
Towards Optimizing Multi-Level Selective Maintenance via Machine Learning Predictive Models


Abstract
:1. Introduction
2. Literature Review
3. Problem Formulation
Problem Description
- Maintenance actions are performed only during the intermission breaks;
- The duration of missions and breaks are assumed known and fixed;
- A minimum threshold of system reliability should be ensured throughout the operating period.
4. Proposed Methodology
4.1. Estimation of Actual Age and System Reliability Function
4.2. Predictive Model for Multi-Level Selective Maintenance Using ANN and SVR
4.2.1. The General Concept of the ANN Model
- -
- : the input node
- -
- : the output of the hidden node
- -
- : the weight connecting the input node to the hidden node
- -
- : the activation function of the model
- -
- : the input layer bias
- -
- : the hidden layer bias
- -
- : the model output: the estimated target value.
- Identity function
- Logistic Sigmoid function
- Rectified linear unit function
- Hyperbolic tangent function
4.2.2. The General Concept of SVR Model
4.2.3. Hyperparameter and Model Evaluation
4.2.4. Predictive Model on the FMS Data
- -
- An input layer of nodes and an activation function Relu (rectified linear unit);
- -
- A first hidden layer of nodes and an activation function Relu;
- -
- A second hidden layer of nodes and an activation function Relu;
- -
- An output layer of one node (regression problem).
4.3. Selective Maintenance with Multi-Strategies
4.3.1. Optimization Model
4.3.2. Resolution Method
5. Numerical Results
5.1. FMS Study Case and Input Data
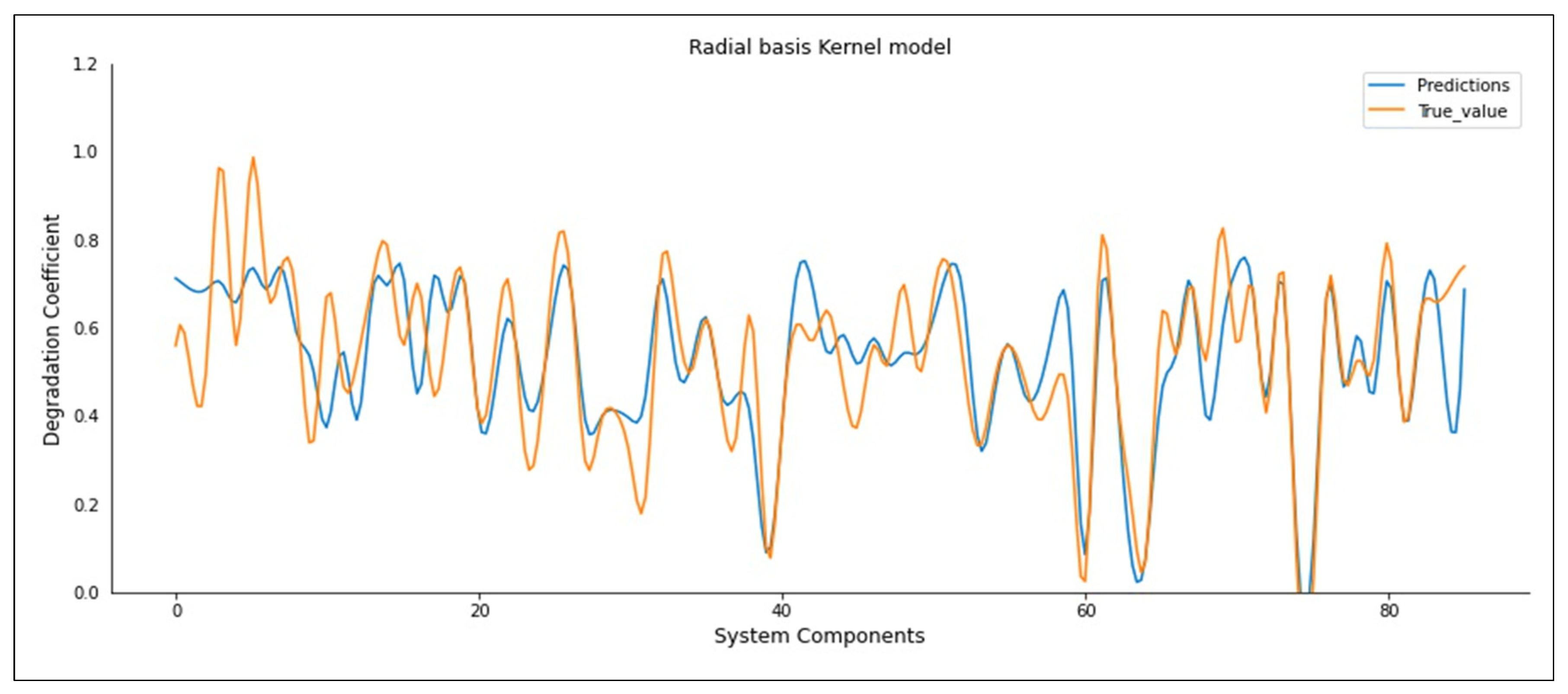
5.2. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Notations
| M | Total maintenance cost during the break between missions and |
| Maintenance level (or strategy) for component with | |
| Cost of the maintenance level | |
| Duration of the maintenance level of component | |
| Maintenance cost per time unit | |
| Cost of assembly\disassembly incurred if at least one component is maintained | |
| Duration of mission | |
| Break duration between mission and | |
| Degradation factor of component at the end of mission | |
| Theoretical component’s age given by the manufacturer | |
| Theoretical remaining useful life of component after performing mission | |
| Actual age of component at the end of the mission | |
| System reliability related to actual ages of multi-components. | |
| Minimal required reliability | |
| Total number of missions |
References
- Duan, C.; Deng, C.; Gong, Q.; Wang, Y. Optimal failure mode-based preventive maintenance scheduling for a complex mechanical device. Int. J. Adv. Manuf. Technol. 2018, 95, 2717–2728. [Google Scholar] [CrossRef]
- Jamshidi, R.; Esfahani, M.M.S. Maintenance policy determination for a complex system consisting of series and cold standby system with multiple levels of maintenance action. Int. J. Adv. Manuf. Technol. 2015, 78, 1337–1346. [Google Scholar] [CrossRef]
