1. Introduction
Clinical prediction models are commonly utilized in clinical practice to screen high-risk patients. This enables healthcare professionals to initiate interventions aimed at delaying or preventing adverse medical events. However, in the realm of the medical literature, most prediction models focus on estimating the probability of an event occurring or a condition developing over a specified time frame. For instance, there are well-known models like the Framingham 10-year risk of general cardiovascular disease [
1] and FRAX, a tool for estimating 10-year fracture risk [
2]. This information can pose challenges for patients to comprehend, potentially causing delays in their treatment decision-making process. In contrast, in engineering reliability research, it is commonplace to employ Weibull accelerated failure time (AFT) models to predict “time to failure”. This is relevant in scenarios like determining the lifespan of machinery, identifying when a component requires replacement, and optimizing maintenance schedules to enhance overall system reliability [
3]. Weibull AFT models also find application in forecasting the shelf life of perishable goods and warranty periods for products [
4,
5].
This statistical methodology estimates when an event will occur without being restricted to a predefined time frame (i.e., when a component will need replacement, as opposed to a 10-year risk of replacement). Additionally, this statistical approach is not limited to predicting engineering or mechanical events; it may also prove valuable in predicting medical events such as fractures, myocardial infarctions, and fatalities. In this paper, our intention is not to develop and present a prediction tool. Instead, we aim to demonstrate how to utilize the Weibull AFT model and evaluate its accuracy in a medical context.
2. Weibull Distribution
The Weibull distribution is also referred to as the type III extreme value distribution [
6]. This distribution is characterized by three parameters: the location parameter
, the scale parameter
, and the shape parameter
. The location parameter
is typically set as the minimum value in the distribution. In the context of survival or failure analysis, it is common to select
as 0, which results in a two-parameter distribution.
The cumulative distribution function (CDF) for a two-parameter Weibull distributed random variable is denoted as:
where
and
.
The probability density function (PDF) of the Weibull distribution is given as:
The survival function of the Weibull distribution is given as:
The mean survival time or mean time to failure (MTTF) is given as:
3. Log-Weibull Distribution
The log-Weibull distribution is also known as the Gumbel distribution, or type I extreme value distribution [
7].
Let us consider a random variable
T, which follows a Weibull distribution
, and we have a one-to-one transformation
that maps support
to
. The inverse of
Y is given by:
The Jacobian is calculated as:
Using Equation (2), we can derive the PDF of
Y:
Here, we let
and
:
This demonstrates that the log-Weibull distribution corresponds to a Gumbel distribution , where and .
The CDF
of the log-Weibull distribution can be derived as:
By Equation (1), we obtain
where
and
The survival function of
is given by
The hazard function
is given by
These equations provide a comprehensive understanding of the log-Weibull distribution and its relationship to the Gumbel distribution, including its PDF, CDF, survival function, and hazard function.
4. Weibull AFT Regression Model
In the Weibull AFT regression model, let
T represent survival time. Consider a random sample of size n from a target population. For each subject
, we have observed values of covariates
and possibly censored survival time
. The Weibull AFT model can be expressed as:
Here,
represent the regression coefficients of interest,
is a scale parameter, and
are i.i.d distributed according to a Gumbel distribution with the PDF
and the CDF
It is important to note that this Gumbel distribution corresponds to a distribution or a standard Gumbel distribution.
Now, we can derive the PDF of
T from Equation (8)
Substituting Equations (11) and (12) into Equation (9), we obtain:
Comparing Equation (13) with Equation (2) and letting
and
, we can see
T has a Weibull distribution
.
As shown in Equation (3), the survival function of
can be written as
Referring to Equations (3) and (4), replacing
with
, and replacing
with
, the expected survival time is given as:
Since most statistical software use
to calculate the parameters, let us show the distribution and characteristics of
. Let
Substituting Equations (16) and (17) into Equation (9), we obtain:
If we compare Equation (18) to Equation (5), we can see Y (i.e., ) has a distribution. We can also observe the use of the error term , which follows a distribution in Equation (8). This is analogous to the error term in a simple linear regression, which has an distribution.
Referring to Equations (13) and (18), we can see that in the Weibull AFT model, T has a Weibull distribution, and has a Gumbel distribution.
From Equation (7), the survival function of
Y (i.e.,
) is given as:
and the expectation of
Y (i.e
) is calculated as:
where
is the Euler–Mascheroni constant.
