Abstract
Sarcasm is a linguistic phenomenon indicating a difference between literal meanings and implied intentions. It is commonly used on blogs, e-commerce platforms, and social media. Numerous NLP tasks, such as opinion mining and sentiment analysis systems, are hampered by its linguistic nature in detection. Traditional techniques concentrated mostly on textual incongruity. Recent research demonstrated that the addition of commonsense knowledge into sarcasm detection is an effective new method. However, existing techniques cannot effectively capture sentence “incongruity” information or take good advantage of external knowledge, resulting in imperfect detection performance. In this work, new modules are proposed for maximizing the utilization of the text, the commonsense knowledge, and their interplay. At first, we propose an adaptive incongruity extraction module to compute the distance between each word in the text and commonsense knowledge. Two adaptive incongruity extraction modules are applied to text and commonsense knowledge, respectively, which can obtain two adaptive incongruity attention matrixes. Therefore, each of the words in the sequence receives a new representation with enhanced incongruity semantics. Secondly, we propose the incongruity cross-attention module to extract the incongruity between the text and the corresponding commonsense knowledge, thereby allowing us to pick useful commonsense knowledge in sarcasm detection. In addition, we propose an improved gate module as a feature fusion module of text and commonsense knowledge, which determines how much information should be considered. Experimental results on publicly available datasets demonstrate the superiority of our method in achieving state-of-the-art performance on three datasets as well as enjoying improved interpretability.
1. Introduction
Sarcasm expresses the true sentiment contrary to the literal meaning and also uses metaphorical expression. Often, sarcasm shows a contrast between positive and negative emotions or between literal and figurative scenarios. In sarcasm, one thing is referred to as another, and occasionally the opposite is true. The contrast typically takes the form of a sarcastic tone, or manner of speech or writing. It is frequently difficult to comprehend the narrator’s attention based solely on the literal words, and the reality is always the opposite. Typically, we need to interpret the real meaning based on the context. It frequently appears on e-commerce platforms, Internet social media, and short video social platforms. Sarcasm detection is critical in various NLP tasks, such as sentiment analysis, opinion mining, dialogue systems, and so on. However, sarcasm, as a sub-domain of sentiment analysis, is difficult to be detected even using AI models because of its sophisticated nature in expressions. Specifically, the difficulty of sarcasm detection mainly comes from the ignorance of the context, such as humorous scenes [1], or from the inability to comprehend the incongruity between the literal meaning and the author’s real emotion, such as metaphor and sarcasm [2].
It is worth noting that many methods have been studied for sarcasm detection. Some of them are based on the text itself [2,3,4,5,6], and some are multi-modal methods [7,8,9,10,11,12]. One of them deserves special mention since it introduces external commonsense knowledge [13]. Neural networks and attention mechanisms are basically used in previous state-of-the-art methods. Thus far, the recent state-of-the-art approaches use external commonsense knowledge and multi-modality to assist sarcasm detection. Some multi-modal methods also draw on external knowledge [12]. They use the CLIP network to generate the picture’s caption as external knowledge, which significantly improves the detection results and performs even more effectively than the image itself for multi-modality sarcasm detection.
Commonsense knowledge, the common daily consensus of society on the same thing, helps people understand information [14]. When the brain tries to make sense of information, it often inadvertently concatenates the scattered commonsense knowledge in life [15]. Understanding sarcasm usually requires corresponding commonsense knowledge [16]. Taking Figure 1 as an example, if we do not know that “homework, work, and practice” is related to external knowledge such as “be late”, “stress,” and “get catch up on homework”, it would be difficult to understand the speaker’s real attention. We input the text into the pre-trained COMET model to generate the knowledge candidate set. COMET can generate rich and diverse commonsense descriptions based on natural language. COMET is an adaptive framework for building commonsense knowledge bases from language models by training them on a seed set of knowledge tuples. The sentences are fed into the pre-trained COMET model to produce the required commonsense knowledge.

Figure 1.
Examples of sarcasm detection with the help of commonsense knowledge.
There is no doubt that commonsense knowledge is crucial for sarcasm detection. Commonsense knowledge also generates a great deal of useless or even irrelevant information, although it offers much effective information in sarcasm detection. The incorporation of commonsense knowledge has also proven to be important in other NLP tasks [13,17,18]. However, the existing models are unable to effectively utilize such external commonsense knowledge for sarcasm detection. Li et al. [13] introduced commonsense knowledge into sarcasm detection for the first time and achieved excellent results that surpassed all previous models. However, commonsense knowledge was not sufficiently utilized in his work. Three knowledge selection approaches are employed, each of which can only obtain optimal results on a certain dataset [13]. In our study, we propose the incongruity cross-attention network to address this challenging issue, which performs the best by effectively testing on three datasets.
Sarcasm often involves contrasting two polarities of sentiment. Here are some examples:
“I just love when people read my text and don’t reply.”
“I totally feel safe on this shuttle with the driver texting.”
“I love being told what can and can’t be said”.
Intuitively, sentiment incongruity between words in a sentence is an important indicator for sarcasm detection. For example, {love, don’t reply}, {feel safe, driver texting}, and {love, can, and can’t be said} show a juxtaposition of positive and negative terms within a sarcastic sentence. Joshi et al. [19] also found this phenomenon, and called it “incongruity”. Therefore, it is very important to capture the words with different sentiment polarities within a sentence. Tay et al. [2] proposed the intra-attention method to detect incongruity. Xiong et al. [5] suggested an innovative self-matching module to detect sentence incongruity. However, their methods consider similarity and assign higher weight scores to highly similar words, which are unable to effectively capture the incongruity information within a sentence. Therefore, we propose an adaptive incongruity extraction module that calculates the Euclidean distance between words to address this issue. Words with different sentiment polarities can get higher weight scores, which can better extract the incongruous semantic information in the sentence. The experimental results indicate that our method can significantly improve performance in sarcasm detection.
In this study, we obtain the feature representation of the text and knowledge by employing the BERT base model as the embedding layer so that words can obtain more affluent and correct semantic information [20]. In the adaptive incongruity extraction module, a learnable network is designed to automatically extract incongruity in order to capture the semantic incongruity of the text itself and the commonsense knowledge itself. Various studies on sarcasm detection have concentrated on the extraction of incongruity. They [3,4,19,21,22,23,24,25] proposed rule-based extractions of incongruity that required manually designed rules for capture, as incongruity can only be identified if it satisfies the associated rules. With the emergence of deep learning, new methods [2,5] employing attention mechanisms have achieved better performance. However, their approaches take into account similarity and assign higher weight scores to highly similar words, which does not effectively capture the incongruity information within a sentence. Incongruity can be more effectively captured when phrases with opposite sentimental polarity are given higher attention scores. In our work, terms with different sentiment polarities can receive higher weight ratings, allowing for a more effective extraction of the incongruous semantic information in the sentence.
We develop a new cross-attention method in the incongruity cross-attention module to make the text interact with the commonsense knowledge. The text is used as a query vector to extract useful information from external commonsense knowledge. Li et al. [13] proposed a new approach to introduce corresponding commonsense knowledge for each text through the COMET model [26]. They suggested three methods for selecting external knowledge. However, each of their methods can only achieve good results on only one certain dataset, whereas we far exceed their best results. The generalization performance of their knowledge selection strategy is inferior [13]. In contrast, our method yields superior experimental outcomes across all three datasets.
The effective utilization of the extracted feature information is also very critical. In previous studies, simple applications of concatenation and element-wise addition failed to effectively take the advantage of extracted feature information. In the fusion module of text features and commonsense knowledge, we design a new gate mechanism that automatically learns the weight of each part inside the text and commonsense knowledge to determine the final output. Then, the fully connected network and residual structure are used to process the fused features and feed them into the final classification layer.
In this paper, our main contributions can be summarized as follows:
(a) We propose an adaptive incongruity extraction module, which can better obtain the incongruent semantics inside the text and inside the commonsense knowledge. Our module significantly outperforms the approaches of [2,5] on three datasets.
