Abstract
Misinformation poses a significant challenge in the digital age, requiring robust methods to detect fake news. This study investigates the effectiveness of using Back Translation (BT) augmentation, specifically transformer-based models, to improve fake news detection in Romanian. Using a data set extracted from Factual.ro, the research finds that BT-augmented models show better accuracy, precision, recall, F1 score, and AUC compared to those using the original data set. Additionally, using mBART for BT augmentation with French as a target language improved the model’s performance compared to Google Translate. The Extra Trees Classifier and the Random Forest Classifier performed the best among the models tested. The findings suggest that the use of BT augmentation with transformer-based models, such as mBART, has the potential to enhance fake news detection. More research is needed to evaluate the effects in other languages.
1. Introduction
Misinformation is spreading through modern media and social networks at an alarming rate. Fake news is a term used to describe news content that contains false, inaccurate, or deceptive information, and often uses more straightforward and repetitive content, which resembles satire more than real news [1]. The proliferation of misinformation can significantly affect issues for individuals and societies, influencing public health [2] and the stability of democracies [3,4]. To tackle this issue, our research proposes a new approach using BT augmentation to improve the detection of fake news in Romanian. Considering the limitations in language resources and prior work predominantly focused on high-resource languages, this study provides significant contributions by adapting and examining the effectiveness of state-of-the-art transformer-based models, including mBART, in a less-studied linguistic context. Moving beyond conventional ML and DL strategies [5,6,7], we can position our work at the forefront of regional language misinformation analysis, which could inform future multilingual and cross-cultural misinformation combat strategies.
Detecting fake news is a research topic of great interest in natural language processing (NLP) and artificial intelligence (AI). In recent years, most research on fake news detection has targeted English documents, with limited research in other languages [8]. However, studies have been conducted in Turkish, Indonesian, Chinese, Albanian, and Romanian [5,9,10]. It is critical to evaluate the language-independent characteristics and linguistic patterns that can be used to automatically detect fake news [1]. Additionally, attention-based models have been proposed to detect fake news in various languages [11]. The effectiveness of different algorithms and techniques, including ML and neural networks, in detecting fake news has been investigated [7,12,13]. Social media platforms, such as Twitter, where fake news can spread rapidly, must also be considered when detecting fake news [14,15]. More research is needed to develop robust and language-independent methods for detecting fake news in Romanian and other languages.
One of the common problems in the detection of fake news for low-resource languages involves difficulties in identifying high-quality sources of annotated data. Even if such sources are identified and a data set is acquired through rigorous data collection processes, it is inclined to be of a small size. Surveys such as those conducted by Bayer [16] have shown that data augmentation is helpful in addressing many challenges and problems for text classification. Such techniques are appropriate to increase the generalization of models and overcome a limited amount of training data.
Paraphrasing is made easier by translation. Since machine translation models have advanced and APIs are available online, it has become a widely used augmentation method. In BT, the original text is translated into another language and then translated again to generate augmented text [17].
This study investigates the effectiveness of BT augmentation, particularly transformer-based solutions, to enhance fake news detection in Romanian. A data set obtained from the fact checking site Factual.ro (accessed on 10 October 2023) was used in the experiment. The site publishes declarations of Romanian politicians labeled by a team of independent public policy specialists. Among the 1227 unique records in the Factual.ro data set, there are five categories: true, false, partially true, partially false, and truncated. To evaluate the effect of increasing the size of the data set with BT, multiple models were trained and evaluated.
Related work is introduced in Section 2, while Section 3 outlines the experiment methodology. This includes the data set, augmentation techniques, preprocessing steps, classifiers, and evaluation procedure. Section 4 presents the results and a discussion of the key findings. Lastly, Section 5 outlines the findings and potential directions for future work.
2. Related Work
Fake news is intentionally created to mislead and distort information, making it difficult to identify using traditional methods. An obstacle to accurately determining fake news is the limited availability of labeling news. Extensive investigations have been conducted to detect false news in English, employing diverse data augmentation techniques. This section presents prior research on data augmentation using transformer-based techniques.
