Abstract
The development of neural machine translation has achieved a good translation effect on large-scale general corpora, but there are still many problems in the translation of low resources and specific fields. This paper studies the problem of machine translation in the field of electrical engineering and fuses the multi-layer vectors at the encoder side of the model. On this basis, the decoder unit of the translation model is improved, and a multi-attention mechanism translation model based on vector fusion is proposed, which improves the ability of the model to extract features and achieves a better translation effect on Chinese-English translation tasks. The experimental results show that the BLEU (bilingual evaluation understudy) value of the improved translation system in the field of electrical engineering has increased by 0.15–1.58 percentage points.
1. Introduction
Machine translation refers to the use of computers to achieve automatic translation technology from one natural language text to another natural language text under the premise of maintaining semantic equivalence [1]. It is an important research direction combining natural language processing and artificial intelligence. With the continuous development of economic globalization, international communication has become increasingly frequent, so it is inevitable that there will be many problems with language barriers. Regarding these “language barriers” that hinder people’s communication, traditional manual translation can no longer meet the growing demand for translation, although its accuracy and translation quality are guaranteed. Moreover, for the translation of some professional fields, translators should not only master linguistic knowledge but also know some professional knowledge of the field to be translated in order to obtain appropriate translation results. In the face of the shortcomings of human translation, such as high cost, few resources and long time, people have the idea of using machines to replace human translation.
With the rapid development of computers, communication and other technologies in recent years, machine translation came into being and has made a series of progress. Although the translation results are not as good as manual translation, machine translation itself also has the advantages of fast translation speed, low cost, convenient use, and can meet the needs of the public. It can better solve the “language barrier” problem of people who use different languages when communicating, which is of great significance for promoting national unity, strengthening cultural exchanges, and promoting foreign trade. Therefore, how to do a better job of machine translation is a necessary research issue to make its effect closer and closer to manual translation and even make the final translation effect reach “faithfulness, expressiveness, and elegance”.
The development of machine translation can be mainly divided into three stages: rule-based machine translation [2], statistical machine translation [3] and neural machine translation [4,5,6,7,8,9]. Neural machine translation, as the current mainstream method of machine translation, has achieved good translation results for general corpora, but it still faces great challenges for machine translation in low-resource fields such as professional fields [10,11].
For machine translation in the professional field, it is not only necessary to master the general technology of machine translation but also to have a basic understanding and mastery of the professional field of translation, including many professional words and technologies in the text, which should be more suitable for the meaning and habits of the professional translation. In particular, some professional words may have very different meanings in different fields, so it is necessary to use the corpus of professional fields to train translation models in specific fields.
In the current social and economic development, electrical engineering involves all aspects of our lives. Machine translation in the field of electrical engineering has great significance in promoting the progress and development of the industry. The model translation results trained by using an electrical corpus will have stronger professional characteristics and can effectively meet the translation needs of professionals in the field of electrical engineering when performing tasks such as document reading and equipment operation. In addition, for this specific field of translation, machine translation will have obvious advantages in translation speed, so it is necessary to do a good job of neural machine translation in the field of electrical engineering.
In this paper, the corpus in the field of electrical engineering is used for model training, and a variety of methods are used to fuse the output vectors of each layer unit inside the encoder for the problem of loss of underlying information in the translation model and the problem of different emphasis on multi-layer information. On this basis, the decoder unit of the translation model is improved, and a multi-attention mechanism translation model based on vector fusion is proposed so that the improved model can not only obtain more comprehensive domain source language information at the encoder side but also so that this information can be better used in the decoding process to improve the translation effect of the model in the electrical engineering domain.
2. Related Works
Since the introduction of neural machine translation, in order to better improve the translation effect of the model, many improved methods of the model have been proposed in succession. Xu [12] adopted the method of transfer learning to transfer the translation model trained on the large-scale Chinese-English parallel corpus to the low-resource Chinese-English and Tibetan-Chinese translation models. Through the method of pre-training and fine-tuning, the translation effect of the model in the low-resource field has been well improved. Wang [13] combined neural machine translation and generative adversarial networks, using BiLSTM and Transformer as the generators of generative adversarial networks, respectively, to distinguish the translation results and reference sentences, taking the evaluation index BLEU value of machine translation as the expected value to adjust the generated part of neural machine translation model, which greatly improved the translation effect of the model. Ying [14] obtained the lexical information, dependency information and location information corresponding to the English corpus through the syntax analysis tool and migrated this information into the Chinese corpus through the relationship matrix between the Chinese and English parallel corpora. On this basis, the mask language generation model is trained in both Chinese and English languages, and then the pre-trained model is transferred to the Chinese-English translation model to accelerate the training speed of the model and improve the translation effect. Li [15] proposed a bi-directional Chinese-English machine translation model, which trains the translation models in both Chinese and English and Chinese, and uses the quality evaluation module to splice, train and evaluate the feature vectors of the source language features and the translated sentences so as to realize the learning of bilingual knowledge. The translation effect has been improved in both monolingual and bilingual corpus. Michiki Kurosawa and Mamoru Komachi [16] used the word prediction probability of the language model as auxiliary information, spliced it with the coding information of the translation model, and then carried out the full-connection layer mapping to obtain the feature vector that fused the language model knowledge and used it in the decoding process of the translation model, which improved the translation effect. Pingfei Zheng [17] used a convolutional neural network to extract character-level features from the training corpus and fused them with word-level feature vectors using the splicing method, and he proposed an LSTM neural machine translation model based on attentional mechanism embedding, which improved the translation effect.
There are many improved methods using vector fusion, but most of them are system fusions of the whole encoder or decoder of the translation model or multilingual information fusion. Tan et al. [18] conducted three system fusion experiments on the same corpus with a multi-encoder single-decoder, single-decoder multi-encoder and multi-encoder multi-decoder. Banik et al. [19] took advantage of the advantages of SMT (statistical machine translation) and NMT (neural machine translation) at the same time, used SMT and NMT models to translate the source language, and then input the translation results together with the source language into the neural network-based system combination model and the statistics-based system combination model. The preference values corresponding to the two methods are obtained, and finally, the preference values and their corresponding translation results are input into the system combination module for fusion to obtain the final translation result. Zoph et al. [20] used multiple encoders to encode different source languages and used the methods of splicing, LSTM (long short-term memory) variants and multilingual attention mechanisms to fuse the output vectors of multiple encoders and then send them to the decoder side for decoding. Banik et al. [21] used a statistical system combination method of alignment, decoding and scoring to select and recombine the best phrases from the translation results obtained by the statistical translation system and the neural translation system. Zhou et al. [22] used an encoder to encode the source language input in the forward and reverse directions, a bidirectional decoder to complete the translation of the target language from both ends to the middle at the same time, and linearly fused the generated language in both directions. Sreedhar et al. [23] proposed a byte-based neural translation model and used two byte vector fusion methods, a convolutional neural network and a self-attention mechanism, to achieve the fusion of n-byte and in-word byte information. The byte translation model after vector fusion has achieved an improved translation effect in multilingual translation tasks. Wang et al. [24] proposed a multi-level information fusion translation model, that is, adding a fusion layer at the encoder or decoder side, and proposed three vector fusion methods, namely, average pooling, a full connection layer, and a self-attention mechanism, to fuse the multi-level output vectors inside the encoder or decoder, improving the model’s translation performance.
