

A Novel Process Recommendation Method That Integrates Disjoint Paths and Sequential Patterns


Abstract
1. Introduction
- A new edge-disjoint path extraction algorithm (EPE), which extracts the behavioral semantics of process library models based on the task-based process structure tree (TPST) [14], was proposed. This solves the problem of ignoring the semi-ordered structure characteristics of the TPST in the existing literature.
- A contiguous path sequential pattern mining (CPSPan) algorithm for process recommendation was proposed; this algorithm mines frequent and continuous subsequences of edge-disjoint paths, increasing the number of process fragments to be matched in the reference model. This provides a greater range of options and more dependable guidance for process recommendations.
- A new process recommendation strategy was proposed, in which the node recommendation degree was introduced to measure the influence of the node position on the recommendation. The lift, confidence, and support degrees were introduced as the basis for measuring the importance of the process fragments to be matched.
- An experimental analysis demonstrated that the proposed method could effectively recommend the next node in the process modeling with an accuracy of 89.67% and 90.57% on the real and simulated datasets, respectively. Additionally, the method met the time requirements.
2. Related Work
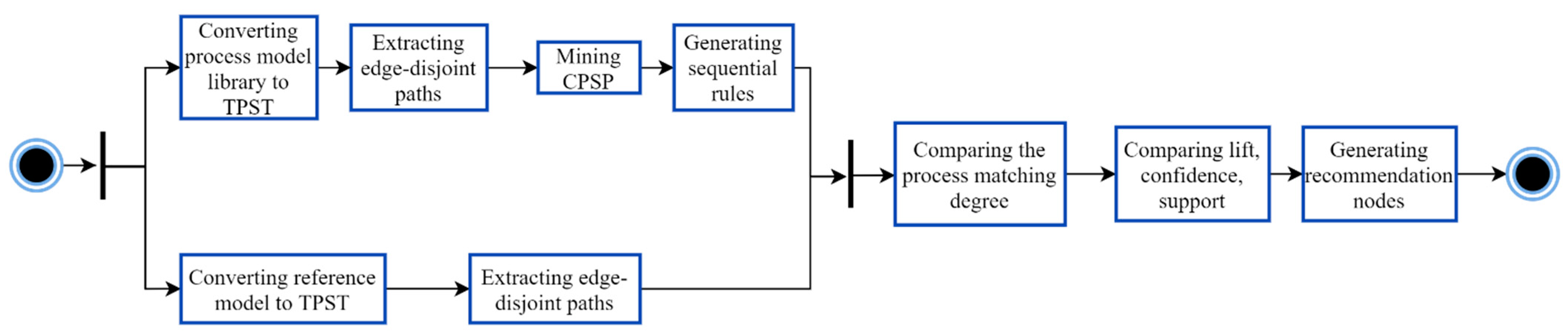
3. Proposed Method
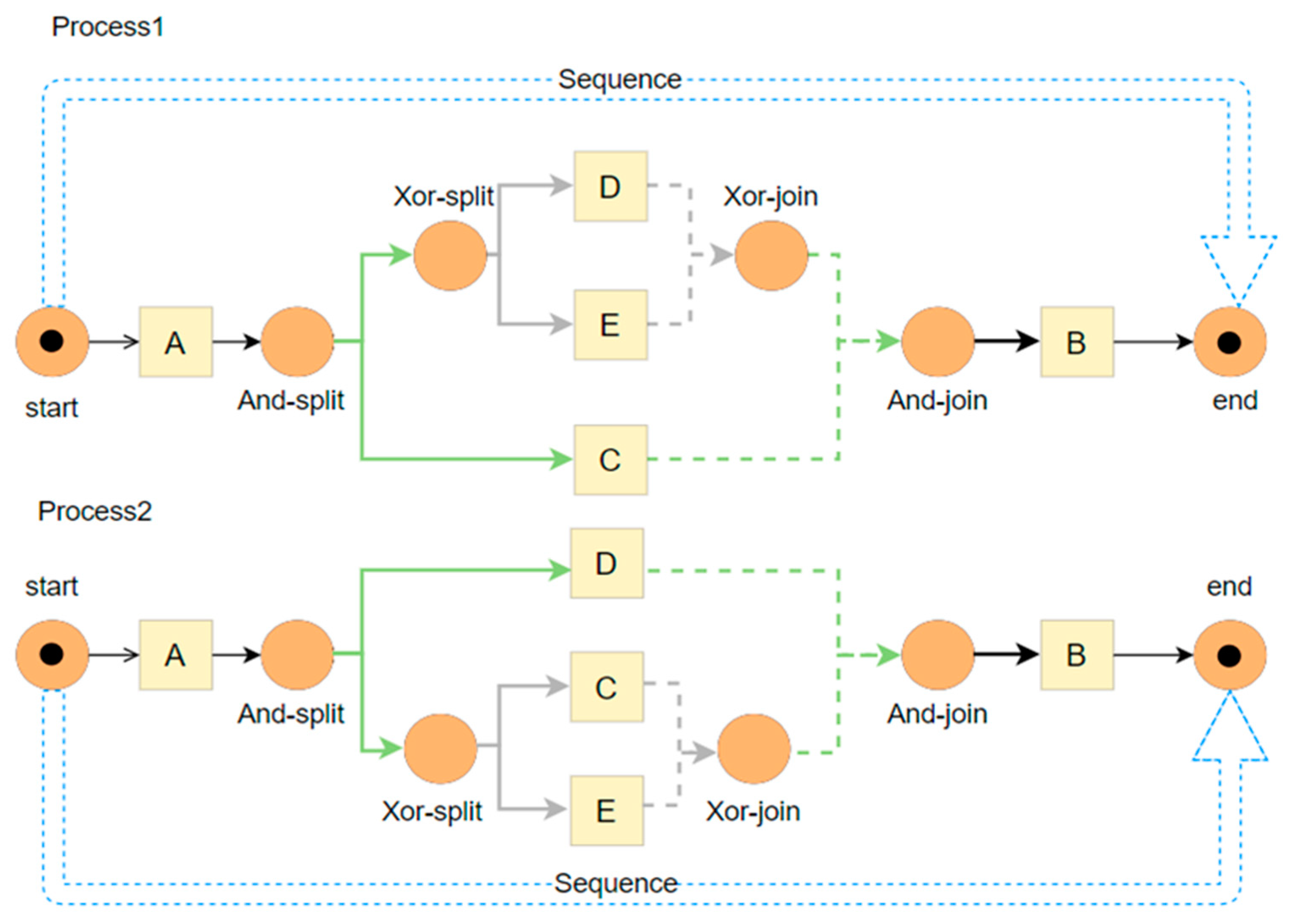
- The preprocessing module is divided into two parts. The first part analyzes the process model library in the TPST and saves it in the TPST library. Figure 4, for example, shows a TPST converted from the business process model in Figure 1. In the second part, all models in the TPST library are extracted according to the different gateway nodes and stored in the edge-disjoint path library.
