
A Fast and Accurate Real-Time Vehicle Detection Method Using Deep Learning for Unconstrained Environments


 , and
, and
Abstract
1. Introduction
- We propose a modified version of the YOLO algorithm to achieve vehicle detection in real time. Earlier-developed works have been trained on massive datasets, but still need to be fine-tuned for use in congested traffic environments. However, we augment these datasets with our gathered datasets. We compare the efficiency of our trained version with several recent state-of-the-art methods.
- We detect and classify vehicles in images that are captured in various traffic scenes. We perform detailed study on the PKU, COCO, and DAWN datasets. To achieve higher accuracy on images from our local traffic patterns, we gathered an extensive dataset and applied transfer learning to the YOLOv5. The input to a system is a real-time image, and the output is a bounding box corresponding to all objects in the image, along with the class of object in each box.
- In addition, we employ a transfer learning approach to utilize the knowledge embedded in our local datasets. We believe that the ITS based applications require rapid and precise vehicle identification and classification. It is a challenging task to detect different vehicles abruptly and precisely due to short gaps between vehicles on the road and interference aspects of pictures or video frames containing vehicle images. Therefore, we are optimistic that our developed method provides a good insight into locating vehicles in congested traffic environments.
2. Related Work
2.1. Conventional Methods
2.2. YOLO-Based Methods
3. Proposed Method
| Algorithm 1: Pseudo code of the proposed vehicle detection algorithm |
 |
3.1. Data Acquisition
3.2. Data Annotation
3.3. Data Augmentation
3.4. The YOLO-v5
3.5. Training Strategy
3.6. Evaluation Criteria
4. Simulation Results
4.1. Analysis on the PKU Dataset
- On the G4 category, the proposed method ranks 3rd among all the compared fourteen methods in terms of detection accuracy. On the other hand, on the G5 category, our developed method outperforms all the compared methods. The PKU G5 is a challenging category due to fact it contains multiple vehicles per image and also contains several disguising crosswalks that pose a threat to any vehicle detection algorithm.
- From Table 5, we also observe that for G1, G2, and G3 categories, the methods developed in [28,29,30,38,40] produce 100% vehicle detection result. Our proposed method yields 99.94% vehicle detection accuracy on the G1 category and 100% for the G2 and G3 categories. Therefore, we observe that methods shown in Table 5 have solved the challenge of vehicle detection on these three categories as most of them yield at least 99% accurate vehicle detection.
- Overall, on the PKU dataset, the proposed method ranks 1st at achieving vehicle detection in terms of the mAP as listed in Table 5. The method by [40] ranks 2nd by yielding 99.86% accurate vehicle detection accuracy. The works developed in [30,31] also yield slightly over 99.75% vehicle detection accuracy. In addition, the methods shown in Table 5 report over 97% detection accuracy, which we believe is encouraging in solving real-world traffic problems.
- To best of our knowledge, we observe that vehicle detection challenge is almost solved on the PKU dataset. However, we observe that non-uniform illuminations or high glare at the night could still affect vehicle detection accuracy. Similarly, the researchers who aim to solve the other object detection problems, such as license plate detection or recognition, may need to perform additional preprocessing or postprocessing to achieve reliable detection results.
4.2. Analysis on the COCO Dataset
- As can be seen for various image resolutions that range from 512 × 512 to 800 × 800 pixels, the proposed method ranks 1st among all the compared methods and reports the highest mAP value of 52.31%. The work reported in [42] ranks 2nd and yields a 50.40% mAp value followed by [41] with a 49.80% mAP value. Our analysis reveals that the work developed in [35,36] are also an encouraging solution for detecting various objects in the challenging COCO dataset.
- On the COCO dataset, the work reported in [31] yields the lowest (27.89%) mAp value followed by [33], whose method yields a mAP value of 29.10%. Moreover, in the current study, work discussed in [40], which uses the ResNet as a backbone, yields a mAP value of 31.80%, which in the context of current study falls on the lower side.
- The crux of this dataset is that the proposed method effectively and reliably detects miscellaneous objects that include vehicles of varying shapes, including motorbikes and jeeps. Furthermore, the proposed method also effectively handles big buses. A few such samples are also in the 1st and 3rd columns of Figure 8.
4.3. Analysis on the DAWN Dataset
- For the snow category as seen in top row of Figure 9, it is obvious that many times the vehicles are partially visible due to adverse weather conditions, such as fog that is normally experienced in severe winters in areas of various parts of the world. However, our developed method handles all such situations except the 2nd last image of front row in Figure 9, where it is obvious that the vehicle is not visible to the human eye as well.
