
Acoustic Material Monitoring in Harsh Steelplant Environments



Abstract
1. Introduction
Our Approach
2. Literature Review
3. Data Acquisition and Preprocessing Methods
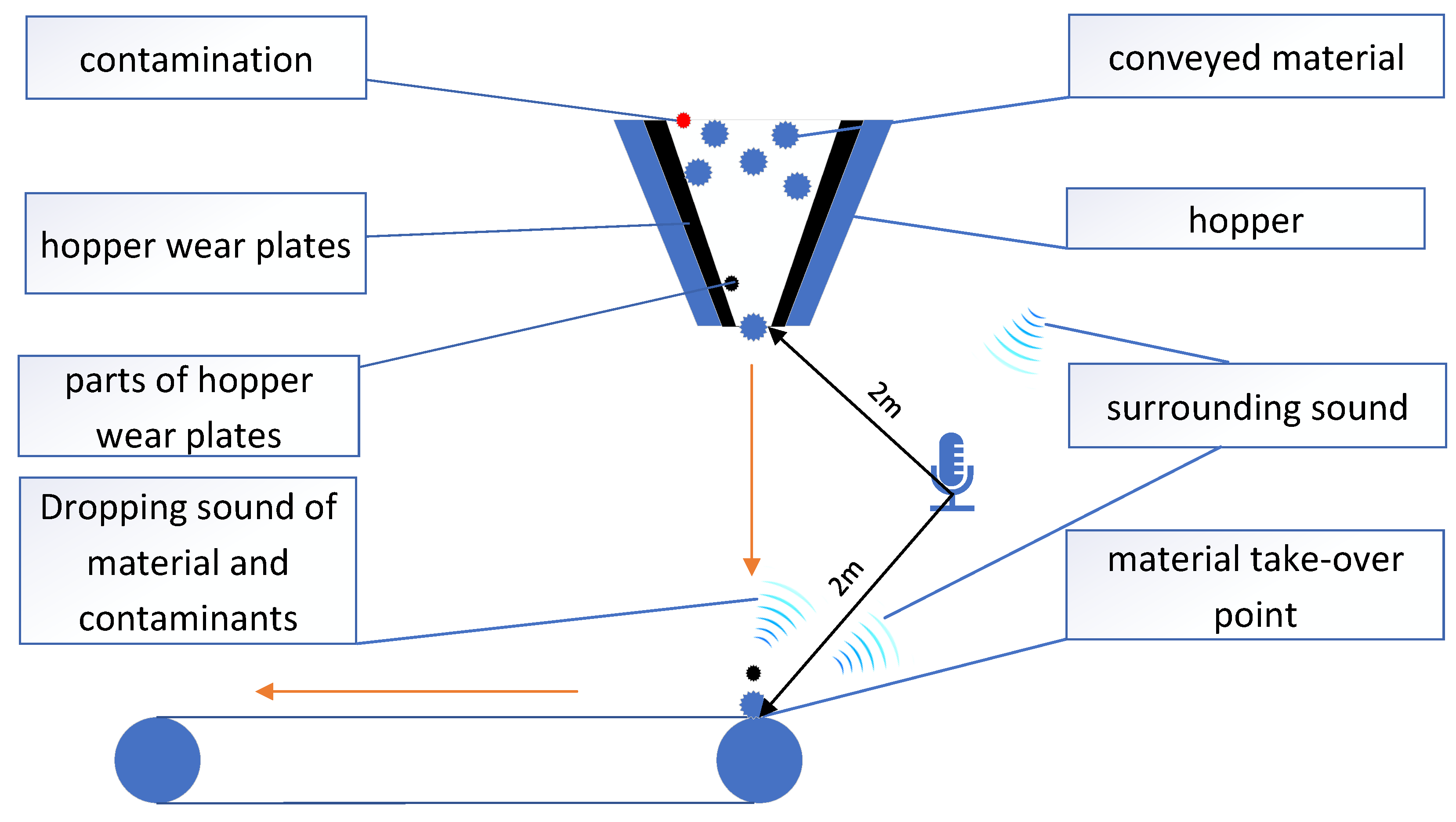
3.1. Measurement Setup
3.2. Dataset
3.3. Audio Frames with Noise
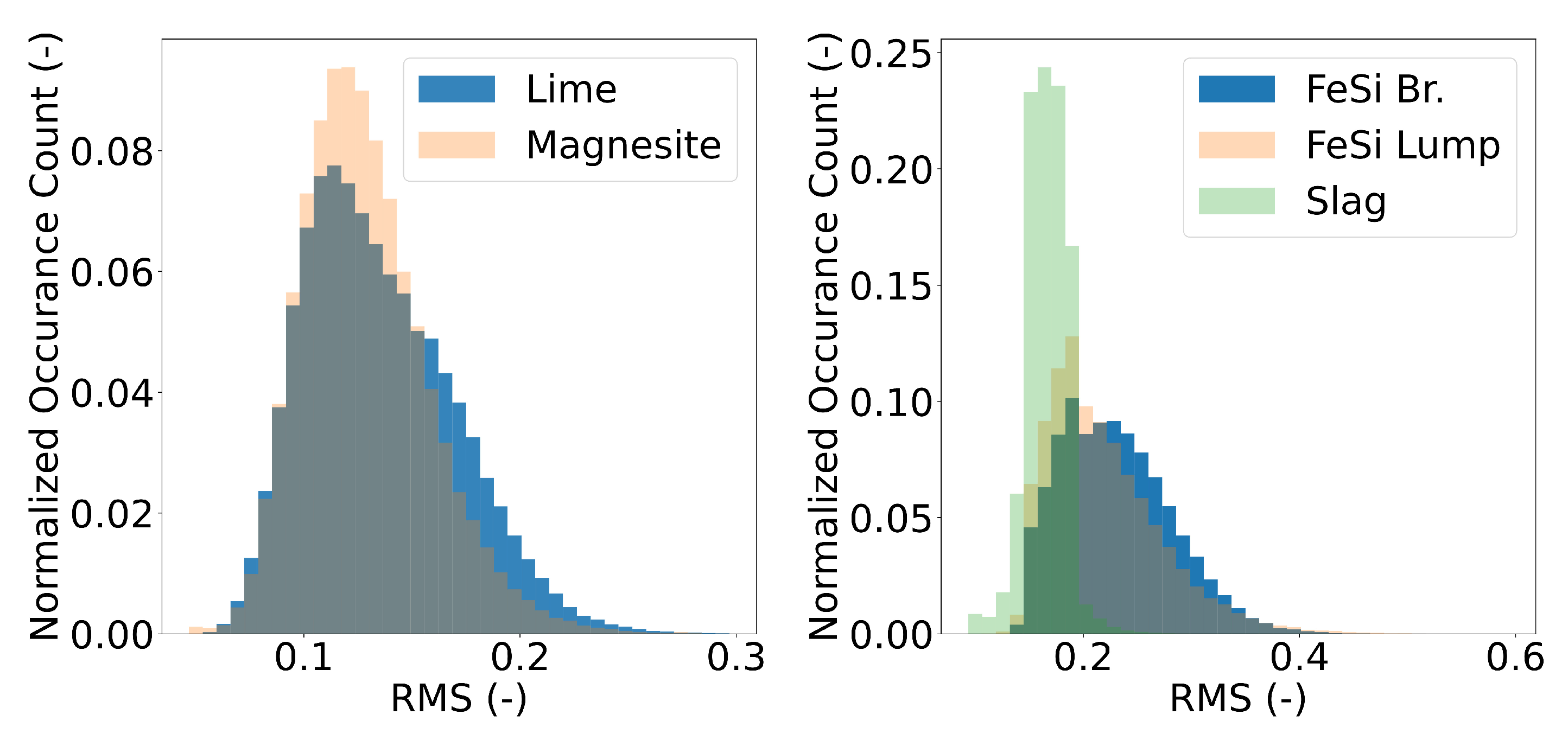
3.3.1. RMSe Outlier Detector
3.3.2. Threshold Determination
4. Classifier
4.1. CNN
4.2. FF-NN
5. Results
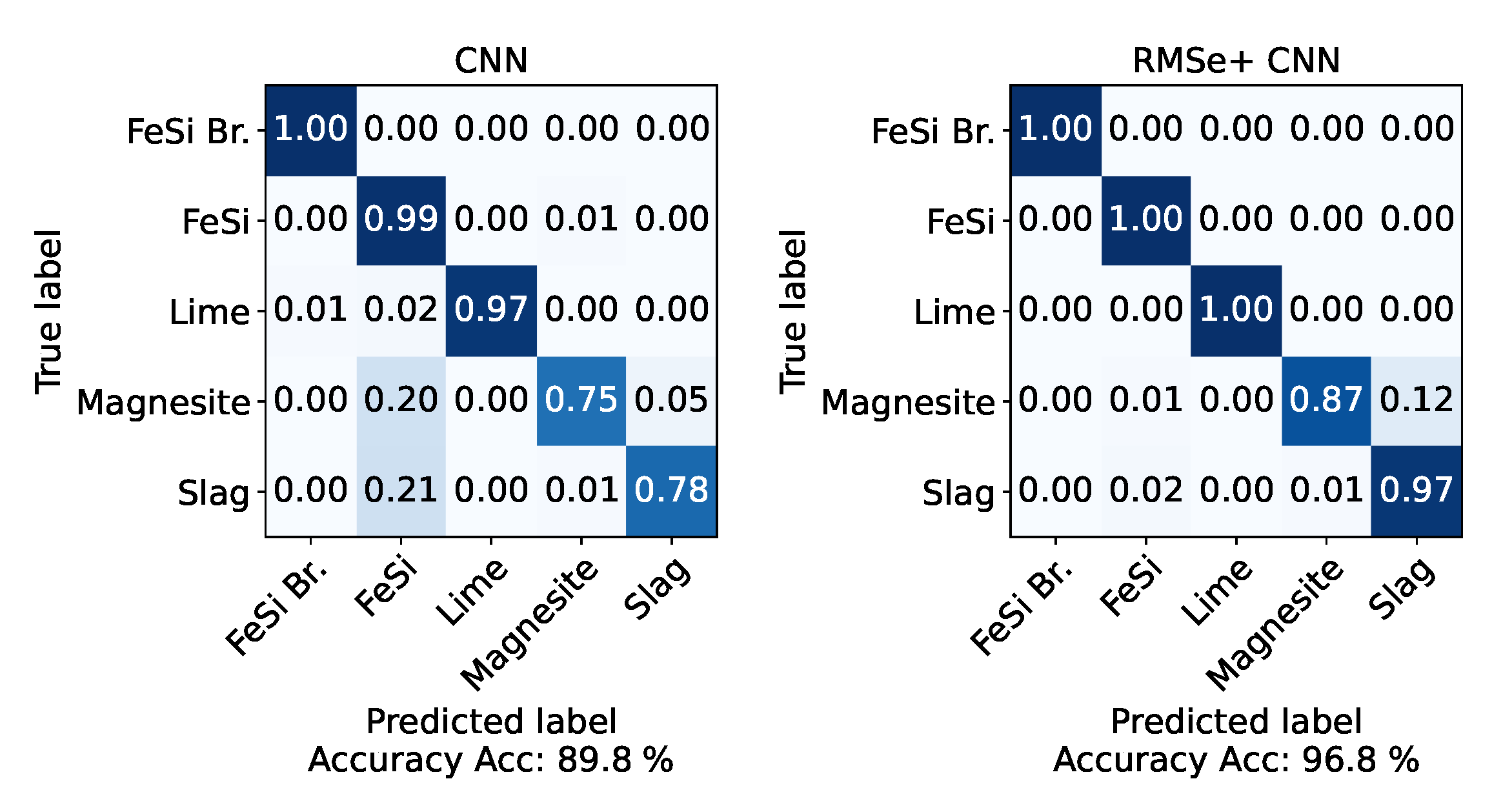
5.1. Model Comparison
5.2. Robustness Test
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Johannes. Update-Fehler verursachte Russ-Ausstoss der Dillinger Huette. Saarbruecker Ztg. 2018, 9, 5–7. [Google Scholar]
- Berckmans, D.; Janssens, K.; Van der Auweraer, H.; Sas, P.; Desmet, W. Model-based synthesis of aircraft noise to quantify human perception of sound quality and annoyance. J. Sound Vib. 2008, 311, 1175–1195. [Google Scholar] [CrossRef]
- Ding, R.; Pang, C.; Liu, H. Audio-Visual Keyword Spotting Based on Multidimensional Convolutional Neural Network. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4138–4142. [Google Scholar] [CrossRef]
- Serizel, R.; Bisot, V.; Essid, S.; Richard, G. Acoustic Features for Environmental Sound Analysis. In Computational Analysis of Sound Scenes and Events; Virtanen, T., Plumbley, M.D., Ellis, D., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 71–101. [Google Scholar] [CrossRef]
- Salamon, J.; Bello, J.P. Deep Convolutional Neural Networks and Data Augmentation for Environmental Sound Classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Husaković, A.; Pfann, E.; Huemer, M. Robust Machine Learning Based Acoustic Classification of a Material Transport Process. In Proceedings of the 2018 14th Symposium on Neural Networks and Applications (NEUREL), Belgrade, Serbia, 20–21 November 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Valenti, M.; Squartini, S.; Diment, A.; Parascandolo, G.; Virtanen, T. A convolutional neural network approach for acoustic scene classification. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1547–1554. [Google Scholar] [CrossRef]
- Nystuen, J.A. Listening to Raindrops; Solstice: An Electronic Journal of Geography and Mathematics; Institute of Mathematical Geography: Ann Arbor, MI, USA, 1999. [Google Scholar]
- Ramona, M.; Peeters, G. AudioPrint: An efficient audio fingerprint system based on a novel cost-less synchronization scheme. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 818–822. [Google Scholar]
- Velankar, M.; Kulkarni, P. Music Recommendation Systems: Overview and Challenges. In Advances in Speech and Music Technology; Springer: Berlin/Heidelberg, Germany, 2023; pp. 51–69. [Google Scholar]
- Andraju, L.B.; Raju, G. Damage characterization of CFRP laminates using acoustic emission and digital image correlation: Clustering, damage identification and classification. Eng. Fract. Mech. 2023, 277, 108993. [Google Scholar] [CrossRef]
- Dong, L.; Zhang, Y.; Bi, S.; Ma, J.; Yan, Y.; Cao, H. Uncertainty investigation for the classification of rock micro-fracture types using acoustic emission parameters. Int. J. Rock Mech. Min. Sci. 2023, 162, 105292. [Google Scholar] [CrossRef]
- Yu, A.; Liu, X.; Fu, F.; Chen, X.; Zhang, Y. Acoustic Emission Signal Denoising of Bridge Structures Using SOM Neural Network Machine Learning. J. Perform. Constr. Facil. 2023, 37, 04022066. [Google Scholar] [CrossRef]
- Temko, A.; Nadeu, C. Classification of acoustic events using SVM-based clustering schemes. Pattern Recognit. 2006, 39, 682–694. [Google Scholar] [CrossRef]
