
Attentional Keypoint Detection on Point Clouds for 3D Object Part Segmentation

 ,
,  ,
,
Abstract
:1. Introduction
- We propose an attentional keypoint detection network that leverages inner-shape information for part segmentation.
- In this network, a keypoint-aware module, a feature extension module, and an attention-aware module are proposed.
- Experiments on the ShapeNet-Part dataset demonstrate the effectiveness and superiority of the proposed modules in improving segmentation accuracy.
- In order to demonstrate that the three proposed modules are not limited by the task itself, we conducted experiments on the ModelNet40 dataset to validate the effectiveness of the modules.
2. Related Work
3. Our Approach
3.1. Background
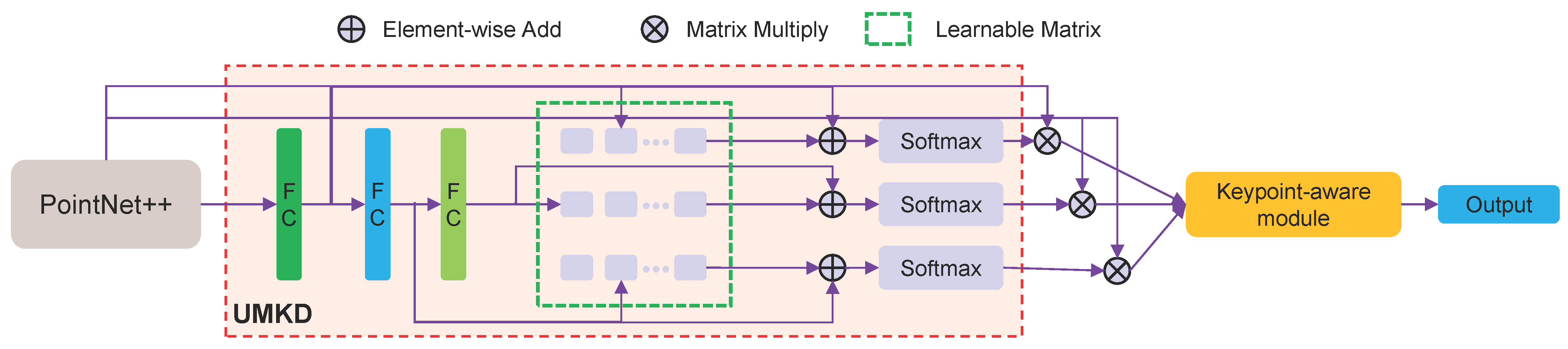
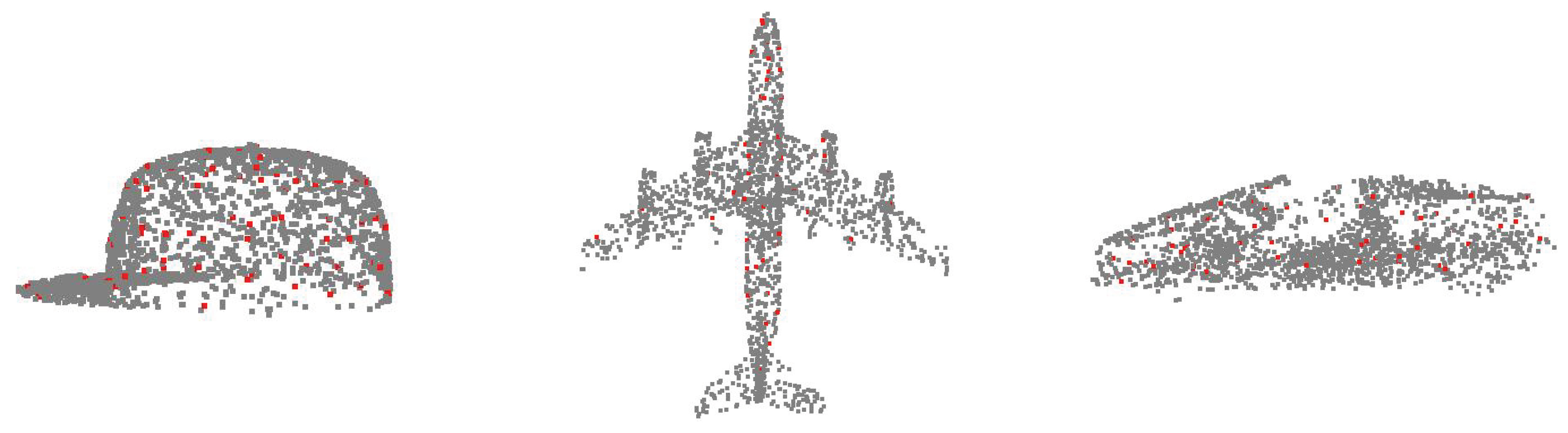