- For a considerably rainy day as seen in second row of Figure 9, the proposed method accurately locates multiple vehicles that appear therein. In this case, the image scene variations, such as shown in the 2nd and 4th images of the second row in Figure 9 indicates that the proposed method is unaffected by such changes in the image scene. Similarly, the skyscrapers in the vehicle’s background as shown in the 5th image of the 2nd row in Figure 9 also do not affect the detection ability of our developed method.
- For a sand situation as indicated in the third row of Figure 9, the proposed method detects all vehicles that appear there in such challenging conditions. In such situations, visibility is normally very low, which poses threats to most of the machine learning algorithms. Particularly, the first two images in the 3rd row of Figure 9 have intra-class scene variations, i.e., both are images effected by sand storms and yet appear differently to the human eye. Even in such cases, our developed method performs well and detects most of the instances that appear in such condition. The 3rd image in this row is quite challenging for human observers as well. However, as indicated there, our developed method handles such situations by successfully locating the vehicles that appear in such scene images.
- The bottom row in Figure 9 is a case when the scene is dominated by snow. In this case, surprisingly, the image appears neat and clean and thus results in a visually pleasing image due to the massive amount of snow which is present in the image. In this case, our developed method accurately detects and labels all the vehicles that appear therein. Particularly, the 3rd image in this row also reveals a red light along with the snow. Yet in this case, the proposed method performs well and successfully locates all the vehicles. Moreover, the last image in this row shows a few vehicles that overlap and result in partial occlusion. However, our developed method performs well in this case as well.
- As can be seen in Table 7, for the fog scenario the work developed in [40] ranks 1st among 14 compared methods by yielding a 29.68% mAP value. Our developed method ranks 2nd out of all compared methods in fog situation and yields a 29.66% mAP value. In the fog situation, the work developed in [38] yields the lowest mAP value (16.50%) followed by [29] whose method yields a mAP value of 24%.
- For the rain scenario on the DAWN dataset, our proposed method and the work developed in [31] yield the highest mAP value of 41.21%. In this category, the work in [34] ranks 2nd and yields an encouraging result of a 41.10% mAP value. For the aforesaid category, results yielded by [36,37] are also encouraging. For images that are affected by rain, the work in [38] delivers the lowest mAP value of 14.08%.