- Šmak, R.; Votava, J.; Lozrt, J.; Kumbár, V.; Binar, T.; Polcar, A. Analysis of the Degradation of Pearlitic Steel Mechanical Properties Depending on the Stability of the Structural Phases. Materials 2023, 16, 518. [Google Scholar] [CrossRef] [PubMed]
- Uher, M.; Beneš, P. Measurement of particle size distribution by the use of acoustic emission method. In Proceedings of the 2012 IEEE International Instrumentation and Measurement Technology Conference Proceedings, Graz, Austria, 13–16 May 2012; pp. 1194–1198. [Google Scholar] [CrossRef]
- Taheri, H.; Koester, L.W.; Bigelow, T.A.; Faierson, E.J.; Bond, L.J. In situ additive manufacturing process monitoring with an acoustic technique: Clustering performance evaluation using K-means algorithm. J. Manuf. Sci. Eng. 2019, 141, 041011. [Google Scholar] [CrossRef]
- Tieghi, L.; Becker, S.; Corsini, A.; Delibra, G.; Schoder, S.; Czwielong, F. Machine-learning clustering methods applied to detection of noise sources in low-speed axial fan. J. Eng. Gas Turbines Power 2023, 145, 031020. [Google Scholar] [CrossRef]
- Liu, B.; Liu, C.; Zhou, Y.; Wang, D.; Dun, Y. An unsupervised chatter detection method based on AE and merging GMM and K-means. Mech. Syst. Signal Process. 2023, 186, 109861. [Google Scholar] [CrossRef]
- Hayashi, T.; Yoshimura, T.; Adachi, Y. Conformer-Based Id-Aware Autoencoder for Unsupervised Anomalous Sound Detection. DCASE2020 Challenge; Technical Report. 2020. Available online: https://dcase.community/documents/challenge2020/technical_reports/DCASE2020_Hayashi_111_t2.pdf (accessed on 23 December 2022).
- Li, W.; Parkin, R.M.; Coy, J.; Gu, F. Acoustic based condition monitoring of a diesel engine using self-organising map networks. Appl. Acoust. 2002, 63, 699–711. [Google Scholar] [CrossRef]
