
Sentiment Analysis of Arabic Course Reviews of a Saudi University Using Support Vector Machine


Abstract
:1. Introduction
2. Related Work
2.1. Sentimental Analysis in Social Media
2.2. Sentimental Analysis Using Arabic Language
2.3. Sentimental Analysis in Education
2.4. SVM for Sentimental Analysis
3. Contributions
- The proposed SVM Sentimental Analysis for Arabic Students’ Review called SVM-SAA-SC algorithm for students’ Arabic course reviews is a general framework that involves collecting student reviews, preprocessing them, and using a machine learning model to classify them as positive, negative, or neutral.
- The suggested technique for preprocessing and classifying reviews includes steps such as collecting data, removing irrelevant information, tokenizing, removing stop words, stemming or lemmatization, and using pre-trained sentiment analysis models.
- To train the classifier, SVM algorithm is used, and performance is evaluated using metrics such as accuracy, precision, and recall.
- Fine-tuning is done by adjusting parameters such as kernel type and regularization strength to optimize performance.
- The use of a real dataset provided by the deanship of quality at PSAU, which is ranked 801–900 globally and 6th in Saudi Arabia according to the 2022 Shanghai Rankings.
- The dataset contains students’ opinions on various aspects of their education, including courses, faculties, assignments, projects, and exams.
- To validate the suggested SVM-SAA-SC algorithm, a comparison with a sentiment analysis tool called CAMeLBERT Dialectal Arabic model (CAMeLBERT-DA SA Model) [30] is adopted. CAMeLBERT represents an interplay of variant, size, and task type in Arabic pre-trained language models.
- The use of textual comments instead of grading-based feedback to reveal the exact sentiment of students.
4. Dataset
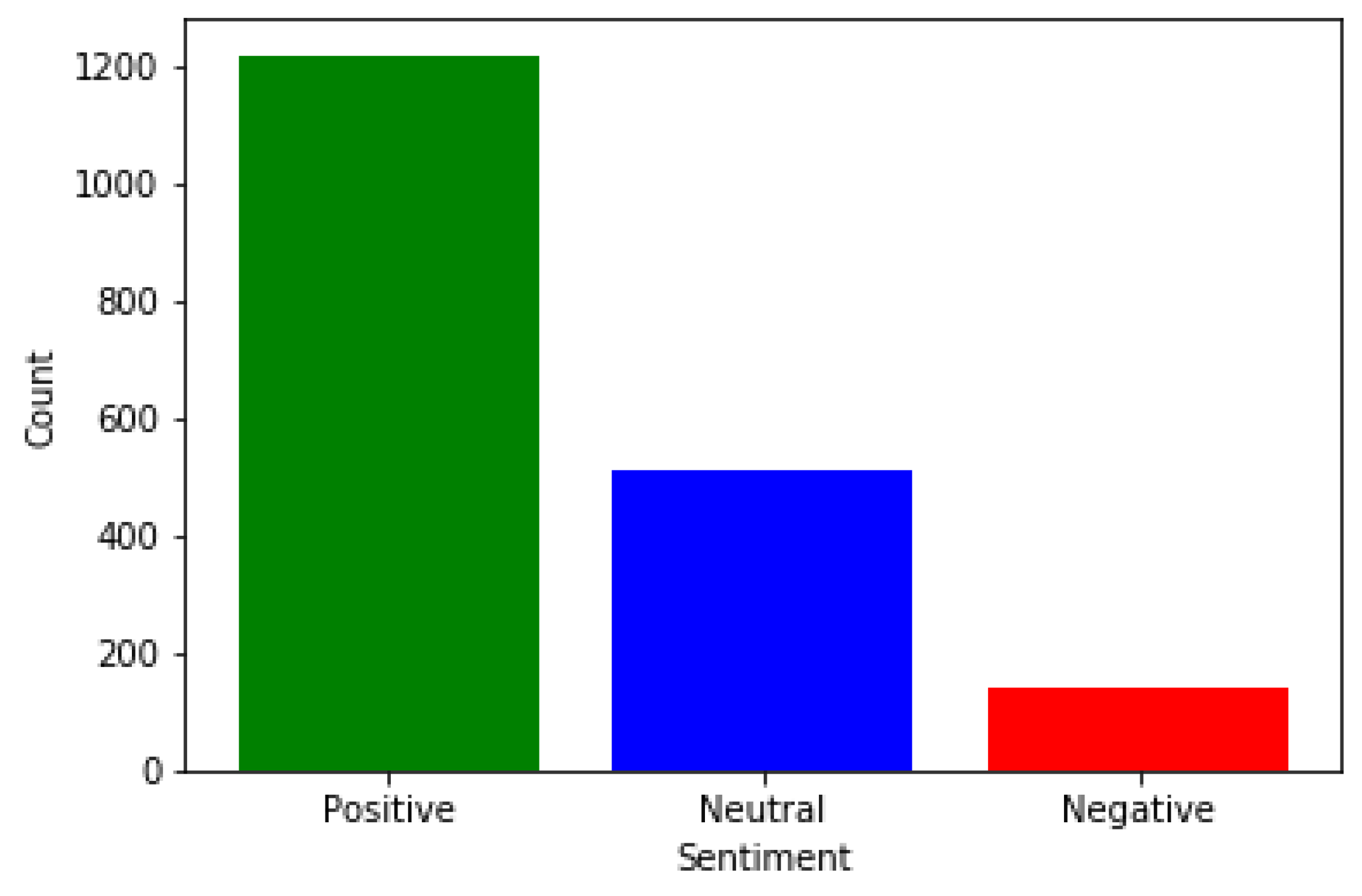
- Positive Class: Significantly more than half of the data, 57.1%.
