1. Introduction
Open-domain question answering (ODQA) aims to answer queries based on large knowledge corpora, like the web, without explicit evidence. The typical framework for ODQA is structured as a two-stage process, consisting of a retriever and a reader [
1]. The retriever selects a candidate set relevant to a given question from a large corpus, and the reader predicts answers to the question from the retrieved set. The performance of the retriever is typically crucial for the overall QA performance, as it determines the quality of the candidate set. Therefore, there has been extensive research conducted to enhance the retriever’s performance [
1,
2,
3].
Traditional retrievers mainly use sparse representations through TF-IDF and BM25 [
2,
3], often encountering term-mismatch problems due to the difference in terms used in the query and those found in the documents. Furthermore, there are limitations in their performance, as it is difficult to reflect the semantic relationship between documents and queries. Recently, the emergence of dense retrieval utilizing deep learning has shown significant improvements in search performance. Pre-trained language model-based search, particularly BERT [
4], has been very effective. However, BERT-based search requires supplying each query–document pair through a large neural network to calculate relevance scores, increasing the computational cost and inference time by tens of thousands of milliseconds (ms) compared to previous approaches [
5]. Although BERT-based search has brought significant performance improvements, it has also led to substantial computational costs.
To address this issue, varied research on retriever models and techniques that pursue a balance between accuracy, computational cost, and latency have been conducted [
6]. In particular, the model for ODQA deals with exceptionally vast datasets, leading to the challenge of retrievers taking considerable time to find question-relevant information or documents. The Learning Index for Learning Passage Retrieval (LIDER) [
7] achieves a balance between search speed and accuracy during training by dynamically adapting the corpus index, as opposed to locality-sensitive hashing (LSH) [
8] and inverted file (IVF) [
9]. While LSH and IVF involve research efforts utilizing efficient approximate nearest neighbor (ANN) methods for enhanced search speed, they often suffer from significant degradation in search accuracy [
10]. ColBERT is an innovative ranking model designed to enhance retrieval by efficiently adapting deep language models (specifically BERT) for document ranking. It employs a novel late-interaction architecture that independently encodes queries and documents using BERT, followed by a cost-effective interaction step to model their fine-grained similarity. This approach not only leverages the power of deep language models but also speeds up query processing by enabling pre-computation of document representations. ColBERT’s efficiency makes it competitive with existing BERT-based models, outperforming non-BERT baselines while being significantly faster and more resource-efficient.
While ColBERT presents itself as a highly efficient retrieval model, its application in the Korean language context remains limited. Research on natural language processing in Korean has not gained as much widespread attention as it has in English, leading to Korean being often referred to as a language with limited resources [
11]. Consequently, this results in a shortage of Korean ODQA data, and the scale of the available data is indeed limited. In this paper, we construct a large-scale dataset for training Korean ODQA, surpassing the existing machine reading comprehension (MRC) datasets. We conduct an analysis of our data, including different question types. Additionally, we apply the efficient ColBERT model to our dataset, conducting comparative experiments with conventional retrieval methods to validate the effectiveness of an efficient retrieval model on a large-scale Korean dataset. The ColBERT approach demonstrates a performance surpassing term-based retrieval BM25 and exhibits significantly faster search times compared to KoBERT. Furthermore, utilizing various pre-trained Korean language models for ODQA tasks, we identify KoSBERT as the most effective and efficient pre-trained Korean language model. Lastly, through performance comparisons based on tokenizers in the ablation study, we underscore the necessity for efficient models tailored to the complexities of the Korean language.
This paper’s main contributions are outlined as follows:
We adapt and propose the application of ColBERT to Korean document retrieval, demonstrating its efficiency and effectiveness in open-domain Korean question answering.
We construct and analyze a large-scale Korean open-domain question answering dataset, filling a gap in Korean natural language processing resources.
Through extensive evaluations using various pre-trained language models, we demonstrate that KoSBERT significantly outperforms other models in document retrieval tasks, emphasizing the effectiveness of KoSBERT specifically for Korean language retrieval tasks.
The rest of this paper is organized as follows:
Section 2 discusses the related work, providing a background and context for this study.
Section 3 delves into the adaptation of ColBERT for Korean open-domain question answering, including details on the query encoder, document encoder, and late interaction mechanism.
Section 4 covers the Korean open-domain question answering dataset construction, detailing the creation of both the training and evaluation datasets.