- Duan, C.; Deng, C.; Wang, B. Optimal multi-level condition-based maintenance policy for multi-unit systems under economic dependence. Int. J. Adv. Manuf. Technol. 2017, 91, 4299–4312. [Google Scholar] [CrossRef]
- Cao, W.; Jia, X.; Hu, Q.; Zhao, J.; Wu, Y. A literature review on selective maintenance for multi-unit systems. Qual. Reliab. Eng. Int. 2018, 34, 824–845. [Google Scholar] [CrossRef]
- Zhu, H.; Liu, F.; Shao, X.; Liu, Q.; Deng, Y. A cost-based selective maintenance decision-making method for machining line. Qual. Reliab. Eng. Int. 2011, 27, 191–201. [Google Scholar] [CrossRef]
- Nguyen, K.T.; Medjaher, K. A new dynamic predictive maintenance framework using deep learning for failure prognostics. Reliab. Eng. Syst. Saf. 2019, 188, 251–262. [Google Scholar] [CrossRef]
- Asadzadeh, S.; Azadeh, A. An integrated systemic model for optimization of condition-based maintenance with human error. Reliab. Eng. Syst. Saf. 2014, 124, 117–131. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- Rice, W.F.; Cassady, C.R.; Nachlas, J.A. Optimal maintenance plans under limited maintenance time. In Proceedings of the Seventh Industrial Engineering Research Conference, Banff, AB, Canada, 9–10 May 1998; pp. 1–3. [Google Scholar]
- Cassady, C.R.; Murdock, W.P., Jr.; Pohl, E.A. Selective maintenance for support equipment involving multiple maintenance actions. Eur. J. Oper. Res. 2001, 129, 252–258. [Google Scholar] [CrossRef]
- Cassady, C.R.; Pohl, E.A.; Murdock, W.P. Selective maintenance modeling for industrial systems. J. Qual. Maint. Eng. 2001, 7, 104–117. [Google Scholar] [CrossRef]
- Djelloul, I.; Khatab, A.; Aghezzaf, E.H.; Sari, Z. Optimal selective maintenance policy for series-parallel systems operating missions of random durations. In Proceedings of the International Conference on Computers & Industrial Engineering (CIE 45), Metz, France, 28–30 October 2015; pp. 28–30. [Google Scholar]
- Pandey, M.; Zuo, M.J.; Moghaddass, R. Selective maintenance modeling for a multistate system with multistate components under imperfect maintenance. IIE Trans. 2013, 45, 1221–1234. [Google Scholar] [CrossRef]
- Meng, M.H.; Zuo, M.J. Selective maintenance optimization for multi-state systems. In Proceedings of the Engineering Solutions for the Next Millennium. 1999 IEEE Canadian Conference on Electrical and Computer Engineering (Cat. No. 99TH8411), Edmonton, AB, Canada, 9–12 May 1999; Volume 3, pp. 1477–1482. [Google Scholar]
- Pandey, M.; Zuo, M.J.; Moghaddass, R. Selective maintenance for binary systems using age-based imperfect repair model. In Proceedings of the 2012 International Conference on Quality, Reliability, Risk, Maintenance, and Safety Engineering (QR2MSE), Chengdu, China, 15–18 June 2012; pp. 385–389. [Google Scholar]
- Khatab, A.; Aghezzaf, E.-H. Selective maintenance optimization when quality of imperfect maintenance actions are stochastic. Reliab. Eng. Syst. Saf. 2016, 150, 182–189. [Google Scholar] [CrossRef]
- Martorell, S.; Sánchez, A.; Carlos, S.; Serradell, V. Simultaneous and multi-criteria optimization of TS requirements and maintenance at NPPs. Ann. Nucl. Energy 2002, 29, 147–168. [Google Scholar] [CrossRef]