(b) We propose an incongruity cross-attention module to make the text interact with commonsense knowledge in order to select useful commonsense knowledge for sarcasm detection.
(c) We design a new gate mechanism that can dynamically learn different weights, which determine how much information should be considered from each word in the text and commonsense knowledge.
2. Related Work
Sarcasm has become increasingly prevalent on the Internet with the rise of various social media. This language phenomenon has been the subject of extensive cognitive psychology and linguistics research. However, the study of it is in the infancy of computational linguistics, and more work is still required. Sarcasm detection was considered as standard classification of text in some previous research. Joshi et al. [27] wrote a very comprehensive overview of sarcasm detection. Existing research methodologies may be loosely categorized into three groups: (1) methods based on rules and machine learning, (2) deep learning-based neural networks, and (3) methods that introduce external knowledge and other multi-modal methods on top of neural networks.
The rule-based approach that tried to find the rules of linguistics has been very classical and traditional. For example, the method of the emotional dictionary establishes the emotional dictionary of sarcasm [28,29,30] and the representative indicators. Meanwhile, feature engineering methods are also used to make use of different features for recognition, such as grammatical patterns, n-gram [21], readability and flips [31], word frequency [32], etc. Generally, traditional machine learning uses a combination of pattern features and semantic features. Among these many semantic features, incongruity-based features have been researched the most. Incongruity information is often found by looking for positive words in negative contexts or vice versa [22,23,24]. Riloff et al. [3] presented a bootstrapping algorithm for extracting incongruity, automatically learning phrases related to positive sentiments and negative situations. They obtain lists of positive emotion items, negative activities, and states to detect sarcasm, and the phrases they obtained were restricted to particular syntactic structures only when the contrasting phrases were in a highly constricted context. Joshi et al. [4] developed a paradigm based on explicit and implicit incongruity with positive-negative pattern-based features, which indicates that extracting the incongruity produced a significant enhancement compared to previous ways of feature engineering. These rule-based extractions of incongruity require manually designed rules for capturing, which fails to capture those incongruities beyond the rules.
Since deep learning has achieved outstanding performance in various domains, it has also achieved excellent results in sarcasm detection. Joshi et al. [19] are among the earliest researchers to demonstrate the efficacy of word embeddings for sarcasm detection. Text-CNN, GRU, LSTM, RNN, Bi-LSTM, and other network models have also been widely used in sarcasm detection. They can capture information from text sequences effectively. Ghosh and Veale integrate fully connected neural networks and Long Short-Term Memory (LSTM) to extract sequential features from sentences [33]. In their subsequent work, Ghosh and Veale enhance model accuracy by including the user’s mood information and contextual information into a neural architecture with two CNN layers and one LSTM layer [1]. Ghosh uses LSTM coupled with the MLP model to obtain the semantic information of the whole sequence [34]. All those previous approaches to deep learning can manage the sequence effectively. However, they are unable to focus on the key items sufficiently as the attention mechanism does, which makes it difficult to extract incongruities. In the field of NLP, the core concept of attention is the soft selection of a sequence of words based on their relative significance to the current task. Attention is also prevalent in various NLP research, including sentiment classification [35,36] and aspect-level sentiment analysis [37,38]. In [2,5], they use a similar approach based on an attention mechanism to extract incongruity. Tay et al. [2] proposed the intra-attention method to detect the incongruity within a sentence and between different words and finally obtain the semantic incongruity information of the whole sentence. Xiong et al. [5] improved the method in [2], increased the learnable attention parameters, and suggested an innovative self-matching module to detect sentence incongruity.
Various research on sarcasm detection focuses on the extraction of incongruity, whether the study employed a rule-based, machine learning, or deep learning approach or not. In [3,4,19,21,22,23,24,25], they proposed rule-based extractions of incongruity that required manually designed rules for capture, as only incongruity that meets the related rules can be identified. With the wide application of deep learning, the approaches of attention mechanisms have also obtained good performance in capturing incongruity [2,5]. These methods, which obtain weights automatically, outperform previous rule-based ones. We suggested an adaptive incongruity extraction module inspired by the notion of searching for words’ contrast and incongruity [2,3,21,25]. However, their methods consider similarity and assign higher weight scores to highly similar words, which cannot effectively capture the incongruity information within a sentence. Incongruity can be more effectively captured when phrases with opposite sentimental polarity are given higher attention scores. We propose an adaptive incongruity extraction module that calculates the Euclidean distance between words to address this issue. Terms with different sentiment polarities can get higher weight scores, which can better extract the incongruous semantic information in the sentence.
Sarcasm detection is becoming increasingly popular in studies of dialogue systems and Multi-modal. Though different from our study employed in areas of brief texts, much of their research is still very enlightening to our future work. Zhang et al. [39] propose a complex-valued fuzzy network to capture the ambiguity and uncertainty of sarcastic human discourse. Chauhan et al. [40] introduced a deep learning-based emoji-aware multitask learning framework and a Gated Emoji-aware Multimodal Attention mechanism. Their methods make full use of emojis for sarcasm detection, which is novel and worth a further study in the future. Zhang et al. [41] have compiled a dataset of Chinese sarcasm with contextual information. In the meantime, they offer a deep learning model for sarcasm detection based on a retrospective strategy. Liang et al. [42] utilize modality-specific sarcastic information with in-modal graphs of text and image modality and a cross-modal graph to extract contradicting expressions between text-modality and image-modality. Sometimes, whether a sentence contains sarcasm or not can only be known by means of context. Some researchers [1,43,44,45,46] have also investigated the type of dialogue with the context. This type of sarcasm detection has become popular in recent years. The most recent approaches for sarcasm detection are based on the pre-trained BERT model with external knowledge or multi-modal information. Li et al. [13] suggested a new method to introduce corresponding commonsense knowledge for each text through the COMET model [26]. They proposed three strategies to select external knowledge, which brings new solutions to sarcasm detection. They also demonstrated the significance of commonsense knowledge in sarcasm detection. Often, it is difficult to understand the correct meaning of sarcasm from the literal words alone. Only by associating relevant commonsense knowledge can we better comprehend the reality, which is consistent with the cognitive process of humans. However, their work contains a few flaws in its application of external commonsense knowledge [13]. In [8,10,11,12,47], they studied multi-modal sarcasm detection, Liu et al. [12] used the CLIP model to generate caption information for each image. The results show that external knowledge of the image caption is much more helpful than the image itself. It further demonstrates that adopting external knowledge is essential for sarcasm detection.
How to make greater use of external knowledge while restraining the noise caused by it is also essential, as is how to utilize the sentence itself more effectively to extract the incongruity within it. The concept of searching for contrast and incongruity in a sequence inspires us. We propose the adaptive incongruity module to extract incongruent semantic information in text and external knowledge. At the same time, to make the sentence interact with external knowledge better, we propose the incongruity cross-attention module to select proper external knowledge and reduce the noise caused by the introduction of external knowledge.