Section 5 presents the experimental setup and results, including the datasets used, baseline comparisons, evaluation metrics, computational details, results, and an ablation study.
Section 6 discusses the implications of the study, highlighting how the ColBERT model’s effectiveness in Korean language processing can be extended to various languages. Finally,
Section 7 concludes the paper with a summary of the findings and suggestions for future research directions.
2. Related Work
The architecture of open domain question answering (ODQA) systems primarily combines information retrieval (IR) and reader modules. IR plays a crucial role in searching for evidence passages within a vast knowledge corpus to answer questions. Traditional non-neural models utilized in IR include TF-IDF [
2] and BM25 [
3]. These methods rely on lexical information, leading to significantly lower performance when there is a mismatch between the query and passage terminology. However, with advancements in deep learning and the introduction of powerful pre-trained language models such as BERT [
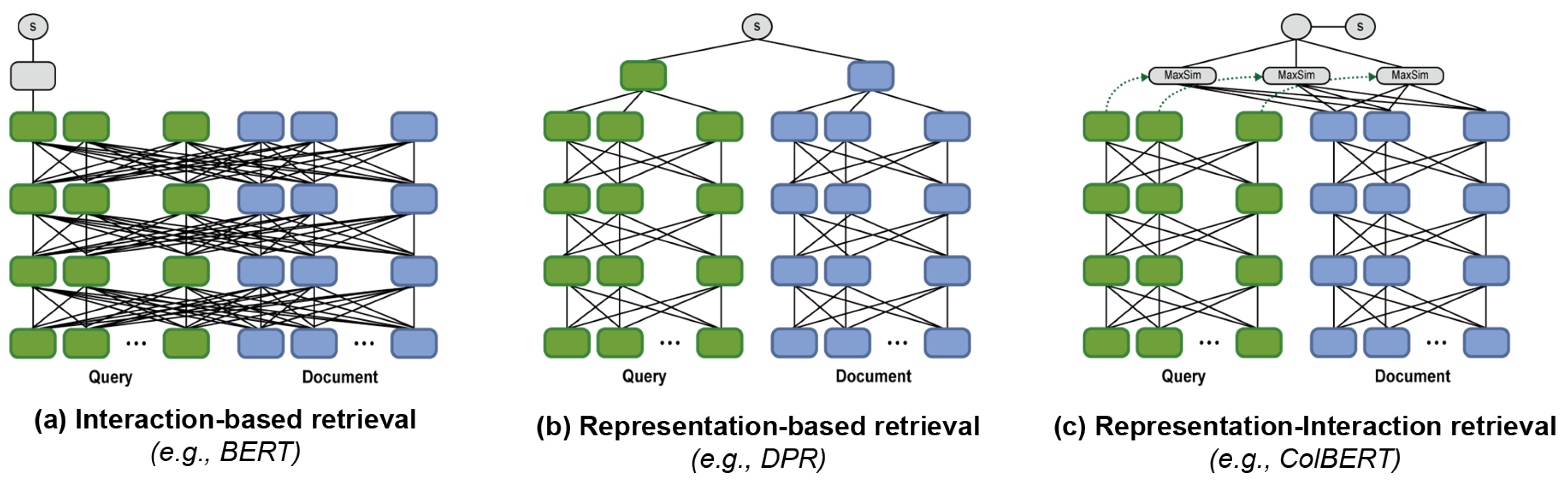
4], methods surpassing lexical-level information have been proposed. These methods leverage semantic correlations between questions and passages for more effective document retrieval. The interaction-based retriever illustrated in
Figure 1a inputs the query and context in the format [CLS] Query [SEP] Context [SEP] into BERT, enabling the computation of scores between queries and documents through derived representations [
12,
13].
Nevertheless, Transformer-based pre-trained language models (PLMs) tend to be computationally intensive and slow when dealing with longer input lengths. In response, dense passage retrieval (DPR) [
3] independently encodes queries and passages for relevance score calculation, as shown in
Figure 1b. Despite its efficiency, DPR does not consider the interaction between query and passage, which can limit its performance.
To balance efficiency and accuracy, ColBERT [
5] has been proposed. ColBERT, a representation–interaction retriever model, is depicted in
Figure 1c. After encoding questions and documents separately using BERT-based encoders, it calculates token embedding scores for each question across all documents. Subsequently, all scores are summed to form the final relevance score between the question and document. ColBERT has demonstrated an effective balance between search performance and processing speed.
