
Cross-Condition Fault Diagnosis of an Aircraft Environmental Control System (ECS) by Transfer Learning


Abstract
:1. Introduction
1.1. Cross-Condition Fault Diagnosis Using Transfer Learning
1.2. Challenge of Cross-Condition Fault Diagnosis of Environmental Control System
2. Background
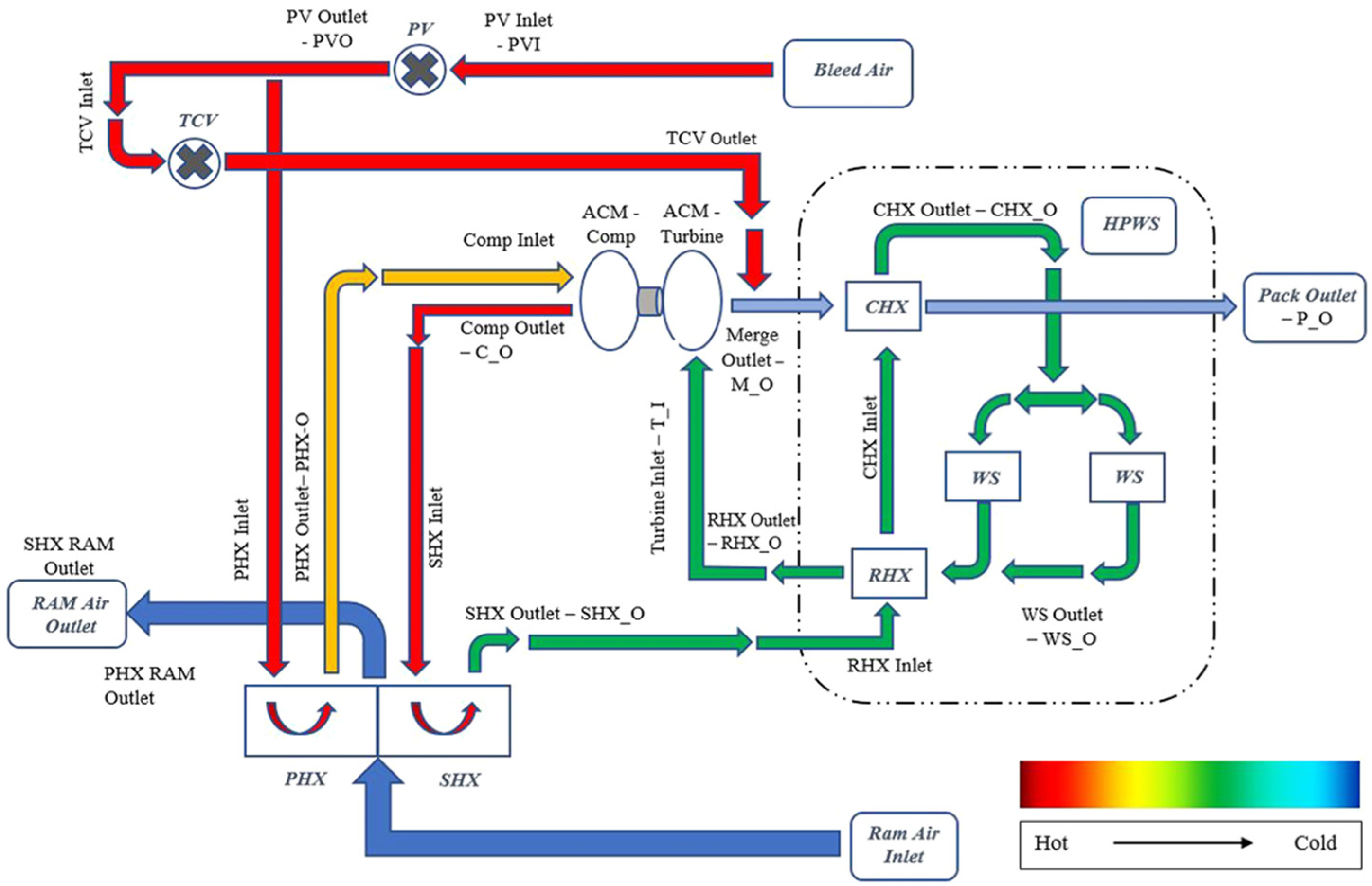
2.1. Environmental Control System Overview and Simulation Platform
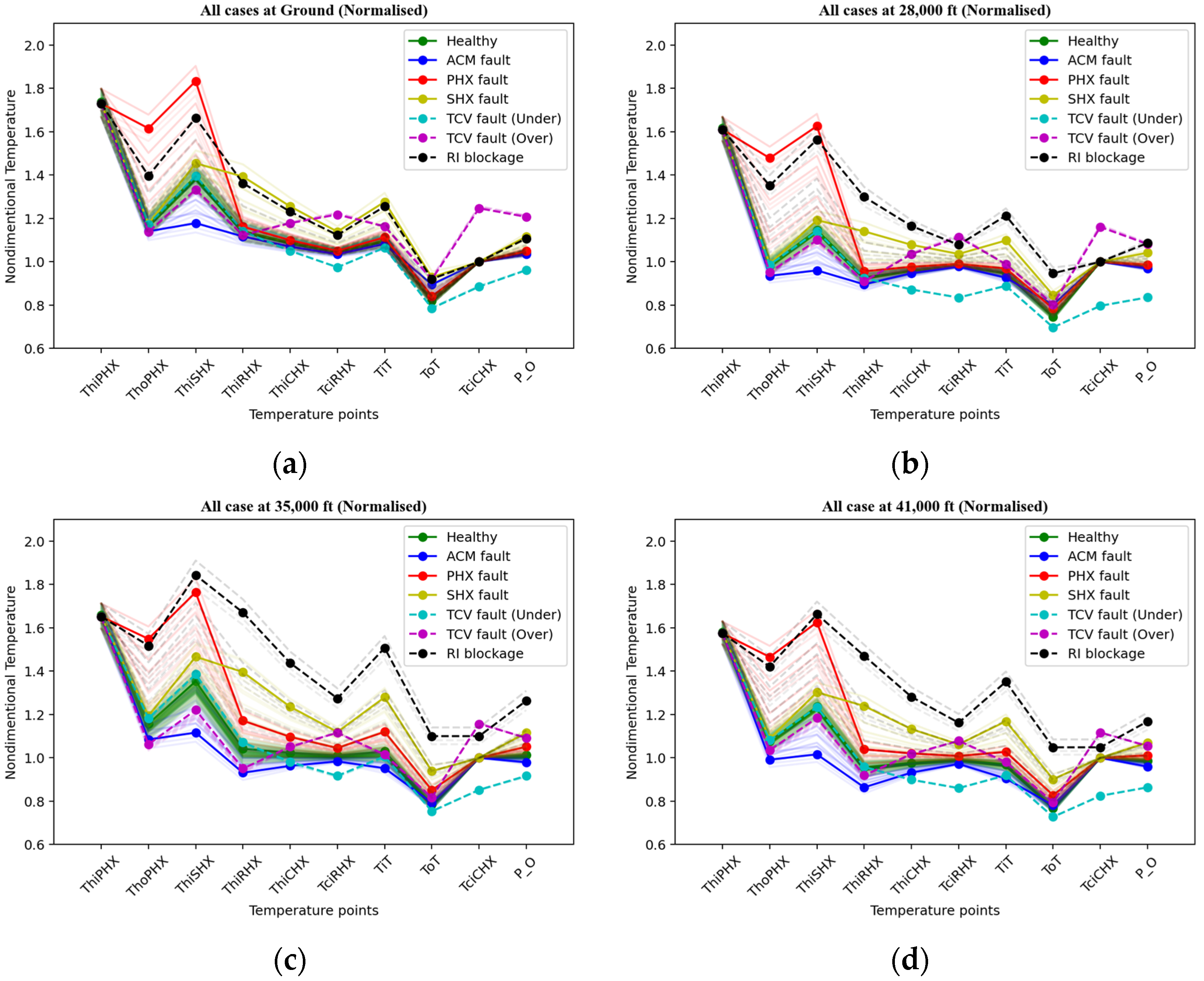
2.2. Data Collection and Processing
2.3. Problem Statement
3. Methodology
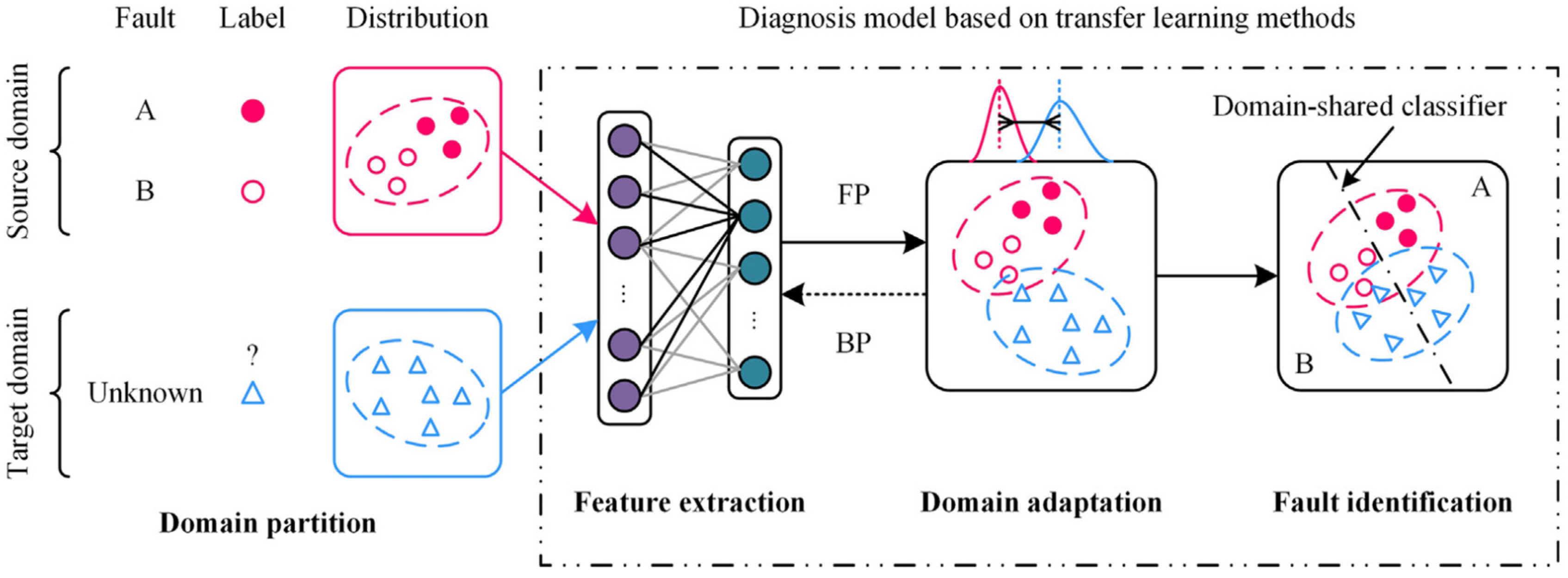
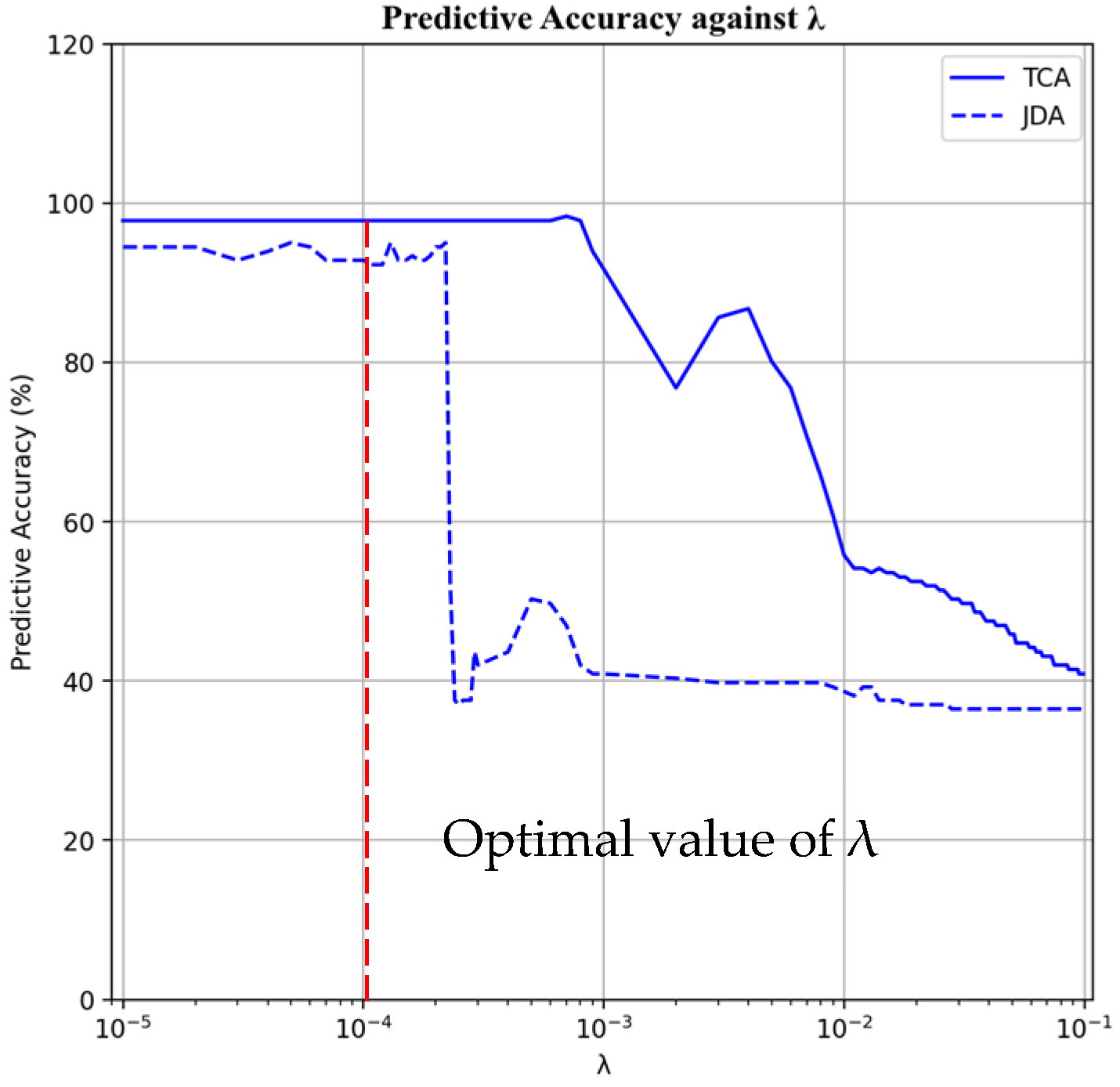
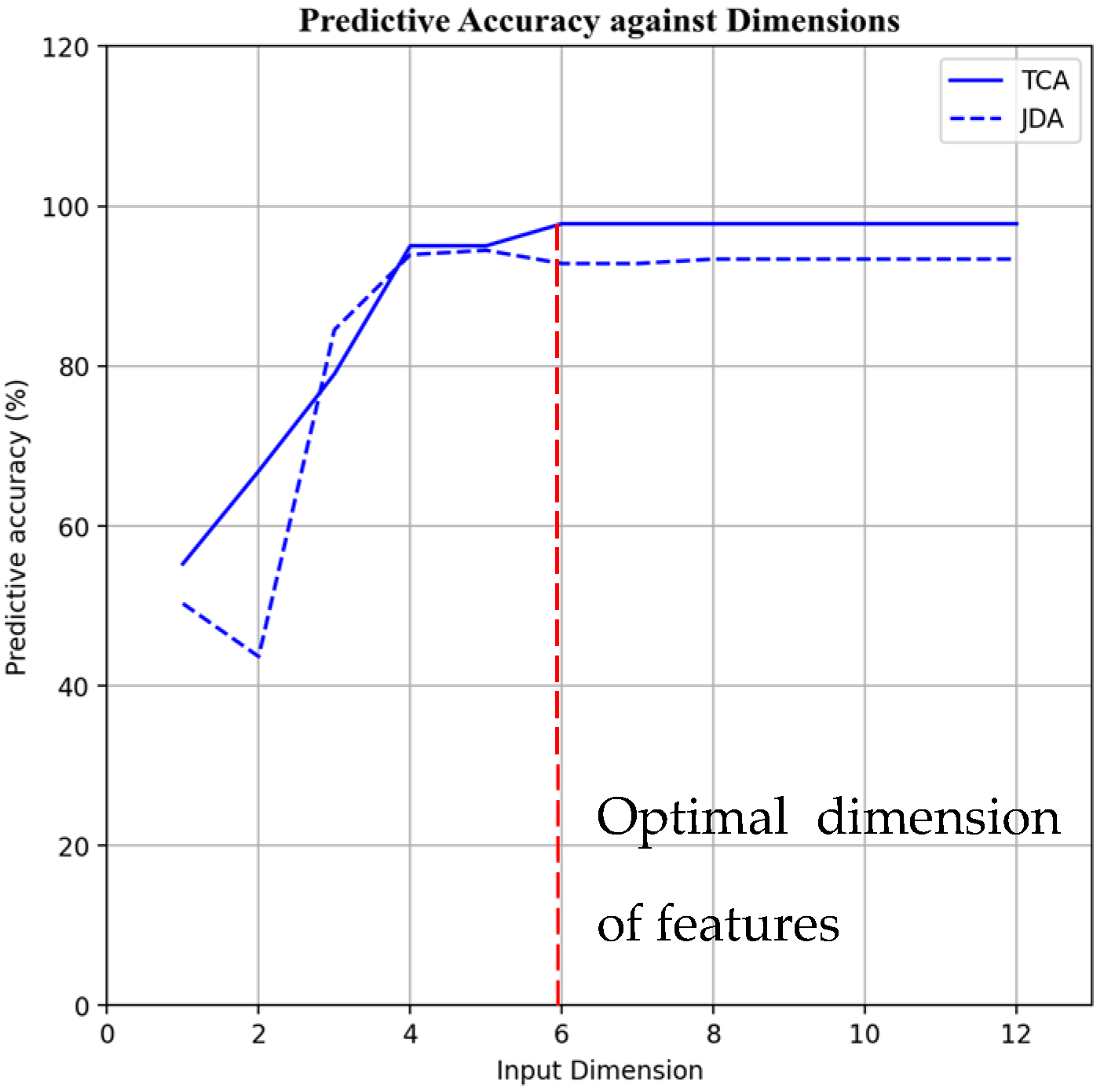
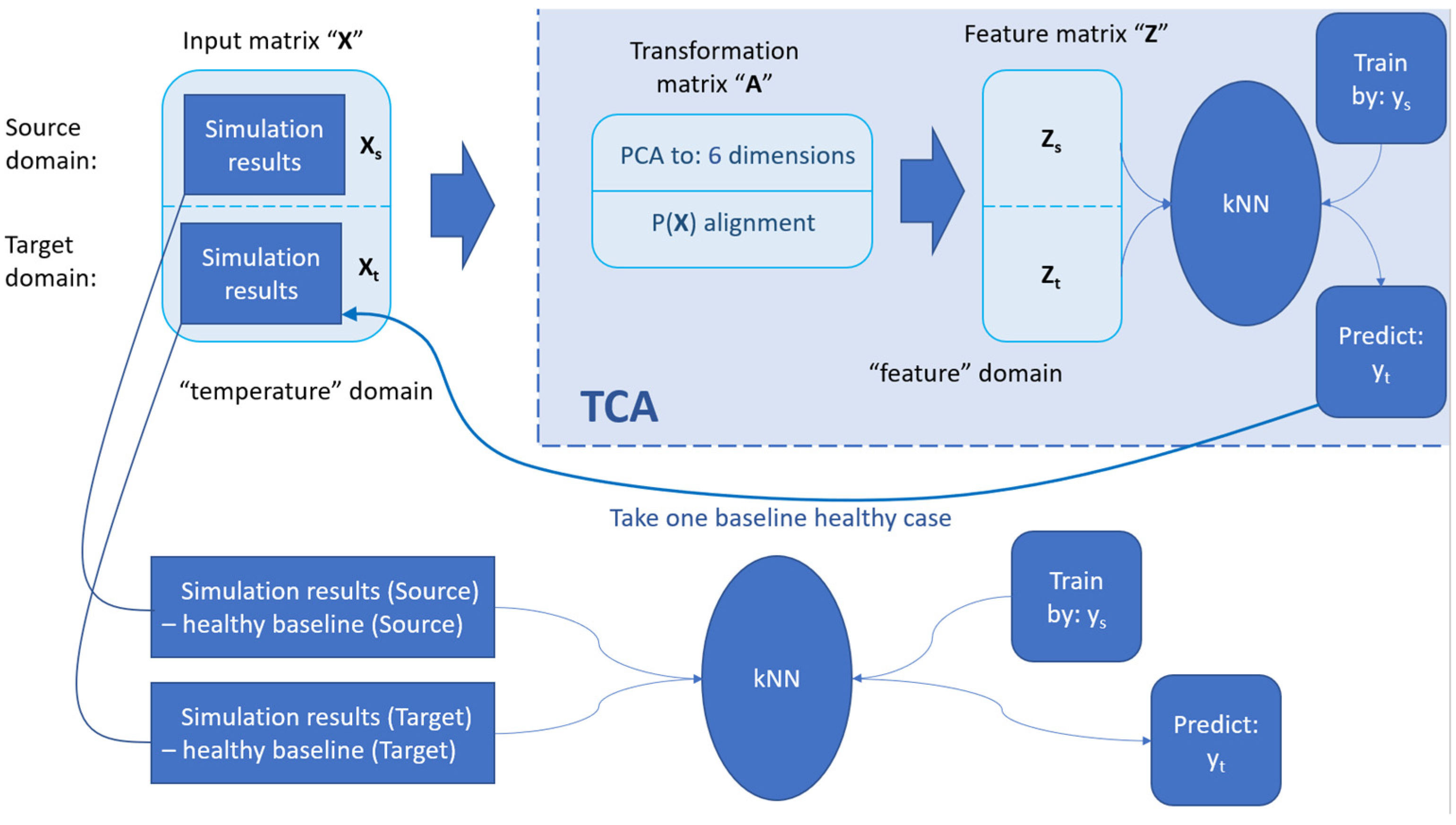
3.1. Feature-Based TL: TCA and JDA
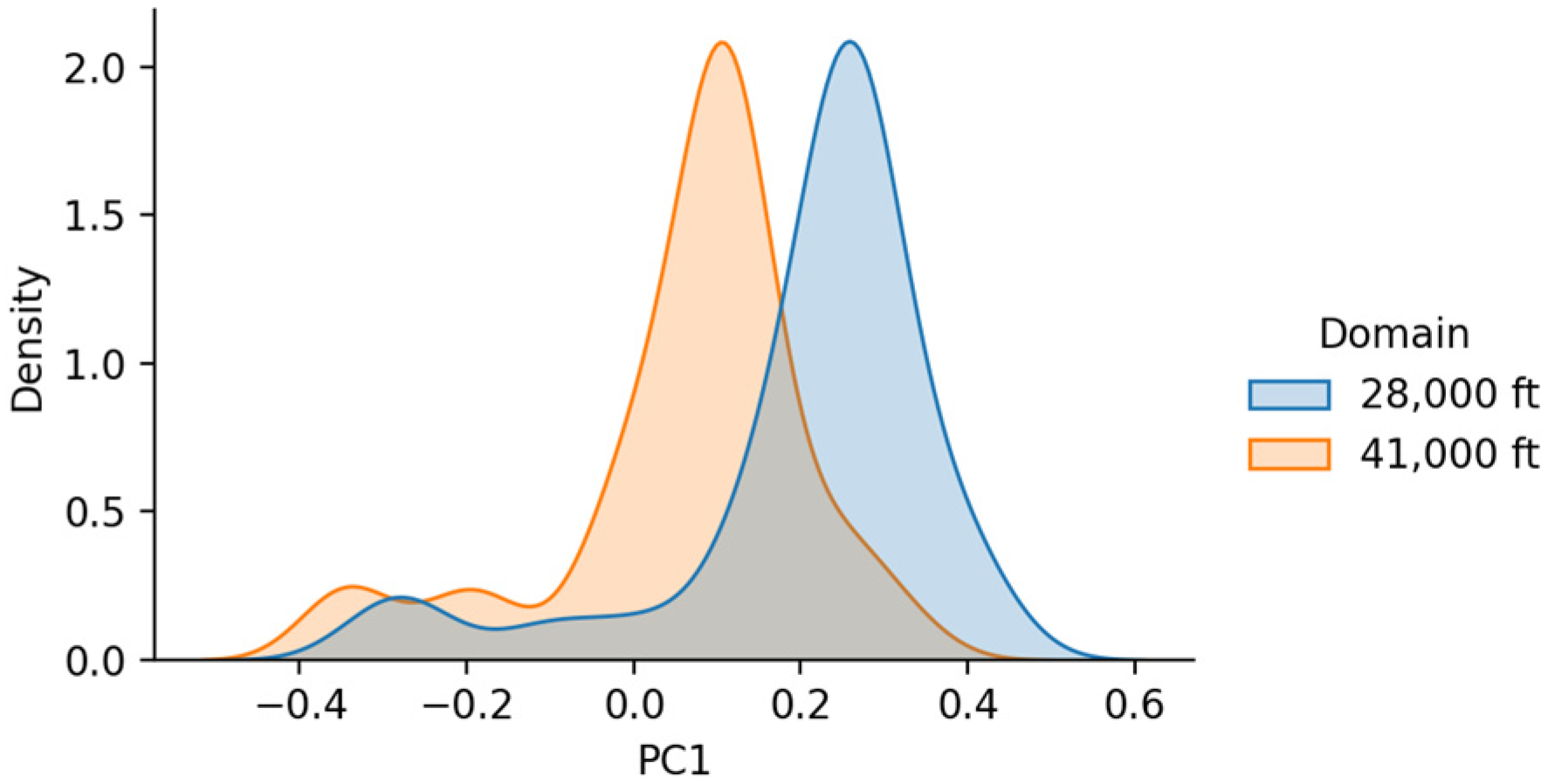
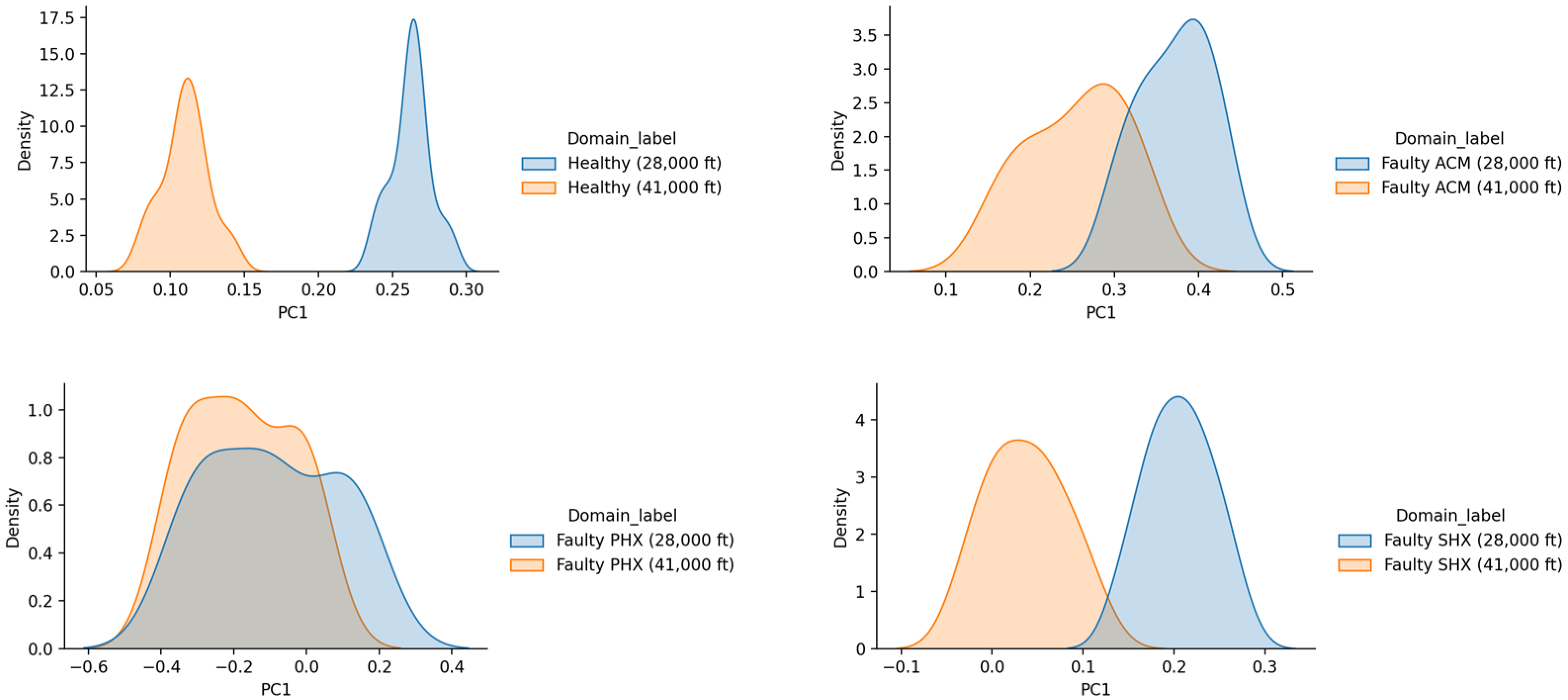
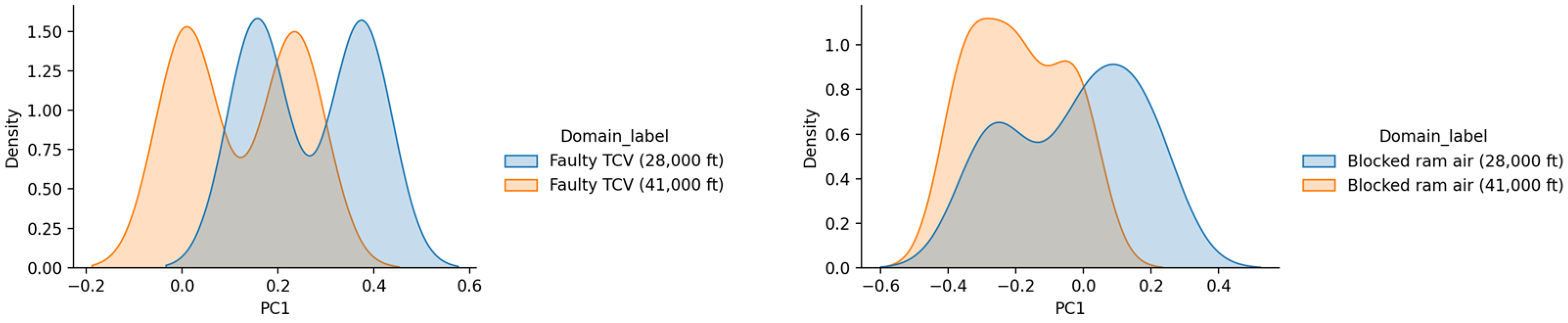
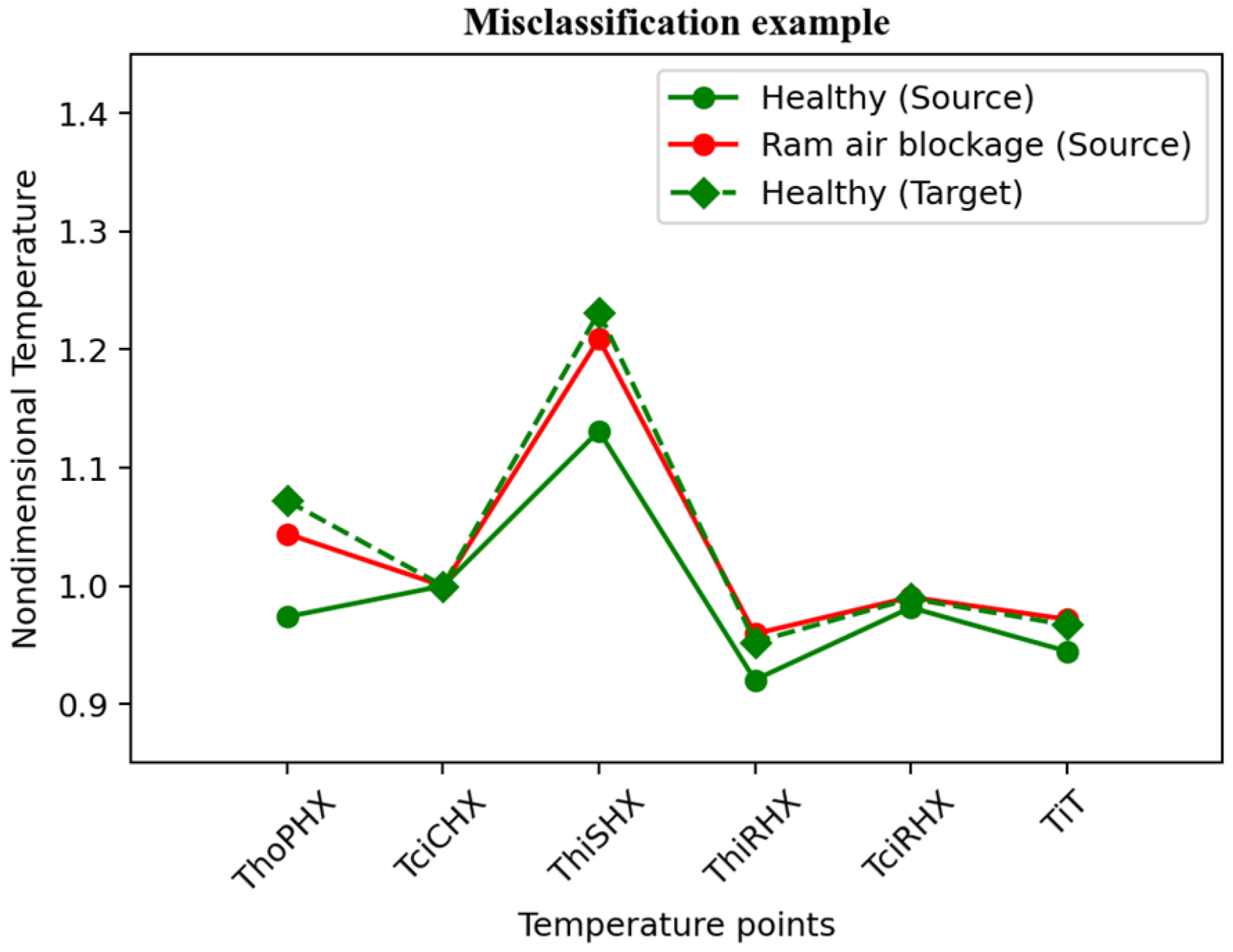
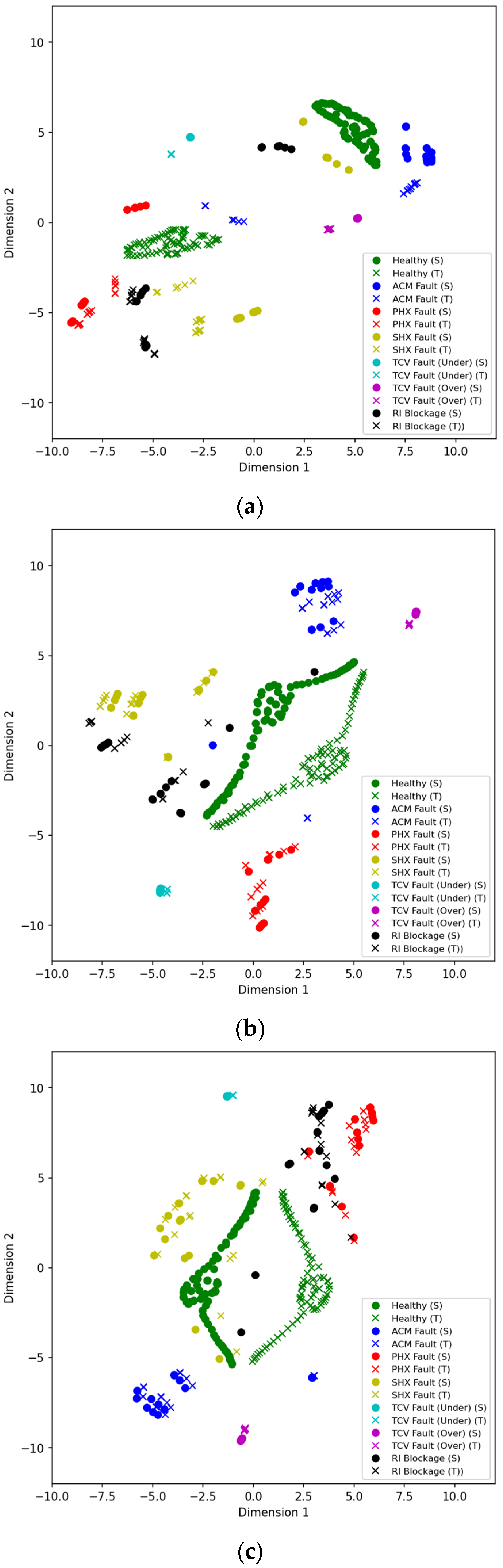
3.2. Visualising Marginal and Conditional Distribution Discrepancy
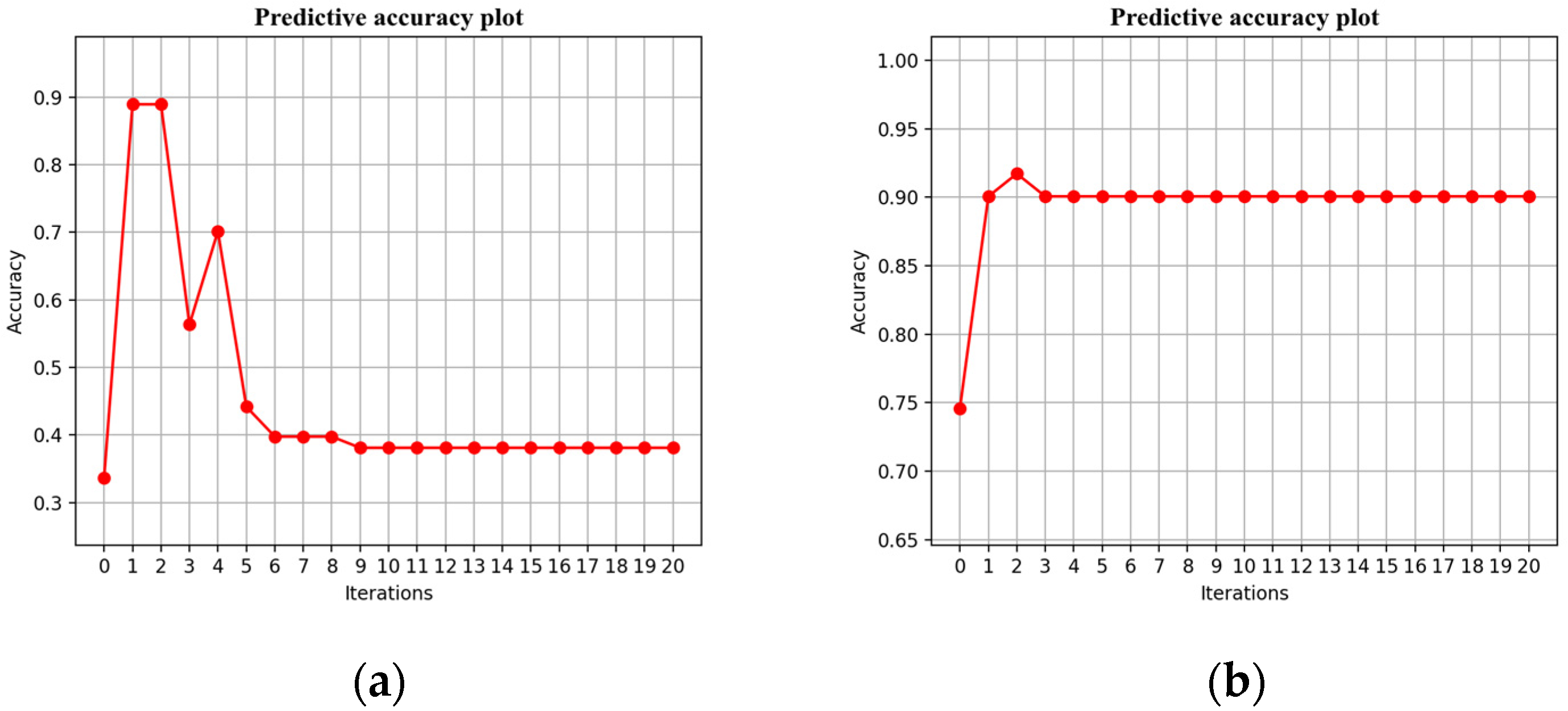
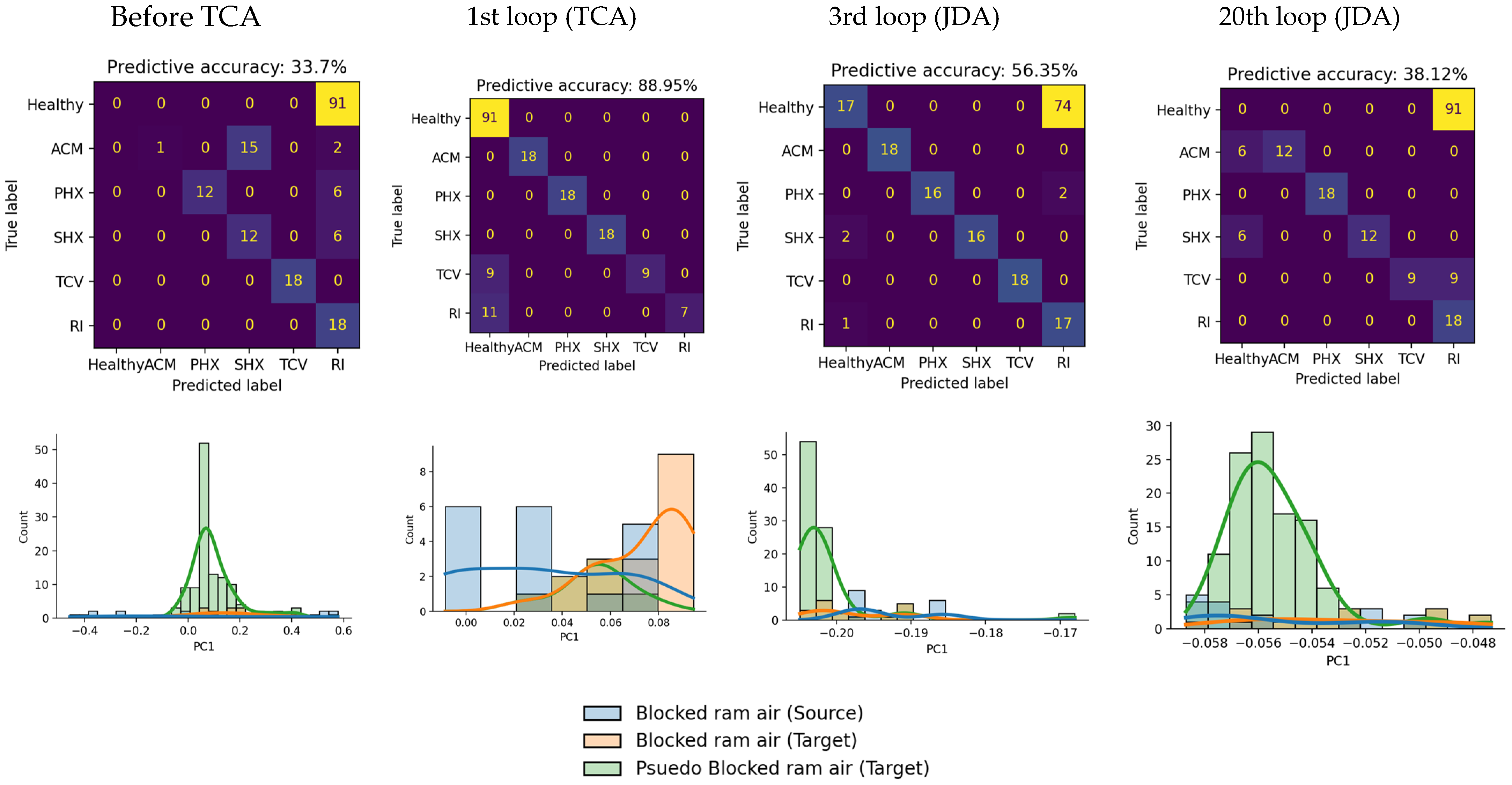
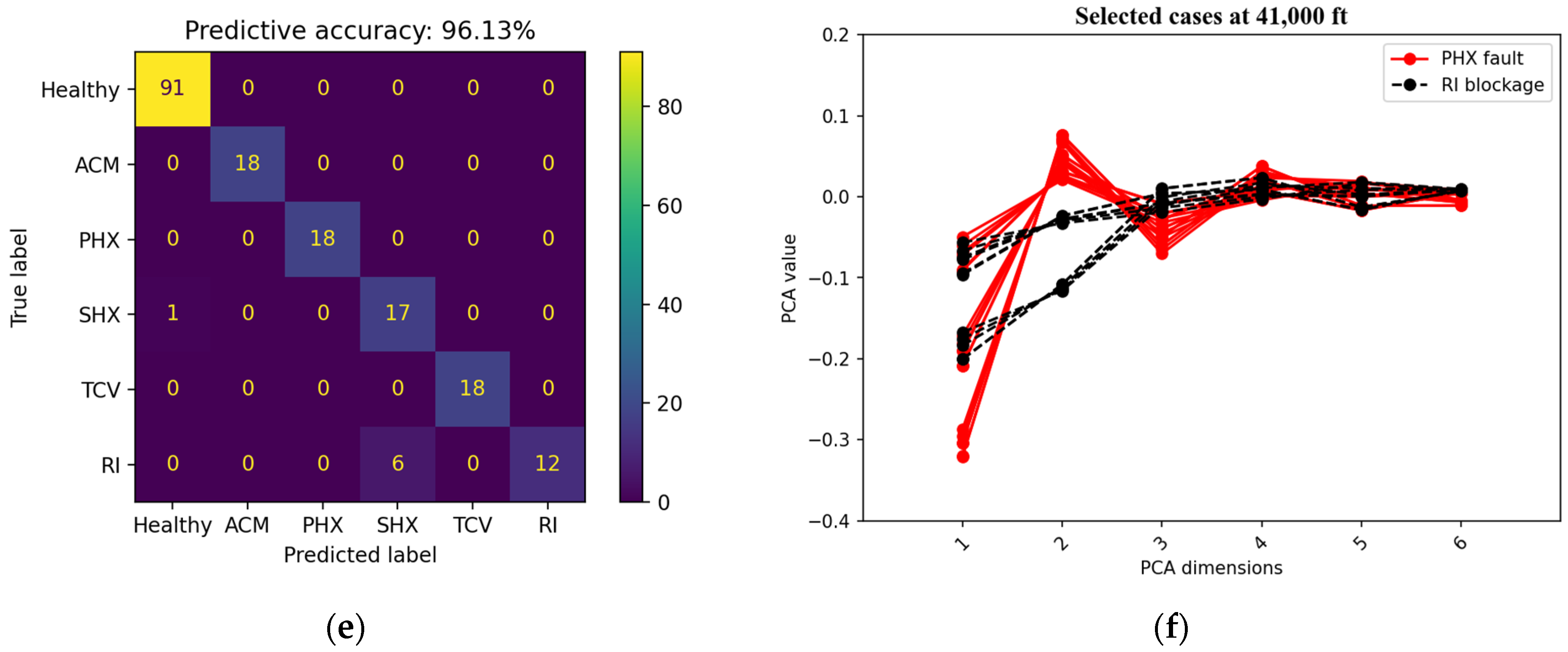
4. Result and Analysis
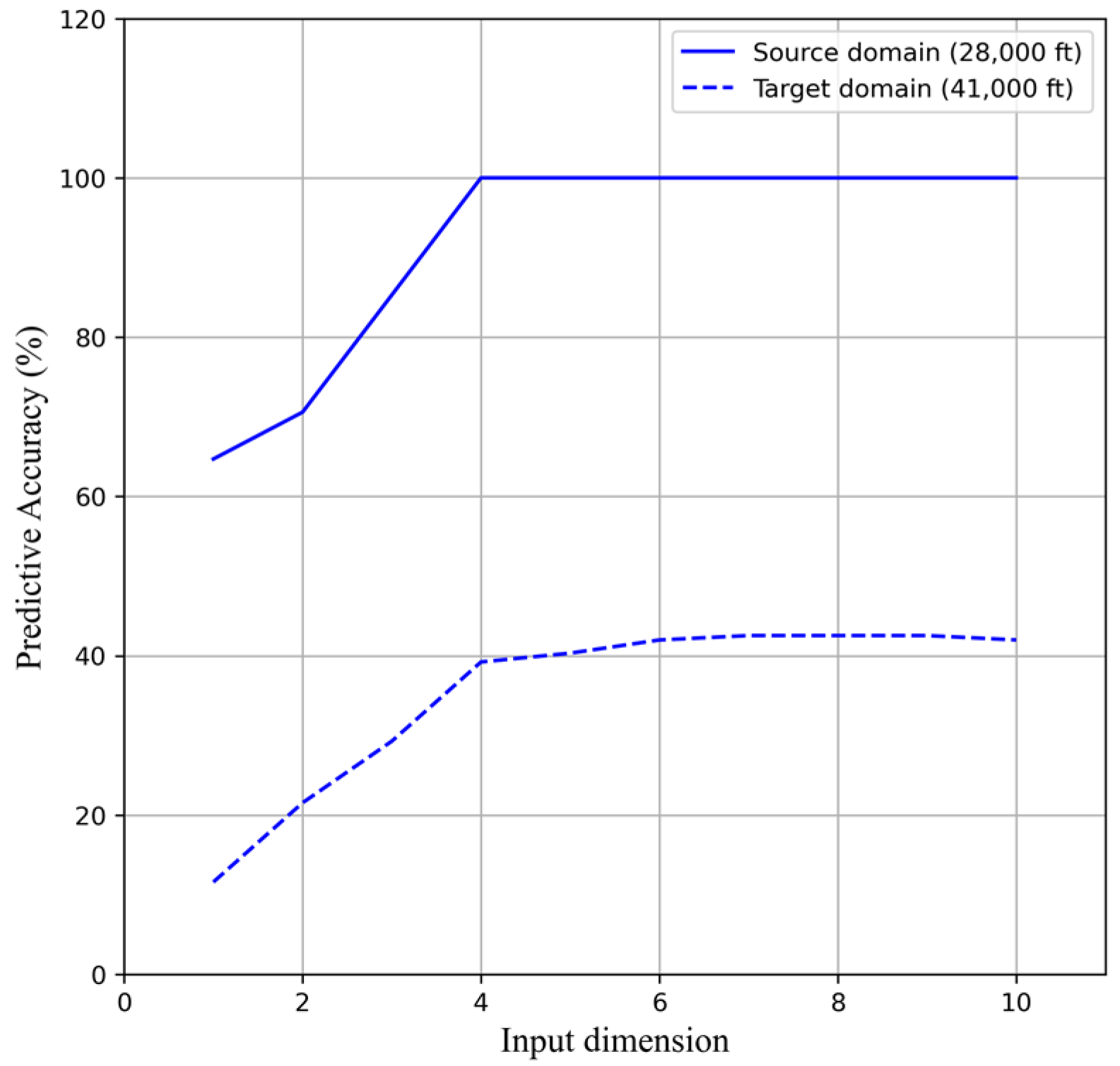
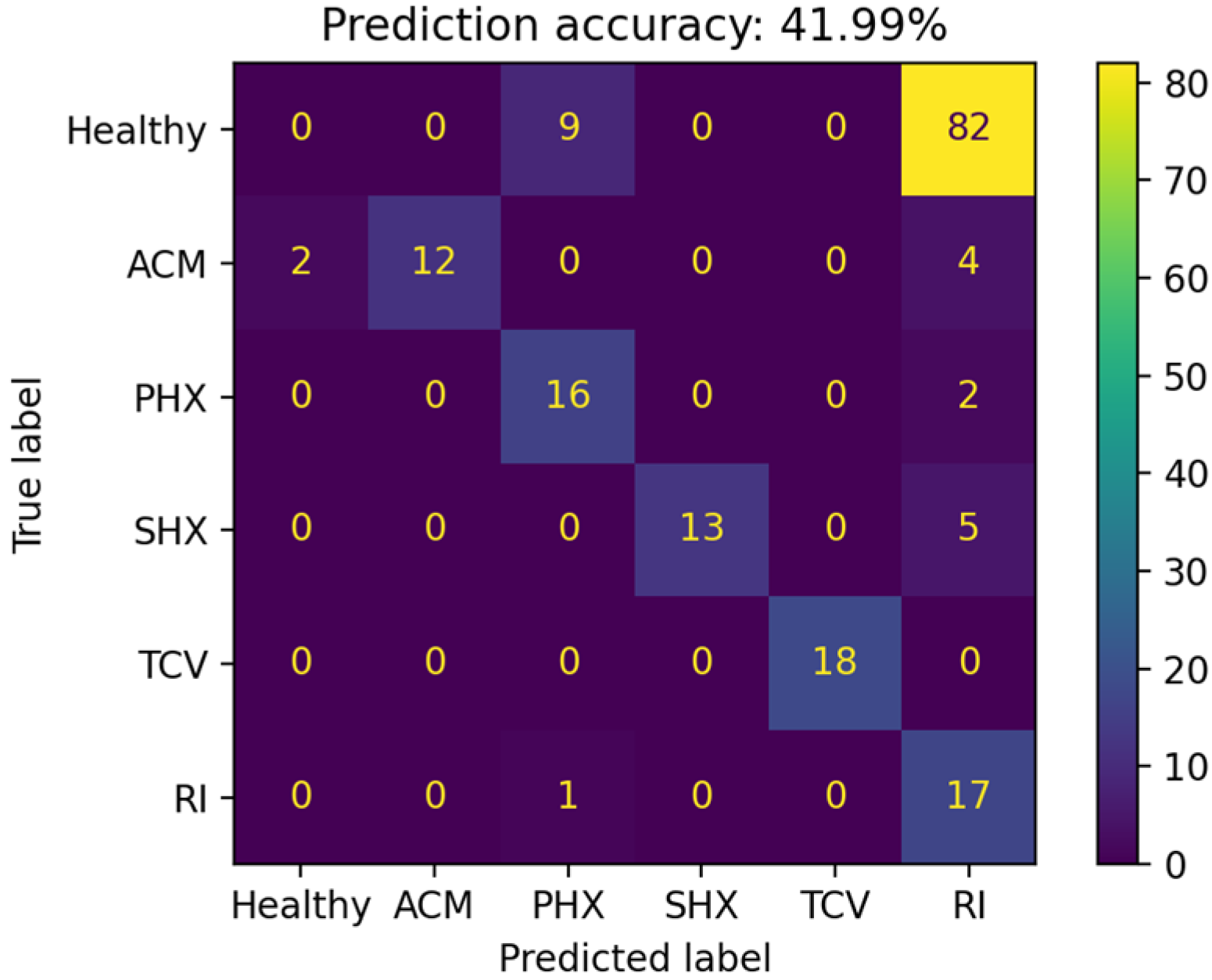
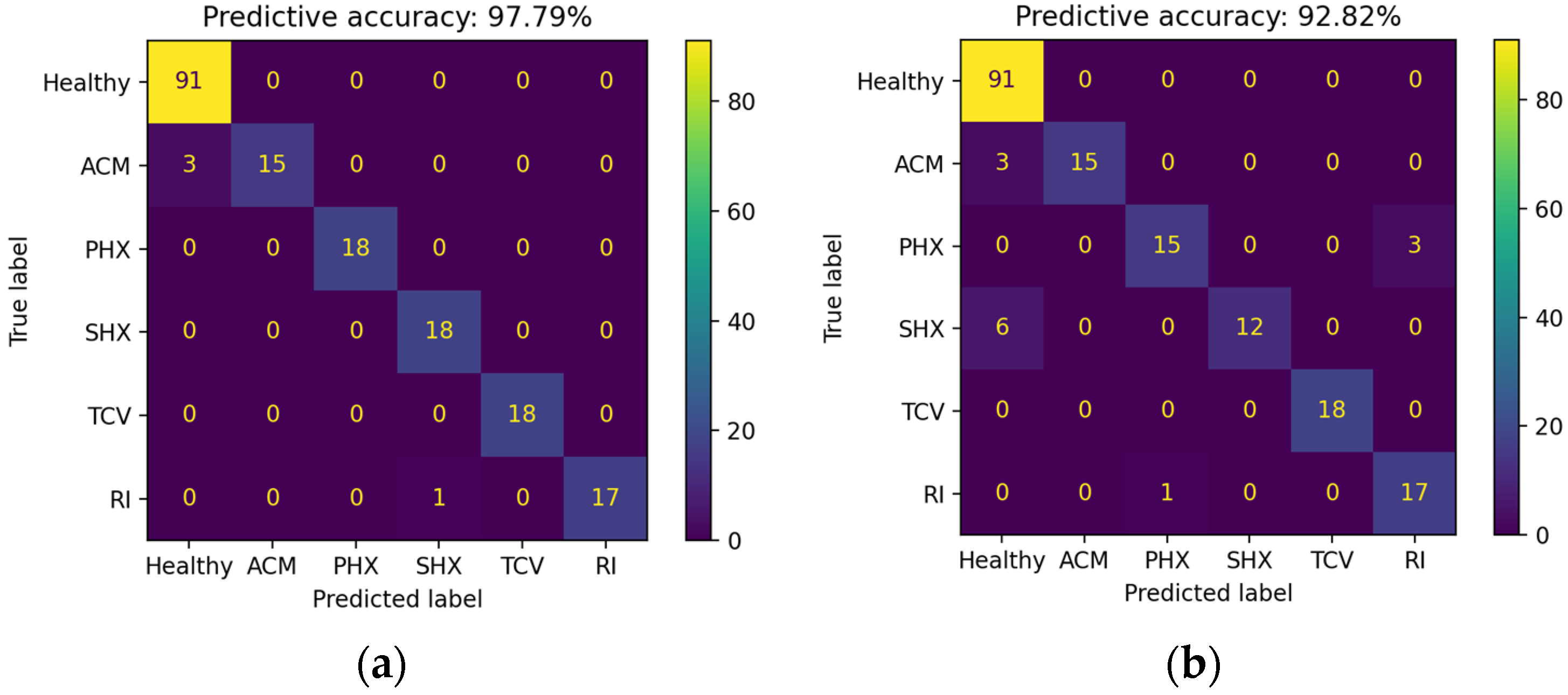
4.1. Non-TL Approach
4.2. TL Approach: TCA and JDA
5. Expanding the Transfer Scenarios of the TL-Based Diagnostic Algorithm
5.1. Transfer between Four Operating Conditions
5.2. Transfer with Different Case Compositions in the Target Domain
6. An Alternative TL-Based Fault Diagnosis Process for Unlabelled Target Domain Using TCA
7. Conclusions and Limitations
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACM | Air cycle machine |
| CNN | Convolutional neural network |
| ECS | Environmental control system |
| JDA | Joint distribution alignment |
| k-NN | k-nearest neighbour |
| ML | Machine learning |
| MMD | Maximum mean discrepancy |
| PACK | Passenger Air Conditioner |
| PCA | Principal component analysis |
| PHX | Primary heat exchanger |
| RI | Ram air inlet |
| SESAC | Simscape Environmental Control System Simulation under All Conditions |
| SHX | Secondary heat exchanger |
| TCA | Transfer component analysis |
| TCV | Temperature control valve |