3. Methodology
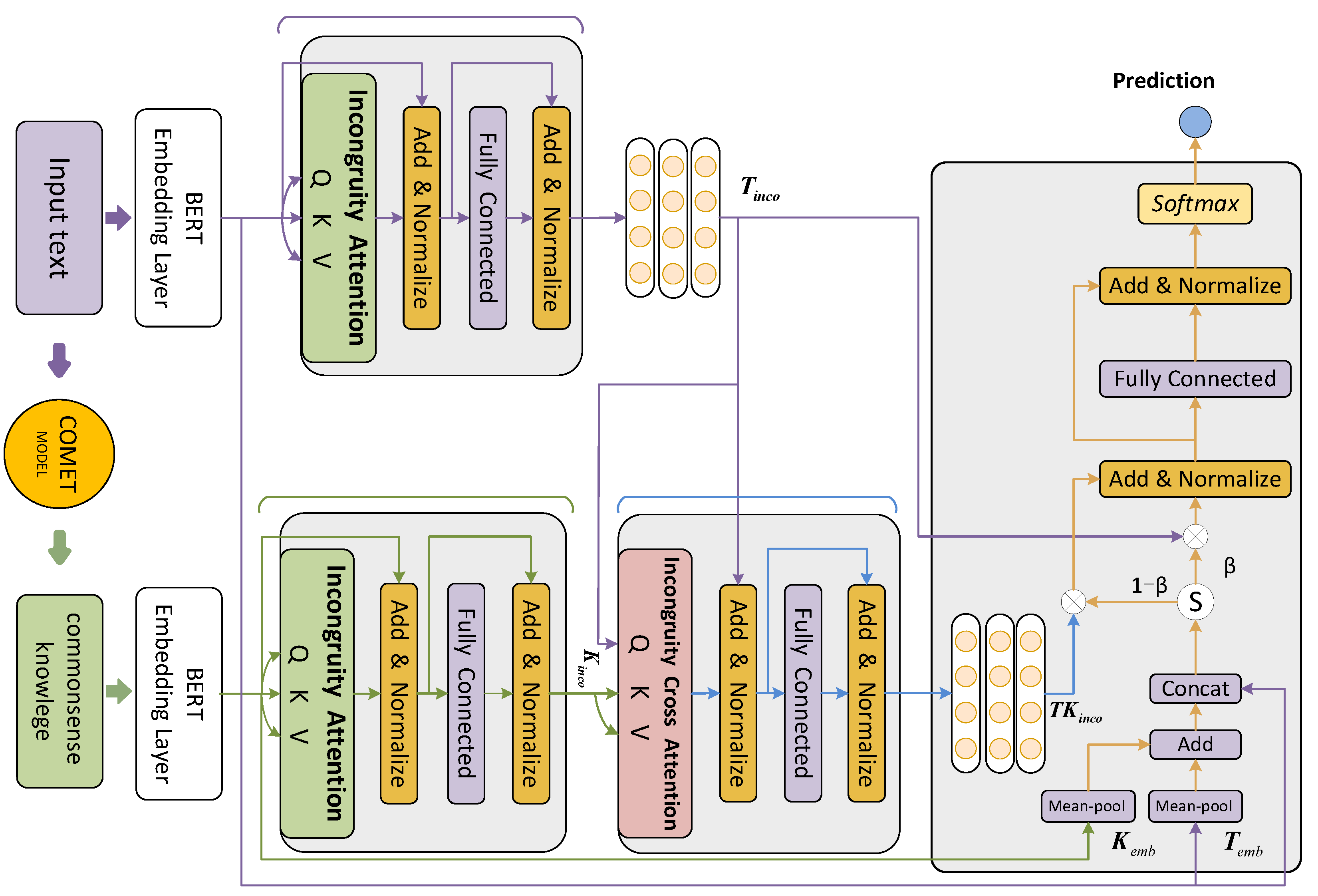
In this part, we will discuss the proposed model in depth. Figure 2 depicts the structure of our model. As the text and knowledge embedding components, there are two independent pre-trained BERT base models. The text incongruity module and knowledge incongruity module extract the incongruous information of text and knowledge, respectively. Cross incongruity module uses an incongruity cross-attention to extract useful information from corresponding knowledge. The text-knowledge fusion module utilizes our gate module to determine how much text and knowledge should be taken into account before making predictions.
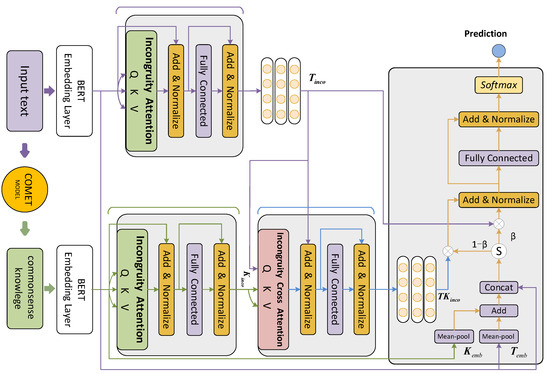
Figure 2.
The structure of our proposed model.
3.1. Task Definition and Motivation
The purpose of sarcasm detection is to determine if a given text is sarcastic. For example, a text sequence X with n tokens, , The goal is to predict an output , 1 indicates that this text is sarcastic category, and 0 otherwise. Our model’s objective is to develop a sarcasm detection model based on text and corresponding commonsense knowledge.
3.2. Commonsense Knowledge Generation
COMET can perform auto-completion on knowledge graphs. We use it to generate the commonsense knowledge we need. COMET automatically learns and generates new, rich, and diverse commonsense descriptions. Before feeding text into COMET, data preprocessing is performed, such as stop words elimination, lemmatization, and token lowercase. Referring to the method and configuration of [48], beam search with the size set to 5 is used to obtain commonsense knowledge candidates. To produce relevant knowledge candidates, we solely employ the causes relations.
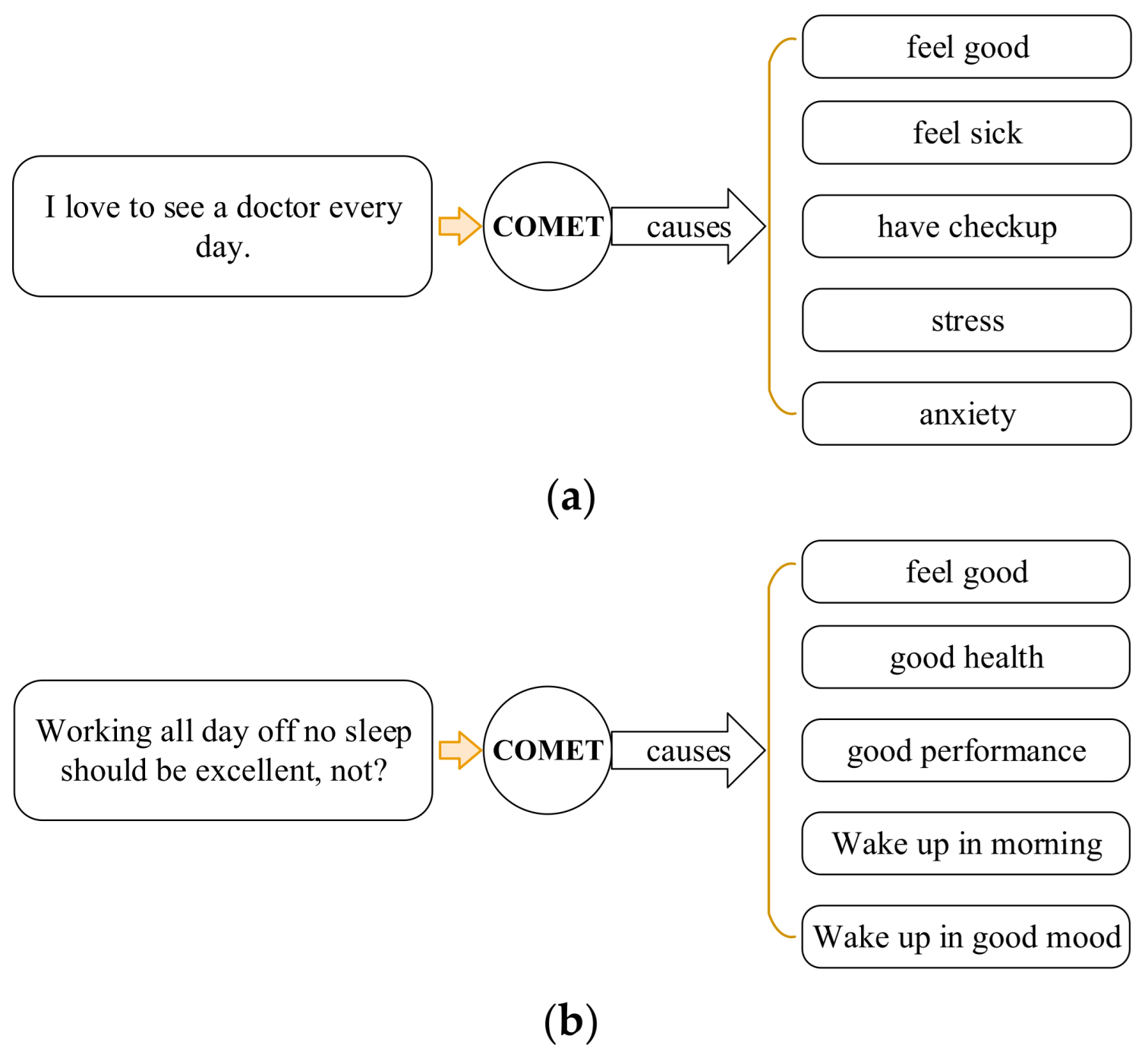
Figure 3 shows our commonsense knowledge generated by the COMET network’s causes relations. Figure 3a illustrates the generated commonsense knowledge that is beneficial for sarcasm detection. However, the COMET model also generates a lot of commonsense knowledge that is useless for our sarcasm detection, which is equivalent to producing a lot of noise, which has a negative impact on sarcasm detection. In Figure 3b, except for one commonsense knowledge of “feel good”, which is useful, the other four commonsense knowledge are basically detrimental noise. Therefore, it is essential to know how to use the relevant commonsense knowledge to correctly identify sarcasm, which is a difficult undertaking. The code and data of the COMET model are available at https://github.com/tuhinjubcse/SarcasmGeneration-ACL2020 (accessed on 30 December 2022).