3. Neural Machine Translation Models for Vector Fusion
This paper uses the current mainstream translation model Transformer [25] as the baseline model, which is the encoder-decoder structure. The encoder consists of 6 layers of identical encoder units stacked to extract source language features. Each layer of encoder units consists of a multi-head self-attention mechanism, a feedforward neural network, residual connections and layer normalization. The decoder is composed of 6 layers of the same decoder unit stacked for the transfer of information between the encoder and the decoder. Each layer of the decoder unit has one more context-dependent multi-head attention mechanism than the encoder unit.
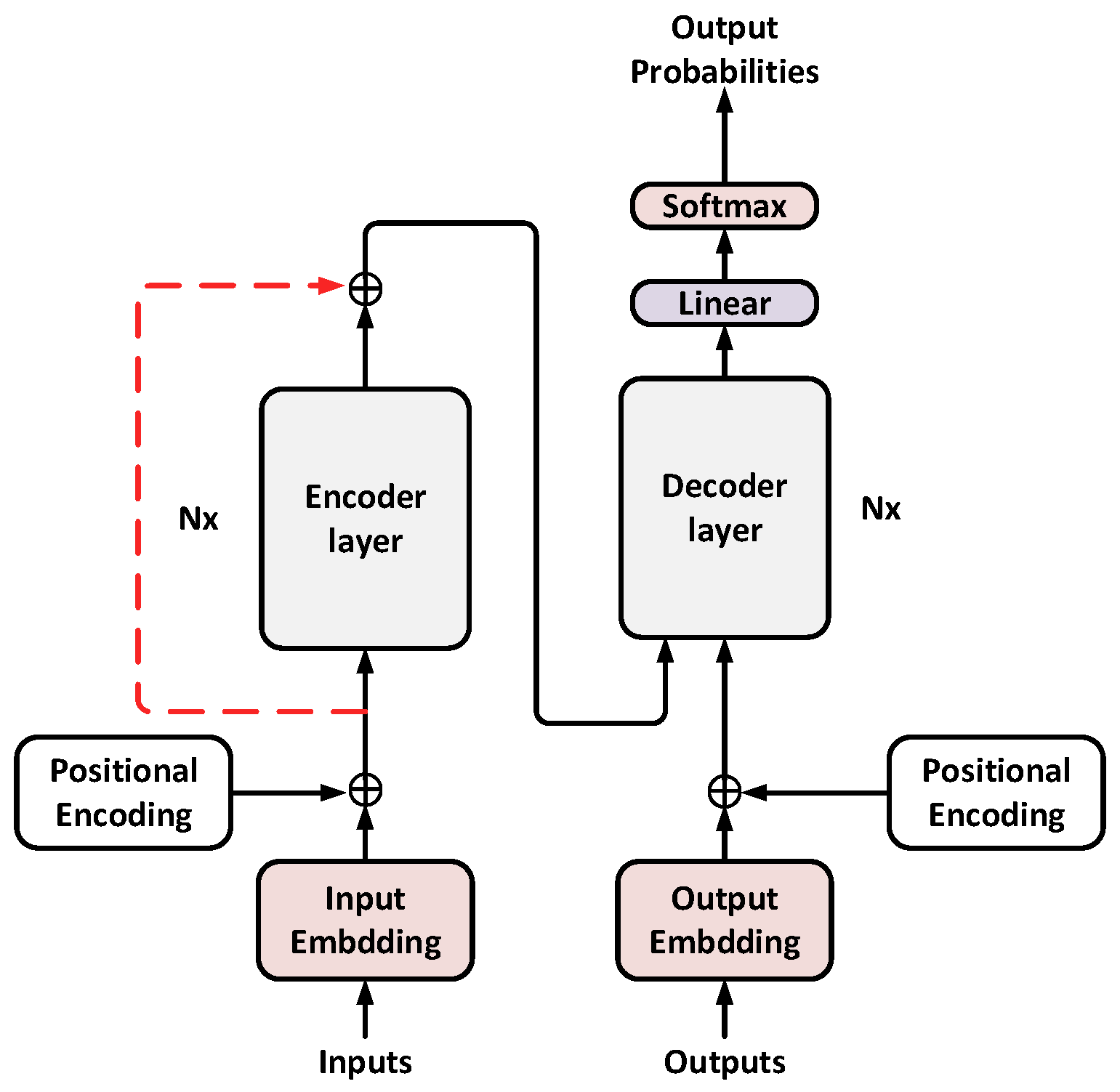
For translation models, the feature extraction performance of the encoder is crucial for subsequent decoding. Transformer is used as a special feature extractor in the pre-training model [26]. Although the stacked structure of multi-layer encoder units can extract a good source language representation, it is inevitable that some underlying information will be lost in the process of model training. This paper first uses the structure of residual connections [27] to send the lowest source language word-embedding vector on the encoder side to the output of the last layer of the encoder unit, as shown in Figure 1.
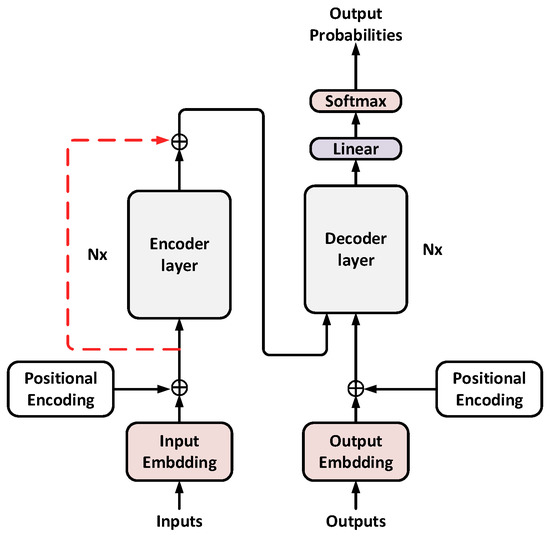
Figure 1.
Residual connection structure diagram.
It is easy for the structure of the multi-layer stacking of the encoder units to cause the multi-layer units inside the encoder to be similar to the Elmo (embedding from language models) [28] model. The information contained in the output vector of each layer unit will have different emphases in syntax and lexical meaning. With the continuous stacking of the unit, the output vector of the unit closer to the top layer is more focused on grammar, and conversely, the output vector of the unit closer to the bottom layer is more focused on the word meaning of the source language itself. Therefore, this paper proposes vector fusion methods, which fuse the word vectors’ output by multiple encoder units and then send them to the decoder for decoding. The structure is shown in Figure 2. The encoder, after vector fusion, can obtain a more comprehensive source language representation vector, and the distribution of the grammar and semantic information contained in it is also more balanced, which can achieve a better source language representation effect, thereby further improving the translation performance of the model.
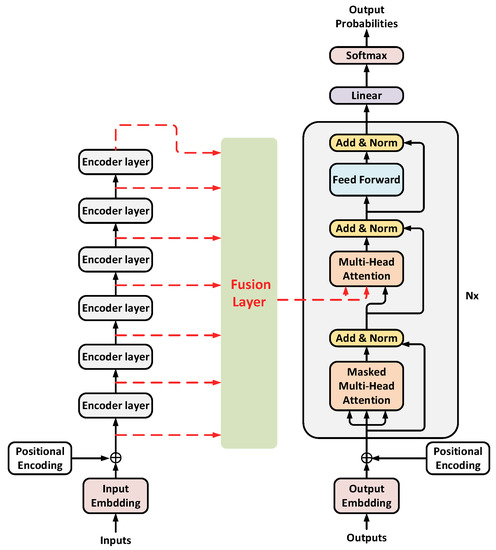
Figure 2.
