

Modified Conditional Restricted Boltzmann Machines for Query Recommendation in Digital Archives


Abstract
:1. Introduction
- We propose a method to recommend queries in DAs called modified conditional restricted Boltzmann machines (M-CRBMs). M-CRBMs provide users with different expert knowledge levels to seek information in the database when given an initial query.
- We modify the conventional CRBMs and construct M-CRBMs by reducing the weight matrices in the model. This makes the model trainable for average-performaing computers. Aside from that, we use free energy instead of energy to efficiently train the model.
- The proposed M-CRBM model is able to predict the queries relevant to the user’s query and predict the relevance degree (ranking) simultaneously.
2. Related Work
2.1. Recommendation in GLAMs
2.2. RBMs and CRBMs for the Recommendation Task
2.3. Query Recommendation
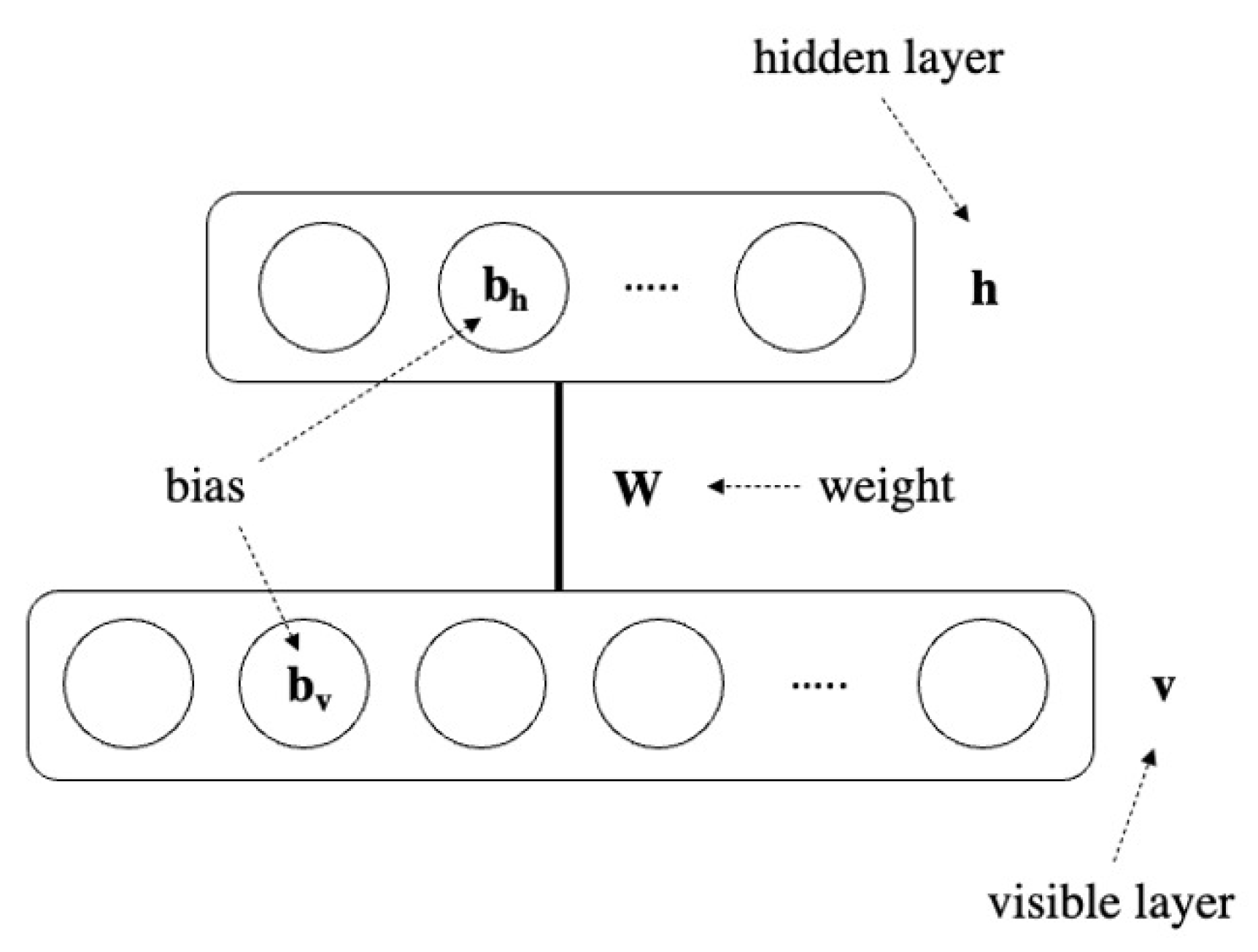
3. RBMs and CRBMs
3.1. Restricted Boltzmann Machines
