
Enhancing Anomaly Detection Models for Industrial Applications through SVM-Based False Positive Classification


Abstract
:1. Introduction
- (1)
- We propose a post-processing optimization method that identifies false alarms from positive predictions of OOD anomaly detection models using a support vector machine (SVM) classifier at the object level, leveraging patch-level features.
- (2)
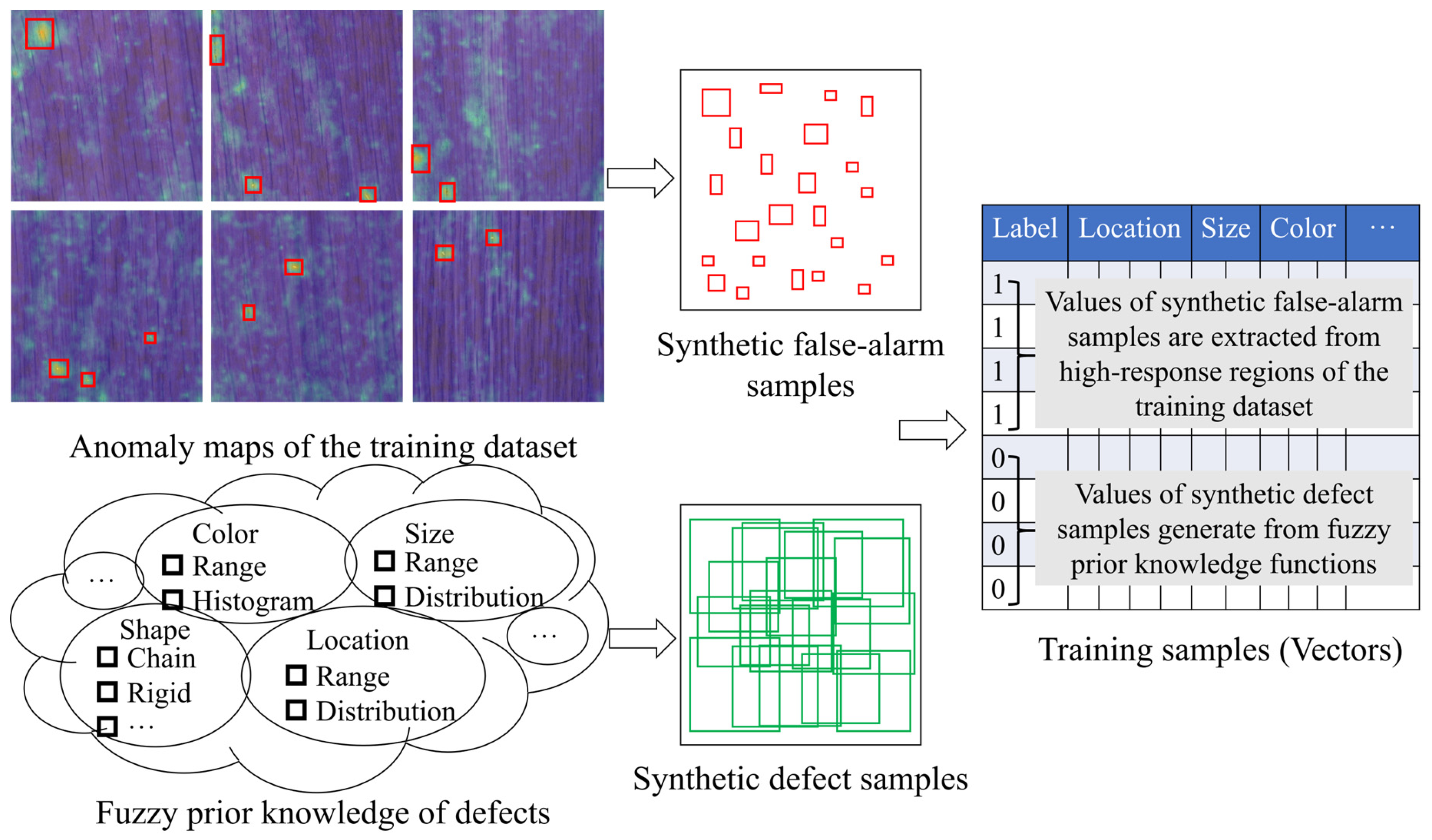
- We devise a sample synthesis strategy that generates synthetic false positives from the trained baseline detector while producing synthetic defect patch features from fuzzy domain knowledge.
