Abstract
Location information on Twitter plays a critical role in emergency detection, event recommendation, and disaster warning. However, only a limited amount of Twitter data are geotagged. Previous research has presented various models for inferring location based on text, social relations, and contextual data, yielding highly promising results. Nonetheless, these existing methods have certain limitations that need to be addressed. Firstly, most of the existing methods overlook the role of local celebrities (well-known users in the local community) as indicators of location within the social network. Secondly, they fail to consider the associations between words in tweets, resulting in insufficiently rich features extracted from the tweets. We propose a multi-view-based location inference model called MVGeo to overcome these limitations. In the network view, our approach employs the Gaussian Mixture Model (GMM) to identify and retain local celebrities, thereby strengthening user location associations. In the tweet view, we construct a heterogeneous graph based on the co-occurrence relationship between words in tweets and the user’s mentioned relationship with the words. This allows us to fully leverage the local correlation between words and the global correlation to extract tweet features more comprehensively. Finally, we employ a modified multi-layer graph convolutional network, called Gate-GCN, to fuse the network and tweet information. This expansion of the feature space enables us to extract sample features from multiple perspectives. To demonstrate the effectiveness of MVGeo, we conduct exhaustive experimental evaluations on a publicly available dataset and compare its performance against several state-of-the-art benchmark models. The results confirm the superior performance of the proposed model.
1. Introduction
Users can share brief updates about their activities on social platforms, acting as social sensors and disseminating information about local events. As a virtual online social platform, Twitter generates millions of tweets daily that contain explicit or implicit information about users’ locations, bridging the virtual and physical worlds. These location data are utilized in a variety of applications, including event detection [1] and location-based recommendations [2]. Users rarely reveal their geographic locations on social platforms due to privacy protection restrictions, despite the diverse applications of user location data. For instance, only 5% of Twitter users include their home locations in their profile [3], and only 1% of tweets are geotagged [4]. Therefore, research on location-based inference methods for Twitter users is an urgent matter. Early research centered on extracting location signals from users’ media posts, such as location-related vocabulary and linguistic patterns. Word distribution comparison [5,6] and location-indicative word extraction [7,8] are representative text-based techniques. In addition, social networks extracted from user interactions online can disclose the distance between users. To process network structure data, the majority of network-based methods employ label propagation or node embedding [9,10]. Recent hybrid approaches [11,12] have emerged that combine text and network features to infer user locations, leveraging the strengths of both approaches and achieving improved performance. Despite the satisfactory results of previous work, there are still some things that need to be improved to address: (1) Highly mentioned users (celebrities) in social networks are categorized as local celebrities (well-known users in the local community) and global celebrities (well-known users worldwide). Since celebrity users in social networks form many connections but rarely carry location information, existing methods remove celebrity users by setting a threshold to prevent them from negatively affecting location inference [13,14]. However, they do not consider the location-indicative role of local celebrities in the network. (2) A tweet is often regarded as a set of unordered lexical items based on the assumption of term independence and is represented as a vector using natural language processing techniques (e.g., TF-IDF and doc2vec) to embed tweets into low-dimensional vectors during text processing. This method is straightforward and quick, but it ignores structural information in the text and does not capture the overall semantics of the text content, resulting in the loss of contextual information. To address the above issues, we propose a multi-view-based location inference model for Twitter users. Firstly, to exploit the role of local celebrities as location indicators in social relationship networks, GMM is used in the network view to detect local celebrities and enhance the location correlation among users by keeping them in the network. Next, to better capture the features of user tweets, we construct the corpus as a heterogeneous graph and mine user tweet features by analyzing user–word and word–word correlations. Finally, we combine the previously processed social relationship network and the learned user tweet embeddings to learn the final embedding representation of users through a modified multilayer graph convolutional network Gate-GCN. The main contributions of our work are as follows:
- We propose a local celebrity discovery algorithm that preserves the location-indicative role of local celebrities in the social relationship network.
- We represent the entire corpus as a heterogeneous graph, leveraging local and global correlations between words to extract user tweet features.
- We introduce MVGeo, a multi-view-based location inference model, which demonstrates superior performance in experimental results on public datasets.
2. Related Work
Existing methods for inferring the location of Twitter users can be divided into three categories: text-based, network-based, and hybrid methods, which combine text- and network-based approaches. Text-based inference methods rely on the geographic bias exhibited by users in their language usage on social media. Users in different regions have different habits when using words [15]. Location-related words, such as regional dialects, building names, and special food names, often appear in tweets from users in the same location. Eisenstein et al. [16] analyzed the relationship between potential topics and geographical regions and proposed a latent variable model to infer user location. Cheng et al. [4] proposed an unsupervised method for autonomously identifying local words from users’ tweets and inferring the user’s city-level location. Rahimi et al. [8] used the Term Frequency–Inverse Document Frequency (TF-IDF) to extract statistical features of the text and inferred the user location using a multilayer perceptron. Rahimi et al. [17] proposed a method to embed two-dimensional locations in a continuous vector space and used logistic regression to localize the user. Some studies extracted local words based on statistical features of words [7,18] and inferred the user’s location from the extracted local words. The text-based approach ignores the influence of users’ friendships and can achieve limited precision. Network-based inference methods rely on the social relationships between users to infer their locations. These methods consider the proximity between a given user and his/her friends, inferring the user’s location based on his/her friends’ locations [19,20]. Earlier studies [21,22] considered users who follow each other as friends and geolocated users through social relationships between them. Davis et al. [9] used a simple maximum-voting strategy for location inference. Jurgens et al. [23] constructed the mentioned network using connectivity between user nodes and extended the label propagation algorithm [24] by propagating location labels from known users to unknown users. Ebrahimi et al. [25] identified and filtered celebrity users and inferred user locations by considering celebrity effects. Rahimi et al. [26] proposed a hybrid method that treated one-way mentions as undirected edges, extended the tag propagation algorithm to connected users, and employed a text-based approach as a fallback strategy for users not connected to the social network. However, the network-based approach is incapable of inferring the locations of non-network-connected users. Hybrid approaches combine user-generated text and social relationships to infer user locations, compensating for the limitations of individual text-based or network-based methods [11]. Rahimi et al. [27] utilized a tag propagation algorithm based on modified adsorption [28], filtered out celebrity influences in the social network, and incorporated textual information for location inference. Rahimi et al. [12] constructed a user relationship view based on user interactions, extracted user text features using Bag-of-Words representations, and employed graph convolutional networks for location inference. Bakerman et al. [29] used tweet content and social network relationships as input features to construct a hybrid method that maps the original spatial distribution of input features to the prediction space. Huu et al. [30] built a multi-view geolocation model that uses not only text and network features but also timestamp data. Graph neural networks have a wide range of applications within this field [31]. For example, Huu et al. [11] combined node2vec-learned user network features with doc2vec-learned text representations to infer the user’s location. Wang et al. [14] proposed a location inference model based on Graph Attention Mechanisms and Graph Convolutional Networks (GCNs) to fuse text and network information.