Vector fusion structure diagram.
3.1. Encoder for Vector Fusion
For the fusion of the output vectors of each unit of the encoder, this paper first uses the fusion method of residual connection to transfer the underlying information to the top encoder unit to verify the loss of the underlying information caused by the unit stacking structure. In order to obtain a more comprehensive source language representation vector at the encoder side, four fusion methods, namely average fusion, splicing fusion, weight fusion and gate mechanism fusion, are used on the encoder side to fuse the output vectors of each layer unit and the underlying word embedding vectors.
3.1.1. Residual Connection Fusion
In order to verify that when the translation model is trained, as the number of layers of the model encoder unit deepens, the underlying information will be lost, this paper designs a residual connection experiment, which adds the underlying source language word vector and the output vector of the last layer of the encoder to obtain the fusion vector as the final encoder output vector:
where is the final output vector of the encoder, is the output vector of the 6th layer encoder unit, and is the underlying word embedding vector.
3.1.2. Average Fusion
For the selection of the fusion method, this paper first considers the most basic average fusion method. The word embedding vector and the output vector of the 6-layer encoder unit are arithmetically averaged, and then the calculated average vector is used as the encoder output vector:
where is the output vector of the encoder unit at layer i.
3.1.3. Splicing Fusion
Splicing fusion splices the word embedding vector and the output vector of the encoder unit of each layer in the dimension of the last word vector, then compresses the dimension of the spliced vector by the two fully connected layers and the activation unit. The obtained vector is used as the final output vector on the encoder side:
Among them, , N is the number of vectors to be fused, and d is the set word vector dimension.
3.1.4. Weight Fusion
There are multiple identical encoder units in the translation model, and the information contained in different layers will also be different. With the deepening of the number of layers, the grammar and semantic information contained in each unit will be emphasized differently. In the method of assigning weights to each vector, the method of average fusion is too simple. For a better source language representation vector, the weights corresponding to the output vectors of the encoder units of each layer containing different information must not be deterministic and the same, which should be learned from subsequent model training:
Among them, are the weight parameters are randomly initialized between 0 and 1, the sum of which is 1, and the network training will be carried out together with the translation model.
3.1.5. Gate Mechanism Fusion
In this paper, the output vector and word embedding vector of each unit on the encoder side are assigned a weight that sums to 1 through the fusion method of the gate mechanism. First, each vector is spliced in the last dimension, and the fully connected layer and the nonlinear unit are used for vector mapping and dimension conversion. Then, the normalization function softmax is used to obtain the corresponding weights of multiple vectors. Finally, the obtained weights are weighted in summation with the corresponding vectors to obtain the final encoder-side output vector:
Among them, , N is the number of vectors to be fused, d is the set word vector dimension, is the bias vector, i is 0~6, represents the word embedding vector , represents the hidden layer output in the encoder successively, and is the corresponding weight of obtained after the segmentation of vector in the last dimension.
3.2. Multi-Attention Mechanism Translation Model Based on Vector Fusion
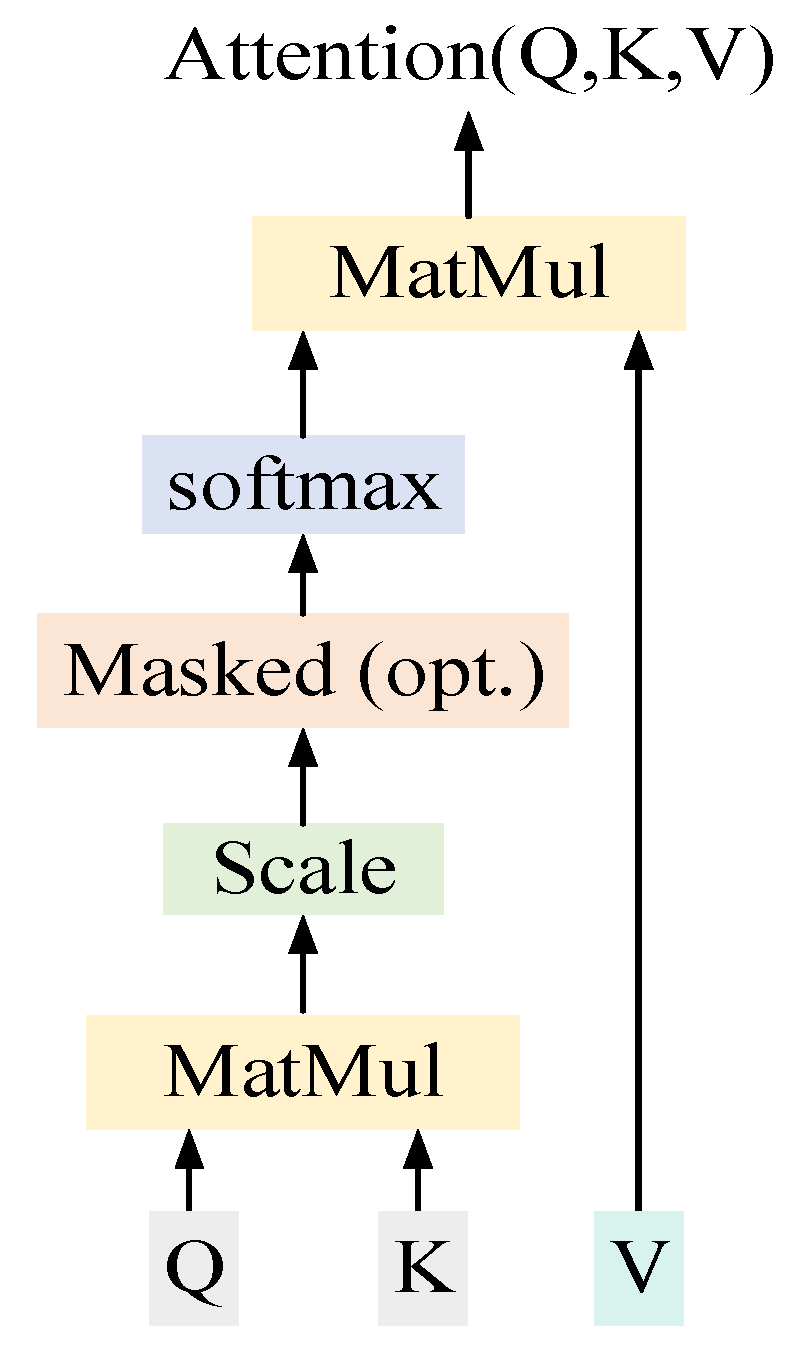
The attention mechanism in the Transformer model is mainly divided into two types: self-attention and context-attention. As shown in Figure 3, the internal structure and calculation method of these two attention mechanisms are the same. The difference between the two is the query vector Q (query). In self-attention, the query vectors Q (query), K (key) and V (value) are exactly the same. However, the context-attention is used to pass the encoder information to the decoder so that in the decoding process, the source language representation vector obtained by the encoder can be better assigned weights according to the target information. Therefore, the query vector Q (query) comes from the decoder unit, while the key-value pairs K (key) and V (value) still come from the encoder’s output vector and have the same value.