- For the snow conditions on the DAWN dataset, the work developed in [37] ranks 1st among all compared methods and slightly outperforms the proposed method by yielding a mAP value of 43.02%. For this category, our developed method yields a mAP value of 43.01%. It is important to state here that for this situation, the works in [31,33,36,37] yield almost similar results.
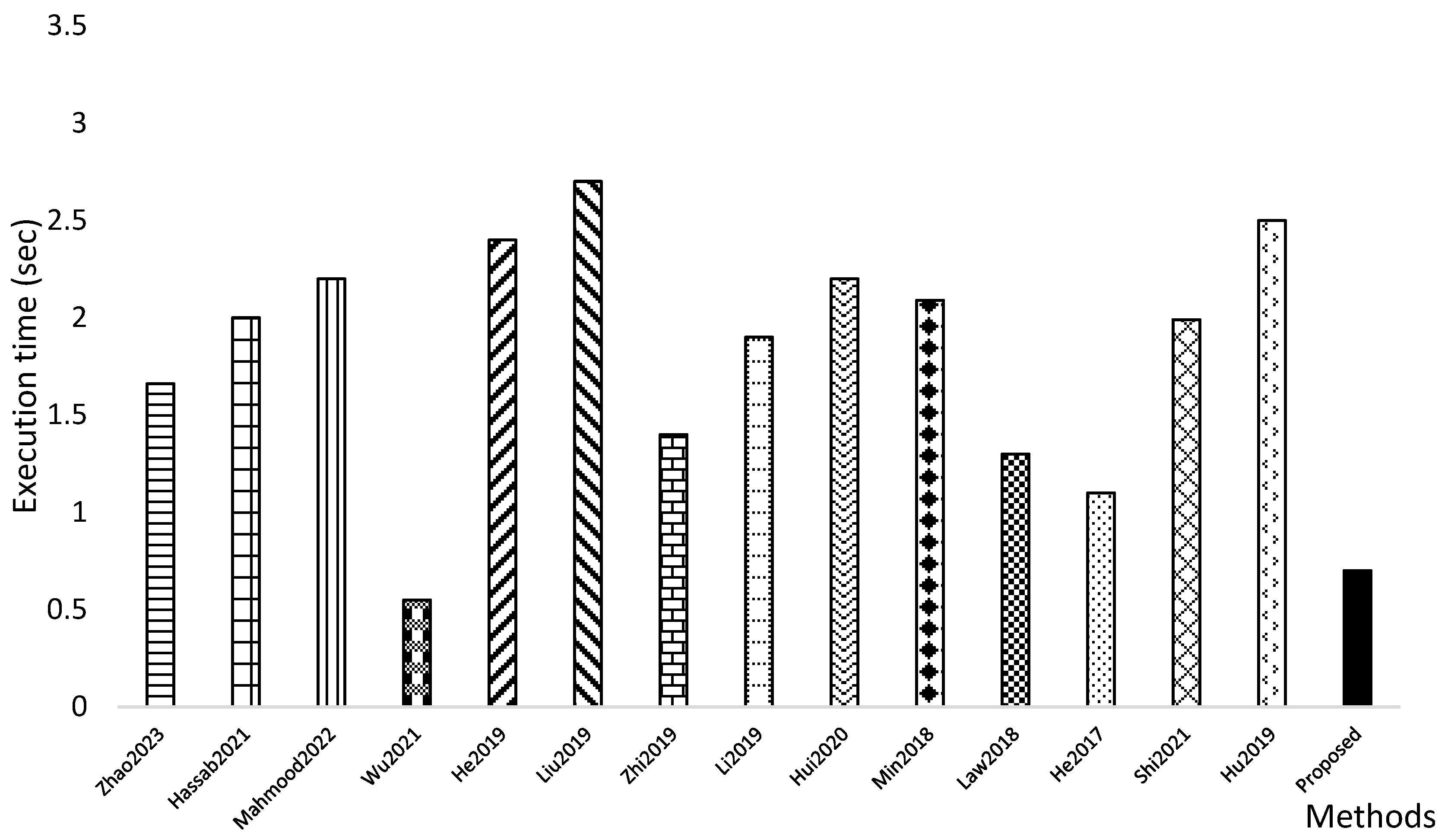
4.4. Computational Complexity
4.5. Discussion
- Methods compared in this study are state-of-the-art object detectors. We observed that specific method performs well on a specific dataset but are challenged by other datasets. For instance, the work developed in [28] investigates BIT-Vehicle and UA-DETRAC datasets only. These datasets mostly contain high quality frontal view of the different vehicles with image resolution of 1920 × 1080 to 1600 × 1200 pixels. In contrast, the method proposed in current study explores three different datasets that have variations, such as different road conditions, varying weathers, or complex backgrounds. Moreover, the study presented in this manuscript also explores the detection ability of this method on three standard and publicly available datasets.
- The works discussed in [29,34] mostly focus on KITTI and the DAWN datasets that contain the variations as described earlier. However, we also explore their detection ability on five different classes of the PKU dataset that contain huge road and traffic variations along with our proposed method. This will essentially provide a nice baseline to beginners and researchers to develop their specified tasks.
- The work reported in [30] investigates the generic PKU dataset in its five distinct categories. However, this study further explores the detection capability of [30] on the COCO and the DAWN datasets. Moreover, the detection accuracy of the method proposed in this study provides a fair insight into vehicle detection in various scenarios.
- The method developed in [31] examined the CARLA dataset, which we believe is a limited and relatively small vehicle dataset. The findings presented in this study extend the detection capability of this method to three other datasets. In addition, its detection comparison with the proposed method and several other techniques provides much detailed insight about issues in the vehicle detection domain.
- In [33,37], the PASCAL VOC 2007 dataset is explored only. Moreover, work in [33] also analyzes the subdomain of the COCO dataset to show the detection of trains only. In contrast, this study explores the detection capability of [33] on various vehicle classes of the COCO dataset along with the PKU and DAWN datasets. Moreover, the detailed comparison provided in the earlier sections provides a fair baseline to the research community. Furthermore, the work in [37] explored the PASCAL dataset that already contains annotated images of various objects. This study further expands the detection capability of this method to three different vehicle datasets. Finally, the detailed analysis and comparison provided in earlier section hints towards additional modifications of this algorithm.
