1. Introduction
With the rapid advancement of industrial automation and informatization, fault diagnosis technology increasingly plays a pivotal role in ensuring the reliable operation of equipment and the safety of industrial systems [
1]. Particularly in complex industrial environments, such as chemical, manufacturing, and energy sectors, the ability to accurately and swiftly identify and address faults is key to enhancing production efficiency and preventing accidents [
2,
3,
4]. The recent surge in big data and Internet of Things (IoT) technologies has catalyzed the extensive deployment of sensors in industrial systems, resulting in a massive influx of data [
5,
6]. This data serve not only to record the operational status of equipment, but also to offer unparalleled opportunities for fault diagnosis. However, the high reliability of industrial equipment renders fault data relatively rare in comparison with data from normal operations, leading to a significant data imbalance, particularly in the context of few-shot fault diagnosis [
7,
8]. Given these circumstances, traditional machine learning and deep learning methods, which generally depend on abundant labeled data to train effective models, face substantial challenges [
9,
10,
11,
12]. Consequently, investigating potent few-shot learning techniques capable of accurately diagnosing faults in data-scarce environments has emerged as a crucial research area in industrial intelligence.
In the realm of few-shot learning, notable advancements and representative technologies or papers have emerged, particularly for addressing challenges in data-scarce environments. Methods such as data augmentation [
13], synthetic data generation [
14], transfer learning [
15], self-supervised learning [
16], and meta-learning [
17] have been instrumental. These methods have demonstrated success in various fields, including object detection, image segmentation, and image classification, subsequently influencing fault diagnosis practices.
Focusing on the domain of fault diagnosis, few-shot learning has seen significant technological progress. Data augmentation techniques, particularly sampling methods and synthetic data generation, have been primarily employed to enhance fault data. Research in the field of rolling bearing fault diagnosis has shown that the use of compressed sensing for limited fault data augmentation can significantly improve diagnostic accuracy [
18]. Furthermore, several studies have demonstrated that combining data augmentation with deep learning can effectively diagnose faults in rotating machinery [
19,
20], thereby enhancing both the precision and robustness of the diagnosis. Beyond data augmentation, alterations in model architecture have shown promise. Noteworthy among these is the development of a novel bidirectional gated recurrent unit (BGRU) for effective and efficient fault diagnosis [
21]. Additionally, research has introduced few-shot fault diagnosis methods based on attention mechanisms, utilizing spectral kurtosis filtering and particle swarm optimization in conjunction with stacked sparse autoencoders [
22]. The Siamese neural network, which learns through sample pair comparisons, is another innovative approach to the few-shot problem [
23]. Transfer learning has played a significant role in enhancing the efficiency and accuracy of machine fault diagnosis, especially in cases where there are a scarcity of labeled data or low-precision sensors are utilized for data collection. Transfer learning has played a significant role in enhancing the efficiency and accuracy of machine fault diagnosis, especially in cases where there is a scarcity of labeled data or low-precision sensors are utilized for data collection [
24,
25]. However, these methods often require retraining the entire network for new tasks, limiting their practical adaptability in industrial settings. Additionally, varying operational conditions in practical engineering can diminish the effectiveness of these diagnostic methods under new circumstances. Hence, the need to identify fault categories across different working conditions remains a critical aspect of ongoing research in few-shot learning within fault diagnosis.
Meta-learning, as an adaptable approach to the few-shot problem, emphasizes the acquisition of learning capabilities rather than the learning process itself [
26]. This strategy, pivotal in practical industrial applications, necessitates only minimal adjustments to accommodate new tasks [
27]. Contrary to direct learning of a predictive mathematical model, meta-learning endeavors to understand the process of learning a generalized model [
17]. Viewing feature extraction as direct data learning, the meta-learner gains insight by evaluating this process, enabling task completion with minimal samples. Among the various optimization-based meta-learning methods, model-agnostic meta-learning (MAML) seeks an initial parameter set sensitive to new tasks [
28,
29]. This approach allows for an enhanced performance following a gradient update on a small dataset of new tasks, demonstrating its potential in rapidly adapting to novel challenges.