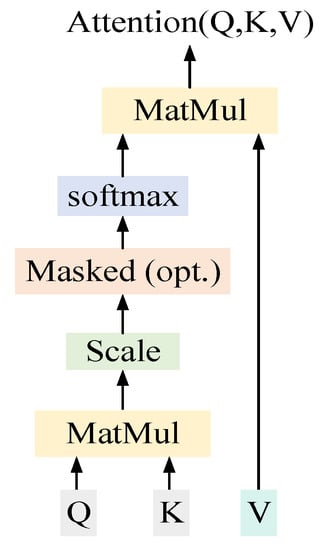
Figure 3.
Attention mechanism.
Its calculation formula is:
where , is the vector dimension within the translation model, and is the number of heads of multi-head attention mechanisms.
The decoder unit of the Transformer model consists of a multi-head self-attention mechanism, a multi-head context-attention mechanism, a fully connected layer, residual connections, and layer normalization structures. The underlying self-attention extracts internal information from the input of the target side. The intermediate context attention layer dynamically assigns weights to the incoming encoder-side source language feature vectors based on the target language feature vectors extracted by the decoder for subsequent decoding.
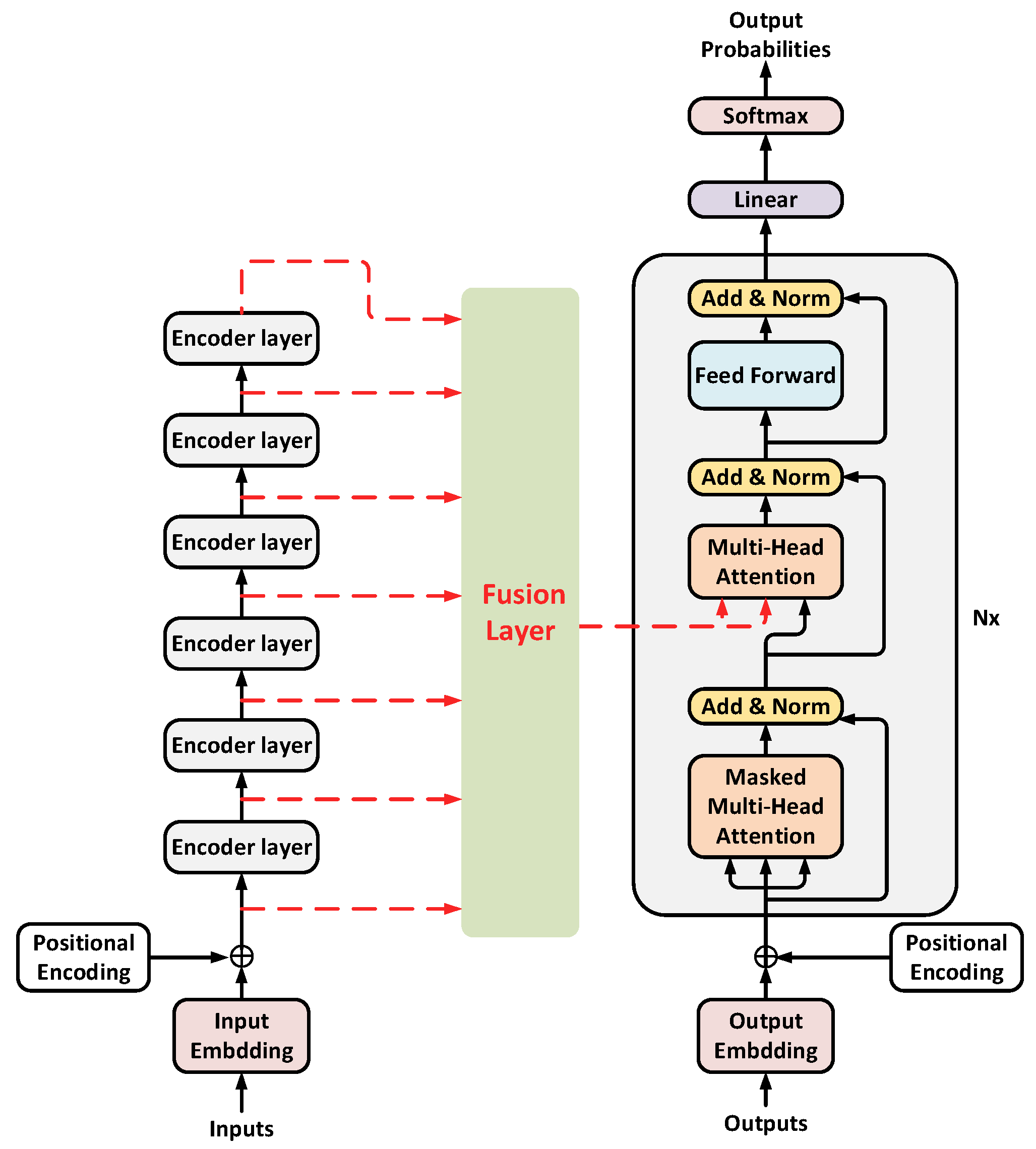
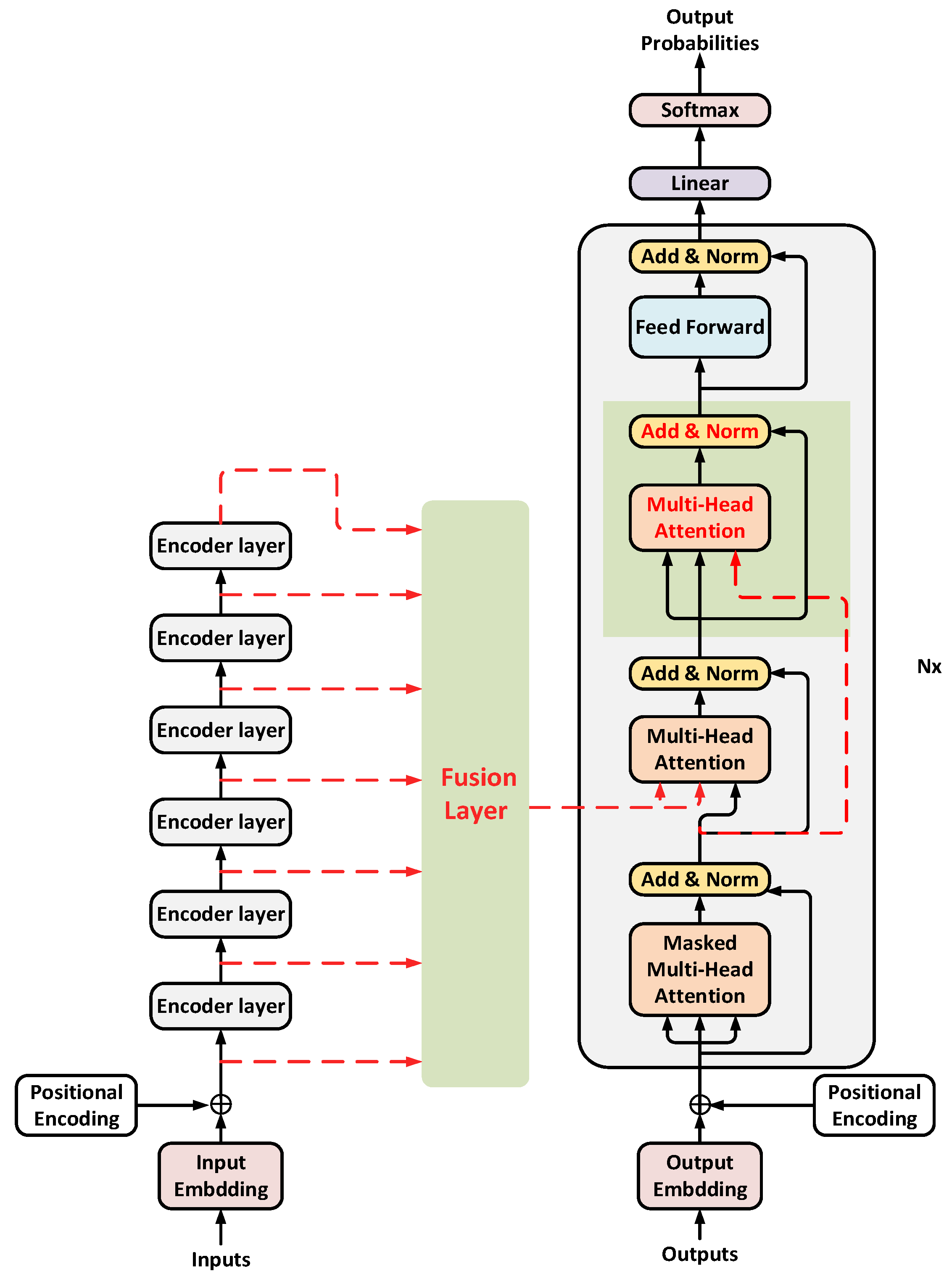
The hidden layer vector obtained after weight allocation integrates the source language information into the decoder side but also reduces the target language information contained in it. Therefore, in order to further improve the ability of the decoder to extract features, the decoder unit has been improved in this paper, and an attention mechanism is superimposed after the context-attention layer. Further, on the basis of vector fusion, a multi-attention mechanism translation model based on vector fusion is proposed, as shown in Figure 4.