- The CPSP mining module mines CPSPin the edge-disjoint path library, and a sequential rule is generated according to the excavated CPSP and its corresponding calculated degree of lift, confidence, and support. All the sequential rules are saved in the sequential rule library for the subsequent recommendation.
- The node recommendation module first calculates the process-matching degree between the edge-disjoint path and each CPSP in the sequential rule library excavated by the reference model. It then selects the appropriate recommendation result based on the process-matching degree, lift degree, confidence degree, and support degree. The specific recommended steps are as follows:
- (i)
- The edge-disjoint path is extracted from the TPST that was transformed by the process model library in the preprocessing module using the EPE.
- (ii)
- The frequent CPSP mining is carried out using CPSPan on the edge-disjoint path library. The corresponding degrees of lift, confidence, and support of each CPSP are calculated, and the results are saved into the sequential rule library T.
- (iii)
- The corresponding TPST is generated by the process decomposition of the reference model, and its edge-disjoint paths are extracted.
- (iv)
- All sequential rules in the sequential rule library are circled to calculate the process-matching degree between each sequential rule’s CPSP and the edge-disjoint path in the reference model.
- (v)
- At the end of the cycle, the nodes are sorted according to the calculation result of the process-matching degree, and the recommended node set is the last node of the CPSP in the top k sequential rules after sorting. If there are CPSPs with the same matching degree, the nodes are ranked according to the degrees of lift, confidence, and support, and the larger value is recommended first.