- Neutral Class: Roughly around half the number of Positive samples, 28.6%.
- Negative Class: Roughly around a quarter of the number of Positive samples, 14.3%.
4.1. Dataset Cleaning
4.2. Removing Straightlining
- TokenizationTo identify the sentiments and extract emotions of sentences, Students’ reviews (e.g., comments) are split into words, or tokens, this task is completed using the tokenize function in the python package natural language toolkit (NLTK).
- NormalizationWe also detect that some comments included repeated characters. In colloquial written speech, some letters are frequently repeated in order to focus on certain emotions. To normalize how this type of emotive word was written, we removed repeated letters and replaced all instances with one only. For example, the word رااااائع was changed to رائع.
- Removal of irrelevant contentPunctuation, stop words, symbols, and prepositions, which are irrelevant for Sentiment analysis, are removed to improve the results, response time and effectiveness.
- StemmingStemming is the most daunting task due to the need to review lexicons. To further facilitate word matching, words in student comments are converted to their root word. For example, المحاضرات, المحاضر. are all converted to محاضرة.
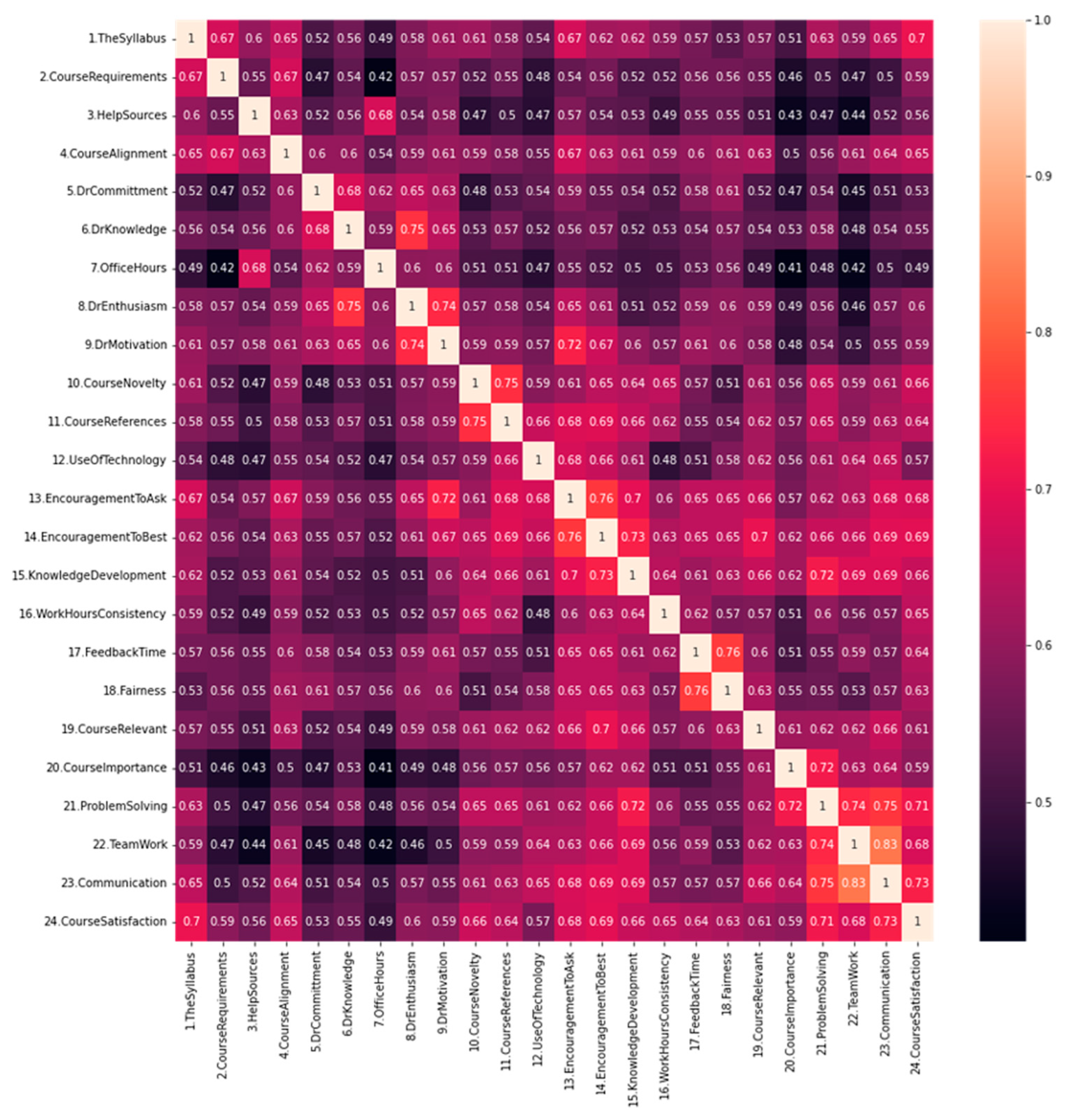
4.3. EDA
5. Methods
5.1. SVM-SAA-SCR
- Collect a dataset of student reviews for an Arabic course.
- Preprocess the reviews by removing any irrelevant information such as special characters and numbers.
- Tokenize the reviews to create a list of words for each review.
- Create a sentiment dictionary or use pre-trained sentiment lexicon to classify each review as positive, negative, or neutral.
- Use a machine learning model to train on the preprocessed and classified reviews.
- Use the trained model to classify new reviews.