In industrial systems, fault diagnosis relies on complex time-series signals gathered from equipment operating under varying conditions. The scarcity of fault samples and the diversity of working conditions pose challenges in discerning intricate fault information. To address this, the article introduces a novel gradient-oriented prioritization meta-learning (GOPML) approach. This method is designed to enhance the adaptability of meta-learning in recognizing few-shot fault conditions across diverse operational scenarios. GOPML optimizes knowledge adaptability, crucial for accurately identifying faults in data-rich yet sample-scarce environments.
The principal contributions of this work are encapsulated as follows:
We introduce a novel gradient-oriented prioritization meta-learning (GOPML) approach that demonstrably mitigates overfitting in few-shot learning scenarios. By refining sensitive initialization parameters and harnessing the robust adaptability of knowledge, GOPML gains a distinct edge in tackling few-shot problems under varying operational conditions.
This study advocates a strategic task sequencing strategy inherent to GOPML, bolstering the stability of the diagnostic performance amidst fluctuating operational conditions. The strategy draws inspiration from curriculum learning, methodically arranging tasks from the simplest to the most complex, thus endorsing a more stable, stepwise learning process. This structured learning trajectory is conducive to the development of a generalized knowledge representation, enhancing convergence efficiency with a reduced number of samples.
The robustness of the GOPML algorithm is rigorously validated through extensive experiments on the Tennessee Eastman Process (TEP) and Skoltech Anomaly Benchmark (SKAB) datasets. The findings confirm GOPML’s adeptness in adapting to new categories in few-shot scenarios and its consistent diagnostic accuracy across varied working conditions. Comparative analysis further underscores the superiority of GOPML over contemporary state-of-the-art methods.
The article is organized to present a coherent exploration of the GOPML methodology in the following section, then empirical case studies are discussed to substantiate the method’s efficacy, culminating in a synthesis of insights in the concluding section.
2. Proposed Method
In this section, we delve into the proposed methodologies for meta-learning within the domain of fault diagnosis. Meta-learning stands as a transformative approach that empowers models to adapt quickly to new tasks, leveraging a small amount of data. Initially, we clarify the core principles and the task-oriented framework of meta-learning, providing clarity for its application in complex learning scenarios. The model-agnostic meta-learning (MAML) algorithm is presented as a foundational optimization-based meta-learning method. It has been pivotal in demonstrating how models can be tuned to new tasks efficiently using just a few iterations. Progressing further, we propose the gradient-oriented prioritization in meta-learning (GOPML) as an enhanced approach. GOPML refines the concept of task prioritization by incorporating gradient directions and magnitudes into the learning process, aiming to optimize the model’s performance across various tasks.
2.1. Rethinking the Meta-Learning Paradigm
In the deep learning domain, the standard approach necessitates voluminous datasets to effectively train models with a high predictive accuracy. This stands in stark contrast with the innate human ability to acquire and generalize new concepts from minimal exposure. An illustrative example of this is a child’s ability to differentiate between species, such as cats and dogs, after only a handful of observations. Meta-learning, or learning to learn, takes inspiration from this human cognitive trait and aims to emulate it within the realm of machine learning. This paradigm shift towards designing algorithms that require fewer examples to adapt and learn new skills embodies the core principle of meta-learning.
Meta-learning algorithms aspire to facilitate the acquisition of generalizable knowledge from a limited set of training examples, enabling the model to apply this knowledge to novel tasks. The objective is to construct a computational framework that allows machines to observe the strategies employed by various machine learning algorithms across a diverse set of tasks, assimilate the underlying patterns, and utilize this consolidated experience to solve new, unseen problems. Consider a machine learning classification task defined by a dataset
, where
x denotes the input sample and
y its corresponding label. The goal is to optimize the model parameters
, such that the model
minimizes the loss function over the dataset, formulated as follows:
Here,
represents the loss function and
the learning strategy. In meta-learning, this is extended to a series of tasks
, classified into training and testing phases, where the model’s efficacy is evaluated across these tasks using the expected loss:
In this equation, refers to the distribution over all tasks and encapsulates the meta-knowledge, which is the knowledge representation that the model aims to generalize across different tasks.