- Barchiesi, D.; Giannoulis, D.; Stowell, D.; Plumbley, M.D. Acoustic Scene Classification: Classifying environments from the sounds they produce. IEEE Signal Process. Mag. 2015, 32, 16–34. [Google Scholar] [CrossRef]
- Chachada, S.; Kuo, C.C.J. Environmental sound recognition: A survey. In Proceedings of the 2013 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, Kaohsiung, Taiwan, 29 October–1 November 2013; pp. 1–9. [Google Scholar] [CrossRef]
- Su, F.; Yang, L.; Lu, T.; Wang, G. Environmental Sound Classification for Scene Recognition Using Local Discriminant Bases and HMM. In Proceedings of the 19th ACM International Conference on Multimedia, MM ’11, Scottsdale, AZ, USA, 28 November–1 December 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 1389–1392. [Google Scholar] [CrossRef]
- Husaković, A.; Mayrhofer, A.; Pfann, E.; Huemer, M.; Gaich, A.; Kühas, T. Acoustic Monitoring—A Deep LSTM Approach for a Material Transport Process. In Proceedings of the Computer Aided Systems Theory—EUROCAST 2019: 17th International Conference, Las Palmas de Gran Canaria, Spain, 17–22 February 2019; Revised Selected Papers, Part II. Springer: Berlin/Heidelberg, Germany, 2019; pp. 44–51. [Google Scholar] [CrossRef]
- Tagawa, Y.; Maskeliūnas, R.; Damaševičius, R. Acoustic Anomaly Detection of Mechanical Failures in Noisy Real-Life Factory Environments. Electronics 2021, 10, 2329. [Google Scholar] [CrossRef]
- Oudre, L. Automatic Detection and Removal of Impulsive Noise in Audio Signals. Image Process. Line 2015, 5, 267–281. [Google Scholar] [CrossRef]
- Zhou, C.; Paffenroth, R.C. Anomaly Detection with Robust Deep Autoencoders. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’17, Halifax, NS, Canada, 13–17 August 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 665–674. [Google Scholar] [CrossRef]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long Short Term Memory Networks for Anomaly Detection in Time Series. ESANN 2015, 2015, 89. [Google Scholar]