- The works in [35,36,39,40] were validated on the MS COCO dataset to detect various objects. The experiments reported in this study extend the detection analysis of the aforementioned approaches to PKU and DAWN datasets as well. Since our method also explores the vehicle detection on these datasets, it will be convenient for researchers and practitioners to choose the appropriate algorithm for their specified applications. Moreover, the work listed in [40] reports the detection of various objects, such as pedestrians, statues, or animals. However, this study reports the detection ability of this algorithm on actual and real-world vehicle images along with several other approaches.
- In [38], the PETS2009 and the changedetection.net 2012 datasets are explored. Results analyzed in their study are mostly standard high quality frontal view images of mono-color cars running on a main highway. In contrast, the analysis presented in this study explores the detection ability this method on different datasets on multiple styles of vehicle and on differently color cars. Moreover, this study also investigates the detection ability of this method on varying illuminations and weathers along with different road conditions.
- The study in [41] analyzed the DLR Munich vehicle and VEDAI datasets. In their study, mostly high-quality aerial vehicle images are analyzed. Few of these are running on roads, while several parked vehicles are shown. However, our study also reports the use of this method on actual daily life vehicle images from three publicly available datasets. We are optimistic that detailed analysis and comparisons provided in this manuscript will be handy for the research community to modify any algorithm for their specified tasks.
- Finally, in [42], the KITTI and the LSVH datasets were explored. Results reported in this study are mostly vans, cars, and bus that run on the main highways. However, our study reports the detection ability of this method on varying illuminations, different weathers, and challenging road conditions from three publicly available datasets. We believe that the analysis provided by our developed method and the detailed comparison listed in this manuscript will provide further insight to the research community.
- All of these are useful efforts to solve and automate the vehicle detection problem under varying conditions. For each of the datasets mentioned above, these methods perform well. One of the objectives of the current study was to test and analyze all of the fourteen methods compared in this paper on standard PKU, COCO, and DAWN datasets. The main reason to choose PKU, COCO, and DAWN datasets is that these datasets contain real world and challenging images. For instance, the PKU dataset has five distinct categories that range from normal images to dark night images along with night glare. Similarly, this dataset also contains multiple images that appear in the input along with partial occlusions and different road conditions. Similarly, as mentioned in Section 4, the COCO dataset is also a huge dataset and contains a diverse range of objects. Moreover, the DAWN dataset also contains various real-world situation, such as fog, rain, snow, and the sand. An evaluation of fourteen different methods on these three datasets will be a fair guideline for researchers and beginners to develop, implement, or modify any algorithm for their specified applications.
- Out of the datasets that are investigated in this study, we find the DAWN dataset a bit more challenging than the others. The main reason is the inclusion of images in challenging conditions, such as fog, rain, contaminated with sand, or snow. Our study indicates that the sandy images reduce the scene visibility and ultimately reduce the detection accuracy of a detector. The 1st image in the top row in Figure 11 depicts such conditions in which very low vehicle detection is achieved. Similarly, as shown in the 2nd image of the top row of Figure 11, low vehicle detection is observed during a rainy night when the head lights of the vehicle are also turned on. In this case an electricity pole also appears, which results in partial occlusion that ultimately results in reduced object detection.
- We observe that our proposed method still needs to perform well in different situations, such as when the scene is contaminated with the snow storm or blizzard as shown in the 2nd row of Figure 11. In such cases, background noise dominates results in low visibility. In this scenario, a Retinex-based image enhancement scheme might be useful. For such a scenario, we suggest that an image dehazing-based enhancement could also be effective. We are optimistic that this proposed solution will essentially enhance the object and image scene, which will later make life easier for any of the vehicle detectors deployed. Ultimately, the application of image enhancement technique will significantly increase the detection ability of object detector.
- For images where snow is dominant, image appears overly white, which also decreases the detection accuracy of state-of-the-art object detection methods. In this case, image contrast correction might produce the desirable results. In many cases, the occlusions on the road also pose a threat to the detector, which ultimately results in false detections. In such cases, an occlusion handling method could also be used to reliably detect any object.
- For all of the aforementioned discussion, Figure 11 shows a few of the sample images where our developed method struggles. In images shown in Figure 11, our method either yields a very low vehicle detection rate or produces false detections. Therefore, future research could also focus on few of the cases as shown in Figure 11.