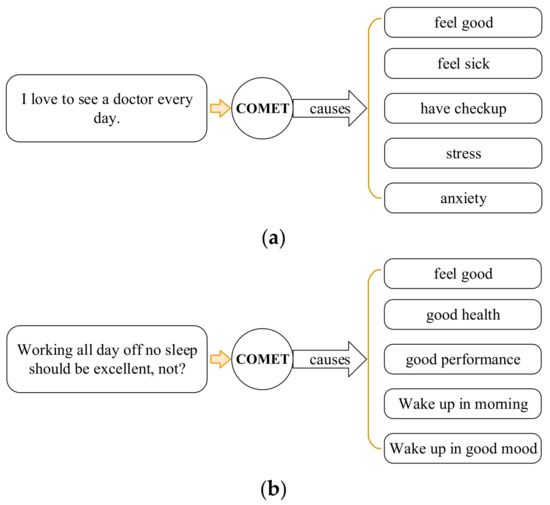
Figure 3.
Examples of commonsense knowledge generation using COMET: (a) Effective commonsense knowledge; (b) Commonsense knowledge with a lot of useless information.
3.3. Sentence Representation
In numerous natural language processing applications., including reading comprehension, emotional dialogue, machine translation, and others, pre-trained language models [20,34,49] have shown strong ability. Devlin et al. [20] designed the pre-trained language representation model of BERT in 2018. BERT is intended to train a bidirectional representation that considers the left and right contexts of each layer at the same time. In their investigation, Vaswani et al. [50] suggested the transformer model. BERT is made up of a stack of transformer encoder and decoder layers. Each layer is divided into two sublayers: multi-head self-attention and a position-wise feed-forward network. In the previous words embedding model, the word vector was fixed, but now the embedding of the pre-trained language model can dynamically change according to the context. Therefore, their feature representation expresses richer semantics.
In this research, we get the feature representation of the text and the knowledge by using the model of the BERT base as the embedding layer. To be specific, an input sequence X with l tokens, . The input sequence X can be encoded as by the BERT model, where is the sum of the token, position, and segment embeddings, where d is the embedding dimensions, and l is a predefined maximum length of the input sequence. We concatenate the corresponding generated commonsense knowledge into a knowledge sequence as K. We also feed the text sequence T and commonsense knowledge sequence K into the BERT model. T can be encoded as , and commonsense knowledge K can be encoded as .
3.4. Adaptive Incongruity Extraction Network
Incongruous sentiment information is crucial for sarcasm detection. In this part, we will describe the adaptive incongruity extraction module in detail, which captures the sentiment incongruity information inside the sequence. The key point of this part is the learnable adaptive incongruity matrix, which is used to calculate the distance between each word in the input sequence. In previous works [2,5], the basic method calculates the inner product, which mainly calculates the similarity. Therefore, [2,5] cannot effectively extract incongruous information. At the same time, after calculating the score matrix, they performed the max operation on each row, which could only obtain the incongruent information between two words in a text sequence, thus losing a lot of information. Because of the incongruous information, not just between two words, but possibly between some phrases, in order to make the adaptive incongruity matrix learnable, we first apply three different linear transformations to the input text sequence , which is encoded by BERT. Thus, we obtain the new feature representations as follows:
where are the trainable parameters in these three linear transformations. are the new feature representations after linear transformation.
Next, we compute the Euclidean distance between different words in and . To be specific, for word pairs , we compute their Euclidean distance as follows:
where denotes the Euclidean distance between the two vectors and . To a certain extent, after BERT embeds a word, the farther the semantic distance between two words is, the larger the value of their Euclidean distance is, which can better capture the semantic incongruity information in the text.
We get an adaptive incongruity matrix based on all Euclidean distances .
where consists of the distance between individual words in the input text. Since each element in the matrix is quite large, we need to mask it first and then normalize each row. For example, we normalize the row as follows:
where represents the semantic gap between the i-th word and the other words. The larger the value is, the farther the semantic gap is for the corresponding word pairs. At the same time, we do not use the max function as in papers [2,5]; only the largest incongruity between word i and other words is obtained after using the Max function in papers [2,5]; their method would lose a lot of information because the semantic incongruity within a sentence should occur between two phrases, not just between two words. The incongruity is computed using the softmax operator between a word and multiple other words. A score matrix Scores measuring semantic incongruity is obtained as follows:
We multiply Scores with the matrix to obtain the new text feature representation enhanced with semantic incongruity information. In order to retain the original feature information, we employ a residual network here. The specific calculation process is as follows:
where is the operation of layer normalization [51], and is the feature representation of the text after incongruent semantic enhancement.
Similarly, we can perform the same computational operation on commonsense knowledge with another adaptive incongruity extraction module and obtain a new commonsense knowledge feature representation , which is enhanced by incongruity semantics also.
3.5. Incongruity Cross-Attention Module
The external commonsense knowledge may contain a lot of noise information, which may be detrimental to our sarcasm detection if we do not screen the knowledge. In order to make better use of external knowledge, we propose an incongruity cross-attention module between text and external commonsense knowledge to fully extract useful commonsense knowledge. In this part, we will introduce the module in detail. Similarly, in order to make knowledge extraction learnable, we perform a linear transformation on and two linear transformations on , which are calculated as follows:
where are the trainable parameters in these three linear transformations. are the new feature representations after linear transformation.
To extract the effective information from commonsense knowledge, we have to compute the Euclidean distance for each word vector in and . Specifically, for word pairs , we calculate it as follows:
where represents the Euclidean distance between the two vectors and , the i-th word in the text sequence and the j-th word in the corresponding knowledge sequence. Similar to the method of the adaptive incongruity extraction module, we can also obtain the cross-incongruity matrix and the score matrix as follows:
where represents the distance score of two words, one word in the text and each word and the other one in the corresponding commonsense knowledge.
Then, the interaction score matrix and were used for matrix multiplication so that useful information in the knowledge could be extracted. We also utilize the residual structure to better retain a part of the original information. The calculation process is as follows:
where is the operation of layer normalization [51], and represents the new features extracted by the incongruity cross-attention module between text and knowledge, which serves as a feature new representation of commonsense knowledge.
3.6. Gate Mechanism Module
Since knowledge and text have different contributions to the final prediction, we design a gated unit to dynamically learn the output quantity of text and knowledge. The text features and knowledge features, which have passed the adaptive incongruity extraction module and incongruity cross-attention module, are used as the input of the gate mechanism.