3.1. Edge-Disjoint Path Extraction Method
| Algorithm 1. EPE for the process model |
| Input: process model library F Output: edge-disjoint path table R FOR (each process p in F) do{ Initialize set of edge-disjoint path r; k = 1; convert p to TPSP; FOR t do BFS{ IF current node Pi in layer1 {r[k-0].add(Pi) ELSE IF Pi’s parent node Pj is Xor{ FOR (each r[i] that contains Pj) do{ IF Pi = Pj’s last child node {replace Pj in r[i] with Pi} ELSE {copy r[k] = r[i]; replace Pj in r[k] with Pi; k++}} ELSE IF Pj is And{ IF Pi = Pj’s first child node {FOR (each r[i] that contains Pj) do{replace Pj in r[i] with Pi}} ELSE FOR (each r[i] that contains Pi’s sibling node Pb) do{ Insert Pi in front of Pb in r[i]; copy r[k] = r[i]; insert Pi after Pb in r[k]; k++}} ELSE IF Pj is Loop{ IF Pi = Pj’s first child node {FOR (each r[i] that contains Pj) do{ Replace Pj in r[i] with Pi}} ELSE FOR (each r[i] that contains Pb) do{ IF Pi = Pj’s last child node{r[i].add(Pi); insert Pj after Pi in r[i]} ELSE {r[i].add(Pi)}}}} Return R → r[i],r[k] |
3.2. CPSP Mining Method
- (1)
- n = k + m;
- (2)
- s1 = α1, s2 = α2, sk = αk, sk+1 = β1, sk+2 = β2, sn = βm.
- Recursive mining is performed only on the first item of local suffixes with support greater than a threshold, thus reducing the projection size and ensuring the continuity of the path sequence.
- It further reduces the size of the projection database by converting the item set expansion into sequence expansion for the case where the modeler does not click on two process nodes simultaneously during the process recommendation.
- It removes frequent 1-sequences that are not meant for process recommendation.
| Algorithm 2. CPSPan for process recommendation |
| Input: R, the threshold of support threshold Output: set of CPSPs patterns Get all frequent 1-sequences i in R Build contiguous suffix projection library SD|i for the current prefix i, and remove sequences that are discontiguous with i |