In [18], Keya et al. propose a solution that integrates data augmentation to detect fake news in Bengali. The researchers used the “BanFakeNews” data set, a highly imbalanced data set with 1300 instances of fake news data out of 50,000 news items. To augment these data efficiently to balance the data set, they employed transfer learning using the BERT multilingual uncased model. This model was trained on a vast multilingual data set without human labeling, using two specific goals: Masked Language Modeling and Next Sentence Prediction. For data augmentation, they performed prediction of the next word instead of prediction of the next sentence, allowing for insertion by prediction. This approach considers surrounding terms to predict the target, addressing issues with static vectors in traditional word embedding models. Using this technique, 2700 fake news content items were generated, and after under-sampling true news items, a balanced augmented data set was produced. Classical ML and DL algorithms were used to train the classifier, with the best performance of AugFake-BERT, the model proposed by the authors. The proposed model has a final accuracy score of 92.45% for the balanced data set and 75.12 for the original. The performance gain is significant, but part of it may be due to leakage, because no strategy was presented to counter this effect. Contrastingly, in this paper, stratified cross-validation is used to address this issue.
Article [19] investigates the effectiveness of text augmentation in detecting position and fake news. The researchers evaluated the effects of multiple augmentation methods: masked words prediction with BERT, BT with Google Cloud Translation API, synonym technique, TF–IDF insertion and substitution. Two publicly available data sets in English were used, FNC-1 for the position on news articles and FakeNewsNet for false news items. The findings of the study suggest that no single augmentation technique works well with all classification algorithms and that text augmentation only occasionally improves prediction performance. Furthermore, combining all augmentation methods does not produce the best results. The best performance to detect fake news was achieved by Bagged Random Forest with BT, with an F1 score of 91.34 compared to 88.09 without data augmentation.
Shushkevich et al. [20] used ChatGPT 4 to balance and enhance an existing data set to detect fake news. The starting data set was the English portion of the CheckThat-2022 Task 3 which contained four labels: true, partially false, false, and other. To overcome the limitations of CheckThat-2022, which is relatively small and imbalanced, the capabilities of ChatGPT 4 were used and the data set was expanded from 900 to 2400 items. A small improvement in the Macro F1 score was reported for the mBERT model, from 0.23 to 0.25. The authors suggest that this technique does not contribute to improving the classification quality of false news due to the ethical limitations of ChatGPT in generating this type of news.
Buzea et al. [21] proposed an ML system for Romanian fake news detection. A large data set of 26,128 items was constructed by crawling a list of online publishers that are untrustworthy for fake news and official sources for real news. The authors compared the performance in predicting fake news from classical algorithms with DL and transformer models. The presented method gained an F1 score of 97.80% for the convolutional neural network model. Our approach differs by using a smaller data set labeled by experts and by using data augmentation to enhance performance. The Factual.ro source was used by Busioc et al. [22] to predict fake news using a BERT-based model. Compared to the previous paper, the data set is small, with only 845 statements. Although the result is not remarkable, with an accuracy of 64.91%, no data augmentation techniques were used.
3. Methodology
This study examined the effectiveness of different models and data augmentation techniques, particularly BT augmentation with Google Translate and mBART, in improving fake news detection in Romanian. Using multiple metrics, including accuracy, precision, recall, F1 score, area under the curve, and Cohen’s kappa score, the performance of the model was evaluated. In addition, the benefits of utilizing pre-trained models similar to mBART for BT augmentation were investigated. During this process, three research questions were examined, as outlined below.
- RQ1: What is the effectiveness of transformer-based data augmentation approaches, specifically using mBART, in improving the detection of fake news in Romanian?
- RQ2: How does the performance of different models compare when augmented with BT data using Google Translate and mBART?
- RQ3: What is the impact of using different target languages, such as English and French, in the BT augmentation process?
The methodology used in this study closely followed the steps of Algorithm 1. The algorithm collected data from the “Factual.ro” source. The collected data were then divided into training and test sets. The data were preprocessed by removing special characters, converting to lowercase, tokenizing, removing stop words, and lemmatizing. After preprocessing, the data were vectorized using the TF–IDF method. Data augmentation was then performed on the training set using BT. The augmented training set was preprocessed using the same preprocessing steps as the original data. The preprocessed training and test sets were used to train and evaluate a classifier. The classifier performance on the original and augmented data sets was compared to analyze the effectiveness of data augmentation.
