4.1. Overview
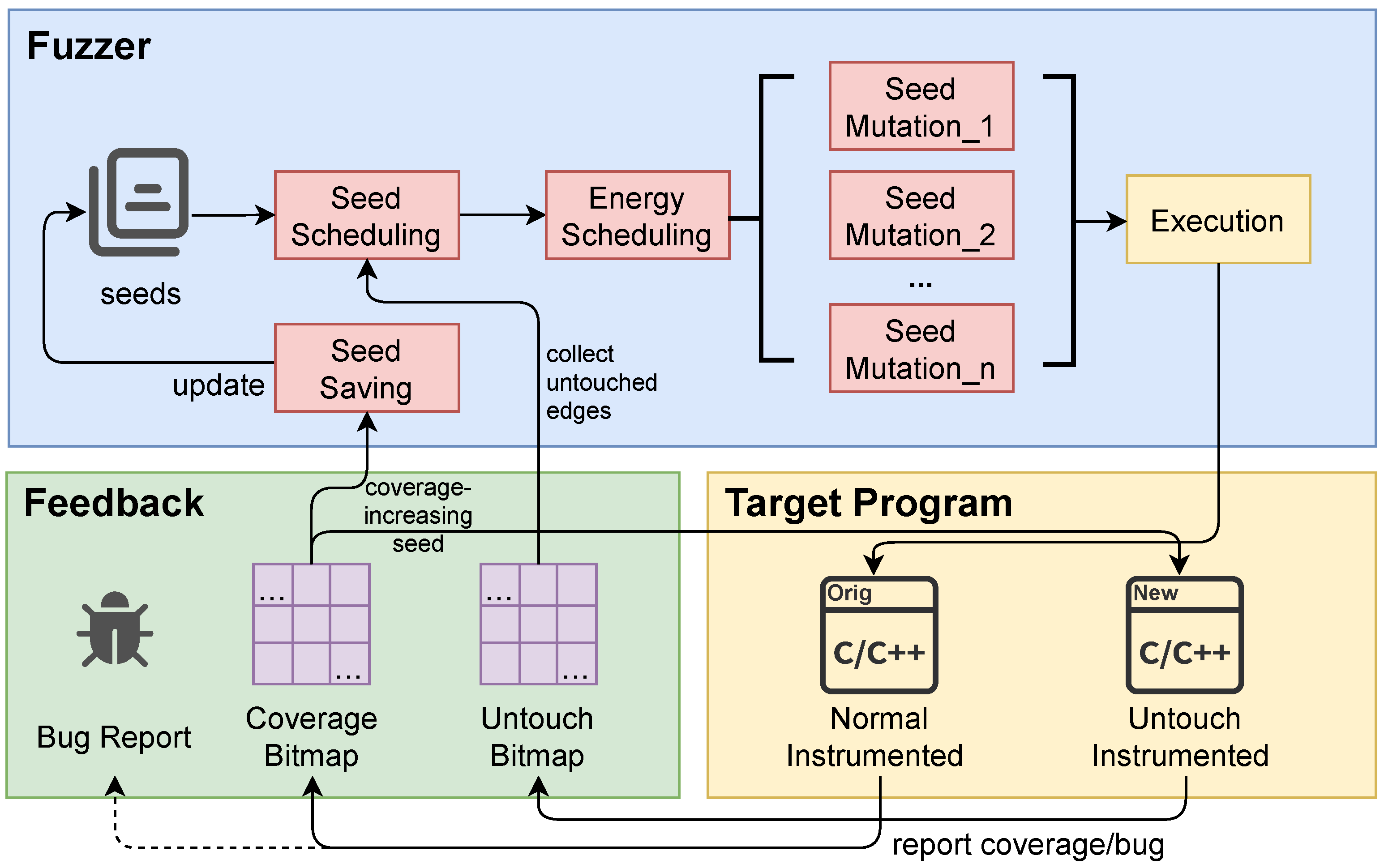
Figure 3 shows the overview of UntouchFuzz. In comparison to traditional coverage-guided greybox fuzzers, UntouchFuzz introduces an additional bitmap for tracking untouched edges. The untouched edge instrumentation mechanism updates this bitmap during program execution. Seed scheduling is then performed based on the information from this bitmap, prioritizing the mutations of favored seeds generated by scheduler.