| FOR (each suffix j in SD|i) do{ Combine the first term of j and the current prefix as a new prefix, obtain frequent 2-sequences Build SD|j prefixed by frequent 2-sequences in SD|i} Repeat (3)~(5), recursively mine patterns of i, returning when the current contiguous suffix projection library SD is empty Repeat (2)~(6), mining patterns of the remaining 1-sequences Delete 1-sequences Return patterns |
3.3. Process Node Recommendation
- Recommend sequential rules with a high process-matching degree first.
- Recommend sequential rules with a high lift under the same conditions first.
- Recommend sequential rules with high confidence under the same conditions first.
- Recommend sequential rules with high support under the same conditions first.
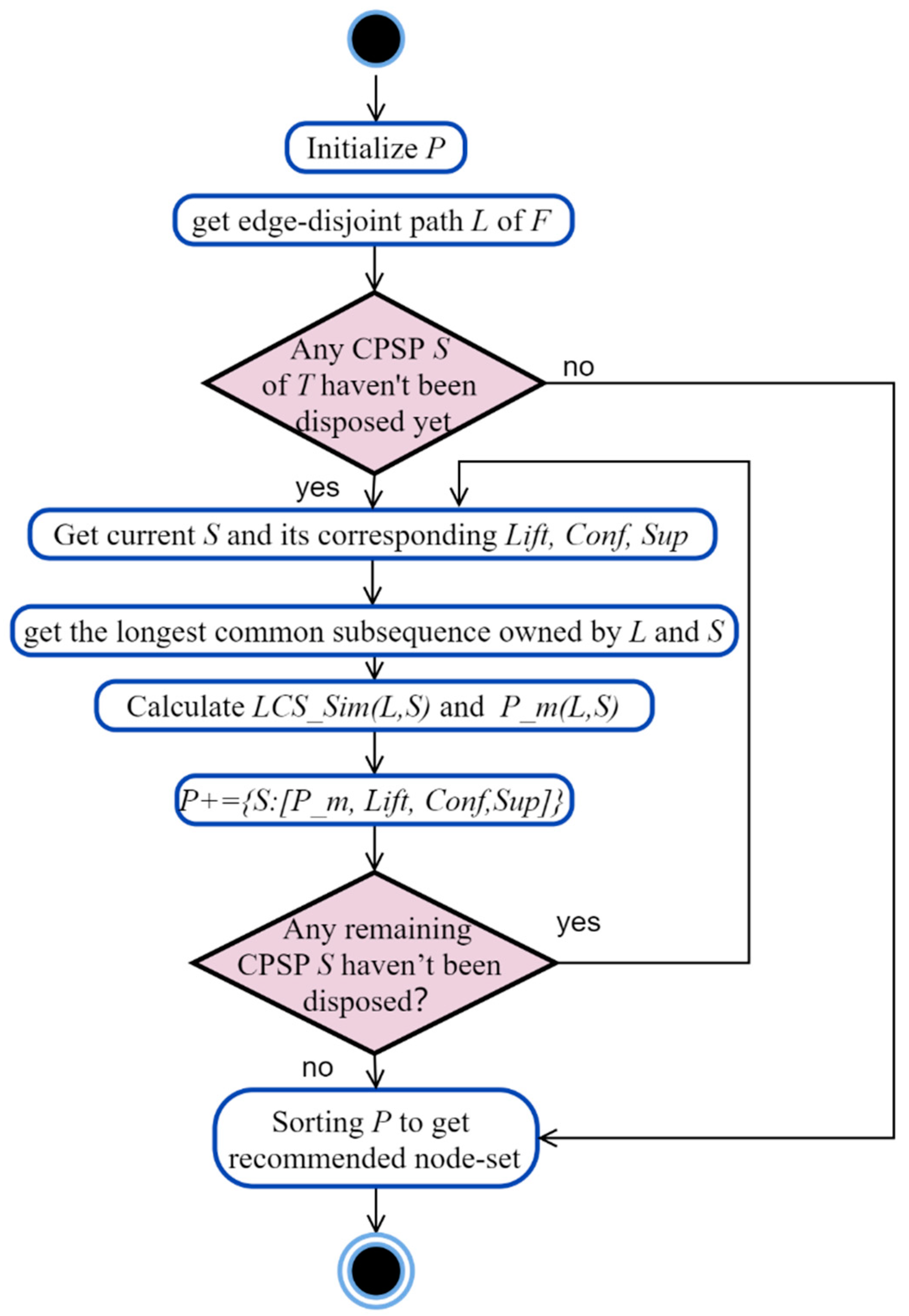
| Algorithm 3. Process node recommendation algorithm |
| Input: reference model F, sequential rules table T* Output: recommended node set Node Initialize candidate recommendation sequential rules dictionary P Call Algorithm1 to get edge-disjoint path R of F FOR (each edge-disjoint path L in R where the last node is the current node) do{ FOR (each sequential rule T in T*) do{ Sequential pattern S and its corresponding Lift, Conf, Sup = T[0], T[1], T[2], T[3] Call LCS(L,S) to get the longest common subsequence owned by L and S Calculate LCS_Sim(L,S) according to Equation (4) Calculate P_m(L,S) according to Equations (5) and (6) P+ = {S:[P_m, Lift, Conf, Sup]}}} Get top k P sorted by P_m; if the same, then sorted by Lift; and so on Get Node→the last node of S in top k P Return Node |
4. Experimental Results and Analysis
4.1. Datasets Introduction
4.2. Validity Test
4.3. Accuracy Test
- When the correct recommendation node appeared in the first position of the recommendation node set (i.e., the top 1 recommendation node), the accuracy was 100%.
- When the correct recommendation node was in the second position, the accuracy was 80%, and so on.
- If the correct recommendation node was in the fifth position of the recommendation node set, the accuracy was 20%.
- If the recommended node set did not include the correct recommended node, the accuracy rate was 0.