It is important to note that by Jensen’s inequality, since is a concave down function. Therefore, it is not appropriate to use to calculate the expected survival time. Equation (15) provides the correct formula for calculating the expected survival time.
5. Estimating Weibull AFT Model Parameters
The parameters of the Weibull AFT model can be estimated using the maximum likelihood method. The likelihood function for the observed
times,
, is given by:
Here, is the event indicator for the ith subject, where if an event has occurred, and if the event has not occurred. The maximum likelihood estimation (MLE) involves calculating parameters: . Taking the natural logarithm of the likelihood function allows the use of the Newton–Raphson method to compute these parameters. Most statistical software packages can perform these calculations.
6. Calculating Expected Survival Time by the Weibull AFT Model
In reliability research, the expected survival time is often referred to as the mean time to failure (MTTF) or mean time between failures (MTBF) [
8].
To predict an individual’s mean survival time
using the Weibull AFT model, we first use the MLE method, as described in Equation (20) to calculate the estimates
and
. Then, by the invariance property of the MLE, we can directly compute the predicted MTTF using Equation (15):
After calculating the MTTF, we can apply the Delta method to establish a confidence interval for the MTTF. This method treats the predicted MTTF as a function of
and
. The standard error of the MTTF can be calculated as:
where
is the variance–covariance matrix of
and
. It can be estimated by the observed Fisher information of the Weibull AFT model. The (1 −
% confidence interval is given as:
Here,
represents the type I error, and
z is the quantile of the standard normal distribution.
7. Calculating Median Survival Time by the Weibull AFT Model
In survival analysis, another crucial statistic is the median survival time or percentile survival time. The
pth percentile of the survival time can be computed from the survival function. For an individual
i, the
pth percentile of survival time is determined by:
For the Weibull AFT model, Equation (14) is used to calculate the
pth percentile survival time for an individual
i:
This leads to the following expression for the estimated
pth percentile survival time after obtaining
and
using the MLE method:
The calculation of the median survival time corresponds to
p = 50, which can be specifically determined as:
Similarly, we can use the Delta method to calculate the standard error of the predicted pth survival time when p is fixed, following the approach detailed in Equations (21) and (22).
8. Minimum Prediction Error Survival Time (MPET)
Both mean and median survival time estimates can be biased when a small sample is used, especially in models that incorporate censoring [
8]. Henderson et al. proposed a method to find the optimum prediction time with the minimum prediction error [
9]. They suggested that if an observed survival time
t falls in the interval
where
p is the predicted survival time and
, then the prediction should be considered accurate. The probability of prediction error
conditional on the predicted time
p is given by:
This probability can be expressed as:
The probability of prediction error
achieves the minimum value.
Now, let us calculate the minimum prediction error for the Weibull AFT model. Referring to Equation (13), we have:
Substituting the above equations into Equation (24) and canceling the common parts, we obtain:
We then take the natural logarithm of both sides:
Rearranging these terms, we can solve for
p to calculate the minimum prediction error survival time:
Here,
p presents the minimum prediction error survival time. To estimate its standard error, the Delta method can be employed, and bootstrap methods can also be used to obtain a confidence interval for the minimum prediction error survival time.
This approach helps to minimize prediction errors and enhance the accuracy of survival time predictions in the Weibull AFT model, especially when dealing with censored data and small sample sizes.
9. An Example to Predict the Survival Time
We use a publicly available larynx cancer dataset to illustrate the process of making survival time predictions. This dataset consists of records for 90 male larynx cancer patients, each with five variables: the stage of the disease (stage: 1, 2, 3, 4), the time to death or the duration of on-study time in months (time), the age at the diagnosis of larynx cancer (age), the year of diagnosis of larynx cancer (diagyr), and a death indicator (death: 0 = alive, 1 = dead). We added a new variable ID into the dataset and changed the variable name delta to death. The dataset can be downloaded from
https://vincentarelbundock.github.io/Rdatasets/datasets.html.