2. Preliminary and Related Works
2.1. Industrial Anomaly Detection
2.2. Unsupervised Anomaly Detection
2.3. Normalizing Flow-Based Anomaly Detection
3. Proposed Method
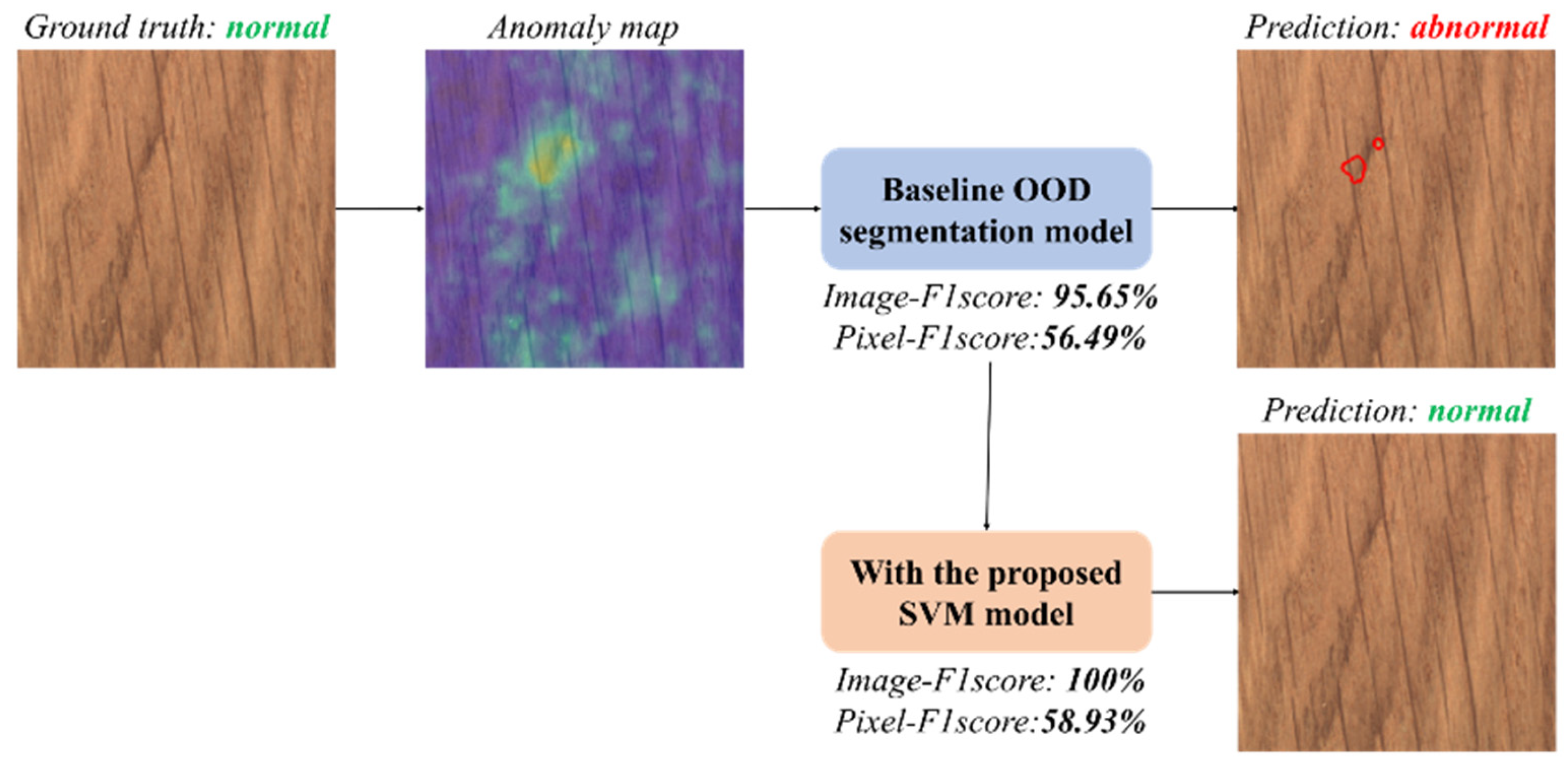
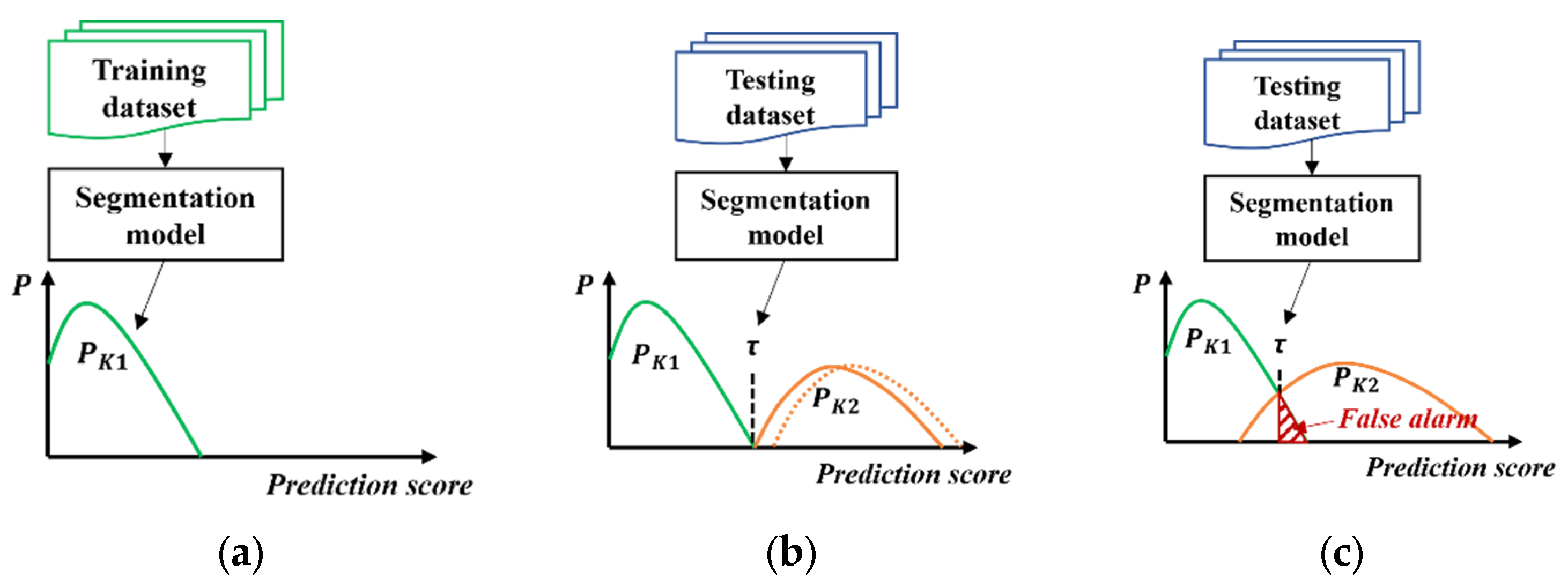
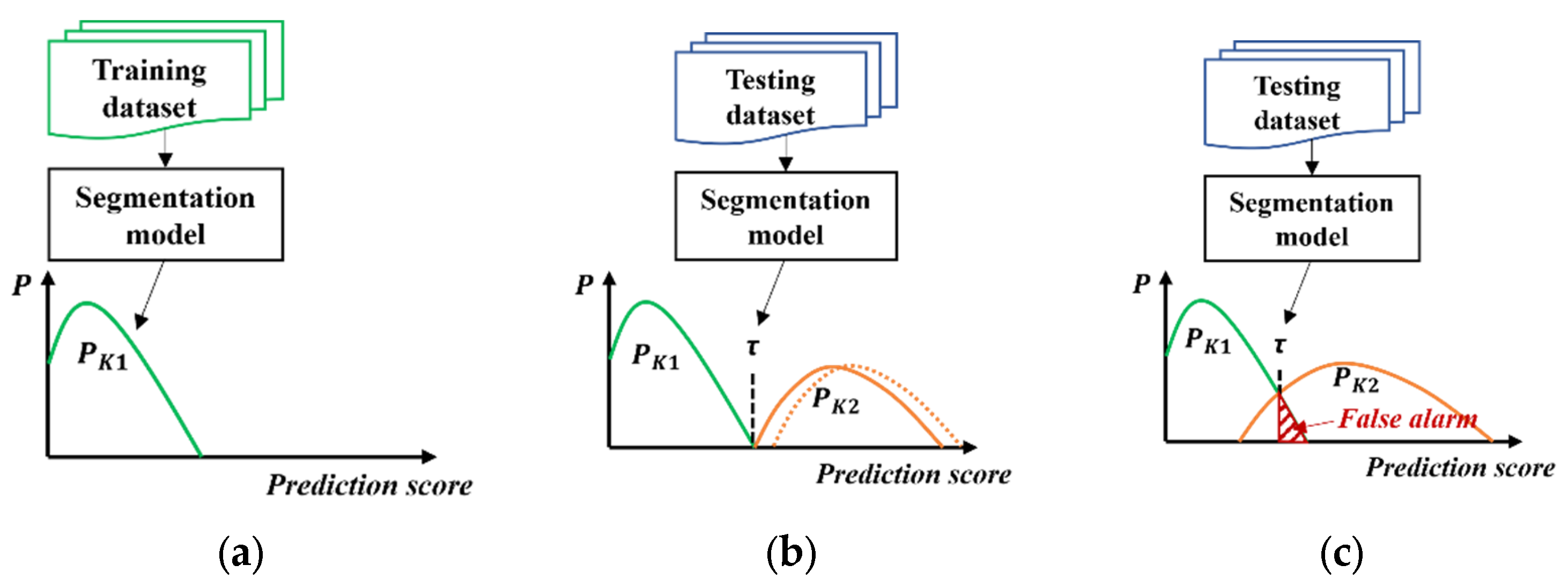
3.1. False Alarm in Unsupervised Anomaly Detection
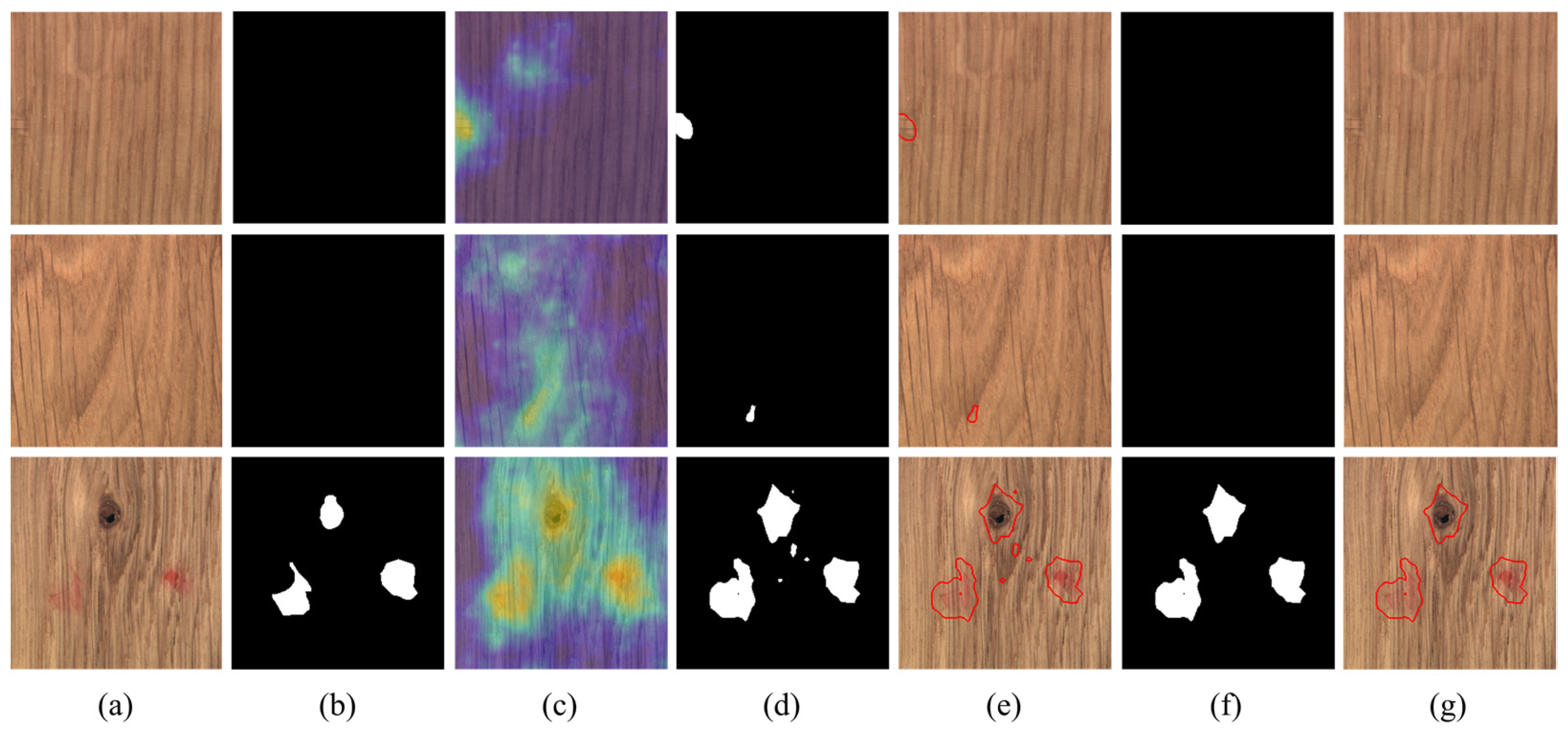
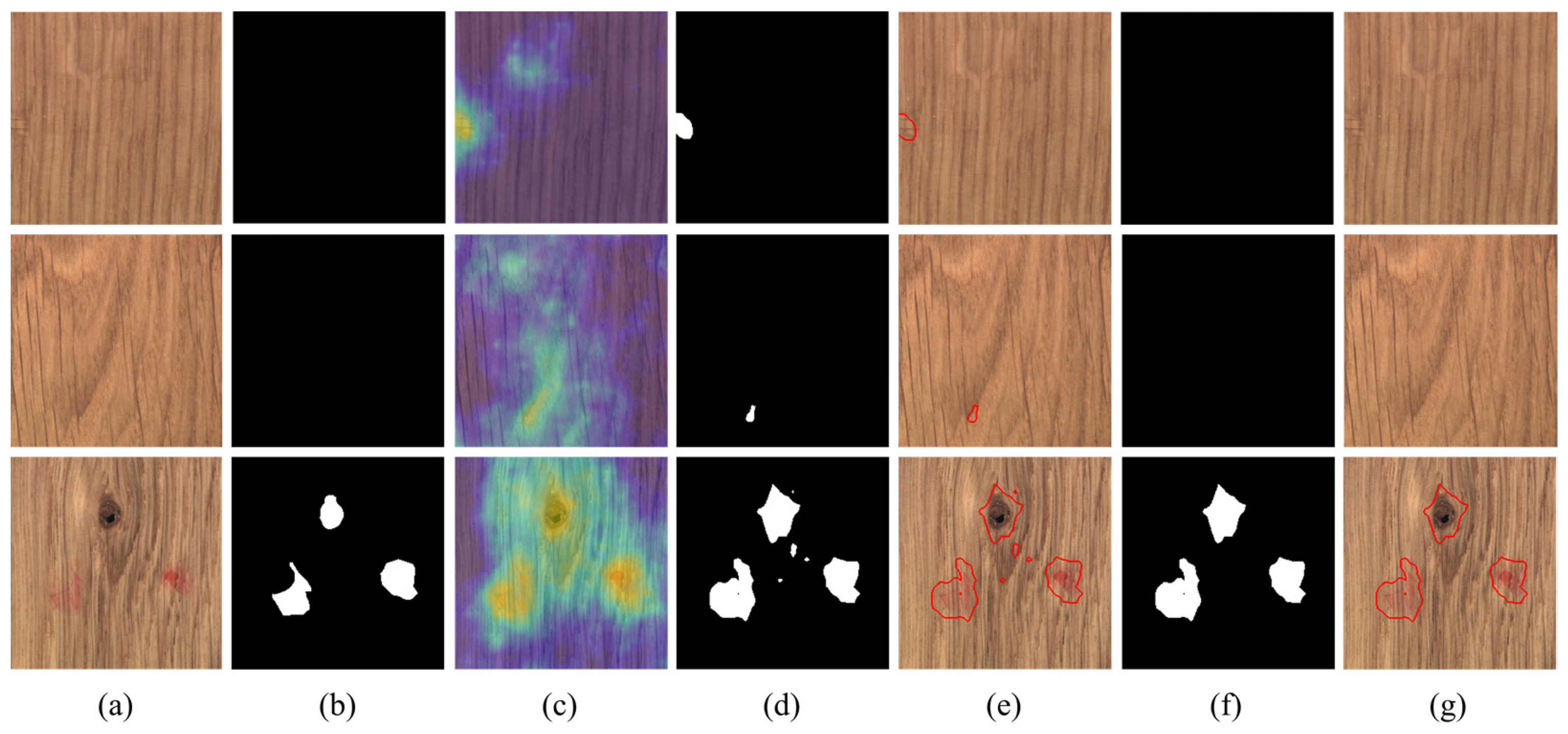
3.2. Proposed Post-Processing Optimization Method
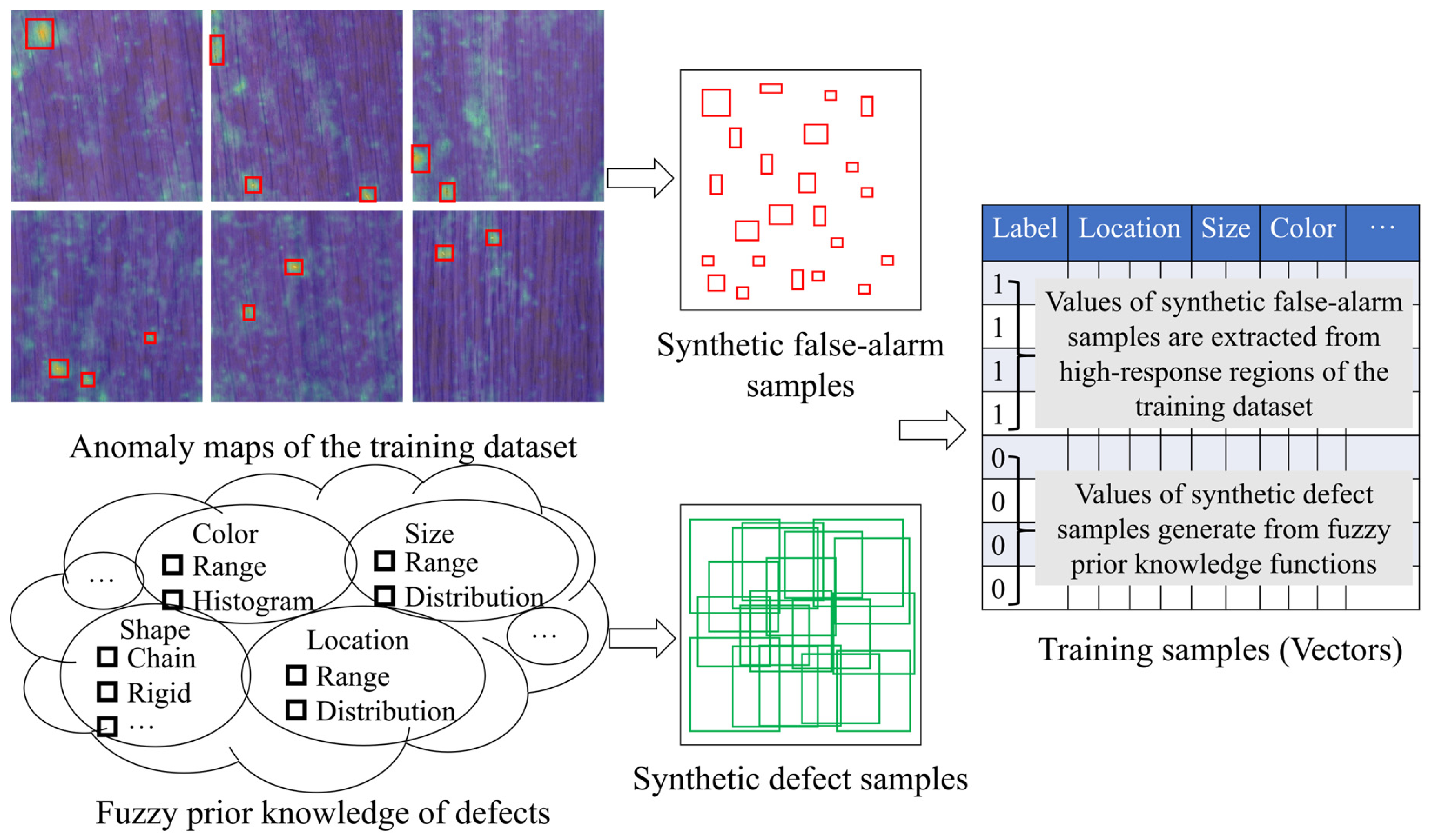
3.3. Unsupervised Sample Synthesis for Classifier Training
4. Experiments
4.1. Experimental Settings
4.1.1. Experimental Dataset
4.1.2. Baseline OOD Model
4.1.3. Performance Evaluation
4.2. Quantitative Experimental Results
4.3. Visual Comparisons for Pixel-Wise Segmentation
4.4. Parameter Study on Proposed Augmentation Strategy
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sharma, M.; Lim, J.; Lee, H. The Amalgamation of the Object Detection and Semantic Segmentation for Steel Surface Defect Detection. Appl. Sci. 2022, 12, 6004. [Google Scholar] [CrossRef]
- Luo, H.; Cai, L.; Li, C. Rail Surface Defect Detection Based on An Improved YOLOv5s. Appl. Sci. 2023, 13, 7330. [Google Scholar] [CrossRef]
- Kang, G.; Gao, S.; Yu, L.; Zhang, D. Deep Architecture for High-Speed Railway Insulator Surface Defect Detection: Denoising Autoencoder with Multitask Learning. IEEE Trans. Instrum. Meas. 2019, 68, 2679–2690. [Google Scholar] [CrossRef]
- Liu, Y.; Garg, S.; Nie, J.; Zhang, Y.; Xiong, Z.; Kang, J.; Hossain, M.S. Deep Anomaly Detection for Time-Series Data in Industrial IoT: A Communication-Efficient On-Device Federated Learning Approach. IEEE Internet Things J. 2021, 8, 6348–6358. [Google Scholar] [CrossRef]