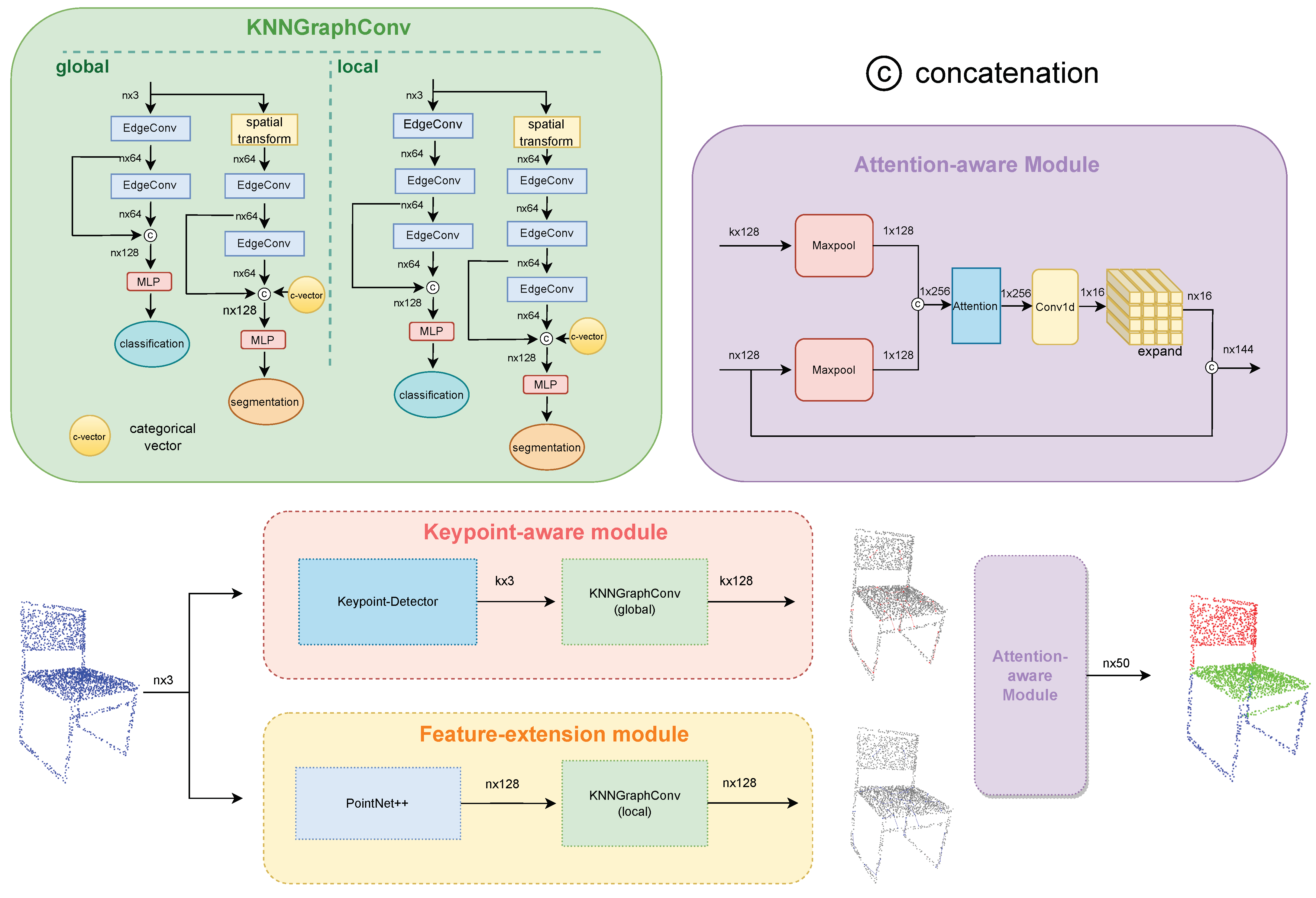
3.2. Keypoint-Aware Module
- Aligned Keypoint Localization: An asymmetric keypoint locator is proposed, which consists of an unsupervised multiscale keypoint detector and a complete keypoint generator. The keypoint detector is designed to identify aligned keypoints from both complete and partial point clouds. Theoretical evidence is presented to demonstrate the detector’s efficacy in capturing aligned keypoints for objects within a subcategory.
- Surface-Skeleton Generation: A new type of skeleton, named Surface-Skeleton, is generated from the localized keypoints based on geometric priors.
- Shape Refinement: The model features a refinement subnet, where multiscale surface-skeletons are fed into each recursive skeleton-assisted refinement module.