Recent research efforts aim to develop efficient ODQA systems [
6]. Techniques like brute search [
15], hierarchical navigable small world graphs (HNSW) [
16], approximate nearest neighbor (ANN) [
17], locality-sensitive hashing (LSH) [
8], and inverted file (IVF) [
9] have been applied in various studies. Additionally, approaches such as removing the reader from the retrieval–reader structure [
18] or directly generating answers from given questions using generative-only methods [
19,
20,
21] have been proposed to enhance ODQA efficiency.
This study aims to apply ColBERT, which shows a balanced performance in terms of search speed and accuracy, to the Korean language. In the ColBERT structure, BERT-based models are used to derive embeddings for queries and passages. BERT has significantly outperformed traditional methods in various tasks, including review classification [
22]. Several versions of BERT exist in Korea [
23], and open-source PLMs have been trained in different environments and datasets, necessitating efforts to find models suitable for specific tasks. Attempts to apply Korean BERT in document classification [
24], comment analysis [
25], and medical fields have been proposed [
26].
3. ColBERT for Korean Open-Domain Question Answering
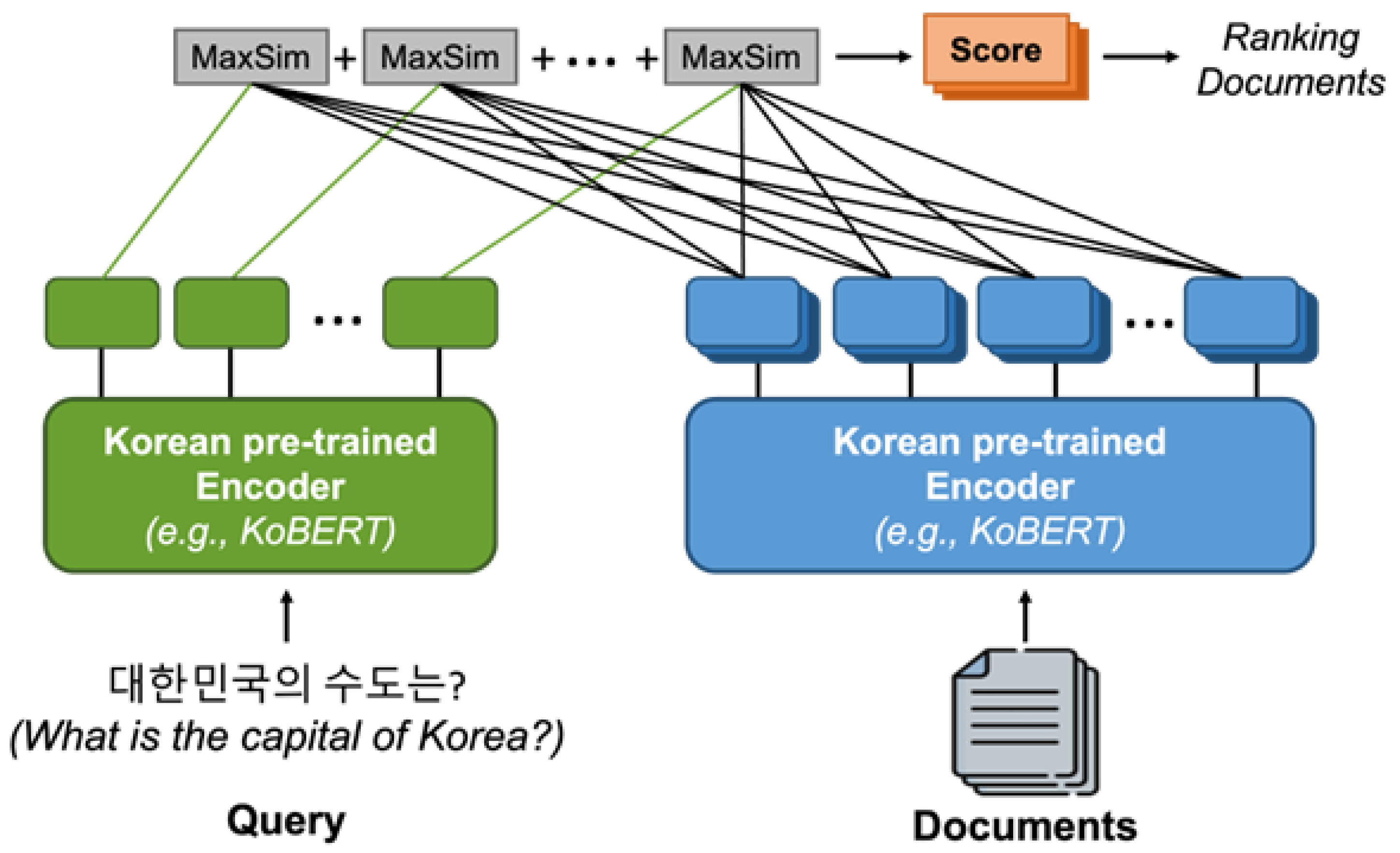
As shown in
Figure 2, the ColBERT model used in this paper can be divided into three main components: the query encoder, document encoder, and late interaction. The given question and document generate their respective vector representations through the KoBERT-based encoders. Since the question and document encoders share a single KoBERT model, special tokens [Q] and [D] are added to each input to differentiate between questions and documents. The resulting question and document representations are passed through the late interaction, which calculates the final relevance score using the MaxSim operation, as in [
5]. This involves calculating the maximum cosine similarity between the document and question embeddings and summing them up to produce the final score.