3. Proposed Methodology
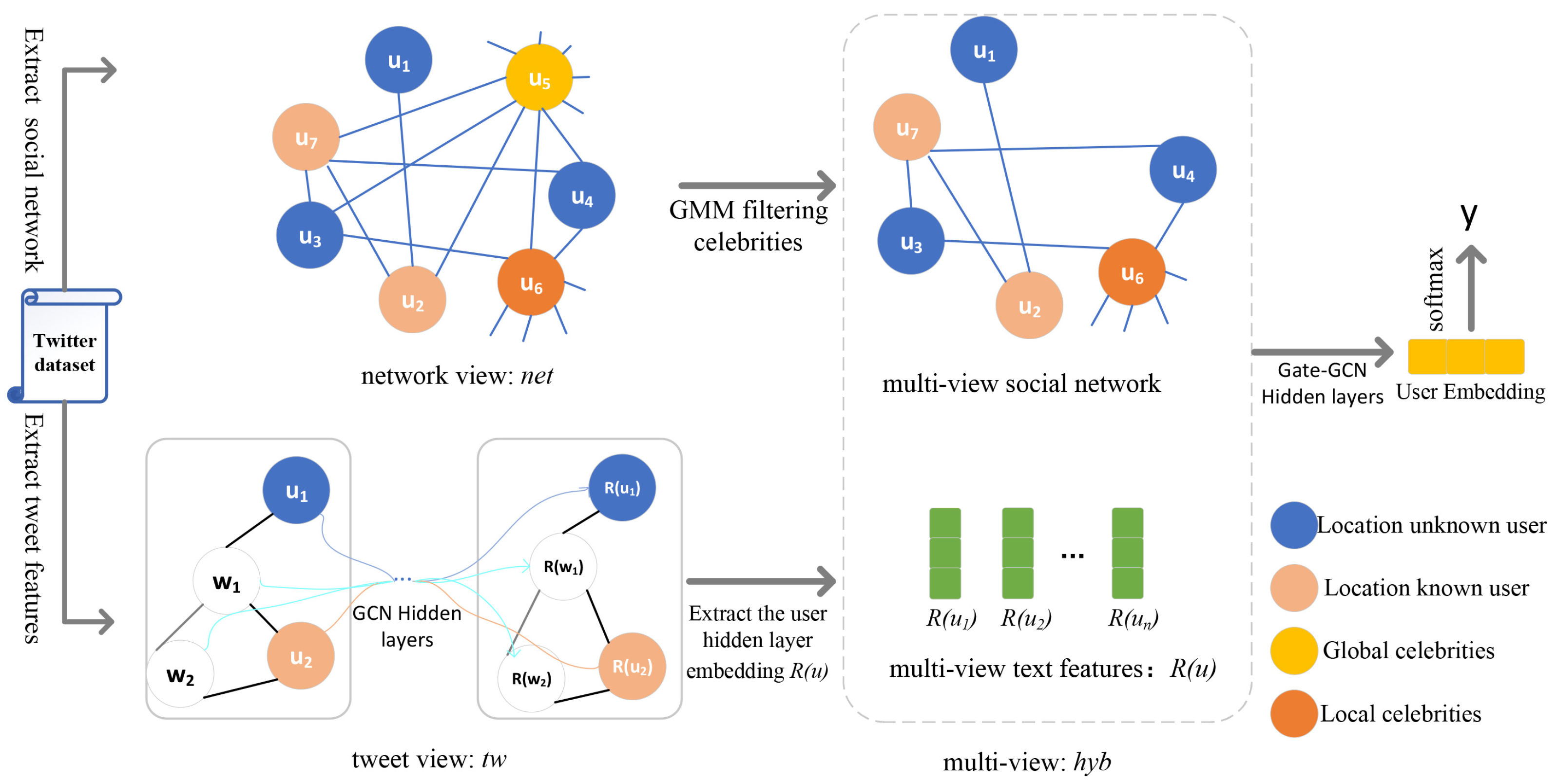
In Section 3, we present a detailed description of the approach proposed in this research work. We introduce how a Gaussian mixture model (GMM) is utilized in the network view to detect and preserve local celebrities within the social relationship network. This step aims to enhance the location correlation among users. Next, we delve into the tweet view, where we represent the entire corpus as a heterogeneous graph. This graph is then used to extract vector embeddings of user tweets, capturing the rich information within the text. Finally, we introduce a modified multilayer graph convolutional network called Gate-GCN, which combines the processed social relationship network and the learned tweet embeddings. This fusion allows us to learn the final embedding representation of the user. We employ a softmax function to determine the user’s location region based on the final vector representation. This function assigns probabilities to each location region, indicating the likelihood of the user belonging to a particular region. Additionally, a cross-entropy loss function is utilized to calculate the loss, enabling us to optimize the model during training. The overall architecture of the proposed model is illustrated in Figure 1, which provides a visual representation of the different components and their interactions.
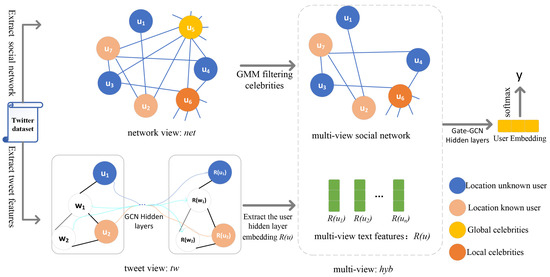
Figure 1.
Technical roadmap of the proposed method in this paper. As shown in the above figure, the nodes starting with u in the tweet view are user nodes; the rest are word nodes. Black edges are user–word edges, and grey edges are word–word edges. After the hidden layer of GCN, and represent the user’s tweet embedding and word embedding, respectively.
3.1. Network View
We construct a social network graph based on the @-mention relationship in users’ tweets and create an undirected edge between user L and user F if user L mentions user F in a tweet, in the same way as Rahimi et al. [27]. We set up users who are mentioned by more than J different users as celebrity users. In this work, we use GMM to identify local celebrities and improve model inference by retaining local celebrities in the social relationship network to increase the location correlation between users. GMM is a clustering model that implies that all data points are a mixture of multiple Gaussian distributions and searches for a mixture representation of the multidimensional Gaussian model probability distribution to fit arbitrarily shaped data distributions. GMM also provides soft clustering, i.e., determines the probability that each data point belongs to each cluster, and this method is highly effective for identifying overlapping clusters and clusters with varying shapes and sizes. The process of discovering local celebrities using the Gaussian mixture model is depicted in Equations (1)–(4).
We define the set of celebrity users as , the neighbors of celebrity users with location information are defined as , are the coordinate points of all celebrity users’ neighbors with location information, and b is the total number of data points. S represents the number of Gaussian distributions in the Gaussian mixture model. is the initialization parameter of the model. First, we calculate the probability matrix of the user coordinate points in the belonging to each Gaussian distribution using the GMM, and then the category corresponding to the maximum value of each row of the probability matrix is used as the category label of the data points by the softmax function. Afterward, the mean coordinates of the corresponding Gaussian subdistribution (category) for each data point are then found by the model mean function . For each user e of , the dispersion of the distribution of user e is measured by calculating the (semi-positive vector formula) distance between e and the mean coordinate of the user’s corresponding Gaussian distribution, and the users whose distance is greater than a threshold T are removed to obtain the set . The function is defined to find the maximum number of users belonging to the same cluster in , and the function is defined to find the total number of sets. If the value of is greater than the threshold p, then is regarded as a local celebrity and retained in the social network. This process allows us to identify and retain local celebrities in the social network, taking into account their influence on location correlation among users.
3.2. Tweet-View Construction
In our work, the entire corpus is represented as a heterogeneous graph based on the co-occurrence relationships between words in users’ tweets and users’ mentions of words in tweets, as shown in Figure 1’s tweet view , to exploit the local and global correlations between words to extract the characteristics of users’ tweets. The weights of the edges between user nodes and word nodes are computed using TF-IDF, which represents the frequency of a word in a user’s tweet, and IDF, which is the Inverse Document Frequency, i.e., the IDF of a particular word is calculated by dividing the total number of users by the number of users whose tweets contain that word and then dividing the quotient by the total number of users. The main idea behind TF-IDF is that if a word appears frequently in one user’s tweets but infrequently in the tweets of other users, it is deemed to have good category differentiation and to be suitable for classification. To exploit the global word co-occurrence information, a sliding window of fixed size was used on all tweets in the corpus to collect co-occurrence information for word pairs [32], and Positive Point Mutual Information (PPMI) was used to calculate the correlation between two-word nodes. The weights of the edges between any two nodes i and j in the tweet text view are defined as shown in Equation (5).
The PPMI values between word nodes i and j are computed according to Equations (6)–(8):
where W is the total number of sliding windows on the corpus and is the number of sliding windows that contain the word i. is the number of sliding windows that contain both the words i and j.