- Thombre, S.; Zhao, Z.; Ramm-Schmidt, H.; Garcia, J.M.V.; Malkamaki, T.; Nikolskiy, S.; Hammarberg, T.; Nuortie, H.; Bhuiyan, M.Z.H.; Sarkka, S.; et al. Sensors and AI Techniques for Situational Awareness in Autonomous Ships: A Review. IEEE Trans. Intell. Transp. Syst. 2022, 23, 64–83. [Google Scholar] [CrossRef]
- Jezequel, L.; Vu, N.-S.; Beaudet, J.; Histace, A. Efficient Anomaly Detection Using Self-Supervised Multi-Cue Tasks. IEEE Trans. Image Process. 2023, 32, 807–821. [Google Scholar] [CrossRef] [PubMed]
- Doorenbos, L.; Sznitman, R.; Márquez-Neila, P. Data invariants to understand unsupervised out-of-distribution detection. In Computer Vision—ECCV 2022; Part XXXI; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2022; Volume 13691, pp. 133–150. [Google Scholar]
- Ran, X.; Xu, M.; Mei, L.; Xu, Q.; Liu, Q. Detecting out-of-distribution samples via variational auto-encoder with reliable uncertainty estimation. Neural Netw. 2022, 145, 199–208. [Google Scholar] [CrossRef] [PubMed]
- Ruff, L.; Kauffmann, J.R.; Vandermeulen, R.A.; Montavon, G.; Samek, W.; Kloft, M.; Dietterich, T.G.; Muller, K.-R. A Unifying Review of Deep and Shallow Anomaly Detection. Proc. IEEE 2021, 109, 756–795. [Google Scholar] [CrossRef]
- Saha, S.; Bovolo, F.; Bruzzone, L. Change Detection in Image Time-Series Using Unsupervised LSTM. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, Y.; Wang, J.; Pan, Z. Unsupervised Deep Anomaly Detection for Multi-Sensor Time-Series Signals. IEEE Trans. Knowl. Data Eng. 2023, 35, 2118–2132. [Google Scholar] [CrossRef]
