
A Parallel Multimodal Integration Framework and Application for Cake Shopping


Abstract
Featured Application
Abstract
1. Introduction
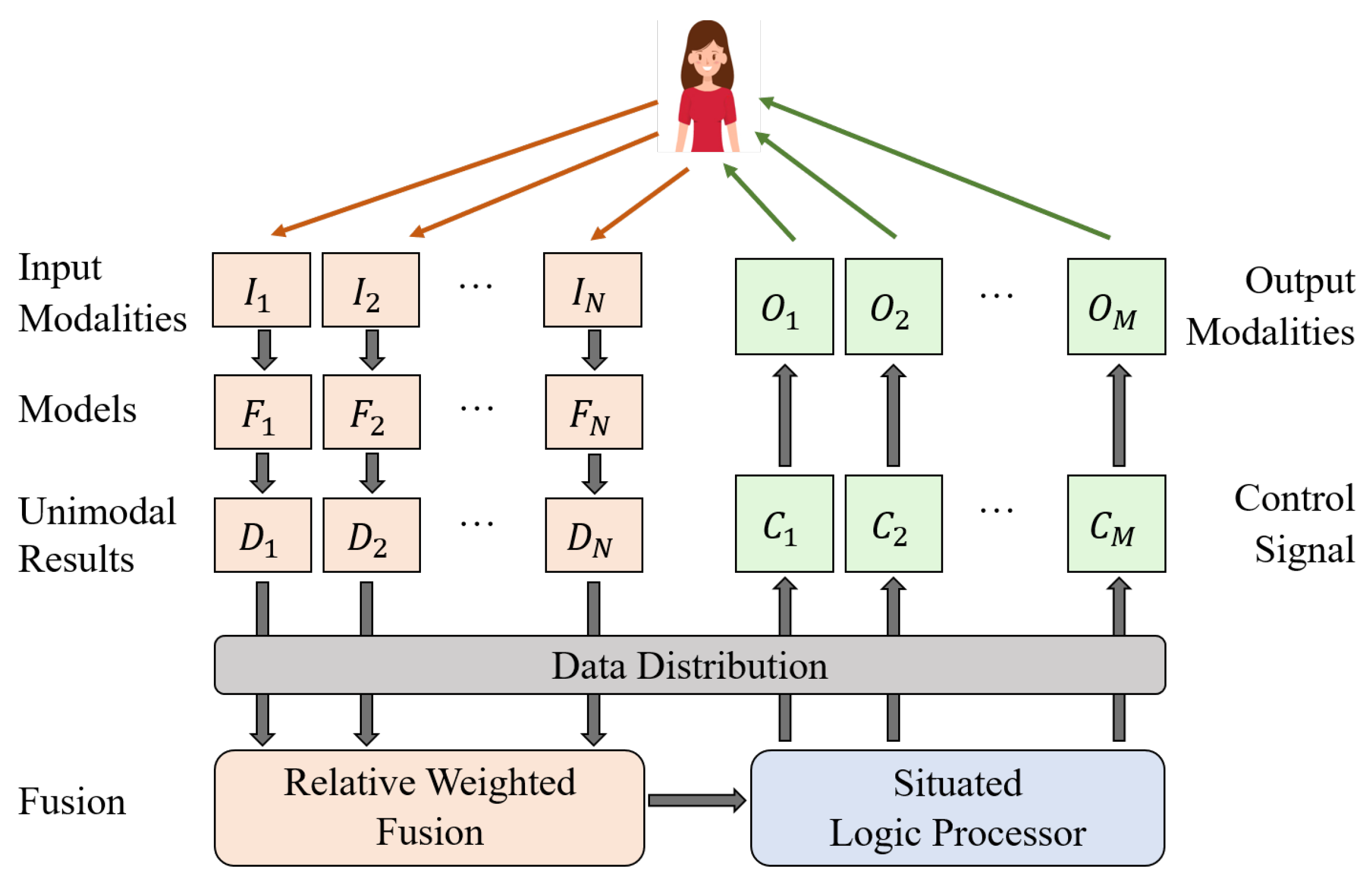
- We propose a versatile parallel multimodal integration framework to support the development of multimodal applications in a reasonable time and with limited resources. It can simplify the MMHCI system implementation process and facilitate the application of multimodal technologies in various fields.