- Khatab, A.; Diallo, C.; Aghezzaf, E.-H.; Venkatadri, U. Condition-based selective maintenance for stochastically degrading multi-component systems under periodic inspection and imperfect maintenance. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2018, 232, 447–463. [Google Scholar] [CrossRef]
- Han, X.; Wang, Z.; Xie, M.; He, Y.; Li, Y.; Wang, W. Remaining useful life prediction and predictive maintenance strategies for multi-state manufacturing systems considering functional dependence. Reliab. Eng. Syst. Saf. 2021, 210, 107560. [Google Scholar] [CrossRef]
- Benkedjouh, T.; Medjaher, K.; Zerhouni, N.; Rechak, S. Remaining useful life estimation based on nonlinear feature reduction and support vector regression. Eng. Appl. Artif. Intell. 2013, 26, 1751–1760. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Sánchez, R.V.; Zurita, G.; Cerrada, M.; Cabrera, D.; Vásquez, R.E. Gearbox fault diagnosis based on deep random forest fusion of acoustic and vibratory signals. Mech. Syst. Signal Process. 2016, 76–77, 283–293. [Google Scholar] [CrossRef]
- He, Z.; Shao, H.; Ding, Z.; Jiang, H.; Cheng, J. Modified Deep Autoencoder Driven by Multisource Parameters for Fault Transfer Prognosis of Aeroengine. IEEE Trans. Ind. Electron. 2021, 69, 845–855. [Google Scholar] [CrossRef]
- Chen, C.; Wang, C.; Lu, N.; Jiang, B.; Xing, Y. A data-driven predictive maintenance strategy based on accurate failure prognostics. Eksploat. I Niezawodn.-Maint. Reliab. 2021, 23, 387–394. [Google Scholar] [CrossRef]
- Shoorkand, H.D.; Nourelfath, M.; Hajji, A. A hybrid CNN-LSTM model for joint optimization of production and imperfect predictive maintenance planning. Reliab. Eng. Syst. Saf. 2023, 241, 109707. [Google Scholar] [CrossRef]
- Zheng, P.; Zhao, W.; Lv, Y.; Qian, L.; Li, Y. Health Status-Based Predictive Maintenance Decision-Making via LSTM and Markov Decision Process. Mathematics 2023, 11, 109. [Google Scholar] [CrossRef]
- Zonta, T.; da Costa, C.A.; Zeiser, F.A.; Ramos, G.d.O.; Kunst, R.; Righi, R.d.R. A predictive maintenance model for optimizing production schedule using deep neural networks. J. Manuf. Syst. 2022, 62, 450–462. [Google Scholar] [CrossRef]
- Deutsch, J.; He, D. Using deep learning-based approach to predict remaining useful life of rotating components. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 11–20. [Google Scholar] [CrossRef]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A survey of deep learning and its applications: A new paradigm to machine learning. Arch. Comput. Methods Eng. 2020, 27, 1071–1092. [Google Scholar] [CrossRef]
- Namuduri, S.; Narayanan, B.N.; Davuluru, V.S.P.; Burton, L.; Bhansali, S. Review—Deep learning methods for sensor based predictive maintenance and future perspectives for electrochemical sensors. J. Electrochem. Soc. 2020, 167, 037552. [Google Scholar] [CrossRef]
