1. Introduction
Social networking platforms play a seamless and intact role in the contemporary digitized world [
1]. The prevalence of information and communication technologies has escalated to the extent that approximately more than half of the human population has a social identity, cumulatively making up more than 3.6 billion people using social media [
2]. This immense user base makes these sites a global discussion forum and an effective tool for the exchange of information, textual communication, collaboration, and sharing of knowledge and ideas. The social network equipment creates a global communication hub among numerous communities and cultures for pruning distances and allowing free speech without borders. Since more voices are empowered and shared, this could serve as myriad benefits to society [
3]. Undeniably, on the positive side, it provides convenience and promotes global unity, but on the darker side, it has also been reported to widely spread cybercrime and cyberhate [
2]. Researchers and scholars worldwide have highlighted the possible perils, hate speech, and cyberbullying dissemination [
4]. Cyberbullying (synonymously known as cyber-harassment, cyber-aggression, and hate speech) is an aggressive, intentional act (such as sending unwanted, derogatory, threatening, offensive, embarrassing, or hurtful messages/comments) carried out by a group or individual using digital technologies against a victim who cannot easily protect him or herself” [
5]. The United Nations defines the term as follows:
“any kind of communication in speech, writing or behaviour, that attacks or uses pejorative or discriminatory language concerning a person or a group based on who they are, in other words, based on their religion, ethnicity, nationality, race, colour, descent, gender or another identity factor” [
6].
Cyberbullying is a kind of violence accomplished using various electronic forms to threaten an individual’s physical or mental well-being, thus inducing emotional, behavioral, and psychological disorders among its victims. Research studies reported cyberbullying victims to have higher levels of depression, poor self-esteem, and increased social anxiety [
7]. The speech freedom feature offered by social platforms has posed risks in numerous ways and is misused by immoral users to elevate hate speech and abusive content. Though, to an extent, adults can manage this peril, children and teenagers are more susceptible to serious mental health issues [
8]. Moreover, the COVID-19 pandemic is a double-edged sword [
9]. The pandemic caused a considerable surge in online traffic. The drastic shifts in lifestyles and adaptation of new social practices and habits resulted in an upsurge in cyberbullying cases. A report, “COVID-19 and Cyber Harassment” by Digital Rights Foundation (DRF) Pakistan in 2020, highlights a considerable upward shift in cyberbullying and harassment incidents during the COVID-19 epidemic. The complaints registered with DRF’s Cyber Harassment cell were escalated by 189% [
10].
This distressing problem of automatic cyberbullying detection, associated with social and ethical challenges, has gained huge research attention in natural language processing and artificial intelligence. Not only is it onerous, but since social networks have become a vital part of individuals’ lives and the consequences of cyberbullying can be appalling, specifically among adolescents, it is also a relevant need [
11]. The growing interest of the research community is evident from the recent workshops on cyber social threats such as cySoc 2022, TRAC, and WOAH 2022. Though many social media platforms have established policies for the moderation of the content and blocking or restricting the hateful content, due to the massive scale of generated big data, we need automated data analytic techniques and proactive systems to critically and rigorously investigate cyberbullying and toxic content in real-time.
In this regard, as detailed in the Literature Review section, most of the existing research work is directed toward resource-rich languages. The Roman Urdu language has been recent adoption on social media, specifically in south Asian countries, and is highly resource deficient.
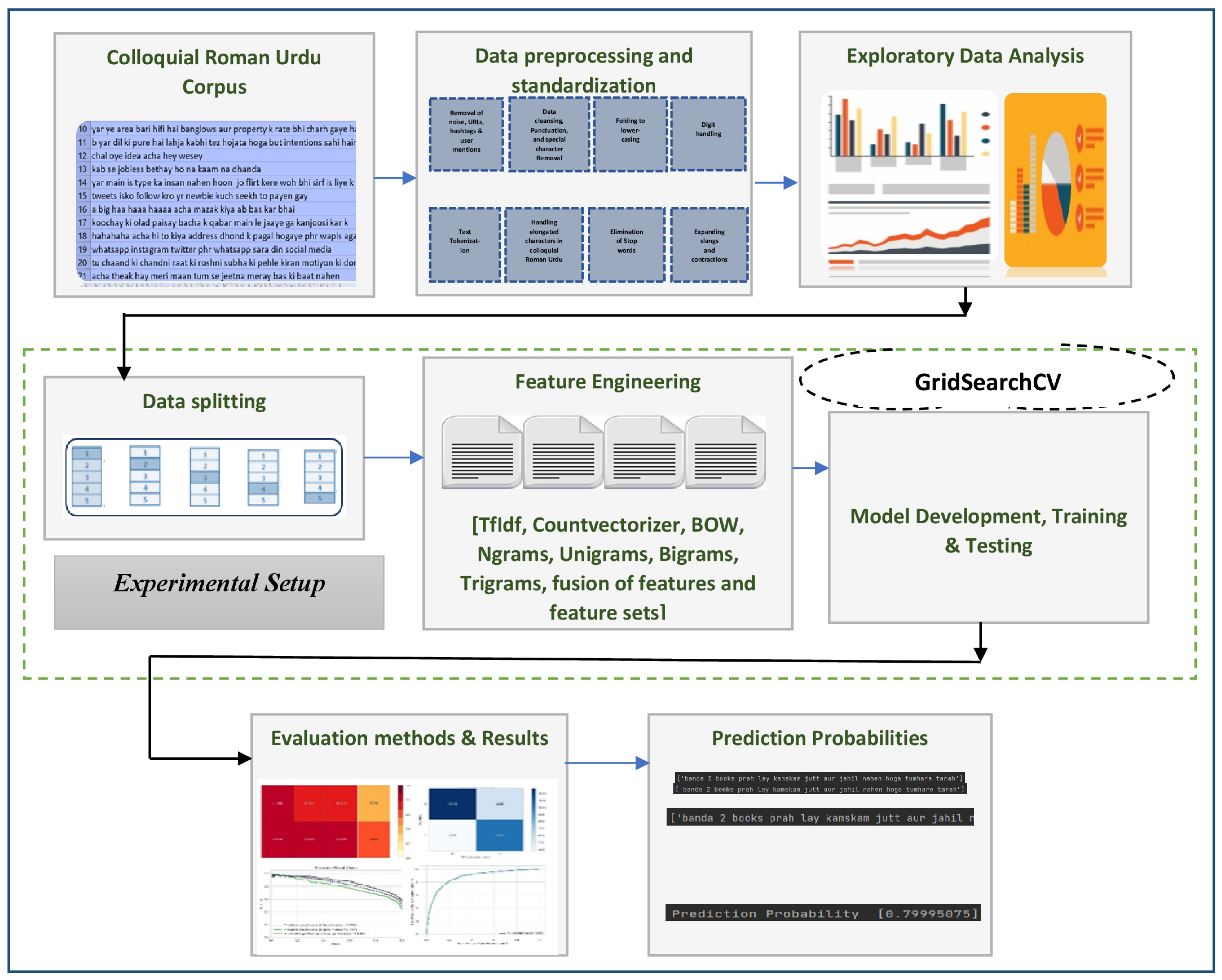
Section 3 details the script, morphology, and challenges associated with the Roman Urdu language. This study puts novel efforts into addressing cyberbullying detection research problems in low-resource Roman Urdu language using natural language preprocessing, machine learning, and ensemble techniques. We have used explicitly designed preprocessing methods to handle unstructured micro text. The complications in analyzing the patterns and structure behind implicit and explicit cyberbullying behaviors, typically in newly embraced colloquial languages, and devising it as a comprehensive computational task is quite challenging.
