
Detect Orientation of Symmetric Objects from Monocular Camera to Enhance Landmark Estimations in Object SLAM


Abstract
1. Introduction
- We propose a projection restoration method to estimate the 3D symmetry plane of an object from the 2D image.
- We integrate object symmetry planes in the factor graph of object SLAM systems to improve the orientation accuracy of ellipsoid landmarks.
- Based on the above two points, we propose a lightweight real-time object-level mapping system.
2. Related Work
2.1. SLAM with Object-Level Landmarks
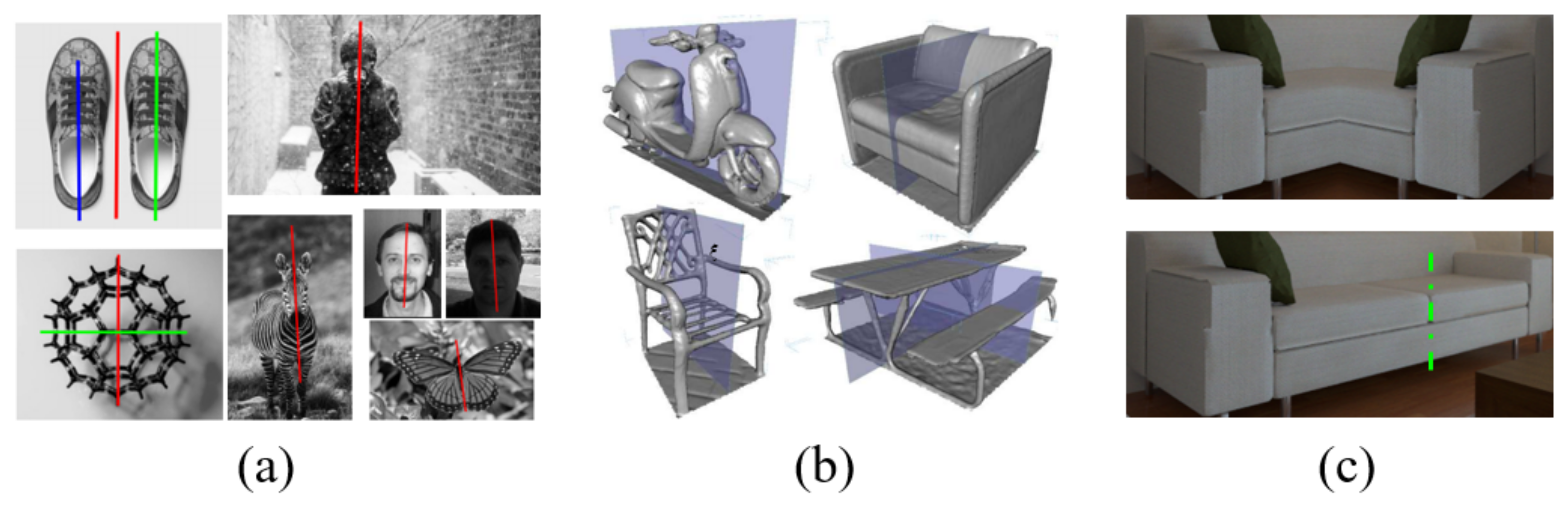
2.2. The Symmetry of Objects
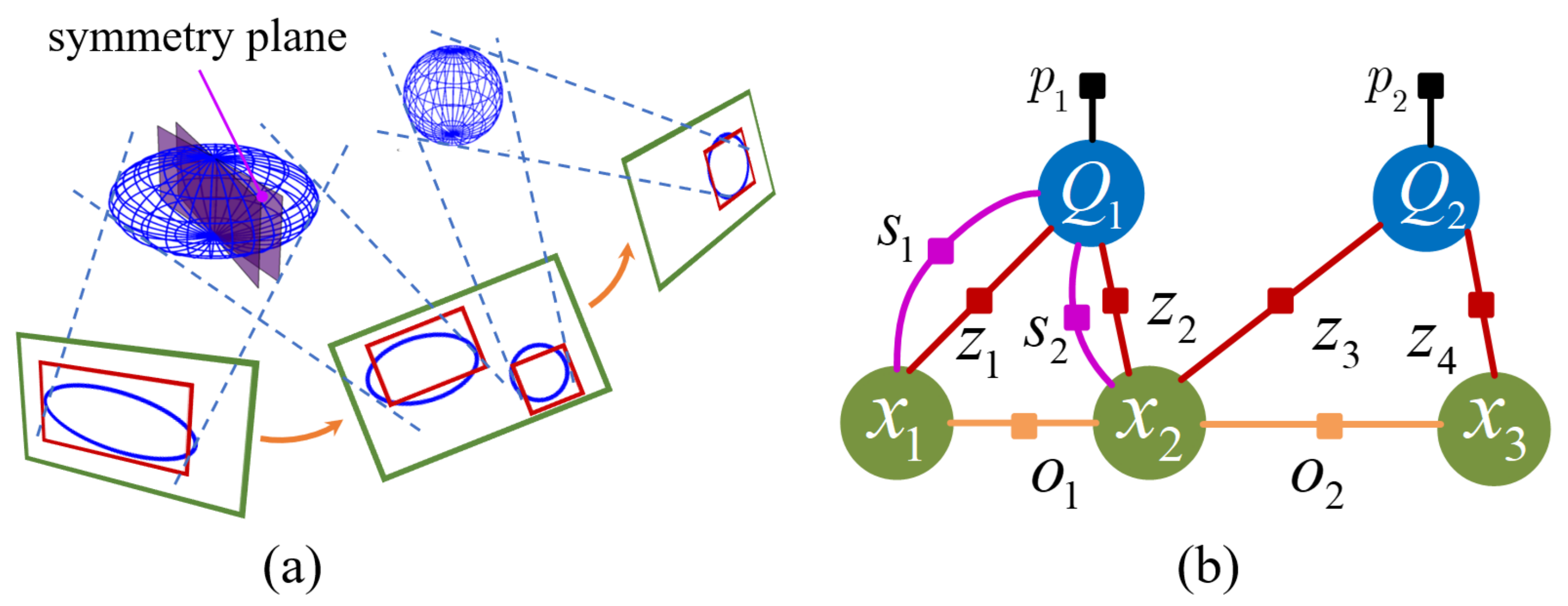
3. Materials and Methods
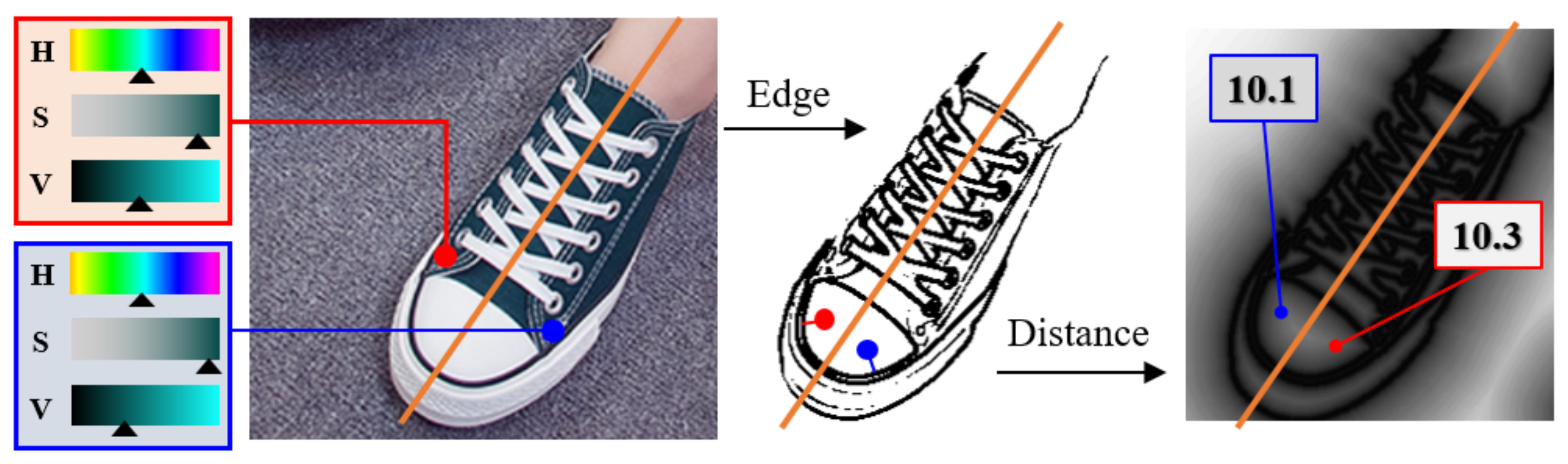
3.1. Description of Ideal Pixel Symmetry
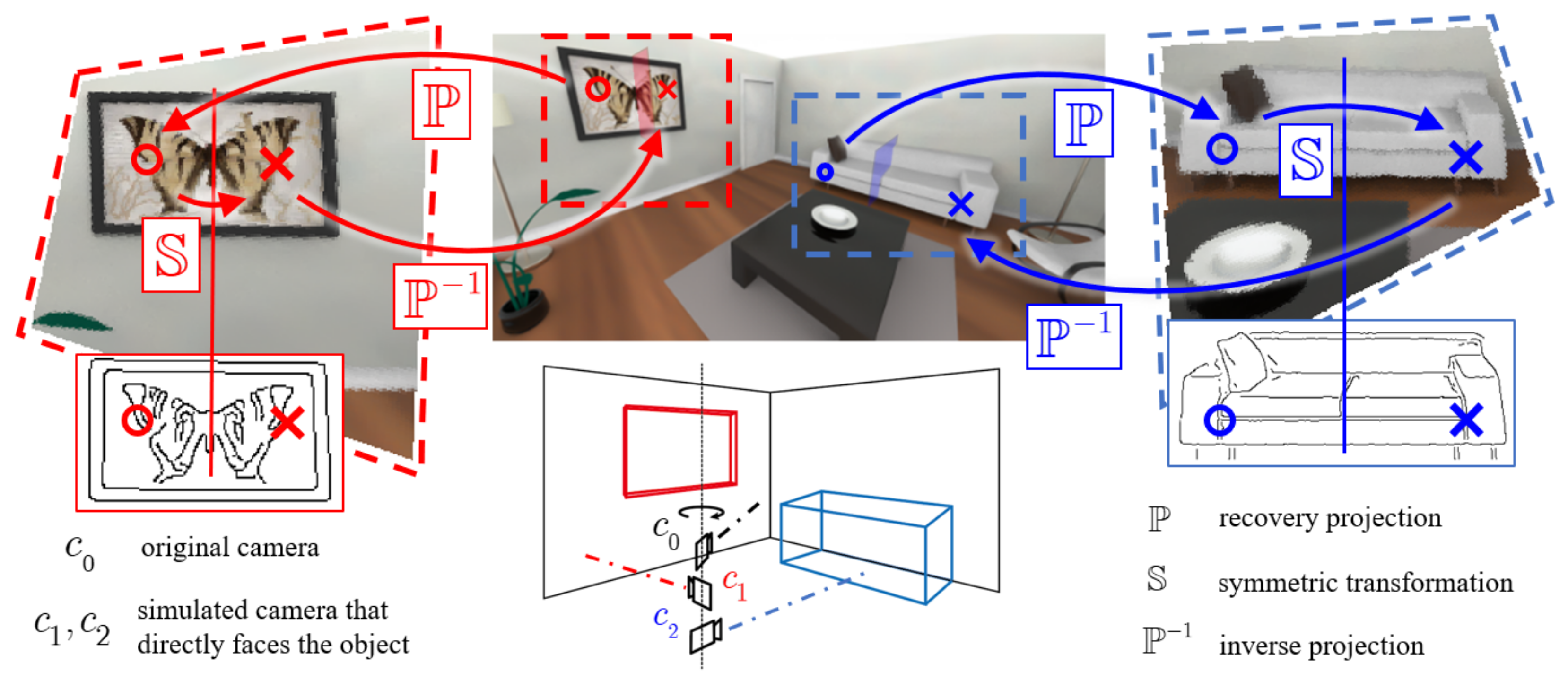
3.2. Projection to Recover Symmetry
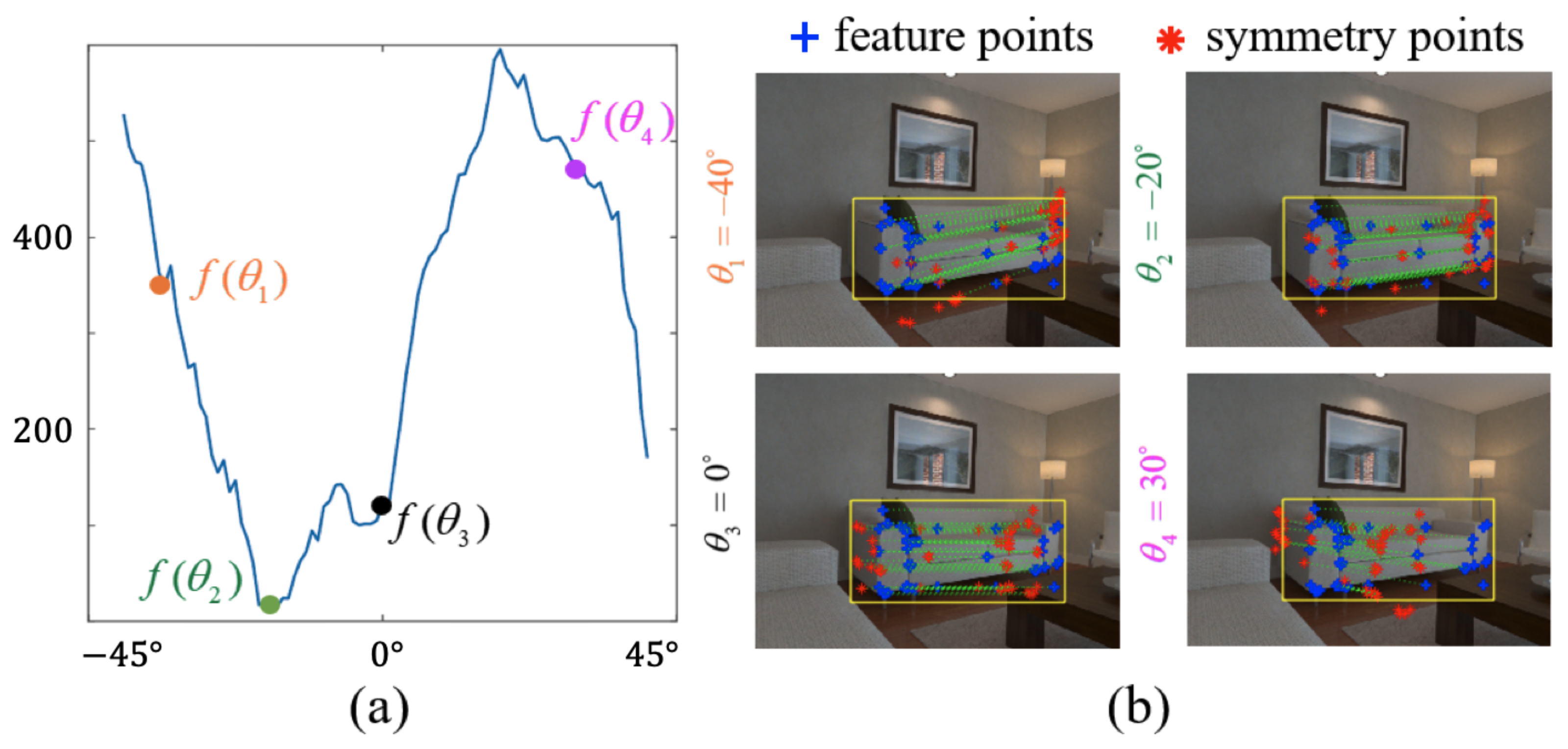
3.3. Obtain the Sampling Point and Symmetry Axis
3.4. System Overview
3.5. Factor Formulation
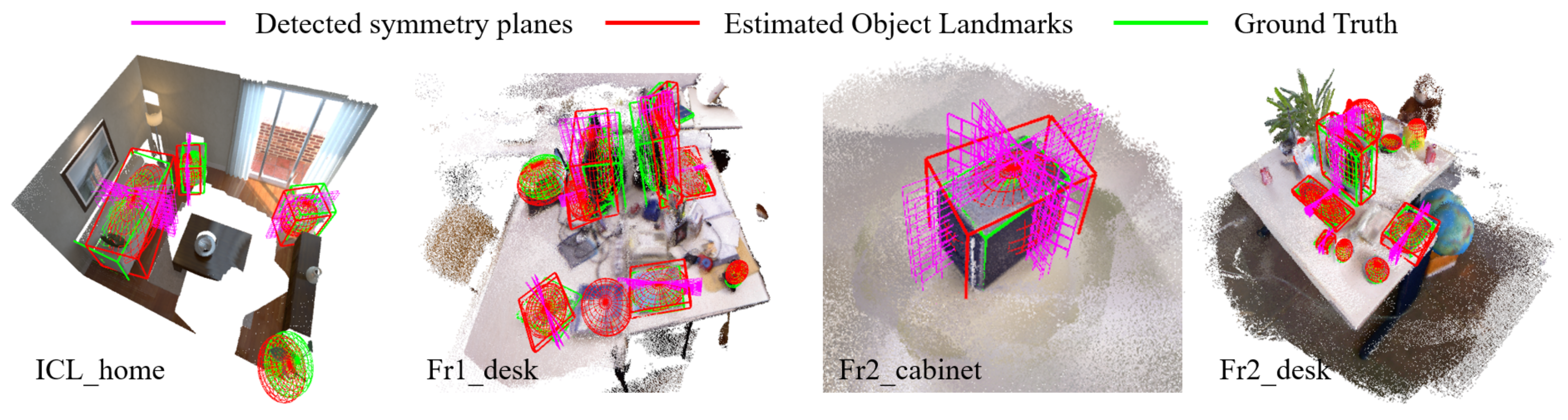
4. Results
4.1. Single-Frame Symmetry Plane Estimation
4.2. Multi-Frame Object-Mapping
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Javaid, M.; Haleem, A.; Singh, R.P.; Suman, R. Substantial capabilities of robotics in enhancing industry 4.0 implementation. Cogn. Robot. 2021, 1, 58–75. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B. Lego-Loam: Lightweight and Ground-Optimized Lidar Odometry and Mapping on Variable Terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4758–4765. [Google Scholar]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-Time Loop Closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Orb-Slam2: An Open-Source Slam System for Monocular, Stereo, and Rgb-d Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Garg, S.; Sunderhauf, N.; Dayoub, F.; Morrison, D.; Cosgun, A.; Carneiro, G.; Wu, Q.; Chin, T.J.; Reid, I.; Gould, S.; et al. Semantics for Robotic Mapping, Perception and Interaction: A Survey. Found. Trends Robot. 2020, 8, 1–224. [Google Scholar] [CrossRef]
- Runz, M.; Buffier, M.; Agapito, L. MaskFusion: Real-Time Recognition, Tracking and Reconstruction of Multiple Moving Objects. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 16–20 October 2018; pp. 10–20. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, Y.; Zhu, D.; Feng, Y.; Coleman, S.; Kerr, D. EAO-SLAM: Monocular Semi-Dense Object SLAM Based on Ensemble Data Association. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2021; pp. 4966–4973. [Google Scholar] [CrossRef]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3d Object Detection for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2147–2156. [Google Scholar]
- Yang, S.; Scherer, S. CubeSLAM: Monocular 3D Object SLAM. IEEE Trans. Robot. 2019, 35, 925–938. [Google Scholar] [CrossRef]
- Nicholson, L.; Milford, M.; Sünderhauf, N. QuadricSLAM: Dual Quadrics From Object Detections as Landmarks in Object-Oriented SLAM. IEEE Robot. Autom. Lett. 2019, 4, 1–8. [Google Scholar] [CrossRef]
- Hosseinzadeh, M.; Latif, Y.; Pham, T.; Suenderhauf, N.; Reid, I. Structure Aware SLAM Using Quadrics and Planes. In Proceedings of the Computer Vision—ACCV 2018; Jawahar, C.V., Li, H., Mori, G., Schindler, K., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; pp. 410–426. [Google Scholar] [CrossRef]