The larynx cancer data are structured as follows:
![Applsci 13 13041 i001]()
We used two predictor variables to make survival time predictions: the stage of the disease and the age at the diagnosis of larynx cancer. Since the “stage” is a categorical variable, we created three dummy variables for stages 2, 3, and 4, with stage 1 as the default reference group. The survival probability of patients at various stages and time intervals can be observed in the following Kaplan–Meier plot (
Figure 1):
The Weibull AFT model can be expressed as follows:
Most statistical software, such as R, can be used to run the Weibull regression model. In R, we can use the following code:
| library(survival) |
| larynx<-read.csv("D:/larynx.csv") |
| wr <- survreg(Surv(time, death) ~ factor(stage) + age, |
| data = larynx,dist="w") |
| summary(wr) |
The following results were obtained from the model:
| Call: |
| survreg(formula = Surv(time, death) ~ factor(stage) + age, data = larynx, |
| dist = "w") |
| Value | Std. Error | z | p |
| (Intercept) | 3.5288 | 0.9041 | 3.903 | 9.50e-05 |
| factor(stage)2 | -0.1477 | 0.4076 | -0.362 | 7.17e-01 |
| factor(stage)3 | -0.5866 | 0.3199 | -1.833 | 6.68e-02 |
| factor(stage)4 | -1.5441 | 0.3633 | -4.251 | 2.13e-05 |
| age | -0.0175 | 0.0128 | -1.367 | 1.72e-01 |
| Log(scale) | -0.1223 | 0.1225 | -0.999 | 3.18e-01 |
| Scale = 0.885 |
| Weibull distribution |
| Loglik(model) = -141.4 | Loglik(intercept only) = -151.1 |
| Chisq= 19.37 on 4 degrees of freedom, p = 0.00066 |
| Number of Newton-Raphson Iterations: 5 |
| n = 90 |
Suppose we want to predict the survival time for a patient with ID = 46, who is at larynx cancer stage 2 and is 74 years old. We can use the following equations:
- 1.
To calculate the mean time to failure (MTTF):
- 2.
To calculate the median survival time:
- 3.
To calculate the minimum prediction error survival time (MPET) using Equation (26) with a fixed
k = 2:
It seems that these prediction methods yield results quite close to the real survival time of patient ID = 46, which was 6.2 months.
10. Calculating the 95% Confidence Interval of the Predicted Time
First, we used Equation (21) to calculate the standard error of the survival time:
The variance–covariance matrix
can be calculated by the observed Fisher information of the Weibull AFT model. In most statistical software, this variance–covariance matrix can be computed directly. In R, we used the following R code to obtain the
matrix:
wr$var
which produces the following:
| (Intercept) | stage2 | stage3 | stage4 | age | Log(scale) |
| (Intercept) | 0.817 | -0.09049 | -0.08479 | -0.0444 | -0.01114 | 0.02591 |
| stage2 | -0.090 | 0.16611 | 0.05319 | 0.0507 | 0.00057 | 0.00016 |
| stage3 | -0.085 | 0.05319 | 0.10237 | 0.0567 | 0.00042 | -0.00731 |
| stage4 | -0.044 | 0.05068 | 0.05668 | 0.1320 | -0.00020 | -0.01070 |
| age | -0.011 | 0.00057 | 0.00042 | -0.0002 | 0.00016 | -0.00026 |
| Log(scale) | 0.026 | 0.00016 | -0.00731 | -0.0107 | -0.00026 | 0.01501 |
Note that in the results above, the last row represents the log(scale), denoted as
, and what we obtained is the covariance of
s and
. For
, we needed to change
back to
. Some extra calculations were needed. To make this adjustment, we can refer to the formulas found on page 401 of John Klein’s book [
10]. Our calculations were:
We replaced the last row of our variance–covariance matrix from R with these six values:
![Applsci 13 13041 i002]()
which is the
matrix needed to calculate the standard error in Equation (26).
If we use SAS software (SAS (SAS Institute Inc., Cary, NC, USA)), we can directly obtain the variance–covariance matrix of
and
by using the following statements:
| proc lifereg data=larynx order=data COVOUT outest=est; |
| class stage; |
| model time∗death(0)=stage age/dist=weibull; |
| run; |
| proc print data=est; |
| run; |
The column vector on the right side of
in Equation (26) can be calculated as follows:
Now, with all the necessary components in place, we can calculate the standard error of the median survival time:
This calculation yields a standard error of approximately 2.156133. Consequently, the 95% confidence interval for the median survival time is given by:
which means we are
confident that the survival time will be within 1.60 to 10.01 months. Alternatively, we can employ the built-in R function
to estimate the median survival time as follows:
| Median46<-predict(wr, newdata=data.frame(stage=2,age=74),type="quantile", |
| p=0.5,se.fit=TRUE) |
| Median46 |
This results in:
| $fit |
| 5.838288 |
| $se.fit |
| 2.095133 |
The standard error differs slightly from our calculations because R uses Greenwood’s formula to calculate the standard error of the survival function [
11].