3.2. Learning Rule of RBMs
| Algorithm 1: Gibbs sampling in RBMs |
 |
| Algorithm 2: CD in RBMs |
 |
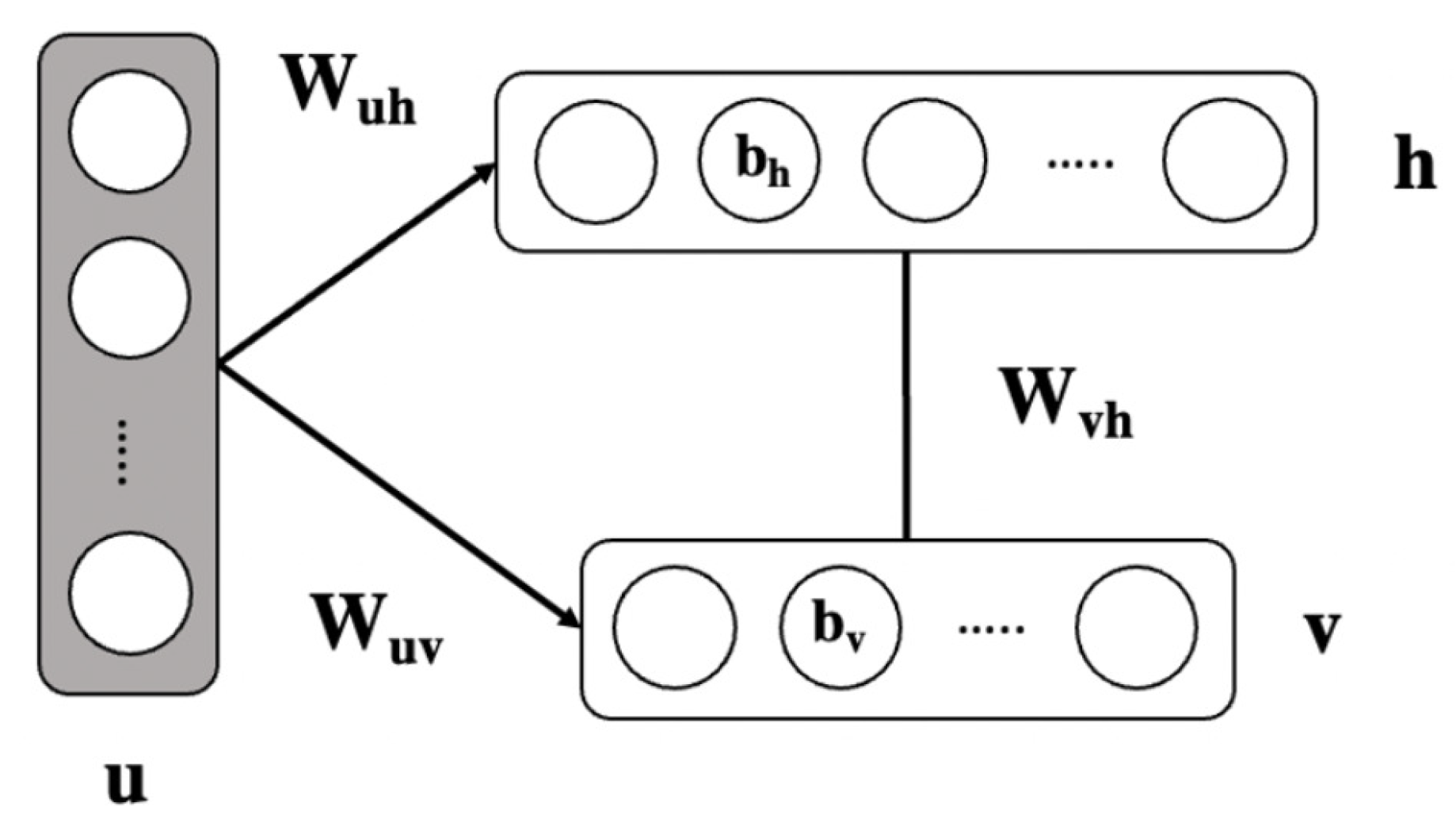
3.3. Conditional RBMs
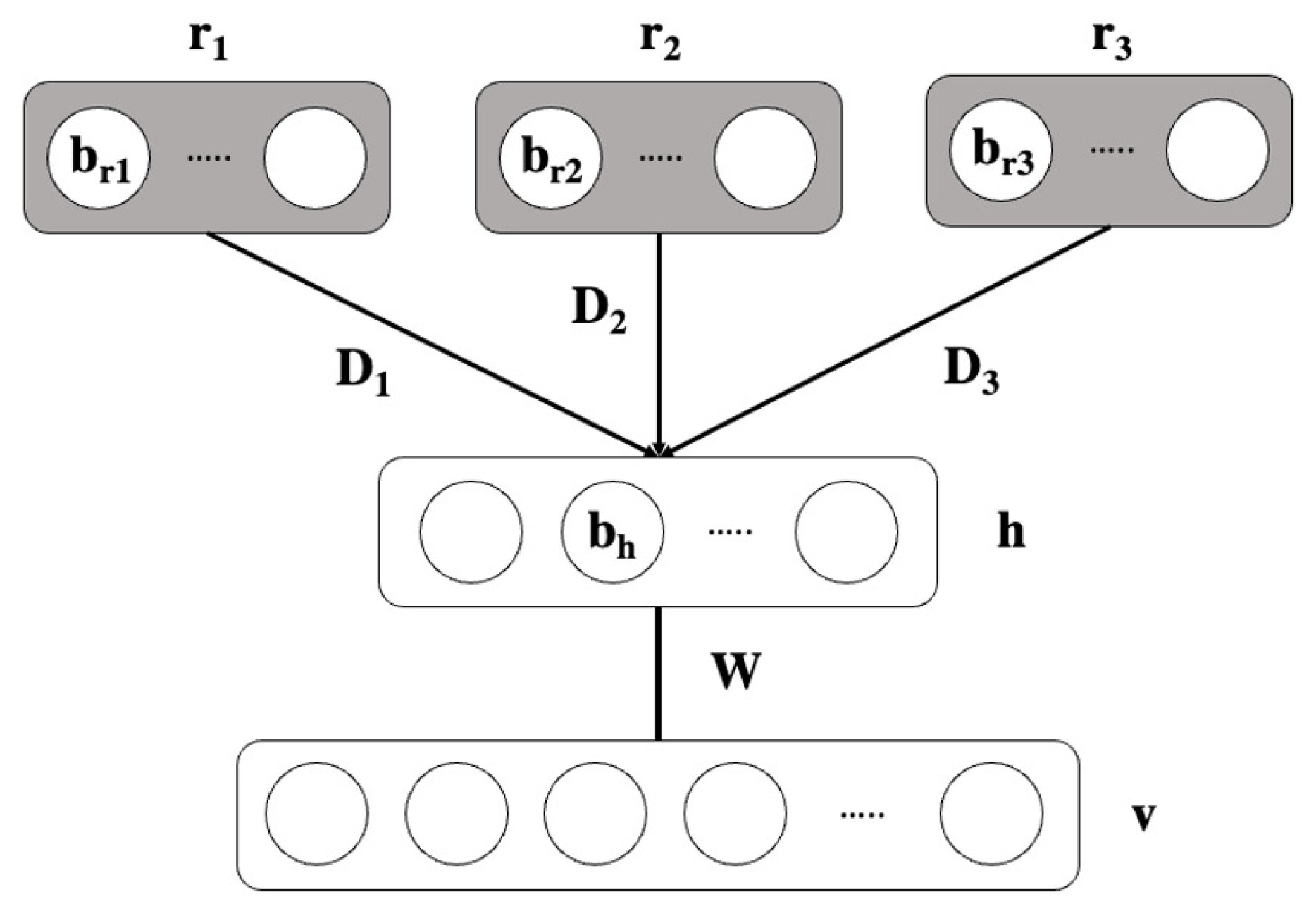
4. Modified CRBMs (M-CRBMs)
| Algorithm 3: CD in M-CRBMs with free energy |
 |
5. Dataset
5.1. ARC-UPD Dataset
5.1.1. Preprocessing
- We removed all the web robots’ access by recognizing the agent names that appeared in the access logs. If the agent name of the record was listed in that web robot list, then the record was removed. The suspicious web robot list was provided by the Apache HTTP Server, which is the front-end web server of the ARC-UPD.
- We removed records from users who frequently accessed (accessed more than 50 times within a time interval of less than 10 s) the ARC-UPD, because these users were perhaps scraping the web page or checking the system. In this work, a unique user is defined by the same IP address and browser (user agent) information.
- We only kept the records that indicated a user used the formulated query (or queries) to access a certain item. In the search engine of the ARC-UPD, a user can input search queries in multiple search fields, such as keyword, artist, publication year, and genre. Although all of the queries to different search fields include extensive expert knowledge, in this research, we only used the queries input in the keyword search field. The reason for this is due to the difficulties of extracting the needed training data from other fields. In the search system’s design, if the users click some metadata shown on the web page and then access a certain item from the access log, it will be recorded as the same as users making a search query in the corresponding metadata field and accessing a certain item. Therefore, only choosing the queries input in the keyword search field would ensure that most of the queries were really formulated by real users.