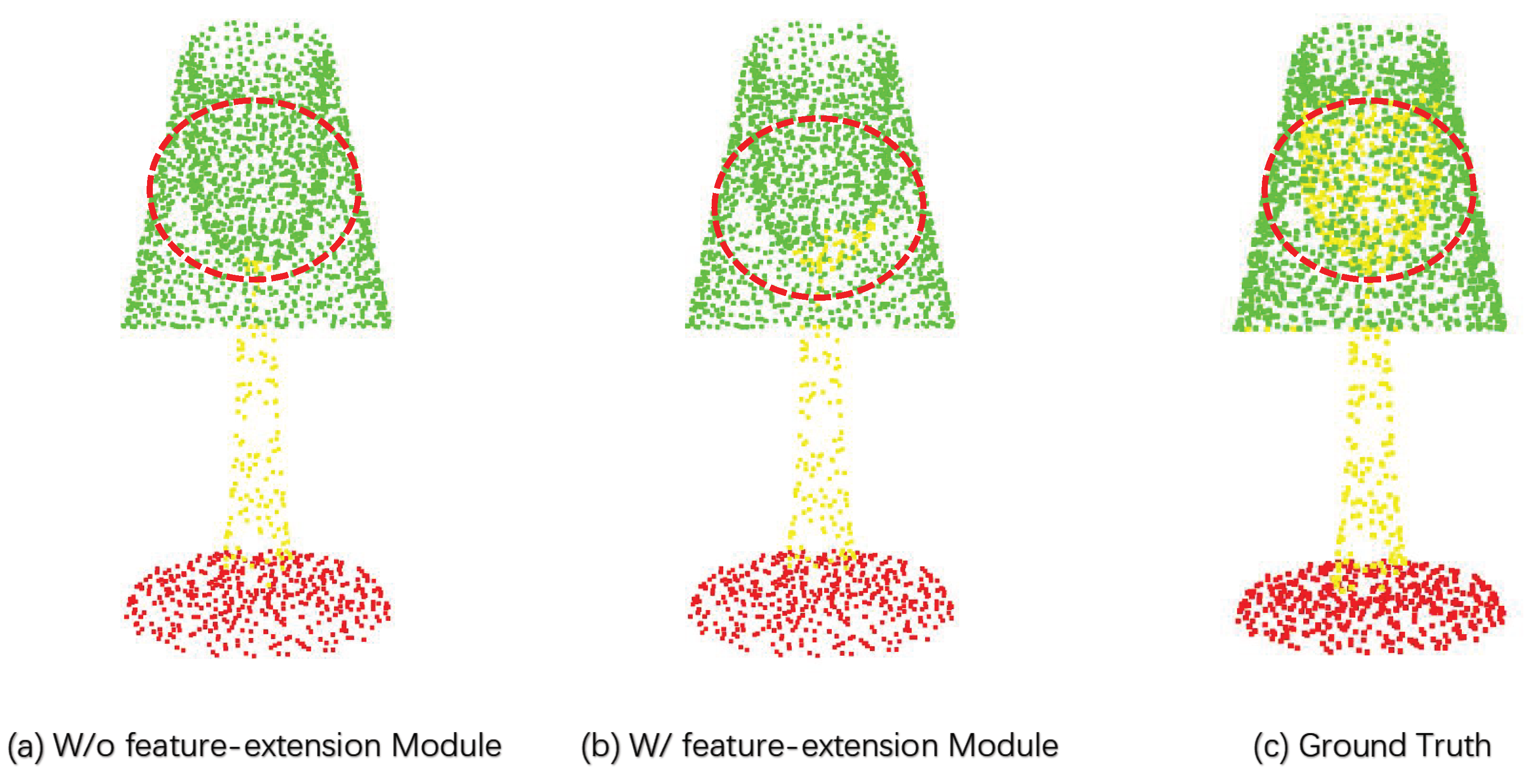
3.3. Feature Extension Module
3.4. Attention-Aware Module
4. Experiments and Discussions on Part Segmentation
4.1. Dataset
4.2. Training Details
4.3. Architecture
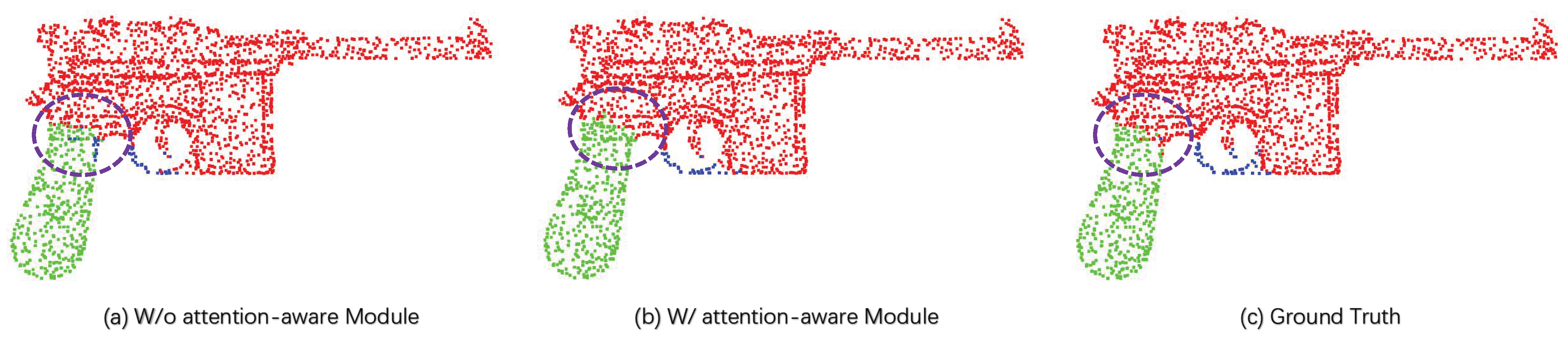
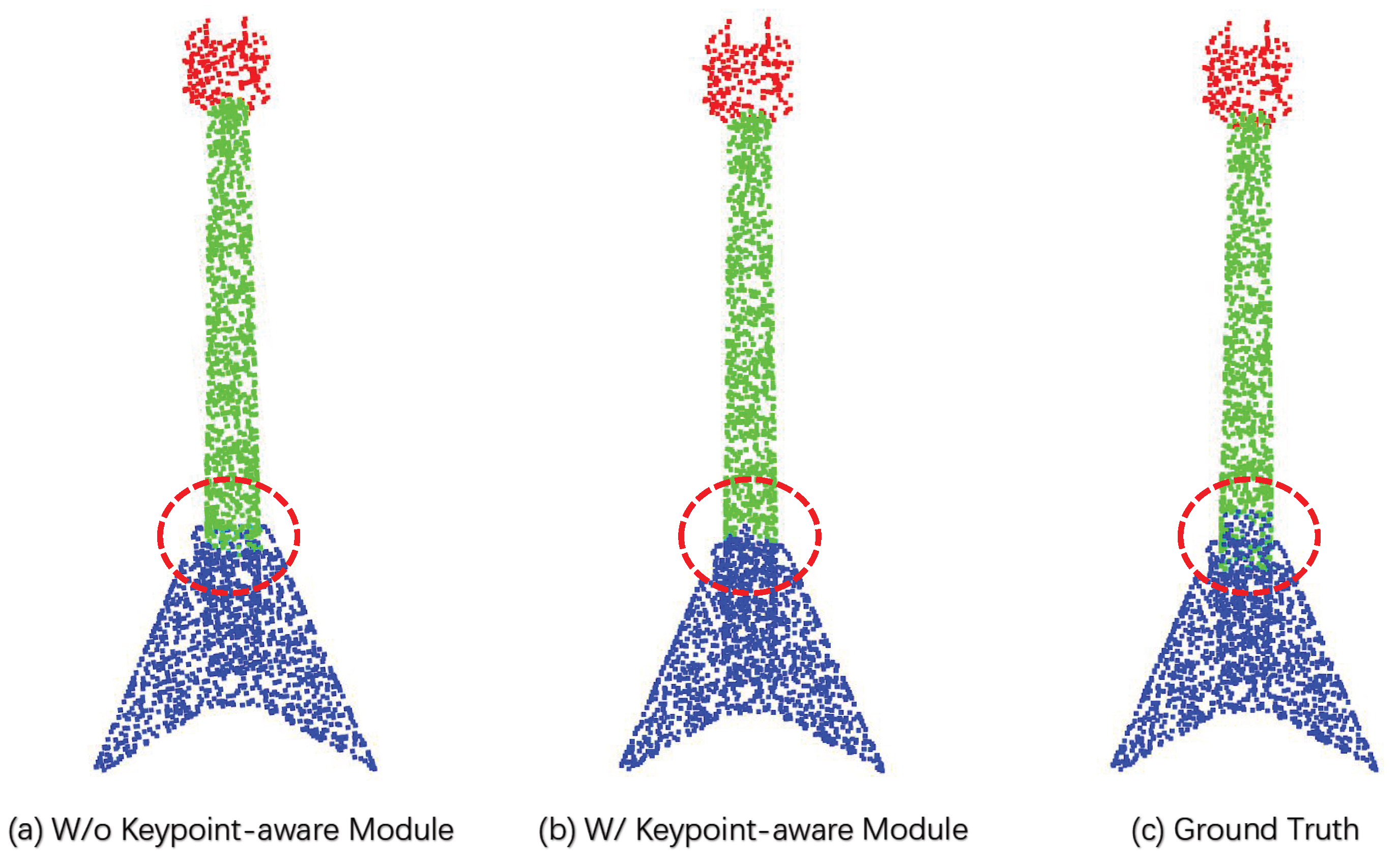
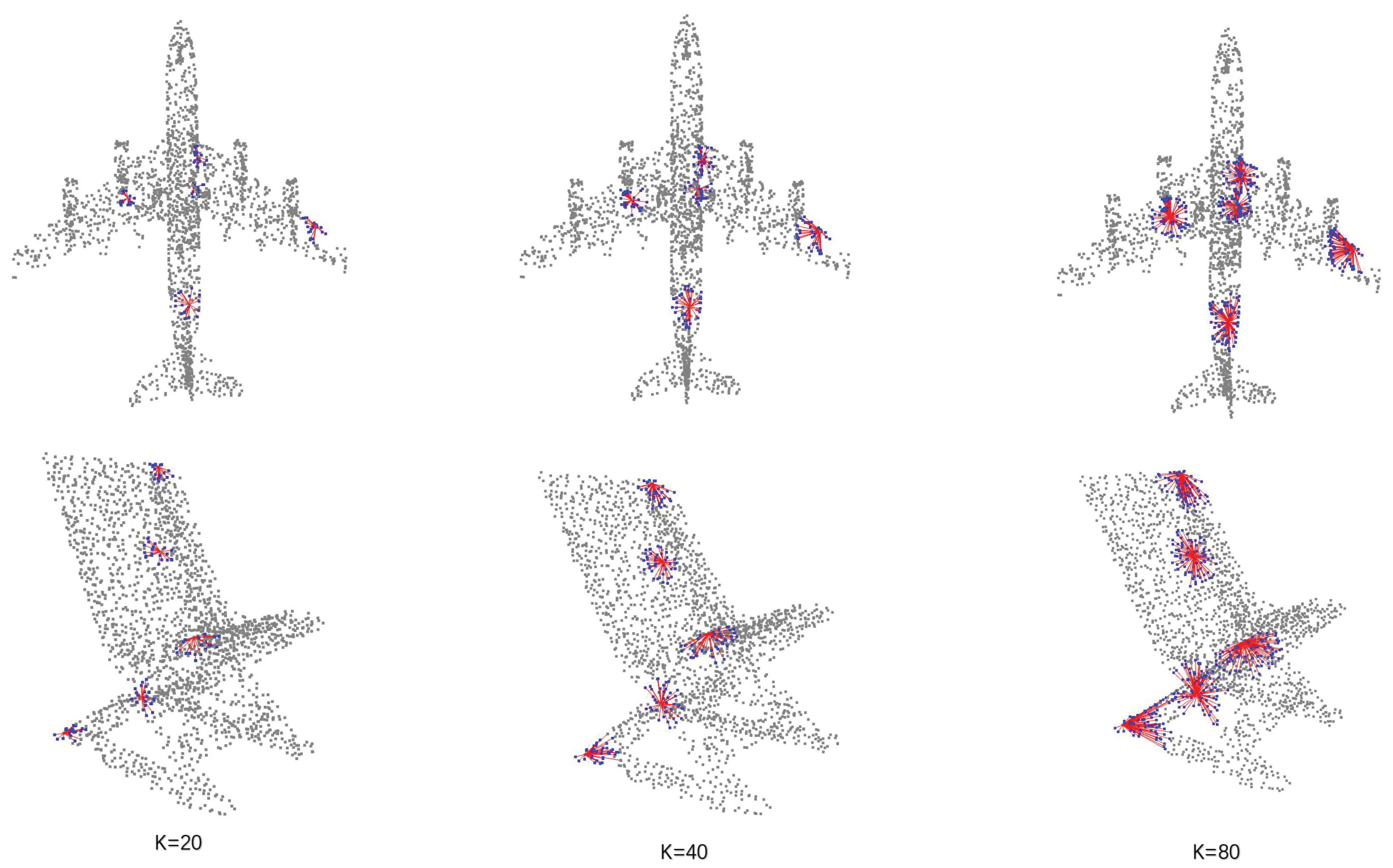
4.4. Ablation Study and Qualitative Results
5. Experiments and Discussions on Point Cloud Classification
5.1. Dataset
5.2. Training Details
5.3. Architecture
5.4. Performance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pauly, M.; Gross, M.; Kobbelt, L.P. Efficient simplification of point-sampled surfaces. In Proceedings of the IEEE Visualization, VIS 2002, Boston, MA, USA, 27 October–1 November 2002; pp. 163–170. [Google Scholar]
- Rusinkiewicz, S. Estimating curvatures and their derivatives on triangle meshes. In Proceedings of the 2nd International Symposium on 3D Data Processing, Visualization and Transmission, 3DPVT 2004, Thessaloniki, Greece, 9 September 2004; pp. 486–493. [Google Scholar]
- Hoppe, H.; DeRose, T.; Duchamp, T.; McDonald, J.; Stuetzle, W. Surface reconstruction from unorganized points. In Proceedings of the 19th Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, 1 July 1992; pp. 71–78. [Google Scholar]
- Botsch, M.; Kobbelt, L. An intuitive framework for real-time freeform modeling. ACM Trans. Graph. 2004, 23, 630–634. [Google Scholar] [CrossRef]
- Ohtake, Y.; Belyaev, A.; Seidel, H.P. Ridge-valley lines on meshes via implicit surface fitting. In ACM SIGGRAPH 2004 Papers; Association for Computing Machinery: New York, NY, USA, 2004; pp. 609–612. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2017; Volume 30, pp. 1–10. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 922–928. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 146. [Google Scholar] [CrossRef]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Kazhdan, M.; Funkhouser, T.; Rusinkiewicz, S. Rotation invariant spherical harmonic representation of 3 d shape descriptors. In Proceedings of the Symposium on Geometry Processing, Aachen, Germany, 23–25 June 2003; Volume 6, pp. 156–164. [Google Scholar]
- Lu, Y.; Sarkis, M.; Bi, N.; Lu, G. From Local to Holistic: Self-supervised Single Image 3D Face Reconstruction Via Multi-level Constraints. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 8368–8375. [Google Scholar]
- Wang, Y.; Solomon, J.M. Deep closest point: Learning representations for point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3523–3532. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2018; Volume 31, pp. 1–11. [Google Scholar]