- Rao, W.; Qu, Y.; Gao, L.; Sun, X.; Wu, Y.; Zhang, B. Transferable network with Siamese architecture for anomaly detection in hyperspectral images. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102669. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, A.; Zhu, Y.; Zheng, S.; Li, M.; Smola, A.J.; Wang, Z. Partial and Asymmetric Contrastive Learning for Out-Of-Distribution Detection in Long-Tailed Recognition. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- Yu, J.; Zheng, Y.; Wang, X.; Li, W.; Wu, Y.; Zhao, R.; Wu, L. Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows. arXiv 2021, arXiv:2111.07677. [Google Scholar]
- Drost, B.; Ulrich, M.; Bergmann, P.; Hartinger, P.; Steger, C. Introducing mvtec—A dataset for 3d object recognition in industry. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2200–2208. [Google Scholar]
- Jiang, J.; Zhu, J.; Bilal, M.; Cui, Y.; Kumar, N.; Dou, R.; Su, F.; Xu, X. Masked Swin Transformer Unet for Industrial Anomaly Detection. IEEE Trans. Ind. Inform. 2023, 19, 2200–2209. [Google Scholar] [CrossRef]
- Alvarenga, W.J.; Campos, F.V.; Costa, A.C.; Salis, T.T.; Magalhães, E.; Torres, L.C.; Braga, A.P. Time domain graph-based anomaly detection approach applied to a real industrial problem. Comput. Ind. 2022, 142, 103714. [Google Scholar] [CrossRef]
- Kong, F.; Li, J.; Jiang, B.; Wang, H.; Song, H. Integrated generative model for industrial anomaly detection via bidirectional lstm and attention mechanism. IEEE Trans. Ind. Inform. 2023, 19, 541–550. [Google Scholar] [CrossRef]
- Zayas-Gato, F.; Jove, E.; Casteleiro-Roca, J.; Quintián, H.; Piñón-Pazos, A.; Simić, D.; Calvo-Rolle, J.L. A hybrid one-class approach for detecting anomalies in industrial systems. Expert Syst. 2022, 39, e12990. [Google Scholar] [CrossRef]
