
Swin Transformer-Based Object Detection Model Using Explainable Meta-Learning Mining


Abstract
1. Introduction
- General transformers have the potential to cause information loss on image local structures such as lines and edges in the process of generating images as patches. Therefore, based on the Swin Transformer, it solves the problem of information loss, because it ignores the modeling for image local structures such as patch lines and edges.
- There are objects of various sizes in the image data. In order to detect all of these, it is necessary to be able to detect objects of various sizes. Therefore, the combination of YOLOv3 and the Swin Transformer makes it possible to detect small objects of various sizes, including the ones which are hard to be detected by YOLOv3.
- Grad-CAM as an explainable visualization technique is used to keep data at high resolution, to reduce noise, and to find the causes of classification accurately.
2. Related Work
2.1. Object Detection Technology Based on Vision Transformer
2.2. Trends in Meta-Learning Technology
2.3. Fire Prediction Technology Using Object Detection
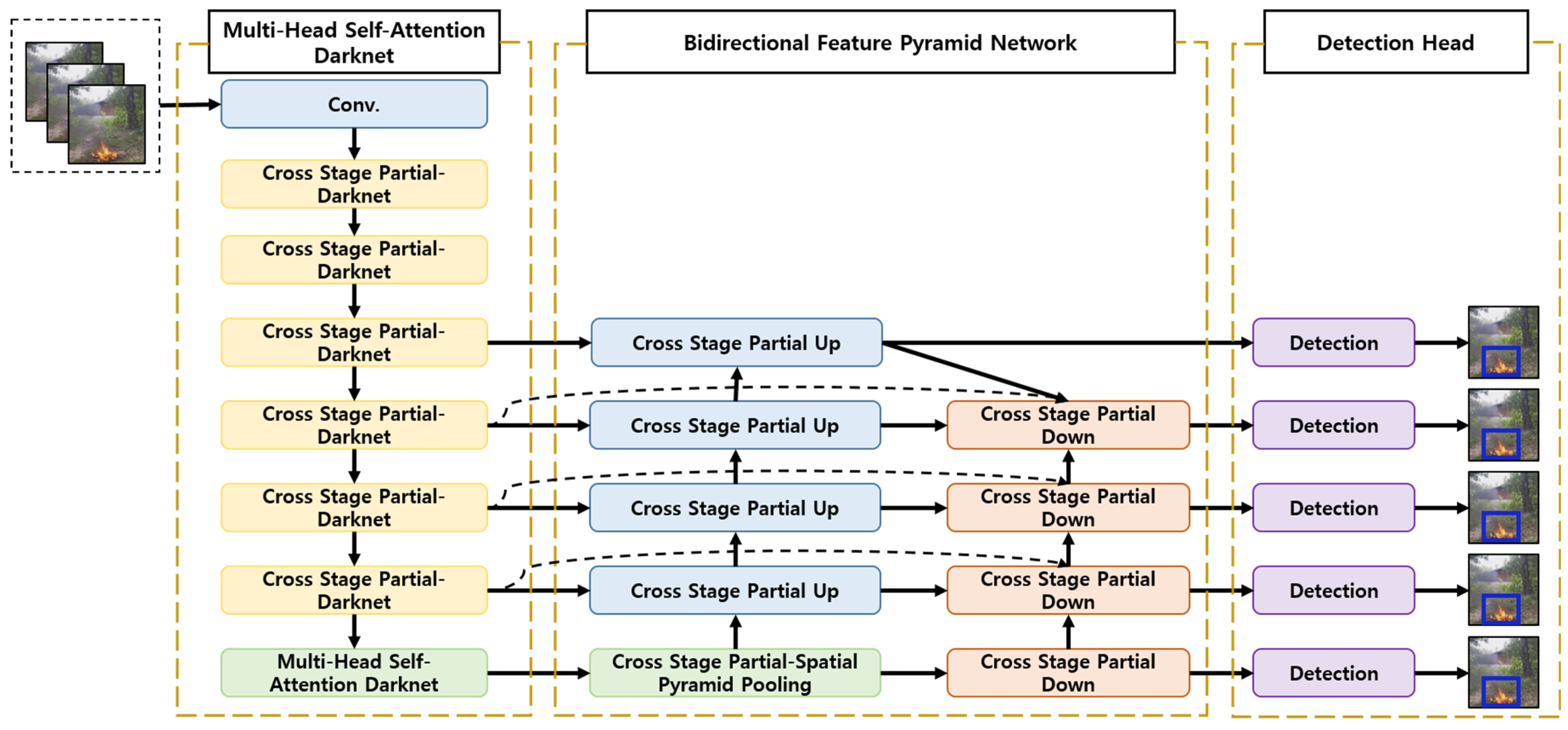
3. Swin Transformer-Based Object Detection Model Using Explainable Meta-Learning Mining
3.1. Collect and Preprocess Risk Prediction Data
3.2. Object Detection Based on Swin Transformer
3.3. Object Detection Mining Using Meta-Learning
4. Results and Performance Evaluation
4.1. Swin Transformer-Based Explainable Object Detection Using Meta-Learning Mining
4.2. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- National Fire Information System. Available online: https://nfds.go.kr/ (accessed on 5 November 2022).