- The parallel framework allows each device to operate across multiple terminals, reducing resource demands on a single computer. The proposed relative weighted fusion method is novel, application-independent, and can be easily extended to support new modalities.
- We develop a multimodal virtual shopping system using the multimodal integration framework. The system seamlessly integrates five input modalities and three output modalities. A tree-structured task-oriented dialogue system is used to accomplish logical processing during shopping. Subjective and objective experiments show the robustness and intelligence of our shopping system.
2. Methods
2.1. Preliminaries
2.2. Parallel Multimodal Integration Framework
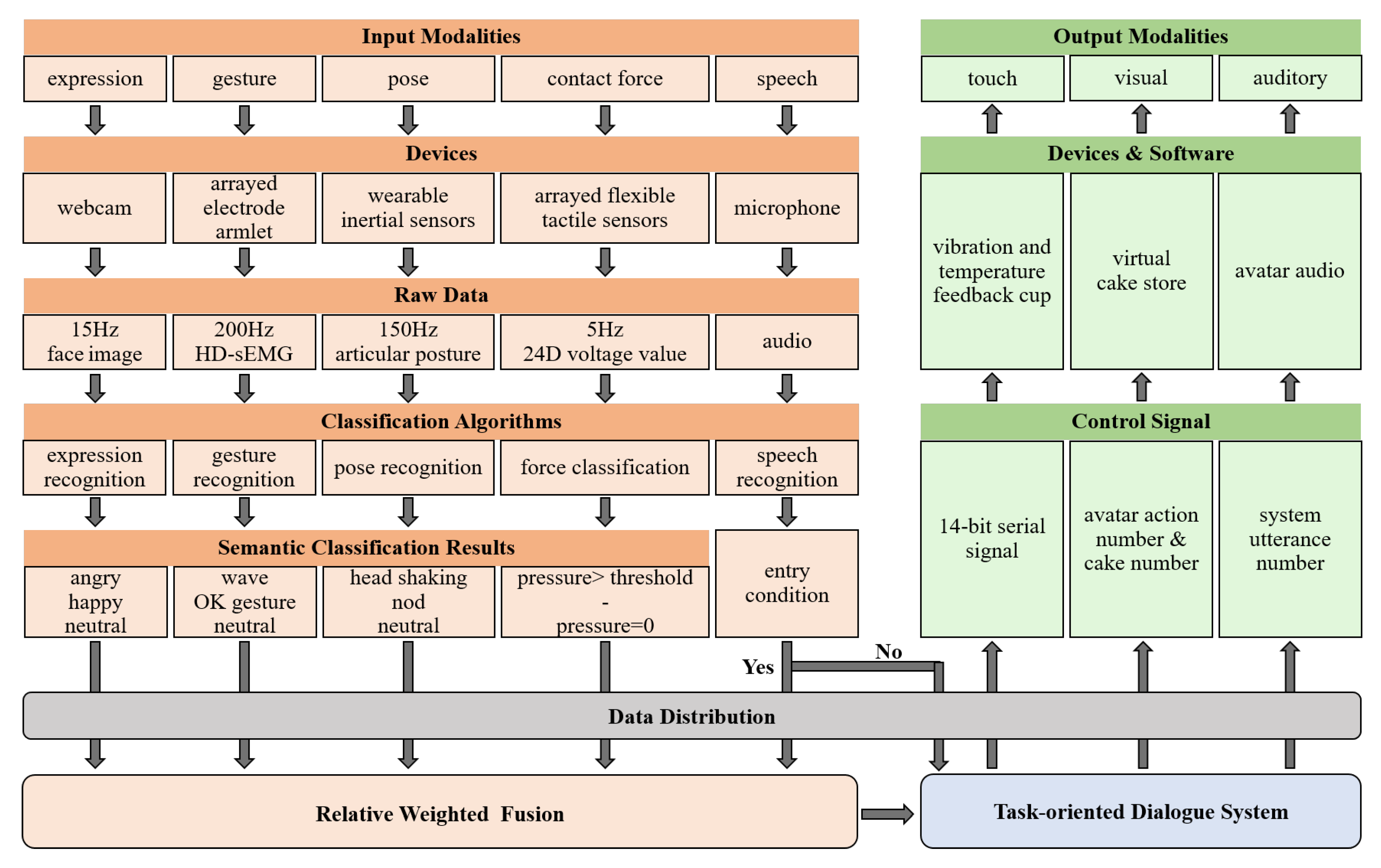
2.3. Multimodal Virtual Shopping System Prototype
2.3.1. The Integrated Modalities
2.3.2. Multimodal Fusion
2.3.3. Situated Multimodal Dialogue
3. Results
3.1. Evaluation of System Robustness
3.2. Evaluation of the Dialogue System
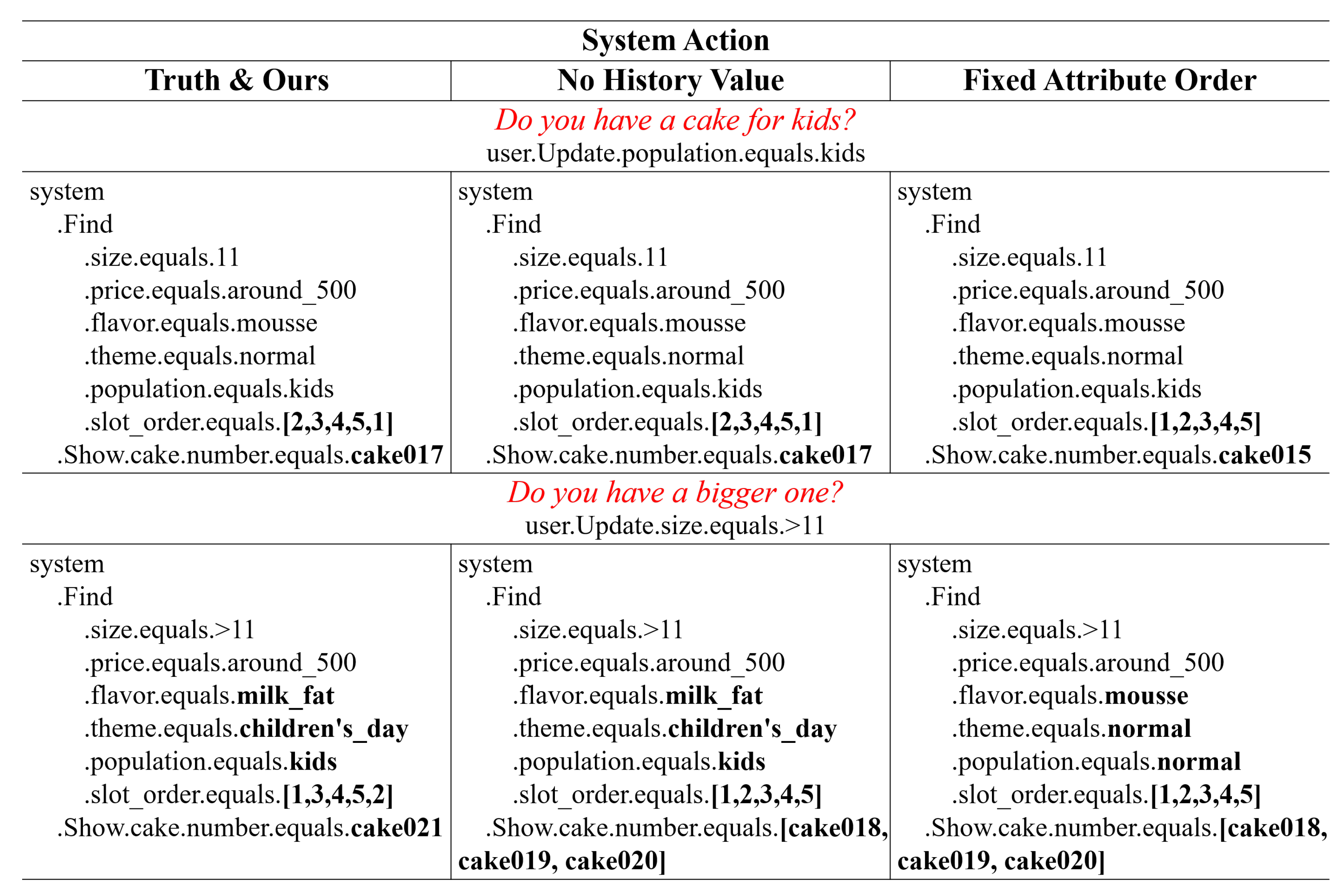
3.3. Evaluation of Multimodal Fusion Method
3.4. User Study
4. Discussion
5. Extension
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jaimes, A.; Sebe, N. Multimodal human-computer interaction: A survey. Comput. Vis. Image Underst. 2007, 108, 116–134. [Google Scholar] [CrossRef]
- Dumas, B.; Lalanne, D.; Oviatt, S. Multimodal interfaces: A survey of principles, models and frameworks. In Human Machine Interaction: Research Results of the Mmi Program; Springer: Berlin, Germany, 2009; pp. 3–26. [Google Scholar]