- Analyze the results to identify patterns and areas for improvement in the Arabic course based on the sentiment classification of the reviews.
- Repeat the process with updated reviews and continue to make improvements to the course based on the analysis of the results.
5.1.1. SVM-SAA-SCR Preprocessing and Classification
- Collect a dataset of students’ Arabic course reviews from various sources, such as online forums, social media, and surveys.
- Preprocess the reviews by removing any irrelevant information, such as URLs, usernames, and special characters.
- Tokenize the reviews by splitting them into individual words or phrases.
- Remove stop words, such as “and” and “the”, which do not carry much meaning in the analysis.
- Perform stemming or lemmatization to reduce words to their base form and improve consistency in the dataset.
- Use pre-trained sentiment analysis models, such as SentimentIntensityAnalyzer or TextBlob, to classify each review as positive, negative, or neutral.
- Use the resulting sentiment scores to create visualizations, such as bar charts or pie charts, to show the distribution of sentiments among the reviews.
- Analyze the results to identify patterns and trends in the students’ sentiments towards the course.
- Use the insights gained from the analysis to improve the educational process and address areas of improvement.
5.1.2. Model Training Based SVM-SAA-SCR
- Collect and preprocess the reviews by removing any irrelevant information such as diacritics, URLs, and names.
- Split the dataset into training and testing sets.
- Convert the text data into numerical features using techniques such as bag-of-words or TF-IDF.
- Train an SVM classifier using the training dataset and the numerical features as input.
- Test the classifier on the testing dataset and evaluate its performance using metrics such as accuracy, precision, and recall.
- Fine-tune the model by adjusting parameters such as the kernel type and regularization strength to optimize performance.
- Use the trained and fine-tuned classifier to classify new reviews and predict their sentiment.
5.1.3. Evaluation of SVM-SAA-SCR Performance
- Split the dataset into a training set and a test set.
- Train the SVM model on the training set.
- Use the trained model to predict the labels of the samples in the test set.
- Compare the predicted labels to the true labels of the test set samples.
- Compute the accuracy, precision, and recall of the model using the following formulas:
- Accuracy = (True Positives + True Negatives)/Total Samples
- Precision = True Positives/(True Positives + False Positives)
- Recall = True Positives/(True Positives + False Negatives)
- Interpret the results and make any necessary adjustments to the model or the data preprocessing steps.
5.1.4. Tuning Hyper-Parameters for SVM-SAA-SCR
- Begin by initializing the model with a default kernel type (e.g., radial basis function kernel) and regularization strength (e.g., C = 1).
- Use cross-validation techniques to evaluate the performance of the model on the training data, using metrics such as accuracy, precision, and recall.
- Experiment with different kernel types (e.g., linear, polynomial, sigmoid) and regularization strengths (e.g., C = 0.1, C = 10) to find the combination that gives the best performance on the training data.
- Once the optimal kernel type and regularization strength have been identified, use these parameters to train the model on the entire training set.
- Evaluate the performance of the optimized model on the test set using the same metrics as before.
- If the performance is not satisfactory, fine-tune the model further by adjusting other parameters such as the degree of the polynomial kernel or the gamma parameter for the radial basis function kernel.
- Repeat the process of evaluating and fine-tuning the model until the desired level of performance is achieved.
5.2. CAMeLBERT-DA SA Model
- The Arabic Speech-Act and Sentiment Corpus of Tweets (ArSAS), where 23,327 tweets have been used [33];
- The Arabic Sentiment Tweets Dataset (ASTD) [34];
- SemEval-2017 task 4-A benchmark dataset [35];
- The Multi-Topic Corpus for Target-based Sentiment Analysis in Arabic Levantine Tweets (ArSenTD-Lev) [36].
- Build three pre-trained language models across three variants of Arabic: Modern Standard Arabic (MSA), dialectal Arabic, and classical Arabic.
- Build a fourth language model pre-trained on a mix of the three variants.
- Build additional models pre-trained on a scaled-down set of the MSA variant to examine the importance of pre-training data size.
- Fine-tune the models on five NLP tasks spanning 12 datasets.
- Compare the performance of the models to each other and to eight publicly available models.
- Analyze the results to identify the importance of variant proximity of pre-training data to fine-tuning data and the impact of pre-training data size.
- Define an optimized system selection model for the studied tasks based on the insights gained from the experiments.
- Make the created models and fine-tuning code publicly available.