- Lin, Y.; Yan, Z.; Huang, H.; Du, D.; Liu, L.; Cui, S.; Han, X. Fpconv: Learning local flattening for point convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4293–4302. [Google Scholar]
- Wiersma, R.; Nasikun, A.; Eisemann, E.; Hildebrandt, K. Deltaconv: Anisotropic point cloud learning with exterior calculus. arXiv 2021, arXiv:2111.08799. [Google Scholar]
- Zhang, K.; Hao, M.; Wang, J.; de Silva, C.W.; Fu, C. Linked dynamic graph cnn: Learning on point cloud via linking hierarchical features. arXiv 2019, arXiv:1904.10014. [Google Scholar]
- Zhou, H.; Feng, Y.; Fang, M.; Wei, M.; Qin, J.; Lu, T. Adaptive graph convolution for point cloud analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4965–4974. [Google Scholar]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph attention convolution for point cloud semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10296–10305. [Google Scholar]
- Shi, W.; Rajkumar, R. Point-gnn: Graph neural network for 3d object detection in a point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1711–1719. [Google Scholar]
- Huang, C.Q.; Jiang, F.; Huang, Q.H.; Wang, X.Z.; Han, Z.M.; Huang, W.Y. Dual-graph attention convolution network for 3-D point cloud classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 99, 1–13. [Google Scholar] [CrossRef]
- Graham, B.; Engelcke, M.; Van Der Maaten, L. 3d semantic segmentation with submanifold sparse convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9224–9232. [Google Scholar]
- Choy, C.; Gwak, J.; Savarese, S. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3075–3084. [Google Scholar]
- Tang, H.; Liu, Z.; Li, X.; Lin, Y.; Han, S. Torchsparse: Efficient point cloud inference engine. Proc. Mach. Learn. Syst. 2022, 4, 302–315. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching efficient 3d architectures with sparse point-voxel convolution. In Computer Vision—ECCV 2020; Springer: Cham, Switzerland, 2020; pp. 685–702. [Google Scholar]
- Liu, Y.; Fan, B.; Xiang, S.; Pan, C. Relation-shape convolutional neural network for point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8895–8904. [Google Scholar]
- Song, W.; Zhang, L.; Tian, Y.; Fong, S.; Liu, J.; Gozho, A. CNN-based 3D object classification using Hough space of LiDAR point clouds. Hum.-Centric Comput. Inf. Sci. 2020, 10, 19. [Google Scholar] [CrossRef]
- Fan, H.; Yu, X.; Ding, Y.; Yang, Y.; Kankanhalli, M. Pstnet: Point spatio-temporal convolution on point cloud sequences. arXiv 2022, arXiv:2205.13713. [Google Scholar]
- Lai, X.; Liu, J.; Jiang, L.; Wang, L.; Zhao, H.; Liu, S.; Qi, X.; Jia, J. Stratified transformer for 3d point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8500–8509. [Google Scholar]