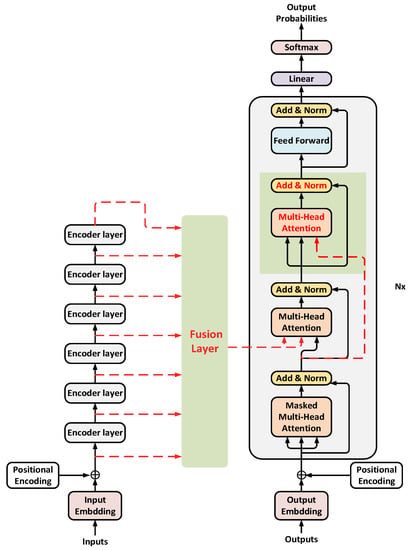
Figure 4.
Multi-Attention Mechanism Translation Model Based on Vector Fusion.
Inside each decoder unit, when the fusion vector output by the encoder is input to the decoder as a key-value pair K (key) and V (value), it first enters the context-attention layer in the model and transmits the fused source language information to the decoder, and the output of the self-attention layer is used as the query vector Q (query) to calculate the attention mechanism. The target language information is used as guidance to extract the source language information contained in the fusion vector at this layer. Then, the output vector obtained from this layer is used as the key-value pair K (key) and V (value) to input into the additional attention mechanism layer. The target language features output from the bottom self-attention layer are still used as the query vector Q (query) to calculate the multi-attention mechanism. The calculation method and parameter setting of the attention layer are consistent with the multi-head attention mechanism in the original model, which is the same as Formula 8. The improved decoder structure can further extract the internal features of the fusion vector and better realize the transformation process from the source language features to the target language features.
4. Experiments and Results
4.1. Dataset
In order to achieve machine translation in the field of electrical engineering, the datasets in this paper all use Chinese and English parallel corpora in the field of electrical engineering [29,30,31,32], literature and some related technical forums and official websites in the electrical field. The training set used in the experiment has about 190,000 bilingual parallel corpora, and the validation set and the test set each contain 2000 bilingual parallel sentence pairs.
4.2. Experimental Setup
This paper adopts the open-source NMT system OpenNMT [33] (https://github.com/OpenNMT/OpenNMT-py, accessed 25 December 2022) to implement the baseline model Transformer. In terms of data set processing, the length of sentences in the corpus is limited to less than 100; that is, sentences longer than 100 are filtered, and the vocabulary size is set to 40,000. Chinese word segmentation uses jieba word segmentation, and English uses NLTK (natural language toolkit) word segmentation. During the training process, the word vector dimension and the hidden layer dimension inside the model were both set to 512, batch_size was set to 64, the number of heads of multi-head attention mechanisms was set to 8, the Adam (a method for stochastic optimization) optimization algorithm was used, and the neuron random deactivation probability (dropout) was set to 0.1. A total of 25,000 steps were trained in this experiment, and the model was verified every 1000 steps. The beam search method was used for decoding, where beam_size was set to 5, and the rest of the parameters used the default parameters of OpenNMT.
All parameters in the experiments were kept consistent, and BLEU (bilingual evaluation understudy) [34] was adopted to evaluate the translation results. The translation effect was judged by calculating the similarity between the machine translation result and the reference statement, the formula of which is as follows:
where is the number of times that the n-element phrase appears in the machine translation result, is the maximum number of times that the n-element phrase appears in the reference statement, is the length of the machine translation statement, is the length of the reference translation, is 4 in this paper, and .
4.3. Results
4.3.1. Results of Vector Fusion
In this paper, Transformer is used as the baseline model, and the model Res_mode of residual connection is first implemented. After that, the four fusion methods of averaging, splicing, weighting and gate mechanism were used to perform fusion experiments on the output vector of the 6-layer encoder unit of the translation model and the underlying word embedding vector, and they obtained the fusion translation models Av_fusion, Cat_fusion, Weight_fusion and Gate_fusion, respectively. The experimental results are shown in Table 1. The BLEU value of the translation model after the residual connection is 0.23 percentage points higher than that of the baseline model, and the BLEU value of the translation model after vector fusion is up to 0.8 percentage points higher than that of the baseline model.

Table 1.
BLEU value of vector fusion experiment.
In order to further verify the effectiveness of the proposed method, this paper also sets up a comparative experiment to compare the N-1 system fusion scheme set in Reference [18] with the encoder internal vector fusion scheme proposed in this paper. With Transformer as the baseline model, the system fusion experiment and the encoder internal vector fusion experiment were carried out using four fusion methods, namely average (Av_fusion), splicing (Cat_fusion), weight (Weight_fusion) and gate mechanism (Gate_fusion). All parameter settings in the experiment were consistent, and the translation model was trained with about 190,000 parallel corpora in Chinese-English in the field of electrical engineering. The number of encoders N in the N-1 system fusion experiment was set to 2 according to Reference [18]. The results of the comparative experiment are shown in Table 2. The vector fusion experiment inside the encoder can achieve an increase of 0.8 BLEU values at most, while the N-1 system fusion scheme can only achieve an increase of 0.4 BLEU values at most.
Table 2.
BLEU value of comparative experiment.