To further explain, UntouchFuzz starts with an initial corpus as a seed set. By using the seed scheduling mechanism, the fuzzer selects a seed from the seed set for mutations. The number of mutations is determined by the energy scheduling mechanism, based on seed attributes. The fuzzer then executes the AFL-instrumented program with mutated test cases. If the program causes a crash, the test case is preserved on the local disk. If it covers new edges, the test case is preserved as a seed and added to the seed queue. Meanwhile, the coverage-increasing seed is provided to the program instrumented for untouched edge tracking, collecting information on untouched edges to guide the next seed scheduling process.
Furthermore, UntouchFuzz allocates more energy to seeds with more low-frequency untouched edges in the seed queue. This allocation aims to encourage these seeds to make more attempts at breaking through these low-frequency untouched edges. In the following sections, we will discuss the methods for collecting information on untouched edges in
Section 4.2, introduce the seed scheduling algorithm based on untouched edges in
Section 4.3, and outline slight improvements to energy scheduling in
Section 4.4.
4.2. Untouched Edges Tracking
As mentioned in
Section 2.1.2, AFL employs a lightweight instrumentation technique to track program edge coverage. In essence, AFL’s instrumentation assigns a random ID to each basic block within the target program’s CFG. During program execution, the instrumentation codes calculate the corresponding edge index based on Equation (
1) and use this index to update the coverage bitmap.
To ensure minimal impact on program execution speed, AFL utilizes a lightweight XOR operation for computing coverage indices. Similarly, the instrumentation codes responsible for gathering untouched edge information should also be lightweight to minimize disruption to program execution.
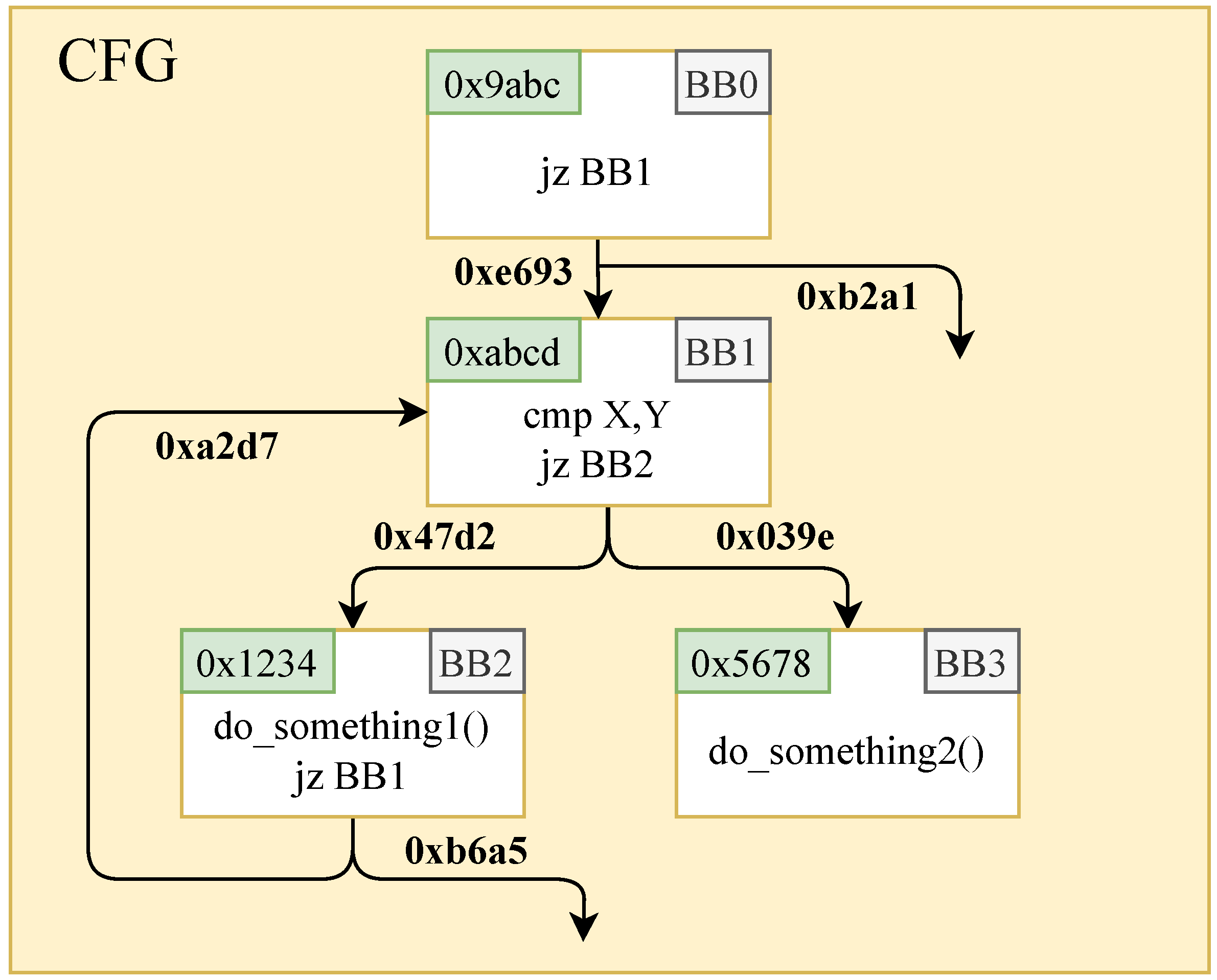
We introduce our instrumentation approach with a practical example.