| Algorithm 1 Fake news detection pipeline with data augmentation |
| data = CollectData(“Factual.ro”) train_set, test_set = SplitDataset(data, ratio = 0.8) def PreprocessData(data): cleaned_data = [] for text in data: text = RemoveSpecialChars(text) text = ConvertToLowercase(text) tokens = Tokenize(text) tokens = RemoveStopWords(tokens) tokens = Lemmatize(tokens) cleaned_text = RejoinTokens(tokens) cleaned_data.append(cleaned_text) vectorized_data = Vectorize(cleaned_data, method = “TF–IDF”) return vectorized_data def AugmentData(train_set): augmented_data = [] for text in train_set: augmented_text = BackTranslation(text) augmented_data.append(augmented_text) return augmented_data augmented_train_set = AugmentData(train_set) def TrainEvaluate(train_data, test_data): classifier = TrainClassifier(train_data) results = EvaluateClassifier(classifier, test_data) return Results train_set = PreprocessData(train_set) test_set = PreprocessData(test_set) original_results = TrainEvaluate(train_set, test_set) augmented_train_set = PreprocessData(augmented_train_set) augmented_results = TrainEvaluate(augmented_train_set, test_set) analysis = ComparePerformance(original_results, augmented_results) |
The graphical representation of the methodology, as shown in Figure 1, supports understanding the workflow by highlighting key components such as data acquisition, data augmentation, preprocessing, vectorization, subsequent training, and evaluation.
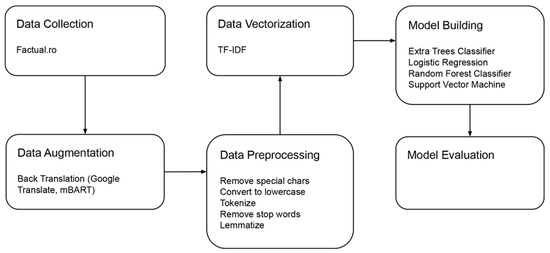
Figure 1.
Workflow of the fake news detection system.
3.1. Data Set
The experiments were carried out using the Factual.ro fake news data set, which we implemented and described in [10,23]. The data included both fake and real news instances extracted from Factual.ro, a platform that verifies shared news and content using independent experts. For this study, we updated our last version of the data set to include all statements available from January 2014 to October 2023. The data set comprised 1227 entries, each representing an individual news article from various Romanian news media. The articles covered a wide range of topics, with the most common category being politics, followed by finance and coronavirus.
Each entry in the data set included information on the author of the article, the statement, the affiliation (if available), the publication date, the source name, the context of the statement, and the label (Table 1).

Table 1.
Factual.ro fake news data set.
When the label occurrences were examined, we found that there were five different labels: true, false, partially true, partially false, and truncated. Subsequently, all entries without a true or false label were removed to focus solely on the detection of real or fake news. This resulted in the classification of two labels: true (including partially true) and false (including partially false). There were 669 true records (54.52%) and 558 false records (45.48%), indicating a relatively balanced data set. This preprocessing provided valuable information on data enrichment strategies for detecting fake news in Romanian.
3.2. Augmentation
BT is a powerful technique for augmenting text data. This technique has been widely used and has been shown to be beneficial in enhancing the performance of different NLP assignments, including the detection of fake news [10]. BT generates new instances of text data that convey a similar meaning, but with different phrasing, by translating it into another language and then back [24]. This approach introduces diversity in training data, exposing fake news detection models to a wider spectrum of linguistic patterns and expressions [6].
BT augmentation is particularly valuable when labeled data are limited or unavailable to train fake news detection models [24]. By generating additional data instances, BT effectively increases the size of the training set. This augmentation technique improves the model’s capability to generalize and capture the underlying patterns in fake news, leading to enhanced classification performance [25].
To provide data augmentation in our fake news detection experiments, we selected the Factual.ro data set as base data. This data set contains labeled instances from Romanian online news sources, accurately identified by independent fact-checkers to differentiate between real and fake news. To train the models and avoid overfitting, we partitioned the original data set into training and test sets with a split of 80–20. The test set remained unseen during training, allowing us to assess the model’s generalization capability. We applied the BT augmentation technique exclusively to the training data set.
Multilingual Denoising Autoregressive BART (mBART) is a powerful sequence-to-sequence model designed to remove noise and improve the quality of natural language text. Using the advanced BART (Bidirectional and Auto-Regressive Transformers) objective, this model is pre-trained on large-scale monolingual corpora from multiple languages [26]. It is a versatile multilingual model suitable for processing various languages and is specifically beneficial for machine translation tasks. One of the applications of mBART is to augment text data through BT.
Using the new training data set, we implemented BT data augmentation using two distinct approaches: Google Translate and the mBART model. In each of these approaches, the training data set was translated into the target language and back to Romanian. We used two different languages as the target language, English and French. As a result, new sets of training data were obtained. By incorporating synthetic data, our fake news detection models were able to learn from a broader range of language patterns and improve their performance in detecting fake news in Romanian.