4.3.2. Results of Model Improvement
In this paper, the decoder unit of the baseline model Transformer is improved, and a translation model with multiple attention mechanisms is proposed. The improved translation model Atten_mode improves the BLEU value of this baseline by 0.85 percentage points. In addition, this paper also combines the encoder after residual connection and vector fusion with the improved decoder to obtain five comprehensively improved translation models of Res+atten, Av+atten, Cat+atten, Weight+atten and Gate+atten. The experimental results are shown in Table 2. The comprehensively improved translation model improves the translation effect of the baseline model by up to 1.58 percentage points.
5. Discussion
5.1. Vector Fusion Experiment
From the analysis of the experimental results shown in Table 1, it can be observed that:
- The improved structure of the residual connection proposed in this paper and the four fusion experiments have improved the translation effect of the model, which verifies that the stacked structure of the network structure will indeed cause the underlying information to be lost in the process of model training, and the information contained in the hidden layer vector output by the multi-layer encoder unit is biased and different in terms of syntax and lexical meaning.
- As shown in Table 1, the BLEU (bilingual evaluation understudy) value of the translation model after the residual connection is increased by 0.23 percentage points, while the BLEU value of the average fusion translation model is increased by 0.15 percentage points, which is slightly lower than the effect of the residual connection. The reason is that although the average fusion method adds the output vector of the middle layer encoder unit, it also reduces the weight of the top encoder unit and the output vector of the word embedding layer, so their final BLEU value is slightly lower than the residual connection.
- It can be seen from the experimental results that the splicing fusion and the gate mechanism fusion have similar improvements in the translation effect of the model, but the BLEU value of the gate mechanism fusion is slightly higher because the calculation process of the two fusion methods is similar.
- Comparing the BLEU values of the four fusion methods, the average fusion is the lowest because the average fusion assigns the same fixed weight to each vector that needs to be fused. However, in fact, the information of each layer of encoder units contained in the fusion vector finally output by the encoder is definitely different. The fusion of the splicing and the gate mechanism is centered because both use the fully connected layer to convert the dimensions of the seven vectors to be fused inside and compress them into one vector, which is better than the average fusion effect. Weight fusion can achieve the best model translation performance improvement because this method performs random weight assignment directly outside the multiple vectors that need to be fused and makes it change with the subsequent model training process, which is simple and effective.
- It can be seen from the comparative data in Table 2 that although the N-1 system fusion method has also achieved some improvements in the translation effect, making the model learn more source language information from multiple angles for the model stack structure of Transformer, only the vector fusion of the output vectors at the top level of multiple encoders cannot make good use of the source language information at the bottom of the encoder. However, the vector fusion method proposed in this paper fuses the multiple hidden layer vectors and the underlying word embedding in the encoder, makes good use of the underlying word meaning information inside the encoder, solves the problem of underlying information loss caused by model stacking to a certain extent, obtains a more comprehensive source language feature vector at the encoder end, and achieves better translation effect, which fully proves the effectiveness of the vector fusion method proposed in this paper.
5.2. Model Improvement Experiment
It can be obtained from the analysis of the experimental results shown in Table 2 that:
- It can be seen from Table 3 that the translation effect of the translation model after the improvement of the decoder unit is 0.85 percentage points higher than the BLEU value of the baseline model, which proves that adding an additional attention mechanism in the decoder unit to further extract feature information is effective.
Table 3. BLEU value of comprehensive improvement experiment.
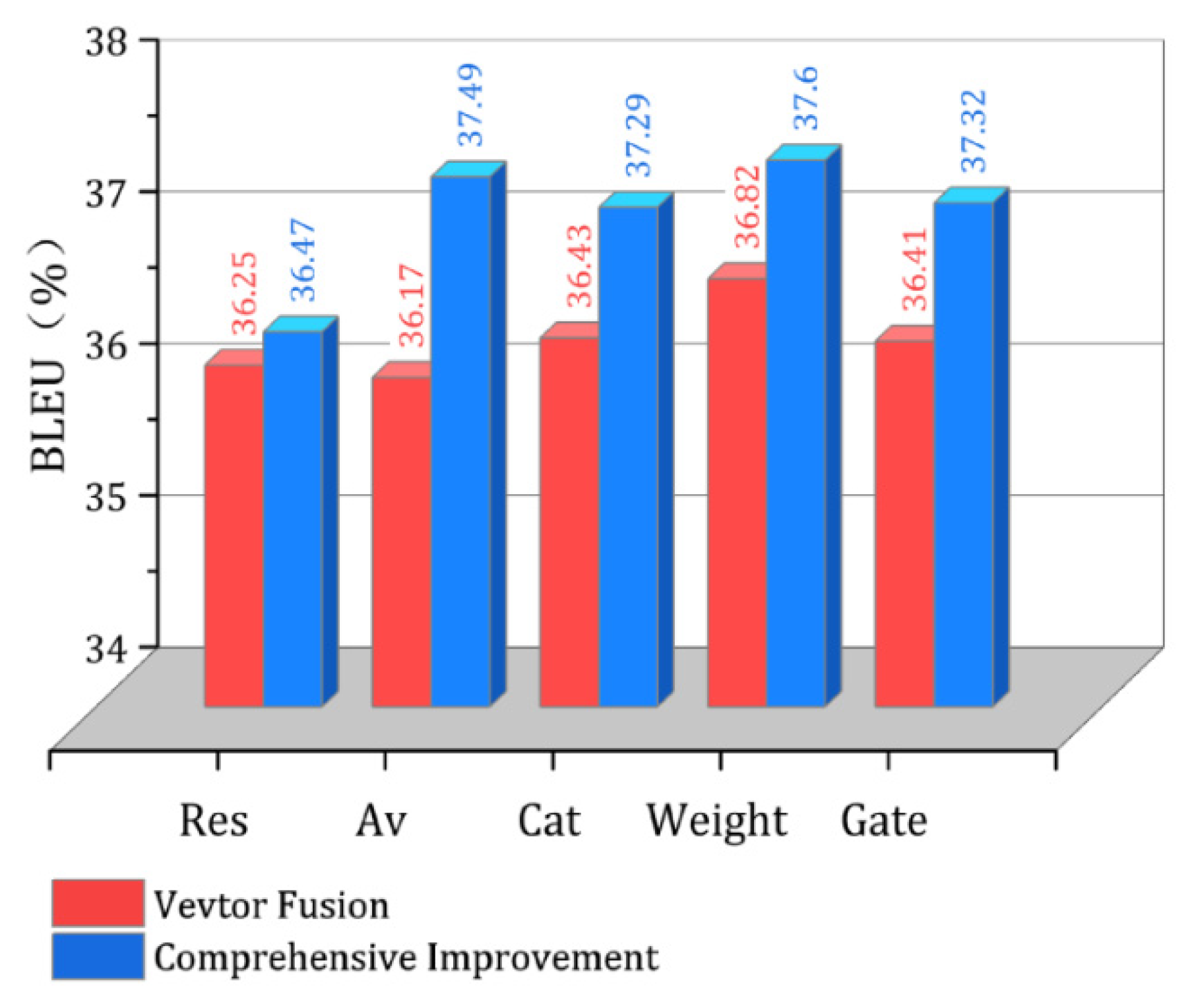
- In this paper, a comparative experiment is carried out on the comprehensive improved model composed of the encoder after vector fusion and the improved decoder. As shown in Figure 5, it can be seen that the translation effect of the improved model has been further improved, and the weight fusion comprehensive improvement model still has the best translation effect; its BLEU value has increased by 1.58 percentage points. The translation effect of the comprehensive improved model of the splicing fusion and the gate mechanism fusion is equivalent, which is consistent with the experimental conclusion of only using vector fusion.