3.1. Query Encoder
Given a question q, it is tokenized into q1, q2, …, ql using the SentencePiece-based KoBERT tokenizer [
27], and a special token [Q] is added after the [CLS] token to distinguish it from the document sequence. If the length of the question is less than the predetermined maximum length Nq, it is padded with BERT’s special [MASK] token to reach Nq; otherwise, it is truncated. The token sequence padded with masked tokens passes through KoBERT to compute the contextualized representation of each token. This padding and masking strategy for questions can serve as a query augmentation, which can improve the model’s performance [
5]. The representations obtained through KoBERT pass through a linear layer without an activation function, adjusting the dimensionality of the embeddings. This dimensionality reduction may impose constraints on the question encoding but significantly benefits the runtime. The output embeddings are then normalized using L2 norm. The cosine similarity between two embeddings, in the range of [−1, 1], is calculated using the dot product.
3.2. Document Encoder
Similar to the query encoder, given a document d, it is tokenized into d1, d2, …, dk using the KoBERT tokenizer, and a special token [D] is added after the [CLS] token to distinguish it from the question sequence. However, unlike the query encoder, the document encoder does not use the [MASK] token for padding based on document length. The document embeddings produced by KoBERT pass through a linear layer. The number of document embeddings is then reduced through punctuation filtering.
3.3. Late Interaction
To compute the relevance score between a query q and a document d, ColBERT employs a late interaction between their bags of embeddings. The query and document are separately input into KoBERT to obtain the token-level embeddings for each query and document token. Next, for each query token, the MaxSim operation is performed by calculating the similarity between the query token and all document tokens and selecting the maximum similarity value. The similarity between tokens is calculated through cosine similarity or squared L2 distance. Finally, the relevance score between query q and document d is obtained by summing the result values from the MaxSim operation conducted for all tokens in the query.
Afterward, the KoBERT encoders are fine-tuned, and the added special token parameters are trained. Given a triple <q, d+, d−>, consisting of a question, a relevant document, and an irrelevant document, the relevance scores for each document with respect to the question are calculated. ColBERT is optimized using Adam while calculating the pairwise softmax cross-entropy loss for each pair.
Top-k Re-ranking Re-ranking involves reordering a pre-indexed set of k documents (e.g., k = 1000) for a given query q. First, ColBERT computes the embedding matrix Eq for the given query q and calculates embeddings for the k documents to form a three-dimensional tensor D, which is then moved to the GPU memory. Next, the dot product between Eq and D is computed across multiple mini-batches. The resulting three-dimensional tensor represents a collection of cross-match matrices between query q and each document. To calculate scores for each document, we reduce the computed matrix through max-pooling across document tokens (MaxSim operation) and then compute the relevance score by summing over query tokens. The documents are re-ranked based on the calculated scores for the k documents.
5. Experimental Setup and Results
5.1. Datasets
In this paper, we evaluated the top-k re-ranking performance of Korean ColBERT using the evaluation dataset constructed in
Section 4.2. To assess the performance based on different query lengths, training was carried out based on those lengths, and the evaluation was then conducted using the corresponding datasets defined by the maximum query lengths. Detailed statistics of the dataset used for the evaluation can be found in
Table 2.