4.6. Final Remarks
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mahmood, Z.; Haneef, O.; Muhammad, N.; Khattak, S. Towards a Fully Automated Car Parking System. IET Intell. Transp. Syst. 2018, 13, 293–302. [Google Scholar] [CrossRef]
- Xiaohong, H.; Chang, J.; Wang, K. Real-time object detection based on YOLO-v2 for tiny vehicle object. Procedia Comput. Sci. 2021, 183, 61–72. [Google Scholar]
- Rani, E. LittleYOLO-SPP: A delicate real-time vehicle detection algorithm. Optik 2021, 225, 165818. [Google Scholar] [CrossRef]
- Tajar, T.; Ramazani, A.; Mansoorizadeh, M. A lightweight Tiny-YOLOv3 vehicle detection approach. J. Real-Time Image Process. 2021, 18, 2389–2401. [Google Scholar] [CrossRef]
- Mahmood, Z.; Bibi, N.; Usman, M.; Khan, U.; Muhammad, N. Mobile Cloud based Framework for Sports Applications. Multidimens. Syst. Signal Process. 2019, 30, 1991–2019. [Google Scholar] [CrossRef]
- Hamsa, S.; Panthakkan, A.; Al Mansoori, S.; Alahamed, H. Automatic Vehicle Detection from Aerial Images using Cascaded Support Vector Machine and Gaussian Mixture Model. In Proceedings of the 2018 International Conference on Signal Processing and Information Security (ICSPIS), Dubai, United Arab Emirates, 7–8 November 2018; pp. 1–4. [Google Scholar]
- Mikaty, M.; Stathaki, T. Detection of Cars in HighResolution Aerial Images of Complex Urban Environments. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5913–5924. [Google Scholar]
- Arı, Ç.; Aksoy, S. Detection of Compound Structures Using a Gaussian Mixture Model With Spectral and Spatial Constraints. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6627–6638. [Google Scholar] [CrossRef]
- Hbaieb, A.; Rezgui, J.; Chaari, L. Pedestrian Detection for Autonomous Driving within Cooperative Communication System. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–6. [Google Scholar]
- Xiong, L.; Yue, W.; Xu, Q.; Zhu, Z.; Chen, Z. High Speed Front-Vehicle Detection Based on Video Multi-feature Fusion. In Proceedings of the 2020 IEEE 10th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 17–19 July 2020; pp. 348–351. [Google Scholar]
- Yawen, T.; Jinxu, G. Research on Vehicle Detection Technology Based on SIFT Feature. In Proceedings of the 8th International Conf on Electronics Info. and Emergency Communication (ICEIEC), Beijing, China, 15–17 June 2018; pp. 274–278. [Google Scholar]
- Li, Y.; Wang, H.; Dang, L.M.; Nguyen, T.N.; Han, D.; Lee, A.; Jang, I.; Moon, H. A Deep Learning-Based Hybrid Framework for Object Detection and Recognition in Autonomous Driving. IEEE Access 2020, 8, 194228–194239. [Google Scholar] [CrossRef]
- Li, Y.; Li, S.; Du, H.; Chen, L.; Zhang, D.; Li, Y. YOLO-ACN: Focusing on small target and occluded object detection. IEEE Access 2020, 8, 227288–227303. [Google Scholar] [CrossRef]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Wang, C.; Wang, H.; Yu, F.; Xia, W. A High-Precision Fast Smoky Vehicle Detection Method Based on Improved Yolov5 Network. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence and Industrial Design (AIID), Guangzhou, China, 28–30 May 2021; pp. 255–259. [Google Scholar] [CrossRef]
- Miao, Y.; Liu, F.; Hou, T.; Liu, L.; Liu, Y. A Nighttime Vehicle Detection Method Based on YOLO v3. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 6617–6621. [Google Scholar] [CrossRef]
- Sarda, A.; Dixit, S.; Bhan, A. Object Detection for Autonomous Driving using YOLO [You Only Look Once] algorithm. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 1370–1374. [Google Scholar] [CrossRef]
