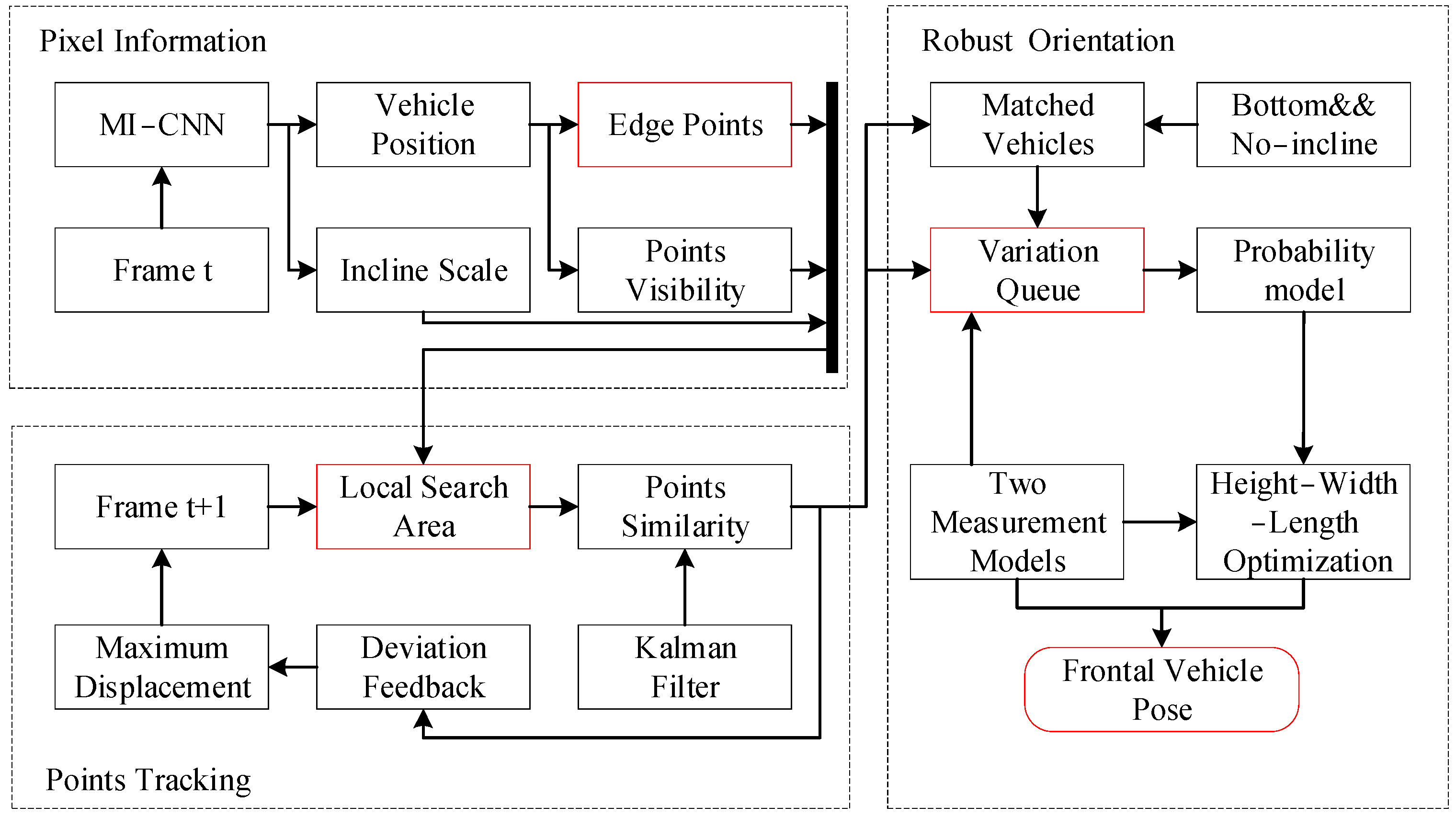
The comprehensive framework for vehicle pose estimation is depicted in
Figure 2. The process consists of three subsystems: pixel information, point tracking, and robust orientation. The pixel information subsystem represents the extraction of information such as vehicle position and edge points from video frames. The point tracking subsystem is used to identify and track the movement of feature points on the vehicle over time. The robust orientation subsystem is used to evaluate and determine the direction of vehicle travel. The first process commences with the utilization of the convolutional neural network (MI−CNN) operating within a two−step detection paradigm, wherein it takes the initial frame (t) as input. This network serves a multi-faceted purpose: It simultaneously forecasts the positions of all vehicles along with their respective yaw angles relative to the host vehicle. Additionally, it is entrusted with the task of ascertaining the coordinates of edge points within the context of each vehicle’s 2D bounding box while also evaluating their visibility. The subsequent stage unfolds in frame t + 1, whereby the local search area for each vehicle is generated via a maximum displacement prediction model, incorporating an auxiliary variable. Within this search area, a fusion of edge point similarity and Kalman filter−predicted values is employed to align with the target vehicle. This matching process is instrumental in refining the redundant variable using the outcomes obtained from the match. Following the persistent tracking of the target vehicle for a span exceeding 10 frames, vehicles devoid of inclination are enlisted to compute a sequence detailing changes in distance. This sequence is established using the bottom edge as a reference point. The stability of this sequence is evaluated by means of a Gaussian distribution, which is applied with a fixed vehicle width. Once this distribution attains a state of stability, the structural parameters of the target vehicle can be refined using the aforementioned distance sequence. Consequently, this refined information facilitates the estimation of the vehicle’s pose.