3.3. Model Structure
As GCN has the advantage of being able to directly process graphically structured data and utilize the graph’s structural information to the fullest, it is superior to other networks. In this work, we use it to construct the location inference model. Given an undirected graph , each node , each edge , an adjacency matrix , and a feature matrix , where N is the number of nodes and C is the dimension of the feature vector. Equation (9) depicts the propagation principles for each convolutional layer:
where , is the unit matrix. is the degree matrix of , i.e., is the activation cell matrix of layer l, where and and are the weight matrix and bias term, respectively, of each layer. Each layer of the GCN is obtained by multiplying the matrix with the feature matrix to obtain a summary of the features of each vertex and its neighbors.
Multi-View Fusion
For each node in the tweet view in Figure 1, GCN is used to aggregate its neighboring nodes and its features, and the feature vector representation of the user’s tweets is obtained by extracting the embedding of the GCN hidden layer. In this work, we take as the initial feature matrix of the nodes in the tweet view (where and are the numbers of users and words, respectively, in the corpus), and the adjacency matrix of the tweet heterogeneity graph is the input to the GCN. Using a two-layer GCN with activation functions of ReLU and softmax, the overall forward-propagation process in the tweet view is shown in Equation (10):
After one round of training, a cross-entropy loss function is used to calculate the loss of all tagged user nodes. For the tweet feature extraction model in tweet view , the user tweet embedding in the model’s hidden layer is extracted and used as the initial text feature in Figure 1’s multi-view . For social networks, access to information about a user’s neighbors three hops away can improve location inference [12]. Therefore, three GCN layers are utilized for multi-view fusion to combine the characteristics of tweets and social relationship networks. As input to the multi-view, the initial text features are and the filtered neighborhood matrix of the social relationship network. Equation (11) depicts the global forward-propagation equation for the multi-view; the activation function uses softmax and Tanh.
As the number of layers in the GCN increases, the number of neighborhood members per node grows exponentially. This may lead to the propagation of noisy information from the extended neighborhood members to the user. To address this situation, with the help of ideas from Srivastava et al. [33], a hierarchical gate is added to the information propagation process at each layer of Equation (11), which in turn controls how much neighborhood information needs to be passed to the nodes. The output of each layer of the modified multilayer graph convolutional network Gate-GCN is shown in Equations (12) and (13):
where is the input to layer , and and are the gating weights matrix and deviations, respectively. Sigmoid is the activation function; ∘ represents the element multiplication. Finally, based on the vector representation of the obtained user nodes, the softmax function is used to infer the location labels to which they belong, and the cross-entropy loss function is used to calculate the loss.
4. Initialization
In Section 4, we detail some groundwork before the experiment, including the introduction of the dataset, the division of the user location regions, the evaluation metrics, the introduction of the baseline model, and the setting of the experimental parameters. Preparation is provided for the subsequent training of the model.
4.1. Datasets
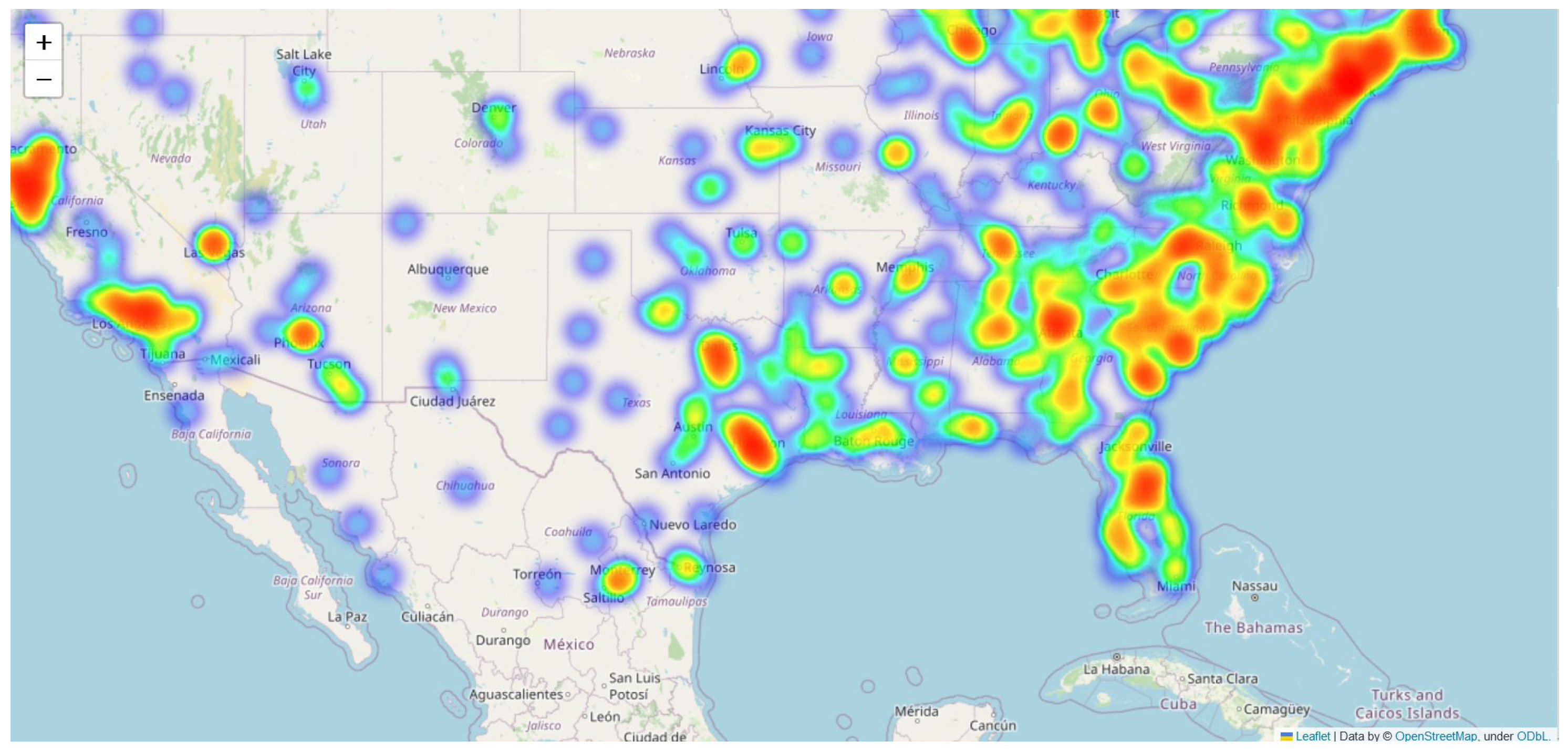
To evaluate our location inference model, we utilized GeoText, the widely used Twitter geolocation dataset. The dataset has been pre-segmented into training, validation, and test sets and has been extensively used for training and evaluating Twitter user location inference models. Each sample consists of four components: the user’s username, longitude, latitude, and tweets. Specific information is shown in Table 1; the distribution of users in GeoText spans the continental United States. Figure 2 depicts a heatmap of the location distribution of GeoText, with darker areas representing a higher density of users.

Table 1.
Specific information about the GeoText dataset used for the experiments.
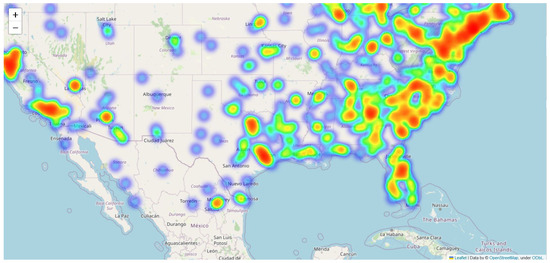
Figure 2.
Heatmap of user location distribution in GeoText.