We first perform averaging operations on and respectively, to obtain representing the text and representing commonsense knowledge. The calculation process of the weight coefficient for the output of the gate mechanism is as follows:
where is a variational weight vector, and are learnable parameters. denotes the tensor’s concatenation operation, which concatenates with the vector of each token in separately. With the weight vector , we can control the output of as and. To make full use of text and knowledge, we also use a residual module as follows:
where is the operation of layer normalization [51], and are learnable parameters.
The use of a full connected network (also known as MLP) is then made, followed by the addition of a layer normalization and a new residual module.
3.7. Prediction and Training Objectives
Then, a linear transformation and a softmax calculation are applied to to obtain the prediction result. The softmax function computes the probabilities of different classes. The categories with high probability values are the ones we predict. The calculation is as follows:
where are the trainable parameters. is our predicted classification.
We use the cross-entropy cost function to train our model.
where J denotes the loss function. represents the true class label for sample i, and denotes the class label forecasted by the model of sample . N denotes the total number of training samples. R denotes the L2 regularization, and on behalf of the corresponding weight coefficient.
4. Experiment
4.1. Dataset
Two Twitter datasets were proposed and created by [33,34]. The Reddit dataset [52] is a dataset about the subreddit’s political data. These three datasets are used to verify the performance of our model. Three datasets are denoted as Twitter-G, Twitter-R, and Reddit-Pol, respectively. In these datasets, each text sample corresponds to a set of commonsense knowledge. The COMET network is well suited to generate commonsense knowledge for brief text. Thus, we selected these three datasets from the popular sarcasm detection datasets. In this paper, we will generate some external commonsense knowledge for each sample using the COMET model. The statistics of the three datasets are shown in Table 1.

Table 1.
Statistics of the dataset.
4.2. Baseline Models
To assess our model, we compare it to the baseline models as follows:
NBOW: In order to represent the complete sentence as a feature in subsequent tasks, this model employs the average of all word embeddings.
TextCNN: Kim [2] has proposed it as an upgrade to image convolution, which is specifically utilized for text feature extraction. With little hyperparameter adjustment and the use of static word vectors, simple TextCNN models may perform rather well when classifying text. Furthermore, if the word vectors are fine-tuned during training, the performance may be increased much further.
Bi-LSTM: The so-called Bi-LSTM is a two-layer neural network. The first layer starts with the first word of the sentence, whereas the second layer starts with the last word and carries out the first layer’s processes backwards. In order to capture context information in words, bidirectional LSTM outperforms unidirectional LSTM.
SIARN: SIARN can learn an intra-attentive feature representation of the input text that may capture contradictory sentiments and incongruence. Previous sequence models, such as LSTMs, were unable to identify the interaction between word pairs.
SMSD-BiLSTM: Self-matching networks are proposed by Xiong et al. [5] as a means of detecting incongruity on the basis of a modified co-attention approach. They also develop the compositional information of the text using a bidirectional LSTM.
BERT: Transformers’ BERT is a bidirectional encoder. In order to pre-train deep bidirectional representations from unlabeled text, it attempts to calculate criteria shared by left and right contexts. Therefore, state-of-the-art models for a variety of natural language processing tasks may be generated by fine-tuning pre-trained BERT models with a single additional output layer. BERT can provide superior semantic expression as compared to conventional word embedding techniques, and its feature representation may be adjusted according to the circumstances. The introduction of BERT is crucial historically for the study of several tasks in natural language processing.
SDCK: SDCK was proposed by Li et al. [13]. They introduced commonsense knowledge into sarcasm detection for the first time and achieved state-of-the-art performance in 2021. It shows the importance of commonsense knowledge in sarcasm detection. However, he also has many shortcomings. He does not make full use of the text itself and commonsense knowledge.
4.3. Experimental Settings
The model we proposed is developed with PyTorch [53], operating on an NVIDIA GeForce RTX 3060 Laptop GPU. Hugging Face released the transformers toolkit, which greatly facilitated researchers. The pre-trained BERT base model we used is from Hugging Face also. Adam [54] is used as our optimizer. We save the model that performs best on the validation set. Since different datasets have their own distribution characteristics, we use different parameters for different datasets, and the specific parameters are shown in Table 2 where MaxSL and MaxKL denote the maximum input text sequence length and the maximum input knowledge sequence length, respectively. Our code and datasets are available at Supplementary Materials.
Table 2.
Different hyperparameters for different datasets in the experiment.
4.4. Experimental Results
In this part, our model is compared with baselines based on normal evaluation metrics, such as precision, recall, and F1 score. Then, we analyze the experimental results of our model with the adaptive incongruity extraction module, the incongruity cross-attention module, and the gate module. The results on the three datasets demonstrate that our model improves the state-of-the-art performance substantially. Our model outperforms earlier benchmarks in precision, recall, and F1 score, and the results perform differently on different datasets.
The performance of our method and the other benchmark models on the three datasets is displayed in Table 3. The experimental results of baseline models are collected from Li et al. [13]. Obviously, our method obtains the best results across all datasets. To be specific, our model achieves 5.34%, 1.88%, and 3.84% improvement on the datasets of Twitter-G, Twitter-P, and Reddte-pol, respectively, compared to the fine-tuned BERT base model on the F1 metric. SDCK-maj, SDCK-min, and SDCK-con represent the model of SDCK [13] under majority, minority, and contrast knowledge selection methods of sentiment-based, respectively. SDCK-att represents the model of SDCK [13] under the attention-based knowledge selection method. Li et al. [13] also introduces commonsense knowledge, but they need several knowledge selection strategies. Moreover, in their work, one method can only work well on a certain dataset [13]. We can achieve good results on all three datasets simultaneously and far surpass their best by just using our model. For example, on the datasets of Twitter-G, Twitter-P, and Reddte-pol, our model achieves 4.59%, 0.66%, and 1.33% improvement, respectively, compared to the SDCK-maj model on the F1 metric. Similarly, our model achieves 3.58%, 2.1%, and 0.48% improvement compared to the SDCK-con model on the F1 metric.
Table 3.
Comparison results for sarcasm detection. The best result is in boldface.
The three methods, SDCK-maj, SDCK-min, and SDCK-con correspond to three selection strategies [13]. Each method can only achieve good results on a certain dataset, and we far exceed their best results. Their knowledge selection strategy has inferior generalization performance [13], and it must use the corresponding knowledge selection method to select the required knowledge in advance and store it in the document, demonstrating the complexity of their method [13]. In contrast, our method is more straightforward and user-friendly, and it yields superior experimental results. Compared with their implicit policy model SDCK-att, on the datasets of Twitter-G, Twitter-P, and Reddit-Pol, our model achieves 3.66%, 2.02%, and 0.87% improvement, respectively. It shows that our model functions much better than the traditional self-attention mechanism method in incongruity extraction.
To further demonstrate the validity of our model, we undertake experiments on SDCK-maj, SDCK-min, and SDCK-con models [13], respectively. We add our two key modules (adaptive incongruity extraction module and incongruity cross-attention module) to the methods [13]. Table 4 provides the experimental comparison before and after the addition of our two key modules. Model-maj, Model-min, and Model-con denote the models that SDCK-maj, SDCK-min, and SDCK-con are combined with in our two key modules, respectively. Our two key modules significantly improved the performance of their models [13] on almost all datasets. For example, on Twitter-G, Twitter-P, and Reddit-Pol datasets, Model-maj achieves 3.9%, 0.46%, and 1.31% improvement compared to the SDCK-maj model on the F1 metric. Similarly, Model-min achieves 1.12%, 1.70%, and 1.20% improvement compared to the SDCK-min model on the F1 metric.
Table 4.
The experimental results of our incongruity extraction module are combined with the knowledge selection strategy.
