


Advancing Financial Forecasts: A Deep Dive into Memory Attention and Long-Distance Loss in Stock Price Predictions

Abstract
:1. Introduction
2. Literature Review
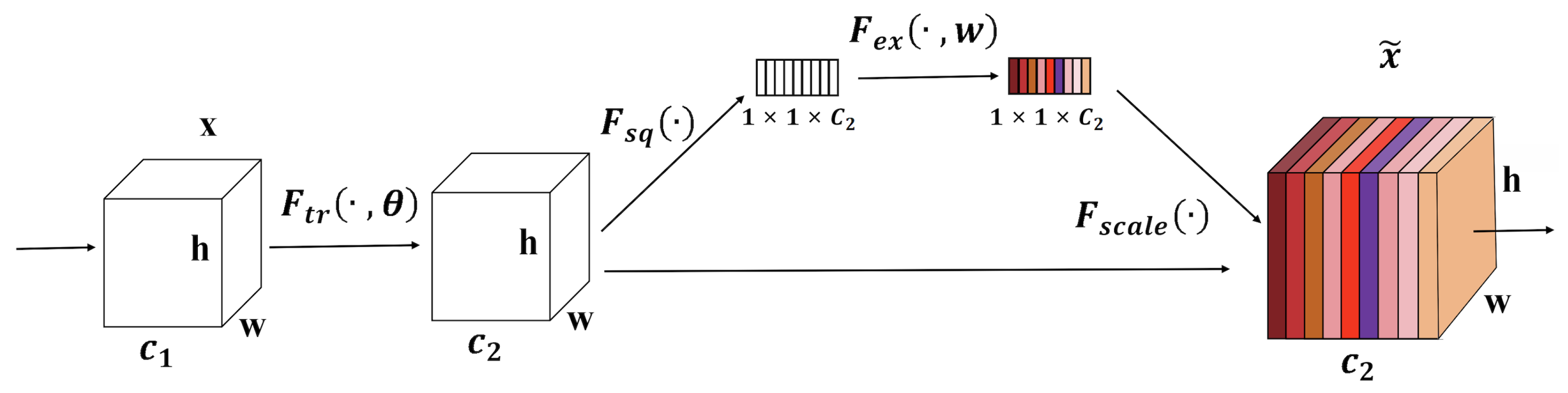
2.1. Attention Mechanism
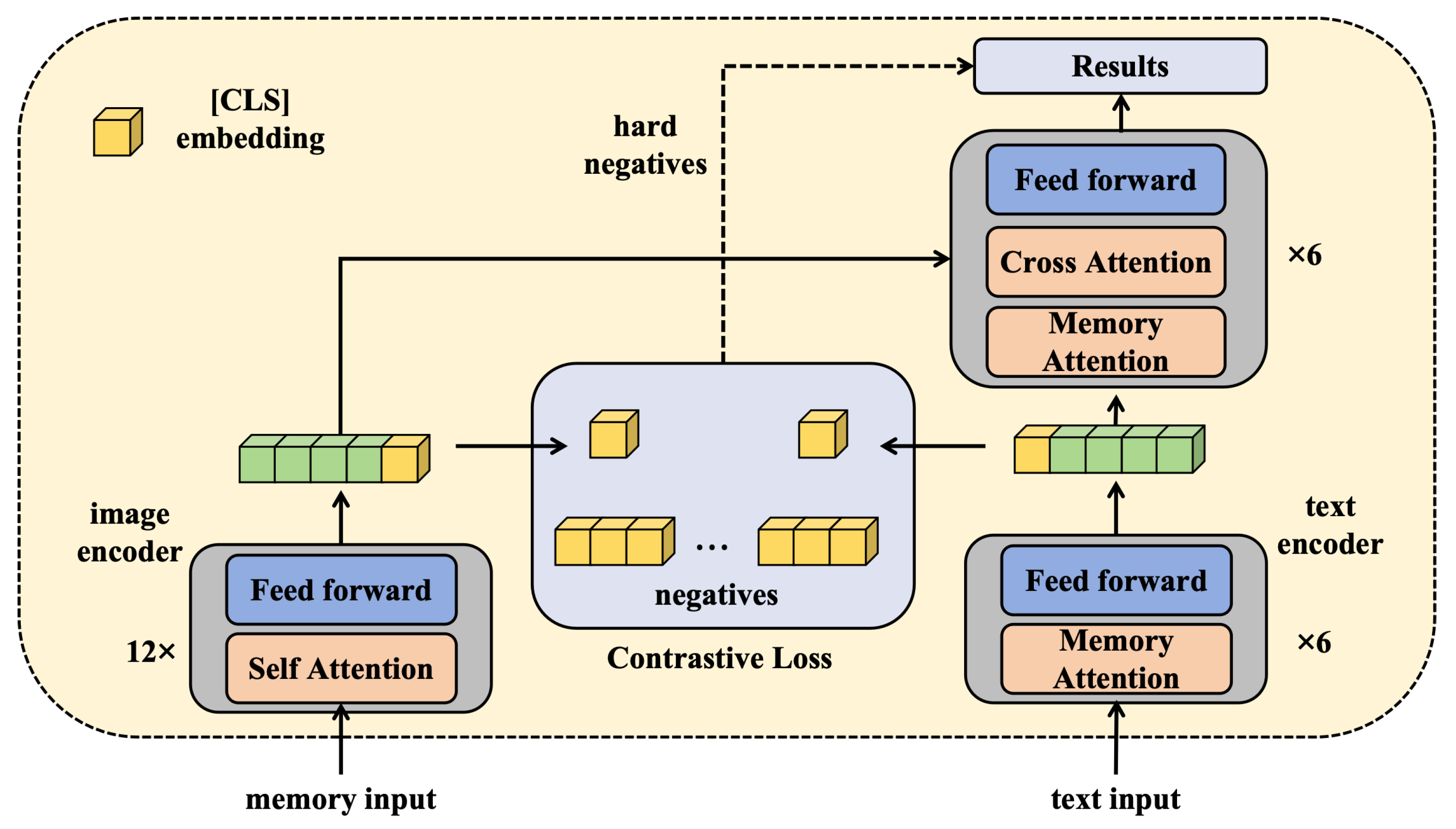
2.2. Transformer-Based Method Application in Stock Price Prediction
3. Data and Method
3.1. Data
3.1.1. Data Retrieval
3.1.2. Data Preprocessing
- Missing Value Handling: Firstly, the presence of missing values in the data is examined. In the case of stock data, some trading days might be missing due to various reasons. Multiple strategies are available for addressing these missing values, such as deleting rows with missing values, filling gaps using the average value of preceding and succeeding days, or employing time series prediction models for estimation. In this study, gaps are filled using the average value of the previous and next days since this method maintains data continuity and is relatively straightforward.
- Data Normalization: Considering the potential for a vast range of values in stock data, with trading volumes possibly reaching several millions while prices might range from tens to hundreds, it is customary to normalize data prior to model input, compressing all data between 0 and 1. This can be achieved using Min-Max normalization, expressed mathematically as:where x denotes the raw data and and represent the minimum and maximum values of the data, respectively.
- Data Smoothing: Stock data might exhibit short-term fluctuations. To counteract these effects and better discern long-term trends, the moving average method can be employed for data smoothing. A window size, for instance, five days, is determined. Subsequently, the average stock data value within this window is computed to represent the value for the day. This method effectively smoothes the data, minimizing short-term fluctuations that might otherwise interfere with the model.