- Wang, Y.; Zheng, Y.; Zhang, Y.; Xie, Y.; Xu, S.; Hu, Y.; He, L. Unsupervised Anomalous Sound Detection for Machine Condition Monitoring Using Classification-Based Methods. Appl. Sci. 2021, 11, 11128. [Google Scholar] [CrossRef]
- Blázquez-García, A.; Conde, A.; Mori, U.; Lozano, J.A. A Review on Outlier/Anomaly Detection in Time Series Data. ACM Comput. Surv. 2021, 54, 1–33. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Probabilistic and Statistical Models for Outlier Detection. In Outlier Analysis; Springer International Publishing: Cham, Switzerland, 2017; pp. 35–64. [Google Scholar] [CrossRef]
- Kasparis, T.; Lane, J. Adaptive scratch noise filtering. IEEE Trans. Consum. Electron. 1993, 39, 917–922. [Google Scholar] [CrossRef]
- Hartl, F.; Mayrhofer, A.; Rohrhofer, A.; Stohl, K. Off the Beaten Path: New Condition Monitoring Applications in Steel Making. In Proceedings of the 3rd European Steel Technology and Application Days—ESTAD 2017, Vienna, Austria, 26–29 June 2017; Austrian Society for Metallurgy and Materials (ASMET): Vienna, Austria, 2017; pp. 44–51. [Google Scholar]
- Nicheng, S.; Wenji, B.; Guowu, L.; Ming, X.; Jingsu, Y.; Zhesheng, M.; He, R. Naquite, FeSi, a New Mineral Species from Luobusha, Tibet, Western China. Acta Geol. Sin. Engl. Ed. 2012, 86, 533–538. [Google Scholar] [CrossRef]
- Watkins, K.W. Lime. J. Chem. Educ. 1983, 60, 60. [Google Scholar] [CrossRef]
- Shanmugasundaram, V.; Shanmugam, B. Characterisation of magnesite mine tailings as a construction material. Environ. Sci. Pollut. Res. 2021, 28, 45557–45570. [Google Scholar] [CrossRef] [PubMed]