- We constructed a dictionary to store the query-item pairs from the previous steps with the format ofWe call this a query dictionary. Here, “frequency” is the frequency of the query that has been used to search for the item.
5.1.2. Characteristics of the Dataset
5.1.3. Training and Test Datasets
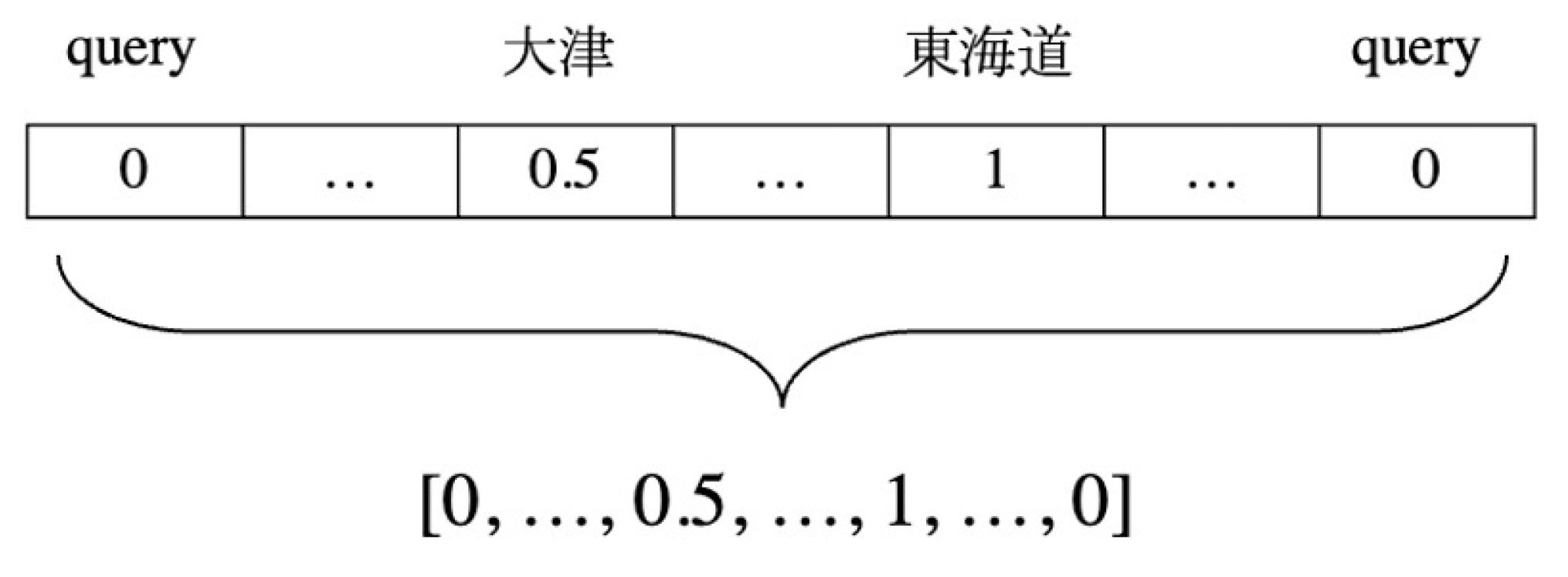
- Query Embedding
- Artist Embedding
- Genre Embedding
- Series Name Embedding
5.2. Europeana Dataset
- Send the query “ukiyo” to the Europeana search API and obtain all the returned records. In this dataset, only the metadata field title was considered suitable conditional information for the proposed M-CRBM model.
- Filter the returned records by record language. Here, we chose to only use records in the German language because the size of this dataset was small, and most records were in the German language. Only using records in German ensured that the model could efficiently learn the patterns of the co-occurrence of words. After filtering, 4089 records remained.
- Perform basic natural language preprocessing, remove punctuation marks, numbers, and stop words, remove the often-appearing words that are not related to the items, and convert all the characters to lowercase.
- Because there were no real access logs for this dataset, we randomly generated the access logs. The random rule was that each item was accessed 1–10 times. The query (queries) to access a certain item was (were) assumed to be 30~50% of the words in the title of the item (less than one word was counted as one). We generated a total of 22,650 query-item access logs.
- Query embedding and title embedding were created for the Europeana dataset. The embedding method was similar to artist embedding in the ARC-UPD. The only difference was that in the Europeana dataset, each dimension represented one word in queries or titles.