- Zhao, S.; You, F. Vehicle Detection Based on Improved Yolov3 Algorithm. In Proceedings of the 2020 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Vientiane, Laos, 11–12 January 2020; pp. 76–79. [Google Scholar] [CrossRef]
- Ćorović, A.; Ilić, V.; Ðurić, S.; Marijan, M.; Pavković, B. The Real-Time Detection of Traffic Participants Using YOLO Algorithm. In Proceedings of the 2018 26th Telecommunications Forum (TELFOR), Belgrade, Serbia, 20–21 November 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Lou, L.; Zhang, Q.; Liu, C.; Sheng, M.; Zheng, Y.; Liu, X. Vehicles Detection of Traffic Flow Video Using Deep Learning. In Proceedings of the 2019 IEEE 8th Data Driven Control and Learning Systems Conference (DDCLS), Dali, China, 24–27 May 2019; pp. 1012–1017. [Google Scholar] [CrossRef]
- Machiraju, G.S.R.; Kumari, K.A.; Sharif, S.K. Object Detection and Tracking for Community Surveillance using Transfer Learning. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20–22 January 2021; pp. 1035–1042. [Google Scholar] [CrossRef]
- Snegireva, D.; Kataev, G. Vehicle Classification Application on Video Using Yolov5 Architecture. In Proceedings of the 2021 International Russian Automation Conference (RusAutoCon), Sochi, Russia, 5–11 September 2021; pp. 1008–1013. [Google Scholar] [CrossRef]
- Jana, A.P.; Biswas, A.; Mohana. YOLO based Detection and Classification of Objects in video records. In Proceedings of the 2018 3rd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 18–19 May 2018; pp. 2448–2452. [Google Scholar] [CrossRef]
- Hu, X.; Wei, Z.; Zhou, W. A video streaming vehicle detection algorithm based on YOLOv4. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; pp. 2081–2086. [Google Scholar] [CrossRef]
- Kasper-Eulaers, M.; Hahn, N.; Berger, S.; Sebulonsen, T.; Myrland; Kummervold, P.E. Short Communication: Detecting Heavy Goods Vehicles in Rest Areas in Winter Conditions Using YOLOv5. Algorithms 2021, 14, 114. [Google Scholar] [CrossRef]
- De Carvalho, O.L.F.; de Carvalho Júnior, O.A.; de Albuquerque, A.O.; Santana, N.C.; Guimarães, R.F.; Gomes, R.A.T.; Borges, D.L. Bounding box-free instance segmentation using semi-supervised iterative learning for vehicle detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3403–3420. [Google Scholar] [CrossRef]
- Tayara, H.; Soo, K.G.; Chong, K.T. Vehicle detection and counting in high-resolution aerial images using convolutional regression neural network. IEEE Access 2018, 6, 2220–2230. [Google Scholar] [CrossRef]
- Zhao, J.; Hao, S.; Dai, C.; Zhang, H.; Zhao, L. Improved Vision-Based Vehicle Detection and Classification by Optimized YOLOv4. IEEE Access 2022, 10, 8590–8603. [Google Scholar] [CrossRef]
- Hassaballah, M.; Mahmoud; Kenk, M.; Muhammad, K.; Minaee, S. Vehicle detection and tracking in adverse weather using a deep learning framework. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4230–4242. [Google Scholar] [CrossRef]
- Mahmood, Z.; Khan, K.; Khan, U.; Adil, S.H.; Ali, S.S.A.; Shahzad, M. Towards Automatic License Plate Detection. Sensors 2022, 22, 1245. [Google Scholar] [CrossRef]
- Wu, T.H.; Wang, W.T.; Liu, Y.Q. Real-time vehicle and distance detection based on improved yolo v5 network. In Proceedings of the 2021 3rd World Symposium on Artificial Intelligence (WSAI), Guangzhou, China, 18–20 June 2021; pp. 24–28. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Romanan, D.; Dollar, P.; Zitnick, C. Microsoft COCO: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- He, Y.; Zhu, C.; Wang, J.; Savvides, M.; Zhang, X. Bounding box regression with uncertainty for accurate object detection. In Proceedings of the In Proceedings of the Ieee/Cvf Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019 pp.; pp. 2888–2897.