4.4. Time Efficiency Test
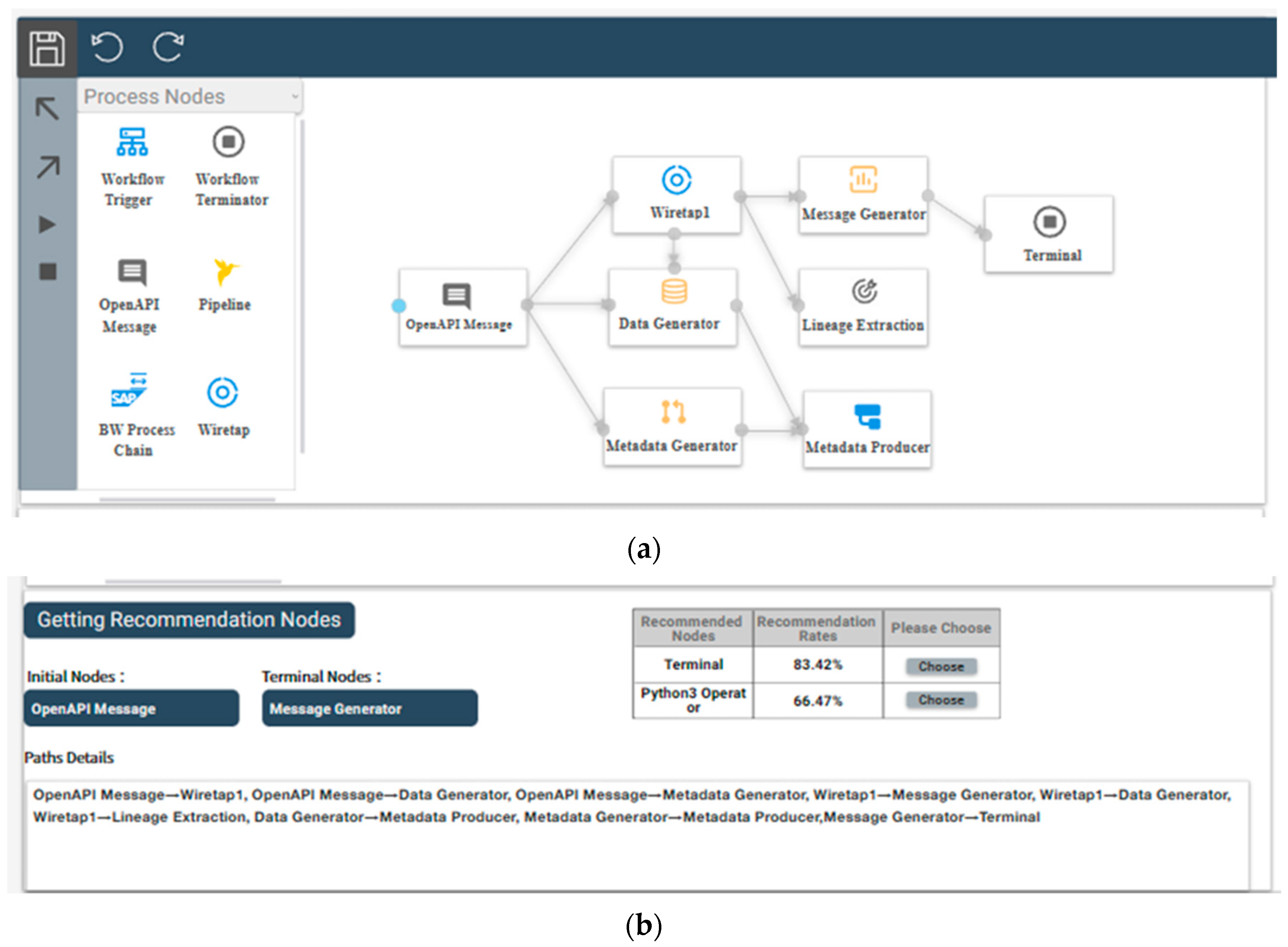
5. Visual Prototyping System
- The upper module, shown in Figure 11a, is a process builder that offers the following features:
- (i)
- Enabling users to add process nodes and build process diagrams freely;
- (ii)
- Enabling users to recommend, add, edit, delete, and drag and drop each node while connecting them;
- (iii)
- Enabling users to undo modifications and reverse undo modifications when accidental deletions or other errors occur;
- (iv)
- Enabling users to save the process with one click once it is built, without any other unnecessary operations.
- The lower module, shown in Figure 11b, is the recommendation and data interaction module.
6. Discussion and Limitations
- This study proposed a method that focuses on the behavioral semantics of the process and uses edge-disjoint path parsing, which offers a more significant efficiency advantage and smaller result differences compared with graph parsing.
