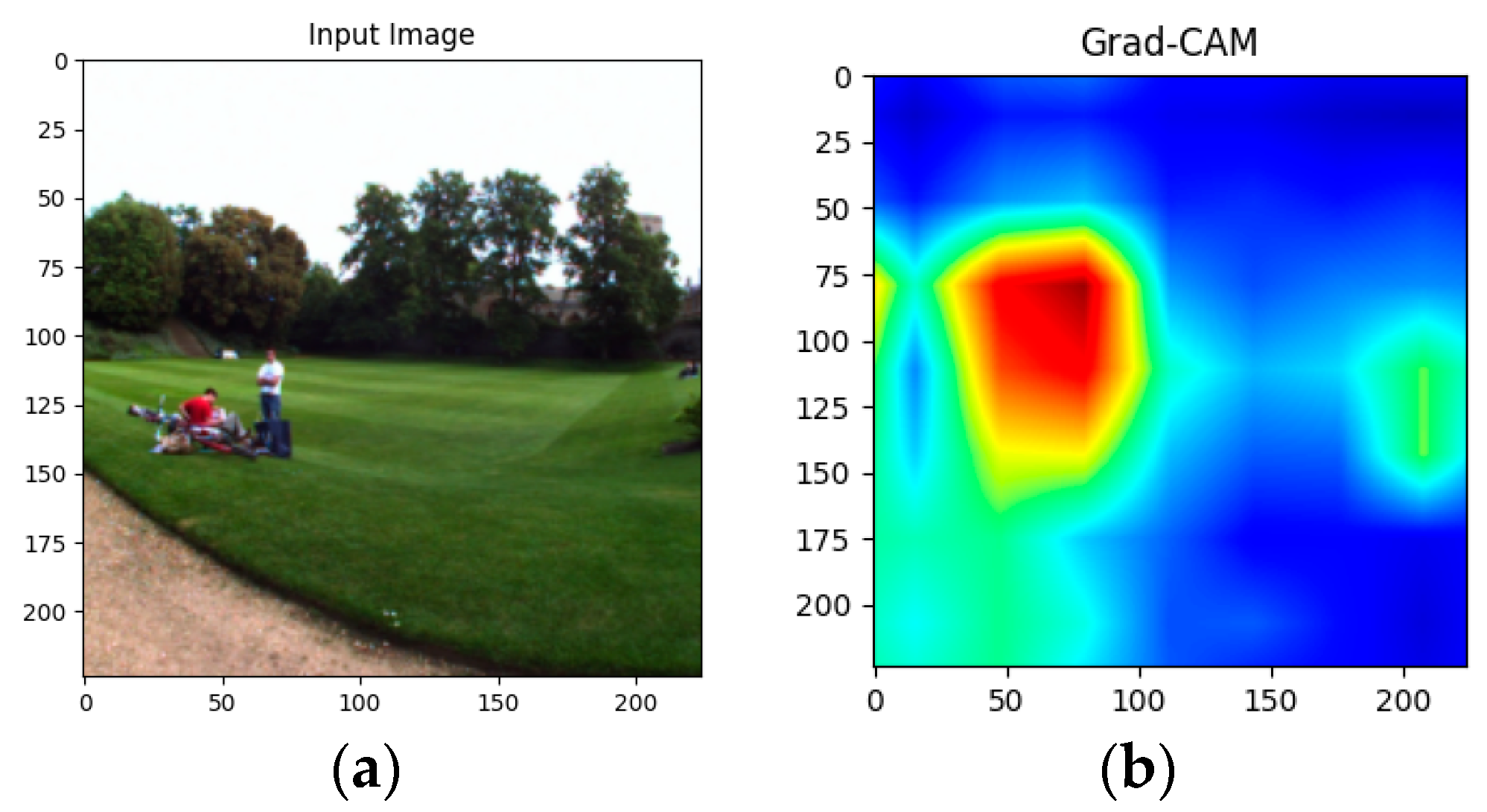
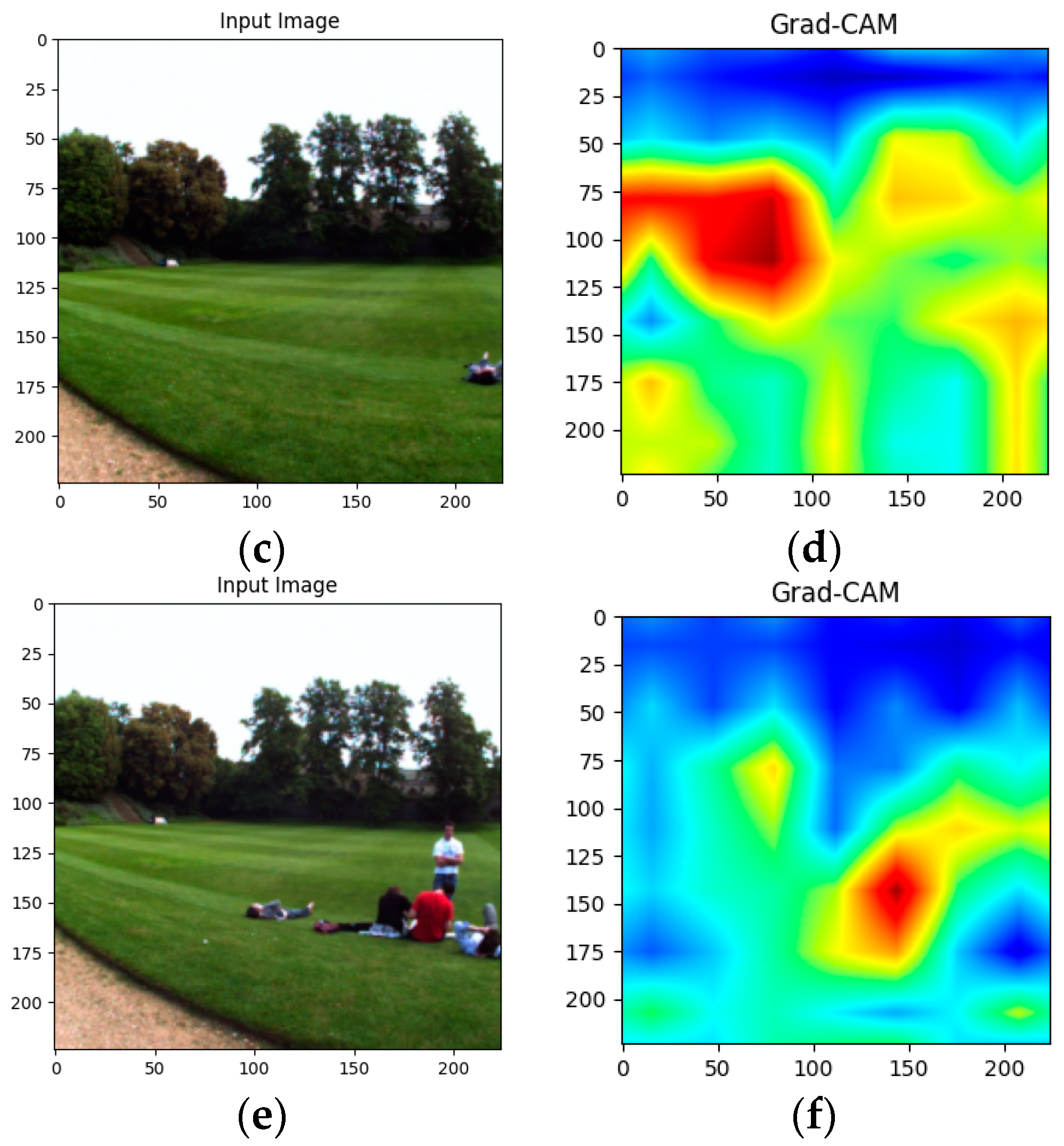
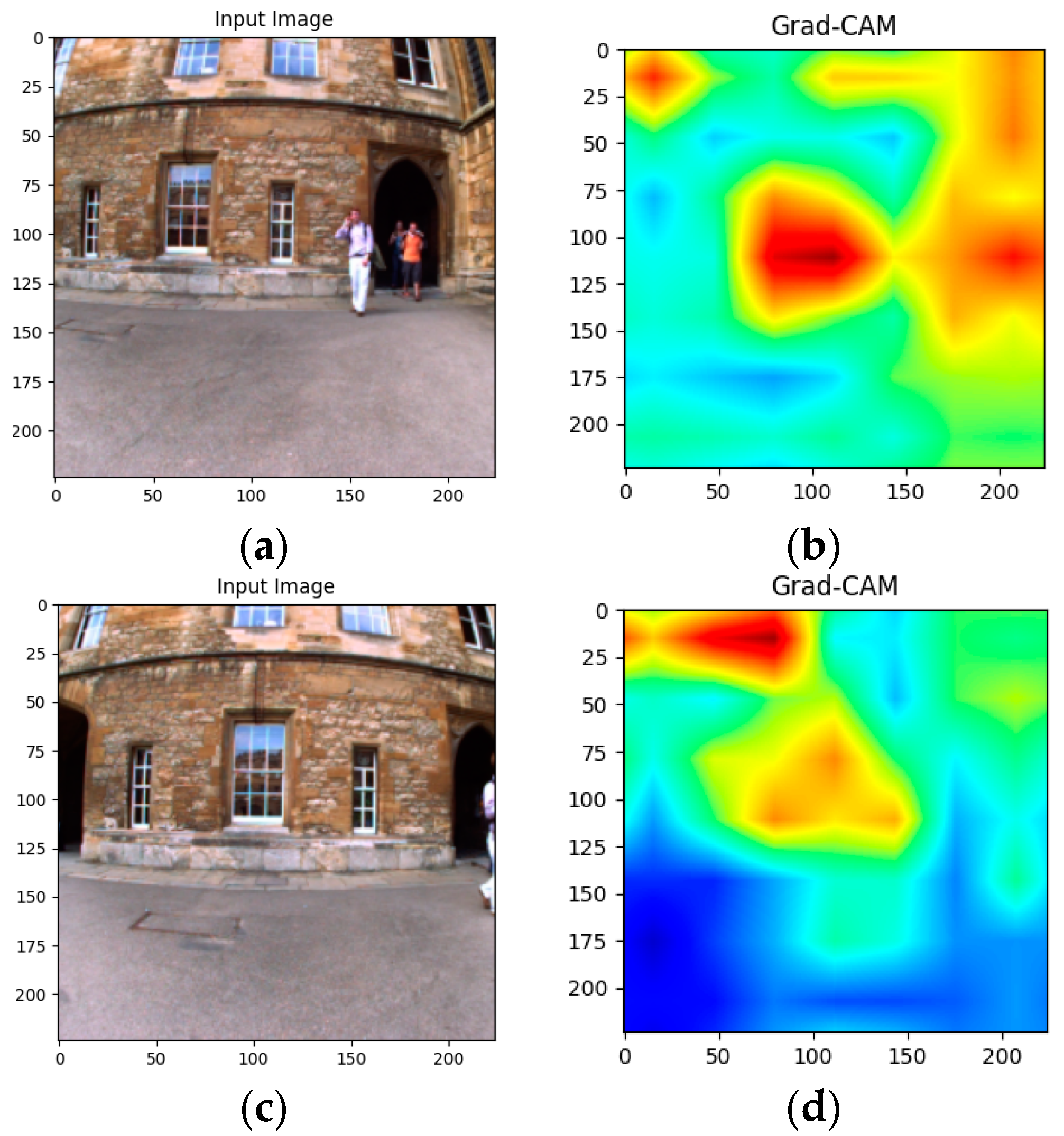
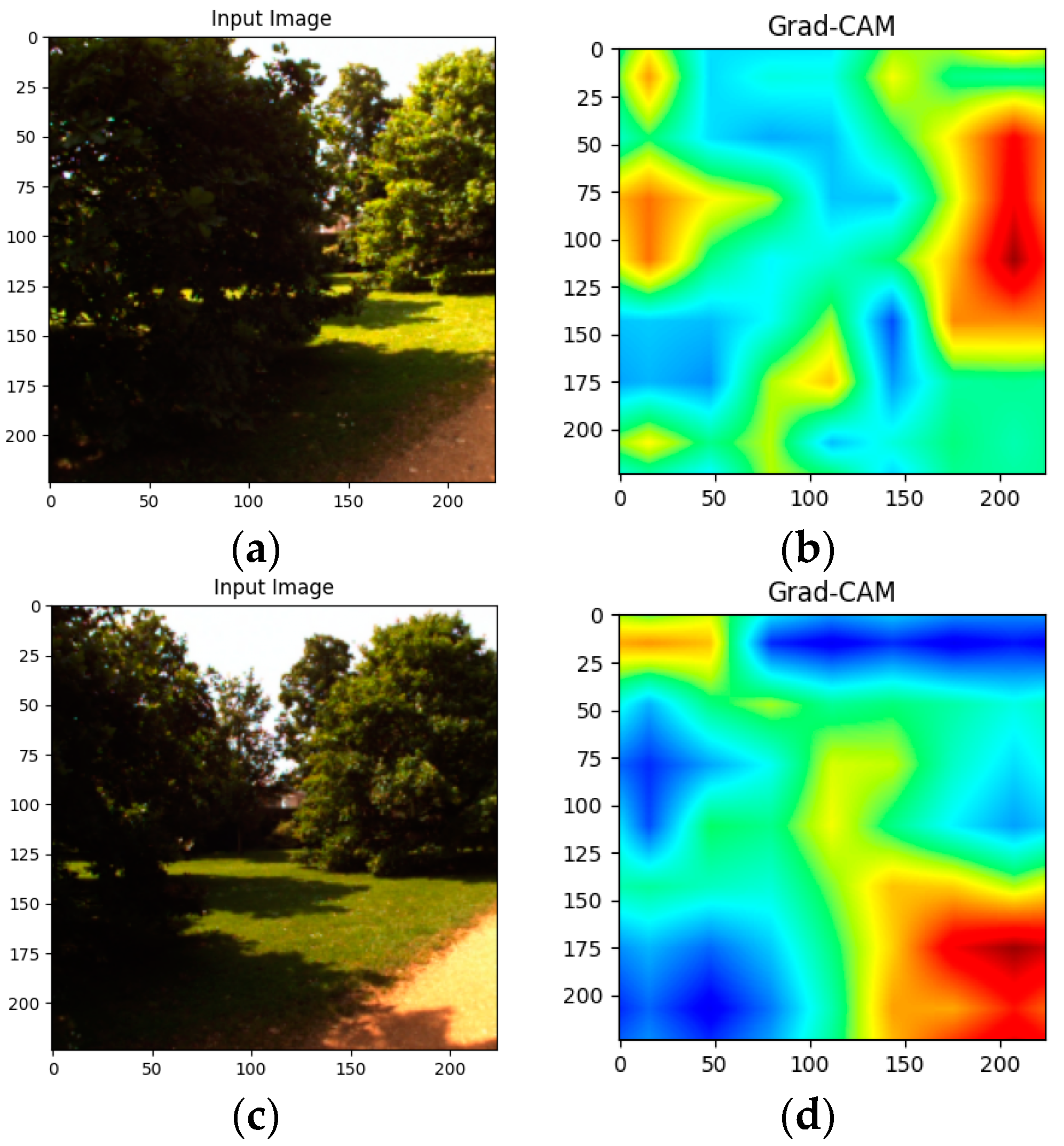
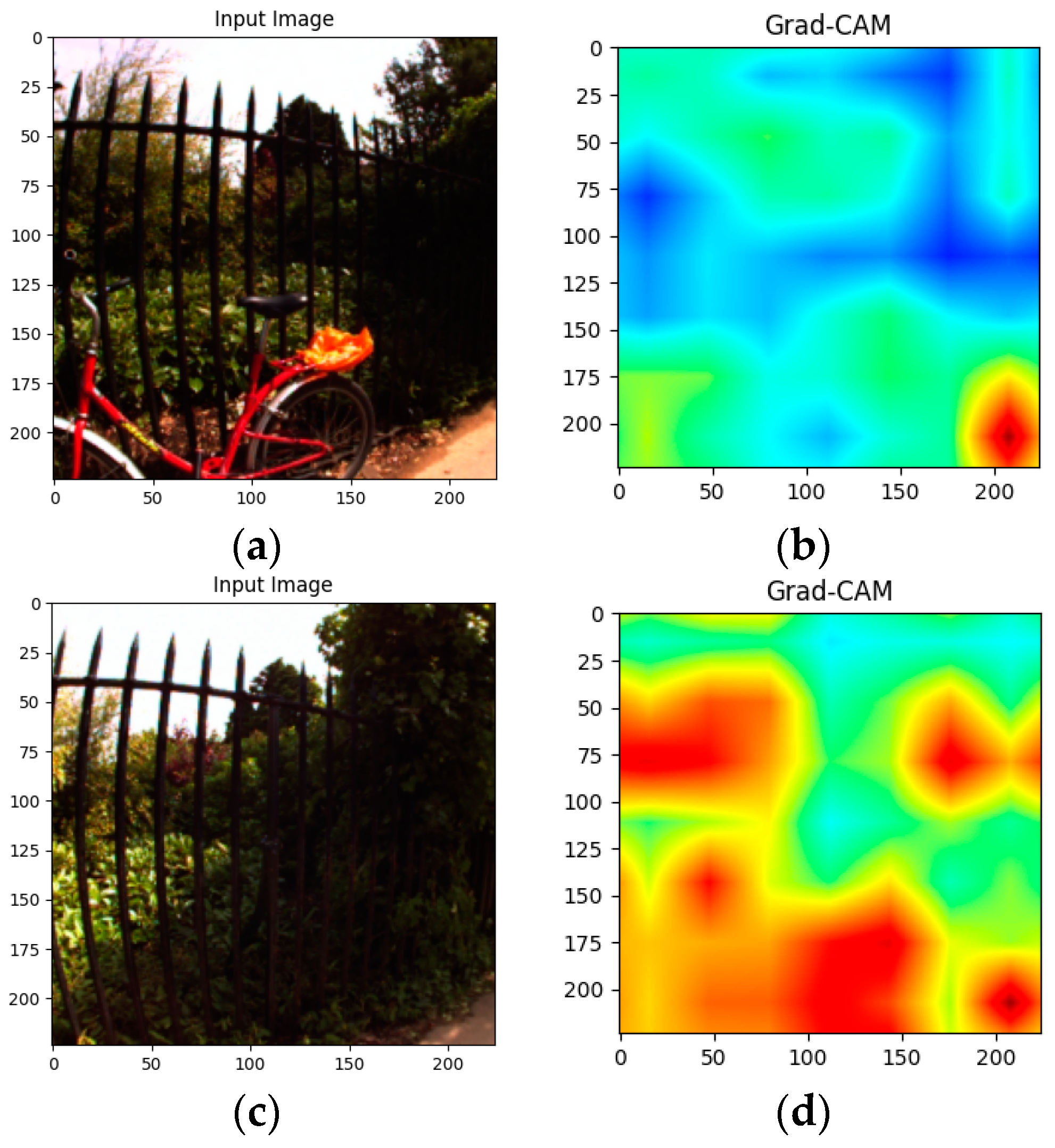
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2016, 128, 336–359. [Google Scholar] [CrossRef]
- Bannour, S.; Azimi-Sadjadi, M.R. Principal component extraction using recursive least squares learning method. In Proceedings of the 1991 IEEE International Joint Conference on Neural Networks, Singapore, 18–21 November 1991; Volume 3, pp. 2110–2115. [Google Scholar] [CrossRef]