Figure 4 provides a snippet of branches within the program’s CFG. The hexadecimal values in green boxes represent random IDs allocated by the AFL instrumentation for each basic block. According to Equation (
1), the edge index for the transition from basic block BB1 to BB2 is calculated as
, while the edge index for the transition from basic block BB1 to BB3 is calculated as
.
Suppose a particular seed triggers a transition from basic block BB1 to BB2, leaving the transition from BB1 to BB3 unexplored. In this scenario, we label edge as an untouched edge within the execution path of the seed. A straightforward method for capturing untouched edges is to insert instrumentation codes within basic block BB2. Such codes update a byte of untouched edge bitmap by using as a static index pre-allocated during compilation. This approach works efficiently when a basic block has only one predecessor, but confusion arises when a basic block has multiple incoming edges.
Consider the seed’s execution path: BB0→BB1→BB2→BB1. Basic block BB1 has two incoming edges: from BB0 and from BB2. The corresponding unexplored edges are and . Employing the aforementioned instrumentation codes, distinguishing between these two untouched edges becomes a challenging endeavor.
Upon analyzing the above example, it becomes evident that static pre-allocation of untouched edge IDs is impractical when a basic block has multiple predecessors. To address this challenge, we propose a dynamic method for obtaining untouched edge IDs based on the properties of XOR operations. Specifically, we employ a global variable named “
” to maintain the XOR value of the IDs of two basic blocks at branch transition point. When a transition between basic blocks occurs, we perform an XOR operation on the ID of the transitioned-to basic block with “
” to retrieve the ID of the other unexplored basic block. Furthermore, we define the equation for calculating untouched edge IDs as follows:
Illustrated with the control flow graph in
Figure 4, consider the branch transition point within basic block BB1, which leads to two transitions to basic blocks BB2 and BB3. At BB1, we update the value of “
” by performing an XOR operation on the IDs of BB2 and BB3, resulting in
. When a transition occurs from basic block BB1 to BB2, we can recover the ID of the unexplored basic block BB3 by using “
”: “
”. Subsequently, we calculate the untouched edge ID between BB1 and BB3 using Equation (
1): “
”. The calculated value is then utilized to update the bitmap information for the untouched edges.
Algorithm 2 delineates the process of instrumenting untouched edges. Initially, in lines 2–6, the algorithm employs AFL’s native edge coverage-based instrumentation, concurrently capturing the random IDs allocated to each basic block. Subsequently, from lines 8 to 27, the algorithm performs to instrument for untouched edges.
| Algorithm 2 Instrumentation for untouched edges |
![Applsci 13 13172 i002]() |
To elucidate further, lines 10–12 of the algorithm determine whether the current “untouch_inst1” is invoked. “untouch_inst1” appends instrumentation codes to the beginning of each basic block. The primary function of these codes lies in fetching the value of the global variable “
” within the program. It subsequently calculates the ID for the untouched edge per Equation (
2) and leverages this ID to update the untouched edge bitmap “
”.