- Turk, M. Multimodal interaction: A review. Pattern Recognit. Lett. 2014, 36, 189–195. [Google Scholar] [CrossRef]
- Flippo, F.; Krebs, A.; Marsic, I. A Framework for Rapid Development of Multimodal Interfaces. In Proceedings of the 5th International Conference on Multimodal Interfaces, ICMI ’03, Vancouver, BC, Canada, 5–7 November 2003; pp. 109–116. [Google Scholar]
- Abdallah, C.; Changyue, S.; Kaibo, L.; Abhinav, S.; Xi, Z. A data-level fusion approach for degradation modeling and prognostic analysis under multiple failure modes. J. Qual. Technol. 2018, 50, 150–165. [Google Scholar]
- Kamlaskar, C.; Abhyankar, A. Multimodal System Framework for Feature Level Fusion based on CCA with SVM Classifier. In Proceedings of the 2020 IEEE-HYDCON, Hyderabad, India, 11–12 September 2020; pp. 1–8. [Google Scholar]
- Radová, V.; Psutka, J. An approach to speaker identification using multiple classifiers. In Proceedings of the 1997 IEEE International Conference on Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997; Volume 2, pp. 1135–1138. [Google Scholar]
- Lucey, S.; Sridharan, S.; Chandran, V. Improved speech recognition using adaptive audio-visual fusion via a stochastic secondary classifier. In Proceedings of the 2001 International Symposium on Intelligent Multimedia, Video and Speech Processing, ISIMP 2001, Hong Kong, China, 4 May 2001; pp. 551–554. [Google Scholar][Green Version]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Adams, W.; Iyengar, G.; Lin, C.Y.; Naphade, M.R.; Neti, C.; Nock, H.J.; Smith, J.R. Semantic indexing of multimedia content using visual, audio, and text cues. EURASIP J. Adv. Signal Process. 2003, 2003, 1–16. [Google Scholar] [CrossRef]