- The proposed method uses the EPE to more accurately represent the behavioral semantics of parallel and selective structures.
- The method also introduces a node recommendation degree to measure the importance of different node positions in the paths and selects the last node of the CPSP as the recommendation result, thus avoiding the influence of duplicate nodes on the result.
- CPSPan was utilized to perform further knowledge discovery of edge-disjoint paths and obtain a wider range of options and more reliable guidance for process recommendations.
- Our approach recommends the next best node, which provides the greatest flexibility for the modeler to choose the next process activity. However, recommending process segments or complete process models can in some way facilitate the modeler to model more easily and quickly.
- Our method is based on the complex structures of process library models for process recommendation. Although event logs do not contain information such as complex structures, event logs contain a large amount of abstract information such as the frequency of process branch directions, which can also serve as a powerful basis for process recommendation.
- From a business process optimization perspective, our approach meets the time requirements and provides highly accurate recommended results. However, it only focuses on the next best node in the business process modeling design, taking into account both the process model and the business requirements, without considering the reliability of the services/components involved in each process node during the modeling process. For instance, we did not consider factors such as process execution time, task execution time, the number of exception events, timeouts, failures, and retries associated with each service/component. However, as this study aimed to address the problem of accuracy in short-process models, there are few business process datasets that contain both short-process models and reliability metrics in the current business process domain.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, F.; Guo, L.P.; Zhang, L. Process Modeling Leveraged by Workflow Fragments and Logs Analysis. J. Chin. Comput. Syst. 2017, 38, 664–670. [Google Scholar]
- Cai, Q.M.; Zhang, L.; Xu, C.H. Research of Process Similarity Based on Single-layer Neural Network. Comput. Eng. Appl. 2022, 58, 295–302. [Google Scholar]
- Li, Y.; Cao, B.; Xu, L.; Yin, J.; Deng, S.; Yin, Y.; Wu, Z. An Efficient Recommendation Method for Improving Business Process Modeling. IEEE Trans. Ind. Inform. 2013, 10, 502–513. [Google Scholar] [CrossRef]
- Wang, D.G.; Deng, S.G.; Cao, B. Efficient and reliable process recommendation system-JTangWFR. Comput. Integr. Manuf. Syst. 2013, 19, 1883–1890. [Google Scholar]
- Deng, S.; Wang, D.; Li, Y.; Cao, B.; Yin, J.; Wu, Z.; Zhou, M. A Recommendation System to Facilitate Business Process Modeling. IEEE Trans. Cybern. 2017, 47, 1380–1394. [Google Scholar] [CrossRef]
- Bobek, S.; Baran, M.; Kluza, K. Application of bayesian networks to recommendations in business process modeling. In Proceedings of the CUER Whokshop, Online, 25–27 November 2013. [Google Scholar]
- Cao, B.; Yin, J.; Deng, S.; Wang, H.; Zaki, M.J. Graph-based workflow recommendation: On improving business process modeling. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, New York, NY, USA, 29 October–2 November 2012. [Google Scholar]
- Fradi, A.; Louhichi, B.; Ali, M.; Eynard, B. 3D Object Retrieval Based on Similarity Calculation in 3D Computer Aided Design Systems. In Proceedings of the 14th IEEE/ACS International Conference on Computer Systems and Applications (AICCSA), Hammamet, Tunisia, 30 October–3 November 2017; IEEE: Piscataway, NJ, USA, 1963; pp. 160–165. [Google Scholar]