4.5. Ablation Study
In order to explore the impact of different components, ablation experiments are conducted to evaluate the performance of the adaptive incongruity semantic extraction module and the incongruity cross-attention module. Specifically, we consider three different scenarios, (1) remove the adaptive incongruity extraction module of text (denoted as w/o text_incon), (2) remove the adaptive incongruity extraction module of knowledge (denoted as w/o know_incon), and (3) remove the incongruity cross-attention that is the module of interaction between the text and knowledge (denoted as w/o cross_incon).
The results are displayed in Table 5. Clearly, our model only performs best when all modules are included. From the results, we can see that each of our modules is indispensable and crucial for sarcasm detection. Discarding different modules, performance will deteriorate differently on different datasets. For example, Model (w/o text_incon) has 0.71% and 1.17% degradation on Twitter-G and Twitter-P, respectively, meanwhile, it has a 1.91% degradation on Reddit-Pol.
Table 5.
Experimental results of the ablation study. The best result is in boldface.
In order to explore the effect of the gated unit, we maintain the normal operation of the other modules while examining the function of the gate module. We begin by removing the gate mechanism, leaving the remaining components intact. In this instance, Model (−gate) has 0.43%, 0.93%, and 1.96% degradation on Twitter-G, Twitter-P, and Reddit-Pol, respectively. To further investigate the performance of this module, we conduct comparison tests using the other two integration approaches. They are concatenation and element-wise addition. Model (+add) has 0.89%, 0.49%, and 1.35% degradation on Twitter-G, Twitter-P, and Reddit-Pol, respectively. Table 6 shows that merely extracting the features of text and knowledge does not achieve satisfactory results. How to effectively utilize the extracted feature information is also very critical. The absence of the gate mechanism leads to poorer performance, indicating the importance of the gate that can dynamically learn weights based on text and knowledge. It demonstrates that the optimum result cannot be achieved by using the integration method of concatenation and element-wise addition alone, which also demonstrates the effectiveness of the gated unit.
Table 6.
Experimental results of ablation study concerning the gate mechanism. The best result is in boldface.
4.6. Model Visualization
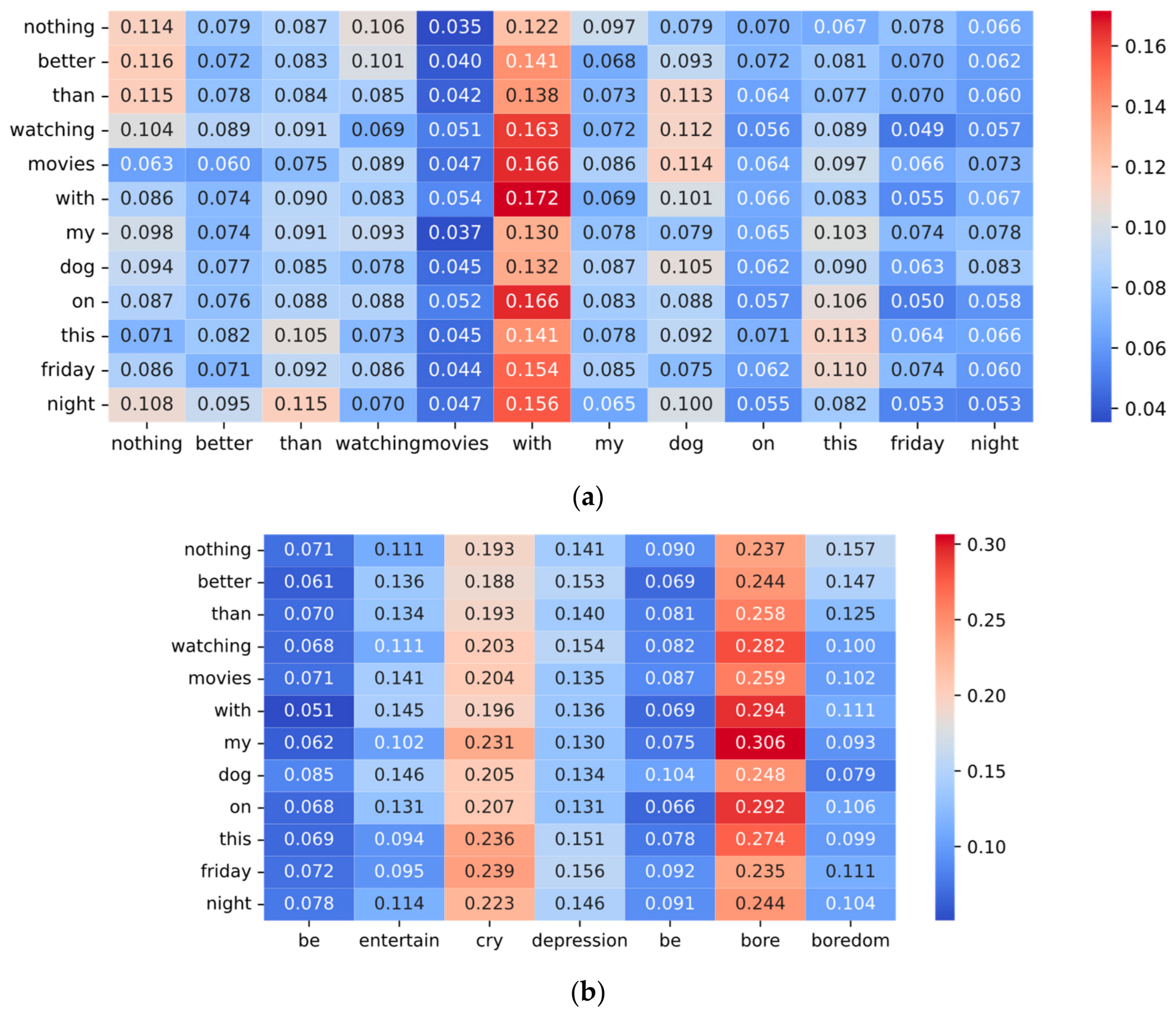
In this part, we visualize the weight scores to demonstrate the mechanism of the adaptive incongruity extraction module and incongruity cross-attention module. The adaptive incongruity extraction module extracts the incongruity in the sentence by calculating the weight scores between words. To make the calculation of the weights learnable, we will apply three different linear transformations to the features after the word embedding, which will change the original meaning of the weight scores. Weight scores are automatically learned to assign higher weights to incongruous words. In Figure 4, the text sequence is “nothing better than watching movies with my dog on this Friday night”, and the commonsense knowledge sequence is “be entertain cry depression be bore boredom”.
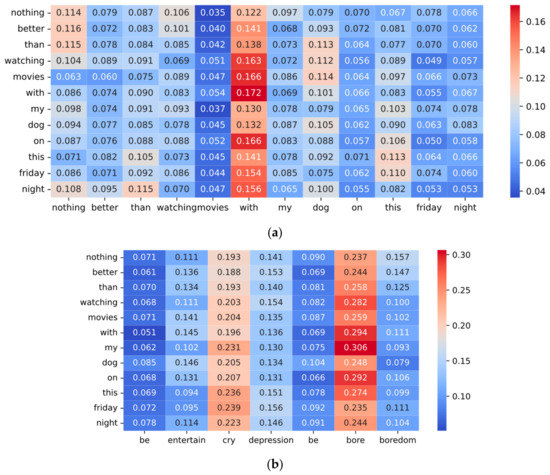
Figure 4.
Visualization of the weight scores of the adaptive incongruity extraction module and incongruity cross-attention module: (a) Text incongruity attention scores; (b)Text and knowledge incongruity cross-attention scores.
For the adaptive incongruity extraction module, Figure 4a shows the attention weight scores of a text obtained after the model is trained. It is evident that “with”, “dog”, “nothing”, “than”, and “watch” have the highest weighting scores. Specifically, “with”, “dog” and “watching”, “movie” have high scores. At the same time, “with”, “dog”, “better”, and “than” have high scores. The above phrases have strong inconsistent semantics among themselves, and our module gives them high weight scores, indicating that it can capture the incongruent semantics effectively. The phrase “with my dog” is the key to determining whether it is sarcasm. Therefore, “with” and “dog” are given very high weight scores along with other words. Next, it adds the vectors “with” and “dog” multiplied by the weights to the corresponding word. Similarly, “nothing better than” represents positive sentiment words, which are also assigned high weights. These reinforce the incongruity information on the corresponding word vector.