- Kammoun, M.A.; Rezg, N. Toward the optimal selective maintenance for multi-component systems using observed failure: Applied to the FMS study case. Int. J. Adv. Manuf. Technol. 2018, 96, 1093–1107. [Google Scholar] [CrossRef]
- Kammoun, M.A.; Hajej, Z.; Rezg, N. A multi-level selective maintenance strategy combined to data mining approach for multi-component system subject to propagated failures. J. Syst. Sci. Syst. Eng. 2022, 31, 313–337. [Google Scholar] [CrossRef]
- Ben-Salem, A.; Gharbi, A.; Hajji, A. Environmental issue in an alternative production–maintenance control for unreliable manufacturing system subject to degradation. Int. J. Adv. Manuf. Technol. 2015, 77, 383–398. [Google Scholar] [CrossRef]
- Bouslah, B.; Gharbi, A.; Pellerin, R. Joint economic design of production, continuous sampling inspection and preventive maintenance of a deteriorating production system. Int. J. Prod. Econ. 2016, 173, 184–198. [Google Scholar] [CrossRef]
- Fan, F.-L.; Xiong, J.; Li, M.; Wang, G. On interpretability of artificial neural networks: A survey. IEEE Trans. Radiat. Plasma Med Sci. 2021, 5, 741–760. [Google Scholar] [CrossRef] [PubMed]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Umar, A.M.; Linus, O.U.; Arshad, H.; Kazaure, A.A.; Gana, U.; Kiru, M.U. Comprehensive review of artificial neural network applications to pattern recognition. IEEE Access 2019, 7, 158820–158846. [Google Scholar] [CrossRef]
- Feng, J.; Lu, S. Performance Analysis of Various Activation Functions in Artificial Neural Networks. J. Phys. Conf. Ser. 2019, 1237, 022030. [Google Scholar] [CrossRef]
- Apicella, A.; Donnarumma, F.; Isgrò, F.; Prevete, R. A survey on modern trainable activation functions. Neural Netw. 2021, 138, 14–32. [Google Scholar] [CrossRef]
- Yan, M.; Wang, X.; Wang, B.; Chang, M.; Muhammad, I. Bearing remaining useful life prediction using support vector machine and hybrid degradation tracking model. ISA Trans. 2020, 98, 471–482. [Google Scholar] [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
- Acan, A.; Ünveren, A. Multiobjective great deluge algorithm with two-stage archive support. Eng. Appl. Artif. Intell. 2020, 87, 103239. [Google Scholar] [CrossRef]
- Fang, H.; Zhang, M.; He, S.; Luan, X.; Liu, F.; Ding, Z. Solving the Zero-Sum Control Problem for Tidal Turbine System: An Online Reinforcement Learning Approach. IEEE Trans. Cybern. 2022, 53, 7635–7647. [Google Scholar] [CrossRef]
- He, S.; Fang, H.; Zhang, M.; Liu, F.; Ding, Z. Adaptive optimal control for a class of nonlinear systems: The online policy iteration approach. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 549–558. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Component_Name | Maintenance_Type | Code_Error |
|---|---|---|---|
| 2019-01-03 06:41:43 | CO | PM | Rkf |
| 2019-02-24 16:33:06 | PK | CM | Ther |
| 2019-03-07 16:05:40 | BD | PM | Chel |
| … | … | … | … |
| 2022-04-04 21:49:32 | KZ | PM | Aron |
| Prediction Model | MSE | MAE | MAPE |
|---|---|---|---|
| SVR with linear Kernel | |||
| SVR with RBF Kernel | |||
| ANN |
) | ) | ) | ) | ||