- Pitsikalis, V.; Katsamanis, A.; Papandreou, G.; Maragos, P. Adaptive multimodal fusion by uncertainty compensation. In Proceedings of the INTERSPEECH, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Meyer, G.F.; Mulligan, J.B.; Wuerger, S.M. Continuous audio–visual digit recognition using N-best decision fusion. Inf. Fusion 2004, 5, 91–101. [Google Scholar] [CrossRef]
- Cutler, R.; Davis, L. Look who’s talking: Speaker detection using video and audio correlation. In Proceedings of the 2000 IEEE International Conference on Multimedia and Expo. ICME2000: Latest Advances in the Fast Changing World of Multimedia, New York, NY, USA, 30 July–2 August 2000; Volume 3, pp. 1589–1592. [Google Scholar]
- Strobel, N.; Spors, S.; Rabenstein, R. Joint audio-video object localization and tracking. IEEE Signal Process. Mag. 2001, 18, 22–31. [Google Scholar] [CrossRef]
- Zotkin, D.N.; Duraiswami, R.; Davis, L.S. Joint audio-visual tracking using particle filters. EURASIP J. Adv. Signal Process. 2002, 2002, 162620. [Google Scholar] [CrossRef]
- Garg, S.N.; Vig, R.; Gupta, S. Multimodal biometric system based on decision level fusion. In Proceedings of the 2016 International Conference on Signal Processing, Communication, Power and Embedded System (SCOPES), Paralakhemundi, India, 3–5 October 2016; pp. 753–758. [Google Scholar]