For the incongruity cross-attention module, Figure 4b shows the incongruity cross-attention scores between the text and the corresponding commonsense knowledge. Text sequence is used as the query vector. In this text sequence, the emotion “entertain” is easily discernible, whereas the emotion “bore” is more difficult to locate and comprehend. Therefore, we should pay more attention to the “bore” in commonsense knowledge to better understand the meaning of this sentence. Our incongruity cross-attention scores also corroborate our analysis. The words “bore”, “cry”, and “depression” have the highest cross-attention scores, which represent negative emotional words, and they are the main sentiment of the text sequence, indicating that we have accurately captured the correct words. Next, the term “entertain” also has a high attention score, which represents a positive emotional word. For the judgment of sarcasm in this text, we can easily find the positive sentiment of “entertain”, but it is challenging to find the negative emotion of “boring”. In this text, the negative semantics of “bore” are much more important, so “entertain” has a slightly lower attention score than “bore”.
It shows that the adaptive incongruity extraction network and the incongruity cross-attention network perform well in extracting incongruent information and words with distinct sentiment polarity, which actually demonstrates the effectiveness of the two modules.
5. Conclusions
In this study, we propose three new modules to optimize the utilization of the text and external commonsense knowledge: an adaptive incongruity extraction module, an incongruity cross-attention module, and an improved gate mechanism module. After word embedding, the farther the Euclidean distance of word vectors with different sentiment polarity is, the higher the weight score is calculated by the model. Then, it is easier for the modules to capture the incongruent semantic information within the sentence effectively. Consequently, our adaptive incongruity extraction module can automatically extract incongruity from the text and commonsense knowledge. With the selection of useful information from commonsense knowledge, the application of the incongruity cross-attention module completes a better interaction between the text and the corresponding commonsense knowledge. The self-learning gate mechanism, as the knowledge-text integration module, controls the specific quantity of information in the final output by assessing and controlling the fusion weight scores in text and knowledge-text. Extensive tests were conducted on three datasets to illustrate the efficacy of our strategy. The experimental results demonstrate that our technique greatly outperforms the benchmark model. Simultaneously, the ablation experiments confirmed the efficiency of the three proposed modules. Finally, the visualization analysis of attention scores reveals the function of the modules, further demonstrating the efficacy of our model. In addition to achieving state-of-the-art performance on three datasets, our proposed model has enhanced interpretability. In future work, we will explore a more general and elegant approach for the integration of text and knowledge owing to the importance of external knowledge in sarcasm detection.
Supplementary Materials
Our code and datasets are available at https://github.com/cathy345345/SD-based-on-AIEN-and-ICA (accessed on 30 December 2022).
Author Contributions
Conceptualization, M.C., Z.Q. and Y.H. (Yuanlin He); methodology, Y.H. (Yuanlin He), Z.W. and J.L.; software, Y.H. (Yuanlin He) and F.Y.; writing—original draft preparation, Y.H. (Yuanlin He), F.H. and Y.H. (Yingying He); writing—review and editing, Y.H. (Yuanlin He), F.H. and Y.H. (Yingying He); funding acquisition, M.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Demonstration Project for Transfer and Transformation of Scientific and Technological Achievements in Sichuan Province (grant number 2022ZHCG0035), the Enterprise Informatization and Measurement and Control Technology of Internet of Things Key Laboratory of Sichuan Province Open Fund (grant number 2021WYY01) and the Open Fund Project of Hainan Key Laboratory of Internet Information Retrieval (grant number 2022KY03).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data underlying this article are available in its Supplementary Materials.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ghosh, A.; Veale, T. Magnets for Sarcasm: Making Sarcasm Detection Timely, Contextual and Very Personal. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 482–491. [Google Scholar]
- Tay, Y.; Luu, A.T.; Hui, S.C.; Su, J. Reasoning with Sarcasm by Reading In-Between. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1010–1020. [Google Scholar]
- Riloff, E.; Qadir, A.; Surve, P.; De Silva, L.; Gilbert, N.; Huang, R. Sarcasm as Contrast between a Positive Sentiment and Negative Situation. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 704–714. [Google Scholar]
- Joshi, A.; Sharma, V.; Bhattacharyya, P. Harnessing Context Incongruity for Sarcasm Detection. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Beijing, China, 26–31 July 2015; pp. 757–762. [Google Scholar]
- Xiong, T.; Zhang, P.; Zhu, H.; Yang, Y. Sarcasm Detection with Self-Matching Networks and Low-Rank Bilinear Pooling. In Proceedings of the The World Wide Web Conference on—WWW ’19, San Francisco, CA, USA, 13–17 May 2019; ACM Press: New York, NY, USA, 2019; pp. 2115–2124. [Google Scholar]
- Mishra, A.; Dey, K.; Bhattacharyya, P. Learning Cognitive Features from Gaze Data for Sentiment and Sarcasm Classification Using Convolutional Neural Network. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 377–387. [Google Scholar]
- Castro, S.; Hazarika, D.; Pérez-Rosas, V.; Zimmermann, R.; Mihalcea, R.; Poria, S. Towards Multimodal Sarcasm Detection (An _Obviously_ Perfect Paper). In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4619–4629. [Google Scholar]
- Cai, Y.; Cai, H.; Wan, X. Multi-Modal Sarcasm Detection in Twitter with Hierarchical Fusion Model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2506–2515. [Google Scholar]
- Pan, H.; Lin, Z.; Fu, P.; Qi, Y.; Wang, W. Modeling Intra and Inter-Modality Incongruity for Multi-Modal Sarcasm Detection. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 1383–1392. [Google Scholar]
- Liang, B.; Lou, C.; Li, X.; Yang, M.; Gui, L.; He, Y.; Pei, W.; Xu, R. Multi-Modal Sarcasm Detection via Cross-Modal Graph Convolutional Network. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 1767–1777. [Google Scholar]
- Wang, J.; Sun, L.; Liu, Y.; Shao, M.; Zheng, Z. Multimodal Sarcasm Target Identification in Tweets. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 8164–8175. [Google Scholar]
- Liu, H.; Wang, W.; Li, H. Towards Multi-Modal Sarcasm Detection via Hierarchical Congruity Modeling with Knowledge Enhancement. arXiv 2022, arXiv:2210.03501. [Google Scholar]
- Li, J.; Pan, H.; Lin, Z.; Fu, P.; Wang, W. Sarcasm Detection with Commonsense Knowledge. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3192–3201. [Google Scholar] [CrossRef]
- Ilievski, F.; Oltramari, A.; Ma, K.; Zhang, B.; McGuinness, D.L.; Szekely, P. Dimensions of Commonsense Knowledge. Knowl. Based Syst. 2021, 229, 107347. [Google Scholar] [CrossRef]
- Storks, S.; Gao, Q.; Chai, J. Commonsense Reasoning for Natural Language Understanding: A Survey of Benchmarks, Resources, and Approaches. arXiv 2019, arXiv:1904.01172. [Google Scholar]