| TL | Transfer learning |
| t-SNE | t-distributed stochastic neighbour embedding |
References
- Pinto, R.; Gonçalves, G. Application of Artificial Immune Systems in Advanced Manufacturing. Array 2022, 15, 100238. [Google Scholar] [CrossRef]
- Tu, W.; Fang, J.; He, Y.; Huang, J. Application Analysis of Machine Learning in Fault Diagnosis: A Bibliometric Analysis. J. Phys. Conf. Ser. 2020, 1629, 012020. [Google Scholar] [CrossRef]
- Van Tung, T.; Yang, B.-S. Machine Fault Diagnosis and Prognosis: The State of The Art. Int. J. Fluid Mach. Syst. 2009, 2, 61–71. [Google Scholar] [CrossRef]
- Li, W.; Huang, R.; Li, J.; Liao, Y.; Chen, Z.; He, G.; Yan, R.; Gryllias, K. A Perspective Survey on Deep Transfer Learning for Fault Diagnosis in Industrial Scenarios: Theories, Applications and Challenges. Mech. Syst. Signal Process 2022, 167, 108487. [Google Scholar] [CrossRef]
- Vachtsevanos, G.; Lewis, F.; Roemer, M.; Hess, A.; Wu, B. Intelligent Fault Diagnosis and Prognosis for Engineering Systems; Wiley: Hoboken, NJ, USA, 2007; pp. 1–434. [Google Scholar] [CrossRef]
- Qian, W.; Li, S.; Yi, P.; Zhang, K. A Novel Transfer Learning Method for Robust Fault Diagnosis of Rotating Machines under Variable Working Conditions. Measurement 2019, 138, 514–525. [Google Scholar] [CrossRef]
- Chen, C.; Shen, F.; Xu, J.; Yan, R. Domain Adaptation-Based Transfer Learning for Gear Fault Diagnosis under Varying Working Conditions. IEEE Trans. Instrum. Meas. 2021, 70. [Google Scholar] [CrossRef]
- An, Y.; Zhang, K.; Liu, Q.; Chai, Y.; Huang, X. Deep Transfer Learning Network for Fault Diagnosis under Variable Working Conditions. In Proceedings of the 2021 CAA Symposium on Fault Detection, Supervision, and Safety for Technical Processes (SAFEPROCESS), Chengdu, China, 17–18 December 2021. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, N.; Shen, C. A New Deep Transfer Learning Method for Bearing Fault Diagnosis under Different Working Conditions. IEEE Sens. J. 2020, 20, 8394–8402. [Google Scholar] [CrossRef]
- Yang, Q.; Zhang, Y.; Dai, W.; Pan, S.J. Transfer Learning; Cambridge University Press: Cambridge, UK, 2020; ISBN 9781139061773. [Google Scholar]