- Atrey, P.K.; Hossain, M.A.; El Saddik, A.; Kankanhalli, M.S. Multimodal fusion for multimedia analysis: A survey. Multimed. Syst. 2010, 16, 345–379. [Google Scholar] [CrossRef]
- Neti, C.; Maison, B.; Senior, A.W.; Iyengar, G.; Decuetos, P.; Basu, S.; Verma, A. Joint processing of audio and visual information for multimedia indexing and human-computer interaction. In Proceedings of the RIAO, Paris, France, 12–14 April 2000; pp. 294–301. [Google Scholar]
- Donald, K.M.; Smeaton, A.F. A comparison of score, rank and probability-based fusion methods for video shot retrieval. In Proceedings of the International Conference on Image and Video Retrieval, Singapore, 20–22 July 2005; pp. 61–70. [Google Scholar]
- Pfleger, N. Context based multimodal fusion. In Proceedings of the 6th International Conference on Multimodal Interfaces, State College, PA, USA, 13–15 October 2004; pp. 265–272. [Google Scholar]
- Corradini, A.; Mehta, M.; Bernsen, N.O.; Martin, J.; Abrilian, S. Multimodal input fusion in human-computer interaction. NATO Sci. Ser. Sub Ser. III Comput. Syst. Sci. 2005, 198, 223. [Google Scholar]
- Holzapfel, H.; Nickel, K.; Stiefelhagen, R. Implementation and evaluation of a constraint-based multimodal fusion system for speech and 3D pointing gestures. In Proceedings of the 6th International Conference on Multimodal Interfaces, State College, PA, USA, 13–15 October 2004; pp. 175–182. [Google Scholar]
- Microsoft. Bing Speech API. Available online: https://azure.microsoft.com/en-us/products/ai-services/ai-speech/ (accessed on 18 August 2023).