6. Results
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Smith, A.; McCarthey, S.; Magnifico, A. Recursive feedback: Evaluative dimensions of e-learning. In E-Learning Ecologies; Routledge: Milton Park, UK, 2017; pp. 118–142. [Google Scholar]
- Jones, B.D. Motivating and engaging students using educational technologies. In Handbook of Research in Educational Communications and Technology; Learning Design; Contemporary Educational Technology: London, UK, 2020; pp. 9–35. [Google Scholar]
- Galante, J.; Friedrich, C.; Dawson, A.F.; Modrego-Alarcón, M.; Gebbing, P.; Delgado-Suárez, I.; Jones, P.B. Mindfulness-based programmes for mental health promotion in adults in nonclinical settings: A systematic review and meta-analysis of randomised controlled trials. PLoS Med. 2021, 18, e1003481. [Google Scholar] [CrossRef] [PubMed]
- Poria, S.; Hazarika, D.; Majumder, N.; Mihalcea, R. Beneath the tip of the iceberg: Current challenges and new directions in sentiment analysis research. IEEE Trans. Affect. Comput. 2020, 14, 108–132. [Google Scholar] [CrossRef]
- Kusal, S.; Patil, S.; Choudrie, J.; Kotecha, K.; Mishra, S.; Abraham, A. AI-based conversational agents: A scoping review from technologies to future directions. IEEE Access 2022, 10, 92337–92356. [Google Scholar] [CrossRef]
- Mirończuk, M.M.; Protasiewicz, J. A recent overview of the state-of-the-art elements of text classification. Expert Syst. Appl. 2018, 106, 36–54. [Google Scholar] [CrossRef]
- Rakshitha, K.H.M.R.; Pavithra, M.H.D.A.; Hegde, M. Sentimental analysis of indian regional languages on social media. Glob. Transit. Proc. 2021, 2, 414–420. [Google Scholar] [CrossRef]
- Morshed, S.A.; Khan, S.S.; Tanvir, R.B.; Nur, S. Impact of COVID-19 pandemic on ride-hailing services based on large-scale twitter data analysis. J. Urban Manag. 2021, 10, 155–165. [Google Scholar] [CrossRef]
- Shelke, N.; Chaudhury, S.; Chakrabarti, S.; Bangare, S.L.; Yogapriya, G.; Pandey, P. An efficient way of text-based emotion analysis from social media using lra-dnn. Neurosci. Inform. 2022, 2, 100048. [Google Scholar] [CrossRef]
- Bonifazi, G.; Cauteruccio, F.; Corradini, E.; Marchetti, M.; Sciarretta, L.; Ursino, D.; Virgili, L. A Space-Time Framework for Sentiment Scope Analysis in Social Media. Big Data Cogn. Comput. 2022, 6, 130. [Google Scholar] [CrossRef]
- Bonifazi, G.; Cauteruccio, F.; Corradini, E.; Marchetti, M.; Terracina, G.; Ursino, D.; Virgili, L. A framework for investigating the dynamics of user and community sentiments in a social platform. Data Knowl. Eng. 2023, 146, 102183. [Google Scholar] [CrossRef]
- Najar, D.; Mesfar, S. Opinion mining and sentiment analysis for arabic on-line texts: Application on the political domain. Int. J. Speech Technol. 2017, 20, 575–585. [Google Scholar] [CrossRef]