6. Experiments
6.1. Evaluation Metrics
6.2. Experiments on ARC-UPD Dataset
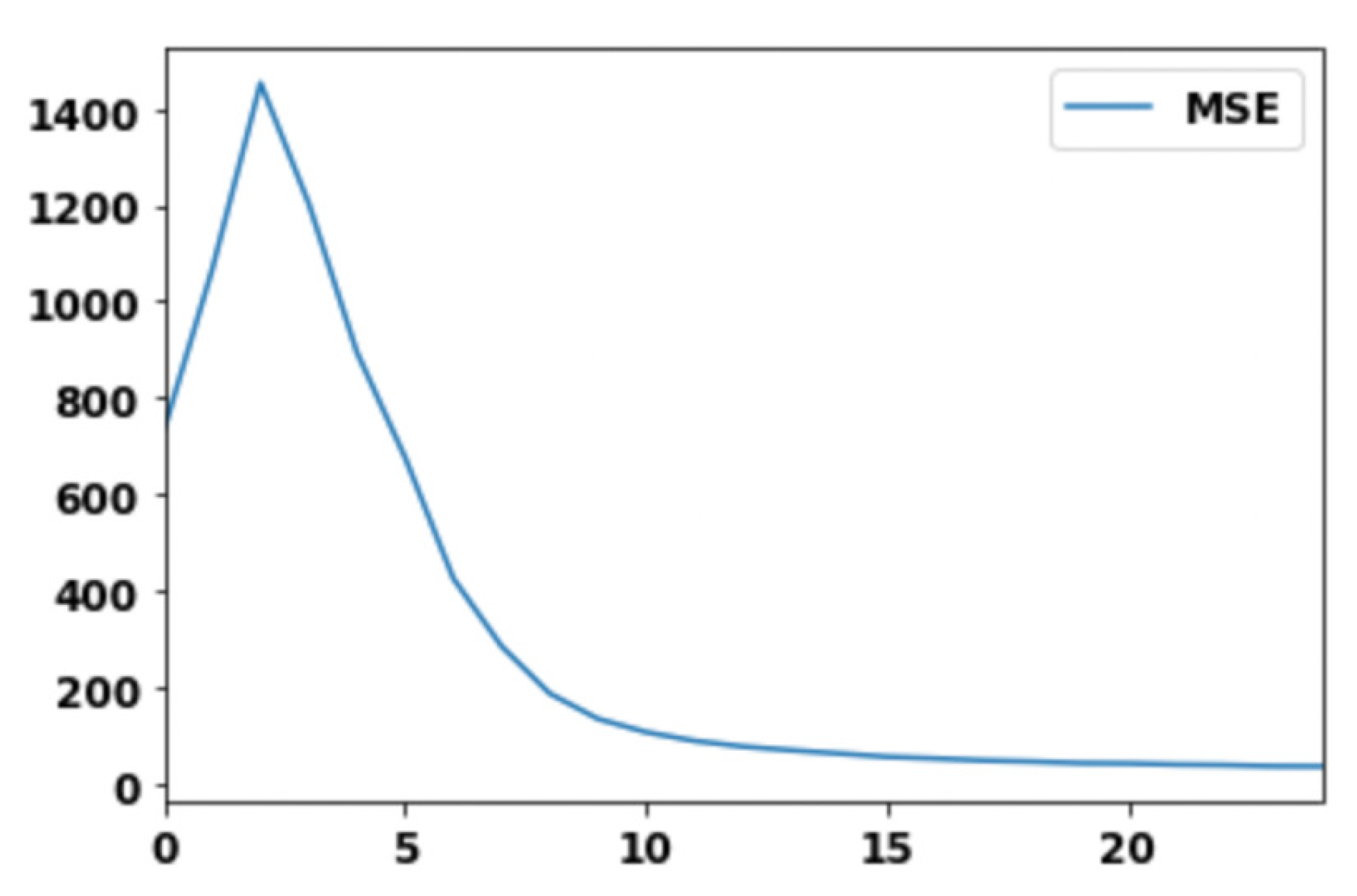
- Mean square error (MSE), which measures the effectiveness of the training method of the proposed M-CRBM model;
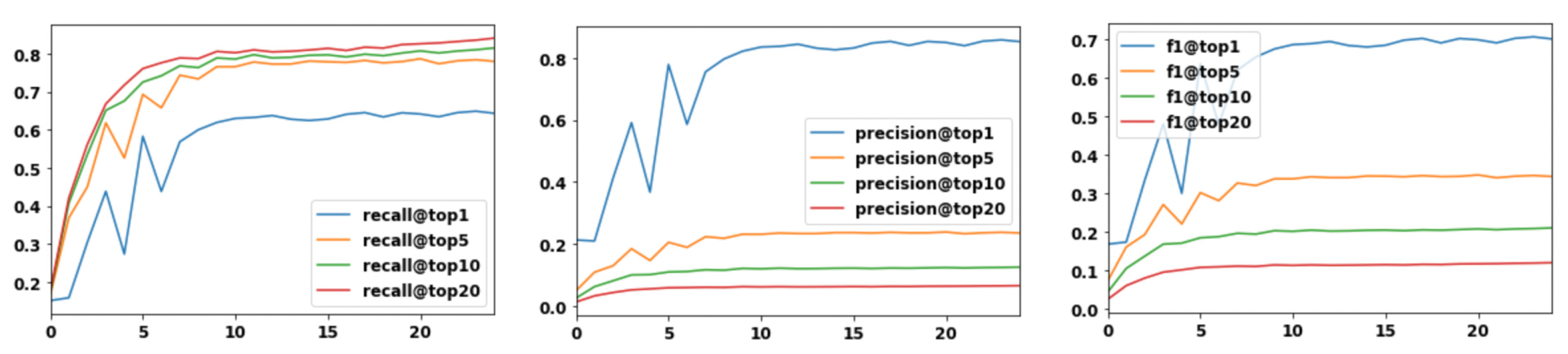
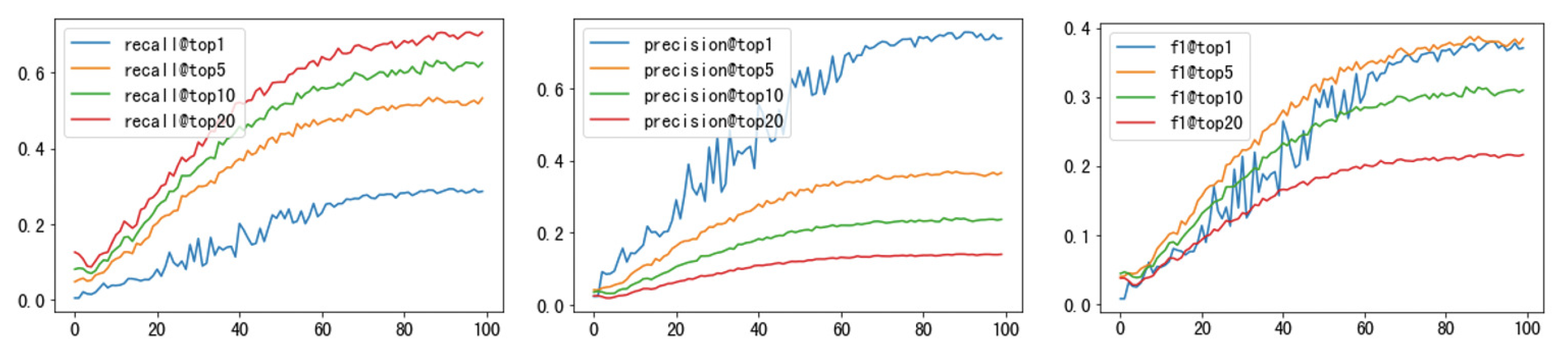
- Recall@k, precision@k, and F1@k to measure the model performance in a recommendation task;
- Ablation experiments that compared the conventional RBMs with M-CRBMs, which took different extra information in the conditional layer(s);
- Recommendation examples, including the predictions of all the models by inputting the same query and typical bad cases.
Experimental Results
6.3. Experiments on Europeana Dataset
7. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pavlidis, G.; Koutsoudis, A.; Arnaoutoglou, F.; Tsioukas, V.; Chamzas, C. Methods for 3D digitization of cultural heritage. J. Cult. Herit. 2007, 8, 93–98. [Google Scholar] [CrossRef]
- Johnson, P.S.; Doulamis, A.; Moura Santo, P.; Hadjiprocopi, A.; Fritsch, D.; Doulamis, N.D.; Makantasis, K.; Stork, A.; Ioannides, M.; Klein, M.; et al. Online 4D reconstruction using multi-images available under Open Access. In Proceedings of the SPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Strasbourg, France, 30 July 2013. [Google Scholar]
