
Monocular Camera-Based Robotic Pick-and-Place in Fusion Applications

 , ,
, ,
Abstract
:1. Introduction
- Unlike other monocular camera-based methods that can only place the target at a fixed location after random object picking, our method allows for completely random object picking and placement.
- Our method does not rely on any a priori information or auxiliary methods, such as visual markers, to aid in target recognition.
- Our approach does not divide the pick-and-place task into multiple phases, such as target recognition and task planning, and does not require an artificially designed task planning module. Rather, it is an end-to-end solution that is data driven.
- We propose a lightweight end-to-end method for handling the pick-and-place task, where all the sessions, from environmental perception to task understanding, are conducted by deep reinforcement learning without any artificially designed components. The proposed method’s training can be executed on a consumer-level GPU.
- The proposed method solely relies on RGB data from an eye-in-hand camera and the end-effector’s center position, both of which are reliable and available for fusion applications.
- We developed multiple sub-environments in the simulation environment for parallel training and rendered each sub-environment’s current state in real time to facilitate adjusting hyper-parameters and accelerating the training speed.
2. Related Work
2.1. Deep Learning-Based Methods
2.1.1. 2D Image Input with Traditional Computer Vision Algorithms
2.1.2. 3D input Data with CNN
2.2. Deep Reinforcement Learning-Based Methods
3. Proposed Method
3.1. Simulation Environment Establishment and Problem Statement
3.2. Distributed Proximal Policy Optimization Algorithms
| Algorithm 1 A2C. |
|
| Algorithm 2 Proximal policy optimization (PPO). |
|
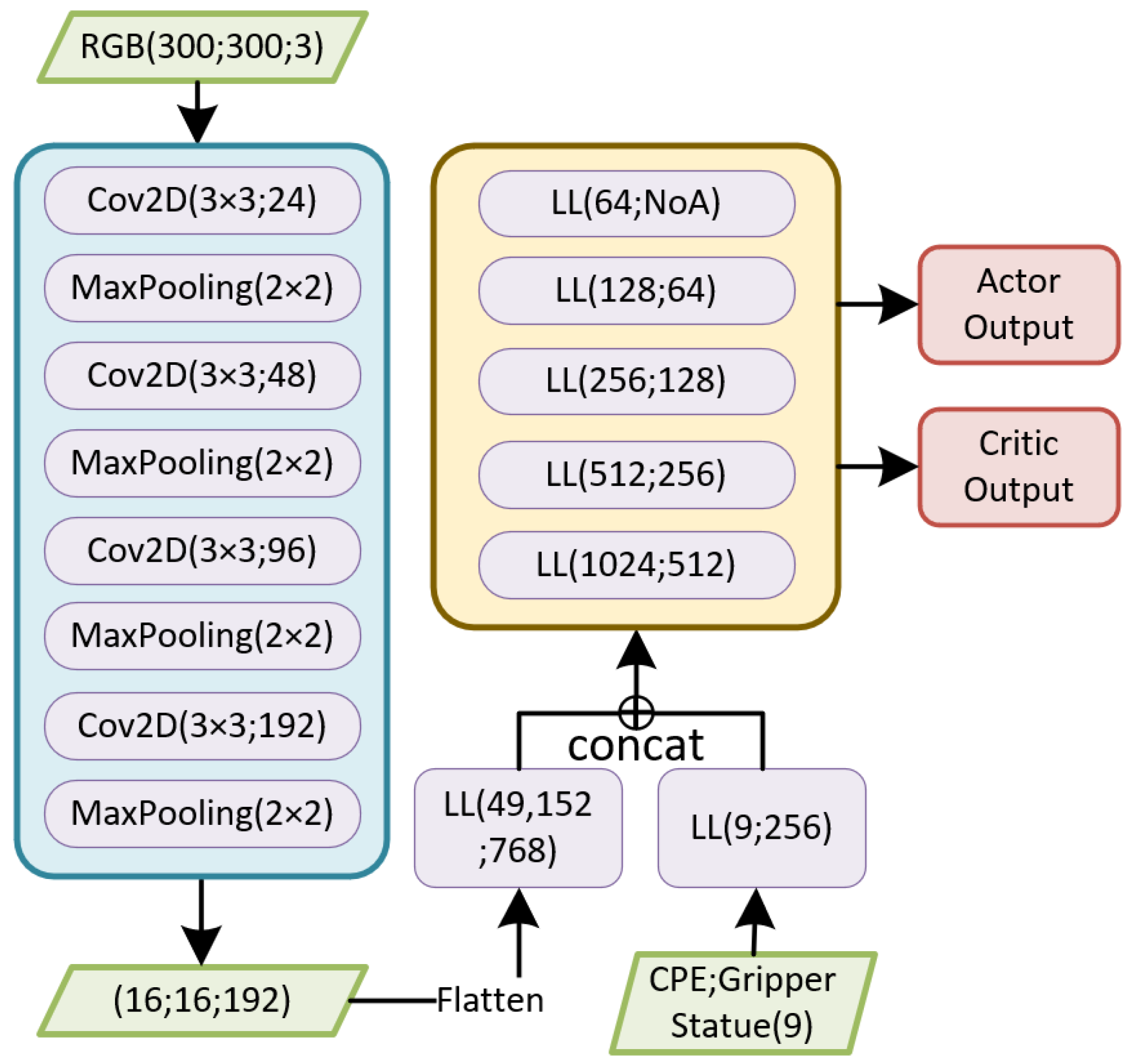
3.3. Network Architecture
3.4. Reward Setting
| Algorithm 3 Reward setting. |
|
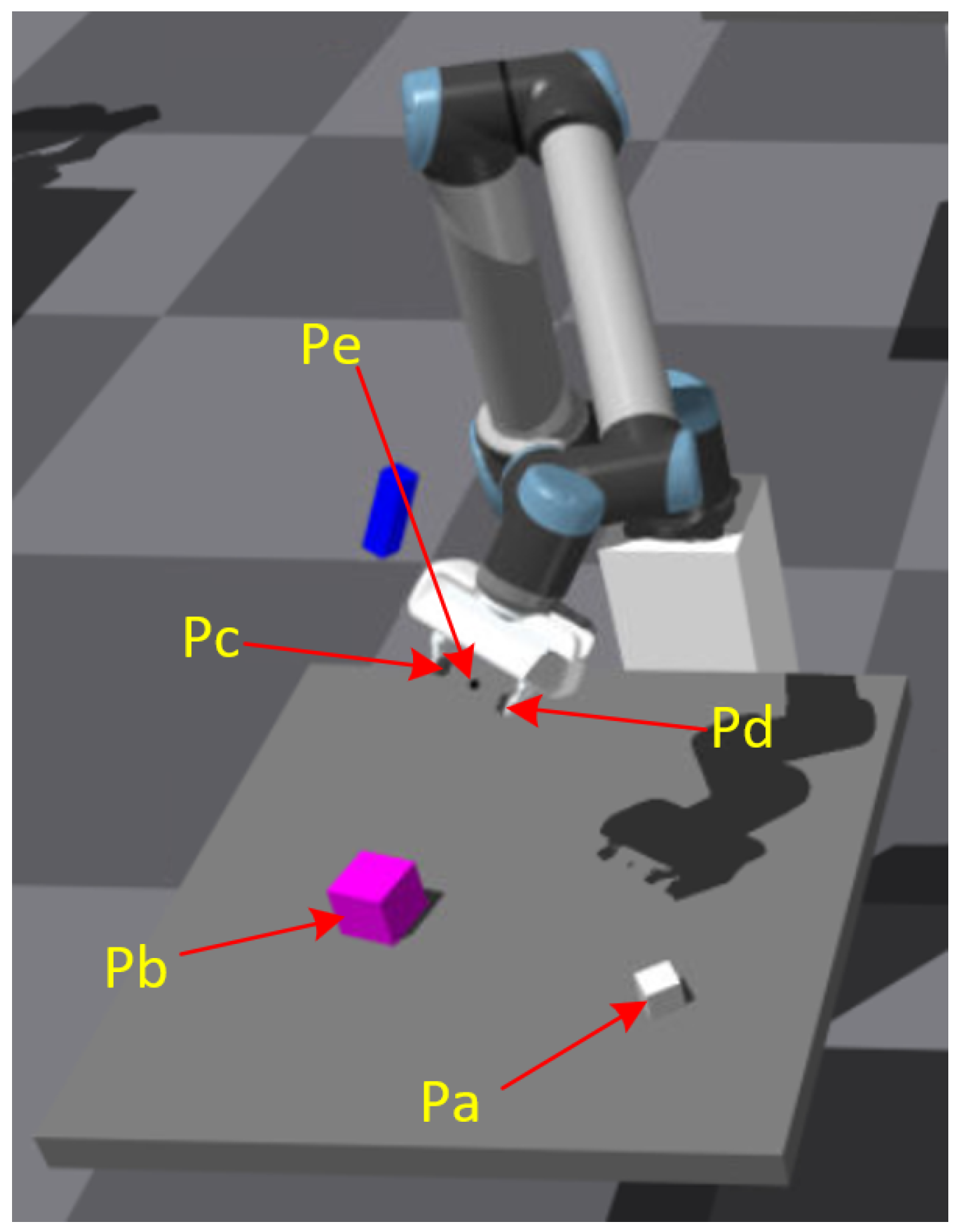
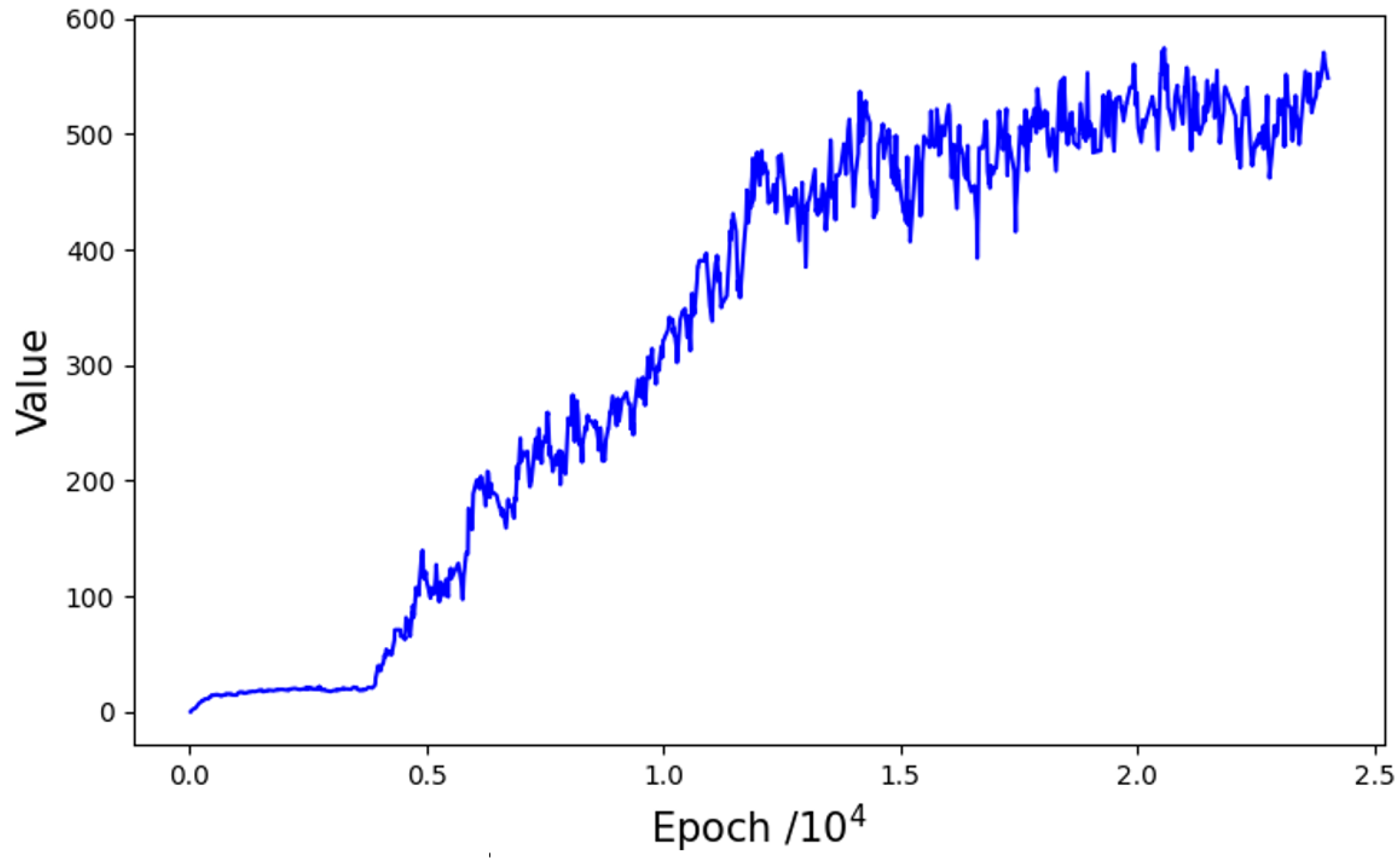
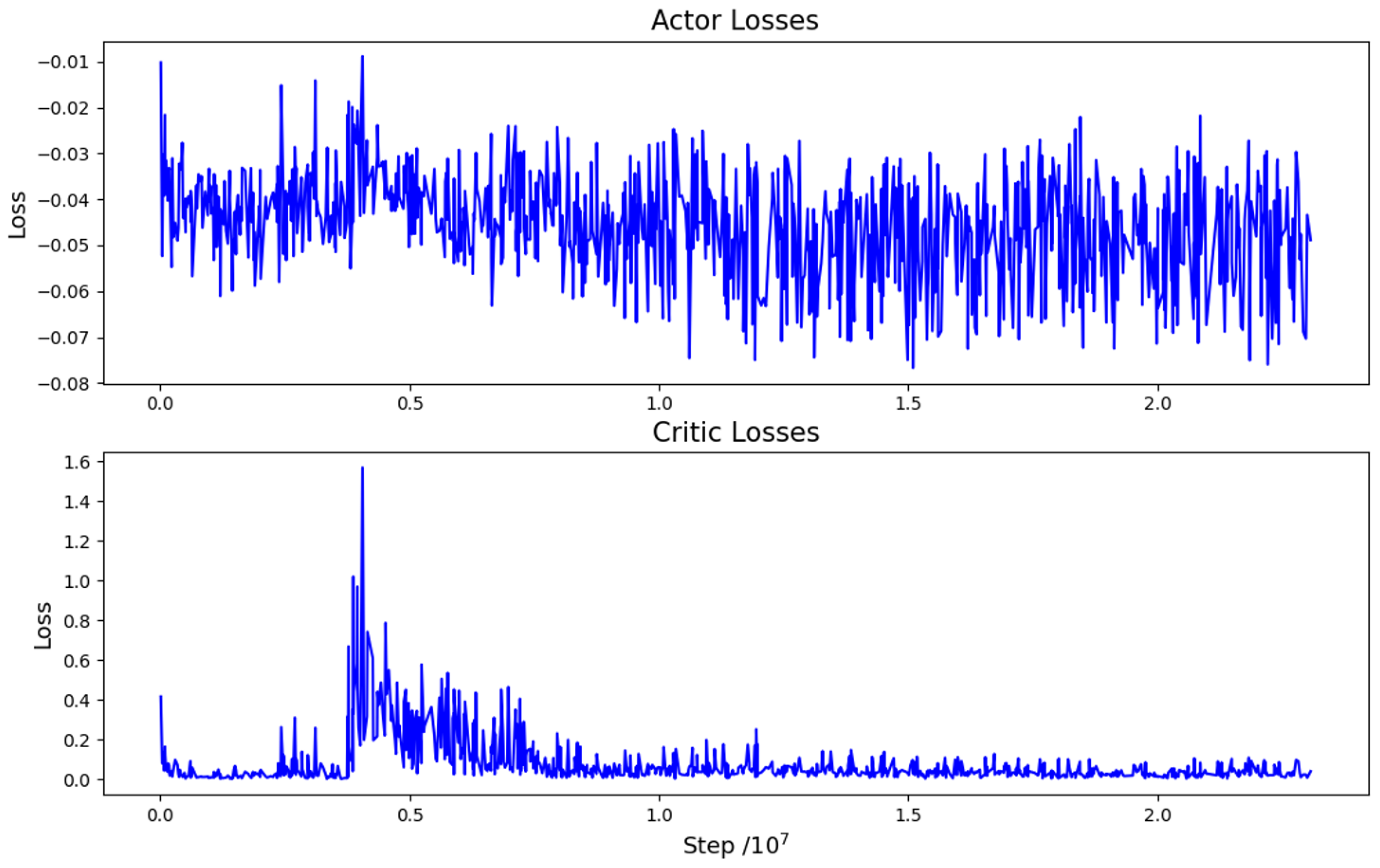
4. Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EP n P: An accurate O (n) solution to the P n P problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef] [Green Version]
- Heess, N.; TB, D.; Sriram, S.; Lemmon, J.; Merel, J.; Wayne, G.; Tassa, Y.; Erez, T.; Wang, Z.; Eslami, S.; et al. Emergence of locomotion behaviours in rich environments. arXiv 2017, arXiv:1707.02286. [Google Scholar]