Note that in R’s built-in function for the Weibull AFT model, type = “response” calculates without considering and type = “lp” computes only; thus, we should not use them to predict MTTF. Additionally, to the best of our knowledge, there is no available software for calculating the minimum prediction error survival time.
11. Assessing Point Prediction Accuracy
Henderson et al. [
9], inspired by Parkes [
12], introduced a simple approach to assess the accuracy of predicted survival times. Let
t represent the observed survival time and
p represent the predicted time. If
, then the point prediction
p is considered as “accurate”, otherwise, it is labeled as “inaccurate”.
Alternatively, Christakis and Lamont proposed a “33 percent rule” to measure accuracy. In that method, the observed time is divided by the predicted survival time, and a prediction is considered “accurate” if that quotient falls between 0.67 and 1.33. Values less than 0.67 or greater than 1.33 are categorized as “errors” [
13]. That method is essentially equivalent to setting
in Parkes’s method. For our accuracy assessment, we chose to use
. The accuracy rate was defined as the proportion of “accurate” predictions relative to the total sample size. The results are presented in
Table 1.
12. Discussion
In this paper, we introduced how to use the Weibull AFT model to predict when an event will occur. We utilized mean survival time (mean time to failure time, mean time between failures), median survival time, and minimum prediction error survival time to make predictions about the time from the baseline to the event. We also assessed prediction accuracy using Parkes’s method. When we fixed
, the accuracy was 55.6% for the median, 50% for the MTTF, and 51.1% for the MPET. However, by setting
, as suggested by Christakis and Lamont, the accuracy rate increased to 77.8%, 66.7%, and 67.8%, respectively. It is worth noting that our sample size was relatively small, and we only used two predictors. With a larger sample and more predictors, the accuracy rate could potentially be even higher. If there are many covariates that could be included in the model, various variable selection methods, such as backward elimination, forward selection, stepwise selection, and all possible subset selection can be employed. These methods may incorporate different stopping rules, such as p-values, Akaike information criterion (AIC), Bayesian information criterion (BIC), and Mallows’s Cp statistic to construct clinical prediction models [
14]. Additionally, in this sample, we did not observe that the MPET had a significantly better accuracy rate than the median survival time.
Parametric survival models offer advantages in predicting survival time compared to the semiparametric Cox regression model. The Cox regression model, which can be specified as
, cannot directly predict time. Instead, it requires first specifying a certain period of time and then calculates the probability of an event within that period of time. The lognormal model is an alternative parametric model that can be employed to fit survival data. However, it comes with a drawback—parametric survival models, including the lognormal model, necessitate stronger assumptions compared to semiparametric models. Other models, like the logistic regression model or neural network models, are typically utilized to model binary events, regardless of when those events occurred. Poisson regression models can also be applied to model survival data with count data types (0, 1, 2, 3, and so forth). Nevertheless, similar to the Cox model, a prespecified period of time is required to calculate the probability of an event. The choice of which model to use should be guided by the specific questions we aim to address and the type of available data [
15].
Currently, most clinical prediction models calculate a patient’s probability of having or developing a specific disease or risk scores based on these probabilities [
16]. However, providing a probability can be challenging to understand for the general population, and probability itself can be defined in various ways [
17]. In practice, the time axis remains the most natural measure for both clinicians and patients. Predicting when an event will occur can offer a practical and concrete guide to clinicians and healthcare providers for managing their patients [
18]. It can also assist families and patients in making suitable plans for the remaining lifespan.
In this paper, our intention was not to utilize the publicly available larynx cancer dataset for the development of an actual prediction tool. Rather, we employed the dataset to illustrate the application of statistical methods and evaluate point accuracy. Developing a real prediction tool would require a much larger dataset and rigorous internal and external validations. Readers interested in the steps to develop such a tool can refer to the book
Clinical Prediction Models: A Practical Approach to Development, Validation, and Updating [
19].




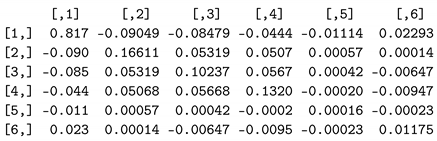 which is the matrix needed to calculate the standard error in Equation (26).
which is the matrix needed to calculate the standard error in Equation (26).

{kind=link}