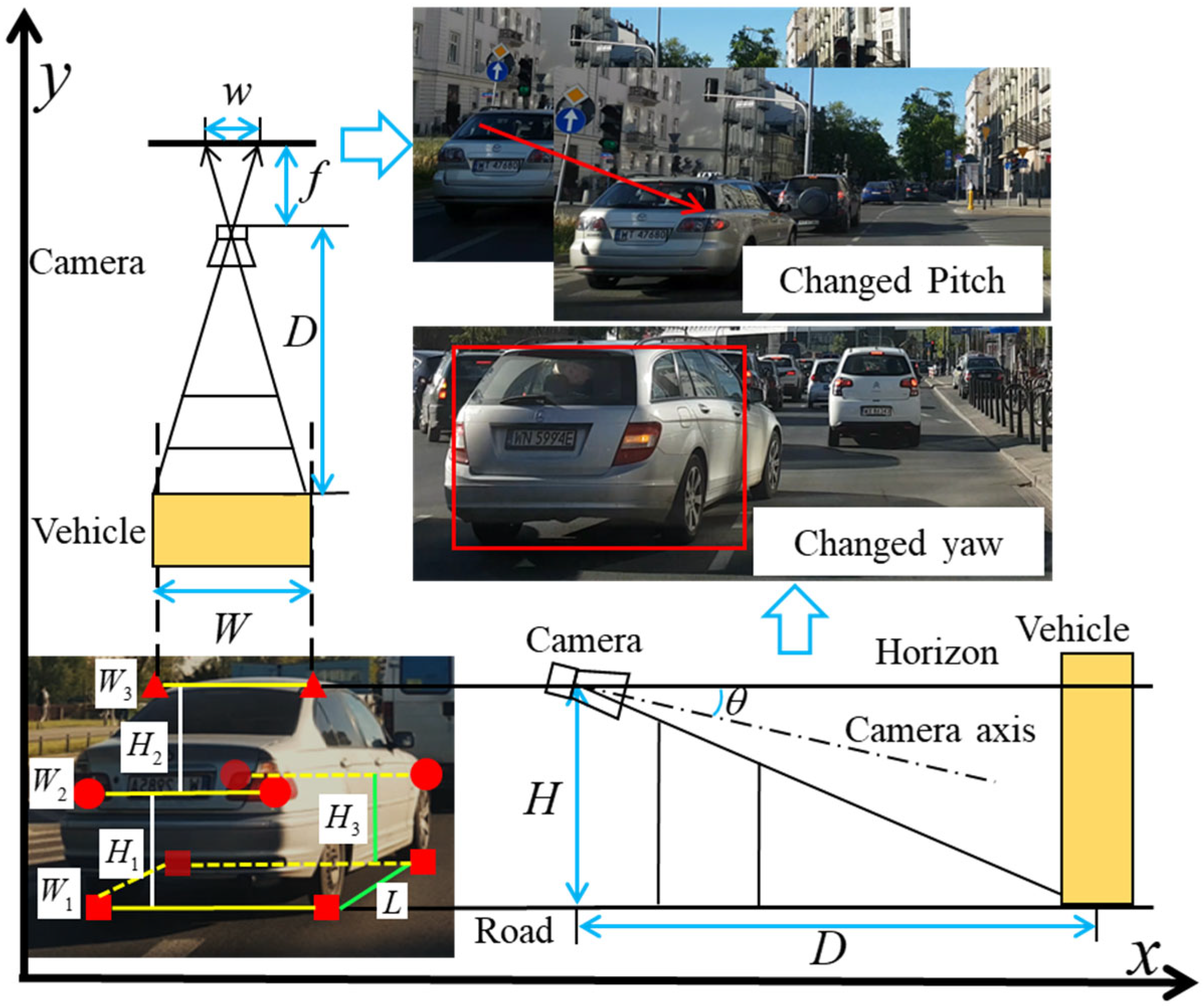
3.1. Multi−Layer Edge Points of Frontal Vehicle
A total of ten edge feature points are encompassed within the framework, spanning various critical locations. These include the left and right contact points between the front and rear wheels and the ground, as well as two edge points positioned at the rear light of the vehicle. Furthermore, two edge points reside on the vehicle’s roof, with an additional two on the apex of the front wheel. Notably, eight of these points are directly discernible in
Figure 3. When the camera pitch angle is fixed, the longitudinal distance
D1 can be measured according to the height difference between the camera and the reference point. The calculation is as follows:
In Equation (1), f is the focal length of the camera; v and v0 are pixel coordinates corresponding to the edge point and the center of the optical axis, respectively; and k is the offset value relative to the selected calibration area. Let k = 0 when Hi corresponds to the bottom edge point. Other edge points can provide reliable pixel information for the distance measurement model when bottom points are invisible or blurred, but D1 is greatly affected by the change in camera pitch angle.
When the frontal vehicle’s slant
Ic relative to the camera is horizontal, the vehicle distance
D2 can be measured according to the actual width
Wi between the left and right edge points on the same layer. The calculation is as follows:
where
w is the pixel width corresponding to the edge points of each layer.
D2 will not be affected by the pitch−angle change, so it is complementary to Equation (1).
After obtaining an accurate
D2, the camera pitch angle
θ can be reversely calculated with Equation (1), and then the target vehicle’s yaw angle
α can be calculated as follows:
where
f indicates the front wheel and
r indicates the rear wheel.
is the distance between the camera and the front wheel that has been corrected by
θ, and
is the distance between the camera and the rear wheel.
L is the distance between the front and rear wheels. Both sets of formulas presented necessitate two essential inputs: the pixel−position data for the edge points and the unchanging rigid structural parameters pertaining to the target vehicle. The former can be predicted through the utilization of a convolutional neural network, harnessing its predictive capabilities. Meanwhile, the latter can be refined and optimized within the context of an ongoing tracking sequence, allowing for the iterative enhancement of accuracy.