5.2. Baselines
In this study, with the aim of applying ColBERT to Korean, we used the traditional IR model BM25 and the dense retrieval model KoBERT as baseline models for comparison. BM25 is a traditional statistics-based information retrieval (IR) model that calculates relevance scores by computing the word weights between the query and documents. KoBERT is a dense retrieval-based model that calculates relevance scores through the [CLS] token embedding obtained by inputting query–document pairs into KoBERT. The proposed ColBERT with KoBERT (ColBERT w/KoBERT) is a model that calculates the relevance scores between the query and documents through the late interaction.
5.3. Evaluation Metrics
In this paper, we used MRR (mean reciprocal rank) and recall to measure the search performance of the open-domain question answering system and latency to measure the speed. MRR is the average reciprocal rank of the most relevant document for a query Q. The reciprocal rank is the inverse of the rank of the most relevant document in the re-ranked document list for query Q. MRR@10 and MRR@100 represent the average reciprocal rank targeting only the top 10 and 100 documents, respectively. If there is no relevant document for the query in the target documents, the reciprocal rank for that question is calculated as 0. MRR@10 and MRR@100 allow us to measure how accurately the model places the most relevant documents at the top for a query. Recall@k is the number of relevant documents in the top k results divided by the total number of relevant documents. Recall@50 and Recall@200 represent the number of relevant documents included in the top 50 and 200 results, respectively, divided by the total number of relevant documents among 1000 documents. Recall@50 and Recall@200 allow us to measure how many relevant documents the model can find in the top search results. Latency is an indicator to measure the search speed of the open-domain question answering system, representing the average delay time that occurs during the re-ranking process of the query-related documents. We can evaluate the overall performance and efficiency of the search system by measuring the search accuracy through MRR and recall and the search speed through latency.
5.4. Computation Details
As mentioned before, when calculating the similarity between the bag of contextualized embeddings for both query and document, the cosine similarity or squared L2 distance can be used for computation. In this experiment, the cosine similarity was used as the similarity measure. However, the computation was implemented as a dot product. This is due to embedding normalization.
In the top-k re-ranking batch computation, the batch size was set to 128. Given that k = 1000, for each query, 1000 documents were divided into a total of 8 mini-batches for computation. By partitioning the calculations across multiple mini-batches, efficient GPU memory utilization was achieved while maintaining a rapid computational speed.
Across all experiments, we used a single A100 GPU that has 40 GB of memory on a server with two Intel Xeon Gold 6226R CPUs, each with 16 physical cores, and 495 GB of RAM.
5.5. Results
We evaluated the efficiency of ColBERT by training it using the triples dataset <q, d+, d−>, as described in
Section 4.1, and then testing its re-ranking performance using the test dataset from
Section 4.2. The dataset for re-ranking was constructed by extracting 1000 documents for each query using the BM25 algorithm. While BM25, a term matching-based document retrieval method, may not be as accurate as neural approaches, it effectively filters documents with at least some relevance to the query. Re-ranking these documents demands not just retrieving relevant documents but also precisely identifying key documents that directly answer the query. Therefore, through our re-ranking experiment, we aimed to demonstrate the precision and efficiency of our proposed method by measuring MRR and latency.
Table 3 shows the performance of re-ranking documents based on their relevance score to each question in a set of k (k = 1000) ranked documents, with the performance varied depending on the maximum length of the query. The xperimental results show that KoBERT-based ColBERT (ColBERT w/KoBERT) achieves about 1.8 times, 1.1 times, and 1.1 times higher performance in MRR@10 compared to the traditional IR model BM25 when the question length is 20, 50, and 200, respectively. Additionally, the search speed is improved by more than 3.5 times. Although ColBERT w/KoBERT has a slightly lower MRR@10 performance by about 0.1 times than the dense retrieval KoBERT for question lengths of 50 and 200, it shows a search speed that is more than ten times faster. For question lengths of 20 or less, it demonstrates about 2.1 times better performance in MRR@10 and more than ten times faster search speed. These experimental results confirm that, while baselines may exhibit slightly better performance due to their ability to compute more complex interactions between the query and the document, ColBERT w/KoBERT is an efficient model that still exhibits excellent search performance while maintaining a fast search speed.