The key objectives of this research work are as follows:
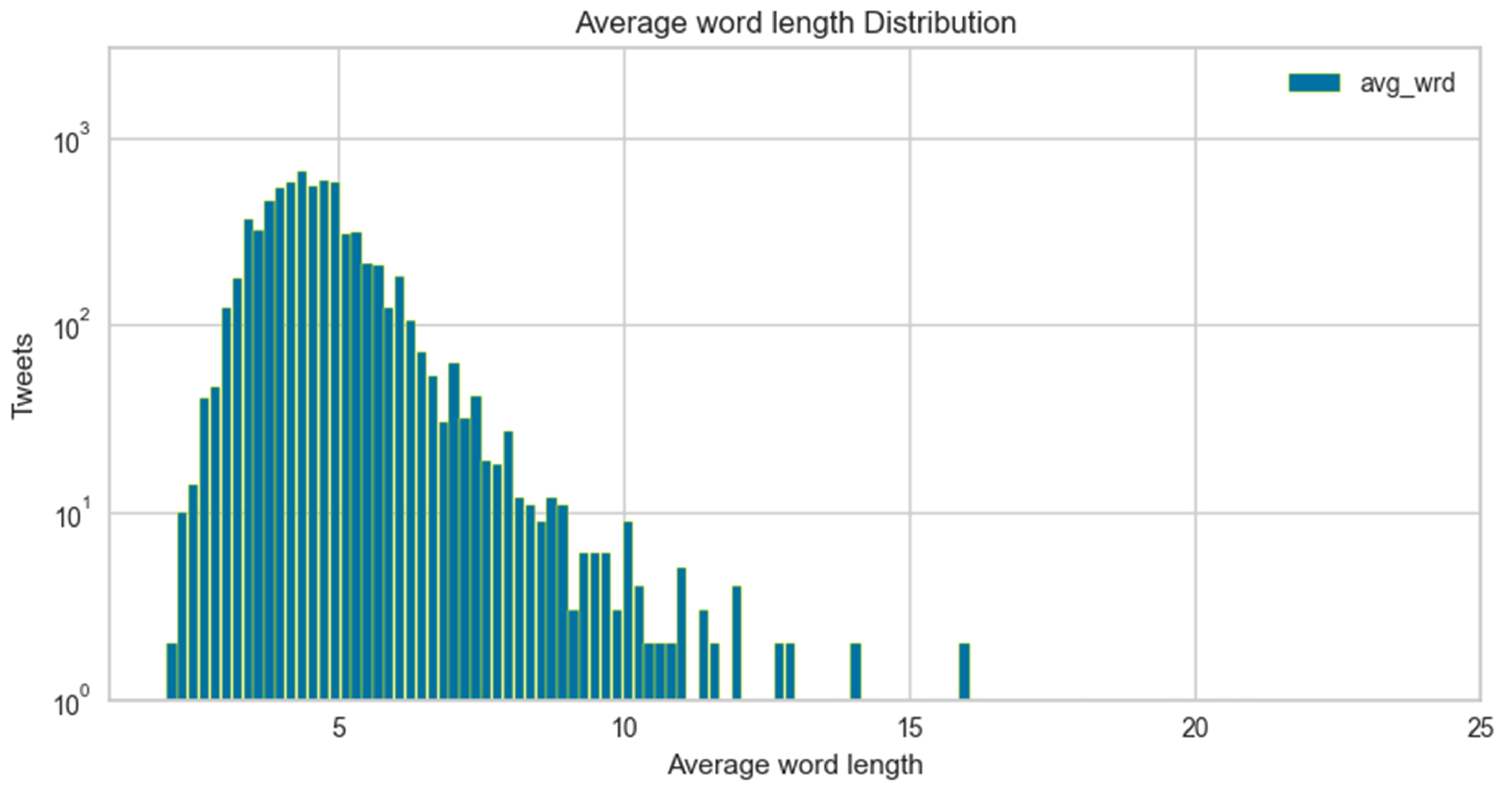
Analyzing low-resource colloquial Roman Urdu language text structure and performing exploratory data analysis to visualize data.
To devise a mechanism for performing advanced preprocessing techniques on Roman Urdu micro text and systematically applying the appropriate preprocessing phases to improve classification performance. This will also have broad implications over other natural language processing applications.