- Zheng, H.; Wang, R.; Yang, Y.; Yin, J.; Li, Y.; Li, Y.; Xu, M. Cross-Domain Fault Diagnosis Using Knowledge Transfer Strategy: A Review. IEEE Access 2019, 7, 129260–129290. [Google Scholar] [CrossRef]
- He, J.; Li, X.; Chen, Y.; Chen, D.; Guo, J.; Zhou, Y. Deep Transfer Learning Method Based on 1D-CNN for Bearing Fault Diagnosis. Shock. Vib. 2021, 2021, 6687331. [Google Scholar] [CrossRef]
- Xiao, D.; Huang, Y.; Zhao, L.; Qin, C.; Shi, H.; Liu, C. Domain Adaptive Motor Fault Diagnosis Using Deep Transfer Learning. IEEE Access 2019, 7, 80937–80949. [Google Scholar] [CrossRef]
- Li, B.; Zhao, Y.P.; Chen, Y. Bin Unilateral Alignment Transfer Neural Network for Fault Diagnosis of Aircraft Engine. Aerosp. Sci. Technol. 2021, 118, 107031. [Google Scholar] [CrossRef]
- Liu, S.; Wang, H.; Tang, J.; Zhang, X. Research on Fault Diagnosis of Gas Turbine Rotor Based on Adversarial Discriminative Domain Adaption Transfer Learning. Measurement 2022, 196, 111174. [Google Scholar] [CrossRef]
- Chowdhury, S.H.; Ali, F.; Jennions, I.K. A Review of Aircraft Environmental Control System Simulation and Diagnostics. Proc. Inst. Mech. Eng. G J. Aerosp. Eng. 2023, 237, 2453–2467. [Google Scholar] [CrossRef]
- Jennions, I.; Ali, F.; Miguez, M.E.; Escobar, I.C. Simulation of an Aircraft Environmental Control System. Appl. Therm. Eng. 2020, 172, 114925. [Google Scholar] [CrossRef]
- Jennions, I.; Ali, F. Assessment of Heat Exchanger Degradation in a Boeing 737-800 Environmental Control System. J. Therm. Sci. Eng. Appl. 2021, 13, 061015. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of Machine Learning to Machine Fault Diagnosis: A Review and Roadmap. Mech. Syst. Signal Process 2020, 138, 106587. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Jia, F.; Xing, S. An Intelligent Fault Diagnosis Approach Based on Transfer Learning from Laboratory Bearings to Locomotive Bearings. Mech. Syst. Signal Process 2019, 122, 692–706. [Google Scholar] [CrossRef]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer Feature Learning with Joint Distribution Adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar] [CrossRef]
- Azari, M.S.; Flammini, F.; Santini, S.; Caporuscio, M. A Systematic Literature Review on Transfer Learning for Predictive Maintenance in Industry 4.0. IEEE Access 2023, 11, 12887–12910. [Google Scholar] [CrossRef]