- Sharma, R.; Rani, S.; Memon, I. A smart approach for fire prediction under uncertain conditions using machine learning. Multimed. Tools Appl. 2020, 79, 28155–28168. [Google Scholar] [CrossRef]
- Bui, K.H.N.; Yi, H.; Cho, J. A multi-class multi-movement vehicle counting framework for traffic analysis in complex areas using cctv systems. Energies 2020, 13, 2036. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural. Netw. Learn Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, H.; Zhang, Z.; Liu, M. CNN-based encoder-decoder networks for salient object detection: A comprehensive review and recent advances. Inf. Sci. 2021, 546, 835–857. [Google Scholar] [CrossRef]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- von Eschenbach, W.J. Transparency and the black box problem: Why we do not trust AI. Philos. Technol. 2020, 34, 1607–1622. [Google Scholar] [CrossRef]
- Minh, D.; Wang, H.X.; Li, Y.F.; Nguyen, T.N. Explainable artificial intelligence: A comprehensive review. Artif. Intell. Rev. 2022, 55, 3503–3568. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Cheng, L.; Li, J.; Duan, P.; Wang, M. A small attentional YOLO model for landslide detection from satellite remote sensing images. Landslides 2021, 18, 2751–2765. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Fang, Y.; Liao, B.; Wang, X.; Fang, J.; Qi, J.; Wu, R.; Niu, J.; Liu, W. You only look at one sequence: Rethinking transformer in vision through object detection. Adv. Neural. Inf. Process. Syst. 2021, 34, 26183–26197. [Google Scholar]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO: Transformer-based YOLO for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-learning in neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5149–5169. [Google Scholar] [CrossRef] [PubMed]
- Rusu, A.A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; Hadsell, R. Meta-learning with latent embedding optimization. arXiv 2018, arXiv:1807.05960. [Google Scholar]
- Gupta, A.; Eysenbach, B.; Finn, C.; Levine, S. Unsupervised meta-learning for reinforcement learning. arXiv 2018, arXiv:1806.04640. [Google Scholar]
- Yao, H.; Wu, X.; Tao, Z.; Li, Y.; Ding, B.; Li, R.; Li, Z. Automated relational meta-learning. arXiv 2020, arXiv:2001.00745. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Zhu, H.; Cai, X.; Dou, J.; Gao, Z.; Zhang, L. Multi-level adaptive few-shot learning network combined with vision transformer. J. Ambient Intell. Humaniz. Comput. 2022, 2022, 1–15. [Google Scholar] [CrossRef]
- Saeed, F.; Paul, A.; Hong, W.H.; Seo, H. Machine learning based approach for multimedia surveillance during fire emergencies. Multimed. Tools Appl. 2020, 79, 16201–16217. [Google Scholar] [CrossRef]
- Tang, Z.; Liu, X.; Chen, H.; Hupy, J.; Yang, B. Deep learning based wildfire event object detection from 4K aerial images acquired by UAS. AI 2020, 1, 166–179. [Google Scholar] [CrossRef]
- Mohana Kumar, S.; Sowmya, B.J.; Priyanka, S.; Ruchita Sharma, S.T. Forest Fire Prediction Using Image Processing and Machine Learning. Nat. Volatiles Essent. 2021, 8, 13116–13134. [Google Scholar]
- AI Hub. Available online: https://aihub.or.kr/ (accessed on 5 September 2022).