Moving to lines 15–24, the algorithm traverses the two successor basic blocks of the current basic block, performing XOR operation on the IDs allocated to these two basic blocks. Finally, in line 25, the function “untouch_inst2” is invoked. The primary aim of the code is to update the value of the global variable “” with the control flow graph, setting it to the outcome of the XOR operation mentioned earlier. At this point, all steps of the untouched edge instrumentation algorithm have been completed.
At the low assembly level, a basic block always has exactly two successor basic blocks. However, when we move up to higher-level compiler intermediate languages, it is not guaranteed that a basic block has always exactly two successor basic blocks, especially in programs that contain Switch statements. Specific solutions to this issue will be provided in
Section 5. Additionally, it is worth noting that the instrumentation approach proposed still leads to the problem of edge index collisions, where different edges in the CFG are assigned with the same index value [
28].
4.3. Seed Scheduling Based on Untouched Edges
In the preceding
Section 4.2, we introduced the method for obtaining untouched edge information. In this section, we delve into seed scheduling based on the collected untouched edges. Similar to AFL, we maintain an array, ‘
’, with a size of MAP_SIZE to store the most favored seed for each untouched edge. We also employ a greedy algorithm, specifically the minimum covering set algorithm [
34], to generate an optimal seed set that contains all currently untouched edges.
Algorithm 3 describes the seed scheduling algorithm based on untouched edges. Initially, in line 1, the algorithm feeds the newly added seed, denoted as ‘s’, to the instrumented program ‘
’ with untouched edges. Subsequently, it acquires the edge coverage bitmap and the untouched edge bitmap of that seed. Following this, in lines 2–27, the algorithm iterates through each index value in the bitmap.
| Algorithm 3 Seed scheduling based on untouched edges |
![Applsci 13 13172 i003]() |
Specifically, in lines 3–10, the algorithm first checks whether the edge has been both marked as a touched edge and an untouched edge in the two bitmaps. If this condition is true, it suggests that the edge is likely in a loop structure. Due to the repeated edges covered in loops, it is possible that edges untouched in a previous iteration of the loop are now covered in the current iteration. To mitigate this effect, the algorithm sets the value of the untouched edge bitmap corresponding to this edge’s index to 0.
The algorithm also maintains a global array called ‘’. The indices of this array correspond to edge IDs, and the array values indicate the status of the respective untouched edges: 0 denotes an untouched edge that has not been covered by the execution path of any seed, 1 denotes that a seed’s execution path includes this untouched edge, and 255 denotes an untouched edge that has been covered by the execution path of another seed, i.e., it has been “explored”. If the current edge is covered by seed ‘s’, and the corresponding value in the ‘’ array is not 0, the algorithm updates the value to 255.
Moving on to lines 11–13, if the edge is an untouched edge for the current seed ‘s’ and has not been “explored” by other seeds in history, the algorithm updates the value in the ‘’ array to 1. In lines 14–17, if the corresponding ‘’ value for this edge is 255, indicating that the edge is no longer untouched, the algorithm sets the ‘’ value for this edge to NULL. The ‘’ maintains the best seed for each untouched edge.
In lines 18–26 of the algorithm, the current seed s is compared with the metrics of the best seed for this untouched edge. We continue to use AFL’s default metrics, which is the seed’s execution speed multiplied by its file size. Then, at line 28, the algorithm invokes the function, which generates a minimal seed set containing all untouched edges found, following the logic described in Algorithm 1.
In the end, the algorithm outputs the optimal seed set based on untouched edges. UntouchFuzz prioritizes testing seeds from this selected seed set.
4.4. Energy Scheduling Optimization
The goal of energy scheduling is to allocate energy efficiently to the chosen seeds for optimal mutations. It is essential to strike the right balance in energy allocation. Allocating excessive energy can lead to a significant waste of fuzzing resources on a single seed. Conversely, insufficient energy allocation may underutilize a seed’s potential to explore new paths, as discussed in reference [
14].
In this paper, we obtain the number of seeds in the seed set for each untouched edge included. Following this, we sort the number of seeds for these untouched edges in ascending order and select the top
(40% is the default in this paper) as rare untouched edges. Then, we calculate the difference between the number of current seed’s rare untouched edge ‘
’ and the maximum number of seed ‘
’ among all rare untouched edges then calculate the average distance value
based on Equation (
4).