- Xie, Y.; Liu, C.; Huang, L.; Duan, H. Ball Screw Fault Diagnosis Based on Wavelet Convolution Transfer Learning. Sensors 2022, 22, 6270. [Google Scholar] [CrossRef]
- Zhang, L.; Duan, L. Cross-Scenario Transfer Diagnosis of Reciprocating Compressor Based on CBAM and ResNet. J. Intell. Fuzzy Syst. 2022, 43, 5929–5943. [Google Scholar] [CrossRef]
- Li, M.; Sun, Z.-H.; He, W.; Qiu, S.; Liu, B. Rolling Bearing Fault Diagnosis under Variable Working Conditions Based on Joint Distribution Adaptation and SVM. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar] [CrossRef]
- Xu, W.; Wan, Y.; Zuo, T.Y.; Sha, X.M. Transfer Learning Based Data Feature Transfer for Fault Diagnosis. IEEE Access 2020, 8, 76120–76129. [Google Scholar] [CrossRef]
- Tang, Y.; Dou, L.; Zhang, R.; Zhang, X.; Liu, W. Deep Transfer Learning-Based Fault Diagnosis of Spacecraft Attitude System. In Proceedings of the 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 4072–4077. [Google Scholar] [CrossRef]
- Guo, W.; Li, S.; Miao, Q.; Shandong-Keji-Daxue Tai’an, S. Institute of Electrical and Electronics Engineers A Cross Domain Feature Extraction Method for Bearing Fault Diagnosis Based on Balanced Distribution Adaptation. In Proceedings of the Prognostics and System Health Management Conference (PHM-Qingdao), Qingdao, China, 25–27 October 2019. [Google Scholar] [CrossRef]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef]
- Wang, J. Everything about Transfer Learning and Domain Adapation. Available online: http://transferlearning.xyz (accessed on 4 September 2023).
- Peng, H.; Long, F.; Ding, C. Feature Selection Based on Mutual Information: Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Pedregosa, F.; Michel, V.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Vanderplas, J.; Cournapeau, D.; Varoquaux, G.; Gramfort, A.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Zhu, P.; Dong, S.; Pan, X.; Hu, X.; Zhu, S. A Simulation-Data-Driven Subdomain Adaptation Adversarial Transfer Learning Network for Rolling Element Bearing Fault Diagnosis. Meas. Sci. Technol. 2022, 33, 075101. [Google Scholar] [CrossRef]