- Sghaier, M.A.; Zrigui, M. Sentiment analysis for arabic e-commerce websites. In Proceedings of the 2016 International Conference on Engineering & MIS (ICEMIS), Agadir, Morocco, 22–24 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–7. [Google Scholar]
- Mourad, A.; Darwish, K. Subjectivity and sentiment analysis of modern standard arabic and arabic microblogs. In Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Atlanta, Georgia, 14 June 2013; pp. 55–64. [Google Scholar]
- Alwakid, G.; Osman, T.; Haj, M.E.; Alanazi, S.; Humayun, M.; Sama, N.U. Muldasa: Multifactor lexical sentiment analysis of social-media content in nonstandard arabic social media. Appl. Sci. 2022, 12, 3806. [Google Scholar] [CrossRef]
- Tartir, S.; Abdul-Nabi, I. Semantic sentiment analysis in arabic social media. J. King Saud Univ. Comput. Inf. Sci. 2017, 29, 229–233. [Google Scholar] [CrossRef]
- Zhou, M.; Mou, H. Tracking public opinion about online education over COVID-19 in China. Educ. Technol. Res. Dev. 2022, 70, 1083–1104. [Google Scholar] [CrossRef] [PubMed]
- Toçoğlu, M.A.; Onan, A. Sentiment analysis on students’ evaluation of higher educational institutions. In International Conference on Intelligent and Fuzzy Systems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1693–1700. [Google Scholar]
- Nikolić, N.; Grljević, O.; Kovačević, A. Aspect-based sentiment analysis of reviews in the domain of higher education. Electron. Libr. 2020, 38, 44–64. [Google Scholar] [CrossRef]
- Mohiudddin, K.; Rasool, A.M.; Mohd, M.S.; Mohammad, R.H. Skill-centered assessment in an academic course: A formative approach to evaluate student performance and make continuous quality improvements in pedagogy. Int. J. Emerg. Technol. Learn. (Online) 2019, 14, 92. [Google Scholar] [CrossRef]
- Dsouza, D.D.; Deepika, D.P.N.; Machado, E.J.; Adesh, N. Sentimental analysis of student feedback using machine learning techniques. Int. J. Recent Technol. Eng. 2019, 8, 986–991. [Google Scholar]
- Louati, A. Cloud-assisted collaborative estimation for next-generation automobile sensing. Eng. Appl. Artif. Intell. 2023, 126, 106883. [Google Scholar] [CrossRef]
- Louati, A. A hybridization of deep learning techniques to predict and control traffic disturbances. Artif. Intell. Rev. 2020, 53, 5675–5704. [Google Scholar] [CrossRef]
- Webb, M.E.; Fluck, A.; Magenheim, J.; Malyn-Smith, J.; Waters, J.; Deschênes, M.; Zagami, J. Machine learning for human learners: Opportunities, issues, tensions and threats. Educ. Technol. Res. Dev. 2021, 69, 2109–2130. [Google Scholar] [CrossRef]
- Singh, N.K.; Tomar, D.S.; Sangaiah, A.K. Sentiment analysis: A review and comparative analysis over social media. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 97–117. [Google Scholar] [CrossRef]
- Alrehili, A.; Albalawi, K. Sentiment analysis of customer reviews using ensemble method. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 3–4 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Al-Smadi, M.; Qawasmeh, O.; Al-Ayyoub, M.; Jararweh, Y.; Gupta, B. Deep recurrent neural network vs. support vector machine for aspect-based sentiment analysis of arabic hotels’ reviews. J. Comput. Sci. 2018, 27, 386–393. [Google Scholar] [CrossRef]
