
Semi-Supervised Learning for Robust Emotional Speech Synthesis with Limited Data


Abstract
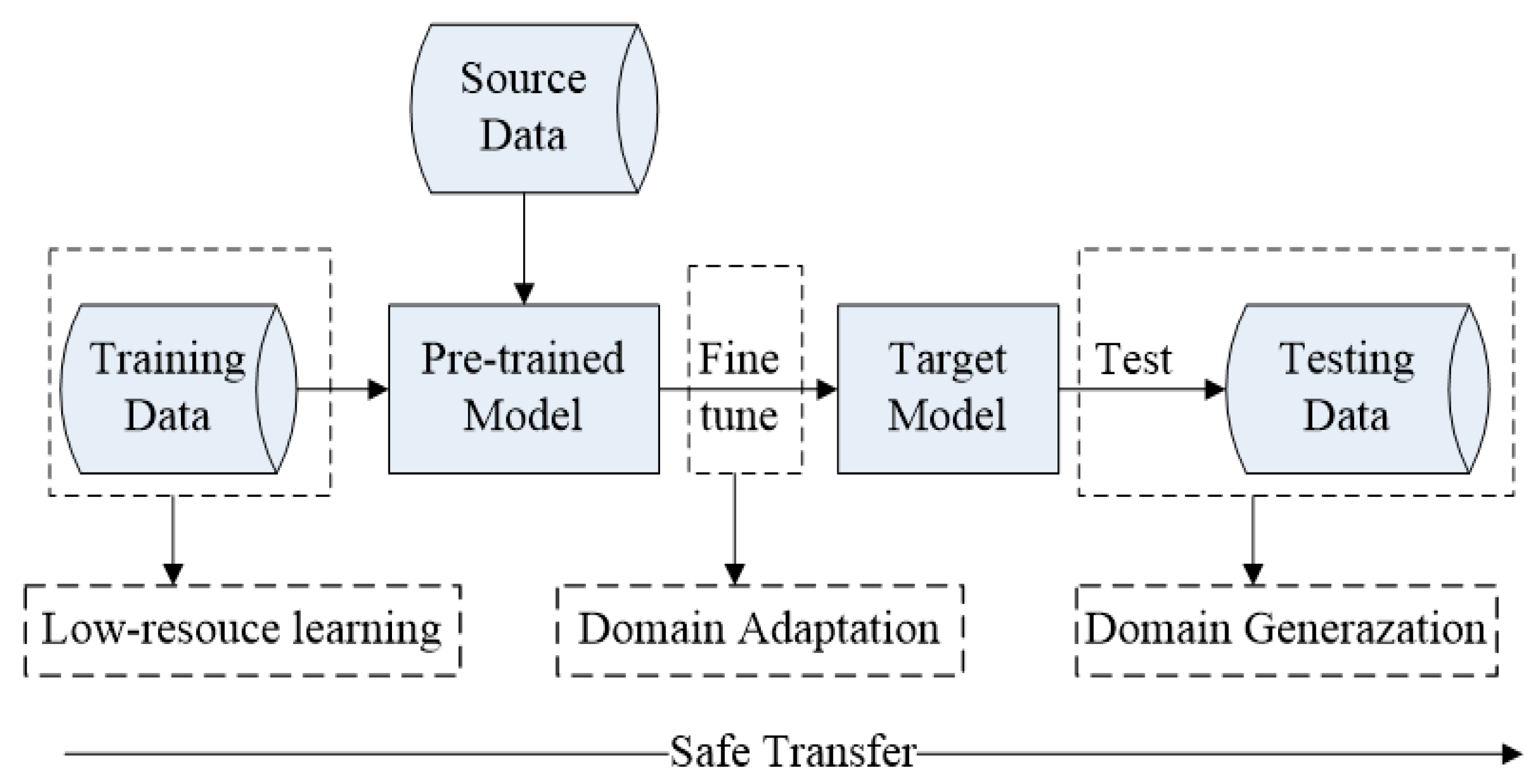
:1. Introduction
- (1)
- An emotional speech synthesis method based on transfer learning and pseudo-labeled reference loss is proposed, in which the model is adaptively learned to generate emotionally perceptible speech with limited emotional speech data after pre-training the model with neutral speech data and then fine-tuning it with emotional speech data that does not contain non-verbal expressions.
- (2)
- Based on the temporal characteristics of Seq2Seq model alignment learning, the attention mechanism used in the initial emotional speech synthesis base framework was modified to add monotonic constraints to strengthen the alignment process during speech synthesis training, allowing for more stable rhyme synthesis and more emotional expressions.