- Deb, D.; Ghose, A.; Chaki, N.A. Framework for business process modeling by QoS-based pruning. Innov. Syst. Softw. Eng. 2017, 13, 1–8. [Google Scholar] [CrossRef]
- Matsuda, T.; Kitajo, K.; Yamaguchi, Y.; Yamaguchi, Y.; Komaki, F. A point process modeling approach for investigating the effect of online brain activity on perceptual switching. NeuroImage 2017, 152, 50–59. [Google Scholar] [CrossRef]
- Alfegadhi, S. Business process modeling:blueprinting. Int. J. Comput. Sci. Inf. Secur. 2017, 15, 286–291. [Google Scholar]
- Hu, H.; Qiao, J.; Hu, H.Y. Process recommendation based on probabilistic and time Petri net. Appl. Res. Comput. 2018, 35, 62–68. [Google Scholar]
- Wang, H.; Wen, L.; Lin, L.; Wang, J. RLRecommender: A Representation-Learning-Based Recommendation Method for Business Process Modeling. In Proceedings of the International Conference on Service Oriented Computing, Online, 7 November 2018. [Google Scholar]
- Cao, B.; An, W.S.; Wang, J.X.; Fan, J. A difference detection algorithm for process models based on process structure tree. Acta Electron. Sin. 2018, 46, 97–105. [Google Scholar]
- Russell, N.; Van Der Aalst, W.M.; Ter Hofstede, A.H. Workflow Patterns: The Definitive Guide; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Gavvala, S.; Jatoth, V.C.; Gangadharan, G. QoS-aware cloud service composition using eagle strategy. Future Gener. Compute. Syst. 2019, 90, 273–290. [Google Scholar] [CrossRef]
- Zhu, Y.; Hu, Z.; He, Z. Edge Intelligence Service Orchestration with Process Mining. Appl. Sci. 2022, 12, 10436. [Google Scholar] [CrossRef]
- Represa, J.G.; Larrinaga, F.; Varga, P.; Ochoa, W.; Perez, A.; Kozma, D.; Delsing, J. Investigation of Microservice-Based Workflow Management Solutions for Industrial Automation. Appl. Sci. 2023, 13, 1835. [Google Scholar] [CrossRef]
- Wang, Q.; Shao, C.; Fang, X.; Zhang, H. Business process recommendation method based on cost constraints. Connect. Sci. 2022, 34, 2520–2537. [Google Scholar] [CrossRef]
- Luo, W.; Peng, Z.; Deng, A.; Bi, X. Toward business process recommendation-based collaborative filtering. Int. J. Internet Manuf. Serv. 2019, 6, 389–402. [Google Scholar] [CrossRef]
- Ye, Y.M.; Yin, J.W.; Cao, B. Process warping matrix based business process recommendation technique. Comput. Integr. Manuf. Syst. 2013, 19, 1868–1875. [Google Scholar]
- Fellmann, M.; Metzger, D.; Jannaber, S.; Zarvic, N.; Thomas, O. Process modeling recommender systems. Bus. Inf. Syst. Eng. 2018, 60, 21–38. [Google Scholar] [CrossRef]
- Wang, J.; Tan, D.; Cao, B.; Fan, J. Samundra Deep. Independent path-based process recommendation algorithm for improving biomedical process modelling. Electron. Lett. 2020, 56, 531–533. [Google Scholar] [CrossRef]
- Jalali, A.; Maria, F.; Reijers, H.A. A hybrid approach for aspect-oriented business process modeling. J. Softw. Evol. Process 2018, 30, 1–21. [Google Scholar] [CrossRef]
- Li, D.Q.; Fang, X.W. Process modeling recommendation method based on behavioral profile definition target rules. J. Comput. Appl. 2022, 42, 223–229. [Google Scholar]
- Gui, S.C.; Wang, J.X.; Hong, F.; Winckler, M.; Trætteberg, H. Behavior- based automated process modeling method using recommendation. Comput. Integr. Manuf. Syst. 2020, 26, 1500–1509. [Google Scholar]
- Sun, Z.S.; Xie, Z.; Chen, Z. Algorithm design of independent path problem. Comput. Eng. 2013, 39, 148–152. [Google Scholar]
- Joseph, M.; Roby, T. Toggling independent sets of a path graph. Electron. J. Comb. 2018, 25, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wang, Y.; Yang, D.Y. CCSpan: Mining closed contiguous sequential patterns. Knowl. Based Syst. 2015, 89, 1–13. [Google Scholar] [CrossRef]