Table 2 provides concrete examples of how machine translation services and transformer-based models augmented the Factual.ro data set using BT. Specifically, this table showcases the application of both Google Translate and mBART in BT.
Table 2.
Statements resulting from BT using Google Translate and mBART.
Initially, the table presents a Romanian example statement without any augmentation. Then, the table shows an instance of BT with Google Translate, illustrating both the process of translation to English and subsequent translation back to Romanian. After that, the table demonstrates BT using mBART, again translating the initial statement into English and then back to Romanian.
Comparing the initial statement with the augmented examples reveals subtle differences, highlighting the variations produced by the BT process and providing an understanding of how different transformer-based models may yield slightly varied results. In particular, the final BT statements using both Google Translate and mBART exhibit disparities in the Romanian translations of the same English statements. Although the Google Translate version remains closer to the original Romanian sentence, the mBART version incorporates slight but meaningful alterations.
3.3. Preprocessing
The data preprocessing steps applied in this study involved data normalization, data cleaning, tokenization, stop words removal, lemmatization, and feature extraction. These steps aimed at cleaning and standardizing the textual data, making it suitable for additional analysis and modeling tasks.
During the data normalization and cleaning phase, we employed specific functions to remove unnecessary characters from the text data. To ensure consistency and standardization, we initially utilized normalization techniques for special characters in Romanian. To further clean up the text, we remove digits, punctuation, and links using regular expressions. We also converted the text to lowercase to ensure consistency and prevent discrepancies resulting from case sensitivity.
Tokenization was conducted to partition the text into single tokens. This process was carried out using the tokenizer from the Natural Language Toolkit (NLTK) library [27], which extracts alphanumeric tokens from the text. Stop words, which are commonly used words that do not carry significant meaning, were then removed from the tokenized text columns. This step helped in reducing noise and improving the quality of the data.
Lemmatization was performed using the Stanza library [28], which reduces terms to their dictionary form. This step helped in reducing the dimensionality of the data and capturing the core meaning of the words. Finally, the lemmatized tokens in each column were joined into a single string, facilitating feature extraction and further analysis.
Finally, we used Term Frequency–Inverse Document Frequency (TF–IDF) to convert the text data into a form that could be more effectively analyzed. TF–IDF is a strategy employed to compute the weight of a word in a document. The process starts with the computation of the frequency of every unique term in the text, which measures the frequency with which a word appears throughout the content.
However, repeating a word many times in a document does not necessarily mean it is significant. To address this, we used the Inverse Document Frequency (IDF). IDF rescales common words across a corpus of documents—in this case, all articles analyzed for fake news detection. The IDF decreases the weight of commonly used words and increases the importance of terms not used very much in a collection of documents. This combination of TF and IDF offers us the TF–IDF score. This allows us to extract features from text data using TF–IDF, which can be used in ML models.
3.4. Classifiers
Our study assessed the detection of Romanian fake news using four classification approaches. The classifiers we selected were the Extra Trees Classifier [29], Random Forest Classifier [30], Support Vector Machine [31], and Logistic Regression [32]. We selected these models because of their strength and ability to effectively handle textual data [8,33]. The models discussed were implemented using Scikit-learn [34], a widely used ML library in Python (https://www.python.org/).
To ensure the robustness of our models, we used different models that vary in complexity and assumptions. This approach provided a broad evaluation scope and ensured that the results were not tailored to a specific model type. To enhance reproducibility, we also fixed random states where there was a factor of randomness, including splitting data sets and algorithmic operations of the classifiers.
The effect of augmentation approaches on fake news detection was investigated in two experiments. In each experiment, the data were first trained on the four mentioned classifiers without any form of augmentation and then trained again using two augmentation techniques, Google Translate and mBART.
The first experiment used English as the target language for the BT data augmentation process. The classifiers were trained on the augmented data, and their performance was compared to their performance on the non-augmented data. This helped us to understand how much improvement, if any, was brought about by the augmentation process.
The second experiment followed a similar protocol, but instead of English, French was used as the target language for the BT data augmentation. Again, the performance metrics resulting from the training of the classifiers in the original data were compared with the metrics resulting from the training of the classifiers in the augmented data. Using a different target language helped to examine the potential variability in the efficacy of the augmentation techniques due to the characteristics of the language.