- Makoviychuk, V.; Wawrzyniak, L.; Guo, Y.; Lu, M.; Storey, K.; Macklin, M.; Hoeller, D.; Rudin, N.; Allshire, A.; Handa, A.; et al. Isaac Gym: High Performance GPU-Based Physics Simulation for Robot Learning. arXiv 2021, arXiv:2108.10470. [Google Scholar]
- Lee, T.E.; Tremblay, J.; To, T.; Cheng, J.; Mosier, T.; Kroemer, O.; Fox, D.; Birchfield, S. Camera-to-robot pose estimation from a single image. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 9426–9432. [Google Scholar]
- Byambaa, M.; Koutaki, G.; Choimaa, L. 6D Pose Estimation of Transparent Object From Single RGB Image for Robotic Manipulation. IEEE Access 2022, 10, 114897–114906. [Google Scholar] [CrossRef]
- Horng, J.R.; Yang, S.Y.; Wang, M.S. Object localization and depth estimation for eye-in-hand manipulator using mono camera. IEEE Access 2020, 8, 121765–121779. [Google Scholar]
- Nguyen, A.; Kanoulas, D.; Muratore, L.; Caldwell, D.G.; Tsagarakis, N.G. Translating videos to commands for robotic manipulation with deep recurrent neural networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3782–3788. [Google Scholar]
- Zeng, A.; Song, S.; Yu, K.T.; Donlon, E.; Hogan, F.R.; Bauza, M.; Ma, D.; Taylor, O.; Liu, M.; Romo, E.; et al. Robotic pick-and-place of novel objects in clutter with multi-affordance grasping and cross-domain image matching. Int. J. Robot. Res. 2022, 41, 690–705. [Google Scholar] [CrossRef] [Green Version]