This research proposes an approach based on seven techniques combining ML and ensemble methods with a fusion of a vast number of features, GridsearchCV and experimentation to detect hateful and cyberbullying patterns in natural writing patterns of Roman Urdu text data.
To evaluate the performance and time efficiency of the proposed approach and visualize results.
The rest of this paper is structured as follows:
Multilingual research and related works are presented in
Section 2.
Section 3 states the structure of low resource Roman Urdu language and discusses the associated challenges.
Section 4 elaborates the methodology used to accomplish this research work and highlights important phases and steps.
Section 5 discusses Roman Urdu corpora.
Section 6 details the systematic phases for advanced preprocessing and standardization on Roman Urdu micro text.
Section 7 highlights exploratory data analysis to investigate data and understand important patterns and insights. Experimental setup and model hypermeters are specified in
Section 8.
Section 9 highlights and discusses study results.
Section 10 elaborates the estimation of prediction probabilities for implicit and explicit instances. Finally,
Section 11 concludes the research work and provides future directions for the research community.
2. Related Work and Multilingual Research
This section presents an extensive survey regarding the techniques and advancements in multilingual hate speech and cyberbullying detection research.
The field of AI has gained enormous research attention worldwide. We understand AI as “machine-learning-based systems with the ability to interpret external data correctly, to learn from such data, and to use those learnings to achieve specific goals and tasks through flexible adaptation” [
1]. Gaining insights from the big data, scholars establish solutions and models that aim to identify toxicity, cyberbullying instances, and hate speech via various techniques and NLP-based tools [
12]. AI-based automated cyberbullying detection is gaining enormous attention of researchers, a progress that is also reflected in the scientific literature (such as [
13,
14,
15]). Identifying cyberbullying is undeniably challenging since there are controversies about how cyber hate speech should be defined. The content can be perceived as cyberbullying and hate speech by a group, not by others, based on their individual subjective assessment and respective definitions.
Currently, there are three significant paradigms of analysis, namely, the network analysis, the content analysis, and the fusion of both the network and content analysis. The network analysis usually considers the usage statistic parameter of digital media, such as data of sender and receiver; users’ names, content, location, and time of communication; account IDs; and so on. The content analysis is typically focused on analyzing textual data and using natural language preprocessing techniques involving data acquisition, corpora development, text preprocessing, feature extraction, feature selection, and text-based classification [
12].
A systematic review of the related articles on various digital libraries and study of review papers is evident that most of the research on content analysis, usage of computational methods, and ML algorithms for cyberbullying detection was only after 2011 [
16]. Research work in [
17] by Dinakar et al. on cyberbullying detection from textual data is a highly cited study in the literature and is considered one of the pioneers. They split the task based on the sensitive topics in text-classification sub-problems and extracted textual comments on controversial YouTube videos. The study formed a detection approach based on SVM, naive Bayes, and J48 binary and multiclass models incorporating specific feature sets. They concluded that the performance of binary classifiers outweighs multiclass classifiers. A study in [
18] performed at yahoo labs developed a corpus by taking comments posted on yahoo related to news and finance. The data were annotated for abusive language. Amazon’s Mechanical Turk experiment was conducted, and Vowpal Wabbit’s regression model was used. Work conducted in [
19] uses a deep learning-based approach for detecting racism and sexism-related hate speech. They trained a convolutional neural network and created word vectors using semantic information and 4 g, which were then downsized for classification. They incorporated 10-fold cross-validation based on word2vec, and the overall f-score was 78.3%. In contrast, a study in [
20] presented a time-aware supervised learning model-based profile, session, and different other comment-related features to detect anti-social and bullying instances from data. The model also penalized late detections. Work accomplished by Maral Dadvar et al. in [
21] compares supervised models, expert systems, and a hybrid model combining the two. Pawar et al. in [
22] employed the distributed computing technique for the detection of cyberbullying instances. Rather than only focusing on detection accuracy, their work also emphasizes robust performance. A study in [
23] proposed a weakly supervised approach inferring vocabulary indicators and user roles in harassment. The model uses small seeds of vocabulary for a large corpus to extract bullying traces. Cynthia Van Hee, Gilles Jacobs et al. in [
24], suggested a model using social media text written by bullies, victims, and bystanders for automatic cyberbullying detection. They described fine-grained annotation on English and Dutch language corpora. The model was based on a support vector machine algorithm and exploited a rich feature set and information sources that contributed most positively to the detection task. They developed an approach and produced 64% accuracy for the English language and 61% for the Dutch language. Work accomplished in [
25] formed a cyberbullying detection algorithm on an unbalanced dataset intended to minimize the cyberbullying alert generation time by reducing the number of feature evaluations. The algorithm design was based on Instagram data and supervised ML techniques.
Several studies have recently been published addressing the English language, and considerable research has been carried out recently in languages such as Urdu [
26] and Arabic [
27], among others. Work carried out in [
28] was an initial attempt towards Turkish language hate speech detection. They formed a corpus of textual comments in the Turkish language, which was unbalanced in nature with respect to abusive and non-abusive contents and performed sentiment annotation. The study implemented CNN, machine learning classifiers, reweighted classifiers, social media features, NGrams, and weighing schemes to improve detection quality. The Arabic language hate speech detection task is addressed in [
27]. The study developed an algorithm for the Arabic language based on word vectors, normalizing techniques with NLP, and supervised ML techniques. The corpus used for experimentation was unbalanced. Work suggests limitations in performance, which is approximately 0.30 in different metrics. Offensive and hate speech categorization for Danish language textual data was focused in [
29]. The work proposed a detection framework generated mainly using Logistic Regression, Learned-BiLSTM (10 Epochs), Fast-BiLSTM (50 Epochs), and AUX-Fast-BiLSTM (40 Epochs). Different experimental settings could achieve an F1-score of 0.7.