- (3)
- To alleviate the overfitting phenomenon of the model under low resource conditions, we analyze the parameter updates of different modules, adjust and formulate the training strategy when fine-tuning the model, add pseudo-label loss to achieve the effect of regularization, and finally synthesize emotional speech that is better than the baseline method in terms of naturalness, robustness and emotional expressiveness.
2. Related Work
3. Proposed Methods
| Algorithm 1 Semi-supervised Training Algorithm of SMAL-ET2 |
| Input: Datasets: LJ-Speech, ESD, BC2013 |
| {SMAL-ET2} ← initialization with random weights |
| Output: The trained Proposed Emotional Speech Synthesis Model |
| Pre-training: |
| 1: Pre-train initial SMAL-ET2 model with LJ-Speech as backbone network |
| 2: Pre-train backbone network with BC2013 as reference model to provide pseudo labels |
| 3: Pre-train the HiFi-GAN model with LJ-Speech as vocoder |
| Fine-tuning: |
| 1. Fine-tune backbone network with ESD subset as fine-tune model, while fix the parameters of decoder’s post-net and HiFi-GAN vocoder |
| 2. Update the weights and recalculate the final loss with pseudo labels |
3.1. Emotional Speech Synthesis Method
3.2. Training Process
4. Experiment and Results
4.1. Dataset and Preprocessing
4.2. Experimental Setup
4.3. Subjective Evaluation
4.4. Objective Evaluation
4.5. Analyses
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Oord, A.V.D.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Wang, Y.; Skerry-Ryan, R.J.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards End-to-End Speech Synthesis. arXiv 2017, arXiv:1703.10135. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerry-Ryan, R.J.; et al. Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions. In Proceedings of the Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions 2018, Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Arık, S.Ö.; Chrzanowski, M.; Coates, A.; Diamos, G.; Gibiansky, A.; Kang, Y.; Li, X.; Miller, J.; Ng, A.; Raiman, J.; et al. Deep Voice: Real-Time Neural Text-to-Speech. In Proceedings of the 34th International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 195–204. [Google Scholar]
- Arik, S.; Diamos, G.; Gibiansky, A.; Miller, J.; Peng, K.; Ping, W.; Raiman, J.; Zhou, Y. Deep Voice 2: Multi-Speaker Neural Text-to-Speech. arXiv 2017, arXiv:1705.08947. [Google Scholar]
- Ping, W.; Peng, K.; Gibiansky, A.; Arik, S.O.; Kannan, A.; Narang, S.; Raiman, J.; Miller, J. Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning. arXiv 2017, arXiv:1710.07654. [Google Scholar]
- Ren, Y.; Ruan, Y.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.-Y. FastSpeech: Fast, Robust and Controllable Text to Speech. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Ren, Y.; Hu, C.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.-Y. FastSpeech 2: Fast and High-Quality End-to-End Text to Speech. arXiv 2022, arXiv:2006.04558. [Google Scholar]
- Tits, N.; Haddad, K.E.; Dutoit, T. Exploring Transfer Learning for Low Resource Emotional TTS. In Intelligent Systems and Applications. IntelliSys 2019. Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Zhou, K.; Sisman, B.; Li, H. Limited Data Emotional Voice Conversion Leveraging Text-to-Speech: Two-Stage Sequence-to-Sequence Training. arXiv 2021, arXiv:2103.16809. [Google Scholar]
- Wang, Y.; Stanton, D.; Zhang, Y.; Skerry-Ryan, R.J.; Battenberg, E.; Shor, J.; Xiao, Y.; Ren, F.; Jia, Y.; Saurous, R.A. Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis. arXiv 2018, arXiv:1803.09017. [Google Scholar]
- Kong, J.; Kim, J.; Bae, J. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 17022–17033. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Tits, N.; Haddad, K.E.; Dutoit, T. ASR-Based Features for Emotion Recognition: A Transfer Learning Approach. arXiv 2018, arXiv:1805.09197. [Google Scholar]