- Ok, K.; Liu, K.; Frey, K.; How, J.P.; Roy, N. Robust Object-based SLAM for High-speed Autonomous Navigation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 669–675. [Google Scholar] [CrossRef]
- Jablonsky, N.; Milford, M.; Sünderhauf, N. An Orientation Factor for Object-Oriented SLAM. arXiv 2018, arXiv:1809.06977. [Google Scholar]
- Liao, Z.; Hu, Y.; Zhang, J.; Qi, X.; Zhang, X.; Wang, W. So-slam: Semantic object slam with scale proportional and symmetrical texture constraints. IEEE Robot. Autom. Lett. 2022, 7, 4008–4015. [Google Scholar] [CrossRef]
- Roy, A.M.; Bhaduri, J.; Kumar, T.; Raj, K. WilDect-YOLO: An efficient and robust computer vision-based accurate object localization model for automated endangered wildlife detection. Ecol. Inform. 2022, 101919. [Google Scholar] [CrossRef]
- Chandio, A.; Gui, G.; Kumar, T.; Ullah, I.; Ranjbarzadeh, R.; Roy, A.M.; Hussain, A.; Shen, Y. Precise single-stage detector. arXiv 2022, arXiv:2210.04252. [Google Scholar]
- Jiang, B.; Chen, S.; Wang, B.; Luo, B. MGLNN: Semi-supervised learning via multiple graph cooperative learning neural networks. Neural Netw. 2022, 153, 204–214. [Google Scholar] [CrossRef] [PubMed]
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.; Davison, A.J. Slam++: Simultaneous Localisation and Mapping at the Level of Objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1352–1359. [Google Scholar]
- Chen, S.; Song, S.; Zhao, J.; Feng, T.; Ye, C.; Xiong, L.; Li, D. Robust Dual Quadric Initialization for Forward-Translating Camera Movements. IEEE Robot. Autom. Lett. 2021, 6, 4712–4719. [Google Scholar] [CrossRef]