3.5. Evaluation
Different metrics were used to evaluate the performance of our models, including accuracy, precision, recall, F1 score, area under the curve, and Cohen’s kappa. Evaluating a classifier’s performance involves presenting actual and predicted classification information in a confusion matrix. This matrix provides a tabular representation of the classifier’s performance, as shown in Table 3.
Table 3.
Confusion matrix.
In detecting fake news, True Positives (TP) refer to instances correctly identified as fake, and False Negatives (FN) refer to fake instances incorrectly classified as real. False Positives (FP) are real instances that are incorrectly classified as fake, and True Negatives (TN) are instances that are correctly classified as real. Based on these elements, we can define the metrics mentioned above as follows:
- Precision is the percentage of fake news instances correctly predicted out of all those predicted as fake.
- Recall is the percentage of instances of false news correctly predicted out of all instances of actual false news.
- Accuracy is the measure of the general correctness of the predictions of the model. It calculates the ratio of correctly predicted instances (fake and non-fake news) to the total number of instances.
- The F1 score provides a balanced assessment of model performance, combining accuracy and recall.
- The area under the curve is a common method to measure the accuracy of a binary classifier system, for example, for the detection of fake news. It provides a single metric that summarizes the classifier’s performance over all possible thresholds. A high AUC value indicates the model’s capability to differentiate between fake and real news accurately.
- Cohen’s kappa score, also known as Kappa, is a statistical measure that assesses the agreement between two classifiers in identifying if a news instance is fake or not. It is calculated by comparing the observed level of agreement between the two classifiers (Po) with the level of agreement expected by chance (Pe) [35].
We used k-fold cross-validation for the original data set, with k set to 10, to provide additional reliability in the model evaluation process. This technique is beneficial in assessing the model’s performance across different subsets of the data. In the 10-fold cross-validation for the augmented data, we employed stratified sampling to maintain the balance between the classes across folds, given that the fake news instances may vary in distribution.
4. Results and Discussion
Our research explored transformer-based data augmentation approaches to improve fake news detection in Romanian. Specifically, we focused on using transformer-based models to augment the Factual.ro data set through BT, employing advanced machine translation methods such as mBART. BT via mBART is a text data augmentation technique that involves translating a sentence back to the source language using a pre-trained machine translation model.
As shown in Table 4 and Table 5, we performed a comparative analysis using four classifiers: Extra Trees Classifier, Random Forest Classifier, Support Vector Machine, and Logistic Regression. We investigated the impact of BT augmentation techniques on model efficacy by evaluating parameters such as accuracy, precision, recall, F1 score, AUC, and Cohen’s kappa. The first experiment of the comparative analysis utilized English as the target language for the BT data augmentation process. However, in the second experiment, the target language was switched to French.
Table 4.
Scores for fake news detection with and without augmentation (Google Translate and mBART) using English as the target language.
Table 5.
Scores for fake news detection with and without augmentation (Google Translate and mBART) using French as the target language.
The “None” row results in both tables show the scores for models trained on the initial data without any augmentation. The overall accuracy ranged from 0.6948 to 0.7371, with the Support Vector Machine performing the lowest and the Random Forest Classifier performing the highest. The precision, recall, and F1 score also varied among the models, with the Random Forest Classifier having the highest recall and F1 score and the Support Logistic Regression having the highest precision. The precision scores for these models were relatively high, with values between 0.7845 and 0.8137, indicating that the models could correctly identify a large proportion of fake news instances. However, the recall scores for these models were relatively low, suggesting that they had difficulty correctly identifying all the fake instances.
When the BT technique was used with Google Translate and English as the target language (Table 4), there was a notable improvement in the scores for all classifiers. The Extra Trees Classifier and Random Forest Classifier achieved high scores across all metrics, with an accuracy of 0.7746 and 0.7793 respectively. Furthermore, the Support Vector Machine model showed impressive enhancement in precision and recall scores, with an 8.12% and 12.05% increase compared to models without data augmentation.
Similar results were observed for models trained on augmented data using the mBART model for BT and the English language as target. The best performing classifier was Random Forest, with an accuracy of 0.7746, a recall of 0.7907, an F1 score of 0.7759, and an AUC of 0.8462. The Extra Trees Classifier performed remarkably well, achieving an accuracy rate of 0.7700 and an F1 score of 0.7716, closely following the top-performing algorithm.
In Table 5, the results of the second experiment showed a significant improvement in the model performance when using transformer-based BT techniques, particularly with French as the target language. For example, the accuracy of the Random Forest Classifier increased from 0.7371 to 0.7793 when Google Translate BT was used and increased to 0.8075 when mBART BT was used.