- Tan, T.; Qian, Y.; Hu, H.; Zhou, Y.; Ding, W.; Yu, K. Adaptive very deep convolutional residual network for noise robust speech recognition. IEEE ACM Trans. Audio Speech Lang. Process. 2018, 26, 1393–1405. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. Openpose: Realtime multi-person 2D pose estimation using part affinity fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Bazarevsky, V.; Vakunov, A.; Tkachenka, A.; Sung, G.; Chang, C.L.; Grundmann, M. MediaPipe Hands: On-device Real-time Hand Tracking. arXiv 2020, arXiv:2006.10214. [Google Scholar]
- Zhang, S.; Huang, Z.; Paudel, D.P.; Van Gool, L. Facial emotion recognition with noisy multi-task annotations. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 21–31. [Google Scholar]
- Scavarelli, A.; Arya, A.; Teather, R.J. Virtual reality and augmented reality in social learning spaces: A literature review. Virtual Real. 2021, 25, 257–277. [Google Scholar] [CrossRef]
- Hu, M.; Luo, X.; Chen, J.; Lee, Y.C.; Zhou, Y.; Wu, D. Virtual reality: A survey of enabling technologies and its applications in IoT. J. Netw. Comput. Appl. 2021, 178, 102970. [Google Scholar] [CrossRef]
- Aziz, K.A.; Luo, H.; Asma, L.; Xu, W.; Zhang, Y.; Wang, D. Haptic handshank—A handheld multimodal haptic feedback controller for virtual reality. In Proceedings of the 2020 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Porto de Galinhas, Brazil, 9–13 November 2020; pp. 239–250. [Google Scholar]
- Liu, S.; Cheng, H.; Tong, Y. Physically-based statistical simulation of rain sound. ACM Trans. Graph. TOG 2019, 38, 1–14. [Google Scholar] [CrossRef]
- Cheng, H.; Liu, S. Haptic force guided sound synthesis in multisensory virtual reality (VR) simulation for rigid-fluid interaction. In Proceedings of the 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Osaka, Japan, 23–27 March 2019; pp. 111–119. [Google Scholar]
- Niijima, A.; Ogawa, T. Study on control method of virtual food texture by electrical muscle stimulation. In Proceedings of the UIST ’16: The 29th Annual ACM Symposium on User Interface Software and Technology, Tokyo, Japan, 16–19 October 2016; pp. 199–200. [Google Scholar]
- Ranasinghe, N.; Tolley, D.; Nguyen, T.N.T.; Yan, L.; Chew, B.; Do, E.Y.L. Augmented flavours: Modulation of flavour experiences through electric taste augmentation. Food Res. Int. 2019, 117, 60–68. [Google Scholar] [CrossRef]
- Frediani, G.; Carpi, F. Tactile display of softness on fingertip. Sci. Rep. 2020, 10, 20491. [Google Scholar] [CrossRef]
- Chen, T.; Pan, Z.G.; Zheng, J.M. Easymall-an interactive virtual shopping system. In Proceedings of the 2008 Fifth International Conference on Fuzzy Systems and Knowledge Discovery, Jinan, China, 18–20 October 2008; Volume 4, pp. 669–673. [Google Scholar]
- Speicher, M.; Cucerca, S.; Krüger, A. VRShop: A mobile interactive virtual reality shopping environment combining the benefits of on-and offline shopping. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–31. [Google Scholar] [CrossRef]
- Ricci, M.; Evangelista, A.; Di Roma, A.; Fiorentino, M. Immersive and desktop virtual reality in virtual fashion stores: A comparison between shopping experiences. Virtual Real. 2023, 27, 2281–2296. [Google Scholar] [CrossRef]
- Schnack, A.; Wright, M.J.; Holdershaw, J.L. Immersive virtual reality technology in a three-dimensional virtual simulated store: Investigating telepresence and usability. Food Res. Int. 2019, 117, 40–49. [Google Scholar] [CrossRef]