- Puchala, D. Approximating the KLT by Maximizing the Sum of Fourth-Order Moments. IEEE Signal Process. Lett. 2013, 20, 193–196. [Google Scholar] [CrossRef]
- Arandjelović, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1437–1451. [Google Scholar]
- Milford, M.J.; Wyeth, G.F. SeqSLAM: Visual route-based navigation for sunny summer days and stormy winter nights. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1643–1649. [Google Scholar] [CrossRef]
- Paul, R.; Newman, P. FAB-MAP 3D: Topological mapping with spatial and visual appearance. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 2649–2656. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Method | Advantages | Shortcomings |
|---|---|---|---|
| Traditional methods | BoW | 1. Simple and easy to execute | 1. Time-consuming |
| 2. Inability to adapt to a new environment | |||
| Incremental BoW | 1. Improved generalization ability of the model | 1. Time-consuming | |
| 2. Inability to adapt to a new environment | |||
| Deep Learning methods | CNN | 1. Powerful image feature extraction capabilities | 1. computationally intensive and occupies memory |
| 2. Strong generalization ability | 2. susceptible to interference from dynamic objects | ||
| CNN-AE | 1. Data dimensionality reduction | 1. Loss of information | |
| 2. Unsupervised, strong generalization ability | 2. Overfitting | ||
| CNN-PCA | 1. Data dimensionality reduction | 1. Loss of information | |
| 2. Removal of redundant information | 2. Difficult of setting parameters |
| Dataset | Classification | The Number of Images | The Size | The Distance |
|---|---|---|---|---|
| New College | Left | 1073 | 640 × 480 | 1900 m |
| Right | 1073 | 640 × 480 | ||
| City Centre | Left | 1237 | 640 × 480 | 2000 m |
| Right | 1237 | 640 × 480 |
| Parameter | Value | Description |
|---|---|---|
| Image Size | 224 × 224 | Input to ResNet152 |