- Schwarz, M.; Milan, A.; Periyasamy, A.S.; Behnke, S. RGB-D object detection and semantic segmentation for autonomous manipulation in clutter. Int. J. Robot. Res. 2018, 37, 437–451. [Google Scholar] [CrossRef] [Green Version]
- Zeng, A.; Florence, P.; Tompson, J.; Welker, S.; Chien, J.; Attarian, M.; Armstrong, T.; Krasin, I.; Duong, D.; Sindhwani, V.; et al. Transporter networks: Rearranging the visual world for robotic manipulation. In Proceedings of the Conference on Robot Learning, London, UK, 8–11 November 2021; pp. 726–747. [Google Scholar]
- Quillen, D.; Jang, E.; Nachum, O.; Finn, C.; Ibarz, J.; Levine, S. Deep reinforcement learning for vision-based robotic grasping: A simulated comparative evaluation of off-policy methods. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 6284–6291. [Google Scholar]
- James, S.; Davison, A.J. Q-attention: Enabling efficient learning for vision-based robotic manipulation. IEEE Robot. Autom. Lett. 2022, 7, 1612–1619. [Google Scholar] [CrossRef]
- Mohammed, M.Q.; Chung, K.L.; Chyi, C.S. Pick and place objects in a cluttered scene using deep reinforcement learning. Int. J. Mech. Mechatron. Eng. IJMME 2020, 20, 50–57. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Gualtieri, M.; Ten Pas, A.; Platt, R. Pick and place without geometric object models. In Proceedings of the 2018 IEEE international conference on robotics and automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 7433–7440. [Google Scholar]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE international conference on robotics and automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3389–3396. [Google Scholar]
- Gu, S.; Lillicrap, T.; Sutskever, I.; Levine, S. Continuous deep q-learning with model-based acceleration. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2829–2838. [Google Scholar]
- Lee, A.X.; Devin, C.M.; Zhou, Y.; Lampe, T.; Bousmalis, K.; Springenberg, J.T.; Byravan, A.; Abdolmaleki, A.; Gileadi, N.; Khosid, D.; et al. Beyond pick-and-place: Tackling robotic stacking of diverse shapes. In Proceedings of the 5th Annual Conference on Robot Learning, London, UK, 8–11 November 2021. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: New York, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Konda, V.; Tsitsiklis, J. Actor-critic algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999; Volume 12. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Makoviichuk, D.; Makoviychuk, V. rl-games: A High-Performance Framework for Reinforcement Learning. 2021. Available online: https://github.com/Denys88/rl_games (accessed on 29 March 2023).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Success No./Experiment No. | Steps | Reward | |||
|---|---|---|---|---|---|
| Grasp | Lift & Align | Stack | NA | NA | |
| Ours | 149/150 | 149/150 | 147/150 | 125.7 | 541.8 |
| MLP | 150/150 | 149/150 | 148/150 | 51.3 | 577.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, R.; Wu, H.; Li, M.; Cheng, Y.; Song, Y.; Handroos, H. Monocular Camera-Based Robotic Pick-and-Place in Fusion Applications. Appl. Sci. 2023, 13, 4487. https://doi.org/10.3390/app13074487
Yin R, Wu H, Li M, Cheng Y, Song Y, Handroos H. Monocular Camera-Based Robotic Pick-and-Place in Fusion Applications. Applied Sciences. 2023; 13(7):4487. https://doi.org/10.3390/app13074487
Chicago/Turabian StyleYin, Ruochen, Huapeng Wu, Ming Li, Yong Cheng, Yuntao Song, and Heikki Handroos. 2023. "Monocular Camera-Based Robotic Pick-and-Place in Fusion Applications" Applied Sciences 13, no. 7: 4487. https://doi.org/10.3390/app13074487
APA StyleYin, R., Wu, H., Li, M., Cheng, Y., Song, Y., & Handroos, H. (2023). Monocular Camera-Based Robotic Pick-and-Place in Fusion Applications. Applied Sciences, 13(7), 4487. https://doi.org/10.3390/app13074487