- Wasinger, R.; Krüger, A.; Jacobs, O. Integrating intra and extra gestures into a mobile and multimodal shopping assistant. In Proceedings of the International Conference on Pervasive Computing, Munich, Germany, 8–13 May 2005; pp. 297–314. [Google Scholar]
- Moon, S.; Kottur, S.; Crook, P.A.; De, A.; Poddar, S.; Levin, T.; Whitney, D.; Difranco, D.; Beirami, A.; Cho, E.; et al. Situated and interactive multimodal conversations. In Proceedings of the 28th International Conference on Computational Linguistics, Virtual, 8–13 December 2020; pp. 1103–1121. [Google Scholar]
- Cutugno, F.; Leano, V.A.; Rinaldi, R.; Mignini, G. Multimodal Framework for Mobile Interaction. In Proceedings of the International Working Conference on Advanced Visual Interfaces, AVI ’12, Capri Island, Italy, 21–25 May 2012; pp. 197–203. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Attig, C.; Rauh, N.; Franke, T.; Krems, J.F. System latency guidelines then and now–is zero latency really considered necessary? In Proceedings of the Engineering Psychology and Cognitive Ergonomics: Cognition and Design: 14th International Conference, EPCE 2017, Vancouver, BC, Canada, 9–14 July 2017; pp. 3–14. [Google Scholar]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion aware facial expression recognition using CNN with attention mechanism. IEEE Trans. Image Process. 2018, 28, 2439–2450. [Google Scholar] [CrossRef] [PubMed]
- Geng, W.; Du, Y.; Jin, W.; Wei, W.; Hu, Y.; Li, J. Gesture recognition by instantaneous surface EMG images. Sci. Rep. 2016, 6, 65–71. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Xu, S.Q.; Cheng, N.; You, Y.; Zhang, X.; Tang, Z.; Yang, X. Orientation Estimation Algorithm for Motion Based on Multi-Sensor. CSA 2015, 24, 134–139. [Google Scholar]
- Chuang, C.H.; Wang, M.S.; Yu, Y.C.; Mu, C.L.; Lu, K.F.; Lin, C.T. Flexible tactile sensor for the grasping control of robot fingers. In Proceedings of the 2013 International Conference on Advanced Robotics and Intelligent Systems, Tainan, Taiwan, 31 May–2 June 2013; pp. 141–146. [Google Scholar]
- Apple Inc. ARKit: Tracking and Visualizing Faces. 2017. Available online: https://developer.apple.com/documentation/arkit/arkit_in_ios/content_anchors/tracking_and_visualizing_faces (accessed on 28 August 2023.).
- Vicon Motion Systems Ltd. UK. Vicon. 1984. Available online: https://www.vicon.com/ (accessed on 10 January 2020.).
- Cheng, J.; Agrawal, D.; Martínez Alonso, H.; Bhargava, S.; Driesen, J.; Flego, F.; Kaplan, D.; Kartsaklis, D.; Li, L.; Piraviperumal, D.; et al. Conversational Semantic Parsing for Dialog State Tracking. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Virtual, 16–20 November 2020; pp. 8107–8117. [Google Scholar]
- Wen, T.H.; Vandyke, D.; Mrksic, N.; Gasic, M.; Rojas-Barahona, L.M.; Su, P.H.; Ultes, S.; Young, S. A Network-based End-to-End Trainable Task-oriented Dialogue System. arXiv 2016, arXiv:1604.04562. [Google Scholar]
- Middya, A.I.; Nag, B.; Roy, S. Deep learning based multimodal emotion recognition using model-level fusion of audio-visual modalities. Knowl. Based Syst. 2022, 244, 108580. [Google Scholar] [CrossRef]
- Bao, S.; He, H.; Wang, F.; Wu, H.; Wang, H.; Wu, W.; Wu, Z.; Guo, Z.; Lu, H.; Huang, X.; et al. PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 107–118. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Dey, A.; Barde, A.; Yuan, B.; Sareen, E.; Dobbins, C.; Goh, A.; Gupta, G.; Gupta, A.; Billinghurst, M. Effects of interacting with facial expressions and controllers in different virtual environments on presence, usability, affect, and neurophysiological signals. Int. J. Hum. Comput. Stud. 2022, 160, 102762. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | Example |