- Abboud, Y.; Boyer, A.; Brun, A. CCPM: A Scalable and Noise-Resistant Closed Contiguous Sequential Patterns Mining Algorithm. In Proceedings of the 13th International Conference on Machine Learning and Data Mining, New York, NY, USA, 15–20 July 2017; pp. 147–162. [Google Scholar]
- Abboud, Y.; Boyer, A.; Brun, A. C3Ro: An Efficient Mining Algorithm of Extended-Closed Contiguous Robust Sequential Patterns in Noisy Data. Expert Syst. Appl. 2019, 131, 172–189. [Google Scholar] [CrossRef]
- Wang, J.; Han, J. BIDE: Efficient Mining of Frequent Closed Sequences. In Proceedings of the 20th International Conference on Data Engineering, New York, NY, USA, 14–17 December 2004. [Google Scholar]
- Yan, X.; Han, J.; Ramin, A. CloSpan: Mining: Closed Sequential Patterns in Large Datasets. In Proceedings of the 2003 SIAM International Conference on Data Mining, Minneapolis, MS, USA, 27–29 April 2003; pp. 176–184. [Google Scholar]
- Pei, J.; Han, J.; Mortazavi, A.; Pinto, H.; Chen, Q.M.; Dayal, U.; Hsu, M.C. PrefixSpan: Mining Sequential Patterns Efficiently by Prefix-Projected Pattern Growth. Proceedings of the 17th International Conference on Data Engineering, Heidelberg, Germany, 2–6 April 2001; IEEE: Piscataway, NJ, USA, 1963; pp. 215–224. [Google Scholar]
- Peng, M.J. A Study on Parallel Minging of Contiguous Sequential Pattern; Hubei University: Wuhan, China, 2015. [Google Scholar]
- Hirschberg, D.S. Algorithms for the Longest Common Subsequence Problem. J. ACM JACM 1977, 24, 664–675. [Google Scholar] [CrossRef]
- Agrawal, R.; Imielinski, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the ACM SIGMOD Conference on Management of Data, Washington, DC, USA, 26–28 May 1993; pp. 207–216. [Google Scholar]
- Brin, S.; Motwani, R.; Silverstein, C. Beyond market baskets: Generalizing association rules to correlations. In Proceedings of the 1997 ACM SIGMOD international conference on Management of data, Tucson, AZ, USA, 13–15 May 1997; pp. 265–276. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Sequential Pattern |
|---|---|
| PrefixSpan | A:2,AC:2,AD:2,AB:2,ACD:1,ACB:2,ADC:1,ADB:2,ACDB:1,ADCB:1,B:2,C:2,CD:1,CB:2,CDB:1,D:2,DB:2,DC:1,DCB:1 |
| CCSpan | ACDB:1,ADCB:1,CB:1,CDB:1,DB:1,DCB:1 |
| CPSPan | AC:1,AD:1,ACD:1,ADC:1,ACDB:1,ADCB:1,CD:1,CB:1,CDB:1,DB:1,DC:1,DCB:1 |
| Process-Matching Degree | Lift | Confidence | Support | Recommended Node |
|---|---|---|---|---|
| 0.9 | 1.43 | 1.0 | 42 | Terminal |
| 0.9 | 1.22 | 1.0 | 49 | Wiretap |
| 0.7 | 5.45 | 4.36 | 11 | ToStringConverter |
| 0.7 | 5.45 | 0.27 | 11 | SAPCPEMProducer |
| 0.7 | 5.45 | 0.18 | 11 | Input |
| Dataset | Experimental Process Model | Process Nodes | Shortest/Longest Model Nodes | Sequential Rules | Complex Structures |
|---|---|---|---|---|---|
| Real dataset | 337 | 276 | 2/8 | 4268 | √ |
| Simulation dataset | 75 | 222 | 8/18 | 10,833 | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, D.; Wang, C.; Bian, G.; Shao, B.; Shi, T. A Novel Process Recommendation Method That Integrates Disjoint Paths and Sequential Patterns. Appl. Sci. 2023, 13, 3894. https://doi.org/10.3390/app13063894
Han D, Wang C, Bian G, Shao B, Shi T. A Novel Process Recommendation Method That Integrates Disjoint Paths and Sequential Patterns. Applied Sciences. 2023; 13(6):3894. https://doi.org/10.3390/app13063894
Chicago/Turabian StyleHan, Danni, Chaoxue Wang, Genqing Bian, Bilin Shao, and Tengteng Shi. 2023. "A Novel Process Recommendation Method That Integrates Disjoint Paths and Sequential Patterns" Applied Sciences 13, no. 6: 3894. https://doi.org/10.3390/app13063894
APA StyleHan, D., Wang, C., Bian, G., Shao, B., & Shi, T. (2023). A Novel Process Recommendation Method That Integrates Disjoint Paths and Sequential Patterns. Applied Sciences, 13(6), 3894. https://doi.org/10.3390/app13063894