The meta-learning framework employs a dual-layer learning structure. The meta-level (outer layer) is dedicated to learning a generalized knowledge representation (), which evolves as it encounters new tasks. The task-level (inner layer) mirrors traditional machine learning models, focusing on updating the model with respect to individual tasks through training and testing. Every task, whether a training or testing instance, utilizes the meta-learner to facilitate a learning process that incorporates both the training data and the testing data . To differentiate the primary dataset D used for the overall learning process from the meta-task specific data, we introduce the terms ‘support set’ for the training data and ‘query set’ for the testing data of the meta-tasks.
The meta-learner is trained on the support set and evaluated on the query set, with the objective of classifying samples into N categories. In an N-way classification, the meta-task is to classify data into N distinct categories. The term K-shot refers to the number of examples in the support set for each category, which results in samples for training in each meta-task. Because of the random selection process, some overlap between the support and query sets of different tasks is expected, which does not compromise the model’s generalization capability due to the intrinsic fast adaptation feature of meta-learning. As long as there are distinctive differences in the training samples of each task, complete independence of tasks is not a prerequisite for effective meta-learning.
2.2. Model-Agnostic Meta-Learning (MAML) Framework
Building on the foundational concepts of meta-learning, the model-agnostic meta-learning (MAML) algorithm sets out to optimize the initialization parameters within the outer layer of the model. These parameters are crafted to be sufficiently broad-ranging, enabling the model to rapidly achieve an optimal performance on new tasks with limited data, following a minimal number of gradient updates. This process is pivotal from the standpoint of representational learning, as MAML seeks out internal representations that are universally applicable and easily transferable across a variety of tasks. The MAML algorithm undertakes the explicit training of parameters, representing the model with a function
, contingent upon the parameter
. The architecture of the model is delineated into two iterative loops: the inner loop focuses on specific task adaptation, and the outer loop targets generalization across tasks, with the parameter
serving as the shared nucleus between them. Within the inner loop, the loss function for the subtask is calculated, precipitating an update of the parameters tailored to the new task. Post gradient descent, the model’s parameter
is updated to
, as delineated by the equation:
where
signifies the inner learning rate.
The outer loop encapsulates the meta-optimization process. It reassesses the inner loop’s optimized parameters
against the novel task. This step facilitates the computation and subsequent update of the initial parameter
’s gradient:
Here,
denotes the learning rate for the outer loop. The meta-learning model’s optimal parameters, tailored to the task distribution
, emerge from the alternating optimization of the inner and outer loops. The meta-optimization’s overarching goal is to minimize the loss function across tasks:
This iterative process, oscillating between the inner loop’s task-specific focus and the outer loop’s generalization-centric perspective, ensures the adaptability of the learned parameters to new, related challenges, embodying the quintessence of meta-learning: enabling a model to learn from the process of learning.
The MAML framework epitomizes the adaptability and flexibility required in rapidly evolving learning environments, demonstrating the profound potential of meta-learning algorithms to revolutionize the landscape of machine learning.
2.3. Gradient-Oriented Prioritization in Meta-Learning (GOPML)
In the domain of optimization-based meta-learning, precise initialization of model parameters forms the bedrock for swift and effective adaptation to new tasks. This pivotal step not only charts the trajectory of learning, but also determines the efficiency with which a model generalizes from a limited dataset. Hence, the strategic selection and sequencing of tasks are imperative in steering the learning process. Moving beyond random selection, a methodical approach to task organization exploits the inherent diversity and correlation among tasks to foster a more robust learning experience. Within this strategic framework, the arrangement of tasks is intentional, aiming to enhance the model’s adaptability to a variety of learning scenarios. Such an orderly engagement with tasks is designed to alleviate the uncertainties often linked with task relevance and complexity, seeking an equilibrium between reinforcing existing knowledge and integrating new, challenging concepts.