4.2. Location Segmentation
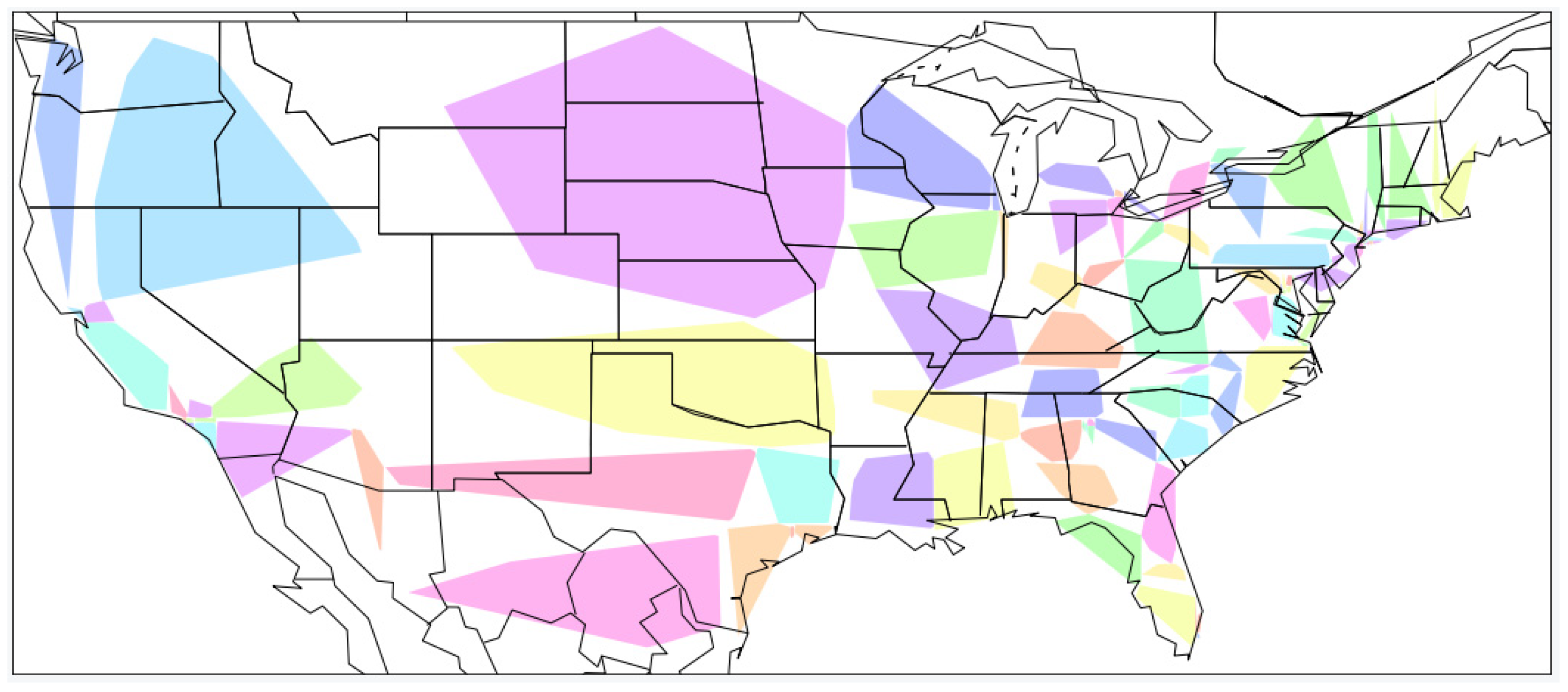
In reality, the majority of user location coordinates are concentrated in urban areas. This paper uses the k-d tree algorithm to discretize the user coordinates to prevent the model prediction results from being substantially biased towards large cities (such as New York City), wherein the hyperparameter bucket_size controls the maximum number of users for each location region. The k-d tree algorithm is then used to assign users in the training set with similar location distances to the same location region, and the central coordinate point of each region is set as the average longitude and latitude coordinates of all users within that region. For each user’s coordinates in the validation and test sets, the centroid of each region is traversed and the formula is used to calculate the distance between the centroid’s coordinates and the user’s coordinates. Then, the users in the training and test sets are designated to the region in which the centroid is closest to them. The area number of the user’s location is used as its label. Figure 3 depicts the result of using k-d tree to classify the user coordinates in the training set in GeoText. Each color block represents a location area.
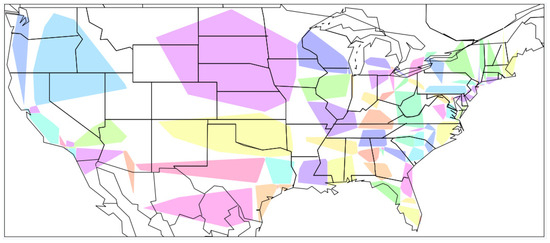
Figure 3.
Results of user coordinate partitioning in the training set in GeoText using k-d tree.
4.3. Evaluation Indicators
The model’s efficacy was assessed using the following three metrics: (1) acc@161: the proportion of users whose locations were estimated to be within 161 miles of the actual location, (2) mean: the average distance of all users’ errors, and (3) median: the user errors are evaluated, and then the median of all user errors is used as the median error. The more effective the location inference model is based on these three metrics, the higher the acc@161 and the lower the mean and median will be. The formulas for the three evaluation indicators are shown as follows:
where and represent the user’s predicted and actual positions, respectively, is the semi-positive vector formula, is the set of users in the test set, q is one of the users in , and is the number of data points in .
4.4. Baseline Model
We compare the multi-view-based location inference model MVGeo to the following baselines:
- MADCEL [27] combines text and web data with a logistic regression model to conduct location prediction.
- MLP4Geo [8] is a text-based model that improves prediction performance by employing dialectal terms. A simple MLP network is utilized for location prediction.
- MENET [30] is an architecture that integrates numerous tweet characteristics. In MENET, we only use text and network information to ensure a fair comparison, i.e., we do not use its metadata, such as timestamps.
- GeoAtt [34] models textual contexts using an RNN based on attention. We omit the location description from GeoAtt to ensure an equitable comparison.
- DCCA [12] is a multi-view geolocation model that uses Twitter text and network data.
- BiLSTM-C [35] is a text-view geolocation model that views user-generated content and its associated locations as sequences and infers locations using bidirectional long short-term memory (LSTM) and convolution operations.
- Attn [35] is an attentional memory network for the localization of social media messages. It consists of an attentional message encoder that concentrates on location-indicative terms selectively to produce a differentiated message representation.
- SGC4Geo [36] is a simplified graph convolutional network that reduces the superfluous complexity of GCNs by removing non-linearities between GCN layers iteratively and collapsing the resulting function into a single linear transformation. It determines a user’s residence based on his/her social posts and connections.
- M-GCN [14] employs graph convolutional networks to extract user text and link information from multiple perspectives to infer the location of the user.
- KB-emb [37] is a location inference technique that relies on entity linking and knowledge base embedding.
- MetaGeo [13] proposes a general framework for identifying user geolocation based on meta-learning to learn the prior distribution of geolocation tasks.
4.5. Experimental Settings
During the training of the model, the hidden layer dimension was assigned to 300 for GeoText. The k-d tree algorithm’s hyperparameters bucket_size was set to 50. For optimization functions, the Adam optimizer was used, and the initial values of and were 0.5 and 0.02, respectively. The sliding window size in the tweet view was set to 20. For detecting local celebrities on the network view of GeoText, the number of sub-distributions S of the Gaussian mixture model, the celebrity threshold J, the distance threshold T, and the scale threshold were set to 125, 5, 80, and 0.7, respectively. The activation functions for each layer of the feature extraction model in the tweet view were (ReLU, softmax), whereas the activation functions for each layer of the feature extraction model in the hybrid view were (Tanh, Tanh, softmax). If the verification loss did not decrease for 20 epochs in a row, the model training procedure was terminated early.
5. Experimental Results
In Section 5, we present the evaluation results of the location inference model proposed in this work on the public dataset. Specifically, we conduct extensive experiments to answer the following research questions:
- How well does the MVGeo model proposed in this work perform on location inference compared to current state-of-the-art baseline models?
- How well does the model proposed in this work perform when trained on a small amount of data using only the tweet view?
- How do the tweet view and the network view affect the inference effectiveness of the model?