- Smith, K.; Morian, D. Use of Air-cooled Blast Furnace Slag as Coarse Aggregate in Concrete Pavements: A Guide to Best Practise. Fed. Highw. Adm.-Tech Rep. 2012, 6, 8. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. In Proceedings of the 25th Annual Conference on Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; p. hal-00642998f. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FeSi Br. | FeSi Lumps | Lime | Magnesite | Slag |
|---|---|---|---|---|
| 6.5 [35] | 6.5 [35] | 3–4 [36] | 3.5–4 [37] | 5–6 [38] |
| Name | Type | Kernel /Filter/Stride Size | Pooling Size | Dropout Rate | Output Activation Function |
|---|---|---|---|---|---|
| L1 | Conv2D | k × k/48/1 × 1 | ReLu | ||
| L2 | Max Pooling | 4 × 4 | |||
| L3 | Dropout | 0.5 | |||
| L4 | Conv2D | k × k/48/1 × 1 | ReLu | ||
| L5 | Max Pooling | 4 × 4 | |||
| L6 | Dropout | 0.4 | |||
| L7 | Conv2D | k × k/96/1 × 1 | ReLu | ||
| L8 | Flatten | ReLu | |||
| L9 | Dropout | 0.5 | |||
| L10 | Dense | 64 | |||
| L11 | Dense | 5 | softmax |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Husaković, A.; Mayrhofer, A.; Abbas, A.; Strasser, S. Acoustic Material Monitoring in Harsh Steelplant Environments. Appl. Sci. 2023, 13, 1843. https://doi.org/10.3390/app13031843
Husaković A, Mayrhofer A, Abbas A, Strasser S. Acoustic Material Monitoring in Harsh Steelplant Environments. Applied Sciences. 2023; 13(3):1843. https://doi.org/10.3390/app13031843
Chicago/Turabian StyleHusaković, Adnan, Anna Mayrhofer, Ali Abbas, and Sonja Strasser. 2023. "Acoustic Material Monitoring in Harsh Steelplant Environments" Applied Sciences 13, no. 3: 1843. https://doi.org/10.3390/app13031843
APA StyleHusaković, A., Mayrhofer, A., Abbas, A., & Strasser, S. (2023). Acoustic Material Monitoring in Harsh Steelplant Environments. Applied Sciences, 13(3), 1843. https://doi.org/10.3390/app13031843