As we evolve towards a more sophisticated meta-learning paradigm, the emphasis shifts towards harnessing the subtle interplay of task characteristics. It is at this juncture that the gradient-oriented prioritization meta-learning (GOPML) algorithm distinguishes itself through the insightful analysis of gradient profiles from the loss function. The magnitude and direction of gradients are posited as crucial indicators of a task’s learning potential. The GOPML algorithm, through an integrated assessment of gradient information, purposefully orchestrates the learning process, concentrating on tasks anticipated to significantly enhance model performance. By quantifying gradient magnitudes and assessing the alignment of gradients across tasks, the learning path is tailor-made to ensure efficient and effective acclimatization to new challenges.
Figure 1 encapsulates the sequential flow of the GOPML algorithm, demonstrating how each task is processed through the system. The diagram explicitly illustrates the gradient computation and the subsequent task prioritization, which are pivotal to the algorithm’s ability to adapt to and excel in new challenges. The orchestrated learning process, depicted in the figure, ensures that the most impactful tasks are prioritized, thus maximizing the model’s performance across a variety of tasks. The methodology unfolds as follows:
Task Sampling: Tasks are sampled from a predetermined distribution , each comprising data points to construct a dataset , correlating inputs x with labels y.
Embedding Computation: Each task is processed to compute an embedding , capturing its distinctive features.
Gradient Computation and Task Prioritization: The gradient of the task-specific loss function
with respect to model parameters
is computed. The magnitude
and alignment
of these gradients are assessed using:
Tasks are then prioritized based on a score derived from their gradient magnitude and alignment:
Gradient Aggregation and Parameter Update: Gradients within each task cluster are aggregated based on prioritization scores, followed by a parameter update using gradient descent, modulated by step size hyperparameter .
Global Parameter Update: After local updates, global adjustment of is performed using step size hyperparameter , to integrate learning from all tasks.