3.2. Proposed Method
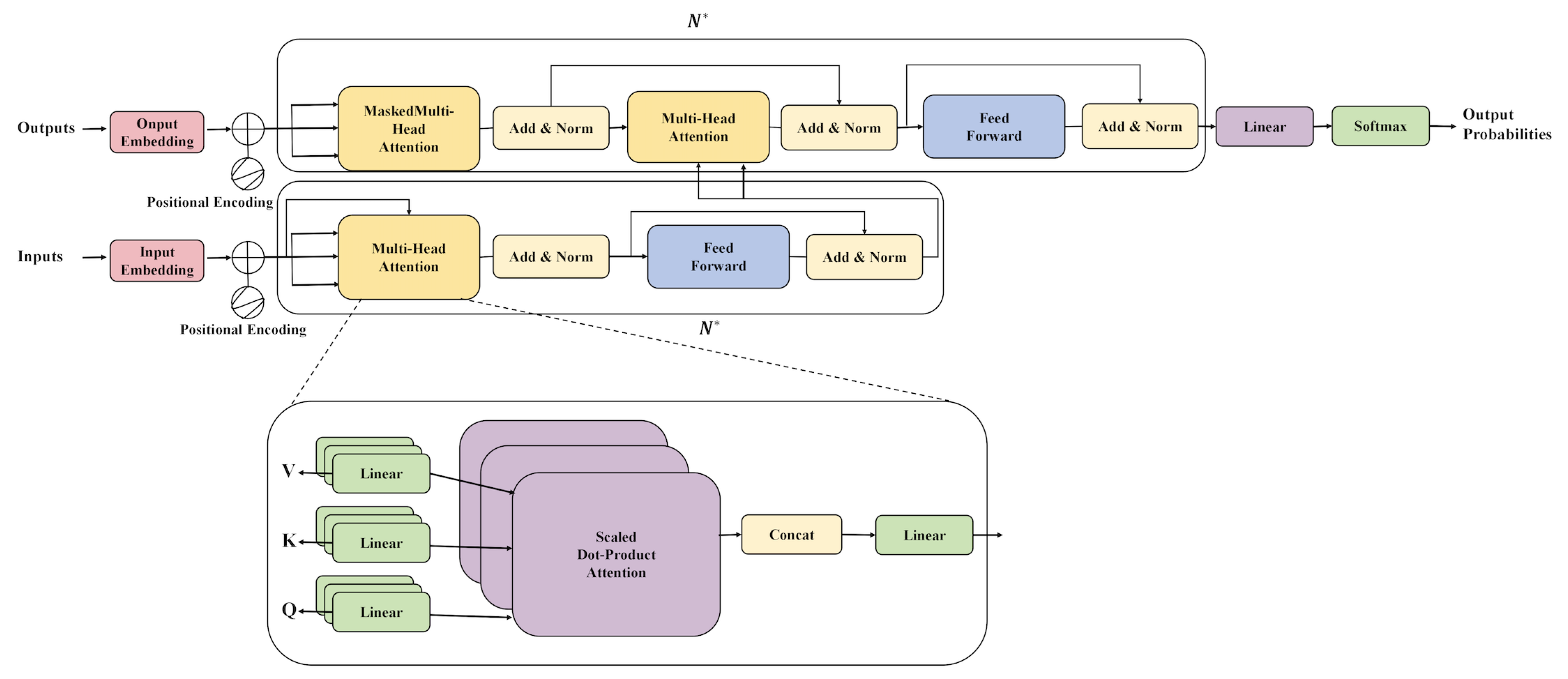
3.2.1. Memory-Transformer
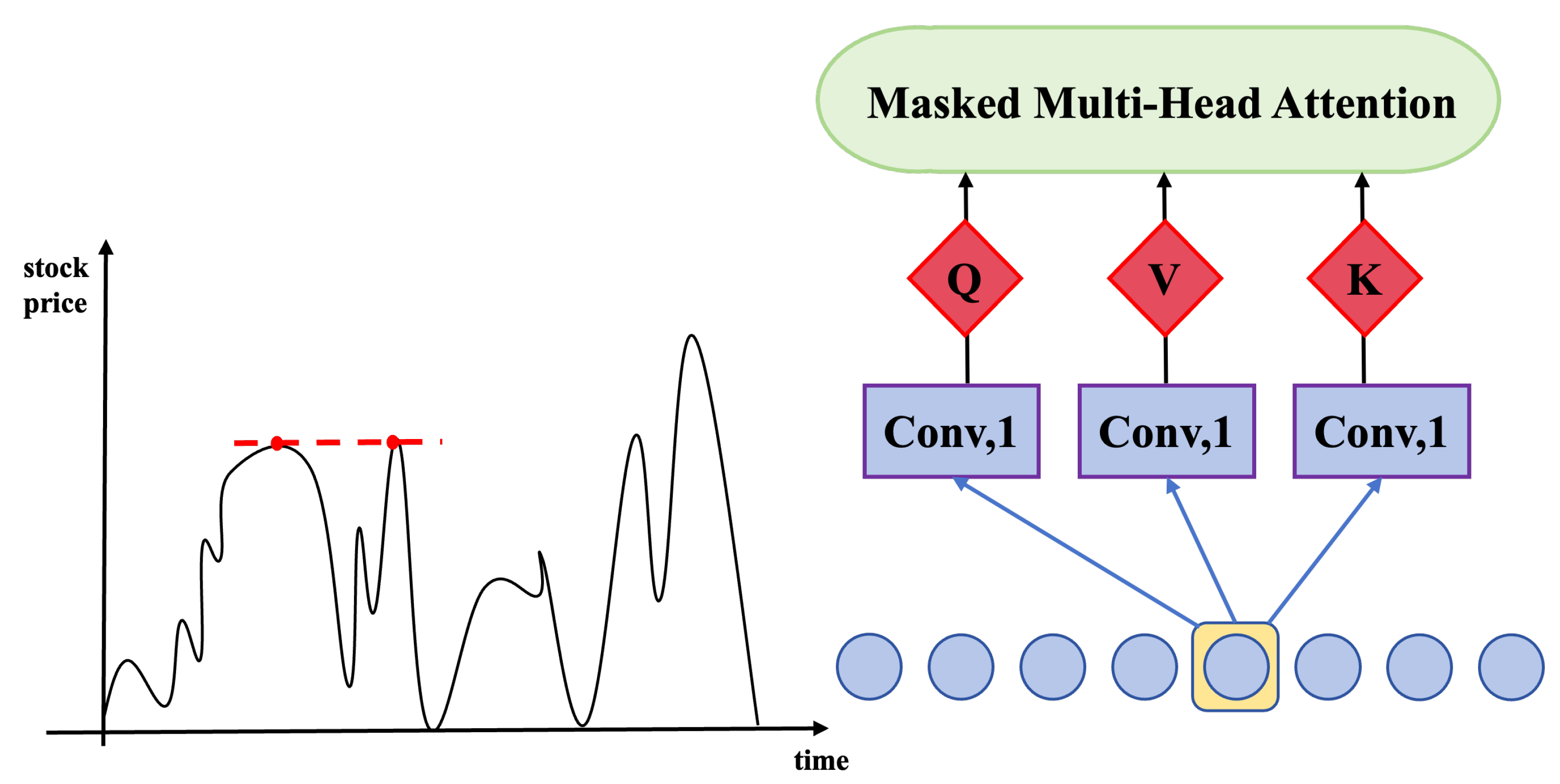
3.2.2. Memory Attention Module
3.2.3. Long-Distance Loss
3.3. Experimental Settings
3.3.1. Experiment Design
3.3.2. Testbed
3.3.3. Experimental Methodology
3.3.4. Evaluation Metric
- Precision quantifies the proportion of correctly predicted positive instances out of all instances predicted as positive. In the context of stock price prediction, a correct prediction implies that an upward price movement was anticipated and the price did indeed rise. The formula for Precision is:Here, True Positives (TP) represents the number of correctly predicted positive instances, while False Positives (FP) denotes the number of instances incorrectly predicted as positive.
- Recall measures the proportion of actual positive instances that were correctly predicted as positive. Its formula is:In this case, False Negatives (FN) are the instances that were incorrectly predicted as negative.
- Accuracy offers insight into the overall proportion of instances that were correctly predicted, regardless of being positive or negative. Its formula is expressed as:Here, True Negatives (TN) are the instances correctly predicted as negative.
- , also known as the coefficient of determination, is a statistical measure reflecting the correlation between the actual and predicted values. Its formula is:where is the actual value, is the predicted value, and is the mean of the actual values.
- In order to rectify for degrees of freedom, the adjusted was utilized, taking into consideration the number of predictive variables within the model:Herein, n denotes the quantity of observations while k represents the number of predictive variables. By employing the adjusted , a more equitable comparison of models incorporating varying quantities of predictive variables is facilitated. The adjusted undertakes a correction for degrees of freedom, ensuring an increase in the value only when the addition of new variables genuinely enhances the predictive capability of the model.