The most effective model here was the Random Forest Classifier augmented with BT via mBART, offering the highest values of accuracy (0.8075), precision (0.8548), recall (0.8217), F1 score (0.8084), and AUC (0.8451) as well as achieving a Kappa score of 0.6012.
We can also observe in Figure 2 that the use of Google Translate for BT resulted in better performance compared to the original data set, but not as significant as mBART. The Extra Trees Classifier and the Random Forest Classifier performed the best, with accuracy scores of 0.7746 and 0.7793, respectively. Support Vector Machine and Logistic Regression models also showed improvements, with the latter achieving an accuracy score of 0.7324.
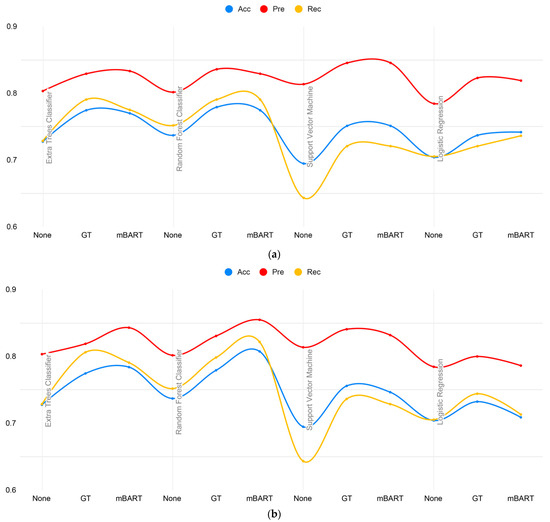
Figure 2.
Comparison of accuracy, precision, and recall for models without BT (None) and with BT (Google Translate and mBART): (a) English as target language; (b) French as target language.
Comparing the performance of the models on the initial data set (without augmentation) and the back-translated data sets, we can see an improvement in all metrics (accuracy, precision, recall, F1 score, AUC, and Cohen’s kappa score) when using transformer-based models to augment the data through BT. The results demonstrate the effectiveness of BT augmentation in improving performance for text classification tasks. This finding is consistent with previous research [36,37], which demonstrated the efficacy of utilizing pre-trained models like mBART for BT augmentation. By leveraging the pre-trained language modeling capabilities of mBART, we can generate high-quality synthetic translations that can be used to augment the training data.
Using pre-trained models like mBART in BT augmentation implementations offers several advantages. First, these models have been trained in large-scale data sets and have learned significant semantic knowledge from text [38]. This enables them to generate high-quality back-translated sentences that preserve the meaning and context of the initial text. Second, pre-trained models provide a transferable knowledge base that can be leveraged for different tasks and languages [39].
Furthermore, comparing the performance of the models using Google Translate and mBART for BT, we can see that using mBART with French as the target language results in slightly better scores for most models, with higher accuracy, precision, F1 score, and Cohen’s kappa score. This suggests that mBART is a more effective augmentation method for Romanian fake news detection when using a language closer to the target language. More research can be undertaken to compare the effectiveness of these methods in other languages and their impact on detecting fake news in Romanian.
The results also show that classifiers such as Extra Trees and Random Forest were the best performing models for both Google Translate and mBART. In contrast, the Support Vector Machine and Logistic Regression models performed poorly. This could be because tree-based models are generally more effective in handling non-linear relationships and noise in the data [29,30], which is often the case in fake news detection.
The methodology employed in this research can improve model performance in languages with limited resources. Nevertheless, there are certain obstacles to consider. First, the pre-trained models used for BT augmentation must be trained in the language in question. For example, the mBART model employed in this study was trained in 50 languages. Second, some target languages may be better suited for the scenario. Several target languages can be employed to generate augmented data sets for model training, and the language that results in the most significant improvements in model performance can be chosen.
5. Conclusions
In this study, we demonstrate the benefits of using pre-trained models, such as mBART, to augment BT in Romanian and to detect fake news. Research demonstrates the effectiveness of models that incorporate BT techniques using both Google Translate and mBART, with mBART performing better when using a language closer to the target language. A Random Forest Classifier augmented with mBART consistently achieves high accuracy, precision, recall, F1 score, and Cohen’s kappa score, making it the most effective combination for classification.