- Tschopp, F.; Nieto, J.; Siegwart, R.; Cadena Lerma, C.D. Superquadric Object Representation for Optimization-Based Semantic SLAM; Working Paper; ETH Zurich, Autonomous System Lab: Zurich, Switzerland, 2021. [Google Scholar] [CrossRef]
- Sucar, E.; Wada, K.; Davison, A. NodeSLAM: Neural Object Descriptors for Multi-View Shape Reconstruction. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 949–958. [Google Scholar] [CrossRef]
- Shan, M.; Feng, Q.; Jau, Y.Y.; Atanasov, N. ELLIPSDF: Joint Object Pose and Shape Optimization with a Bi-Level Ellipsoid and Signed Distance Function Description. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5946–5955. [Google Scholar]
- Speciale, P.; Oswald, M.R.; Cohen, A.; Pollefeys, M. A Symmetry Prior for Convex Variational 3d Reconstruction. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 313–328. [Google Scholar]
- Srinivasan, N.; Dellaert, F. An Image-Based Approach for 3D Reconstruction of Urban Scenes Using Architectural Symmetries. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 362–370. [Google Scholar] [CrossRef]
- Liu, J.; Slota, G.; Zheng, G.; Wu, Z.; Park, M.; Lee, S.; Rauschert, I.; Liu, Y. Symmetry Detection from RealWorld Images Competition 2013: Summary and Results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Funk, C.; Lee, S.; Oswald, M.R.; Tsogkas, S.; Shen, W.; Cohen, A.; Dickinson, S.; Liu, Y. 2017 ICCV Challenge: Detecting Symmetry in the Wild. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 1692–1701. [Google Scholar] [CrossRef]
