
Lightweight You Only Look Once v8: An Upgraded You Only Look Once v8 Algorithm for Small Object Identification in Unmanned Aerial Vehicle Images

Abstract
:1. Introduction
2. Related Work
3. Methods
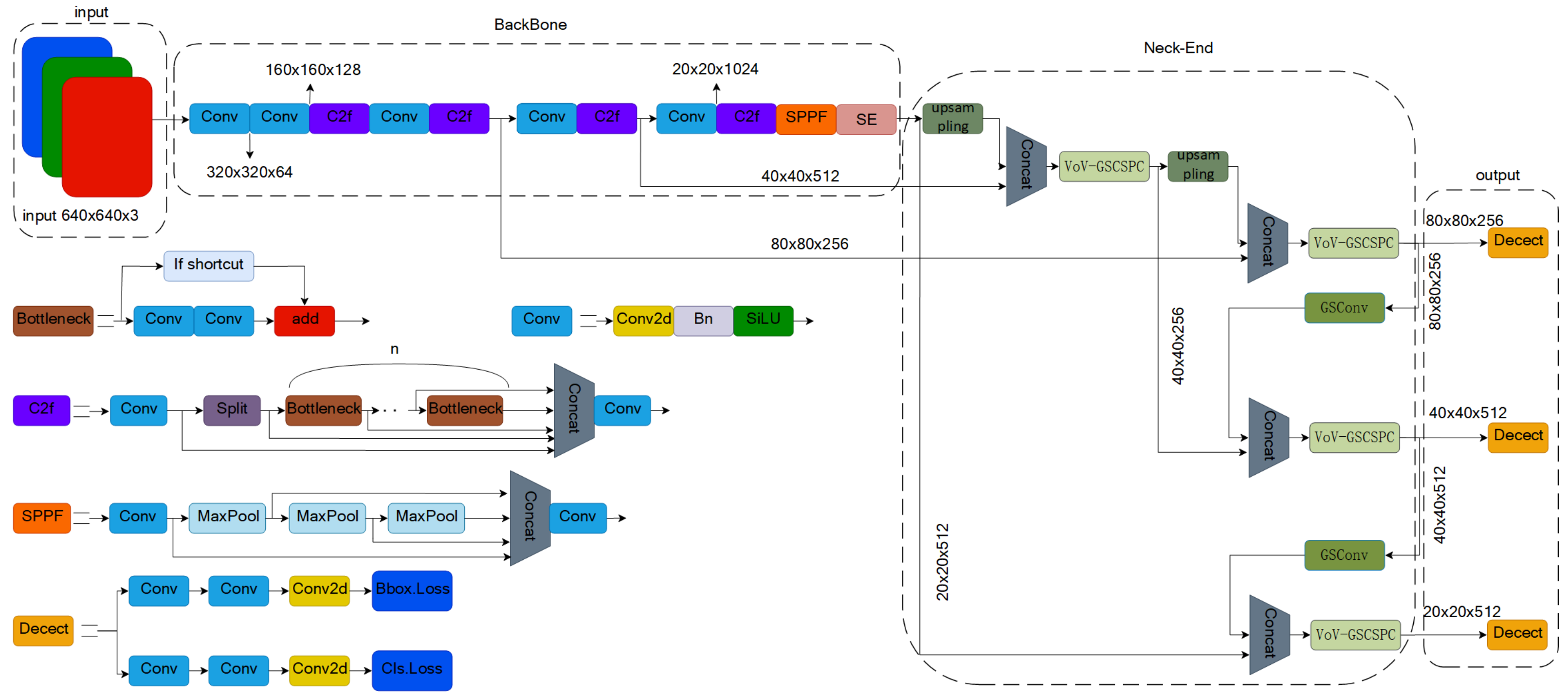
3.1. LW-YOLO v8 Network Model
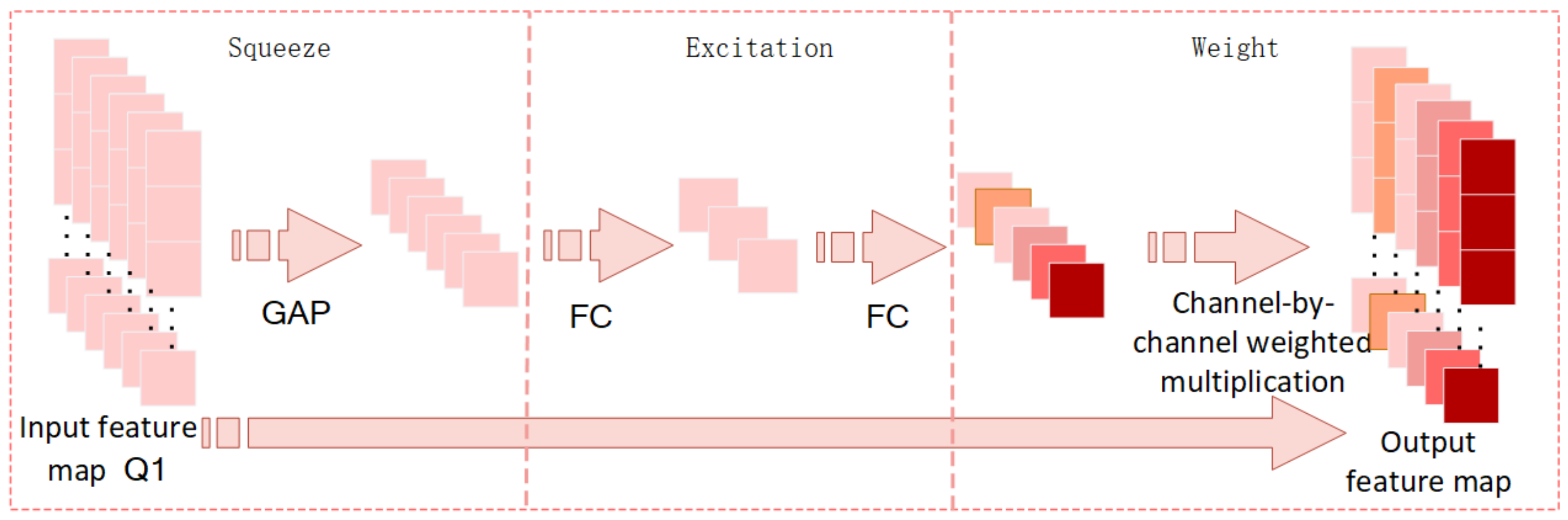
3.2. SE-BackBone Network
3.3. Lightweight Neck-End
4. Experiments
4.1. Evaluation Indicators
4.2. Visualization Results
4.3. Comparison of Improvement Methods and Results
4.3.1. BackBone Improvement Experiment
4.3.2. Neck-End Improvement Experiment
4.4. Ablation Experiment
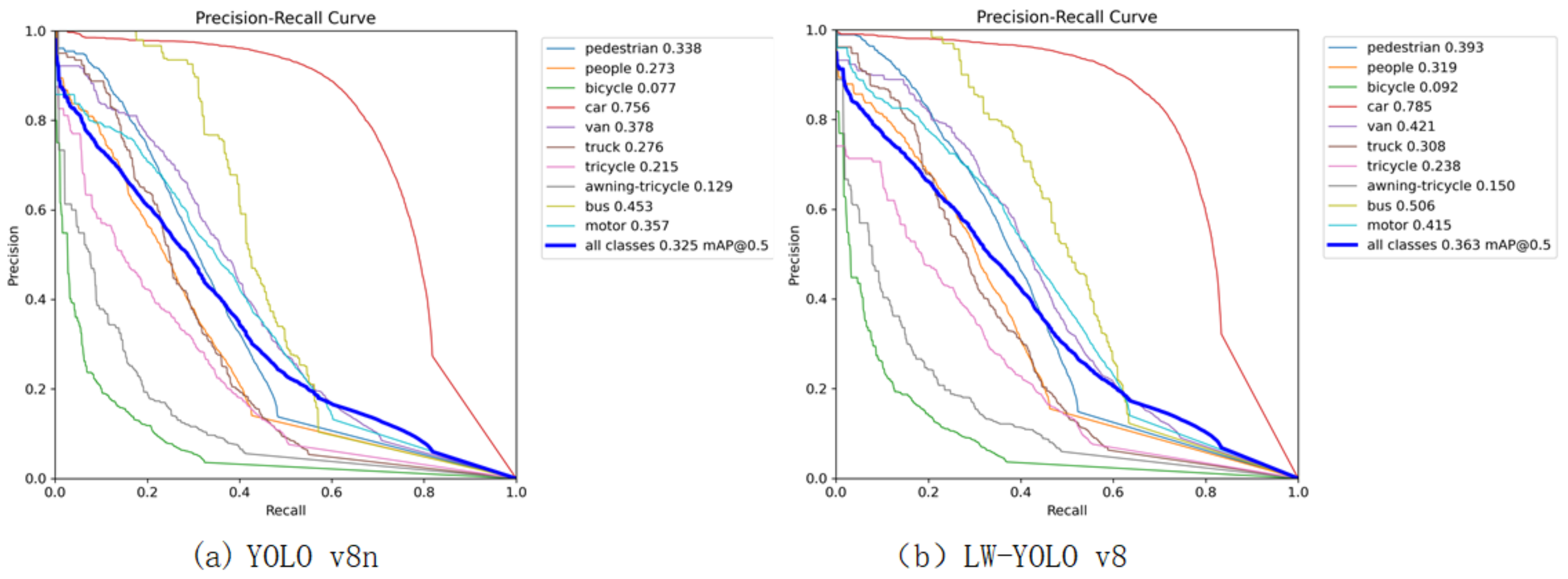
4.5. Comparative Experiments on the Detection of Different Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A review of yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Hu, J.; Wang, Z.; Chang, M.; Xie, L.; Xu, W.; Chen, N. Psg-yolov5: A paradigm for traffic sign detection and recognition algorithm based on deep learning. Symmetry 2022, 14, 2262. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by gsconv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Bekkerman, I.; Tabrikian, J. Target detection and localization using mimo radars and sonars. IEEE Trans. Signal Process. 2006, 54, 3873–3883. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 5–10 December 2016; Volume 29. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Li, W.; Zhang, L.; Wu, C.; Cui, Z.; Niu, C. A new lightweight deep neural network for surface scratch detection. Int. J. Adv. Manuf. Technol. 2022, 123, 1999–2015. [Google Scholar] [CrossRef] [PubMed]