3.2. MI−CNN
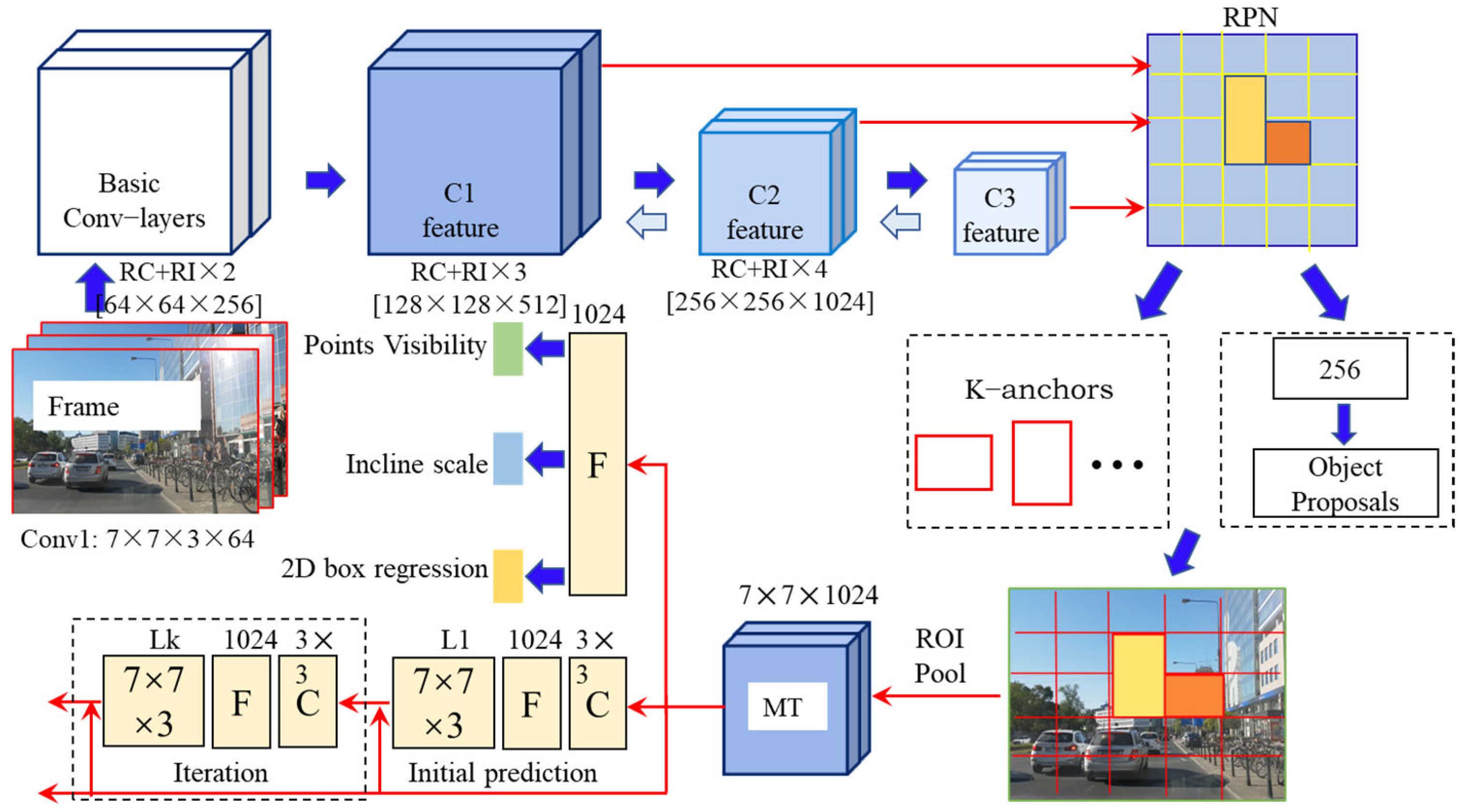
The MI−CNN network introduced within this paper undertakes a cohesive approach by concurrently executing four critical tasks: frontal vehicle detection, edge point localization, visibility assessment for points, and prediction of yaw angles. The fundamental network structure serves the purpose of extracting hierarchical shared features, a pivotal determinant influencing the model’s overall performance. The foundation of the network architecture is established through the utilization of residual convolution modules RI and RC [
26]. These modules are fortified with short, quick connections, as visually depicted in
Figure 4.
The initial layer of the network employs 7 × 7 × 3 × 64 convolution kernels with a stride of 2. Following batch regularization and pooling, it generates the initial features. Subsequently, the second layer incorporates one RC model and two RI models, each comprising a convolution kernel count of [64, 64, 256]. This stage yields a feature map denoted as C1. Advancing to the third layer, an additional RI model is introduced, increasing the convolution kernel count to [128, 128, 512]. The resultant output at this stage is marked as C2. The fourth layer incorporates another RI model while doubling the convolution kernel count to [256, 256, 1024]. Given that the feature scale has been reduced to a quarter of its original size, it becomes imperative to append a sufficient number of extraction channels to ensure the preservation of image details at all levels. The resultant shared feature map at the apex of the hierarchy is designated as C3. The ultimate step involves the combination of vehicle feature maps from distinct levels, achieved through the up−sampling operation. This amalgamation caters to the varied feature−level requirements inherent in each task.
The task of accurately locating points presents challenges when attempting to attain precise positions without initial coordinates. To enhance the network’s precision, an iterative prediction strategy is employed. This approach involves refining accuracy through a sequence of iterative predictions. In the initial prediction of the edge point coordinates {x, y, x, y} on the target vehicle, these coordinates can be rearranged into the format of a 7 × 7 × 3 feature map. This reorganized representation is then combined with the original 7 × 7 × 1024 feature map, forming an integrated input for subsequent iterations. This iterative process is iterated K times. With each iteration, the predicted coordinates of the edge points progressively converge towards more accurate values, building upon the improvements achieved in the previous iterations. In the initial iteration, a single convolutional layer and a fully connected layer, both comprising 1024 kernels of dimensions 3 × 3 × 1024, were employed. The sliding step was set to 1 to facilitate this operation. In the following iterations, the dimensions of the convolution kernels remained consistent at 3 × 3, but their count was augmented by 10 to account for the additional 10 point coordinates. The experimental observations revealed that the branch network achieved superior outcomes in terms of both localization speed and accuracy when utilizing K = 3 iterations.