Due to the pervasiveness of social media content and their possible adverse impacts and alarming consequences on human well-being, an enormous number of academic events and shared tasks on linguistic analysis and identification of offensive and hate speech textual data have also taken place globally. Some of them include the GermEval 2021 Shared Task on the identification of toxic, engaging, and fact-claiming comments [
30]; The First workshop on trolling, aggression, and cyberbullying (TRAC-2018), which focused on the phenomena of online aggression, trolling, and cyberbullying [
31]; OffensEval 2020, which addressed multilingual offensive language identification in social media at an international workshop on semantic evaluation 2020 (SemEval 2020); and EVALITA 2018 [
32], a shared task addressing Italian social media data. Communication by masses in regional dialects has become commonplace in the contemporary era. In its colloquial form, Roman Urdu has been widely adopted by Asian communities to share opinions and ideas easily. Recently, a limited number of preliminary research studies have also been contributed to in the Roman Urdu language. Work contributed in [
33] is based on a lexicon-based approach and extracted unique words separated in bully and non-bully lexicons and polarity scores to categorize contents. While these approaches work fairly well when the text contains an explicit hate or abusive word, they often pose limitations in detecting implicit ones. Research in [
34] proposed a CNN-gram model for offensive language detection. A corpus of almost 10k tweets was developed in RU with both coarse-grained and fine-grained labels. The study is limited in terms of preprocessing techniques, skewed datasets, and colloquial patterns generated by Roman Urdu users. Moreover, the literature suggests deep learning and neural network-based techniques to consume more computational resources, data, and time, thus making them less appealing for real-time applications such as cyberbullying and hate speech detection.
Roman Urdu is a resource-scarce language because of its huge morphological complexity and recent adoption. Because of the inadequacy of resources, despite being a frequently used language globally and in South Asia, only a few efforts have been put forward, as evident from the current scientific literature. The existing systems are also lacking in addressing the challenges such as word variants, naturally occurring highly unbalanced Roman Urdu content on social media, irregular use of capitalization, domain-specific standardized preprocessing methods, and so on. Motivated from this, we address the limitations by considering inherent writing patterns of colloquial Roman Urdu language users and grammatical structure variabilities, focused on novel preprocessing techniques for free text forms. The study has used a comparatively balanced Roman Urdu corpus hand annotated by linguistic experts and validated using Kohen’s kappa statistic. We have developed machine learning and ensemble-based models over many features. Instead of merely considering accuracy, we checked the performance of models and evaluated their time complexity. The performance of models is then compared for efficiency and time complexity.
3. Roman Urdu Language Structure and Challenges
In the recent era, social networks and weblogs publish a massive variety of content and constitute an indispensable hub of information mined for the research community. The unstructured big data (aka eData) produced by these platforms highly deviate in the context of standard dialect, grammatical rules, and lexicons [
35]. These idiolects produce non-standard words in the language lexicon, phonological variations, and syntactic and grammatical variations, thus distinguishing the textual social media form of the language from its corresponding standard counterpart.
Recently, on different social media platforms, the Roman Urdu language has been adopted as a contemporary trend and feasible medium for communication. It originated from the Urdu language, a morphologically rich language with a complex inflectional system. The Urdu language is considered to be the 21st most widely spoken language worldwide and is also called the “Lashkari language” (لشکری زبان) [
36]. It is the national and official language of Pakistan, i.e., “Qaumi Zaban,” and is primarily spoken across different regions and communities [
37]. While Urdu is written in Nastaliq script, Roman Urdu language is written via LTR (Left-to-Right) writing and is based on Roman scripting. A survey statistic presented in [
38] states that there are 300 million people across the globe who speak Urdu language and nearly 11 million Urdu users are in Pakistan, from which the maximum users on social media has recently shifted to informal, colloquial Roman Urdu language for the textual messaging. Roman Urdu is a linguistically rich language and highly differs in the aspect of word structures, irregularities arising from natural writing patterns, and grammatical compositions adopted by users as compared to formal Urdu. There are no diacritics marks (‘zer’, ‘zabar’, ‘pesh’, etc.) in roman Urdu. It is a deficit of standard lexicon and available resources and hence becomes extremely problematic when performing NLP tasks.
A clear elaboration of Roman Urdu LTR pattern script and Urdu RTL scripting is depicted in
Table 1.
The lack of rules and colloquial adoption of this language by social media users also results in a much higher word surface. For example, the word ‘good’ in English is written as ‘acha’ in Urdu in masculine form, feminine form, and singular and plural forms. However, the number of words increases many-fold when written in the Roman Urdu language such as ‘acha’ (masculine form), ‘achi’ (feminine form), achay (plural form), and so on. Moreover, people use their own spellings, writing structures, and elongated characters.
Although the Urdu language has a formal structure and the availability of few resources, colloquial Roman Urdu has no standard and formal structure, and no resources are available to standardize it. The scarcity and lack of language resources make it challenging to analyze and apply data analytics techniques for deducing useful knowledge from text. To cope with this, rigorous language resources, language-specific preprocessing steps, techniques, and well-devised methodologies are needed.