- What is a good choice for the number of subdistributions for the Gaussian mixture model in the network view?
5.1. Location Inference Model Performance
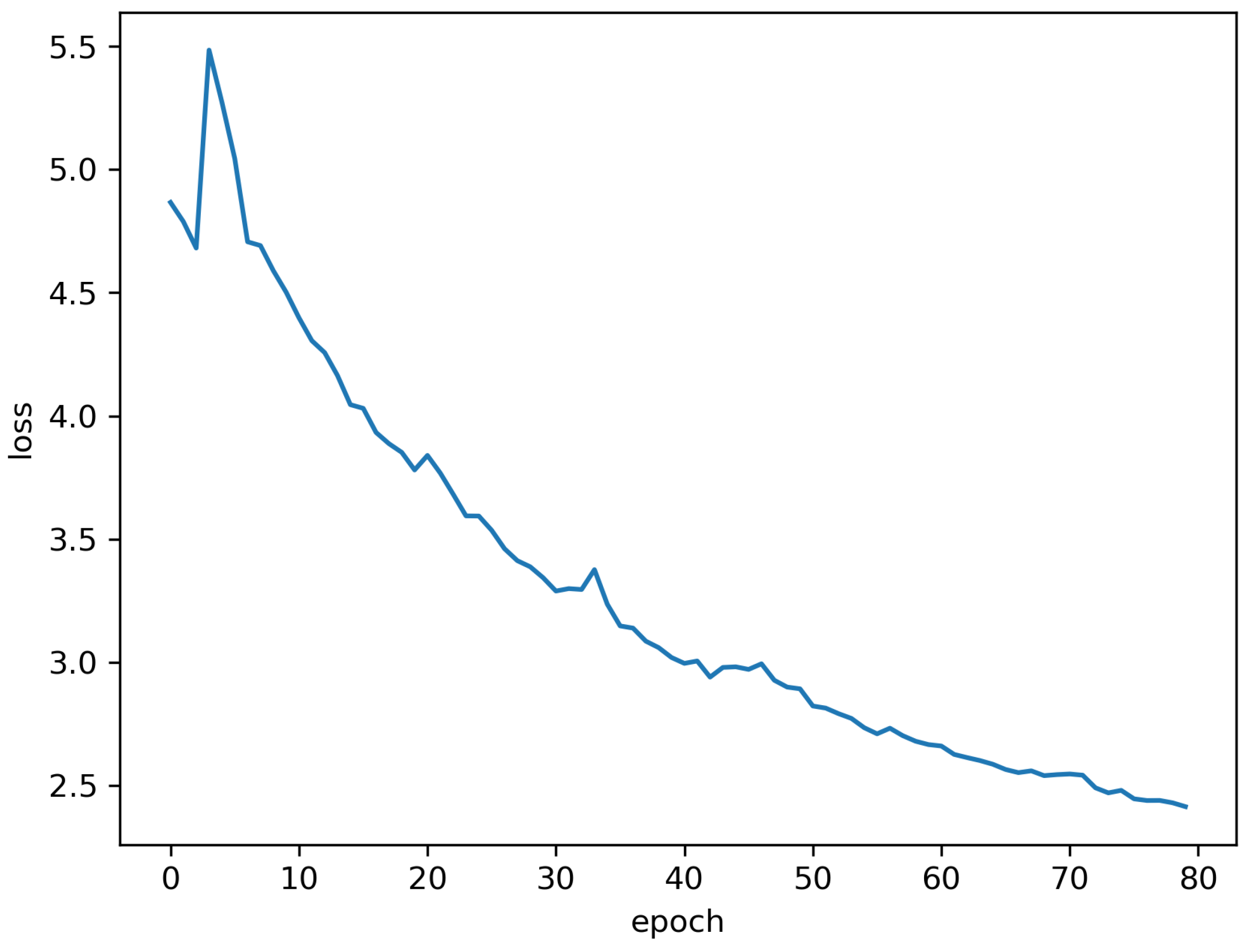
Table 2 shows the performance of our model on the dataset, with the best performance shown in bold and where MVGeo is the model proposed in this work. Compared to the previous baseline approaches, our proposed model improves the evaluation metric on the GeoText dataset by 1.6% for Acc@161, with a 14 km reduction in mean error and 1 km reduction in median error relative to the most-effective baseline model: MetaGeo. This suggests that the multi-view-based location inference task explored in this work is feasible and can be effective at extracting user tweets and network features. In the hybrid view, the variation in loss values during the training of the graph neural network model is shown in Figure 4.
Table 2.
Inference performance on the Twitter dataset.
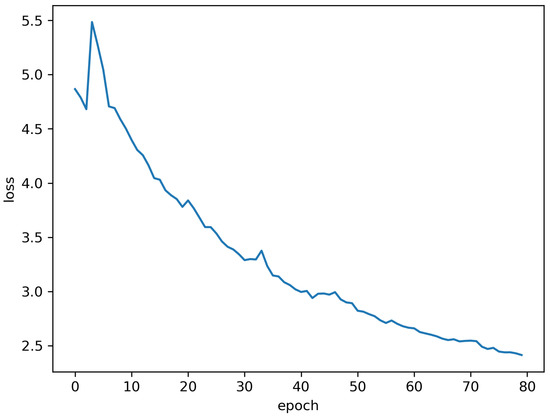
Figure 4.
Loss of GCN for multi-view fusion.
We have added Figure 4 here to show the variation in loss values.
5.2. Single-View Impact
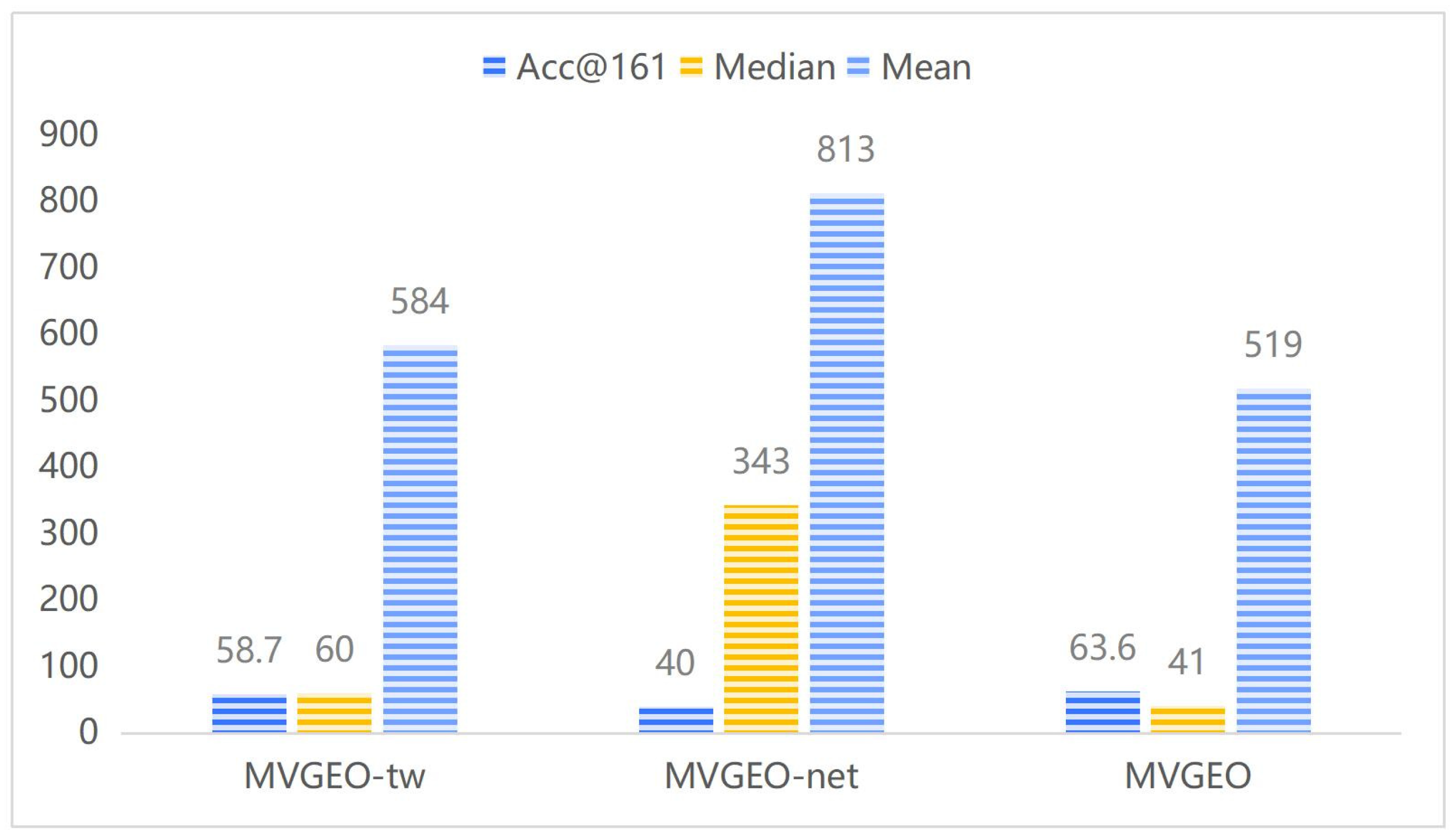
To investigate the respective roles of the tweet view and network view in the location inference model, we adjusted the model to produce two variant experiments: MVGEO-net and MVGEO-tw. MVGEO-net represents the original model MVGEO with the network view removed, while MVGEO-tw represents the original model with the tweet view removed. The experimental results are shown in Figure 5. The results show that, relatively speaking, the network view plays a major role in the location inference process. This also inspires us to continue exploring the extraction of location information in social relationship networks in our future work.