The holistic architecture of the convolutional neural network, referred to as MI−CNN, is visually presented in
Figure 5. Commencing with the initial RGB image as input, the foundational feature extraction network orchestrates a reverse progression. This entails infusing high−level features back into the shallow map through up−sampling. Subsequently, this process culminates in the creation of the shared feature maps, spanning three distinct stages {C
1, C
2, C
3}. ROI pooling discretizes features of candidate regions generated by the Region Proposal Network (RPN) into a fixed size and maps them to a shared task layer MT using 3 × 3 kernels. The column vector (1024) scaled from MT is used to calculate the bounding box coordinates
Bi, point visibility
Vi, and initialization yaw angle
Ii of the frontal vehicle.
represents the applicable range of the width−ranging model, in which
Ii = 0 indicates that the frontal vehicle is completely flush with the host and
Ii = 1 indicates it is changing lanes or turning. The point location task first calculates the primary coordinates of the ten edge points
through a series of 3 × 3 convolutions, a 1024 full−connection layer, and a regression layer. Then, these coordinates and MT are spliced together to be input for the next prediction.
In this paper, the convolutional neural network MI−CNN contains five loss functions that need to be optimized, namely
Lrpn,
Ldec,
Lpoints,
Llic, and
Ldec, which are loss functions of the RPN network and vehicle detection task. Respectively, the calculation process is the same as [
1], and
Lpoint is the loss function of the edge point position task.
Given that the precision of forthcoming vehicle distance measurements is intricately linked to the horizontal pixel separation between the left and right edge points located within the same layer, this study shifts its emphasis. Instead of singularly refining the position of individual edge points, this paper adopts a fresh approach: prioritizing the minimization of ranging errors directly. Through joint optimization, the adjacent left and right points within the same layer are regarded as an integrated unit. Suppose the true coordinates
P of layer
i are
Pi = {
x1,
y1,
x2,
y2} and the 2D bounding box is {
x,
y,
w,
h}; then, its normalized coordinates are:
where
represents the normalized coordinates of the edge points. Let
ϕt indicate the mapping function of the convolutional network in iteration
t,
T be the shared feature map, and
be the normalized coordinates of the edge points from the previous prediction; then, the prediction output of the positioning branch network in iteration
t is:
The loss function
Lpoints of this layer can be calculated as follows:
where
represents the equilibrium coefficient of the point positioning loss function,