- Jawaharlalnehru, A.; Sambandham, T.; Sekar, V.; Ravikumar, D.; Loganathan, V.; Kannadasan, R.; Khan, A.A.; Wechtaisong, C.; Haq, M.A.; Alhussen, A.; et al. Target object detection from unmanned aerial vehicle (uav) images based on improved yolo algorithm. Electronics 2022, 11, 2343. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. Tph-yolov5: Improved yolov5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Zhang, X.; Feng, Y.; Zhang, S.; Wang, N.; Mei, S. Finding nonrigid tiny person with densely cropped and local attention object detector networks in low-altitude aerial images. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2022, 15, 4371–4385. [Google Scholar] [CrossRef]
- Chen, W.; Jia, X.; Zhu, X.; Ran, E.; Hao, X. Target detection in unmanned aerial vehicle images based on DSM-YOLO v5. J. Comput. Eng. Appl. 2023, 59, 226–233. [Google Scholar]
- Zhang, R.; Shao, Z.; Wang, J. Multi-scale void convolutional target detection method for unmanned aerial vehicle images. J. Wuhan Univ. Inf. Sci. Ed. 2020, 45, 895–903. [Google Scholar]
- Xu, C.; Peng, D.; Yu, G. Real time object detection of unmanned aerial vehicle images based on improved yolov5s. Optoelectronics 2022, 49, 210372-1. [Google Scholar]
- Yuan, H.C.; Tao, L. Detection and identification of fish in electronic monitoring data of commercial fishing vessels based on improved Yolov8. J. Dalian Ocean. Univ. 2023, 38, 533–542. [Google Scholar]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-time flying object detection with Yolov8. arXiv 2023, arXiv:2305.09972. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Lee, Y.; Hwang, J.-W.; Lee, S.; Bae, Y.; Park, J. An energy and gpu-computation efficient backbone network for real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. Cspnet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Washington, DC, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Caron, E.; Feuerwerker, L.C.M.; Passos, E.H. Gam, apoio e cuidado em caps ad. Polis Psique 2020, 10, 98–121. [Google Scholar] [CrossRef]