- Zeiser, A.; Özcan, B.; van Stein, B.; Bäck, T. Evaluation of deep unsupervised anomaly detection methods with a data-centric approach for on-line inspection. Comput. Ind. 2023, 146, 103852. [Google Scholar] [CrossRef]
- Yu, L.; Wang, Y.; Zhou, L.; Wu, J.; Wang, Z. Residual neural network-assisted one-class classification algorithm for melanoma recognition with imbalanced data. Comput. Intell. 2023, 1–18. [Google Scholar] [CrossRef]
- Han, P.; Li, H.; Xue, G.; Zhang, C. Distributed system anomaly detection using deep learning-based log analysis. Comput. Intell. 2023, 39, 433–455. [Google Scholar] [CrossRef]
- Kerboua, A.; Kelaiaia, R. Fault Diagnosis in an Asynchronous Motor Using Three-Dimensional Convolutional Neural Network. Arab. J. Sci. Eng. 2023, 1–19. [Google Scholar] [CrossRef]
- Tran, T.M.; Vu, T.N.; Vo, N.D.; Nguyen, T.V.; Nguyen, K. Anomaly Analysis in Images and Videos: A Comprehensive Review. ACM Comput. Surv. 2023, 55, 1–37. [Google Scholar] [CrossRef]
- Shen, H.; Wei, B.; Ma, Y.; Gu, X. Unsupervised industrial image ensemble anomaly detection based on object pseudo-anomaly generation and normal image feature combination enhancement. Comput. Ind. Eng. 2023, 182, 109337. [Google Scholar] [CrossRef]
- Liu, K.; Chen, B.M. Industrial uav-based unsupervised domain adaptive crack recognitions: From database towards real-site infrastructural in-spections. IEEE Trans. Ind. Electron. 2023, 70, 9410–9420. [Google Scholar] [CrossRef]
- Tong, G.; Li, Q.; Song, Y. Two-stage reverse knowledge distillation incorporated and Self-Supervised Masking strategy for industrial anomaly detection. Knowl. Based Syst. 2023, 273, 110611. [Google Scholar] [CrossRef]