- Loy, G.; Eklundh, J.O. Detecting Symmetry and Symmetric Constellations of Features. In Proceedings of the Computer Vision—ECCV 2006; Leonardis, A., Bischof, H., Pinz, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 508–521. [Google Scholar]
- Cicconet, M.; Hildebrand, D.G.; Elliott, H. Finding Mirror Symmetry via Registration and Optimal Symmetric Pairwise Assignment of Curves. In Proceedings of the ICCV Workshops, Venice, Italy, 22–29 October 2017; pp. 1749–1758. [Google Scholar]
- Patraucean, V.; Grompone von Gioi, R.; Ovsjanikov, M. Detection of Mirror-Symmetric Image Patches. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Atadjanov, I.; Lee, S. Bilateral symmetry detection based on scale invariant structure feature. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3447–3451. [Google Scholar] [CrossRef]
- Atadjanov, I.R.; Lee, S. Reflection Symmetry Detection via Appearance of Structure Descriptor. In Proceedings of the Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 3–18. [Google Scholar]
- Elawady, M.; Ducottet, C.; Alata, O.; Barat, C.; Colantoni, P. Wavelet-Based Reflection Symmetry Detection via Textural and Color Histograms: Algorithm and Results. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Gnutti, A.; Guerrini, F.; Leonardi, R. Combining Appearance and Gradient Information for Image Symmetry Detection. IEEE Trans. Image Process. 2021, 30, 5708–5723. [Google Scholar] [CrossRef] [PubMed]
- Doherty, K.J.; Baxter, D.P.; Schneeweiss, E.; Leonard, J.J. Probabilistic Data Association via Mixture Models for Robust Semantic SLAM. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 1098–1104. [Google Scholar] [CrossRef]