- Lee, Y.H.; Kim, Y. Comparison of CNN and YOLO for Object Detection. J. Semicond. Disp. Technol. 2020, 19, 85–92. [Google Scholar]
- Dai, Y.; Liu, W.; Wang, H.; Xie, W.; Long, K. YOLO-Former: Marrying YOLO and Transformer for Foreign Object Detection. IEEE Trans. Instrum. Meas. 2020, 71, 5026114. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Wang, J.X. Meta-learning in natural and artificial intelligence. Curr. Opin. Behav. Sci. 2021, 38, 90–95. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Wang, M.; Ning, H.; Liu, H. Object detection based on few-shot learning via instance-level feature correlation and aggregation. Appl. Intell. 2022, 53, 351–368. [Google Scholar] [CrossRef]
- Jiang, W.; Huang, K.; Geng, J.; Deng, X. Multi-scale metric learning for few-shot learning. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1091–1102. [Google Scholar] [CrossRef]
- Onchis, D.M.; Gillich, G.R. Stable and explainable deep learning damage prediction for prismatic cantilever steel beam. Comput. Ind. 2021, 125, 103359. [Google Scholar] [CrossRef]
- Gulum, M.A.; Trombley, C.M.; Kantardzic, M. A review of explainable deep learning cancer detection models in medical imaging. Appl. Sci. 2021, 11, 4573. [Google Scholar] [CrossRef]
- Chen, K.; Lin, W.; Li, J.; See, J.; Wang, J.; Zou, J. AP-loss for accurate one-stage object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3782–3798. [Google Scholar] [CrossRef]
- Xu, M.; Zhang, Z.; Hu, H.; Wang, J.; Wang, L.; Wei, F.; Bai, X.; Liu, Z. End-to-end semi-supervised object detection with soft teacher. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Yoo, H.; Chung, K. Deep learning-based evolutionary recommendation model for heterogeneous big data integration. KSII Trans. Internet Inf. Syst. 2020, 14, 3730–3744. [Google Scholar]
- Yoo, H.; Park, R.C.; Chung, K. IoT-Based Health Big-Data Process Technologies: A Survey. KSII Trans. Internet Inf. Syst. 2021, 15, 974–992. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF international conference on computer vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact++: Better real-time instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1108–1121. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.C.; Chung, K. Neural-Network based Adaptive Context Prediction Model for Ambient Intelligence. J. Ambient Intell. Humaniz. Comput. 2020, 11, 1451–1458. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP |
|---|---|
| Swin Transformer [28] | 46.5 |
| Swin Transformer + YOLO | 50.54 |
| Swin Transformer + YOLO + Few-Shot Learning (ours) | 51.2 |
| Object Detection Model | mAP |
|---|---|
| YOLACT [40] | 30.45 |
| YOLACT++ [41] | 34.65 |
| YOLOS [15] | 30.04 |
| Swin Transformer + YOLO + Few-Shot Learning (ours) | 51.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baek, J.-W.; Chung, K. Swin Transformer-Based Object Detection Model Using Explainable Meta-Learning Mining. Appl. Sci. 2023, 13, 3213. https://doi.org/10.3390/app13053213
Baek J-W, Chung K. Swin Transformer-Based Object Detection Model Using Explainable Meta-Learning Mining. Applied Sciences. 2023; 13(5):3213. https://doi.org/10.3390/app13053213
Chicago/Turabian StyleBaek, Ji-Won, and Kyungyong Chung. 2023. "Swin Transformer-Based Object Detection Model Using Explainable Meta-Learning Mining" Applied Sciences 13, no. 5: 3213. https://doi.org/10.3390/app13053213
APA StyleBaek, J.-W., & Chung, K. (2023). Swin Transformer-Based Object Detection Model Using Explainable Meta-Learning Mining. Applied Sciences, 13(5), 3213. https://doi.org/10.3390/app13053213