| Layer | conv3, conv4, conv5 | Convolutional layers of ResNet152 |
| [60%, 70%, 80%, 90%] | Compression ratio information | |
| Image Sequence Length | 10 | Number of images in sequence |
| 0.3 | Similarity detection threshold |
| Layer | Max Recall at 100% Precision (%) | |||
|---|---|---|---|---|
| = 60% | = 70% | = 80% | = 90% | |
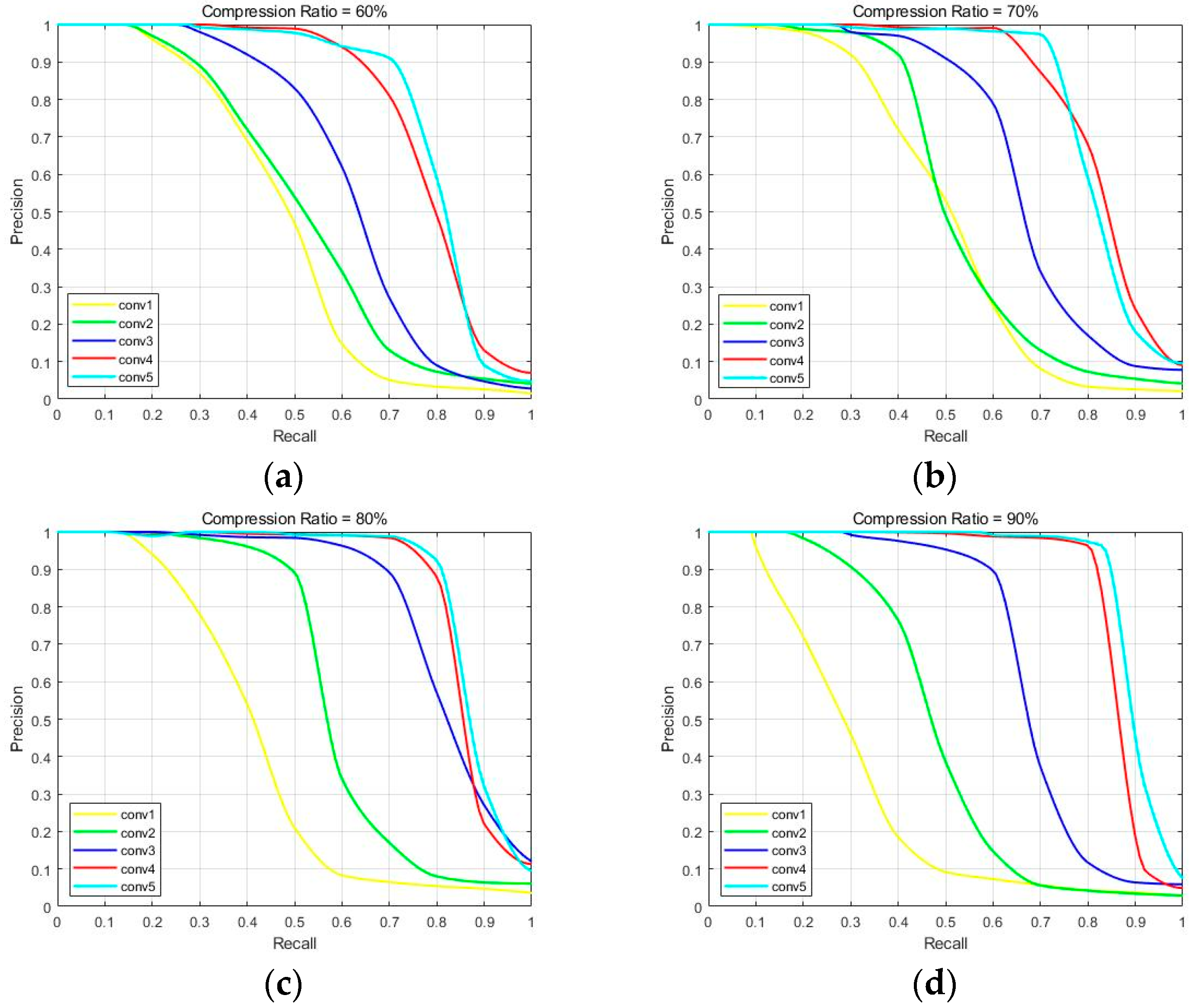
| Conv1 | 14.62 | 14.23 | 12.69 | 9.41 |
| Conv2 | 14.22 | 13.76 | 18.31 | 16.58 |
| Conv3 | 25.34 | 26.86 | 30.21 | 28.17 |
| Conv4 | 30.67 | 28.52 | 40.07 | 45.69 |
| Conv5 | 27.88 | 24.39 | 46.55 | 60.14 |