- Philips, J.; Tabrizi, N. Historical Document Processing: A Survey of Techniques, Tools, and Trends. In Proceedings of the 2th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Online, 2 November 2020. [Google Scholar]
- Clark, J.H. The long-term preservation of digital historical geospatial data: A review of issues and methods. J. Map Geogr. Libr. 2016, 12, 187–201. [Google Scholar] [CrossRef]
- Resig, J. Using computer vision to increase the research potential of photo archives. J. Digit. Humanit. 2014, 3, 5–36. [Google Scholar]
- Phillips, S.C.; Walland, P.W.; Modafferi, S.; Dorst, L.; Spagnuolo, M.; Catalano, C.E.; Oldman, D.; Tal, A.; Shimshoni, I.; Hermon, S. GRAVITATE: Geometric and Semantic Matching for Cultural Heritage Artefacts. GCH 2016, 16, 199–202. [Google Scholar]
- Ardissono, L.; Kuflik, T.; Petrelli, D. Personalization in cultural heritage: The road travelled and the one ahead. User Model. User-Adapt. Interact. 2012, 22, 73–99. [Google Scholar] [CrossRef]
- Wilson-Barnao, C. How algorithmic cultural recommendation influence the marketing of cultural collections. Consum. Mark. Cult. 2017, 20, 559–574. [Google Scholar] [CrossRef]
- Clough, P.; Hill, T.; Paramita, M.L.; Goodale, P. Europeana: What users search for and why. In Proceedings of the International Conference on Theory and Practice of Digital Libraries, Thessaloniki, Greece, 18–21 September 2017. [Google Scholar]
- Europeana. Available online: https://www.europeana.eu/portal/en (accessed on 6 November 2022).