- Park, J.-H.; Kim, Y.-S.; Seo, H.; Cho, Y.-J. Analysis of training deep learning models for pcb defect detection. Sensors 2023, 23, 2766. [Google Scholar] [CrossRef] [PubMed]
- de Oliveira, D.C.; Nassu, B.T.; Wehrmeister, M.A. Image-based detection of modifications in assembled pcbs with deep convolutional autoencoders. Sensors 2023, 23, 1353. [Google Scholar] [CrossRef]
- Smith, A.D.; Du, S.; Kurien, A. Vision transformers for anomaly detection and localisation in leather surface defect classification based on low-resolution images and a small dataset. Appl. Sci. 2023, 13, 8716. [Google Scholar] [CrossRef]
- Kwon, J.; Kim, G. Distilling distribution knowledge in normalizing flow. IEICE Trans. Inf. Syst. 2023, 106, 1287–1291. [Google Scholar] [CrossRef]
- Lo, S.-Y.; Oza, P.; Patel, V.M.M. Adversarially robust one-class novelty detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 4167–4179. [Google Scholar] [CrossRef]
- Gyimah, N.K.; Gupta, K.D.; Nabil, M.; Yan, X.; Girma, A.; Homaifar, A.; Opoku, D. A discriminative deeplab model (ddlm) for surface anomaly detection and localization. In Proceedings of the IEEE 13th Annual Computing and Communication Workshop and Conference, Las Vegas, NV, USA, 8–11 March 2023; pp. 1137–1144. [Google Scholar]
- Rakhmonov, A.A.U.; Subramanian, B.; Olimov, B.; Kim, J. Extensive knowledge distillation model: An end-to-end effective anomaly detection model for real-time industrial applications. IEEE Access 2023, 11, 69750–69761. [Google Scholar] [CrossRef]
- Rudolph, M.; Wehrbein, T.; Rosenhahn, B.; Wandt, B. Asymmetric student-teacher networks for industrial anomaly detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 2591–2601. [Google Scholar]