- Ding, Y.; Jia, M.; Zhuang, J.; Cao, Y.; Zhao, X.; Lee, C.-G. Deep Imbalanced Domain Adaptation for Transfer Learning Fault Diagnosis of Bearings under Multiple Working Conditions. Reliab. Eng. Syst. Saf. 2023, 230, 108890. [Google Scholar] [CrossRef]
- Skliros, C.; Ali, F.; King, S.; Jennions, I. Aircraft System-Level Diagnosis with Emphasis on Maintenance Decisions. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2022, 236, 1057–1077. [Google Scholar] [CrossRef]
- Liu, C.; Sun, J.; Wang, F.; Ning, S.; Xu, G. Bayesian Network Method for Fault Diagnosis of Civil Aircraft Environment Control System. Proc. Inst. Mech. Engineers. Part I J. Syst. Control Eng. 2020, 234, 662–674. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Mode | Degradation Degree | |||||
|---|---|---|---|---|---|---|
| Minor | Medium | Severe | ||||
| ACM fault | 25% | 50% | 75% | |||
| PHX fault | 20% | 50% | 80% | |||
| SHX fault | 20% | 50% | 80% | |||
| RI blockage | 25% | 50% | 75% | |||
| Degraded state | ||||||
| TCV fault (normally 15°–18°) | Undershoot: Fixed at 10° | Overshoot: Fixed at 23° | ||||
| Operating Condition | Altitude (ft) | Bleed Temperature (K) | Bleed Pressure (kPa) | Ram Air Temperature (K) | Mean Target Temperature (K) | Mean Target Mass Flow Rate | Number of Cases |
|---|---|---|---|---|---|---|---|
| A | 0 | 461.2 | 320 | 297.0 | 266.5 | 0.60 | 91 healthy-state cases; 90 faulty-state cases |
| B | 28,000 | 469.0 | 193 | 232.7 | 291.2 | 0.45 | 91 healthy-state cases; 90 faulty-state cases |
| C | 35,000 | 470.7 | 234 | 245.5 | 284.9 | 0.43 | 91 healthy-state cases; 90 faulty-state cases |
| D | 41,000 | 469.3 | 190 | 216.7 | 298.1 | 0.42 | 91 healthy-state cases; 90 faulty-state cases |
| Domain | Altitude (ft) | Bleed Temperature (K) | Bleed Pressure (kPa) | Ram Air Temperature (K) | Target Temperature (K) | Target Mass Flow Rate | Number of Cases |
|---|---|---|---|---|---|---|---|
| Source | 28,000 | 469.0 | 193 | 232.7 | 291.2 ± 10 | 0.45 ± 0.02 | 91 healthy-state cases; 90 faulty-state cases |
| Target | 41,000 | 469.3 | 190 | 216.7 | 298.1 ± 10 | 0.42 ± 10 | 91 healthy-state cases; 90 faulty-state cases |
| TCA: Prediction Accuracy (%) | JDA: Prediction Accuracy (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SOURCE | SOURCE | ||||||||