- Liu, K.; Wang, W.; Tharmarasa, R.; Wang, J. Dynamic vehicle detection with sparse point clouds based on PE-CPD. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1964–1977. [Google Scholar] [CrossRef]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2Det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Montréal, QC, Canada, 17 July 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. arXiv 2019, arXiv:1901.01892. [Google Scholar]
- Zhang, H.; Tian, Y.; Wang, K.; Zhang, W.; Wang, F.-Y. Mask SSD: An effective single-stage approach to object instance segmentation. IEEE Trans. Image Process. 2020, 29, 2078–2093. [Google Scholar] [CrossRef]
- Min, W.; Fan, M.; Guo, X.; Han, Q. A new approach to track multiple vehicles with the combination of robust detection and two classifiers. IEEE Trans. Intell. Transp. Syst. 2018, 19, 174–186. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. CornerNet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 17–24 May 2018; pp. 734–750. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Shi, F.; Zhang, T.; Zhang, T. Orientation-Aware Vehicle Detection in Aerial Images via an Anchor-Free Object Detection Approach. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5221–5233. [Google Scholar] [CrossRef]
- Hu, X.; Xu, X.; Xiao, Y.; Chen, H.; He, S.; Qin, J.; Heng, P.-A. SINet: A scale-insensitive convolutional neural network for fast vehicle detection. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1010–1019. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym | Meaning |
|---|---|
| CNN | Convolutional Neural Networks |
| COCO | Common Objects in Context |
| DLT | Dark Label Tool |
| DNN | Deep Neural Network |
| FPN | Feature Pyramid Network |
| FPS | Frames Per Seconds |
| HDT/LDT | High Density Traffic/Low Density Traffic |
| ITS | Intelligent Transportation Systems |
| LIT | Label Image Tool |
| mAP | mean Average Precision |
| MSR | Multi Scale Retinex |
| PAN | Path Aggregation Network |
| PKU | Peking University |
| R-CNN | Region-based Convolutional Neural Networks |
| RFW | RoboFlow |
| SSD | Single Stage Detector |
| TP/TN | True Positives/True Negatives |
| XAI | Explainable Artificial Intelligence |
| YOLO | You Only Look Once |
| Dataset | HDT Dataset | LDT Dataset | |
|---|---|---|---|
| Source images | 1800 | 600 | |
| Annotations | 15,618 | 903 | |
| Classes | Car | 8457 | 655 |
| Motorcycle | 4136 | 136 | |
| Person | 3025 | 112 | |
| Total | 3036 | 2406 | |
| Dataset | Classes | Classes | Training | Validation | Testing |
|---|---|---|---|---|---|
| HDT data | 3 | car, motorcycle, and person | 3685 | 356 | 177 |
| LDT data | 3 | 1260 | 120 | 60 | |
| COCO 2017 | 80 | car, motorcycle, person, dog, table, and horse | 118,287 | 5000 | 40,760 |
| Total | 123,232 | 5476 | 40,997 | ||
| Category | Vehicle Conditions | Input Image Resolution (pixels) | No. of Images | No. of Plates | Plate Height (pixels) |
|---|---|---|---|---|---|
| G1 | Cars on roads; ordinary environment at different daytimes; contains only one vehicle/license plate per image. | 1082 × 728 | 810 | 810 | 35–57 |
| G2 | Cars/trucks on main roads at different daytimes with sunshine; only one vehicle in each image. | 1082 × 728 | 700 | 700 | 30–62 |
| G3 | Cars/trucks on highways during night; one license plate per image. | 1082 × 728 | 743 | 743 | 29–53 |
| G4 | Cars/trucks on main roads; daytimes with reflective glare; one license plate in input images. | 1600 × 1236 | 572 | 572 | 30–58 |
| G5 | Cars/trucks at roads junctions with crosswalks; several vehicles per image. | 1600 × 1200 | 1152 | 1438 | 20–60 |
| PKU dataset | 3977 | 4263 | 20~62 | ||
| Ref. | G1 | G2 | G3 | G4 | G5 | mAP (%) |
|---|---|---|---|---|---|---|
| [28] | 100 | 100 | 100 | 98.96 | 99.13 | 99.61 |
| [29] | 100 | 100 | 100 | 99.73 | 99.21 | 99.78 |