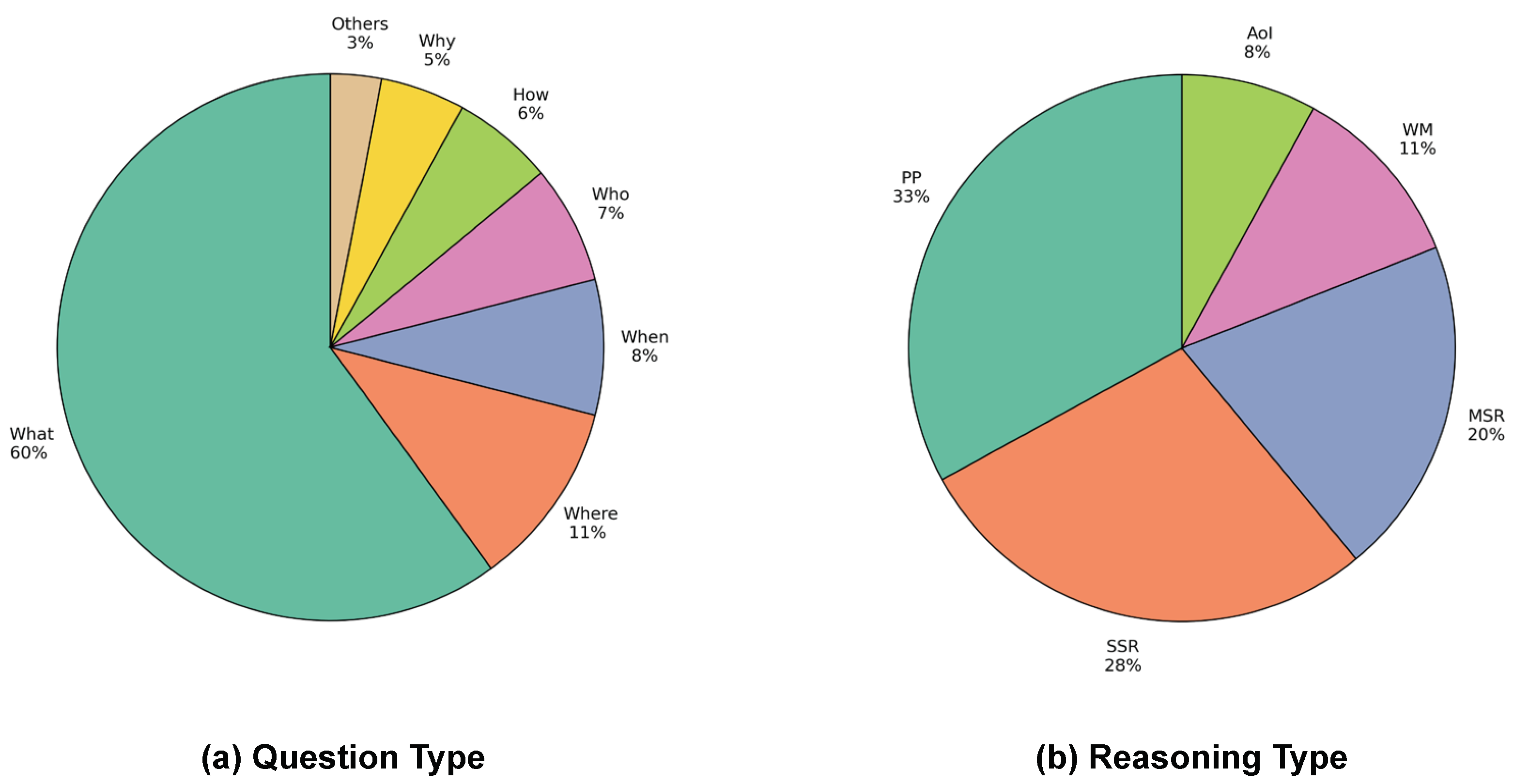
The experimental results indicate that the performance gap in MRR between dense retrieval and the Korean ColBERT is larger compared to the original ColBERT paper [
10]. This could be attributed to the elevated level of reasoning required by the dataset we have constructed. As can be seen in
Figure 4, queries involving single-sentence reasoning (SSR) and multi-sentence reasoning (MSR) inference types make up nearly 48% of our dataset, almost half. Unlike other inference types, these categories do not have direct evidence for the answers within the document, requiring a deeper contextual understanding to find the correct answers. This might explain why dense retrieval exhibits superior performance in our experiments. Nevertheless, ColBERT still demonstrates markedly higher performance than BM25 and offers a search speed that is ten times faster than dense retrieval.