| Ground | 28,000 ft | 35,000 ft | 41,000 ft | Ground | 28,000 ft | 35,000 ft | 41,000 ft | ||
| TARGET | Ground | - | 88.95 | 90.06 | 90.06 | - | 38.12 | 41.99 | 90.06 |
| 28,000 ft | 100.00 | - | 94.48 | 95.58 | 93.37 | - | 91.71 | 64.64 | |
| 35,000 ft | 92.27 | 93.37 | - | 100.00 | 92.82 | 47.51 | - | 100.00 | |
| 41,000 ft | 96.13 | 97.79 | 100.00 | - | 93.37 | 92.82 | 100.00 | - | |
| Average: 94.89 | Average: 78.87 | ||||||||
| Cases Composition Number | Scenario Simulated in Target Domain | Composition of Cases in Source Domain (S) and Target Domain (T) |
|---|---|---|
| 1 | A fault-rich ECS | S: 91 H, 18 ACM, 18 PHX, 18 SHX, 18 TCV, 18 RI |
| T: 46 H, 18 ACM, 18 PHX, 18 SHX, 18 TCV, 18 RI | ||
| 2 | Less degradation level in 1 fault mode | S: 91 H, 18 ACM, 18 PHX, 18 SHX, 18 TCV, 18 RI |
| T: 91 H, 18 ACM, 18 PHX, 18 SHX, 18 TCV, 6 RI (mediums only) | ||
| 3 | Less degradation level in 2 fault mode 2 | S: 91 H, 18 ACM, 18 PHX, 18 SHX, 18 TCV, 18 RI |
| T: 91 H, 18 ACM, 6 PHX (mediums only), 18 SHX, 18 TCV, 6 RI (mediums only) | ||
| 4 | No data for 1 fault mode | S: 91 H, 18 ACM, 18 PHX, 18 SHX, 18 TCV, 18 RI |
| T: 91 H, 18 ACM, 18 PHX, 18 SHX, 18 TCV, 0 RI | ||
| 5 | No data for 2 fault modes | S: 91 H, 18 ACM, 18 PHX, 18 SHX, 18 TCV, 18 RI |
| T: 91 H, 18 ACM, 18 PHX, 18 SHX, 0 TCV, 0 RI |
| TCA: Prediction Accuracy (%) | JDA: Prediction Accuracy (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SOURCE | SOURCE | ||||||||
| Ground | 28,000 ft | 35,000 ft | 41,000 ft | Ground | 28,000 ft | 35,000 ft | 41,000 ft | ||
| TARGET | Ground (1) | - | 85.29 | 86.76 | 88.97 | - | 55.15 | 54.41 | 90.44 |
| Ground (2) | - | 91.12 | 92.90 | 92.90 | - | 36.09 | 90.53 | 95.27 | |
| Ground (3) | - | 69.43 | 92.36 | 91.08 | - | 30.57 | 94.27 | 34.39 | |
| Ground (4) | - | 93.25 | 96.32 | 96.32 | - | 31.29 | 92.64 | 98.77 | |
| Ground (5) | - | 100.00 | 95.86 | 95.86 | - | 26.21 | 28.28 | 28.97 | |
| 28,000 ft (1) | 100.00 | - | 91.18 | 95.59 | 91.18 | - | 87.50 | 91.91 | |
| 28,000 ft (2) | 100.00 | - | 97.63 | 98.82 | 98.82 | - | 44.38 | 44.97 | |
| 28,000 ft (3) | 98.09 | - | 98.73 | 95.54 | 98.09 | - | 42.04 | 42.04 | |
| 28,000 ft (4) | 100.00 | - | 97.55 | 97.55 | 69.94 | - | 97.55 | 97.55 | |