| Layer | Max Recall at 100% Precision (%) | |||
|---|---|---|---|---|
| Ratio = 60% | Ratio = 70% | Ratio = 80% | Ratio = 90% | |
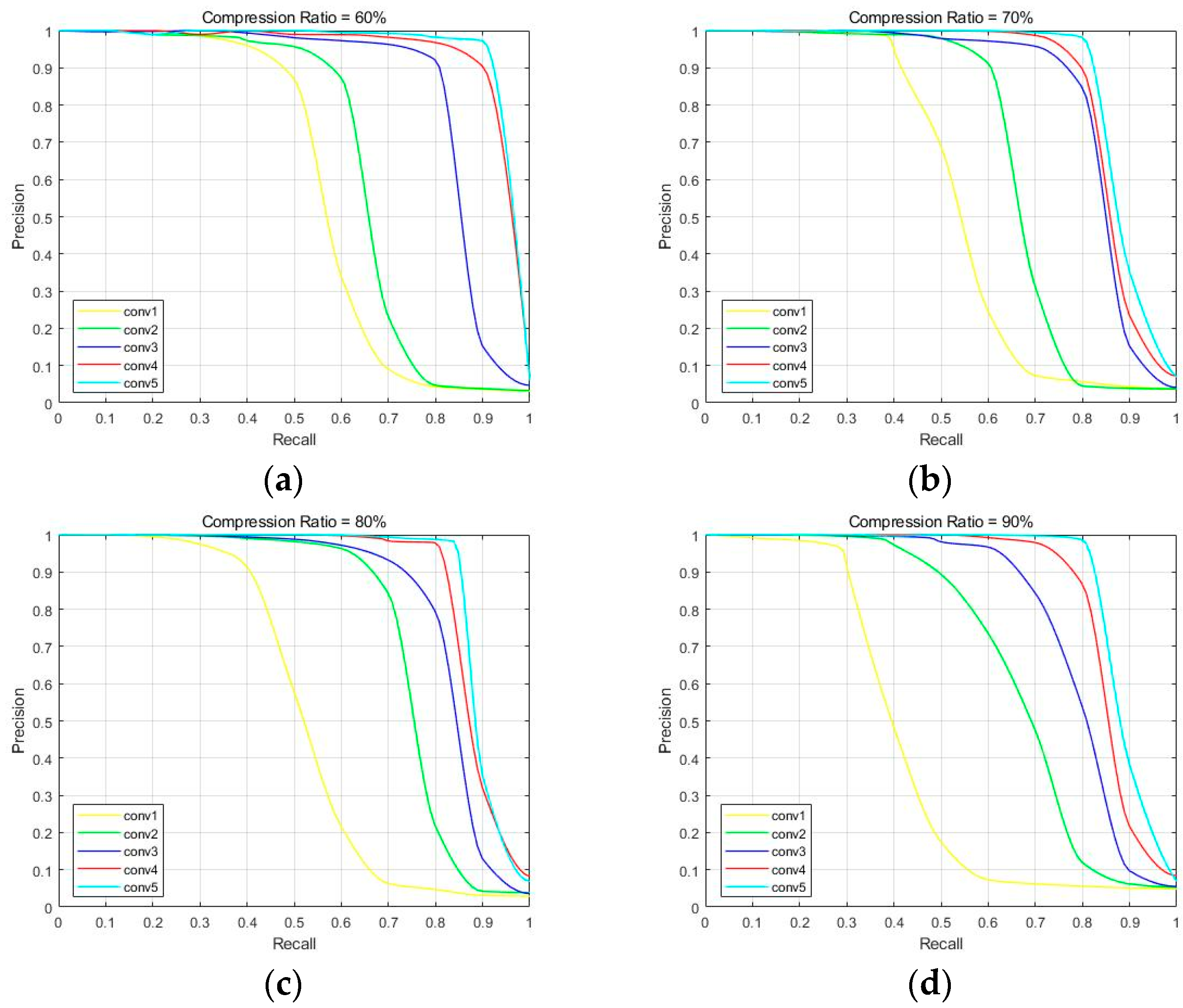
| Conv1 | 33.64 | 39.72 | 37.88 | 29.17 |
| Conv2 | 38.72 | 47.38 | 42.39 | 37.54 |
| Conv3 | 48.13 | 46.75 | 50.21 | 47.68 |
| Conv4 | 62.54 | 71.42 | 69.01 | 63.87 |
| Conv5 | 75.65 | 75.09 | 73.42 | 73.38 |
| Method | Max Recall at 100% Precision (%) | |
|---|---|---|
| New College | City Center | |
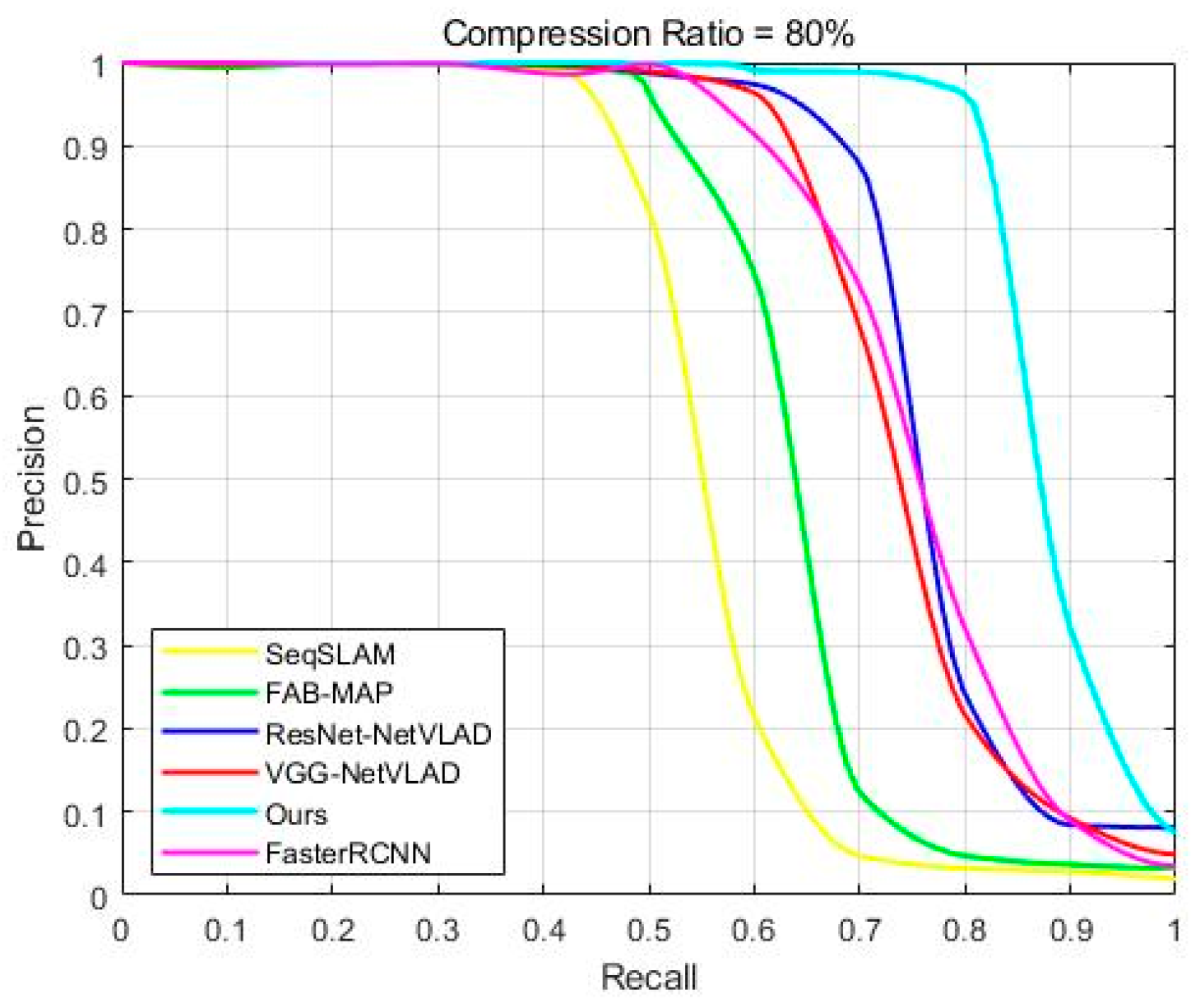
| SeqSLAM | 42.39 | 47.16 |
| FAB-MAP | 49.10 | 52.09 |
| ResNet152_NetVLAD | 54.38 | 58.23 |