|---|---|
| Visual | expression |
| gaze | |
| face-based identity (age, sex, race, etc.) | |
| gesture | |
| body pose | |
| virtual environment * | |
| virtual agent * | |
| virtual body (induce the ownership illusion) * | |
| Auditory | speech |
| non-speech audio (clapping sound, environment noise etc.) | |
| Touch | contact force (contact area, value, etc.) |
| tactile sense * | |
| Other sensors | temperature |
| smell * | |
| taste * |
| Number | Name | Size | Price | Flavor | Theme | Population |
|---|---|---|---|---|---|---|
| cake001 | Teddy Bear | 1 | 39 | cream | normal | normal |
| cake002 | Tiramisu | 1 | 29 | mousse | normal | normal |
| cake003 | Black Forest | 1 | 29 | chocolate | normal | normal |
| cake004 | Roseberry Girl | 1 | 25 | cream | normal | normal |
| cake005 | Grape Bobo | 4 | 289 | mousse | normal | normal |
| cake006 | Star Wish | 4 | 269 | cheese | normal | normal |
| cake007 | Let’s Dance | 4 | 239 | cream | normal | normal |
| cake008 | Candy House | 3 | 269 | chocolate | Children’s day | kids |
| cake009 | Confession of Love | 4 | 269 | mousse | Valentine’s Day | couple |
| cake010 | Happy Growth | 7 | 348 | milk fat | Children’s day | kids |
| cake011 | Sweet Story | 7 | 348 | chocolate | normal | normal |
| cake012 | Happiness and Longevity | 7 | 328 | milk fat | old people birthday | old people |
| cake013 | Overjoyed | 7 | 318 | cream | Valentine’s Day | couple |
| cake014 | Mr. Charming | 7 | 348 | mousse | Valentine’s Day | couple |
| cake015 | Fruit Windmill | 11 | 428 | mousse | normal | normal |
| cake016 | Peach Holding Sun | 11 | 408 | cream | old people birthday | old people |
| cake017 | Carefree | 11 | 428 | milk fat | Children’s day | kids |
| cake018 | Elegant | 15 | 518 | cream | old people birthday | old people |
| cake019 | Cream Cheese | 15 | 568 | cheese | normal | normal |
| cake020 | Chocolate Encounter | 15 | 568 | chocolate | normal | normal |
| cake021 | Princess Party | 25 | 758 | milk fat | Children’s day | kids |
| cake022 | Warm Wishes | 25 | 699 | cream | old people birthday | old people |
| cake023 | Rose Bloom | 25 | 718 | cheese | normal | normal |
| cake024 | Wonderful Life | over 25 | 2098 | cream | wedding | couple |
| Method | Entity Matching Rate (%) | Task Success Rate (%) |
|---|---|---|
| Ours | 100 | 93.94 |
| No History Value | 74.07 | - |
| Fixed Attribute Order | 14.81 | - |
| Method | Overall | 2-Modals | 3-Modals | 4-Modals | 5-Modals |
|---|---|---|---|---|---|
| ACC | ACC | ACC | ACC | ACC | |
| RW | 0.844 | 0.763 | 0.790 | 0.854 | 0.968 |
| MV | 0.684 | 0.721 | 0.677 | 0.641 | 0.698 |
| LW | 0.686 | 0.709 | 0.690 | 0.669 | 0.677 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, H.; Weng, D.; Tian, Z. A Parallel Multimodal Integration Framework and Application for Cake Shopping. Appl. Sci. 2024, 14, 299. https://doi.org/10.3390/app14010299
Fang H, Weng D, Tian Z. A Parallel Multimodal Integration Framework and Application for Cake Shopping. Applied Sciences. 2024; 14(1):299. https://doi.org/10.3390/app14010299
Chicago/Turabian StyleFang, Hui, Dongdong Weng, and Zeyu Tian. 2024. "A Parallel Multimodal Integration Framework and Application for Cake Shopping" Applied Sciences 14, no. 1: 299. https://doi.org/10.3390/app14010299
APA StyleFang, H., Weng, D., & Tian, Z. (2024). A Parallel Multimodal Integration Framework and Application for Cake Shopping. Applied Sciences, 14(1), 299. https://doi.org/10.3390/app14010299