- Yang, C.K.; Chen, M.H.; Chuang, Y.Y.; Lin, Y.Y. 2D-3D Interlaced Transformer for Point Cloud Segmentation with Scene-Level Supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Dalian, China, 27–29 January 2023; pp. 977–987. [Google Scholar]
- Ibrahim, M.; Akhtar, N.; Anwar, S.; Mian, A. SAT3D: Slot Attention Transformer for 3D Point Cloud Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5456–5466. [Google Scholar] [CrossRef]
- Schult, J.; Engelmann, F.; Hermans, A.; Litany, O.; Tang, S.; Leibe, B. Mask3D: Mask Transformer for 3D Semantic Instance Segmentation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 8216–8223. [Google Scholar]
- Wu, X.; Lao, Y.; Jiang, L.; Liu, X.; Zhao, H. Point transformer v2: Grouped vector attention and partition-based pooling. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2022; Volume 35, pp. 33330–33342. [Google Scholar]
- Zhou, J.; Xiong, Y.; Chiu, C.; Liu, F.; Gong, X. SAT: Size-Aware Transformer for 3D Point Cloud Semantic Segmentation. arXiv 2023, arXiv:2301.06869. [Google Scholar]
- Cheng, H.X.; Han, X.F.; Xiao, G.Q. TransRVNet: LiDAR Semantic Segmentation With Transformer. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5895–5907. [Google Scholar] [CrossRef]
- Li, X.; Ding, H.; Zhang, W.; Yuan, H.; Pang, J.; Cheng, G.; Chen, K.; Liu, Z.; Loy, C.C. Transformer-based visual segmentation: A survey. arXiv 2023, arXiv:2304.09854. [Google Scholar]
- Sun, J.; Qing, C.; Tan, J.; Xu, X. Superpoint transformer for 3d scene instance segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2393–2401. [Google Scholar]
- Du, R.; Ma, Z.; Xie, P.; He, Y.; Cen, H. PST: Plant segmentation transformer for 3D point clouds of rapeseed plants at the podding stage. ISPRS J. Photogramm. Remote Sens. 2023, 195, 380–392. [Google Scholar] [CrossRef]
- Zhou, F.; Rao, J.; Shen, P.; Zhang, Q.; Qi, Q.; Li, Y. REGNet: Ray-Based Enhancement Grouping for 3D Object Detection Based on Point Cloud. Appl. Sci. 2023, 13, 6098. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2021; Volume 34, pp. 12077–12090. [Google Scholar]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R.; Hu, S.M. Pct: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Wang, Z.; Guo, J.; Zhang, C.; Wang, B. Multiscale feature enhancement network for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5634819. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, C.; Jiang, X. Imbalanced fault diagnosis of rolling bearing using improved MsR-GAN and feature enhancement-driven CapsNet. Mech. Syst. Signal Process. 2022, 168, 108664. [Google Scholar] [CrossRef]
- Li, Y.; Bao, H.; Ge, Z.; Yang, J.; Sun, J.; Li, Z. Bevstereo: Enhancing depth estimation in multi-view 3d object detection with temporal stereo. In Proceedings of the AAAI Conference on Artificial Intelligence, Arlington, VA, USA, 25–27 October 2023; Volume 37, pp. 1486–1494. [Google Scholar]