Nevertheless, it is essential to note that this study was limited to English and French BT augmentation techniques. The relevance and effectiveness of these techniques in other target languages should be examined in future research. Alternative techniques, such as word embeddings or generative adversarial networks, may be investigated to augment data and improve the effectiveness of fake news detection models. Incorporating diverse data sets and complementary data, such as user metadata and social network interactions, could also improve our understanding of fake news patterns across languages and contexts.
Author Contributions
Conceptualization, M.B.; methodology, M.B.; software, M.B.; validation, M.B.; formal analysis, M.B. and B.D.; investigation, M.B. and B.D.; resources, M.B. and B.D.; data curation, M.B.; writing—original draft preparation, M.B. and B.D.; writing—review and editing, M.B. and B.D.; visualization, M.B.; supervision, M.B.; project administration, M.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Access to this data is subject to certain restrictions. The data was sourced from Factual.ro, a reliable fact-checking platform, and can be obtained through the following URL: https://www.factual.ro/ (accessed on 10 October 2023), with the express permission of Factual.ro.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Horne, B.; Adali, S. This Just in: Fake News Packs a Lot in Title, Uses Simpler, Repetitive Content in Text Body, More Similar to Satire Than Real News. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11, pp. 759–766. [Google Scholar] [CrossRef]
- Zhou, C.; Xiu, H.; Wang, Y.; Yu, X. Characterizing the Dissemination of Misinformation on Social Media in Health Emergencies: An Empirical Study Based on COVID-19. Inf. Process. Manag. 2021, 58, 102554. [Google Scholar] [CrossRef] [PubMed]
- Lorenz-Spreen, P.; Oswald, L.; Lewandowsky, S.; Hertwig, R. A Systematic Review of Worldwide Causal and Correlational Evidence on Digital Media and Democracy. Nat. Hum. Behav. 2023, 7, 74–101. [Google Scholar] [CrossRef] [PubMed]
- Allcott, H.; Gentzkow, M. Social Media and Fake News in the 2016 Election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Taskin, S.G.; Kucuksille, E.U.; Topal, K. Detection of Turkish Fake News in Twitter with Machine Learning Algorithms. Arab. J. Sci. Eng. 2022, 47, 2359–2379. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake News Detection Using Machine Learning Ensemble Methods. Complexity 2020, 2020, 8885861. [Google Scholar] [CrossRef]
- Kumar, S.; Asthana, R.; Upadhyay, S.; Upreti, N.; Akbar, M. Fake News Detection Using Deep Learning Models: A Novel Approach. Trans. Emerg. Telecommun. Technol. 2020, 31, e3767. [Google Scholar] [CrossRef]
- Wang, W.Y. “Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 422–426. [Google Scholar]
- Canhasi, E.; Shijaku, R.; Berisha, E. Albanian Fake News Detection. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 1–24. [Google Scholar] [CrossRef]
- Bucos, M.; Țucudean, G. Text Data Augmentation Techniques for Fake News Detection in the Romanian Language. Appl. Sci. 2023, 13, 7389. [Google Scholar] [CrossRef]
- Ahuja, N.; Kumar, S. Mul-FaD: Attention Based Detection of multiLingual Fake News. J. Ambient. Intell. Hum. Comput. 2023, 14, 2481–2491. [Google Scholar] [CrossRef]
- Hlaing, M.M.M.; Kham, N.S.M. Comparative Study of Fake News Detection Using Machine Learning and Neural Network Approaches. In Proceedings of the 11th International Workshop on Computer Science and Engineering, Shanghai, China, 19–21 June 2021. [Google Scholar]
- Desamsetti, S.; Hemalatha Juttuka, S.; Mahitha Posina, Y.; Rama Sree, S.; Kiruthika Devi, B.S. Artificial Intelligence Based Fake News Detection Techniques. In Recent Developments in Electronics and Communication Systems; IOS Press: Amsterdam, The Netherlands, 2023; pp. 374–380. [Google Scholar]
- Zhang, J.; Dong, B.; Yu, P.S. FakeDetector: Effective Fake News Detection with Deep Diffusive Neural Network. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 1826–1829. [Google Scholar]
- Murayama, T.; Wakamiya, S.; Aramaki, E.; Kobayashi, R. Modeling the Spread of Fake News on Twitter. PLoS ONE 2021, 16, e0250419. [Google Scholar] [CrossRef]