 Figure 5. Comparison of experimental results.
Figure 5. Comparison of experimental results. - The experimental results show that the translation effect of the multi-attention mechanism model based on average fusion leaps beyond that of the improved model based on the splicing and gate mechanism because the improvement of the decoder unit has greatly enhanced the feature extraction effect of the model, and the simple method of average fusion has no effect on the further feature extraction part after the improvement of the decoder unit, while the fusion methods of splicing and gate mechanism both introduce new training parameters into the model network, which affects the parameter training of the subsequent feature extraction part of the decoder to a certain extent.
5.3. Comprehensive Comparison
- From the data in Table 1 and Table 3, it can be seen that the residual connection method and the four vector fusion methods have further improved the translation performance after combining the improved decoder unit experiment, which further verifies the effectiveness of the multi-attention mechanism model.
- Comparing the experimental data in Table 1 and Table 3, it is worth noting that after using the improved decoder unit, the translation effect of average fusion is greatly improved, while the further improvement of the translation effect of the multi-attention mechanism model based on residual connection is not large, indicating that the output vector of the intermediate layer of the encoder has a great effect on the improvement of translation performance after the improved decoder.
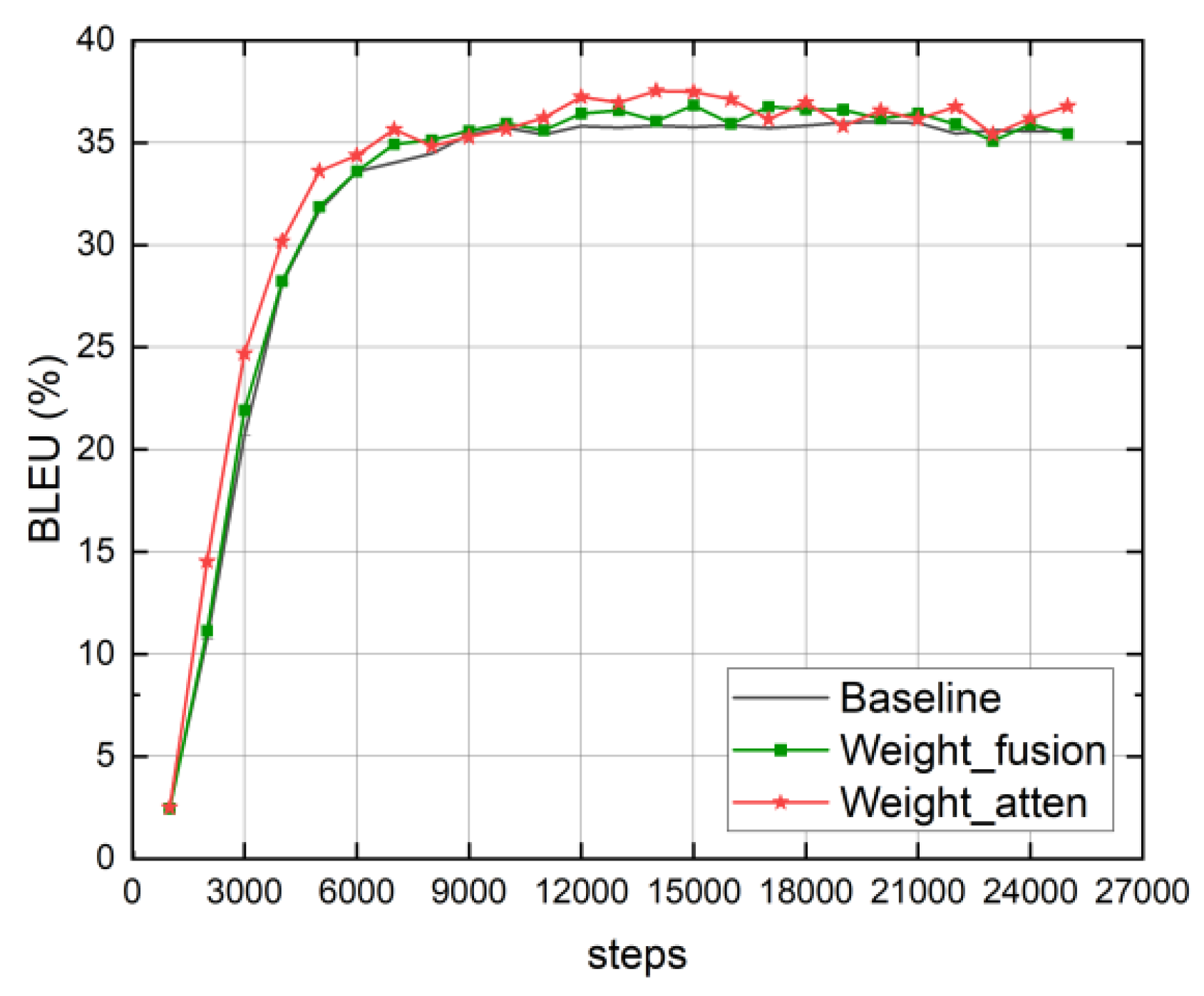
- The comparison between the weight fusion that achieves the best effect in the vector fusion experiment and the translation effect of the multi-attention mechanism model based on weight fusion is shown in Figure 6. It can be seen from the figure that the two improved translation models not only improved the translation effect but also achieved the best translation effect earlier than the baseline model. Furthermore, the multi-attention mechanism model based on vector fusion has better translation performance than the baseline model and the model using only fusion experiments from the beginning of training, indicating that the vector fusion method and the multi-attention mechanism model can improve the translation performance while speeding up the model to reach the best translation performance.
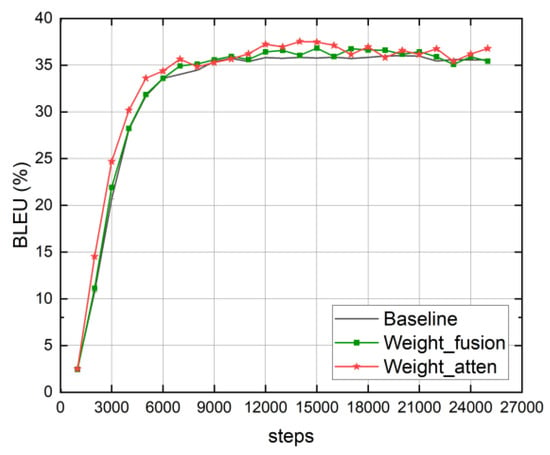 Figure 6. Comprehensive comparison of experimental results.
Figure 6. Comprehensive comparison of experimental results. - The reference sentences of some test sets, the translation results of the baseline model and the translation results of the multi-attention mechanism model based on weight fusion are compared, as shown in Table 4. It can be seen that compared with the baseline model, the translation results of the comprehensively improved model not only reduce the number of unlisted words “<unk>”, but also terms and named entities such as “噪声”, “跳闸” and “福建省” in Table 4 can be well translated. Additionally, the improved model can also translate words into their corresponding synonyms, such as “数字一体化” into “数字集成”. This fully shows that the model improvement method based on vector fusion can improve the translation performance of the model.