| VGG_NetVLAD | 52.11 | 44.26 |
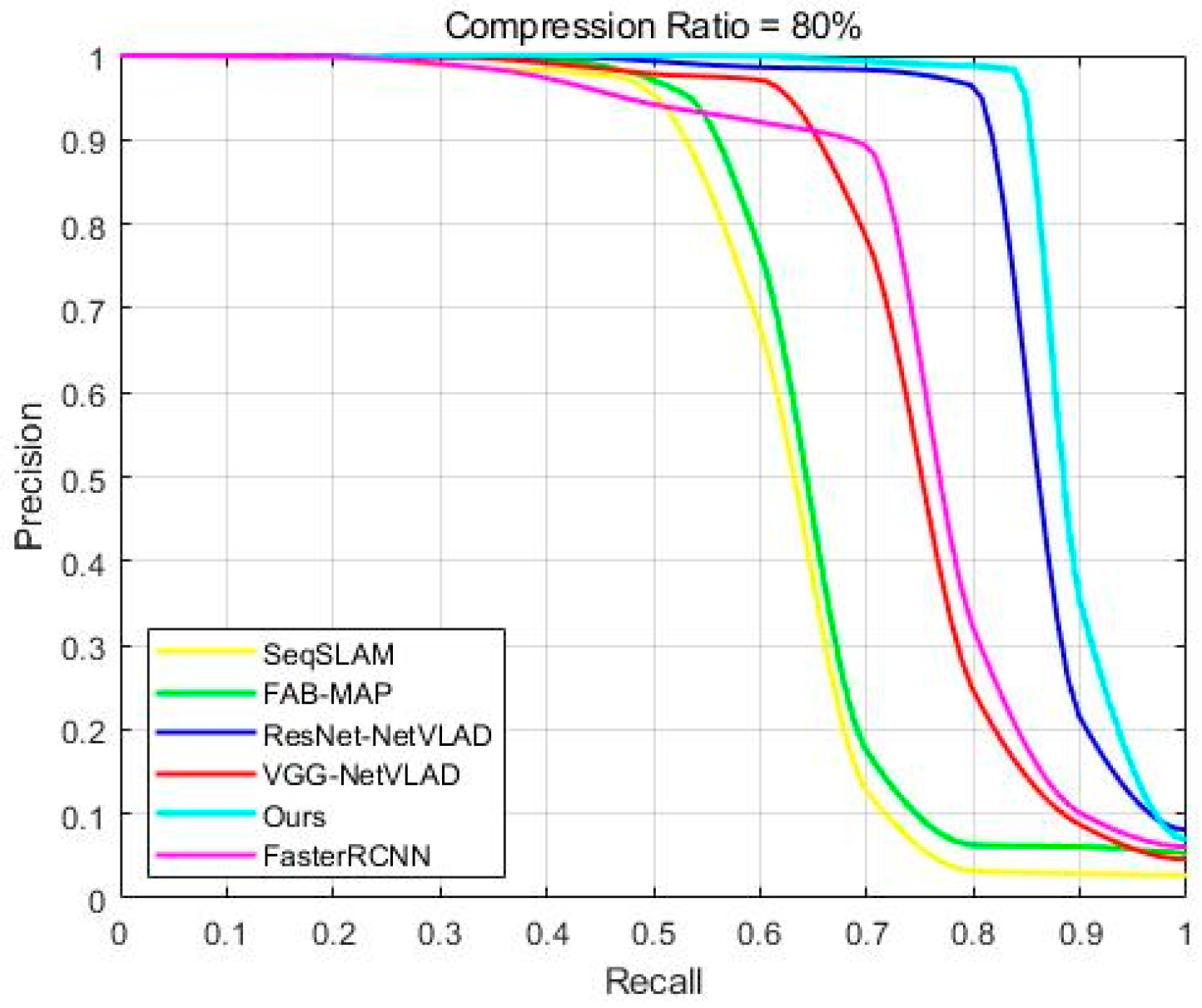
| Our method | 60.14 | 73.38 |
| Faster RCNN | 42.57 | 36.85 |
| Method | Time Consumption | |
|---|---|---|
| Total Time (/s) | Average Time (/ms) | |
| SeqSLAM | 64.32 | 32.16 |
| FAB-MAP | 88.54 | 44.27 |
| ResNet152_NetVLAD | 35.90 | 17.95 |
| VGG_NetVLAD | 49.78 | 24.89 |
| Our method | 27.46 | 13.73 |
| Faster RCNN | 23.24 | 11.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, S.; Zhou, Z.; Sun, S. Loop Closure Detection Based on Compressed ConvNet Features in Dynamic Environments. Appl. Sci. 2024, 14, 8. https://doi.org/10.3390/app14010008
Jiang S, Zhou Z, Sun S. Loop Closure Detection Based on Compressed ConvNet Features in Dynamic Environments. Applied Sciences. 2024; 14(1):8. https://doi.org/10.3390/app14010008
Chicago/Turabian StyleJiang, Shuhai, Zhongkai Zhou, and Shangjie Sun. 2024. "Loop Closure Detection Based on Compressed ConvNet Features in Dynamic Environments" Applied Sciences 14, no. 1: 8. https://doi.org/10.3390/app14010008
APA StyleJiang, S., Zhou, Z., & Sun, S. (2024). Loop Closure Detection Based on Compressed ConvNet Features in Dynamic Environments. Applied Sciences, 14(1), 8. https://doi.org/10.3390/app14010008