4. Results and Discussion
4.1. Stock Price Prediction Results
4.2. Ablation Test on Memory Attention Module
4.3. Ablation Test on Long-Distance Loss Function
4.4. Limitations and Feature Works
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Z.; Li, Y.; Liu, H. Fuzzy time-series prediction model based on text features and network features. Neural Comput. Appl. 2023, 35, 3639–3649. [Google Scholar] [CrossRef]
- Behera, J.; Pasayat, A.K.; Behera, H.; Kumar, P. Prediction based mean-value-at-risk portfolio optimization using machine learning regression algorithms for multi-national stock markets. Eng. Appl. Artif. Intell. 2023, 120, 105843. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, X.; Wa, S.; Liu, Y.; Kang, J.; Lv, C. GenU-Net++: An Automatic Intracranial Brain Tumors Segmentation Algorithm on 3D Image Series with High Performance. Symmetry 2021, 13, 2395. [Google Scholar] [CrossRef]
- Lin, X.; Wa, S.; Zhang, Y.; Ma, Q. A dilated segmentation network with the morphological correction method in farming area image Series. Remote. Sens. 2022, 14, 1771. [Google Scholar] [CrossRef]
- Li, Q.; Ren, J.; Zhang, Y.; Song, C.; Liao, Y.; Zhang, Y. Privacy-Preserving DNN Training with Prefetched Meta-Keys on Heterogeneous Neural Network Accelerators. In Proceedings of the 2023 60th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 9–13 July 2023; IEEE: Piscataway, NI, USA, 2023; pp. 1–6. [Google Scholar]
- Zhang, Y.; He, S.; Wa, S.; Zong, Z.; Lin, J.; Fan, D.; Fu, J.; Lv, C. Symmetry GAN Detection Network: An Automatic One-Stage High-Accuracy Detection Network for Various Types of Lesions on CT Images. Symmetry 2022, 14, 234. [Google Scholar] [CrossRef]
- Rekha, K.S.; Sabu, M.K. A cooperative deep learning model for stock market prediction using deep autoencoder and sentiment analysis. PEERJ Comput. Sci. 2022, 8, e1158. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Wu, L.; Zhao, H.; Zhu, H.; Zhang, W. Forecasting movements of stock time series based on hidden state guided deep learning approach. Inf. Process. Manag. 2023, 60, 103328. [Google Scholar] [CrossRef]
- Eachempati, P.; Srivastava, P.R. Prediction of the Stock Market From Linguistic Phrases: A Deep Neural Network Approach. J. Database Manag. 2023, 34, 1–22. [Google Scholar] [CrossRef]
- Yadav, K.; Yadav, M.; Saini, S. Stock values predictions using deep learning based hybrid models. CAAI Trans. Intell. Technol. 2022, 7, 107–116. [Google Scholar] [CrossRef]
- He, Q.Q.; Siu, S.W.I.; Si, Y.W. Instance-based deep transfer learning with attention for stock movement prediction. Appl. Intell. 2023, 53, 6887–6908. [Google Scholar] [CrossRef]
- Lv, P.; Shu, Y.; Xu, J.; Wu, Q. Modal decomposition-based hybrid model for stock index prediction. Expert Syst. Appl. 2022, 202, 117252. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30–37. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Haryono, A.T.; Sarno, R.; Sungkono, K.R. Transformer-Gated Recurrent Unit Method for Predicting Stock Price Based on News Sentiments and Technical Indicators. IEEE Access 2023, 11, 77132–77146. [Google Scholar] [CrossRef]
- Li, C.; Qian, G. Stock Price Prediction Using a Frequency Decomposition Based GRU Transformer Neural Network. Appl. Sci. 2023, 13, 222. [Google Scholar] [CrossRef]
- Wang, C.; Chen, Y.; Zhang, S.; Zhang, Q. Stock market index prediction using deep Transformer model. Expert Syst. Appl. 2022, 208, 118128. [Google Scholar] [CrossRef]
- Zeng, Z.; Kaur, R.; Siddagangappa, S.; Rahimi, S.; Balch, T.H.; Veloso, M. Financial Time Series Forecasting using CNN and Transformer. arXiv 2023, arXiv:2304.04912. [Google Scholar]
- Xu, C.; Li, J.; Feng, B.; Lu, B. A Financial Time-Series Prediction Model Based on Multiplex Attention and Linear Transformer Structure. Appl. Sci. 2023, 13, 5175. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Huang, Y.; Liu, J.; Lv, C. Chains-BERT: A High-Performance Semi-Supervised and Contrastive Learning-Based Automatic Question-and-Answering Model for Agricultural Scenarios. Appl. Sci. 2023, 13, 2924. [Google Scholar] [CrossRef]
- yfinance. PYPI. Available online: https://pypi.org/project/yfinance/ (accessed on 2 November 2023).