- Zhang, J.; Yuan, L.; Ran, T.; Tao, Q.; He, L. Bayesian Nonparametric Object Association for Semantic SLAM. IEEE Robot. Autom. Lett. 2021, 6, 5493–5500. [Google Scholar] [CrossRef]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Sturm, J.; Burgard, W.; Cremers, D. Evaluating Egomotion and Structure-from-Motion Approaches Using the TUM RGB-D Benchmark. In Proceedings of the Workshop on Color-Depth Camera Fusion in Robotics at the IEEE/RJS International Conference on Intelligent Robot Systems (IROS), Vilamoura, Portugal, 7–12 October 2012. [Google Scholar]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A Benchmark for RGB-D Visual Odometry, 3D Reconstruction and SLAM. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1524–1531. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Label | Quadric-SVD | Quadric-SLAM | Cube-SLAM | Ours |
|---|---|---|---|---|---|
| ICL_home | Bench | 38.14 | 31.91 | 8.20 | 5.82 |
| Chair1 | 38.08 | 41.65 | 17.17 | 3.73 | |
| Chair2 | 34.79 | 43.22 | 35.78 | 5.45 | |
| Fr1_desk | TV | 49.30 | 49.30 | 33.96 | 17.51 |
| Book | 38.46 | 40.09 | 14.36 | 19.75 | |
| Keyboard | 34.70 | 36.50 | 19.74 | 6.97 | |
| Fr2_desk | Mouse | 54.11 | 59.13 | 22.03 | 29.08 |
| Keyboard | 40.82 | 24.89 | 15.31 | 10.72 | |
| TV | 41.65 | 20.88 | 42.76 | 19.22 | |
| Book | 53.37 | 44.96 | 7.28 | 12.85 | |
| Fr3_cabi | Cabinet | 19.98 | 18.31 | 4.17 | 11.44 |
| Real_robot | Chair | 10.87 | 11.31 | 24.73 | 10.07 |
| Bench1 | 41.53 | 11.01 | 36.64 | 11.58 | |
| Bed | 52.38 | 30.67 | 43.18 | 24.62 | |
| TV | 31.92 | 30.58 | 40.09 | 7.28 | |