- Al-Horaibi, L.; Khan, M.B. Sentiment analysis of arabic tweets using text mining techniques. In First International Workshop on Pattern Recognition; SPIE: Tokyo, Japan, 2016; Volume 10011, pp. 288–292. [Google Scholar]
- Alsayat, A.; Elmitwally, N. A comprehensive study for arabic sentiment analysis (challenges and applications). Egypt. Inform. J. 2020, 21, 7–12. [Google Scholar] [CrossRef]
- Inoue, G.; Alhafni, B.; Baimukan, N.; Bouamor, H.; Habash, N. The interplay of variant, size, and task type in arabic pre-trained language models. arXiv 2021, arXiv:210306678. [Google Scholar]
- Louati, A.; Lahyani, R.; Aldaej, A.; Aldumaykhi, A.; Otai, S. Price forecasting for real estate using machine learning: A case study on Riyadh city. Concurr. Comput. Pract. Exp. 2022, 34, e6748. [Google Scholar] [CrossRef]
- Jiang, L.; Yao, R. Modelling personal thermal sensations using C-Support Vector Classification (C-SVC) algorithm. Build. Environ. 2016, 99, 98–106. [Google Scholar] [CrossRef]
- Elmadany, A.; Mubarak, H.; Magdy, W. Arsas: An arabic speech-act and sentiment corpus of tweets. OSACT 2018, 3, 20. [Google Scholar]
- Nabil, M.; Aly, M.; Atiya, A. Astd: Arabic sentiment tweets dataset. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2515–2519. [Google Scholar]
- Rosenthal, S.; Farra, N.; Nakov, P. Semeval-2017 task 4: Sentiment analysis in twitter. arXiv 2019, arXiv:191200741. [Google Scholar]
- Baly, R.; Khaddaj, A.; Hajj, H.; El-Hajj, W.; Shaban, K.B. Arsentd-lev: A multi-topic corpus for target-based sentiment analysis in arabic levantine tweets. arXiv 2019, arXiv:190601830. [Google Scholar]
- Farha, I.A.; Magdy, W. Mazajak: An online arabic sentiment analyser. In Proceedings of the Fourth Arabic Natural Language Processing Workshop, Florence, Italy, 1 August 2019; pp. 192–198. [Google Scholar]
- Obeid, O.; Zalmout, N.; Khalifa, S.; Taji, D.; Oudah, M.; Alhafni, B.; Inoue, G.; Eryani, F.; Erdmann, A.; Habash, N. Camel tools: An open source python toolkit for arabic natural language processing. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 7022–7032. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Review Translated | Sentiment |
|---|---|
| Dr. Elham has faciltated the course content and was very supportive.. | Positive |
| The professor explanation was very good and understandable. | Positive |
| The professor. | Neutral |
| The professor is amazing. | Neutral |
| I like the professor. When I graduate, I will be a database administrator. | Positive |
| The slides are fair but need improvement. | Neutral |
| Slides are not clear. | Negative |
| Slides are good. I think thet deserve to contain more details. | Neutral |
| Explanation. | Neutral |