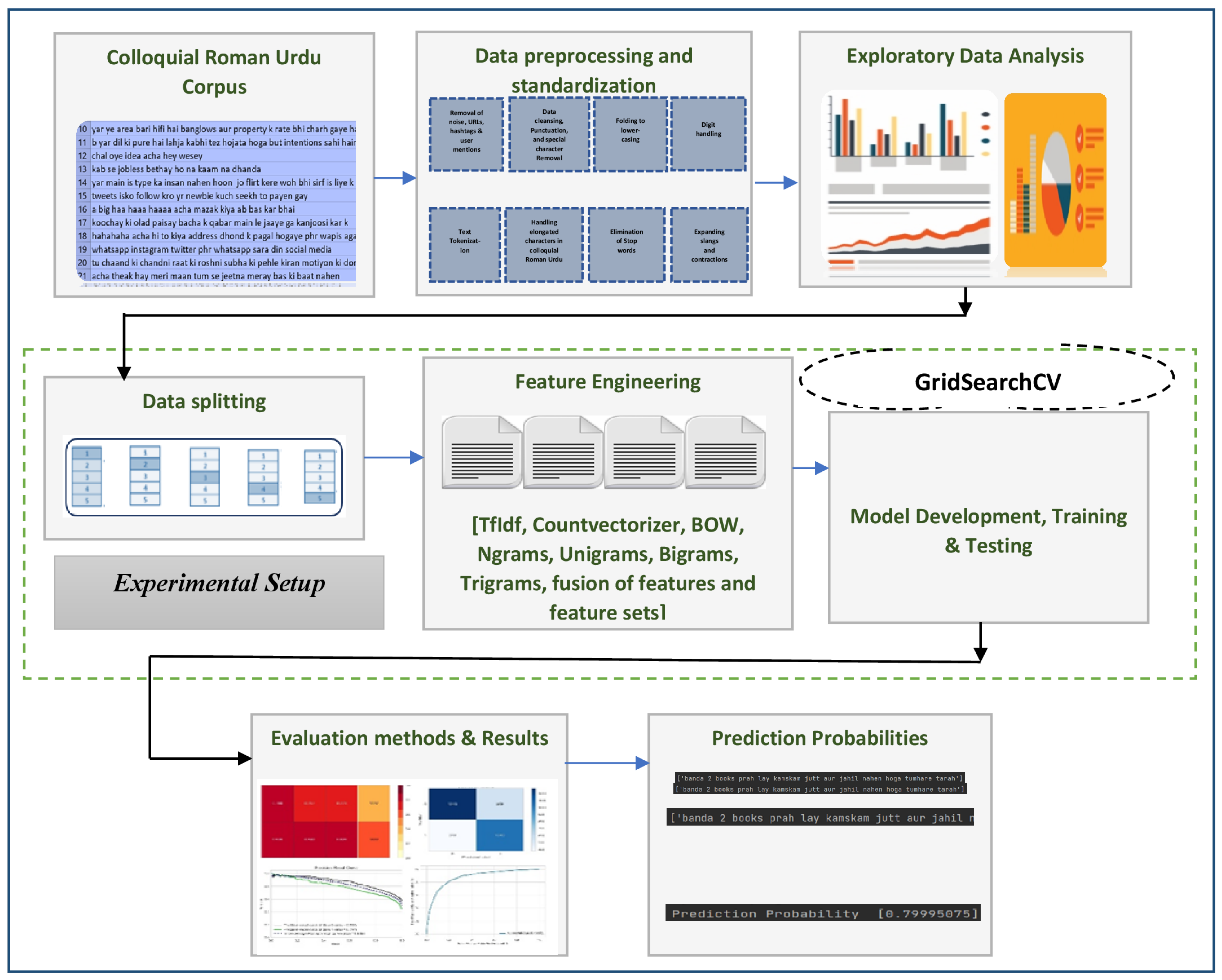
8. Experimental Setup
This section details the proposed models, ensemble techniques, and feature engineering for Roman Urdu cyberbullying detection. To clean and prepare the data for the training phase, the tweets from the Roman Urdu corpus were processed via different language-specific preprocessing phases detailed earlier in
Section 4. Then, various classification models and ensemble techniques were investigated. The experiments and simulations for this research work were carried out on 11 Gen, core i7, with 4 cores, 8 logical microprocessors, 2.8 GHz processor speed, 256 GB Solid State Drive, and python version 3.8, 64 bits.
The models were developed and trained mainly in Scikit-learn and XGBoost apart from numerous other packages. Scikit learn is developed on top of SciPy, NumPy, and matplotlib. It is a robust package providing important and efficient tools for machine learning and statistical learning. XGBoost is an optimized distributed gradient boosting library developed to be highly adaptable, efficient, and portable. The PyCharm IDE was used to accomplish all the implementations. The optimality in results and parameters was achieved via repeated experimentation and GridSearchCV.
The setup involved experimenting with several techniques. Precisely, we investigated the efficiency and performance along with the time complexity for Multinomial Naive Bayes, SVM, Logistic regression, Decision Tree, AdaBoost, XGBoost, and Bagging classifiers. The ensemble learning mechanism combines individual models to improve predictive power and stability. The results were derived based on the vast number of n-grams, n-gram combinations, and statistical features extracted from Roman Urdu preprocessed textual comments. The five-fold cross-validation method is used to evaluate and analyze the performance. The results are elaborated on in the evaluation methods and results section.
Feature Engineering
Text data are inherently highly dimensional in nature. The curse of the multidimensionality issue arises when ML techniques are implemented on high-dimensional data, thus resulting in sparsity, which impacts the classifier’s predictive accuracy. Identifying and categorizing learning patterns from voluminous data is extremely challenging and computationally expensive since repetitive and inappropriate features impede performance in text classification problems. Moreover, In the Roman Urdu language, due to huge lexical variations (refer to
Section 3), a single word gives rise to many dimensions making it more problematic. Extracting significant and relevant features is mandatory to cope with this curse of dimensionality.
The text vectorization was carried out using Count vectorizer and Tfidf techniques after the removal of domain-specific stop words. Count Vectorizer transforms the text document collection into a matrix of integers. It yields a sparse representation using the scipy.sparse.csr_matrix in python. TF–IDF (Term frequency–Inverse document frequency) is an algorithm based on word statistics for text feature extraction. It is intended to reflect the significance of a term in the corpus or the collection. Mathematically, it is described by Equation (
1).
where w(d, t) is the TF–IDF of the weight of a term t in a document N represents the number of documents and df(t) highlights the number of documents in the corpus containing the term t. In the above-given equation, the first term enhances the recall, whereas the second term enhances the word embedding accuracy [
45].
Apart from statistical features, the word-level n-gram features are used in this study, i.e., unigrams, bigrams, trigrams, and hybrid features, i.e., uni-bigram (unigram + bigram), uni + trigrams (unigrams + trigrams) and bi-trigrams (bigrams + trigrams). They are used in combination with countvectorizer and tfidf. Consider a Roman Urdu text: “Wo tha bhi itna bonga aadmi”. This will generate the sequence of unigrams + bigrams as: (‘wo’), (‘tha’), (‘bhi’), (‘itna’), (‘bonga’), (‘aadmi’), (`wo’, `tha’), (`tha’, `bhi’), (`bhi’, `itna’), (`itna’, `bonga’), (‘bonga’, `aadmi’). The drawn features were also used in the form of feature sets.