Table 4 compares the re-ranking performance when using various pre-trained Korean language models other than KoBERT to generate question (question length 200) and document embeddings in ColBERT. We selected PLMs that performed well on the STS (semantic textual similarity) task. The experimental results show that the Korean-adapted Sentence-BERT (SBERT) [
39], KoSBERT [
40], has the best performance. ColBERT with KoSBERT (ColBERT w/KoSBERT) shows the best performance among ColBERT models utilizing pre-trained Korean language models. Although the MRR@10 performance of ColBERT w/KoSBERT is slightly lower by about 0.1 times compared to the dense retrieval KoSBERT, the search speed is improved by 23 times. The experiments confirm that using sentence-level embeddings like SBERT, instead of token-level embeddings like BERT, for generating question and document embeddings in ColBERT results in more accurate and faster search performance.
These experimental results demonstrate the effectiveness of SBERT in ODQA tasks. SBERT is trained to discern the semantic similarity between two sentences by inputting each sentence into BERT separately and using the obtained representations. Therefore, SBERT’s representations may be more suitable for similarity-based tasks compared to those of standard BERT. This is evidenced by KoSBERT exhibiting superior performance over KLUE-BERT. These findings can be instrumental in guiding the selection of pre-trained language models for future ODQA tasks.
Table 5 presents additional comparative experimental results examining the re-ranking performance of KoSBERT for each task. In [
39], BERT’s sentence embeddings are improved by mapping semantically similar sentences close together in the vector space through the natural language inference (NLI) task, which discriminates between implication, contradiction, and neutrality by calculating embeddings for two sentences separately, and the semantic textual similarity (STS) task, which predicts similarity scores between 0 and 5 using the cosine similarity of two sentence embeddings. KoSBERT is a pre-trained Korean language model trained using the SBERT structure proposed in [
39] on the KLUE-BERT model. KoSBERT-STS is a model fine-tuned with the KorSTS dataset [
41], KoSBERT-NLI is a model fine-tuned with the KorNLI dataset [
42], and KoSBERT-Multi is a model fine-tuned with KorNLI and further fine-tuned with KorSTS. The experiments show that the best performance is achieved when using KoSBERT-NLI among the various KoSBERT models. This implies that the model trained on inferring semantic relationships between sentences has a significant impact on exhibiting good search performance.
5.6. Ablation Study
In our experiment, we tokenized the queries and the entire document set using the Kobert tokenizer, then extracted 1000 documents per query via the BM25 algorithm to evaluate the re-ranking performance of ColBERT. However, unlike English, Korean is an agglutinative language, where grammatical functions are determined by appending various suffixes or particles to words or phrases. Due to this characteristic, it can be more effective to process words by first separating them into morphemes, the smallest units bearing meaning, rather than using the words as they are. Hence, we utilized the Korean morpheme analyzer Mecab [
43] to tokenize the queries and the entire document set at the morpheme level, then re-applied the BM25 to extract 1000 documents per query, conducting an additional experiment.
Table 6 compares the performance of re-ranking when using documents extracted by the BM25 after tokenizing with the Kobert tokenizer and when using documents extracted by the BM25 after tokenizing at the morpheme level. The experimental results demonstrate that re-ranking using documents extracted by the BM25 after tokenizing at the morpheme level yielded a higher performance across all metrics. This highlights the significance of morphological analysis when dealing with agglutinative languages like Korean.
7. Conclusions
In this paper, we propose an efficient Korean document retrieval method for open-domain question answering using the ColBERT structure. We construct a Korean dataset for open-domain question answering and evaluate the performance of the proposed method on this dataset. The experimental results show that our proposed KoBERT-based ColBERT achieves about 13% higher performance in MRR@10 compared to the traditional term-based retrieval model BM25 and reduces the search speed by approximately 3.7 times. KoBERT-based ColBERT shows about 8% lower performance in MRR@10 compared to dense retrieval KoBERT, but the search speed is shortened by more than ten times. Furthermore, when utilizing the KoSBERT-based ColBERT method, the sentence-embedding ability for both questions and documents is improved with the use of KoSBERT, achieving the best search performance and the shortest search time.
In this study, the ColBERT method is not only applicable to open-domain question answering tasks but also holds potential for situations requiring both search accuracy and speed simultaneously, such as search engines and recommendation systems. Additionally, given that search performance is improved when utilizing sentence embeddings trained to capture semantic similarity between sentences, future research will investigate approaches to enhance embeddings for effectively capturing semantic similarity between query and document, with the goal of further improving search performance.




{kind=link}
{kind=link}
{kind=link}
{kind=link}