| 28,000 ft (5) | 100.00 | - | 91.03 | 99.31 | 100.00 | - | 96.55 | 97.24 | |
| 35,000 ft (1) | 88.97 | 83.82 | - | 100.00 | 88.24 | 90.44 | - | 100.00 | |
| 35,000 ft (2) | 93.49 | 97.63 | - | 100.00 | 94.67 | 92.90 | - | 98.82 | |
| 35,000 ft (3) | 88.54 | 93.63 | - | 96.18 | 92.99 | 94.90 | - | 98.73 | |
| 35,000 ft (4) | 94.48 | 96.32 | - | 97.55 | 95.09 | 48.47 | - | 100.00 | |
| 35,000 ft (5) | 96.55 | 95.17 | - | 97.93 | 60.00 | 27.59 | - | 95.17 | |
| 41,000 ft (1) | 93.38 | 91.91 | 99.26 | - | 92.65 | 90.44 | 100.00 | - | |
| 41,000 ft (2) | 100.00 | 97.04 | 100.00 | - | 98.82 | 95.27 | 100.00 | - | |
| 41,000 ft (3) | 94.27 | 96.18 | 98.73 | - | 98.73 | 96.18 | 100.00 | - | |
| 41,000 ft (4) | 98.77 | 98.16 | 98.77 | - | 80.37 | 25.77 | 100.00 | - | |
| 41,000 ft (5) | 100.00 | 97.93 | 99.31 | - | 82.07 | 23.45 | 99.31 | - | |
| Average: 95.22 | Average: 77.47 | ||||||||
| TCA: TPR on Healthy Cases (%) | TCA: PPV on Healthy Cases (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SOURCE | SOURCE | ||||||||
| Ground | 28,000 ft | 35,000 ft | 41,000 ft | Ground | 28,000 ft | 35,000 ft | 41,000 ft | ||
| TARGET | Ground (1) | - | 100.00 | 100.00 | 100.00 | - | 69.70 | 71.88 | 75.41 |
| Ground (2) | - | 100.00 | 100.00 | 100.00 | - | 85.85 | 88.35 | 88.35 | |
| Ground (3) | - | 65.93 | 100.00 | 100.00 | - | 80.00 | 88.35 | 91.00 | |
| Ground (4) | - | 100.00 | 100.00 | 100.00 | - | 89.22 | 93.81 | 93.81 | |
| Ground (5) | - | 100.00 | 100.00 | 100.00 | - | 100.00 | 95.79 | 93.81 | |
| 28,000 ft (1) | 100.00 | - | 100.00 | 100.00 | 100.00 | - | 85.19 | 88.46 | |
| 28,000 ft (2) | 100.00 | - | 100.00 | 100.00 | 100.00 | - | 100.00 | 97.85 | |
| 28,000 ft (3) | 96.70 | - | 100.00 | 100.00 | 100.00 | - | 98.91 | 96.81 | |
| 28,000 ft (4) | 100.00 | - | 100.00 | 100.00 | 100.00 | - | 100.00 | 97.85 | |
| 28,000 ft (5) | 100.00 | - | 90.11 | 100.00 | 100.00 | - | 100.00 | 100.00 | |
| 35,000 ft (1) | 100.00 | 86.96 | - | 100.00 | 93.88 | 81.63 | - | 100.00 | |
| 35,000 ft (2) | 96.70 | 100.00 | - | 100.00 | 97.78 | 95.79 | - | 100.00 | |
| 35,000 ft (3) | 87.91 | 95.60 | - | 100.00 | 97.56 | 94.57 | - | 95.79 | |
| 35,000 ft (4) | 92.31 | 100.00 | - | 100.00 | 97.67 | 95.79 | - | 96.81 | |