- Sadorsky, P. A random forests approach to predicting clean energy stock prices. J. Risk Financ. Manag. 2021, 14, 48. [Google Scholar] [CrossRef]
- Xiao, C.; Xia, W.; Jiang, J. Stock price forecast based on combined model of ARI-MA-LS-SVM. Neural Comput. Appl. 2020, 32, 5379–5388. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, R.; Li, Z.; Li, J.; Ge, Y.; Wa, S.; Huang, S.; Lv, C. Time-Series Neural Network: A High-Accuracy Time-Series Forecasting Method Based on Kernel Filter and Time Attention. Information 2023, 14, 500. [Google Scholar] [CrossRef]
- Lohit, S.; Wang, Q.; Turaga, P. Temporal transformer networks: Joint learning of invariant and discriminative time warping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12426–12435. [Google Scholar]
- Lu, Y.; Rai, H.; Chang, J.; Knyazev, B.; Yu, G.; Shekhar, S.; Taylor, G.W.; Volkovs, M. Context-aware scene graph generation with seq2seq transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15931–15941. [Google Scholar]
- Zhou, J.; Li, X.; Ding, T.; You, C.; Qu, Q.; Zhu, Z. On the optimization landscape of neural collapse under mse loss: Global optimality with unconstrained features. In Proceedings of the International Conference on Machine Learning. PMLR, Baltimore, ML, USA, 17–23 July 2022; pp. 27179–27202. [Google Scholar]
- Meyer, G.P. An alternative probabilistic interpretation of the huber loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5261–5269. [Google Scholar]
- Saleh, R.A.; Saleh, A. Statistical properties of the log-cosh loss function used in machine learning. arXiv 2022, arXiv:2208.04564. [Google Scholar]
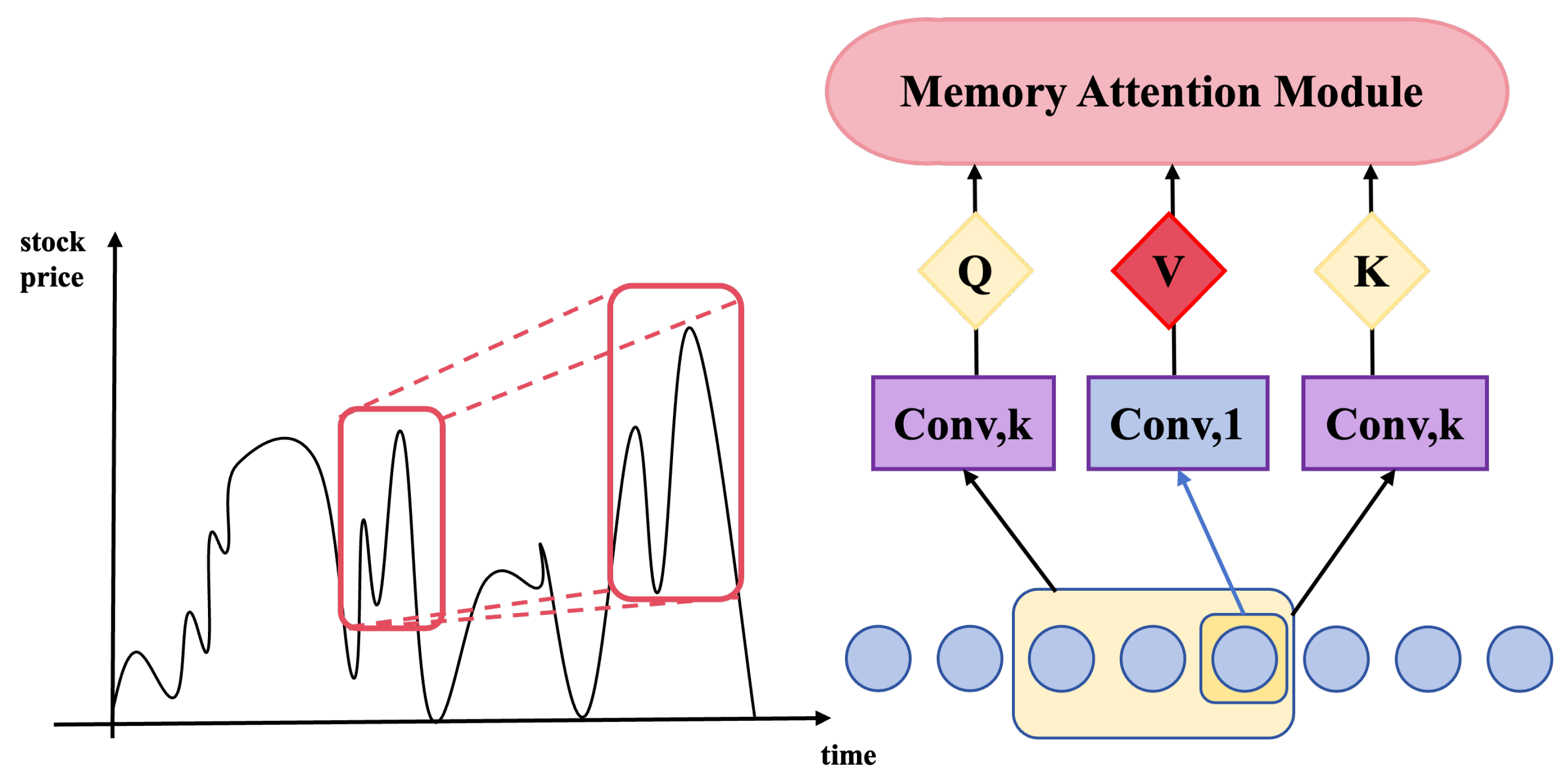

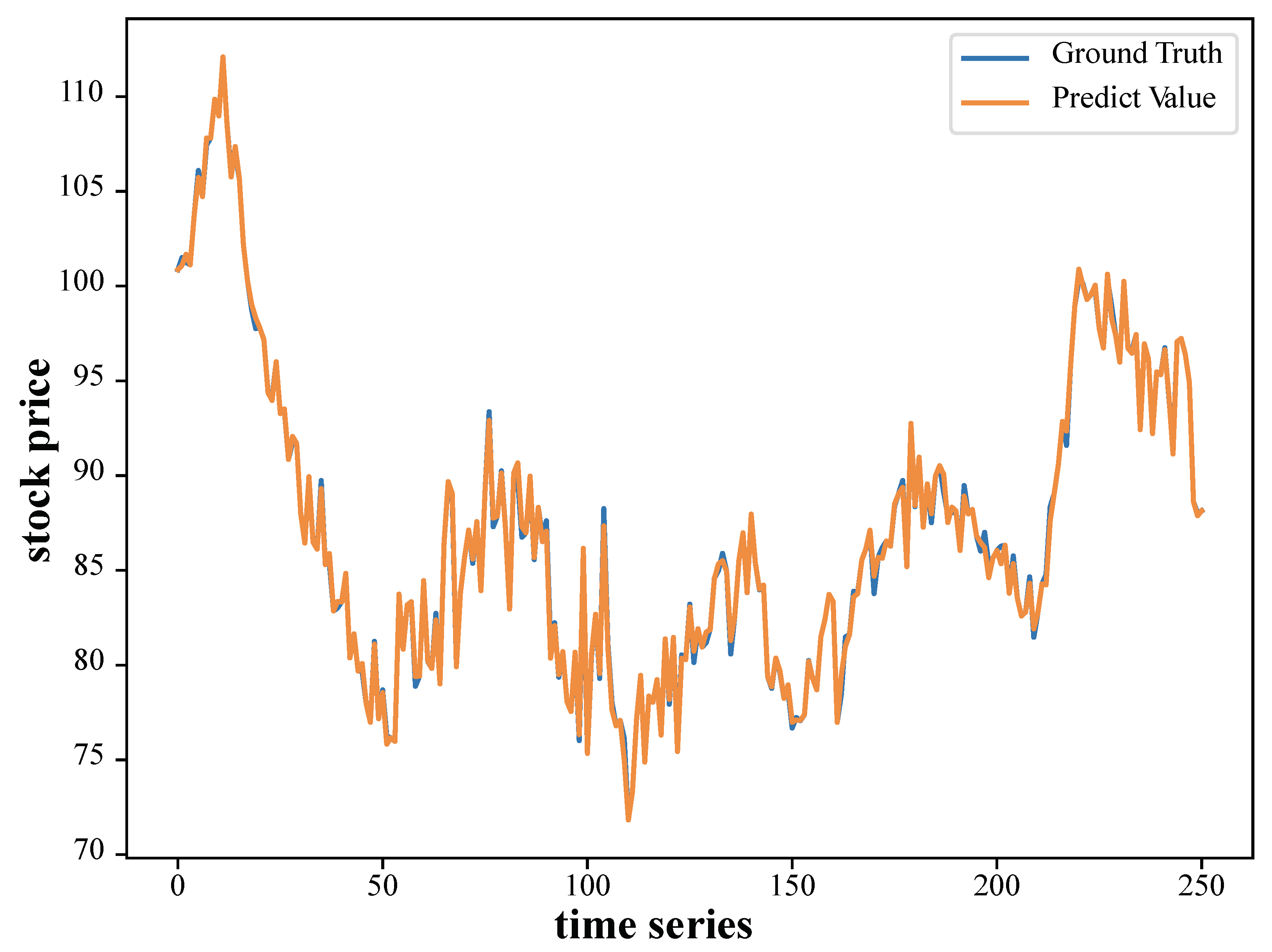

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Recall | Accuracy | Adjusted | |
|---|---|---|---|---|---|
| Random Forest [24] | 0.83 | 0.81 | 0.84 | 0.73 | 0.73 |
| SVM [25] | 0.86 | 0.84 | 0.86 | 0.77 | 0.77 |
| Temporal Transformer [27] | 0.87 | 0.85 | 0.87 | 0.79 | 0.79 |
| Time-series Neural Network [26] | 0.90 | 0.88 | 0.89 | 0.88 | 0.88 |
| Seq2Seq Transformer [28] | 0.92 | 0.90 | 0.91 | 0.90 | 0.90 |