9. Evaluation Methods and Results
This section provides the results of the performance and efficiency of the proposed models, which were examined using a series of experiments and various evaluation parameters via GridSearchCV. We incorporated five-fold cross-validation and averaged the results. In this work, machine learning and ensemble algorithms were constructed, namely SVM, Multinomial NB, LR, DT, AdaBoost, XGBoost, and Bagging classifier. This study performed the analysis using the standard assessment and evaluation metrics, including accuracy, the area under the receiver operating characteristic curve (AUC) curve, Precision, Recall, precision–recall curve, and the F1-score. Accuracy (A) is defined as the proportion of the total number of correct predictions. It can be calculated as the ratio of correctly classified instances to the total number of instances and can be computed as given in Equation (
2).
Precision (P) is the measure of the exactness of the model results. It is the ratio of the number of examples correctly labeled as positive to the total number of positively classified examples. It is given in Equation (
3).
Recall (R) is the overall coverage of the model. It measures the completeness of the classifier results. Recall shows how many of the total instances are correctly classified as cyberbullying instances. It can be identified as in Equation (
4).
F1 score is the weighted average of precision and recall. It is a harmonic mean of precision and recall. Usually, the F1 score is more beneficial than accuracy when even the minor class distribution imbalance occurs. Mathematically, it can be computed as given in Equation (
5).
The results for mean accuracy scores (including standard deviation) of algorithms based on extracted feature vectors are depicted in
Table 5.
All of the significant results are highlighted in bold. It can be observed that the SVM model outperforms with the highest accuracy score of 83% on tfidf and unigrams and combined N-grams, i.e., unigrams and trigrams followed by the LR model. LR produces an accuracy of 80% on tfidf and unigrams closely followed by combined Ngrams with 79% accuracy level. Voting-based ensemble models Adaboost, XGboost, and bagging are unique in this study and we have validated the prediction of tweet labels by achieving the optimal accuracy level of 70%, 79%, and 78%, respectively. These levels were reached typically over tfidf and unigrams, and a combination of unigrams and bigrams.
The performance evaluation of models based on precision (P), recall (R), and F-score (F1), including standard deviation, is presented in
Table 6.
Table 6 shows the mean results of each technique for the highest accuracy levels and feature parameters. Considering the F1-score (for both cyberbullying and non-cyberbullying scenarios), SVM, LR, and multinomial naïve Bayes and among ensemble techniques, XGboost and bagging were the best-performing algorithms.
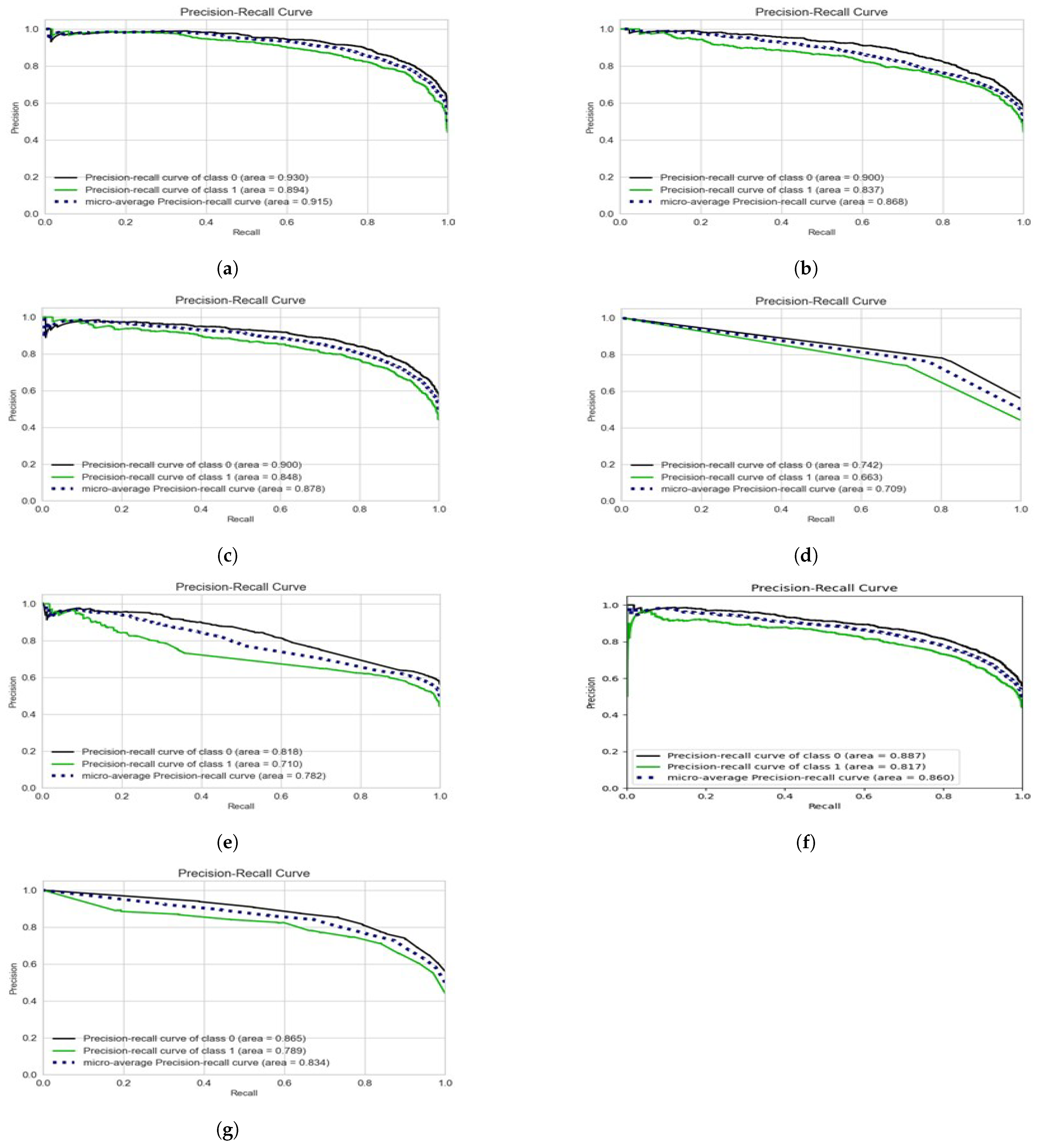
We use the precision–recall (PR) curve as the visual representation for all the experimentations as presented in
Figure 12. For each potential cut-off, the connection between precision (positive predictive value) and recall (sensitivity) is defined by a precision–recall curve. It illustrates the trade-off between recall and precision for various thresholds. Among the machine learning methods, over a cyberbullying class, SVM with the combination of unigrams and TFIDF feature set depicts the best precision–recall area.