indicates whether the current region contains the target vehicle,
R represents the robust
L1 loss function in [
11], and
and
denote, respectively, the width and longitudinal distance error corresponding to one point pair.
is the visibility judgment loss function. Given the true visibility vector
(corresponding to ten edge points in the target area) and the network prediction vector
, the loss function can be calculated as follows:
where
represents the equilibrium coefficient of the visibility judgment loss function and
is the standard softmax loss function.
Llic is the loss function for predicting the frontal vehicle’s yaw angle, which will set
Ii to 0 when the frontal target is parallel to the host. Given the true yaw angle of the target vehicle
and the predicted value of the network
, the function is calculated as follows:
where
represents the equilibrium coefficient of the loss function
Llic. When the candidate vehicle region does not contain the target, i.e.,
B = 0, all the above loss functions are null, and meaningless optimization will no longer count.
3.3. Point Tracking Based on Local Search Area
Tracking edge points form the foundational basis for calculating the unknown structural parameters delineated in Equations (1)–(3). Given that MI−CNN effectively identifies the frontal vehicle and its corresponding edge points within each frame, this section of the paper is dedicated to elucidating the optimal approach for inter-frame matching.
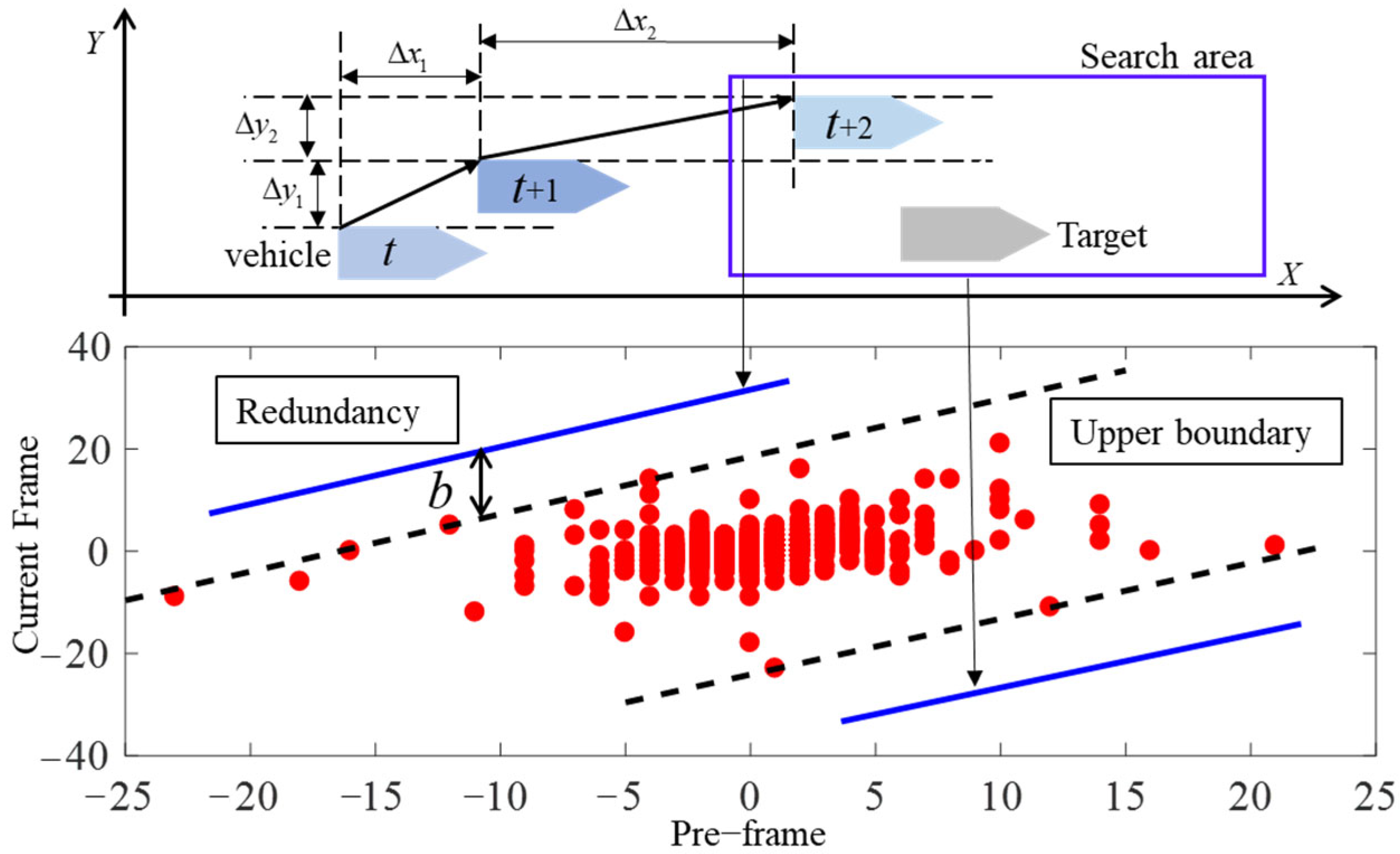
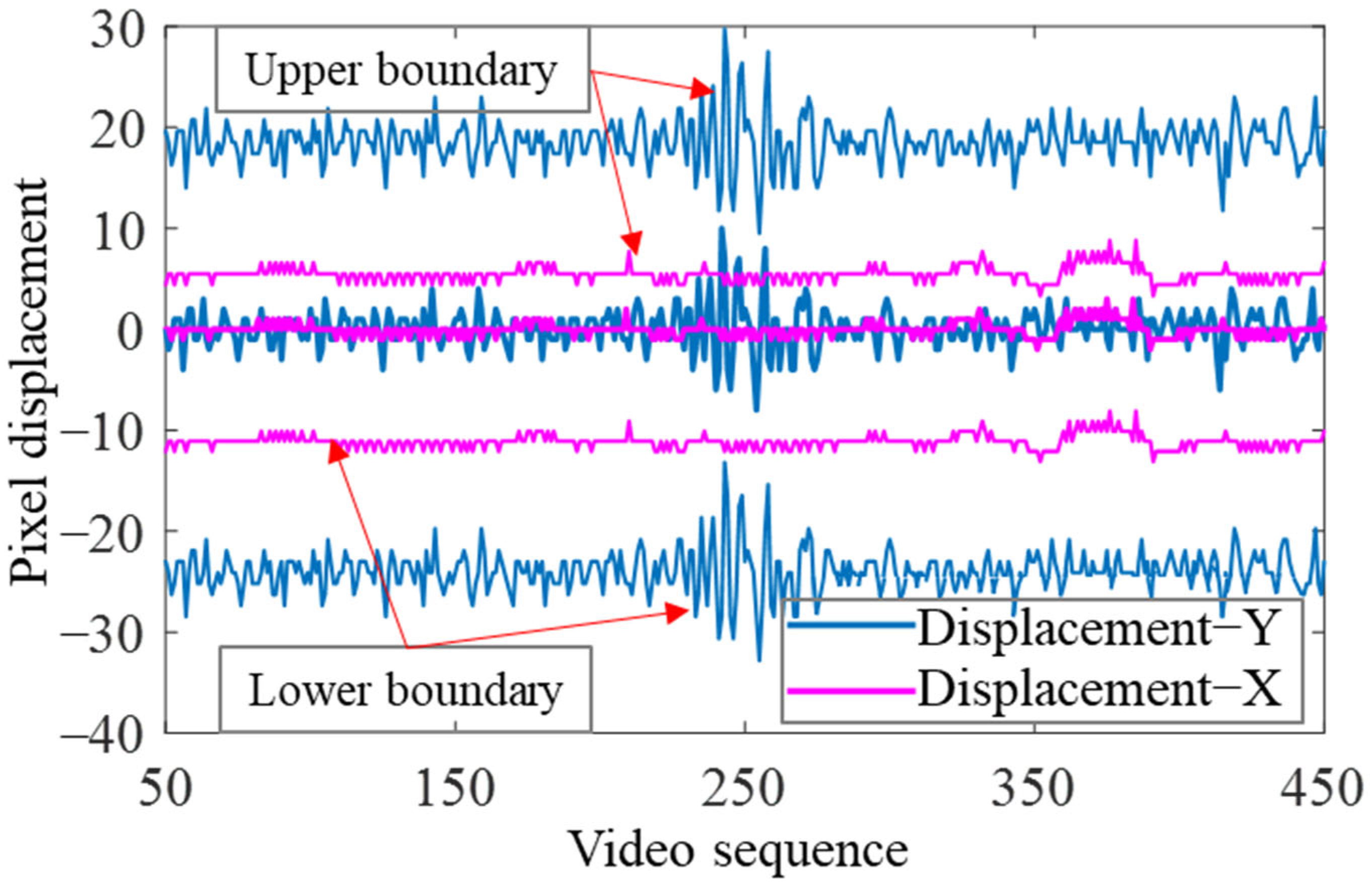
In scenarios characterized by high video frame rates, the intervals between frames translate to minimal inter−vehicle distances, resulting in relatively minor changes in pixel displacement within the image. Consequently, the conventional practice of globally matching target vehicles on a one−by−one basis is deemed unnecessary [
27]. The decomposition of motion and the statistical analysis of pixel displacement for select frontal vehicles across frames are vividly depicted in
Figure 6. The abscissa represents the frontal vehicles’ pixel displacement component in the horizontal or vertical directions in the previous frame (Δ
x1 or Δ
y1), while the ordinate represents the displacement component of the current frame (Δ
x2 or Δ
y2). In
Figure 5, the dotted black lines demarcate the upper and lower envelopes of the scatter diagram. The range
R delineated by the black dashed lines defines the local tracking search area, meticulously aligning with the prerequisites of vehicle matching. Given the inherent limitations of prior datasets to encompass the entirety of working conditions, a redundant variable
b is introduced. This variable dynamically adjusts the search area in real time, guaranteeing continuous adequacy for
R to encompass the upcoming target.