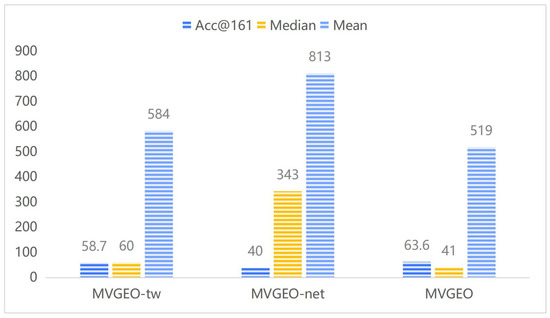
Figure 5.
The impacts of single views on location inference modeling.
5.3. Small-Scale Dataset
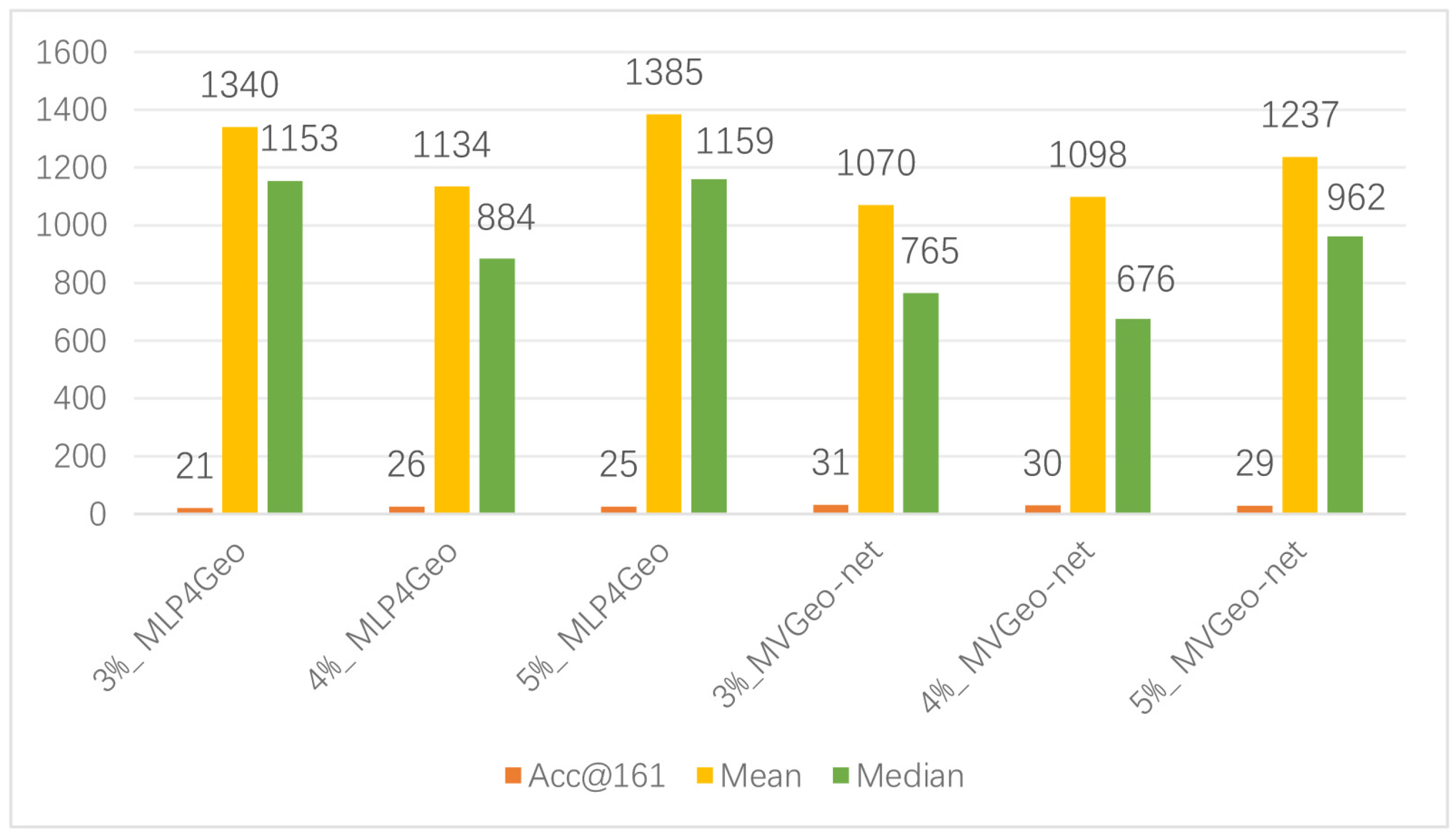
Due to the high cost of data sample annotation and the effect of the collected corpus on location indicator terms and mention relations in tweets, these variables can impact the model’s inferential efficacy. Therefore, to investigate the performance of the model presented in this work in more depth, we conducted experiments using only a small number of samples with annotations on the tweet view. This experiment produced the model variant MVGeo-net, which reduces the labeling cost and removes the effect of mention relations. As demonstrated in Figure 6, by comparison with the text-based model MLP4Geo [8], MVGeo-net’s performance improves on all three evaluation metrics. This shows that the method proposed in this work not only saves resources but also improves our understanding of model performance.
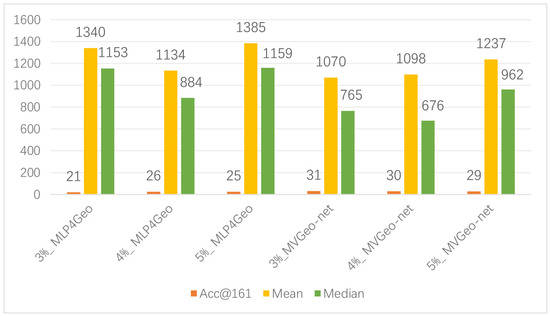
Figure 6.
Inference performance of the model using a small training set. MVGeo-net uses only the text view, and the numbers in front of the model indicate the percentage of the training set that was used.
5.4. Ablation Experiments
To further analyze the model proposed in this research work, we conducted an ablation study, and Table 3 shows the results.
Table 3.
Results of ablation experiments.