| Proposed Method | 0.95 | 0.91 | 0.94 | 0.97 | 0.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Ding, Y.; Xie, B.; Guo, Y.; Bai, X.; Qian, J.; Gao, Y.; Wang, W.; Ren, J. Advancing Financial Forecasts: A Deep Dive into Memory Attention and Long-Distance Loss in Stock Price Predictions. Appl. Sci. 2023, 13, 12160. https://doi.org/10.3390/app132212160
Yang S, Ding Y, Xie B, Guo Y, Bai X, Qian J, Gao Y, Wang W, Ren J. Advancing Financial Forecasts: A Deep Dive into Memory Attention and Long-Distance Loss in Stock Price Predictions. Applied Sciences. 2023; 13(22):12160. https://doi.org/10.3390/app132212160
Chicago/Turabian StyleYang, Shijie, Yining Ding, Boyu Xie, Yingyi Guo, Xinyao Bai, Jundong Qian, Yunxuan Gao, Wuxiong Wang, and Jinzheng Ren. 2023. "Advancing Financial Forecasts: A Deep Dive into Memory Attention and Long-Distance Loss in Stock Price Predictions" Applied Sciences 13, no. 22: 12160. https://doi.org/10.3390/app132212160
APA StyleYang, S., Ding, Y., Xie, B., Guo, Y., Bai, X., Qian, J., Gao, Y., Wang, W., & Ren, J. (2023). Advancing Financial Forecasts: A Deep Dive into Memory Attention and Long-Distance Loss in Stock Price Predictions. Applied Sciences, 13(22), 12160. https://doi.org/10.3390/app132212160