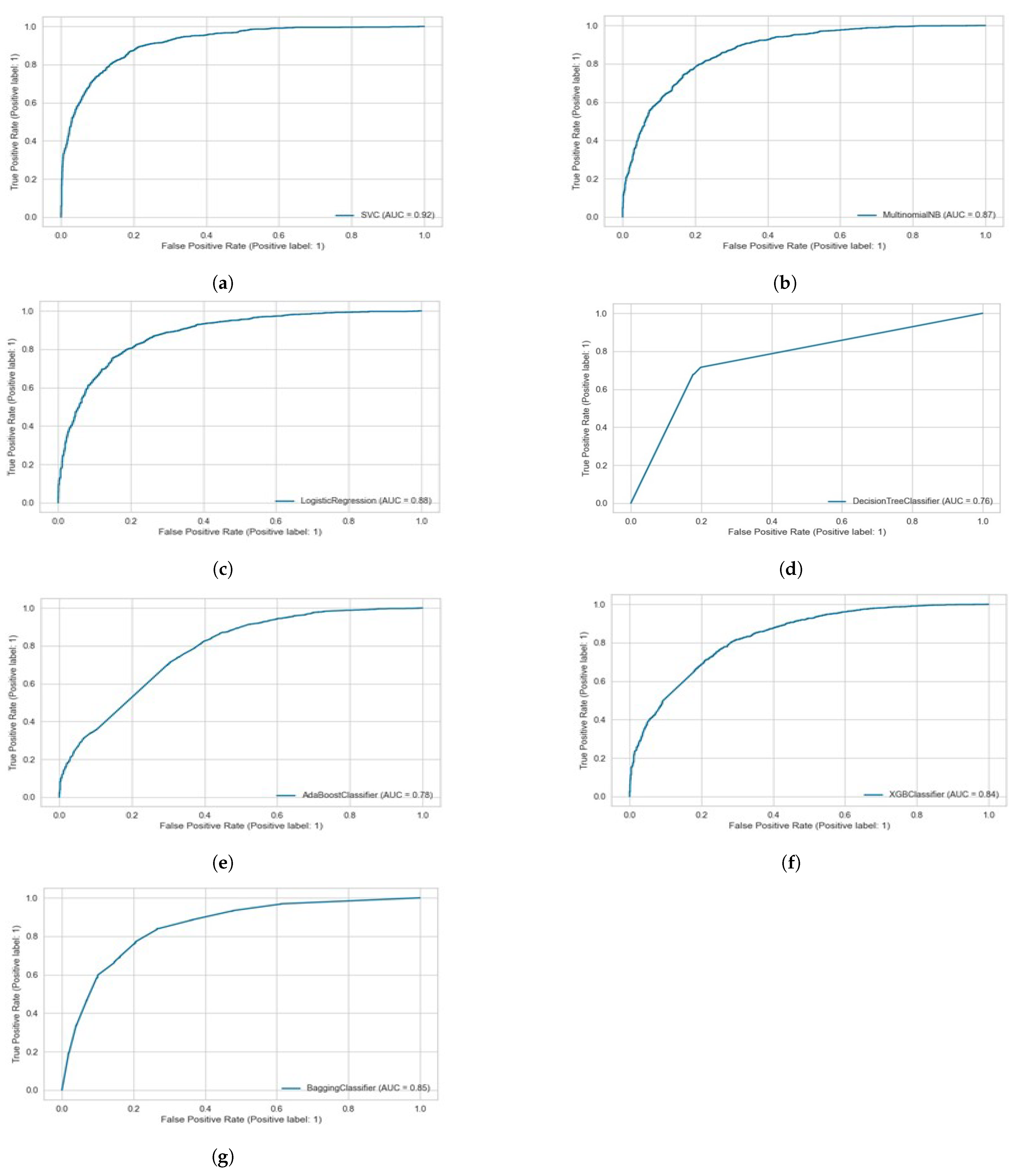
We also visualized the performance of the proposed models using the AUC metric, the area under the receiver operating characteristics (ROC) curve. It is a metric used to assess a classification model’s performance at different thresholds. In binary classification, the thresholds are various probability cutoffs that separate the two classes. It employs probability to use the model’s capacity to distinguish between classes.
Figure 13 presents the AUC curve of the proposed models for the Roman Urdu dataset at hybrid N-Grams and tfidf unigrams. We can observe from the figure that the proposed models show significantly optimal results over SMV and LR. It also highlights better results on the ensemble bagging classifiers over tfidf and unigrams.
Bag-of-words (BOW) features were extracted from Roman Urdu data using Count Vectorizer. The results for mean accuracy, precision, recall, and F1-score, including standard deviation, specifically over the cyberbullying class are highlighted in
Table 7. Most significant results are bold. It can be observed that the LR algorithm produced optimal accuracy of 82% and an f1-score of 79% over cyberbullying class among ML techniques, whereas, from ensemble techniques, the Bagging ensemble algorithm provided better performance with an accuracy score of 78% and F1-score of 72%.