- Jia, Y.; Zhang, Y.; Weiss, R.; Wang, Q.; Shen, J.; Ren, F.; Chen, Z.; Nguyen, P.; Pang, R.; Lopez Moreno, I.; et al. Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Cai, Z.; Zhang, C.; Li, M. From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint. Proc. Interspeech 2020, 2020, 3974–3978. [Google Scholar]
- Chen, Y.; Assael, Y.; Shillingford, B.; Budden, D.; Reed, S.; Zen, H.; Wang, Q.; Cobo, L.C.; Trask, A.; Laurie, B.; et al. Sample Efficient Adaptive Text-to-Speech. arXiv 2019, arXiv:1809.10460. [Google Scholar]
- Zhang, Z.; Tian, Q.; Lu, H.; Chen, L.-H.; Liu, S. AdaDurIAN: Few-Shot Adaptation for Neural Text-to-Speech with DurIAN. arXiv 2020, arXiv:2005.05642. [Google Scholar]
- Sharma, M.; Kenter, T.; Clark, R. StrawNet: Self-Training WaveNet for TTS in Low-Data Regimes. In Proceedings of the Inter Speech 2020, ISCA, Shanghai, China, 25–29 October 2020; pp. 3550–3554. [Google Scholar]
- Moss, H.B.; Aggarwal, V.; Prateek, N.; González, J.; Barra-Chicote, R. BOFFIN TTS: Few-Shot Speaker Adaptation by Bayesian Optimization. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Shang, Z.; Huang, Z.; Zhang, H.; Zhang, P.; Yan, Y. Incorporating Cross-Speaker Style Transfer for Multi-Language Text-to-Speech. Proc. Interspeech 2021, 2021, 1619–1623. [Google Scholar]
- Bollepalli, B.; Juvela, L.; Alku, P. Lombard Speech Synthesis Using Transfer Learning in a Tacotron Text-to-Speech System. In Proceedings of the Interspeech 2019, ISCA, Graz, Austria, 15–19 September 2019; pp. 2833–2837. [Google Scholar]
- Debnath, A.; Patil, S.S.; Nadiger, G.; Ganesan, R.A. Low-Resource End-to-End Sanskrit TTS Using Tacotron2, WaveGlow and Transfer Learning. In Proceedings of the 2020 IEEE 17th India Council International Conference (INDICON), New Delhi, India, 10–13 December 2022. [Google Scholar]
- Kuzmin, A.D.; Ivanov, S.A. Transfer Learning for the Russian Language Speech Synthesis. In Proceedings of the 2021 Interna tional Conference on Quality Management, Transport and Information Security, Information Technologies (IT&QM&IS), Yaroslavl, Russia, 6–10 September 2021; pp. 507–510. [Google Scholar]
- Huang, A.; Bao, F.; Gao, G.; Shan, Y.; Liu, R. Mongolian Emotional Speech Synthesis Based on Transfer Learning and Emotional Embedding. In Proceedings of the International Conference on Asian Language Processing (IALP), Yantai, China, 23–25 December 2021; pp. 78–83. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Taigman, Y.; Wolf, L.; Polyak, A.; Nachmani, E. VoiceLoop: Voice Fitting and Synthesis via a Phonological Loop. arXiv 2018, arXiv:1707.06588. [Google Scholar]
- Lee, Y.; Rabiee, A.; Lee, S.-Y. Emotional End-to-End Neural Speech Synthesizer. arXiv 2017, arXiv:1711.05447. [Google Scholar]
- Liu, R.; Sisman, B.; Li, J.; Bao, F.; Gao, G.; Li, H. Teacher-Student Training for Robust Tacotron-Based TTS. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Lee, D.-H. Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks. In Proceedings of the ICML 2013 Workshop on Challenges in Representation Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Higuchi, Y.; Moritz, N.; Roux, J.L.; Hori, T. Advancing Momentum Pseudo-Labeling with Conformer and Initialization Strategy. 2021. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022. [Google Scholar]
- Chung, Y.-A.; Wang, Y.; Hsu, W.-N.; Zhang, Y.; Skerry-Ryan, R.J. Semi-Supervised Training for Improving Data Efficiency in End-to-End Speech Synthesis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Zhang, X.; Wang, J.; Cheng, N.; Xiao, J. Semi-Supervised Learning Based on Reference Model for Low-Resource TTS. In Proceedings of the 2022 18th International Conference on Mobility, Sensing and Networking (MSN), Guangzhou, China, 14–16 December 2022. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10687–10698. [Google Scholar]
- Schuller, D.M.; Schuller, B.W. A Review on Five Recent and Near-Future Developments in Computational Processing of Emo tion in the Human Voice. Emot. Rev. 2021, 13, 44–50. [Google Scholar] [CrossRef]
- Tachibana, H.; Uenoyama, K.; Aihara, S. Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4784–4788. [Google Scholar]