- Bayer, M.; Kaufhold, M.-A.; Reuter, C. A Survey on Data Augmentation for Text Classification. ACM Comput. Surv. 2023, 55, 146. [Google Scholar] [CrossRef]
- Li, B.; Hou, Y.; Che, W. Data Augmentation Approaches in Natural Language Processing: A Survey. AI Open 2022, 3, 71–90. [Google Scholar] [CrossRef]
- Keya, A.J.; Wadud, M.A.H.; Mridha, M.F.; Alatiyyah, M.; Hamid, M.A. AugFake-BERT: Handling Imbalance through Augmentation of Fake News Using BERT to Enhance the Performance of Fake News Classification. Appl. Sci. 2022, 12, 8398. [Google Scholar] [CrossRef]
- Salah, I.; Jouini, K.; Korbaa, O. On the Use of Text Augmentation for Stance and Fake News Detection. J. Inf. Telecommun. 2023, 7, 359–375. [Google Scholar] [CrossRef]
- Shushkevich, E.; Alexandrov, M.; Cardiff, J. Improving Multiclass Classification of Fake News Using BERT-Based Models and ChatGPT-Augmented Data. Inventions 2023, 8, 112. [Google Scholar] [CrossRef]
- Buzea, M.C.; Trausan-Matu, S.; Rebedea, T. Automatic Fake News Detection for Romanian Online News. Information 2022, 13, 151. [Google Scholar] [CrossRef]
- Busioc, C.; Dumitru, V.; Ruseti, S.; Terian-Dan, S.; Dascalu, M.; Rebedea, T. What Are the Latest Fake News in Romanian Politics? An Automated Analysis Based on BERT Language Models. In Ludic, Co-Design and Tools Supporting Smart Learning Ecosystems and Smart Education; Mealha, Ó., Dascalu, M., Di Mascio, T., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2022; Volume 249, pp. 201–212. ISBN 9789811639296. [Google Scholar]
- Tucudean, G.; Bucos, M. The Use of Data Augmentation as a Technique for Improving Fake News Detection in the Romanian Language. In Proceedings of the 2022 International Symposium on Electronics and Telecommunications (ISETC), Timisoara, Romania, 10–11 Novermber 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–4. [Google Scholar]
- Raza, S.; Ding, C. Fake News Detection Based on News Content and Social Contexts: A Transformer-Based Approach. Int. J. Data Sci. Anal. 2022, 13, 335–362. [Google Scholar] [CrossRef]
- Collins, B.; Hoang, D.T.; Nguyen, N.T.; Hwang, D. Trends in Combating Fake News on Social Media—A Survey. J. Inf. Telecommun. 2021, 5, 247–266. [Google Scholar] [CrossRef]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual Denoising Pre-Training for Neural Machine Translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Loper, E.; Bird, S. NLTK: The Natural Language Toolkit. In Proceedings of the ACL-02 Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics—Volume 1, Philadelphia, PA, USA, 7 July 2002; pp. 63–70. [Google Scholar]
- Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C.D. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. arXiv 2020, arXiv:2003.07082. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Yu, H.-F.; Huang, F.-L.; Lin, C.-J. Dual Coordinate Descent Methods for Logistic Regression and Maximum Entropy Models. Mach. Learn. 2011, 85, 41–75. [Google Scholar] [CrossRef]
- Tufail, H.; Ashraf, M.U.; Alsubhi, K.; Aljahdali, H.M. The Effect of Fake Reviews on E-Commerce during and after COVID-19 Pandemic: SKL-Based Fake Reviews Detection. IEEE Access 2022, 10, 25555–25564. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2018, 12, 2825–2830. [Google Scholar]
- Carletta, J. Assessing Agreement on Classification Tasks: The Kappa Statistic. Comput. Linguist. 1996, 22, 249–254. [Google Scholar]
- Kulkarni, M.; Chennabasavaraj, S.; Garera, N. Study of Encoder-Decoder Architectures for Code-Mix Search Query Translation. arXiv 2022, arXiv:2208.03713. [Google Scholar]
- Jawahar, G.; Nagoudi, E.M.B.; Abdul-Mageed, M.; Lakshmanan, L.V.S. Exploring Text-to-Text Transformers for English to Hinglish Machine Translation with Synthetic Code-Mixing. In Proceedings of the Fifth Workshop on Computational Approaches to Linguistic Code-Switching, Online, 11 June 2021; pp. 36–46. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1441–1451. [Google Scholar]
- Kao, W.-T.; Lee, H. Is BERT a Cross-Disciplinary Knowledge Learner? A Surprising Finding of Pre-Trained Models’ Transferability. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 2195–2208. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).