Suppose the resolved motion of the frontal vehicle is approximately equal to the linear motion with uniform speed. In that case, Δ
ypre is the displacement of the previous frame,
a is the acceleration, and Δ
t is the fixed inter−frame time; then, the current displacement Δ
y is:
Due to the interference caused by system delays, measurement errors, or other factors, a linear fitting model of the local tracking search area can be established according to Equation (3):
where
k1 and
k2 can be obtained after fitting the scatter plot data, and
b can be corrected with the calculated redundancy distance after vehicle matching. It will keep the redundancy constant.
When the tracking search areas overlap with each other or the number of vehicles to be matched is greater than one, the optimal matching association can be obtained by combining motion and texture similarity. Given that the number of vehicles in the current search area is
N1,
Mi,j = 1 represents that vehicle
I in frame
t matches vehicle
j in frame
t + 1, while
Mi,j = 0 represents that they do not match. The set
represents all matching combinations, and the optimal association can be calculated as:
where 0 is filled in when the number of vehicles is insufficient, and
si,j represents the matching confidence between vehicles
i and
j. It can be calculated as follows:
where
is the similarity weight,
is the prediction variance, and
sm,ij is the motion similarity between vehicles.
di,j is the pixel distance between the predicted vehicle with the Kalman filter and the candidate vehicle.
sp,ij is the texture similarity between edge points that can be calculated by the square of the difference (SSD).
and
represent the corresponding pixel between the previous and next seconds. When (
i,
j) belong to the same vehicle, their imaging appearance is similar, and SSD will be small; meanwhile, the corresponding confidence