- Yan, X.; Gao, J.; Zheng, C.; Zheng, C.; Zhang, R.; Cui, S.; Li, Z. 2dpass: 2d priors assisted semantic segmentation on lidar point clouds. In Computer Vision—ECCV 2022; Springer: Cham, Switzerland, 2022; pp. 677–695. [Google Scholar]
- Kong, J.; Wang, H.; Yang, C.; Jin, X.; Zuo, M.; Zhang, X. A spatial feature-enhanced attention neural network with high-order pooling representation for application in pest and disease recognition. Agriculture 2022, 12, 500. [Google Scholar] [CrossRef]
- Zheng, C.; Yan, X.; Zhang, H.; Wang, B.; Cheng, S.; Cui, S.; Li, Z. Beyond 3d siamese tracking: A motion-centric paradigm for 3d single object tracking in point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8111–8120. [Google Scholar]
- Hang, Y.; Boryczka, J.; Wu, N. Visible-light and near-infrared fluorescence and surface-enhanced Raman scattering point-of-care sensing and bio-imaging: A review. Chem. Soc. Rev. 2022, 51, 329–375. [Google Scholar] [CrossRef]
- Song, Y.; He, F.; Duan, Y.; Liang, Y.; Yan, X. A kernel correlation-based approach to adaptively acquire local features for learning 3D point clouds. Comput.-Aided Des. 2022, 146, 103196. [Google Scholar] [CrossRef]
- Zheng, C.; Yan, X.; Gao, J.; Zhao, W.; Zhang, W.; Li, Z.; Cui, S. Box-aware feature enhancement for single object tracking on point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 13199–13208. [Google Scholar]
- Shi, R.; Xue, Z.; You, Y.; Lu, C. Skeleton merger: An unsupervised aligned keypoint detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 43–52. [Google Scholar]
- Tang, J.; Gong, Z.; Yi, R.; Xie, Y.; Ma, L. Lake-net: Topology-aware point cloud completion by localizing aligned keypoints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1726–1735. [Google Scholar]
- Yue, K.; Sun, M.; Yuan, Y.; Zhou, F.; Ding, E.; Xu, F. Compact generalized non-local network. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2018; Volume 31, pp. 1–10. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Lee, S.; Jeon, M.; Kim, I.; Xiong, Y.; Kim, H.J. Sagemix: Saliency-guided mixup for point clouds. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2022; Volume 35, pp. 23580–23592. [Google Scholar]
- Yu, X.; Tang, L.; Rao, Y.; Huang, T.; Zhou, J.; Lu, J. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19313–19322. [Google Scholar]
- Chen, J.; Kakillioglu, B.; Velipasalar, S. Background-aware 3-D point cloud segmentation with dynamic point feature aggregation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5703112. [Google Scholar] [CrossRef]