| Exams are quite difficult. | Neutral |
| We are pressed by the labs and homeworks. | Negative |
| More effort to reach a certificate in Business Architecture. | Positive |
| Team work and I think I found great what we are learning in programming. | Negative |
| The variety of tasks and the presence of a real challenge in the work is what makes the experience unique and valuable. | Positive |
| Practical. | Neutral |
| Benefit. | Negative |
| Idea on organizing information. | Neutral |
| Lot of chapters. | Negative |
| Despite the quantity of theoretical courses that require remembering more than understanding, I was able to understand clearly and it was funny. | Positive |
| Quizzes are hard. | Negative |
| I am quite scared from quizzes that we take at the beginning of lectures. | Negative |
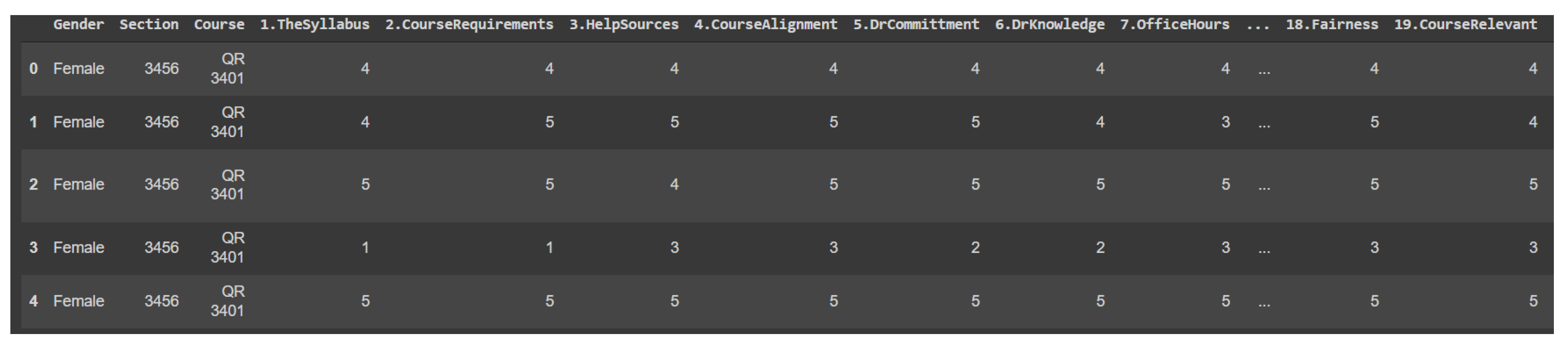
| Feature | Description | Data Type |
|---|---|---|
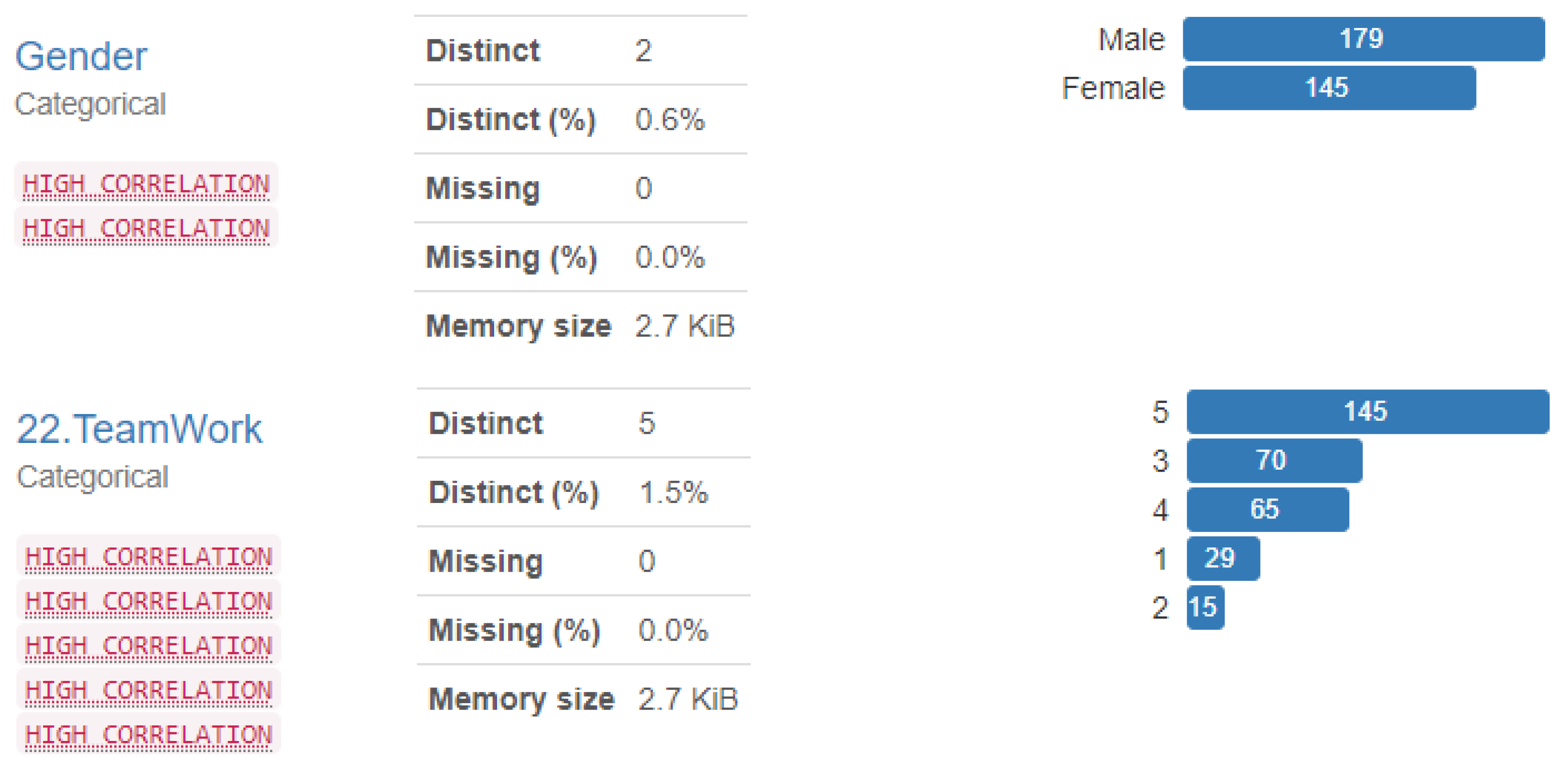
| Gender | Gender of the student | Categorical |
| Section | Course section number | Categorical |
| Course | Course The Course code | Categorical |
| 1. TheSyllabus | The course syllabus | Numerical |
| 2. CourseRequirements | The requirements for success in the course (including the duties to be assessed and the criteria for assessment) were clear to me | Numerical |
| 3. HelpSources | Helping Sources | Numerical |
| 4. CourseAlignment | The implementation of the course and the things I was asked to do aligned with syllabus | Numerical |
| 5. DrCommittment | The faculty member was committed to giving the course completely (such as: starting lectures on time, presence of the faculty member, good preparation of teaching aids, and so on) | Numerical |
| 6. DrKnowledge | The knowledge of instructor about the course | Numerical |
| 7. OfficeHours | The instructor was available to help during office hours | Numerical |
| 8. DrEnthusiasm | The instructor was enthusiastic about what he/she taught | Numerical |
| 9. DrMotivation | The instructor was interested in my progress and was a supporter to me | Numerical |
| 10. CourseNovelty | Everything presented in the course was modern and useful (reading texts, summaries, references, and the like) | Numerical |
| 11. CourseReferences | The sources I needed in this course were available whenever I needed them | Numerical |
| 12. UseOfTechnology | There was effective use of technology to support my learning in this course | Numerical |
| 13. EncouragementToAsk | I found encouragement to ask questions and develop my own ideas in this course | Numerical |
| 14. EncouragementToBest | In this course I was encouraged to do my best | Numerical |
| 15. KnowledgeDevelopment | The things that were asked of me in this course (classroom activities, labs, and so on) helped in developing my knowledge and skills that the course aims to teach | Numerical |