| Average | 38.67 | 32.96 | 24.36 | 13.07 | |
| Datasets | Quadric-SVD | Quadric-SLAM | Cube-SLAM | Ours | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| T | R | S | T | R | S | S | T | R | S | |
| ICL_home | 0.85 | 39.15 | 0.10 | 0.29 | 37.14 | 0.30 | 0.49 | 0.21 | 6.14 | 0.65 |
| Fr1_desk | 0.40 | 46.99 | 0.31 | 0.33 | 47.39 | 0.40 | - | 0.08 | 12.21 | 0.45 |
| Fr2_desk | 0.34 | 36.70 | 0.25 | 0.24 | 38.13 | 0.42 | - | 0.10 | 11.85 | 0.48 |
| Fr3_cabinet | 0.06 | 19.98 | 0.34 | 0.05 | 18.31 | 0.33 | 0.64 | 0.05 | 9.87 | 0.43 |
| Real_robot | 1.58 | 29.85 | 0.24 | 1.14 | 25.51 | 0.19 | - | 0.31 | 24.60 | 0.35 |
| Average | 0.65 | 34.53 | 0.25 | 0.41 | 33.30 | 0.33 | - | 0.15 | 12.93 | 0.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, Z.; Han, J.; Wang, W. Detect Orientation of Symmetric Objects from Monocular Camera to Enhance Landmark Estimations in Object SLAM. Appl. Sci. 2023, 13, 2096. https://doi.org/10.3390/app13042096
Fang Z, Han J, Wang W. Detect Orientation of Symmetric Objects from Monocular Camera to Enhance Landmark Estimations in Object SLAM. Applied Sciences. 2023; 13(4):2096. https://doi.org/10.3390/app13042096
Chicago/Turabian StyleFang, Zehua, Jinglin Han, and Wei Wang. 2023. "Detect Orientation of Symmetric Objects from Monocular Camera to Enhance Landmark Estimations in Object SLAM" Applied Sciences 13, no. 4: 2096. https://doi.org/10.3390/app13042096
APA StyleFang, Z., Han, J., & Wang, W. (2023). Detect Orientation of Symmetric Objects from Monocular Camera to Enhance Landmark Estimations in Object SLAM. Applied Sciences, 13(4), 2096. https://doi.org/10.3390/app13042096