- Yang, F.; Davoine, F.; Wang, H.; Jin, Z. Continuous conditional random field convolution for point cloud segmentation. Pattern Recognit. 2022, 122, 108357. [Google Scholar] [CrossRef]
- Wang, H.; Tang, J.; Ji, J.; Sun, X.; Zhang, R.; Ma, Y.; Zhao, M.; Li, L.; Lv, T.; Ji, R.; et al. Beyond First Impressions: Integrating Joint Multi-modal Cues for Comprehensive 3D Representation. arXiv 2023, arXiv:2308.02982. [Google Scholar]
- Wu, C.; Zheng, J.; Pfrommer, J.; Beyerer, J. Attention-based Point Cloud Edge Sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Dalian, China, 27–29 January 2023; pp. 5333–5343. [Google Scholar]
- Zhou, W.; Jin, W.; Wang, Q.; Wang, Y.; Wang, D.; Hao, X.; Yu, Y. VTPNet for 3D deep learning on point cloud. arXiv 2023, arXiv:2305.06115. [Google Scholar]
- Yi, L.; Kim, V.G.; Ceylan, D.; Shen, I.C.; Yan, M.; Su, H.; Lu, C.; Huang, Q.; Sheffer, A.; Guibas, L. A scalable active framework for region annotation in 3d shape collections. ACM Trans. Graph. 2016, 35, 210. [Google Scholar] [CrossRef]
- Sheshappanavar, S.V.; Kambhamettu, C. Dynamic local geometry capture in 3d point cloud classification. In Proceedings of the 2021 4th International Conference on Multimedia Information Processing and Retrieval (MIPR), Tokyo, Japan, 22–24 March 2021; pp. 158–164. [Google Scholar]
- Yavartanoo, M.; Hung, S.H.; Neshatavar, R.; Zhang, Y.; Lee, K.M. Polynet: Polynomial neural network for 3d shape recognition with polyshape representation. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; pp. 1014–1023. [Google Scholar]
- Qian, G.; Hammoud, H.; Li, G.; Thabet, A.; Ghanem, B. Assanet: An anisotropic separable set abstraction for efficient point cloud representation learning. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2021; Volume 34, pp. 28119–28130. [Google Scholar]
- Berg, A.; Oskarsson, M.; O’Connor, M. Points to patches: Enabling the use of self-attention for 3d shape recognition. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 528–534. [Google Scholar]
- Zhang, R.; Guo, Z.; Gao, P.; Fang, R.; Zhao, B.; Wang, D.; Qiao, Y.; Li, H. Point-m2ae: Multi-scale masked autoencoders for hierarchical point cloud pre-training. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2022; Volume 35, pp. 27061–27074. [Google Scholar]
- Yan, S.; Yang, Y.; Guo, Y.; Pan, H.; Wang, P.S.; Tong, X.; Liu, Y.; Huang, Q. 3D Feature Prediction for Masked-AutoEncoder-Based Point Cloud Pretraining. arXiv 2023, arXiv:2304.06911. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Nearest Neighbors (k) | mIoU |
|---|---|
| 20 | 85.75 |
| 40 | 85.83 |
| 80 | 85.74 |
| Methods | mIoU | |
|---|---|---|
| a. | Baseline | 85.23 |
| b. | Baseline + KP Module | 85.40 |