si,j will increase.
3.4. Parameter Optimization
When the current frontal and host vehicles are on the same ground and the pitch angle is fixed, the camera’s mounting height can be inserted into Equation (1) to calculate the longitudinal vehicle distance
D1, which can be used to optimize other vehicle structural parameters such as height, width, and offset. When
D1 is accurate, given that the true width of the target vehicle is
, and the initial vehicle width with a certain error is
W*, then Formula (2) can be calculated as:
where
and
are the distances calculated by Formula (1) in frames
t and
t+
i, and
and
are the distances calculated by Formula (2). When the errors in Formulas (1) and (2) are small, the ratio of the vehicle distance variation
shall be exactly equal to the ratio between the true and initial vehicle widths. When frontal vehicles are flush with the host, that is,
, the reliability of the current
D1 sequence is judged by the probability distribution of the
sequence for detecting a stable reference vehicle distance to correct the initial ranging parameters.
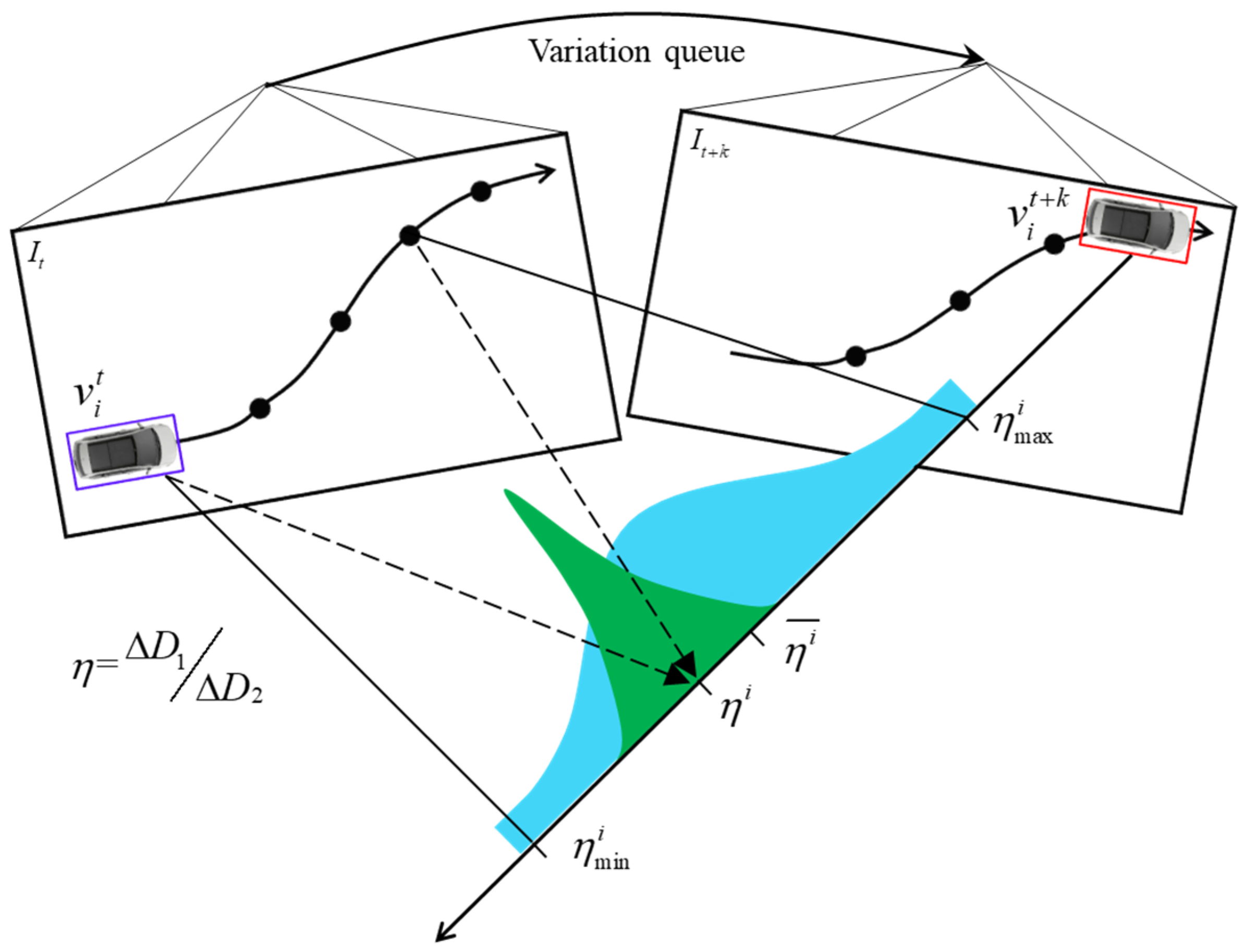
As shown in
Figure 7, the distance variation sequence
is calculated in the given image sequence
It~
It+k. When the distribution of
in the sequence is concentrated, it indicates that the current imaging environment is relatively stable, but if
does not converge, the sequence will be discarded directly. After calculating the mean value
and variance
in the
sequence that is subject to a normal distribution, the reliability of
can be calculated through a mixed model containing a Gaussian and a uniform distribution. When the two distance measurement models are stable, the value interval of
is small and
will approach 0:
where
is the weight of the Gaussian distribution and
is the variance of