- Zhang, J.-X.; Ling, Z.-H.; Dai, L.-R. Forward Attention in Sequence-to-Sequence Acoustic Modelling for Speech Synthesis. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4789–4793. [Google Scholar]
- Battenberg, E.; Skerry-Ryan, R.J.; Mariooryad, S.; Stanton, D.; Kao, D.; Shannon, M.; Bagby, T. Location-Relative Attention Mechanisms for Robust Long-Form Speech Synthesis. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- He, M.; Deng, Y.; He, L. Robust Sequence-to-Sequence Acoustic Modeling with Stepwise Monotonic Attention for Neural TTS. In Proceedings of the Interspeech 2019, ISCA, Graz, Austria, 15–19 September 2019; pp. 1293–1297. [Google Scholar]
- Zhou, K.; Sisman, B.; Liu, R.; Li, H. Emotional Voice Conversion: Theory, Databases and ESD. Speech Commun. 2022, 137, 1–18. [Google Scholar] [CrossRef]
- Low-Resource Emotional Speech Synthesis: Transfer Learning and Data Requirements. SpringerLink. Available online: https://linkspringer.53yu.com/chapter/10.1007/978-3-031-20980-2_43 (accessed on 6 April 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ESD (English Subset) | Number of Utterances |
|---|---|
| Evaluation set | 20 |
| Test set | 30 |
| Training set | 300 |
| Hyperparameters | Settings |
|---|---|
| Adam optimizer β1 | 0.9 |
| Adam optimizer β2 | 0.999 |
| Batch_size | 32 |
| Initial learning rate | 0.002 |
| Finetune learning rate | 0.00002 |
| Decay learning rate | True |
| Sample rate | 22,050 |
| hidden vectors of SMA | 128 |
| Attention dropout | 0.4 |
| Decoder dropout | 0.5 |
| zoneout | 0.1 |
| epochs | 1000 |
| Score | MOS Standards | EMOS Standards |
|---|---|---|
| 0–1.0 | Very poor sound quality, difficult to understand; large latency, poor communication | Emotional similarity unknown |
| 1.0–2.0 | General sound quality, not very clear to hear; large delay, not clear, not smooth; communication needs to be repeated several times | Blurred emotional similarity |
| 2.0–3.0 | Sound quality is not bad, more audible; there is a certain delay, there is noise, but acceptable | Emotional similarity is acceptable |
| 3.0–4.0 | Sound quality is very good, you can hear clearly; only a little delay; willing to accept | Emotional similarity willingness to accept |
| 4.0–5.0 | Sound quality is particularly good, very clear and natural; almost no delay, smooth communication | Ideal emotional similarity |
| Data Size | θ | MOS (Neutral) | WER(%) |
|---|---|---|---|
| 30 | 0 | 2.65 ± 0.20 | 2.5 |
| 100 | 0 | 3.23 ± 0.18 | 2.0 |
| 300 | 0 | 3.85 ± 0.07 | 1.5 |
| 30 | 0.1 (BL) | 3.20 ± 0.28 | 1.5 |
| 100 | 0.1 (BL) | 3.49 ± 0.22 | 0.5 |
| 300 | 0.1 (BL) | 4.14 ± 0.10 | 0.2 |
| 30 | 0.3 | 3.14 ± 0.16 | 2.0 |
| 100 | 0.3 | 3.93 ± 0.35 | 1.0 |
| 300 | 0.3 | 3.96 ± 0.09 | 0.3 |
| Emotion | EGST | ETaco2 | SMAL-ET2 | Ground Truth |
|---|---|---|---|---|
| Neutral | 3.15 ± 0.31 | 3.52 ± 0.23 | 3.97 ± 0.28 | 4.81 ± 0.16 |
| Sad | 3.32 ± 0.29 | 3.55 ± 0.21 | 3.77 ± 0.15 | 4.83 ± 0.19 |
| Happy | 3.47 ± 0.16 | 3.61 ± 0.09 | 4.15 ± 0.19 | 4.94 ± 0.09 |
| Surprise | 3.19 ± 0.27 | 3.43 ± 0.30 | 3.96 ± 0.24 | 4.86 ± 0.07 |
| Angry | 2.92 ± 0.20 | 3.34 ± 0.17 | 3.88 ± 0.25 | 4.81 ± 0.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Wushouer, M.; Tuerhong, G.; Wang, H. Semi-Supervised Learning for Robust Emotional Speech Synthesis with Limited Data. Appl. Sci. 2023, 13, 5724. https://doi.org/10.3390/app13095724
Zhang J, Wushouer M, Tuerhong G, Wang H. Semi-Supervised Learning for Robust Emotional Speech Synthesis with Limited Data. Applied Sciences. 2023; 13(9):5724. https://doi.org/10.3390/app13095724
Chicago/Turabian StyleZhang, Jialin, Mairidan Wushouer, Gulanbaier Tuerhong, and Hanfang Wang. 2023. "Semi-Supervised Learning for Robust Emotional Speech Synthesis with Limited Data" Applied Sciences 13, no. 9: 5724. https://doi.org/10.3390/app13095724
APA StyleZhang, J., Wushouer, M., Tuerhong, G., & Wang, H. (2023). Semi-Supervised Learning for Robust Emotional Speech Synthesis with Limited Data. Applied Sciences, 13(9), 5724. https://doi.org/10.3390/app13095724