Assuming the original energy allocated to the seed was p, it is now assigned a new energy of , where is the default value of 0.3. In our insight, if a certain untouched edge appears frequently in the seed set, it implies a high probability that the selected seed contains this untouched edge and suggests that this particular untouched edge is likely to be difficult to explore. Therefore, if a seed includes many high-frequency untouched edges, it should be allocated less energy. Conversely, if the seed contains numerous low-frequency untouched edges, it should be allocated more energy.
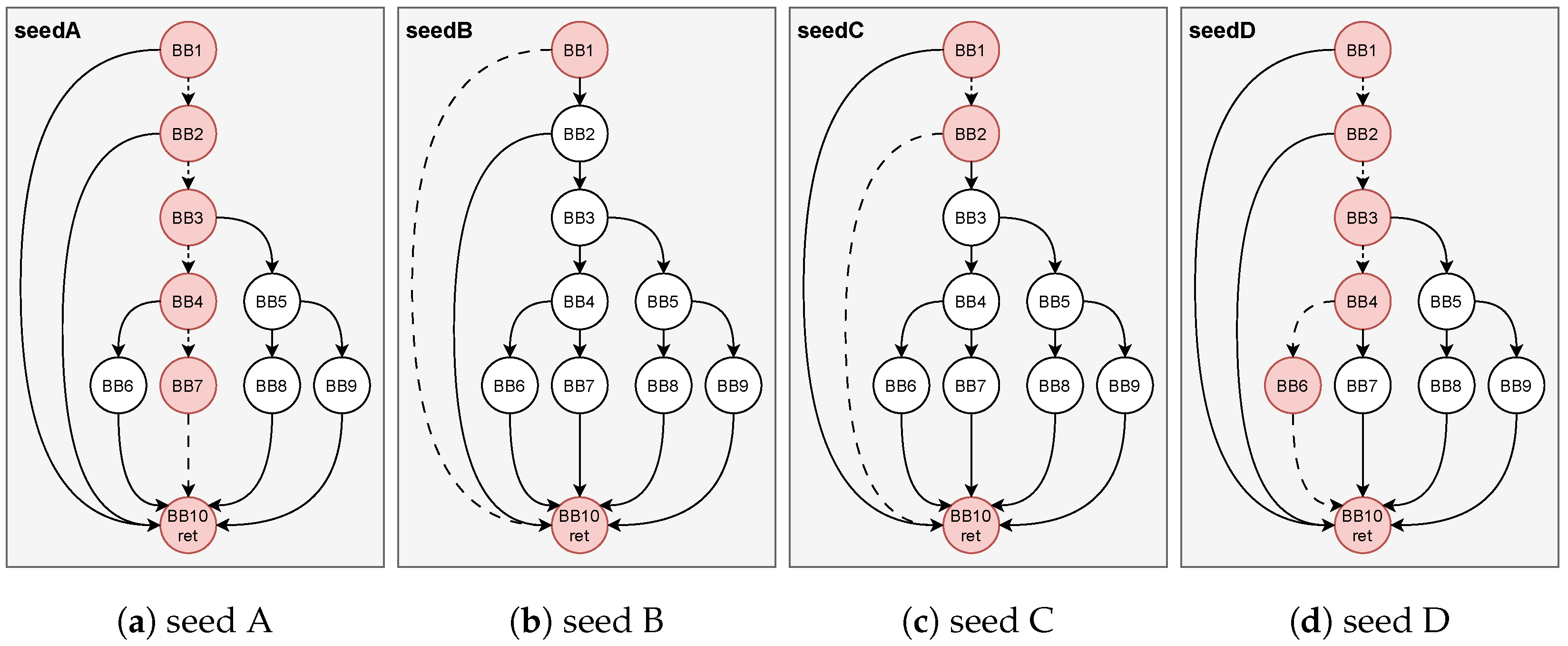
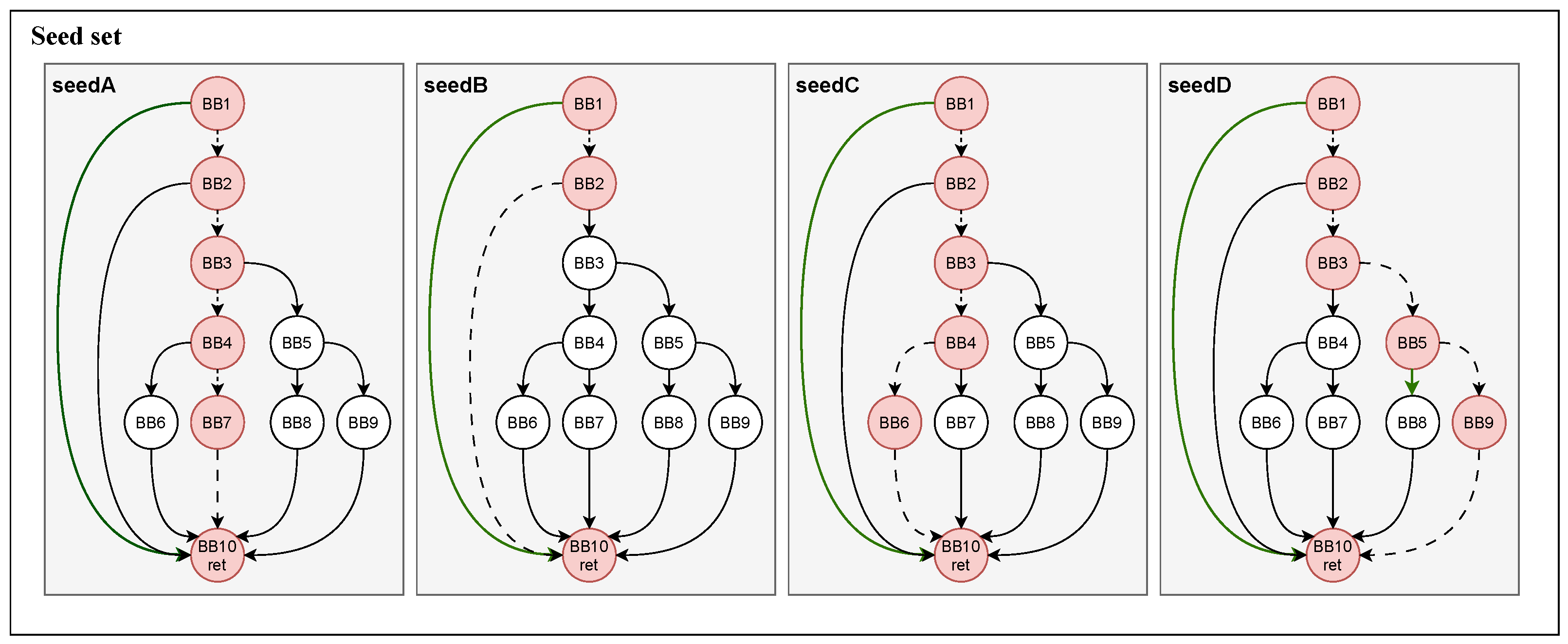
To elaborate on our insight,
Figure 5 illustrates it through an example. Assuming that the current phase has fuzzed for a while and the seed set contains four seeds, with two global untouched edges: BB1→BB10 and BB5→BB8. According to the seed scheduling algorithm outlined in
Section 4.3, seed B is identified as a favored seed due to the presence of untouched edge BB1→BB10 in its execution path and superior seed attribute. Similarly, seed D is designated as a favored seed because of the inclusion of the new untouched edge BB5→BB8 in its execution path.
Subsequently, the fuzzing process prioritizes the mutation of seed B and seed D. As previously mentioned, the untouched edge BB1→BB10 appears in the execution paths of all four seeds, indicating it is not a rare untouched edge. In contrast, BB5→BB8 is considered as a rare untouched edge since it appears only in the execution path of seed D. Consequently, we can make a reasonable conjecture that the untouched edge BB1→BB10 is likely associated with a hard-to-solve constraint, whereas BB5→BB8 is likely to represent a more manageable constraint. To increase the likelihood of covering edge BB5→BB8, we allocate more energy to the mutation of seed D based on the previously outlined energy allocation mechanism. It is essential to note that the provided example is simplified for explanatory purposes, while the real-world program will be complex.
However, in AFL, when new seeds are discovered, the fuzzer doubles the energy allocated to the seeds. Hence, we do not intentionally reduce the energy but instead provide seeds with a higher initial energy value to the seeds, aiming to fully unleash the potential of seeds to discover new paths.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}