- Lin, Z.; Feng, M.; Santos, C.N.D.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A structured self-attentive sentence embedding. arXiv 2017, arXiv:1703.03130. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Nascimento, M.G.D.; Fawcett, R.; Prisacariu, V.A. Dsconv: Efficient convolution operator. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5148–5157. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Detnet: A backbone network for object detection. arXiv 2018, arXiv:1804.06215. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Yu, W.; Yang, T.; Chen, C. Towards resolving the challenge of long-tail distribution in uav images for object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3258–3267. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Zhao, H.; Zhou, Y.; Zhang, L.; Peng, Y.; Hu, X.; Peng, H.; Cai, X. Mixed yolov3-lite: A lightweight real-time object detection method. Sensors 2020, 20, 1861. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP@0.5/% | mAP@0.95/% | Layer | GFLOPs Computation |
|---|---|---|---|---|
| YOLO v8n | 32.5 | 18.8 | 168 | 8.1 |
| YOLO v8n+Self | 34.9 | 21.2 | 179 | 10.3 |
| YOLO v8n+CBAM | 35.1 | 20.4 | 176 | 10.2 |
| YOLO v8n+GAM | 35.3 | 20.4 | 179 | 11.7 |
| YOLO v8n+SE | 35.7 | 20.9 | 175 | 12.0 |
| Model | mAP@0.5/% | Params (M) | GFLOPs Computation |
|---|---|---|---|
| YOLO v8n | 32.5 | 3.01 | 8.1 |
| DSConv+SConv2D | 32.1 | 2.39 | 6.6 |
| DCNv2+C2f_DCN | 32.7 | 3.20 | 7.4 |
| GSConv+VoV-GSCSPC | 33.5 | 2.82 | 7.2 |
| SE | GSConv+VoV-GSCSPC | Precision | Recall | mAP@0.5/% | Params(M) | GFLOPs Computation |
|---|---|---|---|---|---|---|
| ✘ | ✘ | 43.7 | 32.5 | 32.5 | 3.01 | 8.1 |
| ✔ | ✘ | 47.5 | 35.5 | 35.7 | 4.45 | 12.0 |
| ✘ | ✔ | 44.6 | 33.6 | 33.5 | 2.82 | 7.2 |