- Veale, T.; Hao, Y. Detecting Ironic Intent in Creative Comparisons. In Proceedings of the 2010 Conference on ECAI 2010: 19th European Conference on Artificial Intelligence, Lisbon, Portugal, 16–20 August 2010; IOS Press: Amsterdam, The Netherlands, 2010; pp. 765–770. [Google Scholar]
- Li, J.; Lin, Z.; Fu, P.; Wang, W. Past, Present, and Future: Conversational Emotion Recognition through Structural Modeling of Psychological Knowledge. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 7–9 November 2021; pp. 1204–1214. [Google Scholar]
- Li, J.; Meng, F.; Lin, Z.; Liu, R.; Fu, P.; Cao, Y.; Wang, W.; Zhou, J. Neutral Utterances Are Also Causes: Enhancing Conversational Causal Emotion Entailment with Social Commonsense Knowledge. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI-22, Vienna, Austria, 23–29 July 2022; Raedt, L.D., Ed.; Morgan Kaufmann: San Francisco, CA, USA, 2022; pp. 4209–4215. [Google Scholar]
- Joshi, A.; Tripathi, V.; Patel, K.; Bhattacharyya, P.; Carman, M. Are Word Embedding-Based Features Useful for Sarcasm Detection? In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1006–1011. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Reyes, A.; Rosso, P.; Veale, T. A Multidimensional Approach for Detecting Irony in Twitter. Lang Resour. Eval. 2013, 47, 239–268. [Google Scholar] [CrossRef]
- Barbieri, F.; Ronzano, F.; Saggion, H. Italian Irony Detection in Twitter: A First Approach. In Proceedings of the First Italian Conference on Computational Linguistics CLiC-it 2014, Pisa, Italy, 9–10 December 2014; pp. 28–32. [Google Scholar]
- Bouazizi, M.; Ohtsuki, T. Opinion Mining in Twitter How to Make Use of Sarcasm to Enhance Sentiment Analysis. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2015, New York, NY, USA, 25 August 2015; pp. 1594–1597. [Google Scholar]
- González-Ibáñez, R.; Muresan, S.; Wacholder, N. Identifying Sarcasm in Twitter: A Closer Look. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 581–586. [Google Scholar]
- Ptacek, T.; Habernal, I.; Hong, J. Sarcasm Detection on Czech and English Twitter. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics, Dublin, Ireland, 23–29 August 2014; pp. 213–223. [Google Scholar]
- Bosselut, A.; Rashkin, H.; Sap, M.; Malaviya, C.; Celikyilmaz, A.; Choi, Y. COMET: Commonsense Transformers for Automatic Knowledge Graph Construction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4762–4779. [Google Scholar]
- Joshi, A.; Bhattacharyya, P.; Carman, M.J. Automatic Sarcasm Detection: A Survey. ACM Comput. Surv. 2017, 50, 1–22. [Google Scholar] [CrossRef]
- Davidov, D.; Tsur, O.; Rappoport, A. Semi-Supervised Recognition of Sarcastic Sentences in Twitter and Amazon. In Proceedings of the Fourteenth Conference on Computational Natural Language Learning, Uppsala, Sweden, 15–16 July 2010; pp. 107–116. [Google Scholar]
- Maynard, D.; Greenwood, M.A. Who Cares about Sarcastic Tweets? Investigating the Impact of Sarcasm on Sentiment Analysis. In Proceedings of the LREC 2014: 9th Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–30 May 2014. [Google Scholar]
- Tsur, O.; Davidov, D.; Rappoport, A. ICWSM—A Great Catchy Name: Semi-Supervised Recognition of Sarcastic Sentences in Online Product Reviews. Int. Conf. Web Soc. Media 2010, 4, 162–169. [Google Scholar] [CrossRef]
- Rajadesingan, A.; Zafarani, R.; Liu, H. Sarcasm Detection on Twitter: A Behavioral Modeling Approach. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2 February 2015; pp. 97–106. [Google Scholar]
- Barbieri, F.; Saggion, H.; Ronzano, F. Modelling Sarcasm in Twitter, a Novel Approach. In Proceedings of the 5th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Baltimore, MD, USA, 27 June 2014; pp. 50–58. [Google Scholar]
- Ghosh, A.; Veale, T. Fracking Sarcasm Using Neural Network. In Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, San Diego, CA, USA, 1 April–30 June 2016; pp. 161–169. [Google Scholar]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. Available online: https://www.semanticscholar.org/paper/Improving-Language-Understanding-by-Generative-Radford-Narasimhan/cd18800a0fe0b668a1cc19f2ec95b5003d0a5035 (accessed on 14 December 2022).
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Chen, H.; Sun, M.; Tu, C.; Lin, Y.; Liu, Z. Neural Sentiment Classification with User and Product Attention. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1650–1659. [Google Scholar]
- Tay, Y.; Tuan, L.A.; Hui, S.C. Learning to Attend via Word-Aspect Associative Fusion for Aspect-Based Sentiment Analysis. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, New Orleans, LA, USA, 2 February 2018; AAAI Press: Menlo Park, CA, USA, 2018; pp. 5956–5963. [Google Scholar]
- Chen, P.; Sun, Z.; Bing, L.; Yang, W. Recurrent Attention Network on Memory for Aspect Sentiment Analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 452–461. [Google Scholar]
- Zhang, Y.; Liu, Y.; Li, Q.; Tiwari, P.; Wang, B.; Li, Y.; Pandey, H.M.; Zhang, P.; Song, D. CFN: A Complex-Valued Fuzzy Network for Sarcasm Detection in Conversations. IEEE Trans. Fuzzy Syst. 2021, 29, 3696–3710. [Google Scholar] [CrossRef]
- Chauhan, D.S.; Singh, G.V.; Arora, A.; Ekbal, A.; Bhattacharyya, P. An Emoji-Aware Multitask Framework for Multimodal Sarcasm Detection. Knowl. Based Syst. 2022, 257, 109924–109936. [Google Scholar] [CrossRef]
- Zhang, L.; Zhao, X.; Song, X.; Fang, Y.; Li, D.; Wang, H. A Novel Chinese Sarcasm Detection Model Based on Retrospective Reader. In MultiMedia Modeling, Proceedings of the 28th International Conference, MMM 2022, Phu Quoc, Vietnam, 6–10 June 2022; Þór Jónsson, B., Gurrin, C., Tran, M.-T., Dang-Nguyen, D.-T., Hu, A.M.-C., Huynh Thi Thanh, B., Huet, B., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 267–278. [Google Scholar]
- Bedi, M.; Kumar, S.; Akhtar, M.S.; Chakraborty, T. Multi-Modal Sarcasm Detection and Humor Classification in Code-Mixed Conversations. IEEE Trans. Affect. Comput. 2021, 1–13. [Google Scholar] [CrossRef]
- Bamman, D.; Smith, N. Contextualized Sarcasm Detection on Twitter. Int. Conf. Web Soc. Media 2021, 9, 574–577. [Google Scholar] [CrossRef]
- Joshi, A.; Tripathi, V.; Bhattacharyya, P.; Carman, M.J. Harnessing Sequence Labeling for Sarcasm Detection in Dialogue from TV Series ‘Friends’. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 146–155. [Google Scholar]
- Ghosh, D.; Richard Fabbri, A.; Muresan, S. The Role of Conversation Context for Sarcasm Detection in Online Interactions. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, Saarbrücken, Germany, 15–17 August 2017; pp. 186–196. [Google Scholar]
- Wang, Z.; Wu, Z.; Wang, R.; Ren, Y. Twitter Sarcasm Detection Exploiting a Context-Based Model. In Proceedings of the Web Information Systems Engineering—WISE 2015, Miami, FL, USA, 1–3 November 2015; Wang, J., Cellary, W., Wang, D., Wang, H., Chen, S.-C., Li, T., Zhang, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 77–91. [Google Scholar]
- Liang, B.; Lou, C.; Li, X.; Gui, L.; Yang, M.; Xu, R. Multi-Modal Sarcasm Detection with Interactive In-Modal and Cross-Modal Graphs. In Proceedings of the 29th ACM International Conference on Multimedia, New York, NY, USA, 17 October 2021; pp. 4707–4715. [Google Scholar]
- Chakrabarty, T.; Ghosh, D.; Muresan, S.; Peng, N. R3: Reverse, Retrieve, and Rank for Sarcasm Generation with Commonsense Knowledge. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7976–7986. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization CoRR. 2016. Available online: http://arxiv.org/abs/1607.06450 (accessed on 12 December 2022).
- Khodak, M.; Saunshi, N.; Vodrahalli, K. A Large Self-Annotated Corpus for Sarcasm. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).