| c. | Baseline + FE Module | 85.70 |
| d. | Baseline + KP Module + FE Module + AA Module | 85.83 |
| Methods | Presented at | Airplane | Bag | Cap | Car | Chair | Earphone | Guitar | Knife | Lamp | Laptop | Motorbike | Mug | Pistol | Rocket | Skateboard | Toilet | mIOU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet++ + SageMix [57] | NeurIPS2022 | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | 85.7 |
| Point-BERT [58] | CVPR2022 | 84.3 | 88.4 | 88.0 | 79.8 | 91.0 | 81.7 | 91.6 | 87.9 | 85.2 | 95.6 | 75.6 | 94.7 | 84.3 | 63.4 | 76.3 | 81.5 | 85.6 |
| DPFA-Net [59] | TGRS2022 | 84.5 | 81.1 | 88.2 | 79.0 | 90.9 | 69.2 | 91.6 | 87.2 | 83.8 | 95.8 | 70.4 | 92.8 | 82.7 | 63.0 | 77.5 | 81.9 | 85.5 |
| CRFConv [60] | PR2022 | 83.5 | 84.8 | 83.0 | 80.2 | 91.8 | 77.9 | 91.8 | 86.9 | 84.9 | 95.6 | 77.8 | 95.6 | 82.0 | 64.4 | 75.3 | 80.8 | 85.5 |
| JM3d [61] | ACM MM2023 | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | 85.5 |
| APES [62] | CVPR2023 | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | 85.8 |
| VTPNet [63] | Arxiv2023 | 84.4 | 87.5 | 85.6 | 79.8 | 91.2 | 74.1 | 91.2 | 84.8 | 84.5 | 96.0 | 76.1 | 95.4 | 82.8 | 61.3 | 77.9 | 82.9 | 85.8 |
| Our AKDNet | – | 83.5 | 82.5 | 83.4 | 79.6 | 91.3 | 77.1 | 91.5 | 86.0 | 85.6 | 95.5 | 60.5 | 93.8 | 82.1 | 61.6 | 75.6 | 83.7 | 85.83 |
| Methods | Presented At | Overall Class Accuracy |
|---|---|---|
| DynamicScale [65] | MIPR2021 | 92.1 |
| PolyNet [66] | 3DV2021 | 92.42 |
| ASSANet [67] | NeurIPS2021 | 92.9 |
| PointNet++ + SageMix [57] | ICLR2022 | 90.3 |
| Point-TnT [68] | ICPR2022 | 92.6 |
| Point-M2AE-SVM [69] | NeurIPS2022 | 92.9 |
| MaskFeat3D [70] | Arxiv2023 | 91.1 |
| Our AKDNet | – | 93.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, F.; Zhang, Q.; Zhu, H.; Liu, S.; Jiang, N.; Cai, X.; Qi, Q.; Hu, Y. Attentional Keypoint Detection on Point Clouds for 3D Object Part Segmentation. Appl. Sci. 2023, 13, 12537. https://doi.org/10.3390/app132312537
Zhou F, Zhang Q, Zhu H, Liu S, Jiang N, Cai X, Qi Q, Hu Y. Attentional Keypoint Detection on Point Clouds for 3D Object Part Segmentation. Applied Sciences. 2023; 13(23):12537. https://doi.org/10.3390/app132312537
Chicago/Turabian StyleZhou, Feng, Qi Zhang, He Zhu, Shibo Liu, Na Jiang, Xingquan Cai, Qianfang Qi, and Yong Hu. 2023. "Attentional Keypoint Detection on Point Clouds for 3D Object Part Segmentation" Applied Sciences 13, no. 23: 12537. https://doi.org/10.3390/app132312537
APA StyleZhou, F., Zhang, Q., Zhu, H., Liu, S., Jiang, N., Cai, X., Qi, Q., & Hu, Y. (2023). Attentional Keypoint Detection on Point Clouds for 3D Object Part Segmentation. Applied Sciences, 13(23), 12537. https://doi.org/10.3390/app132312537