To extract more significant conclusions, we plotted the classifier results when training and testing over the BoW approach. The summary of model comparison over various evaluation metrics is presented in
Figure 14.
Time Complexity
The time complexity of algorithms in terms of average execution time (training and testing time) is illustrated in
Table 8. Results in
Table 8 indicate that LR was the fastest algorithm to execute in overall experimentation and has achieved the best training and prediction time of 0.06 s, closely followed by multinomial naïve Bayes and Adaboost with 0.156 and 1.63 s, respectively. Whereas SVM consumed the worst time of 35.1 s for training and prediction. However, SVM also outperforms in terms of accuracy, compared on all the models implemented and experimented in this research. The ensemble method XGboost took the second-longest execution time, followed by the Bagging classifier.
11. Conclusions and Future Work
This research work puts novel efforts to address cyberbullying detection problems for both implicit and explicit patterns on social media using Roman Urdu corpora comprising colloquial natural writing styles of users. Our findings contribute to analyzing and understanding colloquial patterns of low-resource Roman Urdu language and associated challenges. The study established advanced preprocessing techniques, typically developed for Roman Urdu corpora to enhance the efficiency and performance of the proposed techniques. We conducted vast experiments using seven text categorization approaches based on machine learning models and ensemble techniques and compared the performances using standard assessment metrics and visualization methods. All the experiments were carried out using Python’s Pycharm IDE. Most suitable parameter values were identified using Grid search. Among ML-based text categorization, SVM with a fusion of Ngrams and Tfidf produced the most satisfactory results. In ensemble techniques, extreme gradient boosting (XGBoost) yields optimal performance with an accuracy of 78%, closely followed by the bagging technique with an accuracy score of 78%, though with relatively greater time complexity as compared to adaptive boosting (Adaboost). The time complexity of algorithms, comprising training and testing durations, was also assessed. Time evaluations indicate that LR produced the optimal execution time of 0.06 s followed by multinomial NB and Adaboost ensemble technique over a fusion of Ngrams. The probability estimations were identified for different scenarios. The major contribution of this research work is the achievement of promising results in the identification of implicit and explicit cyberbullying patterns over both classes in colloquial Roman Urdu text via vast experimentation on machine learning, voting-based ensemble methods, and hybrid features. The models proposed in this research can be implemented and embedded as social media filters to prevent or at least reduce the harassment and bullying instances in the Roman Urdu language that can cause anxiety, depression, emotional changes, and even in some cases may end up in deadly consequences. Additionally, it will help cybercrime investigative teams and centres to monitor social media content and make the internet a secure and safer place for all facets of society.
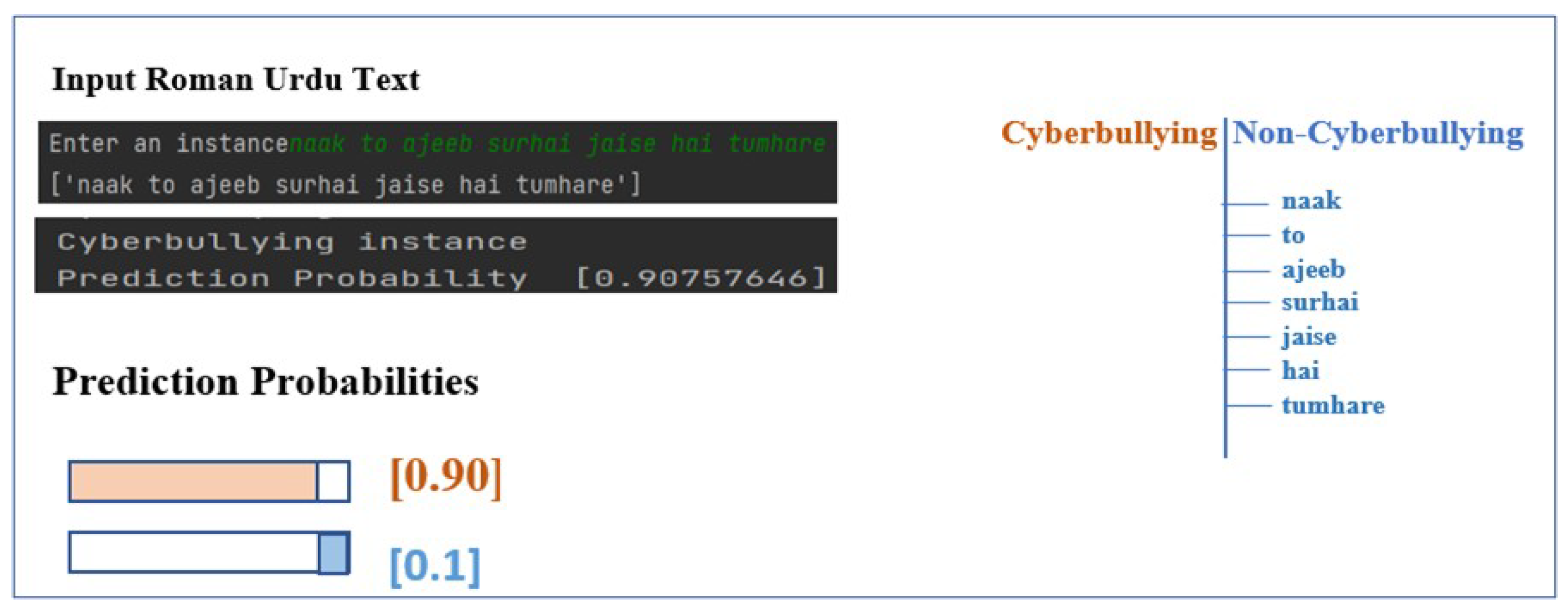
In the future, we aim to investigate the role of user meta-information-related features in detecting cyberbullying patterns. We also plan to develop a web application for the demonstration of the applicability of the proposed models, allowing classifying Roman Urdu tweets and comments both in implicit and explicit forms, evaluating the implemented models and receiving user’s feedback on the prediction of the models.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}