- Hermann, M.; Umlauf, G.; Goldlücke, B.; Franz, M.O. Fast and efficient image novelty detection based on mean-shifts. Sensors 2022, 22, 7674. [Google Scholar] [CrossRef] [PubMed]
- Avola, D.; Cascio, M.; Cinque, L.; Fagioli, A.; Foresti, G.L.; Marini, M.R.; Rossi, F. Real-time deep learning method for automated detection and localization of structural defects in manufactured products. Comput. Ind. Eng. 2022, 172, 108512. [Google Scholar] [CrossRef]
- Szarski, M.; Chauhan, S. An unsupervised defect detection model for a dry carbon fiber textile. J. Intell. Manuf. 2022, 33, 2075–2092. [Google Scholar] [CrossRef]
- Gudovskiy, D.; Ishizaka, S.; Kozuka, K. Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 1819–1828. [Google Scholar]
- Rudolph, M.; Wandt, B.; Rosenhahn, B. Same same but differnet: Semi-supervised defect detection with normalizing flows. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 1906–1915. [Google Scholar]
- Rudolph, M.; Wehrbein, T.; Rosenhahn, B.; Wandt, B. Fully convolutional cross-scale-flows for image-based defect detection. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; Volume 5, pp. 829–1838. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | Pretrained | Decoder | Flow Steps | Learning Rate | Batch | Image Size |
|---|---|---|---|---|---|---|---|
| Fastflow | Resnet18 | True | - | 8 | 0.001 | 32 | 256 |
| Cflow | Wide_resnet50_2 | True | freia-cflow | - | 0.0001 | 32 | 256 |
| Model | Image-Level Metrics | Pixel-Level Metrics | ||
|---|---|---|---|---|
| AUROC | F1-Score | AUROC | F1-Score | |
| Fastflow | 100.00% | 95.65% | 96.98% | 56.49% |
| Filtered Fastflow | 100.00% | 100.00% | 98.28% | 58.93% |
| Cflow | 100.00% | 91.67% | 97.41% | 58.11% |