Table 4. Comparison of translation effects.
6. Conclusions
In this paper, a variety of vector fusion methods are used to fuse the multi-layer output vectors of the encoder unit. On this basis, the decoder unit of the translation model is improved, and a multi-attention mechanism translation model based on vector fusion is proposed. The experimental results show that the improved model has better translation performance, and the BLEU (bilingual evaluation understudy) value is up to 1.58 percentage points higher. In future work, in order to obtain a better representation of the source language at the encoder side, we will try to use the attention mechanism method to fuse the hidden layer vector in the encoder and improve the encoder structure of the translation model. We construct a lexicon of terms in the field of electrical engineering, identify terms in parallel corpora, extract their features, and then integrate the term features into the source language information. At the same time, we use syntactic analysis tools to mark the semantic roles of the training corpus. By improving the training corpus and using the internal features of terms, a better representation vector of the source language can be obtained at the encoder side so as to improve the translation effect of the model in the field of electrical engineering.
7. Limitations
- Fusion method. Although the five vector fusion methods proposed in this paper have achieved improved translation results, vector fusion based on this simple mathematical method is not flexible enough. It is necessary to give appropriate information guidance in the field of electrical engineering and the target language when vector fusion occurs so that the fused vector can obtain the source language feature vector that is more inclined to the field of electrical engineering and contains the target language knowledge.
- Domain characteristics. Although more comprehensive source language information can be obtained at the encoder end by using vector fusion only, its feature extraction still only depends on the internal self-attention mechanism and does not add more lexical features in the field of electrical engineering into the translation model.
- Parameters. Although the translation effect has been improved due to the change in the model structure, the internal parameters of the model have also increased, increasing the complexity of the model.
Author Contributions
Writing—original draft, H.C.; Writing—review & editing, Y.C. and J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data sets are not published. Please contact the author if necessary.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, Z. Introduction to Computer Linguistics and Machine Translation; Foreign Language Teaching and Research Press: Beijing, China, 2010; pp. 84–85. [Google Scholar]
- Yu, X. Rule-Based Machine Translation Technology Review. J. Chongqing Univ. Arts Sci. 2011, 30, 56–59. [Google Scholar]
- Liu, Q. Survey on Statistical Machine Translation. J. Chin. Inf. Process. 2003, 17, 1–49. [Google Scholar]
- Nal, K.; Blunsom, P. Recurrent Continuous Translation Models. In Proceedings of the Paper presented at the Conference on Empirical Methods in Natural Language Processing 2013, Seattle, WA, USA, 1–13 October 2013. [Google Scholar]
- Ilya, S.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. Paper presented at the NIPS 2014. arxiv 2014. [Google Scholar] [CrossRef]
- Dzmitry, B.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Corrado, Macduff Hughes, and Jeffrey Dean. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Jonas, G.; Auli, M.; Grangier, D.; Dauphin, Y. A Convolutional Encoder Model for Neural Machine Translation. arXiv 2016, arXiv:1611.02344. [Google Scholar]
- Jonas, G.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y. Convolutional Sequence to Sequence Learning. In Proceedings of the Paper Presented at the International Conference on Machine Learning 2017, Sydney, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Barret, Z.; Yuret, D.; May, J.; Knight, K. Transfer learning for low-resource neural machine translation. arXiv 2016, arXiv:1604.02201. [Google Scholar]
- Min, T. Research on Neural Machine Translation under Low-Resource Conditions; Soochow University: Suzhou, China, 2020. [Google Scholar]
- Xu, B. English-Chinese Machine Translation Based on Transfer Learning and Chinese-English Corpus. Comput. Intell. Neurosci. 2022, 2022, 1563731. [Google Scholar] [CrossRef]
- Wang, H. Short Sequence Chinese-English Machine Translation Based on Generative Adversarial Networks of Emotion. Comput. Intell. Neurosci. 2022, 2022, 3385477. [Google Scholar] [CrossRef]
- Ying, F. A Study on Chinese-English Machine Translation Based on Migration Learning and Neural Networks. Int. J. Artif. Intell. Tools 2022, 18, 2250031. [Google Scholar] [CrossRef]
- Li, C. A Study on Chinese-English Machine Translation Based on Transfer Learning and Neural Networks. Wirel. Commun. Mob. Comput. 2022, 2022, 8282164. [Google Scholar] [CrossRef]
- Kurosawa, M.; Komachi, M. Dynamic Fusion: Attentional Language Model for Neural Machine Translation. arXiv 2019, arXiv:1909.04879. [Google Scholar]
- Zheng, P. Multisensor Feature Fusion-Based Model for Business English Translation. Sci. Program 2022, 2022, 3102337. [Google Scholar] [CrossRef]
- Tan, M.; Yin, M.; Duan, X. A System Fusion Method for Neural Machine Translation. J. Xiamen Univ. (Nat. Sci. Ed.) 2019, 58, 600–607. [Google Scholar]
- Banik, D.; Asif, E.; Pushpak, B.; Bhattacharyya, S. Assembling Translations from Multi-Engine Machine Translation Outputs. Appl. Soft Comput. 2019, 78, 230–239. [Google Scholar] [CrossRef]
- Zoph, B.; Knight, K. Multi-Source Neural Translation. In Proceedings of the Paper Presented at the 15th Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL HLT 2016, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Banik, D.; Ekbal, A.; Bhattacharyya, P.; Bhattacharyya, S.; Platos, J. Statistical-Based System Combination Approach to Gain Advantages over Different Machine Translation Systems. Heliyon 2019, 5, e02504. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, J.; Zong, C.; Yu, H. Sequence Generation: From Both Sides to the Middle. arXiv 2019. [Google Scholar] [CrossRef]
- Sreedhar, M.N.; Wan, X.; Cheng, Y.; Hu, J. Local Byte Fusion for Neural Machine Translation. arXiv 2022, arXiv:2205.11490. [Google Scholar]
- Wang, Q.; Li, F.; Xiao, T.; Li, Y.; Li, Y.; Zhu, J. Multi-Layer Representation Fusion for Neural Machine Translation. arXiv 2020. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Yue, Z.; Ye, X.; Liu, R. Research Review of Pre-training Technology Based on Language Model. J. Chongqing Univ. Arts Sci. 2021, 35, 15–29. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2015, Las Vegas, NV, USA, 27–30 June 2016. pp. 770–777.
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the Paper Presented at the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL HLT 2018, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Bimal, K. Modern Power Electronics and AC Drives; Prentice-Hall: Hoboken, NJ, USA, 2001. [Google Scholar]
- Bimal, K. Modern Power Electronics and AC Drive; Wang, C.; Zhao, J.; Yu, Q.; Cheng, H., Translators; Machinery Industry Press: Beijing, China, 2005. [Google Scholar]
- Wang, Q.; Glover, J.D. Power System Analysis and Design (Adapted in English); Machinery Industry Press: Beijing, China, 2009. [Google Scholar]
- Glover, J.D. Power System Analysis and Design (Chinese Edition); Wang, Q.; Huang, W.; Yan, Y.; Ma, Y., Translators; Machinery Industry Press: Beijing, China, 2015. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A.M. Opennmt: Open-Source Toolkit for Neural Machine Translation. arXiv 2017, arXiv:1701.02810. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Association for Computational Linguistics (2002), Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).