In (1), we used the commonly used TF-IDF in the tweet view to extract text features to obtain the model variant MVGeo-TF. This was used to verify the effectiveness of the method used in this research work to extract tweet features by analyzing the correlation between words. As can be seen from Table 3, the method proposed in this paper helps to mine user tweet features.
In (2), in order to verify the effectiveness of the local celebrity discovery algorithm proposed in this research work in the network view, we removed the local celebrity discovery algorithm proposed in this research work to obtain the model variant MVGeo-LC. For users who are mentioned by more than J different users, we use the approach of Rahimi et al. [27] to remove them directly from the social network. Table 3 shows that retaining the location-indicating role of local celebrities helps to improve the effectiveness of location inference.
5.5. Choice of S-Value
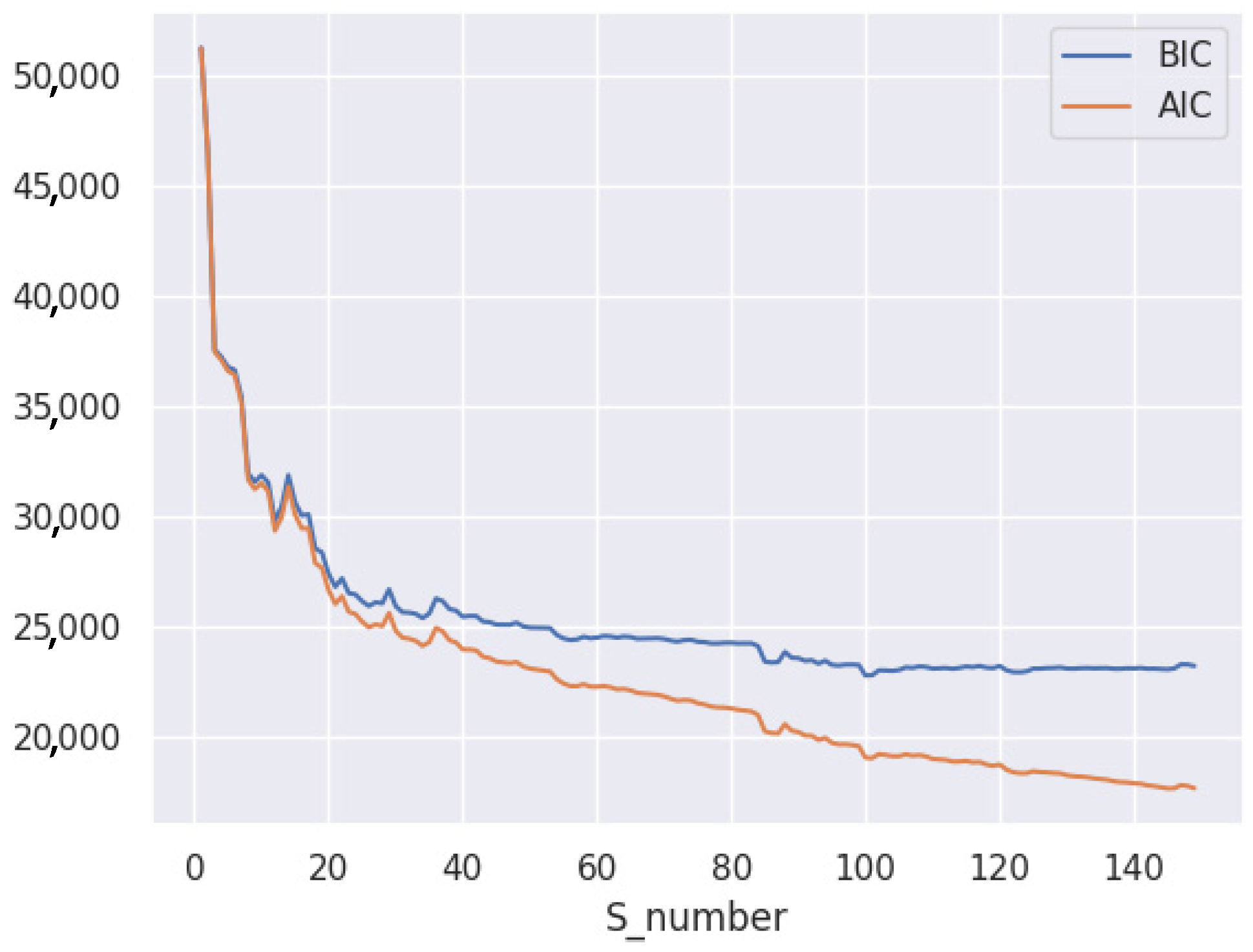
In the network view, the neighbor coordinates of all celebrity users are clustered using a Gaussian mixture model, and the number of Gaussian sub-distributions, S, impacts the model fitting. Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) can be used to determine the extent of the influence of the S value on the Gaussian mixture model. By adding a penalty term proportional to the number of model parameters, these two metrics circumvent the overfitting issue and select the value of S by minimizing the AIC and BIC. Figure 7 depicts the effect of the S value on model fitting on the GeoText dataset. Combining the changes to the two indicators, the magnitude of S on the GeoText dataset is estimated to be 125 in this study.
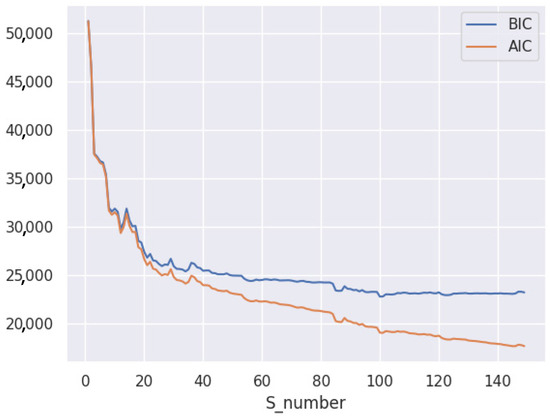
Figure 7.
Selection of the value of S.
6. Conclusions
This paper introduces MVGeo, a comprehensive framework for user location inference that leverages multiple views, including network and tweet features. In the network view, we propose for the first time to utilize Gaussian mixture models to filter and retain local celebrities in social relationship networks, which effectively enhances the location relevance of users in social relationship networks. In the tweet view, we construct tweets as heterogeneous graphs and extract tweet features by graph convolutional networks. Compared to the commonly used TF-IDF method for extracting text features, this approach also takes into account word–word connections to obtain more informative tweet features. We conduct extensive tests on a public Twitter dataset to evaluate the performance of MVGeo. The results demonstrate the superiority of our methodology compared to existing approaches. In the future, we plan to further enhance the performance of MVGeo by incorporating additional user feature data, such as user metadata. This extension will enable us to capture a more comprehensive understanding of users and their location-related patterns, thus improving the accuracy of location inference.
Author Contributions
H.W.: Conceptualization, Methodology, and Writing—review and editing. J.L.: Investigation, Data collection, Data interpretation, Software, and Writing—original draft. S.L.: Data interpretation and Software. H.L.: Validation and Visualization. J.M.: Validation and Writing—reviewing. Y.Q.: Writing—review and editing and Resources. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (No. 62272163), the Open Foundation of Henan Key Laboratory of Cyberspace Situation Awareness (No. HNTS2022005), the Songshan Laboratory (No. YYJC012022023), and the Henan Province Science Foundation (No. 232300420150).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The public data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare that they have no conflict of interest to report regarding the present study.