when
is reliable.
umin and
umax can be set with the maximum and minimum values in the prior dataset
U. By employing the aforementioned methodology, it becomes possible to efficiently filter out unforeseen sequences characterized by significant fluctuations in the distance change ratio. This proactive filtering process effectively mitigates the perturbations introduced by variations in pitch angles. Upon successfully identifying the reference distance sequences, the subsequent phase involves optimizing unknown parameters.
Given an accurate reference distance, the unknown parameters of the vehicle structure can be corrected. Assuming the true ranging sequence is
, take Equation (2) as an example and let
x = 1/
w; then, the optimal vehicle width and offsets can be calculated by minimizing objective function
J:
Calculate the partial derivative of
J with respect to
fW and
k and set
,
,
,
; then, the target parameters can be calculated as follows:
Following the calculation of other structural parameters using similar techniques, a robust estimation of the distance between the camera and the edge points becomes feasible through the utilization of two measurement models. When the bottom edge points are obstructed or offer minimal texture cues, the viability of the middle or top edge points as alternatives becomes evident. In cases involving camera pitch−angle variations, the vehicle distances derived from Formula (2) provide heightened precision. Additionally, the pitch angle can be reverse−calculated using Formula (1). Ultimately, the yaw angle of the target vehicle can undergo further refinement based on the calculated values from Ic, facilitated through the application of Formula (3).






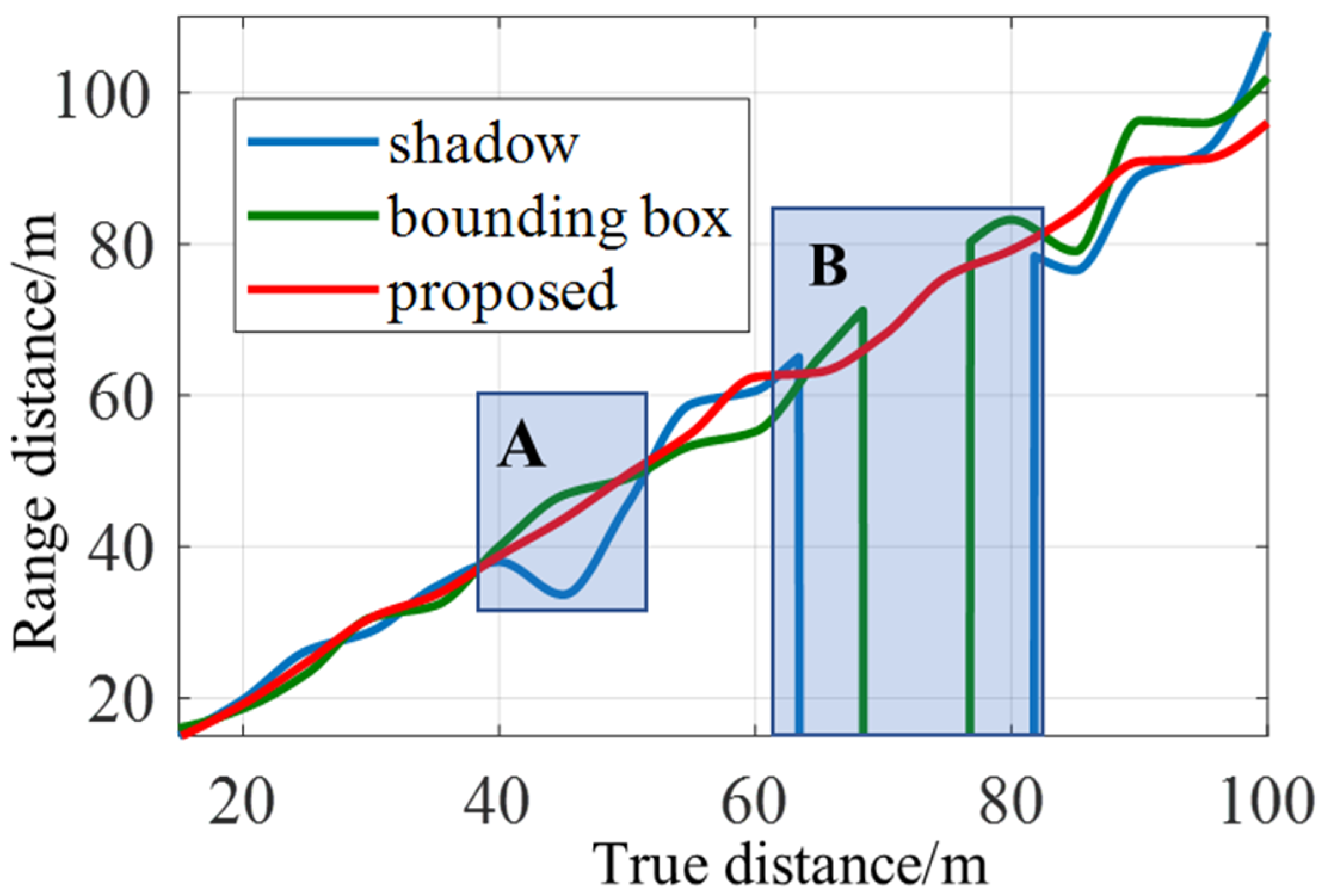
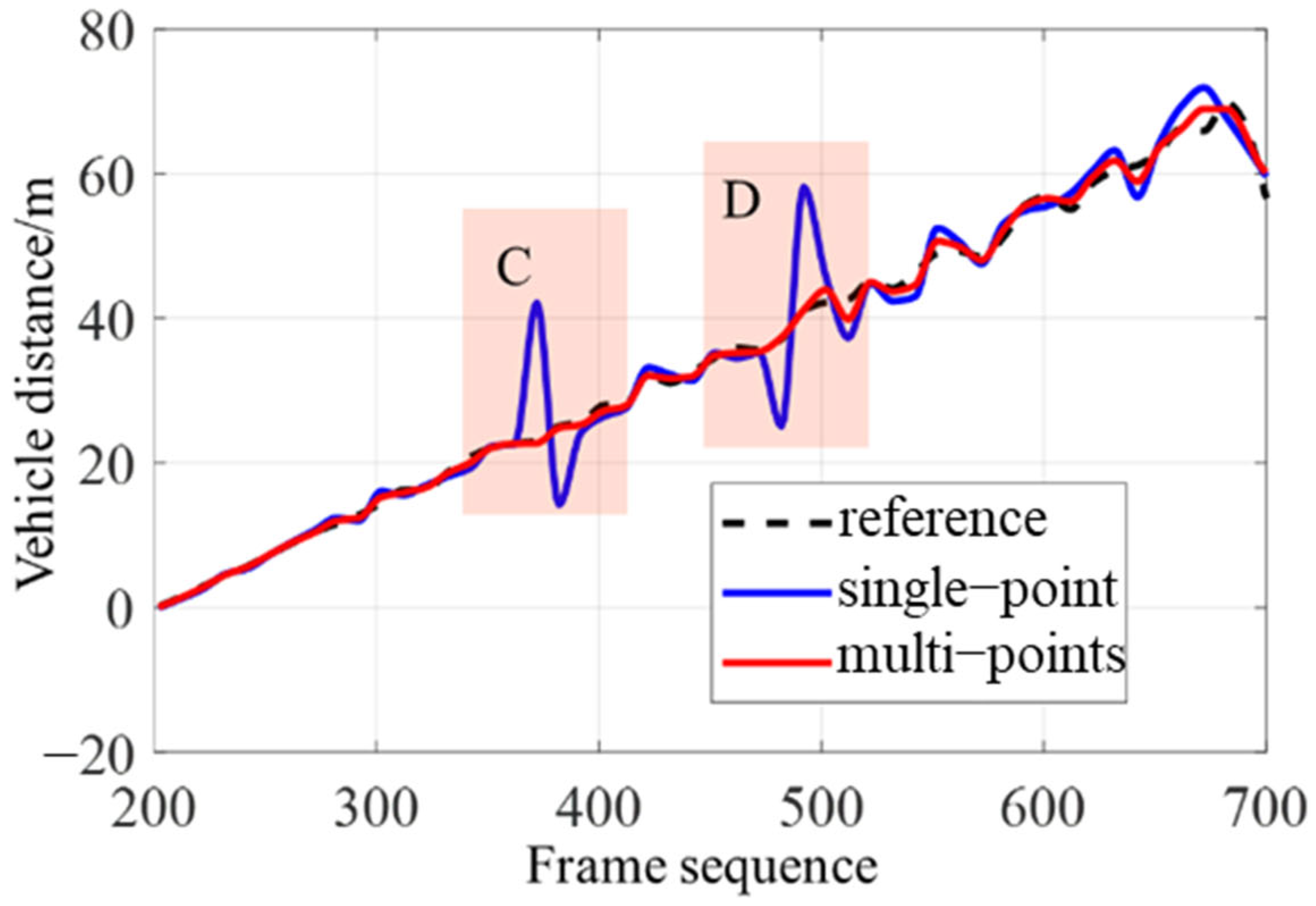

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}