| ✔ | ✔ | 47.6 | 35.5 | 36.3 | 2.83 | 7.2 |
| Networks | Pedestrian | People | Car | Van | Truck | Tricycle | Bus | Motor | mAP@0.5/% |
|---|---|---|---|---|---|---|---|---|---|
| DetNet59 [21] | 15.3 | 4.1 | 36.1 | 17.3 | 20.9 | 13.5 | 26 | 10.9 | 15.3 |
| CornerNet [22] | 20.4 | 6.6 | 40.9 | 20.2 | 20.5 | 14 | 24.4 | 12.1 | 17.4 |
| Fast R-CNN [23] | 21.4 | 15.6 | 51.7 | 29.5 | 19 | 13.1 | 31.4 | 20.7 | 21.7 |
| CenterNet [24] | 22.6 | 20.6 | 59.7 | 24 | 21.3 | 20.1 | 37.9 | 23.7 | 26.2 |
| Mixed YOLO v3-LITE [25] | 34.5 | 23.4 | 70.8 | 31.3 | 21.9 | 15.3 | 40.9 | 32.7 | 28.5 |
| YOLO v8n | 33.5 | 27.3 | 75.5 | 37.9 | 27.7 | 21.6 | 45 | 35.5 | 32.5 |
| LW-YOLO v8 | 39.3 | 31.9 | 78.5 | 42.1 | 30.8 | 23.8 | 50.6 | 41.5 | 36.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huangfu, Z.; Li, S. Lightweight You Only Look Once v8: An Upgraded You Only Look Once v8 Algorithm for Small Object Identification in Unmanned Aerial Vehicle Images. Appl. Sci. 2023, 13, 12369. https://doi.org/10.3390/app132212369
Huangfu Z, Li S. Lightweight You Only Look Once v8: An Upgraded You Only Look Once v8 Algorithm for Small Object Identification in Unmanned Aerial Vehicle Images. Applied Sciences. 2023; 13(22):12369. https://doi.org/10.3390/app132212369
Chicago/Turabian StyleHuangfu, Zhongmin, and Shuqing Li. 2023. "Lightweight You Only Look Once v8: An Upgraded You Only Look Once v8 Algorithm for Small Object Identification in Unmanned Aerial Vehicle Images" Applied Sciences 13, no. 22: 12369. https://doi.org/10.3390/app132212369
APA StyleHuangfu, Z., & Li, S. (2023). Lightweight You Only Look Once v8: An Upgraded You Only Look Once v8 Algorithm for Small Object Identification in Unmanned Aerial Vehicle Images. Applied Sciences, 13(22), 12369. https://doi.org/10.3390/app132212369