References
- Sakaki, T.; Okazaki, M.; Matsuo, Y. Tweet Analysis for Real-Time Event Detection and Earthquake Reporting System Development. IEEE Trans. Knowl. Data Eng. 2012, 99, 919–931. [Google Scholar] [CrossRef]
- Bao, J.; Zheng, Y.; Wilkie, D.; Mokbel, M. Recommendations in location-based social networks: A survey. GeoInformatica 2015, 19, 525–565. [Google Scholar] [CrossRef]
- Cheng, Z.; Caverlee, J.; Lee, K. A Content-Driven Framework for Geolocating Microblog Users. ACM Trans. Intell. Syst. Technol. (TIST) 2013, 4, 1–27. [Google Scholar] [CrossRef]
- Cheng, Z.; Caverlee, J.; Lee, K. You are where you Tweet: A content-based approach to geo-locating Twitter users. In Proceedings of the International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; pp. 759–768. [Google Scholar] [CrossRef]
- Wing, B.; Baldridge, J. Simple supervised document geolocation with geodesic grids. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 21 June 2011; pp. 955–964. [Google Scholar]
- Roller, S.; Speriosu, M.; Rallapalli, S.; Wing, B.; Baldridge, J. Supervised Text-based Geolocation Using Language Models on an Adaptive Grid. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Republic of Korea, 12–14 July 2012. [Google Scholar]
- Chi, L.; Lim, K.H.; Alam, N.; Butler, C. Geolocation Prediction in Twitter Using Location Indicative Words and Textual Features. In Proceedings of the 2nd Workshop on Noisy User-Generated Text (WNUT), Osaka, Japan, 11 December 2016. [Google Scholar]
- Rahimi, A.; Cohn, T.; Baldwin, T. A Neural Model for User Geolocation and Lexical Dialectology. arXiv 2017, arXiv:1704.04008. [Google Scholar]
- Davis Jr, C.; Pappa, G.; Rennó Rocha de Oliveira, D.; Arcanjo, F. Inferring the Location of Twitter Messages Based on User Relationships. Trans. GIS 2011, 15, 735–751. [Google Scholar] [CrossRef]
- Wang, F.; Lu, C.T.; Qu, Y.; Yu, P. Collective Geographical Embedding for Geolocating Social Network Users. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2017; pp. 599–611. [Google Scholar] [CrossRef]
- Huu, T.; Nguyen, D.; Tsiligianni, E.; Cornelis, B.; Deligiannis, N. Multiview Deep Learning for Predicting Twitter Users’ Location. arXiv 2017, arXiv:1712.08091. [Google Scholar]
- Rahimi, A.; Cohn, T.; Baldwin, T. Semi-supervised User Geolocation via Graph Convolutional Networks arXiv 2018. arXiv 2018, arXiv:1804.08049. [Google Scholar]
- Zhou, F.; Qi, X.; Zhang, K.; Trajcevski, G.; Zhong, T. MetaGeo: A General Framework for Social User Geolocation Identification With Few-Shot Learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 8950–8964. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Ye, C.; Zhou, H. Geolocation using GAT with Multiview Learning. In Proceedings of the 2020 IEEE International Conference on Smart Data Services (SMDS), Beijing, China, 19–23 October 2020; p. 88. [Google Scholar] [CrossRef]
- Han, B.; Cook, P.; Baldwin, T. Text-Based Twitter User Geolocation Prediction. J. Artif. Intell. Res. (JAIR) 2014, 49. [Google Scholar] [CrossRef]
- Eisenstein, J.; O’Connor, B.; Smith, N.; Xing, E. A Latent Variable Model for Geographic Lexical Variation. In Proceedings of the EMNLP 2010—Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, Cambridge, MA, USA, 9–11 October 2010; pp. 1277–1287. [Google Scholar]
- Rahimi, A.; Baldwin, T.; Cohn, T. Continuous Representation of Location for Geolocation and Lexical Dialectology using Mixture Density Networks. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 167–176. [Google Scholar] [CrossRef]
- Tang, H.; Zhao, X.; Ren, Y. A multilayer recognition model for twitter user geolocation. Wirel. Netw. 2022, 28, 1197–1202. [Google Scholar] [CrossRef]
- Compton, R.; Jurgens, D.; Allen, D. Geotagging One Hundred Million Twitter Accounts with Total Variation Minimization. In Proceedings of the 2014 IEEE International Conference on Big Data, IEEE Big Data 2014, Washington, DC, USA, 27–30 October 2014. [Google Scholar] [CrossRef]
- McGee, J.; Caverlee, J.; Cheng, Z. A geographic study of tie strength in social media. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Glasgow, Scotland, UK, 24–28 October 2011; pp. 2333–2336. [Google Scholar] [CrossRef]
- McGee, J.; Caverlee, J.; Cheng, Z. Location prediction in social media based on tie strength. In Proceedings of the International Conference on Information and Knowledge Management, Chengdu, China, 20–21 July 2013; pp. 459–468. [Google Scholar] [CrossRef]
- Rout, D.; Preotiuc-Pietro, D.; Bontcheva, K.; Cohn, T. Where’s @wally: A classification approach to Geolocating users based on their social ties. In Proceedings of the 24th ACM Conference on Hypertext and Social Media, Paris, France, 2–4 May 2013. [Google Scholar] [CrossRef]
- Jurgens, D. That’s What Friends Are For: Inferring Location in Online Social Media Platforms Based on Social Relationships. Proc. Int. AAAI Conf. Web Soc. Media 2021, 7, 273–282. [Google Scholar] [CrossRef]
- Kothari, R.; Jain, V. Learning from labeled and unlabeled data. In Proceedings of the 2002 International Joint Conference on Neural Networks, Honolulu, HI, USA, 12–17 May 2002; Volume 3, pp. 2803–2808. [Google Scholar] [CrossRef]
- Ebrahimi, M.; ShafieiBavani, E.; Wong, R.; Chen, F. Twitter user geolocation by filtering of highly mentioned users. J. Assoc. Inf. Sci. Technol. 2018, 69. [Google Scholar] [CrossRef]
- Rahimi, A.; Vu, D.; Cohn, T.; Baldwin, T. Exploiting Text and Network Context for Geolocation of Social Media Users. arXiv 2015, arXiv:1506.04803. [Google Scholar] [CrossRef]
- Rahimi, A.; Cohn, T.; Baldwin, T. Twitter User Geolocation Using a Unified Text and Network Prediction Model. arXiv 2015, arXiv:1506.08259. [Google Scholar] [CrossRef]
- Talukdar, P.; Crammer, K. New Regularized Algorithms for Transductive Learning. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2009, Bled, Slovenia, 7–11 September 2009; pp. 442–457. [Google Scholar] [CrossRef]
- Bakerman, J.; Pazdernik, K.; Wilson, A.; Fairchild, G.; Bahran, R. Twitter Geolocation: A Hybrid Approach. ACM Trans. Knowl. Discov. Data 2018, 12, 1–17. [Google Scholar] [CrossRef]
- Huu, T.; Nguyen, D.; Tsiligianni, E.; Cornelis, B.; Deligiannis, N. Twitter User Geolocation Using Deep Multiview Learning. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6304–6308. [Google Scholar] [CrossRef]
- Sun, Y.; Han, J. Mining heterogeneous information networks: A structural analysis approach. SIGKDD Explor. 2012, 14, 20–28. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. Proc. AAAI Conf. Artif. Intell. 2019, 33, 7370–7377. [Google Scholar] [CrossRef]
- Srivastava, R.; Greff, K.; Schmidhuber, J. Highway Networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- Miura, Y.; Taniguchi, M.; Taniguchi, T.; Ohkuma, T. Unifying Text, Metadata, and User Network Representations with a Neural Network for Geolocation Prediction. In Proceedings of the Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 1260–1272. [Google Scholar] [CrossRef]
- Li, P.; Lu, H.; Kanhabua, N.; Zhao, S.; Pan, G. Location Inference for Non-Geotagged Tweets in User Timelines. IEEE Trans. Knowl. Data Eng. 2018, 31, 1150–1165. [Google Scholar] [CrossRef]
- Wu, F.; de Souza, A.H.S., Jr.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K.Q. Simplifying Graph Convolutional Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6861–6871. [Google Scholar]
- Miyazaki, T.; Rahimi, A.; Cohn, T.; Baldwin, T. Twitter Geolocation using Knowledge-Based Methods. In Proceedings of the 2018 EMNLP Workshop W-NUT: The 4th Workshop on Noisy User-Generated Text, Brussels, Belgium, 1 November 2018; pp. 7–16. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).