|---|---|---|---|---|---|
| 136 | 1 | 0 | 0 | 0 | |
| 2 | +5 | 5 | 2 | ||
| 3 | +17 | 12 | 3 | ||
| 4 | +30 | 16 | 5 | ||
| 5 | 22 | 7 | |||
| 140 | 1 | 0 | 0 | 0 | |
| 2 | +10 | 17 | 4 | ||
| 3 | +15 | 20 | 5 | ||
| 4 | +22 | 27 | 7 | ||
| 5 | 36 | 9 | |||
| 135 | 1 | 0 | 0 | 0 | |
| 2 | +6 | 10 | 5 | ||
| 3 | +19 | 12 | 8 | ||
| 4 | +21 | 15 | 10 | ||
| 5 | 18 | 12 | |||
| 135 | 1 | 0 | 0 | 0 | |
| 2 | +6 | 8 | 5 | ||
| 3 | +19 | 15 | 8 | ||
| 4 | +21 | 25 | 10 | ||
| 5 | 34 | 12 | |||
| 128 | 1 | 0 | 0 | 0 | |
| 2 | +7 | 6 | 1 | ||
| 3 | +12 | 12 | 3 | ||
| 4 | +25 | 17 | 6 | ||
| 5 | 26 | 8 | |||
| 130 | 1 | 0 | 0 | 0 | |
| 2 | +5 | 12 | 2 | ||
| 3 | +20 | 15 | 4 | ||
| 4 | +25 | 28 | 6 | ||
| 5 | 35 | 8 | |||
| 129 | 1 | 0 | 0 | 0 | |
| 2 | +10 | 13 | 3 | ||
| 3 | +15 | 18 | 4 | ||
| 4 | +20 | 25 | 6 | ||
| 5 | 35 | 8 | |||
| 139 | 1 | 0 | 0 | 0 | |
| 2 | +3 | 7 | 5 | ||
| 3 | +15 | 15 | 6 | ||
| 4 | +30 | 26 | 7 | ||
| 5 | 30 | 10 | |||
| 140 | 1 | 0 | 0 | 0 | |
| 2 | +10 | 10 | 2 | ||
| 3 | +36 | 25 | 5 | ||
| 4 | +41 | 30 | 7 | ||
| 5 | 40 | 9 |
| 127 | 131 | 126 | 126 | 119 | 121 | 120 | 130 | 131 | |
| 0.07 | 0.07 | 0.07 | 0.07 | 0.13 | 0.06 | 0.07 | 0.07 | 0.06 | |
| 115 | 120 | 115 | 115 | 108 | 110 | 109 | 119 | 120 | |
| 0.17 | 0.15 | 0.16 | 0.16 | 0.22 | 0.15 | 0.17 | 0.16 | 0.15 | |
| 102 | 107 | 102 | 102 | 95 | 97 | 96 | 106 | 107 | |
| 0.29 | 0.27 | 0.28 | 0.28 | 0.35 | 0.28 | 0.30 | 0.27 | 0.26 | |
| 80 | 84 | 79 | 79 | 72 | 74 | 73 | 83 | 84 | |
| 0.53 | 0.51 | 0.54 | 0.54 | 0.63 | 0.55 | 0.57 | 0.52 | 0.50 | |
| 72 | 71 | 66 | 66 | 66 | 81 | 60 | 100 | 71 | |
| 0.64 | 0.68 | 0.72 | 0.72 | 0.72 | 0.46 | 0.77 | 0.33 | 0.67 | |
| 65 | 63 | 58 | 69 | 81 | 83 | 52 | 82 | 63 | |
| 0.74 | 0.80 | 0.84 | 0.67 | 0.51 | 0.43 | 0.91 | 0.53 | 0.79 | |
| 65 | 47 | 32 | 59 | 77 | 87 | 26 | 96 | 47 | |
| 0.74 | 0.90 | 0.95 | 0.83 | 0.56 | 0.39 | 0.91 | 0.37 | 0.92 |
| Maintenance Plan | |||||
|---|---|---|---|---|---|
() | 0 | 0 | 0.9898 | ||
() | 0 | 0 | 0.9896 | ||
() | 0 | 0 | 0.9868 | ||
| 116 | 13 | 0.9078 | |||
| 132 | 12 | 0.9259 | |||
| 178 | 13 | 0.912 | |||
| 203 | 16 | 0.9087 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Achour, A.; Kammoun, M.A.; Hajej, Z. Towards Optimizing Multi-Level Selective Maintenance via Machine Learning Predictive Models. Appl. Sci. 2024, 14, 313. https://doi.org/10.3390/app14010313
Achour A, Kammoun MA, Hajej Z. Towards Optimizing Multi-Level Selective Maintenance via Machine Learning Predictive Models. Applied Sciences. 2024; 14(1):313. https://doi.org/10.3390/app14010313
Chicago/Turabian StyleAchour, Amal, Mohamed Ali Kammoun, and Zied Hajej. 2024. "Towards Optimizing Multi-Level Selective Maintenance via Machine Learning Predictive Models" Applied Sciences 14, no. 1: 313. https://doi.org/10.3390/app14010313
APA StyleAchour, A., Kammoun, M. A., & Hajej, Z. (2024). Towards Optimizing Multi-Level Selective Maintenance via Machine Learning Predictive Models. Applied Sciences, 14(1), 313. https://doi.org/10.3390/app14010313