| 16. WorkHoursConsistency | The amount of work in this course was proportional to the number of credit hours allocated to the course | Numerical |
| 17. FeedbackTime | received the grades for assignments and tests in this course within a reasonable time | Numerical |
| 18. Fairness | The correction of my homework and exams was fair and appropriate | Numerical |
| 19. CourseRelevant | The link between this course and the other courses in the program (department) was explained to me | Numerical |
| 20. CourseImportance | What I learned in this course is important and will benefit me in the future | Numerical |
| 21. ProblemSolving | This course helped me to improve my ability to think and solve problems instead of just memorizing information | Numerical |
| 22. TeamWork | This course helped me to improve my skills in working as a team | Numerical |
| 23. Communication | This course helped me to improve my ability to communicate effectively | Numerical |
| 24. CourseSatisfaction | I am generally satisfied with the level of quality of this course | Numerical |
| 25. Strengths | What did you especially like about this course? | Textual |
| 26. Recommendations | What did you not especially like about this course? | Textual |
| 27. ImprovementsArea | What suggestions would you make to improve this course? | Textual |
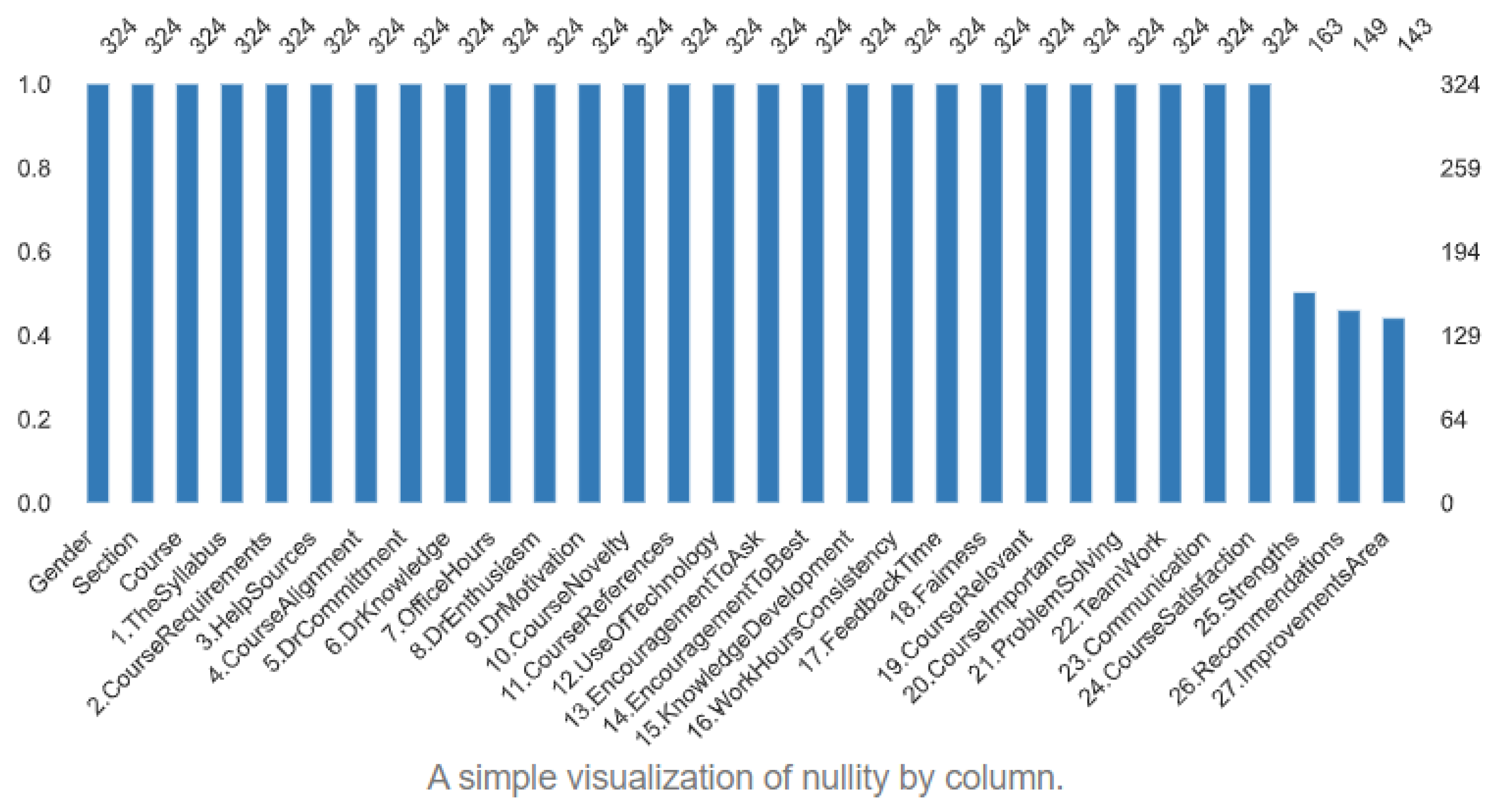
| Number of variables | 30 |
| Number of observations | 324 |
| Missing cells | 517 |
| Missing cells (%) | 5.3% |
| Duplicate rows | 0 |
| Duplicate rows (%) | 0.0% |
| Total size in memory | 76.1 KiB |
| Average record size in memory | 340.4 B |
| Class | Accuracy | Precision | Recall |
|---|---|---|---|
| Positive | 0.84 | 0.86 | 0.85 |
| Neutral | 0.81 | 0.85 | 0.83 |
| Negative | 0.82 | 0.84 | 0.82 |
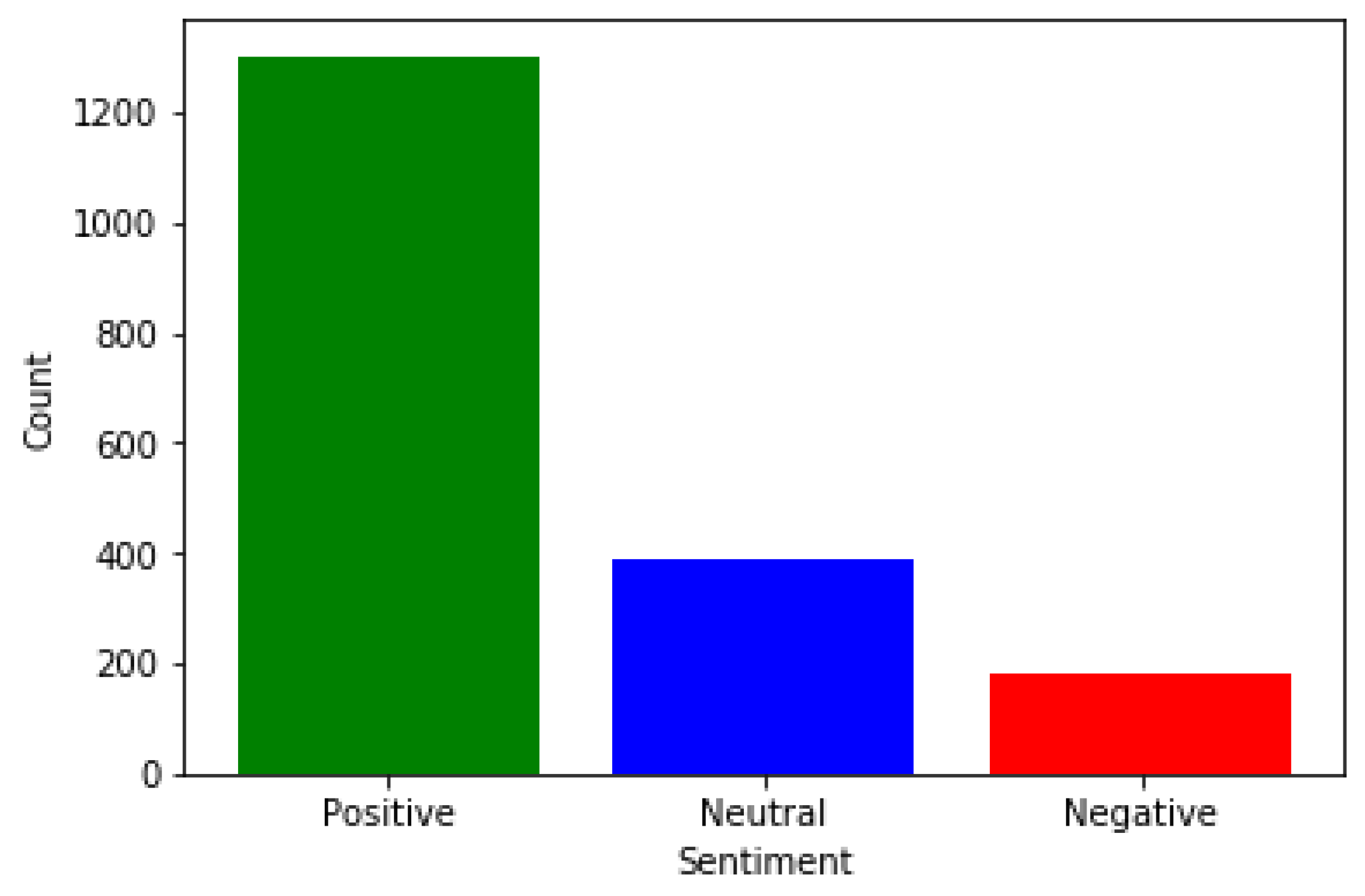
| Class (Count) | SVM-SAA-SCR | CAMeLBERT-DA SA |
|---|---|---|
| Positive | 1302 | 1318 |
| Neutral | 388 | 412 |
| Negative | 180 | 140 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Louati, A.; Louati, H.; Kariri, E.; Alaskar, F.; Alotaibi, A. Sentiment Analysis of Arabic Course Reviews of a Saudi University Using Support Vector Machine. Appl. Sci. 2023, 13, 12539. https://doi.org/10.3390/app132312539
Louati A, Louati H, Kariri E, Alaskar F, Alotaibi A. Sentiment Analysis of Arabic Course Reviews of a Saudi University Using Support Vector Machine. Applied Sciences. 2023; 13(23):12539. https://doi.org/10.3390/app132312539
Chicago/Turabian StyleLouati, Ali, Hassen Louati, Elham Kariri, Fahd Alaskar, and Abdulaziz Alotaibi. 2023. "Sentiment Analysis of Arabic Course Reviews of a Saudi University Using Support Vector Machine" Applied Sciences 13, no. 23: 12539. https://doi.org/10.3390/app132312539
APA StyleLouati, A., Louati, H., Kariri, E., Alaskar, F., & Alotaibi, A. (2023). Sentiment Analysis of Arabic Course Reviews of a Saudi University Using Support Vector Machine. Applied Sciences, 13(23), 12539. https://doi.org/10.3390/app132312539