| Filtered Cflow | 100.00% | 100.00% | 98.63% | 62.08% |
| Model | Image-Level Metrics | Pixel-Level Metrics | ||
|---|---|---|---|---|
| AUROC | F1-Score | AUROC | F1-Score | |
| Fastflow | 72.36% | 28.57% | 91.13% | 7.85% |
| Filtered Fastflow | 94.74% | 40.00% | 91.36% | 15.24% |
| Cflow | 65.78% | 46.15% | 88.64% | 6.84% |
| Filtered Cflow | 81.05% | 78.26% | 93.58% | 13.39% |
| Settings | Image-Level Metrics | Pixel-Level Metrics | ||
|---|---|---|---|---|
| AUROC | F1-Score | AUROC | F1-Score | |
| Cflow | 65.78% | 46.15% | 88.64% | 6.84% |
| Filtered Cflow #1 | 80.26% | 75.00% | 93.41% | 13.32% |
| Filtered Cflow #2 | 81.05% | 78.26% | 93.58% | 13.39% |
| Filtered Cflow #3 | 81.05% | 78.26% | 93.58% | 13.39% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, J.; Shi, H.; Hu, Y.; Yu, Z. Enhancing Anomaly Detection Models for Industrial Applications through SVM-Based False Positive Classification. Appl. Sci. 2023, 13, 12655. https://doi.org/10.3390/app132312655
Qiu J, Shi H, Hu Y, Yu Z. Enhancing Anomaly Detection Models for Industrial Applications through SVM-Based False Positive Classification. Applied Sciences. 2023; 13(23):12655. https://doi.org/10.3390/app132312655
Chicago/Turabian StyleQiu, Ji, Hongmei Shi, Yuhen Hu, and Zujun Yu. 2023. "Enhancing Anomaly Detection Models for Industrial Applications through SVM-Based False Positive Classification" Applied Sciences 13, no. 23: 12655. https://doi.org/10.3390/app132312655
APA StyleQiu, J., Shi, H., Hu, Y., & Yu, Z. (2023). Enhancing Anomaly Detection Models for Industrial Applications through SVM-Based False Positive Classification. Applied Sciences, 13(23), 12655. https://doi.org/10.3390/app132312655