Model Evaluation: The model, with updated parameters , is evaluated against new tasks, iterating until a satisfactory performance is achieved.
GOPML’s strategic framework for task selection and sequencing enhances the model’s ability to adapt and generalize. By focusing on the most impactful tasks, determined by gradient information, GOPML aims for more efficient learning and improved performance across diverse tasks. This approach, outlined in Algorithm 1, marks a shift towards a refined meta-learning paradigm, where the nuanced interplay of task characteristics is leveraged to amplify the learning potential, paving the way for enhanced generalization and mastery of new categories.
| Algorithm 1 Gradient-oriented prioritization meta-learning (GOPML) |
Require:
: distribution over tasks
Require:
: step size and scoring hyperparameters |
- 1:
Randomly initialize - 2:
while convergence not achieved do - 3:
Sample batch of tasks - 4:
for all do - 5:
Generate task embedding using deep learning model - 6:
Sample datapoints from - 7:
Compute task-specific loss and gradient - 8:
Compute gradient magnitude: - 9:
end for - 10:
Perform clustering on to identify groups of similar tasks - 11:
for each cluster do - 12:
for all in the cluster do - 13:
Compute gradient alignment: - 14:
end for - 15:
for all in the cluster do - 16:
Compute task score: - 17:
end for - 18:
Aggregate gradients within the cluster based on - 19:
Compute parameters with gradient descent: - 20:
end for - 21:
Update - 22:
Evaluate model on unseen tasks and adjust if necessary - 23:
end while
|
4. Discussion
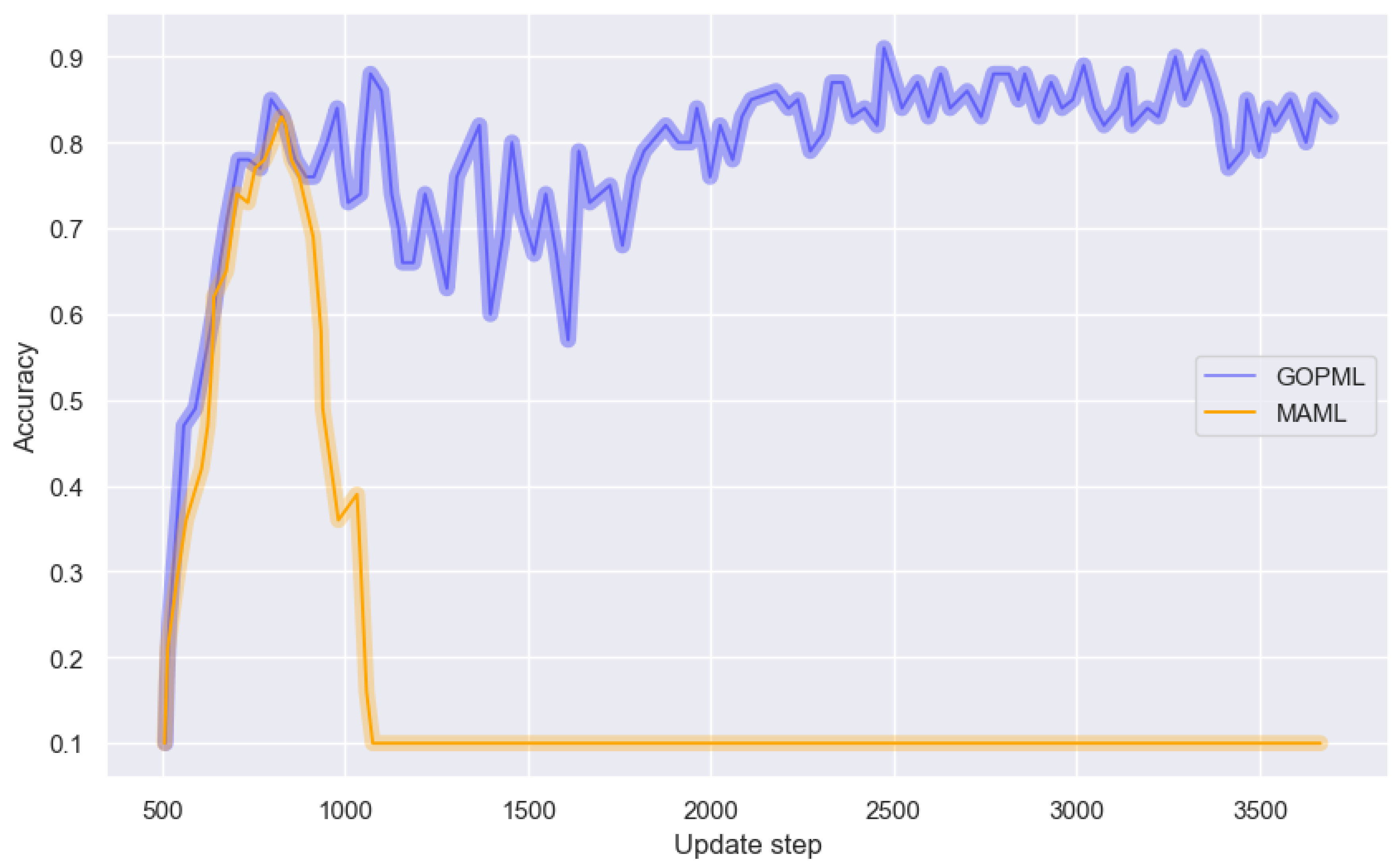
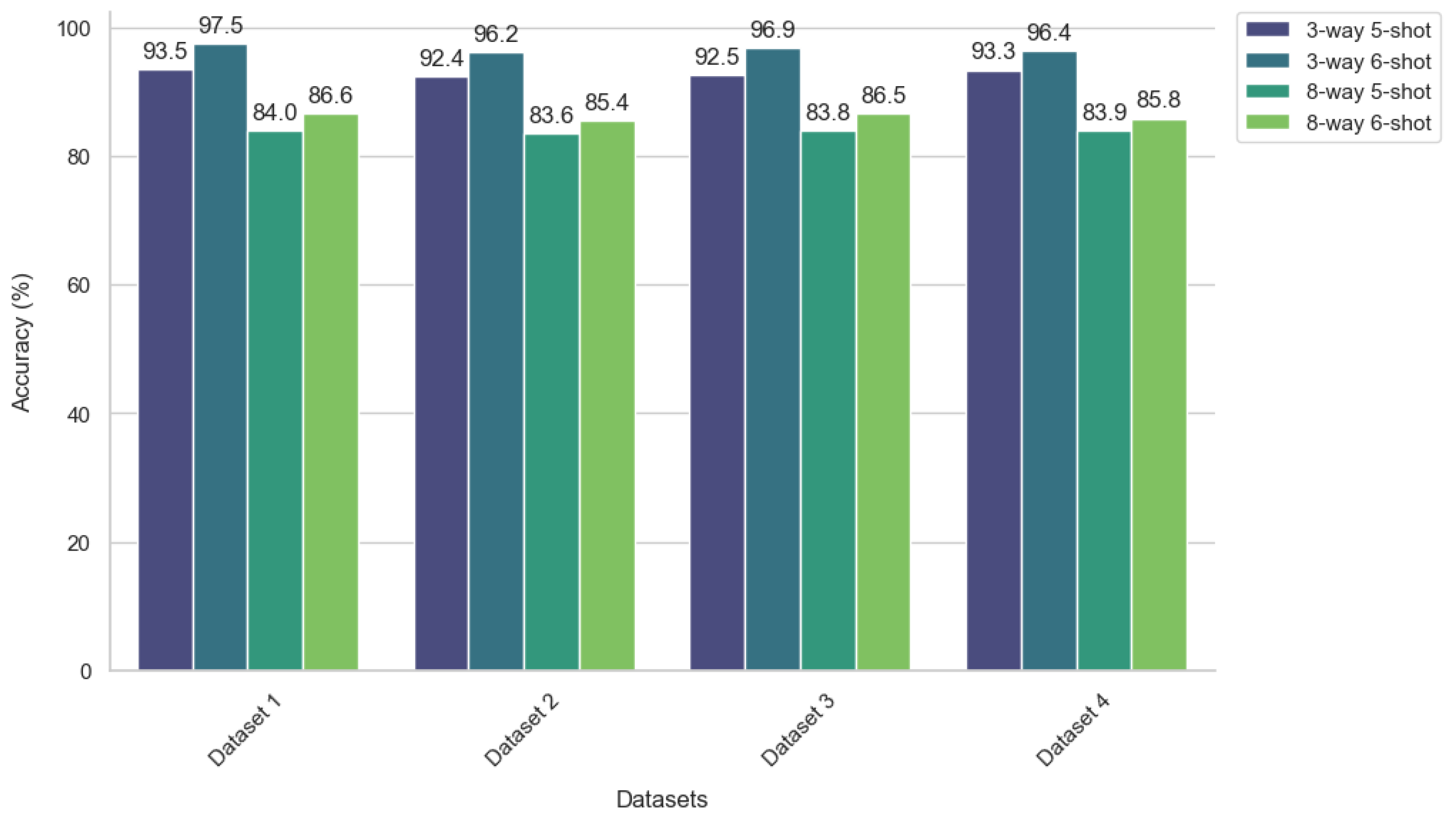
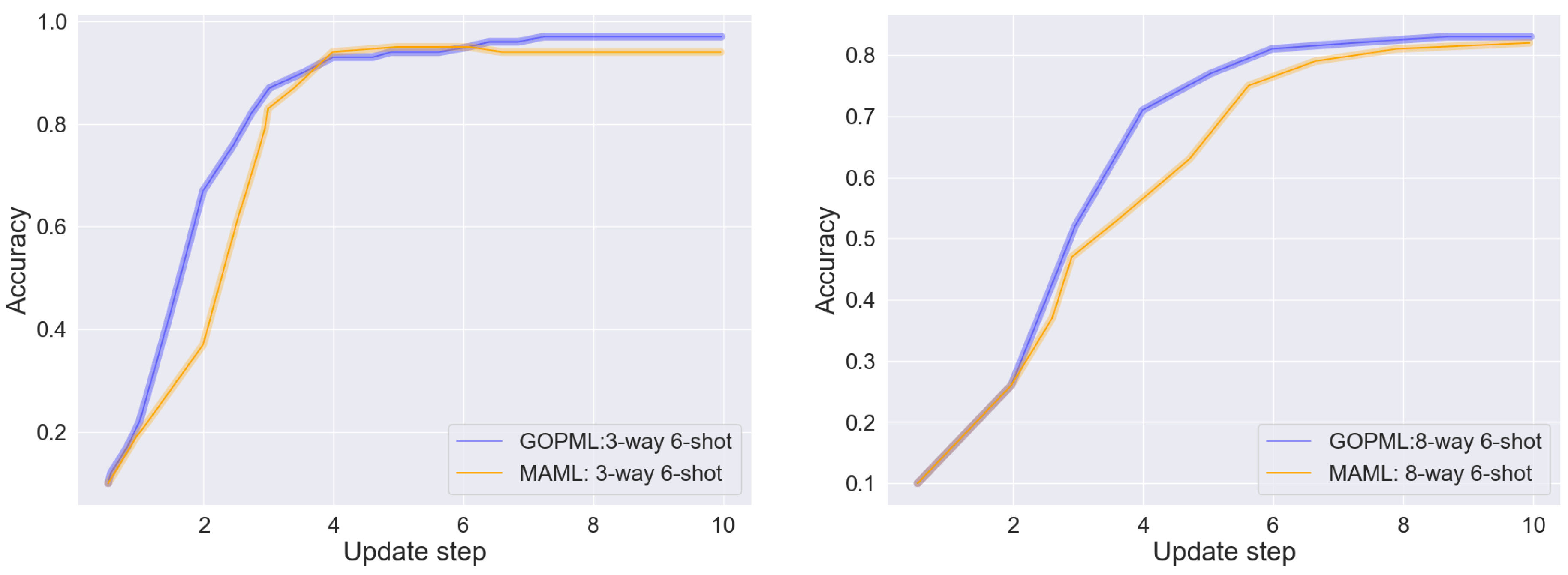
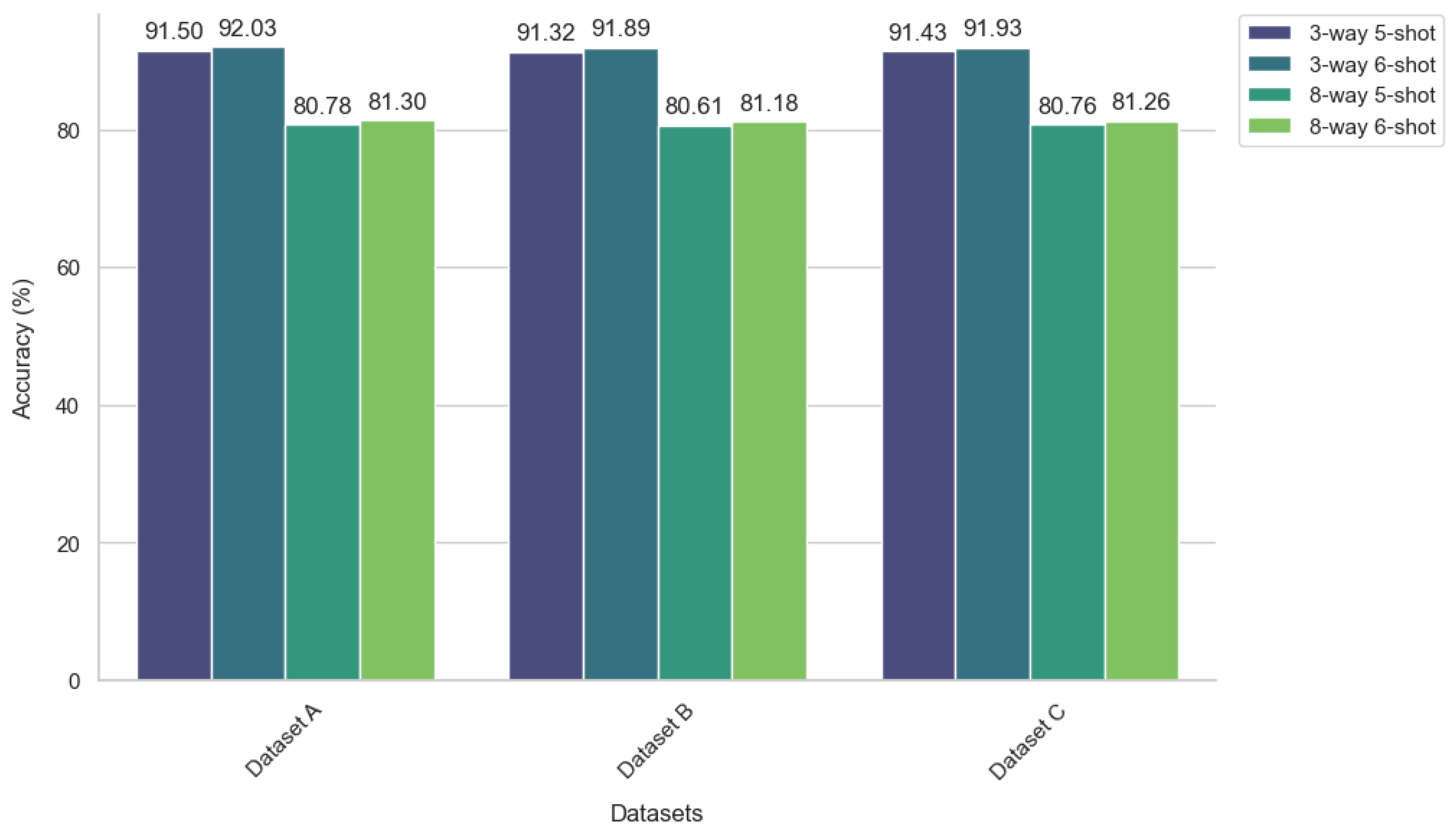
This study introduced a novel gradient-oriented prioritization meta-learning (GOPML) algorithm, designed to enhance the efficiency and effectiveness of few-shot learning in fault diagnosis tasks. The methodological focus was on leveraging the intrinsic patterns embedded in industrial process data to enable robust fault diagnosis, using datasets such as TEP and SKAB. The GOPML algorithm demonstrated significant improvements over traditional methods in fault classification accuracy, precision, and F1 score, particularly in few-shot scenarios. The use of gradient-based task prioritization within GOPML has proven to be a key factor in its success, indicating that the magnitude and alignment of gradients are critical indicators of a task’s learning potential. This finding aligns with previous studies in meta-learning that have emphasized the importance of task selection and prioritization in improving learning outcomes. Another notable aspect of GOPML is its adaptability to different operational conditions and fault scenarios. The algorithm’s ability to maintain a balanced performance across various dataset divisions is indicative of its robustness and reliability in practical industrial contexts. This adaptability is crucial in fault diagnosis applications, where operational conditions can vary significantly.
The results also underscore the potential of GOPML in addressing the challenges posed by limited data availability in industrial settings. By optimizing the learning process through task sequencing and prioritization, GOPML has shown that it is possible to achieve high levels of diagnostic accuracy with a relatively small number of samples.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}