- ukiyo-e Portal Database1 of Art Research Center (ARC-UPD). Available online: https://www.dh-jac.net/db/nishikie/\search_portal.php?enter=portal&lang=en (accessed on 6 November 2022).
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Taylor, G.W.; Hinton, G.E.; Roweis, S.T. Modeling human motion using binary latent variables. Adv. Neural Inf. Process. Syst. 2007, 19, 1345–1352. [Google Scholar]
- Salakhutdinov, R.; Mnih, A.; Hinton, G. Restricted Boltzmann machines for collaborative filtering. In Proceedings of the 24th International Conference on Machine Learning, Buenos Aires, Argentina, 20 June 2007. [Google Scholar]
- Mnih, V.; Larochelle, H.; Hinton, G.E. Conditional restricted boltzmann machines for structured output prediction. arXiv 2012, arXiv:1202.3748. [Google Scholar]
- Wang, Y.; Stash, N.; Aroyo, L.; Gorgels, P.; Rutledge, L.; Schreiber, G. Recommendations based on semantically enriched museum collections. J. Web Semant. 2008, 6, 283–290. [Google Scholar] [CrossRef]
- Semeraro, G.; Lops, P.; De Gemmis, M.; Musto, C.; Narducci, F. A folksonomy-based recommender system for personalized access to digital artworks. J. Comput. Cult. Herit. 2012, 5, 1–22. [Google Scholar] [CrossRef]
- Georgiev, K.; Nakov, P. A non-iid framework for collaborative filtering with restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 26 May 2013. [Google Scholar]
- Wu, X.; Yuan, X.; Duan, C.; Wu, J. A novel collaborative filtering algorithm of machine learning by integrating restricted Boltzmann machine and trust information. Neural Comput. Appl. 2019, 31, 4685–4692. [Google Scholar] [CrossRef]
- Pujahari, A.; Sisodia, D.S. Modeling side information in preference relation based restricted boltzmann machine for recommender systems. Inf. Sci. 2019, 490, 126–145. [Google Scholar] [CrossRef]
- Chen, Z.; Ma, W.; Dai, W.; Pan, W.; Ming, Z. Conditional restricted Boltzmann machine for item recommendation. Neurocomputing 2020, 385, 269–277. [Google Scholar] [CrossRef]
- Baeza-Yates, R.; Hurtado, C.; Mendoza, M. Query recommendation using query logs in search engines. In Proceedings of the International Conference on Extending Database Technology, Berlin, Heidelberg, 14 March 2004. [Google Scholar]
- Huang, C.K.; Chien, L.F.; Oyang, Y.J. Relevant term suggestion in interactive web search based on contextual information in query session logs. J. Am. Soc. Inf. Sci. Technol. 2003, 54, 638–649. [Google Scholar] [CrossRef]
- Song, Y.; He, L.W. Optimal rare query suggestion with implicit user feedback. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26 April 2010. [Google Scholar]
- Feild, H.; Allan, J. Task-aware query recommendation. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin Ireland, 28 July 2013. [Google Scholar]
- LeCun, Y.; Chopra, S.; Hadsell, R.; Ranzato, M.; Huang, F. Energy-Based Training: Architecture and Loss Function. In Predicting Structured Data; Bakir, G., Hofman, T., Scholkopf, B., Smola, A., Taskar, B., Eds.; The MIT Press: London, UK, 2007; pp. 197–205. [Google Scholar]
- Hinton, G.E. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002, 14, 1771–1800. [Google Scholar] [CrossRef]