| [30] | 100 | 100 | 100 | 99.70 | 99.10 | 99.76 |
| [31] | 100 | 100 | 99.40 | 99.74 | 98.96 | 97.74 |
| [33] | 99.00 | 99.00 | 98.70 | 98.00 | 98.90 | 98.72 |
| [34] | 100 | 100 | 100 | 99.00 | 96.50 | 99.10 |
| [35] | 100 | 100 | 99.00 | 99.64 | 99.06 | 98.34 |
| [36] | 100 | 100 | 99.40 | 99.74 | 98.96 | 97.74 |
| [37] | 100 | 98.50 | 100 | 99.50 | 98.10 | 99.22 |
| [38] | 100 | 100 | 100 | 99.00 | 98.00 | 99.40 |
| [39] | 99.00 | 100 | 100 | 99.00 | 98.50 | 99.30 |
| [40] | 100 | 100 | 100 | 99.80 | 99.50 | 99.86 |
| [41] | 99 | 99 | 98.50 | 98.00 | 99.00 | 98.70 |
| [42] | 98.90 | 98.50 | 98.00 | 97.50 | 96.10 | 97.80 |
| Proposed | 99.94 | 100 | 100 | 99.73 | 99.96 | 99.92 |
| Ref. | Backbone | Data | Input Size | Multi Scale | mAP(%) |
|---|---|---|---|---|---|
| [28] | CSPDarkNet53 | trainval35K | 512 × 512 | False | 47.62 |
| [29] | CNN | trainval35K | 512 × 512 | False | 48.00 |
| [30] | R-CNN | trainval35K | 512 × 512 | False | 46.20 |
| [31] | BottlenectCSP | trainval35K | 512 × 512 | False | 27.89 |
| [33] | VGGNet-16 | trainval35K | 512 × 512 | False | 29.10 |
| [34] | ResNet-101-FPN | trainval35K | 512 × 512 | False | 38.30 |
| [35] | VGGNet-16 | trainval35K | 800 × 800 | False | 41.00 |
| [36] | ResNet-101 | trainval35K | 800 × 800 | False | 48.40 |
| [37] | ResNet-101 | trainval35K | 512 × 512 | False | 39.30 |
| [38] | CNN + SVM | trainval35K | 512 × 512 | False | 49.05 |
| [39] | BN + ReLU | trainval35K | 512 × 512 | False | 32.98 |
| [40] | ResNet-C4-FPN | trainval35K | 512 × 512 | False | 31.80 |
| [41] | ResNet-50 | trainval35K | 512 × 512 | False | 49.80 |
| [42] | SiNet | trainval35K | 512 × 512 | False | 50.40 |
| Proposed | CSP | trainval35K | 512 × 512 | False | 52.31 |
| Ref. | Backbone | Image/s | Fog | Rain | Snow | Sand |
|---|---|---|---|---|---|---|
| [28] | CSPDarkNet53 | 0.085 | 26.40 | 31.55 | 39.95 | 24.10 |
| [29] | CNN | 0.085 | 24.00 | 21.10 | 38.32 | 23.80 |
| [30] | R-CNN | 0.085 | 27.20 | 21.30 | 28.30 | 18.00 |
| [31] | BottlenectCSP | 0.085 | 29.31 | 41.21 | 43.00 | 24.02 |
| [33] | VGGNet-16 | 0.085 | 23.40 | 24.60 | 37.90 | 15.83 |
| [34] | ResNet-101-FPN | 0.085 | 28.95 | 41.10 | 43.00 | 24.09 |
| [35] | VGGNet-16 | 0.085 | 23.10 | 27.65 | 34.00 | 24.10 |
| [36] | ResNet-101 | 0.085 | 29.70 | 40.10 | 43.00 | 23.99 |
| [37] | ResNet-101 | 0.085 | 28.10 | 40.40 | 43.02 | 24.10 |
| [38] | ResNet-101-FPN | 0.085 | 16.50 | 14.08 | 15.38 | 10.69 |
| [39] | Hourglass-104 | 0.085 | 25.08 | 19.14 | 23.18 | 17.38 |
| [40] | ResNeXt-101 | 0.085 | 29.68 | 30.32 | 33.93 | 24.00 |
| [41] | ResNet-101-FPN | 0.085 | 28.83 | 27.68 | 30.19 | 24.03 |
| [42] | VGGNet-16 | 0.085 | 26.45 | 20.09 | 27.92 | 11.31 |
| Proposed | CSP | 0.0085 | 29.66 | 41.21 | 43.01 | 24.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farid, A.; Hussain, F.; Khan, K.; Shahzad, M.; Khan, U.; Mahmood, Z. A Fast and Accurate Real-Time Vehicle Detection Method Using Deep Learning for Unconstrained Environments. Appl. Sci. 2023, 13, 3059. https://doi.org/10.3390/app13053059
Farid A, Hussain F, Khan K, Shahzad M, Khan U, Mahmood Z. A Fast and Accurate Real-Time Vehicle Detection Method Using Deep Learning for Unconstrained Environments. Applied Sciences. 2023; 13(5):3059. https://doi.org/10.3390/app13053059
Chicago/Turabian StyleFarid, Annam, Farhan Hussain, Khurram Khan, Mohsin Shahzad, Uzair Khan, and Zahid Mahmood. 2023. "A Fast and Accurate Real-Time Vehicle Detection Method Using Deep Learning for Unconstrained Environments" Applied Sciences 13, no. 5: 3059. https://doi.org/10.3390/app13053059
APA StyleFarid, A., Hussain, F., Khan, K., Shahzad, M., Khan, U., & Mahmood, Z. (2023). A Fast and Accurate Real-Time Vehicle Detection Method Using Deep Learning for Unconstrained Environments. Applied Sciences, 13(5), 3059. https://doi.org/10.3390/app13053059