| 35,000 ft (5) | 96.70 | 100.00 | - | 100.00 | 98.88 | 93.81 | - | 97.85 | |
| 41,000 ft (1) | 100.00 | 100.00 | 100.00 | - | 95.83 | 86.79 | 97.87 | - | |
| 41,000 ft (2) | 100.00 | 100.00 | 100.00 | - | 100.00 | 96.81 | 100.00 | - | |
| 41,000 ft (3) | 90.11 | 100.00 | 100.00 | - | 100.00 | 94.79 | 97.85 | - | |
| 41,000 ft (4) | 98.90 | 100.00 | 100.00 | - | 100.00 | 97.85 | 100.00 | - | |
| 41,000 ft (5) | 100.00 | 100.00 | 100.00 | - | 100.00 | 97.85 | 100.00 | - | |
| Average: 98.30 | Average: 94.56 | ||||||||
| Fault Diagnostic Method | Transfer Scenario | Average | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ground—28,000 ft | Ground—35,000 ft | Ground—41,000 ft | 28,000 ft—Ground | 28,000 ft–35,000 ft | 28,000 ft–41,000 ft | 35,000 ft–Ground | 35,000 ft–28,000 ft | 35,000 ft–41,000 ft | 41,000 ft—Ground | 41,000 ft–28,000 ft | 41,000 ft–35,000 ft | ||
| kNN | 60.77 | 33.15 | 54.14 | 25.97 | 60.77 | 96.69 | 44.20 | 74.03 | 89.50 | 47.51 | 95.58 | 82.32 | 63.72 |
| A healthy baseline case from TCA + kNN on deviation data | 67.40 | 63.54 | 61.88 | 63.54 | 60.77 | 92.27 | 70.17 | 71.82 | 82.87 | 61.33 | 96.13 | 80.66 | 72.70 |
| TCA | 100 | 92.27 | 96.13 | 88.95 | 93.37 | 97.79 | 90.06 | 94.48 | 100 | 90.06 | 95.58 | 100 | 94.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, L.; Ezhilarasu, C.M.; Jennions, I.K. Cross-Condition Fault Diagnosis of an Aircraft Environmental Control System (ECS) by Transfer Learning. Appl. Sci. 2023, 13, 13120. https://doi.org/10.3390/app132413120
Jia L, Ezhilarasu CM, Jennions IK. Cross-Condition Fault Diagnosis of an Aircraft Environmental Control System (ECS) by Transfer Learning. Applied Sciences. 2023; 13(24):13120. https://doi.org/10.3390/app132413120
Chicago/Turabian StyleJia, Lilin, Cordelia Mattuvarkuzhali Ezhilarasu, and Ian K. Jennions. 2023. "Cross-Condition Fault Diagnosis of an Aircraft Environmental Control System (ECS) by Transfer Learning" Applied Sciences 13, no. 24: 13120. https://doi.org/10.3390/app132413120
APA StyleJia, L., Ezhilarasu, C. M., & Jennions, I. K. (2023). Cross-Condition Fault Diagnosis of an Aircraft Environmental Control System (ECS) by Transfer Learning. Applied Sciences, 13(24), 13120. https://doi.org/10.3390/app132413120