- Gelfand, A.E. Gibbs sampling. J. Am. Stat. Assoc. 2000, 95, 1300–1304. [Google Scholar] [CrossRef]
- Dadgar, M.; Hamzeh, A. How to boost the performance of recommender systems by social trust? Studying the challenges and proposing a solution. IEEE Access 2022, 10, 13768–13779. [Google Scholar] [CrossRef]
- Meo, P.D. Trust prediction via matrix factorisation. ACM Trans. Internet Technol. 2019, 19, 1–20. [Google Scholar] [CrossRef]
- Nikolakopoulos, A.N.; Ning, X.; Desrosiers, C.; Karypis, G. Trust your neighbors: A comprehensive survey of neighborhood-based methods for recommender systems. In Recommender Systems Handbook; Francesco, R., Lior, R., Bracha, S., Eds.; Springer: New York, NY, USA, 2021; pp. 39–89. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Recall@1 | Precision@1 | F1@1 |
|---|---|---|---|
| RBMs | 0.685317 | 0.898908 | 0.744208 |
| M-CRBMs (a) | 0.705432 | 0.925713 | 0.766092 |
| M-CRBMs (g) | 0.684667 | 0.900585 | 0.744076 |
| M-CRBMs (s) | 0.723705 | 0.954496 | 0.787330 |
| M-CRBMs (a+g) | 0.687901 | 0.904879 | 0.747577 |
| M-CRBMs (a+s) | 0.715931 | 0.938779 | 0.777305 |
| M-CRBMs (g+s) | 0.663306 | 0.876736 | 0.722109 |
| M-CRBMs (a+g+s) | 0.642967 | 0.852156 | 0.700563 |
| Model | Query Recommendations | Relevant Number |
|---|---|---|
| RBMs | 月百姿, 大坂, 二十四孝, 五十三次之内, 金太郎, 鬼, 人形, 孝子の月, 井筒, 堀川 | 3 |
| M-CRBMs (a) | 月百姿, 玉手箱, 忠臣蔵, 芳年…, 目黒不動境内, 団扇絵, 祇園, 奥州安達, 季翫, 風俗 | 4 |
| M-CRBMs (g) | 月百姿, 春, 役者絵, 義士, 仮名手本忠臣蔵, 美人, 名所絵, 忠臣蔵, 満尭, 之肖像 | 3 |
| M-CRBMs (s) | 月百姿, 淮水月, 武者絵, 祇園まち, 五条橋の月, 金時, 小幡小平次, 孝子の月, 月, 宝蔵院 | 9 |
| M-CRBMs (a+g) | 月百姿, 遊君五節生花会, 忠臣蔵, 大星, 仮名手本忠臣蔵, 八百万神…, 駿河国富士川合戦, 子別れ, 金剛神之図, 孝女 | 2 |
| M-CRBMs (a+s) | 月百姿, 邑増山…, 祇園まち, 平井保昌, 月, 淮水月, 小町, 大日本史略図会, 鳶, 孝子の月 | 7 |
| M-CRBMs (g+s) | 月百姿, 講, 妻恋稲荷, 逢坂関, 月, 十兵衛, 孝子の月, 高の師直, 東都宮戸川之図, 武者 | 2 |
| M-CRBMs (a+g+s) | 月百姿, 伊勢…, 徒然草, の紅葉手古那, 孝子の月, 真乳山山谷堀夜景, 染物, 江戸花柳橋名取, 忠臣蔵, 面売 | 3 |
| Index | Input | Outputs | Relevant Number |
|---|---|---|---|
| 1 | 程義経 | 程義経恋源, 程義経, 義経, 義経恋, 武者, 横川の堪海, 小町, 弁慶, 牛若御曹司, 義経記 | 9 |
| 2 | 比叡山 | 比叡山, 忠臣蔵, 深草少将, 燕青, 中村芝翫, 小町, 藤原保友, 仮名手本忠臣蔵, 衣紋坂, 美人画 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Batjargal, B.; Maeda, A.; Kawagoe, K.; Akama, R. Modified Conditional Restricted Boltzmann Machines for Query Recommendation in Digital Archives. Appl. Sci. 2023, 13, 2435. https://doi.org/10.3390/app13042435
Wang J, Batjargal B, Maeda A, Kawagoe K, Akama R. Modified Conditional Restricted Boltzmann Machines for Query Recommendation in Digital Archives. Applied Sciences. 2023; 13(4):2435. https://doi.org/10.3390/app13042435
Chicago/Turabian StyleWang, Jiayun, Biligsaikhan Batjargal, Akira Maeda, Kyoji Kawagoe, and Ryo Akama. 2023. "Modified Conditional Restricted Boltzmann Machines for Query Recommendation in Digital Archives" Applied Sciences 13, no. 4: 2435. https://doi.org/10.3390/app13042435
APA StyleWang, J., Batjargal, B., Maeda, A., Kawagoe, K., & Akama, R. (2023). Modified Conditional Restricted Boltzmann Machines for Query Recommendation in Digital Archives. Applied Sciences, 13(4), 2435. https://doi.org/10.3390/app13042435